Note: Descriptions are shown in the official language in which they were submitted.
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
SYSTEMS AND METHODS FOR IN-MEMORY DATABASE SEARCH
TECHNICAL FIELD
[0001] The present disclosure relates generally to methods and systems
for
information retrieval; more specifically, a method for searching for related
entities using
entity co-occurrence. The present disclosure relates generally to query
enhancement; more
specifically, search suggestions using fuzzy-score matching and entity co-
occurrence in a
knowledge base. The present disclosure relates generally to computer query
processing;
more specifically, electronic search suggestions of related entities based on
co-occurrence
and/or fuzzy score matching. The present disclosure relates generally to
methods and
systems for information retrieval; more specifically, a method for obtaining
search
suggestions. The present disclosure generally relates to search engines and
content
management; more specifically, extending a content management system's search
engine
technology to enable geotagging and named entities enrichment of digital
content.
BACKGROUND
[0002] In the commercial context, a well known search engine parses a set
of search
terms and returns a list of items (web pages in a typical search) that are
sorted in some
manner. Most known approaches, to perform searches, are usually based on
historical
references of other users to build a search query database that may be
eventually used to
generate indexes based on keywords. User search queries may include one or
more entities
identified by name or attributes that may be associated with the entity.
Entities may also
include organizations, people, location, date and/or time. In a typical
search, if a user is
searching for information related to two particular organizations, a search
engine may return
assorted results that may be about a mixture of different entities with the
same name or
similar names. The latter approach may lead the user to find a very large
amount of
documents that may not be relevant to what the user is actually interested.
1
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0003] Thus, a need exists for a method for searching for related
entities that may
grant the user the ability to find related entities of interest.
[0004] Users frequently use search engines for locating information of
interest either
on the Internet or any database system. Search engines commonly operate by
receiving a
search query from a user and returning search results to the user. Search
results are usually
ordered by search engines based on the relevance of each returned search
result to the search
query. Therefore, the quality of the search query may be significantly
important for the
quality of search results. However, search queries from users, in most cases,
may be written
incomplete or partial (e.g., the search query may not include enough words to
generate a
focused set of relevant results and instead generates a large number of
irrelevant results), and
sometimes misspelled (e.g., Bill Smith may be incorrectly spelled as Bill
Smitth).
[0005] One common approach to improve the quality of the search results
is to
enhance the search query. One way to enhance the search queries may be by
generating
possible suggestions based on the user's input. For this, some approaches
propose methods
for identifying candidate query refinements for a given query from past
queries submitted by
one or more users. However, these approaches are based on query logs that
sometimes may
lead the user to results that may not be of interest. There are other
approaches using different
techniques that may not be accurate enough. Thus, there still exists a need
for methods that
improve or enhance search queries from users to get more accurate results.
[0006] Users frequently use search engines for locating information of
interest either
from the Internet or any database system. Search engines commonly operate by
receiving a
search query from a user and returning search results to the user. Search
results are usually
ordered based on the relevance of each returned search result to the search
query. Therefore,
the quality of the search query may be significantly important for the quality
of search results.
2
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
However, search queries from users, in most cases, may be written incomplete
or partial (e.g.,
the search query may not include enough words to generate a focused set of
relevant results
and instead generates a large number of irrelevant results), and sometimes
misspelled (e.g.,
Bill Smith may be incorrectly spelled as "Bill Smitth").
[0007] One common approach to improve the quality of the search results
is to
enhance the search query. One way to enhance the search query may be by
generating
possible suggestions based on the user's input. For this, some approaches
propose methods
for identifying candidate query refinements for a given query from past
queries submitted by
one or more users. However, these approaches are based on query logs that
sometimes may
lead the user to results that may not be of interest. There are other
approaches using different
techniques that may not be accurate enough. Thus, there still exists a need
for methods that
improve or enhance search queries from users to get more accurate results and
also present
users with useful related entities of interest as they type the search query.
[0008] Search engines include a plurality of features in order to provide
a forecast for
user's query. Such forecast may include query auto-complete and search
suggestions.
Nowadays, such forecast methods are based on historic keywords references.
Such historic
references may not be accurate because one keyword could be referred to a
plurality of topics
in a single text.
[0009] In addition, user search queries may include one or more entities
identified by
name or attributes that may be associated with the entity. Entities may also
include
organizations, people, locations, events, date and/or time. In a typical
search, if a user is
searching for information related to two particular organizations, a search
engine may return
assorted results that may be about a mixture of different entities with the
same name or
3
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
similar names. The latter approach may lead the user to find a very large
amount of
documents that may not be relevant to what the user is actually interested.
[0010] Thus, a need exists for a method for obtaining quicker and more
accurate
search suggestions.
[0011] Content management and document management systems for document
versioning and collaborative project management are known. One non-limiting
example may
be Microsoft's Sharepoint 2013 software and application suite of tools.
Microsoft
SharePoint 2013 is a family of software products developed by Microsoft
Corporation for
collaboration, file sharing and web publishing. SharePoint 2013 may provide a
user with a
vast amount of content or information and it may become difficult for a user
to find the most
relevant information for a particular circumstance. To mitigate these issues
SharePoint
2013 provides a search engine in order to assist users in finding the content
that they need.
A user may enter a keyword based search query and the search engine in
SharePoint 2013
may return to the user a list of the most relevant results found within the
context of the
SharePoint 2013 platform once the content has been indexed.
[0012] At times a user may desire to find content related to geographic
entities in
SharePoint 2013 or other type of entity such as organizations or people
referred to within a
document. SharePoint 2013 does not provide out of the box functionality to
automatically
extract entities from documents. Particularly, it does not support geotagging
content to extract
geographic entities and resolve them to a geographic location. Also,
SharePoint 2013 does
not support entity tagging in order to identify, disambiguate and extract
named entities, such
as, organizations or people in a document. However, SharePoint 2013 search
may be
extended to enable effective geographic searches and other entity related
searches, including
entity-based search facets. Previous versions of SharePoint 2013 included
"FAST Search"
4
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
for SharePoint, from which it was possible to extend the content processing
pipeline through
sandboxed applications, but this was both slow and limited in the information
it could access.
[0013] SharePoint 2013 introduces a much more open API which makes it
possible
to add specialized linguistics such as concept extraction, relationship
extraction, geotagging,
summarization and as well as sophisticated text analytics. Thus, an
opportunity exists to
extend the capabilities of SharePoint 2013 search engine to enable geographic
and other
entity based searches.
SUMMARY
[0014] A method for searching for related entities using entity co-
occurrence is
disclosed. In one aspect of the present disclosure, the method may be employed
in a search
system that may include a client/server type architecture. In one embodiment,
the search
system may include a user interface for a search engine in communication with
one or more
server devices over a network connection. The server device may include an
entity indexed
corpus of electronic data, an entity co-occurrence knowledge base database,
and an entity
extraction computer module. The knowledge base may be built as an in-memory
database and
may also include other components such as one or more search controllers,
multiple search
nodes, collections of compressed data, and a disambiguation module. One search
controller
may be selectively associated with one or more search nodes. Each search node
may be
capable of independently performing a fuzzy key search through a collection of
compressed
data and returning a set of scored results to its associated search
controller.
[0015] In one embodiment, a computer-implemented method comprises
receiving, by
an entity extraction computer, from a client computer a search query
comprising one or more
entities; comparing, by the entity extraction computer, each respective entity
with one or
more co-occurrences of the respective entity in a co-occurrence database;
extracting, by the
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
entity extraction computer, a subset of the one or more entities from the
search query
responsive to determining each respective entity of the subset exceeds a
confidence score of
the co-occurrence database based on a degree of certainty of co-occurrence of
the entity with
one or more related entities in an electronic data corpus according to the co-
occurrence
database; assigning, by the entity extraction computer, an index identifier
(index ID) to each
of the entities in the plurality of extracted entities; saving, by the entity
extraction computer,
the index ID for each of the plurality of extracted entities in the electronic
data corpus, the
electronic data corpus being indexed by an index ID corresponding to each of
the one or more
related entities; searching, by a search server computer, the entity indexed
electronic data
corpus to locate the plurality of extracted entities and identify index IDs of
data records in
which at least two of the plurality of extracted entities co-occur; and
building, by the search
server computer, a search result list having data records corresponding to the
identified index
IDs.
[0016] In one embodiment, a system comprising one or more server
computers
having one or more processors executing computer readable instructions for a
plurality of
computer modules including: an entity extraction module configured to receive
user input of
search query parameters, the entity extraction module being further configured
to: extract a
plurality of entities from the search query parameters by comparing each
entity in the
plurality of extracted entities with an entity co-occurrence database that
includes a confidence
score indicative of a degree of certainty of co-occurrence of an extracted
entity with one or
more related entities in an electronic data corpus, assign an index identifier
(index ID) to each
of the entities in the plurality of extracted entities, save the index ID for
each of the plurality
of extracted entities in the electronic data corpus, the electronic data
corpus being indexed by
an index ID corresponding to each of the one or more related entities; and a
search server
module configured to search the entity indexed electronic data corpus to
locate the plurality
6
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
of extracted entities and identify index IDs of data records in which at least
two of the
plurality of extracted entities co-occur, the search server module being
further configured to
build a search result list having data records corresponding to the identified
index IDs.
[0017] In another embodiment, a non-transitory computer readable medium
having
stored thereon computer executable instructions comprising: receiving, by an
entity
extraction computer, user input of search query parameters; extracting, by the
entity
extraction computer, a plurality of entities from the search query parameters
by comparing
each entity in the plurality of extracted entities with an entity co-
occurrence database that
includes a confidence score indicative of a degree of certainty of co-
occurrence of an
extracted entity with one or more related entities in an electronic data
corpus; assigning, by
the entity extraction computer, an index identifier (index ID) to each of the
entities in the
plurality of extracted entities; saving, by the entity extraction computer,
the index ID for each
of the plurality of extracted entities in the electronic data corpus, the
electronic data corpus
being indexed by an index ID corresponding to each of the one or more related
entities;
searching, by a search server computer, the entity indexed electronic data
corpus to locate the
plurality of extracted entities and identify index IDs of data records in
which at least two of
the plurality of extracted entities co-occur; and building, by the search
server computer, a
search result list having data records corresponding to the identified index
IDs.
