Note: Descriptions are shown in the official language in which they were submitted.
CA 02619778 2014-03-21
,
METHOD AND APPARATUS FOR SEQUENCING TRANSACTIONS
GLOBALLY IN A DISTRIBUTED DATABASE CLUSTER WITH COLLISION
MONITORING
FIELD OF THE INVENTION
[0001 ] This invention relates generally to the sequencing and
processing of transactions
within a cluster of replicated databases.
BACKGROUND OF THE INVENTION
[0002] A database has become the core component of most computer
application
software nowadays. Typically application software makes use of a single or
multiple databases
as repositories of data (content) required by the application to function
properly. The
application's operational efficiency and availability is greatly dependent on
the performance and
availability of these database(s), which can be measured by two metrics: (1)
request response
time; and (2) transaction throughput.
[0003] There are several techniques for improving application
efficiency based on these
two metrics: (1) Vertical scale up of computer hardware supporting the
application - this is
achieved by adding to or replacing existing hardware with faster central
processing units (CPUs),
random access memory (RAM), disk adapters / controllers, and network; and (2)
Horizontal
scale out (clustering) of computer hardware supporting the application - this
approach refers to
connecting additional computing hardware to the existing configuration by
interconnecting them
with a fast network. Although both approaches can address the need of reducing
request response
time and increase transaction throughput, the scale out approach can offer
higher efficiency at
lower costs, thus driving most new implementations into clustering
architecture.
[0004] The clustering of applications can be achieved readily by
running the application
software on multiple, interconnected application servers that facilitate the
execution of the
application software and provide hardware redundancy for high availability,
with the application
software actively processing requests concurrently.
1
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
However current database clustering technologies cannot provide the level of
availability and redundancy in a similar active-active configuration.
Consequently
database servers are primarily configured as active-standby, meaning that one
of the
computer systems in the cluster does not process application request until a
failover
occurs. Active-standby configuration wastes system resources, extends the
windows
of unavailability and increases the chance of data loss.
[0005] To cluster multiple database servers in an active-active
configuration,
one technical challenge is to resolve update conflict. An update conflict
refers to two
or more database servers updating the same record in the databases that they
manage.
Since data in these databases must be consistent among them in order to scale
out for
performance and achieve high availability, the conflict must be resolved.
Currently
there are two different schemes of conflict resolution: (1) time based
resolution; and
(2) location based resolution. However, neither conflict resolution schemes
can be
enforced without some heuristic decision to be made by human intervention. It
is not
possible to determine these heuristic decision rules unless there is a
thorough
understanding of the application software business rules and their
implications.
Consequently, most clustered database configurations adopt the active-standby
model,
and fail to achieve high performance and availability at the same time. There
is a need
for providing a database management system that uses an active-active
configuration
and substantially reduces the possibility of update conflicts that may occur
when two
or more databases attempt to update a record at the same time. Further, it is
recognized that collisions between two or more concurrent transactions in a
selected
database needs to be addressed.
[0006] The systems and methods disclosed herein provide a system for
globally managing transaction requests to one or more database servers and to
obviate
or mitigate at least some of the above presented disadvantages.
SUMMARY OF THE INVENTION
[0007] To cluster multiple database servers in an active-active
configuration,
one technical challenge is to resolve update conflict. An update conflict
refers to two
or more database servers updating the same record in the databases that they
manage.
Since data in these databases must be consistent among them in order to scale
out for
performance and achieve high availability, the conflict must be resolved.
Currently
TOR_LAW\ 6386957\1 2
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
there are two different schemes of conflict resolution: (1) time based
resolution; and
(2) location based resolution. However, neither conflict resolution schemes
can be
enforced without some heuristic decision to be made by human intervention.
Consequently, most clustered database configurations adopt the active-standby
model,
and fail to achieve high performance and availability at the same time.
Further, it is
recognized that collisions between two or more concurrent transactions in a
selected
database needs to be addressed. Contrary to current database configurations
there is
provided a system and method for duplicating a plurality of transactions for a
primary
database received from at least one application over a network as a plurality
of
replicated transactions for a secondary database. The system comprises a
status
module for monitoring a completion status of each of the plurality of
transactions
received by the primary database, such that the completion status indicates a
respective transaction of the plurality of transactions has been successfully
processed
by the primary database. The system comprises a global queue for storing each
of the
plurality of transactions for facilitating the transaction duplication in a
selected
transaction sequence order, wherein the global queue is configured for storing
the
plurality of transactions and the respective completion status of each of the
plurality
of transactions including a respective transaction identification. The
respective
transaction identification represents a unique sequence identification for
each stored
transaction of the plurality of transactions. The system comprises a
controller module
coupled to the global queue and configured for assigning the respective
transaction
identification to each of the plurality of transactions and further configured
for
duplicating as the plurality of replicated transactions all of the
transactions with a
successful completion status of the plurality of transactions for storage in a
replication
queue for facilitating transmission of the plurality of replicated
transactions to the
secondary database for processing.
[0008] One aspect provided is a system for duplicating a plurality of
transactions for a primary database received from at least one application
over a
network as a plurality of replicated transactions for a secondary database,
the system
comprising: a status module for monitoring a completion status of each of the
plurality of transactions received by the primary database, the completion
status for
indicating a respective transaction of the plurality of transactions has been
successfully processed by the primary database; a global queue for storing
each of the
TOR_LAW\ 6386957\1 3
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
plurality of transactions for facilitating the transaction duplication in a
selected
transaction sequence order, the global queue configured for storing the
plurality of
transactions and the respective completion status of each of the plurality of
transactions including a respective transaction identification, the respective
transaction identification representing a unique sequence identification for
each stored
transaction of the plurality of transactions; and a controller module coupled
to the
global queue and configured for assigning the respective transaction
identification to
each of the plurality of transactions and further configured for duplicating
as the
plurality of replicated transactions all of the transactions with a successful
completion
status of the plurality of transactions for storage in a replication queue for
facilitating
transmission of the plurality of replicated transactions to the secondary
database for
processing.
[0009] A further aspect provided is a method for duplicating a
plurality of
transactions for a primary database received from at least one application
over a
network as a plurality of replicated transactions for a secondary database,
the method
comprising the steps of: monitoring a completion status of each of the
plurality of
transactions received by the primary database, the completion status for
indicating a
respective transaction of the plurality of transactions has been successfully
processed
by the primary database; storing each of the plurality of transactions for
facilitating
the transaction duplication in a selected transaction sequence order, the step
of storing
the plurality of transactions including storing the respective completion
status of each
of the plurality of transactions including a respective transaction
identification, the
respective transaction identification representing a unique sequence
identification for
each stored transaction of the plurality of transactions; assigning the
respective
transaction identification to each of the plurality of transactions; and
duplicating as
the plurality of replicated transactions all of the transactions with a
successful
completion status of the plurality of transactions for storage in a
replication queue for
facilitating transmission of the plurality of replicated transactions to the
secondary
database for processing.
