Note: Descriptions are shown in the official language in which they were submitted.
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
Getpage - Workload based Index Optimizer
Field of the Invention
[0001] The present invention relates to a method for
selecting optimized indexes for a relational database.
In particular, the present invention relates to an index
optimization (XOP) for IBM mainframe DB2 database servers
and the like. More specifically, the invention relates to
an index recommendation program that is based on relevant
SQL statements and their getpage activity as monitored by
a DB2 trace for a representative period of time.
Background of the Invention
[0002] A DB2 database on an IBM mainframe server is a
relational database management system. In a relational
database, data is stored in one or more tables, each
containing a specific number of rows. The rows of a table
are divided into columns. Rows can be retrieved and
manipulated at the column level. The language for DB2
data retrieval and manipulation is SQL (Structured Query
Language). Instructions to the database for either
retrieval or manipulation are hereafter referred to as
SQL statements or more generally, as queries. The major
SQL operations commands are SELECT, INSERT, UPDATE, and
DELETE. The performance of SQL statements can be
CONFIRMATION COPY
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
2
enhanced through the use of indexes to accessing the rows
in the DB2 tables more efficiently. An index is an
ordered set of pointers to the data in the table i.e., it
orders the values of columns in a table. Indexes are
stored separately from the data. The decision on whether
and how to use an existing index for a given SQL
statement that retrieves/manipulates table data is made
internally by the IBM DB2 optimizer. This decision is
called the access path of an SQL statement. The access
path and the performance of an SQL statement are directly
related to index design. In large-scale production
environments, thousands of tables may exist. Normally,
index design is a manual process that includes estimates
rather than actual production activity. The manual
process of index design in such an environment is both
inefficient and slow. To allow an easy and fast access
to the physically stored dada, it is appropriate to have
an optimized index. An optimized index reduces the time
for accessing the data and thus increases the physical
computational performance.
[0003] An SQL statement is internally subdivided into
one or more query blocks by the IBM DB2 optimizer. Every
query block has its own access path with one or more
tables and may use one or more indexes, e.g., the query
SELECT * FROM TAB1 UNION SELECT * FROM TAB2 consists of 2
query blocks SELECT * FROM TAB1 and SELECT * FROM TAB2.
Other examples of query blocks are VIEW or SUBSELECT
MATERIALIZATION. The query blocks and their selected
access paths of SQL statements can be analysed using the
EXPLAIN interface of DB2.
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
3
[0004] Statistical data about the tables and indexes
are a major influence on the access path of an SQL
statement selected using the IBM DB2 optimizer. The DB2
catalog is an internal set of tables of data about a DB2
database including information on tables, columns,
indexes, key columns, and SQL statements.
[0005] Buffer pools, also known as virtual buffer
pools, are areas of virtual storage in which DB2
temporarily stores pages of data from tables and indexes.
When an SQL statement requests rows of a table, the DB2
data manager retrieves the pages containing the rows of
the table from the DB2 buffer pool manager. The number of
pages retrieved for a table or index to satisfy an SQL
statement is the "getpages" for the table or index.
[0006] The getpages measured in the buffers of the DB2
database server are always the same for an SQL statement
and a given set of indexes on the tables referenced by
the SQL statement, regardless of the state of the DB2
database server and the machine. In this regard, getpages
are different from disk I/Os which may vary for the same
SQL statement at different times.
[0007] Predicates are located in the WHERE, HAVING and
ON clauses of SQL statements and describe attributes of
table data. To reduce the table getpage activity, the
IBM DB2 optimizer internally uses predicate filter
factors to determine which index is best. Each such
index can serve one or more columns of a table. A filter
factor is a floating value between 0 and 1 that describes
the proportion of rows in a table for which the predicate
is true. It is supplied by the IBM DB2 optimizer EXPLAIN
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
4
interface and stays the same regardless of the indexes
deployed, i.e., filter factors are static for the
predicates of a given query. A predicate with a small
filter factor, i.e., close to zero is very effective
because it selects only a few rows out of all rows in a
table. A predicate with a high filter factor, i.e.,
close to 1, is very ineffective since it encompasses most
rows in the table.
