Note: Descriptions are shown in the official language in which they were submitted.
CA 03039085 2019-04-01
WO 2018/067440 PCT/US2017/054722
- 1 -
SYSTEMS AND METHODS FOR LANGUAGE DETECTION
CROSS REFERENCE TO RELATED APPLICATIONS
[0001] This application claims priority to and the benefit of, and
incorporates herein by
reference in its entirety, U.S. Patent Application No. 15/283,646, which was
filed on October 3,
2016.
BACKGROUND
[0002] The present disclosure relates to language detection and, in
particular, to systems and
methods for detecting languages in short text messages.
[0003] In general, language detection or identification is a process in which
a language
.. present in a body of text is detected automatically based on the content of
the text. Language
detection is useful in the context of automatic language translation, where
the language of a text
message must generally be known before the message can be translated
accurately into a
different language.
[0004] While traditional language detection is usually performed on a
collection of many
words and sentences (i.e., on the document level), a particularly challenging
domain is the chat
text domain, where messages often include only a few words (e.g., four or
less), some or all of
which can be informal and/or misspelled. In the chat text domain, existing
language detection
approaches have proven to be inaccurate and/or slow, given the lack of
information and the
informalities present in such messages.
SUMMARY
[0005] Embodiments of the systems and methods described herein are used to
detect the
language in a text message based on, for example, content of the message,
information about
the keyboard used to generate the message, and/or information about the
language preferences
of the user who generated the message. Compared to previous language detection
techniques,
CA 03039085 2019-04-01
WO 2018/067440 PCT/US2017/054722
- 2 -
the systems and methods described herein are generally faster and more
accurate, particularly
for short text messages (e.g., of four words or less).
[0006] In various examples, the systems and methods use a plurality of
language detection
tests and classifiers to determine probabilities associated with possible
languages in a text
message. Each language detection test can output a set or vector of
probabilities associated
with the possible languages. The classifiers can combine the output from the
language
detection tests to determine a most likely language for the message. The
particular language
detection test(s) and classifier(s) chosen for the message can depend on a
predicted accuracy, a
confidence score, and/or a linguistic domain for the message.
[0007] Certain examples of the systems and methods described herein perform an
initial
classification of a language in a text message so that more focused language
detection
techniques can be performed to make a final determination of the language. For
example, the
systems and methods can perform initial language detection testing on a text
message to
identify a group or category (e.g., Cyrillic languages or Latin languages) for
the language in the
text message. Once the language category is identified, language detection
techniques designed
for the language category can be used to identify the specific language in the
message. In
preferred examples, extraneous elements (e.g., emoji or numerical digits or
characters) are
removed from the text message prior to language detection, thereby resulting
in faster and more
accurate language detection. The systems and methods described herein are
generally more
accurate and efficient than prior language detection approaches. The systems
and methods can
be configured to use any one or more of the language detection methods
described herein.
[0008] In one aspect, the subject matter of this disclosure relates to a
computer-implemented
method of identifying a language in a message. The method includes: obtaining
a text
message; removing non-language characters from the text message to generate a
sanitized text
message; and detecting at least one of an alphabet and a script present in the
sanitized text
message, wherein detecting includes at least one of: (i) performing an
alphabet-based language
detection test to determine a first set of scores, wherein each score in the
first set of scores
represents a likelihood that the sanitized text message includes the alphabet
for one of a
plurality of different languages; and (ii) performing a script-based language
detection test to
determine a second set of scores, wherein each score in the second set of
scores represents a
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 3 -
likelihood that the sanitized text message includes the script for one of the
plurality of different
languages. The method also includes identifying the language in the sanitized
text message
based on at least one of the first set of scores, the second set of scores,
and a combination of the
first and second sets of scores.
[0009] In certain implementations, the non-language characters include an
emoji and/or a
numerical character. The combination can include an interpolation between the
first and
second sets of scores. In some examples, identifying the language in the
sanitized text message
includes performing a language detection test on the sanitized text message to
generate a third
set of scores, wherein each score in the third set of scores represents a
likelihood that the
sanitized text message includes one of a plurality of different languages. The
language
detection test can be selected from a plurality of language detection tests,
based on the at least
one of the first set of scores, the second set of scores, and the combination
of the first and
second sets of scores.
[0010] In certain instances, the language detection test includes a language
detection method
and one or more classifiers. The language detection method can include, for
example, a
dictionary-based language detection test, an n-gram language detection test,
an alphabet-based
language detection test, a script-based language detection test, a user
language profile language
detection test, or any combination thereof The one or more classifiers can
include, for
example, a supervised learning model, a partially supervised learning model,
an unsupervised
learning model, an interpolation, or any combination thereof In various
implementations, the
method includes processing the third set of scores using one or more
classifiers to identify the
language in the sanitized text message. The method can include outputting,
from the one or
more classifiers, an indication that the sanitized text message is in the
identified language. The
indication can include a confidence score.
[0011] In another aspect, the subject matter of this disclosure relates to a
computer-
implemented system for identifying a language in a message. The system
includes a sanitizer
module, a grouper module, and a language detector module. The sanitizer module
obtains a
text message and removes non-language characters from the text message to
generate a
sanitized text message. The grouper module detects at least one of an alphabet
and a script
present in the sanitized text message and is operable to perform operations
including at least
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 4 -
one of: performing an alphabet-based language detection test to determine a
first set of scores,
wherein each score in the first set of scores represents a likelihood that the
sanitized text
message includes the alphabet for one of a plurality of different languages;
and performing a
script-based language detection test to determine a second set of scores,
wherein each score in
.. the second set of scores represents a likelihood that the sanitized text
message includes the
script for one of the plurality of different languages. The language detector
module identifies
the language in the sanitized text message based on at least one of the first
set of scores, the
second set of scores, and a combination of the first and second sets of
scores.
[0012] In various examples, the non-language characters include an emoji
and/or a numerical
character. The combination can include an interpolation between the first and
second sets of
scores. The grouper module can be operable to perform operations that include
selecting the
language detector module from a plurality of language detector modules based
on the at least
one of the first set of scores, the second set of scores, and the combination
of the first and
second sets of scores. The language detector module can include a language
detection methods
module. The language detection methods module can be operable to perform
operations that
include performing a language detection test on the sanitized text message to
generate a third
set of scores, wherein each score in the third set of scores represents a
likelihood that the
sanitized text message includes one of a plurality of different languages. The
language
detection test can include, for example, a dictionary-based language detection
test, an n-gram
language detection test, an alphabet-based language detection test, a script-
based language
detection test, a user language profile language detection test, or any
combination thereof
[0013] In some implementations, the language detector module includes a
classifier module
operable to perform operations that include processing the third set of scores
using one or more
classifiers to identify the language in the sanitized text message. The one or
more classifiers
can include, for example, a supervised learning model, a partially supervised
learning model,
an unsupervised learning model, an interpolation, or any combination thereof
The classifier
module can be operable to perform operations that include outputting an
indication that the
sanitized text message is in the identified language. The indication can
include a confidence
score.