TOR_LAW\ 6386957\1 4
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
BRIEF DESCRIPTION OF THE DRAWINGS
[0010] Exemplary embodiments of the invention will now be described in
conjunction with the following drawings, by way of example only, in which:
[0011] Figure 1A is a block diagram of a system for sequencing
transactions;
[0012] Figure 1B is a block diagram of a transaction replicator of the
system
of Figure 1A;
[0013] Figure 1C, 1D and 1E show an example operation of receiving and
processing transactions for the system of Figure 1A;
[0014] Figure 1F shows a further embodiment of the transaction
replicator of
the system of Figure 1A;
[0015] Figure 2 is a block diagram of a director of the system of
Figure 1A;
[0016] Figure 3 is a block diagram of a monitor of the system of Figure
1A;
[0017] Figure 4 is an example operation of the transaction replicator
of Figure
1B;
[0018] Figure 5 is an example operation of a global transaction queue
and a
replication queue of Figure 1B;
[0019] Figure 6 is an example operation of the transaction replicator
of Figure
1B for resolving gating and indoubt transactions;
[0020] Figure 7 is an example operation of a replication server of
Figure 1B;
[0021] Figure 8 is a further example of the operation of the
transaction
replicator of Figure 1B; and
[0022] Figures 9a,9b,9c shown a block diagram of a further embodiment
of
the example operation of Figure 8.
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS
[0023] A method and apparatus for sequencing transactions in a database
cluster is described for use with computer programs or software applications
whose
functions are designed primarily to replicate update transactions to one or
more
databases such that data in these databases are approximately synchronized for
read
and write access.
TOR LAW\ 6386957\1 5
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
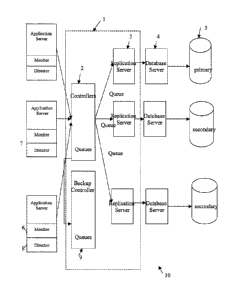
[0024] Referring to Figure 1A, shown is a system 10 comprising a
plurality of
application servers 7 for interacting with one or more database servers 4 and
one or
more databases 5 via a transaction replicator 1. It is understood that in two-
tier
applications, each of the application 7 instances represents a client
computer. For
three-tiered applications, each of the application 7 instances represents an
application
server that is coupled to one or more users (not shown). Accordingly, it is
recognized
that the transaction replicator 1 can receive transactions from applications
7,
application servers 7, or a combination thereof. The system 10 allows
concurrent
updates to be executed on the primary database 5, which then the transactions
representing the updates are replicated to the other databases 5 through the
transaction
replicator, as further described below. Concurrent updates can be viewed as
those
transactions being processed in parallel in one of the databases 5, where a
potential
overlap in record access can occur.
[0025] Referring to Figures 1 A and 1B, the transaction replicator 1 of
the
system 10, receives transaction requests from the application servers 7 and
provides
sequenced and replicated transactions using a controller 2 to one or more
replication
servers 3, which apply the transactions to the databases 5. By providing
sequencing
of transactions in two or more tiered application architectures, the
transaction
replicator 1 helps to prevent the transaction requests from interfering with
each other
and facilitates the integrity of the databases 5. For example, a transaction
refers to a
single logical operation from a user application 7 and typically includes
requests to
read, insert, update and delete records within a predetermined database 5.
[0026] Referring again to Figure 1A, the controller 2 can be the
central
command center of the transaction replicator 1 that can run for example on the
application servers 7, the database servers 4 or dedicated hardware. The
controller 2
may be coupled to a backup controller 9 that is set up to take over the
command when
the primary controller 2 fails. The backup controller 9 is approximately
synchronized
with the primary controller such that transaction integrity is preserved. It
is
recognized that the controller 2 and associated transaction replicator 1 can
also be
configured for use as a node in a peer-to-peer network, as further described
below.
[0027] Referring again to Figure 1A, when a backup and a primary
controller
are utilized, a replica global transaction queue is utilized. The backup
controller 9
TOR LAW\ 6386957\1 6
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
takes over control of transaction replicator 1 upon the failure of the primary
controller
2. Preferably, the primary and backup controllers are installed at different
sites and a
redundant WAN is recommended between the two sites.
[0028] As is shown in Figure 1B, the controller 2 receives input
transactions
11 from a user application 7 and provides sequenced transactions 19 via the
replication servers 3, the sequenced transactions 19 are then ready for
commitment to
the database servers 4. The controller 2 comprises a resent transaction queue
18
(resent TX queue), an indoubt transaction queue 17 (indoubt TX queue), a
global
transaction sequencer 12 (global TX sequencer), a global TX queue 13 (global
TX
queue) and at least one global disk queue 14. The global queue 13 (and other
queues
if desired) can be configured as searchable a first-in-first out pipe (FIFO)
or as a first-
in-any-out (FIAO), as desired. For example, a FIFO queue 13 could be used when
the
contents of the replication queues 15 are intended for databases 5, and a FIAO
queue
13 could be used when the contents of the replication queues 15 are intended
for
consumption by unstructured data processing environments (not shown). Further,
it is
recognized that the global disk queue 14 can be configured for an indexed and
randomly accessible data set.
[0029] The transaction replicator 1 maintains the globally sequenced
transactions in two different types of queues: the global TX queue 13 and one
or more
replication queues 15 equal to that of the database server 4 instances. These
queues
are created using computer memory with spill over area on disks such as the
global
disk queue 14 and one or more replication disk queues 16. The disk queues
serve a
number of purposes including: persist transactions to avoid transaction loss
during
failure of a component in the cluster; act as a very large transaction storage
(from
gigabytes to terabytes) that computer memory cannot reasonably provide
(typically
less than 64 gigabytes). Further, the indoubt TX queue 17 is only used when
indoubt
transactions are detected after a certain system failures. Transactions found
in this
queue have an unknown transaction state and require either human intervention
or
pre-programmed resolution methods to resolve.
[0030] For example, in the event of a temporary communication failure
resulting in lost response from the global TX sequencer 12 to a transaction ID
request,
the application resends the request which is then placed in the resent TX
queue 18.
TOR_LAW\ 6386957\1 7
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
Under this circumstance, there can be two or more transactions with different
Transaction ID in the global TX queue 13 and duplicated transactions are
removed
subsequently.
[0031] In normal operation, the controller 2 uses the global TX queue
13 to
track the status of each of the input transactions and to send the committed
transaction
for replication in sequence. For example, it is recognized that monitoring of
the status
of the transactions can be done by the director 8, the controller 2, or a
combination
thereof, when in communication with the database server 4 of the primary
database 5,
during initial record updating (of the records of the primary database 5)
prior to
replication (to the secondary databases 5) through use of the global queue 13.
