Note: Descriptions are shown in the official language in which they were submitted.
CA 02275832 1999-06-18
1
METHOD AND APPARATUS FOR PROVIDING BACKGROUND ACOUSTIC
NOISE DURING A DISCONTINUED/REDUCED RATE TRANSMISSION MODE
OF A VOICE TRANSMISSION SYSTEM
DESCRIPTION
TECHNICAL FIELD:
This invention relates to a method and apparatus for providing background
acoustic noise during a discontinued/reduced rate transmission mode of a voice
transmission system. The invention is especially applicable to digital voice
communications and more particularly to wireless voice communications systems,
and
bit-rate sensitive applications including digital simultaneous voice and data
(DSVD)
systems, and voice over Internet-protocol (VOIP).
BACKGROUND ART:
In wireless voice communication systems, it is desirable to reduce the level
of
transmitted power so as to reduce co-channel interference and to prolong
battery life of
portable units. In cellular systems, interference reduction enhances spectral
efficiency
and increases system capacity. One way to reduce the power level of
transmitted
information is to reduce the overall transmission bit rate. A typical
telephone
conversation comprises approximately 40 per cent active speech and about 60
per cent
silence and non-speech sounds, including acoustic background noise.
Consequently, it
is known to discontinue transmission during periods when there is no speech.
Other wireless systems require a continuous mode of transmission for system
synchronization and channel monitoring. It is inefficient to use the full
speech-coding
rate mode for the background acoustic noise because it contains less
information than the
speech. When speech is absent, a lower rate coding mode is used to encode the
background noise. In Code Division Multiple Access (CDMA) wireless
communication
systems, variable bit rate (VBR) coding is used to reduce the average bit rate
and to
increase system capacity. The very low bit rate used during speech gaps is
insufficient
to avoid perceptible discontinuities between the background noise accompanying
speech
and during speech gaps.
CA 02275832 1999-06-18
2
A disadvantage of simply discontinuing transmission, as done by early systems,
is that the background noise stops along with the speech, and the resulting
received
signal sounds unnatural to the recipient.
This problem of discontinuities has been addressed by generating synthetic
noise,
known as "comfort noise", at the receiver and substituting it for the received
signal
during the quiet periods. One such silence compression scheme using a
combination of
voice activity detection, discontinuous transmission, and synthetic noise
insertion has
been used by Global System for Mobile Communications (GSM) wireless voice
communication systems. The GSM scheme employs a transmitter, which includes a
voice activity detector (VAD) which discriminates between voice and non-voice
signals,
and receiver which includes a synthetic noise generator. When the user is
speaking, the
transmitter uses the full coding rate to encode the signal. During quiet
periods, i.e.
when no speech is detected, the transmitter is idle except for periodically
updating
background noise information characterizing the "real" background noise. When
the
receiver detects such quiet periods, it causes the synthetic noise generator
to generate
synthetic noise, i.e. comfort noise, and insert it into the received signal.
During the
quiet periods, the transmitter transmits to the receiver updated information
about the
background noise using what are known as Silence Insertion Descriptor (SID)
frames and
the receiver uses the parameters to update its synthetic noise generator.
It is known to generate the synthetic noise by passing a spectrally-flat noise
signal
(white noise) through a synthesis filter in the receiver, the noise parameters
transmitted
in the SID frames then being coefficients for the synthesis filter. It has
been found,
however, that the human auditory system is capable of detecting relatively
subtle
differences, and a typical recipient can perceive, and be distracted by,
differences
between the real background noise and the synthetic noise. This problem was
discussed
in European patent application number EP 843,301 by K. Jarvinen et al., who
recognized that a user can still perceive differences where the spectral
content of the real
background noise differs from that of the synthetic noise. In order to reduce
the spectral
quality differences, Jarvinen et al. disclosed passing the random noise
excitation signal
through a spectral control filter before applying it to the synthesis filter.
