Note: Descriptions are shown in the official language in which they were submitted.
CA 02505370 2005-04-26
Method and System for Website Analysis
FIELD OF INVENTION
[0001] The present invention relates generally to computers and
communications, and
more specifically, to a method and system for analyzing Web sites and similar
data
structures.
BACKGROUND OF THE INVENTION =
[0002] In recent years there has been tremendous growth in data communication
networks such as the Internet, Intranets, Wide Area Networks (WANs) and Metro
Area
Networks (MANs). These data communication networks offer tremendously
efficient
means for organizing and distributing computerized data, which has resulted in
their
widespread use for both business and personal applications. For example, the
Internet
is now a common medium for operating online auctions, academic and public
forums,
distributing publications such as newspapers and magazines, supporting
business
communications, performing electronic commerce and electronic mail
transactions, and
offering government services.
[0003] The tools needed to offer and support such services have not kept pace
with the
growth and demand. The Internet is now pervasive in industrialized countries,
and it is
a necessity for any large organization to have an Internet presence. Some
large
corporate and government agencies, for example, maintain Web sites with
millions of
Web pages, whose content changes daily; yet they do not have the tools to
efficiently
manage this massive data system.
[0004] Before discussing the specific nature of these problems, it is
necessary to outline
the framework for discussion.
[0005] Figure 1 presents an exemplary layout of an Internet communications
system 30.
The Internet 32 itself is represented by a number of routers 34 interconnected
by an
Internet backbone 36 network designed for high-speed transport of large
amounts of
data. Users' computers 38 may access the Internet 32 in a number of manners
including
- 1
CA 02505370 2005-04-26
modulating and demodulating data over a telephone line using audio frequencies
which
requires a modem 40 and connection to the Public Switched Telephone Network
42,
which in turn connects to the Internet 32 via an Internet Service Provider 44.
Another
manner of connection is the use of set top boxes 50 which modulate and
demodulate
data to and from high frequencies which pass over existing telephone or
television
cable networks 52 and are connected directly to the Internet 32 via Hi-Speed
Internet
Service Provider 54. Generally, these high frequency signals are transmitted
outside the
frequencies of existing services passing over these telephone or television
cable
networks 52.
[0006] Web sites are maintained on Web servers 37 also connected to the
Internet 32
which provide content and applications to the User's computers 38.
Communications
between user's computers 38 and the rest of the network 30 are standardized by
means
of defined communication protocols.
[0007] Figure 1 is a gross simplification as in reality, the Internet 32
consists of a vast
interconnection of computers, servers, routers, computer networks and public
telecommunication networks. While the systems that make up the Internet 32
comprise
many different varieties of computer hardware and software, this variety is
not a great
hindrance as the Internet 32 is unified by a small number of standard
transport
protocols. These protocols transport data as simple packets, the nature of the
packet
contents being inconsequential to the transport itself. These details would be
well
known to one skilled in the art.
[0008] While the Internet 32 is a communication network, the World Wide Web
(www
or simply "the Web"), is a way of accessing information over the Internet. The
Web
uses the HTTP protocol (one of several standard Internet protocols), to
communicate
data, allowing end users to employ their Web browsers to access Web pages.
[0009] A Web browser is an application program that runs on the end user's
computer
38 and provides a way to look at and interact with the information on the
World Wide
Web. A Web browser uses HTTP to request Web pages from Web servers throughout
the Internet, or on an Intranet. Currently, most Web browsers are implemented
as
graphical user interfaces. Thus, they know how to interpret the set of HTML
tags
- 2 -
CA 02505370 2005-04-26
within the Web page in order to display the page on the end user's screen as
the page's
creator intended it to be viewed.
[0010] A Web page is a data file that generally contains not only text and
images, but
also a set of HTML (hyper text markup language) tags that describe how text
and
images should be formatted when a Web browser displays it on a computer
screen. The
HTML tags include instructions that tell the Web browser, for example, what
font size
or color should be used for certain contents, or where to locate text or
images on the
Web page.
[0011] The Hypertext Transfer Protocol (HTTP) is the set of rules for
exchanging files
on the World Wide Web, including text, graphic images, sound, video, and other
multimedia files. HTTP also allows files to contain references to other files
whose
selection will elicit additional transfer requests (hypertext links).
Typically, the HTTP
software on a Web server machine is designed to wait for HTTP requests and
handle
them when they arrive.
[0012] Thus, when a visitor to a Web site requests a Web page by typing in a
Uniform
Resource Locator (URL) or clicking on a hypertext link, the Web browser builds
an
HTTP request and sends it to the Internet Protocol address corresponding to
the URL.
The HTTP software in the destination Web server receives the request and,
after any
necessary processing, the requested file or Web page is returned to the Web
browser via
the Internet or Intranet.
[0013] A Web site is a collection of Web pages that are organized (and usually
interconnected via hyperlinks) to serve a particular purpose. An exemplary Web
site 60
is presented in the block diagram of Figure 2. In this example, the Web site
includes a
main page 62, which is usually the main point of entry for visitors to the Web
site 60.
Accordingly, it usually contains introductory text to greet visitors, and an
explanation of
the purpose and organization of the Web site 60. It will also generally
contain links to
other Web pages in the Web site 60.
[0014] In this example, the main page 62 contains hypertext links pointing to
three
other Web pages. That is, there are icons or HTML text targets on the main
page 62,
- 3
CA 02505370 2005-04-26
which the visitor can click on to request one of the other three Web pages 64,
66, 68.
When the visitor clicks on one of these hypertext links, his Web browser sends
a
request to the Internet for a new Web page corresponding to the URL of the
linked Web
page.
[0015] Note that the main Web page 62 also includes a "broken link" 70, that
is, a
hypertext link which points to a Web page which does not exist. Clicking on
this
broken link will typically produce an error, or cause the Web browser to time
out
because the target Web page cannot be found.
[0016] Web page 64 includes hypertext links which advance the visitor to other
parts
within the same Web page 64. These links are referred to as "anchors".
Accordingly, a
hypertext link to an anchor which does not exist would be referred to as a
"broken
anchor".
[0017] Web page 66 includes links to data files. These data files are shown
symbolically as being stored on external hard devices 72, 74 but of course
they could be
stored in any computer or server storage medium, in any location. These data
files
could, for example, contain code and data for software applications, Java
applets, Flash
animations, music files, images, or text.
[0018] There is no limit to the number of interconnections that can be made in
a Web
site. Web page 68, for example, includes links to four other Web pages 76, 78,
80, 82,
but it could be linked to any number of other Web pages. As well, chains of
Web pages
could also be linked together successively, the only limit to the number of
interconnections and levels in the hierarchy being the practical
considerations of the
resources to store and communicate all of the data in the Web pages.
[0019] Organizations often define policies to govern the content and operation
of their
Web sites. Their desire is to make their Web site convenient to visitors, use
their
resources efficiently and maintain whatever privacy concerns they might have.
For
example, an organization may wish to limit the size of graphic images so that
the pages
can be downloaded quickly. An organization may also wish to identify and
remove
"broken links" 70, "broken anchors" and other problems because these may cause
- 4 -I
CA 02505370 2005-04-26
visitors to leave in frustration. There is therefore a need for tools which
search Web
sites and detect such problems which may impact quality, privacy and
accessibility.
Identifying these problems allows the Web site administrator to redesign his
Web site
as required.
[0020] Some organizations have thousands of pages on their Web sites which are
altered and updated almost continuously. Thus, the tools which are used to
analyze
these Web sites must be capable of monitoring compliance with a corporate
Website
policy in a periodic and automated way, with very little need for human
assistance.
[0021] Tools do exist for analyzing Web sites and locating issues, but
existing Web
analysis software is very limited in what it can do. Typically, such software
uses spider
technology to search for matches with very specific elements, for example,
searching
for matches with predetermined character strings. They also use very simply
User
Interfaces (UIs) consisting mostly of "tick boxes" to check for the existence
of common
problems such as broken links and broken anchors. These existing systems find
the
existence of such problems and report on their existence without any
sophisticated
analysis.
[0022] In many cases the limited selection of fields and "tick boxes"
available in
commercial Web site analysis software is completely inadequate. For example, a
given
Web administrator may want a report that shows all the telephone numbers found
anywhere on his Website, but his software limits him to searching for specific
strings of
numbers. Hence, his request cannot be addressed effectively with currently
available
scan rule software.
[0023] There is therefore a need for a means of making the analysis of data
distribution
systems and Web sites over the Internet and similar networks much more
flexible and
effective. Such a system should be provided with consideration for the
problems
outlined above.
SUMMARY OF THE INVENTION
- 5 -
i
CA 02505370 2005-04-26
[0024] It is therefore an object of the invention to provide a method and
system which
obviates or mitigates at least one of the disadvantages described above.
[0025] As noted above, existing Web analysis systems are very limited in what
they can
do. Typically, they use spider technology to search for matches with very
specific
elements, for example, searching for matches with predetermined character
strings.
These existing systems find the specific character strings and report on their
existence
without any further analysis.
[0026] The method and system of the invention allows problems to be defined
using
"extensible scan rules" rather than simple tick boxes. The extensible scan
rules use
regular expressions, not unlike scripts and other high level language code,
which define
the search terms and are interpreted to perform the defined searching and
analysis.
These extensible scan rules are very flexible and can be tailored to
accommodate
specific Website policies, analyzing Websites to measure the level of
compliance with
an organization's corporate policies. As well, these extensible scan rules can
incorporate logic tests and analysis, so that rather than producing raw data,
much more
pertinent reports are generated.
[0027] One aspect of the invention is broadly defined as a method of Web site
analysis
comprising the steps of: establishing parameters for search and analysis of a
Web page,
including customized search rules, formatted according to a defined language
specification; analyzing said Web page to identify structure and content
issues, and
collect data, including executing said customized search rules; and generating
a report
on the results of the analysis.
[0028] Another aspect of the invention is defined as a system for analyzing a
Web site,
the system comprising: a Web server; a Content Analysis server; and a
communication
network for interconnecting the Web server and the Content Analysis server;
the Web
server supporting the Web site; and the Content Analysis server being operable
to:
establishing parameters for search and analysis of a Web page, including
customized
search rules, formatted according to a defined language specification;
analyzing the
Web page to identify structure and content issues, and collect data, including
executing
the customized search rules; and generating a report on the results of the
analysis.
- 6 -
CA 02505370 2005-04-26
[0029] This summary of the invention does not necessarily describe all
features of the
invention.
