Note: Descriptions are shown in the official language in which they were submitted.
CA 02349613 2001-04-24
WO 01/15002 PCT/US00/23193
METHODS AND SYSTEMS FOR PRESENTING INFORMATION IN A
DISTRIBUTED COMPUTING ENVIRONMENT
BACKGROUND OF THE INVENTION
The World Wide Web of the Internet is the most successful distributed
application
in the history of computing. In the Web environment, client machines effect
transactions to
Web servers using the Hypertext Transfer Protocol (HTTP), which is a known
Application
protocol providing users access to files (e.g., text, graphics, images, sound,
video, etc.)
using a standard page description language known as Hypertext Markup Language
(HTML). HTML provides basic document formatting and allows the developer to
specify
"links" to other servers and files. In the Internet paradigm, a network path
to a server is
identified by a so-called Uniform Resource Locator ('CTRL) having a special
syntax for
1 S defining a network connection. Use of an HTML-compatible browser (e.g.,
Netscape
Navigator) at a client machine involves specification of a link via the URL.
In response,
the client makes a request to the server identified in the link and receives
in return a
document formatted according to HTML.
In this environment an enormous amount of information is available to a user.
First
because of the sheer size of the Web environment, and'second because of the
immense
amount of individuals having access to the Web environment. These individuals
currently
author a tremendous amount of content for the Web concerning a vast number of
topics.
To navigate all this information, users of the Web typically use search
engines. A
search engine allows a Web user to enter key words which define the content
they desire.
The search engine then utilizes these key words to rind matches in documents
on the Web,
and then presents these content matches to the user, typically in the form of
a list of
content. Another a strategy for search engines is a hierarchical tree of
content nodes in
which a user can traverse various branches and nodes to find the desired
content. For
example, the f rst level of a hierarchical tree may present various high level
topics, such as
cars or homes. The user may find the content they are looking for at this
general level, or
they may traverse down the hierarchy to a more specific level, such as
exploring the cars
topic which may contain various makes of cars, such as Ford or Ferrari. If the
user does not
CA 02349613 2001-04-24
WO 01/15002 PCT/US00/23193
find the content they desire at this level, the user may continue down the
hierarchy to more
specific topics until they obtain the content they are looking for.
One problem with both of these search strategies is that the content provided
to the
user includes no correlation to tile an count of trust a user may have for the
authors of the
content provided. Although the information may be presented to the user based
on the
amount of key words found in the content, or based on the number of times a
piece of
content gets accessed by others, the prior art does not allow content to be
based on the trust
levels of the individual user. The result is that the user has no way of
knowing whether
they will personally appreciate the content presented to them. Even though a
piece of
content includes a high percentage of key words used in a search, or is
frequently accessed
by others, that does not mean a particular individual will find the content
desirable. On the
other hand, if the particular user trusts an author for providing a certain
type of
information, it is highly likely the user will find other content authored by
that author very
desirable.
What is needed is a method for providing content to a user which has a high
likelihood it will be appreciated by a particular user. The method would need
to keep track
of individual users to provide content structured based on the individual user
preferences.
In addition, the method would need to be able to present content to a user in
such a .fashion
as to allow the user to immediately identify content having a high likelihood
of being
desirable to the user.
SUMMARY OF THE INVENTION
The present invention fills these needs by providing a computer implemented
method that organizes content for a particular user based on the particular
user's Trust
Levels for various authors of content. In one embodiment, the invention
relates to a
method for organizing a pool of content for a user. The method comprises
maintaining a
common pool database which includes a plurality of content data, with each
piece of
content having at least one author associated with it. The method further
includes
maintaining a user database which includes user trust data. The user trust
data includes
user Trust Levels for authors of content included in the common pool database.
Next, a
new content database and content presentation structure are generated for a
user based on
the user trust data of the user.
2
CA 02349613 2001-04-24
WO O1/1500Z PCTNS00/23I93
In another embodiment, a distributed computing system for organizing a pool of
content is disclosed. lip this embodiment, a common pool data base is used
store a plurality
of content data with each piece of content having at least one author
associated therewith.
