Note: Descriptions are shown in the official language in which they were submitted.
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
SYSTEM AND METHOD FOR MULTI-LANGUAGE COMMUNICATION SEQUENCING
BACKGROUND
[0001] The present invention generally relates to telecommunications systems
and methods, as well as
business environments. More particularly, the present invention pertains to
audio playback in interactions
within the business environments.
SUMMARY
[0002] A system and method are presented for multi-language communication
sequencing.
Communication flows may support one or more languages, which may need to be
created, removed, or
edited. During sequence editing, prompts, data, expressions, pauses, and text-
to-speech may be added.
This may be done through the use of inline-selectors, which comprise a prompt
or TTS, or through the
use of dialogs, which may also provide error feedback. A main sequence may be
capable of handling
multiple languages which are supported and managed independent of each other.
[0003] In one embodiment, a method is presented for sequencing communication
to a party utilizing a
plurality of languages in an interactive voice response system, the method
comprising the steps of:
creating, by a user of the system, a prompt, wherein the prompt has a
plurality of resources of attached;
enabling, by the interactive voice response system, at least one supported
language for the
communication, wherein the communication is in the at least one supported
language; enabling, for
editing to the sequence, one or more of: prompts, data, expressions, pauses,
and text-to-speech; enabling
an alternate language for the communication, wherein the alternate language
comprises an alternate
sequence.
[0004] In another embodiment, a method is presented for sequencing
communication to a party utilizing
a plurality of languages in an interactive voice response system, the method
comprising the steps of:
selecting, through a graphical user interface, by a user, a prompt; and
creating, by a computer processor,
at run-time, a communication sequence using the prompt.
[0005] In another embodiment, a method is presented for sequencing
communication to a party utilizing
a plurality of languages in an interactive voice response system, the method
comprising the steps of:
1
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
entering, by a user, text into a graphical user interface, wherein the text is
transformed into text-to-speech
by a computer processor; and creating, by the computer processor, a
communication sequence using the
text-to-speech..
BRIEF DESCRIPTION OF THE DRAWINGS
[0006] Figures lid are diagrams illustrating embodiments of inline selectors.
[0007] Figures 2a-2e are diagrams illustrating embodiments of sequence
selectors.
[0008] Figure 3a-3b are diagrams illustrating embodiments of audio sequences.
[0009] Figures 4a-4e are diagrams illustrating embodiments of multi-language
sequences.
[0010] Figures 5a-5b are diagrams illustrating embodiments of audio sequence
editing.
[0011] Figure 6 is a diagram illustrating an embodiment of an error.
DETAILED DESCRIPTION
[0012] For the purposes of promoting an understanding of the principles of the
invention, reference will
now be made to the embodiment illustrated in the drawings and specific
language will be used to describe
the same. It will nevertheless be understood that no limitation of the scope
of the invention is thereby
intended. Any alterations and further modifications in the described
embodiments, and any further
applications of the principles of the invention as described herein are
contemplated as would normally
occur to one skilled in the art to which the invention relates.
[0013] In a business environment, such as a contact center or enterprise
environment, interactive voice
response systems are often utilized, particularly for inbound and outbound
interactions (e.g., calls, web
interactions, video chat, etc.). The communication flows for different media
types may be designed to
automatically answer communications, present parties to interactions with menu
choices, and provide
routing of the interaction according to a party's choice. Options present may
be based on the industry or
business in which the flow is used. For example, a bank may offer a customer
the option to enter an
account number, while another business may ask the communicant their name.
Another company may
simply have the customer select a number correlated to an option. Systems may
also be required to
2
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
support many languages. In an embodiment, consolidated multi-language support
for automatic runtime
data playback, speech recognition, and text-to-speech (TTS), may be used.
[0014] In an embodiment, the call flows, or logic for the handling of a
communication, that an IVR uses
to accomplish interactions may comprise several different languages. In the
management of these flows,
a main sequence provides an audio sequence for all supported languages in a
flow with the ability for a
system user (e.g., flow author) to specify alternate sequences on a per
language basis. The main sequence
may also be comprised of one or more items. The main sequence may be capable
of handling multiple
languages which are supported in the IVR flow. The languages may be managed
independently of each
other in the event an alternate sequence is triggered. During editing of the
sequences, error feedback may
be triggered by the system and provided to a user for the correction of issues
that arise.