(0008] The following list shows the input data to the
present invention. The abbreviations on the left hand
side will be used herein:
Q SQL statement
T Table
B Query block
P Predicate
FF Filter factor of a predicate
Getp(T,Q) Number of getpages (equates to number of pages
read) for table T for all invocations of SQL
statement Q (regardless whether Q is a SELECT,
UPDATE, INSERT or DELETE statement)
Getp(I,Q) Number of getpages (equates to number of pages
read) for index I for all invocations of SQL
statement Q (regardless whether Q is a SELECT,
UPDATE, INSERT or DELETE statement)
Update(T,Q) Number of pages changed in table T by all
invocations of an UPDATE statement Q
Insert(T,Q) Number of pages changed in table T by all
invocations of an INSERT statement Q
Delete(T,Q) Number of pages changed in table T by all
invocations of a DELETE statement Q
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
Col(T,Q,B) - ~C1,...,Cn~ is the set of columns within
table T and SQL statement Q and query block B
Pred (T, Q, B) - { P,...,P" ~ is the set of predicates in SQL
statement Q and query block B with a column in
table T
[0009] All indexing n, such as Pn, should be understood
as a generic placeholder that differs for each table,
index and query block.
Sununary of the Invention
[0010] The present invention describes an index
recommendation XOP program that computes new and improved
performance indexes based on the getpage workload of a
given set of SQL statements. The term getpage workload of
an SQL statement is defined as the read/change activity
(measured. in getpages) on each table and each index
currently used for all invocations of an SQL statement.
The results of the XOP program are pure computations; the
XOP program itself does not use the DB2 optimizer to
determine the usefulness of potential indexes. By using
optimized indexes the number of and time for read
activities can be decreased. Thus, the hardware
requirements for fast data access can be reduced.
Brief Description of the Drawings:
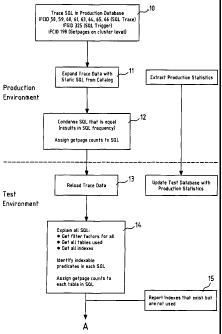
[0011] Fig. 1 is the first page of the flowchart of the
overall processing by the XOP program.
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
6
[0012] Fig. 2 is the second page of the flowchart of
the overall processing by the XOP program.
[0013] Fig. 3 is a flowchart of the table ranking for
index recommendation.
[0014] Fig. 4 is a flowchart showing the retrieval of
the filter factors of the SQL statement predicates.
[0015] Fig. 5 is a flowchart showing the retrieval of
the concatenations of the SQL statement predicates.
[0016] Fig. 6 is a flowchart showing the process of
building column sets.
[0017] Fig. 7 is a flowchart of the recommendation of
new indexes.
[0018] Fig. 8 is a flowchart of column set pruning and
the calculation of the total savings in getpages on the
table level for each column set permutation.
[0019] Fig. 9 is a flowchart of building column
permutations and calculating their filter factors and
savings in getpages on query block level.
[0020] Fig. 10 is a flowchart showing the decision
taking path for index recommendations that support index
only access.
[0021] Fig. 11 is a flowchart of building the best
column combinations to be added to existing indexes for
index only access.
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
7
[0022] Fig. 12 is a flowchart of column combination
pruning.
[0023] Fig. 13 is a flowchart of building indexes for
index only access.
Detailed Description: Information About Giving Activity
[0024] Fig 1 & 2 form a high level flowchart of the XOP
program. For a given set of SQL statements, the programs
major objective is to recommend new or improved
performance indexes based on their ability to minimize
the overall SQL statement getpage workload i.e., the
read/change activity on each table and each index
currently used for all invocations of an SQL statement.
[0025] The initial step in running the XOP program is
to extract production statistics from the existing
database. A conventional DB2 trace is run in the
production environment 10. This captures SQL statements
and their getpage activities on the tables and index
levels for a representative time interval. The trace
data is expanded with static SQL from the database's
catalog 11 and condensed to give the SQL frequency and to
allow assignment of getpage counts to the SQL 12.
[0026] The test environment consist of corresponding
tables and indexes to those in the production
environment, but no data is required to be in the tables.
The trace data is reloaded into the test environment 13.
Production catalog statistics must be simulated in order
to do a one time EXPLAIN of the relevant SQL statements.
The EXPLAIN function of DB2 is used to provide the access
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
8
path for each query block, the predicate filter factors,
and the tables and indexes used by the relevant SQL
statements. As a direct result, a comparison of indexes
that exist with the ones being used, allows
identification of the indexes currently not used 15. Next
the program identifies the indexable predicates in each
SQL, it then assigns a getpage count to each table in the
SQL 14.
