Note: Descriptions are shown in the official language in which they were submitted.
CA 02337798 2001-O1-03
WO 00/02138 PCTIUS99/15236
A METHOD FOR PERFORMTNG MARKET SEGM$NTATION AND
FOR BREDxCTING CONSUMER DEMAND
FIELD OF TbiE IN'~TF1NTION
The present invention relates ger_erally to methods
fox performing market segmentation and to methods predicting
consumer demand. More specifically, the present invention
performs market segmer_tation by determining dissimilarity
measures and predicts consumer demand by constructing a
~0 landscape of consumer demand through focused sampling.
HACKfiROOND
The problem of determining what combination of
factors in a given product (from toothpastes to coakiea or
15 cars) will attract eus~omers is a difficult one because the
relatxor._ahip between ;.he factors may be highly nonlinear and
because the ratings of factors by customers may be biased for
various reasons (formulation of the questions, rating scale,
customer answers do not reflect actual pxeferences, etc.).
20 gor marketing purposes, a company would like to be able to
find clusters composed of a sufficient number of customers
with similar px'eferences in order to either launch a new
produce, or adjust an existing pxoduct. adapted to such
preferences. Of critical importance is that customers with
25 s_milar sets of preferences be assigned to the same Cluster
and that customers with significantly different sets of
preferences be assigned to different clusters.
Clustering al~gorithma exist that can generate
c'uaters that satisfy either one or both of these
30 constraints. Multidimensional scaling methods go one step
furt:.er to allow visualization of high-dimensional data
clusters in a low-dimensional embedding space. Hut
c_ustering algorithms and multidimensional scaling methods
always assume the existence of a well-defined metric or
35 dissimilarity measure in attribute space, here the space of
factors that contribute to a product.
CA 02337798 2001-O1-03
WO 00/02138 PCT/U599/I5236
Accordingly, there exists a need for a method for
partitioning that provides both a relevant metric and a set
of clusters.
Vext, a large body of mathematical and statistical
work exists concerning means to estimate the optimal
composition of a good or service for a given customer, ox
population of customs=s. This body of Work contains
techniques, known in the art, such as CART, and discrete
choice providing means -_"or determining utility functions aver
lp a space of properties o' a good or service for a given
consumer, ae well as means of considering a population of
different custcmers with different preferences oveY that
space of properties and attempting to "segment" the customer
population into subgroups which may then be specifically
15 targeted by marketing, or shifting the property mix of each
product produced and tlae vector of products to "match"
optimally the customer population. Typically the aim ie to
maximize profit for th~~ firm.
The means in the art, in general, attempt to fit
Zp the observed data points by building up sketches of the
utility surface for a given consumer or class of consumers
using, in the simples. case, linear regression of the data
points on all the property axes. Different classes of
consumers are discriminated by discovering different linear
25 regression patterns for different, e.g., demographic classes.
Ir_ more sophisticated approaches, attempts are made to model
the possibly curved properties of ~isoult=lity " surfaces in
the space of properties for a given consumer, or class of
cons~:mers, by fitting higher order polynomials to the sampled
3p data. ~he generic prob:Lem with this approach is that the data
sampled must be used co estimate the coefficients of the
monomial and polynomial terms, and the finite amount of data
is typically used to characterize the lowest order terms,
monomial, quadratic, et:c, first. The data is typically "used
35 up in obtaining reliab7!e statistical estimates of these low
order terms, and little; or none is left over for use
estimating higher order terms.
_ 2
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
On the other hand, the higher order terms are
precisely the measures of the complex context dependent
interactions among properties of a single good or service or
a collection of goods or services. A trivial example ie
breakfast, consisting of ham and eggs. These two are
traditior_ally called "consumption complements" by economists,
The utility of ham for many consumers is much highex in the
presence of eggs, than. alone; so too with eggs. Another case
is niche marketing of cellular telephones. Not only are these
y0 phones of interest to high volume users with expense
accounts, but to low volume users who happen to be women with
small children driving in rural areas and worried about an
accident and no means of calling for help. The context
dependence of the properties: woman, mother, with child in
car, accident and safety demonstrates the combinatorial
character of one niche. occupied by this product.
On a simplex '_evel, a given product, say soap,
might be characterized. by a number of features: color, shape,
smell, saponin content, mass, etc. Or coca-cola packaging may
be characterized by a number of properties, number of cans,
size of cans, fluid in can, colox of package, etc.
Accordingly, there is also a need for a method for
determining Consumer dlemand that finds the context dependent,
or combinatorial optimized set of propertiesr uses, or
customer features that. optimize Lhe value of a product to the
customer base.
s~Y OF THE INVENTION
The present invention presents a method for
partitioning that provides both a relevant metric and a set
of clusters through an evolutionary learning process.
It is an asx>ect of the present invention to present
a method for partitioning a space of data Comprising the
steps of:
choosing a plurality of dissimilarity measures]
- 3 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
partitioning the space for each of said plurality
of dissimilarity measures;
evaluating said partitioning for each of said
plurality of dissimilarity measures; and
S selecting on.e or more of said dissimilarity
measures on the basis of said evaluation.
The present invention ~urther presents a method for
determining consumer demand that finds the context dependent,
or combinatorial optimized set of properties, uses, or
customer features that optimize the value of a product to the
customer base.
It is an aspect of the present invention to present
a method for deterrllning customer demand for products
comprising the steps of:
defining a space having R dimensions wherein each
point in said space corresponds to a vector of properties;
constructing a landscape for said space comprising
the steps of:
locating at least one point on said space
where a predetermined customer would purchase a product
having said corresponding vector of properties at a
predetermined price; and
sampling a set of points on an R-dimensional
sphere surrounding said selected point at a predetermined
Zg step length from said selected point to determine a first
subset of said get of points where the predetermined customer
would make a purchase at said predetermined price and to
determine a second subset of said sampled points where the
customers would not make the purchase at said predetermined
price, said first subset of points and said second subset of
points form at least o;ne indifference surface between a
buying region and a non-buying region at said predetermined
price.