The system further includes a user database for storing user trust data. The
user trust data
includes user Trust Levels for authors of content included its the common pool
database.
Finally, the system includes a system process having logic for generating a
content
database and content presentation structure for a user based on the user trust
data of the
user.
A computer program for organizing a pool of content for a user is disclosed in
yet
another embodiment of the present invention. The computer program includes a
code
segment that maintains a common pool database which includes a plurality of
content data,
with each piece of content having at least one author associated with it. The
computer
program further includes a code segment that maintains a user database which
includes
user trust data. The user trust data includes user Trust Levels of authors of
content included
in the common pool database. Finally, the computer program includes a code
segment that
generates a content database and content presentation structure for a user
based on the user
trust data of the user.
In another embodiment, the invention relates to a method for organizing a
listing of
performances for a user. The method comprises maintaining a common pool
database
which includes a plurality of performance data for television/cable shows,
with each piece
of performance data having at least one author, such as a writer or director,
associated with
it. The method further includes maintaining a user database which includes
user trust data.
The user trust data includes user Trust Levels for authors of performance data
included in
the common pool database. Next, a new performance database and performance
listing
presentation structure are generated for a user based on the user trust data
of the user. In
this manner, users are able to easily determine performances they are likely
to enjoy.
Advantageously, the use of user Trust Levels for authors allows the
presentation of
content to be structured to specifically suit a particular individual. Content
from highly
trusted authors may be placed in more prominent positions in the presentation
data
structure. Furthermore, chat room environments may be structured to simulate
the actual
experience of having a conversation with friends in a crowded room. Moreover,
the use of
Trust Levels allows an email presentation to be structured to allow messages
from highly
3
CA 02349613 2001-04-24
WO 01/15002 PCT/US00/23193
trusted individuals to take precedence over messages from lower trusted
individuals. These
and other advantages of the present invention will become apparent upon
reading the
following detailed descriptions and studying the various figures of the
drawings.
BRIEF DESCRIPTION OF THE DRAWINGS
The invention, together with further advantages thereof, may best be
understood by
reference to the following description taken in conjunction with the
accompanying
drawings in which:
Figure 1 is a chart illustrating. components included in the Trust model
according
to one embodiment of the present invention;
Figure 2 is a chart showing various ways Trust Levels may be created in
accordance with another embodiment of the present invention;
Figure 3 is a flowchart showing a method for creation of a Trust Level using
explicit declaration by a user, in accordance with yet another embodiment of
the present
invention;
Figure 4 is a flowchart showing a method for creation of a Trust Level based
on a
user making evaluations of content from an author, in accordance with one
aspect of the
present invention;
Figure 5 is a flowchart showing a method for creation of a Trust Level based
on
transitive assignment with decay, in accordance with another aspect of the
present
invention;
Figure 6 is a flowchart showing a method for creation of a Trust Level based
on
observing commonalties in patterns between two or more users, in accordance
with another
aspect of the present invention;
Figure 7 is a flowchart showing a method for creation of a Trust Level based
on
membership in a group, in accordance with yet another aspect of the present
invention;
Figure 8 is a diagram showing the flow of Trust information, in accordance
with
one embodiment of the present invention;
Figure 9 is a flowchart showing a method for organizing a pool of content for
a
user, according to another embodiment of the present invention;
4
CA 02349613 2001-04-24
WO O1/1500Z PCT/US00/23193
Figure 10 is an illustration showing a common pool default data structure
restructured for a user based on the user's Webs of Trust data, in accordance
with another
embodiment of the present invention;
Figure 11 is an illustration showing a content presentation structured based
on a
user's Webs of Trust, in accordance with yet another embodiment of the present
invention;
Figure 12 is an illustration showing the use of Webs of Trust for a chat room,
in
accordance with another embodiment of the present invention; and
Figure 13 is an illustration showing a distributed computing system for
organizing
content data based on Trust relationships, in accordance with another aspect
of the present
invention.
