Note: Descriptions are shown in the official language in which they were submitted.
SYSTEMS AND METHODS FOR COMPUTING DATA PRIVACY-
UTILITY TRADEOFF
TECHNICAL FIELD
[001] The embodiments herein generally relate to information security,
and more particularly to systems and methods for assessing tradeoff between
privacy and utility of data.
BACKGROUND
[002] Privacy is generally a state of being free from public attention or a
state in which one is not observed or disturbed by other people. When
sensitive
data from distributed sources are linked, privacy threats have to be
considered. In
this age of globalization, organizations may need to publish micro-data with
business associates in order to remain competitive. This puts personal privacy
at
risk. Again, today dependency of people on smartphones and tablets is huge.
These devices contain a lot of personal information due to the huge number of
operations that they can perform. People access their bank accounts, make
purchases, and pay bills making such devices a potential target for cyber
criminals. Behavioral aspects also add to privacy risks. People aren't always
aware of who is tracking them and how the tracked information will be used.
Preventing identity theft is therefore one of the top priorities for most
sectors
including health, finance, government, manufacturing, banking, retail
business,
insurance, outsourcing.
[003] To surmount privacy risk, traditionally, attributes which clearly
identify individuals, such as name, social security number, driving license
number, and the like are generally removed or suppressed by random values. For
example, consider the following tables which are part of a medical database.
Table (a) is related to micro data and Table (b) is related to public data or
voting
registration data.
Table (a): Medical data (Micro data)
Gender Date of Birth Zipcode Disease
male 21/7/79 52000 Flu
1
CA 3015447 2018-08-29
female 10/1/81 43000 Hepatitis
female 1/10/44 32000 Bronchitis
male 21/2/84 27000 Sprained Ankle
female 19/4/72 41000 Dyspepsia
Table (b): Voting registration data (public)
Name Gender Date of Birth Zipcode
Andre male 21/7/79 52000
Beth female 10/1/81 43000
Carol female 1/10/44 32000
Dan male 21/2/84 27000
Ellen female 19/4/72 41000
The attribute Disease of Table (a) is a sensitive attribute. An attribute is
called
sensitive, if the individual is not willing to disclose the attribute or an
adversary
must not be allowed to discover the value of that attribute. The collection of
attributes {Gender, Date of Birth and Zipcode} is called Quasi Identifier (QE)
attributes; by linking the QI attributes of these two tables an adversary can
identify attribute Name from the Voting registration data. The sensitive
attributes
are not sensitive by themselves, but certain values or their combinations may
be
linked to external knowledge to reveal indirect sensitive information of an
individual. Quasi-identifiers can thus, when combined, become personally
identifying information. Quasi-identifiers have been the basis of several
attacks
on released data. It is therefore critical to be able to recognize quasi-
identifiers
and to apply to them appropriate protective measures to mitigate the identity
disclosure risk.
[004] If a natural join is applied to Table (c) having suppressed medical
data and Table (b) above, it may be easy to re-identify individuals with the
help of
quasi-identifiers as explained herein below.
Table (c): Suppressed medical data (micro data)
Gender Date of Birth Zipcode Disease
male 52* Flu
2
CA 3015447 2018-08-29
female 43* Hepatitis
female 32* Bronchitis
male 27* Sprained Ankle
female 41* Dyspepsia
Table (d): Join of Suppressed Table (c) and Table (b): SELECT Name, Gender,
Date of Birth, Zipcode, Disease FROM Table (c) NATURAL JOIN Table (b)
Identifier Quasi-identifiers Sensitive
Name Gender Date of Birth Zipcode Disease
Andre male 21/7/79 52000 Flu
Beth female 10/1/81 43000 Hepatitis
Carol female 1/10/44 32000 Bronchitis
Dan male 21/2/84 27000 Sprained
Ankle
Ellen female 19/4/72 41000 Dyspepsia
[005] Privacy of data plays a significant role in data trading. There are
several data publishing techniques that tend to perform data transformation to
maintain privacy. It is however pertinent to note that generality and
suppression of
certain components of data can affect utility as well as value of data that
can be
derived by a consumer. Quantifying the tradeoff between privacy and utility is
a
challenge that needs to be addressed in order for data sellers and data buyers
to
make an informed decision.
SUMMARY
[006] Embodiments of the present disclosure present technological
improvements as solutions to one or more of the above-mentioned technical
problems recognized by the inventors in conventional systems.
[007] In an aspect, there is provided a method comprising: receiving, by
a data connector, data from one or more data sources for making the data
consumable by one or more data buyers; analyzing, by an inflow data analyzer,
the received data to extract and process metadata of the received data;
identifying,
3
CA 3015447 2018-08-29
by the inflow data analyzer, a search space comprising at least one sensitive
attribute from the processed metadata based on a pre-defined knowledge base
associated with the data; generating, by an adversary model generator, an
adversary model by partitioning the search space into sets of buckets, each
set
corresponding to the at least one sensitive attribute having a privacy data
associated thereof; computing, by the adversary model generator, bucket count
for
each of the sets of buckets and creating bucket combinations of the buckets
from
the sets of buckets; replacing, by the adversary model generator, the privacy
data
associated with each of the at least one sensitive attribute with a masking
bucket
from the buckets; computing, by the adversary model generator, an entity count
for each of the bucket combinations based on the masking bucket assigned to
the
privacy data; computing, by the adversary model generator, an anonymity index
based on the computed entity count and a pre-defined privacy threshold; and
sanitizing, by a data masking module, the privacy data based on the computed
anonymity index to generate output data.
[008] In another aspect, there is provided a system comprising: one or
more processors; and one or more internal data storage devices operatively
coupled to the one or more processors for storing instructions configured for
execution by the one or more processors, the instructions being comprised in:
a
data connector configured to: receive data from one or more data sources for
making the data consumable by one or more data buyers; an inflow data analyzer
configured to: analyze the received data to extract and process metadata of
the
received data; and identify a search space comprising at least one sensitive
attribute from the processed metadata based on a pre-defined knowledge base
associated with the data; an adversary model generator configured to: generate
an
adversary model by partitioning the search space into sets of buckets, each
set
corresponding to the at least one sensitive attribute having a privacy data
associated thereof; compute bucket count for each of the sets of buckets and
creating bucket combinations of the buckets from the sets of buckets; replace
the
privacy data associated with each of the at least one sensitive attribute with
a
masking bucket from the buckets; compute an entity count for each of the
bucket
combinations based on the masking bucket assigned to the privacy data; compute
4
CA 3015447 2018-08-29
an anonymity index based on the computed entity count and a pre-defined
privacy
threshold; and continually learn and update the adversary model based on the
received data; a data masking module configured to: sanitize the privacy data
based on the computed anonymity index to generate output data; a decision
helper
module configured to: provide recommendations to data sellers based on the
received data; an outflow data analyzer configured to: evaluate the output
data to
match requirements of the one or more data buyers; a data release management
module configured to: determine a release plan based on the recommendations by
the decision helper module; a report and alert management module configured
to:
generate evaluation reports and alerts based on the output data; and an event
logging module configured to: log events associated with the output data.
