Note: Descriptions are shown in the official language in which they were submitted.
CA 02504689 1999-03-16
wo m4soza Pc~rius~rossss
-1
IIVVIPROVED SEARCH ENGINE
Field of the Invention
'The present invention relates to a method and apparatus that allows for
enhanced database
searching, and more particularly, for use as an intemet search engine.
Background of the Related Art
An efficient and practical means of obtaining relevant information and also
screening .
unwanted/uninteresting information has been an ongoing need, especially since
the inception of the
Internet. This need is particularly acute at present due to the exponential
growth in the number of world-
wide web sites and the sheer volume of information contained therein. In an
attempt to index the
information available on the Internet, a number of software search engines
have been created via which a
user enters a search command comprised of suitable keywords from a keyboard at
his personal computer.
The search command is transmitted to a server computer, that has a search
engine associated with the
server computer. The search engine receives the search command, and then using
it scans for these key
words through a database of web addresses and the text stored on the web
sites. Thereafter, the results of
the scan are transmitted from the server computer back to the user's computer
and displayed on the
screen of the user's computer.
In order for the search engine to be aware of new web sites and to update its
records of existing
sites, either the proprietors of the web sites notify the search engine
themselves or the information may
be obtained via a 'web crawler' to update the database at the server computer.
A web crawler is an
automated program which explores and records the contents of a web site and
its links to other sites,
thereby spreading between sites in an attempt to index all the current sites.
This database structure and method of searching it poses some significant
difficulties. The intennet
growth-rate has resulted in a substantial backlog in the scanning of new
sites, notwithstanding the fact
that web sites are frequently deleted, re-addressed, updated and so forth,
thus leaving the search engine
with outdatod and/or misleading information. Although the web crawlers can be
configured to prioritize
possible key-words according to their location (title, embedded Iink, address
etc), nevertheless,
depending on the type of search engine used, substantial portions of the web
site text (often involving the
majority or even all of the site text) is still required to be scarmed. This
results in colossal storage
requirements for the search engine. Furthermore, a typical key word search may
bring up an excessively
large volume of material, the majority of which may be of little interest to
the user. The user typically
makes a selection from the Iist based on the brief descriptions of the site
and explores the chosen sites
until the desired information is located.
These results are in the form of a list, ranked according to criteria specific
to the search engine.
These criteria may range from the number of occurrences of the key-words
anywhere within the searched
CA 02504689 1999-03-16
WO 99/48028 ' PCT/US99/OSS88
-2- '
text, to methods giving a weighting to key-words used in particular positions
(as previously mentioned).
When multiple key-words have been used, sites are also ranked according to the
number of different key-
words applicable. A fundamental drawback of all these ranking systems is their
objectivity - they are
determined according to the programmed criteria of the search engine, and the
emphasis placed on
particular types of site design, rather than any measure of the actual users'
opinions. Indeed this can lead
to the absurd situation whereby in an attempt to ensure a favorable rating by
the most commonly used
search engines, some designers deliberately configure their sites in the light
of the previously mentioned
criteria, to the detriment of the presentation, readability and content of the
site.
to
SUNIHIARY OF THE INVENTION
It is an object of the present invention to ameliorate the aforementioned
disadvantages of
conventional search engines by harnessing the cerebral power of the human
operator.
It is a further object of the print invention to provide a novel search engine
with enhanced
e~cicncy, usability and effectiveness with a reduced system storage and/or
computational requirements
in comparison to existing software engines.
It is a further object of the present invention to provide a variety of
indications of the popularity of
the search data, together with an indication of its date of creation or
updating.
In order to obtain the above recited advantages of the present invention,
among others, one
embodiment of the present invention provides for a method of updating an
intemet search engine
database with the results of a user's selection of specific web page listings
from the general web page
listing provided to the user as a result of his initial keyword search entry.
By updating the database with
the selections of many different users, the database can be updated to
prioritize those web listings that
have been selected the most with respect to a given keyword, and thereby
presenting first the most
popular web page listings in a subsequent search using the same keyword search
entry.
In another embodiment of the present invention, a method of determining
content to provide along
with listings transmitted from a server computer to user sites is provided. In
this embodiment, there is
obtained a content listing from each one of a plurality of different developer
sites. Each of the content
listings includes content, a developer identifier, and a keyword, and a
keyword selection factor.
Thereafter, there is determined a particular keyword from the obtained
keywords that is the same for
different content listings. For that particular keyword, the keyword selection
factor is used in
determining when to transmit different content listings to the user sites.
In still another embodiment, there is provided amethod of updating a keyword
table with the results
of a user's selection of specific keywords which were obtained from a list of
related keywords presented
to the user. Hy updating the database with selections of many differtnt ustrs
associated with that same
CA 02504689 1999-03-16
WO 99!48028 PCTNS99tO5s88
-3
keyword, appropriate keywords can be provided and presented first when that
same keyword is
subsequently entered.
BRIEF DESCRIPTION OF THE DRAWINGS
These and other advantages of the present invention may be appreciated from
studying the following
detailed description of the preferred embodiment together with the drawings in
which:
Fig. 1 illustrates certain of the overall features of the present invention;
Fig. 2 illustrates various inputs to the search, and, for tech of the
different capabilities, illustrates the
outputs that will be provided eng'rae according to the present invention;
Figs. 3A and 3B illustrates an overview of the process by which web pages are
selected in making
up the search results provided to the end user according to the present
invention;
Fig. 4 illustrates the data sets used for different web-page searches
according to the present
mvenrion.
Fig. 5 shows the various data sets deviously described, and various inputs and
actions that result in
a list of suggested web pages being provided according to the present
invention;
Fig. 6 illustrates the implementation of a popular search according to the
present invention:
Fig. 7 illustrates the implementation of a hot off the press search according
to the present invention:
Fig. 8 illustrates the implementation of a high-flyers search according to the
present invention:
Fig. 9 illustrates the implementation of a random search according to the
present invention:
Fig 10 illustrates the implementation of a previous past favorites search
according to the present
invention.
Fig. 11 illustrates the impltmentation of a collective search according to the
present invention.
Fig 12 illustrates the implementation of a date created search according to
the present invention.
Fig 13 illustrates the implementation of a customized search according to the
present invention.
Fig 14 illustrates the implementation searching based upon a group identity
according to the
present invention.
Fig. 15 illustrates a keyword eliminator feature according to the present
invention.
Fig 16 illustrates the process of determining which search results should be
used to make up the
curaulative surfer trace table according to the present invention.
Fig 17 illustrates active suggestion of web pages according to the present
invention.
CA 02504689 1999-03-16
wo 99idso2s rcrnls99rossss
-4-
Fig 18 illustrates passive suggestion of web pages according to the present
invention.
Fig. 19 provides an overview of suggesting keywords according to the pit
invention.
Fig. 20 illustrates the manner of creating data sets for suggested keywords
according to the present
invention.
Fig. 21 illustrates a variety of manners in which a list of suggested
keyovards can be created
according to the present invattion.
Fig. 22 illustrates how content is attached to web page listings according to
the present invention.
Fig. 23 illustrates various content data sets and operations that populate
them according to the
present invention.
Fig. 24 illustrates various content data sets and operations that are used to
select data from them a
according to the present invention.
Fig. 25 illustrates web page listings and other content data according to the
present invention
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENT
Figs. lA and 18 illustrate certain of the overall features of the present
invention, which will be
described in fisrrher detail hereinafter. It is initially noted that like-
numbered reference numerals in
various Figures and descriptions will be used in the following descriptions to
refer to the same or similar
structures, actions or process steps.
The present invention is preferably implemented in a network environment
wherein each
computer contains, typically, a micropmcessor, memory, and modem, and certain
of the computers
contain displays and the like, as are well known. As shown in Fig. 1B, a
plurality of user
siteslcomputers 100A-100D are shown, as are a plurality of server computers
102A-B, and developer
siteslcomputers 104A-B. It is understood that in a typical intemet network,
that different server
computers 102 can be interconnected together, as is illustrated. Further,
while only a few user sites,
developer sites and server computers are shown, it is understood that
thousands of such computers are
interconnected together.
While the specific embodiments of the present invention are written for
applications in which the
invention is implemented as sequences of coded program instructions operated
upon by a server
computer 102 as illustrated, it will be understood that certain sequences of
these program instructions
could instead be implemented in other forms, such as processors having
specific instructions specifically
tailored for the applications described hereinafter.
CA 02504689 1999-03-16
WO 99/48028 PCT/IJS99/05588
-5-
As will be illustrated hereinafter, additional operations, transparent to the
user, are impleQaentcd in
order to obtain search results in the future based upon currently made
searches. As shown, the preacnt
invention has various capabilities, each of which are illustrated in a
parallel flow in Fig. lA, which
illustrates an overview of the different ca~bilities that can be ongoing
simultaneously 1n terms of
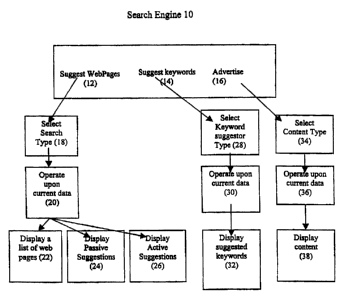
overall capabilities, start block 10 show three: suggesting web pages 12,
suggesting keywords 14, and
content suggestion 16.
In order for web pages I2 to be selected by a user according to the present
invention, there is a step
18 in which the type of search to be performed is selected. Thereafter, in
step 20, search input obtained
from one of a variety of sources is input and used along with the algorithm
selected in step 18 to
l0 determine search results. The results of this search are then displayed to
the user, as shown by steps of
displaying a created list of web pages, displaying passively suggested web
pages, and displaying actively
suggested web pages, identified as steps 22, 24, and 26, respectively, in
Figure 1. This capability, and
how it is implemented, will be described in more detail hereinafter.
In order for keyword suggestion to take place, which the user may or may not
select, there is
preferably an initial step 28 in which the type of keyword search algorithm to
use is selected. Although
many systems may have only one such algorithm, various ones, as described
hereinafter, are possible.
Once the keyword search algorithm is selected, step 30 follows in which, based
upon a keyword entered
by a user, the current set of keyword data is operated upon to determine
associated keywords. The results
of this operation are then displayed to the user in 30. This capability, and
how it is implemented, will be
described in more detail hereinafter.
The previously mentioned web page and keyword selection capabilities inured to
the direct benefit of
the end user. Another novel feature of the present invention, which indirectly
inures to the benefit of the
end user, directly benefits the advertiser, because it allows for content to
be targeted in real time based
upon various criteria. As will be descn'bed more fully hereinafter, a content
providing algorithm is
initially selected which will determine how content is selected in step 34.
Step 36 follows, and based
upon inputs from users and content providers, which content to show is
determined. Thereafter, the
advertisements are displayed for the user to see, simultaneously with the
display of either keywords
andlor web pages
While Fig 1 illustrates certain overall features according to the present
invention, many of the
3o advantageous features of the present invention are not, as mentioned
previously, observable to the user,
but instead transparent to user. They are, however, significant in order to
fully explain how the present
invention is implemented and are explained hereinafter.
Fig. 2 is provided to illustrate various inputs to the search engine according
to the present invention,
and, for different capabilities, illustrates the outputs that will be
provided. More detailed explanations are
provided hereinafter. Data that is potentially input from search engine user
include:
CA 02504689 1999-03-16
WO 99/48028 , PGTNS99/OS588
-6- -
~ keyword 52 - this is the word or phrase that the user enter to fmd a list of
web pages
~ profile types 54 - these are the groups of people they associate them selves
with e.g. US, male,
doctor etc.
~ user ID 56 - this is a unique identification for each user that chooses to
register with the search
engine. This can be done via a cookie or logon.
~ search type 58 - this can be actively chosen by the searcher to determine
the type of search results
they would like (popular, new, etc)
date-time 60 - this is passively recorded when a searcher uses the system
IP address 62 - this is passively recorded when a searcher uses the system
~ other 64 - this includes other personalization infannation such as search
customization preferences,
keywords for web page suggestion etc. This information is enttred actively
once by the user thm
used to personalize the search results each time the users (identified by user
ID) uses the search
engine.
Data from web-page developers include:
~ URL 66 - this is the URL address of the web page or gages that they wish to
submit
~ description 68 - this is a 2-3 line description of the information on their
web-page
~ keywords 70 - these are the keywords that the web page developer would like
to associate their web-
page with
~ target audience 72 - these are the target audience (profile types 54) that
the web page developer
particularly want to target.