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS
An invention is described for organizing content based on a user's trust level
for
specific authors. This content may be anything created by an author, and
includes, for
example, books, articles, art, and/or web pages. In the following description,
numerous
specific details are set forth in order to provide a thorough understanding of
the present
invention. It will be obvious, however, to one skilled in the art that the
present invention
may be practiced without some or all of these specific details. In other
instances, well
known process steps have not been described in detail in order not to
unnecessarily obscure
the present invention.
In accordance with one aspect of the present invention, the aforementioned
problem
of individualized trust based content organization is addressed by the use of
a "Trust" level
model. Trust level, as used in the present application, is a way of ranking
the confidence
level a user has for a specific author in relation to a specific topic.
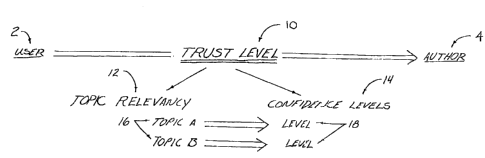
Figure 1 is a chart illustrating components included in a preferred trust
model of the
present invention. As shown in Figure 1, the relationship between a user 2 and
an author 4
is based on a Trust Level 10. The Trust Level 10 includes a Topic Relevancy 12
and
Confidence Levels 14. Topic Relevancy 12 includes at least one topic 16, while
the
Confidence Levels 14 include a number of confidence levels 18 associated with
the topics
16. In this manner, each topic 16 has a related confidence level 18 which
indicates the
confidence the user 2 has for the author 4 in relation to a particular topic
16.
5
CA 02349613 2001-04-24
WO 01/15002 PCTNS00/23193
The present invention allows the Trust Level 10 a user 2 has for a particular
author
4 to be utilized for organizing and ranking content generated by the author 4.
Moreover,
different topics 16 may generate different Trust Levels 10 between a user 2
and an author
4. For example, a user may have a very high Trust Level 10 for a specific
author in relation
to automobiles, and a very low Trust Level 10 for the author in relation to
scuba diving.
The Trust model of the present invention reflects this by assigning specific
confidence
levels 18 to specific related topics 16. The collection of Trust Levels 10 a
user 2 has for
various authors 4 is called the user's "Webs of Trust." Thus, by utilizing a
user's 2 Webs of
Trust, content may be organized to provide content to a user ranked according
to the user's
trust for various authors, as will be described in more detail below.
Figure 2 is a chart showing various ways Trust Levels may be created, in
accordance with another embodiment of the present invention. These include
Explicit
Declaration By the User 100, Content Evaluations 200, Transitive Assignment
300,
Commonalties 400, and Group Membership 500. By using these methods,
collectively
and/or individually, Webs of Trust may be created for a particular user based
on the users
selections, actions, and the actions of selected other users. Each of these
methods will now
be described with reference to Figures 3-7.
Figure 3 is a flowchart showing a method 100 for creation of a Trust Level
using
explicit declaration by a user, in accordance with one aspect of the present
invention. The
method 100 begins with a start operation 102, wherein various predeclaration
operations
take place. These operations may include creation of a user database, user
logon, and other
operations as will be obvious to those skilled in the art.
In an interface operation 104, a user input interface is proved to the user.
The input
interface is preferably designed to allow the user to input information
concerning the
amount of confidence the user has for an author. Thus confidence may be a
general
confidence, i.e., concerning all topics, a particular topic, or a group of
topics. Furthermore,
either the topic, the author, or both may be entered explicitly, or may be
inferred from the
context in which the user input is obtained. For example, while examining a
specific piece
of content, the user may explicitly input confidence for the author. The
identity of the
author could be inferred from the context, i.e., the author of the content. In
addition, the
related topic may also be inferred from the content topic.
6
CA 02349613 2001-04-24
WO 01/15002 PCT/US00/23193
Next, in a receive data operation 106, the information entered by the user is
received. This information is then used to update a user database in an update
operation
108. The update operation 108 includes updating user trust data included in
the user
database.
