Note: Descriptions are shown in the official language in which they were submitted.
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
System and Method for Automated Distributed Diagnostics for
Networks
CROSS-REFERENCE TO RELATED APPLICATIONS
This application claims the benefit of U.S. Provisional Application No.
61/062,718, filed on January 29, 2008, which is incorporated by reference
herein in its
entirety.
FIELD OF THE INVENTION
The present invention relates to the diagnosis of faults in systems by means
of
inferences drawn from the symptoms produced by those faults. Specifically, the
invention
relates to distributed computations for fault-diagnosis carried out by
partitioning the fault-
to-symptom causality model of the system into computational domains and by
coordinating the diagnoses obtained from the individual domains to produce a
global
diagnosis for the whole system.
BACKGROUND OF THE INVENTION
Modern societies depend on the smooth and error-free operation of large and
complex technological systems, such as telecommunication networks and power
plants.
When failures affect the operation of such large systems, it is important to
be able to
diagnose the `root cause' of the observed problems. Consider, as an example, a
telecommunication network that is used to transport the traffic of different
applications. It
is a complex inter-connection of many elements, and hence, can fail in many
different
ways. The failure of a single element, like a transmission link, a router, a
server, or a
database could affect many network-functions and thus give rise to a multitude
of
"alarms", all correlated to the same failure. Similarly, since the successful
operation of an
application depends on many network elements, an "alarm" could have many
different
possible causes. Thus, in a complex system, many different symptoms could
arise from the
I
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
failure of a single element and many different element-failures can give rise
to the same
symptom.
The subject matter of the present inventions pertains to the class of fault
diagnosis
methods known as `model-based', to denote the fact that they take as their
starting point
an analytical representation of the underlying Fault Propagation Model that
specifies the
causal relations between faults and symptoms in the system under
consideration. A
`bipartite graph' is a convenient representation of the relationship of the
Fault Propagation
Model. In a bipartite graph there is a set of nodes, one for each object that
could fail (and
thereby become a `fault'), and another set of nodes, one for each symptom or
alarm that
can appear in the system. An object-node f is connected to a symptom-node s by
a link if
failure of object f (i.e., fault f) causes symptom s to be observed (in the
case of
deterministic causation) or if there is a non-zero probability that fault f
causes symptom 5
to be observed (in the case of probabilistic causation). It is assumed that
the probability
p1 of the occurrence of each fault f is known and that the occurrences of the
different
faults are all independent events. The representation of a Fault Propagation
Model by a
bipartite graph is well-established in the literature.
The fault-diagnosis problem can be stated as follows: given that a set S of
symptoms has
been observed, determine the most probable set or sets of faults F whose
occurrence would
account for the observed symptoms S. If all faults are equally probable, the
`most probable'
hypothesis is one that contains the smallest number of faults. If faults have
different probabilities
of occurrence, then the probability of occurrence of a given set of faults is
the product of the
probabilities of faults in the set and the product of the complement of the
probabilities of faults not
in the set.
In the most general terms, the task is to determine which of the 2N subsets of
the N
objects are consistent with all the observed symptoms, and which among them
have the
highest probability of occurrence. Since the number of possible candidates for
solution
rises exponentially in N, the procedure of searching for a solution is not
scalable, though,
in practice, the effort might be reduced by the prior knowledge or assumption
that there
can be no more than n << N simultaneous faults in the system (which limits the
search to
possibilities) or by special cases of the structure of the bipartite graph.
2
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
For example, in problems where the occurrence of multiple simultaneous faults
is
known, a priori, to be very rare, a method known as "SMARTS Event Management
System Codebook" as described by S. Kliger, S. Yemini, Y. Yemini, D. Ohsie,
and S.
