Note: Descriptions are shown in the official language in which they were submitted.
=
CA 02601144 2007-09-12 =
pa/NO 2006/000492
P.F.Iii:.=== = = 0 9 -19- NE6
=
1
Method and system for adaptive recognition of distorted text in computer
images
The present invention is related to a method and system for recognizing text
in
computer images in a computer system, and specially to a method and system for
s adapting rules used for the text recognition based on an adaptive
iterative adjustment of
recognition rules, related parameters, omitting or adding of further rules
based on the
text that is current being processed in the iteration process, according to
the attached
independent claims 1 and 18, and dependent claims 2 to17, and 19 to 35.
to The present state-of-the art text recognition systems, often denoted as
Optical Character
Recognition Systems, are typically based on template matching with known fixed
templates, by structural matching or by recognizing the characters based on a
set of
fixed set of recognition rules using a set of computed features extracted from
the shapes
of characters. Each character will be assigned a score or an a priori
calculated
Is probability for each character class or set A dictionary is used to
check that each chain
of proposed characters can form words, picking the most probable word.
The state-of¨the art text recognition systems usually fails when they
encounter
moderate to heavily distorted text images.' Such degrading of text images may
be a
ro result of photocopying an original document, typewritten documents which
may be
encountered when scanning older archive material, newspapers which usually
have poor
print and paper quality effecting the quality of the text images, faxes which
usually has
poor resolution in the transmission channel and printing device, etc. These
and similar
problems are described in the book by Stephen Rice eta], "Optical Character
25 recognition ¨ An illustrated Guide to the Frontier", Kluwer Academic
Publishers 1999.
The current text recognition systems do only to a limited extent adapt to
specific font or
deformation of the text without a guided learning phase requiring human
interaction in
the process, which slows down the process considerably. Electronic document
handling,
30 archive systems, electronic storage of printed material etc. requires
scanning of
unlimited number of pages which makes it impossible to use human interaction
to
succeed with such tasks.
An example of guided learning is disclosed in US patent no. 5,917,941 dated
June 29,
33 1999 disclosing a method and system for recognizing handwritten text
based on
recognizing some characters and providing a user interface presenting a
limited list of
probable words comprising the character each time a character has been
identified, and
AMENDED SHEET
CA 02601144 2007-09-12
pct./NO 2006/0000,92
. Svvrvlisti Pat .! t
= pc". iftternational , ,
0 9 .1 2006
2
then let the user select the most probable words used in the text. Based on
these manual
. user selections, the recognition process continues.
An example of an automated adaptive recognition system is disclosed in EP 0
482 427
A2 providing a neural network performing hierarchical pattern recognition.
However,
the adaptation is only related to a specific geometrical feature of the text
to be
recognized, namely gray scale parameters. The neural network according to this
invention can use the grey scale parameter to extract fairly complex features
of input
patterns, including translations, rotation and scaling of input patterns.
However, an
le inherent aspect of neural networks is that they are trained with
specific examples of a
parameter variation, as grey scale in this example, and therefore it is
impossible to adapt
the grey scale rule as such in this embodiment, for example to modify the grey
scale
levels to two levels, such as white and black, which may be a parameter
selected by a
user using a flatbed scanner without training the specific network for this
special case.
is In such cases, threshold levels and adjustments of thresholds as known
to a person
skilled in the art may provide an easier and better adaptation to the actual
features of the
document to be recognized. To be able to cope with the different aspects of
the
recognition process, an OCR system needs not only one algorithm, but a
plurality of
algorithms or strategies to choose from to be able to adapt to the realities
of the
20 document at hand. However, even when there is a plurality of algorifinns
at hand, each
algorithm may also pass through some sort of tuning to provide the best
achievable
results in the OCR process. Therefore, preprogrammed solutions, even when
trained on
actual cases as with neural networks, do not provide an optimal solution to
the OCR
problem as such when the text images are distorted.
US patent No.: 6,028,970 disclose a method and appartus for enhancing optical
character recognition comprising a data processor and memory for maintaining
an error
detection and correction log. The data processor maintains a memory table of a
plurality
of rules for generating a rule base determined by recognition of a particular
context type
of an electronic bit-map portion. The appropriate rule base comprises rules
and
combinations of rules for application to bit-map portion data. A rule, a rule
base or data
may be selected and obtain from an internal or external memory. Upon
application of
the rule base, the error detection and correction log maintains a record og
clear errors,
corrected data, failed rules of the rule base and the original bit-map.