Finally, in operation 110, the user trust data can be used to organize content
ranked
according to the user's trust for various authors.
Figure 4 is a flowchart showing a Method 200 for creation of a Trust Level
based
on a user making evaluations of content generated by an author, in accordance
with
another aspect of the present invention. In an initial operation 202, various
preevaluation
operations take place. These operations include creation of a user database,
creation of a
content pool, and other operations as will be obvious to those skilled in the
art.
In an input operation 204, a user input interface is Provided for content
evaluation.
The input interface is preferably desired to allow the user to input
information concerning
the users evaluation of selected content. The content may be selected by the
user, or
inferred from the context in which: the user input is obtained. For example,
when a user is
examining a particular piece of content, the selected content may be erred to
be the content
currently being examined. Then, in a receive operation 206, the information
entered by the
user is received.
Next, in a Trust Level determination operation 208, the Trust Level for an
author
associated with the selected content is determined. Operation 208 includes
first
determining an associated author for the selected content. Since an associated
author is
typically listed with evaluated content, the author can generally be
determined by looking
up the author listed in the selected content. Second, a Trust Level for the
author is
determined by determining a topic associated with the content and a confidence
level based
on the evaluation of the content. As above, the topic associated with the
content can be
inferred from the context of the content. The evaluation of the content is
then used to
determine a co~dence level for the associated author in relation to the
determined topic,
the better the evaluation of the content, the higher the related confidence
level for the
author.
This information is then used to update a user database in an update operation
210.
The update operation 210 includes updating user trust data included in the
user database.
7
CA 02349613 2001-04-24
WO 01/15002 PCT/US00/23193
Finally, in operation 212, the user. trust data can be used to organize
content ranked
according to the user's trust for various authors.
Figure 5 is a flowchart showing a method 300 for creation of a Trust Level
based
on transitive assignment with decay, in accordance with another aspect of the
present
invention. In an initial operation 302, various pre-declaration operations
take place. These
operations include author and content evaluations from other users, and other
operations as
will be obvious to those skilled in the art.
In an input operation 304, a user input interface is proved to a first user.
The input
interface is preferably 'designed to allow the first user to input information
concerning the
Trust Level the user has for a second user. This Trust Level may be a general
confidence
concerning all topics, a particular topic, or a group of topics. By entering a
Trust level for a
second user, the first user is declaring trust for the second user.
1 n a first Trust Level operation 306, the f rst user's Trust Levels are
determined for
authors trusted by the second user. Generally, all authors trusted by the
second user are
then trusted by the first user. The Trust Levels for each of these authors is
based on both
the Trust Level the second user has for that author, and on the Trust Level
the first user has
for the second user. Preferably, these Trust Levels are decayed, resulting in
the first user's
Trust Levels for the authors being less than that of the second user's Trust
Levels for the
authors.
Next, in a subsequent Trust Level operation 308, the first user's Trust Levels
are
determined for authors trusted by a third user trusted be the second user.
Similar to the first
Trust Level operation 306, generally all authors trusted by the third user are
then trusted by
the first user. The Trust Levels for each of these authors is based on: a) the
Trust Level the
third user has for that author, b) the Trust Level the second user has for the
third user, and
c) the Trust Level the first user has for the second user. Preferably, these
Trust Levels are
decayed, resulting in the first user's Trust Levels for the authors being less
than that of the
second user's Trust Levels for the authors, which, in turn, is less than that
of the third users
trust for the authors. Operation 308 is carned out for each user the second
user trusts.
Furthermore, operation 308 is repeated for each of these further removed users
as well, and
for users they trust, and so on.
Finally, in operation 310, the user trust data can be used to organize content
ranked
according to the user's trust for the various authors. Method 300 simulates
word of mouth
CA 02349613 2001-04-24
WO 01/15002 PC'TNS00/23193
trust in the real world, when one friend tells another friend, and so on. With
each person
removed from the current user, the Trust Level lessens, representing higher
trust for those
close to the user, and lesser trust for those not close to the user.
