Note: Descriptions are shown in the official language in which they were submitted.
CA 02365302 2002-O1-07
i
- 1 -
METHOD OF RECOGNIZING ALPHANUMERIC
STRINGS SPOKEN OVER A TELEPHONE NETWORK
This is a division of co-pending Canadian
Patent Application 2,082,942 filed May 14, 1991.
The present invention relates generally to
voice recognition techniques and more specifically
to a voice recognition/verification method and
system for enabling a caller to obtain access to one
or more services via a telephone network.
Voice verification is the process of verifying
a person's claimed identity,by analyzing a sample of
that person's, voice. This form of security is based
on the premise that each person can be uniquely
identified by his or her voice. The degree of
security afforded by a verification technique
depends on how well the verification algorithm
discriminates the voice of an authorized user from
all unathorized users.
It would be desirable to use voice
2 0 verification schemes to verify the identity of a
telephone caller. Such schemes, however, have not
been successfully implemented. In particular; it
has proven difficult to provide cost-effective and
accurate voice verification over a telephone
2 5 network. Generally, this is because the telephone
network is a challenging environment that degrades
the quality of speech through the introduction of
various types of noise and band-limitations. The
difficulty in providing telephone-based voice
3 0 verification is further complicated by the fact that
many types of microphones are used in conventional
telephone calling stations. These mircophones
include carbon button handsets, electret handsets
and electret speaker phones .. Each of these devices
3 5 possesses unique acoustic properties that affect the
way a person's voice may sound over the telephone
network.
Given the inherent limitations of the prior
art as well as the poor frequency response of the
4 0 telephone network, it has not been possible to
CA 02365302 2002-O1-07
f
-2-
successively integrate a voice recognition and
verification system into a telephone network.
It is an object of the present invention to
recognize -alphanumeric strings spoken over a
telephone network.
It is another object of the invention to
describe a method for recognizsng alphanumeric
strings wherein recognition occurs on the basis of
an ensemble of alphanumeric characters as opposed to-
individual character recognition.
It is. a thus a further object of the invention
to describe a method for recognizing alphanumeric
strings that does not require high individual
character recognition accuracy to achieve
recognition of a spoken alphanumeric string.
It is also an object of the present invention
to provide a method and system for voice recognition
and voice verification over a telephone network.
It is pet another object of the present
2U invention to provide a method and system for -
enabling a caller to obtain access to one or more
services via a telephone network using
voice-controlled access techniques.
Lt is still another object of the invention to
provide simultaneous speaker=independent voice
recognition and voice verification to facilitate
access to services via a band-limited communications
channel.
It is another object of the invention to
provide a method for verifying the claimed'identity.
of an individual at a telephone to enable .the
ir~dividual. to .obtain access to services or
privileges limited to authorized users. '
In a preferred embodiment, these and other
objects of the invention are provided in a method
for enabling a caller to obtain access to services
CA 02365302 2002-O1-07
s
-3-
via a telephone network by entering a spoken
password having a plurality of digits. Preferably,
the method begins by prompting the caller to speak
the password beginning With a first digit and ending
with a last digit thereof. Each spoken digit of the
password is then recognized using a
speaker-independent voice recognition algorithm.
Following entry of the last digit of the password, a
determination is made whether the password is
1D valid. If so, the calle r s identity is verified
using a voice verification algorithm.
This method is implemented according to the
invention using a system comprising a digital
processor, storage means connected to the digital
processor, prompt means controlled by the digital
processor for prompting a caller to speak a password
beginning with a fiist digit and ending with a last
digit thereof, speech processing means controlled by
the digital processor for effecting ,a multistage
data reduction process and generating resultant
voice recognition and voice verification per~ameter
data, and voice recognition and verification
decision routines. The storage means includes a '
reed-only memory , for storing voice recognition
feature transformation data and voice recognition
class reference data both derived from .a first
plurality (e.g:, 1000) of training speakers over a
telephone network. The ROM also stores voice
verification feature transformation data derived
from a second plurality (e. g., 100-150) of training
speakers over a telephone network. The voice
recognition feature transformation and class
reference data and the voice verification feature
transformation data are' derived in off-line training
procedures. The storage means also includes a
database of voice verification class reference data
CA 02365302 2002-O1-07
y
_9_
comprising data derived from users authorized to
access the services.
The voice recognition routine comprises
transformation 'means that receives the speech
f feature data generated for each digit and the voice
recognition feature transformation data and in
response thereto generates voice recognition
parameter data for each digit. A digit decision
routine receives the voice recognition parameter
data and .the (digit-relative) voice recognition
class reference data and in response thereto
generates an output indicating the digit. The voice
recognition routine may also ine~.ude a password
validation routine responsive to entry of the last
digit of the ,password for determining if the
password is valid.