~ date-time 74 - this is passively recordod when every a web-page developer
submits a wcb page
Data from content providers include:
bids 76 - these are $ bids for content as described later.
~ content details 78 -this includes all details of content providers including
address, content details
etc.
Results from other search engines 80 - these are the results for a keyvvord
search from other existing
search engines.
CA 02504689 1999-03-16
WO 99/48028 ' _ PCTNS99/03588
Outputs of the search engine 10 are:
lists of web pages 90 - depending on the input data a list of web pages can be
pcodtiGed in web page
determination step 82, de~ribed further hereinafter;
content keywords 92 - the search engine suggests other keywords for users to
try produced in key wood
determination step 84, described further hereinafter; and
content 94 - the search ~gine studs out selected content as produced in
determine content step 86,
described feather horeinafter
To facilitate ease of reference and aid understanding, the aforemsndoned and
subsequently menti~ed
data-set definitions are reiterated and expanded upon below (and where
appropriate, the struchu~ts of the
t0 dependant data-sets used to create the defined data-set are shown in
tabular form) with reference to the
preferred embodiment of the present invention. Thereafter, certain of these
will be explained in even
greater detail to fully teach how to make and use the present invention.
Locations: a plurality of unique information entities.
Web-pages: Locations in the farm of Web-pages URL (LJnivasel Reference
Locator) addresses.
Key-word: The word or phrase that is entered in the search engine
Hit-list: The list of web-pages (URL addresses) that is the result of the key-
word search. This hit-list
ranks the relevance of the web-pages relative to the key-word. This hit-list
always has a key-word
associated with it.
input data set Output data set
Key-word (tcmponary) Hit-list - Ranked hit-list
of Web-pages
Database to match the key-word(~p~)
with
(P~enent)
Permanent data set: Retained long term (although it changes over time
Temporary data set: Created only for the duration of the search
Surfer trace: This is a measure of how users search. It is a trace of the key
words they search for, the
URLs subsequently selected and how long they spend there, from which a ranking
of web-pages for a
users (surfers) can be calculated. It is a measure of which web-p~aga they
found most useful after the
key-word search. The combination of all surfer traces is used to create a
users' choice hit-list.
CA 02504689 1999-03-16
WO 99/48018 ' PGT/US99/05388
-8- _
Input data set Output data set
Key-word (temporary) Surfer trace - A list of
user web-pages
User selections from initialfound useful for each key-word
search results (can
(temporary), i.e. Web pagesbe permanent or temporary)
visited
Times spent a each URL
IP address of user
Users' choice hit-list: This a semi-perrmanent zaniang of web-pages associated
with every key-word and
indicates how useful Internet users found each of the web-pages associated
with the key-word. The users'
choice hit-list is incrementally updated by a new surfer trace.
Input data set Output data set
Surfer trace (can be permanentNew Users' choice hit-list
or - Ranked hit-
temporary) list of "popular" Web-pages
(permanent)
Users' choice hit-list
(permanent)*
~ The initial users' choice hit-list will be the surfer trace.
New web-page list: This is a list of new web-pages that is created by ULR
submissions from web-page
l0 developers. When a web developer updates a web-page, they can submit the
web-page addr~css, brief
information about the page and a list of key-words that the developer decides
are relevant. The web-page
is then placed on the top of each of the key-word new web-page lists.
Input data set Output data set
All web-page developers New web-page list (permanent)
information
about web address and key
words
Content Provider's list: This is a list (associated with each key-word) of
content providers which must
typically that pay to illustrate content with the key-word. The price paid is
dependent on the number of
other content providers, the amount they spend and the number of times the key
word is searched for.
CA 02504689 1999-03-16
WO 99/48028 PCT/US99/OS588
-9-
Input data set Output data set
Key-word Content Providers list
- a list of content
Content Provider's bids associated with each key-word
for content spots
(permanent)
High-flyers hit-list: This a list of web-pages (associated with every key-wed)
that are increasing in
popularity at the highest rate. It is an indication of how rapidly web-pages
are rising up the ustrs' choice
hit-list and it is used as a means to ensure that new emerging web-pages rise
to the top of the users'
choice hit-list.
Input data set Output data set
Old Users' choice hit-list High-flyers hit-list: A
- (temporary) ranked list of web-
New Users' choice hit-list pa8es that are rising in
- (permanent) popularity the
fastest
Personal hit-list: This a list of web-pages the individual user has found meat
useful for each key-word
search they have done in the past. It is like an automatic book-marking data
set for each individual user.
Input data set Output data set
Key-word Personal hit-list: A ranked
list of web-
Individual surfer trace
- (ptsrrranent) pages that an individual
has found useful
in the past
Collective Search hit-lists: This can be a combination of any of the above hit-
lists. The are manydiffennt
ways that these hit-lists can be combined.
Input data set Output data set
Crawier hit-list (temporary) Collective Search hit-lists
- (Default)
Users' choice hit-list fed hit-list of Web-pages
(permanent) displayed to
the user afar the key-word
search. It can
Advertisers' list (permanent) be a combination of any
of the hit-lists
New web-page list (permanent) above (temporary)
High-flyers list (permanent)
Personal hit-list (permanent)
CA 02504689 1999-03-16
WD ~~,~~g PCT/US99I05588
- l0-
Crawler key-word list: This is a list of key-ward suggestions that the user
may find useful. This is found
by matching the key-word enters by the user to the database of key-words and
phrases that other users
have tried. This is the equivalent of the crawler hit-list, though it is a
ranking of keywords rather than
Web-pages. The method for doing this uses a similar algorithm to a spell-
checker only it does it for
phrases. It also suggest Key-words, based on previous URL selections from
sequences of user key-words.
Input data set Output data set
Key-word (temporary) Ranked hit-list of other
key-words the
Database of all key-words ~~ ~y ~t to try (temporary)
used
(permanent)
Surfer key-word list: This is a data set comprised a list of key-words that
the individual user found useful
after the key-word was selected. This is found by tracking which key-words the
user decided to use. This
l0 is equivalent to the surfer trace.
Input data set Output data set
Key-word (temporary) Ranked list of other key-words
(associated
Data about what key words ~~ ~e key-word) that this
were used individual
from the key-word suggesttruses' found useful (semi-permanent)
key-word suggester: This is a data set consisting of a permanent ranking of
other key-words that users
have found useful, compiled from successive surfer key-word lists and is
linked to each key-word (this is
equivalent of the users' choice hit-list).
Input data sot Output data set
Surfer key-word list (tempNew users' choice key-word
or pernaanent) list
Existing users' choice (~t)
hit list {permanent)
User Based Search Algorithm
The discussion provided above provides the language necessary to more fully
describe the
present invention. As illustrated in Figs. 3A and 3B, which provide an
overview of the search engine
capabilities according to the present invention in which web pages are
selected in making up the search
results provided to the end user. In step 112, the user enters up to 4 sets of
data: keyword 52, profile
type 54, search type 58 and User ID 56. The IP address 62 and date-time 60 are
not entered by the user
but can be read when a user uses the search engine. This data is used is used
in parallel in steps 114 and
116 to produce list of web pages. Step 114, discussed in detail hereinafter,
is the process of selecting web
CA 02504689 1999-03-16
WO 99/48 PCTNS99/05588
-11-
pages from novel new search engine data sets produced in accordance with the
present invention. This
can run, if desired, in parallel with step 116 which obtains a selection of
web pages from otlar existing
search engines. Thereafter, selection of web pages from step 114 and 116 are
combined and tagged in
step 118. The process of tagging the list of web pages, described in more
detail below, enables a set of
data, shown as surfer trace data in Fig. 3, to be created and sent back to the
search engine when the
search engine user selects a web-page fmm the list in step 120. The procxss of
selecting a tagged web-
page creates the following series of data which is used to update the search
engine data sets; keyword 124
URL 126, user ID 128, IP address I30, date-time 132, brief web page
description 134.
Although it is preferred to use alt of these different data types in the
surfer tn~ce data, use of
different combinations of this data is fully within the intended scope of the
present invention. The
description 134 will typically only be included in the prefemd embodiment of
the invention when a new
site is added to the data set 114 of the search engine 10, and the description
used will be that description
that appears on the original list of web pages. The dax-time data 132 may only
indicate that a site was
selected, rather than record the period of time a user was at a particular
site, as explained feather
hereinafter. This process is invisible to the user who, upon selecting the web-
page from the list of web
pages is taken directly to the corresponding URL, step 122. Details of the
implementation of steps 114,
118 and 120 will be described in more detail hereinafter.
After the initial selection the user may choose to access another of the web-
page URL search
results. Depending on the relevance of the site, the user may spend time
reading, downloading, exploring
further pages, embedded links and so forth, or if the site appears
irrelevantluninteresting, the user may
return directly back to the search results after a short period. The time
difference between the two
selections is recorded as the difference between two date/time data 132 from
subsequent selections from
the list of web page searches (in this embodiment, one can only measure the
time spent at one web page
if another selection is made after visiting that web page - this then provides
another surfer trace 132
which allow a time difference to be calculated). This surfer trace data on the
popularity of web pages is
used to rank the subsequent searches, as described further hereinafter.
Thus, according to the present invention, it is the human users' powers of
reasoning and analysis
that is being used to establish the relevance of the different results to the
subject matter of the search.
The present invention utilizes the cumulative processing and reasoning of all
the human users' to provide
a vastly more effective means of obtaining the required information sources
than is presently possible
with the type of method described above.
As described above, human brain power is captured by recording which web pages
the user goes
to after each keyword search. According to the present invention, collecting
the surfer trace data is
achieved by sending, in the list of web pages generated by the search to the
user, hidden links that will
automatically send information back to the search engine (or a subsidiary
server). While the user only
CA 02504689 1999-03-16
WO 99/48028 PCTNS99/05588
-12-
sees that his intended link is displayed, the hidden Iink notifies the search
engine of the transfer, which
process can be executed with a Java applet. Thus, when the Internet user
selects a web-page it takes the
user to that address but also sends off a the surfer trace data to the search
engine 10, which notes what
has been selected. When the user returns to the list of web pages and selects
another web page listing,
another Java applet is then executed which creates another surfer trace. The
difference between the data
time data in this surfer trace from two sequential selections captures the
time period that the user has
been at the previous web site. This occurs without the user imowing this data
is being sent.
In another embodiment, rather than using multiple Java applets to collect a
complete list of surfer
trace data, there is no description data 134, and the date-time data 132
indicates that a user visitod a
particular web site. In one specific embodiment, the user must visit a
particular web site for greater than
a predetermined period of time, such as one minute or fifteen minutes,
depending on what is an
appropriate time to have looked at the site for the visit to the site to count
and for any surfer trace data to
be sent back to the search engine 10, as well be described hereinafter. In
this embodiment, each applet
contains all of the information necessary to update the database at the search
engine. Another
embodiment collects the surfer trace data prior to a user navigating to the
intended web site. Qther ways
of obtaining this surfer trace data are possible and are within the intended
scope of the present invention.
Thus, the search results page according to the present invention is therefore
differently formatted
from conventional search engines' results pages. The difference is in action
rather than content. Visually,
2o the page looks the same to the user as standard search results from other
search engines.
An example illustrates this point: In a conventional search, the results page
for a search of the keyword
"Weather" may read: I. www.weather.com Today's weather forecast. Today is
expected to be fine and
sunny everywhere.
The HTTP link associated with the "www.weathercom" label is
"http://www.weather.com". This means
that if the user selects this link, they will navigate to this page directly
In contrast, according to the present invention, the tagged result page for
the search made suing
the keyword "Weather" may read
1. wwwweather,com Today's weather forecast. Today is expected to be fme and
sunny everywhere.
The HTTP link associated with the "www.weather.com" label is "link.asp?n=1."
If the user selects
3o this link, therefore, in a process is invisible to the user, the user is
fast directed bo the link.asp page on the
site corresponding to the web server using the search ea~gine 10 according to
the present invention, and
pass parameter n with value 1.
Server side code (application code that runs on the web server) uses this
parameter to identify the
URL and description of the user's chosen site. This information is then stored
in a database Table along
CA 02504689 1999-03-16
WO 99/48028 PCT/IJS99/05588
-13-
with other surfer trace data. The server side code then executes a redirect
operation to the user's required
URL. The user then sees their required page appear.
