Note: Descriptions are shown in the official language in which they were submitted.
CA 02620030 2008-11-27
74420-244
[Invention Title]
METHOD AND APPARATUS FOR DECODING AN AUDIO SIGNAL
[Technical Field]
The present invention relates to an audio signal
processing, and more particularly, to an apparatus for
decoding an audio signal and method thereof.
[Background Art]
Generally, in case of an Audi n : i c]ii, i1 , An Auudi o
signal encoding apparatus compresses the audio signal into
a mono or stereo type downmix signal instead of compressing
each multi-channel audio signal. The audio signal encoding
apparatus transfers the compressed downmix signal to a
decoding apparatus together with a spatial information
signal or stores the compressed downmix signal and a
spatial information signal in a storage medium. In this
case, a spatial information signal, which is extracted in
downmixing a multi-channel audio signal, is used in
restoring an original multi-channel audio signal from a
downmix signal.
Configuration information is non-changeable in
general and a header including this information is inserted
in an audio signal once. Since configuration information is
1
CA 02620030 2008-11-27
74420-244
transmitted by being initially inserted in an audio signal
once, an audio signal decoding apparatus has a problem in
decoding spatial information due to non-existence of
configuration information in case of reproducing the audio
signal from a random timing point.
An audio signal encoding apparatus generates a
downmix signal and a spatial information signal into
bitstreams together or respectively and then transfers them
to the audio signal decoding apparatus. So, if unnecessary
information and the like are included in the spatial
information signal, signal compression and transfer
efficiencies are reduced.
Summary of Invention
According to one aspect of the present invention,
there is provided a method of decoding an audio signal,
comprising: receiving a spatial information signal and a
downmix signal; obtaining position information of a timeslot
using a timeslot number and a parameter number included in
the spatial information signal; generating a multi-channel
audio signal by applying the spatial information signal to
the downmix signal according to the position information of
the timeslot; and arranging the multi-channel audio signal.
According to another aspect of the present
invention, there is provided an apparatus for decoding an
audio signal, comprising: a receiving part for receiving a
spatial information signal and a downmix signal; a multi-
channel generating unit for generating a multi-channel audio
signal by applying the spatial information signal to the
downmix signal according to the position information of the
timeslot, and for obtaining position information of a
timeslot using a timeslot number and a parameter number
2
CA 02620030 2008-11-27
74420-244
included in the spatial information signal; and, a signal
arranging unit for arranging the multi-channel audio signal.
Some embodiments of the present invention may
provide an apparatus for decoding an audio signal and method
thereof, by which the audio signal can be reproduced from a
random timing point by selectively including a spatial
information signal in a header.
Some embodiments of the present invention may
provide an apparatus for decoding an audio signal and method
thereof, by which a position of a timeslot to which a
parameter set will be applied can be efficiently represented
using a variable bit number.
Some embodiments of the present invention may
provide an apparatus for decoding an audio signal and method
thereof, by which audio signal compression and transfer
efficiencies can be raised by representing an information
quantity required for performing a downmix signal
arrangement or mapping multi-channel to a speaker as a
minimal variable bit number.
Some embodiments of the present invention may
provide an apparatus for decoding an audio signal and method
thereof, by which an information quantity required for
signal arrangement can be reduced by mapping multi-channel
to a speaker without performing downmix signal arrangement.
Brief Description of the Drawings
Examples of embodiments of the present invention
will now be described with reference to the drawings, in
which:
3
CA 02620030 2008-11-27
74420-244
Figure 1 shows a configurational diagram of an
audio signal transferred from an audio signal encoding
apparatus to an audio signal decoding apparatus, according
to an embodiment of the present invention;
Figure 2 shows a flow chart of a method of
decoding an audio signal according to an embodiment of the
present invention;
Figure 3 shows a flow chart of a method of
decoding an audio signal according to another embodiment of
the present invention;
Figure 4 shows an example of a syntax of position
information of a time slot to which a parameter set is
applied, according to an embodiment of the present
invention;
Figure 5 is a flow chart of a method of decoding a
spatial information signal according to an embodiment of the
present invention;
Figure 6 shows a diagram of an upmixing unit of an
audio signal decoding apparatus, according to an embodiment
of the present invention, and
Figure 7 shows a diagram of an upmixing unit of an
audio signal decoding apparatus according to an embodiment
of the present invention.
Description of Embodiments
Reference will now be made in detail to one
preferred embodiment of the present invention, examples of
which are
3a
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
illustrated in the accompanying drawings.
FIG. 1 is a configurational diagram of an audio
signal transferred to an audio signal decoding apparatus
from an audio signal encoding apparatus according to one
embodiment of the present invention.
Referring to FIG. 1, an audio signal includes an
audio descriptor 101, a downmix signal 103 and a spatial
information signal 105.
In case of using a coding scheme for reproducing an
audio signal for broadcasting or the like, the audio signal
is able to include ancillary data as well as the audio
descriptor 101 and the downmix signal 103. And, the present
invention includes the spatial information signal 105 as
the ancillary data. In order for an audio signal decoding
apparatus to know basic information of audio codec without
analyzing an audio signal, the audio signal is able to
selectively include the audio descriptor 101. The audio
descriptor 101 is configured with small number of basic
informations necessary for audio decoding such as a
transmission rate of a transmitted audio signal, a number
of channels, a sampling frequency of compressed data, an
identifier indicating a currently used codec and the like.