While such
spectral modification of the excitation signal might yield some improvement
over
conventional systems, it is not entirely satisfactory. Mobile telephones, in
particular,
CA 02275832 1999-06-18
3
may be used in a wide variety of locations and the typical user can still
perceive the
concomitant differences between the background noise accompanying speech and
the
synthetic noise inserted during non-speech intervals.
DISCLOSURE OF INVENTION:
An object of the present invention is to provide a background noise coding
method and apparatus capable of providing synthetic noise ("comfort" noise)
which
sounds more like the actual background noise.
To this end, in communications systems embodying the present invention, the
background noise is classified into one or more of a plurality of predefined
noise classes
and the receiver selects one or more of a corresponding plurality of different
excitation
signals for use in generating the synthetic noise.
According to one aspect of the present invention, in a digital communications
system comprising a transmitter and a receiver, the transmitter interrupting
or reducing
transmission of a voice signal during interval absent speech and the receiver
inserting
synthetic noise into the received voice signals during said intervals, there
is provided a
method comprising the steps of assigning acoustic background noise in the
voice signal
to one or more of a plurality of predefined noise classes, selecting a
corresponding one
of a plurality of excitation vectors each corresponding to at least one of the
predefined
classes, using at least part of the selected noise vector to synthesize the
synthetic noise,
and outputting the synthetic noise during a said interval.
According to a second aspect of the present invention, there is provided a
digital
communications system comprising a transmitter and a receiver, the transmitter
having
means for interrupting or reducing transmission of a voice signal during
interval absent
speech and the receiver having means for inserting synthetic noise into the
received voice
signals during said intervals, there being provided means for assigning
acoustic
background noise in the voice signal to one or more of a plurality of
predefined noise
classes, selecting a corresponding one of a plurality of excitation vectors
each
corresponding to at least one of the predefined classes, using at least part
of the selected
excitation vector to synthesize the synthetic noise, and outputting the
synthetic noise
during a said interval.
CA 02275832 1999-06-18
4
In embodiments of either aspect, the transmitter may perform the
classification
of the background noise and transmit to the receiver a corresponding noise
index and the
receiver may select the corresponding excitation vectors) in dependence upon
the noise
index. The receiver may select from a plurality of previously-stored vectors,
or use a
generator to generate an excitation vector with the appropriate parameters.
The predefined noise classes may be defined by temporal and spectral features
based upon a priori knowledge of expected input signals. Such features may
include
zero crossing rate, root-mean-square energy, critical band energies, and
correlation
coefficients. Preferably, however, noise classification uses line spectral
frequencies
(LSFs) of the signal, with a Gaussian fit to each LSF histogram.
Preferably, the noise classification is done on a frame-by-frame basis using
relatively short segments of the input voice signal, conveniently about 20
milliseconds.
In preferred embodiments of either aspect of the invention, linear prediction
(LP)
analysis of the input signal is performed every 20 milliseconds using an
autocorrelation
method and windows each of length 240 samples overlapping by 80 samples. The
LP
coefficients then are calculated using the Levinson-Durbin algorithm and
bandwidth-
expanded using a factor ~y = 0.994. The LP coefficients then are converted
into the LSF
domain using known techniques.
The classification unit may determine that the background noise comprises
noise
from a plurality of the predetermined noise classes and determine proportions
for mixing
a plurality of said excitation vectors for use in generating the synthetic
noise. The
relative proportions may be transmitted as coefficients and the receiver may
multiply the
coefficients by the respective vectors to form a mixture.
The transmitter may transmit one or more hangover frames at the transition
between speech and no speech, such hangover frames including background noise,
and
the receiver then may comprise means for deriving the noise class index from
the noise
in that portion of the received signal corresponding to the hangover frames.
The
extracting means may comprise a noise classifier operative upon residual noise
energy
and synthesis filter coefficients to derive the noise class indices.