[009] In an embodiment, the system of the present disclosure may further
comprise a data privacy-utility tradeoff calculator configured to: compute a
utility
index based on mid-point of the balanced buckets and the privacy data; and
compute attribute variations based on the number of variations between the
buckets and the balanced buckets.
[010] In yet another aspect, there is provided a computer program
product comprising a non-transitory computer readable medium having a
computer readable program embodied therein, wherein the computer readable
program, when executed on a computing device, causes the computing device to:
receive data from one or more data sources for making the data consumable by
one or more data buyers; analyze the received data to extract and process
metadata
of the received data; identify a search space comprising at least one
sensitive
attribute from the processed metadata based on a pre-defined knowledge base
associated with the data; generate an adversary model by partitioning the
search
space into sets of buckets, each set corresponding to the at least one
sensitive
attribute having a privacy data associated thereof; compute bucket count for
each
of the sets of buckets and creating bucket combinations of the buckets from
the
sets of buckets; replace the privacy data associated with each of the at least
one
sensitive attribute with a masking bucket from the buckets; compute an entity
count for each of the bucket combinations based on the masking bucket assigned
to the privacy data; compute an anonymity index based on the computed entity
5
CA 3015447 2018-08-29
count and a pre-defined privacy threshold; and sanitize the privacy data based
on
the computed anonymity index to generate output data.
[011] In an embodiment of the present disclosure, the at least one
sensitive attribute comprises one or more of binary, categorical, numerical
and
descriptive texts.
[012] In an embodiment of the present disclosure, the adversary model
generator is further configured to generate the sets of buckets based on one
of (a)
pre-defined ranges of values or (b) pre-defined upper and lower bounds, for
each
of the at least one sensitive attribute based on the pre-defined knowledge
base.
[013] In an embodiment of the present disclosure, the range of values and
the upper and lower bounds are computed by the inflow data analyzer based on
the at least one sensitive attribute.
[014] In an embodiment of the present disclosure, the data masking
module is further configured to sanitize the privacy data by one of (i)
hierarchy
masking techniques, (ii) bucket masking techniques, (iii) clustering technique
or
(iv) shuffling technique.
[015] In an embodiment of the present disclosure, the shuffling technique
is performed to obtain balanced buckets, wherein each bucket combination has a
balanced entity count.
BRIEF DESCRIPTION OF THE DRAWINGS
[016] The embodiments herein will be better understood from the
following detailed description with reference to the drawings, in which:
[017] FIG.1 illustrates an exemplary block diagram of a system for
computing data privacy-utility tradeoff, in accordance with an embodiment of
the
present disclosure;
[018] FIG.2 is an exemplary representation of functional modules
comprising the system of FIG.1;
[019] FIG.3A and FIG.3B represent an exemplary flow diagram
illustrating a computer implemented method for computing the data privacy-
utility
tradeoff, in accordance with an embodiment of the present disclosure;
6
CA 3015447 2018-08-29
[020] FIG.4 is a graphical illustration of normalized anonymity index
versus privacy threshold for an exemplary set of data, in accordance with the
present disclosure;
[021] FIG.5 is a schematic representation of an exemplary value
generalization hierarchy for an attribute "work class";
[022] FIG.6 is a graphical illustration of normalized attribute variation
versus privacy threshold for an exemplary set of data, in accordance with the
present disclosure;
[023] FIG.7 is a graphical illustration of the Normalized Anonymity
Index and the Normalized Attribute Variation versus privacy threshold for an
exemplary set of data, in accordance with the present disclosure;
[024] FIG.8 is a graphical illustration of forward shifting attribute
variation graph for an exemplary set of data with the help of curve fitting,
in
accordance with the present disclosure; and
[025] FIG.9 is a graphical illustration of backward shifting attribute
variation graph for an exemplary set of data with the help of curve fitting,
in
accordance with the present disclosure.
[026] It should be appreciated by those skilled in the art that any block
diagram herein represent conceptual views of illustrative systems embodying
the
principles of the present subject matter. Similarly, it will be appreciated
that any
flow charts, flow diagrams, state transition diagrams, pseudo code, and the
like
represent various processes which may be substantially represented in computer
readable medium and so executed by a computing device or processor, whether or
not such computing device or processor is explicitly shown.
DETAILED DESCRIPTION
[027] The embodiments herein and the various features and
advantageous details thereof are explained more fully with reference to the
non-
limiting embodiments that are illustrated in the accompanying drawings and
detailed in the following description. The examples used herein are intended
merely to facilitate an understanding of ways in which the embodiments herein
7
CA 3015447 2018-08-29
may be practiced and to further enable those of skill in the art to practice
the
embodiments herein. Accordingly, the examples should not be construed as
limiting the scope of the embodiments herein.
[028] The words "comprising," "having," "containing," and "including,"
and other forms thereof, are intended to be equivalent in meaning and be open
ended in that an item or items following any one of these words is not meant
to be
an exhaustive listing of such item or items, or meant to be limited to only
the
listed item or items.
[029] It must also be noted that as used herein and in the appended
claims, the singular forms "a," "an," and "the" include plural references
unless the
context clearly dictates otherwise. Although any systems and methods similar
or
equivalent to those described herein can be used in the practice or testing of
embodiments of the present disclosure, the preferred, systems and methods are
now described.
[030] Some embodiments of this disclosure, illustrating all its features,
will now be discussed in detail. The disclosed embodiments are merely
exemplary
of the disclosure, which may be embodied in various forms. Before setting
forth
the detailed explanation, it is noted that all of the discussion below,
regardless of
the particular implementation being described, is exemplary in nature, rather
than
limiting.
[031] Exchange or trade of data, particularly in data hubs like data
marketplace is a challenge considering the expected tradeoff between data
privacy
and data utility. Systems and methods of the present disclosure address this
challenge and facilitate computing this tradeoff to establish need for data
transformation such that data buyers and data sellers make a meaningful trade.
[032] Referring now to the drawings, and more particularly to FIGS. 1
through 9, where similar reference characters denote corresponding features
consistently throughout the figures, there are shown preferred embodiments and
these embodiments are described in the context of the following exemplary
system and method.
[033] The expression "data source" in the context of the present
disclosure refers to at least one of (i) one or more entities or vendors who
want to
8
CA 3015447 2018-08-29
monetize data by listing products and solutions including data enrichments and
analytics solutions; (ii) one or more entities or vendors who respond to an
intent
of service through bids and offers; (iii) one or more entities or vendors who
push
data from a premise to a data vault through API (iv) an entity who is selling
personal data through one or more data brokers.
[034] The expression "output data" in the context of the present
disclosure refers to data provided to data buyers in the form received from
the
data source or data that may be selectively transformed based on an anonymity
index as explained hereinafter.