An audio signal decoding apparatus is able to know a
type of a codec done to an audio signal using the audio
4
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
descriptor 101. In particular, using the audio descriptor
101, the audio signal decoding apparatus is able to know
whether an audio signal configures multi-channel using the
spatial information signal 105 and the downmix signal 103.
The audio descriptor 101 is located independently from the
downmix signal 103 or the spatial information signal 105
included in the audio signal. For instance, the audio
descriptor 101 is located within a separate field
indicating an audio signal. In case that a header is not
included in the downmix signal 103, the audio signal
decoding apparatus is able to decode the downmix signal 103
using the audio descriptor 101.
The downmix signal 103 is a signal generated from
downmixing multi-channel. And, the downmix signal 103 can
be generated from a downmixing unit included in an audio
signal encoding apparatus or-generated artificially. The
downmix signal 103 can be categorized into a case of
including a header and a case of not including a header. In
case that the downmix signal 103 includes a header, the
header is included in each frame by a frame unit. In case
that the downmix signal 103 does not include a header, as
mentioned in the foregoing description, the downmix signal
103 can be decoded using the audio descriptor 101. The
downmix signal 103 takes either a form of including a
5
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
header for each frame or a form of not including a header
in a frame. And, the downmix signal 103 is included in an
audio signal in a same manner until contents end.
The spatial information signal 105 is also
categorized into a case of including a header 107 and
spatial information 111 and a case of including spatial
information 111 only without including a header. The header
107 of the spatial information signal 105 differs from that
of the downmix signal 103 in that it is unnecessary to be
inserted in each frame identically. In particular, the
spatial information signal 105 is able to use both a frame
including a header and a frame not including a header
together. Most of information included in the header 107 of
the spatial information signal 105 is configuration
information 109 that decodes spatial information 111 by
interpreting the spatial information 111. The spatial
information 111 is configured with frames each of which
includes timeslots. The timeslot means each time interval
in case of dividing the frame by time intervals. The number
of timeslots included in one frame is included in the
configuration information 109.
Configuration information 109 includes signal
arrangement information, the number of signal converting
units, channel configuration information, speaker mapping
6
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
information and the like as well as the timeslot number.
The signal arrangement information is an identifier
that indicates whether an audio signal will be arranged for
upmixing prior to restoring the decoded downmix signal 103
into multi-channel..
The signal converting unit means an OTT (one-to-two)
box converting one downmix signal 103 to two signals or a
TTT (two-to-three) box converting two downmix signals 103
to three signals in generating multi-channel by upmixing
the downmix signal 103. In particular, the OTT or TTT box
is a conceptional box used in restoring multi-channel by
being included in an upmixing unit (not shown in the
drawing) of the audio signal decoding apparatus. And,
information for types and number of the signal converting
units is included in the spatial information signal 105.
The channel configuration information is the
information indicating a configuration of the upmixing unit
included in the audio signal decoding apparatus. The
channel configuration information includes an identifier
indicating whether an audio signal passes through the
signal converting unit or not. The audio signal decoding
apparatus is able to know whether an audio signal inputted
to the upmixing unit passes through the signal converting
unit or not using the channel configuration information.
7
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
The audio signal decoding apparatus upmixes the downmix
signal 103 into a multi-channel audio signal using the
information for the signal converting unit, the channel
configuration information and the like. The audio signal
decoding apparatus generates multi-channel by upmixing the
downmix signal 1.03 using the signal converting unit
information, the channel configuration information and the
like included in the spatial information 111.
The speaker mapping information is the information
indicating that the multi-channel audio signal will be
mapped to which speaker in outputting the multi-channel
audio signals generated by upmixing to speakers,
respectively. The audio signal decoding apparatus outputs
the multi-channel audio signal to the corresponding speaker
using the speaker mapping information included in the
configuration information 109.
The spatial information 111 is the information used
to give a spatial sense in generating multi-channel audio
signals by the combination with the downmix signal. The
spatial information includes CLDs (Channel Level
Differences) indicating an energy difference between audio
signals, ICCs (Interchannel Correlations) indicating close
correlation or similarity between audio signals, CPCs
(Channel Prediction Coefficients) indicating a coefficient
8
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
to predict an audio signal value using other signals and
the like. And, a parameter set indicates a bundle of these
parameters.
And, a frame identifier indicating whether a position
of a timeslot to which a parameter set is applied is fixed
or not, the number of parameter set applied to one frame,
position information of a timeslot to which a parameter set
is applied and the like as well as the parameters are
included in the spatial information 111.
FIG. 2 is a flowchart of a method of decoding an
audio signal according to another embodiment of the present
invention.
Referring to FIG. 2, an audio signal decoding
apparatus receives a spatial information signal 105
transferred in a bitstream form by an audio signal encoding
apparatus (S201). The spatial information signal 105 can be
transferred in a stream form separate from that of a
downmix signal 103 or transferred by being included in
ancillary data or extension data of the downmix signal 103.
