Note: Descriptions are shown in the official language in which they were submitted.
CA 02524207 1999-07-09
A search system and method for retrieval of data, and the use thereof in
a search engine
The present invention concerns a search system for information retrieval,
particularly information stored in form of text, wherein a text T comprises
words and/or symbols and sequences thereof, wherein the information
retrieval takes place with a given or varying degree of matching between a
query O, wherein the query Q comprises words and/or symbols and
sequences thereof, and retrieved information R, comprising words and/or
symbols and sequences thereof from the text T, wherein the search system
comprises a data structure for storing at least a part of the text T, and a
metric
M which measures the degree of matching between the query Q and retrieved
information R, and wherein the search system implements search algorithms
for executing a search, particularly a full text search on the basis of
keywords
kw; 'a method in a search system for information retrieval, particularly
information stored in form of text, wherein a text T comprises words .and
symbols and sequences thereof, wherein the information retrieval takes place
with a given or varying degree of matching between a query Q, wherein the
query Q comprises words and/or symbols and sequences thereof, and
retrieved information R comprising words and/or symbols and sequences
thereof from the text T, wherein the search system comprises a data structure
for storing at least a part of the text T, and a metric M which measures the
degree of matching between the query O and retrieved. information R, and
wherein the search system implements search algorithms for executing a
search, particularly a full text search on the basis of keywords kw, wherein
the information in the text is divided into words and word sequences; the
words being substrings of the entire .text separated by-word boundary terms
and forming a sequence of symbols, and wherein each word is structured as a
sequence of symbols.
The invention also concern the use of the search system.
A tremendous amount of information in various fields of human knowledge
is collected and stored in computer memory systems. As the computer
memory systems increasingly are linked in public available data
communication networks, there has been an increasing effort to develop
systems and methods for searching and retrieving information for public or
3~ personal use. Present search methods for data have, however, limitations
that
y~NaEO SHE'~C
CA 02524207 1999-07-09
seriously reduce the possibility of efficiently retrieving and using
information
stored in this manner. .
Information may be stored in the form of different data types, and in the
context of information search and retrieval it will be useful to discern
between dynamic data and static data. Dynamic data is data that change often
and continuously, so that the set of valid data varies all the time, while
static
data only changes very seldom or never at all. For instance will economic
data, such as stock values, or meteorological data be subject to very quick
changes and hence dynamic. On the other hand archival storage of books and
documents are usually permanent and static data. The concept the volatility
of the data relates to how long the information is valid. The volatility of
data
has some bearing upon how the information should be searched and
retrieved. Large volumes of data require some structure in order to facilitate
searching, but the time cost of building such structures must not be higher
than the time the data is valid. The cost of building a structure is dependent
on the data volume and hence the building of data structures for searching
the information should take both the data volume and the volatility into
consideration. The information collected are stored in databases and these
may be structured or unstructured. Moreover, the databases may contain
several types of documents, including compound documents which contain
images, video, sound and formatted or annotated text. Particularly structured
databases are usually furnished with indexes in order to facilitate searching
and retrieving the data. The growth of the World Wide Web (WWW) offers a
steadily growing collection of compound and hyperlinked documents. A great
many of these are not collected in structured databases aizd no indexes
facilitating rapid searching are available. However; the need for searching
documents in the World Wide Web is obvious and as a result a number of
so-called search engines has been developed, enabling searching at least parts
of the information in the World Wide Web.
With a search engine it is commonly understood one or more tools for
searching and retrieving information. In addition to the search system proper,
a search engine also contains an index, for instance comprising text from a
large number of uniform resource locators (URLs ). Examples of such search
engines are Alta Vista, HotBot with Inktomy technology, Infoseek, Excite
and Yahoo. All these offer facilities for performing search and retrieval of
information in the World Wide Web. However, their speed and efficiency do
ht~h!(5~D Sf~~(.
CA 02524207 1999-07-09
by no means match the huge amount of information available on the World
Wide Web and hence the search and retrieval efficiency of these search
engines leaves much to be desired.
Searching a large collection of text documents can usually be done with
several query types. The most common query type is matching and variants of
this. By specifying a keyword or set of keywords that has to be present in the
queried information the search system retrieves all documents that fulfils
this
requirement. The basic search method is based on so-called single keyword
matching. The keyyvord p is searched for and all documents containing this
word shall be retrieved. It is also possible to search for a keyword prefix p~
and all documents where this prefix is present in any keyword in the
documents, will be retrieved. Instead of searching with keywords, the search
is sometimes based on so-called exact phrase matching, where the search
uses several single keywords in particular sequence. As well-known by
persons skilled in the art, the exact matching of keyword phrases in many
search systems may be done with the use of Boolean operators, for instance
based on operators such as AND, OR, and NOT which allow a filtering of the
information; e.g. using an AND phrase results in that all documents
containing the two keywords linked by the AND operator will be returned.
