Note: Descriptions are shown in the official language in which they were submitted.
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
DETERMINING EVENT CAUSALITY IN A WAVEFRONT ENVIRONMENT
RELATED APPLICATIONS
This application claims the benefit of priority fiom United States Patent
Applications entitled
"EFFICIENT FILTERED CAUSAL GRAPH EDGE DETECTION IN A CAUSAL
WAVEFRONT ENVIRONMENT" and "PERFORMING EFFICIENT INSERTIONS IN
WAVEFRONT TABLE BASED CAUSAL GRAPHS", both originally filed August 3, 2006.
This application also claims the benefit of priority under 35 U.S.C. 119(e)
from United
States Provisional Application Serial No. 60/705,978 and United States
Provisional
Application Serial No. 60/705,979, both originally filed August 5, 2005.
TECHNICAL FIELD
Embodiments of the present invention relate to the fields of data processing
and data
communication. More specifically, embodiments of the present invention are
related to
methods and apparatuses for determining (or allowing the determining) of event
causality in
a networking environment, and/or the usage (or allowing the usage) of the
determination.
BACKGROUND
Many problems require the understanding of and/or determining the causality
between
events. An exemplary technical problem that requires such understanding and/or
determination is the management of modem networks. Advances in semiconductor,
processor, and related technologies have led to the ubiquitous availability of
a wide range of
general and special purpose computing devices. Additionally, advances in
telecormnunication, networking, and related technologies have led to increased
connectivity
between these computing devices. Understanding the causality of events may
lead to more
efficient and effective management of these increasingly diverse networlcs.
BRIEF DECRIPTION OF THE DRAWINGS
The present invention will be described by way of exemplary embodiments, but
not
limitations, illustrated in the accompanying drawings in which like references
denote similar
elements, and in which:
-1-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
Figure 1 illustrates a block diagram of a computing environment suitable for
use in
accordance with various embodiments of the present invention;
Figure 2 illustrates a block diagram of an exemplary computing system in
accordance
with various embodiments of the present invention;
Figure 3 illustrates a graphical representation of causally related events, in
accordance with various embodiments of the present invention;
Figure 4 illustrates a graphical representation of potentially causally
related events, in
accordance with various embodiments of the present invention;
Figures 5 A-D illustrate a linear causality search progression to determine
event
causality relationships, in accordance with various embodiments of the present
invention;
Figure 6 illustrates a graphical representation of causality showing events
along
transitive edges, in accordance with various embodiments of the present
invention;
Figure 7 illustrates the graphical representation of causality of Figure 3
partitioned
into causal chains, in accordance with various embodiments of the present
invention;
Figure 8 illustrates the partitioned graphical representation of causality of
Figure 7
showing arrays to represent causal tables, in accordance with various
embodiments of
the present invention;
Figure 9 illustrates the partitioned graphical representation of causality of
Figure 7
showing linked lists to represent causal tables, in accordance with various
embodiments of the present invention;
Figure 10 illustrates the partitioned graphical representation of causality of
Figure 7
showing a packed representation for causal tables, in accordance with various
embodiments of the present invention;
Figure 11 illustrates the partitioned graphical representation of causality of
Figure 7
showing an event table where each causal chain maintains a master index of all
other
causal chains, in accordance with various embodiments of the present
invention;
Figure 12 illustrates a partitioned graphical representation of causality
showing two
event types where both event types include binary counters, in accordance with
various embodiments of the present invention;
-2-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
Figure 13 illustrates a partitioned graphical representation of causality of
Figure 7
further showing a causal graph partitioned into subspaces or cells, in
accordance with
various embodiments of the present invention;
Figure 14 illustrates the partitioned graphical representation of causality of
Figure 13
showing boundary events at subspace or cell boundaries, in accordance with
various
embodiments of the present invention;
Figure 15 illustrates inulti-phase storage of events within an event subspace,
in
accordance with various embodiments of the present invention;
Figure 16 illustrates two phase boundary event subspace causality
deterinination, in
accordance with various embodiments of the present invention;
Figure 17 illustrates an inserted node, and the effect on wavefront tables in
the
successor portion of the graph, in accordance with various embodiments of the
present invention;
Figure 18 illustrates how the invalidation zone can be represented through a
successor wavefront, in accordance with various einbodiments of the present
invention; and
Figure 19 illustrates how the invalidation wavefront is represented as a
single value
attached to the chain with insertion, in accordance with various embodiments
of the
present invention.
Figures 20 A and B illustrate a filtered directed acyclic graph (DAG) using a
non-
minimal set of connecting edges and a minimal set, respectively;
Figure 21 illustrates a filtered DAG with aii event to be inserted at the
insertion point,
the filtered DAG including a DAG minimal set of events having no predecessor
events and DAG maximal set of events having no successor events;
Figure 22 illustrates one progression of the explicit search algorithm for
deriving the
maximal predecessor set for the inserted event in accordance with one
embodiment of
the present invention;
Figure 23 illustrates one progression of the explicit search algorithm for
deriving the
minimal successor set for the inserted event in accordance with one embodiment
of
the present invention;
Figure 24 illustrates a filtered DAG with the event inserted;
-3-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
Figure 25 illustrates the DAG from Figure 18 broken down into filtered chain
lists in
accordance with one embodiment of the present invention;
Figure 26 illustrates using a filtered chain list procedure to find the
maximal
predecessor set in accordance with one embodiment of the present invention;
and
Figure 27 illustrates using the filtered chain list procedure to find the
minimal
successor set in accordance with one embodiment of the present invention; and
Figure 28 illustrates a filtered chain list and DAG with the event inserted.
DETAILED DESCRIPTION OF ILLUSTRATIVE EMBODIMENTS
Embodiments of the present invention include, but are not limited to, methods
related to
filtering directed acyclic graphs (DAGs) derived from tracking event causality
in wavefront
tables following at least one node insertion as derived from a plurality of
events, while
maintaining transitive event relationships; in particular, in a network
environment,
employing filtered chain lists and apparatus or systems equipped to practice
the method or
aspects thereof.
In the following detailed description, reference is made to the accompanying
drawings which
form a part hereof wherein like numerals designate like parts througlzout, and
in which are
shown, by way of illustration, specific embodiments in which the invention may
be
practiced. It is to be understood that other embodiments may be utilized and
structural or
logical changes may be made without departing from the scope of the present
invention.