[035] The expression "data attacker" in the context of the present
disclosure refers to an entity having malicious intent.
[036] FIG.1 illustrates a block diagram of a system 100 for computing
data privacy-utility tradeoff and FIG.2 is an exemplary representation of
functional modules comprising the system 100, in accordance with an
embodiment of the present disclosure.
[037] In an embodiment, the system 100 includes one or more processors
102, communication interface device(s) or input/output (I/O) interface(s) 104,
and
memory 106 or one or more data storage devices comprising one or more modules
108 operatively coupled to the one or more processors 102. The one or more
processors are hardware processors that can be implemented as one or more
microprocessors, microcomputers, microcontrollers, digital signal processors,
central processing units, state machines, logic circuitries, and/or any
devices that
manipulate signals based on operational instructions. Among other
capabilities,
the processor(s) is configured to fetch and execute computer-readable
instructions
stored in the memory. In an embodiment, the system 100 can be implemented in
one or more computing systems, such as a laptop computer, a desktop computer,
a
notebook, a workstation, a mainframe computer, a server, a network server,
cloud,
hand-held device, wearable device and the like.
[038] The I/O interface device(s) 104 can include a variety of software
and hardware interfaces, for example, a web interface, a graphical user
interface,
JOT interface, and the like and can facilitate multiple communications within
a
wide variety of networks and protocol types, including wired networks, for
9
CA 3015447 2018-08-29
example, LAN, cable, etc., and wireless networks, such as WLAN, cellular, or
satellite. In an embodiment, the I/O interface device(s) 104 can include one
or
more ports for connecting a number of devices to one another or to another
server.
[039] The memory 106 may include any computer-readable medium
known in the art including, for example, volatile memory, such as static
random
access memory (SRAM) and dynamic random access memory (DRAM), and/or
non-volatile memory, such as read only memory (ROM), erasable programmable
ROM, flash memories, hard disks, optical disks, and magnetic tapes. In an
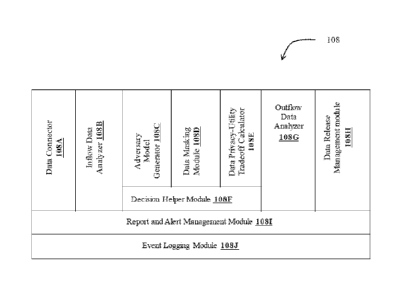
embodiment, various modules 108A through 108J (of FIG.2) of the system 100
can be stored in the memory 106 as illustrated.
[040] FIG.3A and FIG.3B represent an exemplary flow diagram
illustrating a computer implemented method 200 for computing the data privacy-
utility tradeoff, in accordance with an embodiment of the present disclosure.
The
steps of the computer implemented method 200 will now be explained with
reference to the components of the system 100 as depicted in FIG.1 and FIG.2.
In
an embodiment, at step 202, the system 100 is configured to receive via a data
connector 108A, data generated or captured from one or more data sources (Data
Source 1, Data Source 2,.... Data Source n) to make it consumable by one or
more
data buyers. In an embodiment, the data connector 108A can also be configured
to
receive a query and other parameters along with the data. For instance, the
query
may be in the form of a request for data pertaining to people in the age group
40 ¨
50 years and suffering from diabetes or people in a particular region having
heart
problems, and the like, wherein parameters of the query may include age,
gender,
place of residence, and the like. In accordance with the present disclosure,
the
received data is analyzed or processed to make it suitable for dissemination
to one
or more data buyers without losing its utility in the process of retaining
privacy
associated with the data. In an embodiment, the data connector 108A connects
to
the one or more data sources to receive generated or captured data in bulk
format
or streaming content format. Data in bulk format may be uploaded at pre-
determined intervals or randomly by data sellers. Data in streaming content
format
may be data provided in real time by connecting with the one or more data
sources
such as FitbitTM devices, accelerometer devices, temperature devices and
electrical
CA 3015447 2018-08-29
consumption devices.
[041] At step 204, an inflow data analyzer 108B is configured to analyze
the data received by the data connector 108A to extract and process metadata
of
the received data. In an embodiment, at step 206, the inflow data analyzer
108B
processes the metadata to identify a search space comprising at least one
sensitive
attribute based on a pre-defined knowledge base of the platform. In an
embodiment, the pre-defined knowledge base can be domain knowledge. In an
embodiment, the knowledge base can be based on compliance requirements of
prevailing laws / Acts such as HIPAA (Health Insurance Portability and
Accountability Act), and other publicly available data sets. In accordance
with the
present disclosure, the sensitive attributes may comprise one or more of
binary,
categorical, numerical and descriptive texts. For instance, sensitive
attributes can
include tax paid in the current financial year, heart rate, location
information, etc.,
personally identifying information of individuals such as name, address, SSN
(Social Security Number), bank account numbers, passport information,
healthcare related information, credit and debit card numbers, drivers license
and
state ID information, medical insurance information, student information, and
the
like. Data containing such sensitive attributes may lead to data privacy
breaches if
disseminated in its original form.
[042] At step 208, an adversary model generator 108C is configured to
generate an adversary model by partitioning the search space into sets of
buckets;
each set corresponding to a sensitive attribute having a privacy data
associated
thereof. For instance a bucket set may pertain to age and include buckets [0-
9],
[10-19], and the like. Another bucket set may pertain to diseases and include
[diabetes], [heart disease], [lung disease], and the like. Sensitive
attributes of data
can be associated with two types of disclosures, viz., identity disclosure and
value
disclosure. Identity disclosure means a data attacker is able to identify data
subject
pertaining to that data. In addition, the data attacker may also learn data
subject's
PII, and can misuse it to commit fraud, to impersonate, etc. Value disclosure
is the
ability of a data attacker to be able to estimate the value of a sensitive
attribute
using the data available. Thus it is imperative that sensitive attributes that
may
lead to identity or value disclosure must be protected.
11
CA 3015447 2018-08-29
[043] In an embodiment, the adversary model generator 108C is
configured to identify information available in the public domain pertaining
to the
sensitive attributes from the one or more data sources. In an embodiment, the
adversary model generator 108C is configured to continually learn from one or
more of publicly available resources across the world including social media,
collaborative filtering, crowdsourcing, public health data sets such as
census,
hospital data, etc. and also from data provided by data sellers. In an
embodiment,
the adversary model generator 108C is configured to learn and provide a
suitable
default template to the one or more data sources to choose and edit from.
[044] In accordance with the present disclosure, the adversary model
generator 108C is configured to generate one or more adversary models by first
ascertaining the strength of an adversary that comprises knowledge of data and
its
operating strength. It is assumed that entities are points in a higher
dimension real
space Rd and there are n such entities 6' = ej, ez, . . . , en that are points
in d-
dimension. The received data thus comprises n rows and d columns which means
each e, is a d-dimensional point. The adversary tries to single out one or
more
entities by using his/her knowledge. The adversary may have some interest for
attacking a database. For instance, the adversary may be a medical
practitioner of
diabetes and may want to send some spam to people for advertisement purposes.