Also a NEAR operator has been used for returning just the documents with
the keywords matching and located "near" to each other in the document text.
In many structured database the documents contained in the database have
been annotated, e.g. provided with fields which denote certain parts or types
of information in the document. This allows the search for matches in only
parts of the documents and is useful when the type of queried information is
known in advance.
When searching in text documents the data are structured and most likely
present in some natural language, like English, Norwegian etc. When
searching for documents with a certain context it is possible to apply
~0 proximity metrics for matching keywords or phrases that match the query
approximately. Allowing errors in keywords and phrases are common method
for proximity, using a thesaurus is another common method. A proximity
search requires only that there shall be a partial match between the
information retrieved and the query. International published application
W096/00945 titled "Variable length data sequence matching method and
apparatus" (Doringer & al.) which has been, assigned to International
r,h.'f~l~IC~D S'rE~r
CA 02524207 1999-07-09
Business Machines, Corp., discloses the building, maintenance and use of a
database with a trie-like structure for storing entries and retrieving at
least a
partial match, preferably the longest partial match or all partial matches of
a
search argument (input ltey) from the entries.
In order to further illuminate the general prior art mention can be made of
international published patent application W092/15954 (Kimball & al.,
assigned to Red Brick System, U.S.A.) and US patent no. 5 627 748 (Baker
& al., assigned to Lucent Technologies, Inc., U.S.A.), both disclosing data
structures in the form of suffix trees for searching/matching in a square
matrix. Neither of these two publications disclose anything beyond a regular
suffix tree, except for the use of a linked list during matching and do not
teach or suggest approaches to limit the search space when searching for
approximate matches. However; such approaches would be most desirable
when applying data structures based on suffix trees to searching, particularly
for approximate matches in extremely large document collections, such as
may be found on the World Wide Web.
The main object of the present invention is thus to provide a search system
and a method for fast and efficient search and retrieval of information in
large volumes of data. Particularly it is an object of the present invention
to
provide a search system suited for implementing search engines for searching
of information systems with distributed large volume data storage, for
instance Internet. It is to be understood that the search system according to
the invention by no means shall be limited to searching and retrieving
information stored in the form of alphanumeric symbols, but equally well
may be applied to searching and .retrieving information stored in the form of
digitalized .images and graphic symbols, as the word text used herein also
may interpreted as images when these are represented wholly or partly as sets
of symbols. It is also to be understood that the search system according to
the
invention can be implemented as software written in a suitable high-level
language on commercially available computer systems, but it may also be
implemented in the form of a dedicated processor device for searching and
retrieving information of the aforementioned kind.
The above-mentioned objects and advantages are realized according to the
invention with a search system which is characterized in that the data
structure comprises a tree structure in the form of a non-evenly spaced sparse
AN#~f~D SHI=M
CA 02524207 1999-07-09
suffix tree ST(T) for storing suffixes of words and/or symbols, and sequences
thereof in the text T; that the metric M comprises a combination of an edit
distance metric for an approximate degree of matching between words and/or
symbols in the text T and a query O and an edit distance metric for an
approximate degree of matching between sequences S of words and/or
symbols in the text T and a query sequence P of words and/or symbols in the
query Q, the latter edit distance metric including weighting cost functions
for
edit operations which transform a sequence S of words and/or symbols in the
text T into the sequence. P of words and/or symbols in the query O, the
weighting taking place with a value proportional to a change in the length of
sequence upon a transformation or dependent on the size of the words and/or
symbols in sequences to be matched, that the implemented search algorithms
comprise a first algorithm for determining the degree of matching between
words and/or symbols in the suffix tree representation of respectively the
text
1 S T and a query Q, and a second algorithm for determining the degree of
matching between sequences of words and/or symbols in the suffix tree
representation of respectively the text T and the query Q, said first and/or
second algorithms searching the data structure with queries Q in the form of
either words, symbols, sequences of words or sequences of symbols or
combinations thereof, such that information R is retrieved on the basis of
query Q with a specified degree of matching between the former and the
latter, and that the search algorithms optionally also comprise a third
algorithm for determining exact matching between words and/or symbols in
the suffix tree representation of respectively the text T and the query Q
and/or a fourth algorithm for determining exact matching between sequences
of words and/or symbols in the suffix tree representation of respectively the
text T and the query Q, said third and/or fourth algorithms searching the data
structure with queries Q in the form of either words, symbols, sequences of
words, or sequences of symbols or combinations thereof, such that
information R is retrieved on the basis of the query Q with an exact matching
between the former and the latter.
In an advantageous embodiment of the search system. according to the
invention the suffix tree ST(T) is a word-spaced sparse suffix tree SST~,S(T~,
comprising. only a subset of the suffixes in the text T.