[0018] A method for generating search suggestions by using fuzzy-score
matching
and entity co-occurrence in a knowledge base is disclosed. In one aspect of
the present
disclosure, the method may be employed in a search system that may include a
client/server
type architecture. In one embodiment, the search system may include a user
interface to a
search engine in communication with one or more server devices over a network
connection.
The server device may include an entity extraction computer module, a fuzzy-
score matching
7
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
computer module, and an entity co-occurrence knowledge base database. The
knowledge
base may be built as an in-memory database and may also include other hardware
and/or
software components such as one or more search controllers, multiple search
nodes,
collections of compressed data, and a disambiguation computer module. One
search
controller may be selectively associated with one or more search nodes. Each
search node
may be capable of independently performing a fuzzy key search through a
collection of
compressed data and returning a set of scored results to its associated search
controller.
[0019] In another aspect of the present disclosure, the method may
include an entity
extraction module that may perform partial entity extractions from provided
search queries to
identify whether the search query refers to an entity, and if so, to what type
of entity it refers.
Furthermore, the method may include a fuzzy-score matching module that may
spawn
algorithms based on the type of entity extracted and perform a search against
an entity co-
occurrence knowledge base. Additionally, the query text parts that are not
detected as
corresponding to entities are treated as conceptual features, such as topics,
facts, and key
phrases, that can be employed for searching the entity co-occurrence knowledge
base. In an
embodiment, the entity co-occurrence knowledge base includes a repository
where entities
may be indexed as entities to entities, entities to topics, or entities to
facts among others,
which facilitates the return of fast and accurate suggestions to the user to
complete the search
query.
[0020] In one embodiment, a method is disclosed. The method comprises
receiving,
by an entity extraction computer, user input of search query parameters from a
user interface,
extracting, by the entity extraction computer, one or more entities from the
search query
parameters by comparing the search query parameters with an entity co-
occurrence database
having instances of co-occurrence of the one or more entities in an electronic
data corpus and
8
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
identifying at least one entity type corresponding to the one or more entities
in the search
query parameters, and selecting, by a fuzzy-score matching computer, a fuzzy
matching
algorithm for searching the entity co-occurrence database to identify one or
more records
associated with the search query parameters, wherein the fuzzy matching
algorithm
corresponds to the at least one identified entity type. The method further
includes searching,
by the fuzzy-score matching computer, the entity co-occurrence database using
the selected
fuzzy matching algorithm and forming one or more suggested search query
parameters from
the one or more records based on the search, and presenting, by the fuzzy-
score matching
computer, the one or more suggested search query parameters via the user
interface.
[0021] In another embodiment, a system is provided. The system includes
one or
more server computers having one or more processors executing computer
readable
instructions for a plurality of computer modules including an entity
extraction module
configured to receive user input of search query parameters from a user
interface, the entity
extraction module being further configured to extract one or more entities
from the search
query parameters by comparing the search query parameters with an entity co-
occurrence
database having instances of co-occurrence of the one or more entities in an
electronic data
corpus and identifying at least one entity type corresponding to the one or
more entities in the
search query parameters. The system further includes a fuzzy-score matching
module
configured to select a fuzzy matching algorithm for searching the entity co-
occurrence
database to identify one or more records associated with the search query
parameters,
wherein the fuzzy matching algorithm corresponds to the at least one
identified entity type.
The fuzzy-score matching module being further configured to search the entity
co-occurrence
database using the selected fuzzy matching algorithm and form one or more
suggested search
query parameters from the one or more records based on the search, and present
the one or
more suggested search query parameters via the user interface.
9
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0022] A method for generating search suggestions of related entities
based on co-
occurrence and/or fuzzy score matching is disclosed. In one aspect of the
present disclosure,
the method may be employed in a computer search system that may include a
client/server
type architecture. In one embodiment, the search system may include a user
interface to a
search engine in communication with one or more server devices over a network
connection.
The server device may include one or more processors executing instructions
for a plurality
of special purpose computer modules, including an entity extraction module and
a fuzzy-
score matching module, as well as an entity co-occurrence knowledge base
database. The
knowledge base may be built as an in-memory database and may also include
other
components, such as one or more search controllers, multiple search nodes,
collections of
compressed data, and a disambiguation module. One search controller may be
selectively
associated with one or more search nodes. Each search node may be capable of
independently
performing a fuzzy key search through a collection of compressed data and
returning a set of
scored results to its associated search controller.
[0023] In another aspect of the present disclosure, the method may
include
performing partial entity extractions, by an entity extraction module, from
provided search
queries to identify whether the search query refers to an entity, and if so,
to determine the
entity type. Furthermore, the method may include generating algorithms, by a
fuzzy-score
matching module, corresponding to the type of entity extracted and performing
a search
against an entity co-occurrence knowledge base. Additionally , the query text
parts that are
not detected as entities are treated as conceptual features, such as topics,
facts, and key
phrases that can be employed for searching the entity co-occurrence knowledge
base. The
entity co-occurrence knowledge base, which may already have a repository where
entities
may be indexed as entities to entities, entities to topics, or entities to
facts, among others, may
return fast and accurate suggestions to the user to complete the search query.
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0024] In a further aspect of the present disclosure, the completed
search query may
be used as a new search query. The search system may process the new search
query, run an
entity extraction, find related entities with the highest scores from the
entity co-occurrence
knowledge base, and present said related entities in a drop down list that may
be useful for
the user.
[0025] In one embodiment, a method is disclosed. The method comprises
receiving,
by an entity extraction computer, user input of partial search query
parameters from a user
interface, the partial search query parameters having at least one incomplete
search query
parameter, extracting, by the entity extraction computer, one or more first
entities from the
partial search query parameters by comparing the partial search query
parameters with an
entity co-occurrence database having instances of co-occurrence of the one or
more first
entities in an electronic data corpus and identifying at least one entity type
corresponding to
the one or more first entities in the partial search query parameters, and
selecting, by a fuzzy-
score matching computer, a fuzzy matching algorithm for searching the entity
co-occurrence
database to identify one or more records associated with the partial search
query parameters,
wherein the fuzzy matching algorithm corresponds to the at least one
identified entity type.
The method further includes searching, by the fuzzy-score matching computer,
the entity co-
occurrence database using the selected fuzzy matching algorithm and forming
one or more
first suggested search query parameters from the one or more records based on
the search,
presenting, by the fuzzy-score matching computer, the one or more first
suggested search
query parameters via the user interface, receiving by the entity extraction
computer, user
selection of the one or more first suggested search query parameters so as to
form completed
search query parameters, and extracting, by the entity extraction computer,
one or more
second entities from the completed search query parameters. The method further
includes
searching, by the entity extraction computer, the entity co-occurrence
database to identify one
11
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
or more entities related to the one or more second entities so as to form one
or more second
suggested search query parameters, and presenting, by the entity extraction
computer, the one
or more second suggested search query parameters via the user interface.
[0026] In another embodiment, a system is disclosed. The system comprises
one or
more server computers having one or more processors executing computer
readable
instructions for a plurality of computer modules including an entity
extraction module
configured to receive user input of partial search query parameters from a
user interface, the
partial search query parameters having at least one incomplete search query
parameter, the
entity extraction module being further configured to extract one or more first
entities from the
partial search query parameters by comparing the partial search query
parameters with an
entity co-occurrence database having instances of co-occurrence of the one or
more first
entities in an electronic data corpus and identifying at least one entity type
corresponding to
the one or more first entities in the partial search query parameters. The
system further
includes a fuzzy-score matching module configured to select a fuzzy matching
algorithm for
searching the entity co-occurrence database to identify one or more records
associated with
the partial search query parameters, wherein the fuzzy matching algorithm
corresponds to the
at least one identified entity type. The fuzzy-score matching module is
further configured to
search the entity co-occurrence database using the selected fuzzy matching
algorithm and
form one or more first suggested search query parameters from the one or more
records based
on the search, and present the one or more first suggested search query
parameters via the
user interface. Additionally, the entity extraction module is further
configured to receive user
selection of the one or more first suggested search query parameters so as to
form completed
search query parameters, extract one or more second entities from the
completed search query
parameters, search the entity co-occurrence database to identify one or more
entities related
to the one or more second entities so as to form one or more second suggested
search query
12
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
parameters, and present the one or more second suggested search query
parameters via the
user interface.
[0027] A method for obtaining search suggestions related to entities
using entity and
feature co-occurrence is disclosed. In one aspect of the present disclosure,
the method may be
employed in a search system that may include a client/server type
architecture.
[0028] A search system using a method which may employ entities stored in
one or
more servers, which may allow an entity database and a trends database.
Entities on such
databases may have a score for indexing based on the higher score. Method for
obtaining
search suggestions may combine information stored in both databases for
generating a single
list of search suggestions. Trends database may provide previous search
queries from one or
more users in a local network and/or the Internet. Entity database may provide
search
suggestions based on entities extraction from a plurality of data available in
a local network
and/or the Internet. This list may provide a more accurate and quicker group
of suggestions
for the user.