Possible errors are
flagged and clear errors are automatically corrected provided a confidence
level in the
correction is reached or exceeded. Through recognition of patterns of errors
in the error
'AMENDED SHEET
CA 02601144 2013-10-03
3
detection and correction log, new rules may be generated for storage in the
rule
memory table. This scheme also allows implementing a learing phase of the ruls
base.
The teaching of this publication does not disclose what happens if there is
many
errors in the recognition process. For example, if only ten percent of a
document
is recognized correct, a 90% of the document is dubiously recognized this
scheme
have probably some problems of obtaining a set of rules that will solve the
recognition problem. If the error rate is high, and the rules are updated
according
to the errors, and still provides an error when used, it is most probable that
the
error will continue to exist according to this teacing. However, is the number
of
errors are small in the error log, the teacing of this pattern may provide a
solution
to the recognition problem.
An aspect of the present invention is to provide a method and system that can
cope with heavily distorted images of text.
Therefore, there is a need for a method and system that provide more reliable
automatic text recognition when the text is distorted. According to the
present
invention this is achieved by first using at least one a priori known rule to
recognize unknown characters, and then some words or parts of words by using
the at least one rule for unknown characters, for example by dictionary
lookup.
By using those words or parts of words that are reliable recognized, the
recognition of further words or parts may be provided by for example adding at
least one other rule, by adapting the at least one initial recognition rule,
by
adjusting parameters used in established rules, omit established rules or add
further rules based on the preliminary recognized words or parts of words, or
characters, and then iteratively continue the recognition process of the rest
of the
text while at the same time updating, adapting, adding and/or removing a
selection of recognition rules used in the succeeding iterative steps of the
process,
and stopping the process when a defined amount of the text has been reliable
recognized.
In a further aspect, the present invention provides a method configurable in a
computer program in a computer system providing character recognition of
distorted text comprised in a computer image of the text , wherein the method
comprises at least one a priori defined recognition scheme for recognizing
unknown characters, wherein the method comprises steps of: a) using the a
priori
defined recognition scheme, and identifying at least one recognition rule in
the
recognition scheme that provides appropriate recognition of words or partial
words, b) using the identified at least one recognition rule in a) on the
computer
image of the text providing a first output stream comprising reliable
recognized
CA 02601144 2013-10-03
3a
words and a second output stream comprising dubious recognized words, c)
identifying at least one geometrical feature in the distorted text image
related to
actual characters encountered in the output stream of reliable recognized
words in
step b), and establishing at least one additional recognition rule in the
recognition scheme based on the at least one geometrical feature, d) whenever
there is a second output stream in b) comprising dubious recognized words,
provide adaptation of rules in step a), b) and c) before continuing
recognizing
words, e) iteratively carry out step a), b), c) and d), until a predefined
stop
criteria is reached.
Figure 1 illustrates examples of distorted images of the letter t.
Figure 2 depicts a flow diagram of an example of embodiment of the present
invention.
Figure 3a and 3b illustrates an example of adaptation of a grey scale
recognition
rule.
CA 02601144 2007-09-12
PCT/NO 2006/000.0,92
0 9 -10- 2006
4
Figure 1 illustrates the problem sometimes encountered when trying to
recognize text in
distorted images. The human brain is often able to extract which features
related to for
example the letter 't' as illustrated in figure 1 that identifies or
distinguishes this letter
from other letter shapes. However, to provide an algorithmic description of
such a
= s human process seems to be difficult. The basis for automated machine
based
recognition, such as OCR systems, is based on computing or extracting some
features
from the provided image of the text related to characters in the text, and
comparing
these features with similar features computed beforehand for specific letters.
If the
features extracted or computed from the provided image of the text is equal
with the
to corresponding features computed for a specific letter, the probability
that this character
in the image is this letter is by default 1.