In case that the spatial information signal 105 is
transferred by being combined with the downmix signal 103,
a demultiplexing unit (not shown in the drawing) of an
audio signal decoding apparatus separates the received
audio signal into an encoded downmix signal 103 and an
9
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
encoded spatial information signal 105. The encoded spatial
information 105 signal includes a header 107 and spatial
information 111. The audio signal decoding apparatus
decides whether the header 107 is included in the spatial
information signal 105 (S203).
If the header 107 is included in the spatial
information signal 105, the audio signal decoding apparatus
extracts configuration information 109 from the header 107
(S205).
The audio signal decoding apparatus decides whether
the configuration information is extracted from a first
header 107 included in the spatial information signal 105
(S207).
If the configuration information 109 is extracted
from the header 107 extracted first from the spatial
information signal 105, the audio signal decoding apparatus
decodes the configuration information 109 (S215) and
decodes the spatial information 111 transferred behind the
configuration information 109 according to the decoded
configuration information 109.
If the header 107 extracted from the audio signal is
not the header 107 extracted first from the spatial
information signal 105, the audio signal decoding apparatus
decides whether the configuration information 109 extracted
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
from the header 107 is identical to the configuration
information 109 extracted from a first header 107 (S209).
If the configuration information 109 is identical to
the configuration information 109 extracted from the first
header 107, the audio signal decoding apparatus decodes the
spatial information 111 using the decoded configuration
information 109 extracted from the first header 107. If the
extracted configuration information 109 is not identical to
the configuration information 109 extracted from the first
header 107, the audio signal decoding apparatus decides
whether an error occurs in the audio signal on a transfer
path from the audio signal encoding apparatus to the audio
signal decoding apparatus (S211).
If the configuration information 109 is variable, the
error does not occur even if the configuration information
109 is not identical to the configuration information 109
extracted from the first header 107. Hence, the audio
signal decoding apparatus updates the header 107 into a
variable header 107 (S213). The audio signal decoding
apparatus then decodes configuration information 109
extracted from the updated header 107 (S215).
The audio signal decoding apparatus decodes spatial
information 111 transferred behind the configuration
information 109 according to the decoded configuration
11
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
information 109.
If the configuration information 109, which is not
variable, is not identical to the configuration information
109 extracted from the first header 107, it means that the
error occurs on the audio signal transfer path. Hence, the
audio signal decoding apparatus removes the spatial
information 111 included in the spatial information signal
105 including the erroneous configuration information 109
or corrects the error of the spatial information 111 (S217).
FIG. 3 is a flowchart of a method of decoding an
audio signal according to another embodiment of the present
invention.
Referring to FIG. 3, an audio signal decoding
apparatus receives an audio signal including a downmix
signal 103 and a spatial information signal 105 from an
audio signal encoding apparatus (S301).
The audio signal decoding apparatus separates the
received audio signal into the spatial information signal
105 and the downmix signal 103 (S303) and then sends the
separated spatial information 105 and the separated downmix
signal 103 to a core decoding unit (not shown in the
drawing) and a spatial information decoding unit (not shown
in the drawing), respectively.
The audio signal decoding apparatus extracts the
12
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
number of timeslots and the number of parameter sets from
the spatial information signal 105. The audio signal
decoding apparatus finds a position of a timeslot to which
a parameter set will be applied using the extracted numbers
of the timeslots and the parameter sets. According to an
order of the corresponding parameter set, the position of
the timeslot to which the corresponding parameter set will
be applied is represented as a variable bit number. And, by
reducing the bit number representing the position of the
timeslot to which the corresponding parameter set will be
applied, it is able to efficiently represent the spatial
information signal 105. And, the position of the timeslot,
to which the corresponding parameter set will be applied,
will be explained in detail with reference to FIG. 4 and
FIG. 5.
Once the timeslot position is obtained, the audio
signal decoding apparatus decodes the spatial information
signal 105 by applying the corresponding parameter set to
the corresponding position (S305). And, the audio signal
decoding apparatus decodes the downmix signal 103 in the
core decoding unit (S305).
The audio signal decoding apparatus is able to
generate multi-channel by upmixing the decoded downmix
signal 103 as it is. But the audio signal decoding
13
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
apparatus is able to arrange a sequence of the decoded
downmix signals 103 before the audio signal decoding
apparatus upmix the corresponding signals (S307).
The audio signal decoding apparatus generates multi-
channel using the decoded downmix signal 103 and the
decoded spatial information signal 105 (S309) . The audio
signal decoding apparatus uses the spatial information
signal 105 to generate the downmix signal 103 into multi-
channel. As mentioned in the foregoing description, the
spatial information signal 105 includes the number of
signal converting units and channel configuration
information for representing whether the downmix signal 103
passes through the signal converting unit in being upmixed
or is outputted without passing through the signal
converting unit. The audio signal decoding apparatus
upmixes the downmix signal 103 using the number of signal
converting units, the channel configuration information and
the like (S309) A method of representing the channel
configuration information and a method of configuring the
channel configuration information using the less number of
bits will be explained with reference to FIG. 6 and FIG. 7
later.