[0015] In an embodiment, flows may comprise multiple sequences. For example,
the initial greeting in a
flow comprises a sequence, a communicant may be presented with a menu at which
point they may be
provided with another sequence, such as 'press 1 for sales', 'press 2 for
Jim', etc. The selection of an
option, in this example, triggers another sequence for presentation to the
communicant.
[0016] Because business environments are not always consistent, changes may be
needed to the audio
without having to deconstruct the IVR. The TTS of a new prompt on the related
prompt resources will
remain the same TTS set by the author in the flow, which can be modified as
appropriate.
[0017] Prompts such as "hello" may be created for greeting, for example, and
stored within a database
which is accessed by a run-time engine, such as a media server like
Interactive Intelligence Group, Inc.'s
Interaction Edge product, that executes the IVR logic. A prompt may have one
or more resources
attached to it. Resources may comprise audio (e.g., a spoken "hello"), TTS
(e.g., a synthesized "hello"),
or a language (e.g., en-US). In an embodiment, the resource may comprise TTS
and Audio and a
language tag. In another example, the resource may comprise TTS or Audio, and
a language tag. The
language tag may comprise an IETF language tag (or other means for tagging a
language) and may be
used to identify a resource within a prompt. The language tag may also provide
the grouping that is used
3
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
for audio and TTS. In an embodiment, a prompt may only have one prompt
resource per language. For
example, two resources may not be associated with the German language.
[0018] In an embodiment, audio sequences may be edited where a prompt is
followed by TTS or vice
versa. A user may decide to specify a prompt or to specify TTS. The prompt or
TTS may be turned into
a sequence later as business needs dictate. For example, during the
development of a flow, TTS may be
initially used and at some later time converted to a sequence.
[0019] Audio sequences comprise an ordered list of indexed items to play back
to a communicant
interacting with the IVR. The items may include, in no particular order, TTS,
data playback, prompts,
pauses or breaks, and embedded audio expressions. A main sequence may be
designated, with that
designated sequence applying to all supported languages set on a flow.
Alternate sequences may also be
present in the flow. These alternate sequences may be enabled for specific
languages, such that when an
interaction exits the main sequences, such as by the selection of a new
language, the alternate sequence
for that new language takes over. The alternate sequence may be duplicated
from the main sequence
initially and further edited by a flow author. The main sequence may then be
used for all supported
languages in the flow with the exception of the alternate sequence enabled by
the flow author. If alternate
sequences are enabled for each supported language in the flow, the main
sequence no longer applies since
each alternate language overrides the main sequence. Thus, the sequencing of
wording in prompts can be
language specific. In an embodiment, one prompt may be sufficient for all
languages, such as a
"thanks_for_calling" prompt. Within that prompt, each language has the
appropriate audio for use in the
prompt, which is utilized in the main sequence.
[0020] Audio sequences may be configured through a dialog (e.g., a modal
dialog or a window) or an
inline selector. In an embodiment, inline selectors comprise for an easy means
of configuration for TTS
or prompt. Figures la-id are diagrams illustrating embodiments of inline
selectors, indicated generally
at 100. In an embodiment, an inline selector comprises a one-item sequence,
such as a TTS or a prompt.
[0021] With regards to interactions, an author may detail languages for the
flow to support. In an
embodiment, an initial greeting may be made using TTS or a previously created
prompt. For example,
4
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
the author may enter TTS for the initial greeting or select a pre-existing
prompt, without having to open
the sequence editor for configuration. In an embodiment, the inline selectors
comprise TTS that will be
played as an initial greeting. In another embodiment, the inline selectors
comprise a prompt selection that
will be played as an initial greeting.
[0022] Figure la is an example of a one-item sequence utilizing TTS which
Figure lb is an example of a
one-item sequence utilizing prompts. The inline selector, such as in Figure la
and Figure lb, comprises
the "audio" 105. An audio expression may also be included 106. Along with the
audio expression, an
icon 107 may be present where upon selecting the icon, a window for editing
the audio sequence opens.
A window may also open for the addition of prompts. These editing windows are
described in greater
detail in Figures 2a-2e below.
