Note: Descriptions are shown in the official language in which they were submitted.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 1 -
CONTEXT BASED VIDEO ENCODING AND DECODING
RELATED APPLICATION(S)
This application claims the benefit of U.S. Provisional Application No.
61/615,795 filed on March 26, 2012 and US Provisional Application No.
61/707,650
filed on September 28, 2012. This application also claims priority to U.S.
Utility
Application No. 13/725,940, filed December 21, 2012. U.S. Application No.
13/725,940, filed December 21, 2012 also is a continuation-in part of U.S.
Patent
Application No. 13/121,904, filed October 6, 2009, which is a U.S. National
Stage of
PCT/U52009/059653 filed October 6, 2009, which claims the benefit of U.S.
Provisional Application No. 61/103,362, filed October 7, 2008. The '904
application is
also a continuation-in part of U.S. Patent Application No. 12/522,322, filed
January 4,
2008, which claims the benefit of U.S. Provisional Application No. 60/881,966,
filed
January 23, 2007, is related to U.S. Provisional Application No. 60/811,890,
filed June
8, 2006, and is a continuation-in-part of U.S. Application No. 11/396,010,
filed March
31, 2006, now U.S. Patent No. 7,457,472, which is a continuation-in-part of
U.S.
Application No. 11/336,366 filed January 20, 2006, now U.S. Patent No.
7,436,981,
which is a continuation-in-part of U.S. Application No. 11/280,625 filed
November 16,
2005, now U.S. Patent No. 7,457,435, which is a continuation-in-part of U.S.
Application No. 11/230,686 filed September 20, 2005, now U.S. Patent No.
7,426,285,
which is a continuation-in-part of U.S. Application No. 11/191,562 filed July
28, 2005,
now U.S. Patent No. 7,158,680. U.S. Application No. 11/396,010 also claims
priority
to U.S. Provisional Application No. 60/667,532, filed March 31, 2005 and U.S.
Provisional Application No. 60/670,951, filed April 13, 2005. This application
is also
related to U.S. Provisional Application No. 61/616,334, filed March 27, 2012.
The entire teachings of the above applications and patents are incorporated
herein by reference.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 2 -
BACKGROUND
Video compression can be considered the process of representing digital video
data in a form that uses fewer bits when stored or transmitted. Video
compression
algorithms can achieve compression by exploiting redundancies and
irrelevancies in the
video data, whether spatial, temporal, or color-space. Video compression
algorithms
typically segment the video data into portions, such as groups of frames and
groups of
pels, to identify areas of redundancy within the video that can be represented
with fewer
bits than the original video data. When these redundancies in the data are
reduced,
greater compression can be achieved. An encoder can be used to transform the
video
data into an encoded format, while a decoder can be used to transform encoded
video
back into a form comparable to the original video data. The implementation of
the
encoder/decoder is referred to as a codec.
Standard encoders divide a given video frame into non-overlapping coding units
or macroblocks (rectangular regions of contiguous pels) for encoding. The
macroblocks
are typically processed in a traversal order of left to right and top to
bottom in the
frame. Compression can be achieved when macroblocks are predicted and encoded
using previously-coded data. The process of encoding macroblocks using
spatially
neighboring samples of previously-coded macroblocks within the same frame is
referred to as intra-prediction. Intra-prediction attempts to exploit spatial
redundancies
in the data. The encoding of macroblocks using similar regions from previously-
coded
frames, together with a motion estimation model, is referred to as inter-
prediction.
Inter-prediction attempts to exploit temporal redundancies in the data.
The encoder may measure the difference between the data to be encoded and the
prediction to generate a residual. The residual can provide the difference
between a
predicted macroblock and the original macroblock. The encoder can generate
motion
vector information that specifies, for example, the location of a macroblock
in a
reference frame relative to a macroblock that is being encoded or decoded. The
predictions, motion vectors (for inter-prediction), residuals, and related
data can be
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 3 -
combined with other processes such as a spatial transform, a quantizer, an
entropy
encoder, and a loop filter to create an efficient encoding of the video data.
The residual
that has been quantized and transformed can be processed and added back to the
prediction, assembled into a decoded frame, and stored in a framestore.
Details of such
encoding techniques for video will be familiar to a person skilled in the art.
H.264/MPEG-4 AVC (advanced video coding), hereafter referred to as H.264, is
a codec standard for video compression that utilizes block-based motion
estimation and
compensation and achieves high quality video representation at relatively low
bitrates.
This standard is one of the encoding options used for Blu-ray disc creation
and within
major video distribution channels, including video streaming on the internet,
video
conferencing, cable television and direct-broadcast satellite television. The
basic coding
units for H.264 are 16x16 macroblocks. H.264 is the most recent widely-
accepted
standard in video compression.
The basic MPEG standard defines three types of frames (or pictures), based on
how the macroblocks in the frame are encoded. An I-frame (intra-coded picture)
is
encoded using only data present in the frame itself Generally, when the
encoder
receives video signal data, the encoder creates I frames first and segments
the video
frame data into macroblocks that are each encoded using intra-prediction.
Thus, an I-
frame consists of only intra-predicted macroblocks (or "intra macroblocks"). I-
frames
can be costly to encode, as the encoding is done without the benefit of
information from
previously-decoded frames. A P-frame (predicted picture) is encoded via
forward
prediction, using data from previously-decoded I-frames or P-frames, also
known as
reference frames. P-frames can contain either intra macroblocks or (forward-
)predicted
macroblocks. A B-frame (bi-predictive picture) is encoded via bidirectional
prediction,
using data from both previous and subsequent frames. B-frames can contain
intra,
(forward-)predicted, or bi-predicted macroblocks.
As noted above, conventional inter-prediction is based on block-based motion
estimation and compensation (BBMEC). The BBMEC process searches for the best
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 4 -
match between the target macroblock (the current macroblock being encoded) and
similar-sized regions within previously-decoded reference frames. When a best
match
is found, the encoder may transmit a motion vector. The motion vector may
include a
pointer to the best match's frame position as well as information regarding
the
difference between the best match and the corresponding target macroblock. One
could
conceivably perform exhaustive searches in this manner throughout the video
"datacube" (height x width x frame index) to find the best possible matches
for each
macroblock, but exhaustive search is usually computationally prohibitive. As a
result,
the BBMEC search process is limited, both temporally in terms of reference
frames
searched and spatially in terms of neighboring regions searched. This means
that "best
possible" matches are not always found, especially with rapidly changing data.
A particular set of reference frames is termed a Group of Pictures (GOP). The
GOP contains only the decoded pels within each reference frame and does not
include
information as to how the macroblocks or frames themselves were originally
encoded
(I-frame, B-frame or P-frame). Older video compression standards, such as MPEG-
2,
used one reference frame (the previous frame) to predict P-frames and two
reference
frames (one past, one future) to predict B-frames. The H.264 standard, by
contrast,
allows the use of multiple reference frames for P-frame and B-frame
prediction. While
the reference frames are typically temporally adjacent to the current frame,
there is also
accommodation for the specification of reference frames from outside the set
of the
temporally adjacent frames.
Conventional compression allows for the blending of multiple matches from
multiple frames to predict regions of the current frame. The blending is often
linear, or
a log-scaled linear combination of the matches. One example of when this bi-
prediction
method is effective is when there is a fade from one image to another over
time. The
process of fading is a linear blending of two images, and the process can
sometimes be
effectively modeled using bi-prediction. Some past standard encoders such as
the
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 5 -
MPEG-2 interpolative mode allow for the interpolation of linear parameters to
synthesize the bi-prediction model over many frames.
The H.264 standard also introduces additional encoding flexibility by dividing
frames into spatially distinct regions of one or more contiguous macroblocks
called
slices. Each slice in a frame is encoded (and can thus be decoded)
independently from
other slices. I-slices, P-slices, and B-slices are then defined in a manner
analogous to
the frame types described above, and a frame can consist of multiple slice
types.
Additionally, there is typically flexibility in how the encoder orders the
processed
slices, so a decoder can process slices in an arbitrary order as they arrive
to the decoder.
While the H.264 standard allows a codec to provide better quality video at
lower
file sizes than previous standards, such as MPEG-2 and MPEG-4 ASP (advanced
simple profile), "conventional" compression codecs implementing the H.264
standard
typically have struggled to keep up with the demand for greater video quality
and
resolution on memory-constrained devices, such as smartphones and other mobile
devices, operating on limited-bandwidth networks. Video quality and resolution
are
often compromised to achieve adequate playback on these devices. Further, as
video
resolution increases, file sizes increase, making storage of videos on and off
these
devices a potential concern.
SUMMARY OF THE INVENTION
The present invention recognizes fundamental limitations in the inter-
prediction
process of conventional codecs and applies higher-level modeling to overcome
those
limitations and provide improved inter-prediction, while maintaining the same
general
processing flow and framework as conventional encoders.
In the present invention, higher-level modeling provides an efficient way of
navigating more of the prediction search space (the video datacube) to produce
better
predictions than can be found through conventional block-based motion
estimation and
compensation. First, computer-vision-based feature and object detection
algorithms
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 6 -
identify regions of interest throughout the video datacube. The detection
algorithm
may be from the class of nonparametric feature detection algorithms. Next, the
detected
features and objects are modeled with a compact set of parameters, and similar
feature/object instances are associated across frames. The invention then
forms tracks
out of the associated feature/objects, relates the tracks to specific blocks
of video data to
be encoded, and uses the tracking information to produce model-based
predictions for
those blocks of data.
In embodiments, the specific blocks of data to be encoded may be macroblocks.
The formed tracks relate features to respective macroblocks.
Feature/object tracking provides additional context to the conventional
encoding/decoding process. Additionally, the modeling of features/objects with
a
compact set of parameters enables information about the features/objects to be
stored
efficiently in memory, unlike reference frames, whose totality of pels are
expensive to
store. Thus, feature/object models can be used to search more of the video
datacube,
without requiring a prohibitive amount of additional computations or memory.