The voice verification routine is controlled by
the digital processor and is responsive to a
determination that the password is valid for
determining whether the caller is an authorized
user. This routine includes transformation means
that receives the speech feature' data generated for
each digit and the voice verification feature
transformation ,data 'and in response thereto
.generates voice verification parameter data for each
8igit. A verifier routine receiv~s the voice
verification parameter data and the
(speaker-relative) voice verification crass
reference data and in response thereto generates an
output indicating whether the caller is an
authorized user.
In operation of the method and system of the
invention, let us assume that a caller places a call
from a conventional calling station telephone to an
institution to obtain access' to an order-entry
service to which the caller has previously
CA 02365302 2002-O1-07
4
-'-
subscribed. The caller has also previously enrolled
in the voice verification database that .includes his
or her voice verification class reference data. The
institution includes suitable input/output devices
connected to the system (or integrally therewith) to
interface signals to and from the telephone line:
Once the call setup has been established, the
digital processor controls the prompt means to
prompt the caller to begin digit-by-digit entry of
the caller's preassigned password. The voice
recognition algorithm processes each digit and uses
.. a statistical recognition strategy ~o determine
which digit (zero through nine and "oh") is spoken.
After all digits have been recognized, a test is
made to determine whether the entered password is
valid for the system. If so, the caller is
conditionally accepted. In other words, if the
password is valid the system "knows" who the caller
claims to be 'and where the account information is
stored. '
Thereafter,' the system performs voice
verification on the caller to determine if the
entered password has been spoken by a voice
previously enrolled in the voice verification.
reference database and assigned to the entered
password. If, the verification algorithm establishes
a "match." access to the order-entry service is
provided. If the algorithm substantially matches
the voice to the stored version thereof, but not
within a predetermined acceptance criterion. the
system prompts the caller to input additional
personal information ,(e.g., the caller's social'
security number or birthdate) to further test the
identity of the claimed owner of the password. If
the caller cannot provide such information, the
CA 02365302 2002-O1-07
,f
- 6 -
system rejects the access inquiry and the call is
terminated.
Once the caller obtains access to the order
entry service, let us assume that he or she then
desires to place an order for a product/service
uniquely identified by an alphanumeric string known
to the caller. According to another feature of the
invention, a method for recognizing such
alphanumeric strings is implemented using a special
recognition strategy that does not require high
individual character recognition accuracy to achieve
recognition of the spoken alphanumeric string. In
operation, the system prompts the caller to speak
each character of a string sought to be recognized,
beginning with a first character and ending with a
last character. Each character is then captured and
analyzed using the speaker-independent voice
recognition algorithm. The method assigns a
recognition distance between each spoken input
2 0 character and the corresponding letter or digit in
the same position within each reference alphanumeric
string. After each character is spoken, captured
and analyzed, each reference string distance is
incremented and the process is continued,
2 5 accumulating distances for each reference sting,
until the last character is spoken. The reference
string with the lowest cumulative distance is then
declared to be the recognized string.
In accordance with one aspect of the present
3 0 invention, there is provided a method, using a
processing system, for recognizing character strings
spoken by a caller over a telephone network, the
processing system including a digital processor,
means for interfacing to the telephone network and
3 5 storage means for storing a predetermined set of
reference character strings each having at least two
characters, comprising the steps of: (a)
initializing a cumulative recognition distance for
CA 02365302 2002-O1-07
- 6a -
each of the reference character strings to zero; (b)
prompting the caller to speak a character in a
character string to be recognized; (c) capturing and
analyzing the spoken character; (d) calculating a
measure of acoustical dissimilarity between the
spoken character and a corresponding character of
each of the reference character strings to generate
a recognition distance for each of the reference
character strings; (e) incrementing the cumulative
1 0 recognition distance for each of the reference
character strings by the recognition distance
generated in step (d); (f) repeating steps (b)-(e)
for each successive character in the character
string to be recognized and a corresponding
15. character of each of the reference character
strings; (g) determining which of the reference
character strings has a lowest cumulative
recognition distance; and (h) declaring the
reference character string with the lowest
2 0 cumulative recognition distance to be the character
string spoken by the caller.