BRIEF DESCRIPTION OF THE DRAWINGS
[0030] These and other features of the invention will become more apparent
from the
following description in which reference is made to the appended drawings
wherein:
[0031] Figure 1 presents a physical layout of an exemplary data communication
network as known in the prior art;
[0032] Figure 2 presents a block diagram of an exemplary Web site
architecture, as
known in the art;
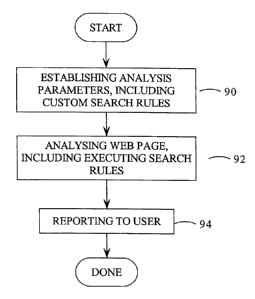
[0033] Figure 3 presents a flow chart of a method of Web page analysis in a
broad
embodiment of the invention;
[0034] Figure 4 presents a flow chart of an exemplary method of Web site
analysis in
an embodiment of the invention;
[0035] Figure 5 presents an exemplary format to report on pages with "Broken
Links"
in an embodiment of the invention;
[0036] Figure 6 presents a block diagram of an exemplary software architecture
for
performing Web site analysis in an embodiment of the invention;
[0037] Figure 7 presents an exemplary user interface (UI) for the entry of
extensible
search rules in an embodiment of the invention; and
[0038] Figures 8 through 39B present blocks of XML instructions for
implementation
of various Web site analysis functions in an embodiment of the invention.
DESCRIPTION OF THE INVENTION
[0039] As noted above, Web sites are becoming larger and larger, and the rate
at which
their content is being changed is ever increasing. Rather than the simple Web
sites of a
few years ago, which contained little more than background and content
information on
- 7 -
CA 02505370 2005-04-26
6 - 10 pages, that changed on a monthly or annual basis, it is now quite
common for
Web sites to have hundreds of thousands of Web pages that change on almost a
daily
basis such as newspaper Web sites. Other Web sites, such as those operated by
governments or large corporations, may even have millions of Web pages.
Software
tools simply do not exist to monitor and manage such Web sites in an effective
and
efficient way.
[0040] Existing technologies have attempted to solve the problem through "scan
rules",
which examine Web page content for the presence (or absence) of specific text
or
patterns. A report showing all the Web pages that contain the specified text
or pattern
is produced by such "scan rules" software.
[0041] For example, existing scan rule software might have a "tick box" and
entry field
which allows one to search for a certain phone number on a Website. In such a
case,
the scan rule would allow the entry of a specific set of characters, such as
"832-4448",
for example. Searching for multiple sets of characters in such an environment
would
require that multiple runs be performed, one for each telephone number. The
use of the
invention however, allows multiple telephone numbers to be searched in a
single run, or
even to have all seven digit numbers be located, matching the pattern "###-
",
without any reference to specific character sets. This is possible because the
invention
allows the user to craft dedicated search instructions using the extensible
scan rules.
That is, he is not bound by whatever search fields and tick boxes the creator
of the
commercial "scan rules" software decided to include in his software
application.
[0042] Figure 3 presents a flow chart of a methodology which allows such large
and
complex Web sites to be maintained and analyzed in a far more efficient and
practical
manner than done in the past. Specifically, this figure presents a method of
unambiguously specifying the compliance criteria corresponding to a Web site
policy,
and analyzing a Web page. It provides an automated system for interpreting
compliance criteria in order to determine the compliance of a Web site to the
Web site
policy and it allows the incorporation of logic and data processing abilities
into the
customized search rules (i.e. the extensible scan rules).
- 8 -I
CA 02505370 2005-04-26
[0043] As will be described hereinafter, this methodology will generally be
applied to
Web sites with large numbers of Web pages, but could be applied to Web sites
of any
size. Hence, Figure 3 refers to the analysis of a single Web page.
[0044] This methodology begins at step 90, where the search and analysis
parameters
are established. Generally, this step will consist of identifying the Web page
or pages
to be analyzed, and the analyses that are to be performed. As part of this
step,
customized search rules, formatted according to a defined language
specification, are
established by the User.
[0045] The way in which the customized search rules are entered and edited
will
depend on how the invention is implemented. In the preferred embodiment
described
hereinafter, the customized search rules are entered in XML code which is
interpreted at
run time. However, customized search rules could also be implemented in many
other
ways including for example: Java applets, Visual Basic scripts, a custom
language or
any high level code. The customized search rules may be entered using any
manner of
text editor, GUI (graphic user interface) or code management tool.
[0046] As well, the search parameters may be entered immediately prior to run
time,
generated well in advance and stored in memory, or provided by a third party
as ready-
to-use tools.
[0047] At step 92, the targeted Web page or pages are analyzed in accordance
with the
search and analysis parameters to identify the corresponding Web page
structure and
content issues. As noted above, these issues may include such things as
identifying
broken links, broken anchors and slow pages. Many other issues are known in
the art
including missing Alt text, spelling errors, forms, compliance with
accessibility
guidelines, cookie handling, third-party links and P3P compact policies. A
more
comprehensive list of issues is included hereinafter.
[0048] The invention may also be used to collect data, such as identifying
URLs to be
added to a list of URLs to be spidered, or it may be used to generate Web
application
security tests.
- 9 -
CA 02505370 2005-04-26
[0049] As well, as part of this step, the customized search rules are executed
which
provides for much more comprehensive searching and analysis. This execution
can be
performed in many ways, which will generally be determined by the way in which
the
customized search rules were developed and entered at step 92. Typically, this
will
require the use of a compiler or interpretor, which may process the code in
advance or
at run time.
[0050] Once the data are obtained and analyzed at step 92, the results are
collated and
reports generated at step 94. The reports of course, will be driven by the
parameters of
the search as determined at step 90.
[0051] Many different reports may be generated. Content issue data would
generally be
collected and indexed by Web page, and thus, reporting by Web page is the most
logical way to report. However, content issue data could also be sorted by the
nature of
the content issue. Certain content issues, for example, might be considered
"fatal"
content issues, such as pages which contain errors which might cause browsers
to crash,
or pages which are not linked to any other page. Other content issues might be
considered to be less significant such as Web pages which contain large images
which
are slow to download, or Web pages which link to outside Web pages which have
become outdated.
[0052] Many GUI-based (graphic user interface-based) data management and
reporting
tools exist, so it is quite straightforward to tabulate this data and produce
the desired
reports. Reports may simply be presented to the Web administrator on a display
screen,
printed out, or stored for future reference.
[0053] The invention can be implemented on the foundation of existing scan
software.
Many such systems are commonly available including for example: Watchfire
WebXMTm, Coast WebMasterTm, Keynote NetMechanicTm, Maxamine Knowledge
PlatformTM, SSB InFocusTM, HiSoftware AccVerifyTM and Crunchy Page Screamer
CentralTM. The actual work that would be required to implement the invention
will
depend on the tools being used, and the design philosophy of the existing scan
software,
but would be clear to one skilled in the art from the teachings herein.
-10-
CA 02505370 2005-04-26
[0054] Thus, the invention of Figure 3 addresses the problems in the art.
Given large,
complex Web sites and a possibly large number of issues with the content of
those Web
sites, the invention provides an effective way of analyzing and presenting the
content of
the Web sites and the issues that the Web sites contain.
[0055] The invention replaces the traditional spider-based Web analysis
architecture
with one in which the Web-analysis is driven by a customizable, logic-based
architecture. The logic layer is fully configurable by the user, so that an
endless variety
of new and more sophisticated analyses can be performed. For example, the
invention
can:
= identify areas of non-compliance with policy that could not previously be
discovered, because of the flexibility in specifying what is being searched
for;
= it defines a language for describing the criteria for compliance to a
policy. This
language allows a much broader range of policies to be described than was
previously
possible with other technologies;
= it can contain logic, allowing complex compliance/non-compliance decision-
making and separation of irrelevant data from relevant data;
= it may access many types of data besides traditionally targeted Web page
content: cookies, headers, other Web pages, etc., to determine compliance/non-
compliance. This is possible because the invention does not have the
predetermined
restrictions that existing scan tools have;
= there is greater flexibility in the format and content of reports that
are generated
because logic can be used to tailor or modify the collected data; and
= the extensible scan rules may be created and deployed in the field,
allowing for
great flexibility (as opposed to compiled code such as dll's or exe's).
[0056] Further advantages will become clear from the description of other
embodiments of the invention which follow.
DESCRIPTION FOF PREFERRED EMBODIMENTS OF THE INVENTION
[0057] The preferred embodiment of the invention provides:
= a system for authoring compliance criteria for Web site policy;
= an extensibility mechanism that allows the extensible scan rules to adapt
to Web
-11-
CA 02505370 2013-06-11
,
Site policy diversity;
. the ability to author extensible scan rules in a text editor
(interpreted, not
Compiled code); and
. the ability to specify the layout and content of reports in the
extensible scan
rules.
[0058] Extensible scan rules, for example, have been integrated into a
scanning product,
available from International Business Machines Corporation and the subject
matter of United
States Patent 7,624,173.
[0059] To assess an organization's Web site policy compliance, the relevant
aspect of the
policy need to be expressed as extensible scan rules or "XRules". In this
embodiment of the
invention an XRule is an XML document that is formatted according to rules
laid out in the
XRules Language Specification. An XRule expresses an aspect of Web site policy
in an
unambiguous, machine-readable manner.
[0060] The content of the organization's Website is discovered and processed
by the WebXM
"scan engine". The scan engine, through a user interface, can be provided with
XRules that
are to be applied to the Website. The XRule Runtime interprets the XRule in
order to assess
the compliance or non-compliance of each page. For each page the scan engine
processes,
when there is an enabled XRule that applies to the region, the XRule Runtime
executes the
XRule. When the XRule is executed, it assesses compliance and can insert data
into the
database. This data is used to produce a report detailing the Website's
compliance to the
aspect of Website policy expressed by the XRule.
[0061] XRule functionality may be extended by creating "Extension Operations"
and
"Extension Functions". To deploy an XRule that uses extension operations, the
XRule XML
needs to be specified and the assembly (di containing the extension
operations must be
placed in a specific directory on each scan server. The XRule Language uses a
mixture of
declarataive and functional programming styles to describe compliance
criteria. The building
blocks of the language area the Core Operation and Core Functions. Some Core
Operations
provide functional programming capabilities, such as:
- 12 -
CA 02505370 2005-04-26
= Variables: xsr:variable, xsr:update-variable
= Repetition: xsr:for-each
= Conditional logic: xsr:if, xsr:choose
= Regular Expressions: xsr:analyze-string
[0062] Some Core Operations use a declarative programming style to describe
aspects
of the policy or retrieve external data:
= Describing the policy: xsr: annotation
= Controlling report appearance: xsr:specify-column-headings
= Accessing the Web: xsr:http-request
[0063] Some Core Functions support regular expression operations:
= Testing for match: xsr:matches
= String replacements: xsr:replace
= Splitting string into substrings: xsr:tokenize
[0064] Some Core Functions provide access to data collected by the scan
engine:
= Obtaining HTML: xsnretrieve-html()
= Obtaining Text: xsnretrieve-text()
= Obtaining Form HTML: xsr:retrieve-formhtml()
= Obtaining Links on Page: xsnretrieve-links()
= Obtaining Cookies: xsnretrieve-cookies()
[0065] A specific method of implementing the invention is presented in the
flow chart
of Figure 4. The invention can be implemented in many different ways. For
example,
it could be deployed in a centralized service bureau configuration, or as a
decentralized
hosted service. Many options and alternatives are described hereinafter, but
it would be
clear to one skilled in the art that many other variants follow from the
teachings herein.