Stolfo, in "A Coding Approach to Event Correlation", Proceedings of the fourth
international symposium on integrated network management, pp. 266 - 277, 1995,
and in
U.S. Patent No.5,661,668, entitled "Apparatus and Method for Analyzing and
Correlating
Events in a System using a Causality Matrix", issued August 26, 1997 relies on
associating a unique `code' of symptoms with each of the fault-occurrences
chosen for
consideration in the system. Here, the bipartite graph of the fault-to-symptom
mapping is
expressed by an M x N matrix F of l's and 0's, where M is the number of
possible
symptoms and N is the number of (independent) objects (which, upon failure,
become
faults), and the element fy (in the deterministic case) is given by
_ 1 if symptom i is present when fault j occurs
f' - {0 otherwise
Thus, column j of F, sayFj, is a vector of alarms that is viewed as a
"codeword"
for fault j . The "codewords" for the different faults must be distinguishable
one from
another; otherwise, there would be faults that produce identical alarm
vectors, which must,
hence, be regarded as "equivalent". Instead of working with an entire column
as a
codeword, it is possible to work with a subset of the rows (symptoms) of F and
still
maintain the uniqueness of the codewords. On the assumption that there can be,
at most, a
single fault, in the absence of errors, the alarm vector either has all zeros
or matches one of
the codewords exactly. However, to guard against inexact matches due to
erroneous or
"lost" alarms, in selecting a subset of the symptoms to work with, one tries
to produce
codewords with a minimum pair-wise separation (Hamming distance) so that an
alarm
vector, when it fails to match any codeword exactly, can be assigned to the
codeword to
which it is closest.
M. Steinder and A.S. Sethi, in "Probabilistic fault diagnosis in communication
systems through incremental hypothesis updating", Computer Networks 45, pp.
537-562,
3
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
2004, consider the diagnostic problem for the case when the coupling between
objects and
symptoms in the bipartite graph is allowed to be probabilistic, and present a
Bayesian
inference algorithm in which certain approximations are used to limit the
number of
computations for finding a solution.
As noted earlier, without assumptions that limit the number of possible
simultaneous faults, the number of hypotheses to be considered in diagnosing
the root
cause of a set of observed symptoms grows exponentially in the number of
potential faults
(objects). This rate of growth in complexity limits the size of the problems
that can be
solved by means of direct, centralized computation. An approach to slowing the
rate of
growth of complexity of diagnostic calculations is to partition the problem in
some fashion
into a number of `computational domains' such that the calculations for the
sub-problem
in each domain can be carried out in parallel, i.e., centralized computation
is replaced with
distributed computation in the domains. Some coordination might then be needed
among
the results from the domains in order to arrive at a solution to the overall
problem.
U.S. Patent No. 6,868,367, entitled "Apparatus and Method for Event
Correlation
and Problem Reporting", issued March 15, 2005, describes the case of multiple
domains,
with the assumption that, in each domain, it is very rare to have more than
one fault. The
diagnostic method appears to consist of a `pooling' of the solutions of the
local domains.
Other methods for coordinating such distributed computations, based on an
exchange
(either one-shot or iterative) of `cost' information among the domains, have
been proposed
by A. T. Bouloutas, S. B. Calo, A. Finkel, and I. Katzela in "Distributed
Fault
Identification in Telecommunications Networks", Journal of 'Network and
Systems
Management. 1995; and by M. Steinder and A.S. Sethi, in "Multi-domain
diagnosis of
end-to-end service failures in hierarchically routed networks", IEEE
Transactions on
Parallel and Distributed Systems, vol. 18, no. 3, pp. 379-392, Mar., 2007.
SUMMARY OF THE INVENTION
The present invention comprises: (1) a method for partitioning the fault
diagnosis
problem into `computational domains' in which the computations can proceed in
parallel,
(2) a method for determining all the optimal local solutions to the sub-
problem in each
4
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
individual domain in which cross-domain symptoms are ignored, and (3) a method
of (a)
finding a combination of local solutions, one from each domain, that maximizes
the
number of cross-domain symptoms explained, such a solution constituting an
optimal
global solution to the diagnosis problem in case all the cross-domain symptoms
have been
explained, or (b) in the case where unexplained cross-domain symptoms remain
in method
3(a), finding a global solution by supplementing the combination of local
solutions chosen
in method 3(a) with additional faults to explain the residual cross-domain
symptoms,
determining also a bound on the deviation of the solution from optimality.