[0023] In an embodiment, errors and their descriptions 108 may be displayed
for items, such as in Figure
lc, where the error indicates that there is a problem with an audio sequence
("1 or more audio sequences
are in error", for example). Attention may be called to the error by
highlighting or by a font color change
to the error and/or error descriptions, for example.
[0024] Figure ld is an embodiment of an audio sequence without an error,
indicating that '1 audio
sequence is set' 109. An icon, such as the dialogue clouds 110 exemplified in
Fig ld, may also be
indicative that this entry is not an inline entry of TTS or a prompt. In an
embodiment, the user may have
manually entered the sequence through a dialog as opposed to selecting a TTS
or a prompt.
[0025] Figures 2a-2d are diagrams generally illustrating embodiments of
sequence selectors. Each of
figures 2a-2d illustrate a single supported language, for simplicity. These
windows generally indicate
examples for configuring the dialog and sequence editing of audio expressions.
In Figure 2a, the window
illustrates the audio expression is a TTS 201. A user may decide to add
additional dialog, such as "Add
Prompt", "Add Data", "Add TTS", "Add Expression", and "Add Blank Audio", to
name a few non-
limiting examples. These options may be displayed in a task bar 202. In Figure
2a, "Add TTS" has been
selected. As a result, an additional item in the sequence may be created. In
Figure 2a, this is identified as
second in the sequence and is "Text to Speech" 203. Any number of items may be
added to the sequence
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
with the order of items editable. In an embodiment, a TTS string may
additionally be promoted to a
prompt and audio added in one or more languages, as further described in
Figure 2c.
[0026] In Figure 2b, "Add Blank Audio" has initially been selected 204. Blank
audio may allow a user
to configure the system to delay or pause in playback for a specified
duration. In an embodiment, this
may be performed from a drop-down menu 205, such as seen in Figure 2b.
Different durations may be
presented for selection, such as 100 ms, 250 ms, 500 ms, etc.
[0027] Further, simple TTS may be promoted to managed prompts that include
audio and TTS for
multiple languages, such illustrated in Figure 2c. A flow author may specify
the prompt name 206 and
description 207 in order to create the prompt. Here, the name is
"ThanksforContacting" and the
description "Used at the end of an interaction to say thanks for contacting
us". After the prompt has been
created in the user interface, the TTS is set on each of the prompt resources,
which are determined by the
supported languages set on the flow 208. In Figure 2c, English, United States,
has been designated. A
flow author may specify the audio to be included as "thank you for contacting
us" 209. In an
embodiment, two resources may be presented as prompt resources, if the
supported languages are English
and Spanish, for example.
[0028] Additional data may also be included in the main sequence. In Figure
2d, for example, four items
have been included in the main sequence. Each item may be created by selecting
the dialog "Add Data"
from the task bar 202. Different types of data may be added, such as: dates
and/or times, currencies,
numbers that may represent customer information, etc. Depending on the type of
data selected, different
options may become available from the system for a user to choose. For
example, data in item 1, 208,
may comprise currency. A user may decide to accept major units only from the
options available. For
item 2, 209, a decimal has been selected. A user may decide that they want the
system to speak each
digit, speak the entire value, etc.
[0029] In certain languages that utilize gender and/or case, options may also
include selecting between
feminine, masculine, neuter, articles, etc., 210. A sequence may also be
altered/reordered/removed
dependent on the language.
6
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
[0030] In an example of gender utilization, a veterinary clinic has an IVR
with a call flow running in
Spanish - United States (es-US). Confirmation with a caller is being performed
automatically as to what
pets the caller has on file. For this particular customer they have one female
cat on file, which needs
confirmation. An example sequence follows, such that:
[0031] TTS: "Usted tiene" ( you have)
[0032] Data: 1, Female
[0033] TTS: "gata"
[0034] At runtime the IVR would return: "Usted tiene una gata".
[0035] The generated expression comprises: Append(ToAudioTTS("Usted tiene"),
ToAudioNumber(1,
Language.Gender.Feminine), ToAudioTTS("gata")).