The
resulting model-based predictions are superior to conventional inter-
predictions,
because the model-based predictions are derived from more of the prediction
search
space.
In some embodiments, the compact set of parameters includes information about
the feature/objects and this set is stored in memory. For a feature, the
respective
parameter includes a feature descriptor vector and a location of the feature.
The
respective parameter is generated when the respective feature is detected.
After associating feature/object instances across frames, one can also gather
the
associated instances into ensemble matrices (instead of forming feature/object
tracks).
In this case, the present invention forms such ensemble matrices, summarizes
the
matrices using subspaces of important vectors, and uses the vector subspaces
as
parametric models of the associated features/objects. This can result in
especially
efficient encodings when those particular features/objects appear in the data.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 7 -
Computer-based methods, codecs and other computer systems and apparatus for
processing video data may embody the foregoing principles of the present
invention.
BRIEF DESCRIPTION OF THE DRAWINGS
The foregoing will be apparent from the following more particular description
of
example embodiments of the invention, as illustrated in the accompanying
drawings in
which like reference characters refer to the same parts throughout the
different views.
The drawings are not necessarily to scale, emphasis instead being placed upon
illustrating embodiments of the present invention.
FIG. lA is a block diagram depicting feature modeling according to an
embodiment of the invention.
FIG. 1B is a block diagram depicting feature tracking according to an
embodiment of the invention.
FIG. 1C is a block diagram illustrating the steps in relating features to
nearby
macroblocks and using the tracks of those features to generate good
predictions for
those macroblocks, according to an embodiment of the invention.
FIG. 2A is a schematic diagram illustrating the modeling of data at multiple
fidelities to provide efficient encodings, according to an embodiment of the
invention.
FIG. 2B is a block diagram illustrating the identification of objects through
feature model correlation and aggregation, according to an embodiment of the
invention.
FIG. 2C is a block diagram illustrating the identification of objects via
aggregation of both nearby features and nearby macroblocks, according to an
embodiment of the invention.
FIG. 3A is a schematic diagram of the configuration of an example transform-
based codec according to an embodiment of the invention.
FIG. 3B is a block diagram of an example decoder for intra-predicted
macroblocks, according to an embodiment of the invention.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 8 -
FIG. 3C is a block diagram of an example decoder for inter-predicted
macroblocks, according to an embodiment of the invention.
FIG. 3D is a schematic diagram of the configuration of an example transform
based codec employing feature-based prediction, according to an embodiment of
the
invention.
FIG. 4 is a block diagram of an example decoder within a feature-based
prediction framework, according to an embodiment of the invention.
FIG. 5 is a block diagram illustrating the state isolation process of feature
instances according to an embodiment of the present information.
FIG. 6A is a block diagram illustrating example elements of a codec employing
parametric modeling, according to an embodiment of the invention.
FIG. 6B is a block diagram illustrating example elements of parametric model-
based adaptive encoder, according to an embodiment of the invention.
FIG. 6C is a block diagram illustrating the motion compensated prediction of
features via interpolation of feature model parameters, according to an
embodiment of
the invention.
FIG. 7A is a block diagram illustrating an overview of example cache
architecture according to an embodiment of the invention.
FIG. 7B is a block diagram illustrating the processing involved in utilizing
the
local (short) cache data, according to an embodiment of the invention.
FIG. 7C is a block diagram illustrating the processing involved in utilizing
the
distant cache data, according to an embodiment of the invention.
FIG. 8A is a schematic diagram of a computer network environment in which
embodiments are deployed.
FIG. 8B is a block diagram of the computer nodes in the network of FIG. 8A.
FIG. 8C is a screenshot of a feature-based compression tool in accordance with
example implementations.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 9 -
FIG. 8D is a screenshot showing features designated with numbers for both face
and non-facial features, according to an embodiment of the invention.
FIG. 8E is a screenshot showing a face designated by the face tracker of FIG.
8D, according to an embodiment of the invention.
DETAILED DESCRIPTION
The teachings of all patents, published applications and references cited
herein
are incorporated by reference in their entirety. A description of example
embodiments
of the invention follows.
The invention can be applied to various standard encodings and coding units.
In
the following, unless otherwise noted, the terms "conventional" and "standard"
(sometimes used together with "compression," "codecs," "encodings," or
"encoders")
will refer to H.264, and "macroblocks" will be referred to without loss of
generality as
the basic H.264 coding unit.
Feature-Based Modeling
Definition of features
Example elements of the invention may include video compression and
decompression processes that can optimally represent digital video data when
stored or
transmitted. The processes may include or interface with a video
compression/encoding
algorithm(s) to exploit redundancies and irrelevancies in the video data,
whether spatial,
temporal, or spectral. This exploitation may be done through the use and
retention of
feature-based models/parameters. Moving forward, the terms "feature" and
"object" are
used interchangeably. Objects can be defined, without loss of generality, as
"large
features." Both features and objects can be used to model the data.
Features are groups of pels in close proximity that exhibit data complexity.
Data
complexity can be detected via various criteria, as detailed below, but the
ultimate
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 10 -
characteristic of data complexity from a compression standpoint is "costly
encoding,"
an indication that an encoding of the pels by conventional video compression
exceeds a
threshold that would be considered "efficient encoding." When conventional
encoders
allocate a disproportionate amount of bandwidth to certain regions (because
conventional inter-frame search cannot find good matches for them within
conventional
reference frames), it becomes more likely that the region is "feature-rich"
and that a
feature model-based compression method will improve compression significantly
in
those regions.
Feature detection
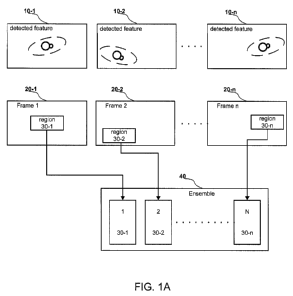
FIG. lA depicts a feature whose instances 10-1, 10-2,...,10-n have been
detected in one or more frames of the video 20-1, 20-2,...,20-n. Typically,
such a
feature can be detected using several criteria based on both structural
information
derived from the pels and complexity criteria indicating that conventional
compression
utilizes a disproportionate amount of bandwidth to encode the feature region.
Each
feature instance can be further identified spatially in its frame 20-1, 20-2,
...,20-n by a
corresponding spatial extent or perimeter, shown in FIG. lA as "regions" 30-1,
30-2,
..., 30-n. These feature regions 30-1, 30-2, ..., 30-n can be extracted, for
instance, as
simple rectangular regions of pel data. In one embodiment in the current
invention, the
feature regions are of size 16x16, the same size as H.264 macroblocks.
Many algorithms have been proposed in the literature for detecting features
based on the structure of the pels themselves, including a class of
nonparametric feature
detection algorithms that are robust to different transformations of the pel
data. For
example, the scale invariant feature transform (SIFT) [Lowe, David, 2004,
"Distinctive
image features from scale-invariant keypoints," Int. J. of Computer Vision,
60(2):91-
110] uses a convolution of a difference-of-Gaussian function with the image to
detect
blob-like features. The speeded-up robust features (SURF) algorithm [Bay,
Herbert et
al., 2008, "SURF: Speeded up robust features," Computer Vision and Image
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 11 -
Understanding, 110(3):346-359] uses the determinant of the Hessian operator,
also to
detect blob-like features. In one embodiment of the present invention, the
SURF
algorithm is used to detect features.
In another embodiment, discussed in full in U.S. Application No., 13/121,904,
filed October 6, 2009, which is incorporated herein by reference in its
entirety, features
can be detected based on encoding complexity (bandwidth) encountered by a
conventional encoder. Encoding complexity, for example, can be determined
through
analysis of the bandwidth (number of bits) required by conventional
compression (e.g.,
H.264) to encode the regions in which features appear. Restated, different
detection
algorithms operate differently, but each are applied to the entire video
sequence of
frames over the entire video data in embodiments. For a non-limiting example,
a first
encoding pass with an H.264 encoder is made and creates a "bandwidth map."
This in
turn defines or otherwise determines where in each frame H.264 encoding costs
are the
highest.
Typically, conventional encoders such as H.264 partition video frames into
uniform tiles (for example, 16x16 macroblocks and their subtiles) arranged in
a non-
overlapping pattern. In one embodiment, each tile can be analyzed as a
potential
feature, based on the relative bandwidth required by H.264 to encode the tile.
For
example, the bandwidth required to encode a tile via H.264 may be compared to
a fixed
threshold, and the tile can be declared a "feature" if the bandwidth exceeds
the
threshold. The threshold may be a preset value. The preset value may be stored
in a
database for easy access during feature detection. The threshold may be a
value set as
the average bandwidth amount allocated for previously encoded features .
Likewise,
the threshold may be a value set as the median bandwidth amount allocated for
previously encoded features. Alternatively, one could calculate cumulative
distribution
functions of the tile bandwidths across an entire frame (or an entire video)
and declare
as "features" any tile whose bandwidth is in the top percentiles of all tile
bandwidths.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 12 -
In another embodiment, video frames can be partitioned into overlapping tiles.
The overlapping sampling may be offset so that the centers of the overlapping
tiles
occur at the intersection of every four underlying tiles' corners. This over-
complete
partitioning is meant to increase the likelihood that an initial sampling
position will
yield a detected feature. Other, possibly more complex, topological
partitioning
methods are also possible.
Small spatial regions detected as features can be analyzed to determine if
they
can be combined based on some coherency criteria into larger spatial regions.
Spatial
regions can vary in size from small groups of pels to larger areas that may
correspond to
actual objects or parts of objects. However, it is important to note that the
detected
features need not correspond to unique and separable entities such as objects
and sub-
objects. A single feature may contain elements of two or more objects or no
object
elements at all. For the current invention, the critical characteristic of a
feature is that
the set of pels comprising the feature can be efficiently compressed, relative
to
conventional methods, by feature model-based compression techniques.