In accordance with another aspect of the
present invention, there is provided a method, using
a processing system; far recognizing character
25 strings spoken by a caller over a telephone network,
the processing system including a digital processor,
means for interfacing to the telephone network and
storage means for storing a predetermined set of
reference. character strings each having at least two
3 0 characters, comprising the steps of: (a)
initializing a combined recognition value for each
of the reference character strings to zero; (b)
prompting the caller to speak a character in a
character string to be recognized; (c) capturing and
3 5 analyzing the spoken character; (d) calculating a
measure of acoustical similarity between the spoken
character and a corresponding character of each of
the reference character strings to generate a
CA 02365302 2002-O1-07
,Y
- 6b -
recognition value for each of the reference
character strings; (e) incrementing the combined
recognition value for each of the reference
character strings by the recognition value generated
in step (d); (f) repeating steps (b)-(e) for each
successive character in the character string. to be
recognized and a corresponding character of each of
the reference character strings; (g) determining
which of the reference character strings has a
highest combined recognition value; and (h)
declaring the reference character .string with the
highest combined recognition value to be the
character string spoken by the caller.
The foregoing has outlined some of the more
pertinent objects of the present invention. These
objects should be construed to be merely
illustrative of some of the more prominent features
and applications of the invention. Many other
beneficial results can be attained by applying the
2 0 disclosed invention in a different manner or
modifying the invention as will be described.
CA 02365302 2002-O1-07
r
9
Accordingly, other objects and a fuller
understanding of the invention may be had by
referring to the following Detailed Description of
the preferred embodiment.
For a more complete understanding of the
present invention and the advantages thereof.
reference should he made to the following Detailed
Description taken in connection With the
accompanying drawiwgs in Which:
FIGURE 1 is a schematic diagram of a telephone
network having a calling station connectable to a
digital processing system of a service provider such
as a financial institution; '
FIGURE 2 is a schematic diagram of the digital
processing system of FIGURE l for use in providing
speaker-independent voice recognition and
verification according to the teachings of the
present invention;
FIGURE 3 is a block diagram of the preferred
ZO voice recognition/verification algorithms of this
invention;
FIGURE 4 is a .flowchart describing the verifier ,
routine of FIGURE 3;
FIGURE 5 is a representation of part of a table
including alphanumeric strings for use in an
order-entry system; and
FIGURE 6 is a flowchart describing a method of
recognizing alphanumeric strings spoken over a
telephone network according to the teach~.ngs o~ the
present invention.
Similar reference characters refer to similar
parts and/or steps throughout the~several views of
the drawings.
FIGURE 1 illustrates a block diagram of a
. convehtional telephone network 1D having a~ calling
station 12 connectable to a digital processing
CA 02365302 2002-O1-07
r
-8-
system 19 of a financial institution. According to
the teachings of the present invention, the digital
processing system 19 includes a speaker-independent
voice recognition algorithm 98 and an associated
voice verification algorithm 50 to facilitate
voice-controlled access to one or more services 20
offered by the financial institution. These
services include, but are not limited to, account
balance inquiry and electronic funds transfer.
Moreover, while the following discussion describes
the use of voice recagnition/verification in the
context of accessing information stored in a
financial institution, it should be appreciated that
the teachings of the invention are not so limited.
The invention can he used for numerous other
applications such as credit card validation,
order-entry o~ goods/serviaes and personal
identification validation. Further, it should also
be appreciated that the telephone network may
include other . devices and switching systems
conventional in the art. Accordingly, calling
station 12 may be connected through a central office
or other switching device, such as an access tandem
or interexchange carrier switching system, before
connection to the service provider.
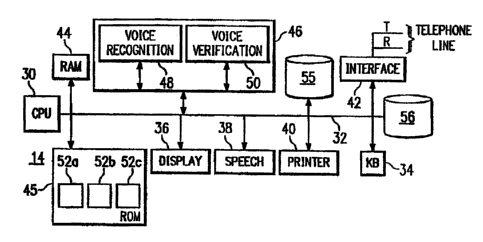
Referring now to FIGURE 2, a block diagram is
shown of the digital processing system 19 of the
present invention for providing simultaneous
speaker-independent voice recognition and
verification. The system includes a central
processing unit (CPU) 30 for controlling the overall
operation of the system. The CPU includes data,
address and control buses represented generally by
the reference numeral 32. As seen in FIGURE 2, the
system 14 also includes conventional input/output
devices such as a keyboard 34, display terminal 36,
r
CA 02365302 2002-O1-07
_g_
speech generator 38 and printer 90. ~ A
communications interface 42 (which may be
microprocessor-controlled) interfaces the system to
the telephone line. Random access memory ("RAM") 99
is connected to the CPU by bus 32 for providing
temporary storage of data processed thereby. Read
only memory ("ROM") 95 is likewise connected to the
digital processor for providing permanent storage of
special recognition and verification data as will be
described below. Disk storage 46 supports control
programs including a voice recognition algorithm 48,
and a voice verification algorithm 50 as well as
suitable control programs (not shown).