Partitioning the Fault Propagation Model
First, the bipartite representation of a fault propagation model is
transformed into
an associated abstract graph, called the `relation graph' of the model. The
relation graph is
constructed as follows: each node of the relation graph corresponds to an
object (potential
fault), and two nodes are connected by a bi-directional `relational link' if
their
corresponding objects, upon failure, produce a symptom in common. Note that a
symptom
that has a unique fault as its possible cause will not be represented in the
relation graph.
Since the occurrence of such a symptom at once establishes the occurrence of
the
corresponding fault, the diagnosis for such symptoms is immediately obtained.
Next, the relation graph is partitioned into several `computational domains',
with
roughly equal numbers of nodes in each domain, while minimizing the number of
relational links that bridge separate domains (which correspond to `cross-
domain'
symptoms). Each domain includes only a subset of the objects (which, upon
failure, are
termed faults) and the symptoms they produce upon failure. Graph partitioning
is a well-
studied problem of graph theory, for which are various fast algorithms even
for graphs
with thousands of nodes. See, for example, B. Hendrickson, R. Leland, "A
Multilevel
Algorithm for Partitioning Graphs", Supercomputing 95, Proceedings of the
IEEE/ACM
SC95 Conference, 1995. In partitioning the relational graph, each relational
link (which
corresponds to one or more symptoms) is assigned a weight equal to the sum,
taken over
the symptoms represented by the relational link, of the reciprocal of the
number of distinct
object-pairs that produce each such symptom. This choice of weights is
intended as an aid
to achieving the objective of minimizing the number of cross-domain symptoms
in the
partition. The size of each domain (the number of objects assigned to it) is
chosen to be
the largest value for which computations for the local diagnosis in each
domain can be
5
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
carried out in a reasonable length of time by a centralized algorithm, i.e.,
one which works
with knowledge of the portion of the fault propagation model pertaining to the
faults and
symptoms in the domain. The number of domains into which the problem needs to
be
partitioned thus depends on the largest problem size that can be handled in a
single
domain.
One could either obtain a fixed partitioning of the relation graph of the
original
bipartite model, comprising all the potential faults and their symptoms, or
adapting the
partitioning to the particular instance of the graph that comprises only the
actually
observed symptoms and all the faults that constitute their potential causes in
each realized
scenario. In the latter case, the relation graph that is sought to be
partitioned into loosely-
coupled domains corresponds to the actual observed symptoms in each scenario
of the
occurrence of faults and symptoms. Owing to the randomness in occurrences of
faults, one
expects, on the whole, that such an adaptive partitioning of the realized
graph, matching
the partitioning to the observed symptoms, offers a higher probability of
being able to find
a partition that minimizes the presence of cross-domain symptoms. Thus, an
innovative
element of our approach is to create virtual `computational domains' for each
realization
of the fault propagation model, grouping faults into these domains solely for
the sake of
computational efficiency, with no necessary connection to the geographical
location of the
elements that, upon failure, become faults. Thus, our approach to distributed
computation
is based on the idea of arranging for a suitable domain-partition that
minimizes the overlap
between domains, which increases the likelihood of finding a provably optimal
global
solution by the mere selection of a combination of optimal local solutions of
the individual
domains.
Once a partition of a relation graph into domains has been obtained, the
following
algorithm is used to obtain a solution to the diagnosis problem.
First, each individual domain determines all its optimum local solutions,
ignoring
all of its cross-domain symptoms. If all faults have the same probability of
occurrence, an
optimal solution is a minimal set of faults that `covers' (explains) all the
observed local
symptoms. This is a standard `set covering' problem that can be solved by
commercial
6
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
integer programming solvers. This procedure is easily adapted to the case
where faults have
different probabilities of occurrence.