Therefore, the following detailed description is not to be taken in a limiting
sense and the
scope of the present invention is defined by the appended claims and their
equivalents.
In the following description, various embodiments will be described with some
details to
facilitate understanding. For purposes of explanation, specific numbers,
materials and
configurations are set forth. However, it will be apparent to one skilled in
the art that
alternate embodiments may be practiced without the specific details. In other
instances,
well-known features are omitted or simplified in order not to obscure these
embodiments.
Parts of the description will be presented in terms such as data, events,
partitions, subspace
boundaries and the like, consistent witli the manner commonly employed by
those slcilled in
the art to convey the substance of their work to others skilled in the art. As
well understood
by those skilled in the art, information may take the form of electric,
magnetic, RF, or optic
-4-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
signals capable of being maintained, stored, transferred, combined, and
otherwise
manipulated through electrical and/or optical components of a processor and
its subsystems.
The description will be presented in sections. Employment of section labels is
to facilitate
ease of understanding, and is not to be construed as limiting on the
invention. Various
operations will be described as multiple discrete steps in turn, in a manner
that is most
helpful in understanding the present invention; however, the order of
description should not
be construed as to imply that these operations are necessarily order
dependent. In particular,
these operations need not be performed in the order of presentation.
Reference in the specification to "one embodiment" or "an embodiment" means
that a
particular feature, structure, or cliaracteristic described in connection with
the embodiment is
included in at least one embodiment of the invention. The appearances of the
phrase "in one
enibodiment" or "in an embodiment" in various places in the specification do
not necessarily
all refer to the same embodiment; however, they may. The terms "comprising",
"having",
and "including" should be considered synonymous, unless context dictates
otherwise. The
phrase "A/B" means "A or B". The phrase "A and/or B" means "(A), (B), or (A
and B)".
The phrase "at least one of A, B, and C" means "(A), (B), (C), (A and B), (A
and C), (B and
C) or (A, B and C)". The phrase "(A) B" means "(A B) or (B)", that is "A" is
optional. The
use of any of these phrases does not imply or indicate that the particular
feature, structure, or
characteristic being described is a necessary component for every embodiment
for which
such a description is included.
Computing Environment Overview
Referring now to Figure 1, wherein a block diagram illustrating a coinputing
enviromnent
100, in accordance with various embodiments, is shown. As alluded to earlier,
while the
present invention will be primarily described in the context of network
management, it is not
so limited, and may be practiced in other applications that require
understanding of causality
between two events and/or phenomenon.
As illustrated, computing environment 100 includes a private network 102
coupled to a
public networlc 114. More specifically, private networlc 102 includes a number
of
application servers 104, user computers 106 and gateways 108 coupled to each
other and
public network 114 as shown. Additionally, private networlc 102 includes
sensors 110 and
-5-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
network management servers 112 coupled to each other and the earlier
enumerated elements
as shown. In various embodiments, public network 114 may include the Internet.
Sensors 110 are einployed to monitor networlc traffic and to detect and report
occurrences of
a wide range of events, whereas management servers 112 are deployed to manage
private
networlc 102 based at least in part on events detected and reported by sensors
110. In
particular, at least one of management servers 112 is equipped with a
communication
interface and a causality module. The communication interface is configured to
receive data
associated with the occurrence of events of interrelated chains of events. The
causality
module is configured to determine causality and associate the
detected/reported events, to
maintain a record of its predecessor events with embodiments of the causality
logic of the
present invention, and to facilitate management of private network 102. The
term "event" as
used in this context broadly includes virtually all occurrences and happenings
that may be
sensed, monitored, and/or reported upon.
By virtue of the causal relationslzip analysis capability, embodiments of the
present invention
are particularly suitable for managing large networks. However, embodiments of
the present
invention are also suitable for and may be deployed to manage medium to small
networlcs.
Thus, depending on the size of private network 102, with respect to the
voluine of network
traffic, and/or the nuniber of events, one or more sensors 110 may be used to
detect and to
report occurrences of events. Similarly, management server 112 may be employed
to
manage the network.
In alternate einbodiments, some or all of sensors 110 may be combined with
management
servers 112. Alternatively, a management server 112 could be used to manage
multiple
networks. In still other einbodiments, some or all of application servers 104
may also be
combined with management servers 112. Likewise some or all user computers may
be
combined with the application servers and/or management servers 104/112.
Except for the causal relationship analysis logic contained in the causality
module provided
to at least one of management servers 112, the enumerated elements of Figure 1
otherwise
represent a broad range of the corresponding elements known in the art. Thus,
the
computing environment 100 may include any number of application servers,
sensors,
management servers, user computers, gateways, and the like. Embodiments of the
present
invention may use a plurality of network device elements, provided the
elements are
-6-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
properly endowed with the resources to handle the resulting number of users
and level of
usage the elements are to collectively support.
Network Management Server
Figure 2 illustrates a blocle diagram of computing device 200, which is
suitable for use as a
management server 112, in accordance with various embodiments. As illustrated,
computing
device 200 includes one or more processors 202, systeni memory 204, mass
storage devices
206, input/output devices 208 and commuiiication interfaces 210. Exemplary
mass storage
devices 206 include diskettes, hard drives, CDROMs, DVDs and the like;
exemplary
input/output devices 208 include keyboards, cursor controls and the like; and,
exemplary
communication interfaces 210 include network interface cards, modems and the
like. The
elements 202-210 are coupled to each other via system bus 212, which may
represent one or
more buses. In the case of multiple buses, the buses may be bridged by one or
more bus
bridges (not shown).
System memory 204 and mass storage device 206 are employed to maintain and/or
to store a
working copy and a permanent copy (not shown) of the programming instructions
implementing network management software 222 including event causal
relationsliip
analysis logichnodule(s) 224. The permanent copy of the prograinming
instructions may be
loaded into mass storage device 206 in the factory or in the field through,
e.g., a distribution
medium (not shown) or through communication interfaces 210 from a distribution
server
(not shown).
Except for networlc management software 222, in particular, causal
relationship analysis
logic/module(s) 224, the constitution and function of elements 202-212 are
known generally
and, accordingly, they will not be further described.
