Note: Descriptions are shown in the official language in which they were submitted.
CA 02325322 2000-11-09 r 9
~ i 9~3 ~~~,~,y~
VOICE CODING AND DECODING APPARATUS AND METHOD
THEREOF
The present invention relates to a voice coding
and a voice decoding apparatus and method thereof for
satisfactorily coding background noise signal
superimposed on a voice signal even at a low bit rate.
As system for highly efficiently coding voice
signal, CELP (Code-Excited Least Predictive Coding)
is well known in the art, as described in, for instance,
M. Schroeder at B. Atal, "Code-excited liner
prediction: High quality speech at very low bit
rates", Proc. ICASSP., pp. 937-940, 1985 (Literature
1) and Kleijn et al, "Improved speech quality and
efficient vector quantization in SELP", Proc. ICASSP,
pp. 155-158, 1988 (Literature 2).
In such prior art system, on the transmitting
side a spectral parameter representing a spectral
characteristic of voice signal is extracted from the
voice signal for each frame (of 20 msec., for
instance) by executing linear prediction (LPC)
analysis . Also, the frame is divided into sub-frames
( of 5 msec . , for instance ) , and pitch prediction of
voice signal in each sub-frame is executed by using
an adaptive codebook. Specifically, the pitch
prediction is executed by extracting parameters in
the adaptive codebook (i.e., delay parameter
corresponding to the pitch cycle and gain parameter )
for each sub-frame on the basis of past excitation
1
CA 02325322 2000-11-09
signal. An excitation signal is obtained as a result
of the pitch prediction, and it is quantized by
selecting an optimum excitation codevector from an
excitation codebook (or vector quantization
codebook), which is constituted by noise signals of
predetermined kinds,and calculatingan optimum gain.
The selection of the excitation codevector is
executed such as to minimize the error power level
between a signal synthesized from a selected noise
signal and the residue signal. A multiplexer
combines an index representing the kind of the
selected codevector with the gain, the spectral
parameter and the adaptive codebook parameters, and
transmits the resultant signal. The receiving side
is not described.
In the prior art method as described above,
reducing the bit rate of coding to be below, for
instance, 8 kb/sec., results in deterioration of
background noise signal particularly in the case
where the voice signal and background noise signal
are superimposed on each other. The deterioration
of the background noise signal leads to deterioration
of the overall sound quality. This deterioration is
particularly pronounced in the case of using voice
coding in portable telephone or the like. In the
methods disclosed in Literatures 1 and 2, bit rate
reduction results in excitation codebook bit number
reduction to deteriorate the accuracy of waveform
reconstitution. The deterioration is not so
2
CA 02325322 2000-11-09
pronounced in the case of high waveform correlation
signal such as voice signal, but it is pronounced in
the case of lower correlation signal such as
background noise signal.
In a prior art method described in C. Laflamme,
"16 kbps wideband speech coding technique based on
algebraic CLEP", Proc. ICASSP, pp. 13-16, 1991
(Literature 3 ) , excitation signal is expressed in the
form of pulse combination. Therefore, although high
model matching property and satisfactory sound
quality are obtainable when voice is dealt with, in
the case of dealing with low bit rate the sound quality
of background noise part of coded voice is extremely
deteriorated due to insufficient number of pulses
employed.
The reason why this is so is as follows. In the
vowel time section of voice, pulses are concentrated
in the neighborhood of a pitch pulse as pitch start
point. It is thus possible to obtain efficient voice
expression with a small number of pulses . In the case
of background noise or like random signal, however,
it is necessary to provide pulses randomly.
Therefore, it is difficult with a small number of
pulses to obtain satisfactory expression of the
background noise. The reduction of the number of
pulses and bit rate suddenly deteriorates the sound
quality with respect to the background noise.
SUMMARY OF THE INVENTION
An object of the present invention, therefore,
3
CA 02325322 2000-11-09
is to solve the above problems and provide a voice
coding and a voice decoding apparatus, which is less
subject to sound quality deterioration with respect
to background noise with relatively less
computational effort even in the lower bit rate case.
According to an aspect of the present invention,
there is provided a voice coding apparatus including
a spectral parameter calculating part for obtaining
a spectral parameter for each predetermined frame of
an input voice signal and quantizing the obtained
spectral parameter, an adaptive codebook part for
dividing the frame into a plurality of sub-frames,
obtaining a delay and a gain from a past quantized
excitation signal for each of the sub-frames by using
an adaptive codebook and obtaining a residue by
predicting the voice signal, an excitation
quantizing part for quantizing the excitation signal
of the voice signal by using the spectral parameter,
and a gain quantizing part for quantizing the gain
of the adaptive codebook and the gain of the
excitation signal, comprising:a mode discriminating
part for extracting a predetermined feature quantity
from the voice signal and judging the pertinent mode
to be either one of the plurality of predetermined
modes on the basis of the extracted feature quantity;
a smoothig part for executing time-wise smoothing of
at least either one of the gain of the excitation
signal, the gain of the adaptive codebook, the
spectral parameter and the level of the excitation
4
CA 02325322 2000-11-09
signal; and a multiplexes part for locally
reproducing synthesized signal by using the smoothed
signal and feeding out a combination of the outputs
of the spectral parameter calculating, mode
discriminating, adaptive codebook, excitation
quantizing and gain quantizing parts.