[0032] Referring to Figures 1C, 1D, and 1E, shown is an example
operation of
the system 10 for receiving and processing a new transaction. In one
embodiment, the
new transaction is placed in the global queue 13 in preparation for commit
time, e.g.
when the transaction ID (represented by references K, L) is issued to the new
transaction, thus denoting to the director 8 (or other primary database 5
status
monitoring entity) that the new transaction transmit request is recordable to
signify
that the application 7 is allowed to commit its transmit request (associated
with the
new transaction) to the database 5.
[0033] In one embodiment, commit time can be defined to include the
steps
of: 1) the transmit request (associated with the application 7 and the new
transaction)
is recorded at the director 8; 2) thus providing for passing of the new
transaction (e.g.
one or more SQL statements) to the controller 2 by the director 8; 3) the
controller 2
then issues the transaction ID (e.g. a commit token K, L) coupled to the new
transaction; 4) the new transaction along with the issued transaction ID (e.g.
K, L) are
added to the transaction sequence held in the global queue 13; 5) the director
passes
the transaction commit request (now identified by the transaction ID) to the
primary
database 5 through the associated database server 4; the director 8 is then in
communication with the database server 4 of the primary database 5 in order to
determine when the new transaction has been committed successfully in the
primary
database 5 (e.g. record updates have been persisted to the database 5 ); the
director 8
then informs the controller 2 that the new transaction is ready for
replication using the
transaction ID to identify the new transaction processed by the primary
database 5;
TOR_LAW\ 6386957\1 8
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
and the controller 2 then replicates the new transaction identified by the
transaction
ID into the replication queues 15.
[0034] In a second embodiment, commit time can be defined to include
the
steps of: 1) the transmit request (associated with the application 7 and the
new
transaction) is recorded at the director 8; 2) the director 8 passes the
transaction
commit request (identification of which is kept track of or otherwise logged
by the
director 8) to the primary database 5 through the associated database server
4; the
director 8 is then in communication with the database server 4 of the primary
database
in order to determine when the new transaction has been committed successfully
in
the primary database 5 (e.g. record updates have been persisted to the
database 5); the
director 8 then informs the controller 2 that the new transaction is ready for
replication and passes the new transaction (e.g. one or more SQL statements)
to the
controller 2; 3) the controller 2 then issues the transaction ID (e.g. a
commit token K,
L) coupled to the new transaction; 4) the new transaction along with the
issued
transaction ID (e.g. K, L) are added to the transaction sequence held in the
global
queue 13; 5) and the controller 2 then replicates the new transaction
identified by the
transaction ID into the replication queues 15.
[0035] The commit process can be referred to as the fmal step in the
successful completion of a previously started database 5 record change as part
of
handling the new transaction by the replication system 10. Accordingly, the
commit
process signifies that the process of application (e.g. insertion) of
information
contained in the new transaction, into all databases' 5 records (both primary
and
secondary) of the system 10, will be carried out (i.e. replicated), further
described
below.
[0036] For example, upon receiving the new transaction at commit time,
the
sequencer 12 assigns a new transaction ID to the received transaction. The
transaction ID is a globally unique sequence number for each transaction
within a
replication group. In Figure 1C, the sequence ID for the newly received
transaction is
"K". Once the controller 2 receives the transaction, the transaction and its
ID are
transferred to the global TX queue 20 if there is space available. Otherwise,
if the
global TX queue 13 is above a predetermined threshold and is full, for
example, as
TOR_LAW\ 6386957\1 9
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
shown in Figure 1C, the transaction K and its ID are stored in the global disk
queue
14 (Figure 1D).
[0037] Before accepting any new transactions in the global TX queue,
the
sequencer distributes the committed transactions from the global TX queue 13
to a
first replication server 20 and a second (or more) replication server 23 for
execution
against the databases. As will be discussed, the transfer of the transactions
to the
replication servers can be triggered when at least one of the following two
criteria
occurs: 1) a predetermined transfer time interval and 2) a predetermined
threshold for
the total number of transactions within the global TX queue 13 is met.
However, each
replication server 20, 23 has a respective replication queue 21, 24 and
applies the
sequenced transactions, obtained from the global queue 13, at its own rate.
[0038] For example, when a slower database server is unable to process
the
transactions at the rate the transactions are distributed by the controller 2,
the
transactions in the corresponding replication queue are spilled over to the
replication
disk queues. As shown in Figures 1C and 1D, transaction F is transferred from
the
global TX queue 13 to the first and second replication servers 20, 23. In the
meantime, transactions J and Z are yet to be applied to their respective
database
servers 4. The first replication server 20 has a first replication queue 21
and a first
replication disk queue 22 and the second replication server 23 has a second
replication
queue 22 and a second replication disk queue 25. The replication queues are an
ordered repository of update transactions stored in computer memory for
executing
transactions on a predetermined database. As shown in Figure 1C, since the
second
replication queue 24 is above a predetermined threshold (full, for example)
transaction F is transferred to the second replication disk queue 25 (Figure
1D).
Similarly in Figure 1E, transaction E is transferred directly from the global
TX queue
13 to the first replication disk queue 22. Referring to Figure 1D and Figure
1E, once
space opens up in the second replication queue 24 as transaction J and
transaction Z
are applied to the corresponding database server 4, the unprocessed
transaction F in
the second replication disk queue 25 is moved to the second replication queue
24 and
transaction E is further accepted into the second replication queue 24 from
the global
queue. These transactions within the replication queue are ready for
subsequent
execution of the transaction request against the data within the respective
database. In
TOR_LAW\ 6386957\1 10
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
the case where both the replication disk queue and the replication queues are
above a
preselected threshold (for example, full), an alert is sent by the sequencer
12 and the
database is marked unusable until the queues become empty.
[0039] Referring to Figure 1F, shown is the replication server 20
further
configured for transmission of the transaction contents 300 of the replication
queue 21
(and replication disk queue 22 when used) to two or more database servers 4
that are
coupled to respective databases 5. Accordingly, the replicated transactions
300
queued in the replication queue 21 may also be executed concurrently (i.e. in
parallel)
through multiple concurrent database connections 304 to the second or
additional
databases 5, for facilitating performance increases in throughput of the
replicated
transactions 300 against the secondary and/or tertiary databases 5. It is
recognised
that the replication server 20 coordinates the emptying of the replication
queue 21 and
disk queue 22 using sequential and/or parallel transmission of the replicated
transactions 300 contained therein. The working principle is that when
selected ones
of the replicated transactions 300 are updating mutually exclusive records Ri,
the
selected replicated transactions 300 have no sequential dependency and can be
executed concurrently using the multiple concurrent database connections 304.