[0027] The actual selection of indexes to be used in
the production database is done through a series of steps
200-800 which will determine the XOP selection process
16. As more fully discussed below, the tables are ranked
200, filter factors are obtained for all predicates 300,
concatanation for all predicates is obtained 400, column
permutations and filter factors and savings are
calculated 500, column permutations are consolidated and
indexes recommended 600, indexes for index only access
are selected 800. Upon completion the recommended
indexes are used to create indexes in the production
database 17.
[0028] Fig. 3 illustrates the process of ranking
tables. This ranking identifies the tables most likely to
benefit as a result of new performance indexes. A set of
tables TAB is introduced in the first step and
initialized to empty 201. Then each table T 202 is
checked whether its read activity GetpT exceeds the
change activity ChngT by a predefined threshold
percentage 203. A table T with a high volume of changed
data is not considered for further processing because
additional indexes on table T increase the change
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
9
activity ChngT to an amount that is higher than the
savings in read activity GetpT. Otherwise, table T is
added to the set of tables TAB 204 which collects all
tables for ranking.
[0029] The read activity GetpT of a table T is defined
as the total sum of getpage requests of all SQL statement
invocations for this table T:
n
GetpT - ~Getp(T,QI)
r=i
[0030] The change activity ChngT of a table T is the
total sum of pages changed of all UPDATE, DELETE and
INSERT statement invocations for this table T:
n n n
ChngT - ~ Update(T, Ql ) + ~ Delete(T, Q; ) +~ Inse~t(T, Q; )
t=i t=i t=i
(0031] As one example, let a first SQL statement be
SELECT * FROM TABA WHERE COLA = "A" with a read activity
of 100 pages and let a second SQL statement be INSERT
INTO TABA VALUES ("A", "B", "C") with a read activity of
pages and a change activity of 100 pages. Let an
additional one-column index using COLA reduce the read
activity by half and double the change activity, then
read activity is reduced to 50+5=55 pages and change
activity is increased to 200 pages. The new overall
workload is 55+200=255 pages which is an increase of 45
pages compared to the old workload of 100+10+100=210
pages.
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
[0032] Finally, all tables T in TAB are sorted by read
activity GetpT in descending order 205. The result is a
table ranking that lists the tables having a high
potential for workload savings from new performance
indexes.
[0033] The flowchart of Fig. 4 shows the process of
retrieving filter factors of all predicates. For each
table T being processed in ranking order 301, for each
SQL statement Q using this table T 302 and for each query
block B inside this SQL statement Q 303, each predicate
out of Pred (T, Q, B) - f PT1,...,PT" ~ 304 is analyzed. If the
predicate is not indexable 305, its filter factor is set
to 1 which prevents this predicate from having any
influence on future index recommendations 307.
Predicates that do not have any table column will receive
a filter factor of 1. Examples for such predicates are
special registers or constants.
[0034] The flowchart of Fig. 5 illustrates the
retrieval of the predicate concatenations, i.e., the
boolean operators AND and OR. For each table T selected
in ranking order 401, for each SQL statement Q using this
table T 402, and for each query block B inside this SQL
statement Q 403, each predicate out of Pred(T,Q,B) -
P,...,P,1 ~ 404 is investigated to determine how it is
concatenated to the next predicate and whether the next
predicate in the concatenation of SQL statement Q belongs
to Pred(T,Q,B), i.e., contains columns of table T 405.
If no such columns are found, such predicates are
replaced by TRUE and removed from the predicate
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
11
expression using boolean rules. Note that expressions in
inner brackets are evaluated first.
[0035] As an example, let a predicate expression be A=1
AND B=5 AND C=1 OR D=1 where A, B and D are columns of a
first table and C is a column of a second table. Then the
expression for predicate set (A=1 ,B=5, D=1~ can be
rewritten as A=1 AND B=5 AND TRUE OR D=1 which is
equivalent to A=1 AND B=5 OR D=1.
[0036] The next step of the program is shown in the
flow diagram of Fig. 6. The objective is to build column
sets that are input to the calculation of the total
savings in getpages at table level for each column set
permutation in a later step.
(0037] First, for each table T being processed in
ranking order 501 a set of column sets ColCombT is
introduced in a first step and initialized as being empty
502. Then, for each SQL statement Q using this table T
503 and for each query block B inside this SQL statement
Q 504, the set of columns Col(T,Q,B) - ~C1,...,Cn~ is
checked to determine whether column set (CI,...,C,Z) is
already an element in ColCombT 506. If it is not, column
set (C1,...,C,1~ is added to ColCombT 507.