The mode discriminating part executes mode
discriminatingfor eachframe. Thefeature quantity
is pitch prediction gain. The mode discriminating
part averages the pitch prediction gains each
obtained for each sub-frame over the full frame and
classifying a plurality of predetermined modes by
comparing a plurality of predetermined threshold
values with the average value. The plurality of
predetermined modes substantially correspond to a
silence, a transient, a weak voice and a strong voice
time section, respectively.
According to another aspect of the present
invention, there is provided a voice decoding
apparatus including a multiplexes part for
separating spectral parameter, pitch, gain and
excitation signal as voice data from a voice signal,
an excitation signal restoring part for restoring an
excitation signal from the separated pitch,
excitation signal and gain, a synthesizing filter
part for synthesizing a voice signal on the basis of
the restored excitation signal and the spectral
parameter, and a post-filter part for post-filtering
the synthesized voice signal by using the spectral
5
CA 02325322 2000-11-09
parameter, comprising: an inverse filter part for
estimating an excitation signal through an inverse
post-filtering and inverse synthesis filtering on
the basis of the output signal of the post-filter part
and the spectral parameter, and a smoothing part for
executing clockwise filtering of at least either one
of the level of the estimated excitation signal, the
gain and the spectral parameter, the smoothed signal
or signals being fed to the synthesis filter part,
the synthesized signal output thereof being fed to
the post-filter part to synthesize a voice signal.
According to other aspect of the present
invention, there is provided a voice decoding
apparatus including a multiplexer part for
separating a mode discrimination data, spectral
parameter, pitch, gain and excitation signal on the
basis of a feature quantity of a voice signal to be
decoded, an excitation signal restoring part for
restoring an excitation signal from the separated
pitch, excitation signal and gain, a synthesis filter
part for synthesizing the voice signal by using the
restored excitation signal and the spectral
parameter, and a post-filter part for post-filtering
the synthesized voice signal by using the spectral
parameter, comprising: an inverse filter part for
estimating the voice signal on the basis of the output
signal of the post-filter part and the spectral
parameter through an inverse post-filtering and
inverse synthesis filtering, a smoothing part for
6
CA 02325322 2000-11-09
executing time-wise smoothing of at least either one
of the level of the estimated excitation signal, the
gain and the spectral parameter, the smoothed signal
being fed to the synthesis filter part, the synthesis
signal output thereof being fed to the post-filter
part.
The mode discriminating part executes mode
discriminating for eachframe. Thefeature quantity
is the pitch prediction gain. The mode
discrimination is executed by averaging the pitch
prediction gains each obtained for each sub-frame
over the full frame and comparing the average value
thus obtained with a plurality of predetermined
threshold values. The plurality of predetermined
modes substantially correspond to a silence, a
transient, a weak voice and a strong voice time
section, respectively.
According to still other aspect of the present
invention, there is provided a voice decoding
apparatus for locally reproducing a synthesized
voice signal on the basis of a signal obtained through
time-wise smoothing of at least either one of
spectral parameter of the voice signal, gain of an
adaptive codebook, gain of an excitation codebook and
RMS of an excitation signal.
According to further aspect of the present
invention, there is provided a voice decoding
apparatus for obtaining a residue signal from a
signal obtained after post-filtering through an
7
CA 02325322 2000-11-09
inverse post-synthesis filtering process, executing
a voice signal synthesizing process afresh on the
basis of a signal obtained through time-wise
smoothing of at least one of RMS of residue signal,
spectral parameter of received signal, gain of
adaptive codebook and gain of excitation codebook and
executing a post-filtering process afresh, thereby
feeding out a final synthesized signal.
According to still further aspect of the
present invention, there is provided a voice decoding
apparatus for obtaining a residue signal from a
signal obtained after post-filtering through an
inverse post-synthesis filtering process, and in a
mode determined on the basis of a feature quantity
of a voice signal to be decoded or in the case of
presence of the feature quantity in a predetermined
range, executing a voice signal synthesizing process
afresh on the basis of a signal obtained through
time-wise smoothing of at least either one of RMS of
the residue signal, spectral parameter of a received
signal, gain of an adaptive codebook and gain of an
excitation codebook, and executing a post-filtering
process afresh, thereby feeding out a final
synthesized signal.