The
system allows concurrent execution of transactions on the primary database, as
described above. So naturally these transactions executed concurrently on the
primary database can be assured exclusivity by the respective database
engine/servers
4 through locking, and can be executed concurrently as the replicated
transactions 300
on the secondary databases 5 accordingly.
[0040] Further, it is recognised that each of the replicated
transactions 300
include one or more individual statements 302(e.g. SQL statement or database
record
access requests) for execution against the respective database 5. For example,
each of
the statements 302 in a respective replicated transaction 300 can be used to
access
different records Ri (e.g. R1 and R2) for the databases 5. The replication
server 20
can be further configured for concurrent transmission of individual statements
302,
from the same or different ones of the replicated transactions 300, for
execution
against the same or different databases 5 using the one or more concurrent
database
connections 304. For example, the SQL statements 302 in one of the replicated
transactions 300 may be executed concurrently with the SQL statements 302 from
TOR_LAW\ 6386957\1 11
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
another of the replicated transactions 300 in the replication queue 21. The
replication
server 20 has knowledge of the contents (one or more individual statements
302)of
the replicated transactions 300 to assist in selection (e.g. accounting for
execution
order and/or which record Ri affected) of which transactions 300 to apply in
parallel
using the multiple concurrent database connections 304, i.e. have no
sequential
dependency. This knowledge can be represented in the transaction IDs
associated
with the replicated transactions 300 and/or the individual statements 302, for
example.
[0041] In view of the above, it is also recognised that the replication
server 20
can coordinate the transmission of the replicated transactions 300 and/or the
individual statements 302 from multiple replication queues 21 to two or more
databases 5, as desired.
[0042] The core functions of the controller 2 can be summarized as
registering
one or more directors 8 and associating them with their respective replication
groups;
controlling the replication servers 3 activities; maintaining the global TX
queue 13
that holds all the update transactions sent from the directors 8;
synchronizing the
global TX queue 13 with the backup controller 9 (where applicable); managing
all
replication groups defined; distributing committed transactions to the
replication
servers 3; tracking the operational status of each database server 4 within a
replication
group; providing system status to a monitor 6 (and/or the director 8); and
recovering
from various system failures.
[0043] The registry function of the controller 2 occurs when
applications are
enabled on a new application server 7 to access databases 5 in a replication
group.
Here, the director 8 on the new application server contacts the controller 2
and
registers itself to the replication group. Advantageously, this provides
dynamic
provisioning of application servers 7 to scale up system capacity on demand.
The
registration is performed on the first database call (e.g. the transmit
request) made by
an application. Subsequently the director 8 communicates with the controller 2
for
transaction and server 3,4 status tracking.
[0044] The replication server control function allows the controller 2
to start
the replication servers 3 and monitors their state. For example, when an
administrator
requests to pause replication to a specific database 5, the controller 2 then
instructs the
TOR_LAW\ 6386957\1 12
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
replication server to stop applying transactions until an administrator or an
automated
process requests it.
[0045] The replication group management function allows the controller
2 to
manage one or more groups of databases 5 that require transaction
synchronization
and data consistency among them. The number of replication groups that can be
managed and controlled by the controller 2 is dependent upon the processing
power of
the computer that the controller 2 is operating on and the sum of the
transaction rates
of all the replication groups.
Director
[0046] Referring to Figure 2, shown is a block diagram of the director
8 of the
system 10 of Figure 1A. The director can be installed on the application
server 7 or
the client computer, for example. The director 8 is for initiating a sequence
of
operations to track the progress of a transaction. The director 8 comprises a
first 27, a
second 28, a third 29 and a fourth 30 functional module. According to an
embodiment of the system 10, the director 8 wraps around a vendor supplied
JDBC
driver. As discussed earlier, the director 8 is typically installed on the
application
server 7 in a 3-tier architecture, and on the client computer in a 2-tier
architecture. As
a wrapper, the director 8 can act like an ordinary JDBC driver to the
applications 7,
for example. Further, the system 10 can also support any of the following
associated
with the transaction requests, such as but not limited to:
1. a database access driver/protocol based on SQL for a relational database 5
(ODBC, OLE/DB, ADO.NET, RDBMS native clients, etc...);
2. messages sent over message queues of the network;
3. XML (and other structured definition languages) based transactions; and
4. other data access drivers as desired.
[0047] As an example, the first module 27 captures all JDBC calls 26 to
recognize the new transactions, determines transaction type and boundary, and
analyzes any SQLs in the new transaction. Once determined to be an update
transaction, the director 8 initiates a sequence of operations to track the
progress of
the transaction until it ends with a commit or rollback. Both DDL and DML are
TOR_LAW\ 6386957\1 13
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
captured for replication to other databases in the same replication group. The
first
module 27 can also implement the recording of the transmit requests at commit
time.
[0048] The second module 28 collects a plurality of different
statistical
elements on transactions and SQL statements for analyzing application
execution and
performance characteristics. The statistics can be exported as comma delimited
text
file for importing into a spreadsheet.
[0049] In addition to intercepting and analyzing transactions and SQL
statements, the director's third module 29, manages database connections for
the
applications 7. In the event that one of the databases 5 should fail, the
director 8
reroutes transactions (through the fourth module 4) to one or more of the
remaining
databases 5. Whenever feasible, the director 8 also attempts to re-execute the
transactions to minimize in flight transaction loss. Accordingly, the director
8 has the
ability to instruct the controller 2 as to which database 5 is the primary
database 5 for
satisfying the request of the respective application 7.
[0050] Depending on a database's workload and the relative power
settings of
the database servers 4 in a replication group, the director 8 routes read
transactions to
the least busy database server 4 for processing. This also applies when a
database
server 4 failure has resulted in transaction redirection.
[0051] Similarly, if the replication of transactions to a database
server 4
becomes too slow for any reason such that the transactions start to build up
and spill
over to the replication disk queue 16, the director 8 redirects all the read
transactions
to the least busy database server 4. Once the disk queue becomes empty, the
director
8 subsequently allows read access to that database. Accordingly, the
fill/usage status
of the replication disk queues in the replication group can be obtained or
otherwise
received by the director 8 for use in management of through-put rate of
transactions
applied to the respective databases 5.
[0052] For example, when the director 8 or replication servers 3 fails
to
communicate with the database servers 4, they report the failure to the
controller 2
which then may redistribute transactions or take other appropriate actions to
allow
continuous operation of the transaction replicator 1. When one of the database
servers
4 cannot be accessed, the controller 2 instructs the replication server 3 to
stop
TOR_LAW\ 6386957\1 14
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
applying transactions to it and relays the database lock down status to a
monitor 6.