The audio signal decoding apparatus maps a multi-
channel audio signal to a speaker in a preset sequence to
14
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
output the generated multi-channel audio signals (S311). In
this case, as the mapped audio signal sequence increases,
the bit number for mapping the multi-channel audio signal
to the speaker becomes reduced. In particular, in case that
numbers are given to multi-channel audio signals in order,
since a first audio signal can be mapped to one of the
entire speakers, an information quantity required for
mapping an audio signal to a speaker is greater than that
required for mapping a second or subsequent audio signal.
As the second or subsequent audio signal is mapped to one
of the rest of the speakers excluding the former speaker
mapped with the former audio signal, the information
quantity required for the mapping is reduced. In particular,
by reducing the information quantity required for mapping
the audio signal as the mapped audio signal sequence
increases, it is able to efficiently represent the spatial
information signal 105. This method is applicable to a case
of arranging the downmix signals 103 in the step S307 as
well.
FIG. 4 is syntax of position information of a
timeslot to which a parameter set is applied according to
one embodiment of the present invention.
Referring to FIG. 4, the syntax relates to
`FramingInfo' 401 to represent information for a number of
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
parameter sets and information for a timeslot to which a
parameter set is applied.
`bsFramingType' field 403 indicates whether a frame
included in the spatial information signal 105 is a fixed
frame or a variable frame. The fixed frame means a frame in
which a timeslot position to which a parameter set will be
applied is previously set. In particular, a position of a
timeslot to which a parameter set will be applied is
decided according to a preset rule. The variable frame
means a frame in which a timeslot position to which a
parameter set will be applied is not set yet. So, the
variable frame further needs timeslot position information
for representing a position of a timeslot to which a
parameter set will be applied. In the following description,
the `bsFramingType' 403 shall be named `frame identifier'
indicating whether a frame is a fixed frame or a variable
frame.
In case of a variable frame, `bsParamSlot' field 407
or 411 indicates position information of a timeslot to
which a parameter set will be applied. The `bsParamSlot[0]'
field 407 indicates a position of a timeslot to which a
first parameter set will be applied, and the
`bsParamSlot[ps]' field 411 indicates a position of a
timeslot to which a second or subsequent parameter set will
16
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
be applied. The position of the timeslot to which the first
parameter set will be applied is represented as an initial
value, and a position of the timeslot to which the second
or subsequent parameter set will be applied is represented
as a difference value `bsDiffParamSlot[ps]' 409, i.e., a
difference between `bsParamSlot[ps]' and `bsParamSlot[ps-
1]'. In this case, `ps' means a parameter set. The first
parameter set is represented as `ps=0'. And, `ps' is able
to represent value ranging from 0 to a value smaller than
the number of total parameter sets.
(i) A timeslot position 407 or 409 to which a
parameter set will be applied increases as a ps value
increases (bsParamSlot[ps] > bsParamSlot[ps-1]). (ii) For a
first parameter set, a maximum value of a timeslot position
to which a first parameter set will be applied corresponds
to a value resulting from adding 1 to a difference between
a timeslot number and a parameter set number and a timeslot
position is represented .as an information quantity of
`nBitsParamSlot(0)' 413. (iii) For a second or subsequent
parameter set, a timeslot position to which an Nth
parameter set will be applied is greater by at least 1 than
a timeslot position to which an (N-1)th parameter set will
be applied and is even able to have a value resulting from
adding a value N to a value resulting from subtracting a
17
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
parameter set number from a timeslot number. A timeslot
position `bsParamSlot[ps]' to which a second or subsequent
parameter set will be applied is represented as a
difference value `bsDiffParamSlot[ps]' 409. And, this value
is represented as an information quantity of
`nBitsParamSlot[ps]'. So, it is able to find a timeslot
position to which a parameter set will be applied using the
(i) to (iii).
For instance, if there are ten timeslots included in
one spatial frame and if there are three parameter sets, a
timeslot position to which a first parameter set (ps=O)
will be applied is applicable to a timeslot position
resulting from adding 1 to a value resulting from
subtracting a total parameter number from a total timeslot
number. In particular, the corresponding position is
applicable to one of timeslots belonging to a range between
1 to maximum 8. By considering that a timeslot position to
which a parameter set will be applied increases according
to a parameter set number, it can be understood that
timeslot positions to which the remaining two parameter
sets are applicable are maximum 9 and 10, respectively. So,
the timeslot position 407 to which the first parameter set
will be applied needs three bits to indicate 1 to 8, which
can be represented as ceil {loge (k-i+1) } . In this case, `k'
18
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
is the number of timeslots and `i' is the number of
parameters.
If the timeslot position 407 to which the first
parameter set will be applied is 15', the timeslot position
`bsParamSlot[1]' to which the second parameter set will be
applied should be selected from values between 15+1=6'
and '10-3+2=9'. In particular, the timeslot position to
which the second parameter set will be applied can be
represented as a value resulting from adding a difference
value `bsDiffParamSlot[ps]' 409 to a value resulting from
adding 1 to the timeslot position to which the first
parameter set will be applied. So, the difference value 409
is able to correspond to 0 to 3, which can be represented
as two bits. For the second or subsequent parameter set, by
representing a timeslot position to which a parameter set
will be applied as the difference value 409 instead of
representing the timeslot position in direct, it is able to
reduce the bit number. In the former example, four bits are
needed to represent one of 6 to 9 in case of representing
the timeslot position in direct. Yet, only two bits are
needed to represent a timeslot position as the difference
value.