Preferably is then the word space sparse suffix tree SST,~S(T) a
keyword-spaced sparse suffix tree SSTkWS(T)
Af~#fh~ED Si-~~E~
CA 02524207 1999-07-09
In further advantageous embodiments of the search system accor ding to the
invention the first.algorithm for detecting the degree of keyword-matching in
a keyword=spaced sparse suffix tree SSTk,~,s(T) is implemented as disclosed
by dependent claim 4, the second algorithm for determining the degree of
sequence matching in a keyword-spaced sparse suffix tree SST,;r,,s(T)
implemented as disclosed by dependent claim 5, whereby a subroutine of the
second algorithm preferably is implemented as disclosed by dependent claim
6, the third algorithm for determining an exact keyword matching in a
keyword-spaced sparse suffix tree SSTkWS(T) implemented as disclosed by
dependent claim 7, and finally the fourth algorithm for determining an exact
keyword sequence matching in a keyword-spaced sparse suffix tree SST~WS
implemented as disclosed by dependent claim 8.
The above-mentioned objects and advantages are also realized according to
the invention with a method which is characterized by generating the data
IS structure as a word-spaced sparse suffix tree SST,~,S(T) of a text T for
representing all the suffixes starting at a word separator symbol in the text
T,
storing sequence information of the words in the text T in the word-spaced
sparse suffix tree SSTws(T), generating a combined edit distance metric M
comprising an edit distance metric D(s, q) for words s in the text T and a
query wozd q in a query Q and a word-size dependent edit distance metric
DWS(S,P) for sequences S of words in the text T and a sequence P of words q
in the query O, the edit distance metric D~,,S(S,P) being the minimum sum of
costs for edit operations transforming the sequence S into the sequence P, the
minimum sum of costs being the minimum sum of cost functions for each
edit operation weighted by a parameter proportional to the change in the total
length of the sequence S or by the ratio of the current'word length and
average word length in the sequences S;P, and determining the degree of
matching between words s, q by calculating the edit distance D(s, q) between
the words s of the retrieved information R and the word q of a query Q, or in
case the words s,q are more than k errors from each other, determining the
degree of matching between the word sequences SR, Po of retrieved
information R and a query Q respectively by calculating the edit distance
D,~,S(SR,Po) for all matches.
Advantageously the method according to the invention additionally
comprises weighting an edit operation which changes a word s into word q
with a parameter for the proximity between the characters of the words s; q,
kf;~~hIDED SH~EI
CA 02524207 1999-07-09
thus taking the similarity of the words s; g in regard when determining the
cost of the edit operation in question.
In an advantageous embodiment of the method according to the invention the
number of matches is limited by calculating the edit distance by calculating
S the edit distance DWS(SR,Po) for restricted number of words in the query
word
sequence Po.
In another advantageous embodiment of the method according to the
invention the edit distance D(s,c~ between word s and a word q is defined ,
recursively and the edit distance D(s, q) calculated by means of a dynamic
programming procedure, and the edit distance D",S(S,P) between sequences S
and a sequence P is correspondingly recursively defied and the edit distance
D~,,s(S,P) calculated by means of a dynamic programming procedure.
According to the invention the above=mentioned objects and advantages are
also realized with the use of the search system according to the invention in
1 S an approximate search engine.
The search system and the method according to the invention shall now be
discussed in greater detail in the following with reference to the
accompanying drawing figures, of which
fig. 1 shows an example of a suffix tree,
fig. 2 examples of word-spaced sparse suffix trees as used with the present
invention,
fig. 3 an example of a so-called PATRICIA trie as know n in prior art,
fig. 4 a further example of a word-spaced sparse suffix tree as used with the
present invention,
fig. ~ an example of explicitly stored word sequence information as used
with the present invention,
fig. 6 a leaf node structure as used with the present invention, and
fig. 7 schematically the structure of a search engine with the search system
according to the present invention.
The search system according to the invention consists essentially of thxee
parts, namely the data strnctore, the metrics for approximate matching and
At~EI~t~D SHEEN
CA 02524207 1999-07-09
the search algorithm. When full text retrieval is the target, as essentially
will
be the case with the search system according to the present invention, then
the entire data set which shall be retrievable, will be stored in a data
structure
which supports a high query performance.
The basic concepts underlying the present invention shall first be discussed
in some detail. Stored information in the fonn of text T is divided into words
s and word sequences S. Words are substrings of the entire text separated by
word boundary terms. The set of word boundary terms is denoted BTWOra. A
,. ..~ . . , , , , ..
common set of word boundary terms could be the set { , . , It, In , 10 , . ,
IO '; ; '?'} where \t denotes a tab character, \n denotes a linefeed character
and \0
denotes an end-of document indicator. In connection with the following
description of the present invention it will be useful with some definitions
concerning strings and sequences.
Definition l: String
1 ~ A string is a sequence of symbols taken from an alphabet, such as the
ASCII
characters. Then the length of a string is the number of instances of symbols
or characters comprising the suing, and is denoted ~x~. If x has the length m
the string may also be written as x~x~...x;...x"" where x; represents the ith
symbol in the string.
20 A substring of x is a string given by a contiguous group of symbols within
x.
