Note: Descriptions are shown in the official language in which they were submitted.
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
AGILE COMMUNICATION OPERATOR
Background
[001] Computer systems often include one or more general purpose processors
(e.g.,
central processing units (CPUs)) and one or more specialized data parallel
compute nodes
(e.g., graphics processing units (GPUs) or single instruction, multiple data
(SIMD)
execution units in CPUs). General purpose processors generally perform general
purpose
processing on computer systems, and data parallel compute nodes generally
perform data
parallel processing (e.g., graphics processing) on computer systems. General
purpose
processors often have the ability to implement data parallel algorithms but do
so without
the optimized hardware resources found in data parallel compute nodes. As a
result,
general purpose processors may be far less efficient in executing data
parallel algorithms
than data parallel compute nodes.
[002] Data parallel compute nodes have traditionally played a supporting role
to general
purpose processors in executing programs on computer systems. As the role of
hardware
optimized for data parallel algorithms increases due to enhancements in data
parallel
compute node processing capabilities, it would be desirable to enhance the
ability of
programmers to program data parallel compute nodes and make the programming of
data
parallel compute nodes easier.
[003] Data parallel algorithms often operate on large sets of data that may be
distributed
across multiple computing platforms. Large sets of data provide challenges in
representing and tracking the data structures that describe the data as well
as in moving the
data across the multiple platforms. As a result, the process of managing large
sets of data
across multiple computing platforms is often complex and difficult to
implement.
Summary
[004] This summary is provided to introduce a selection of concepts in a
simplified form
that are further described below in the Detailed Description. This summary is
not intended
to identify key features or essential features of the claimed subject matter,
nor is it
intended to be used to limit the scope of the claimed subject matter.
[005] A high level programming language provides an agile communication
operator that
generates a segmented computational space based on a resource map for
distributing the
computational space across compute nodes. The agile communication operator
decomposes the computational space into segments, causes the segments to be
assigned to
compute nodes, and allows the user to centrally manage and automate movement
of the
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
segments between the compute nodes. The segment movement may be managed using
either a full global-view representation or a local-global-view representation
of the
segments.
Brief Description of the Drawin2s
[006] The accompanying drawings are included to provide a further
understanding of
embodiments and are incorporated in and constitute a part of this
specification. The
drawings illustrate embodiments and together with the description serve to
explain
principles of embodiments. Other embodiments and many of the intended
advantages of
embodiments will be readily appreciated as they become better understood by
reference to
the following detailed description. The elements of the drawings are not
necessarily to
scale relative to each other. Like reference numerals designate corresponding
similar
parts.
[007] Figure 1 is a computer code diagram illustrating an embodiment of code
with an
agile communication operator.
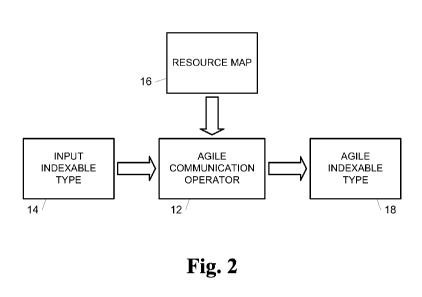
[008] Figure 2 is a block diagram illustrating an embodiment of applying an
agile
communication operator to an input indexable type.
[009] Figures 3A-3C is are block diagrams illustrating examples of generating
and using
an agile indexable type.
[0010] Figure 4 is a block diagram illustrating an embodiment of a computer
system
configured to compile and execute data parallel code that includes an agile
communication
operator.
Detailed Description
[0011] In the following Detailed Description, reference is made to the
accompanying
drawings, which form a part hereof, and in which is shown by way of
illustration specific
embodiments in which the invention may be practiced. In this regard,
directional
terminology, such as "top," "bottom," "front," "back," "leading," "trailing,"
etc., is used
with reference to the orientation of the Figure(s) being described. Because
components of
embodiments can be positioned in a number of different orientations, the
directional
terminology is used for purposes of illustration and is in no way limiting. It
is to be
understood that other embodiments may be utilized and structural or logical
changes may
be made without departing from the scope of the present invention. The
following
detailed description, therefore, is not to be taken in a limiting sense, and
the scope of the
present invention is defined by the appended claims. It is to be understood
that the
2
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
features of the various exemplary embodiments described herein may be combined
with
each other, unless specifically noted otherwise.
[0012] Figure 1 is a computer code diagram illustrating an embodiment of code
10 with an
agile communication operator 12. When compiled and executed, agile
communication
operator 12 generates a segmented computational space based on a resource map
for
distributing the computational space across compute nodes (e.g., compute nodes
121
shown in Figure 4 and described in additional detail below). The agile
communication
operator decomposes the computational space, (represented by an input
indexable type 14
in the embodiment of Figure 1) into segments 20 of an agile indexable type 18
(also
shown in the example of Figure 3B), causes segments 20 to be assigned to
compute nodes,
and allows the user to centrally manage and automate movement of segments 20
between
the compute nodes. The segment movement may be managed using either a full
global-
view representation or a local-global-view representation of the segments as
described in
additional detail below.
[0013] Code 10 includes a sequence of instructions from a high level general
purpose or
data parallel programming language that may be compiled into one or more
executables
(e.g., DP executable 138 shown in Figure 4) for execution by one or more DP
optimal
compute nodes (e.g., DP optimal compute nodes 121 shown in Figure 4).
[0014] In one embodiment, code 10 includes a sequence of instructions from a
high level
general purpose programming language with data parallel extensions (hereafter
GP
language) that form a program stored in a set of one or more modules. The GP
language
may allow the program to be written in different parts (i.e., modules) such
that each
module may be stored in separate files or locations accessible by the computer
system.
The GP language provides a single language for programming a computing
environment
that includes one or more general purpose processors and one or more special
purpose, DP
optimal compute nodes. DP optimal compute nodes are typically graphic
processing units
(GPUs) or SIMD units of general purpose processors but may also include the
scalar or
vector execution units of general purpose processors, field programmable gate
arrays
(FPGAs), or other suitable devices in some computing environments. Using the
GP
language, a programmer may include both general purpose processor and DP
source code
in code 10 for execution by general purpose processors and DP compute nodes,
respectively, and coordinate the execution of the general purpose processor
and DP source
code. Code 10 may represent any suitable type of code in this embodiment, such
as an
application, a library function, or an operating system service.
3
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
100151 The GP language may be formed by extending a widely adapted, high
level, and
general purpose programming language such as C or C++ to include data parallel
features.