The source of search results is independent to this activity. The destination
page of the user is
independent of this activity. The ~o~xss is one of recording a user, keyword
and destination into a
database. This method of tracking can only record the initial web-page visits
after a keyword search. If
the user continues to return to the search results list then subsequent web-
page visits can be recorded.
The surfer trace data that is sent back to the data sets 114 of the search
engine 10 as a result of the
user selecting the web-page can be encrypted to prevent fraudulent users from
sending fake data to the
search engine.
Another method of tracking where a user may connect to from an initial URL
selection (if they do
not return to the search result page) is to nm the selected web-pages as part
of a 'frame' located at the
search engine web-site. This permits a complete record of the web pages
visited to be recorded after a
keyword is entered. However, this imposes an additional level of complexity to
the system with a
possible decrease in system response time.
As previously mentioned, the surfer trace data that can be collected includes
keyword 124 , URL
126, user ID 128, IP address 130, date-time 132, brief web page description
134, and is identified as such
since it provides a trace or record of how searchers (surfers) use the search
engine. This data is used to
improve future searches building on the preferences of previous searchers. The
surfer trace is thus a
measure of the preferred choices of an individual user or web 'surfers' from
the initial search results for a
particular set of key-words.How the data sets are created that determine the
list of web pages
Fig. 4 illustrates the data sets used for different web-page searches
according to the present
invention. The data sets (tables) that are used to determine the list if web
pages include keyword table
164, profile 1D table 166, security table 168, cumulative surfer trace table
170, keyword URL link table
172, personal link table 174, and web-page (URL) table 188.
The structure of the aforementioned tiara sets are described in more detail
hereinafter. The
descriptions that follow show the data arranged in a spreadsheet fashion, with
multiple values per cell
and many blank cells. rilustration in this rnarmer is convenient for
explaining the present invention, but is
not an efficient storage and retrieval method. As will be apparent to those
skilled in the art, a relational
database model would be used to implement the data storage according to the
present invention such that
there may tx multiple fields or Tables involved to store the data and each
field will store only one value.
Keyword Table (164)
The contents of keyword data table 164 of Fig. 4 ~e shown in more detail in
Table 1 shown below, and
is a list of keywords, including phrases, and the number of times they have
been requested. If the list
CA 02504689 1999-03-16
wo ~ma rcTNS~rossss
-14-
becomes unmanageably large, the key-words that are not used again aftsr a
predetermined time period
could be deleted from the list. However is would be desirable to keep the
majority or sii keyword phrases
that are entered, if possible.
Key-word Cumulative number of timesUnique number for
the key-word is each key-word
requested (V~
Key-word WI, W2, W3 ete
1
Key-word
2
Key-word
3
Keyword
4
Key-word
Key-word
6
Key-word
7
5 Table 1 List of information requests sad the number of times it is requests
The cumulative number of times a keyword is requested may be segregated
according to the different
"users profiles" selected (W 1, W2, W3, ....), e.g. Wl = total searches, W2=
male profile, W3 = Female
profile , W4 = USA profile and so forth. It should be noted that the sum of
W's will be greater that the
total number of times a site has been visited because the user may fall into
more than one profile category
e.g. a male-(W2) from the USA (W3). This would become a list of not only the
number of user searchers
using that key-word but also a list of the type of user (according to the
profile type selected) searching
for that keyword. Keywords that mean the same thing in different languages are
different keywords, as
long as the spelling is differait, although they could be related using the
keyword suggester, as described
hereinafter.
IS Web-page Table (188)
The contents of web-page table 188 of Fig. 4 are shown in more detail in Table
2 shown below, and
contains a list of Internet web-pages. Each web-page has a URL address, an
associated 2-3 line
description, a unique web page number for each URL(which can also be any
character, symbol code or
representation) and the cumulative numbtr of times the URL has been visited.
The URL address will
have a unique number (which can also be any character, symbol code or
representation) assigned to it
rather than storing the full URL string in the subsequent data-Tables.
CA 02504689 1999-03-16
wo ~nsozs rcrms~rossss
.15-
Address 2-3 line descriptionUnique number Frequency the
for each URL
URL address (web page) is
visited
URL address
1
URL address
2
URL address
3
URL address
4
URL address
URL address
6
URL address
7...
Table 2 List of information suppliers and a description of the wetrpage
Keyword URL link Table (172)
The contents of keyword UItL link table 172 of Fig. 4 are shown in more detail
in Table 3 shown below.
This table is of particular significance with respect to the present invention
because it contains
5 information about the links between information supplies (URL addresses ar
web pages) and information
requests (keywords).
This data is recorded in fiatber data sets which describes the relationship
between the key-words and
occurrences as defined by the following three parameters.
- the cumulative number of significant visits (hits) to each URL addresses
corresponding to each key-
word (herein referred to as X or weighting factor X). This is a measure of the
popularity of the URL
for each keyword and is determine from the surfer traces.
- the previous cumulative number of significant visits measured at an earlier
predetermined instant;
(herein refemd to as Y or weighting factor Y)
- a date time factor relating to the instant of the creation or input of each
said web-page(herein referred
i5 to as Z or weighting factor Z). Z is the data time in which a web-page
developer submitted a web-page
to the search engine.
Not all combinations of key-words and URL addresses will have data for X, Y
and Z.
CA 02504689 1999-03-16
wo ~mo28 Pcrrusmossss
- 16-
Key word Key-word Key-wordKey-word Key-word
LTRL addressX,Y,Z
1
URL address X,Y,Z
2
URL address X,Y,Z
3
URL address X,Y,Z
4
URL address X,Y,Z X,Y,Z
URL address
6
URL address
7
Table 3 Links between Information suppliers (web-pagm) and information
requests (key-words)
Profile type s with the keyword URL link Table
The popularity of web pages will be different for different groups of people.
'The inclusion of
5 multiple profile type s will produce multiple values of X Y and Z in Table
3, e.g. one may have a Global
and New Zealand popularity rating denoted by Xl X2 Yi Y2 ate.
IJRT. address relating Xl = 520 , X2 =52
to Rugby
URL address relating Xl = 4000 X2 = 20
to Basketball
In this example the global popularity (using the general profile type ) for
the Rugby and Basketball URL
addresses are 520 and 4000 respectively and 52 and 20 rapxtively for the New
Zealand profile type .
When the general profile type setting is used (ranked based on Xl), the
Basketball site would be
ranked at the top. When the New Zealand setting is chosen (racked based on X2)
the rugby site would be
highest. This would be a reflection of the preferences of the New Zealanders.
This is a very simple
method of storing the preference of different groups of people.
One would expect New Zealand-based rugby web-sites to rate higher than an
overseas site on the
I S New Zealand list, but there is no reason that this has to be the case.
Someone in Spain may have the best
Rugby site in the world. The system evaluates web-ages only on the perceived
quality of information
by the users -the physical location of the site is immaterial.
CA 02504689 1999-03-16
WO 99/48028 PCTIUS99/05588
There could be a vast range of X values r~p~saiting different countries,
occupations, sex , age and
so forth, enabling. the popularity of different groups to be captured very
simply. Users could choage to
combine any of the X values according to their personal
interests/characteristics.
As an example, if say,
~ Xl is for males
~ X2 is for females
~ X3 is for New Zealanders
~ X4 is for USA
~ XS is for engineers
~ X6 is for lawyers ...
A "male" and a "New Zealander" would using the search tngine increment both X3
and XI. This facility
would increase the data requirement of the system but it could vastly improve
the search results for
different users. The total popularity of the web-page needs to be stored as a
separate number as users may
contribute to more than one of the groups of people. The sum of all of the
individual popularity's would
be greater than the total popularity because user can belong to more than one
profile type.
To simplify the system for the user there would be a default prof le type
(selection of X's) with an
option is to use other profile type s to do specific searches. For example, a
user may have a default profile
type of a New Zealand male, but if a technical search is txquired a "global
engineers" profile type may
be chosen that reflects the cumulative search knowledge of enginetrs around
the world.
2o The extent of personalization could be dependent on the frequency of
searching. For example,
common keywords such as "news" would have a high degree of personslization (a
large range of X
values) and less common key-word such as "English stamps" would have little or
no personalization
(only a global X value). The degree of personalization could be a function of
the frequency that the key-
word is used (found from Table 1).
Camulatlve surfer trace 'lhble (170)
The contents of cumulative surfer trace table 170 of Fig. 4 are shown in more
detail in Table 4
shown below. Information about the links between web pages and keywords in
Table 3 ( also referred to
as keyword URL link table 172) is updated by the surfer trace data. The
cumulative surfer trace is the
combined information from all individual surfer traces and it is used to
determine how many "hits"
(significant visits) each web-page had for each key-word.
The information collected from each individual surfer trace is a series of
inputs previously described, and
shown below in Table form
CA 02504689 1999-03-16
WO 99/48028 PCf/US99/05588
-18- _
IP Number User ID Keyword URL (webpage) Date-time
Table 4 Eacb row is one surfer trace and the combined rows are the eumnlative
surfer trace
The way the surfer trace data is processed to update Table 3 is described
further hereinaRer.ProSle
ID Table (166)
The contents of profile >D table 166 of Fig. 4 are shown in more detail in
Table 5 shown below. This
table includes a unique identification, password, contact small and a default
profile type which they
normally use to perform their searches.
User identificationpasswordsmall Default ~~
profile information
3oe Bloggs dogs jbloggs~AOLUS, Male
Table 5 Uaer identltlcatlon Table
The users default profile type is stored as the part of the user's personal
preferences profile, which
would accessed by entering some form of personal identification to the system.
This information could
be supplied when logging on to the data search rngine or the search engine
could leave a "cookie", as
that term is known in the art, on the camputa to identify a user, (there would
be an optional e-mail
address and password (ar similar) associated with the logon procedure). The IP
address itself would not
be a sufficient means of identification as it is not necessarily unique to the
individual users.
The other information can include ustr defined preferences for how the search
results are combined
and keywords that are of particular interest to the user. This information can
be used to actively
customize the search results and suggestions of web pages to visit.
Personal link Table (174)
The contents of personal link table 1'14 of Fig. 4 are shown in more detail in
Table 6 shown below.
Table 6 is identical in structure as Table 3, and can be used to record a
users personal preferences relating
to each UItL including the number of times visited and the kcy-wards. In this
Table 6, however, Z is not
the date that the web-page developer submitted the web-page by it iS the date-
time that the user visited
CA 02504689 1999-03-16
WO 99/8 PCTNS99/05~
the web page. This allow the users could refine a search by defining the last
time they visited the web
page.
Key-word Kcy-word Key-wordKey-word Key-word
URL address x,y,z
1
UI;tL address x,y,z
2
URL address xy,z
3
URL address x,y,z
4
URL address x,y,z x,y,z
URL address -
6
U'RL address
7
Table 6 Links between information auppllers (web-pages) and Information
requests (key-words)
5 for an Individual user
The data in Tabte 6 is only accessed by the individual that created it, and
accessible using a user B7
that is preferably independent of ~ changes in the user's e-mail or 1P address
changes and would thus
enable their past personal preferences to be retained during such changes.
This Table 6 data set could be stored either at the search engine site or on
an individual's computer.
Storing on local PC's would require additional software to be installed on the
users computer. There are
numerous advantages to storing the information at the search engine including
the fact that users are
likely to go there more often and unlikely to change search engines once they
have a substantial book
mark list.
Security l~ble (lb>~
The contents of security table 168 of Fig. 4 are shown is more detail in Table
7 shown below. To
ensure that users do not submit the same key-word over and over to increase
its popularity the following
security data table is used. Each entry is a single piece of information i.e.
yes or no. This table can be
created for iinks between keywords and 1P addresses or links between keywords
and User 1D's.
Key-word Key-word Key-word Key-word
1 2 3 4
IP address 1
1
1P address 1
2
CA 02504689 1999-03-16
WO 99J480Z8 PCTNS99I0.S588
-20-
IP address
3
IP sadness i
a
IP address i
Table 7 Security Table to ensure one rempater user does not sabmlt keyAOrds to
artiilda~y boost
the popularity of a web-page
Described hereinaf3er are the processes that are used by the present invention
to populate each of the Fig.
4 tables mentioned previously.