[0029] In one embodiment, a computer-implemented method comprises
receiving, by
a computer, from a search engine a search query comprising one or more strings
of data,
wherein each respective entity corresponds to a subset of the one or more
strings; identifying,
by the computer, one or more entities in the one or more strings of data based
on comparing
the one or more entities against an entity database and a trends database;
identifying, by the
computer, one or more features in the one or more strings of data not
identified as
corresponding to at least one entity; assigning, by the computer, each of the
one or more
features to at least one of the one or more entities based on a matching
algorithm; assigning,
by the computer, an extraction score to each respective entity based on a
score assigned to
each respective feature assigned to the respective entity; receiving, by the
computer, from an
13
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
entity database a first search list containing one or more entities having a
score within a
threshold distance from the extraction score of each respective entity;
receiving, by the
computer, from a trends database a second search list containing one or more
entities having
a score within a threshold distance from the extraction score of each
respective entity;
generating, by the computer, an aggregated list comprising the first search
list and the second
search list, wherein the entities of the aggregated list are ranked according
to the score of
each respective aggregated list; and providing, by the computer, a suggested
search according
to the aggregated list.
[0030] Disclosed herein are systems and methods for enabling geographic
entity-
based searches in content management systems, like Microsoft's SharePoint
2013t.
Embodiments described The method involves extending the SharePoint 2013
search
architecture by adding a geographic tagging web service. The system includes a
computer
processor operatively associated with a computer memory and one or more I/O
device, in
which the processor and memory are configured to operate one or more
SharePoint 2013
processes. The system also includes another computer processor operatively
associated with
a computer memory and one or more I/O devices, in which the processor and
memory are
configured to host and provide processing for a geotagging web service. The
SharePoint
2013 system may include a crawling component, a content processing component
and a
search indexing component in order to enable search of content. The content
processing
component in SharePoint 2013 search may extend its functionality by using the
Content
Enrichment Web Service (CEWS) feature.
[0031] The method involves crawling content from the different sources in
order to
obtain an array of crawled properties that are sent for content processing.
During content
processing, a trigger condition may determine if crawled properties may
benefit from
14
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
additional processing in order to enrich the original content with additional
geographic
metadata properties. If the crawled properties don't benefit from additional
processing the
crawled properties may be mapped to managed processing and sent to a search
index. If the
crawled properties benefit from external web services processing, the CEWS may
make a
simple object access protocol (SOAP) request to a configurable endpoint using
hypertext
transfer protocol (HTTP) or any other web service call method. An entity
enrichment service
may determine the type of content. If the content is in an image format, its
metadata such as
file location may be sent to an optical character recognition (OCR) engine so
that the original
document can be retrieved and processed asynchronously to convert to text and
sent back to
the crawl component to be re-crawled in text format. If the content is in text
format the
geotagging web service may identify geographic metadata and associate it with
the content as
managed properties. After the content has been geotagged, it may be sent to
the indexing
component.
[0032] An additional search user interface (UI) may be added using either
SharePoint
2013 web parts or by modifying the standard layout of SharePoint 2013 search
with
standard web development tools such as HTML, HTML 5, JavaScript and CSS among
others.
The search UI may assist a user in performing geographic search queries or
displaying
geographic search results using digital geographic features such as for
example and without
limitation, digital maps. The search UI can also be enhanced to perform
faceted search using
the additional enriched entities or their associated metadata.
[0033] Numerous other aspects, features and benefits of the present
disclosure may be
made apparent from the following detailed description.
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
BRIEF DESCRIPTION OF THE DRAWINGS
[0034] The present disclosure can be better understood by referring to
the following
figures. The components in the figures are not necessarily to scale, emphasis
instead being
placed upon illustrating the principles of the disclosure. In the figures,
reference numerals
designate corresponding parts throughout the different views.
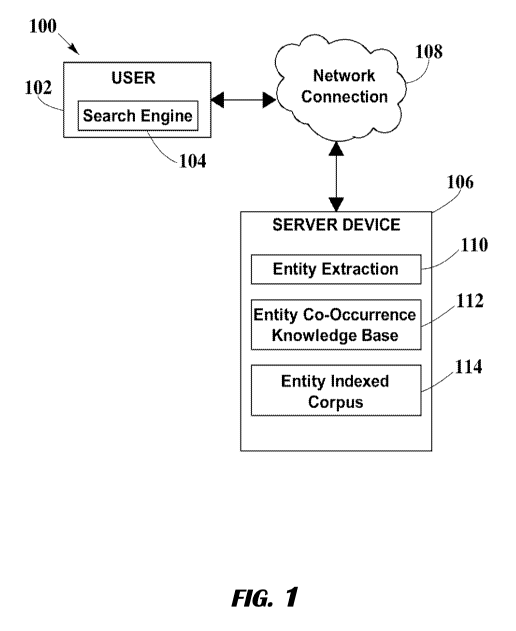
[0035] FIG. 1 is a block diagram illustrating an exemplary environment of
a
computer system in which one embodiment of the present disclosure may operate;
[0036] FIG. 2 is a flowchart illustrating a method for searching using
entity co-
occurrence, according to an embodiment; and
[0037] FIG. 3 is a flowchart illustrating an embodiment of a simple
search where the
search results returned by the system may include related entities of
interest.
[0038] FIG. 4 is a block diagram illustrating an exemplary system
environment in
which one embodiment of the present disclosure may operate;
[0039] FIG. 5 is a flowchart illustrating a method for search suggestions
using fuzzy-
score matching and entity co-occurrence in a knowledge base, according to an
embodiment;
and
[0040] FIG. 6 is a diagram illustrating an example of a user interface
through which a
search suggestion may be produced using fuzzy matching and entity co-
occurrence in a
knowledge base of FIGS. 4-6.
[0041] FIG. 7 is a block diagram illustrating an exemplary system
environment in
which one embodiment of the present disclosure may operate.
16
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0042] FIG. 8 is a flowchart illustrating a method for generating search
suggestions
of related entities based on co-occurrence and/or fuzzy score matching,
according to an
embodiment.
[0043] FIG. 9 is an example embodiment of a user interface associated
with the
method described in FIG. 8.
[0044] FIG. 10 is a block diagram illustrating a method for obtaining
search
suggestions based on entities and trends databases.
[0045] FIG. 11 is a block diagram illustrating a method for obtaining
search
suggestions based on entities and trends databases, by generating a list of
suggestions based
on an individual score of search suggestions in each databases.
[0046] FIG. 12 is a block diagram illustrating a method for obtaining
search
suggestions based on entities and trends databases, by generating a list of
suggestions based
on an overall score of search suggestions on both databases.
[0047] FIG. 13 is a system architecture for tagging and entity enrichment
of content
in a content management system.
[0048] FIG. 14 is a process by which content is tagged and indexed for
named and
geographic entity searches.
DEFINITIONS
[0049] As used here, the following terms may have the following
definitions:
[0050] "Entity Extraction" refers to information processing methods for
extracting
information such as names, places, and organizations.
17
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0051] "Corpus" refers to a collection of one or more documents
[0052] "Features" is any information which is at least partially derived
from a
document.
[0053] "Event Concept Store" refers to a database of Event template
models.
[0054] "Event" refers to one or more features characterized by at least
the features'
occurrence in real-time.
[0055] "Event Model" refers to a collection of data that may be used to
compare
against and identify a specific type of event.
[0056] "Module" refers to a computer or software components suitable for
carrying
out at least one or more tasks.
[0057] "Feature attribute" refers to metadata associated with a feature;
for example,
location of a feature in a document, confidence score, among others.
[0058] "Fact" refers to objective relationships between features.
[0059] "Entity knowledge base" refers to a computer database containing
features/entities.
[0060] "Query" refers to a computer generated request to retrieve
information from
one or more suitable databases.
[0061] "Topic" refers to a set of thematic information which is at least
partially
derived from a corpus.
[0062] "Geotagging" refers to the process of extracting geographic
entities from
unstructured text files. Geotagging may include disambiguating the entity to a
specific
18
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
geographic place and appending geographic metadata such as geographic
coordinates,
geographic feature type and other metadata.
[0063] "Entity Tagging" refers to the process of extracting named
entities from
unstructured text. Entity Tagging may include entity disambiguation, entity
name
normalization and appending entity metadata.
[0064] "Named Entity" refers to a person, organization or topic.
[0065] "Geographic Entity" refers to geographic location or geographic
places.
[0066] "Crawled Properties" refers to content management system metadata
obtained from inspecting documents during crawls.
DETAILED DESCRIPTION
[0067] Reference will now be made in detail to the preferred embodiments,
examples
of which are illustrated in the accompanying drawings. The embodiments
described above
are intended to be exemplary. One skilled in the art recognizes that numerous
alternative
components and embodiments may be substituted for the particular examples
described
herein and still fall within the scope of the invention. Other embodiments may
be used
and/or other changes may be made without departing from the spirit or scope of
the present
disclosure. The illustrative embodiments described in the detailed description
are not meant
to be limiting of the subject matter presented here.
[0068] It will nevertheless be understood that no limitation of the scope
of the
invention is thereby intended. Alterations and further modifications of the
inventive features
illustrated here, and additional applications of the principles of the
inventions as illustrated
here, which would occur to one skilled in the relevant art and having
possession of this
disclosure, are to be considered within the scope of the invention.
19
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0069] The present disclosure describes a system and method for
detecting, extracting
and validating events from a plurality of sources. Sources may include news
sources, social
media websites and/or any sources that may include data pertaining to events.
[0070] Various embodiments of the systems and methods disclosed here
collect data
from different sources in order to identify independent events.
[0071] FIG. 1 is a block diagram of a search system 100 in accordance
with the
present disclosure. The search system 100 may include one or more client
computing device
comprising a processor executing software modules associated with the search
system 100,
which may include graphical user interfaces 102 accessing a search engine 104
communicating search queries in the form of binary data with a server device
106, over a
network 108. In the exemplary embodiment, the search system 100 may be
implemented in a
client-server computing architecture. However, it should be appreciated that
the search
system 100 may be implemented using other computer architectures (e.g., a
stand-alone
computer, a mainframe system with terminals, an application service provider
(ASP) model,
a peer-to-peer model, and the like). The network 108 may comprise any suitable
hardware
and software modules capable of communicating digital data between computing
devices,
such as a local area network, a wide area network, the Internet, a wireless
network, a mobile
phone network, and the like. As such, it should also be appreciated that the
system 100 may
be implemented over a single network 108, or using a plurality of networks
108.