According to the invention, ROM 45 stores voice
recognition reference information for use by the
voice recognition algorithm 98. This information is
of two (2) types: voice recognition feature
transformation data 52a and voice recognition class
reference data 52b derived from a first plurality of
training speakers over a telephone netwozk. In
particular, voice recognition feature transformation
data 52a end voice recognition class reference data
52b is derived, in a prior off-line process, from a
voice recognition training database (not showw)
including "digit" data from a large number of
training speakers (e.g., 1000) collected over the
telephone network. This training database 52
includes local and long distance date, and
significant amounts of data are collected through
qarbon button handset microphones and electret
handset microphones. The voice recognition class
reference data 52b includes a representation for
each digit word (e.g., "one," "two,"wetc.) as a
"class" sought to be recognized by the voice
recognition algorithm 48. For example, the
representation of the class for the digit "one" is
CA 02365302 2002-O1-07
r
s
-10-
derived from the data from all of the training
speakers who spoke the digit "one."
The voice recognition training database is thus
designed to represent the distribution of acoustic
characteristics of each digit word across a large
population of speakers. The purpose and effect of
the analysis performed on this database is to
optimize the parameters of a multiple stage data
reduction process so as to discover anr7 accurately
represent those characteristics of each digit word
that differentiate it from each other digit word,
regardless of speaker.
According to another feature of the invention,
ROM 45 also supports voice verification. feature
transformation data 52c.' This data is derived, in~a
prio r off-line process, from a voice verification
training database (not shown ). In particular, the
voice verification training database preferably
includes data generated from approximately 100-150
training speakers and is collected over the
telephone network. The database includes local and
long distance data, and significant amounts of data
are collected through carbon button. handset
microphones and electret handset microphones. Each
training speaker is provided with a script
containing random digit sequences. The seguences
are spoken in a predetermined number (e.g., 5) of
separate recording sessions, with the first
recording session containing a predetermined number
(e. g., 5) of passes of the digits spoken in random
order. The subsequent sessions each contain a
predetermined number (e.g., 3) of pastes of the
'digits spoken in random order, and each recording
session is~ separated from the~wprevious session by at
least one day.
CA 02365302 2002-O1-07
.
k
-11-
The voice verification training database is
thus designed to represent the distribution of
acoustic characteristics of each digit word spoken
by a particular training speaker across multiple
utterances of the digit word by that speaker. The
purpose and effect of the analysis performed on this
database is to optimize the parameters of a multiple
stage data reduction process so as to discover and
accurately represent those characteristics of each
digit word uttered by each particular training
speaker that differentiate it from the same digit
Word uttered by each other training speaker.
The voice verification technique requires the
authorized users of the system (i.e., those persons
expected to call over the telephone system to~access
information) to have previously enrolled in the
system. Accordingly, the system 19 also includes a
voice verification reference database 55 comprising
voice verification class reference dot a collected
from users authorized to access the services.
Enrollment is preferably accomplished by having the
user speak a ten-digit password five times. For
further security, the caller is asked to answer a
few factual personal questions that can be answered
2S using digits recognizable by the voice recognition
algorithm 98. These questions may include. but need '
not be limited to, the user's social security
number. account number or birthdate. Each iiclasa"
' of. the. voice verification class referencedata
represents an authorized user of the system. The
class reference data for all authorized users of the
system is then stored in the voice verification
reference database 55.
The system 14 also includes a transaction
database 56 for storing financial and transaction
data, such as account balsnce5, credit information
CA 02365302 2002-O1-07
-12-
and the li k e~ This information is preferably stored
at predate rnnined locations addressed by the caller's
password. . Thus the password identifies both the
caller anc7 the location of the data sought to be
accessed.
In operation of the preferred method. assume a
caller places a call from the calling station 12 to
the financ i al institution in order to access account
informatio n. The callei has previously anrolled~in
the voice verification reference 'database 55~. Once
the call setup has been established, the speech
generator 3 8 of the digital processing system 14
prompts the caller to begin digit-by-digit entry of
the caller's predetermined password starting with
the first digit and ending with the ~laat digit
thereof. Prompting of the digits, alternatively,
can be effected in any~desired manner or sequence.
6ignals are interfaced to the telephone line by the
communicati vna interface 42. As each digit is
spoken, the voice recognition afigorithm 48 processes
the received informa.tian and, as will be described
below, uses a statistical recognition decisio~p
.strategy to determine the digit (zero through nine
and "oh").