Other examples of general purpose languages in which DP features may appear
include
JavaTM, PHP, Visual Basic, Perl, PythonTM, C#, Ruby, Delphi, Fortran, VB, F#,
OCaml,
Haskell, Erlang, NESL, Chapel, and JavaScriptTM. The GP language
implementation may
include rich linking capabilities that allow different parts of a program to
be included in
different modules. The data parallel features provide programming tools that
take
advantage of the special purpose architecture of DP optimal compute nodes to
allow data
parallel operations to be executed faster or more efficiently than with
general purpose
processors (i.e., non-DP optimal compute nodes). The GP language may also be
another
suitable high level general purpose programming language that allows a
programmer to
program for both general purpose processors and DP optimal compute nodes.
[0016] In another embodiment, code 10 includes a sequence of instructions from
a high
level data parallel programming language (hereafter DP language) that form a
program. A
DP language provides a specialized language for programming a DP optimal
compute
node in a computing environment with one or more DP optimal compute nodes.
Using the
DP language, a programmer generates DP source code in code 10 that is intended
for
execution on DP optimal compute nodes. The DP language provides programming
tools
that take advantage of the special purpose architecture of DP optimal compute
nodes to
allow data parallel operations to be executed faster or more efficiently than
with general
purpose processors. The DP language may be an existing DP programming language
such
as HLSL, GLSL, Cg, C, C++, NESL, Chapel, CUDA, OpenCL, Accelerator, Ct, PGI
GPGPU Accelerator, CAPS GPGPU Accelerator, Brook+, CAL, APL, Fortran 90 (and
higher), Data Parallel C, DAPPLE, or APL. Code 10 may represent any suitable
type of
DP source code in this embodiment, such as an application, a library function,
or an
operating system service.
[0017] Code 10 includes code portions designated for execution on a DP optimal
compute
node. In the embodiment of Figure 1 where code 10 is written with a GP
language, the GP
language allows a programmer to designate DP source code using an annotation
26 (e.g.,
declspec(vector) ... ) when defining a vector function. The annotation 26 is
associated
with a function name 27 (e.g., vector func) of the vector function that is
intended for
execution on a DP optimal compute node. Code 10 may also include one or more
invocations 28 of a vector function (e.g., forall ... , vector func, ... ) at
a call site (e.g.,
forall, reduce, scan, or sort). A vector function corresponding to a call site
is referred to as
4
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
a kernel function. A kernel function may call other vector functions in code
10 (i.e., other
DP source code) and may be viewed as the root of a vector function call graph.
A kernel
function may also use types (e.g., classes or structs) defined by code 10. The
types may or
may not be annotated as DP source code. In other embodiments, other suitable
programming language constructs may be used to designate portions of code 10
as DP
source code and / or general purpose processor code. In addition, annotations
26 may be
omitted in embodiments where code 10 is written in a DP language.
[0018] Figure 2 is a block diagram illustrating an embodiment of applying
agile
communication operator 12 to an input indexable type 14 to produce an agile
indexable
type 18. As used herein, an indexable type is any data type that implements
one or more
subscript operators along with a rank, which is a non-negative integer, and a
type which is
denoted element type. If index<N> is a type that represents N-tuples of
integers (viz., any
type of integral data type), an instance of index<N> is a set of N integers
{i0, il, ..., im}
where m is equal to N-1 (i.e., an N-tuple). An index operator of rank N takes
an N-tuple
instance of index<N> and associates the instance with another instance of a
type called the
element type where the element type defines each element in an indexable type.
In one
embodiment, an indexable type defines one or more of the following operators:
element type operator[] (index declarator);
const element type operator[] (index declarator) const;
element type& operator[] (index declarator);
const element type& operator[] (index declarator) const;
element type&& operator[] (index declarator); or
const element type&& operator[] (index declarator)
const;
where index declarator takes the form of at least one
of:
const index<rank>& idx;
const index<rank> idx;
index<rank>& idx;
index<rank> idx.
[0019] In other embodiments the operators may be functions, functors or a more
general
representation. An indexable type's shape is the set of index<rank> for which
one of the
above subscript operators is defined. An indexable type typically has a shape
that is a
polytope ¨ i.e., an indexable type may be algebraically represented as the
intersection of a
finite number of half-spaces formed by linear functions of the coordinate
axes.
5
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
[0020] With reference to Figures 1 and 2, the high level language of code 10
provides
agile communication operator 12 for use on input indexable type 14 in a data
parallel
computing environment in one embodiment. Input indexable type 14 has a raffl(
(e.g., raffl(
N in the embodiment of Figure 1) and element type (e.g., element type T in the
embodiment of Figure 1) and defines the computational space that is operated
on by agile
communication operator 12. Agile communication operator 12 receives input
indexable
type 14 and a resource map 16 (e.g., resource map in the example of Fig. 1).
From input
indexable type 14 and resource map 16, agile communication operator 12
generates an
agile indexable type 18 with segments 20, also referred to as sub-grids,
specified by
resource map 16 (also shown in the example of Figure 3B). As shown in code 10,
agile
communication operator 12 may be used to pass agile indexable type 18 to a DP
call site
(i.e., forall in the example of Figure 1). By doing so, agile communication
operator 12
causes the vector function specified by the call site to be replicated on all
compute nodes
(e.g., compute nodes 121 shown in Figure 4) with each compute node receiving
the
segments 20 assigned to the compute node.
[0021] Agile communication operator 12 causes input indexable type 14 to be
decomposed into segments 20 and assigns each segment 20 to a compute node as
specified
by resource map 16. Resource map 16 provides a specification of where memory,
i.e.,
input indexable type 14, is stored across at least one compute node. Resource
map 16
specifies segments 20 such that the collection of segments 20 covers agile
indexable type
18 without overlap. Resource map 16 allows segments 20 to be specified with
the same or
different block sizes and / or regular or irregular block combinations.
[0022] Figures 3A-3C is are block diagrams illustrating examples of generating
and using
an agile indexable type 18(1). In the example of Figures 3A-3C, agile
communication
operator 12 partitions a 6 x 6 matrix with elements numbered 0 to 35 (i.e., an
input
indexable type 14(1)) into nine segments 20 in agile indexable type 18(1)
shown in Figure
3B as specified by a corresponding resource map 16 (shown in Figure 2). Each
segment
20 is represented by a different shading in Figure 3B. For example, a first
segment 20(1)
includes elements 0, 1, 6, and 7, a second segment 20(2) includes elements 2,
3, 8, and 9,
etc. Agile communication operator 12 also causes segments 20(1)-20(9) to be
assigned to
a set of one or more compute nodes 121(1)-121(Q), where Q is an integer that
is greater
than or equal to one, as specified by a protocol in resource map 16 and
indicated by an
arrow 30 in Figure 3C.