Thus, a substring may be obtained from x by deleting one or more characters
from the beginning or the end of the string.
Definition 2: Substrina, suffix and prefx
A substring of x is a string x/ = x;x;t~...x~ for some 1<,i < j.< n. The
string
25 x; =x;" = x;:..x" is a suffix of string x and the string xj =xl = xl
xl...x~ is a
prefzx of string x.
Also the notion of a word sequence will be used.
Definition 3: Word sequence ,
A word sequence is a sequence of separated, consecutive woxds. A word
30 sequence S = sl,s2, ...,s" consists of n single words (or strings) s~,s2,
up to s".
Word sequences are delimited by sequence boundary terms. The set sequence
boundary terms are denoted BTse9. A common set of sequence boundary terms
could be the set {'01'}, where \0 indicates an end-of document marker.
Pa~l~'.~D 5'r~~
CA 02524207 1999-07-09
The concept approximate word matching can be described as follows.
Given a string s = sls2...s" and a query term q = qlqZ...q",. Then the task is
to
find all occurrences of q in s that is at most k errors away from the original
query term q. A proximity metric determines how to calculate the errors
between q and a potential match s;...s~.
A common metric for approximate word matching is the Levenstein distance
or edit distance (V.I. Levenstein, "Binary codes capable of correcting
deletions, insertions, and reversals", (Russian) Doklady Akademii nauk
SSSR, Vol. 163, No. 4, pp. 845-8 (1965); also Cybernetics and Control
Theory, Vol. 10, No. 8, pp. 707-10, (1966)). This metric is defined as the
minimum number of edit operations needed to transform one string into
another. An edit .operation is given~by any rewrite rule, for instance:
~ (a-~E), deletion
(s--~a), insertion
~ (a-~b), change
Let p and ~n be two words of size i and j, respectively. Then D(i,j) denotes
the edit distance between the ith prefix of p and the jth prefix of m. The
edit
distance can then recursively be defined as:
D(i,0) = D(0, i) = i
D(i-l, j)+1
D~r'j) ' min D~i, j -1~+1 (1)
D(i-1, j-1)+8~i, j)
where
8(i, j ) = 0 if p~ = nz~ else 1 '
It is also possible to define an approximate matching on the level of words in
a word sequence and this can be described as follows.
Given a text T consisting of the n words wj,wz...w" where each of the words
is a string of characters. A sequence pattern P consists of the m words
pi, pz, ..., p",. The sequence pattern P is said to have an approximate
occurrence in T if the sequence p~, p2, ..., pm differs with at most k errors
from a sequence w;, w;+~, ..., w~ for some i,j, such that 1< i < j < n. Again,
a
proximity metric detennines how to calculate the number of errors between
the two sequences.
~M~N~D S~~
CA 02524207 1999-07-09
A text that shall be retrieved in a search system must be indexed in a manner
which facilitates searching the data. Consequently the data structure is a
kernel data structure of the search system according to the present invention
and is based on so-called suffix trees and particularly a sparse suffix tree.
These two kinds of structures shall be defined in the following. A suffix tree
S(T) is a tree representation of all possible suffixes in the text T. AlI
unary
nodes in a suffix tree S(T) are concatenated with its child to create a
compact
variant.
Fig. 1 shows the suffix tree for the text T = "structure".
Even more particularly the present invention is based on sparse suffix trees.
These were introduced by J. Karkkainen & E. Ukkonen, in "Sparse Suffix
Trees", Proceedings of the Second Annual International Computing and
Combinatorics Conference (COCOON '96), Springer Verlag, pp.219-230,
which again was based on ideas published by D.R. Morrison, "PATRICIA -
Practical Algorithm To Retrieve Information Coded in Alphanumeric",
Journal of the ACM, 15, pp. 514-534 (1968). A sparse suffix tree is defined
as follows.
Definition 4: Sparse suffix tree
A sparse suffix tree SST(T) of the text T is a suffix tree, containing only a
subset of the suffixes present in the suffix tree ST(T) of the text.
When using the search system according to the present invention searching
for entire words, advantageously a non-evenly spaced sparse suffix tree may
be created by storing suffixes starting at word boundaries only. The concept
words-spaced sparse suffix tree is defined as follows. .
Definition ~: Word-spaced sparse suffix tree
A word-spaced sparse suffix tree SSTwf(T) of a text T is a sparse suffix tree
SST(T) containing only the suffixes starting at a word separator character in
the text.
Fig. 2 shows two .examples of word-spaced sparse suffix trees. Parts of the
suffixes have been omitted to enhance the readability. The word-spaced
sparse suffix tree for T = "to be the best" is the left structure, and T = "to
make the only major modification" is the right structure in fig. 2.
a~~0 Sft~y
CA 02524207 1999-07-09
In the search system of the present invention the text is naturally dmded mto
words which are stored independently in the word-spaced sparse suffix tree.