The present invention further includes a framework
for tine marketing and introduction of noval products. The
framework has means to model customers and to derive an
optimal set of goods to produce alone or in the face of a
- 4 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/I5236
coevolving compet'_tive a~nvironment where other firms are
ntroducing and modifying their own goods.
It is a further aspect of the present invention to
present a method fox creating a model of consumer preferences
from consumer data comprising the steps of:
co:~structing a plurality of candidate maps form the
consumer data to actual consumer preferences;
constructing a family of agent-based models;
evaluating said plurality of candidate maps and
lQ said family of agent-based models with respect to said
consumer data;
selecting one or more of said plurality of
candidate maps and said family of agent based models based on
said evaluation; and
performing at least one operation on said selected
candidate maps and said selected agent-based models to
generate a new plurality of candidate maps and a new family
of agent-based models.
2 0 8RI$F DE~3CRIPTION OF TH8 DR.AWINGs
FIG. 1 provides a flow diagram of the adaptive
dissimilarity partitivr~ing method 100 of the present
invention.
FIG. 2 provides a flow diagram of a method for
determining consumer demand 200 that finds the context
dependent, or combinatorial optimized set of properties,
uses, or Customer features that optimize the value of a
product to the customer- base.
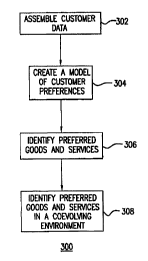
FIG. 3 provides a flow diagxam of the framework 300
for the marketing and introduction of novel products.
FIG. 4 provides a flow diagram of the method for
creating a model of cuEStomer preferences.
FIG. 5 discloses a representative computer system
in conjunction with wh:icr the embodiments of the present
invention may be implemented.
- 5 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
DETAILED DESGRIF'TION OF THE PREFERRED EI~ODIMENT
The present ~Lnvention presents methods for
partitioning that prav:ide both a relevant metric and a set of
clusters through an evolutionary learning process called an
adaptive dissimilarity partitioning methcd. Without
limitation, many of ths: following embodiments of the adaptive
dissimilarity partitioning method are explained in the
illus~rative context of market segmentation. However, it
will be apparent to pe:ceons of ordinary skill in the art that
lp the aspects of the embodiments of the invention are also
applicable in any context in which the natural metric or
dissimilarity measure of attribute space is not precisely
known.
Let us define a set of n m-dimensional data vectors
Xi (i~l~ ~ ~ ~ ~ n) ~ The components xi~ (jø1, . . . , m) may be real
variables, binary vari.~ables, or other types of variables.
The aim of a typical clustering algcrithm is to assign the
data points to clusters to minimize some cost function. A
proto~ype vector is usually associated with each cluster: a
cluster is defined as the set of data vectors that are closer
tc the cluster's prototype than to any other prototype. For
example, in the k-means clustering algori~hm, one has to
determine the coordinates of k prototype vectors yh Ch=1,
..,, k) to minimize the following cost function:
E'k - ~~~~~~h~ ~ yh~~2~
i-1 h=t
where ms;=1 if x. is assigned to clus~er h and m~" = 0
otherwise, and ~...~ is a distance in the space of data
vectors. The k-means clustering algorithm is explained in
Same methods for classification and analysis of mufti variat2
observations, McQueen, J., Proc. Fifth Berkeley Symp. on
Mathematical Statistics and Probability, Vol. 2 (Le Cam, L.
M. & Neyman, J., eds), University of California Press,
-
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
Berkeley, CA, 1965, pp. 281-297. An acceptable clustering
solution is given by {mi"}, where each data vector is assigned
to one and only one clu.ater. In the k-means algorithm, the
cluster prototypes are initialized with the first k data
a vectors. A new data vector xt, irk, is assigned to the
closest prototype vector y";i~. '''he prototype is adjusted in
response to xl, or, moms precisely, is moved closer to xi:
E- + i 1 ~:C~ - yh(;)~.
~h;i) y6(i)
muh(i)
a=1
The total adjustment of the prototype is normalized to the
number of vectors that have already been assigned to that
prototype. A randomized. version of this algorithm,
supplemented with topological constraints on prototypes, is~
the self-organizing map, an unsupervised neural network.
Unsupervised neuxal networks are explained in The self-
Organiaing Map, Kohonen, T., I,990, the contents of which are
herein incorporated by reference. We have assumed the
existence of a well-defined disr.a~ce Ilw'I ~ Sometimes, only
pairwise (or higher-order) relationships among vector
components are availab?e. In such cases, the cost function ~a
be minimized is the product of the dissimilarities of data
vectors assigned to the; same cluster.
Multidimensional scaling (MDS) is used to represent
z0 data points in a two-or three-dimensional Euclidian space
such that pairwise diat,ances in representation space closely
match pairwise dissimil,aritiea as explained in
Multidimensional Scaling, Cox, T. F. & Cox, M. A. A., Chapman
& Hall, London, 1994 (~°Multidimensianal Scaling"), the
Contents of which are herein incorporated by reference. A
clustering algorithm cam be applied to the xepresertation
'vectors. Let y~ be the vector that represents data vector xi.