According to other aspect of the present
invention, there is provided a voice coding method
including a step for obtaining a spectral parameter
for each predetermined frame of an input voice signal
and quantizing the obtained spectral parameter, a
8
CA 02325322 2000-11-09
step for dividing the frame into a plurality of
sub-frames, obtaining a delay and a gain from a past
quantized excitation signal for each of the sub-
frames by using an adaptive codebook and obtaining
a residue by predicting the voice signal, a step for
quantizing the excitation signal of the voice signal
by using the spectral parameter, and a step for
quantizing the gain of the adaptive codebook and the
gain of the excitation signal, further comprising
steps of: extracting a predetermined feature
quantity from the voice signal and judging the
pertinent mode to be either one of the plurality of
predetermined modes on the basis of the extracted
feature quantity; executing time-wise smoothing of
at least either one of the gain of the excitation
signal, the gain of the adaptive codebook, the
spectral parameter and the level of the excitation
signal; and locally reproducing synthesized signal
by using the smoothed signal and feeding out a
combination of the outputs of the spectral parameter
data, mode discriminating data, adaptive codebook
data, excitation quantizing data and gain quantizing
data.
According to still other aspect of the present
invention, there is provided a voice decoding method
including a step for separating spectral parameter,
pitch, gain and excitation signal as voice data from
a voice signal, a step for restoring an excitation
signal from the separated pitch, excitation signal
9
CA 02325322 2000-11-09
and gain, a step for synthesizing a voice signal on
the basis of the restored excitation signal and the
spectral parameter, and a step for post-filtering the
synthesized voice signal by using the spectral
parameter, further comprising steps of: estimating
an excitation signal through an inverse post-
filtering and inverse synthesis filtering on the
basis of the post-filtered signal and the spectral
parameter; and executing clockwise filtering of at
least either one of the level of the estimated
excitation signal, the gain and the spectral
parameter, the smoothed signal or signals being fed
to the synthesis filtering, the synthesized signal
output thereof being fed to the post-filtering to
synthesize a voice signal.
According to further aspect of the present
invention, there is provided a voice decoding method
including a step for separating a mode discrimination
data, spectral parameter, pitch, gain and excitation
signal on the basis of a feature quantity of a voice
signal to be decoded, a step for restoring an
excitation signal from the separated pitch,
excitation signal and gain, a step for synthesizing
the voice signal by using the restored excitation
signal and the spectral parameter, and a step for
post-filtering the synthesized voice signal by using
the spectral parameter, comprising steps of:
estimating the voice signal on the basis of the
post-filtered signal and the spectral parameter
CA 02325322 2000-11-09
through an inverse post-filtering and inverse
synthesis filtering; and executing time-wise
smoothing of at least either one of the level of the
estimated excitation signal, the gain and the
spectral parameter; the smoothed signal being fed to
the synthesis filtering, the synthesis signal output
thereof being fed to the post-filtering.
According to still further aspect of the
present invention, there is provided a voice decoding
method for locally reproducing a synthesized voice
signal on the basis of a signal obtained through
time-wise smoothing of at least either one of
spectral parameter of the voice signal, gain of an
adaptive codebook, gain of an excitation codebook and
RMS of an excitation signal.
According to still other aspect of the present
invention, there is provided a voice decoding method
for obtaining a residue signal from a signal obtained
after post-filtering through an inverse post-
synthesis filtering process, executing a voice
signal synthesizing process afresh on the basis of
a signal obtained through time-wise smoothing of at
least one of RMS of residue signal, spectral
parameter of received signal, gain of adaptive
codebook and gain of excitation codebook and
executing a post-filtering process afresh, thereby
feeding out a final synthesized signal.
According to other aspect of the present
invention, there is provided a voice decoding method
11
CA 02325322 2000-11-09
for obtaining a residue signal from a signal obtained
after post-filtering through an inverse post-
synthesis filtering process, and in a mode determined
on the basis of a feature quantity of a voice signal
to be decoded or in the case of presence of the feature
quantity in a predetermined range, executing a voice
signal synthesizing process afresh on the basis of
a signal obtained through time-wise smoothing of at
least either one of RMS of the residue signal,
spectral parameter of a received signal, gain of an
adaptive codebook and gain of an excitation codebook,
and executing a post-filtering process afresh,
thereby feeding out a final synthesized signal.
Other objects and features will be clarified
from the following description with reference to
attached drawings.
BRIEF DESCRIPTION OF THE DRAWINGS
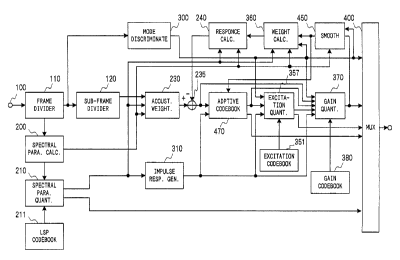
Fig. 1 is a block diagram showing a first
embodiment of the voice coding apparatus according
to the present invention;
Fig. 2 is a block diagram showing a second
embodiment of the voice coding apparatus according
to the present invention; and
Fig. 3 is a block diagram showing a third
embodiment of the voice coding apparatus according
to the present invention.