BRIEF DESCRIPTION OF THE DRAWINGS:
CA 02275832 1999-06-18
Figure 1 illustrates, schematically, a speech communication system in which a
codec includes a voice activity detector which selects, alternatively, active
and inactive
voice encoders depending upon whether or not speech is detected;
Figure 2 illustrates an encoder of a linear prediction-based noise codec
according
5 to one embodiment of the present invention;
Figure 3 illustrates a decoder of the linear prediction-based noise codec;
Figure 4 illustrates functions of a noise classifier of the encoder of Figure
2;
Figure 5 illustrates an excitation module of the decoder of Figure 3;
Figure 6 is a flow chart illustrating the internal operation of the excitation
selection module of Figure 5;
Figure 7 is a block schematic representation of a second embodiment of the
invention, namely an encoder part of a linear prediction-based noise coder
which
transmits a noise index indicating a plurality of weights for a particular
noise type;
Figure 8 is a block schematic representation of a part of a decoder
corresponding
to the encoder of Figure 7 and which provides an excitation signal from a
mixture of
excitation vectors;
Figure 9 is a block schematic representation of another embodiment of the
invention, namely a decoder part of a linear prediction-based noise coder
which includes
a noise classifier for deriving the noise class index internally.
BEST MODES) FOR CARRYING OUT THE INVENTION:
In the drawings, identical or corresponding items in the different Figures
have the
same reference numeral, a prime being used to denote modification.
Referring to Figure 1, which illustrates a part of a digital communications
system,
a transmitter section comprises an encoding unit 10 coupled to a decoding unit
12 in a
receiver section by way of a communications channel 14 which, in the case of a
wireless
system, might be free space. The encoding unit 10 comprises an active voice
encoder
16 and an inactive voice encoder 18 connected to respective outputs of a
selector 20,
shown as a switch, having its input connected to an input port 22 whereby the
encoding
unit 10 receives the incoming signal for encoding and transmission. The
respective
outputs of the active voice encoder 16 and inactive voice encoder 18 are
connected to
inputs terminals of a second selector 24, also shown as a switch, having its
output
CA 02275832 1999-06-18
6
connected to the communications channel 14. The selectors 22 and 24 are
"ganged" for
simultaneous operation under the control of a voice activity detector (VAD) 26
which has
an input connected directly to encoding unit input port 22 and an output
connected
directly to the communications channel 14.
The decoding unit 12 has an active voice decoder 28 and an inactive voice
decoder 30 with their inputs connected to respective outputs of a selector 32,
which has
its input connected to the communications channel 14. The outputs of the
active voice
decoder 28 and the inactive voice decoder 30 are connected to respective
inputs/poles of
a selector 34, the output of which is the output of the decoding unit 12. The
selectors
32 and 34 are "ganged" for operation simultaneously by control signals from
the VAD
26 communicated over the channel and link 36.
In operation, when the VAD 26 detects that the incoming signal comprises
speech, it operates the selectors 20 and 24 to connect the active voice
encoder 16 in
circuit and signals to the decoding unit 12 to cause the latter to connect the
active voice
decoder 28 in circuit. Conversely, when the VAD 26 detects no speech, it
connects the
inactive voice encoder 18 in circuit and instructs the selectors 32 and 34 to
connect the
inactive voice decoder in circuit.
The encoders 16 and 18 are linear prediction encoders and the decoders 28 and
30 complementary linear prediction decoders. The active voice encoder 16 and
active
voice decoder 28 are conventional and will not be described in detail.
An inactive voice encoder 18 according to a first embodiment of the invention
is
illustrated in Figure 2. The input signal s(n) is processed on a frame-by-
frame basis
(i.e. each frame is a short segment of length 10-40 ms). Each frame of the
input signal
s(n) is supplied to both an LP Inverse filter 38 and an LP Analysis module 40.
The LP
analysis module 40 analyses the input signal frame to estimate a set of linear
prediction
coefficient (LPC) spectral parameters of order p, where p typically is between
S and 12.