Say, in an exemplary case, the adversary may want to send emails on say,
diabetes
to a group of people who are above 40 years of age. Furthermore, the adversary
may want to categorize people like mildly prone if age group between [40, 50],
medium prone if age group between [50, 60] and say highly prone if age group
above 60. In a majority of cases, the adversary is not interested in an exact
age
group or exact gender. The adversary is mainly interested in a range of given
attributes. This helps the adversary to narrow down the search space (of
people
above 40 years of age) by finding elements that fall in the same range in the
database. More precisely, the adversary will find groups of people of interest
and
then attack them. i.e. she will partition the space in buckets (or groups).
[045] Data transformation to prevent privacy breach is required only if
the adversary has knowledge of data under consideration. In the exemplary
case,
the strength of the adversary depends on parameters such as how many emails
the
12
CA 3015447 2018-08-29
adversary can send together, how many times the adversary can send emails and
how much background knowledge the adversary has. If the number of emails the
adversary can send together is k and number of times the adversary can send
emails is equivalent to number of partitions or buckets of the database, the
adversary will form as many partitions in the database as many messages she
can
send.
[046] A bucketing technique, in accordance with the present disclosure is
based on pre-defined upper and lower bounds for each of the sensitive
attributes
based on the pre-defined knowledge base. Alternatively, in an embodiment, the
privacy data associated with each of the sensitive attributes is scanned by
the
inflow data analyzer 108B to get a lower bound and upper bound. For numeric
attributes, buckets may be created after entering an interval. For example, in
case
of the attribute age, if lower bound is 4 and upper bound is 87 and entered
interval
is 40, then buckets for the attribute age may be [4,44] [45,85] [86,126].
[047] For categorical attributes such as attribute marital status, buckets
may be [Married] [Unmarried] [Divorced] [Separated] [Widowed].
[048] Another bucketing technique based on pre-defined ranges of
values, in accordance with the present disclosure is explained using an
exemplary
case wherein say, the adversary is interested in people who fall in the age
group
range 0 to 60. Let riki denote the buckets along each attribute at column i,
where
k, denotes the number of buckets in column.
Each riki is associated with an
integer number j such that index, (riki) = j where 1<j < k,. index, () is the
bucket
number for the entity in ith-dimension. For example, let there be a 3-
dimensional
table of attributes age, gender and zipcode. In the case of the attribute age,
the
adversary may have knowledge that a particular person belongs to the age group
of [0 ¨ 10] or [10 ¨20] or [20 ¨ 30] or [30 ¨40] or [40 ¨ 50] or [50 ¨ 60].
So, k,
for the attribute age is 6 and it can be represented as rlage, r2 age, . . . ,
r6 age. In case
of the attribute gender, the adversary may have knowledge that the person is
male
or female. So, k, for the attribute gender is 2 and it can be represented as r
I gender,
r2 gender (assuming male = 1 and female = 2). In case of the attribute zipcode
where
the range is from 1 to 105 approximately, the adversary may have knowledge up
to
1000 buckets. For simplicity, 105 is divided by 1000 and hence the buckets are
[0
13
CA 3015447 2018-08-29
¨ 10001, [1000 ¨ 2000], . . . , [99900¨ 100000]. So, k, for the attribute
zipcode is
100 and it can be represented as T' zipcode, r2 zipcode, = = = , ri zipcode=
Let age be the 1St
dimension, gender be the 2nd dimension, and zipcode be the 3' dimension for
each
entity. So, instead of using age, gender, zipcode in the suffix of rki, the
dimensions can be used as riki for i = 1, 2, 3. In an embodiment, the above
bucketing technique can be made more complicated by considering that the
adversarial knowledge is hierarchical or the adversary is interested in a
particular
value of the attributes.
[049] In another exemplary case, say the adversary is interested in
person(s) whose information may be as follows: the person's age is between 20
and 30, gender is female, and zipcode is in between 7000-8000 (assuming these
are all the zipcodes belong to New York city). Let all the n points be plotted
in a
d-dimensional space. Then the adversary would search for all persons
satisfying
the d-dimensional rectangle made by the above range of information. If the
adversary finds no element in that rectangle then he/she has not found
anything. If
the adversary finds only one person there then he/she has got the person.
Again, if
the adversary finds more than one person there then all those persons are
equally
likely and the adversary will be confused and have difficulty in identifying a
particular person. In the above exemplary case, the index (riki ) are 3, 2, 8
for
age, gender and zipcode respectively. It implies that the person falls in the
3rd
bucket in 1' dimension, 2nd bucket in 2nd dimension, 81h bucket in 3rd
dimension.
So, a person's identity can be represented in the form of an index format
which is
a single dimension representation of the multidimensional search space. The
index
format of a person can be discovered using the same search space in 0(d) time
(where time is proportional to number of dimensions), assuming k, is constant
for
a given database. In accordance with the present disclosure, the total number
of
distinct buckets are B = 171ki. Here each bucket is a d-dimensional rectangle,
say DRõ for 1 < i< B. For an array A of size B, each entry of the array
contains an
integerp, and p, denotes the number of entities in each bucket DR,.
[050] In accordance with the present disclosure, if the index format of an
entity is known, then following formula will put the entity in the right place
of the
array position, say array index p given by ¨
14
CA 3015447 2018-08-29
p = (indexi¨ 1) fr2 ki + (index2¨ 1)1r3k1 + = == ..(indexi ¨
1)1ri+1k1 + (indexd_i + (indexd)
(1)
[051] In accordance with the present disclosure, array A is initialized to
zero. Array A maintains count of all buckets DR, where the number of entities
correspond to ith location of each bucket DR In the present example, DR,,
contains
180 bucket combinations defined in Table (f) herein below. The index format
for
entity is computed. The array index p for the entity is calculated using
equation 1
herein above and for the array index p, update A [p] by 1 as Alp] +=I.
[052] In accordance with the present disclosure, in the technique for
computing the count of entities in each bucket DR, the number of entities can
be
found just using one pass through the database and one pass in the array A.
Also,
the number of elements p, computed in each bucket DR, is correct, which is
validated by the fact that the formula above shows that entities in different
index
format will fall in different buckets.
[053] In an embodiment, at step 210, the adversary model generator
108C is configured to compute bucket count for each of the sets of buckets and
further create bucket combinations of the buckets from the sets of buckets.
For
instance, let there be a 5-dimensional table of attributes age, gender,
marital status,
salary and zipcode and assuming privacy data is available for 300 people as
shown in Table (e) herein below.
Table (e):
Attribute Buckets Count Of Bucket
age [4,44] [45,85] [86,126] 3
gender [male] [female] 2
[Married] [Unmarried]
Marital status [Separated] [Divorced] 5
[Widowed]
[5000,105000]
salary [105001,205001] 3
[205002,305002]
[7000,507000]
zipcode 2
[507001,1007001]
Bucket combinations may be created in accordance with the present disclosure
as
shown (partially) in Table (f) herein below.