CA 03039085 2019-04-01
WO 2018/067440 PCT/US2017/054722
-5-
100141 In another aspect, the subject matter of this disclosure relates to an
article. The article
includes: a non-transitory computer-readable medium having instructions stored
thereon that,
when executed by one or more computers, cause the computers to perform
operations
including: obtaining a text message; removing non-language characters from the
text message
to generate a sanitized text message; detecting at least one of an alphabet
and a script present in
the sanitized text message, wherein detecting includes at least one of: (i)
performing an
alphabet-based language detection test to determine a first set of scores,
wherein each score in
the first set of scores represents a likelihood that the sanitized text
message includes the
alphabet for one of a plurality of different languages; and (ii) performing a
script-based
language detection test to determine a second set of scores, wherein each
score in the second
set of scores represents a likelihood that the sanitized text message includes
the script for one of
the plurality of different languages. The operations further include
identifying the language in
the sanitized text message based on at least one of the first set of scores,
the second set of
scores, and a combination of the first and second sets of scores.
[0015] Elements of examples described with respect to a given aspect of this
subject matter
can be used in various examples of another aspect of the subject matter. For
example, it is
contemplated that features of dependent claims depending from one independent
claim can be
used in apparatus, systems, and/or methods of any of the other independent
claims.
DESCRIPTION OF THE DRAWINGS
[0016] FIG. 1A is a diagram of an example system for performing language
detection.
[0017] FIG. 1B is a flowchart of an example method of detecting a language in
a text
message.
[0018] FIG. 2 is a flowchart of an example n-gram method of detecting a
language in a text
message.
.. [0019] FIG. 3 is a flowchart of an example dictionary-based method of
detecting a language
in a text message.
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
-6-
100201 FIG. 4 is a flowchart of an example alphabet-based method of detecting
a language in
a text message.
[0021] FIG. 5 is a flowchart of an example script-based method of detecting a
language in a
text message.
[0022] FIG. 6 is a flowchart of an example user language profile method of
detecting a
language in a text message.
[0023] FIG. 7 is a schematic diagram of an example language detection module.
[0024] FIG. 8 is a schematic diagram of an example classifier module.
[0025] FIG. 9 is a flowchart of an example method of detecting a language in a
text message
using the language detection module of FIG. 7 and the classifier module of
FIG. 8.
[0026] FIG. 10 is a flowchart of an example method of detecting a language in
a text
message.
[0027] FIG. 11 is a flowchart of an example method of detecting a language in
a text
message.
[0028] FIG. 12 is a flowchart of an example method of detecting a language in
a text
message.
[0029] FIG. 13 is a schematic diagram of an example system for detecting a
language in a
text message.
[0030] FIG. 14 is a flowchart of an example method of detecting a language in
a text
message.
[0031] FIG. 15 is a flowchart of an example method of detecting a language in
a text
message.
CA 03039085 2019-04-01
WO 2018/067440 PCT/US2017/054722
- 7 -
DETAILED DESCRIPTION
[0032] In general, the language detection systems and methods described herein
can be used
to identify the language in a text message when language information for the
message (e.g.,
keyboard information from a client device) is absent, malformed or unreliable.
The systems
and methods improve the accuracy of language translation methods used to
translate text
messages from one language to another. Language translation generally requires
the source
language to be identified accurately, otherwise the resulting translation can
be inaccurate.
[0033] FIG. 1A illustrates an example system 10 for detecting a language in a
message, such
as a text message or an audio message. A server system 12 provides message
analysis and
language detection functionality. The server system 12 comprises software
components and
databases that can be deployed at one or more data centers 14 in one or more
geographic
locations, for example. The server system 12 software components can comprise
a detection
module 16, a classifier module 18, and a manager module 20. The software
components can
comprise subcomponents that can execute on the same or on different individual
data
processing apparatus. The server system 12 databases can comprise training
data 22,
dictionaries 24, alphabets 26, scripts 28, and user profile information 30.
The databases can
reside in one or more physical storage systems. The software components and
data will be
further described below.
[0034] An application, such as a web-based application, can be provided as an
end-user
application to allow users to provide messages to the server system 12. The
end-user
applications can be accessed through a network 32 by users of client devices,
such as a personal
computer 34, a smart phone 36, a tablet computer 38, and a laptop computer 40.
Other client
devices are possible. The user messages can be accompanied by information
about the devices
used to create the messages, such as information about the keyboard, client
device, and/or
operating system used to create the messages.
[0035] Although FIG. 1A depicts the classifier module 18 and the manager
module 20 as
being connected to the databases (i.e., training data 22, dictionaries 24,
alphabets 26, scripts 28,
and user profile information 30), the classifier module 18 and/or the manager
module 20 are not
necessarily connected to some or all of the databases. In general, the
classifier module 18 can
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 8 -
receive input from the detection module 16, and the manager module 20 can
receive input from
the classifier module 18. No other inputs are required to be received by the
classifier module
18 and/or the manager module 20.
[0036] FIG. 1B illustrates an example method 100 that uses the system 10 to
detect a
language in a message. The method 100 begins by receiving or obtaining (step
102) a text
message generated by a user. The text message is analyzed (step 104) using one
or more
language detection methods (e.g., by the detection module 16) that each
provide an indication
of the language or languages present in the message. The output from the
language detection
methods is then combined (step 106) using one or more classifiers (e.g., by
the classifier
.. module 18) that provide a further indication of the language present in the
message. The one or
more classifiers can include, for example, a supervised learning model, a
partially supervised
learning model, an unsupervised learning model, and/or an interpolation. Other
classifiers are
possible. The output from the one or more classifiers is then used to
determine (step 108) the
language in the message (e.g., using the manager module 20).
[0037] In some implementations, the language indication from the one or more
classifiers can
be selected by the manager module 20 according to a computed confidence score
and/or a
linguistic domain. For example, the classifiers can compute a confidence score
indicating a
degree of confidence associated with the language prediction. Additionally or
alternatively,
certain classifier output can be selected according to the linguistic domain
associated with the
user or the message. For example, if the message originated in a computer
gaming
environment, a particular classifier output can be selected as providing the
most accurate
language prediction. Likewise, if the message originated in the context of
sports (e.g.,
regarding a sporting event), a different classifier output can be selected as
being more
appropriate for the sports linguistic domain. Other possible linguistic
domains include, for
example, news, parliamentary proceedings, politics, health, travel, web pages,
newspaper
articles, microblog messages, and the like. In general, certain language
detection methods or
combinations of language detection methods (e.g., from a classifier) can be
more accurate for
certain linguistic domains, when compared to other linguistic domains. In some
implementations, the domain can be determined based on the presence of words
from a domain
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 9 -
vocabulary in a message. For example, a domain vocabulary for computer gaming
could
include common slang words used by gamers.
[0038] The language detection methods used by the detection module 16 can
include, for
example, an n-gram method (e.g., a byte n-gram method), a dictionary-based
method, an
alphabet-based method, a script-based method, and a user language profile
method. Other
language detection methods are possible. Each of these language detection
methods can be
used to detect a language present in a message. The output from each method
can be, for
example, a set or vector of probabilities associated with each possible
language in the message.
In some instances, two or more of the language detection methods can be
performed
simultaneously, using parallel computing, which can reduce computation times
considerably.
[0039] In one implementation, a byte n-gram method uses byte n-grams instead
of word or
character n-grams to detect languages. The byte n-gram method is preferably
trained over a
mixture of byte n-grams (e.g., with 1 < n < 4), using a naive Bayes classifier
having a
multinomial event model. The model preferably generalizes to data from
different linguistic
domains, such that the model's default configuration is accurate over a
diverse set of domains,
including newspaper articles, online gaming, web pages, and microblog
messages. Information
about the language identification task can be integrated from a variety of
domains.