After all digits have been recognized, a test
is made to determine whether the entered password is .
valid for the system. I~F the outcome of the test if
positive, the caller is conditionally accepted
because the system "knows" Who the caller claims to
be and thus where the account information 's,s
stored. Thereafter, the system uses .the voice
verification algorithm 50 to perform voice
verification on the caller to determine if~.~the
entered password , hasbeen spoken by a voles
previously enrolled in the database 55 and assigned
to the entered password. If the verification
CA 02365302 2002-O1-07
a
' -1~-
algorithm 50 establishes a "match" within
predetermined acceptance criteria, access to the
data or other system service is allowed. If the
algorithm 50 cannot substantially match the entered
voice to a voice stored in the database 55. the
system rejects the access inquiry and the call is
terminated. If the algorithm 50 substantially
matches the entered voice to a voice stored in the
database 55. but not within a predetermined
acceptance criterion,~the system grompts the caller
to input additional personal information (e.g., the
caller's social security number or account number)
associated with the password to further test the
identity of the claimed owner of the password. If'
the caller cannot provide such information, the
system rejects the access inquiry and th~ call is
terminated. Correct entry of the requested
information enables the caller to gain access to the
service.
Referring now to FIGURE 3, a block diagram is
shown of a preferred embodiment of the voice
recognition and verification algorithms 48 and 50.
As will be seen, algorithms 48 and 50 share the
.functional blocks set forth in the upper portion of
the block diagram. These blocks comprise a speech
processing means for carrying out a first tier of a
multistage data reduction process. In particular,
as speech is input to the system 19, a feature
extractor 60 extracts a set of primary features that
are computed in real time every 10 milliseconds. . '
The primary features include heuristically-developed
time domain features (e.g., zero crossing rates) and
freguency domain information such as Feat Fourier
Transform ("FFT") coefficients. The output of the
feature extractor b0 is a reduced data set
(approximately 4,000 data points/utterance .instead
CA 02365302 2002-O1-07
Y
-19-
of the original approxima ely 8,000 data
points/utterance) and is applied to a trigger
routine 62 that captures spoken words using the
primary features. The trigger routine is connected
to a secondary feature routine 63 for computing
"secondary features" from the primary features. The
secondary features preferably result from nan-linear
transformations of the primary features. The output
of the routine 63 is connected to phonetic
segmentation routine 64. After an utterance is
captured and the secondary features are computed, .
the routine 69 provides automatic phonetic
segmentation. To achieve segmentation, the phonetic
segmentation routine 64 preferably locates voicing
I5 boundaries by determining an optimum state seguence
of a two-state Markow process based on a sequence of
scalar discriminant function values. The
discriminant function values are generated by a
two-class Fisher linear transformation of secondary
feature vectors. The voicing boundaries are then
used as anchor points for subsequent phonetic
segmentation.
After the phonetic boundaries are located by
the phonetic segmentation routine, the individual
phonetic units of the utterance are analyzed and
so-called "tertiary features" are computed by a
tertiary feature calculation routine 65. These
tertiary features preferably comprise information
(e.g., means or variances) derived from the
secondary features within the phonetic boundaries.
The tertiary features are used by both the voice
recognition algorithm 48 and the voice verification
algorithm 50 as will be described. The output of
the routine 65 is a tertiary feature vector of
approaimately 300 data points/utterance. 'As can be
seen then. the upper portion of FIGURE 3 represents
CA 02365302 2002-O1-07
-15-
the first tier of the multistage data reduction
process wr~ich significantly reduces the amount of
data to be analyzed but still preserves the
necessary class separabi~lity, whether digit-relative
or speaker-relative,' necessary to achieve
recognition or verification, respectively. The
middle portion of FIGURE 3 represents a second tier
of the data reduction process and, as will be
described. comprises the transformation routines 99a .
' and 49b.
To effect speaker-independent voice
zecognition, the tertiary features are first
supplied to the voice recognition linear
transformation routine 99a.~ This routine multiplies
the tertiary feature vector by the voice recognition
feature transformation data (which is a matrix) 52a
to generate a voice recognition parameter data
vector for each digit. The output of the
transformation routine 99a is then applied to a
voice recognition statistical decision. routine 66a
for comparison with the voice recognition class
reference datav 52b. The output of the decisionw
routine 66a is a yes/no decision identifying whether'
the digit is .recognized and, if so, which digit is
spoken.
Specifically, decision routine 66a evaluates a
measure of word similarity for each of the eleven
digits (zero through nine, and oh) in w the
vocabulary. The voice recognition class reference
data 52b includes various elements (e. g., acceptance
thresholds for each digit class, inverse covariances
and mean vectors' for each class) used. by the
decision strategy. FOr a digit to be declared~(as
ogposed to being rejected), certain acceptance
35. criteria must .be met. The acceptance criteria may .
include, but need not be limited. to. the following.
CA 02365302 2002-O1-07
-16-
The voice recognition algorithm determines the
closest match between the class reference data and
the voice recognition parameter vector for the
digit; this closest match is a so-called °first
choice." The next closest match is a "second
choice." Each choice has its own matching score.