Table (1):
CA 3015447 2018-08-29
Attributes Combination Of Buckets
age-gender-marital_status-salary- [4,441-[maleHMarried] - [5000,105000] -
zipcode [7000,507000]
age-gender-marital_status-salary- [4,44]- [male]-[Married]- [5000,1050001-
zipcode [507001,1007001]
age-gender-marital status-salary- [4,441- [male]-
[105001,205001]-[7000,507000]
[054] In an embodiment, at step 212, the adversary model generator
108C is configured to replace the privacy data associated with each of the at
least
one sensitive attribute with a masking bucket from the buckets. Accordingly,
the
privacy data associated with each of the at least one sensitive attribute is
replaced
with buckets that have been created in Table (e) that now serve as masking
buckets. For instance, assume privacy data available is as shown (partially)
in
Table (g) herein below.
Table (g):
age gender marital status salary zipcode
55 female Separated 27000 80003
67 female Married 37000 40001
51 male Widowed 56000 40009
67 male Married 80000 54003
The privacy data of Table (g) may be replaced by masking buckets as shown
(partially) in Table (h) herein below.
Table (h):
age gender marital status salary zipcode
[45-85] [female] [Separated] [5000,105000] [7000,507000]
[45-85] [female] [Married] [5000,105000] [7000,507000]
[45-85] [male] [Widowed] [5000,105000] [7000,507000]
[45-85] [male] [Married] [5000,105000] [7000,507000]
16
CA 3015447 2018-08-29
[055] In an embodiment, at step 214, the adversary model generator
108C is configured to compute an entity count for each of the bucket
combinations of Table (f) based on the masking bucket assigned to the privacy
data in Table (h) as shown in Table (i) herein below.
Table (i):
Attributes Combination Of Buckets .. Count Of Entity
age-gender- [4,44]-[male]Married1- 6
marital status-salary- [5000,105000]-
zipeode [7000,507000]
age-gender- [4,44]-[male]-[Married]- .. 8
marital status-salary- [5000,105000]-
zipcode [507001,1007001]
age-gender- [4,441-[maleHMarried]- .. 0
marital_status-salary- [105001,205001]-
zipcode [7000,507000]
age-gender- [4,441-[male] -[Married] 5
marital status-salary- [105001,205001]-
zipcode [507001,1007001]
If comparison is same for more than one row in Table (f), the entity count is
incremented by one. For instance, Table (i) shows that there are 6 people
whose
age lies in the range 4-44, have gender as male, marital status is married,
salary
lies in the range 5000-105000, and zipcode falls in the range 7000-507000.
[056] Privacy of a database follows the principles listed herein below ¨
= If the population surrounding an entity increases, the privacy for
that particular entity increases.
= If the power of adversary increases, then privacy decreases.
= If the adversary knowledge of the dimensions increases, the
privacy decreases.
17
CA 3015447 2018-08-29
= If total population increases then the overall privacy increases.
In an embodiment, privacy is based on K-anonymity or blending in a crowd.
[057] In an embodiment, at step 216, the adversary model generator
108C is configured to measure an anonymity index of each entity associated
with
the received data. The anonymity index may be computed based on the computed
entity count (Table (i)) and a pre-defined privacy threshold. The adversary
has the
knowledge only up to the buckets. The elements that lie inside the same bucket
are equally likely to the adversary. Higher the anonymity-index, higher is the
associated privacy. Hence, in accordance with the present disclosure, the
anonymity-index is the privacy measure of a database.
[058] Anonymity index shows how much the received data is safe with
respect to an adversary. To calculate the anonymity index, firstly a pre-
defined
privacy threshold is set, which in the example case presented herein, is the
size of
the crowd to blend in. Privacy laws may be adhered to pre-define the privacy
threshold. For instance, Health Insurance Portability and Accountability Act
(HIPAA) privacy rule says that threshold should be 20,000 and for Family
Educational Rights and Privacy Act (FERPA), threshold is 5.
[059] In accordance with the present disclosure,
if entity count < privacy threshold,
entity count
anonymity index =
privacy threshold
else anonymity index = I.
Accordingly, for a case wherein the privacy threshold = 10 and the entity
count
from Table (i) = 5, the entity count < the pre-defined privacy threshold, the
index= ¨5 = 0.5.
25 For a case wherein the privacy threshold = 10 and the entity count from
Table (i)
= 15, the entity count >= the pre-defined privacy threshold, the
anonymity index = ¨15 = 1.5 1 (rounded
off to 1.0, as it cannot be higher
io
than 1.0).
Accordingly, for a privacy threshold = 10, the anonymity index may be computed
30 for privacy data of the 300 people under consideration as shown
(partially) in
Table (j) herein below.
18
CA 3015447 2018-08-29
Table ):
Attributes Combination Of Count Of Anonymity
Buckets Entity Index
age-gender- [4,44]-[male]- 6 0.6
marital_status- [Married]-
sal ary-zipcode [5000,105000]-
[7000,507000]
age-gender- [4,44]-[male]- 8 0.8
marital status- [Married]-
sal ary-z i pcode [5000,105000]-
[507001,1007001]
age-gender- [4,44]-[mal el- 0
marital_status- [Married]-
salary-zipcode [105001,205001]-
[7000,507000]
age-gender- [4,44]-[male]- 5 0.5
marital status- [Married]-
salary-zipcode [105001,2050011-
[507001,1007001]
age-gender- [4,44]-[male]- 0 0
marital_status- [Married]-
salary-zipcode [205002,3050021-
[7000,507000]
age-gender- [4,441-[male]- 0 0
marital_status- [Married]-
salary-zipcode [205002,305002]-
[507001,1007001]
age-gender- [4,44]-[male]- 6 0.6
marital_status- [Unmarried]-
salary-zipcode [5000,105000]-
[7000,507000]
age-gender- [4,44]-[male]- 14 1
19
CA 3015447 2018-08-29
marital_status- [Unmarried]-
salary-zipcode [5000,105000]-
[507001,1007001]
[060] In accordance with the present disclosure, if anonymity index < 1,
then the entities are moved to another combination of buckets. The data may be
normalized to facilitate drawing of an anonymity graph between normalized
anonymity index and privacy threshold since normalization of data may be
necessary to convert anonymity index values to a common scale and facilitate
comparing the shape or position of two or more curves. Accordingly, further
comparison of anonymity index with attribute variations may be performed as
explained herein under.
E(entity count * anonymity index)
Normalized anonymity index [0,1] = ________________________________
total no. of people
For a scenario wherein total no. of people = 20, privacy threshold = 10 and
entity
count for two bucket combinations = 5 and 15, the anonymity index for these
entity counts are 0.5 and 1 respectively.