Hence, a position information indicating quantity
`nBitsParamSlot(0)' or `nBitsParamSlot(ps)' 413 or 415 of a
19
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
timeslot to which a parameter set will be applied can be
represented not as a fixed bit number but as a variable bit
number.
FIG. 5 is a flowchart of a method of decoding a
spatial information signal by applying a parameter set to a
timeslot according to another embodiment of the present
invention.
Referring to FIG. 5, an audio signal decoding
apparatus receives an audio signal including a downmix
signal 103 and a spatial information signal 105 (S501).
If a header 107 exists in the spatial information
signal, the audio signal decoding apparatus extracts the
number of timeslots included in a frame from configuration
information 109 included in the header 107 (S503) . If a
header 107 is not included in the spatial information
signal 105, the audio signal decoding apparatus extracts
the number of timeslots from the configuration information
109 included in a previously extracted header 107.
The audio signal decoding apparatus extracts the
number of parameter sets to be applied to a frame from the
spatial information signal 105 (S505).
The audio signal decoding apparatus decides whether
positions of timeslots, to which parameter sets will be
applied, in a frame are fixed or variable using a frame
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
identifier included in the spatial information signal 105
(S507).
If the frame is a fixed frame, the audio signal
decoding apparatus decodes the spatial information signal
105 by applying the parameter set to the corresponding slot
according to a preset rule (S513).
If the frame is a variable frame, the audio signal
decoding apparatus extracts information for a timeslot
position to which a first parameter set will be applied
(S509) As mentioned in the foregoing description, the
timeslot position to which the first parameter will be
applied can maximally be a value resulting from adding 1 to
a difference between the timeslot number and the parameter
set number.
The audio signal decoding apparatus obtains
information for a timeslot position to which a second or
subsequent parameter set will be applied using the
information for the timeslot position to which the first
parameter set will be applied (S511) . If N is a natural
number equal to or greater than 2, a timeslot position to
which a parameter set will be applied can be represented as
a minimum bit number using a fact that a timeslot position
to which an Nth parameter set will be applied is greater by
at least 1 than a timeslot position to which an (N-1)th
21
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
parameter set will be applied and even can have a value
resulting from adding N to a value resulting from
subtracting the parameter set number from the timeslot
number.
And, the audio signal decoding apparatus decodes the
spatial information signal 105 by applying the parameter
set to the obtained timeslot position (S513).
FIG. 6 and FIG. 7 are diagrams of an upmixing unit of
an audio signal decoding apparatus according to one
embodiment of the present invention.
An audio signal decoding apparatus separates an audio
signal received from an audio signal encoding apparatus
into a downmix signal 103 and a spatial information signal
105 and then decodes the downmix signal 103 and the spatial
information signal 105 respectively. As mentioned in the
foregoing description, the audio signal decoding apparatus
decodes the spatial information signal 105 by applying a
parameter to a timeslot. And, the audio signal decoding
apparatus generates multi-channel audio signals using the
decoded downmix signal 103 and the decoded spatial
information signal 105.
If the audio signal encoding apparatus compresses N
input channels into M audio signals and transfers the M
audio signals in a bitstream form to the audio signal
22
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
decoding apparatus, the audio signal decoding apparatus
restores and output the original N channels. This
configuration is called an N-M-N structure. In some cases,
if the audio signal decoding apparatus is unable to restore
the N channels, the downmix signal 103 is outputted into
two stereo signals without considering the spatial
information signal 105. Yet, this will not be further
discussed. A structure, in which values of N and M are
fixed, shall be called a fixed channel structure. A
structure, in which values of M and N are represented as
random values, shall be called a random channel structure.
In case of such a fixed channel structure as 5-1-5, 5-2-5,
7-2-7 and the like, the audio signal encoding apparatus
transfers an audio signal by having a channel structure
included in the audio signal. The audio signal decoding
apparatus then decodes the audio signal by reading the
channel structure.
The audio signal decoding apparatus uses an upmixing
unit including a signal converting unit to restore M audio
signals into N multi-channel. The signal converting unit is
a conceptional box used to convert one downmix signal 103
to two signals or convert two downmix signals 103 to three
signals in generating multi-channel by upmixing downmix
signals 103.
23
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
The audio signal decoding apparatus is able to obtain
information for a structure of the upmixing unit by
extracting channel configuration information from the
configuration information 109 included in the spatial
information signal 105. As mentioned in the foregoing
description, the channel configuration information is the
information indicating a configuration of the upmixing unit
included in the audio signal decoding apparatus. The
channel configuration information includes an identifier
that indicates whether an audio signal passes through the
signal converting unit. In particular, the channel
configuration information can be represented as a
segmenting identifier since the numbers of input and output
signals of the signal converting unit are changed in case
that a decoded downmix signal passes through the signal
converting unit in the upmixing unit. And, the channel
configuration information can be represented as a non-
segmenting identifier since an input signal of the signal
converting unit is outputted intact in case that a decoded
downmix signal does not pass through the signal converting
unit included in the upmixing unit. In the present
invention, the segmenting identifier shall be represented
as `1' and the non-segmenting identifier shall be
represented as 10'.