It should be noted here that if a partition of the potential faults into
domains
succeeds in creating isolated individual domains with no `cross-domain'
symptoms at all,
then an optimum overall solution consists of the collection of the optimum
local
diagnoses, one from each domain. Each such collection is an optimal solution.
In this
special case of isolated domains, the overall global optimal solution is
available once the
local optimal solutions of all the domains are found.
If the partitioning of the relation graph into individual domains turns out to
contain
cross-domain symptoms, then a check is made to see whether a combination of
optimal
local solutions, one from each domain, can also `cover' all the cross-domain
symptoms.
This is accomplished by solving a maximum set cover problem, i.e., by finding
a
combination of optimal local solutions, one from each domain that maximizes
the number
of cross-domain symptoms that are explained. If a collection of such optimal
local
solutions, one from each domain, obtained by ignoring cross-domain symptoms,
nevertheless manages to explain all the cross-domain symptoms as well, then
again, such a
collection is a proven optimal global solution made up of local optimum
solutions.
If unexplained cross-domain symptoms remain after solving the maximum set
cover problem above, then, a `central' manager solves the smaller problem of
selecting
additional faults to explain merely the residual unexplained cross-domain
symptoms. This
residual problem of the remaining unexplained cross-domain symptoms and the
faults that
could have been their potential causes, should generally be a much smaller
problem than
the original problem and is solved by application of the same method that is
used to find
local solutions in each individual, viz., by finding a minimal set of faults
to explain the
residual cross-domain symptoms. The final solution that is found after the
solution of the
residual problem may or may not be optimal, though it is not possible to make
a definite
statement one way or the other. However, what is known is how far it could
deviate, in the
worst case scenario, from an optimal solution. It is clear that whenever a
solution to
explain all the symptoms is found by a combination of local optimal solutions,
then a
global optimum solution has been found.
7
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
Thus, the innovation of the present invention consists of distributed
computations
implemented by means of partitioning the relation graph associated with the
fault
propagation model, determining all optimal local solutions, and fmding a
combination of
local solutions, one from each domain, that provide a global solution that is
either
provably optimal or deviates from optimality at most by a known bound.
The present invention will be. more clearly understood when the following
description is read in conjunction with the accompanying drawings.
BRIEF DESCRIPTION OF THE DRAWINGS
Figure 1 is an example of a bipartite graph used to represent a fault
propagation
model, showing the correlation of potential faults to symptoms.
Figure 2 shows the relation graph associated with the bipartite graph of
Figure 1.
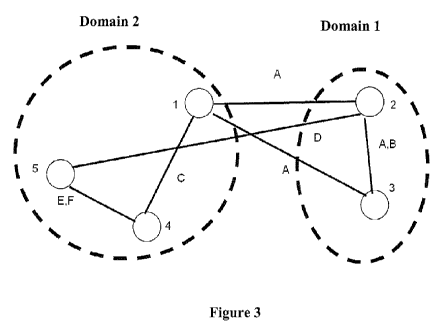
Figure 3 shows a two-domain partition of the relation graph of Figure 2.
Figure 4 is a flow chart of the diagnostic algorithm of the present invention.
DETAILED DESCRIPTION
Referring now to the figures and to Figure 1 in particular, there is shown the
diagnostic problem represented by a bipartite graph. Nodes numbered 1, 2, 3,
4, and 5
represent five objects, each of which might fail (then becoming a fault) and
nodes labeled
A, B, C, D, E, and F which are six possible symptoms produced by the various
faults. The
directed links in the bipartite graph display the causal relation between
objects and
symptoms. For example, if Object 1 fails, symptoms A and C are activated.
Symptom D
could be activated by the failure of either Object 2 or Object 5, or both.
Referring to Figure 2, there is shown the transformation of a bipartite graph
of
Figure 1 into its associated relation graph. The objects 1, 2, 3, 4, 5 appear
as nodes in the
relation graph. Figure 1 shows, for example, that faults 1 and 2 both cause
symptom A;
8
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
hence, the corresponding nodes in the relation graph of Figure 2 are connected
by a
`relational link'. Similarly, since symptom A in Figure 1 is also common to
the object-
pairs (1-3) and (2-3), these pairs are also connected by relational links.