Coherency criteria for combining small regions into larger regions may
include:
similarity of motion, similarity of appearance after motion compensation, and
similarity
of encoding complexity. Coherent motion may be discovered through higher-order
motion models. In one embodiment, the translational motion for each individual
small
region can be integrated into an affine motion model that is able to
approximate the
motion model for each of the small regions. If the motion for a set of small
regions can
be integrated into aggregate models on a consistent basis, this implies a
dependency
among the regions that may indicate a coherency among the small regions that
could be
exploited through an aggregate feature model.
Feature model formation
After features have been detected in multiple frames of a video, it is
important
that multiple instances of the same feature be related together. This process
is known as
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 13 -
feature association and is the basis for feature tracking (determining the
location of a
particular feature over time), described below. To be effective, however, the
feature
association process must first define a feature model that can be used to
discriminate
similar feature instances from dissimilar ones.
In one embodiment, the feature pels themselves can be used to model a feature.
Feature pel regions, which are two-dimensional, can be vectorized and similar
features
can be identified by minimizing mean-squared error (MSE) or maximizing inner
products between different feature pel vectors. The problem with this is that
feature pel
vectors are sensitive to small changes in the feature, such as translation,
rotation,
scaling, and changing illumination of the feature. Features often change in
these ways
throughout a video, so using the feature pel vectors themselves to model and
associate
features requires some accounting for these changes. In one embodiment, the
invention
accounts for such feature changes in the simplest way, by applying standard
motion
estimation and compensation algorithms found in conventional codecs (e.g.,
H.264),
which account for translational motion of features. In other embodiments, more
complex techniques can be used to account for rotations, scalings, and
illumination
changes of features from frame to frame.
In an alternate embodiment, feature models are compact representations of the
features themselves ("compact" meaning "of lower dimension than the original
feature
pels vectors") that are invariant (remain unchanged when transformations of a
certain
type are applied) to small rotations, translations, scalings, and possibly
illumination
changes of the feature ¨ meaning that if the feature changes slightly from
frame to
frame, the feature model will remain relatively constant. A compact feature
model of
this type is often termed a "descriptor." In one embodiment of the current
invention, for
example, the SURF feature descriptor has length 64 (compared to the length-256
feature
pel vectors) and is based on sums of Haar wavelet transform responses. In
another
embodiment, a color histogram with 5 bins is constructed from a colormap of
the
feature pels, and this 5-component histogram acts as the feature descriptor.
In an
CA 02868448 2014-09-25
WO 2013/148002
PCT/US2013/025123
- 14 -
alternate embodiment, feature regions are transformed via 2-D DCT. The 2-D DCT
coefficients are then summed over the upper triangular and lower triangular
portions of
the coefficient matrix. These sums then comprise an edge feature space and act
as the
feature descriptor.
When feature descriptors are used to model features, similar features can be
identified by minimizing MSE or maximizing inner products between the feature
descriptors (instead of between the feature pel vectors).
Feature association
Once features have been detected and modeled, the next step is to associate
similar features over multiple frames. Each instance of a feature that appears
in
multiple frames is a sample of the appearance of that feature, and multiple
feature
instances that are associated across frames are considered to "belong" to the
same
feature. Once associated, multiple feature instances belonging to the same
feature may
either be aggregated to form a feature track or gathered into an ensemble
matrix 40
(FIG. 1A).
Afeature track is defined as the (x,y) location of a feature as a function of
frames in the video. One embodiment associates newly detected feature
instances with
previously tracked features (or, in the case of the first frame of the video,
with
previously detected features) as the basis for determining which features
instances in the
current frame are extensions of which previously-established feature tracks.
The
identification of a feature's instance in the current frame with a previously
established
feature track (or, in the case of the first video frame, with a previously
detected feature)
constitutes the tracking of the feature.
FIG. 1B demonstrates the use of a feature tracker 70 to track features 60-
1, 60-2, ..., 60-n. A feature detector 80 (for example, SIFT or SURF) is used
to identify
features in the current frame. Detected feature instances in the current frame
90 are
matched to previously detected (or tracked) features 50. In one embodiment,
prior to
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 15 -
the association step, the set of candidate feature detections in the current
frame can be
sorted using an auto-correlation analysis (ACA) metric that measures feature
strength
based on an autocorrelation matrix of the feature, using derivative-of-
Gaussian filters to
compute the image gradients in the autocorrelation matrix, as found in the
Harris-
Stephens corner detection algorithm [Harris, Chris and Mike Stephens, 1988, "A
combined corner and edge detector," in Proc. of the 4th Alvey Vision
Conference, pp.
147-151]. Feature instances with high ACA values are given priority as
candidates for
track extension. In one embodiment, feature instances lower in the ACA-sorted
list are
pruned from the set of candidate features if they are within a certain
distance (e.g., one
pel) of a feature instance higher in the list.
In different embodiments, feature descriptors (e.g., the SURF descriptor) or
the
feature pel vectors themselves may serve as the feature models. In one
embodiment,
previously-tracked features, depicted as regions 60-1, 60-2, ..., 60-n in FIG.
1B, are
tested one at a time for track extensions from among the newly detected
features in the
current frame 90. In one embodiment, the most recent feature instance for each
feature
track serves as a focal point (or "target feature") in the search for a track
extension in
the current frame. All candidate feature detections in the current frame
within a certain
distance (e.g., 16 pels) of the location of the target feature are tested, and
the candidate
having minimum MSE with the target feature is chosen as the extension of that
feature
track. In another embodiment, a candidate feature is disqualified from being a
track
extension if its MSE with the target feature is larger than some threshold.
In a further embodiment, if no candidate feature detection in the current
frame
qualifies for extension of a given feature track, a limited search for a
matching region in
the current frame is conducted using either the motion compensated prediction
(MCP)
algorithm within H.264 or a generic motion estimation and compensation (MEC)
algorithm. Both MCP and MEC conduct a gradient descent search for a matching
region
in the current frame that minimizes MSE (and satisfies the MSE threshold) with
respect
to the target feature in the previous frame. If no matches can be found for
the target
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 16 -
feature in the current frame, either from the candidate feature detection or
from the
MCP/MEC search process, the corresponding feature track is declared "dead" or
"terminated."
In a further embodiment, if two or more feature tracks have feature instances
in
the current frame that coincide by more than some threshold (for example, 70%
overlap), all but one of the feature tracks are pruned, or dropped from
further
consideration. The pruning process keeps the feature track that has the
longest history
and has the largest total ACA, summed over all feature instances.
The following combination of the above steps is henceforth referred to as the
feature point analysis (FPA) tracker and serves as an embodiment of the
invention:
SURF feature detection, ACA-based sorting of candidate features, and feature
association via minimization of MSE from among candidate features,
supplemented by
MCP/MEC search.
In another embodiment of the invention, macroblocks in the video frame are
thought of as features, registration of the features/macroblocks is done
through the MCP
engine found in H.264, and feature/macroblocks are associated using the inter-
frame
prediction metrics (such as sum of absolute transform differences [SATD]) of
H.264;
this combination is termed the macroblock cache (MBC) tracker. The MBC tracker
is
differentiated from standard inter-frame prediction because certain parameters
are
different (for example, search boundaries are disabled, so that the MBC
tracker
conducts a wider search for matches) and because certain aspects of the
matching
process are different. In a third embodiment, SURF detections are related to
nearby
macroblocks, and the macroblocks are associated and tracked using the MCP and
inter-
frame prediction engines of H.264; this combination is termed the SURF
tracker.
In an alternate embodiment, multiple feature instances may be gathered into an
ensemble matrix for further modeling. In FIG. 1A, the feature instances,
depicted as
regions 30-1, 30-2, ..., 30-n, have been associated and identified as
representing the
same feature. The pel data from the regions can then be vectorized and placed
into an
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 17 -
ensemble matrix 40, with the whole of the ensemble representing the feature.
When a
sufficient number of these samples are gathered into an ensemble, they can be
used to
model the appearance of the feature in those frames, and also in other frames
in which
the feature was not sampled. This feature appearance model is of the same
dimension
as the feature and is distinct from the feature descriptor model described
above.
The ensemble of regions can be spatially normalized (brought into conformity
with a standard by removing sources of variation) toward one key region in the
ensemble. In one embodiment, the region closest to the geometric centroid of
the
ensemble is selected as the key region. In another embodiment, the earliest
feature
instance in the ensemble is selected as the key region. The deformations
required to
perform these normalizations are collected into a deformation ensemble, and
the
resulting normalized images are collected into a modified appearance ensemble,
as
described in U.S. Patent Nos. 7,508,990, 7,457,472, 7,457,435, 7,426,285,
7,158,680,
7,424,157, and 7,436,981 and U.S. Application Nos. 12/522,322 and 13/121,904,
all by
Assignee. The entire teachings of the above listed patents and applications
are
incorporated by reference.
In the above embodiment, the appearance ensemble is processed to yield an
appearance model, and the deformation ensemble is processed to yield a
deformation
model. The appearance and deformation models in combination become the feature
model for the feature. The feature model can be used to represent the feature
with a
compact set of parameters. In one embodiment, the method of model formation is
singular value decomposition (SVD) of the ensemble matrix followed by a raffl(
reduction in which only a subset of singular vectors and their corresponding
singular
values are retained. In a further embodiment, the criterion for raffl(
reduction is to retain
just enough principal singular vectors (and corresponding singular values)
that the
reduced-rank reconstruction of the ensemble matrix approximates the full
ensemble
matrix to within an error threshold based on the 2-norm of the ensemble
matrix. In an
alternate embodiment, the method of model formation is orthogonal matching
pursuit
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 18 -
(OMP) [Pati, Y.C. et al., 1993, "Orthogonal matching pursuit: Recursive
function
approximation with applications to wavelet decomposition," in Proc. of the
27th
Asilomar Conference, pp. 40-44], wherein the ensemble is considered a pattern
dictionary that is repeatedly searched to maximize reconstruction precision.