Network Management
In various embodiments, network manageinent software 222 is adapted to be able
to
compute and to track the causal relationship of occurrences of events in
private network 102
through analysis of networlc traffic. The causal relationship analysis logic
in causality
module(s) 224 allows network management software 222 to efficiently perform
analysis on
all or selected traffic occurring in private network 102 even though it may be
constrained in
-7-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
computation power and/or storage space. In particular, in various embodiments,
networlc
management software 222 is able to establish causal relationships between
noticeably odd
behaviors and to detect subtleties that would have been hidden otherwise. What
constitutes
"odd behavior" and/or "subtleties" is application dependent. As will be
apparent from the
description to follow, the nature of "odd behavior" and/or "subtleties" of a
particular
application may be reflected through the configuration of the analysis and/or
usage of the
analysis.
For example, in one embodiment, one or more sensors 110 may be allocated to
track
connections between computers 106 and/or application servers 104, their
connection types,
and the quantity of data transferred. Then, assume that the one or more of
sensors 110 are
able to detect a connection from a first coinputer 106 to a finance file
application server 104
transferring a large quantity of data; and, some time later, another
connection between the
first computer 106 and second computer 106 performs another transfer of a
large quantity of
data. Finally, a connection is detected between the second computer 106 and an
Internet
based disgruntled employee website, performing a similarly large data
transfer. From these
reported detections, management server 112 may infer that one or more
employees may have
transferred some amount of financial data to a disgruntled einployee web site.
While
management server 112 may not have immediate insight into the actual data
transferred, the
events justify issuing an alert for a deeper investigation.
Causal Granularity
In various embodiments the immediate causal relationship, which may be of
value to
subsequent computations, may be selectively determined using different levels
of
granularity. Thus, depending on the information available to a particular
management server
112, e.g., with respect to a particular computer and/or communications on the
network, the
causal relationship may be selectively determined. For example, in one
embodiment, if a
management server 112 has no information on how the processes executing on a
particular
server modify the file system or interact through shared memory, the
management server 112
may assume that all events that occur on that ser=ver are causally related.
-8-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
Causal Chain Application
In various embodiments, to simplify and reduce the amount of analysis, a
management
server 112 may use causal chains and associate the causal chains with one or
more
recognizable entities. Exemplary recognizable entities include a work station,
a process, a
server, and the like. In one embodiment, several entities may be excluded from
being
considered, because some events they produce may be considered locally
causally
independent. Some examples of these excluded entities include firewalls,
routers, switches,
hubs, and the lilce. In one embodiment a management server 112 does not
automatically
consider two events on a firewall to be necessarily causally independent,
rather management
server 112 further determines the causality by observing the effects both
observed events
have on the rest of the networlc.
Storage Approach
In various embodiments, each management server 112 used to compute the causal
relationship is endowed with a relatively very large but relatively slow hard-
drive, and a
relatively small but relatively very fast bank of physical memory. The
arrangement
facilitates a two phase approach to the causal relationship analysis wherein
one phase of the
analysis exploits the large size of one type of storage and the other phase of
the analysis
exploits the speed of the other type of storage. However, in one embodiment, a
management
server 112 may use the memory for first phase storage due to its limited size,
and use the
hard-drive for second phase storage because of its limited speed.
In various embodimeirts, the causal relationship analysis may employ the
concept of event
subspaces or cells, and involve looking up events in a small number of
subspaces or cells.
Thus, for speed, events of the subspaces or cells may be maintained and/or
stored in physical
memory. In one embodiment, the causal relationship analysis may involve a
lookup event in
a large number of infrequently referenced subspaces or cells. Thus, the data
will be archived
for a long period of time and events in these subspaces or cells are stored in
the storage space
of the hard-drive. However, in one embodiment, a caching mechanism is employed
whereby
events associated with subspaces or cells which are not frequently needed are
flushed out of
physical memory and events associated with subspaces or cells that are
required for new
computations are imported from the hard-drive. Under this scheme, it is not
necessary to
-9-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
conserve as much space in physical memory as on disk nor is it necessary to
require that
much performance from the disk. Therefore, the embodiment designates the disk
as first
phase storage and doubly optimizes events associated with subspaces or cells
stored there for
space and designates physical memory as second phase storage and doubly
optimize events
associated with subspaces or cells stored there for speed.
Introduction To Causal Relationship Analysis
For the purpose of this application, a causal relationship is a relationship
between two
events, a and b, which states that a meaningfully preceded b. By this, we mean
that not only
did a happen at an earlier time than b but, rather, that a was part of the
chain of events that
led to b. The causal relationship is transitive and anti-reflexive. In other
words, a> b and
b-> c implies that a-> c and that b -/> a. The causal relationship is also the
transitive
closure of the immediately causal relationsliip (-->) between two events, a
and b, wliich
states that not only did a precede b, but there were no intermediate events
between a and b.
In various einbodiments, maintenance of the immediate causal relationship is
effectuated by
each event having pointers back to immediate causal predecessors. In order to
quickly
determine whether two events are causally related, a summary of the transitive
closure of
this relationship is maintained.
In general, this can be both time consuming (O(n3), where 0 is the number of
operations to
be performed and n is the number of events tracked), and space consuming
(O(n2), in
addition to the space required for storing eveilts). The alternative to
maintaining a transitive
summary is to search through the immediate causal relationships to find
whether one event
transitively leads to another (O(n) per query, with n2 possible queries).
Below a series of
techniques are described in turn to exploit the commonalities in communication
behavior,
which may significantly reduce the space required to maintain and/or to store
a transitive
suinmary and the time required to compute it.
Turning now to Figures 3, 4, and 6-16, particular methods of various
embodiments are
described in terms of operational mechanisms with reference to a causality
graph. The
methods and techniques to be performed by a causality module constitute
operational
programs performed by computing devices or computer-controlled network
devices, such as
management server 112. Describing the operational methods of the causality
module by
-10-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
reference to a graphical representation enables one skilled in the art to
develop such
operational programs including such instructions to carry out the methods on
suitably
configured network devices (causality management server, user computers,
servers,
gateways, sensors, and the like).
The operations may be perforined in a computer controlled device or may be
embodied in a
network device. If written in a prograinming language conforming to a
recognized standard,
such instructions can be executed on a variety of hardware platforms and for
interfaces to a
variety of operating systems. In some embodiments, all or portions of the
methods may be
implemented via firmware. In yet other embodiments, all or portions of the
methods may be
implemented in hardware.
It will be appreciated that a variety of devices and methods may be used to
iinplement the
causality management system for a network as described herein. Furthermore, it
is common
in the art to speak of operations, in one form or another (e.g., program,
procedure, process,
application, etc.), as taking an action or causing a result. Such expressions
are merely a
shorthand way of saying that execution of the operation by a device causes the
causality
module of the management system to perform an action or to produce a result.