The LP analysis module 40 supplies the parameters to LP inverse filter 38
which filters
the input signal s(n) to produce the LP residual signal r(n). The LP residual
signal r(n)
is not encoded but rather is applied to an energy computation module 42 which
computes
its energy and supplies a corresponding value to a quantization and encoding
module 44.
The coding of the energy for transmission to the quantization and encoding
module may
be done by any suitable means, such as those used in existing GSM and CDMA
systems.
CA 02275832 1999-06-18
7
The LP analysis module 40 also supplies to the quantization and encoding
module 44 the
LPC spectral parameters used by the LP inverse filter 38 when filtering the
frame.
The residual signal r(n) and the LPC spectral parameters are also supplied to
a
noise classifier 46 which uses them to determine the type of background noise
and, using
criteria to be described later, produce a noise class index which it supplies
to the
quantization and encoding unit 44. The quantization and encoding unit 44
quantizes and
encodes the LPC spectral parameters, the residual energy g~ and the noise
class index
into a bit stream for transmission via the communications channel 14.
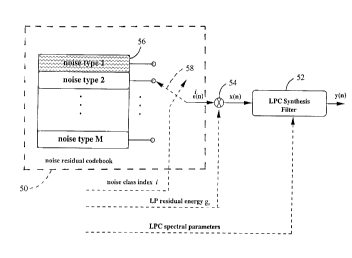
Referring now to Figure 3, the pertinent parts of the inactive voice decoder
30
comprise a decoding and dequantization unit 48, an excitation selection module
50, and
LPC synthesis filter 52 and a multiplier 54. The decoding and dequantization
unit 48
decodes and dequantizes the incoming bitstream from the channel 14 to extract
the LPC
spectral parameters, which it supplies to the LPC synthesis filter 52, the
value of the
residual energy g~, which it supplies to the multiplier 54, and the noise
class index,
which it supplies to the excitation selection module 50. In response to the
noise class
index, the excitation selection module 50 selects the appropriate excitation
vector e'(n)
and applies it to the multiplier 54 which scales the excitation vector e'(n)
with the
residual energy g~ to give the LPC excitation signal x(n). The LPC synthesis
filter 52,
with its coefficients updated with the LPC spectral parameters from decoding
and
dequantizing module 48, is excited by the LPC excitation signal x(n) to output
a synthetic
noise signal y(n).
In embodiments of the present invention, information about the type of
background noise is used to substitute, at the receive side, an appropriate
stored or
generated LP residual that preserves the perceptual texture of the input
background noise.
Figure 4 depicts the internal processing of the noise classifier 46. Before
use,
however, the classifier 46 must be programmed with suitable classification
rules and
decision rules. The first step in designing an M-class noise classifier 46 is
to define the
M noise classes of interest. The noise classes usually will be different types
of
background noise, for example car noise, "babble" (a large number of
simultaneous
talkers), and other noise types common in wireless environments. A set of
signal
features then is specified that, in combination with a selected classification
algorithm,
give good classification results. A common way to represent such a classifier
is in terms
CA 02275832 1999-06-18
g
of a set of discriminant functions g;(x), i = l, 2,..., M. The classifier
assigns a feature
vector x to class C; if g;(x) > g~(x), for every j ~ i.
The effect of any decision rule is to divide the feature space into M disjoint
decision regions R~, R2, ..., RM separated by decision surfaces. Generally, if
the
features are chosen well, vectors belonging to the same class will group
together in
clusters in the feature space. During the training phase, the training data
for each noise
class, in the form of labelled feature vectors, is used to design the decision
rule.
Conveniently, the training data is obtained from a large number of recordings
of each
type of background noise made in the appropriate environment.
In operation, the noise classifier 46 will determine the class to which the
feature
vector extracted from the actual background noise most likely belongs. The
classification
of an input vector x reduces to its assignment to a class based upon its
location in feature
space.