Again, just
enough ensemble vectors (and corresponding OMP weights) are retained such that
the
OMP reconstruction satisfies an error threshold based on the 2-norm of the
ensemble
matrix. Once formed, the appearance and deformation models of the feature can
be
used in feature-based compression, as will be described below.
The feature ensemble can be refined by comparing ensemble members to each
other. In one embodiment, the ensemble is refined by exhaustively comparing
each
sampled region (ensemble vector) to every other sampled region. This
comparison is
comprised of two tile registrations. One registration is a comparison of a
first region to a
second region. The second registration is a comparison of the second region to
the first
region. Each registration is performed at the position of the regions in their
respective
images. The resulting registration offsets, along with the corresponding
positional
offsets, are retained and referred to as correlations. The correlations are
analyzed to
determine if the multiple registrations indicate that a sampled region's
position should
be refined. If the refined position in the source frame yields a lower error
match for one
or more other regions, then that region position is adjusted to the refined
position. The
refined position of the region in the source frame is determined through a
linear
interpolation of the positions of other region correspondences that temporally
span the
region in the source frame.
Feature-Based Compression
Feature modeling (or data modeling in general) can be used to improve
compression over standard codecs. Standard inter-frame prediction uses block-
based
motion estimation and compensation to find predictions for each coding unit
(macroblock) from a limited search space in previously decoded reference
frames.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 19 -
Exhaustive search for good predictions throughout all past reference frames is
computationally prohibitive. By detecting and tracking features throughout the
video,
feature modeling provides a way of navigating the prediction search space to
produce
improved predictions without prohibitive computations. In the following, the
terms
"feature-based" and "model-based" are used interchangeably, as features are a
specific
type of model.
In one embodiment of the invention, feature tracks are used to relate features
to
macroblocks. The general steps for this are depicted in FIG. 1C. A given
feature track
indicates the location of a feature across frames, and there is an associated
motion of
that feature across frames. Using the location of the feature in the two most
recent
frames prior to the current frame, one can project the position of the feature
in the
current frame. This projected feature position then has an associated nearest
macroblock, defined as the macroblock having greatest overlap with the
projected
feature position. This macroblock (now the target macroblock that is being
encoded)
has been associated to a specific feature track whose projected position in
the current
frame is nearby the macroblock (100 in FIG. 1C).
The next step is to calculate an offset 110 between the target macroblock and
the
projected feature position in the current frame. This offset can then be used
to generate
predictions for the target macroblock, using earlier feature instances in the
associated
feature's track. These earlier feature instances occupy either a local cache
120,
comprised of recent reference frames where the feature appeared, or a distant
cache 140,
comprised of "older" reference frames 150 where the feature appeared.
Predictions for
the target macroblock can be generated by finding the regions in the reference
frames
with the same offsets (130, 160) from earlier feature instances as the offset
between the
target macroblock and the projected feature position in the current frame.
Generating model-based primary and secondary predictions
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 20 -
In one embodiment of the present invention, feature-based prediction is
implemented as follows: (1) detect the features for each frame; (2) model the
detected
features; (3) associate features in different frames to create feature tracks;
(4) use
feature tracks to predict feature locations in the "current" frame being
encoded; (5)
associate macroblocks in the current frame that are nearby the predicted
feature
locations; (6) generate predictions for the macroblocks in Step 5 based on
past locations
along the feature tracks of their associated features.
In one embodiment, features are detected using the SURF algorithm and they
are associated and tracked using the FPA algorithm, as detailed in the
previous section.
Once features have been detected, associated, and tracked, the feature tracks
can be
used to associate each feature track with a nearest macroblock, as detailed
above. It is
possible for a single macroblock to be associated with multiple features, so
one
embodiment selects the feature having maximum overlap with the macroblock as
the
associated feature for that macroblock.
Given a target macroblock (the current macroblock being encoded), its
associated feature, and the feature track for that feature, a primary or key
prediction for
the target macroblock can be generated. Data (pels) for the key prediction
comes from
the most recent frame (prior to the current frame) where the feature appears,
henceforth
referred to as the key frame. The key prediction is generated after selecting
a motion
model and a pel sampling scheme. In one embodiment of the present invention,
the
motion model can be either "0th order," which assumes that the feature is
stationary
between the key frame and the current frame, or "1st order," which assumes
that feature
motion is linear between the 2nd-most recent reference frame, the key frame,
and the
current frame. In either case, the motion of the feature is applied (in the
backwards
temporal direction) to the associated macroblock in the current frame to
obtain the
prediction for the macroblock in the key frame. In one embodiment of the
present
invention, the pel sampling scheme can be either "direct," in which motion
vectors are
rounded to the nearest integer and pels for the key prediction are taken
directly from the
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
-21 -
key frame, or "indirect," in which the interpolation scheme from conventional
compression such as H.264 is used to derive a motion-compensated key
prediction.
Thus, the present invention can have four different types of key prediction,
depending
on the motion model (0th or 1st order) and the sampling scheme (direct or
indirect).
Key prediction can be refined by modeling local deformations through the
process of subtiling. In the subtiling process, different motion vectors are
calculated for
different local portions of the macroblock. In one embodiment, subtiling can
be done
by dividing the 16x16 macroblock into four 8x8 quadrants and calculating
predictions
for each separately. In another embodiment, subtiling can be carried out in
the Y/UN
color space domain by calculating predictions for the Y, U, and V color
channels
separately.
In addition to the primary/key prediction for the target macroblock, one can
also
generate secondary predictions based on positions of the associated feature in
reference
frames prior to the key frame. In one embodiment, the offset from the target
macroblock to the (projected) position of the associated feature in the
current frame
represents a motion vector that can be used to find secondary predictions from
the
feature's position in past reference frames. In this way, a large number of
secondary
predictions can be generated (one for each frame where the feature has
appeared
previously) for a given target macroblock that has an associated feature. In
one
embodiment, the number of secondary predictions can be limited by restricting
the
search to some reasonable number of past reference frames (for example, 25).
Composite predictions
Once primary (key) and secondary predictions have been generated for a target
macroblock, the overall reconstruction of the target macroblock can be
computed based
on these predictions. In one embodiment, following conventional codecs, the
reconstruction is based on the key prediction only, henceforth referred to as
key-only
(KO) reconstruction.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 22 -
In another embodiment, the reconstruction is based on a composite prediction
that sums the key prediction and a weighted version of one of the secondary
predictions.
This algorithm, henceforth referred to as PCA-Lite (PCA-L), involves the
following
steps:
1. Create the vectorized (1-D) versions of the target macroblock and key
prediction. These can then be denoted as the target vector t and key vector k.
2. Subtract the key vector from the target vector to compute a residual
vector r.
3. Vectorize the set of secondary predictions to form vectors s, (Without
loss of generality, assume that these secondary vectors have unit norm.) Then
subtract
the key vector from all the secondary vectors to form the key-subtracted set,
s,-k. This
has the approximate effect of projecting off the key vector from the secondary
vectors.
4. For each secondary vector, calculate a weighting c = rT (s, - k) .
5. For each secondary vector, calculate the composite prediction as
= k + c = (s, - k).
In general, the steps in the PCA-Lite algorithm approximate the operations in
the well-known orthogonal matching pursuit algorithm [Pati, 1993], with the
composite
prediction meant to have non-redundant contributions from the primary and
secondary
predictions. In another embodiment, the PCA-Lite algorithm described above is
modified so that the key vector in Steps 3-5 above is replaced by the mean of
the key
and the secondary vector. This modified algorithm is henceforth referred to as
PCA-
Lite-Mean.
The PCA-Lite algorithm provides a different type of composite prediction than
the bi-prediction algorithms found in some standard codecs (and described in
the
"Background" section above). Standard bi-prediction algorithms employ a
blending of
multiple predictions based on temporal distance of the reference frames for
the
individual predictions to the current frame. By contrast, PCA-Lite blends
multiple
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 23 -
predictions into a composite prediction based on the contents of the
individual
predictions.
Note that the formation of composite predictions as described above does not
require feature-based modeling; composite predictions can be formed from any
set of
multiple predictions for a given target macroblock. Feature-based modeling,
however,
provides a naturally-associated set of multiple predictions for a given target
macroblock, and composite predictions provide an efficient way to combine the
information from those multiple predictions.
Multiple Fidelity Data Modeling
The current invention provides the ability to model the data at multiple
fidelities
for the purpose of model-based compression. One embodiment of this is
illustrated in
FIG. 2A, which displays four levels of modeling. These four levels are
summarized in
the following table and discussed in more detail below.
Grid- Can Span H.264 Motion
Size
Aligned Multiple MBs
Vector Predictors
Macroblocks 16x16 Yes No Yes
Macroblocks as
16x16 Yes No Yes
Features
Features 16x16 No Yes Sometimes
Up to
Objects No Yes No
Frame Size
The bottom level 200 in FIG. 2A is termed the "Macroblock" (MB) level and
represents conventional compression partitioning frames into non-overlapping
macroblocks, tiles of size 16x16, or a limited set of subtiles. Conventional
compression
(e.g., H.264) essentially employs no modeling; instead, it uses block-based
motion
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 24 -
estimation and compensation (BBMEC) to find predictions 212 for each tile from
a
limited search space in previously decoded reference frames. At the decoder,
the
predictions 212 are combined with residual encodings of the macroblocks (or
subtiles)
to synthesize 210 a reconstruction of the original data.
The second level 202 in FIG. 2A is termed the "Macroblocks as Features"
(MBF) level and represents compression based on the MBC tracker described
above
and represented at 216 in Fig 2A. Here, macroblocks (or subtiles of
macroblocks) are
treated as features, through recursive application of conventional BBMEC
searches
through previously encoded frames. The first application of BBMEC is identical
to that
of the MB level, finding a conventional prediction for the target macroblock
from the
most recent reference frame in 216. The second application of BBMEC, however,
finds
a conventional prediction for the first prediction by searching in the second-
most-recent
frame in 216. Repeated application of BBMEC through progressively older frames
in
216 creates a "track" for the target macroblock, even though the latter has
not been
identified as a feature per se. The MBC track produces a model 214 that
generates a
prediction 212 that is combined with residual encodings of the macroblocks (or
subtiles)
to synthesize 210 a reconstruction of the original data at the decoder.