The Causality Problem
In various embodiments, the causality problem of determining the causal
relationship of the
events and event associations may be represented by a causality graph
representing the
immediate causal relationship of all events. The causality problem is to
determine whether
two events are causally related. In other words, for two events, determine
whether there is a
path between them in the immediate causality graph.
Figure 3 shows an example with two events, a and e, that are causally related
through
intermediate events b, c, and d. Accordingly, there is a path between events a
and e in this
graph of immediate causal relationships.
Although this graph is small enough that the relationship is fairly apparent
to the observer; in
general, the problem looks more like Figure 4, wllere there is local
information for each
event and a cloud of unknown events on the graph or network between the
events.
Accordingly, determining whether two arbitrary events, a and e, are causally
related requires
clarifying the cloud of events that exist between events a and e.
-11-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
In various embodiments, one or more of several approaches may be used to solve
this
causality problem. Exemplary approaches include a linear search, an explicit
transitive
closure, variations on table-based approaches, and mixed counter methods. A
linear search
approach investigates a potentially large number of events to determine
whether two
arbitrarily chosen events are causally related. The explicit transitive
closure methods could
require a large ainount of space to store the relationship information for a
relatively small
number of events. Variations of table methods produce rapid results with
significantly less
storage than the explicit transitive closure methods. Mixed counter methods
produce results
that take slightly more time than the various table methods, but also require
significantly less
space.
Partial Causality
As previously discussed, the mere knowledge of the times at wliich events
occur is
insufficient to determine the causal order. For example, events that happened
at different
times may still be causally independent. However, knowing that one event
occurred at an
earlier time than another event does reveal that the second event cannot be a
causal
predecessor of the first event. As a result, it is often possible to compute
part of the causality
equation very quickly based on simple time stamps, and to aclcnowledge how
those time
stamps relate to each other. For example, if all timestamps are assumed to be
precisely
accurate, given two events, a and b, such that b has a later time stamp than
a, it can be ruled
out b-> a as a possibility.
Linear Search Approach
In various embodiments, the linear search approach begins with one of the two
events, and
searches outward on all immediate causal links, seeking the other event. In
the worst case, it
may be necessary to investigate all known events to determine that there is no
causal link
between the two. Figure 5 demonstrates the linear search approach to determine
a-> b.
The term "outward" is employed for ease of understanding. The directional
characterization
is not to be limiting on the present invention.
-12-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
A partial causality test, where possible, can restrict the direction of
search. In our example,
we may be able to rule out e -> a, so we need only search events that succeed
a and precede
e.
Explicit Transitive Closure Approach
In various embodiments, the explicit transitive closure approach adds
annotations to the
graphical representation of causality to help reduce the time it takes to
determine whether
there is a path between a particular pair of events. In this case, the
annotations are the edges
that specifically represent the full causal relationship or the transitive
closure of the
inunediate causal relationship. Figure 6 shows part of an example graph with
the transitive
edges as dashed lines. a-> e is represented as a single transitive edge.
Although these annotations can provide an answer to the causal problem in
constant time, it
takes O(n3) time to compute the annotations, and O(n2) space to store tllem.
The Table Approach
In various embodiments, a causality annotation method that allows us to find a-
> b in
substantially constant time is employed. This methodology may also require
significantly
less space than storing one based on the explicit transitive closure method.
Some practical
issues with respect to data structure are discussed in greater detail at the
end of the section.
For the embodiments, the first operation of a table-based approach is to
partition the
iinmediate causal graph into causal chains, where a causal chain is an
incomplete sequence
of events such that each event in the chain is causally related to all other
events in the chain.
Figure 7 shows the graphical representation of causality from Figure 3
partitioned into
causal chains. This partition is not unique - there may be otlier, and
possibly better, ways to
partition this causality graph; however, in various embodiments, this is afull
partition, which
means that none of the causal chains can be merged. To understand this,
consider merging
chains c2 and c3. Since events b and c are not causally related to many of the
events in c2,
they are not allowed to be in the same causal chain with those events.
As Figure 7 shows, many edges are not part of any causal chain. In fact, each
chain can be
as small as selected - down to a single event. But as explained below, it is
beneficial to lceep
the largest possible causal chains.
-13-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
The next operation is to annotate the graphical representation of causality
with the position
of each event relative to the causal chains. For example, event a is the first
event in chain
c2; event b is the first in chain c3, but it follows the first in chain c2;
event c is the second in
chain c3, but it follows the first in chain c2; etc. These annotations can
take the form of
tables, where each chain with a causal predecessor has an entry, and each
entry contains the
position of the latest predecessor in that chain, plus 1. If an event is the
first in its chain, the
table entry for its own chain contains the value 1. In the example, the table
for a contains
c2:1; the table for b contains c2:2 and c3:1; the table for event c contains
c2:2 and c3:2; etc.
From another perspective, each causal table contains data representative of a
predecessor
wavefront, where all preceding events for a particular event are either on or
behind its
wavefront. In this manner, each causal table identifies the events that are on
the predecessor
wavefront (hereinafter, may also simply be referred to as wavefront), and as
such, these
causal tables may also be known as predecessor wavefront tables (or simply,
wavefront
tables). For the purpose of this specification, these terms, i.e., "causal
tables", "predecessor
wavefront tables", and "wavefront tables" may be considered synonymous unless
the context
clearly indicates otherwise.
Assuming the causal chain for an event can be determined in substantially
constant time
(feasible for many causal chain schemas), the complexity of this algorithm
with n causal
chains and a maximum of p predecessors per event is O(np). There is usually a
small upper
bound on the number of immediate predecessors each event can have ( 3 ) which
means that
the complexity of computing the predecessor wavefront table is O(n) for each
event added.
For the embodiments, the methodology for evaluating the causal relationship
between two
events, a, b, given the predecessor wavefront (PW) tables for both is as
follows:
Look up the entries for a's causal chain in both PW tables. If b's value is
greater than a's value, then a-> b.
Look up the entries for b's causal chain in both PW tables. If a's value is
greater than b's value, than b-> a (properly constructed PW tables will ensure
that both conditions do not occur).
If neither of the two conditions are true, then neither a-> b, nor b-> a.
If a PW table does not have an entry for a particular chain, the value for
that chain is
assumed to be 0.