CA 02337798 2001-O1-03
WO 00/02138 PC'T/US99/15236
Let dlu be the distance between two representation vectors y~,
and y" (d," _ ~~y, -- y"II); avnd Dt" the dissimilarity between xS and
xu. The cost function (also called stress? to be minimized
is typically given by:
n a
r _ 2
~: ~ ~ ~ Wiu\diu Diu) s
I-1 ual
where the weights w~" are introduced to normalize the
absolute values of tha: disparities D;". A common Choice for wiu
is
_ 1
flu - n n '
~iu ~ ~ Da,9
asl Q=I
other definitions of stress and algorithms for minimizing
stress are surveyed by Multidimensional SCalfng.
In both clustering and t~7S, the initial
dissimilarity measure is assumed to be known. Given the
dissimilarity, a clustering algorithm provides clusters
whereas 1~S provides a low-dimensional representation. The
obtained clusters or representations critically depend on the
choice of the dissimz7.arity measure. Such a measure is
usually defined on the: basis of "intuitive" criteria and
relies on the "expert~_se" of the designer. Defining a
dissimilarity measure, however, can in principle be
automated, Clustering ar scaling data, although it is
sometimes used for exploratory data analysis, is usually a
first "preprocessing" step in a particular task to be
performed (compression, understanding, market segmentation,
;5 etc.). The performance: of clustering or MDS can therefore be
measured not only with respect to the cost function or stress
to be minimized but also in connection with the task to be
_ g _
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/I5236
performed. The appropriate dissimilarity measure can be
learned in a supervised manner on a training set, tested on a
validation set, and applied to new data, The proposed
learning algorithm is a: genetic algarithm. Genetic
algorithms are described in Genetic AZgor~thms in Search,
Optitrcization and Machir.~e Learning, Goldberg, D. E,, Addison-
Wesley, Reading, MA,,19~89 (Genetic Algorithms in Search,
Optimization and Machir:e Learning?, the contents of which are
herein incorporated by reference.
FIG. 1 provides a flow diagram of the adaptive
dissimilarity partitioning method 100 of the p=esent
invention. In step 102, the method 100 chooses a family of
of distance functions or dissimilarity measures. In step
104, the method 100 randomly generates a population of
1' dissimilarity meaauresD~ ~ f D~~ or distance functions d° in
the chosen family, where v is the index of a given
dissimilarity measure i,n that population. Each "individual"
v is encoded into a "genotype".
In step 106, the method 100 performs clustering or
multidimensional scaling with a given algorithm for each
distance function. or dissimilarity measure. In step 108, the
method 100 evaluates the performance of clus;.er'ng or
multidimensional scalir,.g and assigns fitness to every
dissimi'arity measure v. In step 120, the method 100 selects
individuals on the basis of fitness. In step 112, the method
100 applies operators to selected individuals and pairs of
individuals. Preferably, the operations are genetic
operators such as mutation and crossover.
. In step 114, the method 100 determines whether the
partitioning results are satisfactory with respect to the
fitness computed in step 108. If the partitioning results
are not satisfactory, control returns to step 106 to perform
clustering or multidimensional scaling for each new distance
v5 functions or dissimilarity measure created in steps 110 and
112, If the partitioning results are satisfactory, control
proceeds to step 116 where the method l00 terminates,
_ g _
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
The distance functicn c. dissimilarity measure can
be represented by a true function of the vectors' coordinates
or by a set of pairwise relationships. when only pairwise
relationships between data vectors are available one needs to
generalize the dissimilarity measure to data vectors Which
have not been presented. The simplest generalizatior.
procedure is to use a locally linear interpolation, using the
k nearest ne_ghbors: the dissimilari~y between the new vector
V and any other vector 0 is given by the average
dissimilarity between the k nearest neighbors of V and 0.
The following examples 111ustrates the operation of
the adaptive dissimilarity partitioning method 100. Let ue
assume for definitene~ss that each data vector xlis two-
dimensional. The twa components of xlrepresent two properties
of a cookie, fcr exam~~le, sweetness and chewiyness. A set of;
n customers is asked 'to determine the respective levels of
sweetness and chewyne~ss they like in a cookie, on a scale of
1 to 10 for each property. In addition, each customer is
asked to tell which type of cookie he or she is currently
using. Assume that k different types of cookies are
represented. The distance function it the space of customer
preferences is unknown. For example, one factor may be more
'_mportant than another. A simple fami~y of distance functions
is:
2lvz
d iu - I J ! ~xt 1 ~ x11 r.Yul ~ xu2,txl:l ~ xut ~ + f2 ~xr 1 ~ xi: ~'xul ~
xuz,(xi2 ~ xuZ ~ s
where fl and f~ are, for example, second-degree polynomial
functions of their variables. Each function is characterized
by 15 parameters, the coefficients of the polynomials. The
variations of these p~~rameters is assumed to be restricted to
x-10,10]. A clusceriog algorithm, such as k-means, is
applied co the data set using this distance function. The
fitness of a distance d" is given by
- 10 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
1
F" _
1 + Min + Ma"e '
where M;" is the number' of customers assigned to the same
g cluster that do no buy the same cookie type and Ma~~ is the
number of customers assigned to different clusters that buy
the same cookie type. Depending on the task at hand, these
two types of mismatch can be give? different weights.
The best individuals obtained after, say, 1000
generations of the genetic algorithm, correspond to distance
functions that allow to obtain the right clusters of
customers in the sense described above.
The adaptive dissimilarity partitioning method 100
or the present invention finds the natural dissimilarity
measure or distance function in a space of attributes. ~hie
function may be unknown. Instead of resorting to ad hoc
functions, the method systematically generates a distance
function adapted to the task at han6. ~'he obtained distance
function reflects the true structure of the space of
2C attribstes and therefore can be used, in the context of
market segmentation, to cluster customers, extract the
"natural" clusters in the data using a non parametric
clustering algorithm (that is, one in which in the number of
clusters zs not predefined), extract the effective dimension
of the space of preferences, test product differentiation,
improve positioning by product adjustment, and test potential
new products, taking into account the Cost of moving from one
product to another or of launchir_g a new product.