24
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
The channel configuration information can be
represented in two ways, a horizontal method and a vertical
method.
In the horizontal method, if an audio signal passes
through a signal converting unit, i.e., if channel
configuration information is 11', whether a lower layer
signal outputted via the signal converting unit passes
through another signal converting unit is sequentially
indicated by the segmenting or non-segmenting identifier.
If channel configuration information is `0', whether a next
audio signal of a same or upper layer passes through a
signal converting unit is indicated by the segmenting or
non-segmenting identifier.
In the vertical method, whether each of entire audio
signals of an upper layer passes through a signal
converting unit is sequentially indicated by the segmenting
or non-segmenting identifier regardless of whether an audio
signal of an upper layer passes through a signal converting
unit and then whether an audio signal of a lower layer
passes through a signal converting unit is indicated.
For the structure of the same upmixing unit, FIG. 6
exemplarily shows that channel configuration information is
represented by the horizontal method and FIG. 7 exemplarily
shows that channel configuration information is represented
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
by the vertical method. In FIG. 6 and FIG. 7, a signal
converting unit employs an OTT box for example.
Referring to FIG. 6, four audio signals X1 to X4 enter
an upmixing unit. X1 enters a fist signal converting unit
and is then converted to two signals 601 and 603. The
signal converting unit included in the upmixing unit
converts the audio signal using spatial parameters such as
CLD, ICC and the like. The signals 601 and 603 converted by
the first signal converting unit enter a second converting
unit and a third converting unit to be outputted as multi-
channel audio signals Y1 to Y4. X2 enters a fourth signal
converting unit and is then outputted as Y5 and Y6. And, X3
and X4 are directly outputted without passing through
signal converting units.
Since X1 passes through the first signal converting
unit, channel configuration information is represented as a
segmenting identifier `1'. Since the channel configuration
information is represented by the horizontal method in FIG.
6, if the channel configuration information is represented
as the segmenting identifier, whether the two signals 601
and 603 outputted via the first signal converting unit pass
through another signal converting units is sequentially
represented as a segmenting or non-segmenting identifier.
The signal 601 of the two output signals of the first
26
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
signal converting unit passes through the second signal
converting unit, thereby being represented as a segmenting
identifier 1. The signal via the second signal converting
unit is outputted intact without passing through another
signal converting unit, thereby being represented as a non-
segmenting identifier 0.
If channel configuration information is `0', whether
a next audio signal of a same or upper layer passes through
a signal converting unit is represented as a segmenting or
non-segmenting identifier. So, channel configuration
information is represented for the signal X2 of the upper
layer.
X2, which passes through the fourth signal converting
unit, is represented as a segmenting identifier 1. Signals
through the fourth signal converting unit are directly
outputted as Y5 and Y6r thereby being represented as non-
segmenting identifiers 0, respectively.
X3 and X4, which are directly outputted without
passing through signal converting units, are represented as
non-segmenting identifiers 0, respectively.
Hence, the channel configuration information is
represented as 110010010000 by the horizontal method. In
this case, the channel configuration information is
extracted through the configuration of the upmixing unit
27
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
for convenience of understanding. Yet, the audio signal
decoding apparatus reads the channel configuration
information to obtain the information for the structure of
the upmixing unit in a reverse way.
Referring to FIG. 7, like FIG. 6, four audio signals
X1 to X4 enter an upmixing unit. Since channel
configuration information is represented as a segmenting or
non-segmenting identifier from an upper layer to a lower
layer by the vertical method, identifiers of audio signals
of a first layer 701 as a most upper layer are represented
in sequence. In particular, since X1 and X2 pass though
first and fourth signal converting units, respectively,
each channel configuration information becomes 1. Since X3
and X4 doe not pass through signal converting units, each
channel configuration information becomes 0. So, the
channel configuration information of the first layer 701
becomes 1100. In the same manner, if represented in
sequence, channel configuration information of a second
layer 703 and a third layer 705 become 1100 and 0000,
respectively. Hence, the entire channel configuration
information represented by the vertical method becomes
110011000000.
An audio signal decoding apparatus reads the channel
configuration information and then configures an upmixing
28
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
unit. In order for the audio signal decoding apparatus to
configure the upmixing unit, an identifier indicating that
whether the channel configuration is represented by the
horizontal method or the vertical method should be included
in an audio signal. Alternatively, channel configuration
information is basically represented by the horizontal
method. Yet, if it is efficient to represent channel
configuration information by the vertical method, an audio
signal encoding apparatus may enable an identifier
indicating that channel configuration is represented by the
vertical method to be included in an audio signal.
An audio signal decoding apparatus reads channel
configuration information represented by the horizontal
method and is then able to configure an upmixing unit. Yet,
in case of channel configuration information is represented
by the vertical method, an audio signal decoding apparatus
is able to configure an upmixing unit only if knowing the
number of signal converting units included in the upmixing
unit or the numbers of input and output channels. So, an
audio signal decoding apparatus is able to configure an
upmixing unit in a manner of extracting the number of
signal converting units or the numbers of input and output
channels from the configuration information 109 included in
the spatial information signal 105.