[0040] The task of attaining high accuracy can be relatively easy for language
identification
in a traditional text categorization setting, for which in-domain training
data is available. This
task can be more difficult when attempting to use learned model parameters for
one linguistic
domain to classify or categorize data from a separate linguistic domain. This
problem can be
addressed by focusing on important features that are relevant to the task of
language
identification. This can be based on, for example, a concept called
information gain, which
was originally introduced for decision trees as a splitting criteria, and
later found to be useful
for selecting features in text categorization. In certain implementations, a
detection score can
be calculated that represents the difference in information gain relative to
domain and language.
Features having a high detection score can provide information about language
without
providing information about domain. For simplicity, the candidate feature set
can be pruned
before information gain is calculated, by means of a feature selection based
on term-frequency.
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 10 -
[0041] Referring to FIG. 2, an example byte n-gram method 200 begins by
training the
method using the training data 22. For example, the method can be trained over
a mixture of
byte n-grams, using the naive Bayes classifier having the multinomial event
model. Training
data 22 is preferably collected (step 202) for a wide number and variety of
languages and
adjusted so that the amount of data available per language is made uniform. A
small portion of
the training data 22 is set aside (step 204) as a test set. Once the training
data 22 is selected, a
byte n-gram model is trained (step 206) on the training data 22 with
appropriate smoothing and
backoff techniques. The input features to the model are byte streams from each
input sentence,
and since the source language label is known for these sentences, the model
adjusts its
parameters to learn byte sequences typical to a given language. The test set
that was isolated in
the beginning is then used to predict (step 208) language labels based on the
model that had
been trained. The accuracy of prediction gives the performance of this byte n-
gram language
identification system. In some instances, it is difficult to train such a byte
n-gram system for
each linguistic domain by collecting data across numerous languages for said
domain. The
difficulty arises from a lack of sufficient data per domain. Hence, these byte
n-gram systems
are typically trained to cater to a generic domain and not to any specific
domains. The trained
model can be compiled (step 210) into a program along with intermediate
machine parameters.
The program can serve as a general purpose language identification system.
[0042] In general, the dictionary-based language detection method counts the
number of
tokens or words belonging to each language by looking up words in a dictionary
or other word
listing associated with the language. The language having the most words in
the message is
chosen as the best language. In the case of multiple best languages, the more
frequent or
commonly used of the best languages can be chosen. The language dictionaries
can be stored
in the dictionaries database 24.
[0043] FIG. 3 is a flowchart of an example dictionary-based language detection
method 300.
A text message is provided (step 302) and a set of possible languages for the
text message is
identified (step 304) using, for example, the detection module 16. A first
possible language is
then chosen (step 306) from the set. The words in the text message that are
present in a
dictionary for the possible language are counted (step 308). If additional
possible languages
from the set have not yet been considered (step 310), a new possible language
is selected (step
CA 03039085 2019-04-01
WO 2018/067440 PCT/US2017/054722
- 11 -
312), and step 308 is repeated. Once all possible languages from the set have
been considered,
the language with the most words in the text message can be identified (step
314) as the
language in the message. Alternatively or additionally, the method can be used
to compute the
likelihood that a language is in the message, for each language in the set.
For example, the
output from the dictionary-based method can be a vector of probabilities for
each language in
the set.
[0044] To ensure accuracy of the dictionary-based language detection method,
particularly
for short sentences, it is preferable to use dictionaries that include
informal words or chat words
(e.g., abbreviations, acronyms, slang words, and profanity), in addition to
formal words.
Informal words are commonly used in short text communications and in chat
rooms. The
dictionaries are preferably augmented to include informal words on an ongoing
basis, as new
informal words are developed and used.
[0045] The alphabet-based method is generally based on character counts for
each language's
alphabet and relies on the observation that many languages have unique
alphabets or different
sets of characters. For example, Russian, English, Korean, and Japanese each
use a different
alphabet. Although the alphabet-based method can be unable to distinguish some
languages
precisely (e.g., languages that use similar alphabets, such as Latin
languages), the alphabet-
based method can generally detect certain languages quickly. In some
instances, it is preferable
to use the alphabet-based method in combination with one or more other
language detection
.. methods (e.g., using a classifier), as discussed herein. The language
alphabets can be stored in
the alphabets database 26.
[0046] FIG. 4 is a flowchart of an example alphabet-based language detection
method 400.
A text message is provided (step 402) and a set of possible languages for the
text message is
identified (step 404) using, for example, the detection module 16. A first
possible language is
then chosen (step 406) from the set. The characters in the text message that
are present in an
alphabet for the possible language are counted (step 408). If additional
possible languages
from the set have not yet been considered (step 410), a new possible language
is selected (step
412), and step 408 is repeated. Once all possible languages from the set have
been considered,
the language with the most characters in the text message can be identified
(step 414) as the
language in the message. Alternatively or additionally, the alphabet-based
method can be used
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 12 -
to compute a likelihood that a language is in the message, for each language
in the set. For
example, the output from the alphabet-based method can be a vector of
probabilities for each
language in the set.
[0047] In general, the script-based language detection method determines the
character
counts for each possible script (e.g. Latin script, CJK script, etc.) that are
present in the
message. The script-based method relies on the observation that different
languages can use
different scripts, e.g., Chinese and English. The method preferably uses a
mapping that maps a
script to a list of languages that use the script. For example, the mapping
can consider the
UNICODE values for the characters or symbols present in the message, and these
UNICODE
values can be mapped to a corresponding language or set of possible languages
for the
message. The language scripts and UNICODE values or ranges can be stored in
the scripts
database 28.
[0048] Referring to FIG. 5, in an example script-based method 500, a text
message is
provided (step 502) and the scripts present in the message are identified
(step 504) using, for
example, the detection module 16. The number of characters falling into each
script is then
counted (step 506). The script with the highest number of characters is
considered to be the
best script (step 508), and the languages corresponding to the best script are
identified (step
510). When the best script corresponds to only one language, that language can
be considered
to be the best language. Otherwise, when the best script corresponds more than
one language,
additional language detection methods can be used to do further detection. In
some
implementations, the output from the script-based method is a set of
probabilities (e.g., in
vector form) for each possible language in the message.
[0049] The user language profile based method uses the user profile
information database 30,
which stores historical messages sent by various users. The languages of these
stored messages
are detected using, for example, one or more other language detection methods
described
herein (e.g., the byte n-gram method), to identify the language(s) used by
each user. For
example, if all of a user's prior messages are in Spanish, the language
profile for that user can
indicate the user's preferred language is Spanish. Likewise, if a user's prior
messages are in a
mixture of different languages, the language profile for the user can indicate
probabilities
associated with the different languages (e.g., 80% English, 15% French, and 5%
Spanish). In
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 13 -
general, the user language profile based method addresses language detection
issues associated
with very short messages, which often do not have enough information in them
to make an
accurate language determination. In such an instance, the language preference
of a user can be
used to predict the language(s) in the user's messages, by assuming the user
will continue to
use the language(s) he or she has used previously.
[0050] Referring to FIG. 6, an example user language profile detection method
600 begins by
storing (step 602) a user's previous messages and detecting (step 604) the
language(s) present
in the stored messages. The frequency with which different language(s) appear
in the user's
message is determined (step 606) and a use probability for such language(s) is
outputted (step
608).