PREFERRED EMBODIMENTS OF THE INVENTION
Preferred embodiments of the present invention
will now be described with reference to the drawings .
12
CA 02325322 2000-11-09
Fig. 1 is a block diagram showing a first
embodiment of the voice coding apparatus according
to the present invention. Referring to Fig. 1, a
frame circuit 110 divides a voice signal inputted
from an input terminal 100 into frames (of 20 msec.,
for instance). A sub-frame divider circuit 120
divides each voice signal frame into sub-frames (of
5 msec. for instance) shorter than the frame.
A spectral parameter calculating circuit 200
cuts out the voice from at least one voice signal
sub-frame as window (of 24 msec., for instance)
longer than the sub-frame length, and calculates a
spectral parameter in predetermined degree (for
instance P - 10). The spectral parameter may be
calculated by using well-known LPC analysis and, Brug
analysis, etc. In this description, the use of the
Brug analysis is assumed. The Brug analysis is
detailed in Nakamizo, "Signal analysis and system
identification", Corona Co., Ltd., pp. 82-87, 1988
(Literature 4), and is not described here. The
circuit 200 converts linear prediction coefficients
cr; ( i being 1 to 10 ) , calculated by the Brug analysis,
to LSP parameter suited for quantization and
interpolation. As for the conversion of the linear
prediction coefficients to the LSP parameter,
reference may be had to Sugamura et al, "Voice data
compression in linear spectrum pair (LSP) voice
analysis and synthesis system", Trans. ECIC Japan,
J64-A,pp.599-606,1981(Literature5). For example,
13
CA 02325322 2000-11-09
the circuit 200 converts linear prediction
coefficients obtained in the 2-nd and 4-th sub-frames
by the Brug method to LSP parameter data, obtains LSP
parameter data in the 1-st and 3-rd sub-frames by
interpolation, inversely converts the 1-st and 3-
rd sub-frame LSP parameter data to restore linear
prediction coef f is Tents , and thus feeds out the 1-st
to 4-th sub-frame linear prediction coefficients cr
il (i being 1 to 10, 1 being 1 to 5) to an acoustic
weighting circuit 210. The circuit 200 further feeds
out the 4-th sub-frame LSP parameter data to a
spectral parameter quantizing circuit 210.
A spectral parameter quantizing circuit 210
efficiently quantizes LSP parameter in predetermined
sub-frame, and feeds out quantized LSP value for
minimizing distortion given as
D~ _ ~W(i)[LSP(i) -QLSP(i)~ JZ ( 1 )
where LSP(i), QLSP(i)j and W(i) are the i-th LSP
before the quantization, the j-th result obtained
after the quantization and the weighting coefficient.
An LSP codebook 211 is referred by the spectral
parameter quantizing circuit 210.
In the following, it is assumed that vector
quantization is used and that the 4-th sub-frame LSP
parameter is quantized. The LSP parameter may be
vector quantized by a well-known method. Specific
examples of the method are described in Japanese
Patent Laid-Open No. 4-171500 (Japanese Patent
14
CA 02325322 2000-11-09
Application No. 2-297600) (Literature 6), Japanese
Patent Laid-Open No. 4-363000 (Japanese patent
Application No. 3-261925) (Literature 7), Japanese
Patent Laid-Open No. 5-6199 (Japanese Patent
Application 3-155049) (Literature 8) and T. Nomura
et al, "LSP Coding Using VQ-SVQ With Interpolation
in 4,075 kbps M-LCELP Speech Coder", Proc. Mobile
Multimedia Communication, pp. B. 2.5, 1993
(Literature 9), and are not described here.
The spectral parameter quantizing circuit 210
restores the 1-st to 4-th LSP parameters from the
quantized LSP parameter data obtained in the 4-th
sub-frame. Specifically, the circuit 210 restores
the 1-st to 3-rd sub-frame LSP parameters by
executing linear interpolation from the 4-th sub-
frame quantized LSP parameter data in the prevailing
frame and immediately preceding frames . The 1-st to
4-th sub-frame LSP parameters can be restored by
linear interpolation after selecting one kind of
codevector corresponding to minimum error power
level between the LSP parameter data before and after
the quantization. For further performance
improvement, it is possible to arrange such as to
select a plurality of candidates of the codevector
corresponding to the minimum error power level,
evaluate cumulative distortion about each candidate
and select a set of a candidate minimizing cumulative
distortion and the interpolated LSP parameter data.
For further detail, reference may be had to, for
CA 02325322 2000-11-09
instance, Japanese Patent Laid-Open No. 6-222797
(Japanese Patent Application No. 5-8737)(Literature
10).