Otter significant areas of appl.cation include
protein data visualization, protein function and structure
prediction, dimensiona:Lity reduction for virus data sets,
general classification and pattern recognition problems, and
data visualization, including database visualization and
navigation.
In another eacample, two hundred two-dimensional
data vectors were randomly generated. Let x:l and x;a be the
x- and y-coordinates of the ith data vector. island xsa are
- 11 -
CA 02337798 2001-O1-03
WO 00/02138 PCTNS99/15236
drawn from a uniform random distribution on [C,1). Let us
assume that xi, and xs, represent customer preferences for two
selected features of a given product type, that two products
axe on the market, and that a customer i purchases product 1
if and only if xil<0.5 and purchases product 2 if and only if
xilto.5. In this example, therefore, only x~l is relevant in
the determination of what product ie purchased by a customer
whose preference vector is (xi~, x~,). But vhis information is
not known to the analyst, who simply assumes that the
relevant distance in preference space is, for example, the
Euclidian distance. Using such a distance, the analyst will
be unable to correctly segregate customers into two classes.
WY:at the algorithm has to find is the relevant distance in
preference apace that will naturally lead to the Correct
segregation after application of a simple clustering
algorithm. Here we use: a modified version of the k-creans
clustering algorithm with k=2. Two centroids are initially
located at (0.5, 0.25) and (C.5, 0.75). Ideally, after
application of the clustering algorithm with the appropriate
distance function, the centroids should eor_verge to (0.25,
C.5) and (0.75, O.S). Remember than with this clustering
a?gorithm a data vector belongs to the cluster whose centroid
is closest to that data vector. Let C"~;~ be the centroid
closest to vector x, ( CM(;) ~ ArgMin(d~C,",x;~) , where d is the
distance function), and C"i,;j the jth coordinate (j=1,2) of
C"ti:. The centroid update upon presentation of xs is giver.
by:
3 ~ ~ dlCm(i) > ~i \
Cm(iu E- ~~mC)i + ~ n ~ ~Xij ~ Cm(i~j~~
where d is tree current: distance function, 6() ie the sign
function (Q(u)=+' if a>0, 6(u)~-1 if ue0, and Q=0 if a=0), n
is a learning rate, and n=20C is the number of data vectors..
- 12 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
The family of dietance~ function used in this example has
three parameters:
_a
I l a ~ l ~~a+a
s d ~x;, x,, ~ w~x;; - x 1 + {2 - w) x;2 = x z) ,
where w, a, and ø e[0,2~. When w=1 and a= ø=2, the usual
Euclidian distance is recovered, and when w=1 and a=ø=1 one
l0 gets the city-block (or L1) distance.
This family of distance functions can easily be
generalized to higher-dimensional spaces. For exac:iple, let
us consider a D-dimensional apace:
D
~P
Cl~(x~ " ,aCh ) :~ ~ ~, 1Ny JC~o - .1C>p '°-a f
pa ~
2~ with
D
wp = D,
p=1
where a~(pil,.. .,D) and wp (p=1,. .,D) are 2D parameters (of
which only 2D-1 are fr~ae parameters) that determine the
relative importance of the pth coordinate and the amount of
distortion along the pi:h coordinate. Th1$ family of
functions assumes no correlation among coordinates, which is
certainly a limitation in certain cases. Other distance
functions should be used in such cases.
For the simple two-dimensional example, a simple,
fitness-proportionate (.relitism) genetic algorithm (GA) was
used with the following fitness function for distance d":
- 13 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
1
v__
Min + lYlovt
where Nor is the number cf customers assigned to the same
cluster that do no purchase the same cookie type and Mo,,r is
the number of customers assigned to different clusters'that
buy the same product. The population size was 40, the
.0 mutation. rate 0.1, and crossover was replaced with averaging
of parameters (that is, two selected individuals prcduce one
o~ispring the parameters of which are the arithmetic average
of its parents' parameters). After 10 generations, the GA
finds values of the parameters that consistently produce a
perfect clustering of customers after application of the
modified k-means algorithm. During one application (200
iterations) of the k-means algorithm for "bad" values of the
parameters (w=0.96, a=1.81, p=1.77), close to the Euclidian
distance; the centroids are unable to move to the optimal
locations and remain confined in the vicinity of their
initial values. For "good" values of the parameters found by
the GA after 10 generations (w=1.98, Ot=1.67, (i=0.03), the
centroids move to the optimal locations because the distance
function assigns almost all the weight to the x-coordinate.
The GA has therefore been able to find a distance function,
within the family of distance functicns, that reflects the
"true" structure of preference space.
Assume now that instead of being uniformly
distributed in IO,i] x [0,1] customers form tour clusters
(with the same "purchase" rule: customer i purchases product
1 if and only if xs:<0.5 and purchases product 2 if and only
if xi: z0.5). Two situations can occur: the four clusters may
discriminate along the y-axis or along the x-axis. Upon
application of a non-parametric (number of clusters
undefined) clustering or multidimensional scaling algorithm,
the situation where th.e four clusters may discriminate alo:~g
the y-axis should lead. to the detection of 2 clusters while
- 14 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
the situation Where the four clusters discriminate along the
x-axis should lead to the discovery of 4 clusters if the
appropriate distan~e function is used, If the Euclidian
distance function is used both situations lead to the
detection of 4 clusters, A non-parametric (ant-based)
algorithm leads to 4 c:l~.aters in both cases using the
Euclidian distance. The .same algorithm Leads to 2 clusters
when applied to the situation where the four clusters
discriminate along the y-axis and ~ clusters in the situation
where the four clusters discriminate along the x-axis.