6
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
[0023] Resource map 18 may incorporate any suitable assignment protocol such
as a
block decomposition, a cyclic decomposition, a block-block decomposition, or a
block-
cyclic decomposition. The following protocol examples assume that there are
three
compute nodes 121(1)-121(3) (i.e., Q = 3) or four compute nodes 121(1)-121(4)
(i.e., Q=
4) and that segments 20 are numbered 20(1)-20(9) in across rows from left to
right starting
from the first (i.e., the top) row.
[0024] With row block decomposition and Q= 3, the thirty-six elements of input
indexable type 14(1) are divided by three such that each compute node 121 is
assigned
twelve elements. Thus, resource map 18 causes elements 0 to 11 (i.e., segments
20(1)-
20(3)) to be assigned to compute node 121(1), elements 12 to 23 (i.e.,
segments 20(4)-
20(6)) to be assigned to compute node 121(2), and elements 24 to 35 (i.e.,
segments 20(7)-
20(9)) to be assigned to compute node 121(3).
[0025] With row block decomposition and Q = 4, the thirty-six elements of
input
indexable type 14(1) are divided by four such that each compute node 121 is
assigned nine
elements. Accordingly, resource map 18 causes elements 0 to 8 to be assigned
to compute
node 121(1), elements 9 to 17 to be assigned to compute node 121(2), elements
18 to 26 to
be assigned to compute node 121(3), and elements 27 to 36 to be assigned to
compute
node 121(4).
[0026] With column block decomposition and Q = 3, resource map 18 causes the
first and
second columns of segments 20 (i.e., segments 20(1), 20(4), and 20(7)) to be
assigned to
compute node 121(1), the third and fourth columns of segments 20 (i.e.,
segments 20(2),
20(5), and 20(8)) to be assigned to compute node 121(2), and the fifth and
sixth columns
of segments 20 (i.e., segments 20(3), 20(6), and 20(9)) to be assigned to
compute node
121(3).
[0027] With row cyclic decomposition and Q = 3, resource map 18 causes
elements (3*k),
for k = 0 to 11, to be assigned to compute node 121(1), elements (3*k+1) to be
assigned to
compute node 121(2), and elements (3*k+2) to be assigned to compute node
121(3).
[0028] With row cyclic decomposition and Q = 4, resource map 18 causes
elements (4*k),
for k = 0 to 8, to be assigned to compute node 121(1), elements (4*k+1) to be
assigned to
compute node 121(2), elements (4*k+2) to be assigned to compute node 121(3),
and
elements (4*k+3) to be assigned to compute node 121(4).
[0029] With row block- cyclic decomposition and Q= 3, decomposition is the
cyclic
decomposition on segments 20(1)-20(9) shown in Figure 3B. Accordingly,
resource map
18 causes segments 20(1), 20(4), and 20(7) to be assigned to compute node
121(1),
7
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
segments 20(2), 20(5), and 20(8) to be assigned to compute node 121(2), and
segments
20(3), 20(6), and 20(9) to be assigned to compute node 121(3).
[0030] With row block- cyclic decomposition and Q= 4, resource map 18 causes
segments 20(1), 20(5), and 20(9) to be assigned to compute node 121(1),
segments 20(2)
and 20(6) to be assigned to compute node 121(2), segments 20(3) and 20(7) to
be assigned
to compute node 121(3), and segments 20(4) and 20(8) to be assigned to compute
node
121(4).
[0031] With row block-block decomposition and Q = 3, resource map 18 causes
segments
20(1)-20(3) to be assigned to compute node 121(1), segments 20(4)-20(6) to be
assigned
to compute node 121(2), and segments 20(7)-20(9) to be assigned to compute
node 121(3).
[0032] The row or column decomposition decision for resource map 16 may depend
upon
memory layout. For example, column-major memory layout may imply column
decomposition using a suitable protocol.
[0033] In one embodiment, resource map 16 includes a collection of resource
segments
where each resource segment associates a segment 20 with a resource view
(i.e., an
abstraction of a compute node) (not shown). For example, for an indexable type
14
defined by:
grid<rank> parent grid;
where grid<rank> contain two data members:
extent<rank> _M _extent;
index<rank> _M _offset;
For example, the second segment 20(2) in Figure 3B, the shape or grid has
_M _extent= {2,2} and _M _offset= {0,1}, and the sixth segment 20(6) has
_M _extent= {2,2} and _M _offset= {1,2}. Accordingly, parent grid may be
decomposed
using:
grid<rank> algorithmic blocks[M1];
grid<rank> memory blocks[M2];
grid<rank> compute nodes[M3];
where M1, M2, M3 > 0 and M1 >= M2 >= M3. Typically, M3 divides M2 and M2
divides Ml. All three of algorithmic blocks, memory blocks and compute nodes
cover
parent grid with no overlap. algorithmic blocks represents decomposition used
in the
algorithm being implemented. memory blocks represents the granularity in which
memory is moved between nodes, when necessary. Compute nodes represents the
granularity at which compute nodes are assigned to store the corresponding
data.
8
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
[0034] It is assumed there are associations so that every algorithmic block or
memory-
block can look up where it is stored on a compute node and so that each
algorithmic block can look up where it is stored on a memory block. A class
called
resource map may be generated with resource segments that form an association
between
a child grid and a resource view:
template <int rank>
struct resource segment {
int _M _id;
grid<rank> _M _child; // representing compute nodes[k] for some k
resource view M resource view;
};
[0035] Using agile communication operator 12, data of an agile indexable type
18 may be
accessed seamlessly without the user having knowledge of the compute node
where the
data is currently residing. For an example indexable type 14, A, with shape
parent grid,
the storage of A is determined by the instances of resource segment. To access
an
element of A at:
index<rank> Index;
the child-grid that contains Index is first found, then an offset:
index<rank> Offset;
is determined such that:
Index = child-grid-offset + Offset.
With the resource segment notation the relationship is:
Index = Resource segment. M child. M offset + Offset.