(5 * 0.5) + (15 * 1) 2.5 + 15
Normalized anonymity index [0,1] = ____________________
= 20
17.5
= ¨20 = 0.875
15 FIG.4 is a graphical illustration of normalized anonymity index versus
privacy
threshold for an exemplary set of privacy data for 300 people, in accordance
with
the present disclosure. It may be observed from the anonymity graph of FIG .4
that
as long as privacy threshold increases, anonymity index keeps on decreasing.
It
may be further noted that if anonymity index is higher privacy will be higher.
The
20 two columns with horizontal hatch patterns in FIG. 4 denote values of
normalized
anonymity index which has crossed certain limits, thereby suggesting a need
for
data sanitization for the particular exemplary set of privacy data.
[061] In an embodiment, at step 218, a data masking module 108D is
configured to sanitize the privacy data based on the computed anonymity index
to
generate output data. In an embodiment, data masking or data sanitizing may be
CA 3015447 2018-08-29
performed by one or more (i) hierarchy masking techniques, (ii) bucket masking
techniques, (iii) clustering technique or (iv) shuffling technique. In an
embodiment, the shuffling technique is performed to obtain balanced buckets,
wherein each bucket combination has a balanced entity count. In accordance
with
the present disclosure, the data masking module 108D sanitizes data such that
utility of the masked data is ensured for a meaningful trade. Utility is a
measure of
distortion of data. Randomization techniques may change data too much and may
also generate data which is close to original.
[062] In an embodiment, the hierarchy / bucket masking technique
enables user to control amount of data change required while preserving
privacy.
FIG.5 is a schematic representation of an exemplary value generalization
hierarchy for an attribute "work class". In the exemplary embodiment of a work
class hierarchy, if root node at level 0 refers to work class, nodes at level
1 refer to
work classes viz., self-employed, government, private and unemployed and nodes
at level 2 refer to further sub-work classes such as Incorporated or not
Incorporated for self-employed class, Federal, State or Local for government
class
and without pay or never worked classes for unemployed class. In an
embodiment, input to the hierarchy / bucket masking technique can include
generalized hierarchy as explained in the work class example herein above, pre-
defined masking levels for each class and merging or segregation of neighbor
buckets (neighbor flag). The technique is configured to identify whether the
count
of people satisfy the privacy threshold or not after merging siblings of leaf
node at
level 2. If count of people does not satisfy the privacy threshold, the leaf
nodes at
level 2 may be merged with nodes at level 1 and the merging may continue until
the requirement is satisfied at level 0.
[063] In accordance with the present disclosure, utility index is a
negative of the sum of distortion added to each individual data point. In an
embodiment, the data masking module 108D is further configured to minimize the
maximum distortion for a data point using a clustering based sanitization
technique. In accordance with the present disclosure, when data is
transformed,
the transformed data must preserve privacy requirements based on the pre-
defined
privacy threshold T. For a given privacy threshold t and database DB, data has
to
21
CA 3015447 2018-08-29
be transformed from DB to DBT such that either each bucket contains a fraction
of
data or the bucket is empty. In accordance with the present disclosure, while
transferring DB to DBF another constraint to be satisfied is that data
distortion
must be as minimum as possible with respect to a pre-defined metric. In an
embodiment, if the entities in the database are considered as points in real
space
Rd, then Euclidean metric is to be considered.
[064] In an embodiment, the clustering based sanitization technique to
minimize the maximum distortion for a data point provides a constant factor
approximation with respect to a very strong adversary. Using a 2-factor
approximation algorithm for r-gathering as known in the art, clusters C,
(CI,C2, . .
. ,Ck) are identified such that each cluster C, contains at least r database
points and
the radius of the cluster is minimized. It is similar to data sanitization
concept,
where each balanced bucket contains a value greater than or equal to the
privacy
threshold. Subsequently, buckets are identified for each cluster C,. Let DR!,
DR, .
.. ,DRI are the buckets inside C, such that all the data points that belong to
C, are
pushed in the bucket DR that contains the center c of C,.
[065] In an embodiment, the clustering based sanitization technique may
be K- Means clustering to replace actual values with centroids. Euclidean
distance
is used to calculate centroids and it uses Manhattan distance to evaluate
clusters.
Accordingly, K-medoid clustering algorithm for heterogeneous datasets may be
used. For categorical datasets, this algorithm uses co-occurrence based
approach.
For numerical datasets, K-medoid uses Manhattan distance. For binary datasets,
K-medoid uses hamming distance (011).
[066] In an embodiment, the data masking module 108D is further
configured to minimize the maximum distortion for a data point by providing a
heuristic technique to produce k-anonymity and comparing it with a naive
technique. In an embodiment the naive technique involves replacing all
attributes
of first k-entities by a first entity. Then the next k entities are replaced
by (k-Fl)th
entity and so on. In an embodiment, the heuristic technique involves inputting
an
array A with entity count p, and outputting an array AT with entity count
either (p,
¨ 0) or (p, k) for bucket DR,.
[067] In an embodiment, the shuffling based sanitization technique
22
CA 3015447 2018-08-29
includes moving entity count to nearest position in forward or backward
direction.
Forward shifting example: Let Array A with entity count A(i) for bucket DR,.
A={1, 2, 3, 4, 5, 7, 8}
Let the privacy threshold = 10, elements are moved from first position in
forward
direction until it becomes greater than or equal to the privacy threshold. If
the
entity count is balanced, then the shifting of elements resumes from next
position.
(2
A=[1, 2?\ 4, 5, 7, 8]
N=[0, 3, 3 4 5, 7, 8]
A'=[0, 0, 6,4, 58]
A'=[0, 0, 0, 10, 5, 7]
A'=[0, 0, 0, 10, 0, 12, 8]
A'=[0, 0, 0, 10, 0, 0, 201 L________,>Balanced Entity Count
The forward shifting is continued until all balanced values are obtained.
Backward shifting example: Elements are moved from last position until it
becomes greater than or equal to the privacy threshold. Similar to the forward
shifting, the backward shifting is continued until all balanced values are
obtained.
A=[1, 2, 3, 4, 5, 7, 8 ]
A'=[1, 2, 3, 4 5, 15, 0]
A'=[1, 2,3 9, 0, 15, ]
A'=[1, 2 12, 0, 0, 15, 0 ]
A'=[114, 0, 0, 0, 15, 0]
A'=[1\5;0, 0, 0, 0, 15, 0 1 r> Balanced Entity Count
Table (k) herein below depicts (partially) balanced entity count for the
privacy
data of 300 people, if the privacy threshold = 10.