Referring now to Figures 2 and 4, in step 4.1, a set of noise features from
the
LP residual signal r(n) and the LPC spectral parameters are input to the noise
classifier.
As illustrated in Figure 4, the feature extraction step 4.2 extracts from the
input noise
frame the set of predetermined features and applies them to a classification
rule module,
which in step 4.3 maps the input feature vector to the predefined classes to
determine the
optimum background noise class, i.e. that closest to the actual background
noise type,
and supplies the decision to a decision processing module.
Classification at the transmitter can use any set of features from the input
signal
that discriminates between noise classes. It has been found, however, that
Line Spectral
Frequencies (LSFs) give better quantization properties than the LPC spectral
parameters.
Such LSFs are derived from the LPC spectral parameters and are commonly used
in
linear predictive speech coders to parameterize the spectral envelope.
Accordingly, it
is preferable to perform noise classification in the noise classifier 46 using
the
unquantized LSFs. Hence, the feature extraction module supplies LSFs as the
required
features to the classification algorithm. Experiments have shown that the LSFs
are
robust features in distinguishing different classes of background environment
noises.
Nevertheless, it would be possible to use other features, such as zero
crossing rate, root-
mean-square energy, critical band energies, correlation coefficients, and so
on. For
more information about the classification of background noise, the reader is
directed to
CA 02275832 1999-06-18
9
the article "Frame-level Noise Classification in Mobile Environments" by
Khaled E1-
Maleh et al. , 1999 I. E. E. E. International Conference on Acoustics, Speech
and Signal
Processing, vol. I, pp. 237-240, which is incorporated herein by reference.
To improve the classification accuracy further, in step 4.4 the decision
processing
module detects spurious or obviously incorrect classifications by the
classification rule,
for example one frame different from preceding and succeeding frames. In step
4.5, the
decision is output as the noise class index i which is transmitted to the
receiver for
class-dependent excitation selection.
Figure 5 illustrates the complementary class-dependent decoder 30 without the
decoding and dequantization unit 48 but with the corresponding excitation
selection
module 50 shown in more detail. The excitation selection module 50 comprises a
codebook 56 storing a plurality of LP excitation vectors from M noise types,
each
comprising an LP residual waveform, with normalized energy, of a typical
segment of
each noise class. Each vector is previously selected, stored and labelled by
the
corresponding noise class index i. The excitation codebook has a size of M x
L, where
M is the number of noise types, i.e. each representing one of the different
background
noise types from which the noise classifier 46 in encoder 18 made its
selection, and L
is the length (in frames) of the stored LP excitation for each noise type. The
length of
each stored excitation vector should be long enough to avoid any perceived
repetition of
noise. For example, each excitation vector may comprise 50 to 1000 frames,
each frame
typically of 20 milliseconds duration (160 samples). Sequential selection of
the
appropriate vector frames is made by a selector 58 controlled by the noise
class index
i. Each excitation vector frame e'(n), when applied to the synthesis filter
52, will
produce a synthetic noise which is perceptually similar to the corresponding
noise type
selected by the noise classifier 46 in the encoder 18.
Figure 6 is a flow chart illustrating the internal operation of the excitation
selection module 50, which has M excitation frame counters. To preserve the
perceptual
texture of the reconstructed noise, and to avoid interruptions, the excitation
signal is
constructed from sequential excitation samples. In step 6.1, the noise class
index is input
from the decoding and dequantization unit 48. In steps 6.2 to 6.6, the frame
counter of
the a'"' noise class is used in the process of copying a segment of the i"'
excitation
codevector. Logical tests are done in steps 6.3 and 6.4 to allow for the re-
use of the
CA 02275832 1999-06-18
excitation codevectors. Thus, step 6.3 determines if the frame counter value
is equal to
the length of the excitation codevector (i.e. end of the codevector),
whereupon step 6.4
initializes the frame counter to point to the start of the codevector. In step
6.6, the
frame counter is incremented by one whenever it is used to output an
excitation vector.