[0036] In order to increase the speed of lookups, the following check is
performed to
determine whether Index (as Index varies) still belongs to
Resource segment. M child:
index<rank> Local offset = Index - Resource segment. M child. M offset;
extent<rank> Local bounds = Resource segment. M child. M extent;
if ( Local offset < Local bounds ) {
// access data wrt machine M resource view
... local array[ Local offset ] ...
}
[0037] The determination of the child grid or Resource segment that a given
Index
belongs to depends on the decomposition pattern. At worst-case a binary search
in every
dimension may be used but may not be avoided. However with a 2048 x 2048 tile
9
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
decomposition where all tiles have equal extent, for example, find the
Resource segment
with M child. M offset equal to:
index<2> Tile(2048,2048);
(_Index + Tile - 1) / Tile.
That Resource segment (i.e., the current resource segment) may be used until:
if ( Local offset < Local bounds ) {... }
is violated, in which case divide a new Index by Tile again and repeat. This
mechanism
may be optimal for algorithms that have locality where new containing resource
segments
only need to be found infrequently.
[0038] In the local-global-view representation described below, the user index
operators
may omit the if-check (referred to herein as bounds checking):
if ( Local offset < Local bounds ) {... }
because the user is trusted to be within bounds upon every access. If a given
resource segment is exhausted and another will be used, the user is trusted to
call a
function that resets the current resource segment. In the simplest form of
local-global-
view, all three decompositions:
grid<rank> algorithmic blocks[M1];
grid<rank> memory blocks[M2];
grid<rank> compute nodes[M3];
are regular with the same sized blocks or tiles. A tile communication operator
that
partitions an indexable type into tiles may be applied to the first
decomposition to yield:
algorithmic tiles
An individual tile is:
algorithmic tiles( tile index).
When owner copy is initiated on:
algorithmic tiles( tile index)
the containing memory blocks[kl] and compute nodes[k2] are determined. The
owner
compute nodes[k3] is determined next, and then memory blocks[kl] is moved from
compute nodes[k2] to compute nodes[k3].
[0039] Automatic memory movement granularity is often at a finer granularity
than the
sub-grid decomposition of segments 20. For example, suppose the matrix of
Figure 3A
represents a 6144 x 6144 element matrix, viz., each numbered algorithmic block
represents 1024 x 1024 data elements. Assume that the 6144 x 6144 matrix is
decomposed into 2048 x 2048 compute nodes blocks, such as in Figure 3B. In
addition,
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
assume that Q=4 and the compute nodes 121(1), 121(2), 121(3), and 121(4) are
assigned
to the 2048 x 2048 blocks (viz., segments 20(1)-20(9)) according to the block-
cyclic
decomposition. Then segments 20(1), 20(5), 20(9) are assigned to compute node
121(1),
segments 20(2), 20(6) are assigned to compute node 121(2), segments 20(3) and
20(7) are
assigned to compute node 121(3), and segments 20(4) and 20(8) are assigned to
compute
node 121(4). Memory may be moved in 1024 x 1024 blocks in this example.
Accordingly, if a computation seeks to move a single data element from a 1024
x 1024
block, the whole 1024 x 1024 block is moved.
[0040] Agile communication operator 12 allows data parallel (DP) algorithms to
be coded
with a full global-view representation or a local-global-view representation
of segments 20
of agile indexable type 18 to manage the movement of segments 20 between
compute
nodes.
[0041] The full global-view representation allows DP algorithms to be coded as
if they
were going to be run on a single compute node with automatic owner-copy memory
movement happening behind the scenes. As an example with matrix addition,
assume that
A, B and C are each 6144 x 6144 matrices as shown in Figure 3A where each
numbered
block represents 1024 x 1024 data elements. A and B carry valid data, but C is
allocated
but not necessarily carrying any data. Further assume that A, B and C are each
allocated
on compute nodes 121(1)-121(Q) where Q is equal to 4 in this case and where
segments
20(1)-20(9) of each of A, B, and C are stored on compute nodes 121(1)-121(Q),
respectively. With the following computation:
C = A + B: where C(i,j) = A(i,j) + B(i,j): 0 <= i, j < 6
each (i,j) represents 1024 x 1024 elements.
[0042] Owner copy means that data is moved, if necessary, to the compute node
121
where the answer, i.e., C, is being computed. In this example, blocks of A and
B are
moved to compute nodes 121 where corresponding blocks of C are stored as the
computation dictates. For simple matrix addition, however, no movement is
needed
because the blocks of A and B are stored on the same compute nodes 121 as the
corresponding blocks of C. The computation;
C(1,2) = A(1,2) + B(1,2)
uses block 8 in Figure 3B for each of A, B and C. Block 8 is part of segment
20(2) which
is stored on compute node 121(2) for each of A, B and C, so no data movement
occurs.
Similarly, the following computations occur on the corresponding segments 20
and
compute nodes 121:
11
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
C(0,0) = A(0,0) + B(0,0) on segment 20(1), compute node 121(1)
C(1,0) = A(1,0) + B(1,0) on segment 20(1), compute node 121(1)
C(2,0) = A(2,0) + B(2,0) on segment 20(4), compute node 121(4)
C(3,0) = A(3,0) + B(3,0) on segment 20(4), compute node 121(4)
C(4,0) = A(4,0) + B(4,0) on segment 20(7), compute node 121(3)
C(5,0) = A(5,0) + B(5,0) on segment 20(7), compute node 121(3)
Here a segment refers to one element of the decomposition:
grid<2> compute nodes[9].
In fact:
grid<2> algorithmic blocks[36];
grid<2> memory blocks[18];
grid<2> compute nodes[9];
where the algorithmic blocks have extent 1024 x 1024, the memory blocks have
extent
2048 x 1024, and the compute nodes have extent 2048 x 2048. Thus, matrix
addition is a
fairly elementary example.
[0043] In another example with the above assumptions, the transpose of B is
added to A to
generate C as follows:
C = A + BT: where C(i,j) = A(i,j) + B(j,i)T: 0 <= i, j < 6
where each (i,j) represents 1024 x 1024 elements and B(j,i)T is the transpose
of the
underlying 1024 x 1024 block.
[0044] In this case, B(j, i) is moved over to the compute node 121 where
C(i,j) (and A(i,j))
is stored for all blocks except for those in segments 20(1), 20(5), and 20(9).