5 Populating the keyword Table 164
This table is populated every time a user enters a keyword 52 to the search
engine. A submittal
keyword is compared to the keyword list in Table 1 (keyword able 164) and
added if it is not already
present. If it is present, the cumulative number is increased by one. If the
user has a profile type then the
cumulative number for the keyword for each type of profile will also be
incremented (W I,W2 W3 etc).
Populating the web-page data Table (~1RL Table) 188
This table is populated in a number of ways, including:
~ user selecting a URL address 126 that is not already in Table 2 (URL table
188). The URL
address 126 and description 134 are put directly into the web-page data table
188. The new
URL is assigned a unique identification number.
i 5 ~ in Step I 76, as shown in Fig. 4, web-page developers can submit a URL
18? and description
68 which also goes directly into the web-page data table 188,
~ web crawlers may also add URL addresses and descriptions (the description is
either the first
few lines of the web-page or in the H'TML coded "title'. This is not an
essential element of the
system but it could be a method to obtain URL's and descriptions. With this
search system web
crawlers are more likely to be used to verify the information rather than fend
new information.
Populating the cnmalative surfer truce Table 170
The cumulative surfer trace table 170, also referred to above as Table 4, is
populated each time a
"tagged" web-page is selected by a user. This sends a packet of surfer trace
infrnmation, such that the
surfer trace data is added to the table each time the user selects another web
page from a web page list.
Populating the keyword URL link Table 172
The data fmm the cumulative surfer trace 170 is used to update the popularity
of web pages as recorded in Table 3
(3C,5~, also referred to as the keyword iJRL link table 172. The frequency of
updating Table 3 with the data from
CA 02504689 1999-03-16
wo m4soZS rcT~s~rossss
-2t -
tl~ cumulative surfer tract ( 170) to obtain new values of X and Y is a
variable that eau be changed, from ranges
that ate shorter than every hour to longer than every path. It should be noted
that different l~eyvvamds can be
updated at different intervals of time.
An intermediary step in processing the cumulative surfer trace is to fmm a
cumulative surfer hit
table. This is subsequently used to modify the values of and X,Y in Table 3
As mentioned above, the simplest method of rxording a link ("useful visit" or
"hit's between a
keyword and a URL would be to count each keyword, URL paring in a surfer trace
as a "hit". A more
meaningful and sophisticated method is only to count a location selection as a
valid if the user meets
certain criteria. This criterion could be the user exceeding a specified time
at a location. If this criterion
l0 was not met, the selection would not be increase the cumulative value of X
in Table 3.
It is also possible to increment the value of X based on the time spent at the
web page. The longer
the time spent the more this increments the value of X. X does not have to be
a whole number.
Due to the variations in web-site capabilities in terms of log-on times, down
loading times,
bandwidth, and response times, the predetermined time used to denote a valid
'hit' may be suitably
I S altered. Specialist web crawltrs may be employed to independently validate
such data.
The selection of a content provider's bama;r after s keyword search counts as
a hit for their web.
page (increment the value of X). This will enable their web pages to possibly
go up the popularity list
associated with the keyword. This acts as a mechanism to enable a web-page
developer to pay to lx xen
with a keyword. They can not pay to go up the popularity list - this will only
occur if people visit their
20 site and spend time there and record a valid hit for the popular list. The
values of a content hit can vary
(e.g. if could be I or 0.5 or 'n depending on the emphasis one wants to place
how much that content
affects the popularity ranking.
This cumulative surfer trace information can be processed in a large number of
ways to populate
Table 8 (below). Grouping the cumulative surfer trace according to the IP
addresses or user iD produces
25 the search pattern for an individual uses. Thin is a list of key-words and
IJRLs and times. This allow the
time spent at each web-page to be calculated for each user (it is not possible
to calculated the time spent
at the last web pages of a search session as there is no time record after
they go to that web page)
If the time between each visit is longer than a certain time period, one is
added to the cumulative
surfer hit (a) table for the key-word URL. (this is the simplest method,
methods in which relevancy is
30 proportional to the time spent at the site, for example, are also properly
within the scope of the present
invention).
CA 02504689 1999-03-16
WO 99/48028 PCTNS99/05588
_u_ _
Key-word Key-word Key-word Key-word
URL address
1
URL address a a
2
URL address a a
3
URL address a
4
URL address
URL address a
6
URL address a
7
Table 8 camniative sarfer hit table created from ucamalated surfer trues
The cumulative surfer hit is used to update the value X in Table 3 in the
following way
X c~W> _ (X c~a~ . HF )+ a.
HF is the history factor which is a number between 0 and 1. The history factor
does not have to be the
5 same for every key-ward and could be varied dtptnding on the rate at which
the keyword is used.
The data colleebed for Table 8 is used to recalculate the values of X in Table
3 after a predetermined
time period. The freqwency of updating Table 3 will influence the value of the
History factor (HF)
chosen. The reason for multiplying the existing X by a "history factor" is so
that the perceived
popularity does not last indefinitely. The history factor reduces the
weighting attached to the past
popularity. To illustrate by way of an example, the key-word "sports news" may
have an existing
popularity with the following ranking (based on the number of hits per web-
page, X)
1 Winter Olympics web-page X=19000
2 Soccer results web-page X=18000
3 Baseball results web-page X=15000
4 Golf news web-page X=15000
The cumulative surfer hit Table for a week may be:
1. Wiater Olympics web-paga a=500
2. Soccer results web-page a=1800
3. Baseball results web-page a=1500
4. Golf news web-page a=4600
CA 02504689 1999-03-16
wo 94i4sozs ~ rcT~rs99~assas
-23-
The reason for the change in the number of hits reflects the fact that the
winter Olympics has finished aad
the Master golf tournament has started. If one has a "history factor" of 0.9
then the new popularity (3~
will be:
1 Golf news web-page18100 (0.9 xl 5000+4600)
2 Soccer results 18000 (0.9 x 18000+1800)
web page
3 Winter Olympics 17600 (0.9 x 19000+500)
web-page
4 Baseball results 15000 (0.9 x15000-1500)
web-page
Thus, the more popular web-ages can emerge and the less popular decline,
reflecting the flora of
interest over time in different subjects and events.
The database is therefore utilizing the human mind to provide a powerful
indication of what people
find useful on the Internet. The users themselves replace a substantial
computation requirement that
would otherwise be required to filter through such searches.
l0 The value of Y in Table 3 is the old value of X, and the value of Y will be
updated at intervals that
are deemed appropriate, which interval could be minutes, hours, days, weeks or
longer. The update
interval does not need to be the same for all different keywords, as
previously mentioned. This is used
to calculate the rate of chaage of popularity of web pages and can be used as
a selection criteria.
Different profile type s In the web-pagelURL link'Tlsble
The cumulative surfs trace includes information on users profiles so Table 8
can be calculate with
subscripted values of a for different profile types. These values of a,3 ai a,
etc would correspond to the
profile types for the subscripted values of X. This allows the popularity of
different groups of people to
be recorded.
New web-page data input to the web-page/IJRL lick Table 172
The simplest method of having new pages recorded by the search engines is for
web-page
developers to submit information, shown as action 1?6 in Fig. 4, which
information includes URL 66,
key-words 70, site descriptions 68, target audience 72 and date-time 74, each
time they create or update a
web-page.
This information directly updates Tables 2 (URL table 188 of Fig. 4) and 3
(Keyword URL link table
172 of Fig. 4). The URL 66 and description 68 are entered in Table 2 and the
date-time (74) at which the
page is submitted (the Z value) is inserted in Table 3 for each of the key-
words (70). Users are allowed a
set number of loeywords 70 with which they can submit their web page. An
example of what Table 3
v~rould look like with just Z values is given below (format dd-mm-yy).
CA 02504689 1999-03-16
WO 99/48028 PCT/iIS99/05588
-24-
Kcy-wordKey-wordKey-wordKey-wordKey-wordKey-word
URL address27/02/98 27102/98
URL address28/02/9828/02/98 28/02/98
URL address
IJRL address 18/02/98 18/0219818/02/98
URL address
URL addmss 28/02/98
URL address 29102/98
Table 9 Data Table created from enbmission by web developers
If there is no date for the combination of the URL and keyword in Table 3,
then the new date is
automatically inserted. If a date already exists in the Table, then the dates
are compared and if the dates
are too close, i.e. less than a pre-determined period, then the old date
remains and the new date is
ignored. This stops people from constantly resubmitting to get on the top of
the new web page list by
resubmitting their web pages. If the URL in Table 3 has other keywords with
values of Z closer than the
pre-determined period then the submission is also not allowed. This stops web-
page developers from
resubmitting their web pages with different sets of keywords.
When users submit a URL they could target it at specific types of users
(different profile type s Z1,
l0 Z2, Z3 etc) as per Table 3. For example, an URL submission specifically
targeted at New Zealanders
(e.g. Zl) will appear at the top of keyword new list when New Zealanders
search for that keyword. It
will remain at the top until someone else submits a URL for that keyword
targeted at New Zealan~rs.
URL's that are targeted at other audiences will not appear as new sites for
New Zealanders or
alternatively they will not feature as high in the new list as the ones
specifically targeted at New
Zealanders.
The data on new web pages does not necessarily have to be entered by web-page
developers. It
could be automated by having a web document template that automatically
submits data to the search
engine whenever the information on the web-page has been significantly
changed. It would prompt the
web-page developer to change any key-words as appropriate.
2o Another embodiment requires sending specialist crawlers out to fmd web site
addresses and key-
words, though this has many of the drawbacks of existing web-crawlers. It
could only be effective if web
designers deliberately configured their page with the key-words identified.
Any web site
designer/proprietor willing to do this would also presumably be willing to
submit any updates to the
search engine to benefit from the instantaneous listing on the search results.
CA 02504689 1999-03-16
WO 99/48028 PCTNS99/o5588
-25-
An extension of this principle is to auto-detect if a web addt~ess possessed
key-word informati~ in
the database and then automatically send an invitation to pmvide the
information to enable their web-
page to be found easily. The ideal number of key-words to be submitted with
each web-page is
preferably less than 50 and probably preferable within the range of about 5
and 20. This also
advantageously forces web-site designers to find the most appropriate keywords
to describe their site and
also enable them to choose the audience they wish to target.
The web-page submission process may also include web-page developer
identification process that
restricts the ability of people to use the system fraudulently. This may
include a payment to prevent
multiple web-page submissions.
Populating the profile ID Table 166
ID table 166 of Fig. 4 is populated from the direct inputs from users. When
users search the can
choose their profile type 54 from a layered drop down menu, which could
include, for example:
~ Gender (Male or Female)
~ Occupation (Professional, student etc)
~ Age category etc
The user selects diet profile types from the c~tions they are prompted if they
wish to save this as
their default profile type. This is then recorded in Table 5 (profile ID's
table166). The user may also
select personalization options from a spxific personalization options page
rather than a drop down menu
on the search page.
Populating the personal link Tsble 174
The cumulative surfer trace is used to identify the search patterns of
individuai users based of
sorting by User ID 126. This information is used to update the personal link
table 174 in the same way
that the cumulative surfer trace 170 is used to update Table 3 (keyword URL
link table 172). This table
stores users past preferences as a form of automatic book marking.
Populating the aecarlty Table 168
Each time a user enters a keyword 52 into the search engine it updates the
security table 168 (Table
7) by making a link between the keyword 52 and the IP address 62 (or making a
link betwetn the
keyword 52 and the User ID 56). The data in Table 7 is cleared periodically as
the purpose is to stop
systematic repeat searching from affecting the popularity lists (value of X in
Table 3) rather than
stopping individusis who occasionally perform the a repeat keyword search from
affecting the popularity
list.
CA 02504689 1999-03-16
WO 99148028 PCTNS99/OS588
Determining the list of web pages
-26-
Fig 5 shows the various data sets previously described, and various inputs and
actions that result is a
list of suggested web pages being provided, and will be described in more
detail hereinafter. As shown in
Fig. 5, user data entered into the search engine can include: keyword 52, user
ID 56, search type 58, IP
address 62 , profile types 54. How this data can be used to determine a list
of web pages 250 as well and
deciding which of the list of web pages to tag (step 118 of Fig. 3) for the
purposes of creating a surfer
trace is described hereinafter.