The transactions start to accumulate within the queues until the database
server 3 is
repaired and the administrator or an automated process instructs to resume
replication
via the monitor 6. The monitor 6 may also provide other predetermined
administrative commands (for example: create database alias, update
parameters,
changing workload balancing setting).
Monitor
[0053] Referring again to Figure 1A, the monitor 6 allows a user to
view and
monitor the status of the controllers 2, the replication servers 3, and the
databases 5.
Preferably, the monitor 6 is a web application that is installed on an
application or
application server 7 and on the same network as the controllers 2.
[0054] Referring to Figure 3, shown is a diagrammatic view of the
system
monitor 6 for use with the transaction replicator 1. The system monitor 6
receives
input data 32 from both primary and backup controllers 2, 9 (where
applicable),
replication servers 3, the database servers 4 and relevant databases 5 within
a
replication group. This information is used to display an overall system
status on a
display screen 31.
[0055] For example, depending on whether the controller is functioning
or a
failure has occurred, the relevant status of the controller 2 is shown.
Second, the
status of each of the replication servers 3 within a desired replication group
is shown.
A detailed description of the transaction rate, the number of transactions
within each
replication queue 15, the number transactions within each replication disk
queue 16 is
further shown. The monitor 6 further receives data regarding the databases 5
and
displays the status of each database 5 and the number of committed
transactions.
[0056] The administrator can analyze the above information and choose
to
manually reroute the transactions. For example, when it is seen that there
exists many
transactions within the replication disk queue 16 of a particular replication
server 3 or
that the transaction rate of a replication server 3 is slow, the administrator
may send
output data in the form of a request 33 to distribute the transactions for a
specified
amount of time to a different database server within the replication group.
TOR LAW\ 6386957\1 15
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
[0057] Referring to Figure 4, shown is a flow diagram overview of the
method
100 for initializing and processing transactions according to the invention.
The global
TX sequencer 12 also referred to as the sequencer hereafter and as shown in
Figure
1B, is the control logic of the transaction replicator 1.
[0058] When the controller 2 is started, it initializes itself by
reading from
configuration and property files the parameters to be used in the current
session 101.
The global TX Queue 13, indoubt TX queue 17 and resent TX queue 18 shown in
Figure 1B, are created and emptied in preparation for use. Before accepting
any new
transactions, the sequencer 12 examines the global disk queue 14 to determine
if any
transactions are left behind from previous session. For example, if a
transaction is
found on the global disk queue 14, it implies at least one database in the
cluster is out
of synchronization with the others and the database must be applied with these
transactions before it can be accessed by applications. Transactions on the
global disk
queue 14 are read into the global TX queue 13 in preparation for applying to
the
database(s) 5. The sequencer 12 then starts additional servers called
replication
servers 3 that create and manage the replication queues 15. After
initialization is
complete, the sequencer 12 is ready to accept transactions from the
application servers
7.
[0059] The sequencer 12 examines the incoming transaction to determine
whether it is a new transaction initiating a commit to its unit of work (e.g.
database
record) in the database 5 or a transaction that has already been recorded in
the global
TX queue 102. For a new transaction, the sequencer 12 assigns a Transaction ID
103
and records the transaction together with this ID in the global TX queue 13.
If the new
transaction ID is generated as a result of lost ID 104, the transaction and
the ID are
stored in the resent TX queue 109 for use in identifying duplicated
transactions. The
sequencer 12 checks the usage of the global TX queue 105 to determine if the
maximum number of transactions in memory has already been exceeded. The
sequencer 12 stores the transaction ID in the global TX queue 13 if the memory
is not
full 106. Otherwise, the sequencer 12 stores the transaction ID in the global
disk
queue 107. The sequencer 12 then returns the ID to the application 108 and the
sequencer 12 is ready to process another request from the application.
TOR_LAW\ 6386957\1 16
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
[0060] When a request from the application or application server 7,
comes in
with a transaction that has already obtained a transaction ID previously and
recorded
in the global TX queue 13, the sequencer 12 searches and retrieves the entry
from
either the global TX queue 13 or the disk queue 110. If this transaction has
been
committed to the database 111, the entry's transaction status is set to
"committed" 112
by the sequencer 12, indicating that this transaction is ready for applying to
the other
databases 200. If the transaction has been rolled back 113, the entry's
transaction
status is marked "for deletion" 114 and as will be described, subsequent
processing
200 deletes the entry from the global TX queue. If the transaction failed with
an
indoubt status, the entry's transaction status is set to "indoubt" 115. An
alert message
is sent to indicate that database recovery may be required 116. Database
access is
suspended immediately 117 until the indoubt transaction is resolved manually
300 or
automatically 400.
[0061] Referring to Figure 5, shown is a flow diagram of the method 200
for
distributing transactions from the global TX queue 13. The global TX queue 13
is
used to maintain the proper sequencing and states of all update transactions
at commit
time. To apply the committed transactions to the other databases, the
replication
queue 5 is created by the sequencer 12 for each destination database. The
sequencer
12 moves committed transactions from the global TX queue to the replication
queue
based on the following two criteria: (1) a predetermined transaction queue
threshold
(Q threshold) and (2) a predetermined sleep time (transfer interval).
[0062] For a system with sustained workload, the Q Threshold is the
sole
determining criteria to move committed transactions to the replication queue
201. For
a system with sporadic activities, both the Q Threshold and transfer interval
are used
to make the transfer decision 201, 213. Transactions are transferred in
batches to
reduce communication overhead. When one or both criteria are met, the
sequencer 12
prepares a batch of transactions to be moved from the global TX queue 13 to
the
replication queue 202. If the batch contains transactions, the sequencer 12
removes all
the rolled back transactions from it because they are not to be applied to the
other
databases 204. The remaining transactions in the batch are sent to the
replication
queue for processing 205. If the batch does not contain any transaction 203,
the
sequencer 12 searches the global TX queue for any unprocessed transactions
(status is
TOR LAW\ 6386957\1 17
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
committing) 206. Since transactions are executed in a same order of
occurrence,
unprocessed transactions typically occur when a previous transaction has not
completed, therefore delaying the processing of subsequent transactions. A
transaction that is being committed and has not yet returned its completion
status is
called a gating transaction. A transaction that is being committed and returns
a status
of unknown is called indoubt transaction. Both types of transactions will
remain in the
state of "committing" and block processing of subsequent committed
transactions,
resulting in the transaction batch being empty. The difference between a
gating
transaction and an indoubt transaction is that gating transaction is
transient, meaning
that it will eventually become committed, unless there is a system failure
that causes it
to remain in the "gating state" indefinitely. Therefore when the sequencer 12
fmds
unprocessed transactions 207 it must differentiate the two types of
"committing"
transactions 208. For a gating transaction, the sequencer 12 sends out an
alert 209 and
enters the transaction recovery process 300. Otherwise, the sequencer 12
determines if
the transaction is resent from the application 210, 211, and removes the
resent
transaction from the global TX queue 211. A resent transaction is a duplicated
transaction in the global TX queue 13 and has not been moved to the
replication
queue 15. The sequencer 12 then enters into a sleep because there is no
transaction to
be processed at the time 214. The sleep process is executed in its own thread
such
that it does not stop 200 from being executed at any time. It is a second
entry point
into the global queue size check at 201. When the sleep time is up, the
sequencer 12
creates the transaction batch 202 for transfer to the replication queue 203,
204, 205.