[0036] In an embodiment, where submitted numbers to `ToAudioNumbef have gender
specific
representations, the runtime playback will play the correct prompt. For the
example of the veterinary
clinic above, "una" is used since the number '1' will need to agree with the
gender of the noun (the
female cat) that follows.
[0037] Articles may also be supported for languages. Meta-data may be retained
about a language on
whether or not it supports gender, what gender types are there (e.g.,
masculine, feminine, neuter), or case.
If one of those options is specified by a flow author and the runtime has a
special audio handler set up for
that option, that handler will be played back to the communicant. In an
embodiment, case and gender
may also be combined together on playback and are not exclusive of each other.
For example, using
"ToAudioNumber(1, Language.Gender.masculine, Language.Case.article)", the
gender options are
grouped together and then the case options are grouped together. In an
embodiment, the case and gender
may be supported in the same dropdown menu of a user interface.
[0038] Errors may also be automatically indicated by the system during
sequence editing. In Figure 2e,
an example is provided of an in-line error, 211. In-line errors may be
indicated by means such as a color
change, a warning, high-lighting, icons, etc. In Figure 2e, the item entry
field is highlighted. In this
example, a user has added an item to the sequence, but did not specify
expression text in the dialog. The
7
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
system recognizes an error has occurred and provides an indication, such as
feedback, to allow the user to
correct the error in a quick edit form. In embodiments with longer
expressions, an editor may be opened
which provides more detailed feedback, such as converting audio to numbers,
for example. In Figure 2e,
an indication is being made that "There is no expression defined" 212,
allowing the user to quickly
pinpoint the error and, in this example, define an expression.
[0039] Expressions may also be included in the sequence graphical user
interface, which allow for
greater flexibility such as, for example,
`ToAudioTTS(If(Hour(GetCurrentDateTimeUTC())>=12, "Good
Afternoon", "Good Morning"))'. If a caller is in Greenwich, England, the
expression would play TTS of
"Good Morning" if running before 12:00 PM, otherwise, "Good Afternoon".
Expressions may also allow
for dynamic playback within a sequence, such as the TTS of "are the last four
digits of your social
security number". The expression may become:
"ToAudioTTS(Substring(Flow.CustomerSSN,
Length(Flow.CustomerSSC)-4,4), Format.String.PlayChars)". The expression in
this example is being
used to extract part of the data. The data comprises the social security
number of the customer with the
last four characters picked to be read back to the customer as spoken integers
in the language in which the
flow is running. Expressions may be used to also perform mathematical
calculations and text
manipulation, such as adding orders together or calculating a delivery date.
[0040] Expressions may also comprise grammars that return a type of audio to
provide more control with
the type of data played back. In an embodiment, this may also be applied to
communications and/or to
flows that run while a communicant (e.g., caller) is waiting on hold for an
agent (e.g., In-Queue flows).
[0041] Audio sequences may be edited. In Figures 3a and 3b, examples of audio
sequences are generally
provided. An audio sequence may be presented and a user may decide to use the
large/long expression
editor. In figure 3a, for example, index 1, 301, describes a prompt, such as
"Prompt.Hello" 302, followed
by an item for TTS 303. A user may indicate that they want the time to be
provided 304. Another data
item 305 may be added to provide the current time 306. In Figure 3b,
integrated expression help may be
provided such that a user may obtain more detailed error feedback, if
available. The output of the audio
sequencing editor comprises an expression. Here, the system may append to an
audio prompt the custom
8
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
audio "the time is" followed by an insert of the time, as exemplified with the
expression
"Append(ToAudio(Prompt.Hello), ToAudioTTS("The time is"),
ToAudioTime(Flow.currentTime))" 307.
[0042] In embodiments where an alternate language is enabled, for example, an
expression may be
generated for that language in addition to an expression generated for the
main sequence. Items within
the audio sequence editor are validated for correctness individually in order
to display appropriate errors
for each sequence item. In an embodiment, if one or more sequence items are in
error within a sequence,
either the main sequence or language specific sequence tab near the dialog
will reflect that it is in error as
well.