[0072] A user's computing device 102 may access a search engine 104,
which may
include software modules capable of transmitting search queries. Search
queries are
parameters provided to the search engine 104 indicating the desired
information to retrieve.
Search queries may be provided by a user or another software application in
any suitable data
format (e.g., integers, strings, complex objects) compatible with the search
engine's 104
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
parsing and processing routines. In some embodiments, the search engine 104
may be a web-
based tool that is accessible through the user's computing device 102 browser
or other
software application, and enables users or software applications to locate
information on the
World Wide Web. In some embodiments, the search engine 104 may be application
software
modules native to the system 100, enabling users or applications to locate
information within
databases of the system 100.
[0073] Server device 106, which may be implemented as a single server
device 106 or
in a distributed architecture across a plurality of server computers, may
include an entity
extraction module 110, an entity co-occurrence knowledge base 112, and an
entity indexed
corpus 114. Entity extraction module 110 may be a computer software and/or
hardware
module able to extract and disambiguate independent entities from a given set
of queries such
as a query string, structured data and the like. Example of entities may
include people,
organizations, geographic locations, dates and/or time. During the extraction,
one or more
feature recognition and extraction algorithms may be employed. Also, a score
may be
assigned to each extracted feature, indicating the level of certainty of the
feature being
correctly extracted with the correct attributes. Taking into account the
feature attributes, the
relative weight or relevance of each of the features may be determined.
Additionally, the
relevance of the association between features may be determined using a
weighted scoring
model.
[0074] According to various embodiments, entity co-occurrence knowledge
base 112
may be built, but is not limited to, as an in-memory computer database (not
shown) and may
include other components (not shown), such as one or more search controllers,
multiple
search nodes, collections of compressed data, and a disambiguation computer
module. One
search controller may be selectively associated with one or more search nodes.
Each search
21
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
node may be capable of independently performing a fuzzy key search through a
collection of
compressed data and returning a set of scored results to its associated search
controller.
[0075] Entity co-occurrence knowledge base 112 may include related
entities based
on features and ranked by a confidence score. Various methods for linking the
features may
be employed, which may essentially use a weighted model for determining which
entity types
are most important, which have more weight, and, based on confidence scores,
determine
how confident the extraction of the correct features has been performed.
Entity indexed
corpus 114 may include data from a plurality of sources such as the Internet
having a massive
corpus or live corpus.
[0076] FIG. 2 is a flowchart illustrating a method 200 for searching
related entities
using entity co-occurrence that may be implemented in a search system 100,
such as the one
described in FIG. 1. According to various embodiments, prior to start of
method 200, an
entity indexed corpus 114 similar to that described by FIG. 1 may have been
fed with data
from a plurality of sources such as a massive corpus or live corpus of
electronic data (e.g., the
Internet, website, blog, word-processing file, plaintext file). Entity indexed
corpus 114 may
include a plurality of indexed entities that may constantly update as new data
is discovered.
[0077] In one embodiment, method 200 may start when a user or software
application
of a computing device 102 provides one or more search queries containing one
or more
entities to a search engine 104, in step 202. Search queries that were
provided in step 202
may be processed by search system 100, from one to n, at each time. An example
of a search
query in step 202 may be a combination of keywords, such as a string,
structured data, or
other suitable data format. In this exemplary embodiment of FIG. 2, the
keywords of the
search query may be entities that represent people, organizations, geographic
locations, dates
and/or times.
22
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0078] Search queries from step 202 may then be processed for entity
extraction, in
step 204. In this step, the entity extraction module 110 may process search
queries from step
202 as entities and compare them all against entity co-occurrence knowledge
base 112 to
extract and disambiguate as many entities as possible. During the extraction,
one or more
feature recognition and extraction algorithms may be employed. Also, a score
may be
assigned to each extracted feature, indicating the level of certainty of the
feature being
correctly extracted with the correct attributes. Taking into account the
feature attributes, the
relative weight or relevance of each of the features may be determined.
Additionally, the
relevance of the association between features may be determined using a
weighted scoring
model.
[0079] Furthermore, various methods for linking the features may be
employed,
which may essentially use a weighted model for determining which entity types
are most
important, which have more weight, and, based on confidence scores, determine
how
confident the extraction of the correct features has been performed. Once the
entities are
extracted and ranked based on confidence scores, an index ID, which in some
cases may be a
number, may be assigned in step 206 to the extracted entities.
[0080] Next, in step 208, a search based on the entities index ID
assigned in step 206
may be performed. In the search step 208, the extracted entities may be
located within the
entity indexed corpus 114 data by using standard indexing methods. Once the
extracted
entities are located, an entity association step 210 may follow. In the entity
association step
210, all the data such as documents, videos, pictures, files or the like,
where at least two
extracted entities overlaps may be pulled from the entity indexed corpus 114.
Finally, a list of
potential results is built, sorted by relevance, and presented to the user as
search results, step
23
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
212. The list of results may then show only links to data where the user may
find related
entities of interest.
[0081] FIG. 3 is a particular example of a method 300 for searching
related entities
using entity co-occurrence, as discussed above in connection with FIG. 2. As
described in
FIG. 2, according to various embodiments, prior to the start of the method
300, an entity
indexed corpus 114 similar to that described by FIG. 1, may have been fed with
data from a
plurality of sources such as a massive corpus or live corpus (the Internet).
Entity indexed
corpus 114 may include a plurality of indexed entities that may constantly
update as new data
is discovered.
[0082] In this example embodiment, a user may be looking for information
regarding
"jobs" at the company "Apple". For this, the user may input one or more
entities (e.g., search
queries in step 302) through a user interface 102 which may be, but is not
limited to, an
interface with a search engine 104, such as the one described in FIG. 1. By a
way of
illustration and not by way of limitation, the user may input a combination of
entities such as
"Apple + Jobs". Next, the search engine 104 may generate search queries, step
302, and send
these queries to server device 106 to be processed. At server device 106,
entity extraction
module 110 may perform an entity extraction step 304 from search queries input
in step 302.
[0083] Entity extraction module 110 may then process search queries that
were input
in step 302, such as "Apple" and "Jobs", as entities and compare them all
against entity co-
occurrence knowledge base 112 to extract and disambiguate as many entities as
possible.
During the extraction, one or more feature recognition and extraction
algorithms may be
employed. Also, a score may be assigned to each extracted feature, indicating
the level of
certainty of the feature being correctly extracted with the correct
attributes. Taking into
account the feature attributes, the relative weight or relevance of each of
the features may be
24
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
determined. Additionally, the relevance of the association between features
may be
determined using a weighted scoring model.
[0084] Furthermore, various methods for linking the features may be
employed,
which may essentially use a weighted model for determining which entity types
are most
important, which have more weight, and, based on confidence scores, determine
how
confident the extraction of the correct features has been performed. As a
result, a table 306
including entity and co-occurrences may be created. Table 306 may then show
the entity
"apple" and its co-occurrences, which in this case, may be Apple and Jobs,
Apple and Steve
Jobs. The table 306 may also include Apple and organization A which may have
been found
relevant because Organization A is doing business with Apple and generating
"jobs" in said
organization A. Other co-occurrences may be found with less importance. As
such, Apple
and Jobs may then have the highest score (1), thus listed at the top, then
Apple and Steve Jobs
may have the second highest score (0.8), and finally Apple and other
organization A may be
at the bottom list with the lowest score (0.3).
[0085] Once the entities are extracted and ranked based on confidence
scores, an
index ID, which in some cases may be a number, may be assigned in step 308 to
the extracted
entities. Table 310 shows index IDs assigned to extracted entities. Table 310
then shows
"Apple" with index ID 1, "Jobs" with index ID 2, "Steve Jobs" with index ID 3,
and
"Organization A" with index ID 4.
[0086] Next, a search step 312 based on the entities index ID 308 may be
performed.
In the search step 312, the extracted entities such as "Apple", "Jobs", "Steve
Jobs", and
"Organization A", may be located within the entity indexed corpus 114 data by
using
standard indexing methods.
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0087] After locating extracted entities within the entity indexed corpus
114, an entity
association 314 step may follow. In Entity association step 314, all the data
such as
documents, videos, pictures, files or the like, where at least two extracted
entities overlaps
may be pulled from the entity indexed corpus 114 to build a list of links as
search results
(step 318). By a way of illustration and not by way of limitation, table 316
shows how
extracted entities may be associated to data in entity indexed corpus 114. In
table 316,
documents 1, 4, 5, 7, 8, and 10 show overlapping of two extracted entities,
thus the links for
these documents may be shown as search results in step 318.
[0088] FIG. 4 is a block diagram of a search computer system 400 in
accordance with
the present disclosure. The search system 400 may include one or more user
interfaces 402 to
a search engine 404 in communication with a server device 406 over a network
408. In this
embodiment, the search system 400 may be implemented in one or more special
purpose
computers and computer modules referenced below, including via a client/server
type
architecture. However, the search system 400 may be implemented using other
computer
architectures (for example, a stand-alone computer, a mainframe system with
terminals, an
ASP model, a peer to peer model and the like). In an embodiment, the search
computer
system 400 includes a plurality of networks such as, a local area network, a
wide area
network, the internet, a wireless network, a mobile phone network and the
like.
[0089] A search engine 404 may include a user interface, such as a web-
based tool
that enables users to locate information on the World Wide Web. Search engine
404 may also
include user interface tools that enable users to locate information within
internal database
systems. Server device 406, which may be implemented in a single server device
406 or in a
distributed architecture across a plurality of server computers, may include
an entity
26
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
extraction module 410, a fuzzy-score matching module 412, and an entity co-
occurrence
knowledge base database 414.
[0090] Entity extraction module 410 may be a hardware and/or software
module
configured to extract and disambiguate on-the-fly independent entities from a
given set of
queries such as a query string, partial query, structured data and the like.