[0066] At step 100, the parameters for analysis are collected. This may
consist of the
User entering entirely new search information, or simply calling a stored file
that was
generated earlier. The analysis parameters will generally include:
= the address of the targeted Web site or Web pages to be analyzed;
= standard scan data of interest;
- 13 -
I
CA 02505370 2005-04-26
= XRules;
= any report parameters, including fields, titles, etc.; and
= any other standard parameters used in scanning tools, such as defining
how
URLs are to be normalized (some Web sites will direct user's to servers in
close
geographic proximity, or use multiple servers which are load balanced.
"Normalizing
URLs" refers to how these multiple servers are handled in the XRules reports.)
[0067] In this embodiment, the extensible scan rules are written in XML
(extensible
markup language), using a standard text editor. XML is a standard, software
development language-independent text format for representing data. XML is a
markup
language in the same sense as Standard Generalized Markup Language (SGML), and
Hyper Text Markup Language (HTML). XML is desirable in this application
because it
can easily be converted to executable object-oriented code.
[0068] Object-oriented software languages are an attempt to mirror the real
world, in
the sense that "physical" Objects are identified, and certain functionality is
associated
with each given Object. Software Objects are not easily portable, so it is
common to
convert software Objects to markup language code for transmission over the
Internet,
re-assembling the Objects when they are received - a number of protocols have
been
developed to support the communication of XML data over the Internet. It is
much
easier to transmit database queries and structures over the Internet using XML
(eXtensible Markup Language) code rather than, for example, Java Objects.
[0069] XML documents are usually prepared following a set of syntax rules
called a
"schema". A given group of XML documents all follow the same XML schema, which
is an XML document itself, so that they are compatible with one another. The
syntax
rules may, for example, indicate what elements can be used in a document,
define the
order in which they should appear, define which elements have attributes and
what
those attributes are, and identify any restrictions on the type of data or
number of
occurrences of an element. Schemas can be custom designed, though many schema
are
established by standards groups for general areas of application.
- 14
CA 02505370 2005-04-26
S
[0070] Once the parameters have been established an analysis of the Web site
or Web
pages can now begin at step 102. Clearly, this step flows logically from the
parameters
set at step 102 and the nature of the analysis being performed.
[0071] This step requires that the XRules Execution Environment "preprocess"
the
XRules by performing the following:
= parsing the XML document and generating a path tree;
= walking the path tree, creating objects from compiled c# code; and
= determining what data are needed by the XRules.
[0072] The XML document can be parsed using an XML parser as known in the art,
which generates a tree of XML nodes. XPath queries are then used to collect
the
desired information from the XML tree of nodes. Again, )(Path is known in the
art and
this is standard practice for collecting information from XML documents.
[0073] The XPath queries are used to collect the data needed to affect the
desired
mapping. Once this data has been collected, the corresponding pre-compiled or
interpreted C# code can be populated with data.
[0074] While doing this, the application builds a listing of data that will be
searched for
when the targeted Web site or Web page is analyzed.
[0075] The loop through steps 104, 106 and 108 then searches through each Web
page
specified in the analysis parameters at step 100. At step 106, the desired
data for each
page in the current Web page is collected, and at step 108, the )(Rules
Runtime Engine
is executed on the collected data.
[0076] Step 108 generally consists of the following substeps:
= walking the path tree, creating objects from compiled c# code;
= executing logic, matching patterns;
= processing on found matches; and
= inserting processed data into database.
[0077] Once it has been determined at step 104 that all of the targeted pages
have been
analyzed, processing passes to step 110, where reports are generated. Reports
can be
- 15 -
;
CA 02505370 2005-04-26
,
,
,
<
generated and presented in many formats, including for example, that of Figure
5. This
display uses a Web browser as an interface application, and was written in
XML. Other
display formats and software could also be used.
[0078] Figure 5 presents a graphic display of a "Pages with Broken Links"
report, with
a set of Help, About and Logout Tabs 111, which are standard for all of the
reports in
this embodiment of the invention. It also includes four information frames:
1. an index frame 112 which lists headings for each Web page in the
software
package of the invention;
2. a "report properties frame" 114 which lists the properties of the
current report,
the "Pages with Broken Links" report;
3. an "overview frame" 116 which summarizes the results of the report; and
4. a "details frame" 118 which breaks down the results of the report for
each Web
page in the analysis.
[0079] The index frame 112 is common to all of the reports. By clicking on
different
headings the Web administrator can expand the entry identifying all of the
subpages
linked to the Web page heading that he has clicked on. Also at the top of this
index
frame 112 are two icons, one labelled "expand all" and the other labelled
"collapse all";
clicking on the "expand all" icon shows the headings for all of the Web pages
in the
hierarchy and clicking on the "collapse all" icon reduces this list only to
the main
headings.
[0080] Note that Figure 5 presents an expanded list of the reports under the
"Site
Defects" heading in the index frame 112, specifically, reports titled: Broken
Links,
Broken Anchors, and Pages with Broken Anchors. Other similar reports could
also be
entered under this heading.
[0081] The report properties frame 114 lists the relevant properties and
parameters as
set by the Web administrator for this particular report. As shown in Figure 5
this
embodiment of the invention includes the title for the report ("Pages with
Broken
Links"), the date on which this report was last updated, the source of the
analysis data
(along with a link to a page containing all of the parameters and preferences
for the
- 16 -I
CA 02505370 2005-04-26
analysis), the scope of the data and which scope of metatags were considered
in the
analysis.
[0082] In this embodiment, the overview frame 116 provides three pieces of
information:
1. a pie chart which shows the percentage of the Web pages in the scope of
the
analysis which include content issues;
2. the absolute number of Web pages with the content issues; and
3. the percentage of Web pages that meet the problem threshold (i.e. In
some
reports it may be of interest to only report on pages which have a certain
minimum
number of warnings or defects).
[0083] As shown in Figure 5, the details frame 118 presents five columns of
information:
1. a list of the Web pages that contain broken links;
2. the number of broken links contained by each of these pages;
3. the percentage of total site traffic directed to those pages over the
specified
historical period for traffic data use;
4. an "About" column which provides an iconic representation of the overall
quality of the page. This measure is derived from the total number of defects
and the
severity of that particular Web page; and
5. a column containing a "View" icon.
[0084] Clicking on various elements in the table will result in new views of
the data:
1. clicking on either the URL, Quantity, Traffic, or About columns will
cause the
data to be resorted in accordance with the heading that has been struck;
2. clicking the URL for a page will access a detailed report of all of the
broken
links on that page;
3. clicking the icon in the "About" column will access a detailed report of
all of
the characteristics of, and defects on that Web page; and
4. clicking the icon in the "View" column will open the specified Web page
in a
new Web browser window.
- 17 -I
CA 02505370 2005-04-26
[0085] The reports generated at step 110 may be printed out, stored in data
files, or
presented to the Web administrator graphically, for example, using HTML, ASP
or
XML documents. (HTML and XML are markup languages which are well known.
ASP or "Active Server Pages", is a script-based, server-side Microsoft
technology for
dynamically created Web pages).
[0086] Reports can be produced to detail a very large number of content issues
and
Web page characteristics. The content issues and Web page characteristics may
include
the following:
1. Content Issues:
a. Broken links - links to resources that cannot be found;
b. Broken anchors - links to locations (bookmarks) within a page that
cannot be
found;
c. Spelling errors - spelling errors, with respect to a language dictionary
and / or a
domain terminology dictionary;
d. Links to local files - resources whose location is defined with respect
to a local
network, and that are not accessible by an external Web browser;
e. Missing keywords - resources that are missing keywords cannot be indexed
by
many search engines;
f. Duplicate keywords - pages that use the same keyword multiple times may
be
rejected by some search engines;
g. Missing titles - pages missing a title cannot be indexed by many search
engines;
h. Duplicate titles - identical titles that are used on more than one page
cannot be
catalogued by many search engines;
i. Missing descriptions - pages missing descriptions may not be as
effectively
indexed by many search engines;
j. Images missing Alt text - images missing Alt text are an accessibility
issue;
k. Images missing height or width attributes - images missing height or
width
attributes force the web browser to infer the proper layout of a pages. This
consumes
system resources and affects the visitor experience;
1. Deep pages - content that is deeply embedded in the structure of a web
site (i.e.,
many clicks away from the home page) are difficult for visitors to navigate
to;
- 18 -
CA 02505370 2005-04-26
m. Slow pages - pages whose total download size (the page itself plus any
images,
applets, and other downloadable components) exceed some size specified by the
Web
administrator which may be prohibitive to download over slow connections;
n. Warnings and redirects - pages that either redirect the user to other
content or
return a server warning;
o. Browser compatibility - pages whose markup elements may not be
interpreted
properly by one or more types or versions of Web browser;
p. Cookie handling by browser privacy settings - cookies that may be
rejected
under default privacy settings in popular Web browsers;
cl. Missing privacy links - pages that do not have a link to a privacy
statement may
expose website owners to legal liability;
r. Forms on pages missing privacy links - pages with forms but that are
missing
links to a privacy statement may be collecting personal information without
giving
visitors access to a privacy statement; this may expose website owners to
legal liability;
s. Forms with controls that are prepopulated - form controls that are pre-
populated
can expose website owners to legal liability;
t. Forms by submit method (GET or POST) - forms using the GET submit method
transmit data non-securely; this may expose Web site owners to legal
liability;
u. Forms by page security level - forms on pages with low or no security
may
transmit data that is easily decrypted; this may expose Web site owners to
legal
liability;
v. Cookies - cookies set by a third-party may use personal information
inappropriately, and may expose Web site owners to legal liability,
w. Web beacons - Web beacons are a common way of having one site 'spy' on
the
visitors to a third-party site. This may expose Web site owners to legal
liability;
x. P3P compact policy - cookies on pages without a P3P compact policy may
be
rejected by web browsers, and so may affect a visitor's experience;
y. Third-party links - third-party links may lead to inappropriate content,
and may
expose site owners to legal liability, and
z. adherence to accessibility guidelines (e.g., US Section 508; W3C WCAG
1.0,
2.0, etc.; user-specified guideline) - ensuring that pages comply with
accessibility
guidelines may be mandated by local legislation, and is good business practice
-19-
CA 02505370 2005-04-26
2. Content characteristics
a. Website domains - the domains that are internal to or that can be linked
to from
a website
b. File (MIME) types in use - the different types of content that are in
use across a
website
c. Image inventory - images that are in use across a website
d. File inventory - files that are in use across a website
e. Multimedia content - multimedia content that is in use across a website
f. Server-side image maps - server-side image maps affect page performance,
and
are a largely deprecated web-technique
g. Style sheets in use - style sheets in use across a website
h. Pages using style sheets - pages that make use of style sheets
i. Old pages - content that is old, and may be in need of updating
j. New pages - content that is new, and may be in need of review
k. Small pages - pages that may be missing content, and so are of no value
to site
visitors
1. Metadata inventory - metadata elements that are in use across a site
[0087] Figure 6 presents a block diagram of the software architecture 140 for
the
preferred embodiment of the invention.