[0038] when all SQL statements and all their query
blocks are processed for a given table T, i.e., the build
up of ColCombT has finished for given table T, column
sets Col(T,Q,B) inside ColCombT are pruned 508 as seen
more fully in the flow diagram of Fig. 8. Column
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
12
permutations are built and their filters and savings in
getpages for each query block B are computed. The
purpose of column set pruning is to avoid redundant
combinations in the column set permutations that are done
in a later step 711. For each column set ~C1,...,Cn~ out
of ColCombT 701 it is checked whether it is a real subset
of another column set ~dl,...,dx} out of ColCombT 702. If
this is true, the element ~C1,...,Cn~ is removed from
ColCombT 703.
[0039] As an example, let ~A,B,C~, ~A,C~ and ~D,E~ be
the elements in ColCombT, the element fA,C~ will be
removed from ColCombT because it is a subset of {A,B,C~.
[0040] As seen in the flow diagram of Fig. 6, the
program then verifies whether there is enough. read
activity GetpT left over for all tables T not yet
processed. If the remaining read activity is sufficient
according to a predefined threshold, the process of
building column sets and the calculation of the total
savings in getpages on table level for each column set
permutation continues for the next table T 501.
[0041] The savings SavT,Q,a,Pe for each permutation Pe and
query block B inside every SQL statement Q using table T
are known 704. Thus, the total saving SavT,pe for table T
and each permutation Pe (705) can be computed 706 as:
n n
Sc7.VT pe = ~~SCIVT ~r B~>Pe
i=1 j=1
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
13
[0042] The program verifies new indexes are recommended
based on the calculated savings SavT,Pe for all processed
tables T as shown in the flow diagram of Fig. 7. First,
the savings SaVTpe for all permutations Pe and all tables
T are sorted in descending order 601, so that the
permutations Pe with the highest savings in getpages are
first. For each saving SavT,Pe being processed in sort
order 602, it is verified whether it exceeds a predefined
threshold value 603. If so, a recommendation is made for
a new index with a key Pe = (Et,...,E,i). Depending on the
getpage activity caused by ORDER BY, MIN and MAX the
index key columns E1,...,E,1 are put in either ascending
or descending order. To avoid redundant index
recommendations, the sorted list is searched for elements
SavT,PX of the same table T where the permutation Px is
covered by the index key (E1,...,En) just recommended.
Such elements SavT,pX are ignored for further processing
and removed from the sorted list 602.
[0043] As an example, let (A, B, C) be the key columns
of the recommended new index, permutations (A) and (A, B)
do not need any further attention and are deleted because
they are already covered by index key (A, B, C).
[0044] The flowchart 508 of Fig. 8 shows returning the
savings SaVT,Q,B,pe for each permutation Pe and query block B
inside every SQL statement Q using table T 704 Fig. 7:
[0045] First, for each column set Col(T,Q,B) -
~C1,...,C"~ inside ColCombT 710 all column permutations
are built 711. As one example, let ~A, B, C~ be the
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
14
column set. Then there are 15 column permutations which
are (A) , (B) , (C) , (A, B) , (A, C) , (B, A) , (B, C) , (C,
A) , (C, B) , (A, B, C) , (A, C, B) , (B, A, C) , (B, C, A) ,
(C, A, B) and (C, B, A) .
[0046] Then, for each permutation Pe 712, all query
blocks B with a column in Table T for any SQL statement Q
713 are processed in the following manner:
1. The filter factor FFT,g,B,Pe for query block B and
permutation Pe and the filter factor FFT,~,B for the
complete query block B are calculated 714.
2. The getpage number GetpT,Q,B on query block level B is
calculated based on FFT,Q,B 715.
3. Depending on the current index usage 716, 717 of query
block B, the savings Sa.VT,~,B,Pe for permutation Pe is
computed 718, 719, 720.
[0047] For each predicate set Pred(T,Q,B) and its
concatenations (modified as described in Fig. 4), the
overall filter factor FFT,Q,B is calculated using the
following boolean AND and OR rule:
~ Filter factors of predicates that are concatenated
with an AND will be multiplied.
~ Filter factors of predicates that are concatenated
with an OR will be added and the product of both
filter factors is subtracted.
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
~ Filter factors of predicate expressions in inner
brackets are computed first.