For example,
C(0,0) = A(0,0) + B(0,0)T
C(0,1) = A(0,1) + B(1,0)T // B(1,0)T is in segment 20(1) of B
C(1,0) = A(1,0) + B(0,1)T // B(0,1)T is in segment 20(1) of B
C(1,1) = A(1,1) + B(1,1)T
However, for the blocks of segment 20(4) of C:
C(2,0) = A(2,0) + B(0,2)T
C(2,1) = A(2,1) + B(1,2)T
C(3,0) = A(3,0) + B(0,3)T
C(3,1) = A(3,1) + B(1,3)T
the B blocks are from the blocks of segment 20(2) stored on compute node
121(2) and the
C blocks are from the blocks of segment 20(4) stored on compute node 121(4) .
12
CA 02821745 2013-06-13
WO 2012/088174
PCT/US2011/066285
of block 8 of B (i.e., B(1,2)T) are moved to compute node 121(4), added to
A(2,1), and
assigned to C(2,1), the 1024 x 1024 elements of block 3 of B (i.e., B(0,3)T)
are moved to
compute node 121(4), added to A(3,0) and assigned to C(3,0), and the 1024 x
1024
elements of block 9 of B (i.e., B(1,3)T) are moved to compute node 121(4),
added to
A(3,1) and assigned to C(3,1).
[0045] With the full global-view representation, the memory movements are done
automatically because each block carries the information of which compute node
121
stores the block. The computations may be directed from any of compute nodes
121 or a
host, such as host 101 shown in Figure 4 and described in additional detail
below.
[0046] In other variations of the example above, multiple segments 20 may be
assigned to
the same compute node 121 where the number of compute nodes 121 are less than
the
number of segments 20. In addition, the processing capabilities of the compute
nodes 121
may be weighted such that faster compute nodes 121 may be assigned more
segments 20
than slower compute nodes 121. The assignments may be performed according to
one or
more the protocols described above.
[0047] Automatic load balancing using work-stealing may also be implemented in
variations of the above. When a compute node 121 completes its computations,
the
compute node 121attempts to steal computations assigned to other nodes 121.
The
compute node 121, or possibly host, that directs the computations may store
work-stealing
queues of work-items where the queues contain tasks that represent the
computation of
memory-movement-granularity (e.g., 1024 x 1024) on the owner matrix (e.g., C).
[0048] With A, B, and C from above matrix addition with B transpose example
with four
equally-weighted compute nodes 121(1)-121(4) and a block-cyclic decomposition
protocol, the following four work-stealing queues may be stored as follows.
[0049] So with the above picture and C = A + BT and memory-movement-
granularity =
1024 x 1024 and 4 machines equally weighted (w0=w1=w2=w3=1) and block-cyclic
decomposition:
queue consist of 12 tasks ¨ the four 1024 x 1024 blocks each of segments
20(1),
20(5), and 20(9);
queuel consist of 8 tasks ¨ the four 1024 x 1024 blocks each of segments 20(2)
and 20(6);
queue2 consist of 8 tasks ¨ the four 1024 x 1024 blocks each of segments 20(3)
and 20(7);
queue3 consist of 8 tasks ¨ the four 1024 x 1024 blocks each of segments 20(4)
and 20(8).
13
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
For example, queue2 includes the tasks:
C(0,4) = A(0,4) + B(4,0)T
C(0,5) = A(0,5) + B(5,0)T
C(1,4) = A(1,4) + B(4,1)T
C(1,5) = A(1,5) + B(5,1)T
C(4,0) = A(4,0) + B(0,4)T
C(4,1) = A(4,1) + B(1,4)T
C(5,0) = A(5,0) + B(0,5)T
C(5,1) = A(5,1) + B(1,5)T
Each compute node 121 takes a task from the top of its corresponding work-
stealing queue
until all tasks from the work-stealing queue are completed. When the work-
stealing queue
of a compute node 121 is empty, the compute node 121 steals a task from the
bottom of a
work-stealing queue that corresponds to another compute node 121. Local-global-
view is
typically enabled through the tile communication operator at the algorithmic
blocks level
of granularity. Assuming a regular tile decomposition, the tile communication
operator is
applied to the first to yield:
algorithmic tiles
An individual tile is:
algorithmic tiles( tile index).
When owner copy is initiated on:
algorithmic tiles( tile index)
the containing memory blocks[kl] and compute nodes[k2] are determined. The
owner
compute nodes[k3] is determined next, and then memory blocks[kl] is moved from
compute nodes[k2] to compute nodes[k3]. This is all done at the level of
accessing
algorithmic tiles( tile index). When implementing the algorithm, an element
(or,
recursively, a finer block) is accessed as:
algorithmic tiles( tile index)( local index)
[0050] In contrast with the full global-view representation, the local-global-
view
representation allows memory movement to be explicitly specified by the user.
In the
above full global-view representation examples, the memory movement
granularity was
1024 x 1024 blocks such that the entire 1024 x 1024 block was moved to a
compute node
121 if the compute node 121 accessed a single element in the block.
[0051] In some computations, the granularity of the computation is finer than
the memory
movement granularity and the local-global-view representation provides
advantages over
the user explicitly directing where every memory block is to be moved. For
example,
assume that the memory movement granularity is 2048 x 1024 in the full global-
view
14
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
representation examples, viz., two blocks are moved whenever an element is
moved from
either of the two blocks. So for C = A + BT, the compute for blocks of segment
20(4) of C
are:
C(2,0) = A(2,0) + B(0,2)T
C(2,1) = A(2,1) + B(1,2)T
C(3,0) = A(3,0) + B(0,3)T
C(3,1) = A(3,1) + B(1,3)T
In each case, the B blocks are stored on compute node 121(2) and the C and A
blocks (C is
the owner) are stored on compute node 121(4). Thus, the first two of the above
statements
are carried out by explicitly directing any element of block 2 of B (i.e.,
B(0,2)T) to be
moved to compute node 121(4) . Because of the 2048 x 1024 memory granularity,
both
blocks 2 and 8 of B (i.e., B(0,2)T and B(1,2)T) are moved to compute node
121(4) to allow
the additions of the first two statements to be performed by compute node
121(4).
Likewise, the last two of the above statements are carried out by explicitly
directing any
element of block 3 of B (i.e., B(0,3)T) to be moved to compute node 121(4) .
Because of
the 2048 x 1024 memory granularity, both blocks 3 and 9 of B (i.e., B(0,3)T
and (1,3)T) are
moved to compute node 121(4) to allow the additions of the last two statements
to be
performed by compute node 121(4).