Examples of entities
may include people, organizations, geographic locations, dates and/or time.
During the
extraction, one or more feature recognition and extraction algorithms may be
employed.
Also, a score may be assigned to each extracted feature, indicating the level
of certainty of
the feature being correctly extracted with the correct attributes. Taking into
account the
feature attributes, the relative weight or relevance of each of the features
may be determined.
Additionally, the relevance of the association between features may be
determined using a
weighted scoring model.
[0091] Fuzzy-score matching module 412 may include a plurality of
algorithms that
may be selected according to the type of entity being extracted from a given
search query.
The function of the algorithms may be to determine whether the given search
query received
via user input and other searched strings identified by the algorithm are
similar to each other,
or approximately match a given pattern string. Fuzzy matching may also be
known as fuzzy
string matching, inexact matching, and approximate matching. Entity extraction
module 410
and fuzzy-score matching module 412 may work in conjunction with entity co-
occurrence
knowledge base 414 to generate search suggestions for the user.
[0092] According to various embodiments, entity co-occurrence knowledge
base 414
may be built, but is not limited to, as an in-memory database and may include
components,
such as one or more search controllers, multiple search nodes, collections of
compressed data,
and a disambiguation module. One search controller may be selectively
associated with one
27
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
or more search nodes. Each search node may be capable of independently
performing a fuzzy
key search through a collection of compressed data and returning a set of
scored results to its
associated search controller.
[0093] Entity co-occurrence knowledge base 414 may include related
entities based
on features and ranked by a confidence score. Various methods for linking the
features may
be employed, which may essentially use a weighted model for determining which
entity types
are most important, which have more weight, and, based on confidence scores,
determine
how confident the extraction of the correct features has been performed.
[0094] FIG. 5 is a flowchart illustrating a method 500 for generating
search
suggestions using fuzzy-score matching and entity co-occurrence in a knowledge
base.
Method 500 may be implemented in a search system 400, similar to that
described by FIG. 4.
[0095] In one embodiment, method 500 may initiate when a user starts
typing a
search query in step 502 into a search engine interface 402, as described in
FIG. 4. As the
search query is typed in step 502, search system 400 may perform an on-the-fly
process.
According to various embodiments, search query input in step 502 may be either
complete or
partial, either correctly spelled or misspelled. Followed, at search system
400, a partial entity
extraction step 504 from the search query input of step 502 may be performed.
The partial
entity extraction step 504 may run a quick search against entity co-occurrence
knowledge
base 414 to identify whether the search query that was input in step 502 is an
entity, and if so,
what type of entity it is. According to various embodiments, search query
input of step 402
may then refer to a person, an organization, the location of a place, and a
date among others.
Once the entity type of the search query input is identified, fuzzy-score
matching module 412
may select a corresponding fuzzy matching algorithm, step 506. For example, if
search query
was identified as an entity that is referring to a person, then fuzzy-score
matching module 412
28
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
may select the string matching algorithm for persons, for example, such as by
extracting
different components of the person's name including first, middle, last, and
title. In another
embodiment, if search query was identified as an entity that is referring to
an organization,
then fuzzy-score matching module 412 may select the string matching algorithm
for
organizations, which can include identifying terms like school, university,
corp, inc, and the
like. Fuzzy-score matching module 412 may then select the string matching
algorithm that
corresponds to the type of identified entity in the search query input so as
to excel the search.
Once the string matching algorithm is adjusted to the type of identified
entity, a fuzzy-score
matching step 508 may be performed.
[0096] In fuzzy-score matching step 508, extracted entity or entities, as
well as non-
entities, may be searched and compared against entity co-occurrence knowledge
base 414.
Extracted entity or entities may include incomplete names of persons, for
example first name
and the first character of the last name, abbreviations of organizations, for
example "UN" that
may stand for "United Nations", short forms, and nicknames among others.
Entity co-
occurrence knowledge base 414 may already have registered a plurality of
records indexed as
an structured data, such as entity to entity, entity to topics, and entity to
facts, among others.
The latter may allow fuzzy-score matching in step 508 to happen in a very fast
way. Fuzzy-
score matching in step 508 may use, but is not limited to, a common string
metric such as
Levenshtein distance, strcmp95, ITF scoring, and the like. Levenshtein
distance between two
words may refer to the minimum number of single-character edits required to
change one
word into the other.
[0097] Finally, once fuzzy-score matching step 508 finishes comparing and
searching
search query against all records in the entity co-occurrence knowledge base
414, the record
that dominates the most or is the closest to match the given pattern string
(i.e., the search
29
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
query input of step 502) may be selected as first candidate for a search
suggestion in step 510.
Other records with less proximity to match the given pattern string may be
placed under the
first candidate in a descending order. Search suggestion in step 510 may then
be presented to
the user in a drop down list of possible matches that the user may or may not
ignore.
[0098] FIG. 6 is an example user interface 600 in accordance with the
method for
generating search suggestions using fuzzy-score matching and entity co-
occurrence in a
knowledge base, as discussed in FIGS 4-5 above. In this example, a user
through a search
engine interface 602, similar to that described by FIG. 4, inputs a partial
query 604 in a
search box 606. By a way of illustration and not by way of limitation, partial
query 604 may
be an incomplete name of a person such as "Michael J", as shown in FIG. 6. It
may be
considered a partial query 604 because the user may not have yet selected
search button 608,
or otherwise submitted the partial query 604 to search system 400 to perform
an actual search
and obtain results.
[0099] Following the method 500 (FIG.5), as the user types "Michael J",
the entity
extraction module 410 performs a quick search on-the-fly of the first word
(Michael) against
entity co-occurrence knowledge base 414 to identify the type of entity, in
this example, the
entity may refer to the name of a person. Consequently, fuzzy-score matching
module 412
may select a string match algorithm tailored for names of persons. Name of
persons may be
found in databases written in different forms such as using only initials
(short forms), or first
name and first character of the last name, or first name, initial of the
middle name and last
name, or any combination thereof Fuzzy-score matching module 412 may use a
common
string metric such as Levenshtein distance to determine and assign a score to
the entity, topic,
or fact within entity co-occurrence knowledge base 414 that may match the
entity "Michael".
In this example, Michael matches with a great amount of records having that
name. However,
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
as the user types the following character "J", fuzzy-score matching module 412
may perform
another comparison based on Levenshtein distance against all co-occurrences
with Michael
with the entity co-occurrence knowledge base 414. Entity co-occurrence
knowledge base 414
may then select all possible matches with the highest scores for "Michael J".
For example,
fuzzy-score matching module 412 may return search suggestions 610 such as
"Michael
Jackson", "Michael Jordan", "Michael J. Fox", or even "Michael Dell" in some
cases to the
user. The user may then be able to select from the drop down list one of the
persons
suggested as to complete the search query. Expanding on the aforementioned
example, a
query like "Michael the basketball player", would lead to the suggestion of
"Michael Jordan",
based on the results returned by searching entity co-occurrence knowledge base
for
"Michael" in person entity name variations and "the basketball player" in the
co-occurrence
features like key phrases, facts, and topics. Another example can be
"Alexander the actor",
would lead to the suggestion of "Alexander Polinsky". Those skilled in the art
will realize
that the presently existing search platforms cannot generate suggestions in
the
aforementioned manner.
[0100] FIG. 7 is a block diagram of a search system 700 in accordance
with the
present disclosure. The search system 700 may include one or more user
interfaces 702 to a
search engine 704 in communication with a server device 706 over a network
708. In this
embodiment, the search system 700 may be implemented in a client/server type
architecture;
however, the search system 700 may be implemented using other computer
architectures (for
example, a stand-alone computer, a mainframe system with terminals, an ASP
model, a peer
to peer model and the like) and a plurality of networks such as, a local area
network, a wide
area network, the internet, a wireless network, a mobile phone network and the
like.
31
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0101] A search engine 704 may include, but is not limited to, an
interface via a web-
based tool that enables users to locate information on the World Wide Web.
Search engine
704 may also include tools that enable users to locate information within
internal database
systems. Server device 706, which may be implemented in a single server device
706 or in a
distributed architecture across a plurality of server computers, may include
an entity
extraction module 710, a fuzzy-score matching module 712, and an entity co-
occurrence
knowledge base database 714.
[0102] Entity extraction module 710 may be a hardware and/or software
computer
module able to extract and disambiguate on-the-fly independent entities from a
given set of
queries such as a query string, partial query, structured data and the like.
Example of entities
may include people, organizations, geographic locations, dates and/or time.
During the
extraction, one or more feature recognition and extraction algorithms may be
employed.
Also, a score may be assigned to each extracted feature, indicating the level
of certainty of
the feature being correctly extracted with the correct attributes. Taking into
account the
feature attributes, the relative weight or relevance of each of the features
may be determined.
Additionally, the relevance of the association between features may be
determined using a
weighted scoring model.
[0103] Fuzzy-score matching module 712 may include a plurality of
algorithms that
may be adjusted or selected according to the type of entity extracted from a
given search
query. The function of the algorithms may be to determine whether the given
search query
(input) and suggested searched strings are similar to each other, or
approximately match a
given pattern string. Fuzzy matching may also be known as fuzzy string
matching, inexact
matching, and approximate matching. Entity extraction module 710 and fuzzy-
score
32
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
matching module 712 may work in conjunction with Entity co-occurrence
knowledge base
714 to generate search suggestions for the user.
[0104] According to various embodiments, entity co-occurrence knowledge
base 714
may be built, but is not limited to, as an in-memory database and may include
components
such as one or more search controllers, multiple search nodes, collections of
compressed data,
and a disambiguation module. One search controller may be selectively
associated with one
or more search nodes. Each search node may be capable of independently
performing a fuzzy
key search through a collection of compressed data and returning a set of
scored results to its
associated search controller.