The numbers (X, Y and Z) in Table 3, which carrespond to keyword URL link
table 172 in Fig. 5
contain all the infa~rmation required to give the following types of searches
58:
~ Popular-list search ranked hit-list of the most popular URLs for that
keyword based on the number X
~ Hot off the press search ranked hit-list of newest URLs for the keyword
based on the date/time (Z)
~ High-flyers search ranked hit-list of best emerging URLs based the
difference between X and Y
~ Random search hit-list that is a random sample of URLs that have any of the
numbers X, Y or Z
~ Date created search this is hit-list based on the date time Z and the user-
specified data of interest (not
just the newest)
The personal links table 174 also allows past preferences to be listed as
search results
~ Previous favorites search is a ranked hit-list base on the previous
popularity for the individual (X from
Table 6). This search is based only on the previous searching of the
individual user. This allows the
users to very quickly find site that they have previously visited.
A number of other search options are also available.
~ Conventional search is the list of search results from a normal search
engine (116 Fig 3)
~ Other content only search. This is a list of other content, such as
advertisements, associated with the
key-word.
These search results can be combined in a number of different ways
~ Collective search ranked hit-list that is a collection of any of the search
hit-lists described above (this
is the default set of search results)
~ Customized search ranked hit-list that can be a user defined combination of
any of the above Lists.
Fig. 5 also illustrates the use of keyword table 164 and security table 168 in
a decision 246 to send
out tagged web pages. This decision is based upon the frequency of key word
usage, the data in the
CA 02504689 1999-03-16
WO 99/48028 PCTNS99/05588
-x~- _
security table and the presence of a user identification. The details of
thedecision to send out tagged web
pages is described fully in figure 16.
How the different types of search lists are implemented
More details on how each of these types of searches is implemented is provided
below along with
some of the advantage and disadvantages of each. The system relies on the
brain power of the user, this
time to determine what sort of search they want to do which will depend on
what they wit to find. The
search methods are described easily so users should intuitively Irnow which
one to use.
Popular search.
Fig 6 illustrates the process far determining a list of popular web pages
associated with tlu entry of
a keyword 270 in step 272. If this search is selected and a keyword is
entsred, step 274 follows and
produces a list of web pages based on the values of X taken from Table 3 (172,
Fig S) for the keyword
270 entered. These web pages are identified by a unique web-page(ZJRL) number
from Table 3.
Thereafter, in step 276 the list of web-page numbers found from step 274 is
combined with the URL
address and web-page description from Table 2 (188 Fig 5). In step 278 the
resulting list of web pages is
then tagged, depending on the results of step 246 in Fig 5 as described
previously, and sent to the user for
them to make their selections.Hot off the press search.
Fig 7 illustrates the process for detertttining a list of new web pages
associated with the loeyarord
entered in step 290. If this search is selected and a keyword is entered, step
294 follows and produces a
list of web pages based on the vales of Z taken from Table 3 (keyword URL link
table 172 of Fig. 5) for
the keyword entered in step 290. These web pages are identified by a unique
web-page (URL) number
from Table 3. Thereafter, in step 296 the list of web-page numbers found from
step 294 is combined with
the URL address and web-page description fi~om Tabie 2 (LJRh table 188 of Fig.
5). In step 298 the
resulting list of web pages is then tagged depending on the results of step
246 in Fig 5 as described
previously, and sent to the user for them to make their selections.
The user will also be able to see exactly when each web-page was submitted so
Internet users can be
aware of its currency. An indirect consequence of this feature is the
incentive for web designers to
update their sites. The prominence given to new and updatai sites provides a
means of becoming
established on the popular hit-list and encourages the use of appropriate key-
words and rewards the up
keeping of web pages that users find useful.
High-flyers arch.
Fig 8 illustrates a high-flying web pages search associated with the kcyv~ord
enba~ed in step 320.
This is a list of web pages that are increasing in popularity fastest. If this
search is selected and a
is entered, step 324 follows and a list of web pages based on the relationship
between
CA 02504689 1999-03-16
WO 99l480?.8 PCT/US99105588
-28-
the values X and Y taken from'I3~bie 3 (172, Fig 5) for the keyword 320
entered. They web pages are
identified by a unique web-age (URL) number from Table 3. lifter, in step 326
the list of web-page
numbers found from step 324 is combined with the URL address and web-page
description from Table 2
(188 Fig 5). In step 328 the resulting list of web pages is then tagged
depending on the results of step 246
in Fig 5 and sent to the user for them to make their selection.
The high-flyer list is calculated by comparing the old popular ranking (Y) and
the cuw popular
ranking (7f) from Table 3. From this the percentage increase in hits is
calculated. An alternative method
would be to rank the rate of change of popularity by the number of places they
rose compared to last
time.
The formula of calculating the rate of change of popularity for this
embodiment is given by:
where Xm is the maximum value of X for the comsponding key-wards and B is an
additional variable
that can be changed to alter the relative significance of changes at the top
and bottom of the popularity
list.
The reason for multiplying by the maximum value of X is to ensure that small
changes at the lower
popularity levels do not swamp more significant changes higher up the table.
For exa~le, a web site
having previously recorded only one selection and then attracting 5 hits the
next day would exhibit
perventage increase of 500% whilst another web-page may have experienced an
increase from 520 hits to
4000 hits (a much more significant increase) though this would otherwise
appear as a lower percentage
increase.
Random search.
This is a random selection of less-popular web-pages for the user that want to
look at web-pages off
the beaten track, based upon a random selection of web pages that has any
value of X, Y, and Z
associated with a keyword that is entered. Accordingly, after a user enters a
keyword in step 352 as
indicated in Fig. 9, reference is made to the keyword URL link table 172
illustrated in Fig 5, and a
random list of web pages numbers are generated automatically using a random
number generator are
determined, as illustrated at step 354. Only web pages that have values for X,
Y or Z associated with the
key word are chosen in this random selection as this indicates that at some
stage in the past as used or
web page developer thought the web page had some connection to the keyword.
Thereafter, in step 356
the list of web-page numbers found from step 354 is combined with the URL
address a~ web-page
description from Table 2 (188 Fig 5). In step 358 the resulting list of web
pages is then tagged, depending
on the results of step 246 in Fig 5 as described previously, and sent to the
ustr f~ them to make their
selections.
CA 02504689 1999-03-16
WO 99/48028 PCT/US99/05588
Conventional search.
-29-
This is the normai search method of a conventional search engine, referenced
as other search engine
116 in Fig 3, which may or may not be included along with the searches
according to the present
invention, at the option of the user, as noted previously.
Content only search.
This is a list of content, such as advertisements, associated with the key-
word, which the user cannot
contmi. The ones that have paid the most will be at the top of the list, as
described further hereinafter, in
accordance with the preferred embodiment of the invention. Of course, other
systems for identifying the
order of paying content providers can also me implemtnted.
l0 Previous fav~ites search.
Fig. 10 illustrates a previous past favorites search, that is based only on
the previous searching of
the individual user. This silows the users to very quickly find sites that
they have previously visited and
performs, therefare, automatic book marking. It should be noted that since a
password is preferably used
to logon to the search engine system according to the present invention, the
user will be able to access
their personal prefertnces from any computer.
Thus, when the user types in a heyvvord at step 372 ss indicated in Fig. 10,
step 374 follows during
which it is determined what are the favorite sites (based on previous usage)
for that keyword from the
personal link table 174 illustrated in Fig. 5. Heeause the user has a password
that can be used to logon to
the system the user will thus be able to access their personal preferences
form from any caa~aputer.
Due to this search capability there is, therefore, no need to manually
bookmark web pages. If a user
forgot to book-mark a good site on, for example, 'marbles', they can easily
find it by retyping the
keyword that lead them to that site. If a ustr's preferences change they will
be reflected in the personal
links table 174.
Another embodiment of the personal preference search includes specifying the
date the web page
was last visited, with or without using a keyword. The web pages are then
ranked based on Z in personal
links table 1?4 of Fig. 5. For example if a user looked at a site in the
middle of last year the use can
refine the search by date, thus making it easier to fund a previously useful
web-pages more easily, even if
they could not remember the relevant keyword.
This automatic book-marking feature can also act as a device for monitoring
the type of Internet use
being undertaken by a particular computer and thus for example, can provide
warning to
parents/cmployers of children/eraployees accessing undesirable sites, such as
adult web-pages. In a
~ emit, for parents/employers unlikely to use the computer themselves,
notification of
such usage is automatically provided by letter to the parcnt/employer
thatlists the keywords selected and
CA 02504689 1999-03-16
wo gyms ~ rcrnis~
-30-
web pages visited by the children/employces. 'Ibis information is found
directly from each user table
174 of Fig. S.This requires a user identification code that also included
parentaUemployee information.
Collective search
The collective search, as illustrated in Fig. 11, is the default search
according to the present
invention and is used when the user does not actively choose on of the other
search options.
Upon entry of a keyword in step 402, that keyword is used to select from a
combination of web page
selections associated with that keyword. As shown, for example, in step 404,
an equally weighted
combination of conventional, popular, highflier, aew and past search results
is used to obtain a list of
web page numbers. Thereafter, in step 406 the list of web-page numbers found
from step 404 is
combined with the URL address and web-page description from Table 2 (188 Fig
5). In step 408 the
resulting list of web pages is then tagged, depending on the results of step
246 in Fig 5 as described
previously, and sent to the user for thera to make tlsrir selections, the
system is fast configured, the
search engine 10 database will not posses any information on popular, high
flyers and new web page hit-
lists, so search results will initially be obtained from the conventional hit-
list (normal search engine), and
the tagged web pages then used to create the database sets as have been
described. As the system
develops, the data sets associated with each of the other search types will
become populated, and
searches using the other search types will become more useful.
Date created search.
Fig 12 illustrates a date created search that allows the user to select the
date that the web-page was
submitted. This feature will only work for web-pages that contain a date
created data entry, identified as
date-time submission 74 in Fig. 4. Upon entry of a date-time and/or a keyword
in step 432, the search
engine 10 will perform step 434 in which a list of web page numbers associated
with these variables is
obtained. Thereafter, in step 436 the list of web-page numbers found from step
404 is combined with the
URL address and web-page description from Table 2 (188 Fig 5).1n step 438 the
resulting list of web
pages is then tagged, depending on the results of step 246 in Fig 5 as
described previously, and sent to the
user for them to make their selections.
Customized search
Fig 13 illustrates a customized search that allows the user to decide how they
want their default hit-
list to appear. In step 462, the keyword and User ID is selected in order to
initiate the customized search.
Prior to initiating the customized search in step 466, which step is identical
to step 404 of the collective
search previously described with respect to Fig. 1 l, however, step 464 is
applied to customize the users
default mixture of hit-lists For example a user may want their default search
results to include only
popular and new web pages but no high flying web pages, This custom search is
then performed in step
466 to generate a list of web page numbers. Thereafter, in step 468 the list
of web-page numbers found
CA 02504689 1999-03-16
WO 99148028 PCT/US99/OS588
-31-
from step 466 is combined with the URL address and web-page description from
Table 2 (188 Fig 5). In
step 470 the resulting list of web pages is then tagged, depending on the
results of step 246 in Fig 5 as
described previously, and sent to the user for them to make thtir selections.
one prefernd embodiment,
the make-up of the default search results list can be amended by 'learning'
from the user's beln<vior to
create a changing customized search based on the user's own search patterns.
If a user consistently
chooses new web pages or high-flying web pages for example, then their set of
default search results will
be changed to reflect their normal search style.
Magazine search.
The magazine search according to the present invention enables users to search
by following a
1o series of menu-dc~iven subject choices (or similar hienuchical structure),
rather than entering a specific
key-word(s).
Existing magazine-style search engines require editors to set the structure of
information, decide on
its relevant merits and set the criteria, such as price, for space on a given
page transmitted to the
userlviewer. Using the search system of the present invention, the users'
themselves dynamically decide
what is and is not worth seeing. Thus, although editorial input is needed
regarding a hierarchy of
subjects, the web-pages that emerge as the most popular for each of these
subjects will evolve
automatically.
Use of data sets for different =ronpa of people
Different popular hit-lists may be employed to provide results which would
reflect different cultural,
geographical, professional, gender or age interests. Thus, as shown in Fig.
14, when a user enters a
keyword and User 1D in step 490, the default profile of the user can be used
to reflect the type of web
pages that people of the same "group" as the user profiles desire to see.
Thus, the search that takes place
in step 494 is based on the subscripted X,Y and Z values obtained from the
default profile of people of
those "group" affiliations identified in the user's personal prof le obtained
in step 492. Thus, therather
than an overall global search result, search results are obtained
particularized for the group that the user
identifies with. The resulting list of web pages, derived from steps 496 and
498, as have been previously
described, are particularized for that group.