In an alternate embodiment, for more complicated
prob~ems, general function approximators such as neural
networks are used instead of family of distance functions. In
the case of neural networks connections weights are evolved
1~ using the genetic algorithm.
In another alternate embodiment, GA is interactive:
the outcome of the clustering or SIDS algorithm is evaluated
by a human observer who picks the good solutions.
The adaptive dissimilarity method 100 is also
aPPlicable to graph partitioning. Let G=(V, E) be a non-
directed graph. V= {Vij'i.l.,...n is the set of n vertices and E,
a subset of VxV, the set of edges, of cardinal ~E~. E can be
represented as a matrix (eiy] of edge weights, eis being the
weight of edge (vi, vj ) , where ezi x0 if (v" v~ ) a E and ei~=0
if (v~,v~) E E. The bi;partitioning problem consists of
finding 2 sets of n/2 vE:rtices each such that the total edge
weight between clusters is mimimal. This problem is known to
be NP-complete, and man~~ heuristics have been proposed to
find reasonably good so7.utions in polynomial time. The
guestion we may ask is the following: is there a natural
distance in connection ~~pace (where the coordinate of a
vertex vi is given by e;~,, j=1, . . . , n) such that the
application of the k-means clustering algorithm (k=2)
generates a good solution of the bipartitioning problem?
The adaptive dissimilarity partitioning method 100
has been tested or. random graphs C3 (n, c, pi, P~) , where n=100
is the total number of vertices, c=2 is the number of
- 15 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
clusters, p, is the probability that two vertices within a
cluster are Connected. and Pe is the probability that zwo
vertices belonging to different clusters are connected.
Edges are characterized by ei~=1 if (vs,v~) a E and ej~=0 if
(v.,v~) a E. Such graphs are convenient to test the algorithm
because the optimal solution of bipartitioning is known when
c=2: the optima? partitioning sol~;tion consists of having as
many vertices as possible that belong to the same graph
c-uster allocated to the same partition claster. These graphs
i0 have been introduced a.nd are used as difficult benchmark
problems in the contexa of VLSI design.
A modified version of the k-means algorithm is
applied. The twa centroids are initially assigned random
coordinates. Let C"rr; be the centroid closest to vertex vi
( C~rl~ = Arg'~in (d(C~, v,) ) ) , where d is the current distance
,~-i.~
function) , ar_d C~,,i;~ the jth coordinate (j=1, . . . , n) of C,"ri; .
The centroid update upon presentation of xi is given by:
G~~~rW y'
C~:cdi ~ ~nr:~i + ~ ~ 0 e=i r ~
n
where d is the current distance function, Q() is the sign
function (a (u)=-~1 if a>0, Q(u)=-1 if a<0, and a=0 if u=0), n
is a learning rate, and n~200 is the number of data vectors.
The family of distance function used in this example has
three parame~ers:
- 16 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
1
1a
J _ _ a
~~vi ~ VA ) ' ~ l elu ehu
a
n
+~lw) ~em~~~~n'~hrl~+~ehW~le~-eal~ ~
rc l a 1
where w a [0,11, and a and [3 tr [0,2j. When w=l, one gets
usual distances. The first term contains only zerotr. and
firs:.-order relationships between the two vertices: this
term is small when the two vertices are connected (0th-order
and are connected to tine same set of vertices (first-order).
The second term, which gate activated when w<1, represents
second-order relationships between two vertices: this term is
small when the neighbors of the two vertices have a lot of
adjacent vertices in common. Such relationships rnay be
important for graph partitioning, but the e;ttent to which
they improve the partitioning is not known.
The fitness :unction used in the GA for distance d°
is given by;
2a
Fy _ 1
n'
1 + Ein~ + ~'7i - 2
where E~n~ is the total inter-cluster weight, and n=is the
number of vertices assigned to cluster 1. The (n,-2term is
there to favor well-balanced solutions.
The present invention further presents a method for
_ 17 _
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
determining consumer demand that finds zhe context dependent,
or combinatorial optimized set of properties, uses, or
customer features that optimize the value of a product to th.e
customer base.
previous work has developed a general model of
rugged fitness landscapes Called the NK model as explained ir.
The Origins of Order, Stuart A. Kauffman, Oxford University
Press, 1993, Chapter 2, the contents of which are herein
incorporated by refer~Grce. The NK model is also explained in
At Home in the Universe, Stuart A. Kauffman, Oxford
University Press, 1995. Chapter 9, the contents of which are
hsrein incorporated by reference.
NK landscapes are members of a still more general
class of models in physics, and known in the art as P spin
models. A P spin model consists of N spins, each of which
can take on a discrete number of values, say ,1 and +1, or
and 0, or a,b,c,d. Each spin contributes an "energy" to the
total energy of a system of N spins. The enexgy of a given
sp'_n configuration of the N spins is given by the sum of the
energies of the N spins. Each spin's energy contribution is,
in general, given by a sum of a monomial term which is a
function of ite own state, plus quadratic terms which are
sums of energies Lhat are functions of the states of all
spins that influence it in pairwise interactions, plus a
similar sum of cubic terms listing all the contributions of
all triples of spins of which that spin is a member, plus
higher order terms. In the NK model, K is the highest order
coupling.