[0105] Entity co-occurrence knowledge base 714 may include related
entities based
on features and ranked by a confidence score. Various methods for linking the
features may
be employed, which may essentially use a weighted model for determining which
entity types
are most important, which have more weight, and, based on confidence scores,
determine
how confident the extraction of the correct features has been performed.
[0106] FIG. 8 is a flowchart illustrating an embodiment of a method 800
for
generating search suggestions of related entities based on co-occurrence
and/or fuzzy score
matching. Method 800 may be implemented in a search system 700, similar to as
described in
FIG. 7.
[0107] In one embodiment, method 800 may initiate when a user starts
typing a
search query, step 802, in the search engine 704, as described above in FIG.
7. As the search
query is typed, search system 700 may perform an on-the-fly process. According
to various
embodiments, search query may be complete and/or partial, correctly spelled
and/or
misspelled. Next, a partial entity extraction step 804 of search query may be
performed. The
partial entity extraction step 804 may run a quick search against entity co-
occurrence
33
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
knowledge base 714 to identify whether the search query includes an entity
and, if so, the
entity type. According to various embodiments, search query entity may refer
to a person, an
organization, the location of a place, and a date among others. Once the
entity is, a fuzzy-
score matching module 712 may select a corresponding fuzzy matching algorithm,
step 806.
For example, if search query was identified as an entity that is referring to
a person, then
fuzzy-score matching module 712 may adjust or select the string matching
algorithm for
persons, which can extract different components of the person's name,
including first,
middle, last, and title. In another embodiment, if search query was identified
as an entity that
is referring to an organization, then fuzzy-score matching module 712 may
adjust or select
the string matching algorithm for organizations, which can include identifying
terms such as
school, university, corp., and inc. Fuzzy-score matching module 712 therefore
adjusts or
selects the string matching algorithm for the type of entity in order to
facilitate the search.
Once the string matching algorithm is adjusted or selected to correspond to
the type of entity,
a fuzzy-score matching may be performed in step 808.
[0108] In fuzzy-score matching step 808, extracted entity or entities, as
well as any
non-entities, may be searched and compared against entity co-occurrence
knowledge base
714. Extracted entity or entities may include incomplete names of persons, for
example first
name and the first character of the last name, abbreviations of organizations,
for example
"UN" that may stand for "United Nations", short forms, and nicknames among
others. Entity
co-occurrence knowledge base 714 may already have registered a plurality of
records indexed
in an structured data, such as entity to entity, entity to topics, and entity
to facts index among
others. This may allow fuzzy-score matching in step 808 to happen
expeditiously. Fuzzy-
score matching may use, but is not limited to, a common string metric such as
Levenshtein
distance, strcmp95, ITF scoring, and the like. Levenshtein distance between
two words may
34
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
refer to the minimum number of single-character edits required to change one
word into the
other.
[0109] Once fuzzy-score matching in step 808 step finishes comparing and
searching
the search query against all records in the entity co-occurrence knowledge
base 714, the
record that dominates the most or is the closest to match the given pattern
string of the search
query input may be selected as first candidate for a search suggestion, step
810. Other
records with less proximity to match the given pattern string of the search
query input may be
placed under the first candidate in a descending order. Search suggestion in
step 810 may
then be presented to the user in a drop down list of possible matches that the
user may select
to complete the query.
[0110] In another embodiment, after the user selects a match of his/her
interest,
search system 700 may take that selection as a new search query, step 812.
Subsequently, an
entity extraction step 814 from said new search query may be performed. During
the
extraction, one or more feature recognition and extraction algorithms may be
employed.
Also, a score may be assigned to each extracted feature, indicating the level
of certainty of
the feature being correctly extracted with the correct attributes. Taking into
account the
feature attributes, the relative weight or relevance of each of the features
may be determined.
Additionally, the relevance of the association between features may be
determined using a
weighted scoring model. Entity extraction module 710 may then run a search
against entity
co-occurrence knowledge base 714 to find related entities, step 816, based on
the co-
occurrences with the highest scores. Finally, a drop down list of search
suggestions, in step
818, including related entities, may be presented to the user before
performing the actual
search of the data in the electronic document corpus.
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0111] FIG. 9 is an example embodiment of a user interface 900 associated
with the
method 800 for generating search suggestions of related entities based on co-
occurrence
and/or fuzzy score matching. In this example, a user through a search engine
interface 902,
similar to that described by FIG. 7, inputs a partial query 904 in a search
box 906. By a way
of illustration and not by way of limitation, partial query 304 may be an
incomplete name of a
person such as "Michael J", as shown in FIG. 9. It may be considered a partial
query 904
because the user may not have yet selected search button 908, or otherwise
submitted the
partial query 904 to search system 100 to perform an actual search and obtain
results.
[0112] Following the method 800, as the user types "Michael J", the
entity extraction
module 710 performs a quick search on-the-fly of the first word (Michael)
against entity co-
occurrence knowledge base 714 to identify the type of entity, in this example,
the entity may
refer to the name of a person. Subsequently, fuzzy-score matching module 712
may select a
string match algorithm tailored for names of persons. Name of persons may be
found in
databases written in different forms such as using only initials (short
forms), or first name and
first character of the last name, or first name, initial of the middle name
and last name, or any
combination thereof Fuzzy-score matching module 712 may use a common string
metric
such as Levenshtein distance to determine and assign a score to the entity,
topic, or fact
within entity co-occurrence knowledge base 714 that may match the entity
"Michael". In this
example, Michael matches with a great amount of records having that name.
However, as the
user types the following character "J", fuzzy-score matching module 712 may
perform
another comparison based on Levenshtein distance against all co-occurrences
with Michael
with the entity co-occurrence knowledge base 714. Entity co-occurrence
knowledge base 714
may then select all possible matches with the highest scores for "Michael J".
For example,
fuzzy-score matching module 712 may return search suggestions 910 to complete
"Michael
J" such as "Michael Jackson", "Michael Jordan", "Michael J. Fox", or even
"Michael Dell" in
36
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
some cases to the user. The user may then be able to either select from the
drop down list one
of the persons suggested, or ignore the suggestion and keep typing. Expanding
on the
aforementioned example, a query like "Michael the basketball player", would
lead to the
suggestion of "Michael Jordan", based on the results returned by searching
Entity co-
occurrence knowledge base for "Michael" in person entity name variations and
"the
basketball player" in the co-occurrence features like key phrases, facts,
topics, and the like.
Another example can be "Alexander the actor", would lead to the suggestion of
"Alexander
Polinsky". As those skilled in the art will realize, the existing search
platforms cannot provide
suggestions generated in the aforementioned manner.
[0113] In this embodiment, the user may select "Michael Jordan" from the
drop down
list to complete the partial query 904, as indicated in FIG. 9. Said selection
may then be
processed as a new search query 912 by search system 700. Subsequently, an
entity
extraction from said new search query 912 may be performed. During the
extraction, one or
more feature recognition and extraction algorithms may be employed. Also, a
score may be
assigned to each extracted feature, indicating the level of certainty of the
feature being
correctly extracted with the correct attributes. Taking into account the
feature attributes, the
relative weight or relevance of each of the features may be determined.
Additionally, the
relevance of the association between features may be determined using a
weighted scoring
model. Entity extraction module 710 may then run a search for "Michael Jordan"
against
entity co-occurrence knowledge base 714 to find related entities based on the
co-occurrences
with the highest scores. Finally, a drop down list of search suggestions 914,
including related
entities, may be presented to the user before performing the actual search by
clicking on the
search button 908. The foregoing system and method described in FIGS. 7-9 may
be fast and
convenient for the user since the user may find useful relationships.
37
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0114] FIG. 10 is a block diagram of a search system 1000 in accordance
with the
present disclosure. The search system 1000 may include a search engine 1002,
such search
engine 1002 may include one or more user interfaces allowing data input from
the user, such
as user queries.
[0115] Search system 1000 may include one or more databases. Such
databases may
include entity database 1004 and trends database 1006. Databases may be stored
in a local
server or in a web based server. Thus, search system 1000 may be implemented
in a
client/server type architecture; however, the search system 1000 may be
implemented using
other computer architectures, for example, a stand-alone computer, a mainframe
system with
terminals, an ASP model, a peer to peer model, and the like, and a plurality
of networks such
as, a local area network, a wide area network, the internet, a wireless
network, a mobile
phone network, and the like.
[0116] A search engine 1002 may include, but is not limited to, a web-
based tool that
enables users to locate information on the World Wide Web. Search engine 1002
may also
include tools that enable users to locate information within internal database
systems.
[0117] Entity database 1004, which may be implemented as a single server
or in a
distributed architecture across a plurality of servers. Entity database 1004
may allow a set of
entities queries, such as a query string, structured data and the like. Such
set of entities
queries may be previously extracted from a plurality of corpus available in
the internet and/or
local network. Entities queries may be indexed and scored. Example of entities
may include
people, organizations, geographic locations, dates and/or time. During the
extraction, one or
more feature recognition and extraction algorithms may be employed. Also, a
score may be
assigned to each extracted feature, indicating the level of certainty of the
feature being
correctly extracted with the correct attributes. Taking into account the
feature attributes, the
38
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
relative weight or relevance of each of the features may be determined.
Additionally, the
relevance of the association between features may be determined using a
weighted scoring
model.
[0118] Trends database 1006, which may be implemented as a single server
or in a
distributed architecture across a plurality of servers. Trends database 1006
may allow a set of
entities queries, such as a query string, structured data, and the like. Such
set of entities
queries may be previously extracted from historical queries performed by the
user and/or a
plurality of users in the intern& and/or local network. Entities queries may
be indexed and
scored. Example of entities may include people, organizations, geographic
locations, dates
and/or time. During the extraction, one or more feature recognition and
extraction algorithms
may be employed. Also, a score may be assigned to each extracted feature,
indicating the
level of certainty of the feature being correctly extracted with the correct
attributes. Taking
into account the feature attributes, the relative weight or relevance of each
of the features may
be determined. Additionally, the relevance of the association between features
may be
determined using a weighted scoring model.