Thus, for a particular user with the profile type New Zealand selected as a
geographical factar, a
search for team field sports and related key-words, rugby material might
figure prominently, whereas an
American profile type may produce a bias towards baseball/American football
material, for example.
This technique offers the ability to discriminate betwan the different
meanings of the same words,
' according to the context of the popular hit-list associated with a
particular profile type. A gtneral search
using s key-word 'accommodation' for example would include results related to
housing, renting and
CA 02504689 1999-03-16
WO 99/48fl28 PCTNS99105388
-32-
similar, whereas if the user indicated an interest in optometry in their
profile type , then the term
'accommodation' would be interpreted quite differently.
The relevance of such sites will evolve automatically, without any active
evaluation of the sites by
the search engine operator or the user. There are no complex algorithms
required to analyze the
relevance of web-sites for particular types of users. Instead, the type of
site deemed relevant will be
decided by these users selecting those characteristics for their profile type
, i.e. American females
interested in rock-climbing. Sites of greater relevance will naturally attract
more hits, increasing their
ranking and thus increasing the chance of a subsequent user also investigating
the site. In the above
example, any web sites listed for the keyword 'accommodation' which were
unrelated to optometry,
sight, lens, vision, etc., would not be accessed for the period of time
raluired to make a valid hit. It
would therefore receive a very low ranking and hence be even less likely to be
accessed by further users.
The user can select different profile types far different searches during a
single session and is not be
restricted to the default profile types.
In a further embodiment of tlx inv~tion, there can be included a level of
authentication for person's
of a certain group to have their search results actually be used for purpose
of updating the database
relating to that gtroup. For example, doctors who have a user ll~ that
identifies them as doctors may
perform a search related to a certain medical condition, and their selections
can be tagged and used in the
database for that group of doctors as has been previously described. However,
although patient's may
desire to identify their profile with that of the same group of doctors, their
selections are not as
significant as those of the actual doctors, and thus while they are able to
view the web page listings that
doctors deem most pertinent, their selections are not used to update the
doctor's group database, since
their IDs do not identify them as a doctor
Limiting search options
Another feature of the present invention is keyword eliminator feature, which
is illustrated in Fig.
15, and prevents certain users, such as children, from searching for
undesirable keywords and web-pages
when the keyword eliminator feature is turned on. The present inventar's have
realized that it is
potentially much easier for example, to stop children searching for
pornography, rather than attempting to
trace and prevent access to all sites on the Internet with pornographic
content. This would be used as a
complimentary tool to existing "net nanny" type devices. Thus, as shown in
Fig. 15, with the keyword
eliminator turned on, a preexisting table inaccessible keywords is stored in a
table and compare in step
522 with a keyword previously entered, as shown by step 520. Thus, keywords
that are inaccessible will
not be searched. Thus, for example, parents could choose the types of keywords
552 that they do not
want their children to search for - and this will be different for different
sets of parents. The system
filters out the keywords that may be used for subsequatt searching in step
524.
CA 02504689 1999-03-16
WO 99/48028 PGT/US99/05588
- ~3 _ _
Determining which nsera to sample
Fig 16 illustrates the process of determining which search results should be
sampled and used to
make up the cumulative surfer trace table 170 of fig. 4, also referred to as
Table 4. While possible, it is
not necessary to collect data concerning curry single search, and this can be
controlled by determining
which sets of results get sent out with "tagged" web pages. Reference with
respect to this was already
mentioned with respect to authenticating user's of a particular group, doctors
in the example provided.
As shown in Fig. 16, after entry of keywords and other data in step 554, there
are three decisions
that determine whether results are actually "tagga3" as has been previously
described in step 118 of Fig.
3.
l0 As shown by step 556, for a user that has a user )D and has chosen to use
the personal links table
174 of Fig. 5 (Table 6) as previously described, it is necessary to "tag" all
of their results so that all of
their past preferences are recorded in their personal links table174. The
search engine according to the
present invention system can update the user's personal preferences but not
update Table 3 if certain
security levels have not been satisfied (see below). If, however, the personal
link table 174 is stored on
an individual's computer rather than at central location there is no need to
send out tagged results as the
data is stored locally
As shown by step 558, when a keyword is submitted, a check is made that the IP
address 62 has not
already searched the keyword using security table 168 (Table 7) before the
user is sent a set of tagged
results. If so, the user can still undertake the search though it will not
contribute to the cumulative surfer
trace 170 (Table 4). This allows all normal users to affect the popular hit-
list and all users to search
whatever they would like, but prevents fraudulent users, such as spamraers,
from contributing to the
popular hit-list. The security table 168 can also include information on links
between keywords S2 and a
user ID 56 to detect repeat searching.
While it is possible for user's to change the IP address of their computer,
this is also detectable and
preventable by a number of methods such registering and tracking the use of IP
numbers.
Other methods to exclude false searches include:
~ Only creating a surfer trace for users with a user ID 554 recorded with the
search engine.
~ Extending the time limit requited to make a visit count as a useful hit.
~ Do not count single visits to a URL from a keyword (for which there is no
means of measuring a
lapsed-time).
As shown by step 560, popular keywords can be traced once every tenth,
hundredth, or even
thousandth occurrence, and the frequency of this selection can be changed to
optimize the system. The
CA 02504689 1999-03-16
WO 99/48028 ~ PG'f1US99/05588
-34-
frequency of keyword usage is determined from keyword table 164 as shown in
Fig, 5 ('Ihble 1). The
frequency of sending out tagg~ results can also be linked to the rate at which
popularity is changing for
different key words. For example the keyword "IBM" would probably have IBM's
home page at the top
and most user's would go there, whereas the key word "latest fads" may have a
constantly changes set of
web pages that needs to be sampled more frequently.
To avoid the keyword URL link table 172 of fig. 5 (Table 3) from becoming
unduly large, one method
is to only register keywords in Table 3 once they reach a certain frequency of
usage. This is controlled by
not sending out tagged results for less frequently used keywords (found from
Table 1 ).
Active suggeatioa of web pagan to visit
Another feature of the present is illustrated by Fig 17, and involves using
data to actively suggest
web pages. This is different from a s~rch because the user sets up the request
and is informed if there is
any new data on the subject. To do this the users has to actively specify
which keywords they are
interested in and the profile type that they would like to act as a filter or
agent and the search type (new,
highflying, popular) in step 588. This information is stored in the user's
profile ID 166 shown in Fig. 5
(Table 5).
Thus, at various interval's the user receives a list of suggested web pages
determined by a group of
like minded humans. For example a user may choose to be notified of web pages
with the following
Keyword 582 profile type (agent 588)Search type 586
Rugby New Zealand, Male highflying
Decay treatments Dentist new
This way if there are highflying web pages on "rugby" that other New Zealand
males found useful
(i.e. they spent a significant amount of time looking at the information -
high rate of change of X in
Table 3) the user would be notified. Similarly if there was any new
information on "decay treatments"
submitted for dentists to look at, the user would be identified about it
(value of Z in Table 3). It is
unlikely that a computer agent will ever be as good at filtering information
as a selected group of peers.
An advantage of this system compare to other "agent type" software is that
this does not require any
software on the user's computer. It is all included as a natural extension to
the other search engine data
SCtB.
The suggested web-sites can be displayed for the user when they next access
the search engine or
they may choose to be notified of these suggested web pages via e-mail
notification. This way web
pages can be drawn to the user's attention without a~ active searching for
these keywords.
CA 02504689 1999-03-16
WO 99/48028 PCT/US99/05588
Passive suggestion of web pages to visit
-35-
Another feature of the present is illustrated by Fig 18, and involves
automatic web-page suggestion
based on how the user has searched in the past and requires no active input
from the user.
As shown, in step 620, upon the entry of a user ID, the system can be
activated passively, at various
intervals or times (such as at each login to the search engine), by looking at
which keywords, profile
types and search types, the users frequently looks at using the personal links
table 174 of Fig. 5 (Table
6). For example, it may be that the user frequently looks at Rugby information
as a "New Zealand, male"
and looks at decay treatments as a "dentist". This information can be found
from the automatic book
marking table, previously referred to personal links table 174. If the user
has not looked at these subjects
to for a certain length of time and there are new or highflying information
sources, the user will be
automatically notified of these new information sources.
In a modification of this embodiment, a periodic e-mail can be sent out with
the two newest and
highest flying sites related to the key-words of the user.
Deterrdlning a list of suggested keywords
A problem with Internet searching far many users is knowing which key-word to
use for searching.
While the present invention could be implemented with an infinite number of
keywords, too many key.
words (includes phrases) that users choose can be problematic.
Accordingly, as shown in Fig. 19, the present invention also provides for a
data set 642 that provides
synonyms for the keywords entered along with the particular profile type in
step 640. The system
represented in Fig 19 is referred to as a key word suggester. This is
implemented, in one embodiment,
by matching the key-word entered by the user in step 640 with the existing key-
words and phrases in
keyword table 164 of Fig. 5 (Table I) that other users have tried using other
search methods, identified in
step 646. Each keyword is then tagged in step 660, and those that are selected
by a user in step 662 are
used to form a keyword surfer trace 648 as shown in Fig. 19, which contains
the original keywcxd 52 that
the user entered, the keyword selected 652, and the IP address 130, user ID
I28 and date-time 132 data as
in the previously described web page surfer trace.
The data from the cumulative keyword surfer trace 648 is then used to
reinforce links between
keywords. In this way the system learns which keywords are associated with
each other. The system
learns which words are related to each other in the same way that the system
learns which URL's are
3o associated with the key-words. The lists of suggested keywords will become
more relevant over time as
the relevancy is improved each time the keyword suggester is used.
Creating data sets that determine the saggested keywords
CA 02504689 1999-03-16
WO 991d80Z8 ~TNS~
-36.
As shown in Fig. 20, a keyword link table 696 and a cumulative keyword trace
table 698 ere used
along with the previously described security table 168 to create the data sets
for suggested keywords.
The key-word link table 696, shown in Table 10 below, records how often each
key-word is selected from
the suggested key-word list. This can then be used to rank the of the
usefulness of different key-words
relative to each other.
Key-wordKey-word Key-wordKey-word Key-word
1 2 3 4 5
Key-word 5
1
Key-word 20 1134
2
Key-word 356
3
Key-word
4
Key-word 20
5
Key-word 3
6
Key-word 168
7
Table 10 Keyword link Table
It can be seen from the Table 10 that people who entered key-word 2 found key-
word 3 the most useful
followed by keyword 5 then key-word 1. The keywords can have a directional
aspect, for example,
keyword 3 was found useful 1134 times after trying keyword 2. However keyword
2 was found useful
only 356 times after users tried key-word 3.
Information about the links between keywords in Table 10 is updated by the
information about how
people are using suggested keywords (keyword surfer fracas 648). The
cumulative keyword surfer trace
698 is the combined information from all individual keyword surfer traces 648
and it is used to determine
how many "hits" (significant visits) each keyword had for each kcy-wmd.
The information collected from each individual surfer trace is a series of
inputs become a cumulative
keyword surfer trace, shown in table form below in Table 11.
IP Number User ID Keyword Keyword Date-time
(original)(suggested)
Table 11 Keyword cumulative surfer trace
CA 02504689 1999-03-16
~y~ g9~~g PCT/US99/05588
Populating the keyword link Table
-37-
Fig 20 also illustrates how links between keywords in Table 10 can be
initiated by reeordiug
sequences of keywords that users put into the search engine. If, for example
someone searches using the
keyword "IVHL" and then "National Hockey League", this would then draw an
association between these
two key-words in Table 10 by recording this as one hit. Again this captures
the reasoning power of
to define the link between two keywords. Often the keyword in sequence will be
totally unrelated to
the previous key-word but sometimes it will be relevant. If the next user
chooses it from the key word
selector it will reinforce the key-word link in the same way that Yepeat
selection to web pages reinforces
links between a keyword and a URL.
The following is an example of keywords that may be suggested after entering
the a simple key-word
like "Book"
~ book sales
~ book reviews
~ specialist books
~ second hand books
~ used books
~ special edition books
All of these key-words (pleases) would come from information seekers (users)
and information providers
(web-page developers). The most appropriate keywords will emerge naturally
over time.