As the atomic search term for searching is the word itself, advantageously
each suffix will be terminated at the end of the word. This reduces the sparse
suffix tree to a so-called PATRICIA trie (Morrison, op.cit.). A trie as
defined
in the literature is a rooted tree with the properties that each node, except
the
root, contains a symbol of the alphabet and that no two children of the same
node contain the same symbol. It should be noted that the word trie derives
from the word "retrieval" and hence indicates that the trie is a tree
structure
suitable for retrieval of data. A PATRICIA trie is defined as a
keyword-spaced sparse suffix tree (KWS tree) where the suffixes stored in.
the leaf nodes are limited by keyword delimiters. Ail example of a
PATRICIA trie for the set of keywords {"avoid", "abuse", "be", "become",
"breathe", "say"} is shown in fig. 3. The structure used in the search system
IS of the present invention differs from the PATRICIA trie because the search
system explicitly stores sequence information of the words. Reducing the
suffix length requires that the representation of the leaf node is changed.
Pointers to the original text are replaced by the suffix string itself. A
suffix
length reduction of this kind is shown in fig. 4 for the same two strings as
shown in fig. 2. In other words fig. 4 shows word-spaced sparse suffix trees
with suffixes cut off at word boundaries. The word-spaced sparse suffix tree
for T= "to be the best" is shown at left and the word-spaced sparse suffix
tree for T= "to make the only major modification" is shown at right in the
figure. A leaf node will contain a list of all positions where the word
represented by the leaf node occurs.
Instead of using the irnpli.cit sequence of information~found in the original
text, the present invention explicitly stores sequence information in the
word-spaced sparse suffix tree. This is done by using pointers between the
leaf nodes that represent consecutive words in the original text. As at least
all
the occurrences of the word represented by a particular leaf node are
available, a pointer must be added to the next consecutive leaf.
A leaf node contains only the suffix of the word it represents, so when
traversing the sequence pointers in the occurrence list only the suffixes of
each of the consecutive words are revealed. This is handled by storing the
entire word in the leaf node instead of just the suffix and thus also data
structure of the invention differs from the PATRICIA trie in this respect. The
~~:~'~~lC!~L'~ Si-r=t~ _
CA 02524207 1999-07-09
data structure for explicitly stored word sequence information with an
occurrence list with pointers to the next consecutive word and to its
occurrence is shown in fig. S.
The search system according to the present invention uses a PATRICIA trie
S for organizing the occurrence list (Morrison, op.cit.). The PATRICIA trie
enables the search system to access the Iist of all consecutive words matching
the string p1 in a time O(~pzj), where ~pl~ of course is the length of p2. By
using a PATRICIA trie to organize the list of occurrences, a completely
defined tree structure is obtained for storing words from a text and
IO maintaining the sequence information. A typical leaf node, with both a
PATRICIA trie for the organized occurrence list and the extra unsorted list of
occurrences, is shown in f g. 6. As an example the memory requirement for
an occurrence list as used in the search system of the present invention, a
database with about 742358 documents has a total of 333 856 744 words and
15 a lexicon of 538 244 distinct words. The total size of the database is
2054.52
MB. The average word length is thus 6.45 bytes. A sparse suffix tree will use
8 bytes for each internal node, using 32 bit pointers. It is assumed that an
average of 3 internal nodes is used for each word: The leaf node would then
require 6.45 bytes for storing the entire word plus 32 bits for a pointer to
an
20 occurrence list. A total of 34.45 bytes/word gives a total size of 18.108
MB.
In addition the occurrence list has the size of 4 bytes per entry and I2 bytes
if
the full version is to be used. Hence the total memory requirement of the
occurrence List varies from 1273 MB to 3820 MB. The data structure using a
sparse. suffix tree will have a size between 60% to 200% of the original text.
25 This is comparable with the requirements of an inverted file, but the
sparse
suffix tree as used in th-e search system according to the invention provides
much faster searching, enables approximate matching and makes sequence
matching easy to perform.
In approximate searching, a metric is used to give an error measure of a
30 possible match. The search system according to the present inventiori
employs several metrics, and particularly a unique combination of metrics.
These metrics along with the combined metric shall be discussed ixt the
following.
An edit distance metric as defined above allows the operations del etion,
3~ insertion and change which intuitively apply to words as well as
characters.
AD~D SHEEP
CA 02524207 1999-07-09
Common errors in matching phrases are missing, extra or changed words.
Hence the edit distance metric as previously defined shall be adapted and
extended in order to apply to the approximate word sequence matching
problem. Edit operations for sequences are defined below.
Definition 6: Edit oQerations for sequences
For transforming one sequence S of words into another sequence P of words,
the edit operations allowed on the word in the sequences may be written
according to the following rewrite rules:
~ (a--~s), deletion of word a from the sequence
~ . (s--~a), insertion of word a into the sequence
~ (a-->b), change of word a into word b
~ (ab---~ba), transposition of adjacent words a and b.