[0119] Entity database 1004 and trends database 1006 may include entity
co-
occurrence knowledge base, which may be built, but is not limited to, as an in-
memory
database (not shown) and may include other components (not shown), such as one
or more
search controllers, multiple search nodes, collections of compressed data, and
a
disambiguation module. One search controller may be selectively associated
with one or
more search nodes. Each search node may be capable of independently performing
a fuzzy
key search through a collection of compressed data and returning a set of
scored results to its
associated search controller.
39
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0120] Co-occurrence knowledge base may include related entities based on
features
and ranked by a confidence score. Various methods for linking the features may
be
employed, which may essentially use a weighted model for determining which
entity types
are most important, which have more weight, and, based on confidence scores,
determine
how confident the extraction of the correct features has been performed.
[0121] Search system 1000 may compare user query at search engine 1002
against
entity database 1004 and trends database 1006. Auto-complete mode on search
engine 1002
may be enabled from both databases; entity databases 1004 and trends databases
1006.
Search system 1000 may deploy a list of search suggestions 1008 to the user,
such list may be
generated and indexed based on a fuzzy score assigned to each entity
suggestion in databases.
Score of each entity suggestion may be assigned automatically by the search
system 1000
and/or manually by a system supervisor. Entities suggestion may be ordered
from the most
relevant to the less relevant based on the score achieved by each entity. In
addition, score in
trends database 1006 may be assigned using trends and query frequency from one
or more
users in a local network and/or Internet.
[0122] Entity suggestion of each database may be compared among them and
then
indexed and ordered by the rank obtained in the score, thus a list of search
suggestions 1008
may be shown to user combining entity suggestions in both databases; entity
database 1004
and trends database 1006. If user select a suggestion from the list or select
another result out
of the suggestion list, then search system 1000 may save such information in
trends database
1006. Thus, a self-learning system may be allowed, which may increase search
system 1000
reliability and accuracy. In brief, the trends co-occurrence knowledge base
can be
continuously updated, with the features extracted from the user's query and
the selected
suggestions, providing a means of on-the-fly learning, which improves the
search relevancy
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
and accuracy. Further, trends co-occurrence knowledge base can be populated by
the
different users using the system and also by automatic methods like trend
detection modules.
[0123] FIG. 11 is a block diagram of a search system 1100 in accordance
with the
present disclosure. The search system 1100 may include a search engine 1102,
such search
engine 1102 may include one or more user interfaces allowing data input from
the user, such
as user queries.
[0124] Search system 1100 may include one or more databases. Such
databases may
include entity database 1104 and trends database 1106. Databases may be stored
in a local
server or in a web based server. Thus, search system 1100 may be implemented
in a
client/server type architecture; however, the search system 1100 may be
implemented using
other computer architectures, for example, a stand-alone computer, a mainframe
system with
terminals, an ASP model, a peer to peer model, and the like, and a plurality
of networks such
as, a local area network, a wide area network, the internet, a wireless
network, a mobile
phone network, and the like.
[0125] In one embodiment, search system 1100 may start when a user inputs
one or
more entities (in search queries) through a user interface in search engine
1102. An example
of a search query may be a combination of keywords in a string data format,
structured data,
and the like. These keywords may be entities that represent people,
organizations, geographic
locations, dates and/or time. In the present embodiment, "Indiana Na" is used
as search query.
[0126] "Indiana Na" may then be processed for entity extraction. An
entity extraction
module may process search queries such as, "Indiana Na" as entities and
compare them all
against entity co-occurrence knowledge base in entity database 1104 and trends
database
1106 to extract and disambiguate as many entities as possible. Additionally,
the query text
parts that are not detected as entities (e.g., person, organization,
location), are treated as
41
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
conceptual features (e.g., topics, facts, key phrases) that can be employed
for searching the
entity co-occurrence knowledge bases (e.g., entity and trend databases).
During the
extraction, one or more feature recognition and extraction algorithms may be
employed.
Also, a score may be assigned to each extracted feature, indicating the level
of certainty of
the feature being correctly extracted with the correct attributes. Taking into
account the
feature attributes, the relative weight or relevance of each of the features
may be determined.
Additionally, the relevance of the association between features may be
determined using a
weighted scoring model.
[0127] In the present embodiment, entity database 1104 may show a list of
search
suggestions, as a list of entity suggestions 1108, which may be indexed and
ranked. Trends
database 1106 may show a list of search suggestions, as trends based
suggestion list 1110,
which may be indexed and ranked. Subsequently, search system 1100 may build a
search
suggestions list 1112 based on those provided by entity database 1104 and
trends database
1106. The search suggestions list 1112 may be indexed and ranked based on the
individual
score of each entity suggestion in each database; thus, the most relevant may
be shown first
and the less relevant result may continue below it.
[0128] In search system 1100, an exemplary use for obtaining search
suggestion is
disclosed. Search suggestions list 1112 may show suggestions based on "Indiana
Na" user
query. As a result, "Indiana Name" may appear first based on an individual
score of 0.9 for
that entity, then "Indiana Nascar" may be shown as a result of an individual
score of 0.8,
finally "Indiana Nashville" may be shown based on an individual score of 0.7.
The individual
score may be compared using list of entity suggestions 1108 and trends based
suggestion list
1110, without applying considering repeated entities.
42
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
[0129] FIG. 12 is a block diagram of a search system 1200 in accordance
with the
present disclosure. Search system 1200 may include a search engine 1202, such
search engine
1202 may include one or more user interfaces allowing data input from the
user, such as user
queries.
[0130] Search system 1200 may include one or more databases. Such
databases may
include entity database 1204 and trends database 1206. Databases may be stored
in a local
server or in a web based server. Thus, search system 1200 may be implemented
in a
client/server type architecture; however, the search system 1200 may be
implemented using
other computer architectures; for example, a stand-alone computer, a mainframe
system with
terminals, an ASP model, a peer to peer model, and the like, and a plurality
of networks such
as, a local area network, a wide area network, the internet, a wireless
network, a mobile
phone network, and the like.
[0131] In one embodiment, search system 1200 may start when a user inputs
one or
more entities (search queries) through a user interface in search engine 1202.
An example of
a search query may be a combination of keywords such as a string, structured
data and the
like. These keywords may be entities that represent people, organizations,
geographic
locations, dates and/or time. In the present embodiment, "Indiana Na" is used
as search query.
[0132] "Indiana Na" may then be processed for entity extraction. An
entity extraction
module may process search queries such as, "Indiana Na," as entities and
compare them all
against entity co-occurrence knowledge base in entity database 1204 and trends
database
1206 to extract and disambiguate as many entities as possible. Additionally,
the query text
parts that are not detected as entities (e.g., person, organization,
location), are treated as
conceptual features (e.g., topics, facts, key phrases), which may be employed
for searching
the entity co-occurrence knowledge bases (e.g., entity database, trend
databases). During the
43
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
extraction, one or more feature recognition and extraction algorithms may be
employed.
Also, a score may be assigned to each extracted feature, indicating the level
of certainty of
the feature being correctly extracted with the correct attributes. Based on
the respective
feature attributes, the relative weight and/or the relevance of each of the
features, may be
determined. Additionally, the relevance of the association between features
may be
determined using a weighted scoring model.
[0133] In the present embodiment, entity database 1204 may show a list of
search
suggestions, list of entity suggestions 1208, which may be already indexed and
ranked.
Equally, trends database 1206 may show a list of search suggestions, trends
based suggestion
list 1210, which may be already indexed and ranked. Subsequently, search
system 1200 may
build a search suggestions list 1212 based on those provided by entity
database 1204 and
trends database 1206. The search suggestions list 1212 may be indexed and
ranked based on
the overall score of each entity suggestion in both databases, thus, the most
relevant may be
shown first and the less relevant result may continue below it.
[0134] In Search system 1200, an exemplary use for obtaining search
suggestion is
disclosed. Search suggestions list 1212 may show suggestions based on "Indiana
Na" user
query. As a result, "Indiana Nascar" may appear first based on an overall
score of 1.4
resulting from the sum of score 0.8 at list of entity suggestions 1208 and
score 0.6 at trends
based suggestion list 1210. Similarly, "Indiana Name" may be shown as a result
of an overall
score of 0.9, finally "Indiana Nashville' may be shown based on an overall
score of 0.7.
[0135] FIG. 13 is a system architecture 1300 for geotagging content in
SharePoint
2013t. A Search index 1324 is one of a number of key components in order to
enable search
in SharePoint 1302. Another key part of enabling search in SharePoint 2013
1302 may be
44
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
content capturing in order to index the content. SharePoint 1302 includes a
crawler 1304
component in order to enable content capturing.
[0136] Crawler 1304 may crawl through different content sources 1306
adding a list
of metadata properties to each content. Examples of content sources may
include without
limitation, SharePoint content, network file-share or user or intranet
content. Crawler 1304
may be configured perform the functions of connecting securely to a content
source 1306,
associating document from the sources to their metadata as crawled properties.
The crawler
1304 may be configured to full or incremental crawls to content. Examples of
crawled
properties may include for example and without limitation author, title,
creation date among
others.
[0137] SharePoint 2013 includes a content processing 1308 component. The
content processing 1308 component takes content from the crawler 1304 and
prepares it for
indexing. Content processing 1308 may involve stages of linguistic processing
(language
detection), parsing, entity extraction management, content-based file format
detection,
content processing error reporting, natural language processing and mapping
crawled
properties to managed properties among others.