All keywords used by users are enterod into the key-word link table 696 of
Fig. 20. Thus, if people
enter an uncommon keyword such as "cassetes" instead of "cassettes" the key-
word suggester will
suggest that the user tries "cassettes". There is therefore, no need to create
a set of URL-keyword links in
Table 3 for "cassetes" Thus saving on data space and there is also no need to
send a tagged set of results
for the keyword "cassetes". Hence there will be less data sent back to the
search engine.
It is also a contemplated embodiment to run the keyword suggester like Table 3
and have high flying
keyword associations and new keyword associations so the system can learn how
keyword associations
clsange over time. For example, the keyword suggester trace can store the most
recent keyword links and
modify the main key-word trace by a history factor, in the same way as Table 3
is modified by the
cumulative surfer trace.
The cumulative keyword surfer trace 698 is processed in the same way as the
cumulative web-page
surfer trace 170 of Fig 5 to reinforce links between keywords in the keyword
link table 696 (Table 10).
A time variable can also be included so that if a user chooses anotlarr
keyword very quickly it is assumed
that the previous keyword was not useful and is not countod as a keyword
surfer trace.
CA 02504689 1999-03-16
wo 99i4sozs pcrius99rosss3s
-38-
Also, the individual keyward suggester can store, for each user, their
personal keyword links.
Further, the keyword suggester can be based on a number of di~ent profile
types. The ward
associations may be quite different for people of different culture,
nationality, occupation and age etc.
Different keyword suggesters can capture the key-word association of different
groups of people. The
keyword hits in Table 10 can be subscripted in the same way that the values of
X,Y and 2 are subscripted
far different types of profiles in Table 3, as explained previously.
Using the Tables to create a list of saggeabed keywords
Fig. 21 illustrates a variety of manners in which a list of suggested kaywords
can be created.
One manner is by ranking the values of X in the keyword link table 696 (Table
10). This zaalood
l0 list of keywords is combined with keywards from a normal search of
keywards, described previously
with respect to step 646 of Fig. 19. nother manna of suggesting keywords,
shown as step 730, is to
compare the popular list (URLs X values) far the user.entered key-word with
the popular-list of other
key-words in Table 3. A similarity pattern X values in Table 3 indicates that
these keywords are similar.
For example a user may search for "film reviews" and the keyword suggester may
come up with "movie
reviews" which has a mare comprehensively searched list of sites. In this case
there is no physical
similarity between the words movie and film, but they are linked by the
similarity of the patterns of
URLs links they have in common in Table 3.
The usefulness of the key word suggester list is enhanced indicated by step
744, by associating with
each key-word on the suggestion list an indication of whether there are any of
the afarementioned
searches available (popular, high flyer, etc.) for that key-word in keyword
URL links table 172 of Fig. 5
(Table 3). The keywords with the most search results are then highlighted.
Decision to send out tagged keyword suggestions list.
The security table 168 and keyword link table 696 are used to determine which
keyword links to
sample in a manner similar to that previously described with respect to
tagging web pages. As with the
decision far tagging web pages this can depend on whethtr it is a repeat
keyword (found from security
table 168) and on the frequency of keyward usage (found from keyword table
164), as well as the
considerations previously discussed.
Determining other content
When searching on the Internet, various different web pages listings and web
pages are displayed as
3o has been described. One common characteristic of each these different web
page listings that have been
described is that when they are displayed they appear substantially identical
to one another, As shown in
Fig. 25, each of the different listings 900, though the text may be different,
is otherwise visually identical.
Other listings 902, however, are many times larger than the listings 900, may
include graphical conttnt,
CA 02504689 1999-03-16
WO 99/48028 PCT/US99~05388
-39-
and appear more prominent when displayed to the user. Such listings can
contain the same content as a
web page listing, or other content, such as advertisements, pictures,
editorials and the like.
This other content may be displayed to a particular user based upon key-words,
user pro$Ie type
(nationality, age ,gender, occupation, and so forth) and the time of the day,
for example.
In many instances, this cantent that is displayed along with web page listings
is inserted into the
display area using mechanisms that are different from the searching system
described previously with
respect to conventional search engines. The mechanism by which this content is
displayed in Iarge
measure based upon some other criteria, such as payment for the space that is
used. While the system for
selxting this content works, it is difficult to keep track of which content
was displayed when, espxially
if that content is frequently changed. Thus, another aspect of the present
invention, which will now be
discussed, is a system for tracking changing content, and allowing for content
providers to dynamically
select when their content will be displayed. This dynamic selectable content,
as illustrated in Fig. 22,
may be displayed to the viewer based upon keyword or profile type as entered
by the viewer in step 762
as shown. Within the content selector step 764 that then follows, the time of
the day is considered and
I S used in selecting the appropriate content 902 as illustrated in Fig. 25
along with the web page listings
900. Each content 902 transmitted with the search results made up of web page
listings 900 is tagged in
step 766. Thus, if a user in step 768 selects that content 902, the results of
that selection is fed back to
the content selector 764 so that the content database associated therewith,
can be updated as surfer trace
data in a manner such as has been previously described. Thereafter, in step
770, that content 902 is
displayed, typically simultaneously with content 900
In addition to the surfer trace data being input as has been previously
described, this conttnt
embodiment also provides for the web page developer, or content provider, to
determine the frequency
with which this content will be reviewed, and, depending upon the patterns of
users with respect to web
page listings that are viewed, alter the manner in which the content
provider's content 902 is displayed
based upon key words, user profile and the like. In order to impleraant this
dynamic content flexibility,
there are three additional data tables, illustrated in Fig. 23, which are used
to track the changing content
902. These tables are keyword content data table 804, personal profile content
data table 806; and
content provider data table 812. Keyword content data table 804 is illustrated
in more detail in Table 12
below, and its characteristics are:
H is the cumulative number of hits far one time period for the keyword. This
is the number of times
people choose that keyword;
N is the number of times particular content 900 that is associated witha
keyword has been sent out for
display. This is not necessarily the same as H since content aasociat~ with a
profile type may be have
a different selection factor than content associated with the keyword. This
selection factor can be
various variables, such as votes or price;
CA 02504689 1999-03-16
WO 99/4$028 PCT/US99~05388
_øp_
~ A is the selection factor for the keyword from each content provider (e.g. a
selection factor could be a
$ bid to be associated with that keyword);
~ T is the total of the selection factors for each keyword and is the sum of
A's; and
~ P is the content value, as determined by votes or price, for each keyword
and is T/N (e.g. this could be
the $ per time content is sent out with that key word- this is a price of
being associated wilt that key
word)
Keyword CumulativeAmount Content Content Total
of
hits for Content ProviderProvider
one I 2
month (H) sent (A 1 (p2)
out )
(N)
Books
Fish
Table l2Keyword content data ~s
This Table can also include the maximum content value M that the content
provider is prepm~ed to give.
There is no limit to the number of content providers that may attempt to have
content 902 displayed with
a web page listing that is associated with a particular keyword.
It is possible to have a separate Table 12 for each country or area, so that
the content value per
country or arm, per keyword could be different. In addition there could be
different content vahxs for
different time periods in each country or area.
It is possible that provider's of content 902 could target both the key-word
and the audience by
identifying each of the keywords with target audiences, e.g. the number of
hits associated with the word
rugby could be bmken down into the different profile type s that search for
the word rugby. The
cumulative number of searches for rugby could be 6000 split into 520 under
21's and 4000 21-50 year
olds and 520 50+ age group. Thus, there may be a different content value for
each of these sub classes
within a keyword search.
In addition to the key-word dataset 804 it is possible to have a data set of
the following type for
different profile types 806. It contains the same entries for each profile
type, instead of keyword as
described above with respect to the keyword conttnt data table 804 of Fig. 23.
CA 02504689 1999-03-16
WO 99/48028 PCTlUS99/05588
-41 -
Profile typecumulativeAmount Content Content Total
of
hits for Content ProviderProvider(T)
one sent 1 2
(P)
month out (A1) (A2)
(H)
Male
Female
Professional
etc
Undefined
profile
Table 13 Personal groiale content Table
Table 13 determines the content value of the content 902 to specific audiences
of people as opposed to
different keywords and allows for targeting of specific audiences.
It is within the scope of the present invention to include combination profile
types in Table 13 as well,
such as male, professional or New Zealand, females. The content value for the
combined profiles will be
different than the content value of individual profiles. The mechanics
involved in determining the content
value and choosing the content 902 will be the same, and described further
hereinafter.
Content provider data table 812 of Fig. 23 is illustrated in more detail below
as Table 14 and
contains information about the content provider, such as name, address,
advertiser, content information
such as the Bitmap (HTML or Java appltt or similar) that the content 902 will
use and a unique number
to identify each different item of content 902.
Name Address Content InfarmatiariUnique number for each
etc ConLettt
E.g. Content, no.
John
Content. no.
Table 14
t5
This Table rnay also store details of the content provider, such as passwords,
payment details (e.g. credit
card number and authorization), content delivery (number of times content has
been sent to users) etc.
The data sets for the above mentioned cmttent tables are populated as follows.
For the keyword content
data table 804
CA 02504689 1999-03-16
WO 99/48028 PCTlUS99l05588
-42
~ H, the cumulative number of hits for a particular key word for one time
period, is taken directly from
Table 1 (800).
~ N is the number of times content is sent out associated with the keyword.
This is incremented each
time an item of content 902 is displayed to a user that is specifically
associated with that
810.
~ The values for A 802 are selected by content providers for each keyword. The
content provider earn
also enter a maximum value M over which they will no longer select to be sent
out with the keywoed.
~ T is the total for each keyword and is the sum of As
P is the content value, as determined by votes or price, for each keyword and
is TIN
Populating the p~aonal profile content data
~ H is the cumulative number of hits for each proRle type and this information
is taken directly from
Table 1 (sum of the indexed W's).
~ N is the number of items of contest 902 sent out associated with the
personal profile. This is
incremented each time an item of content 902 is sent out that is specifically
associated with that
profile type 810
~ The values for A 808 are placed, through an entry process akin to bidding,
for each profile type. The
content provider can also enter a maximum M they are prepared to pay, or vats,
as the case may be.
~ T is the total for each pmfile type, and is the sum of As.
P is the content value for each profile and is T/N
Populating the content provider's details table
The majority of the content provider's details 812 are electronically entered
by the content
providers. Each time a content provider's content 902 is sent out this event
is also recorded in the
content provider's details Table 812. This will also record the number of
click-throughs
(820,822,824,826,828) and the cost, in terms of payment or votes, of the
content 902. This will form the
basis of the electronic bill or tabulation that is thereaRer forwarded to the
content provider.
How the data seta are used to select content Gent out to users
In the discussion that follows, with refaoncx to Fig. 24, it is assumed that
only one banner of
content 902 is transmitted with cash set of web page search results 900. The
same algorithms apply if
there are multiple sets of content transmitOed with each set of web page
results.
A keyword and profile type are submitted to the search engine in step 852.
From keyword conttnt
data table 804, personal profile content data table 806, the value of content
902 far each is found from the
value of P in the Tables. The highest value of P for the keyword or profile
type, determined in step 862,
CA 02504689 1999-03-16
wo 99r4soZS rcr>US99rosssa
-43-
determines the type of content (keyword or profile type) that is transmitted
along with the web page
listings 900. It may be that there is no spxific value for the keyword and the
user may not be using a
specific profile type. In this case the values for unassigned content items
will be used (from Table 13 for
users without a profile). Choosing which specific content item 902 is sent out
is discussed below The
details for the content item (their graphics, text, associated programs, etc)
are taken from Table 14,
content provider details table 814 and transmitted to the user in step 868.
Details of the content items 902
transmitted for each convent provider are also sent to the content provider,
as shown by step 870, at
regular intervals.
Determining whether it is keyvrurd or proffile content that is tranamitred
l0 The type of content 902 transmitted is depehdent upon whether it is a key
word based content or
pmfile option based content. For example a Male from the US may search for
fish. The value applicable
to this search is, keyword = fish, profile = male, profile = US, profile = US,
male. When deciding which
content gets displayed, the system compares the value of the content for all
the possibilities (keyword,
combinations of profile types) and sends out the content that has the most
value, as determined in step
862. For example an un~r 21 male may search using the key-word "Rugby" and the
value for the
associated content for Rugby is 0.1 per view, wliaeas the value per view for
targeting an under 2I male
is 0.2 and thus the content targeted at the male under 21 would be displayed
rather than the rugby
content. It is important to note that the cumulative frequency of times that
content items 902 are
transmitted (N) will be different to the total cumulative frequency for the
targeted area (I~. In this
example the cumulative frequency (H) of the number of times 'rugby' is
searched for and 'males under
21' would both incremented by one (via Table 1 ). However, the number of times
an item of content 902
is displayed would be incremented only for the 'male under 21' Table (this is
the figure used to
determine the value of the content per unit view.