Instead of characters as atoW s-, the search system according to the invention
applies the edit operations to words which then should be regarded as the
operational atoms.
A cost function cedlr(x--~y) is a constant which is defined as
1 delete
1 insert
c"~'(~~y)' I transpose (2)
8(x, y) change
where 7(x,y) is defined as
o x=y
7(x, y) _
1 else
By using the edit operations as defined above the edit distance for sequences
can now be defined.
Definition 7: Edit distance for sequences
The edit distance metric for sequences defines the distance Dse9(S, P) between
the sequence S = s~,s~, ...,s" and the sequence P = pl,p2, ...,pin as the
minimum
sum of cast c(x--~y) for the sequence of edit operations transforming the
sequence S into the sequence P.
The search system according to the present invention enhances the edit
distances metric for sequences to weight the cost of the edit operations by
the
~l,~~s~0 SHEEN _
CA 02524207 1999-07-09
size of the words operated upon.
Definition 8: Word size-dependent edit distance for seQuences
The word size dependent edit distance for sequences is defined as the
minimum sum of costs for the editing operations needed to transform one
sequence into the other. The cost functions are dependent on the word size of
its operands.
In the search system according to the invention a definition of cost functions
is given by the equations
!al
Ciaac~r ~~ --~ a'
Cdelele ~a -~ ~ = a
1 (4)
Ctrarcspore (ab --~ ba) =1
max(~la,-Ibil, I)
Cchange (a ~ b/ =
where 1 denotes the average length of a word in the two sequences being
compared. The cost of each edit operation is weighted by a size proportional
to the change in the total length of the sequence or by the ratio of the
current
word length and the average word length in the sequences considered.
Now the distance metric reflects the assumption of some relation between the
word length and how important the word is to the semantic context of the
word sequence. Furthermore the search system according to the invention
employs proximity at the character level when the change edit operation
(a-~b) is used. Replacing a word a by another word b should be related to the
similarity between these tu~o words. The new cost function for the change
edit operation hence is given as:
Cchange a -'~ b = V aPPror a~ b ~ ' S
( ) ~ ) ~ ~b'j (
where
aaPP~or(a~b~= D(a,b) (6)
Where D(a, b) is the normalized edit distance measuring function for words, 0
means full similarity, 1 means no similarity.
~,a~~t~~ED ~ i 'sc
CA 02524207 1999-07-09
The search system according to the invention combines the eau ais~auuC
metric for sequences with the cost functions as. given by formulas (4), (5)
and
(6), with an edit distance metric for words as given by fonnula (1). This
means that sequence edit operations are only used when the words being
matched are more than k errors away from each other.
The algorithms used in the search system according to the invention perform
efficient searching of the described structures. Matches are found according
to the metrics as given above.
Approximate word matching in a word-spaced sparse suffix tree is done by
combining the calculation of the edit distance matrix and a traversal of the
suffix tree. An algorithm for this is written in pseudo-code and given in
table I.
This algorithm is adapted from a trie-matching algorithm as proposed by H.
Shang & T.H. Merrettal, "Tries for Approximate String Matching", IEEE
Transactions on Knowledge and Data Engineering, Vol.S, No. 4, pp. 540-547
( 1996). The expected worst case running time of the algorithm is O(k~~~~)
according to Shang & Merrettal (op.cit.).
Approximate word sequence matching requires the calculation of the word
sequence edit distance for all possible matches. However, the number of
possible matches can be limited by starting the calculation of the edit
distance only on the possible words. The cost of deleting a word from the
sequences determines the number of possible start words. If the accumulated
cost of deleting the i first words in a query sequence PQ rises above a given
error threshold, the candidate sequence starting with the ith word of the
query cannot possibly be a match. Therefore for a query sequence PQ of i
words, at most i possible start words will be tried. Since there are no
backpointers in the sequence structure of the tree, it will not be ensured
that
all possible matches are obtained. Adding backpointers would solve this
problem. The algorithm for approximate word sequence matching as used in
the search system according to the present invention, is given in pseudo-code
in table II below. This algorithm tries to match the first keyword with
p~,pz...
sequentially, testing all possible start positions.
~t~'(Et~t~d .SMEE~
CA 02524207 1999-07-09
In the ApproxSequenceMatch algorithm in table II the ApproxMatchReSt
function is defined by the algorithm in table lII below. This function matches
the remaining sequence; using an initial error value.