'Note that the
relational link between nodes 2 and 3 represents both the symptoms A and B
that are
common to the object-pair (2-3). Each relational link (which might correspond
to one or
more symptoms) is weighted by the sum, taken over the symptoms represented by
the
relational link, of the reciprocal of the number of distinct object-pairs that
produce each
such symptom. This choice of weights is intended as an aid to achieving the
objective of
partitioning the relation graph into a specified number of computational
domains in order
to minimize the number of cross-domain relational links. These weights are
shown next to
the relational links in Figure 2. For example, the relational link for the
object-pair (1-2)
corresponding to symptom A has a weight of (113 since the same symptom is also
caused by two other object-pairs (1-3) and (2-3). The relational link for the
object-pair (2-
3) corresponds to two symptoms A and B, of which A is caused by a total of
three object-
pairs (1-2), (1-3), and (2-3), while B is caused by the single object-pair (2-
3). Thus, the
relational link for the object-pair (2-3) has a weight of + 1 4/3. Similar
explanations apply to the weights assigned to the other relational links in
Figure 2.
Figure 3 shows the partition of the relation graph of Figure 2 into two
domains of
approximately the same number of nodes per domain. For this partitioning,
symptoms A
and D become `cross-domain' symptoms (i.e., symptoms whose parent faults lie
in
different domains), while each of the other symptoms B,C,E, and F is a `local'
symptom
(i.e., whose parent objects all lie within the same domain).
Figure 4 is a flow chart of the diagnostic algorithm of the present invention.
At input 401, the diagnostic problem is represented by a bipartite graph, such
as
that shown in Figure 1.
In step 402, the bipartite-graph representation of the problem is transformed
into its
associated relation graph. An example of such transformation of a bipartite
graph into its
associated relation graph is shown in Figure 2. Each relational link is
weighted by the sum,
9
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
taken over the symptoms represented by the relational link, of the reciprocal
of the number
of distinct object-pairs that produce each such symptom.
In step 403 the relation graph is partitioned into the required number of
domains,
determined by the maximum number of nodees to be assigned to each domain. As
an
example, Figure 3 shows the optimal partition of the relation graph of Figure
2 into two
domains. For this partitioning, symptoms A and D become `cross-domain'
symptoms (i.e.,
symptoms whose parent objects lie in different domains), while each of the
other
symptoms B,C,E, and F is a `local' symptom (i.e., whose parent objects all lie
within the
same domain).
At step 404, in each domain, all optimal solutions (solutions with minimal
number
of faults, for the case of equally probable faults) are found for just the
local symptoms,
ignoring all cross-domain symptoms. For the two-domain partition in Figure 3,
the
following are the optimal local solutions:
Domain 1:
Local Symptom: B
Optimal Local Solutions: {Fault 2}, {Fault 3)
Domain 2:
Local Symptoms: C, E and F
Optimal Local Solution: {Fault 4}
Let L,,,, = the sum of the number of faults in optimal local solutions from
all the
domains, one from each domain. For Figure 3, L = 2, comprising one fault from
Domain 1 and one fault from Domain 2.
In step 405, a combination of local solutions, one from each domain, that
explains
the largest number of cross-domain symptoms is found by solution of a `maximum
set
cover' problem. In Figure 3, there is precisely one combination of local
solutions that
explains both the cross-domain symptoms A and D: Fault 2 from Domain 1 and
Fault 4
from Domain 2.
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
In step 406, if a combination of optimal local solutions, one from each
domain,
obtained in step 405 can explain all the cross-domain symptoms as well, each
such
combination is a provably optimal global solution, and the diagnostic problem
is solved at
step 407. In the Example of Figure 3, {Fault 2, Fault 41 is the unique global
solution. That
is, there are no residual cross-domain symptoms. Then the algorithm ends at
step 410.