Furthermore, method 300
illustrates one method for updating a user's Webs of Trust through the actions
of others,
i.e., when others alter their Trust Levels, the Trust Levels of the current
user can be altered.
Turning next to Figure 6, a method 400 for creation of a Trust Level based on
observing commonalties in patterns between two or more users is shown, in
accordance
with yet another aspect of the present invention. In an initial operation 402,
various pre-
evaluation operations take place. These operations include author and content
evaluations
from other users, and other operations as will be obvious to those skilled in
the art.
In an input operation 404, a user input interface is provided for content
evaluation.
The input interface is preferably designed to allow a first user to input
information
concerning the first users evaluation of selected content. The content may be
selected by
the first user, or inferred from the context in which the user input is
obtained. For example,
when a user is examining a particular piece of content, the selected content
may be inferred
to be the content currently being examined.
In a compare operation 406, the user content evaluations obtained from step
404
and from previous content evaluations by the first user, are compared to
content
evaluations from a second user.
Next; in a selecting operation 408, the second user is flagged if a
predetermined
threshold number of commonalties exist between the first user content
evaluations and the
second user content evaluations. A selected second user represents a user in
which the first
user is likely to share points of view with, and the two are likely to trust
the same
individuals.
In a Trust determination operation 410, a Trust Levels for authors trusted by
second
user are determined for the first user. Generally, authors trusted by the
second user are then
trusted by the first user. Preferably, these Trust Levels are decayed,
resulting in the first
user's Trust Levels for the authors being less than that of the second user's
Trust Levels for
the authors. Furthermore, this operation may be combined with method 300, and
further
Trust Levels determined by transitive assignment with decay.
Finally, in operation 412, the user trust data can be used to organize content
ranked
according to the user's trust for the various authors.
9
CA 02349613 2001-04-24
WO 01/15002 PCT/US00/23193
Figure 7 is a flowchart showing a method 500 for creation of a Trust Level
based
on membership in a group, in accordance with another aspect of the present
invention. In
an initial operation 502, various pre-declaration operations take place. These
operations
include author arid content evaluations from other groups, and other
operations as will be
S obvious to those skilled in the art.
In an input operation 504, a user input interface is proved to a first user.
The input
interface is preferably designed to allow the user to input information
concerning the Trust
Level the user has for a group. This Trust Level may be a general confidence
concerning
all topics, a particular topic, or a group of topics. By entering a Trust
level for a group, the
user is declaring trust for the group.
In a Trust Level determination operation 506, the user's Trust Levels are
determined for authors trusted by the group. Generally, all authors trusted by
the group are
then trusted by the user. The Trust Levels for each of these authors is based
on both the
Trust Level the group has for that author, and on the Trust Level the user has
for the group.
Preferably, these Trust Levels are decayed, resulting in the user's Trust
Levels for the
authors being less than that of the group's Trust Levels for the authors.
Finally, in operation 508, the user trust data can be used to organize content
ranked
according to the user's trust for the various authors. Method S00 simulates a
user's similar
points of view as that o~ the groups to which the user belongs. Furthermore,
since the
present invention typically treats groups like individual entities, methods
100-400 may
generally use a group as one of the users.
Referring next to Figure 8, a diagram showing the flow of Trust information is
shown, in accordance with one embodiment of the present invention. As the
diagram
shows, the present invention includes a common pool database 50 and a user
database 52.
The common pool database 50 includes a plurality of content data 54, each
associated with
at least one author 55. The content data 54 may include the actual authored
data, such as an
article, or a link to the authored data, such as a URL, post address, or any
other means to
enable contact with the authored content. For example, content data 54 may
represent
physical paintings by an artist (author). In this case, the actual content
data 54 may include
a digital picture of the art, a URL to where the art may be ordered, or a post
address to
order the piece of art.