[0052] As these examples show, the granularity of the computation may be finer
than the
memory movement granularity, which may be finer than the compute node
granularity, so
that there may be many tasks executing on a given memory movement block with
one or
more algorithms. A single directive to move an element of a block allows the
tasks
operating on the block to be more efficiently executed. Both the user and the
implementation may omit checking to see whether memory needs to be moved until
the
directing algorithm begins working on another memory movement block, and, as
seen
above, the tile communication operator corresponding to the algorithmic blocks
decomposition actually directs the memory movement when necessary. If a 1024 x
1024
tile (e.g. block 3) is to be moved, then the containing 2048 x 1024 memory
movement
block (e.g. mem-movement block 3) is moved from the containing 2048 x 2048
compute
node block (e.g., segment 20(2)) to the owner-copy determined 2048 x 2048
block (e.g.,
segment 20(4)). If block 9 now is to be moved, accessing the corresponding
tile will look
up its containing memory-movement block and determine that it has already been
moved
to segment 20(4), so no movement is necessary. Bounds checking as set forth
above may
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
be omitted because the correct memory movement has occurred at the tile level
before the
actual data element access in the tile. That is to say:
algorithmic tiles( tile index).
generates any necessary memory movement, then:
algorithmic tiles( tile index)( local index)
can be accessed without bounds checking each local index. For example, in the
above
computation, there are two algorithmic tasks for each memory movement block.
[0053] In practice, all computation performed on a given memory block on the
owner memory (e.g., C) may be grouped into a large task and the first
statement in the task
may be a single memory movement directive. The directive may be in the form of
a
standard C++ annotation on the task as follows in one embodiment.
[[move memory(C, B)]]
void kerne1(fie1d<2, double>& C, const fie1d<2, double>& A, const fie1d<2,
double>& B);
Using this annotation, a compiler may optimize and interleave memory movement
and
computation.
[0054] The following code provides an overview of an implementation of agile
communications operator 12 in one embodiment.
//
// A resource view is a handle for a physical compute engine.
// The only hard requirement is a memory hierarchy in which to realize data.
// The fundamental property of resource view is Buffer<T>, which is
// essentially a concrete 1-dimensional array of type T.
//
struct resource view;
//
// Given an allocation of memory with a structure to represent it as a Rank-
dimenional
// array (viz., field, cf. infra), construct a partioning or segmentation of
it. The allocation of
memory has
// indices as integral points in a rectangular set with offset, as described
by a grid (cf.
infra).
//
template <int Rank>
struct index {
// overloaded subscript and ctors
int m base[ Rank];
};
template <int Rank>
struct extent {
// overloaded function-call, subscript and ctors
unsigned int M base[ Rank];
};
template <int Rank>
16
CA 02821745 2013-06-13
WO 2012/088174
PCT/US2011/066285
struct grid {
static assert(_Rank > 0, "rank must be > O");
unsigned int total extent() const {
unsigned int total extent = M extent[0];
for (int i = 1; i < Rank; ++i)
total extent *= M extent[i];
return total extent;
1
// various overloads
extent< Rank> _M _extent;
index< Rank> _M _offset.
1;
//
// Here is the fundamental data type of DPC++.
// Various indexable types inherit from fields or other
// indexable types. Each indexable types just gives a
// different view of its parent (viz., base class) and the data
// does not physically change. The overloaded subscript
// operator represents the different view. For example, the transpose
// indexable type would have subscript operator in Rank=2:
//
// template <typename Parent type>
// struct transpose range : public Parent type {
// element type& operator[] (const index<2>& Index) {
// Parent type& base = *static cast< Parent type*>(this);
// return (*this)[index<2>( Index[1], Index[0]);
// 1
// };
11
template <int Rank, typename Element type>
struct field {
// basic indexable type characteristics
const static int rank = Rank;
typedef Element type element type;
//
// Construct _M _multiplier so that it maps Rank-dimensional => 1-dimensional.
//
field(const extent < Rank>& Extent, const resource view& Resource view)
: M grid( Extent), M store( Buffer< Element type>( Grid.total extent())) {
// create a row-major multiplier vector
M multiplier[0] = 1;
if ( Rank > 1)
M multiplier[1] = M grid[0];
if ( Rank > 2)
for (int i = 2; i < Rank; ++i)
M multiplier[i] = M grid[i-1]* M multiplier[i-1];
1
//
// Construct a subfield from another
//
17
CA 02821745 2013-06-13
WO 2012/088174
PCT/US2011/066285
template <typename Other>
field(const grid< Rank>& Grid, const Other& Parent)
: M grid( Grid), M store( Parent.get store()),
M multiplier( Parent.get multiplier()) {
}
//
// Checking that Index is within _M grid, is elided for now.
//
element type& operator[] (const index < Rank>& Index) {
return Buffer[ flatten( Index) ];
I
private:
grid< Rank> _M _grid;
extent< Rank> _M _multiplier;
Buffer< Element type> m store;
//
// Map Rank-dimensional => 1-dimensional.
//
unsigned int flatten(const index < Rank>& Index) {
unsigned int Flat index = Index[0];
if ( Rank > 1)
Flat index += Index[1]* M multiplier[1];
if ( Rank > 2)
for (int i = 2; i < Rank; ++i)
Flat index += Index[i]* M multiplier[i];
return Flat index;
1
1;
//
// Given a grid, define grid segment to represent a single segment in the
segmentation.
//
//
// M_parent is the grid being segmented (viz., partitioned).
// _M _child describes the extent and offset of the owned grid segment which
must be
within parent.
// _M _id is an identifier for this grid segment.
//
template <int Rank>
struct grid segment {
int M id;
grid< Rank> _M _child;
grid< Rank> M_parent;
};
11
// resource segment associates a grid segment with a resource view
//
template <int Rank>
struct resource segment {
grid segment< Rank> _M _segment;
resource view M resource view;
18
CA 02821745 2013-06-13
WO 2012/088174
PCT/US2011/066285
1;
//
// resource map is a collection of resource segments covering a parent grid.
// resource map is not marshaled to a device.
// It is a structure that either completely resides on a single compute node
or a host.
// resource map can be specialized for block, cyclic and block-cyclic
decompositions,
// as well as sparse, strided, associative, and unstructured.
//
template <int Rank>
struct resource map {
//
// Create a resource map by specifying the split points and parent grid.
// The ith slot of every split point in Split_points that is != -1, determines
the
// partition points on the ith axis. Let the number of such points be N(i).
// Then there are N(0)*N(1)*...*N( Rank - 1) resource segments.