The third level 204 in FIG. 2A is termed the "Features" level and represents
feature-based compression as described above. To review, features are detected
and
tracked independent of the macroblock grid, but features are associated with
overlapping macroblocks and feature tracks are used to navigate previously-
decoded
reference frames 216 to find better matches for those overlapping macroblocks.
If
multiple features overlap a given target macroblock, the feature with greatest
overlap is
selected to model that target macroblock at 214. In an alternate embodiment,
the codec
could encode and decode the features directly, without relating the features
to
macroblocks, and process the "non-feature" background separately using, for
example,
MB-level conventional compression. The feature-based model 214 generates a
CA 02868448 2014-09-25
WO 2013/148002
PCT/US2013/025123
- 25 -
prediction 212 that is combined with residual encodings of the associated
macroblocks
(or subtiles) to synthesize 210 a reconstruction of the original data at the
decoder.
The top level 206 in FIG. 2A is termed the "Objects" level and represents
object-based compression. Objects are essentially large features that may
encompass
multiple macroblocks and may represent something that has physical meaning
(e.g., a
face, a ball, or a cellphone) or complex phenomena 208. Object modeling is
often
parametric, where it is anticipated that an object will be of a certain type
(e.g., a face),
so that specialized basis functions can be used for the modeling 214. When
objects
encompass or overlap multiple macroblocks, a single motion vector 212 can be
calculated for all of the macroblocks associated with the object 216, which
can result in
savings both in terms of computations and encoding size. The object-based
model 214
generates a prediction 212 that is combined with residual encodings of the
associated
macroblocks (or subtiles) to synthesize 210 a reconstruction of the original
data at the
decoder.
In an alternate embodiment, objects may also be identified by correlating and
aggregating nearby feature models 214. FIG. 2B is a block diagram illustrating
this
type of nonparametric or empirical object detection via feature model
aggregation. A
particular type of object 220 is detected by identifying which features have
characteristics of that object type, or display "object bias" 222. Then, it is
determined
whether the set of features in 222 display a rigidity of the model states 224,
a tendency
over time for the features and their states to be correlated. If the
individual feature
models are determined to be correlated (in which case an object detection is
determined
226), then a composite appearance model with accompanying parameters 228 and a
composite deformation model with accompanying parameters 230 can be formed.
The
formation of composite appearance and deformation models evokes a natural
parameter
reduction 232 from the collective individual appearance and deformation
models.
FIG. 2C illustrates a third embodiment of the "Objects" level 206 in FIG. 2A,
employing both parametric and nonparametric object-based modeling. A
parametrically
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 26 -
modeled object is detected 240. The detected object 240 may be processed to
determine
if there are any overlapping features 250. The set of overlapping features may
then be
tested 260 to determine whether they can be aggregated as above. If
aggregation of the
overlapping features fails, then the process reverts to testing the
macroblocks
overlapping the detected object 240, to determine whether they can be
effectively
aggregated 270 to share a common motion vector, as noted above.
A multiple-fidelity processing architecture may use any combination of levels
200, 202, 204, 206 to achieve the most advantageous processing. In one
embodiment,
all levels in FIG. 2A are examined in a "competition" to determine which
levels
produce the best (smallest) encodings for each macroblock to be encoded. More
details
on how this "competition" is conducted follow below.
In another embodiment, the levels in FIG. 2A could be examined sequentially,
from bottom (simplest) to top (most complex). If a lower-level solution is
deemed
satisfactory, higher-level solutions do not have to be examined. Metrics for
determining
whether a given solution can be deemed "good enough" are described in more
detail
below.
Model-Based Compression Codec
Standard codec processing
The encoding process may convert video data into a compressed, or encoded,
format. Likewise, the decompression process, or decoding process, may convert
compressed video back into an uncompressed, or raw, format. The video
compression
and decompression processes may be implemented as an encoder/decoder pair
commonly referred to as a codec.
FIG. 3A is a block diagram of a standard encoder 312. The encoder in FIG. 3A
may be implemented in a software or hardware environment, or combination
thereof
Components of the example encoder may be implemented as executable code stored
on
a storage medium, such as one of those shown in FIGs. 8A and 8B, and
configured for
CA 02868448 2014-09-25
WO 2013/148002
PCT/US2013/025123
-27 -
execution by one or more of processors 820. The encoder 312 may include any
combination of components, including, but not limited to, an intra-prediction
module
314, an inter-prediction module 316, a transform module 324, a quantization
module
326, an entropy encoding module 328 and a loop filter 334. The inter
prediction module
316 may include a motion compensation module 318, frame storage module 320,
and
motion estimation module 322. The encoder 312 may further include an inverse
quantization module 330, and an inverse transform module 332. The function of
each of
the components of the encoder 312 shown in FIG. 3A is well known to one of
ordinary
skill in the art.
The entropy coding algorithm 328 in FIG. 3A may be based on a probability
distribution that measures the likelihood of different values of quantized
transform
coefficients. The encoding size of the current coding unit (e.g., macroblock)
depends
on the current encoding state (values of different quantities to be encoded)
and the
relative conformance of the state to the probability distribution. Any changes
to this
encoding state, as detailed below, may impact encoding sizes of coding units
in
subsequent frames. To fully optimize an encoding of a video, an exhaustive
search may
be conducted of all the possible paths on which the video can be encoded
(i.e., all
possible encoding states), but this is computationally prohibitive. In one
embodiment of
the current invention, the encoder 312 is configured to focus on the current
(target)
macroblock, so that optimization is applied locally, rather than considering a
larger
scope, (e.g., over a slice, a frame, or a set of frames).
FIGs. 3B and 3C are block diagrams of a standard decoder 340 providing
decoding of intra-predicted data 336 and decoding of inter-predicted data 338,
respectively. The decoder 340 may be implemented in a software or hardware
environment, or combination thereof Referring to FIGs. 3A, 3B, and 3C, the
encoder
312 typically receives the video input 310 from an internal or external
source, encodes
the data, and stores the encoded data in the decoder cache/buffer 348. The
decoder 340
retrieves the encoded data from the cache/buffer 348 for decoding and
transmission.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 28 -
The decoder may obtain access to the decoded data from any available means,
such as a
system bus or network interface. The decoder 340 can be configured to decode
the
video data to decompress the predicted frames and key frames (generally at 210
in FIG.
2A). The cache/buffer 348 can receive the data related to the compressed video
sequence/bitstream and make information available to the entropy decoder 346.
The
entropy decoder 346 processes the bitstream to generate estimates of quantized
transform coefficients for the intra-prediction in FIG. 3A or the residual
signal in FIG.
3B. The inverse quantizer 344 performs a rescaling operation to produce
estimated
transform coefficients, and the inverse transform 342 is then applied to the
estimated
transform coefficients to create a synthesis of the intra-prediction of the
original video
data pels in FIG. 3A or of the residual signal in FIG. 3B. In FIG. 3B, the
synthesized
residual signal is added back to the inter-prediction of the target macroblock
to generate
the full reconstruction of the target macroblock. The inter-prediction module
350
replicates at the decoder the inter-prediction generated by the encoder,
making use of
motion estimation 356 and motion compensation 354 applied to reference frames
contained in the framestore 352. The decoder's inter-prediction module 350
mirrors the
encoder's inter-prediction module 316 in FIG. 3A, with its components of
motion
estimation 322, motion compensation 318, and framestore 320.
Hybrid codec implementing model-based prediction
FIG. 3D is a diagram of an example encoder according to an embodiment of the
invention that implements model-based prediction. At 362, the codec 360 can be
configured to encode a current (target) frame. At 364, each macroblock in the
frame
can be encoded, such that, at 366, a standard H.264 encoding process is used
to define a
base (first) encoding that yields an H.264 encoding solution. In one preferred
embodiment, the encoder 366 is an H.264 encoder capable of encoding a Group of
Pictures (set of reference frames). Further, the H.264 encoder preferably is
configurable so that it can apply different methods to encode pels within each
frame,
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 29 -
i.e., intra-frame and inter-frame prediction, with inter-frame prediction able
to search
multiple reference frames for good matches for the macroblock being encoded.
Preferably, the error between the original macroblock data and the prediction
is
transformed, quantized, and entropy-encoded.
Preferably, the encoder 360 utilizes the CABAC entropy encoding algorithm at
382 to provide a context-sensitive, adaptive mechanism for context modeling.
The
context modeling may be applied to a binarized sequence of the syntactical
elements of
the video data such as block types, motion vectors, and quantized
coefficients, with the
binarization process using predefined mechanisms. Each element is then coded
using
either adaptive or fixed probability models. Context values can be used for
appropriate
adaptations of the probability models.
Competition Mode
In Fig. 3D, at 368, the H.264 macroblock encoding is analyzed. At 368, if the
H.264 encoding of the macroblock is judged to be "efficient," then the H.264
solution is
deemed to be close to ideal, no further analysis is performed, and the H.264
encoding
solution is accepted for the target macroblock. In one embodiment, efficiency
of the
H.264 encoding can be judged by comparing the H.264 encoding size (in bits) to
a
threshold, which can be derived from percentile statistics from previously
encoded
videos or from earlier in the same video. In another embodiment, efficiency of
the
H.264 encoding can be judged by determining whether an H.264 encoder has
declared
the target macroblock a "skip" macroblock, in which the data in and around the
target
macroblock is uniform enough that the target macroblock essentially requires
no
additional encoding.
At 368, if the H.264 macroblock solution is not considered efficient, then
additional analysis is performed, and the encoder enters Competition Mode 380.