[0063] In a further embodiment, referring to Figures 1 and 8, an
example
operation 600 of the commit sequence for collision inhibition in replication
of the
concurrent transactions A,B,C (in a primary database 5a) is shown. Once the
transactions A,B,C are received 601 by the director 8, the transactions A,B,C
are
passed 602 to the primary database 5a. At this stage, the director 8 can
optionally
send 605 the transactions A,B,C to the controller 2 to initially get
transaction IDs
issued and the transactions A,B,C with the IDs are then placed in to the
global queue
13 in preparation for replication (i.e. first stage of the replication
process). The
director 8 then communicates 603 with the database server 4 of the primary
database
5a to determine when the statements of each transaction have been processed by
the
database 5a. For example, shown are the concurrent transactions A,B,C, where
TOR_LAW\ 6386957\1 18
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
transaction A updates 608 record R1, transaction B updates 608 record R5, and
transaction C updates 608 records R1 to R5. In this case, as record processing
is done
by the database 5a, transactions A and B complete first (transaction C is held
back
from completing due to potential conflicts with records R1 and R5), as
indicated by
the communication 603 of the transactions' A,B completed status to the
director 8.
[0064] Accordingly, the director 8 then requests 604 (i.e. second stage
of the
replication process or only first stage if step 605 was not followed) to the
controller 2
that transactions A,B are ready for commit and are therefore ready for
replication. At
this stage, the transaction IDs for received transactions A,B are issued by
the
controller 2 (if not already done so at step 605) and the transactions A,B
with their
corresponding IDs are replicated 606 to the replication queues 15. It should
be noted
that transaction C, if present in the global queue 13, would remain behind in
the
global queue 13 until the director 8 is informed 607 of completion of
transaction C by
the database server 4, thus signifying that the director 8 should request
subsequent
replication (not shown) of the transaction C by the controller 2. The
replicated
transactions A,B in the queues 15 are then sent 609 to the database servers 4
associated with the secondary/replication databases 5b and processed
accordingly.
The director 8 can also get feedback (not shown) from the database servers 4
of the
secondary/replication databases 5b to indicate that the transactions A,B have
been
processed properly.
[0065] Accordingly, the completion status of the transactions A,B,C are
monitored by the director 8, or other monitoring entity ¨ e.g. controller 2,
such that
the transactions A,B,C are each passed 604,605 to the controller 2 at their
own
determined commit time, or request for commit, thus helping to prevent
collisions and
therefore to help provide for database 5a,b integrity. For example, the
director 8 will
not receive a commit request for transaction C until the director 8 acquired
transaction
IDs for transaction A and B from the controller 2, and sent the commit
requests to
database server 4 of the primary database 5. The commit requests from
transaction A
and B effectively removed the collision condition on records R1 ,R5 for
transaction C,
allowing transaction C to update R1, R5 and to proceed with a commit request
to
director 8.
TOR LAW\ 6386957\1 19
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
[0066] Referring to Figures 9a, 9b, 9c, representing consecutive time
intervals
ti, t2, t3 respectively, concurrent update transactions T1,T2,T3 (or any
number of
transactions or transaction types) are forwarded (e.g. by the director 8) to
the primary
database 5a. It is recognized that during concurrent updating any of the
database
records R1-R12 (generically identified as Ri) only one of the transactions
T1,T2,T3
can access a particular database record Ri at any one time. This restricted
access of
database records Ri can be implemented though locking of the records Ri
currently
being processed at any one time by the respective transaction T1,T2,T3 . For
example, it is noted in Figure 9a that currently locked records Ri are
represented as
shaded boxes ¨ e.g. transaction T3 has locked records R9, R10, and R12 at time
ti,
while transaction T2 has locked records R5,R7,R11 and transaction Ti has
locked
records R1,R2,R3,R4,R6,R8. It is further noted that transaction Ti is waiting
to
complete it's record Ri updates to records R9,R10, while transaction T2 is
waiting to
complete it's record Ri updates to records R8,R9,R10, all waiting records Ri
represented as crosshatched boxes in Figure 9a. Accordingly, each of the
concurrent
transactions T1,T2,T3 are able to lock exclusively some records Ri to
access/update
as well as to wait on those other records Ri that other concurrent
transactions
T1,T2,T3 are in the process of updating (or otherwise accessing). At any given
point
in time tl,t2,t3, a different combination of update transactions
T1,T2,T3,T4,T5 can be
executing simultaneously.
[0067] Referring to Figure 9a, at time ti, for example, three
concurrent update
transactions T1,T2,T3 are executing, where transaction T3 successfully updated
all
the required records R9,R10,R12, while transactions Ti and T2 are waiting for
transaction T3 to commit the changes to the records R9, R10 and R12.
Therefore,
transaction T3 is the only transaction that at time ti can possibly request a
Transaction
ID (Commit Token) from the replication system 10 (e.g. where the director 8
passes
the transaction T3 to the controller 2 for subsequent issuance of the
corresponding
transaction ID and placement in the global queue 13 for subsequent replication
to the
replication queues 15), despite the fact that transaction T3 is started after
transactions
Ti and T2. With the transaction ID granted, transaction T3 proceeds to commit
its
unit of work in the primary database 5a, thus providing for replication of the
transaction T3 via the controller 2 to the secondary databases 5b (see Figure
8), as
described above by example. It is recognized that the concurrent transactions
TOR_LAW\ 6386957\1 20
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
T1,T2,T3 may also be ordered by the director 8 and/or the database server 4 of
the
primary database 5a due to time stamping or other means of transaction
sequencing.
[0068] Referring to Figure 9b, at time t2 following time ti,
transaction Ti
successfully locked the records R9 and R10 and updated them, after transaction
T3
released the respective locks, while transaction T2 waits for transaction Ti
to release
the records R8, R9 and R10. At the same time a new update transaction T4 is
received
by the database server 4 (see Figure 9b) starts to execute in the primary
database 5a. It
is noted at time t2, transaction Ti is the only transaction that can request
its
Transaction ID from replication system 10 (as described above by example) to
complete its unit of work in the primary database 5a, thus providing for
replication of
the transaction Ti via the controller 2 to the secondary databases 5b (see
Figure 8). It
is further noted at time t2 that transaction T4 is waiting on records R2,R4,R6
locked
by transaction Ti and R7 locked by transaction T2.