The above rule will be referenced in the following
description as Rule~andoR~ As a continuation of the
example already given, let a predicate expression be A=1
AND B=5 OR D=1 where A, B and D are all columns of table
T. Let FFa, FFb and FFd be the filter factors of the
columns A, B and D . Then FFT,~,B is computed as
( (FFa*FFb) +FFd) - ( (FFa*FFb) *FFd) . In the next step, only
those predicates and concatenations are kept. in the
predicate expression that contain a column in permutation
Pe . All others are set to TRUE and removed using boolean
rules. The filter factor FFT,~,B,Pe is now calculated using
RLl~-eANDandOR~ Note that expressions in inner brackets are
evaluated first. In the above example, let (A, D) be the
permutation Pe. Then predicate expression A=1 AND B=5 OR
D=1 equates to an expression A=1 OR D=1 and filter factor
FFT,g,s,Pe is computed as FFa+FFd- (FFa*FFd) .
[0048] The number of getpages GetpT,~,B for table T and
query block B in SQL statement Q is computed as:
GetpT,~,B - ~etp(T~~) ~ »FFT~Q~B
FFT,Q,ar
where Bi are the query blocks in SQL statement Q.
[0049] The savings SaVT,Q,B,Pe for permutation Pe is
calculated in one of the following three ways:
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
16
Formula 1:
[0050] The query block B currently uses a matching
index access 718:
Sa.V T,~.B,Pe = GetpT,Q,B ~ (1 _ FFT.Q,s.re)
FilterFactorI
where FilterFactorI stands for the filter factor of the
used index. It is calculated for a specific query block B
with the same AND and OR rule already described. Assume
Predi are the predicates in query block B with columns
covered by the index, then the FilterFactorI is
calculated as follows:
FilterFactorI = Rule,,NDanaox [ FF(Pred, ) Concat(Pred z ) FF(Pred 2 ) ...
FF(Pred n_1 ) Concat(Pred" ) FF(Pred" ) ]
where FF(Predi) are the filter factors of Predi and
Concat(Predi+1) are the concatenations AND and OR to the
next predicate Predi+1.
Formula 2:
[0051] The query block B currently uses a non-matching
index access 719:
SaVTQB,Pe= (GetpT,Q,B+ Getp(I.Q) ) * (1 - FFT,Q,a,Pe )
where Getp(I,Q) is the number of index getpages.
Normally, Getp(I,Q) exceeds GetpT,Q,B by far and will be
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
17
theoretically eliminated by a new index with matching
access.
Formula 3:
[0052] The query block B does not currently use any
index 716, i.e., uses a table space scan 720:
S aV T.~~B~Pe = Ge tp T,Q,B * ( 1 - FF T~Q~B~pe )
[0053] All permutations Pe 712 are processed for all
column sets Col(T,Q,B) - ~C1,...,Cn~ inside ColCombT710.
Now, the total saving SavT,Pe for table T and permutation
Pe can be computed as the sum of all SavT,~,B,Pe 706 .
[0054] The final steps in the XQP program is shown in
flowchart of Fig. 10 to 12 where recommendations are made
for new or extended indexes which allow index only access
results for selected SQL statements. Index only access
means that SQL statements are solely processed by
retrieving index pages. No pages have to be read on the
table level because all SQL statement columns are part of
the index.
[0055] First, each table T being processed in ranking
order 801 is checked whether its read activity GetpT
exceeds the total read activity of all tables by a
predefined threshold percentage 802. If this threshold is
not reached, this table T and all tables that follow
table T in ranking order are not considered any further
and processing continues with flowchart Fig. 13 809.
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
18
Otherwise, if the read activity on table T is still
sufficient, there should be no index recommendation
already made for this table T by the XOP program 803. If
this is true, all existing indexes I for table T are
retrieved (804) and sets AddCoIT,I are initialized to
"empty" for table T and all indexes I.
[0056] A set AddColT,I will store elements
(B, ( C1 , . . . , C" } , GetpT,Q,B ) which represent the column
combination fCl,...,C"~ and its savings GetpT,Q,B in
getpages for a query block B 805 inside SQL statements
Q using table T (806) that is to be added to index I for
index only access. The construction of AddColT,I is
illustrated in flowchart Fig. 11 where all indexes 810
are investigated for query block B which columns
{C1,...,Cn~ are to be added 811 to the index key for
index only access. If the total length and the total
number of the index key and additional columns do not
exceed DB2 limits and if DB2 supports index only access
for any additional column variable in length 812, then
the column combination {CI,...,Cn~ is stored together
with its savings in set AddCoIT,I 813 for index I and
table T, i . a . , AddCol T,I - AddCol T,I U ~ ( B, { C 1 , . . . , C n ~ ,
GetpT,Q,B)~. When all indexes I are checked for query block
B (810), processing returns to flowchart Fig. ~ 807.