Table (k):
Attributes Combination Of Forward Backward
Buckets Shifted Entity Shifted Entity
Count Count
age-gender- [4,44]-[male]- 0 14
marital status- [Marriedl-
salary-zipcode [5000,105000]-
[7000,507000]
23
CA 3015447 2018-08-29
age-gender- [4,44]-[male]- 14 0
marital_status- [Married]-
salary-zipcode [5000,105000]-
[507001,1007001]
age-gender- [4,44]-[male]- 0 0
marital_status- [Married]-
salary-zipcode [105001,205001]-
[7000,507000]
age-gender- [4,44]-[male]- 0 11
marital_status- [Married]-
salary-zipcode [105001,205001]-
[507001,1007001]
age-gender- [4,44]-[male]- 0 0
marital_status- [Married]-
salary-zipcode [205002,305002]-
[7000,507000]
age-gender- [4,44]-[male]- 0 0
marital_status- [Married]-
salary-zipcode [205002,305002]-
[507001,1007001]
age-gender- [4,44]-[male]- 11 0
marital_status- [Unmarried]-
salary-zipcode 15000,1050001-
[7000,507000]
age-gender- [4,44]-[male]- 14 22
marital_status- [Unmarried]-
salary-zipcode [5000,105000]-
[507001,1007001]
For minimum shuffling between elements, the order of bucket values may be
sorted or changed based on attributes. For instance, it may be sorted as Order
by
24
CA 3015447 2018-08-29
attribute age, Order by attribute gender, Order by attribute marital status,
Order by
attribute salary, Order by attribute zip code. Order by attribute age may be
as
shown below in Table (1)
Table (1):
Attributes Combination Of Buckets
age-gender-marital_status-salary- [4,44]-[male]-[married]-
zipcode [5000,105000]-[7000,507000]
age-gender-marital_status-salary- [45,85]-[male]-[married]-
zipcode [5000,105000]-[7000,5070001
age-gender-marital_status-salary- [86,126]-[male]-[married]-
zipcode [5000,105000]-[7000,507000]
age-gender-marital_status-salary- [4,44]-[male]-[married]-[ 1 05001-
zipcode 205001]-[7000,507000]
age-gender-marital_status-salary- [45,85]-[male]-[married]-[105001-
zipcode 205001]-[7000,507000]
age-gender-marital_status-salary- [86,126]-[maleMmarriedH105001-
zipeode 205001]-[7000,507000]
Similar sorting of the order of bucket values may be performed for attributes
gender, marital status, salary and zip code in the exemplary embodiment
provided.
[068] After changing the order of attributes, forward and backward
shifting is applied as explained above which may result in less stress on data
for
some particular attributes. Thus if curve fitting is performed for forward and
backward shifting of attribute variations, then R squared has a value near to
1.
where R squared is the coefficient of determination which is indicative of how
well a regression line approximates actual data points. If R squared is near
to 1,
then the curve fitting is considered as a best curve fitting.
[069] In an embodiment, the utility index provides how far values have
been moved from original position to balanced position. As an example, suppose
a
person belongs to New York and another person belongs to Washington. To get a
desired amount of privacy, if the person belonging to New York is moved to
Washington, the utility index is indicative of the distance between New York
and
Washington.
CA 3015447 2018-08-29
[070] In accordance with the present disclosure, at step 220, a data
privacy-utility tradeoff calculator 108E is configured to compute the utility
index
for numerical attributes:
Utility Index = Mid points of balanced bucket - Privacy data (Primary value of
original bucket)
For instance, suppose a bucket [6999, 507000] of attribute zipcode has been
moved from original position to bucket [507001,1007002] of balanced position.
Also, primary value of [6999,507000] is 50001 and mid-point of
[507001,1007002] is 757001((507001+1007002)/2).
Utility Index of zipcode = 757001 - 50001 = 707000
[071] In case of categorical attributes, Utility Index = 1. For instance, if
attribute marital status, [Married] is changed to [Unmarried], the Utility
Index = 1.
[072] Furthermore, to minimize the maximum distortion of values, the
utility index is normalized as given below.
Normalized Utility Loss [0,1]
Existing value of utility index - Min value of utility index
Max value of utility index - Min value of utility index
For instance, in case of numerical attributes, let existing value of the
utility index
for attribute zipcode = 707000 and its min and max value be 264254 and 722978
respectively.
707000- 264254
Normalized Utility Loss [0,1] = = 0.965168595
722978- 264254
For categorical attributes, Normalized Utility Loss [0,1] = 1.000000.
Table (m) herein below depicts the utility index (partially) for the privacy
data of
300 people, if the privacy threshold = 10.
Table (m):
7:1
7,"zs cu
a) (/'
c.) 0:1 c.)
7ci .E; -0 8
age [4,44] [4,44] 27 24 0 0
gender [male] [male] male male 0 0
marital_st [Married] [Married] Married Married 0 0
26
CA 3015447 2018-08-29
atus
salary [5000,1050 [5000,1050 80000 55000 0 0
00] 00]
zipcode [7000,5070 [507001,10 50001 757001 70700 0.98
00] 07001] 0
[073] In an embodiment, at step 222, the data privacy-utility tradeoff
calculator 108E is configured to compute attribute variations based on the
number
of variations between the buckets (original buckets) and the balanced buckets.
For instance, if values of one combination of attributes
age-gender-marital status-salary-zipcode
[3,44]-[male]-[MarriedM105001,205002H507001,1007002]
has been moved to
[3,441-[maleHUnmarriedH4999,1050001-16999,5070001
Total number of attribute moves = 3
Table (n) illustrates attribute variations for the privacy data (partially) of
300
people if the privacy threshold =10.
Table (n):
Attributes Original Buckets Balanced
Buckets Movement Of
Attributes
age-gender- [4,44]-[male]- [4,44]-[male]- 1
marital status- [Married]- [Married]-
salary-zipcode [5000,1050001- [5000,105000]-
[7000,507000] 1507001,10070011
age-gender- [4,44]-[malel- [4,44]-[male]- 0
marital_status- [Married]- [Married]-
salary-zipcode [5000,105000]- [5000,105000]-
[507001,1007001] [507001,1007001]
age-gender- [4,44]-[male]- [4,44]-[male]- 0
marital_status- [Married]- [Married]-
27
CA 3015447 2018-08-29
salary-zipcode [105001,2050011- [105001,205001]-
[7000,507000] [7000,507000]
age-gender- [4,44]-[male]- [4,44]-[male]- 3
marital_status- [Married]- [Unmarried]-
salary-zipcode [105001,2050011- 15000,1050001-
[507001,1007001] 17000,5070001
age-gender- [4,44]-[male]- [4,44]-[male]- 0
marital_status- [Married]- [Married]-
salary-zipcode [205002,3050021- [205002,305002]-
[7000,507000] [7000,507000]
[074] Furthermore, to bring all the variables into proportion with one
another, normalizing attribute movement as ¨
Normalized attribute movement [0,1]
'Existing attribute move ¨ Min. attribute move'
IMax. attribute move ¨ Min. attribute move'
Total no of people
For instance, if attribute movement for four combination of buckets are 1, 0,
0, 3
and total no. of people are 20, min. value of attribute move is 1 and max.
value of
attribute move is 3.