[0069] Referring to Figure 9c, at time t3 following time t2,
transaction T5
started execution in the primary database 5a and successfully updated records
R1 and
R3, while transaction T2 also successfully updated records R8, R9 and R10.
Both
transactions T2,T5 request respective transaction IDs from the replication
system 10,
as described above by example, to complete their unit of work, while
transaction T4
continues to wait for transaction T2 and T5 to complete their units of work in
the
primary database 5a, thus providing for replication of the transactions T2,T5
via the
controller 2 to the secondary databases 5b (see Figure 8).
[0070] In view of Figures 9a,9b,9c, it is recognized that the database
server 4
(see Figure 8) of the primary database 5a can indicate to the director 8 that
the
transactions T3 ,T2,T5 were completed and thus were candidates for being
issued their
respective transaction IDs in preparation for replication of the transactions
T3 ,T2,T5
to the secondary databases 5b.
[0071] Referring to Appendix A, an example embodiment of the
replication
transaction sequencing is provided, where Ti represents the instance of time
in the
database 5 engine, Ui represents an update statement of the transaction for
processing
and eventual replication, Di represents a delete statement of the transaction
for
processing and eventual replication, Si represents a select statement of the
transaction
=
TOR_LAW\ 6386957\1 21
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
for processing and eventual replication, Ri represents records currently
locked (lock
list) for the transaction, Wi represents records Ri to be locked (lock wait
list), W
represents wait action for lock, C represents eligible to commit action for
the
completed transaction to the replication queues 15, R represents victimized
action to
rollback for the transaction, a Lock Dependency set when evaluated to empty
set F
implies logical "True" or (C "Eligible to commit"), the Lock Dependency set
when
evaluated to non-empty set F' implies logical "False" or (W "Wait for lock"),
and
Sequence represents the replication sequence of the transactions to the other
databases
5b. It is recognized that the sequencing information can be accessible or
otherwise
hosted by the database server 4 (e.g. of the primary database 5a), the
director 8, the
controller 2, other system entities not shown, or a combination thereof.
[0072] Further, it is recognized that the replication system 10 can be
implemented inside a database engine (RDBMS), not shown, as an alternative
embodiment. For example, the database engine (e.g. of IBM's DB2 product) can
incorporate the replication system 10, including such as but not limited to
including
the functionality (or a portion thereof) of the director 8 and/or the
controller 2 and/or
hosting of the global queue 13 and/or the respective replication queue 15.
[0073] Referring to Figure 6, shown is a flow diagram illustrating the
method
300 for providing manual recovery of transactions 116 as shown in Figure 100.
There are two scenarios under which the sequencer 12 is unable to resolve
gating
transactions and indoubt transactions caused by certain types of failure and
manual
recovery may be needed. First, a gating transaction remains in the global TX
queue
13 for an extended period of time, stopping all subsequent committed
transactions
from being applied to the other databases. Second, a transaction status is
unknown
after some system component failure. The sequencer 12 first identifies the
transactions causing need resolution 301 and send out an alert 302. Then the
transaction can be manually analyzed to determine whether the transaction has
been
committed or rolled back in the database 304 and whether any manual action
needs to
be taken. If the transaction is found to have been rolled back in the
database, the
transaction entry is deleted manually from the global TX queue 305. If the
transaction
has been committed to the database, it is manually marked "committed" 306. In
both
cases the replication process can resume without having to recover the
database 500.
TOR_LAW\ 6386957 \ 1 22
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
If the transaction is flagged as indoubt in the database, it must be forced to
commit or
roll back at the database before performing 304, 305 and 306.
[0074] Referring again to Figure 6, the process 400 is entered when an
indoubt transaction is detected 115 and automatic failover and recovery of a
failed
database is performed. Unlike gating transactions that may get resolved in the
next
moment, an indoubt transaction is permanent until the transaction is rolled
back or
committed by hand or by some heuristic rules supported by the database. If the
resolution is done with heuristic rules, the indoubt transaction will have
been resolved
as "committed" or "rolled back" and will not require database failover or
recovery.
Consequently the process 400 is only entered when an indoubt transaction
cannot be
heuristically resolved and an immediate database failover is desirable. Under
the
automatic recovery process, the database is marked as "needing recovery" 401,
with
an alert sent out 402 by the sequencer 12. To help prevent further transaction
loss, the
sequencer 12 stops the generation of new transaction ID 403 and moves the
indoubt
transactions to the indoubt TX queue 404. While the database is marked
"needing
recovery" the sequencer 12 replaces it with one of the available databases in
the group
405 and enables the transaction ID generation 406 such that normal global TX
queue
processing can continue 200. The sequencer 12 then executes a user defined
recovery
procedure to recover the failed database 407. For example, if the database
recovery
fails, the recovery process is reentered 408, 407.
[0075] Referring to Figure 7, shown is a flow diagram illustrating the
processing of committed transactions by the replication servers 3 and the
management
of transactions in the replication queue 15 according to the present
invention.
Replication queues 15 are managed by the replication servers 3 started by the
sequencer 12. One of the replication servers 3 receives batches of
transactions from
the sequencer 12. The process 500 is entered if a new batch of committed
transactions arrives or at any time when queued transactions are to be applied
to the
databases.
[0076] If the process is entered because of new transactions 501, the
batch of
transactions is stored in the replication queue in memory 508, 509, or in
replication
disk queue 511 if the memory queue is full. Replication disk queue capacity is
determined by the amount of disk space available. If the disk is above a
TOR LAW\ 6386957\1 23
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
predetermined threshold or is full for example 510, an alert is sent 512 by
the
sequencer 12 and the database is marked unusable 513 because committed
transactions cannot be queued up anymore.
[0077] If the process is entered in an attempt to apply transactions in
the
replication queue to the databases, the replication server first determines
whether
there is any unprocessed transaction in the replication queue in memory 502.
If the
memory queue is empty but unprocessed transactions are found in the
replication disk
queue 503, they are moved from the disk queue to the memory queue in batches
for
execution 504, 505. Upon successful execution of all the transactions in the
batch they
are removed from the replication queue by the replication server and another
batch of
transactions are processed 501. If there are transactions in the replication
disk queue
16, the processing continues until the disk queue is empty, at which time the
replication server 3 waits for more transactions from the global TX queue 501.
During
execution of the transactions in the replication queue 15, error may occur and
the
execution must be retried until the maximum number of retries is exceeded 507,
then
an alert is sent 512 with the database marked unusable 513. However, even
though a
database is marked unusable, the system continues to serve the application
requests.