29
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
An audio signal decoding apparatus interprets channel
configuration information in sequence from a front. In case
of detecting the number of segmenting identifiers 1
includes in the channel configuration information as many
as the number of signal converting units extracted from the
configuration information, the audio signal decoding
apparatus needs not to further read the channel
configuration information. This is because the number of
segmenting identifiers 1 included in the channel
configuration information is equal to the number of signal
converting units included in the upmixing unit as the
segmenting identifier 1 indicates that an audio signal is
inputted to the signal converting unit.
In particular, as mentioned in the forgoing example,
if channel configuration information represented by the
vertical method is 110011000000, an audio signal decoding
apparatus needs to read total 12 bits in order to decode
the channel configuration information. Yet, if the audio
signal decoding apparatus detects that the number of signal
converting units is 4, the audio signal decoding apparatus
decodes the channel configuration information until the
number of 1s included in the channel configuration
information appears four times. Namely, the audio signal
decoding apparatus decodes the channel configuration
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
information up to 110011 only. This is because the rest of
values are represented as non-segmenting identifiers 0
despite not using the channel configuration information
further. Hence, as it is unnecessary for the audio signal
decoding apparatus to decode six bits, decoding efficiency
can be enhanced.
In case that a channel structure is a preset fixed
channel structure, additional information is unnecessary
since the number of signal converting units or the numbers
of input and output channels are included in configuration
information that is included in the spatial information
signal 105. Yet, in case that a channel structure is a
random channel structure of which channel structure is not
decided yet, additional information is necessary to
indicate the number of signal converting units or the
numbers of input and output channels since the number of
signal converting units or the numbers of input and output
channels are not included in the spatial information signal
105.
For example of information for a signal converting
unit, in 'case of using an OTT box only as a signal
converting unit, information for indicating the signal
converting unit can be represented as maximum 5 bits. In
case that an input signal entering an upmixing unit passes
31
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
through an OTT or TTT box, one input signal is converted to
two signals or two input signals are converted to three
signals. So, the number of output channels becomes a value
resulting from adding the number of OTT or TTT boxes to the
input signal. Hence, the number of the signal converting
units becomes a value resulting from subtracting the number
of input signals and the number of TTT boxes from the
number of output channels. Since it is able to use maximum
32 output channels in general, information for indicating
signal converting units can be represented as a value
within five bits.
Accordingly, if channel configuration information is
represented by the vertical method and if a channel
structure is a random channel structure, an audio signal
encoding apparatus separately should represent the number
of signal converting units as maximum five bits in the
spatial information signal 105. In the above example, 6-bit
channel configuration information and 5-bit information for
indicating signal converting units are needed. Namely,
total eleven bits are required. This indicates that a bit
quantity required for configuring an upmixing unit is
reduced rather than the channel configuration information
represented by the horizontal method. Therefore, if channel
configuration information is represented by the vertical
32
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
method, the bit number can be reduced.
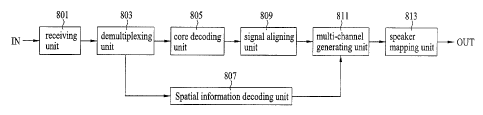
FIG. 8 is a block diagram of an audio signal decoding
apparatus according to one embodiment of the present
invention.
Referring to FIG. 8, an audio signal decoding
apparatus according to one embodiment of the present
invention includes a receiving unit, a demultiplexing unit,
a core decoding unit, a spatial information decoding unit,
a signal arranging unit, a multi-channel generating unit
and a speaker mapping unit.
The receiving unit 801 receives an audio signal
including a downmix signal 103 and a spatial information
signal 105.
The demultiplexing unit 803 parses the audio signal
received by the receiving unit 801 into an encoded downmix
signal 103 and an encoded spatial information signal 105
and then sends the encoded downmix signal 103 and the
encoded spatial information signal to the core decoding
unit 805 and the spatial information decoding unit 807,
respectively.
The coder decoding unit 805 and the spatial
information decoding unit 807 decode the encoded downmix
signal and the encoded spatial information signal,
respectively.
33
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
As mentioned in the foregoing description, the
spatial information decoding unit 807 decodes the spatial
information signal 105 by extracting a frame identifier, a
timeslot number, a parameter set number, timeslot position
information and the like from the spatial information
signal 105 and by applying a parameter set to a
corresponding timeslot.
The audio signal decoding apparatus is able to
include the signal arranging unit 809. The signal arranging
unit 809 arranges a plurality of downmix signals according
to a preset arrangement to upmix the decoded downmix signal
103. In particular, the signal arranging unit 809 arranges
M downmix signals into M' audio signals in an N-M-N channel
configuration.
The audio signal decoding apparatus directly can
upmix downmix signals according to a sequence that the
downmix signals have passed through the core decoding unit
805. Yet, in some cases, the audio signal decoding
apparatus may perform upmixing after the audio signal
decoding apparatus arranges a sequence of downmix signals.
Under certain circumstances, signal arrangement can
be performed on signals entering a signal converting unit
that upmixes two downmix signals into three signals.
In case of performing signal arrangement on audio
34
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
signals or in case of performing signal arrangement on an
input signal of a TTT box only, signal arrangement
information indicating the corresponding case should be
included in the audio signal by the audio signal encoding
apparatus. IN this case, the signal arrangement information
is an identifier indicating whether signal sequences will
be arranged for upmixing prior to restoring an audio signal
into multi-channel, whether arrangement will be performed
on a specific signal only, or the like.