[0088] The software architecture 140 includes a database 142 which provides
storage
for the XRules 144, which are XML documents. The database also stores XRules
Metadata 146, for instance the column headings to display in a report. The
database
also stores XRules Data 148, which is the data collected by the )(Rules and
used to
create the compliance reports. The database 142 may comprise any
readable/writable
storage media or combination of different readable and writable media
including
random access memory (RAM), optical media (such as CD Roms) and magnetic media
(such as hard drives).
[0089] The XRules Content Consumer 150 provides the interface between the scan
engine WFCScan 152 and the extensible scan rules in the XRules Execution
- 20 -
!
CA 02505370 2005-04-26
Environment 154. Data collected by the scan engine WFCScan 152 is provided to
the
XRules Execution Environment 154 via the XRules Content Consumer 150.
[0090] The WE0 is the set of Watchfire Enterprise Objects 156. It provides the
interface between the targeted application (WebApp 164) and the Website
analysis
system.
[0091] The XRules Execution Environment 154 preprocesses the set of XRules and
maintains state between XRule executions. For each page processed by the scan
engine
152, the XRules Runtime 158 executes the applicable XRules. As the XRules
Runtime
158 navigates the XRule XML, it invokes the operations and functions as
specified in
the XRule XML. Operations and functions are objects implemented in compiled
code
that are invoked dynamically from the XRule. Operations and functions can
retrieve
data collected by the scan engine 152, can perform processing on that data,
can cause
data to be stored in the database and can control which portions of the )(Rule
are
executed. WebXM provides a set of "Core Operations" 160, but "External
Operations"
162 can also be supported. XRules written to use only core operations 160 can
be
deployed most easily since only the )(Rule XML needs to be specified in the
WebXM
User Interface.
EXEMPLARY XRULES
[0092] A number of exemplary XRules are described hereinafter, including, for
example:
= a SQL Injection XRule, for pages containing a form, which makes
additional
requests for the page with a SQL payload in the post data and detects
unexpected
responses;
= a cross-site scripting (XSS) )(Rule which makes additional requests for
the page
with a JavaScript payload and detects the presence of the JavaScript payload
in the
response page;
= a Protected Resources )(Rule which identifies all pages that require
credentials
by making a separate HTTP request to the page without any credentials and
examining
the response;
= a Session Timeout )(Rule which gathers a list of URLs and posts data
(including
- 21 -
CA 02505370 2005-04-26
the session cookies) and after a specified duration re-requests each of the
pages and
checks the response to ensure the session has been expired; and
= a Table Classification 3CRule which contains a heuristic that
distinguishes
between "data tables" and "layout tables" and contributes results to existing
accessibility reports.
[0093] Related Documents
[0094] Other documentation which may assist in the understanding of and
implementation of the invention include the following:
= )(Path 2.0 Specification: http://www.w3.org/TR/xpath20/
= XPath 2.0 Functions and Operators: http://www.w3.org/TR/xquery-operators/
= XSLT 2.0 Specification: http://www.w3.org/TR/xs1t20/
= Microsoft .Net Regular Expressions syntax references:
http://msdn.microsoft.com/library/default.asp?ur1=/library/en-
us/cpgenref/html/cpconregularexpressionslanguageelements.asp
= Common regular expressions library: http://www.regxlib.com/Search.aspx
FEATURES
[0095] Ability to find issues using regular expressions
[0096] )(Rules can use regular expressions to find any content that can be
matched with
a regular expression pattern. This is considerably more powerful than the
current text
matching.
[0097] Ability to specify additional logic
[0098] Sometimes regular expressions will be sufficiently expressive to alone
find the
issues that need to be reported. An example of this is the regular expression
in the
previous section that finds only tables with width >= 760.
[0099] However, sometimes the regular expression will find a potential issue
that needs
further evaluation to determine whether or not it should be reported. In order
to
- 22 -
4 ..÷
CA 02505370 2005-04-26
perform these evaluations, XRules supports some basic programming constructs,
such
as conditional logic, variables and repetition.
[00100] For example, a regular expression can be defined to report all of
the
RGB (red, green, blue) colors used in a Web page's HTML code. However, logic
can
be used to check whether each found color is in a list of acceptable colors,
and report
any colors which are not.
[00101] Ability to generate reports
[00102] )(Rules includes some basic report definition and generation
functionality. Existing scan rules do not require a custom report be created;
XRules
offers similar functionality. For simple )(Rules, professional services can
paste the
XRule 3CML into the User Interface, enable the scan rule and do a Create and
Package
All to create the report defined by the XRule.
[00103] The basic report definition functionality XRules provides, may not
meet
all customer reporting requirements. In these cases, the role of the XRule
will be to
populate the database with the desired data, and traditional techniques for
creating
custom reports will be used to create the report.
[00104] Provide convenient programming model
[00105] This embodiment of the invention:
= does not require compilation or a specialized development environment;
= can be easily shared by email; and
= can be leverage existing technical skills.
[00106] An XML-based format originally designed for describing security
checks
will be adapted to become XRules. This format relies on XPath in the same way
that
XSLT relies on XPath; so the XRules programming model will look familiar to
Professional Services people who have worked with XSLT to customize reports.
[00107] Provide user interface for adding/editing 'Mules
-23
CA 02505370 2005-04-26
[00108] The user interface for the existing Watchfire scanning software is
largely
unchanged by the addition of the extensible scan rules.
[00109] The Rule Type drop down in Custom Rule Type and Options will
display in its list the XRule rule type if:
a) the string "XRule&" is added to the url to the page after the "?'
b) the rule being edited is an XRule
[00110] When a rule type of XRule is selected, a multiline text box is
displayed.
The XRule XML can be entered or pasted into this text box, or is displayed
there when
editing an existing XRule. When Back/Next/Finish is selected, the XRule will
be
validated against an XML Schema and highlighted if invalid. An exemplary User
Interface (Ul) for implementing such functionality is presented in Figure 7.
[00111] Note that validation against an XML Schema will not guarantee that
(a)
the )(Rule will run without errors or that (b) the )(Rule will do what the
author
intended. Unfortunately, those types of errors can only be detected by running
the scan
and examining the error log.
[00112] Create and Package All will create a report named according to the
rule
name, and in the selected report categories, just as is done for other custom
rules.
[00113] Provide 'Mules diagnostics
[00114] When execution of an XRule terminates unexpectedly, the following
data is dumped into the WebXM log to assist the XRule developer's debugging
efforts:
= the last operation (XML element) executed successfully;
= the current state of the )(Rule XML tree (including the in-memory
updates); and
= the stack trace.
1001151 'Mule by mime-type
[00116] It is preferable to declare which mime-types an XRule is
applicable to so
that they are not processed indiscriminately against all text.
1001171 Programming language selection
-24-
CA 02505370 2005-04-26
[00118] The XRule runtime and operations were implemented
as .Net assemblies
that interoperate with COM in both directions.
[00119] Doing this in C#/.Net is a more complicated from a
deployment
perspective then doing this in C++/ATL. The decision to do it in C#/.Net is
justified as
follows:
= The .Net XML/XPath framework allows extensions we need that cannot be
done with MSXML in C++. We need to extend Xs1tContext to control resolution of
XPath extension functions and variables. Some of the components of the .Net
version
of the XSLT implementation are open API and may be overridden to create new
XML
based languages, like XRules. MSXML does not offer similar functionality. If
MSXML is only available technology for XML/XPath, a different design approach
would be required.
= Pro Services will be able to further extend the )(Rule environment by
adding
new operations. It will be easier for Pro Services to create extension
operations in .Net
= than in COM (fewer lines of code, potentially use System.Relection.Emit
to
dynamically generate operations from code provided in a UT.)
[00120] Interesting Note: Sufficient regular expression
functionality is now
available in either .Net or ATL! (CAtlRegexp class in the ATL Server Library.)
[001211 External Brand Management/External Trademark Use
[00122] XRules can handle data collection for External
Brand Management
report ¨ i.e. show me pages on the Web that use my brand and contain issues.
XRules
can:
1) perform search against Google/Altavista (using core functionality or
maybe
using an extension operation);
2) use Regexp to parse out URLs; and
3) add found urls to scan
[00123] Combined with the External Scan Rules
functionality, that is all that is
required to collect the data for the report. The benefit of this approach is
that if the
- 25
CA 02505370 2005-04-26
Google/Altavista HTML format changes, we only need to email a modified version
of
the XRule to customers to paste into the XRule UI.
[00124] Web Linking Disclosures
[00125] Report any page that has an external link and is missing a warning
message to tell the user she is leaving my site. 'Mule can:
1) Retrieve the number of external links the page has from the scan engine
2) Fast return if no external links
3) Otherwise, pattern match page HTML for warning message
4) Add record to database if warning message not found
5) Provide list of pages missing Web linking disclosure in a standard
report
)(RULES SPECIFICATION
[00126] Introduction
[00127] This specification defines the syntax and semantics of the )(Rules
language. An XRule is expressed as a well-formed XML document that conforms to
the schema defined in this specification.
[00128] The term XRule is short for extensible scan rule. An XRule
describes
processing to be performed when a page is evaluated. The XRule language
provides
sufficient functionality for creating solutions for many common page
evaluation
problems. When core functionality is insufficient, the XRule language can be
extended
to perform more sophisticated processing.
[00129] Concepts
[00130] The component responsible for processing an XRule is the XRule
Runtime 156, referred to here unambiguously as the runtime 158.