~~~ ~H~E~ - _
CA 02524207 1999-07-09
Table I
FindApproximate (root,p,k)
node E-- root;
i +- 1 i
nodes ~ Children (node); // A stack of nodes
for all v E nodes do
if IsLeaf (v) then
for j ~-- i to length (Suffix (node) ) do
w~ ~- Suffix (node) ~_i;
if w~ - '$' then // '$' is a stopchar
output w~~~:~;
return;
if EditDist ( 1 ) - a~ then
break;
else //Internal node
i.~ i+1;
wi ~-- label (v)
if EditDist (i) - ~ then
break;
nodes ~-- Children (v) V nodes;
// end for
EditDistance(j) /l Calculates jth row
for i~- 1 to length ( P) do
if pi = w~ then 8 E- 0 else 8 E- 1; ,
CI - DLi-.1. jJ + Cins (mj) ;
C2 = D~1, j-1~ + Cdel (pi)
C3 = D~1-l, j-1~ -~. Cchange(pirmj)
Cq - D~i-2 , j-2~ + Ctranspose,(pi r mj-1 )
D~1, ]~ E- Cfraction ( J ~1 ) ~ IillI1 ( C1~, Cp, C3 r Cq ) i
if D(i, j~ > k
return o~; // No distance below k
return D(i, j~
y
d
CA 02524207 1999-07-09
Table II
ApproxSequenceMatch_ED (root, P(=pl,pZ,...,Pm),k)
mF- ~p~
matches f- ~
startError f- 0
startlndex ~-- 1
whi7.e startErro.r 5 k OR startlndex < m do
startNode <- FindExa c t (pStartmdexJ
list f- UriorderedOccurrenceList (startNode)
for all v E lists do
if ApproxMatchRest2 (v,P,k,startError) then
matches E- U v;
startError F- startError + Cde1 (pstartlndex~
startlndex ~- startlndex + 1;
i.
~~ ~-~;~ i.
~;~~, ~~~;3 ~r~ ~ _
CA 02524207 1999-07-09
Tab 1 a III
ApproxMatchRest ( u, P, K, startError).
error ~-- startError;
lastError ~- startError;
col umn E- 0 ;
node E-- u;
for v ~- p2. to p~P~ do
node ~- NextOccurrence (node) ;
word ~- Keyword (node) ;
1 a s tError f-- error;
error f-- startError + EditDistance (column);
if error > k AND IastError > k then
return false;
return true:
EditDistance(j) // Calculates jth row
for if- 1 to length (P) do
if pi = w~ then 8 E-- 0 else 8 f-- l;
c1 = D~1-l, j~ ~ cins (mj)
C2 = D~Z r~-~-~ -1- Cdel (.pi) ~
C3 - D~1-1, j-1~ + Cohange (pir mj) i
Cq - D~I-2, j-Z~ -~ Ctranspose (pi, mj-1) i
Dji r j] ~- Cfra~cion.( j/1 ) ~ min ( c~, cZ, c3, cq ) ;
if D[i, j~ >- k
return co; // No distance below k .-
return D(i, j)
~,~v";ENDED Sl-~
CA 02524207 1999-07-09
The algorithms in tables II and III are written in the same pseuoo-coae as mC
algorithm in table I. .
The FindExact function used to find the leaf node matching the first word in
the sequence performs a simple traversal of the tree and its running time is
O(p jJ where p~ denotes the first word in a query sequence PQ. Calculating the
edit distance can be done in JPJz time using straightforward dynamic
projramming or in D(k) time (where k denotes the error threshold) using
improved versions of the calculation algorithm, see E. Ukkonen, "Finding
Approximate Patterns in Strings", Journal of Algorithms, vol. 6, pp. 132-137
(1985).
If ~no~~(p;) denotes the total sum of the number of occurrerices of each~word
p; in the word sequence, then the worst case running time is O(k~no~~(p;)).
Finally the implementation of a search engine based.on the search system
according to the invention shall briefly be discussed. Particularly a search
engine based on the search system according to the invention is implemented
as an approximate search engine (ASE) and is intended as a search engine for
indexing large document collections and providing algorithms for exact and
approximate searching of these document collections. ASE shall provide a
data structure for storing large texts or collection of documents. It is to be
understood that the data structure may be generated from documents which
contain additional information, such as images, video, sound, and the text
may be formatted and/onannotated. The data structure is identical to the
word-spaced sparse suffix tree as discussed above and it is, of course, to be
understood that the words is the keywords of the search system, hence the
word-spaced sparse suffix tree may instead be termed a keyword-spaced
sparse suffix tree (KWS tree). The ASE shall contain algorithms for indexing
documents in the KWS tree. These algorithms, of course, do not form a part
of the search system according to the present invention, but they are
well-known to persons skilled in the art and described in the literature, see
for instance J. Karkkainen & E. Uklconen'(op.cit.) and D.R. Morris on
(op. city.
The search system according to the invention and as used in the ASE
employs. algorithms both for exact and approximate matching of a pattern in a
KWS tree. The algorithms given above in table I and table II are used for
3~ approximate word and word sequence matching with the non-uniform edit
~~~~t~D~C S!-il'~~
CA 02524207 1999-07-09
distance as a metric. Finding an exact match of keyword p with length nz in a
.