-14-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
In the example, event a has the PW table {C2 : 1} and e has the PW table {c2 :
2, 0 : 3, e4
:
2, C6 : 5}. Coinparing a's entry for e's chain (c6) to e's entry for c6 yields
0< 5 meaning e
a. Comparing e's entry for a's chain (c2) to a's entry for c2 yields 2> 1
wllich means a
e, exactly as expected.
For these embodiments, this approach only requires four lookups and two
comparisons,
regardless of the size of the PW tables. Because lookups are expected to be
the most
common behavior, this is a very desirable property. However, these benefits
are typically
balanced with other factors, including that the PW tables, in a worst case,
have as many
elements as there are causal chains.
Another factor alluded to earlier, to be considered in implementing this
technique is the
number of operations 0 required for the completion of the analysis.
Specifically, if the
number of chains depends on the nuinber of events, it would require O(n) space
for each PW
table, or O(n2) space for the complete set of annotations (the saine as the
explicit transitive
closure). Moreover, if there is no limit on the number of events in a chain,
the PW table
elements may each require limitless space to store.
Maintaining Tables Efficiently
In various embodiments, the PW tables are implemented with arrays whose size
are equal to
the total number of causal chains recognized by the system, as illustrated in
Figure 8. Each
causal chain is then assigned a number and that number is the index to the
value
corresponding to that chain. This may tend to produce a very large
representation if there are
a large number of causal chains and much of the array may be either unused or
contain
redundant information.
Linked Table Technique
Alternatively, in other embodiments, each causal chain may be assigned an
index, as
illustrated in Figure 9. As previously discussed, instead of allocating a full
array for each
PW table, the array is allocated as necessary one element at a time. Each
element containing
useful data also contains a pointer to the next element that contains useful
data. Since the
index is no longer implicit based on an offset into the array, in various
embodiments, the
index of each element is stored with the element as well. To find the entry
for a particular
-15-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
index, in various embodiments, a linear search of all elements is performed,
comparing the
index to our desired index until the desired element is encountered. In a
worst case scenario,
this technique could require up to three times the memory of the native
approach.
Chunk Allocated Tables
In various embodiments, if the maximuin size of a PW table is known and the
size is
considered to be satisfactorily below the total number of causal chains, this
may justify use
of this sparse method where all of the memory required for each PW table may
be allocated
at once. In this case, since all elements are packed within a single chunk of
memory with no
spaces between them, it is not necessary for any element to include a pointer
to the next
element. Finding a particular element is implemented with a binary search to
first read the
index of the middle element. Second, if the middle element index is equal to
the index
sought, that element is returned as a result of the search. Third, if the
middle element index
is greater than the index sought, perform the first operation on the lower
half of the block.
Fourth, if the middle element index is less than the index sought, perform the
first operation
on the upper half of the block.
Hash Tables
In various embodiments, PW tables may be stored as hash tables. Depending on
the quality
of the hash function and hash table loading, this can provide effectively the
substantial
constant time lookup of elements as the case with explicit arrays, and much of
the storage
efficiency of the linked list or chunk allocated sparse arrays. However, in
order to ensure
fast lookups, the hash table often needs to be much larger thaii the amount of
data stored.
Chain Indexed Tables
One issue with the block allocated method is that the offset of a particular
key may differ
from one PW table to another, even within the same causal chain. This is wlzy
it is necessary
to perform a binary search for each lookup. The reason the position of a lcey
may differ from
one PW table to another is because each event may require a PW table with one
or more
cells than the previous event in the chain and there is implicit requirement
that all elements
must occur in array order.
-16-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
In various embodiments, the chain indexed method is employed to relax this
requiremeilt.
As shown in Figure 11, the size of each PW table is sized to the number of
entries required,
but entries are ordered based on when each of the other causal chains becomes
known to the
chain containing the PW tables. Thus, for each causal chain, each index
appears in the same
place in every array that contains that index.
The Mixed Counter Method
In various embodiments, a mixed counter method is employed. For these
embodiments, the
mixed counter method keeps two or more types of counters instead of uniformly
assigning a
PW table to each event. This approach works well when there are a large number
of events
within a causal chain wliose immediate causal relatioiis are in the chain as
well.
Binary Mixed Counters
In various einbodiments, a binary mixed counter method is employed. For these
embodiments, it is assumed there are at least two types of events; a type e
event has no
immediate predecessors outside of its own causal chain; and a typef event has
at least one
immediate predecessor outside of its own causal chain.
As illustrated in Figure 12, the events with dashed outlines are of type e,
and the solid
outline events are of typef
Type e events are then assigned scalar counters that maintain a count back to
the most recent
type f event, and only typef events require full PW tables. Determining
causality between
two events; however, becomes a little more complicated. Specifically, the
causality of
events, a and b, then becomes a determination of whether a and b are type e or
f. For typef
events, look up the values for a's and b's causal chain in the respective PW
table. For type e
events, look up the values for a's and b's causal chain in the most recent
typef event and add
the scalar counter to the value from its own chain. Compare the resultant
values as above. If
event a's value for b's causal chain is larger than b's own value, than b a.
Likewise, if
event b's value for a's causal chain is larger than a's own value, than ab.
Otherwise,
there is no relationship.
Again, for properly maintained PW tables, there is no chance that a's value
for b's causal
chain will be greater than b's value at the same time as b's value for a's
causal chain is larger
-17-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
than a's own value. In the worst case, computing causality between two events
using binary
mixed counters may now require up to eight loolcups, two adds, and two
comparisons.
Ternary Mixed Counters
In various einbodiments, the ternary mixed counter method is employed. For
these
embodiments, there are three types of events and two types of causal chains.
This method
works well when there is a clear dichotomy between the numbers of
intersections found in
causal chains. The types of causal chain are Type 1 and Type 2.
A Type 1 causal chain has direct intersections with a vast number of other
causal chains.
A Type 2 causal chain has direct intersections with only a few other causal
chains, and most of those are type 1 causal chains.
The definition of these causality chain types is based in part on factors that
help reduce the
storage space necessary for each application. These factors provide some
flexibility in
assigning causal chains to one type or the other.
The three types of events are type e, type f, and type i. Type e is an event
on either type of
chain that has no immediate predecessors outside of its own chain. Type f is
an event on a
type 1 chain that has predecessors outside of its own causal chain. Type i is
an event on a
type 2 chain that has predecessors outside of its own causal chain.