5 Step 6.5 selects the excitation signal for the a'"' noise class and, in step
6.7, the selector
58 outputs the selected excitation signal e'(n) to the LPC synthesis filter 52
and the loop
6.8 returns to the start 6.9.
As discussed in the article by El-Maleh et al. (supra), it might be desirable
to
classify a particular background noise as containing components of several of
the
10 predefined noise types. Figure 7 illustrates an encoding unit which differs
from that
shown in Figure 2 in that it uses a noise classifier 46' which can determine
that a
particular background noise segment contains noise from more than one of the
classes,
and determine approximate proportions in which the noise vectors at the
receiver should
be mixed. The mixture excitation signal e(n) is modelled as a linear mixture
of M
excitation signals from the M noise classes. Mathematically, e(n) is given as:
M
a (n) _~ ~iiei (n)
where el(n) is an excitation signal from the ith noise class, and Vii; is the
ith mixing
coefficient, taking a value between 0 and 1.
Rather than transmit the exact proportions, the noise classifier 46'
approximates
proportions to derive mixing coefficients which quantify the contribution of
the noise
class. More particularly, the mixing coefficients a1 to ~3M represent
proportions in which
the noise vectors at the receiver should be mixed to approximate the mix of
noise types
in the input signal. Conveniently, the noise classifier 46' has a table of
different valid
combinations of the mixing coefficients ,Q1 to ~3M, each combination assigned
a distinct
noise index. The soft-decision classification module 46' determines the
appropriate
combination of mixing coefficients, determines the corresponding noise index,
and
transmits it to the receiver. Using known vector quantization techniques, the
vector of
weights from the classifier 46' is compared to the allowable combinations of
weights and
the noise index of the closest allowable combination chosen.
CA 02275832 1999-06-18
11
Figure 8 illustrates parts of a corresponding decoder which is similar to that
shown in Figure 5. The excitation module in Figure 8 has a codebook storing
the M
excitation vectors, as before, but also has a set of multipliers 60, to 60M
for multiplying
the selected vectors by corresponding weighting coefficients ~3, to ~3M,
respectively. In
addition, the excitation module 50 has a translation module 62 which receives
the noise
class index from the decoding and dequantization unit 48 and, using a look-up
table
similar to that used in the noise classifier 46', or the like, determines the
corresponding
set of coefficients ~3, to aM and supplies them to the multipliers 60, to 60M.
The outputs
of the multipliers 601 to 60M are summed by summing device 64 and the sum is
supplied
to the multiplier 54 which scales the excitation signal e(n) with the residual
energy g~ to
give the LPC excitation signal x(n) for filtering by the LPC synthesis filter
52.
An advantage of mixing several vectors in various proportions is that
transitions
between different synthetic noises are less abrupt and many combinations may
be
provided using only a limited number of "basic" excitation vectors.
While it is preferable to transmit only one noise index, because that requires
minimal bit rate, it would be possible for the noise classifier 46' to
transmit several noise
indices and their respective proportions. At the receiver, the translation
module 62 then
could be omitted and the noise indices applied directly to the multipliers 601
to 60M.
Various other modifications and alternatives to components of the above-
described
coders are encompassed by the present invention. Thus, it is envisaged that
the receiver
could perform the noise classification using, for example, hangover frames,
rather than
the transmitter doing the classification and sending a class index to the
receiver. To
minimize the occurrence of speech clipping resulting from classification of
speech as
background noise, a typical voice activity detection (VAD) algorithm includes
a hangover
mechanism that delays the transition from speech to silence. A hangover period
of a few
frames (i.e. 3 - 10) is commonly used. In most cases, the hangover frames
contain
background noise which is encoded using the full-rate of the speech coder.
Using the
background noise information contained in the hangover frames, it is possible
to do noise
classification at the receiver side. This saves the transmitter from
transmitting noise
classification bits, so the receiver can be used with existing encoders, which
may be
unchanged.