CA 02349613 2001-04-24
WO 01/15002 PCTNS00/23193
The user database 52 includes a plurality of user trust data 56. Each user
trust data
56 includes Trust Levels associated with an individual user. The Trust Levels
include Trust
Levels for authors 58, and Trust Levels for other users or groups 60. Trust
information, in
the form of Explicit Declarations 100, Content Evaluations 200, Transitive
Assignment
300, Commonalties 400, and Group Membership 500, flows into a user database
52. The
Trust information is then used to create the various Trust Levels 58 and 60,
as explained
above with reference to Figures 2-7. The Trust Levels for an individual user
are then used
to generate a content database and content presentation structure for a the
user, as
described below.
Figure 9 is a flowchart showing a method 600 for organizing a pool of content
for a
user, according to one embodiment of the present invention. In an initial
operation 602,
system initialization operations are performed, such as generating a content
pool database,
generating a user database, and other initial operations that will be obvious
to those skilled
in the art.
In a contribution operation 604, contributors transmit content into a common
pool
database. Preferably all content transmitted to the common pool database
includes at least
one associated author who generated the content. Authors include, but are not
limited to,
literary authors, artists, groups, and corporations.
Next, in operation 606, the content stored in the common pool database is
structured according to a default data structure. This can be any data
structure suitable for
storing the particular type of content in the common pool database. For
example, in the
case of a chat database, content may be stored as a list based on temporal
priority. In the
case an article database, content may be stored in a hierarchical tree based
on topics. The
appropriate default data structure for a particular data type will be obvious
to those skilled
in the art.
In a content structuring operation 608, a content database is generated from
the
content in the common pool. The content database is structured specifically
for the user
based on the user trust data of the user. Preferably, content generated by an
author having a
high Trust Level with respect to the user is ranked higher in the data
structure than content
generated by an author having a lower Trust Level with respect to the user.
For example,
when organizing a content database of articles, articles generated by authors
having a high
Trust Level with respect to the user may be listed before other articles.
11
CA 02349613 2001-04-24
WO Oi/I5002 PCT/US00/23193
Finally, in operation 610, the user may utilize the structured content
presentation to
obtained needed information. Since the content presentation is structured such
that content
from trusted authors takes precedence over other content, the user can easily
find and
utilize desired information, as illustrated further in Figures 10-12.
Figure 10 is an illustration showing a common pool default data structure
restructured for a user based on the user's Webs of Trust data, in accordance
with another
embodiment of the present invention. One example of a common pool default data
structure is a hierarchical tree 70 of nodes 72 and directories 74. In this
example each node
72 represents a link to an article, however, in other embodiments nodes 72 can
represent
anything enabling a user to obtain information from an author, as described
above. In
addition, each directory 74 contains links to other, more topic specific
directories and
nodes. For example, a cars directory may contain links to general articles and
directories
on cars. One of these directories may be "Corvettes" and lead to articles and
directories on
the more specific car topic "Corvettes." Continuing with the example, the
Corvettes
directory may lead to a "Convertible Corvettes" directory, which in turn, may
lead to an
article on "1998" convertible Corvettes.
Using Webs of Trust for a specific user, the present invention may restructure
the
default common pool data structure 70 into a new content database structure 76
to more
particularly suit the user. For example, if a particular user had a high Trust
Level for the
author of the article on "1998 Convertible Corvettes" 78, that article 78 may
be placed in a
higher level in the content database structure 76, for example, at the level
of articles on
general Corvettes.
Figure 11 is an illustration showing a content presentation structured based
on a
user's Webs of Trust, in accordance with yet another embodiment of the present
invention.
A default content presentation 80, based on the default common pool data
structure,
includes a presentation of nodes 72 at a particular level of the hierarchical
tree, in this case
the "Corvette" level. As is shown, the nodes 72 concern general information on
Corvettes.