In this
mode, several different predictions are generated for the target macroblock,
based on
multiple models 378. The models 378 are created from the identification of
features
CA 02868448 2014-09-25
WO 2013/148002
PCT/US2013/025123
- 30 -
376 detected and tracked in prior frames 374. Note that as each new frame 362
is
processed (encoded and then decoded and placed into framestore), the feature
models
need to be updated to account for new feature detections and associated
feature track
extensions in the new frame 362. The model-based solutions 382 are ranked
based on
their encoding sizes 384, along with the H.264 solution acquired previously.
Because
of its flexibility to encode a given macroblock using either a base encoding
(the H.264
solution) or a model-based encoding, the present invention is termed a hybrid
codec.
For example, in Competition Mode, an H.264 encoding is generated for the
target macroblock to compare its compression efficiency (ability to encode
data with a
small number of bits) relative to other modes. Then for each encoding
algorithm used
in Competition Mode, the following steps are executed: (1) generate a
prediction based
on the codec mode/algorithm used; (2) subtract the prediction from the target
macroblock to generate a residual signal; (3) transform the residual (target
minus
prediction) using an approximation of a 2-D block-based DCT; (4) encode the
transform
coefficients using an entropy encoder.
In some respects, the baseline H.264 (inter-frame) prediction can be thought
of
as based on a relatively simple, limited model (H.264 is one of the algorithms
used in
Competition Mode). However, the predictions of the encoder 360 can be based on
more
complex models, which are either feature-based or object-based, and the
corresponding
tracking of those models. If a macroblock exhibiting data complexity is
detected, the
encoder 360 operates under the assumption that feature-based compression can
do a
better job than conventional compression.
Use of feature-based predictions in Competition Mode
As noted above, for each target macroblock, an initial determination is made
whether the H.264 solution (prediction) is efficient ("good enough") for that
macroblock. If the answer is negative, Competition Mode is entered.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
-31 -
In FIG. 3D for Competition Mode 380, the "entries" into the competition are
determined by the various processing choices for feature-based prediction
described
above. Each entry comprises a different prediction for the target macroblock.
Full
description of the invention's feature-based prediction requires specification
of the
following processing choices:
- tracker type (FPA, MBC, SURF)
- motion model for key prediction (0th or 1st order)
- sampling scheme for key prediction (direct or indirect)
- subtiling scheme for key prediction (no subtiling, quadrants, Y/UN)
- reconstruction algorithm (KO or PCA-L)
- reference frames for secondary prediction (for PCA-L).
The solution search space for a given target macroblock is comprised of all of
the invention's feature-based predictions represented above, plus the H.264
solution
(the "best" inter-frame prediction from H.264). In one embodiment, Competition
Mode
includes all possible combinations of processing choices noted above (tracker
type,
motion model and sampling scheme for key prediction, subtiling scheme, and
reconstruction algorithms). In another embodiment, the processing choices in
Competition Mode are configurable and can be limited to a reasonable subset of
possible processing combinations to save computations.
Potential solutions for the competition are evaluated one at a time by
following
the four steps noted previously: (1) generate the prediction; (2) subtract the
prediction
from the target macroblock to generate a residual signal; (3) transform the
residual; (4)
encode the transform coefficients using an entropy encoder. In FIG. 3D the
output of
the last step, 382 is a number of bits associated with a given solution 384.
After each
solution is evaluated, the encoder is rolled back to its state prior to that
evaluation, so
that the next solution can be evaluated. In one embodiment, after all
solutions have
been evaluated, a "winner" for the competition is chosen 370 by selecting the
one with
smallest encoding size. The winning solution is then sent to the encoder once
more 372
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 32 -
as the final encoding for the target macroblock. As noted above, this winning
solution
is a locally-optimum solution, as it is optimum for the target macroblock
only. In an
alternate embodiment, the selection of the optimal solution is hedged against
larger
scale encoding tradeoffs that include, but are not limited to, context intra-
frame
prediction feedback and residual error effects in future frames.
Information pertaining to the winning solution is saved into the encoding
stream
386 and transmitted/stored for future decoding. This information may include,
but is
not limited to, the processing choices noted above for feature-based
prediction (e.g.,
tracker type, key calculation, subtiling scheme, reconstruction algorithm,
etc.).
In some cases, the encoder 360 may determine that the target macroblock is not
efficiently coded by H.264, but there is also no detected feature that
overlaps with that
macroblock. In this case, the encoder uses H.264 anyway to encode the
macroblock as
a last resort. In an alternate embodiment, the tracks from the feature tracker
can be
extended to generate a pseudo-feature that can overlap the macroblock and thus
produce
a feature-based prediction.
In one embodiment, movement among the four levels in Fig. 2A is governed by
Competition Mode.
Decoding using feature-based predictions
FIG. 4 is a diagram of an example decoder according to an embodiment of the
invention implementing model-based prediction within the Assignee's
EuclidVision
codec. The decoder 400 decodes the encoded video bitstream to synthesize an
approximation of the input video frame that generated the frame encoding 402.
The
frame encoding 402 includes a set of parameters used by the decoder 400 to
reconstruct
its corresponding video frame 418.
The decoder 400 traverses each frame with the same slice ordering used by the
encoder, and the decoder traverses each slice with the same macroblock
ordering used
by the encoder. For each macroblock 404, the decoder follows the same process
as the
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 33 -
encoder, determining 406 whether to decode the macroblock conventionally 408
or
whether to decode the macroblock utilizing feature models and parameters at
416. If a
macroblock was encoded via the invention's model-based prediction, the decoder
400
extracts whatever feature information (feature tracks, feature reference
frames [GOP],
feature motion vectors) needed to reproduce the prediction for that solution
418. The
decoder updates feature models (410, 412, 414) during the decoding so they are
synchronized with the encoder feature state for the particular
frame/slice/macroblock
that is being processed.
Note that, because of memory limitations, conventional codecs do not typically
retain the entire prediction context for decoded frames in the framestore 352
and cache
348 of FIG. 3C, but only the frames (pels) themselves. By contrast, the
invention
extends the prediction context stored in the framestore 352 and cache 348 of
FIG. 3C by
prioritizing retention of feature-based models and parameters.
The full set of parameters that describe a feature model is known as the state
of
the feature, and this state must be isolated to retain feature models
effectively. FIG. 5 is
a block diagram illustrating the state isolation process 500 of feature
instances
according to an embodiment of the present invention. This state isolation
information
can be associated with a target macroblock and include parameters associated
with
relevant feature instances 502 that can be of assistance in the encoding of
that target
macroblock. The state isolation information can be also used to interpolate
predicted
features in future video frames. Each respective feature instance has an
associated GOP
504. Each GOP includes respective state information regarding, for example,
respective
boundary information. The respective state isolation information of a feature
instance
may further include state information about any relevant associated objects,
their
respective slice parameters 506, and their respective entropy state 508. In
this way, the
state information provides instructions regarding the boundaries of
GOP/slice/entropy
parameters of feature instances and their corresponding extensions into new
states and
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 34 -
state contexts. The state information 506, 508 can be used to predict and
interpolate the
state of a predicted feature in future frames.
Together, the macroblock data (pels) and state isolation information from
associated features form an extended prediction context. Extended contexts
from
multiple feature instances and their previously decoded neighbors may be
combined.
The extended prediction context for the encoder 312 in FIG. 3A and decoder 340
in
FIGs. 3B and 3C may include, but is not limited to: (1) one or more
macroblocks, (2)
one or more neighboring macroblocks, (3) slice information, (4) reference
frames
[GOP], (5) one or more feature instances, (6) object/texture information.
Parametric Model-Based Compression
Integration of parametric modeling into codec framework
In contrast to the hybrid codec implementation described above, where feature
models are used implicitly to cue the encoder where to find good predictions
for
macroblocks, feature models may be used explicitly in the codec framework.
Specific
regions in the target frame can be represented by certain types of models (for
example,
face models), and the representation is dependent on the parameters in the
models. This
type of explicit modeling is henceforth referred to as parametric modeling,
whereas the
codec implementation described in the above section uses nonparametric or
empirical
modeling. Because parametric modeling expects certain types of features or
objects
(e.g., faces), the modeling usually consists of a set of basis vectors that
span the space
of all possible features/objects of that type, and the model parameters are
the projections
of the target region onto the basis functions.
FIG. 6A is a block diagram illustrating example elements of a codec 600
according to an alternative embodiment of the invention implementing
parametric
modeling. The codec 600 in FIG. 6A may include modules to perform adaptive
motion
compensated prediction 610, adaptive motion vector prediction 612, adaptive
transform
processing 614, and/or adaptive entropy encoding 616.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 35 -
The adaptive motion compensation module 610 can be configured to select
reference frames 618 based on frames having instances of features. If models
of the
features provide improved compression efficiency, then the frames from which
those
models were derived can be selected as reference frames, and an associated
Group of
Pictures may be generated. Interpolation of the motion vector offsets 626 may
be
performed based on the parameters from the detected features. In this way, new
data
pels for a predicted feature instance may be constructed within the range of a
discrete
set of known data points based on previously detected features. Subtile
partitioning
processing 612 decisions in the conventional encoder are supplemented by the
constraints of deformation variation models 620. Transform processing 614 can
be
adapted to utilize appearance variation modeling 622 to constrain appearance
variation
parameters. Entropy encoding processing 616 can be supplemented by parametric
range/scale analysis 624 and adaptive quantization 628 in the inventive codec
600. The
resulting macroblock supplementary data 630 is outputted by codec 600.
Use of parametric modeling to improve hybrid codec via adaptive encoding
In an alternative embodiment, parametric modeling can be used to improve the
predictions provided by the original hybrid codec described above. In one
embodiment,
elements of a parametric model are applied to an existing target macroblock
prediction
(such as, for example, the output of Competition Mode above) to determine
whether the
prediction can be improved.