11 ¨ 11 13 ¨ 11
(13 _ ii) + 0 + 0 + (13_ ii) 1
Normalized attribute movement [0,1] = ______________ = T.0 20
= 0.05
FIG.6 is a graphical illustration of normalized attribute variation versus
privacy
threshold for an exemplary set of data for 300 people, in accordance with the
present disclosure. It may be observed from the attribute variation graph of
FIG.6
that as long as privacy threshold increases, attribute variation keeps on
increasing.
Accordingly, if the attribute movement is lower, then utility loss will be
minimum
since there will be less data massaging.
[075] In accordance with the present disclosure, a comparison, by the
data privacy-utility tradeoff calculator 108E, of the attribute variations and
the
28
CA 3015447 2018-08-29
anonymity index provides a data privacy-utility tradeoff. In accordance with
the
present disclosure, the data privacy-utility tradeoff facilitates a data buyer
to
decide the utility of the output data. For example, it could be generalization
details
for some specific attributes (e.g., only first 2 digits of zipcode are going
to be
made available, or it could be only last 4 digits of SSN, etc.). In an
embodiment,
the data privacy-utility tradeoff calculator 108E can compute a utility index
and
utility loss as illustrated in Table (m).
[076] FIG.7 is a graphical illustration of the Normalized Anonymity
Index and the Normalized Attribute Variation versus privacy threshold for an
exemplary set of data, in accordance with the present disclosure. It may be
observed from the comparison graph of FIG.7 that as long as privacy threshold
increases, anonymity-index keeps on decreasing and attribute variation keeps
on
increasing.
If privacy thresholdfi anonymity index and attribute variation
[077] FIG.8 is a graphical illustration of forward shifting attribute
variation graph for an exemplary set of data of 300 people with the help of
curve
fitting, in accordance with the present disclosure; and FIG.9 is a graphical
illustration of backward shifting attribute variation graph for an exemplary
set of
data of 300 people with the help of curve fitting, in accordance with the
present
disclosure. It may be observed that R2 (the coefficient of determination is a
statistical measure of how well the regression line approximates the real data
points) for backward shifting of attribute movement is 0.94, which is better
than
forward shifting of attribute movement (0.91). So based on above result, for
the
illustrated example dataset, it may be noted that backward shifting is
superior than
forward shifting. It may be noted that forward and backward shifting of
attribute
variation totally depends on structure of data.
[078] In an embodiment, at step 224, the adversary model 108C
continually learns and updates itself based on the received data. In an
embodiment, information gathering may be done by web crawlers. Consequently
these web crawlers continuously monitor public domains for any new information
29
CA 3015447 2018-08-29
being made available about people, and accordingly enrich the adversary model
108C.
[079] In an embodiment, the method 200 described herein above may
further include step 226, wherein a decision helper module 108F is configured
to
provide recommendations to the data sellers based on the received data. The
recommendations may be calculated from the data seller's preference set for
similar data from the received data such as age, demographics, type of data,
and
the like. In an embodiment, recommendations can also depend on regulations of
the domain and / or country. For instance, HIPAA (Health Information
Portability
and Accountability Act of USA) suggests the privacy threshold to be minimum
20,000. So, the decision helper module 108F may consider these aspects before
suggesting options.
[080] In an embodiment, the method 200 described herein above may
further include step 228, wherein an outflow data analyzer 108G is configured
to
evaluate the output data for quality and authenticity. Before getting
released, the
output data is checked for validating whether the metadata that the data buyer
is
requesting is what the data seller is providing.
[081] In an embodiment, the method 200 described herein above may
further include step 230, wherein a data release management module 108H is
configured to decide the release plan based on risk and rewards configured by
data
owners/sellers. In an embodiment, the data release management module 108H
may also consult the decision helper module 108F and give a final decision to
the
end user for manual release.
[082] At step 232, a report and alert management module 1081 is
configured to generate report and alerts based on the output data.
[083] At step 234, an event logging module 108J is configured to log all
events in log files associated with the output data for monitoring and
evidence
purposes.
[084] Thus transformation of data based on the computed data privacy-
utility tradeoff assists both data sellers and data buyers in executing a
meaningful
trade.
[085] The written description describes the subject matter herein to
CA 3015447 2018-08-29
enable any person skilled in the art to make and use the embodiments of the
invention. The scope of the subject matter embodiments defined here may
include
other modifications that occur to those skilled in the art. Such other
modifications
are intended to be within the scope if they have similar elements that do not
differ
from the literal language of the claims or if they include equivalent elements
with
insubstantial differences from the literal language.
[086] It is, however to be understood that the scope of the protection is
extended to such a program and in addition to a computer-readable means having
a message therein; such computer-readable storage means contain program-code
means for implementation of one or more steps of the method, when the program
runs on a server or mobile device or any suitable programmable device. The
hardware device can be any kind of device which can be programmed including
e.g. any kind of computer like a server or a personal computer, or the like,
or any
combination thereof. The device may also include means which could be e.g.
hardware means like e.g. an application-specific integrated circuit (ASIC), a
field-
programmable gate array (FPGA), or a combination of hardware and software
means, e.g. an ASIC and an FPGA, or at least one microprocessor and at least
one
memory with software modules located therein. Thus, the means can include both
hardware means and software means. The method embodiments described herein
could be implemented in hardware and software. The device may also include
software means. Alternatively, the invention may be implemented on different
hardware devices, e.g. using a plurality of CPUs.
[087] The embodiments herein can comprise hardware and software
elements. The embodiments that are implemented in software include but are not
limited to, firmware, resident software, microcode, etc. The functions
performed
by various modules comprising the system of the present disclosure and
described
herein may be implemented in other modules or combinations of other modules.
For the purposes of this description, a computer-usable or computer readable
medium can be any apparatus that can comprise, store, communicate, propagate,
or transport the program for use by or in connection with the instruction
execution
system, apparatus, or device. The various modules described herein may be
implemented as either software and/or hardware modules and may be stored in
31
CA 3015447 2018-08-29
any type of non-transitory computer readable medium or other storage device.
Some non-limiting examples of non-transitory computer-readable media include
CDs, DVDs, BLU-RAY, flash memory, and hard disk drives.
[088] A data processing system suitable for storing and/or executing
program code will include at least one processor coupled directly or
indirectly to
memory elements through a system bus. The memory elements can include local
memory employed during actual execution of the program code, bulk storage, and
cache memories which provide temporary storage of at least some program code
in order to reduce the number of times code must be retrieved from bulk
storage
during execution.
[089] Further, although process steps, method steps, techniques or the
like may be described in a sequential order, such processes, methods and
techniques may be configured to work in alternate orders. In other words, any
sequence or order of steps that may be described does not necessarily indicate
a
requirement that the steps be performed in that order. The steps of processes
described herein may be performed in any order practical. Further, some steps
may be performed simultaneously.
[090] The preceding description has been presented with reference to
various embodiments. Persons having ordinary skill in the art and technology
to
which this application pertains will appreciate that alterations and changes
in the
described structures and methods of operation can be practiced without
meaningfully departing from the principle and scope.
32
CA 3015447 2018-08-29