If the maximum set cover problem leaves one or more residual cross-domain
symptoms unexplained, the algorithm proceeds to step 408.
If unexplained cross-domain symptoms remain after solving the maximum set
cover problem at step 405, a minimum number of additional faults are selected
to explain
only the residual cross-domain symptoms. This residual problem in step 408,
comprising
the remaining unexplained cross-domain symptoms and the objects that could
have been
their causes, is solved by application of the same algorithm that is used in
step 404, viz.,
finding a minimal set of faults to explain the residual cross-domain symptoms.
In this
case, the final solution-set is these additional faults together with the
faults chosen in the
maximum set cover solution that is found in step 405.
Let .?~et = total number of faults in final solution.
The final solution found in step 408 may or may not be optimal. However, what
is
known is how far the final solution could deviate, in the worst case scenario,
from an
optimal global solution.
Let. GP; = total number of faults in an optimal global solution. Then, the
following
bound holds:
Lope ~ GO-3Pt = Glinar
The deviation bound is found and the algorithm ends at step 410.
11
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
In the example shown in Figure 1 that has been described above, the failure-
probabilities of all the objects were assumed to be equal, which implies that
an optimal
solution is one that explains all the observed symptoms and contains the
fewest number of
faults. The case where the objects have different failure-probabilities is
readily handled as
follows.
Let a' = number of objects.
Letpk = failure-proibabi1ityof object kk = L,,..,N,with 0 < 'x < I
(excluding the cases p = 0 obectthat never fails) and
pk 1 (object al-ways in the failed. state) as cases that do not need to be
`diagnosed').
A solution which consists of the objects (k , . k2, = -, k, ,) (and excludes
the
objects ( , k, - , = - = , k , )), has a probability given by
t
3 =1Px j=im+1 - Pk_
In comparing the relative probabilities of such sets, the form of the
expressions can
be simplified by dividing by the common product-1 - - p J. Thus, a solution
consisting of the objects (k1, k.,, a t e, kr), is assigned the metric H,
defined by:
Pei
1 =1
Then, an optimal solution is one which has the smallest value of H.
If the probabilities p;, can assume any value in the interval (0, 1), it is
highly
unlikely for two solutions to have exactly the same value of H,. and thus
highly unlikely
that any domain will have more than a single optimal `solution'. However,
keeping in
mind the difficulty of assigning precise values to the failure-probabilities
in actual
systems, it is perhaps more realistic to assume that the failure-probabilities
only take
values from a limited set (such as values corresponding to `low, `medium', or
`high'
failure-probability). Such a discrete set of values allows for multiple local
solutions to
12
APP 1826 CA 02713736 2010-07-29
WO 2009/097435 PCT/US2009/032445
exist in the domains, from which a combination can then be selected to
maximize the
number of cross-domain symptoms that are explained.
System and method of the present disclosure may be implemented and run on a
general-purpose computer or special-purpose computer system. The computer
system
may be any type of known or will be known systems and may typically include a
processor, memory device, a storage device, input/output devices, internal
buses, and/or a
communications interface for communicating with other computer systems in
conjunction
with communication hardware and software, etc.
The terms "computer system" and "computer network" as may be used in the
present application may include a variety of combinations of fixed and/or
portable
computer hardware, software, peripherals, and storage devices. The computer
system may
include a plurality of individual components that are networked or otherwise
linked to
perform collaboratively, or may include one or more stand-alone components.
The
hardware and software components of the computer system of the present
application may
include and may be included within fixed and portable devices such as desktop,
laptop,
and/or server. A module may be a component of a device, software, program, or
system
that implements some "functionality", which can be embodied as software,
hardware,
firmware, electronic circuitry, or etc.
While there has been described and illustrated global fault-diagnosis in
systems, it
will be apparent to those skilled in the art that variations and modifications
are possible
without deviating from the broad teachings and scope of the present invention
which shall
be limited solely by the scope of the claims appended hereto.
13