[00131] The role of the runtime is to navigate the XRule XML. The runtime
maintains a cursor into the parsed 3CNIL tree of the XRule. When the cursor
arrives on
an XML element, it attempts to create and execute an Operation that
corresponds to the
namespace and name of the XML element. Operations are able to direct the
movement
- 26 -I
CA 02505370 2005-04-26
of the runtime's cursor, retrieve data from the scan engine, write data to the
WebXM
database, and perform other processing.
[00132] The runtime is installed with a set of operations known as the
Core
Operations. )(Rules that make use only of core operations are portable; the
XRule
XML can be deployed alone on other Web)CM installations. Extension Operations
can
be created to perform processing that is not possible or awkward to perform
exclusively
with core operations. To deploy an XRule that makes use of extension
operations on
another Web)CM installation, the XRule XML must be deployed and the dll
containing
the extension operations must be installed on each content scan server.
[00133] The )(Rules language shares many syntactic similarities with XSLT,
as
both languages leverage XPath extensively. The runtime provides an )(Path
evaluation
facility that is used by operations. )(Path may be extended by adding new
functions.
)(Rules provides a number of )(Path extension functions, and it is possible to
create
new )(Path extension functions for use within )(Rules.
[00134] Namespaces
[00135] The namespace of an XML element is used by the runtime to load the
appropriate Operation.
[00136] Operations are contained in dll's. The namespace of the XML
element
must identify the dll to load. For instance, the core operations are contained
in a dll
named WFCXsrOps.d11. The namespaceUri for the core operations is declared as
follows: xmlns:xsr='urn:coreops-watchfire-com:assembly:WFCXsrOps.d11'
[00137] All namespaces within an )(Rule that are intended to identify
assemblies
(dll's) containing operations or XPath extension functions must conform to the
following pattern: urn:[a-zA-Z0-9-] {2,32} :assembly:(.*)
[00138] Informally, the `urn:' identifier, followed by between 2 and 32
alphanumeric characters and dashes, followed by the token ':assembly:'
followed by the
unqualified name of the dll. In addition, all the other restrictions for
Uniform Resource
- 27 -
CA 02505370 2005-04-26
Names apply (although these are unlikely to be encountered) per RFC 2141. See
http://www.faqs.org/rfcs/rfc2141.html.
[00139] The dll must be placed in the <install-directory>\Watchfire\WebXM
directory on each Web3CM content scan server.
[00140] Extensibility
[00141] )(Rules provides two hooks for extending the language, one hook
for
extending the set of operations and one hook for extending the set of
functions used in
XPath expressions. These hooks are both based on XML namespaces.
[00142] Extension operations are created by extending the Operation
abstract
base class contained in the WFCXsrRuntime assembly. Operations can be written
in
any .Net programming language.
[00143] XPath extension functions are created by implementing the
System.Xml.Xs1.1Xs1tContextFunction interface. XPath extension functions can
be
written in any .Net programming language.
[00144] Operations and functions must be packaged into an assembly (a
dill).
Also present in the assembly must be a class implementing the MxtensionFactory
interface. The lExtensionFactory class is instantiated by the runtime and is
used by the
runtime to obtain instances of operations and functions contained within the
assembly.
[00145] XRules document structure, lifecycle and concurrency
[00146] An )(Rule document contains three executable sections, each one
invoked at a different stage of the XRule's lifecycle.
[00147] The initialize section is invoked before any pages are processed.
The
initialize section may be used to specify metadata about the XRule's results
such as
column headers and report format.
[00148] The evaluate section is invoked each time a page is ready to be
evaluated by the XRule.
-28 -
I
CA 02505370 2005-04-26
[00149] The finalize section is invoked when the processing of pages has
been
completed. The finalize section can be used to release resources and perform
cleanup.
[00150] In the preferred embodiment, the XRules are invoked in a
multithreaded
environment. Each scanning thread has its own instance of the XRules runtime.
Each
instance of the XRules runtime operates completely independently of the other
instances. The initialize and finalize sections of the XRule are processed
once for each
scanning thread. Therefore any processing contained in initialize or finalize
will be
executed multiple times when multiple scanning threads are used. The evaluate
section
will be processed for each page that a scanning thread processes; when there
are
multiple scanning threads, no one instance of the )(Rule will process all of
the pages in
the scan.
CORE OPERATIONS
[00151] Terminology
[00152] For XRules, a sequence constructor is sequence of sibling nodes in
the
)(Rule that can be evaluated by the runtime.
[00153] A sequence expression is an XPath expression that evaluates to a
sequence of items.
[00154] When a sequence constructor is evaluated, the runtime keeps track
of
which nodes are being processed by means of a set of implicit variables
referred to
collectively as the focus. More specifically, the focus consists of the
following three
values:
= The context item is the item currently being processed. An item is either
an
atomic value (such as an integer, date, or string), or a node. The context
item is initially
set to the element currently being evaluated. It changes whenever instructions
such as
xsr:for-each or xsnanalyze-string are used to process a sequence of items;
each item in
such a sequence becomes the context item while that item is being processed.
The
context item is returned by the Xpath expression. (dot).
= The context position is the position of the context item within the
sequence of
items currently being processed. It changes whenever the context item changes.
When
-29 -
CA 02505370 2005-04-26
an instruction such as xsr:for-each is used to process a sequence of items,
the first item
in the sequence is processed with a context position of 1, the second item
with a context
position of 2, and so on. The context position is returned by the Xpath
expression
position().
= The context size is the number of items in the sequence of items
currently being
processed. It changes whenever instructions such as xsr:for-each are used to
process a
sequence of items; during the processing of each one of those items, the
context size is
set to the count of the number of items in the sequence (or equivalently, the
position of
the last item in the sequence). The context size is returned by the Xpath
expression
last().
[00155] A QName is a qualified name: a local name optionally preceded with
a
namespace prefix. Two QNames are considered if the corresponding expanded-
QNames are the same.
[00156] An expanded-QName is a pair of values containing a local name and
an
optional namespace URI. A QName is expanded by replacing the namespace prefix
with the corresponding namespace URI, from the namespace declarations that are
in
scope at the point where the QName is written. Two expanded-QNames are equal
if the
namespace URIs are the same (or both absent) and the local names are the same.
[00157] Dynamic errors are detected by the runtime when executing the
XRule
and cause execution to terminate. Static errors are detected when an XRule is
validated and cause the Webapp to disallow the )(Rule for the job.
[00158] Looping: for-each
[00159] Exemplary coding to implement "for-each looping" is presented in
Figure 8. The xsr:for-each instruction processes each item in a sequence of
items,
evaluating the child elements within the xsr:for-each instruction once for
each item in
that sequence. The select attribute is required, and the )(Path expression
must evaluate
to a sequence, called the input sequence.
[00160] The xsr:for-each instruction contains a sequence constructor,
which is
evaluated once for each item in the sorted sequence. The sequence constructor
is
-30-
CA 02505370 2005-04-26
evaluated with the focus set as follows:
= The context item is the item being processed. If this is a node, it will
also be the
context node. If it is not a node, there will be no context node: that is, the
value of
self: :node() will be an empty sequence.
= The context position is the position of this item in the sequence.
= The context size is the size of the sequence (which is the same as the
size of the
input sequence).
[00161] An exemplary XRule fragment that detects images with a width
greater
than 800px is presented in Figure 9.
[00162] Conditional Processing: if
[00163] Exemplary coding to implement an "if" condition is presented in
Figure
10. The xsr:if element has a test attribute, which specifies an expression.
The content
is a sequence constructor.
[00164] The result of the xsr:if instruction depends on the effective
boolean value
of the expression in the test attribute. The rules for determining the
effective boolean
value of an expression are given in XPath 2.0: they are the same as the rules
used for
XPath conditional expressions.
If the effective boolean value of the expression is true, then the sequence
constructor
contained by the xsr:if instruction is evaluated. If the effective boolean
value of the
expresion is false, the contents of the xsr:if instruction are not evaluated
and the
runtime's cursor moves to the next element.For example, an XRule fragment that
fast-
exits execution of an XRule if the page being evaluated has no cookies, is
presented in
Figure 11.
[00165] Conditional Processing: choose
[00166] Exemplary coding to implement a "choose" condition is presented in
Figure 12. The xsr:choose element selects one among a number of possible
alternatives. It consists of a sequence of xsr:when elements followed by an
optional
xsr:otherwise element. Each xsr:when element has a single attribute, test,
which
-31 -I
CA 02505370 2005-04-26
specifies an expression. The content of the xsr:when and xsr:otherwise
elements is a
sequence constructor.
[00167] When an xsr:choose element is processed, each of the xsr:when
elements
is tested in turn (that is, in document order as the elements appear in the
stylesheet),
until one of the xsr:when elements is satisfied. An xsr:when element is
satisfied if the
effective boolean value of the expression in its test attribute is true. The
rules for
determining the effective boolean value of an expression are given in XPath
2.0: they
are the same as the rules used for XPath conditional expressions.
[00168] The content of the first, and only the first, xsr:when element
that is
satisfied is evaluated. If no xsr:when element is satisfied, the content of
the
xsr:otherwise element is evaluated, and the resulting sequence is returned as
the result
of the xsr:choose instruction. If no xsr:when element is satisfied, and no
xsr:otherwise
element is present, the result of the xsr:choose instruction is an empty
sequence.
[00169] Only the sequence constructor of the selected xsr:when or
xsr:otherwise
instruction is evaluated. The test expressions for xsr:when instructions after
the
selected one are not evaluated.
[00170] The exemplary code in Figure 13 logs a message or writes a row to
the
database, depending on the outcome or a request.
[00171] Variables: variable
[00172] Exemplary coding for declaring variables is presented in Figure
14. The
xsr:variable element has a required name attribute, which specifies the name
of the
variable. The value of the name attribute is a QName, which is expanded as
described
in the Terminology section above.
[00173] The initial value of the variable is computed using the expression
given
in the select attribute and/or the contained sequence constructor. This value
is referred
to as the supplied value of the variable.
- 32 -
CA 02505370 2005-04-26
[00174] A variable-binding element can specify the value of the variable in
three
alternative ways:
= If the variable-binding element has a select attribute, then the value of
the
attribute must be an expression and the value of the variable is the object
that results
from evaluating the expression. In this case, the content must be empty.
= If the variable-binding element does not have a select attribute and has
non-
empty content (i.e. The variable-binding element has one or more child nodes),
then
the content of the variable-binding element specifies the value. The content
of the
variable-binding element is text that becomes the value of the variable.