This situation is the ideal situation for OCR. However, any moderate to heavy
distortion
of the image comprising the text may alter the appearance of letters in the
text such that
is the probability for being for example the letter = as described above
may be diminished
considerably. The first image of the letter 't' in the upper left corner of
figure 1 is
simple to recognize, while the rest of the distorted images will provide
different
probabilities for being the letter Another aspect regarding character
recognition is
that characters belong to different fonts ortypefaces.
zo
However, according to a preferred example of embodiment of the present
invention, as
depicted in figure 2, it is possible to apply an adaptive iterative approach
to the text
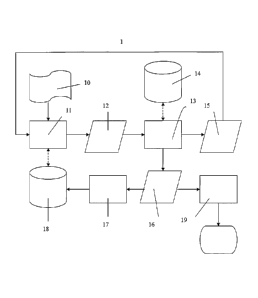
recognition problem of distorted images In figure 2 the original text image 10
is
communicated to the text recognition process 11, such as found in OCR programs
in a
2s computer (not shown). According to this preferred example of embodiment,
the text
recognition system 1 includes a scheme comprising at least one recognition
rule that is
applied on the communicated image 10. This at least one rule may be available
in a
computer storage 18 communicating with the recognition process 11. For
example, the
output of the recognition process 11 may be a score value 12 for characters
encountered
30 in the image 10. These score values may be used in a dictionary look up
table 13. The
dictionary lookup table communicates with computer storage 14 comprising
statistics
such as character frequency tables as known to a person skilled in the art.
The dictionary
lookup process 13 provides one of two possible output streams: a) reliable
recognized
words 16, orb) dubious recognized words 15. A reliable recognized word may be
a
35 word comprising characters with a score value exceeding a predefined
level. In another
embodiment of the present invention at least two recognition rules are tested
in the
recognition process 11, and the result of the one of the at least two rules
providing
AMENDED SHEET
CA 02601144 2007-09-12
,
peritiO 20(S/0000g2
,
0 9 -10- 2096
-
higher probability of being a certain word or part of words is selected as the
reliable
word or part of words. The dubious recognized items are processed again in the
recognition process 11 while at the same time, the reliable recognized words
are
processed to adapt rules in a rule adaptation process 17. The adaptation
process 17 may
s comprise adapting the recognition rules to a specific font type or a
specific identified
geometrical feature that is related for example to a specific deformation of
the text. The
rest* of the rule adaptation process 17 is communicated to the storage 18
providing an
updating of the rules used in the recognition process 11.
When recognizing documents with text of low quality comprising unknown fonts,
it is
possible to analyze the actual properties of the original font in the document
and the
distortion the characters have been through, for example due to the printing
or typing
process of the document, or due to aging, as known to a person skilled in the
art, in an
automatic analysis program, for example in a computer system. The parameters
is obtained this way regarding characters in the document may then be used
to
automatically configure an initial recognition run in an OCR system. However,
the
result of the initial OCR process is that not all characters are identified to
a certain
degree of robustness. Some characters may be viewed as having alternative
representations, for example the characters "i", sr and "1" may easily be
mixed when
distorted. One way of handling all the possible alternatives is by character
classification.
Character classification is a method where images of individual characters of
unknown
type are classified using a classifier that decides which character class the
unknown
character probably belong to using quantitative information of one or more
characteristics inherent in the character. One example of a classification
technique is
clustering. Clustering is based on partitioning of a data set into subsets
(clusters), so that
the data in each subset share some common trait.
Usually, the OCR system may exclude many character classes in the initial run,
and
only leave a limited number of competing character classes. A word list,
dictionary, cue
words (cribs), statistics or pattern analysis may further be utilized to
identify words or
parts of words that may be assumed to be correct.
For example, according to an example of embodiment of the present invention,
the
words ("documents', 'characters', 'initial', 'incapable', 'of, and 'range}
have been
recognized as outlined above initially, and for example has been identified in
a
dictionary. This provides a result comprising at least one instance of the
characters
'acdefghihnnoprstus that are probably correct, and at least two instances of
the
characters 'aceilnorsi. The multiple instances of the same character class
provides a
AMENDED SHEET
CA 02601144 2007-09-12
,
4= /140 2006 / 0 0
OA 9 2
0 9 -10- 1008
=
6
basis for verifying that they are similar based on, for example, direct
character grey-
level or bit-map image matching. After verification, the original recognition
scheme
may be improved by adapting the initial rule(s) by fitting the rules to the
actual
identified character classes. For example, the fitting or adaptation of the
rule(s) may be
done by adding new rules related to for example geometrical features (for
example
strokes), removing rules from the scheme, or changing weight or range of
rules.