In such spin-glass models, the discrete system has
a rugged "fitness" "coat" "efficiency" or "utility" landscape
over the combinations of states of the N spins. New
techniques have been developed to characterize a number of
features of such landscapes. And it is these features that
allow ready asaessmen.t of the importance of higher order,
3g comb=natorial propert.iea on landscape structure. These
properties include: 1) The number of peaks in the landscape;
2) The expected number of steps to a peak from any given
- 18 -
CA 02337798 2001-O1-03
WO 00/02138
PCT/US99/15236
point in tre landscape:. 3) The dwindling number of
directions "uphill" as: :he Beak is climbed. 4) The number
of different peaks that can be climbed from a single point or.
the landscape by adaptive walks which must proceed only
uphill. 5~ The correlation structure of the landscape which
is, roughly, the corr~:lation between fitnesses at two points
on the landscape as a function of their distance.
~hese properties of discrete landscapes, where the
spins take on only di~:crete values, a,b,c,d.., can be
generalized to the case of continuous dimensions, where each
variable is a real number. This continuous case, the lengths
of walks uphill, and dwindling directions uphill must be
parameterized by a "st,ep length' in the space of reasonably
smooth hill aides, any point on the landscape that is on a
,5 hillside has the property that, for infinitesimal steps away
r from that poinC, half the directions are uphill and half are
downhill. Only on ridges, saddles and peaks is that false.
However, if a discrete: step length, say 100 yards, is
specified, then as a uralk continues uphill and a ridge or
saddle or peak is approached, the "cone" that is still uphill
will dwindle. The rate of dwindling is a measure that can be
used to characterize the ruggedness of a continuous
landscape. 'Thus, on nfK landscapes, with K modestly large,
the generic feature ie~ that at every step uphill, the number
of directions uphill falls by a consta:~t fraction. As
landscape ruggedness increases, the fraction by which the
directions uphill dwir:dles increases from a few percent to
50% for fully ~andom landscapes in the K - N 1 "random
energy" limit. In a similar vray, the rate at which the
gp uphill cone decreases as walks uphill continue provides a
measure of landscape ruggedness for continuous landscapes.
Consider a product space, without loss of
generality taken to be: soap, Features of this product were
noted above, and in general, include other features of
interest. Consider, t.a be concrete and without loss of
generality, discrete choice methods. A customer is presented
with different choices: of a bundle of properties, or vector
- 19 -
CA 02337798 2001-O1-03
wo oo/ozi3s
PCTNS99/15236
of properties. Each bundle is a point in the property space,
A price is attached t.o each such point. The customer is
asked to choose which., if any, he/she would buy. Examination
of the nectar is the property space after a fi:~ite number of
such choices, reveals a price zr. tre vicinity of those
positions in property space at which the customer will just
atop buying. Thus, o;n one side of a point on a surface in
property space, at that price, the customer will not buy, on
the other side of a point on a surface in property space, at
lp that price, the custorner will not buy, on the other side he
will buy. The point 7Ln question estimates the price for that
specific vector of properties. By sampling at many points
for one customer, it i.s possible to build up a set of pointy
that escir~a:es the utili=y curve, or surface, in property
Space at one price for' that customer, hence ar_ indifference
surface, and a set of such surfaces at different prices.
F'or a population of customers, a population of such
data pcints can be assembled. In principle, much data cou?d
be obtained from each customer, but typically it is only
feasible to obtain a limited,arnount of data from a given
customer. Typically, this is obtained over a moderate large
region of property space. The data points are then typically
each labeled by a vector of demographic traits, and an
attempt i8 made using t~tandard analysis to discriminate both
hi9r utility positions in the space of properties, and
simultaneously tr.e targeted demographic populations that are
well matched tv good positions in the space of properties in
order to optimize the vector of goods produced, each at a
different position in the property space, and targeted to one
or more positions in the demographic space, such that a total
figure of merit such as total profit after total manufacture
and sales.
The application of landscape ideas can improve
these standards procedures both by directing the limited
sampling that can be done that it helps capture higher order
terms, or context depercient features, of these marketscapes,
helps build statistical models of the right ~~equivalence
- ao -
CA 02337798 2001-O1-03
WO 00/02138
PCTNS99/15236
alass~~ of the real market scape, and helps build actual
models of the actual marketscape.
FZG. 2 provides a flow diagram of a method for
determining consumer demand 200 that finds the context
dependent, or combinatorial optimized set of properties,
uses, or customer features that optimize the value of a
product to the customer base. In step 202, the method for
determining consumer da~mand 200 selects a point in property
space that lies on a surface that divides a region where a
predetermined customer would buy from a region where the
predetermined customer would net buy.
Ir. step 204, tre method for predicting consumer
demand 200 samples a se:t of points on an R-dimensional sphere
surrounding the poi:~t ..elected fn step 202. Step 204
contrasts with previous methods for predicting consumer
demand that sample widely over the product space. The radius
of the sphere is defined in a well specified way where the
radius is defined as th.e "step length" an the surface. An
exemplary distance is the Euclidean distance. With the same
customer, or more generally, the same class of customers,
step 204 characterizes for many points in the spherical
surface surrounding the point whose price has been
determined, whether that new point would or would not be
purchased by the customer at the given price. Since the true
Price surface in the space of properties contains the first
determined point, that ~?rice surface will, in general, pierce
the spherical surface surrounding the point whose price is
determined. The points on the sphere which axe purchased and
the points which are not: purchased determine, in the simplest
case, a curve of points whose price is the transition between
buying and not buying ak; the price. In this way, the
neighborhood surrounding that first priced point can be
examined.
In step 206, the method for predicting consumer
demand 200 determines whether the indifference surface has
been substantially completed. If the method for predicting
consumer demand 200 determines that the indifference surface
- 21 -
CA 02337798 2001-O1-03
WO 00/02138
PCTNS99/15236
has not been substantially completed, control proceeds to
step 208. In step 208., the method for predicting consumer
demand selects another point on the indifference surface from
the transition curve determined in step 204. After step 208,
contrcl returns to step 204. Step 204 samples a set of
points on an R-dimensional sphere surrounding the point
selected in step 208. In this fashion, the method for
predicting consumer demand 200 operates to extend the
indifference surface at the predetermined price in any
direction in the prop~er~y space.