[0051] Referring to FIG. 7, the various language detection methods can be
incorporated into
the detection module 16. A text message can be input into the detection module
16, and one or
more of the language detection methods can identify the language(s) in the
message. For
example, each language detection method can provide a vector of probabilities,
where each
probability in the vector is associated with a possible language in the
message and represents
the likelihood that the message is in the given language. Due to the different
methods
employed and the information available in the message, the probabilities from
each language
detection method may not be consistent. The detection module 16 can include or
utilize, for
example, an n-gram module 702 for performing an n-gram detection method (e.g.,
the byte n-
gram detection method 200), a dictionary-based module 704 for performing the
dictionary-
based method 300, an alphabet-based module 706 for performing the alphabet-
based method
400, a script-based module 708 for performing the script-based method 500, and
a user
language profile module 710 for performing the user language profile method
600. Additional
or alternative language detection methods can be incorporated into the
detection module 16, as
desired. Some known methods include using, for example, word level n-grams,
Markov
models, and predictive modeling techniques.
[0052] The output from the various language detection methods in the detection
module 16
can be combined using the classifier module 18. Referring to FIG. 8, the
classifier module 18
can include an interpolation module 802, a support vector machines (SVM)
module 804, and a
linear SVM module 806.
CA 03039085 2019-04-01
WO 2018/067440 PCT/US2017/054722
- 14 -
[0053] The interpolation module 802 is used to perform a linear interpolation
of the results
from two or more language detection methods. For purposes of illustration, the
language of a
text message can be determined by interpolating between results from the byte
n-gram method
and the dictionary-based method. For the chat message "lol gtg," the byte n-
gram method can
determine the likelihood of English is 0.3, the likelihood of French is 0.4,
and the likelihood of
Polish is 0.3 (e.g., the output from the byte n-gram method can be len:0.3,
fr:0.4, p1:0.31). The
dictionary-based method can determine the likelihood of English is 0.1, the
likelihood of
French is 0.2, and the likelihood of Polish is 0.7 (e.g., the output can be
len:0.1, fr:0.2, p1:0.71).
To interpolate between the results of these two methods, the output from the
byte n-gram
method is multiplied by a first weight and the output from the dictionary-
based method is
multiplied by a second weight, such that the first and second weights add to
one. The weighted
outputs from the two methods are then added together. For example, if the byte
n-gram results
are given a weight of 0.6, then the dictionary-based results are given a
weight of 0.4, and the
interpolation between the two methods is: len:0.3, fr:0.4, p1:0.31*0.6 +
len:0.1, fr:0.2,
p1:0.71*0.4 = len:0.22, fr:0.32, p1:0.461. Other weightings are possible.
[0054] In general, the optimal weights for interpolating between two or more
values can be
determined numerically through trial and error. Different weights can be tried
to identify the
best set of weights for a given set of messages. In some instances, the
weights can be a
function of the number of words or characters in the message. Alternatively or
additionally, the
weights can depend on the linguistic domain of the message. For example, the
optimal weights
for a gaming environment can be different than the optimal weights for a
sports environment.
For a combination of the byte n-gram method and the dictionary-based method,
good results
can be obtained using a weight of 0.1 on the byte n-gram method and a weight
of 0.9 on the
dictionary-based method.
.. [0055] The SVM module 804 can be or include a supervised learning model
that analyzes
language data and recognizes language patterns. The SVM module 804 can be a
multi-class
SVM classifier, for example. For an English SVM classifier, the feature vector
can be the
concatenation of the two distributions above (i.e., len:0.3, fr:0.4, p1:0.3,
en:0.1, fr:0.2, p1:0.71).
The SVM classifier is preferably trained on labeled training data. The trained
model acts as a
predictor for an input. The features selected in the case of language
detection can be, for
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 15 -
example, sequences of bytes, words, or phrases. Input training vectors can be
mapped into a
multi-dimensional space. The SVM algorithm can then use kernels to identify
the optimal
separating hyperplane between these dimensions, which will give the algorithm
a
distinguishing ability to predict languages (in this case). The kernel can be,
for example, a
linear kernel, a polynomial kernel, or a radial basis function (RBF) kernel,
although other
suitable kernels are possible. A preferred kernel for the SVM classifier is
the RBF kernel.
After training the SVM classifier using training data, the classifier can be
used to output a best
language among all the possible languages.
[0056] The training data can be or include, for example, the output vectors
from different
language detection methods and an indication of the correct language, for a
large number of
messages having, for example, different message lengths, linguistic domains,
and/or languages.
The training data can include a large number of messages for which the
language in each
message is known.
[0057] The linear SVM module 806 can be or include a large-scale linear
classifier. An
SVM classifier with a linear kernel can perform better than other linear
classifiers, such as
linear regression. The linear SVM module 806 differs from the SVM module 804
at the kernel
level. There are some cases when a polynomial model works better than a linear
model, and
vice versa. The optimal kernel can depend on the linguistic domain of the
message data and/or
the nature of the data.
[0058] Other possible classifiers used by the systems and methods described
herein include,
for example, decision tree learning, association rule learning, artificial
neural networks,
inductive logic programming, random forests, clustering, Bayesian networks,
reinforcement
learning, representation learning, similarity and metric learning, and sparse
dictionary learning.
One or more of these classifiers, or other classifiers, can be incorporated
into and/or form part
of the classifier module 18.
[0059] Referring to FIG. 9, an example method 900 uses the detection module
16, the
classifier module 18, and the manager module 20 to detect the language in a
message. The
message is provided or delivered (step 902) to the detection module 16. The
message can be
accompanied by information about the message and/or the user who generated the
message.
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 16 -
The information can include, for example, an identification number for the
user, information
about the keyboard used by the user to generate the message, and/or
information about the
operating system controlling the software used by the user to generate the
message. For
example, the message can be accompanied by data indicating the user used a
French keyboard
to generate the message and that user's operating system is in English.
[0060] In the detection module 16, one or more language detection methods are
used (step
904) to detect a language in the message. Each method used by the detection
module 16 can
output a prediction regarding the language present in the message. The
prediction can be in the
form of a vector that includes a probability for each possible language that
can be in the
message.
[0061] The output from the detection module 16 is then delivered to the
classifier module 18
where the results from two or more language detection methods can be combined
(step 906).
Various combinations of the results from the language detection methods can be
obtained. In
one example, the results from the byte n-gram method and the dictionary-based
method are
combined in the classifier module 18 by interpolation. In another example, a
SVM
combination or classification is performed on the results from the byte n-gram
method, the
dictionary-based method, the alphabet method, and the user profile method.
Alternatively or
additionally, the combination can include or consider results from the script-
based method. A
further example includes a large linear combination of the byte n-gram method,
the language
profile method, and the dictionary method. In general, however, the results
from any two or
more of the language detection methods can be combined in the classifier
module 18.
[0062] The method 900 uses the manager module 20 to select output (step 908)
from a
particular classifier. The output can be selected based on, for example, a
confidence score
computed by a classifier, an expected language detection accuracy, and/or a
linguistic domain
for the message. A best language is then chosen (step 910) from the selected
classifier output.
[0063] In some instances, the systems and methods described herein choose the
language
detection method(s) according to the length of the message. For example,
referring to FIG. 10,
a method 1000 includes receiving or providing a message (step 1002) that can
include
information about the keyboard language used to generate the message. If the
message is
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 17 -
greater than a threshold length (e.g., 25 bytes or 25 characters, although any
suitable threshold
length is possible) (step 1004), the language can be detected (step 1006)
using the byte n-gram
method (or other method or combination of methods). The language of the
message can then
be chosen (step 1008), based on the results from the byte n-gram method.