[0057] As an example, let the columns of table T be A,
B, C, D, E, F, G, and H. Let the 3 indexes on this table
be:
Index : II I2 I3
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
19
Key: (B, C) (D, G) (E)
[0058] Furthermore, let the columns of 6 query blocks
with columns in T be COL (T, Q, B1) - f B, C, D~ , COL (T, Q, B~)
- ~B, D, G~ , COL (T, Q, B3) - ~B, C, F~ , COL (T, Q, B4) - ~B,
C, D~ , COL (T, Q, BS) - f B, C, D, E, F~ , and COL (T, Q, B6) -
F ~ . Then, the sets AddCol T,z~ , AddCol T Iz , and AddCol T,r3 will
contain the following elements:
AddCol T z~ AddCol
T,zz AddCol
T z3
~B,C, D~: (Bl,~D},30)
~B,D, G}: (Bz,fB},7o)
(B,C, F~: (B3,{F~,10)
~B,C, D~: (B4,~D},20)
~B,C, D, E, (B5, ~D, E, F}, (B5, ~B, C,D,
F} : 30) F~, 10)
~F~:
[0059] When the sets AddColT,I are built for a given
table T and all its indexes I 805, processing continues
with flowchart Fig. 12 808 where the column combination
found before is pruned. Here, for each index I on table T
820, each element (B,~C1,...,Cn~,Getp) inside AddColT,I is
checked 821 whether fCI,...,Cn~ covers any other element
inside AddColT,I 823, i . e. , {dl , . . . , do ~ is a subset of
~C1, . . .,Cn ~ and (Bd, f dl, . . .,dn ~,Getpd) E AddColT,T. If
this is true, the read activity Getpd is added to the
overall savings GetpT,r,H that an index I on table T will
have if columns ~C1,...,C"~ are added to its index key
824. The overall savings GetpT,r,B is initially set to Getp
822.
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
[0060] For a given table T and index I, the element
(B, {C1 , . . . , Cn ~ , Getp) with the maximum GetpT,I,B finally
remains in AddCoIT,T 825 and all AddCoIT,I elements for
other query blocks Bd covered by { C 1 , . . . , C" ~ are removed
from AddCoIT,I. Furthermore, all elements for query blocks
B and Bd are removed from the sets AddColT,rx for any other
Index Ix 826.
[0061] Processing returns to flowchart Fig. 10 at 808
if all indexes I on table T are checked 820 or the sum of
getpages in the remaining query blocks is below a
predefined threshold 827.
[0062] When all tables are processed 801 or the read
activity GetpT of the next table T does not exceed the
total read activity of all tables by a predefined
threshold percentage 802, processing continues with
flowchart Fig. 83 809. Here the indexes are recommended
that support index only access. For every element
(B,{C1,...,Cn~,Getp) out of AddCoIT,I and its overall
savings GetpT,T,B 830, it is checked whether GetpT,I,H exceeds
the read activity GetpT of table T by predefined
threshold 831. If the savings GetpT,I,B are not sufficient,
the next element (B,{C1,...,C,t~,Getp) is checked 830.
Otherwise, it is decided whether a new index should be
built with a key containing the columns copied from the
existing index I plus the columns {C1,...,C,=~ 833 or
whether the columns {C1,...,C"} should be just added to
the existing index I 834. To avoid changes to the data
model, the recommendation for a new index is always made
CA 02477580 2004-08-26
WO 03/075174 PCT/EP03/02129
21
if the existing index is unique or clustering 832.
Otherwise, recommendations are made to modify the
existing index 834.
[0063] The recommendations can then be used to create
indexes in the production database 17 which are
accordingly optimized based on getpage work load.
[0064] It is understood that the present embodiments
described above are to be considered as illustrative and
not restrictive. It will be obvious to those skilled in
the art to make various changes, alterations and
modifications to the invention described herein. To the
extent that these variations, modifications and
alterations depart from the scope and spirit of the
appended claims, they are intended to be encompassed
therein.