The digit is declared if (1) he matching score of
the first choice is below a predetermined threshold,
and (2) the difference between the matching scores)
of the first choice and the second choice digits is
. , greater than another predetermined threshold. When
all digits of the password have been recognized, the
voice recognition portion of the method is complete.
To effect voice verification, the tertiary
features are also supplied to a linear
transformation routine 49b that multiplies each
tertiary feature vector by the voice verification
feature transformation dot a (which is a matri~c).
The output of the routine 99b is an Np-element
vector p of voice verification parameter data for
each digit of the password,, with Np preferably
approximately egual to. 25. The voice verification
parameter data vector p is then input to a verifier
routine 66b. which . also receives the voice
verification class reference data S2c for the
caller. Specifically, .the voice verification class
reference data is provided from the voice
verification'reference database 55. As noted above,
.the address in the database 55 of the caller's voice
verification class reference data is defined by the
caller's password -derived by. the voice recognition
.algorithm 9B.
Verifier routine 66b generates one of three .
' different outputs: ACCEPT, REJECT and TEST. An
ACCEPT output authorizes the caller to access data
from the transaction database 56. The REJECT output
CA 02365302 2002-O1-07
-17- _
is provided if the verifier disputes the purported'
identity of the caller. The TEST outpu t initiates
the prompting step wherein additional follow-up
questions are asked to verify the caller's identity.
Referring now to FIGURE 9, a flowchart is shown
of verifier routine 66b of FLGURE 3. By way of
background, the routine begins after the
determination, preferably by the voice recognition
algorithm 98, that the password is valid. Although
in the preferred embodiment each voice verification
parameter vector is generated. as each 'digit is
recognized. it is equally possible to refrain from
generating the voice verification parameter vectors
until after a test is performed Lo determine whether
the password is valid.
The verifier routine begins at step 78. In
particular. the Np-element voice verification
parameter vectors for, each digit of the spoken
password are compared with the previously-generated
voice verification class reference data vectors
stored in the voice verification reference database
55. First, a weighted Euclidean distance d(i) is
computed for each digit at step 80:
Np
2 1/2
. d(i) a I ~ wl(.j) (p(i.j) - pr(i,j)) 7
jsl
where: p(i,j) is the jth component of the
~ length-Np vector generated from, the
ith digit in the length-Nd current
password entry sequence,
pr(i,j) is the jth component of the
reference vector of the ith digit
for the alleged enrolled caller;
CA 02365302 2002-O1-07
. . -18-
wl is a constant weighting vector,
precalculated to yield optimum
system performance; and
d(i) is the resultant weighted Euclidean
distance measure for the ith digit
in the current password entry
sequence.
Z'he distance vector d is then sorted in ascending
to order:
Nd Nd
d(i),...,d(Nd) - min(d(i)) , .... ,, maa(d(i))
i.l i-1
An ensemble distance is then calculated at step 82
as a weighted combination of these sorted distances:
Nd
w2(i) d(i)
i~l
where: d is the sorted distance vector
w2 is another constant weighting
vector, precalculated~ to yield
optimum system performance, and
D is the resultant ensemble distance
measure for the 'entire current
password entry seguence, with
respect to the alleged enrolled
caller.
At step 84, the ensemble distance is compared
to two (2) acceptance thresholds, an upper
threshold and a lower threshold. If the ensemble
distance is below the lower acceptance threshold,
the test is positive and .the caller gains immediate
access to the reguested service. This is the
ACCEPT output 88. If the distance is greater than
CA 02365302 2002-O1-07
-19-
the uppe r threshold, the caller's access to the
servic a is denied and the method terminates. This
corresponds to the REJECT output 89. If the.
outcome of the test 89 is between the upper and
lower thresholds, the method continues at step 90
by prompting the caller to answer one or more
factual questions uniquely associated with the
password. This is the TEST output. For eaample.
the caller is requested to speak his/her social
security number or his/her account number.
Alternatively, the caller can be prompted to ante r
such identifying information manually through .the
telephone keypad or by pulling a credit card or the
like through a card reader. Of course, the nature
and scoge of the personal information requested by
the system depends entirely on the system operator
and the degree of security sought by the caller and
operator. A test is then performed at step 92 to
detecmine if the questions) have been correctly
answered. If the outcome of the test is positive,
the caller again gains access to the requested
service. If the outcome of the test at step' 92 f s
negative, access is' denied and the method
terminates.