The ruggedn~sss of the indifference surface at a
given price will show up by any of the properties we have
discussed. Thus, mea:aured in property space, the
indifference surface <~t a given price may have one or more
;5 correlation lengths itl the space of properties. These
correlation lengths, a.n the NK model are long, for K small,
and short for K large. Thus, short correlation lengths
estimate highe_ order couplings among the properties. The
cone "uphill" in property space on an indifference surface at
z0 a given price can be determined. Good combinations of
properties will show u;p as peaks or minima, depending upon
direction of defiritio~n, in the surface. That is, a very
good combination of properties in property space will show
up, for example, as a willingness to pay the fixed price for
25 a small "amot:nt" of the given vector of properties. Having
defined a local "peak" .n the indifference landscape surface,
we can define the typical wa'k length, given step size, the
peak, and the number of peaks to which o:~e can walk from any
point. In addition, we can examine the similarity of peaks
3C Climbed from the same or nearby points on the indifference
landscape at a given price. We can ask if high peaks cluster
near one another. We c:an ask whether recombination is a good
means to find the high peaks. If so, ws can search out the
h=gh peaks by focusing ou= questioning in precise ways, to
35 look "between" the high peaks on the current landscape, and
hill climb from those points to still higher peaks.
- 22 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
All these properties allow focused sampling of the
landscape to estimate the higher order context dependent,
combinatorial feature.a of a given market scape.
Scatis~ical models of the sampled market sCape can
be built by utilizing P spin-like models, where the class of
models with all possible values of the coeff~.cients of all
the Padic terms in then polynomials constitute the family of
landscape models. Ma~samum entropy Bayesian updating similar
techniques can then beg used to estimate the most likely
landscape parameters to fit the observed data. A majo-
diøference between the current approach and usual approaches
is that the detailed sampling in specific regions of the
indifference surface at a given price yimlds estimates of the
how "high" the higher order terms, (K in the Nk model?
actually are. Thus, we can estimate from such focused local
measurements at several points on the landscape, that, for
examp'e, fifth order interactions, P=5, are critical for
determining the local structure of the mark~tscape. Knowing
that, we can use a preponderance of the data to tit or
2o estimate the 5'" order terms, and only a small amount of the
data to estimate the monomial terms that may determine the
overall non-isotropic features of the marketscape on long
length scales across tl:~e marketscape. Thus, we can optimize
use of the sampled data to discover both long range features
of the landscape and '_ocal features.
Given this analysis, one can derive a class of
statistical models of t:he landscape, and specif=c models of
the lar_dscape.
The method for predicting consumer aemand 200 was
explained in tie context of computing an indifference surface
for a prede~ermined pri.ae in the property apace fvr a
predetermined customer. However, as is known by one of
ordinary skill in the art, the method for predicting consumer
demand 200 could also be used to sample the property space of
the product for a given class of customer at a predetermined
price or at a set of predetermined prices. Further, the
method for predicting consumer demand 200 could also be used
- 23 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/1523b
to arrange the demographically characterized population of
customers into a customer-scape for any given point i:~ the
product space. This new approach to market segmentation
arises by Casting the agents into an M dimensional
demographic space. At any given price, we can determine the
fraction of customers in any small volume of demographic
space who will buy the good at that point in product space at
the given price. This determines a "customer-scape" for that
good at that price. Once again, the customer-geape is a
landscape, and we can define all the properties noticed
above: correlation structure, lengths of fixed step length
walks to peaks, the dwindling cone uphill as peaks are
climbed, th~ number of peaks accessible from a given point,
the similarity of Such peaks, and whether high peaks cluster
lg near one another. In the latter case, recombination is a
good means to search th.e landscape. This procedure defines
one or more optimal customer features for a given good, or
position in product space. The same procedure allows
multiple points in product space to be utilized, indeed just
the points normally utilized, to find the best set of
positions in product space to match the best targeted
populations of customers in customer space. Again, the
advantage of our procedure is that it allows tre higher order
terms, the context dependent features in customer space, to
be more readily detected, for it ells us that K order terms
are important. Again, we can then construct statistical
models of customer-soapes, and models of specific customer
stapes.
The present invention further includes a framework
fo= the marketing and introduction of novel products, which
is a central function of businesses. rIG. 3 provides a flow
diagram of the framework 300 for the marketing and
introduction of novel products. The framework 300 concerns
means to model customers and derive an optimal set of goods
3' to produce alone or in the face of a coevolvirig competitive
environment where other firms are introducing and modifying
their vwn gccds.
- 24 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US!~9/15236
In step 302, the framework fox the marketing and
introduction of novel products 300 assembles data on
customers from statements of preferences on questionnaires,
point of purchase data, neilson data, etc. In step 304, the
framework for the marketing and introduction of novel
products 300 creates a model of customer preferences. In
step 306, the framework 300 uses the models of customer
preferences created in step 304 to identify preferred goods
and services. In step 3oB, the framework considers the
behavior of other firms in the environment in addition to the
models of customer preferences created in step 304 to
identify preferred goods and services in a coevolving
competitive environment.
FIG. 4 provides a flow diagram of the method for
creating a model of customer preferences of step 304. In
step 402, the method for creating a model of customer
preferences 304 determines whether to perform market
segmentation. If step 402 indicates that market segmentation
should be performed, control proceeds to step 404 where the
method for Creating a model of customer preferences executes
the adaptive dissimilarity partitioning method 100 shown by
the flow ciagracl of FIC. 1. If step 402 indicates that
market segmentat_on should not be performed, control proceeds
to step 406.