= If the variable-binding element has empty content and does not have a
select
attribute, then the value of the variable is an empty string. Thus,
<xsl:variable
name="x"/> is equivalent to: <xsl:variable name="x" select= />.
[00175] Variables are scoped by their placement within the )(Rule XML. For
any variable-binding element, there is a region of the )(Rule within which the
binding is
visible. The set of variable bindings in scope for an XPath expression
consists of those
bindings that are visible at the point in the XRule where the expression
occurs. A
variable binding element is visible for all following siblings and their
descendants.
Unlike XSLT, variables may be assigned a new value using the update-variable
operator.
[00176] It is a dynamic error to specify a variable using a QName used by
another variable currently in scope.
[00177] The value of the variable is evaluated by the runtime when the
variable
binding element is processed by the runtime. If the select attribute is used,
the )(Path
expression is evaluated at that time.
[00178] In XSLT, there is the possibility of creating a circular reference
using
variables. In XSLT and XRules this is a dynamic error. Because of the reduced
functionality of the variable binding element in XRules, and because the XPath
expression in the select attribute is evaluated before the variable is
registered, the
potential for creating circularity is diminished, perhaps eliminated, and is
certainly
avoidable.
- 33 -
,
CA 02505370 2005-04-26
[00179] Variables: update-variable
[00180] Exemplary coding for updating variables is presented in Figure 15.
The
xsr:update-variable element has a required name attribute, which specifies the
name of
the variable. The value of the name attribute is a QName, which is expanded as
described in the Terminology section above.
[00181] It is a dynamic error if the xsr:update-variable element specifies
a
variable that is not currently in scope.
[00182] The new value of the variable is computed using the expression
given in
the select attribute or the contained sequence constructor. Subsequent
evaluations of
the variable will retrieve the value provided by the most recent xsr:update-
variable
instruction.
[00183] Exemplary coding to update a "cookie counting" variable is
presented in
Figure 16.
[00184] Regular Expressions: analyze-string
[00185] The xsr:analyze-string instruction takes as input a string (the
value of the
select attribute) and a regular expression (the effective value of the regex
attribute).
Exemplary coding is presented in Figure 17.
[00186] The flags attribute may be used to control the interpretation of
the
regular expression. If the attribute is omitted, the effect is the same as
supplying a zero-
length string. This is interpreted in the same way as the $flags attribute of
the functions
xsr:matches, xsr:replace, and xsr:tokenize.
[00187] Specifically, if it contains the letter "m", the match operates in
multiline
mode, otherwise it operates in string mode. If it contains the letter "i", it
operates in
case-insensitive mode, otherwise it operates in case-sensitive mode. For more
detailed
specifications of these modes, see Microsoft .Net Regular Expressions
references.
[00188] Note: Because the "regex" attribute is not an attribute value
template as
it is in XSLT, curly braces within the regular expression must not be doubled.
For
- 34 -
I
õ,.
CA 02505370 2005-04-26
example, to match a sequence of one to five characters followed by whitespace,
write
regex=÷. {1,5} \s", not regex=".{ {1,5} } \s" as is necessary in XSLT.
[00189] The xsr:analyze-string instruction may have two child elements:
xsr:matching-substring and xsr:non-matching-substring. Both elements are
optional,
and neither may appear more than once.
[00190] This instruction is designed to process all the non-overlapping
substrings
of the input string that match the regular expression supplied.
[00191] It is a dynamic error if the effective value of the regex
attribute does not
conform to the required syntax for regular expressions, as specified in the
Microsoft
.Net Regular Expressions references, or if the effective value of the flags
attribute has a
value other than "i", "m" or "im". The runtime must signal the error. If the
regular
expression and/or flags are known statically (for example, if the attributes
do not
contain any expressions enclosed in curly braces) then the runtime may signal
the error
as a static error.
[00192] It is a dynamic error if the effective value of the regex
attribute is a
regular expression that matches a zero-length string. The processor must
signal the
error. If the regular expression is known statically (for example, if the
attribute does
not contain any expressions enclosed in curly braces) then the processor may
signal the
error as a static error.
[00193] The xsr: analyze-string instruction starts at the beginning of the
input
string and attempts to find the first substring that matches the regular
expression. If
there are several matches, the first match is defined to be the one whose
starting
position comes first in the string. Having found the first match, the
instruction
proceeds to find the second and subsequent matches by repeating the search,
starting at
the first character that was not included in the previous match.
[00194] The input string is thus partitioned into a sequence of
substrings, some
of which match the regular expression, others which do not match it. Each
substring
will contain at least one character. This sequence of substrings is processed
using the
xsr:matching-substring and xsr:non-matching-substring child instructions. A
matching
- 35 -
CA 02505370 2005-04-26
substring is processed using the xsr:matching-substring element, a non-
matching
substring using the xsr:non-matching-substring element. Each of these elements
takes a
sequence constructor as its content. If the element is absent, the effect is
the same as if
it were present with empty content. In processing each substring, the contents
of the
substring will be the context item (as a value of type xs:string); the
position of the
substring within the sequence of matching and non-matching substrings will be
the
context position; and the number of matching and non-matching substrings will
be the
context size.
[00195] If the input is a zero-length string, the number of substrings
will be zero,
so neither the xsr:matching-substring nor xsr:non-matching-substring elements
will be
evaluated.
[00196] While the xsr:matching-substring instruction is active, a set of
captured
substrings is available, corresponding to the parenthized sub-expressions of
the regular
expression. These captured substrings are accessible using the function regex-
group
(see exemplary coding in Figure 18). This function takes an integer argument
to
identify the group, and returns a string representing the captured substring.
In the
absence of a captured substring with the relevant number, it returns the zero-
length
string.
[00197] Note: The function also returns a zero-length string in the case
of a
group that matched a zero-length string, and in the case of a group that
exists in the
regular expression but did not match any part of the input string.
[00198] Put another way, the XPath expression regex-group, for the set of
all
matching substrings, returns the substring whose index matches the integer
parameter
you pass in.
[00199] While no xsr:matching-substring instruction is active the regex-
group
returns an empty sequence. The function also returns an empty sequence if an
xsr:non-
matching-substring instruction has been activated more recently than an
xsr:matching-
substring instruction.
-36-
CA 02505370 2005-04-26
[00200] For example, consider the XRule fragment in Figure 19, that
pattern
matches the HTML of a page for North American phone numbers. Matches are saved
to the database, and non-matches are of no interest.
[00201] Output to Database: insert-row
[00202] The xsr:insert-row instruction is used to add data to the WebXM
database. Exemplary coding is presented in Figure 20.
[00203] The level attribute may be used to control the default
presentation of this
data. The level attribute must have the value of 1 or 2 for standard
reporting, however,
other integer values may be specified if the )(Rule data will be displayed
exclusively
with custom reports. If unspecified, 1 is the default value. When the
effective value of
the level attribute is 1 the row of data is displayed at the top level of the
report. When
the level attribute is 2 the row of data is displayed in the second level of
the report.
[00204] The top level of the report always shows the URL of the page for
which
this XRule has found an issue along with any other string or integer data
added to the
row. The second level of the report displays the string and integer data in
the row. In
order for second level data to be accessible in the report, a top level row
must be added
whenever second level rows are added.
[00205] The xsr:insert-row instruction may have as many as six child
elements:
xsr:cell-strl, xsr:cell-str2, xsr:cell-str3 are used to add textual data to
the database;
while xsr:cell-intl, xsr:cell-int2, xsr:cell-int3 are used to add integer data
to the
database.
[00206] If the xsr:cell-X instruction has a select attribute, then the
value of the
attribute must be an expression and the result of evaluating the expression is
inserted
into the database. In this case, the content must be empty.
[00207] If the xsr:cell-X instruction does not have a select attribute and
has non-
empty content, then the content of the element specifies the value. The
content of the
element is inserted into the database.
- 37 -
I
4.
CA 02505370 2005-04-26
[00208] It is a static error if the xsr:cell-X instruction contains both a
select
attribute and content.
[00209] The xsr:cell-strl, xsr:cell-str2, xsr:cell-str3 instructions treat
their data as
a string with maximum length of 1024 characters. Strings longer that 1024
characters
are truncated to 1024 characters.
[00210] The xsr:cell-intl, xsr:cell-int2, xsr:cell-int3 instructions
convert their
data to an integer. The value of the integer must be in the range of negative
2,147,483,648 through positive 2,147,483,647.
[00211] A dynamic error is reported if the provided data cannot be
converted to
an integer, or if the integer falls outside the allowed range. To parse
correctly as an
integer, the supplied data must have the following form: [ws][sign]digits[ws]
[00212] Items in square brackets ([ and]) are optional; and the values of
the
other items are as follows:
ws - An optional white space.
sign - An optional sign.
digits - A sequence of digits ranging from 0 to 9.
[00213] For effective report display, XRule authors are encouraged to begin
using the lowest numbered instructions, xsr:cell-strl and xsr:cell-intl,
placing data in
the higher numbered locations only after the lower numbered locations have
already
been used.
[00214] When a new row is created, some cells are added to each row
implicitly:
= UrlId, the identifier of the page url is added so that XRule data may be
associated with the current page in the report.
= ScanRuleId, the identifier for the )(Rule, so that data gathered by
various
)(Rules may be distinguished.
[00215] For example, consider the )(Rule in Figure 21 that pattern matches
the
HTML of a page for North American phone numbers and saves matches in such a
form
that it can be displayed as a two level report. The top level of the report
will be the list
- 38 -
========-=
CA 02505370 2005-04-26
of pages containing phone numbers, and the url and count of phone numbers
found is
shown. The second level will be the list of phone numbers found on the page.
[00216] Output to Logfile: log
[00217] The xsr:log instruction is used to log messages to the WebXM log.
Exemplary coding is presented in Figure 22. The xsr:log element has a required
level
attribute, which specifies the minimum logging level setting required in order
to log the
message. The following are acceptable values, in order of most restrictive to
least
restrictive: off, error, warning, information, verbose.
[00218] When the level attribute is set to error, the message will be
logged if the
current logging level (a WebXM registry setting) is error, warning,
information or
verbose. When the level attribute is set to information, the message will be
logged if
the current logging level (a WebXM registry setting) is information or
verbose.
[00219] If the xsr:log instruction has a select attribute, then the value
of the
attribute must be an expression and the result of evaluating the expression
will be
logged. In this case, the content must be empty.
[00220] If the xsr:log instruction does not have a select attribute and
has non-
empty content, then the content of the variable-binding element specifies the
value.
The content of the element is inserted into the database.
[00221] It is a static error if the xsr:log instruction contains both a
select attribute
and content.