FIG. 6B illustrates one application of a parametric model-based adaptive
encoder 634. The adaptive encoder 634-1 can be configured to supplement the
encoding that would be performed in a conventional codec, such as H.264, or in
a
hybrid codec such as that described above. The pel residual 636 resulting from
a
conventional motion compensation prediction process is analyzed 638 to
determine if
the deformation and appearance variation of the residual can be modeled 642
more
efficiently by a parametric feature model. In one embodiment, one can
determine the
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 36 -
relative efficiency of the parametric model by measuring the reduction in the
sum of
absolute transform differences (SATD) 640 between the prediction residual 636
and the
parametric model 638. If the parametric model is determined to be an efficient
representation, the target region (macroblock) is projected onto the feature
model
(appearance and deformation bases), yielding features parameters that serve as
the
encoding of the residual signal.
Additional rollback capabilities 634-2 are provided by this embodiment to test
the applicability of the alternate residual modeling within the current GOP,
slice, and
entropy state. For example, reference frames 644, GOPs, and features (slices)
646 that
are remote in the video frame sequence to the current frame being encoded in
the series
can be considered for references in prediction, whereas with conventional
encoding this
would not be practical. Further, it is also possible that the rollback may
come from
other video data, such as other video files, if feature models from those
other video files
provide improved compression.
Feature-based prediction via interpolation of parametric model parameters
When multiple instances of a feature appear in a video stream, it is desirable
to
preserve the invariant components of the feature model, defined as the
components that
do not change from frame to frame. For parametric feature modeling, the
invariant
components are certain parameters of the feature model (for example,
coefficients that
represent weightings of different basis functions). For nonparametric
(empirical)
feature modeling, the invariant components are typically the feature pels
themselves.
The preservation of invariant model components can serve as a guiding
principle
(henceforth referred to as the "invariance principle") for how feature motion
estimation
and compensation is performed.
FIG. 6C is a block diagram illustrating motion compensated prediction of
features via interpolation of feature model parameters, guided by the
invariance
principle, according to an embodiment of the invention. In FIG. 6C, the motion
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 37 -
compensated prediction process 668 begins by adjusting model parameters from
several
feature instances toward an invariant instance of the parameters, a process
known as
normalization. The collection 670 of feature instances ("matched macroblocks")
can be
used 672 to generate several types of interpolation functions (674, 676, 678,
680) for
normalizing the instances toward the invariant instance. The invariant
instance of the
model parameters 682 can be defined as the set of model parameter values in
the key
frame. The invariant instance is then representative of most of (if not all)
the
predictions/patterns in the feature-based model. The invariant instance is
conceptually
similar to the centroid of a vector space comprised by the vectorized form of
the
instances' appearance parameters.
The invariant instance 682 can then serve as the key pattern on which to
extrapolate the target's position 684 using one of the interpolation functions
(674, 676,
678, 680). This interpolation/extrapolation process can be used to predict the
frame
position, appearance variation, and deformation variation of the feature in
the target
frame. The combination of the invariant representation of the features with a
compact
parametric form of the feature instances represents a drastic reduction in the
amount of
memory required to cache the appearance and deformation of features contained
in
source reference frames as compared with conventional compression. In other
words,
the data in the frame that is relevant and useful for compression is captured
concisely in
the feature models.
In an alternate embodiment, the feature model parameters from two or more
feature instances can be used to predict the state of the target region given
the known
temporal interval between reference frames where the feature instances
occurred and the
current (target) frame. In this case, a state model, an extrapolation of two
or more
feature parameters given temporal steps, can be used to predict the feature
parameters
for the target region, following the invariance principle. The state model can
be linear
or higher-order (for example, an extended Kalman filter).
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 38 -
Cache Organization and Access of Feature Model Information
During the process of generating feature models, it is often the case that
multiple
instances of a specific feature are found in a given video. In this case, the
feature model
information can be stored or cached efficiently by organizing the model
information
prior to caching. This technique can be applied to both parametric and
nonparametric
model-based compression schemes.
In FIG. 3C, for example, if it is determined that the use of feature-based
modeling prediction context information improves compression efficiency, the
cache
348 (including the framestore 352) can be configured to include feature-based
modeling
prediction context information. Attempts to access uncached feature-based
prediction
context data can generate overhead that degrades the system's responsiveness
and
determinism. This overhead can be minimized by caching, ahead of time, the
preprocessed feature-based encoding prediction context. Doing this provides a
means
by which much of the repetition of accessing data related to the feature-based
prediction
context can be avoided.
The encoder 312/decoder 340 (FIGs. 3A, 3C) can be configured using, for
example, a cache that is adapted to increase the execution speed and
efficiency of video
processing. The performance of the video processing may depend upon the
ability to
store, in the cache, feature-based encoding prediction data such that it is
nearby in the
cache to the associated encoded video data, even if that encoded video data is
not
spatially close to the frame(s) from which the feature-based encoding
prediction data
was originally derived. Cache proximity is associated with the access latency,
operational delay, and transmission times for the data. For example, if the
feature data
from a multitude of frames is contained in a small amount of physical memory
and
accessed in that form, this is much more efficient than accessing the frames
from which
those features were derived on a persistent storage device. The encoder
312/decoder
340 (FIGs. 3A, 3C) may include a configurator that stores the prediction data
in the
cache in such a way to ensure that, when a macroblock or frame is decoded, the
feature-
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 39 -
based prediction context information is easily accessible from the
cache/buffer/framestore.
Certain embodiments of the present invention can extend the cache by first
defining two categories of feature correlation in the previously decoded
frames, namely
local and non-local previously decoded data for the cache. The local cache can
be a set
of previously decoded frames that are accessible in batches, or groups of
frames, but the
particular frames that constitute those groups are determined by detected
features. The
local cache is driven by features detected in the current frame. The local
cache is used
to a greater extent when there are relatively few "strong" feature models
(models having
a long history) for the current frame/macroblock. The local cache processing
is based on
batch motion compensated prediction, and groups of frames are stored in
reference
frame buffers. FIG. 7A is a block diagram illustrating an overview of example
cache
architecture 710-1 according to an embodiment of the invention. The cache
access
architecture 710-1 includes the decision processes 710 for local cache access
712 (716,
718, 720, 722, and 724) and distant cache access 714 (726, 728, 730, and 732).
If the
features are mostly local 712 (for example, there are few strong feature
models for the
current frame/macroblock), then local cache processing 718 is provided.
FIG. 7B is a block diagram illustrating the processing involved in utilizing
the
local (short) cache data 734. The local cache can be a set of previously
decoded frames
that are accessible in batches, or groups of frames, but the particular frames
that
constitute those groups are determined by detected features. The local cache
734 in
FIG. 7B groups only "short history" features, those whose tracks only comprise
a small
number of frames. The aggregate set of frames encompassed by the short history
features determines a joint frameset 738 for those features. Frames in the
joint frameset
738 may be prioritized 740 based on the complexity of the feature tracks in
the
respective frames. In one embodiment, complexity may be determined by the
encoding
cost of the features from a base encoding process such as H.264. Referring to
FIGs. 3B,
3C, 7A, and 7B, the local cache may be stored in the framestore 352 or in the
cache
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 40 -
buffer 348. The locally cached frames are utilized at 720. A GOP/batch 742
based on
detected feature instances can then be formed at 722. The GOP/batch based on
detected
feature instances can be tested at 724 as reference frames 744 for the motion
compensation prediction process. Motion compensated prediction done in this
way can
be said to be "biased" toward feature tracking information, because the
reference frames
for the motion estimation are the frames with previously-detected feature
instances. At
746, additional rollback capabilities are provided to test the applicability
of the residual
modeling within the GOP/batch, slice, and entropy state. In this way,
reference frames
that are remote in the video frame sequence to the current frame being encoded
can be
evaluated more efficiently.
Thus, certain embodiments of the invention are able to apply analysis to past
frames to determine the frames that will have the highest probability of
providing
matches for the current frame. Additionally, the number of reference frames
can be
much greater than the typical one-to-sixteen reference frame maximum found in
conventional compression. Depending on system resources, the reference frames
may
number up to the limit of system memory, assuming that there are a sufficient
number
of useful matches in those frames. Further, the intermediate form of the data
generated
by the present invention can reduce the required amount of memory for storing
the same
number of reference frames.
When the features have an extensive history 726 in FIG. 7A, features are
located
in storage that is mostly in the non-local/distant cache. The non-local cache
is based on
two different cache access methods, frame and retained. The frame access of
the non-
local cache accesses frames directly to create feature models that are then
utilized to
encode the current frame. The retained mode does not access the previously
decoded
data directly, but rather utilizes feature models that have been retained as
data derived
from those previously decoded frames (the feature model and the parameters of
the
instances of the feature model in those frames) and thereby can be used to
synthesize
that same data. At 728, the models for the feature instances are accessed. At
730, the
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
-41 -
reference frames are accessed, and at 732 the combination of optimal reference
frames
and models are marked for use. Criteria for optimality are based on
intermediate
feature information for the feature models in each reference frame, including
feature
strength and feature bandwidth.
The distant cache 714 can be any previously decoded data (or encoded data)
that
is preferably accessible in the decoder state. The cache may include, for
example,
reference frames/GOPs, which are generally a number of frames that precede the
current frame being encoded. The decoder cache allows for other combinations
of
previously decoded frames to be available for decoding the current frame.