As described above, using the Using Webs of Trust for a specific user, the
present
invention may restructure the default common pool data structure 70 into a new
content
database structure 76 to more particularly suit the user. A new content
presentation 82,
based on a new content database structure, includes a presentation of nodes 72
as in the
default content presentation 80. However, as in Figure 10, if the user has a
high Trust
12
CA 02349613 2001-04-24
WO 01/15002 PCTNS00/23193
Level for the author of the article on "1998 Convertible Corvettes" 78, that
article 78 may
be placed in a higher level in the content presentation structure 82, for
example, at the level
of articles on general Corvettes.
Referring next to Figure 12, an illustration showing the use of Webs of Trust
for a
chat room is shown, in accordance with one aspect of the present invention. In
a standard
chat environment 90, messages received from others in the chat room are all
listed for the
user, generally, in reverse temporal order, with the newer messages above
older messages.
Thus, if a chat user has friends 92, messages from the friends 92 will be
interlaced with
messages from strangers 94, depending on the temporal order in which the
messages are
received.
In a chat environment based on Webs of Trust 96, messages may be listed in an
order based on the user's Webs of Trust. For example, if the user sets high
Trust Levels for
their friends 92, messages from the friends 92 will be listed before messages
from
strangers 94. Messages from individuals at the same Trust Level typically are
listed in
reverse temporal order, as in a standard chat environment. Furthermore, a Webs
of Trust
chat environment is preferably designed such that Trust Level constraints are
relaxed over
time when no trusted individuals are transmitting messages. In this manner,
the Webs of
Trust chat environment represents a group of friends talking in a crowded
room. As long as
someone in the group is talking the other group members hear that person above
all others.
When no one in the group is talking, group members will start over hearing
other
conversations.
Figure 13 is an illustration showing a distributed computing system 1300 for
organizing content data based on Trust relationships, in accordance with
another aspect of
the present invention. The distributed computing system 1300 includes a server
1302,
client users 1304, and a network 1306, such as the Internet. The server 1302
includes a
content database 1308, a system process 1310, and a user database 1312. The
content
database 1308 includes submitted content wherein each piece of content
includes at least
one author. The content database 1308 is coupled to the system process 1310
which
includes the logic for creating and updating Webs of Trust for users. The
system process
1310 also includes logic for generating content databases and content
presentation
structures for users. Also coupled to the system process 1310 is the user
database 1312.
13
CA 02349613 2001-04-24
WO 01/15002 PCT/US00/23193
The user database 1312 includes user trust information, which is utilized by
the system
process 1312 to generate content databases and content presentation structures
for users.
In use, a user 1304 can connect with the server 1302 through the network 1306.
This is typically accomplished using a browser and the Internet. Once a
connection is
established, the user can request information from the system process 1310.
The system
process 1310 then utilizes the content database 1308 in conjunction with the
user database
1312 to generate new content database particularly structured for the
individual user 1304.
In this manner, a content presentation for user 1 may be completely different
from a
content presentation for user 2, even though each user requested the same
information.
Because user 1 and/or 2 may have different Trust Levels for different authors,
the content
presented to each user may take a different form. In one embodiment of the
present
invention, the same request from different users will generate the same pool
of content,
however, the pool of content will be structured differently for each user
based on the users
Webs of Trust.
It should be noted that the Webs of Trust model of the present invention may
be
used to organize any type data needed by a user. Examples include, but are not
limited to,
email, search results, marketing, chat rooms, e-commerce listings, and
television/cable/satellite performance listings. For example, the Webs of
Trust model may
be utilized to organize scheduled television/cable performances listings. In
this case, a
Webs of Trust based performance listing may list performances by the most
trusted authors
before other performance listings.
While this invention has been described in terms of several preferred
embodiments,
there are many alterations, permutations, and equivalents which fall within
the scope of
this invention. It should also be noted that there are many alternative ways
of
implementing the methods and apparatuses of the present invention. It is
therefore intended
that the following appended claims be interpreted as including alI such
alterations,
permutations, and equivalents as fall within the true spirit and scope of the
present
invention
14