With this method, type e events are assigned scalar counters which count back
to the most
recent type f or type i event. Type f eveiits get full PW tables, but type i
events can either
have full PW tables or pointers to a type e or typef event on a type 1 chain.
Divided Event Space
In various embodiments, to further improve efficiency, the event space is
partitioned into
subspaces so that the simple formulation may be applied to each subspace. The
scope of an
event space is application dependent. An example is a networlced computing
environment in
support of one or more mission critical applications for an
organization/entity. For these
embodiments, this configuration allows both the number of causal chains and
the number of
events per causal chain to be controlled. Provided the partition is causally
consistent,
completion of causality comparisons between events in the same subspace may
stay
-18-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
relatively constant. Causality comparisons made between events from different
subspaces
require additional computation time based in part on the number of subspaces
and the
number of boundary events.
Figure 13 shows an event space partitioned into four subspaces or cells. A
subspace or cell
is effectively a container for a number of events. Connections between events
in different
subspaces or cells are facilitated by adding boundary events. Figure 14 shows
the
partitioned causality graph from Figure 13 with appropriate boundary events.
In order to
compute the causal relationship between events in two different subspaces, the
causal
relationship between each event and the boundary event or events for its
subspace are first
computed. Thereafter, the causal relationship between the boundary events on
the different
subspaces are computed. For example, to determine the causal relationship
between event a
and event e in a divided space, the system would first determine that a-> abi,
a-> acl, cdl
-> e, and cd2 -> e. Next, the system would determine that acl -> cdl, and acl -
> cd2.
Finally, the system constructs applicable paths from one event to another,
resulting in the
conclusion that a-> e through two paths: a-> acl -> cdl -> e and a-> aci ->
cd2 -> e,
therefore a-> e. Of course, e-> a through zero paths, therefore e-l> a.
As described earlier, the divided event space technique works better if the
subspace
partitions are substantially consistent, i.e., if one arrow points from
subspace a to subspace b,
then no arrows will point from subspace b to subspace a and, more restrictive,
if one can
trace a path from subspace a to subspace b by traveling arrows from tail to
head, then there
is no similar path between subspace b and subspace a. If the subspace
partition is not
substantially consistent, it becomes necessary to evaluate boundary events
when determining
the causality between events in the same subspace.
When using PW tables to determine causality within a subspace, the boundary
events must
each maintain a separate PW table for each subspace they belong to. These
boundary events
may also maintain a higher order PW table to establish the relationships among
boundary
events directly.
-19-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
Hierarchical Divided Event Space
In various embodiments, a hierarchical divided event space method is employed.
For these
embodiments, subspaces can contain either events or other subspaces. This
gives us a way
to quickly determine between boundary events. Pushed to an extreme, the
approach
provides a method for quickly (O(lg n)) solving the causality problem without
PW tables.
For example, each event comprises a subspace, and these subspaces are grouped
into higher
subspaces, etc. until all events are contained within a single very high order
subspace.
Determining the relationships between events relies on first finding a
hierarchical level
where each event is in a separate subspace, but the subspaces are neighbors.
On each side of
the split, perform the same algorithm between the query event and the boundary
events. The
process is repeated until there is an answer.
Multi-Phase Storage Approaches
In various embodiments, a multi-phase approach is employed. For these
einbodiments, the
approach requires different amounts of storage depending on storage phases.
Storage phases
account for different types of storage media and optimize for space, access
time, and other
factors. Subspaces can move from one phase to another over time. Multi-phase
storage can
demonstrate a great deal of benefit when applied heterogeneously to a network
of storage
subspaces; that is, different cells in the system are in different storage
phases.
Figure 15 illustrates an extreme case of multi-phase storage. In one phase,
the subspace is
represented without any causal markings; aiid, in the second phase, the entire
subspace is
fully marked. In this extreme case, there may be two storage phases. Phase one
has no
causal optimization tags at all, and phase two has all events fully tagged
(with PW table, or
full transitive closure). This extreme approach does not work well in a
heterogeneous
environment because moving a subspace from phase one to phase two may require
moving a
number of otller subspaces as well. In order to compute the relations for the
boundary
subspaces, the other side of the boundary needs to be computed.
As shown in Figure 16, in various embodiments, a mix approach has phase one
identify
boundary events, and phase two reconstruct the subspace with a binary or
ternary count. In
this manner, much of the space savings of the extreme case is retained, but
the causal tags
may be rebuilt based on purely local information and the storage space
required for the
-20-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
second phase is also reduced. For example, events not having a boundary event
as a
predecessor event may include a counter to the next fully tagged event.
The Insertion Problem
Each of the approaches described above requires that some form of wavefront
table is
maintained for each event in the causal graph. Since this wavefront table
represents, to some
degree, the state of the graph preceding each event, the wavefront table is
valid only if there
are no changes to this predecessor state. Such a change may occur when new
events are
inserted into a graph, such that the inserted events precede events that are
already in the
graph. In this case, the wavefroizt tables of all successor events must be
recomputed.
In one embodiment, all wavefront tables of existing events are recomputed
whenever an
event with existing successors is inserted into the graph. While this approach
is adequate, it
may require excessive coinputation for each insertion. Alternatively, one
embodiment only
re-computes those tables whose events succeed the inserted node.
Unfortunately, the data
structures and algorithms described do not contain enough information to make
this
determination a pNioNi. Fortunately, it is possible, given a small amount of
additional
information per causality chain, to determine whether a particular table is
still valid, or
whether the table has been invalidated by predecessor insertion. Given this,
it is then
possible to re-compute an event's wavefront table only when it is needed, and
only if it has
been invalidated by one or more predecessor insertions. This has the
additional benefit of
allowing a table to be invalidated by multiple predecessor insertions and be
re-computed
only once. Figure 17 shows the effect of an insertion, illustrating the
successor nodes whose
tables are invalidated by the insertion in accordance with at least one
embodiment of the
present invention.
The Successor Wavefront
Similar to predecessor wavefronts, each event with successors can have its
entire set of
successors represented by a successor wavefront. In one einbodiment, an event
is an element
of the successor wavefront if either 1) it is an immediate successor of the
inserted event or 2)
it is an indirect successor of the inserted event but it has at least one
immediate predecessor
that is not a successor of the inserted event. All events, x, that succeed a
particular event, e,
-21-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
must either be on the successor wavefront or in front of the successor
wavefront. Figure 18
illustrates the nodes that make up the successor wavefront of the graph in
Figure 17.