CA 02275832 1999-06-18
12
Part of such a receiver for performing receive-side noise classification is
shown
in Figure 9 and has, in addition to the same components as the decoder part
shown in
Figure 3, a noise classifier 66 connected between the decoding and
quantization unit 48
and the codebook. The decoding and dequantizing unit 48 detects the hangover
frames
in known manner and passes them to the noise classifier 66 which classifies
the
background noise therein using the same kind of analysis as that performed in
the noise
classifier 46 in Figure 2. Where variable rate continuous transmission is
used, with a
low coding rate during speech gaps, the features in the received signal are
detected. If
transmission is discontinued during speech gaps, SID frames may provide
quantized
LSFs and quantized energy using full-rate coding. In the example shown in
Figure 9,
the noise classifier 66 receives from the decoding and dequantizing unit 48
the residual
energy gr and the LPC parameters and uses them to determine the noise class
index ;
using similar principles to those used by the noise classifier 48, but
operating with
quantized features. The noise classifier 66 supplies the noise class index i
to the
excitation selection module 50 which uses it, as before, to select the
appropriate
normalized excitation vector e'(n) for scaling by the residual energy g~ to
form the scaled
excitation signal x(n).
Preferably, the noise classifier 66 uses quantized LSFs as input features of
the
hangover frames.
It should be appreciated that determination of the noise class index at the
receiver
could also be applied to the "soft-decision" embodiment of Figures 7 and 8.
Thus, the
outputs of the excitation module 50 of Figure 9 could be supplied to a set of
multipliers
60, to 60M for scaling by a corresponding set of coefficients ~3, to ~3M
before summing
by an adder 64, and the noise classifier 66 of Figure 9 then could be replaced
by a soft-
decision noise classifier 46' similar to that described with reference to
Figure 7 and
which would generate the coefficients ,Q, to ~3M.
It is also envisaged that hangover frames could be used to update the contents
of
the noise residual codebook 56. The M noise excitation codevectors are
populated with
prototype LP residual waveforms from the M noise classes. To update the
contents of
the noise residual codebook dynamically at the receive side, the excitation
signal of the
hangover frames could be used. The hangover frames are encoded with the full-
rate of
the speech coder, with a good reproduction of the LP residual at the transmit
side. After
CA 02275832 1999-06-18
13
classifying a hangover frame to one of the M noise classes, its excitation
signal would
be used to update the excitation codevector of the corresponding noise class.
It should be noted that the combination of noise classification and residual
substitution in accordance with the present invention is not limited to linear
predictive
synthesis models. It can be retrofitted into other speech coding systems such
as Multi-
band Excitation (MBE) and Waveform Interpolation (WI) speech coders. For
example,
multiband class-dependent excitation substitution can be used during speech
gaps.
The codebook could store vectors for the basic classes only, all of the mixing
being done by multiplying the basic vectors by the mixing coefficients.
Alternatively,
the codebook could also store some "premixed" vectors which comprise mixtures
of two
or more basic vectors, in which case some of the multipliers could be omitted.
It is
conceivable, of course, for the codebook to store all valid combinations of
the noise
vectors, in various proportions, in which case the multipliers 60, to 60,M and
the
translation module 62 would not be needed and the noise classifier 46' would
be
modified to store information linking each of the valid combinations to a
corresponding
noise index.
In any of the above-described embodiments, the codebook of stored vectors
could
be replaced by a suitable "engine" for generating the required vectors as
needed. A
suitable "engine" might employ mufti-band excitation or waveform
interpolation.
INDUSTRIAL APPLICABILITY
Embodiments of the present invention, using pre-classification of background
noise types and class-dependent reproduction of background noise during voice
inactivity,
produce synthesized noise that sounds similar to the background noise during
voice
activity. This improvement in noise synthesis results in a much-enhanced
overall noise
environment for the listener, and improves the overall perceived quality of a
voice
communication system.