KWS tree is known in the art and easily implemented as a simple traversal of
the tree structure. An appropriate algorithm for exact keyword matching
written in pseudo-code is liven in table IV. The search system according to
the invention also shall be able to support algorithms for exact keyword
sequence matching. Algorithms for exact keyword sequence matching are
known in the art and easily implemented as e.g. shown in pseudo-code in
table V below. The algorithm given here will find the exact match of the first
keyword, if any. Then it will for all occurrences of the first keyword check
if
the second keyword matches the second keyword of the query. If so, the
MatclzRest procedure in table V is used to determine if the occurrence of the
two first keywords are matching in the entire sequence. For approximate
keyword matching in a KWS tree the search system implements the algorithm
in table I above. For approximate keyword sequence matching the search
system implements the algorithm in table II above, matching a first keyword
sequentially with p~;p~... and testing all possible start positions, applying
the
.4pproxMatchRest function as given in table III to match a sequence starting
at a particular position and handle-the initial error value.
Finally, the ASE shall need a simple front end which gives the user control of
iridexing and querying the document collection. The front end should, also be
able to furnish statistics of the document collection and provide both a
network interface for.remote access, e.g. via WWW, and a local server user
interface.
The ASE with the search system according to the invention should be general
in a manner that allows for the adding new indexing and searching
algorithms easily. Also, storing extra information about each document or
keyword shall be possible to implement in an easy manner. Particularly the
front end should be independent of the data structure and the search
algorithms, such that internal changes in these has no effect on the design of
the former.
The use of the search system according to the invention the ASE should be
designed to have as low memory overhead as possible in the data structure.
Also, searching should be designed to be as fast as possible, However, there
will usually be a trade-off between these two factors.
~~~1~~~ Sl~:~l
CA 02524207 1999-07-09
' Table IV
FindExact (root,p)
i~ l;
node E- Find Child (root,p;,);
while node AND i 5-length (p) do
if IsLeaf (node) AND Suffix (node) - Pi...Pm then
return node;
i f- i+1
node f-- FindChild (node, pi) ;
return NIL:
Table V
MatchSequenceExact (P, root)
ma tches ~-- 0;
v f-- FindExact (pl,root) ;
it ~P~ > 1 then
if v T NIL then
list f- UnorderedOccurrenceList (v);
for all a E list do
if NextKeyword(u) - pZ then
if MatchRest (p3...pm, u) then
matches E- matches U Occurrence(u);
return matches;
MatchRest (P,u) '
node E-
u;
for v F- p1 to p~ p~ do
node f- NextOccurrence (node) ; ,
word ~ Keyword(node);
if v ~ word then
return false;
~e~~~~i~la ,t;;:.~:<~r
CA 02524207 1999-07-09
To sum up, an ASE with a search system according to the invention snau
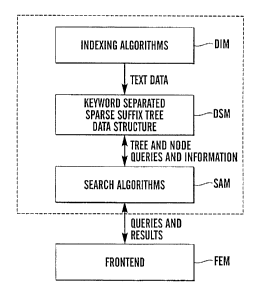
comprise four major modules.
1. Document indexing module DIM for indexing documents in the KWS tree
structure. This module should also contain all extensions to support
several document types.
2. Data storage module DSM based on a keyword-spaced sparse suffix tree
(KWS tree).
3. Search algorithm module SAM for searching the KWS'tree, comprising
algorithms for exact and/or approximate matching of respectively words
and word sequences.
4. User interface front-end module FEM comprising both a local server user
interface and a network interface for remote queries.
The four modules of the ASE works together to offer a complete search
engine functionality. The data flow between the different modules is shown
1~ in fig. 7. Indexing a collection of documents in done in the document
indexing module DIM comprising indexing algorithms. This module is, of
course, not a part of the search system according to the invention, but
indexing algorithms that can be used are well-known in the art. The text
found in the documents is passed on to the data storage DSM module for
storage. The data storage module is, of course, a part of the search system
according to the invention and is as stated based on the KWS tree structure.
The search algorithm module SAM contains algorithms for searching the data
located in the data storage module. This module implements the search
system according to the present invention and allows 'for a search process
querying the data structure for tree and node information, while maintaining
state variables. The front-end module may for instance be implemented on a
work station or a personal computer and the Like, providing the functionality
as stated above.
As already stated in the introduction, it is to be understood that the search
system according to the invention can be implemented as software written in
a suitable high-level language on commercially available computer systems,
including workstations. It may also as stated be implemented in the form of a
dedicated processor device which advantageously may comprise a large
number of parallel processors being able to process large word sequences in
~tJIEI~D StiEE~
CA 02524207 1999-07-09
parallel for approximate matching with a large numbei of query word
sequences. The fixed operational parameters of the processor may then be
entered in a low-level code, while keyword sequences input from the KWS
tree structure allows for an extremely fast processing of queries on a huge
amount of data, and the search system according to present invention shall
hence in high degree be suited for performing searches on e.g. the World
Wide Web, even in a KWS tree structure large enough to index all documents
presently offered on the World Wide Web and moreover capable of handling
.the expected data volume growth on the World Wide Web in the future.
~tf~~I~CK~ SNl=~ ~