FIG. 7C is a block diagram illustrating the processing involved in utilizing
the
distant cache data. The distant (non-local) cache 748 illustrates the longer
range cache
architecture. The distant cache is initialized from the local cache 750 in
response to a
determination 752 that the detected features have an extensive history, both
in terms of
reoccurring instances and the repeated applicability of the correspondence
models
associated with those features. The process then determines which retention
mode 754
is used. The two modes of the non-local cache are the retained 760 and non-
retained
756. The non-retained 756 is a conventional motion compensated prediction
process
augmented with predictions based on feature models (similar to the usage of
implicit
modeling for the hybrid codec described above). The non-retained mode 756 thus
accesses 758 reference frames to obtain working predictions. The retained mode
is
similar to the non-retained mode, but it uses predictions that come explicitly
from the
feature model itself 762, 766. The retained model necessarily limits the
prediction
searches to that data for which the feature model is able to synthesize the
feature that it
models. Further, the feature model may contain the instance parameterizations
for the
feature's instances in prior frames, which would be equivalent to the pels
contained in
those prior frames. The interpolation of the function describing those
parameters is also
used to provide predictions to the motion compensation prediction process to
facilitate
frame synthesis 764.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 42 -
Some embodiments of the present invention that use feature ensembles
illustrate
the use of cached feature information for encoding. In these embodiments, a
subset of a
feature ensemble is used to represent (model) the entire ensemble. As noted
above,
such subsets can be selected using SVD, for example. Once selected, a subset
of feature
instances acts as a basis for the ensemble and can be cached and used to
encode the
corresponding feature whenever it occurs in subsequent frames of the video (or
in other
videos). This subset of feature instances models the feature both compactly
and
accurately.
Digital Processing Environment and Communication Network
Example implementations of the present invention may be implemented in a
software, firmware, or hardware environment. In an embodiment, FIG. 8A
illustrates
one such environment. Client computer(s)/devices 810 and a cloud 812 (or
server
computer or cluster thereof) provide processing, storage, and input/output
devices
executing application programs and the like. Client computer(s)/devices 810
can also be
linked through communications network 816 to other computing devices,
including
other client devices/processes 810 and server computer(s) 812. Communications
network 816 can be part of a remote access network, a global network (e.g.,
the
Internet), a worldwide collection of computers, Local area or Wide area
networks, and
gateways that currently use respective protocols (TCP/IP, Bluetooth, etc.) to
communicate with one another. Other electronic device/computer network
architectures
are suitable.
FIG. 8B is a diagram of the internal structure of a computer/computing node
(e.g., client processor/device 810 or server computers 812) in the processing
environment of FIG. 8A. Each computer 810, 812 contains a system bus 834,
where a
bus is a set of actual or virtual hardware lines used for data transfer among
the
components of a computer or processing system. Bus 834 is essentially a shared
conduit that connects different elements of a computer system (e.g.,
processor, disk
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 43 -
storage, memory, input/output ports, etc.) that enables the transfer of
information
between the elements. Attached to system bus 834 is an I/O device interface
818 for
connecting various input and output devices (e.g., keyboard, mouse, displays,
printers,
speakers, etc.) to the computer 810, 812. Network interface 822 allows the
computer to
connect to various other devices attached to a network (for example the
network
illustrated at 816 of FIG. 8A). Memory 830 provides volatile storage for
computer
software instructions 824 and data 828 used to implement an embodiment of the
present
invention (e.g., codec, video encoder/decoder code). Disk storage 832 provides
non-
volatile storage for computer software instructions 824 (equivalently, "OS
program"
826) and data 828 used to implement an embodiment of the present invention; it
can
also be used to store the video in compressed format for long-term storage.
Central
processor unit 820 is also attached to system bus 834 and provides for the
execution of
computer instructions. Note that throughout the present text, "computer
software
instructions" and "OS program" are equivalent.
In one embodiment, the processor routines 824 and data 828 are a computer
program product (generally referenced 824), including a computer readable
medium
capable of being stored on a storage device 828, which provides at least a
portion of the
software instructions for the invention system. The computer program product
824 can
be installed by any suitable software installation procedure, as is well known
in the art.
In another embodiment, at least a portion of the software instructions may
also be
downloaded over a cable, communication, and/or wireless connection. In other
embodiments, the invention programs are a computer program propagated signal
product 814 (in Fig 8A) embodied on a propagated signal on a propagation
medium
(e.g., a radio wave, an infrared wave, a laser wave, a sound wave, or an
electrical wave
propagated over a global network such as the Internet, or other network(s)).
Such
carrier media or signals provide at least a portion of the software
instructions for the
present invention routines/program 824, 826.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 44 -
In alternate embodiments, the propagated signal is an analog carrier wave or
digital signal carried on the propagated medium. For example, the propagated
signal
may be a digitized signal propagated over a global network (e.g., the
Internet), a
telecommunications network, or other network. In one embodiment, the
propagated
signal is transmitted over the propagation medium over a period of time, such
as the
instructions for a software application sent in packets over a network over a
period of
milliseconds, seconds, minutes, or longer. In another embodiment, the computer
readable medium of computer program product 824 is a propagation medium that
the
computer system 810 may receive and read, such as by receiving the propagation
medium and identifying a propagated signal embodied in the propagation medium,
as
described above for computer program propagated signal product.
Feature-based display tool
FIG. 8C is a screenshot 840 of a feature-based display tool in accordance with
example implementations. Screenshot 840 shows a frame of video with features
identified in boxes 842. The video frame sequence context for the frame is
identified at
844. The features 842 were tracked through the frames 844, creating several
feature
sets that are represented in section 846 of the display. Within a particular
feature set
846, there is a plurality of feature members (feature instances) 848. A data
area
displays the feature bandwidth 852, the number of bits required by
conventional
compression to code the feature. An indication 850 of the feature detection
process is
also displayed in the data area. The tool displays all features and feature
tracks that
were identified in the subject video.
A face tracker that is biased to faces may be used to facilitate face
detection.
Face detection may be used to group features together. FIG. 8E is a screenshot
860-2
showing a face 864 designated by the face tracker. FIG. 8D is a screenshot 860-
1
showing features designated with numbers 862 for both face and non-facial
features.
In this example, the numbers shown in FIG. 8D represent the length of tracking
of the
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 45 -
features through frames. By grouping features together based on face bias, a
model can
be created that can be used to encode multiple macroblocks overlapping each
face.
All pels/pixels within a region of interest may be encoded using the face
model
instead of strictly using an H.264 encoder process. With direct application of
a face
model, biasing is not needed, and H.264 is not used to select prior reference
frames.
The face is generated based on the feature correspondence models, and then
lower level
processing is used to encode the residual.
Digital rights management
In some embodiments, the models of the present invention can be used as a way
to control access to the encoded digital video. For example, without the
relevant
models, a user would not be able to playback the video file. An example
implementation of this approach is discussed in U.S. Application No.
12/522,357, filed
January 4, 2008, the entire teachings of which are incorporated by reference.
The
models can be used to "lock" the video or be used as a key to access the video
data.
The playback operation for the coded video data can depend on the models. This
approach makes the encoded video data unreadable without access to the models.
By controlling access to the models, access to playback of the content can be
controlled. This scheme can provide a user-friendly, developer-friendly, and
efficient
solution to restricting access to video content.
Additionally, the models can progressively unlock the content. With a certain
version of the models, an encoding might only decode to a certain level; then
with
progressively more complete models, the whole video would be unlocked. Initial
unlocking might enable thumbnails of the video to be unlocked, giving the user
the
capability of determining if they want the full video. A user that wants a
standard
definition version would procure the next incremental version of the models.
Further,
the user needing high definition or cinema quality would download yet more
complete
versions of the models. The models are coded in such a way as to facilitate a
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
- 46 -
progressive realization of the video quality commensurate with encoding size
and
quality, without redundancy.
Flexible macroblock ordering and scalable video coding
To improve the encoding process and produce compression benefits, example
embodiments of the invention may extend conventional encoding/decoding
processes.
In one embodiment, the present invention may be applied with flexible
macroblock
ordering (FMO) and scalable video coding (SVC), which are themselves
extensions to
the basic H.264 standard.
FMO allocates macroblocks in a coded frame to one of several types of slice
groups. The allocation is determined by a macroblock allocation map, and
macroblocks
within a slice group do not have to be contiguous. FMO can be useful for error
resilience, because slice groups are decoded independently: if one slice group
is lost
during transmission of the bitstream, the macroblocks in that slice group can
be
reconstructed from neighboring macroblocks in other slices. In one embodiment
of the
current invention, feature-based compression can be integrated into the
"foreground and
background" macroblock allocation map type in an FMO implementation.
Macroblocks associated with features comprise foreground slice groups, and all
other
macroblocks (those not associated with features) comprise background slice
groups.
SVC provides multiple encodings of video data at different bitrates. A base
layer is encoded at a low bitrate, and one or more enhancement layers are
encoded at
higher bitrates. Decoding of the SVC bitstreams can involve just the base
layer (for low
bitrate/low quality applications) or some or all of the enhancement layers as
well (for
higher bitrate/quality applications). Because the substreams of the SVC
bitstream are
themselves valid bitstreams, the use of SVC provides increased flexibility in
different
application scenarios, including decoding of the SVC bitstream by multiple
devices (at
different qualities, depending on device capabilities) and decoding in
environments with
varying channel throughput, such as Internet streaming.
CA 02868448 2014-09-25
WO 2013/148002 PCT/US2013/025123
-47 -
There are three common types of scalability in SVC processing: temporal,
spatial, and quality. In one embodiment of the current invention, feature-
based
compression can be integrated into a quality scalability implementation by
including the
primary feature-based predictions in the base layer (see the section above on
model-
based primary and secondary predictions). The coded frames in the base layer
can then
serve as reference frames for coding in the enhancement layer, where secondary
feature-
based predictions can be used. In this way, information from feature-based
predictions
can be added incrementally to the encoding, instead of all at once. In an
alternate
embodiment, all feature-based predictions (primary and secondary) can be moved
to
enhancement layers, with only conventional predictions used in the base layer.
It should be noted that although the figures described herein illustrate
example
data/execution paths and components, one skilled in the art would understand
that the
operation, arrangement, and flow of data to/from those respective components
can vary
depending on the implementation and the type of video data being compressed.
Therefore, any arrangement of data modules/data paths can be used.
While this invention has been particularly shown and described with references
to example embodiments thereof, it will be understood by those skilled in the
art that
various changes in form and details may be made therein without departing from
the
scope of the invention encompassed by the appended claims.