Otherwise, if the
.. message is less than or equal to the threshold length, the system can
determine if the keyboard
language is available (step 1010). If the keyboard language is available, the
language of the
message can be chosen (step 1012) to be the same as the keyboard language.
Alternatively, if
the keyboard language is not available, the method 1000 can again consider the
length of the
message. For example, if the message length is less than a second threshold
(e.g., 4 bytes or 4
characters, although any suitable second threshold is possible) (step 1014),
the language can be
detected (step 1016) and chosen using the dictionary-based method. Otherwise,
if the message
length is greater than the second threshold, the byte n-gram method (or other
method or
combination of methods) can be used (step 1018) to detect the language in the
message. The
results from the byte n-gram method and the dictionary-based method can be
combined (e.g.,
.. using an interpolator or other classifier), and the language of the message
can be determined
based on the combination (step 1020).
[0064] FIG. 11 is an example method 1100 of identifying a language in a text
message. A
text message that was generated on a client device of a user is received or
provided (step 1102).
The alphabet-based method and/or the script-based method are used to determine
(step 1104)
.. an alphabet and/or a script associated with the text message. A candidate
language associated
with the alphabet and/or the script is identified. If the candidate language
is a language with a
unique alphabet and/or script (e.g., Russian, Arabic, Hebrew, Greek, Chinese,
Taiwanese,
Japanese, Korean, or the like) (step 1106), then the candidate language is
determined (step
1108) to be the language of the text message.
[0065] Otherwise, if the candidate language is not a language with a unique
alphabet and/or
script, then the length of the text message is evaluated. If the message
length is less than a
threshold length (e.g., 4 bytes or 4 characters, although any suitable
threshold length is
possible) and the text message includes or is accompanied by a keyboard
language used by the
client device (step 1110), then the language of the message is chosen (step
1112) to be the
keyboard language.
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 18 -
[0066] Alternatively, if the message length is greater than the threshold
length or the
keyboard language is not available, then the message is processed with an n-
gram method (e.g.,
the byte n-gram method) to identify (step 1114) a first set of possible
languages for the text
message. The message is also then processed with the dictionary-based method
to identify
(step 1116) a second set of possible languages for the text message. If a user
language profile
exists for the user (step 1118), then the user language profile is obtained
(step 1120) and
combined (e.g., using an SVM classifier or a large linear classifier) with the
first set of possible
languages and the second set of possible languages to obtain a first
combination of possible
languages (step 1122). The language of the text message is then chosen (step
1124), based on
the first combination of possible languages. Otherwise, if the user language
profile is not
available, then the first set of possible languages and the second set of
possible languages are
combined (e.g., using a linear interpolator or other classifier) to obtain a
second combination of
possible languages (step 1126). Finally, the language of the text message is
chosen (step 1128),
based on the second combination of possible languages.
[0067] In some instances, language detection is performed by combining the
output from
multiple language detection methods in two or more steps. For example, a first
step can use the
alphabet-script based method to detect special languages that use their own
unique alphabets or
scripts, such as, for example, Chinese (cn), Japanese (ja), Korean (ko),
Russian (ru), Hebrew
(he), Greek (el), and Arabic (ar). The alphabet-script based method refers to,
for example,
using one or both of the alphabet-based method and the script-based method. If
necessary, the
second step can use a combination (e.g., from a classifier) of multiple
detection methods (e.g.,
the byte n-gram method, the user language profile based method, and the
dictionary-based
method) to detect other languages (e.g., Latin languages) in the message.
[0068] In certain examples, the message provided or received for language
detection includes
certain digits, characters, or images (e.g., emoticons or emoji) that are not
specific to any
particular language and/or are recognizable to any user, regardless of
language preference. The
systems and methods described herein can ignore such characters or images when
performing
language detection and can ignore messages that include only such characters
or images.
Alternatively or additionally, the systems and methods can remove such
characters or images
from messages, prior to performing language detection. The process of removing
extraneous
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 19 -
characters or images from messages can be referred to herein as sanitizing the
messages. The
sanitizing process can result in faster detection times and/or improved
language detection
accuracy.
[0069] FIG. 12 is a flowchart of an example method 1200 for detecting a
language in a
message. The method uses the detection module 16, the classifier module 18,
and the manager
module 20 to identify a most likely or best language 1202 for a given input
message 1204. The
input message 1204 can be accompanied by information about the user or the
system(s) used to
generate the message. For example, the input message 1204 can be accompanied
by a user
identification number (or other user identifier), information about the
keyboard (e.g., a
keyboard language) used to generate the message, and/or information about the
operating
system (e.g., an operating system language) used to generate the message.
[0070] In the depicted example method 1200, the detection module 16 includes
ten different
language detection methods. Three of the language detection methods in the
detection module
16 are Byte n-gram A 1206, Byte n-gram B 1208, and Byte n-gram C 1210, which
are all byte
n-gram methods and can be configured to detect a different set or number of
languages. For
example, Byte n-gram A 1206 can be configured to detect 97 languages, Byte n-
gram B 1208
can be configured to detect 27 languages, and Byte n-gram C 1210 can be
configured to detect
languages. Two of the language detection methods in the detection module 16
are
Dictionary A 1212 and Dictionary B 1214, which are both dictionary-based
methods and can
20 be configured to detect a different set or number of languages. For
example, Dictionary A
1212 can be configured to detect 9 languages, and Dictionary B 1214 can be
configured to
detect 10 languages. Two of the language detection methods in the detection
module 16 are
Language Profile A 1216 and Language Profile B 1218, which are user language
profile
methods and can be configured to detect a different set or number of
languages. For example,
Language Profile A 1216 can be configured to detect 20 languages, and Language
Profile B
1218 can be configured to detect 27 languages. Two of the language detection
methods in the
detection module 16 are Alphabet A 1220 and Alphabet B 1222, which are
alphabet-based
methods and can be configured to detect a different set or number of
languages. For example,
Alphabet A 1220 can be configured to detect 20 languages, and Alphabet B 1222
can be
CA 03039085 2019-04-01
WO 2018/067440 PCT/US2017/054722
- 20 -
configured to detect 27 languages. The detection module 16 also includes a
script-based
language detection method 1224.
[0071] Output from the different language detection methods in the detection
module 16 is
combined and processed by the classifier module 18. For example, an
interpolation classifier
1226 combines output from Byte n-gram B 1208 and Dictionary B 1214. Weights
for the
interpolation can be, for example, 0.1 for Byte n-gram B 1208 and 0.9 for
Dictionary B 1214.
The classifier module 18 can also use an SVM classifier 1228 that combines
output from Byte
n-gram C 1210, Dictionary B 1214, Language Profile B 1218, and Alphabet B
1222. The
classifier module 18 can also use a first combination 1230 of the script-based
method 1224 and
an SVM classifier combination of Byte n-gram C 1210, Dictionary A 1212,
Language Profile A
1216, and Alphabet A 1220. Additionally, the classifier module 18 can use a
second
combination 1232 of the script based method 1224 and a Linear SVM classifier
combination of
Byte n-gram C 1210, Dictionary A 1212, and Language Profile A 1216. While FIG.
12 shows
specific language detection tests, classifiers, and combinations of detection
test output being
used in the classifier module 18, other language detection tests, classifiers,
and/or combinations
can be used.