The successor wavefront could be tracked by tables (as is the predecessor
wavefront), but
successor wavefronts often change more rapidly than predecessor wavefronts,
and, as such,
would incur more frequent invalidation. In this case, the successor tables
would become
invalid every time an event having at least one successor event was added to
the graph.
Since most insertion events would be expected to be added to the causal graph
towards the
end (i.e., with no successors already in the graph), the maintenance costs of
successor tables
would quicldy overcome the benefits they provide.
Fortunately, it is not necessary to track an event's successor wavefront. In
order to
determine if a wavefront table is invalid, the causality module determines
whether that event
is on the edge or in front of the successor wavefront of any inserted events.
This can be
determined by adding a value to each causality cliain that represents the
count of the highest
valid table entry for that chain. To determine whether a particular wavefront
table is valid,
its entries are compared with the count value for each chain. If any entry is
greater than the
count value for any of the causality chains, then the table is invalid. Figure
19 illustrates the
valid number derived from the insertion point of the inserted node in
accordance with one
embodiment of the present invention.
Before using a particular table, the table should be checked for validity.
Since the table is
only checked when data in the table is accessed, a table may be invalidated
many times but is
only rebuilt once. Although this process does add a computation cost to
checking tables, the
embodiment can also leverage the cellular nature of some of the storage
techniques
described above. In many cases, all tables in a particular cell are valid and,
if so, the detailed
clzeck described above may be unnecessary. To deterinine whether all tables in
a cell are
valid, tone embodiment associates a Boolean state with each cell that is set
to "true" when all
tables are rebuilt and "false" when any changes are made to a cell that would
either
invalidate one or more tables or that add events that have no tables yet.
The Filtering Problem
The descriptions above focus on ways in which the causality between two
individual events
can be computed quickly. In most applications of causality it is likely that
only a relatively
-22-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
small set of significant events will be chosen from the complete set of all
events and the
causal relationship between all the chosen events must be computed. In one
embodiment,
the system is configured using a simplistic approach to perform an all pairs
comparison of
selected significant events, using the causal methods described above and to
record the
relationships as edges in a filtered graph. This technique would require O(n2)
comparisons,
where n is the number of significant events. With the constant time
tecluiiques for causal
comparisons described above, this would still require O(n2) time. If the
filtered graph is
particularly large, calculating O(n) comparisons miglit be difficult to
provide timely
responses from the previously described simplistic approach.
Furthermore, in many cases, the filtered graph will be constructed in
preparation for display
to a user. The inclusion edges for all relationships would include a number of
edges that
could easily be inferred by the user and which could significantly add to the
visual clutter.
For this reason, one embodiment actually only includes a minimal set of edges
(i.e., the
smallest set of edges that characterizes all relationships in the filtered
graph) in the filtered
graph. As sucll for each event, the focus is placed on finding the set of
"relatively maximal"
predecessors and the set of "relatively minimal" successors around which
explicit edges are
to be added.
Figure 20 shows graphs containing edges for causal relationships between
events on the
graph. Specifically, Figure 20 a) depicts a graph that contains edges (X, Y,
and Z) for all
causal relationships present in the graph and Figure 20 b) shows the same
graph with only
maximal predecessors and miiiimal successors. For example, in Figure 20 b)
edge Z is
removed because it represents a relationship between event c's non-maximal
predecessor a,
and c (or in other words, a relationship between event a and its non-ininimal
successor, c).
Forward/Reverse Search Algorithm
One embodiment employs a "Forward/Reverse Search Algorithm" to compute the
maximal
predecessors and minimal successors. In one embodiment this search algorithm
maintains a
set of relatively minimal events and a set of relatively maximal events, where
the relatively
minimal set includes all events that have no predecessors in the filtered
graph and the
relatively maximal set includes all events that have no successors in the
filtered graph.
-23-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
To add a node representing an event to a filtered graph, one embodiment
creates two search
sets: one search set is initialized with the members of the overall graph
minimal set that are
also predecessors of the inserted node (called the forward search set) and the
other search set
is initialized with the members of the overall graph maximal set that are also
successors of
the inserted node (called the reverse search set). To determine a maximal
predecessors set,
the search moves the forward search set forward by replacing the immediate
forward search
set with the set of successors of the previous forward search set that are
also predecessors of
the inserted event. At each step, the events in the forward search set that
have no such
successors are added to a maximal predecessors set for the inserted
node/event. Continue
stepping until the forward search set is enipty. At this point, edges are
added between each
element in the maximal predecessors set and the inserted node/event. To move
the reverse
search set backwards, the search replaces the reverse search set with the set
of predecessors
of the previous reverse search set that are also successors of the inserted
node/event.
Likewise, at each step the events in the reverse search set that have no such
predecessors are
added to a minimal successors set for the inserted node/event until the
reverse search set is
empty. At this point, edges are added between the inserted node/event and the
nodes/events
in the minimal successors set. If, upon conclusion of the search, the set of
maximal
predecessors is empty, the inserted node/event is added to the overall graph
minimal set. On
the other hand, if the set of minimal successors is empty, the inserted
node/event is added to
the overall graph maximal set. If appropriate, an inserted node/event may be
added to both
the overall graph minimal set and the overall graph maximal set.
Figures 21 through 24 demonstrate the insertion of an event using the
previously described
procedure. Figure 21 shows an initial directed acyclic graph with the
projected insertion
point highlighted and Figures 22 and 23 illustrate the forward and reverse
searches from the
graph minimal and maximal sets to find the insertion point. Specifically,
Figure 22 a) shows
the forward search set, initialized with events from the graph minimal set
that precede the
insertion point, Figure 22 b) shows the set containing the step 0 set
successors that are also
predecessors of the insertion point, and Figure 22 c) shows the set containing
the step 1 set
successors that are also predecessors of the insertion point. Since the step 2
set contains no
successors that are also predecessors of the insertion point, this set also
represents the
maximal predecessor set.
-24-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
Similarly, we find the minimal successor set by starting in Figure 23 a) with
the graph
maximal set members that also succeed the insertion point; the reverse search
moves
backwards from this initial set to build the set of predecessors in Figure 23
b) that are also
successors of the insertion point; and finally, the reverse search moves
backwards in Figure
23 c) to build the set of all predecessors of the step 1 set that are also
successors of the
insertion point. In Figure 23 c), the reverse search also arrives at the
minimal successor set,
since the step 2 set contains no predecessors that are also successors of the
insertion point.