[00222] For example, an XRule fragment that logs an error if the HTML has
been truncated and additional information when the verbose setting is enabled,
is
presented in Figure 23.
[00223] Specifying Column Headings: column-heading-strings and column-
heading-keys
- 39 -
CA 02505370 2005-04-26
[00224] The xsr:column-heading-strings instruction is used to specify the
headings for the columns to be displayed in a report. Exemplary coding is
presented in
Figure 24.
[00225] Alternatively, the xsr:column-heading-keys instruction may be used
to
specify the headings for the columns to be displayed in a report. When the
column
headings need to appear in different languages for different users, this
alternative must
be used. At runtime, the Webapp will use the provided keys to lookup the
displayable
string using the theme of the current user. The string resources corresponding
to the
keys must be added to the strings.txt file, or another strings resource file,
in the themes
directory of the Webapp.
[00226] The xsr:column-heading-strings and xsr:column-heading-keys
instructions are valid in the xsr:initialize section of the )(Rule.
[00227] Both xsr:column-heading-strings and xsr:column-heading-keys
elements
have a required level attribute, which is used to indicate which level of the
report the
column headings should be used for. The level attribute must have the value of
1 or 2
for standard reporting, however, other integer values may be specified if the
XRule data
will be displayed exclusively with custom reports.
[00228] Other attributes are optional and may contain a string of up to
255
characters in length.
[00229] For example, an XRule fragment that specifies column names for the
first and second levels of a report that has as the first level a list of urls
with a number
of phone numbers found on the page, and as a second level a list of all the
area codes
and phone numbers found on the page, is presented in Figure 25.
[00230] Describing an XRule: annotation
[00231] The xsr: annotation element is used annotate an XRule. The
xsr:documentation element is intended to contain descriptive text for the
benefit of
human readers. Exemplary coding is presented in Figure 26.
-40-
I
t4t-
CA 02505370 2005-04-26
[00232] The xsr:documentation element has an optional theme attribute. If
specified, the user agent (the Webapp) will attempt to locate a version of the
documentation suitable for the current theme.
[00233] The Webapp will display the contents of the xsr:documentation
element
in the read-only properties page for a job.
[00234] For example, an XRule fragment that finds all North American
telephone numbers is presented in Figure 27.
[00235] Accessing the Web: http-request
[00236] The xsr:http-request instruction is used to retrieve data from the
Web for
processing in the XRule. Exemplary coding is presented in Figures 28A through
28C.
[00237] The xsr:http-request element must contain xsr:request-data and xsr-
response-data elements. The xsr:request-data element contains all data
specified as part
of the HTTP request. The xsr:response-data element is used to identify the
desired data
to make available from the HTTP response, and also to contain that data. The
initially
empty elements in xsr:response-data are populated once the data becomes
available and
before processing of the xsr:http-request instruction is complete. Items are
populated
by adding a text-node containing the data as a child.
[00238] It is a static error if the xsr:request-data element does not
contain a
xsr:request-header element that contains a xsr:uri element. It is a dynamic
error if a uri
is not specified by either the select or the content of the xsrarri
instruction.
[00239] For instructions that allow a "select" attribute and #PCDATA
content, it
is a dynamic error if both are specified (as it is for xsr:variable and
others).
[00240] Instructions map directly to properties of the
System.Net.HttpWebRequest and System.Net.HttpWebResponse classes. It may be
useful to refer to the documentation for those classes to infer the semantics
and valid
values for the various instructions:
-41-
I
CA 02505370 2005-04-26
http://msdn.microsoft.comilibrary/default.asp?ur1=/library/en-
us/cpreghtrnliffirfsysterrmethttpWebrequestmemberstopic.asp
[00241] There are many other properties that one might like to set on the
System.Net.HttpWebRequest class, or access on the System.Net.HttpWebResponse
class that have not been described herein. The implementation of these would
be
straightforward to one skilled in the art from the teachings herein. These
could be
placed in the core tag library or provided as sample code for creating
extension
operations.
[00242] For example, an XRule fragment that requests a page, and logs a
message based on the response, is presented in Figure 29.
[00243] Core XPath Extension Functions
[00244] Testing for Match: matches
[00245] Exemplary coding to test for matches is presented in Figure 30.
The
effect of calling the first version of this function (omitting the argument
$flags) is the
same as the effect of calling the second version with the $flags argument set
to a zero-
length string. If $input is the empty sequence, the result is the empty
sequence. The
function returns true if $input matches the regular expression supplied as
$pattern;
otherwise, it returns false.
[00246] Unless the metacharacters A and $ are used as anchors, the string
is
considered to match the pattern if any substring matches the pattern. But if
anchors are
used, the anchors must match the start/end of the string (in string mode), or
the start/end
of a line (in multiline mode).
[00247] A dynamic error is raised ("Invalid regular expression") if the
value of
$pattern is invalid according to the rules described in the Microsoft .Net
Regular
Expressions references. Similarly, a dynamic error is raised ("Invalid regular
expression flags") if the value of $flags is invalid according to the rules
described in the
Microsoft .Net Regular Expressions references.
-42 -
õ
CA 02505370 2005-04-26
[00248] For example:
fn:matches("abracadabra÷, "bra") returns true
frumatches("abracadabra", "^a.*a$") returns true
fn:matches("abracadabra", "bra") returns false
[00249] Note: This function is syntactically and functionally equivalent
to the
matches function described in "XQuery 1.0 and XPath 2.0 Functions and
Operators
W3C Working Draft 02 May 2003" and will eventually be replaced by core
functionality offered by the XPath processor.
1002501 String Replacements: replace
[00251] Exemplary coding to implement string replacements is presented in
Figure 31.
[00252] The effect of calling the first version of this function (omitting
the
argument $flags) is the same as the effect of calling the second version with
the $flags
argument set to a zero-length string. The $flags argument is interpreted in
the same
manner as for the xsr:matches() function.
[00253] If $input is the empty sequence, the result is the empty sequence.
The
function returns the xs:string that is obtained by replacing all non-
overlapping
substrings of $input that match the given $pattern with an occurrence of the
$replacement string.
[00254] If two overlapping substrings of $input both match the $pattern,
then
only the first one (that is, the one whose first character comes first in the
$input string)
is replaced. Within the $replacement string, the variables $1 to $9 may be
used to refer
to the substring captured by each of the first nine parenthesized sub-
expressions in the
regular expression. A literal $ symbol must be written as \$. For each match
of the
pattern, these variables are assigned the value of the content of the relevant
captured
sub-expression, and the modified replacement string is then substituted for
the
characters in $input that matched the pattern.
-43 -
CA 02505370 2005-04-26
[00255] If a variable $n is present in the replacement string, but there
is no nth
captured substring (which may happen because there were fewer than n
parenthesized
sub-expressions, or because the nth parenthesized sub-expression was not
matched)
then the variable is replaced by a zero-length string.
[00256] If two alternatives within the pattern both match at the same
position in
the $input, then the match that is chosen is the one matched by the first
alternative. For
example: fn:replace("abcd", "(ab)I(a)", "[1=$1][242]") returns "[1=ab][2=]cd"
[00257] A dynamic error is raised ("Invalid regular expression") if the
value of
$pattern is invalid according to the rules described in the Microsoft .Net
Regular
Expressions references.
[00258] A dynamic error is raised ("Invalid regular expression flags") if
the value
of $flags is not one of `i', `m' or 'im'.
[00259] A dynamic error is raised ("Regular expression matches zero-length
string") if the pattern matches a zero-length string. It is not an error,
however, if a
captured substring is zero-length.
[00260] A dynamic error is raised ("Invalid replacement string") if the
value of
$replacement contains a "$" character that is not immediately followed by a
digit 1-9
and not immediately preceded by a "I". A dynamic error is raised ("Invalid
replacement
string") if the value of $replacement contains a "\" character that is not
part of a "\\"
pair, unless it is immediately followed by a "$" character.
[00261] For example:
replace("abracadabra", "bra", "*") returns "a*cada*"
replace("abracadabra", "a.*a", "*") returns "*"
replace("abracadabra", "a.*?a", "*") returns "*c*bra"
replace("abracadabra", "a", ") returns "brcdbr"
replace("abracadabra", "a0", "a$1$1") returns "abbraccaddabbra"
replace("abracadabra", ".*?", 11") raises an error, because the pattern
matches the
zero-length string
-44-
CA 02505370 2005-04-26
[00262] Note: This function is syntactically and functionally equivalent
to the
replace function described in "Xcluery 1.0 and XPath 2.0 Functions and
Operators
W3C Working Draft 02 May 2003" and will eventually be replaced by core
functionality offered by the XPath processor.
[00263] Splitting a String into Substrings: tokenize
[00264] Exemplary coding to split a string into substrings is presented in
Figure
32. The effect of calling the first version of this function (omitting the
argument $flags)
is the same as the effect of calling the second version with the $flags
argument set to a
zero-length string.
[00265] This function breaks the $input string into a sequence of strings,
treating
any substring that matches $pattern as a separator. The separators themselves
are not
returned.
[00266] The $flags argument is interpreted in the same way as for the
xsr:matches() function.
[00267] If $input is the empty sequence, the result is the empty sequence.
[00268] If the supplied $pattern matches a zero-length string, the
xsr:tokenize()
function breaks the string into its component characters. The nth character in
the $input
string becomes the nth string in the result sequence; each string in the
result sequence
has a string length of one.
[00269] If a separator occurs at the start of the $input string, the
result sequence
will start with a zero-length string. Zero-length strings will also occur in
the result
sequence if a separator occurs at the end of the $input string, or if two
adjacent
substrings match the supplied $pattern.
[00270] If two alternatives within the supplied $pattern both match at the
same
position in the $input string, then the match that is chosen is the first. For
example:
xsr:tokenize("abracadabra", "(ab)I(a)") returns ("", "r", "c", "d", "r", "")
-45 -
CA 02505370 2005-04-26
[00271] A dynamic error is raised ("Invalid regular expression") if the
value of
$pattern is invalid according to the rules described in the Microsoft .Net
Regular
Expressions references. A dynamic error is raised ("Invalid regular expression
flags") if
the value of $flags is not one of T, 'in' or 'im'.
[00272] For example:
= xsrtokenize("The cat sat on the mat", "\s+") returns ("The", "cat",
"sat", "on",
"the", "mat")
= xsr:tokenize("1, 15, 24, 50", ",\s") returns ("1", "15", "24", "50")
= xsrtokenize("1,15õ24,50,", ",") returns ("1", "15", "", "24", "50", "")
= xsr:tokenize("Some unparsed <br> HTML <BR> text", "\s*<br>\s", "i")
returns ("Some unparsed", "HTML", "text")
[00273] Note: This function is syntactically and functionally equivalent
to the
tokenize function described in "XQuery 1.0 and XPath 2.0 Functions and
Operators
W3C Working Draft 02 May 2003" and will eventually be replaced by core
functionality offered by the XPath processor.