' Accordingly; it can ~be seen that the present
invention provides.a voice recognition/verification
system and method' having several advantages ever
prior art telephone-based data access schemes. The
problems inherent in the limited frequency response
environment of a telephone network are ameliorated
through the use of a speaker-independent voice
recognition system and a voice verification
algorithm: The voice verification algorithm is
"trained" by a voice verification training database
that includes speaker classifications as opposed to
word classifications. Moreover, the verification
CA 02365302 2002-O1-07
-20-
algorithm uses tertiary features and voice
verification feature transformation parameters to
calculate a preferably Z5-element vector 'for each
spoken digit of the entered password. These
vectors are then compared with voice verification
class reference data (for the caller) and a
weighted Euclidean distance is calculated for each
digit. An ensemble distance for the entire
password is then computed and compared to two
20 acceptance thresholds to determine if the caller's
voice matches his or her previously stored voice
templates. Callers who "almost match" must get
through an additional level of security before..
access to the data or service is authorized.
The digital processing system of the invention
may be, but is not limited to, a IBM AT personal
computer which is connected to a local area network
for storing and accessing .verification reference
data. P'or telephone-based applications requiring
confidential access to information, the system 19
has numerous applications. .Bp way of example only,
voice verification over the telephone network has
significant potential for eliminating calling card
fraud. 1n addition, beaks. and other financial
institutions can provide more security to
telephone-based account access systems. Presently,
banking systems use personal identification numbers
or "PIN" digits entered via the telephone keypad to
determine eligibility for system entry. Voice
verification as well as PIN digits may be employed '
to determine if a caller is authorized for access
to account information. Other uses for the system
described above include credit information access,
long distance telephone network access, and
electronic funds transfer. Because the vaice
verification operates in conjunction with voice
s i
CA 02365302 2002-O1-07
-21-
recognition, rotary telephone users are also able
to use any automated application employing the
system.
The performance of the system is characterizes
in terms of authorized user rejection rates (type 1
error) and casual importer acceptance rates (type 2
error). Authorized user rejection needs to be less
than 2% for most applications. At the same time.
casual importer acceptance also needs to be kept
under i%. In general, there is a definite tradeoff
between these error rates, since raising thresholds
to reduce authorized user rejection will always
result in increased casual importer acceptance, and
vice versa. Error rates have been determined from
a preliminary database containing a mixture of
electret arid carbon button microphones for
individual speakers, In this test, type 1 error
rates were below 2% while tyge 2 error rates were
also below 2%. Improved rates are achieved by
increasing the size and diversity of the data in
the voice verification training database 55'.
As described above, the digital processing
system 14 of FIGURE Z can _be used fork numerous
applications. One such application is a telephone
order-entry system Wherein authorized users of the
system have the capability of dialing into the
system and, following verification as described .
above, ordering products/services via coded
alphanumeric strings. As seen in FIGURE 5, for
example,, the telephone order-entry system may
comprise a table 100 of alphanumeric strings 102,
each identifying a gart or component capable of
being ordered by 'the caller over the telephone
network via input of an alphanumeric string
corresponding to the part or component. As shown
in FIGURE 5, each alphanumeric string 102~compriaes
Y
x.
CA 02365302 2002-O1-07
-22-
letters of the alphabet and/or the digits "zero"
through "nine". For example, one string comprises
the characters "FA9921R3." Of course, an
alphanumeric string 102 can be composed of only
digits, only letters, or a combination of both.
The order-entry system includes a predetermined
finite set of the alphanumeric strings 102.
The class reference data 52b representing the
variou s characters of the alphanumeric strings, as
well as the control words "stop" and "clear;" are
generated according to the teachings described
above. In particular, the voice recognition class
reference data 52b is expanded to include
representations for each characte r of the
recognition vocabulary (the alphabet; the digits
"zero" through "nine," "stop" and "clear"). This
vocabulary is then used by the voice recognition
algorithm 48 for the purpose of automatically
recognizing alphanumeric strings that are spoken
ZO over the telephone network.
Because such an extensive vocabulary is so
difficult to recognize, a special recognition
strategy is employed in order to achieve high
accuracy. The strategy ~utilizes.an ensemble-based
t5 recognition approach instead of individual
character recognition. In particular; according to
this aspect of the present invention, recognition
does not occur at the character level. Rather,
individual spoken characters are merely captured
30 and analyzed. Once an ensemble of characters
(corresponding to an alphanumeric string) is
processed in this way, recognition proceeds on the
ensemble itself ' as opposed to any individual
characters therein. As will be shown, the strategy
35 thus does not require high individual character
CA 02365302 2002-O1-07
t
-Z3-
recognition accuracy to achieve ,recognition of the
spoken alphanumeric string.