In step 406,.the method for creating a model of
customer preferences 304 constructs a family of linear or
non-linear models of customers. These models are candidate
:naps from answers to questions, point of purchase data, etc.
tc the actual predictive preferences of the customers for th:a
goods in question. Accordingly, an aim of the method for
creating a model. of customer preferences 304 is to order the
goods in a match to actual preferences of customers.
In step 40B, the method for creating a model of
customer preferences 304 constructs agent based models of
customers based on default hierarchies, rules of thumb, etc.
in their strategy space. Default hierarchies, etc. do not
require that preferences be transitive, which is often true
- 25 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
of customers. Tn contrast, a preference space does require
transitivity. Agent based models of customers are described
in A System and Method' for the Synthesis of an Economic Web
and the Identification of New Market Niches, Attorney docket
number 9392-0007-999, filed May 15, 1998, the contents of
which are herein. incorporated by reference. Agent based
models of customers axe further described in An Adaptive and
Reliable System and Method for Operations Management,
Attorney docket number 9392-0004-999, filed July 1, 1999, the
lp contents of which are .herein incorporated by reference.
In step 410, the method for creating a model of
customer preferences 304 utilizes adaptive algorithms over
the space of mappings ;produced by step 406 and the space of
agent strategies produced by step 408 to find a set of models
that predicts customer purchasing preferences for a set of
goods. Tn the preferred embodiment, the adaptive algorithms
are genetic algorithms. In an alternate embodiment, the
adaptive algorithms are genetic programming.
In step 412, the method for creating a model of
customer preferences 304 determines whether the output of
step 410 has produced ~3ood predictive models of customer
purchasing preferences. If step 412 determines that the
output of step 410 has not produced good predictive models of
customer purchasing pr~~ferenees, control returns to step 406
where processing proce~aas with the new set of models produced
by the adaptive algorithm of step 410. If step 412
determines that the output of step 410 has produced good
predictive models of customer purchasing preferences, control,
proceeds to step 414 where the processing terminates.
Ag previously discussed, in step 306, the framework
300 us3es the models of Customer preferences created in step
304 to identify preferred goods and se=vices. zf the
customers have preferences for may features of a product that
add up to a single pret:erence landscape, then step 306
executes the method foz: predicting consumer demand 200
illustrated by the Elov~ diagram of FIG. 2. In contrast, if
the cuscomer preferences are not commensurable, then step 30E
- 26 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
executes an optimization tool to find the global pareto
optimal points such as Configuration Sherpa, which is
described in A System c~.nd Method for Coordinating Economic
Activities Within and Between Economic Agents. In either
g case, one of ordinary skill in the art would understand that
there are a variety of clustering and mufti-dimensional
scaling algorithms that. can seek optimal choices of locations
o. goods 'n the product: space to attract the most customers.
Such algorithms may preapecify the number of goods, or seek
ip optimal numbers and locations of goods based on a firm's
budget constraints, and other aspects of firm operations in
its competitive environment.
As previously explained, in step 308, the framework
considers the behavior of other firms in the environment in
15 addition to the models of customer preferences created in
step 304 to identify preferred goods and services in a
coevolving competitive environment. Firms compete by
introducing or improving products. Hence, there is a
coevolutionary dynamic. Generically, there are two regimes:
Za a "red queen" regime of persistent coevolution in the space
of products and ar. evol.utionary stable strategies regime
where all products reach local or g?obal wash equilibria and
stop moving in product space. See At Home zn the Universe.
T_f the firm completes the observe, orient, decide and act
25 loop (OOOA1 faster than the other firms with respect to tre
introduction, innovation, improvement and wise placement of
products, it can systematically win.
Step 3C8 of the framework for the marketing and
introduction of novel products 300 uses models of customers
30 ar_d capacity to predict preferences over the space of
products to build agent based or other dynamical models of
the coevolution of market shares of products, utilizing data
to locate optimal positions for new or improved products in
coevolutionary dynamics subject to constraints on budget,
35 Capacity, and time to market fox new or improved goods, etc.
- 27 -
CA 02337798 2001-O1-03
WO 00/02138 PCT/US99/15236
Agent based models that identify new products are described
in A System and Method! for the Synthesis of an Economic Web
and Che Identification of New Market Niches,
FIC3. ~ discloses a representative computer system
510 in conjunction with which the embodiments of the present
invention may be implemented. Computer system 510 may be a
personal computer, workstation, or a larger system such as a
minicomputer. However, one skilled in the art of computer
systems will understand that the present invention is not
limited to a particular class or model of computer.
As shown in ~rIG. 5, representative computer system
510 includes a central processing unit (CPU) 512, a memory
unit 514, one or more :3torage devices 516, an input device
518. an output device E520, and communication interface.2922.
A system bus 524 is provided for communications between these
elements. Computer sysstem 510 may additionally function
through use of an operating system such as Windows, DOS, or
UNIX. ~!owever, one sic__lled in the art of computer systems
will understand that t?~ie present invention is zot limited to
a particular configuration or operating system.
Storage devices 51.6 may illustratively include one or
more floppy or hard disk drives, CD-ROMs, DVDs, or tapes.
Input device 518 comprises a keyboard, mouse, microphone, or
other similar device. Output device 520 is a computer
monitor or any other known computer output device.
Communication interface 522 may be a modem., a network
interface, or ether connection to external electronic
devices, such as a serial or parallel port
While the above invention has been described with
reference to certain preferred embodiments, the scope of the
present invention is not limited to these embodiments. One
skill in the art may find variations of these preferred
embodiments which, nevertheless, fall witrin the spirit of
the present invention, 'whose scope is defined by the claims
3a set forth below.
- 2s -