The spectral parameter quantizing circuit 210
converts the thus restored 1-st to 3-rd sub-frame LSP
and quantized 4-th sub-frame LSP parameter data to
the linear prediction coefficients ~x il ( i being 1 to
10, 1 being 1 to 5 ) for each sub-frame, and feeds out
the coefficient data thus obtained to an impulse
response calculating circuit 310. The circuit 210
further feeds out an index representing the
codevector of the quantized 4-th sub-frame LSP
parameter to a multiplexer 400.
An acoustic weighting circuit 230, receiving
the linear prediction coeff icients cr il ( i being 1 to
10, 1 being 1 to 5) in each sub-frame, executes
acoustic weighting of the sub-frame voice signal in
the manner as described in Literature 1 noted above,
and feeds out an acoustically weighted signal.
A response signal calculating circuit 240
receives the linear prediction coefficients cr;l in
each sub-frame from the spectral parameter
calculating circuit 200, and the interpolated,
quantized and restored linear prediction
coefficients cr il from the spectral parameter
quantizing circuit 210, then calculates a response
signal with input signal made to be zero d(n) = 0 for
one sub-frame by using preserved filter memory values,
and feeds out the calculated response signal to a
16
CA 02325322 2000-11-09
subtracter 235. The response signal xz(n) is given
as
xZ(n)=d(n)-~ aid(n-i)+~a;y'y(n-i)+
'~ '~ (2 )
~a; ~YIxZO-t)
when n - i s 0
y(n - i) = p(N + (n - i)) (3)
xZ (n - i) = sw (N + (n - i)) (4)
where N is the sub-frame length, y is a weight
coefficient for controlling the extent of the
acoustic weighting and the same as the value given
by Equation ( 7 ) given below, and sw( n ) and p ( n ) are
the output signal of a weighting signal calculating
circuit to be described later and the output signal
as denomenator of the right side first term filter
in Equation (7) given below, respectively.
The subtracter 235 subtracts the response
signal from the acoustically weighted signal for one
sub-frame as shown by the equation shown below, and
feeds out x' W ( n ) to an adaptive codebook circuit 300 .
xW~ (n) = xw (n) - xz (n)
The impulse response calculating circuit 310
calculates a predetermined number of impulse
responses hW(n) of acoustic weighting filter, in
which z transform is expressed by the following
equation, and feeds out the calculated data to the
adaptive codebook circuit 470 and an excitation
17
CA 02325322 2000-11-09
quantizing circuit 350.
1- ~ a;z-'
io io 1 ~6)
1-~atY~z t 1-~ai~Y~z t
''i''s~~
A mode discriminating circuit 300 executes mode
discrimination for each frame by extracting a feature
quantity from the frame circuit output signal. As
feature quantity the pitch prediction gain may be
used. Specifically, in this case the circuit 800
averages the pitch prediction gains obtained in the
individual sub-frames over the full frame, and
executes classification into a plurality of
predetermined modes by comparing the average value
with a plurality of predetermined threshold values.
Here, it is assumed that four different modes are
provided. Specifically, it is assumed that modes 0
to 3 are set substantially for a silence, a transient,
a weak voice and a strong voice time sections,
respectively. The circuit 800 feeds out mode
discrimination data thus obtained to the excitation
quantizing circuit 350, a gain quantizing circuit 365
and the multiplexer 400.
The adaptive codebook circuit 470 receives the
past excitation signal v(n) from the gain quantizing
circuit 370, output signal x' W ( n ) from the subtracter
235 and acoustically weighted impulse response hw(n)
from the impulse response calculating circuit 310,
then obtains a delay T corresponding to the pitch such
as to minimize the distortion given by the following
18
CA 02325322 2000-11-09
equation, and feeds out an index representing the
delay to the multiplexes 400.
N-1 N-1 N-1
DT =~xw~2(n)- yxW~(n)YW(n-T) ~Z~~~YWz(n-T)~ (
n. n~ n=
where
yw (n - Twh ) = v(n - T ) * hw (n) (8)
In Equation (8), symbol * represents
convolution.
The adaptive codebook circuit 500 then obtains
gain ,Q given as
N-1 N-1
~ _ ~xW~(n)Yw(n-T)~~ Y"~2(n-T) (9)
n= n=
For improving the accuracy of delay extraction
for women' s and children' s voices, the delay may be
obtained as decimal sample value instead of integer
sample value. As for a specific method, reference
may be had to, for instance, P. Kroon et al, "Pitch
predictors with high temporal resolution", Proc.
ICASSP, pp. 661-664, 1990 (Literature 11).
The adaptive codebook circuit 470 further
executes pitch prediction as in the following
Equation ( 10 ) , and feeds out the prediction residue
signal eW(n) to the excitation quantizing circuit
355.
eW (n) = xW~ (n) - w(n -T ) * hW (n) (10)
The excitation quantizing circuit 355 receives
mode discrimination data, and switches the
excitation signal quantizing methods on the basis of
the discriminated mode.