//
// For example, rank=2,
// parent grid. M extent={36,36},
// Split_points[0] = {16},
// Split_points[1] = {16}, then there are 4 = (1+1)*(1+1) segments of extent
{16, 16}.
//
// This specifies the compute nodes
// decomposition. There are also methods/ctors that
// allow the specification of memory blocks
// and algorithmic blocks.
//
// The resource map provides the mechanism for
// both every data element and every algorithmic
// tile to determine the containing memory movement
// block and the containing resource segment.
// This is enough for an agile field to determine when
// to move memory and when to just access for free
// (local-global-view). Or for global-view, enough
// information for every data element to find the
// containing resource segment whenever the
// if-check set forth above (i.e., bounds checking) is violated.
//
//
// Now create an agile indexable type
//
template <typename Parent type>
struct agile range : public Parent type {
const static int rank = Parent type::rank;
typedef typename Parent type::element type element type;
agile range(const Parent type& Parent, const resource map<rank>&
Resource map)
: Parent type( Parent), M resource map(_Resource map) {
}
19
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
private:
resource map<rank> M resource map;
1;
//
// agile communications operator 12 is the standard way to change resource
view, usually
to multiple resource views.
//
template <typename Parent type>
agile range< Parent type> agile(const Parent type& Parent, const
resource map<rank>& Resource map) {
return agile range < Parent type>(_Parent, Resource map);
}
[0055] Figure 4 is a block diagram illustrating an embodiment of a computer
system 100
configured to compile and execute data parallel code 10 that includes an agile
communication operator 12.
[0056] Computer system 100 includes a host 101 with one or more processing
elements
(PEs) 102 housed in one or more processor packages (not shown) and a memory
system
104. Computer system 100 also includes zero or more input / output devices
106, zero or
more display devices 108, zero or more peripheral devices 110, and zero or
more network
devices 112. Computer system 100 further includes a compute engine 120 with
one or
more DP optimal compute nodes 121 where each DP optimal compute node 121
includes
a set of one or more processing elements (PEs) 122 and a memory 124 that
stores DP
executable 138.
[0057] Host 101, input / output devices 106, display devices 108, peripheral
devices 110,
network devices 112, and compute engine 120 communicate using a set of
interconnections 114 that includes any suitable type, number, and
configuration of
controllers, buses, interfaces, and / or other wired or wireless connections.
[0058] Computer system 100 represents any suitable processing device
configured for a
general purpose or a specific purpose. Examples of computer system 100 include
a server,
a personal computer, a laptop computer, a tablet computer, a smart phone, a
personal
digital assistant (PDA), a mobile telephone, and an audio/video device. The
components
of computer system 100 (i.e., host 101, input / output devices 106, display
devices 108,
peripheral devices 110, network devices 112, interconnections 114, and compute
engine
120) may be contained in a common housing (not shown) or in any suitable
number of
separate housings (not shown).
[0059] Processing elements 102 each form execution hardware configured to
execute
instructions (i.e., software) stored in memory system 104. The processing
elements 102 in
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
each processor package may have the same or different architectures and / or
instruction
sets. For example, the processing elements 102 may include any combination of
in-order
execution elements, superscalar execution elements, and data parallel
execution elements
(e.g., GPU execution elements). Each processing element 102 is configured to
access and
execute instructions stored in memory system 104. The instructions may include
a basic
input output system (BIOS) or firmware (not shown), an operating system (OS)
132, code
10, compiler 134, GP executable 136, and DP executable 138. Each processing
element
102 may execute the instructions in conjunction with or in response to
information
received from input / output devices 106, display devices 108, peripheral
devices 110,
network devices 112, and / or compute engine 120.
[0060] Host 101 boots and executes OS 132. OS 132 includes instructions
executable by
the processing elements to manage the components of computer system 100 and
provide a
set of functions that allow programs to access and use the components. In one
embodiment, OS 132 is the Windows operating system. In other embodiments, OS
132 is
another operating system suitable for use with computer system 100.
[0061] When computer system executes compiler 134 to compile code 10, compiler
134
generates one or more executables ¨ e.g., one or more GP executables 136 and
one or
more DP executables 138. In other embodiments, compiler 134 may generate one
or more
GP executables 136 to each include one or more DP executables 138 or may
generate one
or more DP executables 138 without generating any GP executables 136. GP
executables
136 and / or DP executables 138 are generated in response to an invocation of
compiler
134 with data parallel extensions to compile all or selected portions of code
10. The
invocation may be generated by a programmer or other user of computer system
100, other
code in computer system 100, or other code in another computer system (not
shown), for
example.
[0062] GP executable 136 represents a program intended for execution on one or
more
general purpose processing elements 102 (e.g., central processing units
(CPUs)). GP
executable 136 includes low level instructions from an instruction set of one
or more
general purpose processing elements 102.
[0063] DP executable 138 represents a data parallel program or algorithm
(e.g., a shader)
that is intended and optimized for execution on one or more data parallel (DP)
optimal
compute nodes 121. In one embodiment, DP executable 138 includes DP byte code
or
some other intermediate representation (IL) that is converted to low level
instructions from
an instruction set of a DP optimal compute node 121 using a device driver (not
shown)
21
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
prior to being executed on the DP optimal compute node 121. In other
embodiments, DP
executable 138 includes low level instructions from an instruction set of one
or more DP
optimal compute nodes 121 where the low level instructions were inserted by
compiler
134. Accordingly, GP executable 136 is directly executable by one or more
general
purpose processors (e.g., CPUs), and DP executable 138 is either directly
executable by
one or more DP optimal compute nodes 121 or executable by one or more DP
optimal
compute nodes 121 subsequent to being converted to the low level instructions
of the DP
optimal compute node 121.
[0064] Computer system 100 may execute GP executable 136 using one or more
processing elements 102, and computer system 100 may execute DP executable 138
using
one or more PEs 122 as described in additional detail below.
[0065] Memory system 104 includes any suitable type, number, and configuration
of
volatile or non-volatile storage devices configured to store instructions and
data. The
storage devices of memory system 104 represent computer readable storage media
that
store computer-executable instructions (i.e., software) including OS 132, code
10,
compiler 134, GP executable 136, and DP executable 138. The instructions are
executable
by computer system 100 to perform the functions and methods of OS 132, code
10,
compiler 134, GP executable 136, and DP executable 138 as described herein.