The marked database is inaccessible until the error condition is resolved. The
replication server 3 stops when it is instructed by the sequencer during the
apparatus
shutdown process 118, 119 and 120 shown in Figure 4.
[0078] It will be evident to those skilled in the art that the system
10 and its
corresponding components can take many forms, and that such forms are within
the
scope of the invention as claimed. For example, the transaction replicators 1
can be
configured as a plurality of transaction replicators 1 in a replicator peer-to-
peer (P2P)
network, in which each database server 4 is assigned or otherwise coupled to
at least
one principal transaction replicator 1. The distributed nature of the
replicator P2P
network can increase robustness in case of failure by replicating data over
multiple
peers (i.e. transaction replicators 1), and by enabling peers to find/store
the data of the
transactions without relying on a centralized index server. In the latter
case, there
may be no single point of failure in the system 10 when using the replicator
P2P
network. For example, the application or application servers 7 can communicate
with
a selected one of the database servers 7, such that the replicator P2P network
of
TOR_LAW\ 6386957\1 24
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
transaction replicators 1 would communicate with one another for load
balancing
and/or failure mode purposes. One example would be one application server 7
sending the transaction request to one of the transaction replicators 1, which
would
then send the transaction request to another of the transaction replicators 1
of the
replicator P2P network, which in turn would replicate and then communicate the
replicated copies of the transactions to the respective database servers 4.
[0079] Further, it is recognized that the applications/ application
servers 7
could be configured in an application P2P network such that two or more
application
computers could share their resources such as storage hard drives, CD-ROM
drives,
and printers. Resources would then accessible from every computer on the
application
P2P network. Because P2P computers have their own hard drives that are
accessible
by all computers, each computer can act as both a client and a server in the
application P2P networks (e.g. both as an application 7 and as a database 4).
P2P
networks are typically used for connecting nodes via largely ad hoc
connections. Such
P2P networks are useful for many purposes, such as but not limited to sharing
content
files, containing audio, video, data or anything in digital format is very
common, and
realtime data, such as Telephony traffic, is also passed using P2P technology.
The
term "P2P network" can also mean grid computing. A pure P2P file transfer
network
does not have the notion of clients or servers, but only equal peer nodes that
simultaneously function as both "clients" and "servers" to the other nodes on
the
network. This model of network arrangement differs from the client-server
model
where communication is usually to and from a central server or controller. It
is
recognized that there are three major types of P2P network, by way of example
only,
namely:
1) Pure P2P in which peers act as clients and server, there is no central
server,
and there is no central router;
2) Hybrid P2P which has a central server that keeps information on peers and
responds to requests for that information, peers are responsible for hosting
the
information as the central server does not store files and for letting the
central server
know what files they want to share and for downloading its shareable resources
to
peers that request it, and route terminals are used as addresses which are
referenced
by a set of indices to obtain an absolute address; and
3) Mixed P2P which has both pure and hybrid characteristics.
TOR _LAW 6386957\1 25
CA 02619778 2008-02-19
WO 2007/028249
PCT/CA2006/001475
Accordingly, it is recognized that in the application and replicator P2P
networks the
applications/ application servers 7 and the transaction replicators 1 can
operate as both
clients and servers, depending upon whether they are the originator or
receiver of the
transaction request respectively. Further, it is recognized that both the
application and
replicator P2P networks can be used in the system 10 alone or in combination,
as
desired.
In view of the above, the spirit and scope of the appended claims should not
be
limited to the examples or the description of the preferred versions contained
herein.
TOR_LAW\ 6386957\1 26
CA 02619778 2008-02-19
WO 2007/028249 PCT/CA2006/001475
Annendix A
Time SQL Record Set Lock Dependency
Action Sequence
Ui {R, W} {Wx} n {Ry} 0 4:1 v {Wx } n {Rz} # (1) W -
Ti U2 {Ry, Wy} { Wy} n IRO = 0 A {Wy} n {Rz} = cr. C
1
U3 {R, W} {Wz} n {Rx} = 0 A Ma n IRO = (1) C 2
Ui {R, W} {Wx} n (Ry1 0 cp v {Wx} n {11,1 0 cD W -
T2 U4 {R, Wy} {Wy} n {Rx} = 0 A {W} n {itz} = 0 C 3
U5 {R, W} (Wz} n (R.) # cp v {Wz1 n {Ry} 0 cr. W -
U1 {R, W} {WO n {Ry1 = cre A {Wx} n {Rz} = cD C
4
T3 U5 {Rz, Wz} {Wz} n {Rx} = ()A {Wz} n {Ry} = cre C
5
U6 {Ry, Wy} {Wy} n {Rx} 0 cD v {Wy} r) {Rz} 0 CD W -
,
U6 {R, W} {Wy} n {KJ = (13 A {Wy} n {Rz} = (I) C
6
T4 U7 { Rz, Wx} {Wx} n {Ry} # CD v {Wx } n {V # cD W -
U8 {R, W} {Wz} n {Rx} = CD A {Wz} n {Ry} = ID C
7
U7 {Rz, Wx} {W} n {Ry} = 0 A {W} n {Rz} = cp C 8
T5 19 {R, W} {Wy} = (13 V ({Wy} n {Rx} = 0 A {Wy} n {Rz} = cr.)
C 9
110 {R., Wz} {Wz} = CD v ({Wz} n IRO =43 A {Wz} n {Rx} = 0)
C 10
Sll {Rx, Wx} {Wx} = cD C -
T6 U12 {Ry, Wy} {Wy} n {itx} # (Dv {Wy} n {Rz} 0 c13 W -
U13 {R, W} {Wz} n {Rx} = (13 A {Wz} n IRO =43 C 11
Sii 1%, Wx} {Wx} = (13 C -
T7 U12 {Ry, Wy} {Wy} n {R.} # 0 A {Wy} n {Rz} = 0:13 w -
D14 {R, W} {Wz1 n {Rx} 0 .r. v {Wz} n {Ry} (1) W -
U12 {R, W} {Wy} n {Rx} # 0 A MO n {Rz} = cr. W -
T8 D14 {Rz, Wz} {Wz} n 1RJ= CD A {Wz} n IRO =4) C 12
D15 {Rx, Wx} {Wx} n {Ry} # 0 A {Wx} n {Rz} #.13 R -
,
U12 {R, W} {Wy} n {Rx} = (1) A {Wy} n {Rz} =c1) C
13
T9 116 Iltx, W.} {Wx} n {Ry} = cp A IWO n {Rz} = 0:1) C
14
U17 {R, W} {Wx} n {Rx} # (13 v {Wz} n {Ry} # cD W -
T10 U17 {tz, Wz} {Wz} = 4) C 15
TOR_LAW\ 6386957\1 27
,