19
CA 02325322 2000-11-09
It is assumed that M pulses are provided in the
modes 1 to 3. It is also assumed that in the modes
1 to 3 an amplitude or a polarity codebook of B bits
is provided for collective pulse amplitude
quantization of M pulses. Thefollowing description
assumes the case of using a polarity codebook. The
polarity codebook is stored in an excitation codebook
351.
In the voice section, the excitation quantizing
circuit 355 reads out individual polarity
codevectors stored in the excitation codebook 351,
allots a pulse position to each read-out codevector,
and selects a plurality of sets of codevector and
pulse position, which minimize the following
equation (11).
N-1 M
Dk = ~ Lew \n) - ~ gik'~w O - mi )~2
n= t=
where hw(n) is the acoustically weighted impulse
response. The Equation (11) may be minimized by
selecting a set of polarity codevector gik and pulse
position mi, which maximizes the following equation
(12).
N-1 N-1
D(k,i) - ~~ ew ln)Swk lmi )JZ ~ ~ Swk z ~~i ) 12
ns n-
Alternatively, it is possible to select a set,
which maximizesthefollowing Equation(13). In this
case, the computational effort necessary for the
numerator calculation is reduced.
CA 02325322 2000-11-09
N-1 N-1
D~k,~~ _ ~~ ~'(n)vk (n)~2 ~ ~ sWk z (m~ ) (13)
n= n-
N-1
where ~(n) _ ~ e", (i)hW (i - n), n = 0,..., N -1 (14)
i~n
For computational effort reduction, the
positions which can be allotted for the individual
pulses in the modes 1 to 3, can be restricted as shown
in Literature 3. As an example, assuming N = 40 and
M = 5, the positions which can be allotted by the
individual pulses are as shown in Table 1 below.
Table 1
PULSE No. POSITION
1ST PULSE 0, 10,15, 20, 25, 30,
5, 35
2ND PULSE 1, 11,16, 21, 26, 31,
6, 36
3RD PULSE 2, 12,17, 22, 27, 32,
7, 37
4TH PULSE 3, 13,18, 23, 28, 33,
8, 38
5TH PULSE 4, 14,19, 24, 29, 34,
9, 39
After the end of polarity codevector retrieval,
the excitation quantizing circuit 355 feeds out the
selected plurality of sets of polarity codevector and
position to the gain quantizing circuit 370. In a
predetermined mode ( i . a . , the mode 0 in this case ) ,
a plurality of extents of shifting the pulse
positions of all the pulses are predetermined by
determining the pulse positions at a predetermined
interval as shown in Table 2. In the following
example, for different extents of shift ( i.e. , shifts
0 to 3 ) are used, to which the positions are shifted
by one sample after another. In this case, the shift
21
CA 02325322 2000-11-09
extents are transmitted by quantizing them in two
bits.
Table 2
SHIFT AMOUNT POSITION
0 0, 4, 8, 12, 16, 20, 24, 28,
32, 36
1 1, 5, 9, 13, 17, 21, 25, 29,
33, 37
2 2, 6, 10, 14, 18, 22, 26, 30,
34, 38
3 3, 7, 11, 15, 19, 23, 27, 31,
35, 39
The polarities corresponding to the individual
shift extents and pulse positions shown in Table 2
are preliminarily obtained from the above Equation
(14).
The pulse positions shown in Table 2 and
corresponding polarities are fed out for each shift
extent to the gain quantizing circuit 365.
The gain quantizing circuit 370 receives the
mode discrimination data from the mode
discriminating circuit 300. In the modes 1 to 3, the
circuit 370 receives a plurality of sets of polarity
codevector and pulse position, and in the mode 0 it
receives the set of pulse position and corresponding
polarity for each shift extent.
The ga in quant iz ing c ircu it 3 7 0 reads out gain
codevector from the gain codebook 380. In the modes
1 to 3, the circuit 370 executes gain codevector
retrieval for the plurality of selected sets of
polarity codevector and pulse position such as to
minimize the following Equation ( 15 ) , and selects one
set of gain and plurality codevectors, which
minimizes distortion.
22
CA 02325322 2000-11-09
N-1 M
Dk = ~ [x", (n) - ~ ~ rv(n - T ) * hw (n) - G ~r ~ g ~,khW (n - m; )]2
ns '''gym
In the above example, both the excitation gains
represented by the gain and pulse of the adaptive
codebook are simultaneously vector quantized. The
gain quantizing circuit 370 feeds the index
representing selected polarity codevector, the code
representing pulse position and the index
representing gain codevector to the multiplexer 400.
When the discrimination data is in the mode 0,
the gain quantizing circuit 370 receives a plurality
of shift extents and polarity corresponding to each
pulse position in each shift extent case, executes
gain codevector retrieval, and selects one set of
gain codevector and shift extent, which minimizes the
following Equation (16).