After the adaptation of the rule(s) has been performed, the OCR process may
continue
in an iteratively manner, by running the OCR process once more thereby
producing
to more probable recognized words based on the adapted rule(s), since there
is a smaller
remaining set of competing character classes after the adaptation. For
example, assume
the words ("quality', 'unknown', 'font', 'through', 'recognition', 'system',
'dictionary',
and 'typical') are identified in addition to the words listed above. The new
words leads
to more multiple instances of characters, which further leads to the
possibilities of
is adapting rules even more, and then iteratively continue the OCR process.
In this
example, the new words leads to at least one instance of the characters
'acdefghiklmnopqrstuwy% and at least two instances of the characters
'acdefghilmnoprstuy', that are recognized properly.
20 it is important to understand that this adaptation of the initial
rule(s) related to unknown
character classes comprised in the initial scheme is adapted according the
actual
encountered characters in the actual text processed in the OCR system in an
automatic
manner, without any human interception in the iterative process according to
the present
invention. Therefore, unlike any known prior art solution, parameters like
weighting
2s threshold limits etc., are all adjusted according to how the actual
document has been
distorted. Therefore, the actual recognition according to this aspect of the
present
invention performs the recognition not based on a model related to fonts, type
of
distortion (such as bending of a sheet (cylinder model)), etc., but on how the
text images
actually appears.
Therefore, it is important to understand that unlike any other prior art
solutions that try
to cope with distorted text or handwritten text etc., by providing models or
steps
directed towards identifying types of distortions, the present invention
merely iteratively
adapts to the actual distortions encountered in the documents, if there are
distortions
3.5 present. Therefore, if there are no distortions present, the
method and system according
to the present invention iteratively adapts to the conditions of the non-
distorted image.
- =
AMENDED gar
CA 02601144 2007-09-12
= =
pa/NO 2006/0(0082
09 -10- ZON
7
According to another aspect of the present invention, it is also possible to
resolve
.= conflicts related to quasi-unique words. For example, the word 'foot'
may easily be
misclassified as 'feet when an image comprising this word is distorted. Assume
that the
words 'floor' and 'of is also present in the text. Since words hie 'fleef and
'ef is not
found in it dictionary, it is more probable that the word is 'foot'.
According to another aspect of the present invention, a dictionary or word
list is only
one of several methods for verification that maybe used in the context of the
present
invention. For example:
= Language specific unilateral frequency distributions,
= Vowel-consonant relationships (vowels are more likely to neighbour many
character classes),
= Positional frequency distributions,
is = Common digraphs (two-letter combinations) and trigraphs (three-letter
combinations),
= Cipher patterns (unique patterns of repeated positions of letters in a
word),
= Common short words and cribs (unique words that we expect to find in any
text),
are examples of techniques that may be used single handed' or in combinations
for
verification purposes, including tuning of respective parameters providing
adjustments
of performance of the respective techniques during the iterative process,
according to
the present invention.
Geometrical features identified and used in the adaptation process 17,
according to the
present invention includes also aspects such as grey scale, pixel count, and
pixel density
etc. In figure 3a, the word red is depicted with a certain resolution to the
left in the
figure. To the right is illustrated how a shape is typically identified
according to the
grey scale image. As can be seen, the shape of the word is hard to identify
because of
the resolution provided in the grey rade image of the word. In figure 3b the
grey scale
is adapted by providing an interpolation of the grey scale in additional
pixels
constituting the image of the word red. On the right hand side of figure 3b it
is
illustrated how this enhanced resolution simplifies the identification of the
word by
providing a better shape of the characters in the word.
AMENDED SHEET
CA 02601144 2007-09-12
PCl/Nef 2006/00c092
4
0 9 -10- Z000
8
Another embodiment of the present invention comprise creating a word list or
dictionary lookup table based on the adaptation of the rules, for example by
adding
words to the dictionary lookup process 13 depicted in figure 2.
s When the first pass through the recognition and adaptation is completed,
the remaining
unrecognized items 15 are passed through the recognition system 1 using the
modified
sat of recognition rules stored in 18 and the process is repeated as described
above. In
most cases the recognition system 1 will identify further reliable recognized
words,
which iteratively can be used to improve the recognition rules until the true
text
io comprised in image 10 is recognized throughout the whole text The steps
of the method
according to the present invention are thus repeated until convergence.