Determining which spedHc content is transmitted
The example below shows how content associated with the keyword is selected.
It is the same
process for content associated with pmfile types.
Keyword CumulativeNumber Content Content Total
of
hits for content Provider Provider (.~ (P)
one 1 2
month items (Al) (A2)
(H) sent
out (1~
Book 134 134 10 10 0.050
Fish 52 80 5 5 10 0.52
CA 02504689 1999-03-16
WO 99/48028 PGT/US991115588
For the key-word "book" the content 902 of content provider 2 would be
displayed whenever the
keyword was searched, as they are the only content provider associated with
that key-word. However, for
the key-word "fish", content providers 1 and 2 would have their content sent
out the same number of
times. In the system scaled to the levels at which it is intended to be used,
there will be a very large
number of content providers bidding for different keywords and profile types.
Calcalatin; the vaiae of content
If there is a new content provider who, f~ the keyword "book," values the
content at, for instance, ~5
per month, this will change the value to 0.075 and this will mean that the
total associated with the word
book is X15. Therefore, content provider 2 would now get transmitted 66% of
the time (10/15) and the
l0 new content provider would be displayed 33% of the time. The proportion of
time an content provider's
content is transmitted is A/T'.
How content provider's use the data hbles
When bidding for content 902, content providers select a keyword or profile to
target their content
fiom Tables 12 & 13. The search engine indicates automatically the number of
times this search has been
performed for the previous time period (H), the number of times items of
content were seat out
associated with that selection (I~ and the value of the content P.
The new conttnt provider then enters the selection factor A and the system can
then instantly
calculate the new value (P) based on the new total bids (T). The advertiser
can also be told the number of
views per month they are likely to get for their bid (N~(A/T)). These changes
are calculated in real-time
to give the new content provider an indication of how their bid will influence
the value and the views
they will receive for their bid. If a value and number of views are agreeable
to the advertiser they can
choose to submit it as a bid for the defined period, such as a day, week, or
month, for instance. The
details of other content providers are, preferably, not made public. Content
providers may also enttr a
maximum value M they can part with for their content. This provides content
providers with some
security against paying too much if the value changes. If the value goes too
high then a content
provider's bid can drop off the list (if P is greater than M then A is not
counted as a bid for that particular
content provider). The bid would go back on the list if the value went down
again, thus acting as a
stabilizing mechanism. The c~tent provider can, in a preferred embodiment, be
notified by o-mail if
their content 902 has dropped off the list due to their value limit M .
As shown by the content provider details table 812 of Fig. 24, for instance,
content providers thus
have an account with the search engine proprietors and ~ for debiting their
account for their
content is automatically calculated from the account details on a periodic
basis.. An electronic statement
of the number of views, cost per view, number of click throughs and cost per
click through for each
CA 02504689 1999-03-16
WO 99!48028 . PCT/US99/05388
-45-
content provider is also forwarded to each content provider, since this
information is also stored in
content provider details table 812 (Table 14).
In a preferred embodiment, it is possible to identify clusters of similar
keywords based on the
keyword link table. The reason for identifying clusters of keywords is so that
content 902 can be targeted
at groups of words rather than just individual words. The cluster for the key-
word "car" tray include
hundreds or thousands of words that have links to the word car (e.g.
convertibles, automobiles, vans).
Statistical clustering techniques are used to define the size and frequency of
key-word clusters. This
makes it a much more automatic process than an editor deciding on clusters of
keywords for content
provider's to target.
to The same system can be used to set values for keyword clusttrs. While
grouping words in this way
would incur an increased administration cost, it is nevertheless
computationallysimilar and only initiated
once a certain level of hits on a keyword had been exceeded .
Content only search Users can also purposely clmose to search only the content
provider associaroed
with a keyword. In this case the search results will be based on the values of
A in Table 12. The content
providers that pay the most will be at the top of the list.
The key-word suggester can also help content providers choose key-words or
sets of key-words that
they would like to display.
Controlling the sestrch engine system There are a number of parameters that
can change the way in
which the search engine according to the present invention ranks web pages.
These factors (described in
detail below) are:
~ History factor
This determines the rate of decay of the existing popular lists (popular hit
list) as descn'bed in the
text previously. This is a number between I and 0. A high history factor will
make it difficult to
change the existing popularity lists. As an exaraple if the rate of searching
for a particular keyword
is increasing quickly, then the history factor should be lower to enable
emerging web pages to rise
up the popularity list.
~ Frequency of updating Table 3 from the cumulative surfer trace
This is a measure of the frequency with which the popularity lists are updated
with information
about the users' activities (i.e. the surfer trace), for example, this may be
measured once a day or
even once a month depending on the rate of change of popularity of particular
keyword searches.
~ Sampling frequency
CA 02504689 1999-03-16
wo ~rasoss ~'NS~~~8
-46-
This is the frequency of sampling the infonmatioa of how users are searching.
If it is a common
keyword it is not naxssaiy to monitor every search. It may be that only a
percentage of all
searches need be monitored to accurately determine web-page popularity.
~ The coraposition of the default search list (mix of results from the new web-
page list, high flyers
and popular-lists etc.)
The mix of web page's presented to the user as a default can be changed if
necessary to reflect the
way in which search results evolve over time.
~ Content 'hit factor'
The "content hit factor" is a measure of the weighting given to a hit
oncontent being recorded as a
i0 hit for a keyword. The default setting is that a hit oncontent counts the
same as a hit from the list
of web pages. The value of content hits can be set higher or lower than unity,
depending on the
price of the content, c.g. the "content hit factor" may need to be increased
for valuable keywords
as this would decrease the ability to spam these commercially valuable
keywords. The higher the
content factor, the higher the resistance to spam as the search results would
be mare dependent on
price rather than popularity.
The time period for content bidding
Content providers bid a certain amount for a particular time period e.g. one
month. This time
period may be different depending on the rate-of-change of the price. If the
price is changing
rapidly or is very stable, the time period may be respectively shortened or
lengthened
correspondingly.
Number of key-words per web-page submission
This number could be changed to influence how the system learns from new web
pages
submissions.
Length of time between accepting new-web-page submissions
If the date of submission for a web-page is too close to the existing
submission for that web-pagt,
then it is not accepted. This length of time can be changed depending on any
of the above factors
Nuiaber of searches per day, per person (IP address or user ID) that count as
valid hits
This number can be changod to reduce the possibility of spamming
~ Length of time before renewing the security Table
CA 02504689 1999-03-16
wo ~nsozs rcrNS~rossss
-47-
The security Table that restricts abuse, notes the links between keywords and
IP addresses of user
identifications. The length of time between refreshing this Table can be
changed to make it harder
to spam the system.
The settings for these factors can be different for different keywords or
groups of people depending on:
~ Frequency with which searches are done
~ The rate-of change of frequency of searches
~ The price of the content
~ The rate of change of price of content
The precise setting of each of these factors will not be known until the
system begins operation
'learning' about the users behaviors. The optimum settings for different
situations may be determined by
experimentation.
Other applicatIonsThough the preferred embodiment has been described with
reference to a software
useable on a computer network for searching the Internet, it will be
appreciated that the invention may be
readily applied to any search system where a human user chooses results from a
set of initial search
IS results. Such a system may for example be part of an, a T.,AN or WAN or
even a database on an
individual PC.
Examples of other possible arses of application for the present invention are
described below.
Iatranet searches and other debt bstse searches
Intranet searches at present suffer from similar drawbacks from Internet
searches, indeed some
intranets can in themselves be extremely substantial systems, in which
identifying a particular
information source or item can be equally problematic. Utilizing the present
invention in such
applications is within the intended scope of the present invention .
Searching other media forms
The present invention is also intended to be applied matching a user's profile
to other media sources
(such as pay pcr-view, television, videos, music arid the like), thus allowing
content targeted to a
particular auditnce. The same form of search lists as described above (Popular-
list, High-ityers, Hot-off
the press, etc) may be employed to direct users to appropriate material.
Shopping
The search techniques described I~rein can be implemented in a consumer
network to assist
shoppers in selecting items from within one shop or among a large number of
shops. Instead of using a
CA 02504689 1999-03-16
WO 99/48028 PCT/US99/05588
-48-
keyword-URL link Table, there would be used a keyword item purchased link
Table, that then records
what items were purchased after each shopping request (key-word). This
embodiment also records where
the user purchased the product. Each time a shopper purchased an item this
would increment the
popularity of that item, using the same techniques described previously.
The profile type s in this embodiment can be used to record the types of
purchases made by different
sets of people. One could, for example, select a profile type and see what are
the most commonly
purchased items for a range of users, and would provide assistance in choosing
gifts for people who have
a diet profile type than yourself.
SdenHBc publications
Searching scientific data bases (on-line papers, journals, etc.) with the
present invention will
dramatically reduce the time spent examining obscure, or esoteric areas only
to find the infotmati~
irrelevant. The criteria for a valid hit for such uses would typically
incorporate the extended timefeature
described above to establish the usefulness of the information source. The
refereeing and referencfrrg of
academic/seientific papers using the present invention could enhanced by
classifying different levels ~
types of user, e.g. Dr, Professor etc. postgraduate, and so forth. This will
enable users to see. for
example, what information sources the eminent authorities in a particular
field found of interest. It would
also allows the authors of a paper to become aware of how often their
publication was accessed and
possibly fiutlur indicate where and how often the paper was used as a
reference in subsequent papers.
Users may have to formally register with different organizatioas to obtain
levels of ability to referee.
Users may also choose the level of refereeing for their searching.
Online help
There is currently a substantial global requirement for on-line help and
support, particularly for
computer/software applications. Such a need would be considerably assuaged by
use of the present
invention as the software developers obtain a direct feedback to the type and
frequency of particular
inquiries, whilst the users receive the accumulated benefit of the previous
users. Different profile type s
would enable the answers to be provided in an appropriate form for the user ,
e.g, novice, expert, etc.
The keyword suggester may, for example, suggest searching with key-words
(questions) more likely to
yield a satisfactory response. There can be a range of answers to each
question and as the system learns it
will converge on to the bcst answers.
Qnadoa and answer services
G~usent On-line question/answer programs could be configured to run via the
present invention, thus
enabling answers to repeatedly asked questions to be based on previous
questions and similar questions
to be suggested.
CA 02504689 1999-03-16
WO 99/4SOZ8 PCT/US99105588
-49-
Content optimization on other parts of tfre Internet
The same content bidding mechanism could be used ~ determine the price of
content for any
location on the Internet, not just web page listings as identified above. In
this embodiment, content
providers will bid for a general content space to set the price automatically.
The profile type information from the search engine could lx used as a
passport so that other
advertisements on the Internet could be more targeted to different audiences.
This pm8le type
information could also be usal by web-page developers to customize their web-
page for different sets of
users.
People matching aervtce
1 o In another embodiment, the system according to the present invention can
be used as a dating
service and/or a method for matching people with similar preferences by doing
a statistical analysis to
compare the individual preferences (Table 6) of groups of users. The
individual past preference Tables,
in this embodiment, would preferably be normalized and compare to each other
using a standard
correlation coefficient. When compared to other users it would give a
numerical indication of how
similar their preferences are.
The same embodiment could also be used to find information about similar
people from there past
preferences Tables. For example one could ask to be give the nags of people in
New Zxaland with an
interest in Ecological Economics and a search could be made of the personal
preferences Tables. Such an
embodiment, however, would typically include a password/consent indicator that
provides consent of
2o identified persons to give out their information, which consent could be
given, for example, in only
certain circumstances, which circumstances are limited to searchers who have a
level of authority and
password indicating the same, or for persons who identify themselves with
certain characteristics.
While the invention has been described in connection with what is presently
considered to be the
most practical and prefand embodiments, it is understood that the invention is
not limited to the
disclosed embodiment. For example, each of the features described above can be
use singly or in
combination, as set forth below in the claims, without other features
described above which are
patentably significant by themselves. Accordingly, the present invention is
intended to cover various
modifications and equivalent arrangements included within the spirit and scope
of the appended claims.