Finally in Figure 24, the new event may be added to the filtered graph. As
shown in Figure
24, to do so, edges are added from each event in the maximal predecessor set
of Figure 22 c)
to the inserted node and edges from the inserted node to each event in the
minimal successor
set of Figure 23 c).
Although this approach produces a graph with fewer edges than the previous
approach, the
search still requires O(n2) coinparisons to build the graph (i.e., each
inserted node may
require a comparison with all events already in the graph).
Filtered Chain List Algorithm
Fortunately, in one embodiment, the use of filtered causal chains allows inser-
tions of events
into a filtered causal graph that only require a logarithmic number of
comparisons per
insertion. To perform this search and insertion using the filtered chain
algorithm, filtered
events are first arranged into filtered chain lists, such that each causal
chain in the original
graph has, at most, one filtered chain list and each filtered chain list
contains all filtered
events which are in the corresponding chain in the non-filtered graph. These
filtered chain
lists preserve the order from the original chain.
In one embodiment, the process for inserting an event into a filtered graph
starts with
obtaining a chain relative maximal predecessor set (which contains the highest
order
predecessors for the inserted event in each causal chain for which any
predecessors exist) and
a chain relative minimal successor set for each inserted event (which contains
the lowest
order successors for the inserted event in each causal chain for which any
successors exist).
The maximal predecessor set may be generated by performing a binary search on
each
filtered chain list for the predecessor of the inserted event using the
wavefront values that
correspond to the chain of the given filtered chain list. The minimal
successor set may be
-25-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
generated by performing a binary search on each filtered chain list for the
successor of the
inserted event using the wavefront values that correspond to the inserted
event's own chain.
Then, the process proceeds to reduce the chain relative maximal predecessor
set to the
inserted event's maximal predecessor set (note: the latter is a subset of the
former), and to
reduce the chain relative minimal successor set to the inserted event's
minimal successor set
(again, the latter is a subset of the former). The first part can be performed
by checking the
filtered graph successors of each event in the chain relative maximal
predecessor set to
determine whether any of the successors of each event precedes the inserted
event. If not,
then the starting event being checked is part of the maximal predecessors set.
Additionally, if
a successor of the starting event beiiig checked precedes the inserted event,
the starting event
is not part of the maximal predecessor set. The second part can be performed
by checking
the filtered graph predecessors of each event in the chain relative minimal
successor set to
determine whether any of the predecessors succeed the inserted event. If not,
then the
starting event being checked is part of the minimal successors set.
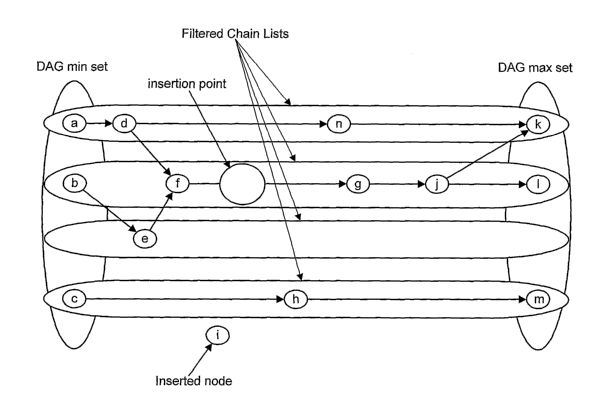
This algorithm is illustrated in Figures 25 through 27. Figure 25 sliows the
filtered chain list
breakdown of the graph from Figure 21. Figure 26 a) shows the first step of
finding the
relative maximal predecessor set, which is performing a binary search on each
filtered chain
list to find the chain relative maximal predecessor set. Figure 26 b) shows
the next step of
reducing the chain relative maximal predecessor set to the maximal predecessor
set by
removing those events that have successors that precede the insertion point.
In this case,
event f is a successor of both d and e aiid, since f precedes the insertion
point, both d and e
must be eliminated. On the other hand, f has no successors that precede the
insertion point so
it remains in the maximal predecessor set.
The process of finding the minimal successors is similar. Figure 27 a) shows
the result of
finding the chain relative minimal successor set through binary search (g
andj). Figure 27 b)
shows the result of the second step, reducing chain relative minimal successor
set to the
minimal successor set by eliminating all events that have predecessors that
succeed the
insertion point. Since g precedes j, j inust be eliminated. Since g has no
predecessors that
succeed the insertion point, g remains and forms the complete minimal
successor set. Now
the new event can be inserted as shown in Figure 28.
-26-
CA 02620369 2008-02-05
WO 2007/019524 PCT/US2006/030932
Figure 28 adds the new event to the filtered graph. As shown in Figure 28, to
do so, edges
are added from each event in the maximal predecessor set of Figure 26 b) to
the inserted
node and edges from the inserted node to each event in the minimal successor
set of Figure
27 b).
The complexity of building a filtered graph in accordance with this embodiment
is
approximately O(n lgn), which can be determined as follows: each filtered
chain binary
search takes O(lgn) time, and there are at most 2m of these wh.ere yn is the
number of chains.
For each of the O(m) events in each of the chain relative sets, there are
several comparisons
on preceding or succeeding events in the graph but, since the filtered graph
contains a
minimal set of edges, there are typically a small number of such events (this
can be
reasonably approximated to be within O(lg n)) giving a complexity of 2m O(lg
n) (for the
binary searches) + 2m O(lg n) (for the predecessor/successor checks), which
gives ni O(lg n)
complexity for each insertion. Since chains are typically associated with
physical resources
in a networlc (such as networked computers), the number of chains is
practically a constant,
giving O(lg n) time per insertion. Since there are n insertions, one
embodiment provides for
n O(lg n) or 0(n lg n) time to construct a filtered graph in accordance with
the outlined
process.
Thus, it can be seen from the above descriptions that various novel methods
for performing
causal relationship analysis and efficient filtered causal graph edge
detection in a causal
wavefront environment and apparatuses equipped to practice various aspects of
the methods;
in particular, for network managenient, have been described. While the present
invention
has been described in terms of the earlier described einbodiments, those
skilled in the art will
recognize that the invention is not limited to the embodiments described. The
present
invention can be practiced with modification and alteration within the spirit
and scope of the
description and specification and appended drawings of the provisional
application. Thus,
the description is to be regarded as illustrative instead of restrictive on
the present invention.
-27-