N-1 M
Dk =~[x",(n)-~~rv(n-T)*hw(n)-G~r~g~~khw(n-m; -b(j))]2 (16)
nm ~'i~''f.
where ,C~, k and G' k is the k-th codevector in a
two-dimensional gain codebook stored in the gain
codebook 380, ~ ( j ) is the j-th shift extent, and g'
k is the selected gain codevector. The circuit 370
feeds out index representing the selected gain
codevector and code representing the shift extent to
the multiplexer 400.
In the modes 1 to 3, it is possible as well to
preliminarily learn and store a codebook for
amplitude quantization of a plurality of pulses by
using voicesignal. Asfor codebooklearning method,
23
CA 02325322 2000-11-09
reference may be had to Linde et al, "An algorithm
for vector quantization design", IEEE Trans.Commun.,
pp. 84-95, January, 1980 (Literature 12).
A smoothing circuit 450 receives the mode data
and, when the received mode data is in a predetermined
mode (for instance the mode 0), executes time-wise
smoothing of at least either one of gain of excitation
signal in gain codevector, gain of adaptive codebook,
RMS of excitation signal and spectral parameter.
The gain of excitation signal is smoothed in
a manner as given by the following equation.
G~ (m)=~, GL (m-1)+(1-~,)G't (m) (17)
where m is the sub-frame number.
The gain of adaptive codebook is smoothed in
a manner as given by the following equation.
/~~ (m)=~~t (m-1)+(1-~)~~~ (m) (1g)
The RMS of excitation signal is smoothed in a
manner as given by the following equation.
RMS (m) _ ~, RMS (m -1) + (1- ~, ) RMS (m) (19)
The spectral parameter is smoothed in a manner
as given by the following equation.
LSP; (m) = a, LsP; (m -1 ) (1- a, ) LsP; (m) (20)
A weighting signal calculating circuit 360
receives the mode discrimination data and the
smoothed signal output of the smoothing.circuit and,
in the cases of the modes 12 to 3, obtains drive
excitation signal v(n) as in the above Equation (21).
M
v(n) _ ~ ~ ~(n - T) + G', ~ g' ;k b (n - m; ) (21)
24
CA 02325322 2000-11-09
The weighting signal calculating circuit 360
feeds out v( n ) to the adaptive codebook circuit 470 .
In the case of the mode 0, the weighting signal
calculating circuit 360 obtains drive excitation
signal v ( n ) in the manner as given by Equation ( 22 ) .
_ _ M
v(n) _ ~3vt (n - T) + Gt ~ g~~x ~ (n - m; - b (j)) (22)
,s
The weighting signal calculating circuit 360
feeds out v(n) to the adaptive codebook circuit 470.
The weighting signal calculating circuit 360
calculates response signal xw(n) for each sub-frame
by using the output parameters of the spectral
parameter calculating circuit 200, the spectral
parameter quantizing circuit 210 and the smoothing
circuit 450. In the modes 1 to 3, the circuit 360
calculates xW ( n ) as given by Equation ( 23 ) , and feeds
out the calculated xw(n) to the response signal
calculating circuit 240.
x W (n) = v(n) - ~ aiv(n - i) + ~ ai y' p(n - i) + ~ a~ y'sw (n - i) (23)
1' im i~
In the mode 0, the weighted signal calculating
circuit 500 receives smoothed LSP parameter obtained
in the smoothing circuit 450, and converts this
parameter to smoothedlinear prediction coefficient.
The circuit 360 then calculates response signal xW(n)
as given by Equation ( 24 ) , and feeds out the response
signal xw(n) to the response signal calculating
circuit 240.
CA 02325322 2000-11-09
io _ io _ io _
x ~,, (n) = v(n) - ~ a; v(n - i) + ~ a ; y 'p(n - i) + ~ a; y 's ", (n - i)
(24)
,_ ~_ ,_
A second embodiment of the present invention
will now be described with reference to drawings.
A demultiplexer 500 separates, from the
received signal, index representing gain codevector,
index representing delay of adaptive codebook, data
of voice signal, index of excitation codevector and
index of spectral parameter, and feeds out individual
separated parameters.
A gain decoding circuit 510 receives index of
gain codevector and mode discrimination data, and
reads out and feeds out the gain codevector from a
gain codebook 380 on the basis of the received index.
An adaptive codebook circuit 520 receives mode
discrimination data and delay of adaptive codebook,
generates adaptive codevector, multiplies gain of
adaptive codebook by gain codevector, and feeds out
the resultant product.
When the mode discrimination data is in the
modes 1 to 3, an excitation restoring circuit 540
generates an excitation signal on the basis of the
polarity codevector, pulse position data and gain
codevector read out from excitation codebook 351, and
feeds out the generated excitation signal to an adder
550.
The adder 550 generates the drive excitation
signal v(n) by using the outputs of the adaptive
codebook circuit 520 and the excitation signal
26
CA 02325322 2000-11-09
decoding circuit 540, feeds out the generated v(n)
to a synthesizing filter circuit 560.