According to the invention, it is assumed that
a spoken alphanumeric string is a member of the
given finite set of alphanumeric strings previously
stored in the database 56 or other suitable storage
area. In operation, the identity of the caller
desiring access to the order-entry service is
preferably first verified according to the methods
l0 described in FIGURES 3-4 above. In general, the
method for recognizing a spoken alphanumeric string
involves determining a recognition distance between
each spoken input and the corresponding letter or
digit in the same position within eachr string
15~ represented in the database. Each recognition
distance is preferably a measure of the acoustic
dissimilarity between a spoken input and a
hypothetical character. For example, if an "A" is
spoken; then the recognition distance for "A" is
ZO expected to be quite low. It is also likely that
the distances for characters that sound similar to
"A", such as "8,"~ "H," "J" and "X," will be- higher
but also fairly low and that distances for highly
dissimilar characters such as "9,". "Q" and "W" v~ill .
25, be quite high.
Referring now to FIGURE 6, a flowchart is
shown of the preferred embodiment of the method for
recognizing alphanumeric strings according to .the
invention. Each of the predetermined reference
30 alphanumeric strings is presumed to comprise at
least two characters that can be either letters,
' digits: or a combination of letters and digits.
The method begins ,at step 104 by initializing
to zero a cumulative recognition distance for each
35 of the alphanumeric reference strings. At step
1D5, the caller is prompted to speak an
CA 02365302 2002-O1-07
-29-
alphanumeric character in an alphanumeric string to
be recognized, starting with the first.charaeter in
the string. The method continues at step 106 to
capture and analyze the spoken alphanumeric
character. This function is effected by the
recognition algorithm 98 as previously vdescribed.
A test 107 is then performed to determine whether a
predetermined command, e.g., "stop," has been
spoken. Such a command indicates that all of the
characters of the string have already been spoken.
If the outcome of test 107 is negative, the method,
continues at step 108 to calculate a measure of
acoustical dissimilarity between the spoken
alphanumeric character and a corresponding
alphanumeric character of each of the reference
alphanumeric strings to generate an initial
recognition distance for each of the reference
alphanumeric strings. In particular, it the caller
speaks the first character of an input string. step
108 compares this character with the first
character of each of the reference strings. At .,
step i10~, the~cumulative recognition distance for '
each of the reference strings is incremented by the
recognition distance. calculated in step 108.
The method then returns and repeats steps,105,
106, 107. 108 and 110 for each successive
alphanumeric character in the alphanumeric string
to be recognized and the corresponding alphanumeric
character of . each of~ the reference alphanumeric
strings. ff at any time during this process the
outcome of the tes t 107 is positive. indicating
that all characters of the string have already been
spoken, the method performs a test at step 112 to
determine which of the reference alphanumeric
strings has the lowest cumulative recognition .
distance. The reference alphanumeric string with
.
CA 02365302 2002-O1-07
-25-
the lowest cumulative recognition distance is then
assumed at step 114 to be the alphanumeric string
spoken by the caller.
If desired, the step 107 can be omitted. For
example, if the alphanumeric string to be
recognized is of a fixed length, the method can
automatically initiate step 112 upon receipt of a
predetermined number of characters.
The above-described technique has proven to be
rather robust even for strings containing only two
characters. In .general, long strings are easier to
recognize than short strings because more
information is available to determine which string
(from a finite set) is spoken. The size of the
string database is important for two reasons.
First, for a fiaed string Tength, string accuracy
decreases as the size of the database (i.e., the
number of possible 'strings) increases. Second,
more computation is required as the database size
increases.
It should be noted that individual character
recognition accuracy does not need to be uniformly
high in order to achieve high string accuracy. For
example, if the average substitution rate for the
alphanumeric vocabulary is 15% (i.e., 15% of the
time a spoken character is individually
misrecognized), then for alphanumeric strings with
four (4) characters, an average string substitution
rate of less than 2% should be achievable.
While the method of FIGURE 6 is preferred, the
recognition strategy could alternatively be carried
aut by calculating .acoustical .similarities between
spoken and stored characters and generating
recognition values in .response thereto. Larger
reference values would then be assigned to
characters having greater acoustical similarities.
r ., '
CA 02365302 2002-O1-07
-26-
Under this approach, the reference string having
the highest combined reference value would be
declared to be the recognized string. Also, while
the method for recognizing alphanumeric strings has
been described in the context of an order-entry
system following voice verification, the teachings
of the invention are not limited to such
applications. Indeed, even password verification
can be effected using the method if desired.
. T_t should. be appreciated by those skilled in
the nrt that the specific embodiments disclosed
above may be readily utilized as a basin for
modifying or designing other structures or methods
for carrying out the same purposes of the present
invent_on. For example, the voice recognition
algorithm 98 could alternatively be
speaker-dependent instead of speaker-independent as
described in the preferred embodiment. It should
also be realized by those skilled in the art that
such eguivalent constructions do. not depart from
the spirit and scope of 'the invention as set forth
in the appended claims.
Z5
3D