Memory
system 104 stores instructions and data received from processing elements 102,
input /
output devices 106, display devices 108, peripheral devices 110, network
devices 112, and
compute engine 120. Memory system 104 provides stored instructions and data to
processing elements 102, input / output devices 106, display devices 108,
peripheral
devices 110, network devices 112, and compute engine 120. Examples of storage
devices
in memory system 104 include hard disk drives, random access memory (RAM),
read only
memory (ROM), flash memory drives and cards, and magnetic and optical disks
such as
CDs and DVDs.
[0066] Input / output devices 106 include any suitable type, number, and
configuration of
input / output devices configured to input instructions or data from a user to
computer
system 100 and output instructions or data from computer system 100 to the
user.
Examples of input / output devices 106 include a keyboard, a mouse, a
touchpad, a
touchscreen, buttons, dials, knobs, and switches.
[0067] Display devices 108 include any suitable type, number, and
configuration of
display devices configured to output textual and / or graphical information to
a user of
22
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
computer system 100. Examples of display devices 108 include a monitor, a
display
screen, and a projector.
[0068] Peripheral devices 110 include any suitable type, number, and
configuration of
peripheral devices configured to operate with one or more other components in
computer
system 100 to perform general or specific processing functions.
[0069] Network devices 112 include any suitable type, number, and
configuration of
network devices configured to allow computer system 100 to communicate across
one or
more networks (not shown). Network devices 112 may operate according to any
suitable
networking protocol and / or configuration to allow information to be
transmitted by
computer system 100 to a network or received by computer system 100 from a
network.
[0070] Compute engine 120 is configured to execute DP executable 138. Compute
engine
120 includes one or more compute nodes 121. Each compute node 121 is a
collection of
computational resources that share a memory hierarchy. Each compute node 121
includes
a set of one or more PEs 122 and a memory 124 that stores DP executable 138.
PEs 122
execute DP executable 138 and store the results generated by DP executable 138
in
memory 124. In particular, PEs 122 execute DP executable 138 to apply an agile
communication operator 12 to an input indexable type 14 to generate an output
indexable
type 18 as shown in Figure 4 and described in additional detail above.
[0071] A compute node 121 that has one or more computational resources with a
hardware architecture that is optimized for data parallel computing (i.e., the
execution of
DP programs or algorithms) is referred to as a DP optimal compute node 121.
Examples
of a DP optimal compute node 121 include a node 121 where the set of PEs 122
includes
one or more GPUs and a node 121 where the set of PEs 122 includes the set of
SIMD units
in a general purpose processor package. A compute node 121 that does not have
any
computational resources with a hardware architecture that is optimized for
data parallel
computing (e.g., processor packages with only general purpose processing
elements 102)
is referred to as a non-DP optimal compute node 121. In each compute node 121,
memory
124 may be separate from memory system 104 (e.g., GPU memory used by a GPU) or
a
part of memory system 104 (e.g., memory used by SIMD units in a general
purpose
processor package).
[0072] Host 101 forms a host compute node that is configured to provide DP
executable
138 to a compute node 121 for execution and receive results generated by DP
executable
138 using interconnections 114. The host compute node includes is a collection
of general
purpose computational resources (i.e., general purpose processing elements
102) that share
23
CA 02821745 2013-06-13
WO 2012/088174 PCT/US2011/066285
a memory hierarchy (i.e., memory system 104). The host compute node may be
configured with a symmetric multiprocessing architecture (SMP) and may also be
configured to maximize memory locality of memory system 104 using a non-
uniform
memory access (NUMA) architecture, for example.
[0073] OS 132 of the host compute node is configured to execute a DP call site
to cause a
DP executable 138 to be executed by a DP optimal or non-DP optimal compute
node 121.
In embodiments where memory 124 is separate from memory system 104, the host
compute node causes DP executable 138 and one or more indexable types 14 to be
copied
from memory system 104 to memory 124. In embodiments where memory system 104
includes memory 124, the host compute node may designate a copy of DP
executable 138
and / or one or more indexable types 14 in memory system 104 as memory 124 and
/ or
may copy DP executable 138 and / or one or more indexable types 14 from one
part of
memory system 104 into another part of memory system 104 that forms memory
124. The
copying process between compute node 121 and the host compute node may be a
synchronization point unless designated as asynchronous.
[0074] The host compute node and each compute node 121 may concurrently
execute
code independently of one another. The host compute node and each compute node
121
may interact at synchronization points to coordinate node computations.
[0075] In one embodiment, compute engine 120 represents a graphics card where
one or
more graphics processing units (GPUs) include PEs 122 and a memory 124 that is
separate
from memory system 104. In this embodiment, a driver of the graphics card (not
shown)
may convert byte code or some other intermediate representation (IL) of DP
executable
138 into the instruction set of the GPUs for execution by the PEs 122 of the
GPUs.
[0076] In another embodiment, compute engine 120 is formed from the
combination of
one or more GPUs (i.e. PEs 122) that are included in processor packages with
one or more
general purpose processing elements 102 and a portion of memory system 104
that
includes memory 124. In this embodiment, additional software may be provided
on
computer system 100 to convert byte code or some other intermediate
representation (IL)
of DP executable 138 into the instruction set of the GPUs in the processor
packages.
[0077] In further embodiment, compute engine 120 is formed from the
combination of one
or more SIMD units in one or more of the processor packages that include
processing
elements 102 and a portion of memory system 104 that includes memory 124. In
this
embodiment, additional software may be provided on computer system 100 to
convert the
24
CA 02821745 2013-06-13
WO 2012/088174
PCT/US2011/066285
byte code or some other intermediate representation (IL) of DP executable 138
into the
instruction set of the SIMD units in the processor packages.
[0078] In yet another embodiment, compute engine 120 is formed from the
combination
of one or more scalar or vector processing pipelines in one or more of the
processor
packages that include processing elements 102 and a portion of memory system
104 that
includes memory 124. In this embodiment, additional software may be provided
on
computer system 100 to convert the byte code or some other intermediate
representation
(IL)of DP executable 138 into the instruction set of the scalar processing
pipelines in the
processor packages.
[0079] Although specific embodiments have been illustrated and described
herein, it will
be appreciated by those of ordinary skill in the art that a variety of
alternate and/or
equivalent implementations may be substituted for the specific embodiments
shown and
described without departing from the scope of the present invention. This
application is
intended to cover any adaptations or variations of the specific embodiments
discussed
herein. Therefore, it is intended that this invention be limited only by the
claims and the
equivalents thereof