A spectral parameter decoding circuit 570
decodes the spectral parameter, executes conversion
thereof to linear prediction coefficient, and feeds
out the coefficient data thus obtained to a
synthesizing filter circuit 560.
The synthesizing filter circuit 560 receives
the drive excitation signal v(n) and linear
prediction coefficient, and calculates reproduced
signal s(n).
A post-filtering circuit 600 executes post-
filtering for masking quantized noise with respect
to the reproduced signal s(n), and feeds out
post-ffiltered output signal Sp(n). The post-ffilter
has a transfer characteristic given by Equation (25) .
H(z)= [1- ~a~i Y~ 'z ' ]/[ly,a~i Yz 'z ' ] (25)
's
An inverse post/synthesizing filter circuit
610 constitutes inverse-filter of post and
synthesizing filters, and calculates a residue
signal e(n). The inverse filter has a transfer
characteristic given by Equation (26).
P(z) =(1/H(z)][1-~ a~; z-' ] (26)
'~
A smoothing circuit 620 executes time-wise
smoothing of at least either one of gain of excitation
signal in gain codevector, gain of adaptive codebook,
27
CA 02325322 2000-11-09
RMS of residue signal and spectral parameter. The
gain of excitation signal, the gain of adaptive
codebook and the spectral parameter are smoothed in
manners as given by the above Equations (17), (18)
and (20), respectively. RMSe(m) is the RMS of the
m-th sub-frame residue signal.
RMSe (m) _ ~. RMSe (m -1) + ( 1- ~, ) RMS a (m) (27)
The smoothing circuit 620 restores the drive
excitation signal by using the smoothed parameter or
parameters. The instant case concerns the
restoration of drive voice surface signal by
smoothing the RMS of residue signal as given by the
following Equation (28).
e(n) _ [ e(n) / RMSe (m)] RMSe (m) (28)
The synthesizing filter 560 receives drive
excitation signal e(n) obtained by using the smoothed
parameter or parameters, and calculates reproduced
signal s(n) . As an alternative, it is possible to use
smoothed linear prediction coefficient.
The post filter 600 receives the pertinent
reproduced signal, executes post-filtering thereof
to obtain final reproduced signal sp(n), and feeds out
this signal.
Fig. 3 is a block diagram showing a third
embodiment. In Fig. 3, parts like those in Fig. 2
are designated by like reference numerals, and are
28
CA 02325322 2000-11-09
no longer described.
Referring to Fig. 3, an inverse
post/synthesizing filter circuit 630 and a smoothing
circuit 640 receive discrimination data from a
demultiplexer 500 and, when the discrimination data
is in a predetermined mode (for instance mode 0),
executes their operations. These operations are the
same as those of the inverse post/synthesizing filter
circuit 610 and the smoothing circuit 620 in Fig. 2,
and then no longer described.
As has been described in the foregoing, in the
voice coding apparatus according to the present
invention a synthesized signal is locally reproduced
by using the data obtained by time-wise smoothing of
at least either one of spectral parameter, gain of
adaptive codebook, gain of excitation codebook and
RMS of excitation signal. Thus, even with voice with
background noise superimposed thereon, it is
possible to suppress local time-wise parameter
variations in the background noise part even at a low
bit, thus providing coded voice less subject to sound
quality deterioration.
Also, in the voice decoding apparatus according
to the present invention, used on decoding side, a
residue signal is obtained from a signal obtained
after post-filtering in an inverse post-synthesis
filtering process, a voice signal synthesizing
process is executed afresh on the basis of a signal
obtained as a result of time-wise smoothing of at
29
CA 02325322 2000-11-09
least either one of RMS residue signal, spectral
parameter of received signal, gain of adaptive
codebook, and gain of excitation codebook, and a
post-filtering process is executed afresh, thereby
feeding out a final synthesized signal. Processes
thus may be added as perfect post-processes to the
prior art decoding apparatus without any change or
modification thereof. It is thus possible to
suppress local time-wise parameter variations in the
background noise part and provide synthesized voice
less subject to sound quality deterioration.
Furthermore, in the voice decoding apparatus
according to the present invention, a parameter
smoothing process is executed in a predetermined mode
or in the case of presence of feature quantity in a
predetermined area. It is thus possible to execute
process only in a particular time section (for
instance a silence time section) . Thus, even in the
case of coding voice with background noise
superimposed thereon at a low bit, the background
noise part can be satisfactorily coded without
adversely affecting the voice time section.
Changes in construction will occur to those
skilled in the art and various apparently different
modifications and embodiments may be made without
departing from the scope of the present invention.
The matter set forth in the foregoing description and
accompanying drawings is offered by way of
illustration only. It is therefore intended that
CA 02325322 2000-11-09
the foregoing description be regarded as
illustrative rather than limiting.
31