If a header 107 is included in the spatial
information signal 105, the audio signal decoding apparatus
arranges downmix signals using the audio signal arrangement
information included in configuration information 109
extracted from the header 107.
If a header 107 is not included in the spatial
information signal 105, the audio signal decoding apparatus
is able to arrange audio signals using the audio signal
arrangement information extracted from configuration
information 109 included in a previous header 107.
The audio signal decoding apparatus may not perform
the downmix signal arrangement. In particular, the audio
signal decoding apparatus is able to generate multi-channel
by directly upmixing the signal decoded and transferred to
the multi-channel generating unit 811 by the core decoding
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
unit 805 instead of performing downmix signal arrangement.
This is because a desired purpose of the signal arrangement
can be achieved by mapping the generated multi-channel to
speakers. In this case, it is able to compress and transfer
an audio signal more efficiently by not inserting
information for the downmix signal arrangement in the audio
signal. And, complexity of the decoding apparatus can be
reduced by not performing the signal arrangement
additionally.
The signal arranging unit 809 sends the arranged
downmix signal to the multi-channel generating unit 811.
And, the spatial information decoding unit 809 sends the
decoded spatial information signal 105 to the multi-channel
generating unit 811 as well. And, the multi-channel
generating unit 811 generates a multi-channel audio signal
using the downmix signal 103 and the spatial information
signal 105.
The audio signal decoding apparatus includes the
speaker mapping unit 813 to output an audio signal through
the multi-channel generating unit 811 to a speaker.
The speaker mapping unit 813 decides that the multi-
channel audio signal will be outputted by being mapped to
which speaker. And, types of speakers used to output audio
signals in general, are shown in Table 1 as follows.
36
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
[Table 1]
BsOutputChannelPos Loudspeaker
0 FL: Front Left
1 FR: Front Right
2 FC: Front Center
3 LFE: Low Frequency Enhancement
4 BL: Back Left
BR: Back Right
6 FLC: Front Left Center
7 FRC: front Right Center
8 BC: Back Center
9 SL: Side Left
SR: Side Right
11 TC: Top Center
12 TFL: Top Front Left
13 TFC: Top Front Center
14 TFR: Top Front Right
TBL: Top Back Left
16 TBC: Top Back Center
17 TBR: Top Back Right
18 ... 31 Reserved
Generally, maximum 32 speakers are available for
being mapped to an outputted audio signal. So, as shown in
Table 1, the speaker mapping unit 813 enables the audio
5 signal to be mapped to the speaker (Loudspeaker)
corresponding to each number in a manner of giving a
specific one of numbers (bsOutputCahnnelPos) between 0 and
31 to the multi-channel audio signal. In this case, since
37
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
one of total 32 speakers should be selected to map a first
audio signal among multi-channel audio signals outputted
from the multi-channel generating unit 811 to a speaker, 5
bits are needed. Since one of the remaining 31 speakers
should be selected to map a second audio signal to a
speaker, 5 bits are needed as well. According to this
method, since one of the remaining 16 speakers should be
selected to map a seventeenth audio signal to a speaker, 4
bits are needed. In particular, as the number of mapping
audio signals increases, an information quantity required
for indicating speakers mapped to audio signals decreases.
This can be expressed by ceil[log2(32-bsOutputChannelPos)]
representing the bit number required for mapping an audio
signal to a speaker. The required bit number decreases due
to the increase of the number of audio signals to be
arranged, which can be applicable to the case that the
number of downmix signals arranged by the signal arranging
unit 809 increases. Thus, the audio decoding apparatus maps
the multi-channel. audio signal to a speaker and then
outputs the corresponding signal.
While the present invention has been described and
illustrated herein with reference to the preferred
embodiments thereof, it will be apparent to those skilled
in the art that various modifications and variations can be
38
CA 02620030 2008-02-21
WO 2007/027056 PCT/KR2006/003435
made therein without departing from the spirit and scope of
the invention. Thus, it is intended that the present
invention covers the modifications and variations of this
invention that come within the scope of the appended claims
and their equivalents.
[Advantageous Effects]
Accordingly, by an apparatus for decoding an audio
signal and method thereof according to the present
invention, a header can be selectively included in a
spatial information signal.
By an apparatus for decoding an audio signal and
method thereof according to the present invention, a
transferred data quantity can be reduced in a manner of
representing a position of a timeslot to which a parameter
set will be applied as a variable bit number.
By an apparatus for decoding an audio signal and
method thereof according to the present invention, audio
signal compression and transfer efficiencies can be raised
in a manner of representing an information quantity
required for performing downmix signal arrangement or for
mapping multi-channel to a speaker as a minimum variable
bit number.
By, an apparatus for decoding an audio signal and
39
CA 02620030 2011-02-08
74420-244
method thereof according to the present invention, an audio
signal can be more efficiently compressed and transferred
and complexity of an audio signal decoding apparatus can be
reduced, in a manner of upmixing signals decoded and
transferred to a multi-channel generating unit by a core
decoding unit in a sequence without performing downmix
signal arrangement.