[00274] Retrieving Substring Matches: regex-group
[00275] The format for this command is as follows:
xsr:regex-group($group-number as xs:integer?) as xs:string?
[00276] The functionality is basically the same as that described in
xsranalyze-
string.
[00277] Obtaining HTML: retrieve-html
[00278] This function is used to obtain the HTML of the page in an XRule.
The
format for this command is as follows:
xsrretrieve-html() as xs:string?
[00279] Some maximum limit is imposed on the size of the HTML that can be
retrieved. To determine if the HTML this function provides is complete or
truncated,
use the function xsr:retrieve-html-truncated.
- 46 -
CA 02505370 2005-04-26
[00280] Determining if HTML is complete: retrieve-html-truncated
[00281] This function is used to determine if a call to retrieve-html
while
evaluating the current page with return the complete HTML of the page or a
truncated
version. The format for this command is as follows:
xsr:retrieve-html-truncated() as xs:boolean?
[00282] The function returns true if the HTML has been truncated, false
otherwise.
[00283] Obtaining Text: retrieve-text
[00284] This function is used to obtain the text of the page in an XRule.
The
format for this command is as follows:
xsr:retrieve-text() as xs:string?
[00285] Some maximum limit is imposed on the size of the text that can be
retrieved. To determine if the text this function provides is complete or
truncated, use
the function xsr:retrieve-text-truncated.
[00286] Determining if text is complete: retrieve-text-truncated
[00287] This function is used to determine if a call to retrieve-text
while
evaluating the current page with return the complete text of the page or a
truncated
version. The format for this command is as follows:
xsr:retrieve-text-truncated() as xs:boolean?
[00288] The function returns true if the text has been truncated, false
otherwise.
[00289] Obtaining Form HTML: retrieve-formhtml
[00290] This function is used to obtain the HTML contained with forms on
the
page. The format for this command is as follows:
xsnretrieve-form-html() as xs:string?
-47 -
+
CA 02505370 2005-04-26
[00291] Some maximum limit is imposed on the size of the HTML that can be
retrieved. To determine if the HTML this function provides is complete or
truncated,
use the function xscretrieve-form-html-truncated.
[00292] Determining if Form HTML is complete: retrieve-formhtml-
truncated
[00293] This function is used to determine if a call to retrieve-formhtml
while
evaluating the current page with return the complete form HTML of the page or
a
truncated version. The format for this command is as follows:
xsr:retrieve-form-html-truncated() as xs:boolean?
[00294] The function returns true if the form HTML has been truncated,
false
otherwise.
[00295] Obtaining the UFtL of the page: retrieve-url
[00296] This function is used to obtain the URL used to retrieve the
current page.
The format for this command is as follows:
xsr:retrieve-url() as xs:string?
[00297] Obtaining Request Post Data: retrieve-post-data
[00298] This function is used to obtain the post data sent when the
current page
was requested. The format for this command is as follows:
xsnretrieve-post-data() as xs:string?
[00299] Obtaining Request Headers: retrieve-headers
[00300] This function is used to obtain the headers sent when the current
page
was requested. The format for this command is as follows:
xsr:retrieve-headers() as xs:string?
[00301] Obtaining Mime Type of Page: retrieve-mime-type
- 48 -
CA 02505370 2005-04-26
[00302] This function is used to obtain the mime-type of the current page.
The
format for this command is as follows:
xsr:retrieve-mime-type() as xs:string?
[00303] Obtaining Status Line of Page: retrieve-status-line
[00304] This function is used to obtain the status line returned in the
response for
the current page. The format for this command is as follows:
xsr:retrieve-status-line() as xs:string?
[00305] Determining if Page is Internal: retrieve-is-internal
[00306] This function is used to obtain determine if the current page is
considered to be an internal page by the scan engine. The format for this
command is
as follows: xsr:retrieve-is-internal() as xs:boolean?
[00307] Determining if Page contains Frameset: retrieve-has-frameset
[00308] This function is used to obtain determine if the current page
contains a
frameset. The format for this command is as follows:
xsr:retrieve-has-frameset() as xs:boolean?
[00309] Determining if Page contains JavaScript: retrieve-has-javascript
[00310] This function is used to obtain determine if the current page
contains
JavaScript method calls. The format for this command is as follows:
xsr:retrieve-has-javascript() as xs:boolean?
[00311] Obtaining the Cookies: retrieve-cookies
[00312] This function is used to obtain the set of cookies for the page.
The
format for this command is as follows:
xsr:retrieve-cookies() as node*
[00313] The cookies are returned as a collection of cookie XML elements of
the
type described by the XML schema complexType, as presented in Figure 33.
-49 -
CA 02505370 2005-04-26
[00314] For example, an )(Rule fragment which retrieves the cookies for
the
page and reports any cookies that are persistent and do not have a compact
policy, is
presented in Figure 34.
[00315] Obtaining Image Tags: retrieve-image-tags
[00316] This function is used to obtain the set of image tags on the page.
The
format for this command is as follows:
xsr:retrieve-image-tags() as node*
[00317] The image tags are returned as a collection of image-tag XML
elements
of the type described by the XML schema complexType presented in Figure 35.
[00318] For an example of usage, see the description of xsr:for-each.
[00319] Obtaining Meta Tags: retrieve-meta-tags
[00320] This function is used to obtain the set of meta tags on the page.
The
format for this command is as follows:
xsr:retrieve-meta-tags() as node*
[00321] The image tags are returned as a collection of meta-tag XML
elements of
the type described by the XML schema complexType presented in Figure 36.
[00322] Obtaining Response Headers: retrieve-response-headers
[00323] This function is used to obtain the set of response headers for
the page.
The format for this command is as follows:
xsnretrieve-response-headers() as node*
[00324] The response headers are returned as a collection of response-
header
XML elements of the type described by the XML schema complexType as presented
in
Figure 37.
[00325] Obtaining Links on Page: retrieve-links
- 50 -
CA 02505370 2005-04-26
[00326] This function is used to obtain the set of links found on the
page. The
format for this command is as follows:
xsr:retrieve-links() as node*
[00327] The links are returned as a collection of link XML elements of the
type
described by the XML schema complexType, as presented in Figure 38.
[00328] Obtaining Parsed Form Data on Page: retrieve-forms
[00329] This function is used to obtain the set of form information found
on the
page. The format for this command is as follows:
xsr:retrieve-forms() as node*
[00330] The forms found are returned as a collection of form XML elements
of
the type described by the XML schema complexType as presented in Figures 39A
and
39B.
LIMITATIONS
[00331] Maximum Page Size Limitation
[00332] In order to simplify the )(Rule programming model, and to
facilitate the
use of regular expressions, )(Rules processes HTML page input as a string, not
a
stream. Elsewhere the scan engine processes pages as streams.
[00333] This implies that the stream is gathered into a string at some
point.
Some limit must be placed on the maximum size of page that can be processed
without
truncation by )(Rules.
[00334] The maximum size for pages must balance system resource usage
against the number of pages that are truncated. For )(Rules to be effective,
very few
pages should be truncated. The maximum page size without truncation should be
governed by a registry setting, perhaps ¨1MB. This figure is going to change
over time
as the speed, processing power and strange capacity of computers and servers
improves.
- 51
' T'
CA 02505370 2005-04-26
[00335] Whether or not the page has been truncated must be provided as
input to
an )(Rule. The XRule can then take the appropriate action for truncated pages.
For
instance, some XRules may wish to ignore the fact that a page was truncated
and
proceed with the test normally, using the truncated content. Other )(Rules may
wish to
flag all truncated pages as pages potentially containing issues.
[00336] Localized Column Headers
[00337] Most strings that appear in the Webapp come from string resources -
- the
strings.txt and report-str.txt files. String resources combined with the
themes support
constitutes the localization strategy for the Webapp. The current means of
specifying
column headers is not theme or locale aware. One could create an XRule that
specifies
the column headers in some language other than English, but this is still
somewhat
deficient. In theory, an instance of the Webapp could be modified to
simultaneously
support users in multiple different languages, whereas the XRule column
headers would
always be in one language, the one specified in the XRule.
[00338] The invention will first be released in the simple form, because
localized
versions of Web)CM are not available nor are customers running multiple UT
languages
at once. The solution for the advanced solution is somewhat complex.
[00339] We can add the more complex solution in a later release as needed.
When specifying column headers, the text would be provided with a theme name.
The
theme name would be stored in the database. WE0 would select the column header
for
the 'Mule, level, column and theme and generate the )(MIL with the themized
heading.
OPTIONS AND ALTERNATIVES
[00340] A number of embodiments of the invention have been described, but
clearly many others can be effected from the teachings herein. For example,
the
invention:
1. is preferably implemented as a server application but may also be PC
(personal
computer) based;
2. may be provided with a schedule agent so that it can run each day as a
midnight
batch, for instance;
- 52 -
I
. -
CA 02505370 2005-04-26
3. is preferably provided with a complete development environment, which
would
be clear to one skilled in the art, including:
= an editing environment;
= an interactive regular expression authoring environment;
= an interactive execution environment with step-by-step debugging; and
= a performance testing environment;
4. is preferably implemented using XML as the rule specification language,
but
may also be implemented using JavaScript, VBScript, Pen l or another script-
based or
compiled programming language; and
5. is ideally suited to analysis on web site content for security, privacy,
accessibility, quality and compliance related issue detection, but could be
also applied
to other types of analysis of web sites.
[00341] The present invention has been described with regard to one or
more
embodiments. However, it will be apparent to persons skilled in the art that a
number
of variations and modifications can be made without departing from the scope
of the
invention as defined in the claims.
[00342] The method steps of the invention may be embodiment in sets of
executable machine code stored in a variety of formats such as object code or
source
code. Such code is described generically herein as programming code, or a
computer
program for simplification. Clearly, the executable machine code may be
integrated
with the code of other programs, implemented as subroutines, by external
program calls
or by other techniques as known in the art.
[00343] The embodiments of the invention may be executed by a computer
processor or similar device programmed in the manner of method steps, or may
be
executed by an electronic system which is provided with means for executing
these
steps. Similarly, an electronic memory medium such computer diskettes, CD-
Roms,
Random Access Memory (RAM), Read Only Memory (ROM) or similar computer
software storage media known in the art, may be programmed to execute such
method
steps. As well, electronic signals representing these method steps may also be
transmitted via a communication network.
- 53 -