[0072] For both the first combination 1230 and the second combination 1232,
the script-
based method 1224 and the classifier can be used in a tiered approach. For
example, the script-
based method 1224 can be used to quickly identify languages having unique
scripts. When
such a language is identified in the message 1204, use of the SVM classifier
in the first
combination 1230 or the Linear SVM classifier in the second combination may
not be required.
[0073] In general, the manager module 20 can select specific language
detection methods,
classifiers, and/or combinations of detection method output to identify the
language in the
message 1204. The manager module 20 can make the selection according to the
linguistic
.. domain or according to an anticipated language for the message. The manager
module 20 can
select specific classifiers according to a confidence score determined by the
classifiers. For
example, the manager module 20 can select the output from the classifier that
is the most
confident in its prediction.
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 21 -
[0074] In certain implementations, the systems and methods described herein
are suitable for
making language detection available as a service to a plurality of users. Such
a service is made
possible and/or enhanced by the speed at which the systems and methods
identify languages,
and by the ability of the systems and methods to handle multiple
identification techniques at
.. runtime, based on service requests from diverse clients.
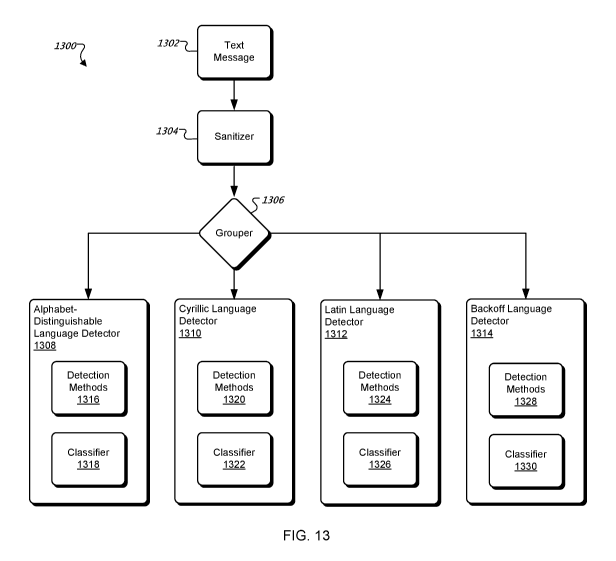
[0075] Referring to FIG. 13, in certain examples, a language detection system
1300 obtains
or receives a text message 1302 and uses a sanitizer module 1304, a grouper
module 1306, and
one or more language detector modules to identify a language present in the
text message 1302.
In general, the sanitizer module 1304 prepares the text message 1302 for
language detection by
deleting certain characters or other extraneous elements from the text message
1302. The
sanitizer module 1304 can remove, for example, one or more numerical
characters (e.g., "1,"
"3," "15," "249," etc.), one or more emoji (e.g., in the form of images and/or
combinations of
characters, such as ":-D" or ":-<"), and/or one or more other non-language
characters or
elements that may not be useful for language detection, such as, for example,
certain
punctuation marks (e.g., periods or commas), extra spaces, and/or carriage
returns. In
alternative examples, the extraneous elements are not removed from the text
message 1302, but
are simply ignored or avoided during subsequent language detection. The
sanitizer module
1304 can be used to flag or identify the extraneous elements in such
instances. References to
"the text message 1302" in subsequent paragraphs are intended to cover, for
example, text
messages with extraneous elements removed or ignored. In various examples, the
extraneous
elements are referred to herein as "non-language characters."
[0076] In general, the grouper module 1306 is used to perform an initial
classification of the
language in the text message 1302 and, based on the initial classification,
select one or more
subsequent language detection methods to make a final determination of the
language in the
text message 1302. In preferred examples, the grouper module 1306 performs the
initial
classification by detecting an alphabet and/or a script present in the text
message 1302. The
alphabet and/or the script can be detected using, for example, the alphabet-
based method and/or
the script-based method, described herein. In some instances, the alphabet-
based method can
determine a first set of scores for the text message 1302, with each score
representing a
probability or likelihood that the alphabet is for one of a plurality of
different languages. The
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 22 -
grouper module 1306 can detect the alphabet in the text message 1302 based on
the highest
score from the first set of scores. Likewise, the script-based method can
determine a second set
of scores for the text message 1302, with each score representing a
probability or likelihood
that the script is for one of a plurality of different languages. The grouper
module 1306 can
detect the script in the text message 1302 based on the highest score from the
second set of
scores. Alternatively or additionally, the grouper module 1306 can combine
results or scores
(e.g., using an interpolator or other classifier) from the alphabet-based
method and the script-
based method to detect the alphabet and/or the script in the text message
1302. Once the
alphabet and/or the script have been detected, the grouper module 1306 selects
a language
.. detector module to use for making a final determination of the language in
the text message
1302, as described below and herein. The grouper module 1306 can pass results
or other
information (e.g., one or more scores) from the alphabet-based method and/or
the script-based
method to the selected language detector module.
[0077] In the depicted example, the language detection system 1300 can include
or utilize the
following language detector modules: an alphabet-distinguishable language
detector 1308, a
Cyrillic language detector 1310, a Latin language detector 1312, and a backoff
language
detector 1314. However, other additional or alternative language detector
modules can be
included or utilized. Each of these language detector modules 1308, 1310,
1312, and 1314 can
include a detection methods module and a classifier module. For example, the
alphabet-
distinguishable language detector 1308 can include a detection methods module
1316 and a
classifier module 1318, the Cyrillic language detector 1310 can include a
detection methods
module 1320 and a classifier module 1322, the Latin language detector 1312 can
include a
detection methods module 1324 and a classifier module 1326, and the backoff
language
detector 1314 can include a detection methods module 1328 and a classifier
module 1330.
.. [0078] In general, the detection methods modules 1316, 1320, 1324, and 1328
include or
utilize one or more language detection methods, which can be or include, for
example, the n-
gram method (e.g., the byte n-gram method), the dictionary-based method, the
alphabet-based
method, the script-based method, and/or the user language profile method.
Other language
detection methods are contemplated. The detection methods modules 1316, 1320,
1324, and
1328 can use the language detection methods to produce output providing an
indication of the
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 23 -
language present in the text message 1302. The output can be or include, for
example, one or
more scores representing a likelihood that the text message 1302 is in one or
more languages.
In some instances, the language in the text message 1302 is determined
directly from the output
of one of the detection methods modules 1316, 1320, 1324, or 1328.
Alternatively or
additionally, the language in the text message 1302 can be determined from the
output of one
of the classifier modules 1318, 1322, 1326, or 1330. In general, each
classifier module 1318,
1322, 1326, or 1330 processes output from a corresponding detection methods
module 1316,
1320, 1324, or 1328 to provide a further indication of the language present in
a text message.
The classifier modules 1318, 1322, 1326, and 1330 preferably use or include
one or more
classifiers, such as, for example, a supervised learning model, a partially
supervised learning
model, an unsupervised learning model, and/or an interpolation.