The criteria for determining that the process has achieved convergence may
vary in
different embodiments. For example, when the recognition process ii has
recognized a
rs certain amount of the text in the provided image 10, such as for example
90 A, the
recognition process 11 terminates in the present example of preferred
embodiment. The
recognition system 1 continues processing the recognized text by organizing
the text in
the organizing process 19. For example, the organizing process 19 may assign
specific
words to remaining dubious recognized words 15. The assignment may be based on
the
20 result from the character score process 12 and the dictionary process 13
providing the
most probable word related to the dubious word under preient investigation in
the
organizing process 19.
Another example of convergence criteria may be that the number of reliable
recognized _
25 words in the output stream a) from the dictionary lookup process 13 is
not increasing
from iteration to the next. When this is event is identified in the
recognition system 1,
the process continues with the organizing process 19 as described above.
Generally stated, the convergence criteria according to the present invention
may be one
30 of following examples:
1. All characters are completely recognized.
2. All characters are partially recognized. Remaining partially recognized
=
characters are considered to be within groups of predefined character
confusion
alternatives (examples are 'oce',111I', '000', '58$') that have similar
geometric
35 features.
3. The list of features to test is exhausted.
4. Remaining characters are considered to be part of the image and not text
based
on low recognition results for any set of rules considered through the process
or
based on a specific non-character filter.
AMENDED SHEET
= CA 02601144 2007-09-12
.
PCT 'NO 2006 0 00092
0 9 -10- us
9
5. A timer is used to limit the processing time.
6. The recognition rate reaches a predefined level (this approach is only used
in
= = certain applications where the recognition rate is less
critical and only in
combination with a two-step timer with a minimum and maximum processing
time).
Another example of embodiment of the present invention provides also a
labeling of
= such assigned wonis for dubious recognized words, by for example
highlighting the
= words in the final recognized text.
Another embodiment of the present invention includes deciding that the dubious
recognized word is garbage and excluding the word from the recognition result
if no
satisfactory interpretation is found, or if geometrical considerations
indicate that the
dubious recognized word is indeed garbage. Examples may be scribble in a
margin or
is graphics in an image that has been mistaken for being a real word.
Another example of embodiment of the present invention provides recognition
rules
based on a word list as 'mown to a person skilled in the art.
to Another example of embodiment of the present invention traces variations
of specific
identified characters, providing this as recognition rules. For example, the
recognized
character can also be used to identify the existence, curvature and length of
the bottom
bow stroke of for example the letter 't', the position and shape of the cross
stroke of the
letter 't' or the typical fragmentation pattern of the stem stroke of the
letter 't' in
ts vertically fragmented text. The letter 't' is quite common in normal
texts and will most
likely occur among the set of reliable recognized characters. All these
parameters are
vital for recognizing the letter In the present example of embodiment,
these
parameters are adapted in the rule adaptation process 17 to correspond with
the specific
appearance of these features in the provided tee image 10. However, if the
adaptation
30 of a rule leads to for example that score values 12 never exceeds a
predefined threshold
level after some iterations, an example of embodiment of the present invention
omits
the recognition rule by removing or marking the rule as lapsed in the storage
18. As an
alternative, parameters associated with the lapsed rules may be adjusted or
restored to
provide a feasible recognition rule again.
33
Another example of embodiment of the present invention may adapt the general
rules or
common rules valid for several character classes based on the occurrence of a
feature or
AMENDED SNEE'T
= CA 02601144 2007-09-12
Perit40 2006 /0 0 00 9 2
=
0 9 -1(k 201M
rule in a single reliable recognized character class. As an example any rule
concerning
the dot over the letter T is also valid for the dot over the letter T.
Another example of embodiment of the present invention may remove a general
rule far
s a character class or a set of characters classes, such as removing rules
related to the
bottom right serif of the letter 'a' when we encounter the version without
serif as in `a'.
Another embodiment of the present invention comprises a computer program
executing
the method according to the invention outlined above, wherein the original
text image
10 10 is provided by an attached scanner device or another electronic image
acquisition
device (such as a digital camera) in communication with the computer system
rumring
the computer program. Dictionary or character frequency tables 14 and set of
rules 18
are organized as database records in this example of embodiment.
pArigiEl) StiE5r