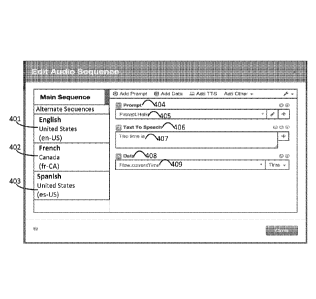
[0043] Figures 4a-4d are diagrams generally illustrating multi-language
sequences. A plurality of
language sequences may be defined such that there may be one or more main
language sequences, or a
main language with alternate language sequences, to name some non-limiting
examples. Errors may
automatically indicate if a main language sequence does not support an
alternate language sequence. For
example, TTS may be selected for a language in which the TTS engine may be
unable to read the selected
language's TTS back. A validation error may thus be generated reflecting that
TTS cannot be used in that
language. In Figure 4a, an example of a multi-language sequence is provided.
Languages which may be
supported include US English (en-US) 401, Canadian French (fr-CA) 402, and US
Spanish (es-US) 403,
to name a few non-limiting examples. The audio sequence presented comprises a
prompt 404, such as
"Prompt.Hello" 405, followed by an item for TTS 406, such as "The time is"
407. A third item for data
408 is also presented to provide the current time, such as "Flow.currentTime"
409.
[0044] In Figure 4b, a language, such as es-US 403 may be designated for the
main sequence, with edits
to items being made. In this example, the item for TTS 406 may be edited to
"es el momento" 407 and
the sequence reordered with the item for TTS moved into position 3 and the
data item 408 moved into
position 2. Alternate sequences may be enabled for the main language, such as
fr-CA 402, as illustrated in
Figure 4c. In an embodiment, an indicator may confirm with the user that they
want to enable alternate
sequences for French (Canada) 410.
9
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
[0045] Each language may have different pieces of information associated with
it, as generally
exemplified in Figure 4d. For example, information such as "Supports runtime
data playback" 411,
"Supports speech recognition" 412, and "Supports text to speech" 413, may be
included to allow for more
information about what the system supports. In this non-limiting example, a
"yes" after each piece of
information indicates that these are supported in the desired language. Thus,
indications may be made as
to whether that language sequence supports certain features or not.
[0046] In another embodiment, the main audio sequence may not be designated to
play at run time,
whether by error or intentionally. In this scenario, as generally indicated in
Figure 4e, an indicator 414
may let the user know that this sequence will not play. As a result, the
system may revert to one of the
alternate sequences.
[0047] Figures 5a-5c are general diagrams of different options available for
audio sequence editing. In
item 3, 501, of the dialog exemplified in Figure 5a, for example, data for
playback may be chosen. In an
embodiment, if the current time is indicated (e.g., "Flow.currentTime") in an
item, options may include to
present time as a "date", "date and time", "month", etc. The options may be
presented in a drop down
menu 503, for example, or by another means such as a separate window.
[0048] In an embodiment, such as illustrated generally in Figure 5b, if an
integer is indicated in the data
item 504 (e.g., "Flow.decimal" 505), options may be presented 506 which
include for the synthesized
speech to "speak each digit", provide the "entire value", provide "as
percentage", etc.
[0049] In embodiments where errors arise, these may be indicated to a user,
such as generally presented
in Figure 6. In an embodiment, the indexed item may be highlighted and include
a tool tip indicating that
an error has occurred. In this example, item 1, 601, has been highlighted 602
to indicate an error. Within
the item, the message "Select prompt" is provided 603 to the user.
[0050] Application of the embodiments described herein is not limited to
calls. Communications in
general may be applied, such as for text based interactions like web chat, to
name a non-limiting example.
In the case of a web chat, runtime might utilize the TTS component of a prompt
resource instead of trying
to pick up audio. As such, TTS of "Hello" on a web chat would be the text
'Hello'.
CA 03005710 2018-05-17
WO 2017/065770 PCT/US2015/055686
[0051] While the invention has been illustrated and described in detail in the
drawings and foregoing
description, the same is to be considered as illustrative and not restrictive
in character, it being understood
that only the preferred embodiment has been shown and described and that all
equivalents, changes, and
modifications that come within the spirit of the invention as described herein
and/or by the following
claims are desired to be protected.
[0052] Hence, the proper scope of the present invention should be determined
only by the broadest
interpretation of the appended claims so as to encompass all such
modifications as well as all
relationships equivalent to those illustrated in the drawings and described in
the specification.
11