[0079] For example, when the alphabet and/or script detected by the grouper
module 1306
are associated with one or more alphabet-distinguishable languages, the
grouper module 1306
selects the alphabet-distinguishable language detector 1308. In general, an
alphabet-
distinguishable language is a language that has a unique alphabet and/or a
unique script, such
that the language in the text message 1302 can be determined once the alphabet
and/or the
script for the language are detected. Examples of alphabet-distinguishable
languages include,
for example, Simplified Chinese (cn), Traditional Chinese (tw), Japanese (ja),
Arabic (ar),
Hebrew (he), Greek (el), Korean (ko), and Thai (th). In various instances, the
grouper module
1306 passes results (e.g., one or more scores or probabilities, a detected
alphabet, and/or a
detected script) from the alphabet-based method and/or the script-based method
to the alphabet-
distinguishable language detector 1308. Alternatively or additionally, if the
grouper module
1306 does not pass such results to the alphabet-distinguishable language
detector 1308, the
detection methods module 1316 can perform the alphabet-based method and/or the
script-based
method to detect the alphabet and/or the script in the text message 1302. The
alphabet-
distinguishable language detector 1308 can determine the language in the text
message 1302
once the alphabet and/or the script are detected. In some instances, such a
determination can be
made using the classifier module 1318 to process any output from the detection
methods
module 1316.
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 24 -
[0080] In some examples, when the alphabet and/or script detected by the
grouper module
1306 are associated with one or more Cyrillic languages, the grouper module
1306 selects the
Cyrillic language detector 1310. Examples of Cyrillic languages include, for
example,
Bulgarian (bg), Ukrainian (uk), and Russian (ru). To determine the specific
Cyrillic language
in the text message 1302, the detection methods module 1320 can include or
utilize one or
more language detection methods described herein, such as the byte n-gram
method and/or the
dictionary-based method. In a preferred example, the detection methods module
1320 utilizes
the dictionary-based method, which can use one or more dictionaries specific
to Cyrillic
languages. The dictionary-based method can count the number of tokens or words
in the text
message 1302 that belong to one or more Cyrillic languages by looking up words
in the one or
more dictionaries. In some examples, the Cyrillic language having the most
tokens or words in
the text message 1302 is determined to be the language in the text message
1302. Alternatively
or additionally, the detection methods module 1320 can provide output from one
or more
language detection methods (e.g., the dictionary-based method) to the
classifier module 1322,
which can process the output to determine the language in the text message
1302. For example,
the classifier module 1322 can receive a set of scores from the detection
methods module 1320
and can determine the Cyrillic language in the text message 1302 by
identifying the language
having the highest score.
[0081] In certain instances, when the alphabet and/or script detected by the
grouper module
1306 are associated with one or more Latin languages, the grouper module 1306
selects the
Latin language detector 1312. Examples of Latin languages include, for
example, English (en),
French (fr), Spanish (es), German (de), Portuguese (pt), Dutch (n1), Polish
(pp, Italian (it),
Turkish (tr), Catalan (ca), Czech (cs), Danish (da), Finnish (fi), Hungarian
(hu), Indonesian
(id), Norwegian (no), Romanian (ro), Slovak (sk), Swedish (sv), Malay (ms),
Vietnamese (vi).
To determine the specific Latin language in the text message 1302, the
detection methods
module 1324 can include or utilize one or more language detection methods
described herein.
In preferred examples, the detection methods module 1324 includes or utilizes
the byte n-gram
method and/or the dictionary-based method. The output from one or both of
these preferred
methods can be processed or combined using the classifier module 1326 to
determine the
specific Latin language in the text message 1302. For example, the n-gram
method and the
dictionary-based method can each output a set of scores, with each score
representing a
CA 03039085 2019-04-01
WO 2018/067440 PCT/US2017/054722
- 25 -
likelihood that the text message 1302 is in one of a plurality of different
Latin languages. The
classifier module 1326 can process the sets of scores using, for example, one
or more classifiers
and/or interpolation techniques described herein, to determine the Latin
language in the text
message 1302.
[0082] In some examples, the grouper module 1306 selects the backoff language
detector
1314 to detect a language in the text message 1302. The backoff language
detector 1314 can be
selected, for example, when the grouper module 1306 does not select the
alphabet-
distinguishable language detector 1308, the Cyrillic language detector 1310,
or the Latin
language detector 1312. Such a situation may occur, for example, when the
grouper module
1306 fails to detect an alphabet and/or a script associated with an alphabet-
distinguishable
language, a Cyrillic language, or a Latin language. When the backoff language
detector 1314 is
selected, the detection methods module 1328 and/or the classifier module 1330
can be used to
identify the language in the text message 1302. The language detection methods
used by the
detection methods module 1328 can be or include, for example, the n-gram
method (e.g., the
byte n-gram method), the dictionary-based method, the alphabet-based method,
the script-based
method, the user language profile method, and any combination thereof The
specific
classifiers used by the classifier module 1330 can be or include, for example,
a supervised
learning model, a partially supervised learning model, an unsupervised
learning model, an
interpolation, and/or any combination thereof Other language detection methods
and/or
classifiers can be used. In general, the backoff language detector 1314 can
use any of the
language detection methods and classifiers described herein. The backoff
language detector
1314 is preferably flexible and can be configured to include or use new
detection methods
and/or new combinations of detection methods as such new methods and/or
combinations are
developed or become available. In some instances, by resorting to the backoff
language
detector 1314, the language detection system 1300 is able to provide a valid
output rather than
a NULL output.
[0083] For purposes of illustration, FIG. 14 is a flowchart of an example
method 1400 for
identifying a language in a text message. The method 1400 includes receiving
the text message
(step 1402) and detecting (step 1404) at least one of a Latin alphabet and a
Latin script in the
text message. A dictionary-based language detection test is performed (step
1406) to determine
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 26 -
a first set of scores, with each score in the first set of scores representing
a likelihood that the
text message is in one of a plurality of different Latin languages. An n-gram
language
detection test is performed (step 1408) to determine a second set of scores,
with each score in
the second set of scores representing a likelihood that the text message is in
one of the plurality
of different Latin languages. The first and second sets of scores are combined
(step 1410)
using, for example, one or more classifiers and/or interpolation techniques.
The language in
the text message is identified (step 1412) based on the combination.
[0084] FIG. 15 is a flowchart of an example method 1500 for identifying a
language in a text
message. A text message is obtained (step 1502) and non-language characters
are removed
(step 1504) from the text message to generate a sanitized text message. An
alphabet and/or a
script are detected in the sanitized text message by performing at least one
of: (i) an alphabet-
based language detection test to determine a first set of scores (step 1506)
and (ii) a script-
based language detection test to determine a second set of scores (step 1508).
Each score in the
first set of scores represents a likelihood that the sanitized text message
includes the alphabet
for one of a plurality of different languages. Each score in the second set of
scores represents a
likelihood that the sanitized text message includes the script for one of the
plurality of different
languages. The language in the sanitized text message is identified (step
1510) based on the
first set of scores, the second set of scores, and/or a combination of the
first and second sets of
scores.
[0085] Embodiments of the subject matter and the operations described in this
specification
can be implemented in digital electronic circuitry, or in computer software,
firmware, or
hardware, including the structures disclosed in this specification and their
structural
equivalents, or in combinations of one or more of them. Embodiments of the
subject matter
described in this specification can be implemented as one or more computer
programs, i.e., one
or more modules of computer program instructions, encoded on computer storage
medium for
execution by, or to control the operation of, data processing apparatus.
Alternatively or in
addition, the program instructions can be encoded on an artificially generated
propagated
signal, e.g., a machine-generated electrical, optical, or electromagnetic
signal, that is generated
to encode information for transmission to suitable receiver apparatus for
execution by a data
processing apparatus. A computer storage medium can be, or be included in, a
computer-
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 27 -
readable storage device, a computer-readable storage substrate, a random or
serial access
memory array or device, or a combination of one or more of them. Moreover,
while a
computer storage medium is not a propagated signal, a computer storage medium
can be a
source or destination of computer program instructions encoded in an
artificially-generated
.. propagated signal. The computer storage medium can also be, or be included
in, one or more
separate physical components or media (e.g., multiple CDs, disks, or other
storage devices).