[0138] Content processing 1308 may be extended by means of a content
enrichment
web service (CEWS 1310). CEWS 1310 may enable the enrichment of content
processing
1308 by allowing a web service callout 1312 to call external web service to
perform
additional actions and enrich the crawled data properties. Web service callout
1312 may be a
standard simple object access protocol (SOAP) request or any other web service
call method
used to exchange structured information of the crawled data with an entity
enrichment service
1314. Web service callout 1312 may include trigger conditions configured in
the content
enrichment configuration object that control when to call an external web
service for
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
enrichment processing. Entity enrichment service 1314 may also determine the
document
type of the crawled data in order to determine content that may come in the
form of an image
(scanned documents, pictures, etc.). Whenever content in the form of an image
is found the
entity enrichment service 1314 may send the location of the crawled document
to an OCR
processing engine 1316 such as for example and without limitation an optical
character
recognition component or other image processing component. OCR processing
engine 1316
may then retrieve and process the image files and convert them to text files
asynchronously.
The OCR'd processed files 1318 may subsequently be re-fed to crawler 1304 in
order to be
crawled as text files and sent back to content processing 1308 and proceed
with the rest of the
workflow.
[0139] System architecture 1300 may include an external geotagger web
service 1320
and a named entity tagger service 1322. Both geotagger web service 1320 and
named entity
tagger service 1322 may be a software module configured to function as a web
service
application provider and to respond to web service callout 1312. Geotagger web
service 1320
may use natural language processing entity extraction techniques, machine
learning models
and other techniques in order to identify and disambiguate geographic entities
from crawled
content. For example, geotagger web service 1320 may disambiguate geographic
entities by
analyzing statistical co-occurrence of entities found in a gazetteer.
Geotagger web service
1320 may include a database of statistical co-occurring entities which may be
linked against
content found by crawler 1304. Following the same technique, named entity
tagger service
1322 may be used to extract additional entities or text features such as
organizations, people
or topics.
[0140] Geotagger web service 1320 may analyze an array of managed
properties sent
as input properties by CEWS 1310 and identify any geographic entities referred
in text. Non-
46
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
limiting examples of input properties may include: FileType, IsDocument,
OriginalPath and
body among others. Geotagger web service 1320 may then geotag the text by
creating or
modifying managed properties with reference to each geographic entity found.
Geotagger
web service 1320 may send modified or new managed properties to the entity
enrichment
service 1314 where a conversion is made that maps the modified managed
properties and
returns them as output properties back to CEWS 1310. The same process may be
used to
interact with the named entity tagger service 1322 for the extraction and
entity tagging of
other entities or text features such as organizations, people or topics.
[0141] After the augmented managed properties are returned by the entity
enrichment
service 1314 the properties are merged with the crawled file managed
properties and sent to a
search index 1324.
[0142] Once geographic and other entity tags have been associated with
content and
indexed, search queries may also be performed using geographic or named entity
features. A
search UI 1326 in SharePoint 2013 may include specific displays that may
assist a user in
performing a geographic based search as well as support enhanced displays of
faceted search
results. The search UI 1326 may be a custom web part or may also be done by
modifying the
standard layout of SharePoint 2013 search with standard tools such as HTML,
HTML 5,
JavaS cript and C S S .
[0143] FIG. 14 is a flow chart 1400 illustrating the process steps for
tagging content
for SharePoint 2013 search. The process may begin when the crawler component
in
SharePoint 2013 performs a crawl for content (step 1402). In one embodiment
the crawl
may be a full crawl, wherein in another embodiment the crawl may be an
incremental crawl.
The crawler component may then feed crawled properties and metadata to the
content
processing (step 1404). A determination is made to verify if the crawled
content may include
47
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
geographic or named entities. For example and without limitation a trigger
condition may be
used. The trigger condition may contain a set of programmatic logic or rules
which may
determine if content may benefit from geotagging or entity tagging. If the
trigger condition
evaluates to false crawled content may be associated with managed properties
(step 1406)
and passed to the search index component (step 1408). If the trigger condition
evaluates to
true the CEWS may send a web service callout (step 1410) to an entity
enrichment service.
The entity enrichment service may analyze the content sent in order to
determine if the
content may be in an image format (scanned documents, pictures, etc.). Content
found in an
image format may be processed asynchronously by an OCR engine and sent back to
be re-
crawled by the crawling component as text files (step 1412). If the content is
not in image
format, the content may be processed by a geotagging web service or a name
entity tagger
service (step 1414). The web service may extract and disambiguate geographic
or named
entities referred in the content and enrich them with entity metadata. The
identified entities
and their metadata may be sent back as managed properties to the content
processing
component and associated with the content (step 1416). The associated metadata
may then be
sent to the search index component (step 1406).
[0144] While various aspects and embodiments have been disclosed, other
aspects
and embodiments are contemplated. The various aspects and embodiments
disclosed are for
purposes of illustration and are not intended to be limiting, with the true
scope and spirit
being indicated by the following claims.
[0145] The foregoing method descriptions and the process flow diagrams
are
provided merely as illustrative examples and are not intended to require or
imply that the
steps of the various embodiments must be performed in the order presented. As
will be
appreciated by one of skill in the art the steps in the foregoing embodiments
may be
48
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
performed in any order. Words such as "then," "next," etc. are not intended to
limit the order
of the steps; these words are simply used to guide the reader through the
description of the
methods. Although process flow diagrams may describe the operations as a
sequential
process, many of the operations can be performed in parallel or concurrently.
In addition, the
order of the operations may be re-arranged. A process may correspond to a
method, a
function, a procedure, a subroutine, a subprogram, etc. When a process
corresponds to a
function, its termination may correspond to a return of the function to the
calling function or
the main function.
[0146] The various illustrative logical blocks, modules, circuits, and
algorithm steps
described in connection with the embodiments disclosed herein may be
implemented as
electronic hardware, computer software, or combinations of both. To clearly
illustrate this
interchangeability of hardware and software, various illustrative components,
blocks,
modules, circuits, and steps have been described above generally in terms of
their
functionality. Whether such functionality is implemented as hardware or
software depends
upon the particular application and design constraints imposed on the overall
system. Skilled
artisans may implement the described functionality in varying ways for each
particular
application, but such implementation decisions should not be interpreted as
causing a
departure from the scope of the present invention.
[0147] Embodiments implemented in computer software may be implemented in
software, firmware, middleware, microcode, hardware description languages, or
any
combination thereof. A code segment or machine-executable instructions may
represent a
procedure, a function, a subprogram, a program, a routine, a subroutine, a
module, a software
package, a class, or any combination of instructions, data structures, or
program statements.
A code segment may be coupled to another code segment or a hardware circuit by
passing
49
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
and/or receiving information, data, arguments, parameters, or memory contents.
Information,
arguments, parameters, data, etc. may be passed, forwarded, or transmitted via
any suitable
means including memory sharing, message passing, token passing, network
transmission, etc.
[0148] The actual software code or specialized control hardware used to
implement
these systems and methods is not limiting of the invention. Thus, the
operation and behavior
of the systems and methods were described without reference to the specific
software code
being understood that software and control hardware can be designed to
implement the
systems and methods based on the description herein.
[0149] When implemented in software, the functions may be stored as one
or more
instructions or code on a non-transitory computer-readable or processor-
readable storage
medium. The steps of a method or algorithm disclosed herein may be embodied in
a
processor-executable software module which may reside on a computer-readable
or
processor-readable storage medium. A non-transitory computer-readable or
processor-
readable media includes both computer storage media and tangible storage media
that
facilitate transfer of a computer program from one place to another. A non-
transitory
processor-readable storage media may be any available media that may be
accessed by a
computer. By way of example, and not limitation, such non-transitory processor-
readable
media may comprise RAM, ROM, EEPROM, CD-ROM or other optical disk storage,
magnetic disk storage or other magnetic storage devices, or any other tangible
storage
medium that may be used to store desired program code in the form of
instructions or data
structures and that may be accessed by a computer or processor. Disk and disc,
as used
herein, include compact disc (CD), laser disc, optical disc, digital versatile
disc (DVD),
floppy disk, and blu-ray disc where disks usually reproduce data magnetically,
while discs
reproduce data optically with lasers. Combinations of the above should also be
included
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
within the scope of computer-readable media. Additionally, the operations of a
method or
algorithm may reside as one or any combination or set of codes and/or
instructions on a non-
transitory processor-readable medium and/or computer-readable medium, which
may be
incorporated into a computer program product.
[0150] It is to be appreciated that the various components of the
technology can be
located at distant portions of a distributed network and/or the Internet, or
within a dedicated
secure, unsecured and/or encrypted system. Thus, it should be appreciated that
the
components of the system can be combined into one or more devices or co-
located on a
particular node of a distributed network, such as a telecommunications
network. As will be
appreciated from the description, and for reasons of computational efficiency,
the
components of the system can be arranged at any location within a distributed
network
without affecting the operation of the system. Moreover, the components could
be embedded
in a dedicated machine.
[0151] Furthermore, it should be appreciated that the various links
connecting the
elements can be wired or wireless links, or any combination thereof, or any
other known or
later developed element(s) that is capable of supplying and/or communicating
data to and
from the connected elements. The term module as used herein can refer to any
known or later
developed hardware, software, firmware, or combination thereof that is capable
of
performing the functionality associated with that element. The terms
determine, calculate and
compute, and variations thereof, as used herein are used interchangeably and
include any type
of methodology, process, mathematical operation or technique.
[0152] The preceding description of the disclosed embodiments is provided
to enable
any person skilled in the art to make or use the present invention. Various
modifications to
these embodiments will be readily apparent to those skilled in the art, and
the generic
51
CA 02932401 2016-06-01
WO 2015/084759 PCT/US2014/067997
principles defined herein may be applied to other embodiments without
departing from the
spirit or scope of the invention. Thus, the present invention is not intended
to be limited to the
embodiments shown herein but is to be accorded the widest scope consistent
with the
following claims and the principles and novel features disclosed herein.
[0153] The embodiments described above are intended to be exemplary. One
skilled
in the art recognizes that numerous alternative components and embodiments
that may be
substituted for the particular examples described herein and still fall within
the scope of the
invention.
52