[0086] The operations described in this specification can be implemented as
operations
performed by a data processing apparatus on data stored on one or more
computer-readable
storage devices or received from other sources.
[0087] The term "data processing apparatus" encompasses all kinds of
apparatus, devices,
and machines for processing data, including by way of example a programmable
processor, a
computer, a system on a chip, or multiple ones, or combinations, of the
foregoing. The
apparatus can include special purpose logic circuitry, e.g., an FPGA (field
programmable gate
array) or an ASIC (application-specific integrated circuit). The apparatus can
also include, in
.. addition to hardware, code that creates an execution environment for the
computer program in
question, e.g., code that constitutes processor firmware, a protocol stack, a
database
management system, an operating system, a cross-platform runtime environment,
a virtual
machine, or a combination of one or more of them. The apparatus and execution
environment
can realize various different computing model infrastructures, such as web
services, distributed
computing and grid computing infrastructures.
[0088] A computer program (also known as a program, software, software
application, script,
or code) can be written in any form of programming language, including
compiled or
interpreted languages, declarative or procedural languages, and it can be
deployed in any form,
including as a stand-alone program or as a module, component, subroutine,
object, or other unit
suitable for use in a computing environment. A computer program can, but need
not,
correspond to a file in a file system. A program can be stored in a portion of
a file that holds
other programs or data (e.g., one or more scripts stored in a markup language
document), in a
single file dedicated to the program in question, or in multiple coordinated
files (e.g., files that
store one or more modules, sub-programs, or portions of code). A computer
program can be
CA 03039085 2019-04-01
WO 2018/067440 PCT/US2017/054722
- 28 -
deployed to be executed on one computer or on multiple computers that are
located at one site
or distributed across multiple sites and interconnected by a communication
network.
[0089] The processes and logic flows described in this specification can be
performed by one
or more programmable processors executing one or more computer programs to
perform
actions by operating on input data and generating output. The processes and
logic flows can
also be performed by, and apparatus can also be implemented as, special
purpose logic
circuitry, e.g., an FPGA (field programmable gate array) or an ASIC
(application-specific
integrated circuit).
[0090] Processors suitable for the execution of a computer program include, by
way of
example, both general and special purpose microprocessors, and any one or more
processors of
any kind of digital computer. Generally, a processor will receive instructions
and data from a
read-only memory or a random access memory or both. The essential elements of
a computer
are a processor for performing actions in accordance with instructions and one
or more memory
devices for storing instructions and data. Generally, a computer will also
include, or be
operatively coupled to receive data from or transfer data to, or both, one or
more mass storage
devices for storing data, e.g., magnetic disks, magneto-optical disks, optical
disks, or solid state
drives. However, a computer need not have such devices. Moreover, a computer
can be
embedded in another device, e.g., a mobile telephone, a personal digital
assistant (PDA), a
mobile audio or video player, a game console, a Global Positioning System
(GPS) receiver, or a
portable storage device (e.g., a universal serial bus (USB) flash drive), to
name just a few.
Devices suitable for storing computer program instructions and data include
all forms of non-
volatile memory, media and memory devices, including, by way of example,
semiconductor
memory devices, e.g., EPROM, EEPROM, and flash memory devices; magnetic disks,
e.g.,
internal hard disks or removable disks; magneto-optical disks; and CD-ROM and
DVD-ROM
disks. The processor and the memory can be supplemented by, or incorporated
in, special
purpose logic circuitry.
[0091] To provide for interaction with a user, embodiments of the subject
matter described in
this specification can be implemented on a computer having a display device,
e.g., a CRT
(cathode ray tube) or LCD (liquid crystal display) monitor, for displaying
information to the
user and a keyboard and a pointing device, e.g., a mouse, a trackball, a
touchpad, or a stylus, by
CA 03039085 2019-04-01
WO 2018/067440 PCT/US2017/054722
- 29 -
which the user can provide input to the computer. Other kinds of devices can
be used to
provide for interaction with a user as well; for example, feedback provided to
the user can be
any form of sensory feedback, e.g., visual feedback, auditory feedback, or
tactile feedback; and
input from the user can be received in any form, including acoustic, speech,
or tactile input. In
addition, a computer can interact with a user by sending documents to and
receiving documents
from a device that is used by the user; for example, by sending web pages to a
web browser on
a user's client device in response to requests received from the web browser.
[0092] Embodiments of the subject matter described in this specification can
be implemented
in a computing system that includes a back-end component, e.g., as a data
server, or that
includes a middleware component, e.g., an application server, or that includes
a front-end
component, e.g., a client computer having a graphical user interface or a Web
browser through
which a user can interact with an implementation of the subject matter
described in this
specification, or any combination of one or more such back-end, middleware, or
front-end
components. The components of the system can be interconnected by any form or
medium of
.. digital data communication, e.g., a communication network. Examples of
communication
networks include a local area network ("LAN") and a wide area network ("WAN"),
an inter-
network (e.g., the Internet), and peer-to-peer networks (e.g., ad hoc peer-to-
peer networks).
[0093] The computing system can include clients and servers. A client and
server are
generally remote from each other and typically interact through a
communication network. The
relationship of client and server arises by virtue of computer programs
running on the
respective computers and having a client-server relationship to each other. In
some
embodiments, a server transmits data (e.g., an HTML page) to a client device
(e.g., for
purposes of displaying data to and receiving user input from a user
interacting with the client
device). Data generated at the client device (e.g., a result of the user
interaction) can be
received from the client device at the server.
[0094] While this specification contains many specific implementation details,
these should
not be construed as limitations on the scope of any inventions or of what can
be claimed, but
rather as descriptions of features specific to particular embodiments of
particular inventions.
Certain features that are described in this specification in the context of
separate embodiments
can also be implemented in combination in a single embodiment. Conversely,
various features
CA 03039085 2019-04-01
WO 2018/067440
PCT/US2017/054722
- 30 -
that are described in the context of a single embodiment can also be
implemented in multiple
embodiments separately or in any suitable subcombination. Moreover, although
features can
be described above as acting in certain combinations and even initially
claimed as such, one or
more features from a claimed combination can in some cases be excised from the
combination,
and the claimed combination can be directed to a subcombination or variation
of a
subcombination.
[0095] Similarly, while operations are depicted in the drawings in a
particular order, this
should not be understood as requiring that such operations be performed in the
particular order
shown or in sequential order, or that all illustrated operations be performed,
to achieve
desirable results. In certain circumstances, multitasking and parallel
processing can be
advantageous. For example, parallel processing can be used to perform multiple
language
detection methods simultaneously. Moreover, the separation of various system
components in
the embodiments described above should not be understood as requiring such
separation in all
embodiments, and it should be understood that the described program components
and systems
can generally be integrated together in a single software product or packaged
into multiple
software products.
[0096] Thus, particular embodiments of the subject matter have been described.
Other
embodiments are within the scope of the following claims. In some cases, the
actions recited in
the claims can be performed in a different order and still achieve desirable
results. In addition,
the processes depicted in the accompanying figures do not necessarily require
the particular
order shown, or sequential order, to achieve desirable results. In certain
implementations,
multitasking and parallel processing can be advantageous.
[0097] What is claimed is: