Note: Descriptions are shown in the official language in which they were submitted.
CA 03071892 2020-02-133
WO 2019/025744 - 1 -
PCT/FR2018/052014
SYSTEME INFORMATIQUE POUR LA VISUALISATION DE PARCOURS
LOGISTIQUE D ' ENTITES DANS LE TEMPS
Domaine de l'invention
La présente invention concerne le domaine de
l'analyse automatique de processus par le traitement de données
brutes constituées par une collection d'informations
descriptives de tâches isolées, pour calculer des enchaînements
récurrents, et fournir des représentations graphiques et des
traitements prédictifs.
Etat de la technique
On connaît dans l'état de la technique la demande de
brevet américain U52017068705 décrivant une méthode mise en
uvre par ordinateur pour l'analyse des données de processus. Le
procédé comprend la réception d'une instruction APE (Advanced
Process Algebra Execution), dans laquelle l'instruction APE
définit une requête d'instances de processus à partir des moyens
de stockage, et dans lequel l'instruction APE comprend au moins
un opérateur de processus et l'exécution de l'instruction APE et
la lecture du processus Instances selon l'instruction APE à
partir des moyens de stockage, et fournissant le résultat de la
requête pour un traitement ultérieur.
On connaît aussi le compte-rendu du colloque
International Conference on Advanced Information Systems
Engineering (CAiSE) 2017
Predictive Business Process
Monitoring with LSTM Neural Networks , auteurs Niek Tax, Ilya
Verenich, Marcello La Rosa, Marlon Dumas.
Cet article concerne une analyse comparative de
méthodes de surveillance des processus métier prédictifs
exploitant les journaux des tâches achevées d'un processus, afin
de calculer des prédictions sur les cas d'exécution de ceux-ci.
CA 03071892 2020-02-03
WO 2019/025744 - 2 -
PCT/FR2018/052014
Les méthodes de prédiction sont appliquées sur
mesure pour des tâches de prédiction spécifiques. L'article
considère que la précision des méthodes de prédiction est très
sensible à l'ensemble de données disponible, ce qui oblige les
utilisateurs à procéder à des essais et erreurs et à les ajuster
lorsqu'ils les appliquent dans un contexte spécifique. Cet
article étudie les réseaux de neurones à mémoire à court terme
(LSTM) comme une approche pour construire des modèles précis
pour une large gamme de tâches de surveillance de processus
prédictifs. Il montre que les LSTM surpassent les techniques
existantes pour prédire l'événement suivant d'un cas en cours et
son horodatage. Ensuite, nous montrons comment utiliser des
modèles pour prédire la tâche suivante afin de prédire la suite
complète d'un cas en cours.
On connaît aussi l'article TensorFlow: A System for
Large-Scale Machine Learning USENIX
https://wvw.usenix.orq/conference/osdi16/technica1.../abadi de
M Abadi, Paul Barham, et al. XP061025043.
On connaît encore la demande de brevet américaine
US 2014214745 décrivant un procédé de surveillance d'un ou
plusieurs messages de mise à jour envoyés et reçus parmi les
composants du système de réseau distribué, les messages de
mise à jour comprenant des informations associées à un état
d'un objet sur le réseau distribué décrivent l'état de
l'objet, pour fournir un modèle d'état d'objet prédictif et
prédire l'occurrence d'un artefact en réponse à l'état de
l'objet.
Inconvénients de l'art antérieur
Les solutions de l'art antérieur ne sont pas adaptées
à la gestion de plusieurs sites, pour fournir pour chaque site
non seulement des informations prédictives, mais aussi une
représentation graphique paramétrable des parcours à partir
d'estimateurs prédictifs communs à l'ensemble des sites et basés
sur des données d'apprentissages communes.
CA 03071892 2020-02-133
WO 2019/025744 - 3 -
PCT/FR2018/052014
De plus, la transposition à une telle application de
visualisation de parcours pour une pluralité de site
nécessiterait des temps de calcul très longs pour l'analyse des
données à partir d'un grand nombre de données. Typiquement, pour
des fichiers d'entrée de plusieurs téraoctets, le nombre de
combinatoires possibles peut nécessiter plusieurs dizaines
d'heures de calcul sur un calculateur standard.
Les solutions de l'art antérieur nécessitent donc
des équipements de calcul surdimensionnés pour permettre à
l'utilisateur de procéder aux traitements requis.
Par ailleurs, les solutions analytiques proposées
dans l'art antérieur ne permettent pas l'utilisation de données
additionnelles à celles du processus et nécessitent de
recalculer à partir de la totalité des données, sans qu'il ne
soit possible de mettre à jour le résultat de manière
incrémental. De plus, ces solutions analytiques ne permettent
d'utiliser que des données qui ne présentent aucune valeur
manquante aussi bien dans les données du processus que dans les
données additionnelles au processus.
Solution apportée par l'invention
L'invention vise à remédier à ses inconvénients par
un système informatique permettant à un grand nombre
d'utilisateurs d'accéder à des modèles complexes, obtenus par
des algorithmes d'apprentissage profond, à partir d'équipements
connectés simples.
A cet effet l'invention concerne selon son acception
la plus générale un système informatique pour la visualisation
de parcours à partir du traitement d'au moins une série de
données d'entrées comportant une liste de tâches horodatées
comprenant l'identifiant d'un objet, l'identifiant d'une action
et une information temporelle, ledit système comportant un
équipement informatique utilisateur connecté exécutant une
application de visualisation ainsi qu'au moins un serveur
CA 03071892 2020-02-03
WO 2019/025744 - 4 -
PCT/FR2018/052014
distant exécutant une application de calcul d'un modèle de
parcours à partir desdites tables,
caractérisé en ce que ledit système comprend :
- un serveur d'administration, comportant des moyens
de gestion d'une pluralité de comptes d'utilisateur et
d'enregistrement, dans le compte de chaque utilisateur, des
tables provenant de l'utilisateur ainsi que des données
relatives à la configuration spécifique de l'utilisateur et le
résultat des traitements effectués sur un serveur de calcul
mutualisé
- au moins un serveur de calcul mutualisé, comportant
un processeur graphique GPU pour exécuter une application
d'apprentissage profond à partir des données associées à un
utilisateur et à construire un modèle numérique enregistré
ensuite dans le compte dudit utilisateur sur l'un au moins
desdits serveurs d'administration ou de calcul
- l'équipement de l'utilisateur exécutant une
application pour commander le calcul, sur l'un desdits serveurs
de calcul, d'un état analytique ou prédictif pour la récupération
et la visualisation des données correspondant au résultat de ce
calcul sur l'interface de l'équipement utilisateur.
Avantageusement, le système informatique comporte en
outre au moins un serveur CPU de répartition de la charge de
calcul entre une pluralité de serveurs de calcul mutualisés.
Selon une variante, il comporte des moyens
d'anonymisation des identifiants des objets et/ou des
identifiants des actions de chaque utilisateur, et
d'enregistrement sous une forme chiffrée sur le compte de
l'utilisateur des moyens de conversion des données anonymisées,
les données traitées par le ou les serveurs de calcul étant
exclusivement constituées de données anonymisées.
De préférence, ledit chiffrement est réalisé par une
fonction de hachage.
CA 03071892 2020-02-133
WO 2019/025744 - 5 -
PCT/FR2018/052014
Description détaillée d'un exemple non limitatif de
l'invention
La présente invention sera mieux comprise à la
lecture de la description détaillée d'un exemple non limitatif
de l'invention qui suit, se référant aux dessins annexés où :
- la figure 1 représente une vue schématique
simplifiée de l'architecture matérielle du système selon
l'invention
- la figure 2 représente une vue schématique de
l'architecture fonctionnelle de la préparation des données
- la figure 3 représente une vue schématique de
l'architecture fonctionnelle de l'exploitation des données
- la figure 4 représente une vue schématique d'un
premier exemple de réseau de neurones pour l'apprentissage
- la figure 5 représente une vue schématique d'un
deuxième exemple de réseau de neurones pour l'apprentissage
- la figure 6 représente une vue schématique d'un
serveur de calcul
- la figure 7 représente une vue schématique
détaillée de l'architecture matérielle du système selon
l'invention
- la figure 8 représente une vue schématique d'un
entrepôt de préparation de commandes pour la mise en uvre de
l'invention.
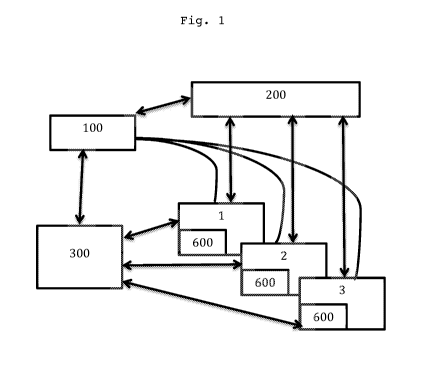
Architecture matérielle
Le système pour la mise en uvre de l'invention
comprend trois types de ressources principales :
- des équipements connectés (1 à 3), pour chacun des
utilisateurs
- un serveur d'administration (100)
- un serveur de calcul mutualisé (200)
- un serveur de récupération des données (300).
CA 03071892 2020-02-03
WO 2019/025744 - 6 -
PCT/FR2018/052014
Par serveur , on entend une machine informatique
unique, ou un groupe de machines informatiques, ou un serveur
virtuel ( cloud en anglais).
Equipement connecté
L'équipement connecté (1 à 3) est typiquement un
équipement standard tel qu'un téléphone cellulaire, une tablette
ou un ordinateur connecté à un réseau informatique, notamment
Internet.
L'invention ne nécessite pas de modification
matérielle de l'équipement connecté (1 à 3). L'accès aux services
est réalisé :
- soit par l'intermédiaire d'un navigateur
permettant de communiquer aux fonctionnalités du serveur
d'administration (100)
- soit par une application dédiée installée sur
l'équipement connecté, pour commander les interactions entre
l'équipement connecté et le serveur d'administration (100).
L'invention permet de gérer une pluralité
d'utilisateur, à partir d'un ou de plusieurs serveurs
d'administration mutualisés et d'un ou de plusieurs serveurs de
calcul mutualisés.
Architecture fonctionnelle
La figure 2 représente une vue schématique de
l'architecture fonctionnelle.
La première étape consiste à créer un compte sur le
serveur d'administration (100).
La création du compte (10) peut être réalisée par
l'administrateur directeur, qui fournit alors les informations
d'accès à l'utilisateur, notamment un identifiant et un mot de
passe ainsi qu'un lien vers l'application ou la page web d'accès
au service.
CA 03071892 2020-02-03
WO 2019/025744 - 7 -
PCT/FR2018/052014
La création du compte (10) peut aussi être réalisée
par l'ouverture d'une session entre un équipement connecté (1)
et le serveur d'administration (100), par une session permettant
de créer un identifiant associé à un mot de passe.
Un compte peut être associé à une pluralité de
parcours, accessible par le même identifiant.
La création d'un nouveau compte (10) commande par
ailleurs l'affectation d'un espace de stockage (50) spécifique
et affecté à l'identifiant correspondant au compte. L'espace de
stockage (50) attribué à un identifiant est privé et inaccessible
aux autres utilisateurs. Optionnellement, cet espace de stockage
(50) est sécurisé et accessible seulement par l'utilisateur
disposant du compte associé, à l'exclusion d'un accès par un
tiers, y compris par un administrateur.
Lors de la création du compte (10), on procède
également à un paramétrage autorisant ou interdisant certaines
fonctionnalités ou des préférences de l'utilisateur (par exemple
langue des messages, ou affichage d'un logo ou personnalisation
des interfaces utilisateur).
L'identification peut être purement déclarative, ou
associée à une procédure sécurisée par exemple par double ou
triple identification.
L'étape suivante (11) consiste à créer un fichier
numérique de configuration (51) d'un parcours se traduisant par
un nom, des paramètres définissant la structure des tables qui
seront transmises, par exemple :
- Nature de l'objet à suivre : par exemple
client , produit , tâche ,...
- Domaine : par exemple service , industrie
qui permettra d'adapter les interfaces utilisateurs.
L'étape suivante (12) consiste à enregistrer dans
l'espace de stockage dédié (50) un fichier numérique de données
(52) comprenant une série d'enregistrements numériques
horodatés. Cet enregistrement peut être réalisé par transfert
depuis l'équipement connecté (1), ou encore par une désignation
CA 03071892 2020-02-03
WO 2019/025744 - 8 -
PCT/FR2018/052014
de l'adresse informatique où sont enregistrées les données
considérées pour une importation via une session sécurisée
commandée par le serveur d'administration (100).
Cette fonctionnalité est réalisée via un connecteur
entre le compte de l'utilisateur dans l'équipement connecté (1)
et le compte de l'utilisateur sur le serveur d'administration
(100), ainsi qu'une tierce application.
Structure des données d'entrée (53, 54)
Les données d'entrée comprennent des données
d'entrée transmises directement (53) ou des données (54)
enregistrées sur une ressource distante à laquelle le serveur
d'administration (100) peut se connecter. Elles sont constituées
par des enregistrements horodatés, par exemple une table, dont
la structure est par exemple de type suivant :
Id. Evènement Date de début Date de fin
(optionnel)
EA21313 Arrivée 2017 05 26 14 25 06 2017 05 26 17 14 56
Les enregistrements peuvent comporter en outre des
informations ou données additionnelles sous forme de chaines de
caractères, de nom, de valeurs numériques ou de valeurs
temporelles telles que :
- localisation de l'événement
- descripteur d'une catégorie d'événement
- un coût de l'événement
- un commentaire ou une annotation
- ...
Ces données peuvent être fournies par un traitement
automatique utilisant des capteurs sur un site, ou un fichier de
log, ou la sortie d'un logiciel d'ERP, ou encore par une saisie
manuelle et plus généralement par tout système de collecte
automatique ou manuelle de données horodatées relatives à des
évènements.
CA 03071892 2020-02-03
WO 2019/025744 - 9 -
PCT/FR2018/052014
Les données (54) peuvent aussi être issues de
systèmes connectés, à partir de l'analyse des signaux échangés
lors d'un protocole de communication, par exemple à partir de
l'identifiant IMSI dans un protocole de communication GSM, ou
les identifiants uniques d'objets connectés transportés dans le
protocole de communication de type LORA.
Enregistrement des données d'entrée
Les données d'entrées sont constituées :
- de données d'entrée (53) transférables sur le
serveur d'administration et/ou
- de données d'entrée (54) accessibles à la volée
depuis une ressources externe.
L'étape (12) consiste à adapter le format des données
d'entrée (53, 54) en fonction de la configuration du fichier de
configuration (51), et à enregistrer les données d'entrée (53)
sous la forme convertie (55) sur le serveur d'administration
(100), les données d'entrée (54) étant conservées sous la forme
originelle sur la ressource d'origine, pour permettre une
conversion à la volée lors des étapes ultérieures
d'apprentissage. L'adaptation consiste à normaliser la structure
des données et éventuellement à convertir le format des dates en
un format standardisé.
Le mode de conversion est enregistré pour permettre
le traitement des données transmises ultérieurement.
On procède ensuite à une étape de configuration (13)
détaillée du parcours par l'analyse des fichiers d'entrée
convertis (54, 55) pour établir une liste (56) des évènements
identifiés dans les données d'entrée converties (54, 55).
Cette liste (56) peut être associée à des
informations additionnelles telles que l'origine de l'événement,
par exemple interne ou externe ou un ordonnancement des
événements selon une séquence préférée.
CA 03071892 2020-02-03
WO 2019/025744 - 10 -
PCT/FR2018/052014
Cette liste (56) est également enregistrée dans
l'espace de stockage du client considéré, dans le fichier de
configuration (51) du parcours.
Optionnellement, on procède à une étape (14) d'ajout
d'informations additionnelles (57) provenant d'une base de
données transférées (58) ou de données interrogeables à la volée
(59) permettant d'extraire des données en fonction de la nature
de l'événement, après conversion et normalisation le cas
échéant. Cette solution permet d'automatiser l'ajout des
informations additionnelles (57) aux données converties (54, 55)
pour enregistrer un fichier enrichi (60) dans le fichier de
configuration (51) et de procéder à un enrichissement à la volée
du fichier (54) en fonction de la procédure d'ajout susvisée.
L'alternative de conversion et d'enrichissement à la
volée permet de mettre en uvre l'invention en temps réel, alors
que l'alternative consistant à enregistrer sur le serveur
d'administration des fichiers convertis et enrichis permet de
procéder à une analyse en temps différé, notamment pour des
usages où les données d'entrées sont rafraîchies en temps
différé.
Anonymisation des données
Les étapes (12) et/ou (14) peuvent comporter en outre
un traitement d'anonymisation consistant par exemple à procéder
à un hachage de l'identifiant de chaque événement, et à masquer
le nom de l'événement, par exemple en substituant un intitulé
aléatoire à chaque événement.
Génération du modèle
La figure 3 représente une vue schématique de
l'architecture fonctionnelle de l'exploitation des données et de
génération du modèle.
Les données ainsi préparées sont utilisées, soit en
temps réel, soit en différé, pour optionnellement construire un
CA 03071892 2020-02-03
WO 2019/025744 - 11 -
PCT/FR2018/052014
modèle numérique (73) mis en service sous la forme d'un code
informatique (80).
La première étape (70) de cette opération consiste
à calculer le graphe des parcours en fonction des enregistrements
(54, 55). Ce calcul est réalisé par l'identification, pour chacun
des individus, des transitions entre deux évènements en fonction
de l'information horodatage.
On enregistre le résultat sous forme d'un graphe
orienté numérique (71) dont les sommets correspondent aux
évènements, et les arêtes correspondent aux transitions avec
l'indication du sens de parcours. Ce graphe numérique (71) est
enregistré dans l'espace de stockage associé au compte, et le
fichier de configuration (51) est modifié pour prendre en compte
l'information relative au calcul d'un nouveau graphe.
Compte tenu du grand nombre de calculs à effectuer,
ceux-ci sont réalisés sur un serveur de calcul mutualisé. En
effet, les calculs portent sur une combinatoire extrêmement
importante, pouvant conduire à des traitements nécessitant
plusieurs heures de calcul sur un ordinateur usuel. A fortiori,
lorsque le serveur est exploité par plusieurs utilisateurs y
disposant chacun de leur compte, le temps de calcul dépasse les
capacités d'un serveur habituel.
Le recours à un serveur dédié au calcul permet au
serveur d'administration de commander la sollicitation du
serveur de calcul de manière optimale, et enregistrer les graphes
numériques dans les comptes des utilisateurs de manière
asynchrone. Il notifie dans ce cas l'utilisateur de la
disponibilité du graphe numérique après la finalisation du
traitement. Le traitement peut également fournir des indicateurs
de qualité du graphe numérique obtenu.
Le graphe numérique (71) est utilisé lors de l'étape
de visualisation (72) en relation avec le fichier de
configuration (51) contenant la liste des évènements (56) et les
fichiers (54, 55) ainsi que le fichier de données additionnelles
(59, 60) pour fournir les données permettant à une application
CA 03071892 2020-02-133
WO 2019/025744 - 12 -
PCT/FR2018/052014
graphique hébergée sur le serveur d'administration (100) pour un
accès en mode web via un navigateur, ou une application exécutée
sur le terminal (1 à 3) de l'utilisateur, de fournir une
représentation visuelle.
Cette représentation visuelle représentant les flux
en fonction du graphe numérique (71), avec des moyens de
paramétrage tel que des filtrages ou des ajouts d'informations
statistiques (par exemple épaisseur des traits fonction du
nombre d'occurrence), et d'extraire des motifs correspondant à
des chemins typiques.
Par ailleurs, le traitement permet également
d'extraire des informations sur des individus et leurs chemins
pour les exporter sous forme de table numérique après filtrage
des parcours ainsi que certains résumés numériques ou
graphiques.
Création d'alerte
Lorsque la durée de certaines interactions dépasse
une valeur de référence ou correspond à une valeur extrême pour
la distribution des valeurs observées, le traitement peut aussi
générer une alerte sous la forme d'un message généré
automatiquement, par exemple sous forme de courriel ou de SMS.
Prédiction de parcours
Pour exploiter les données à des fins de prédiction
de parcours futurs d'un individu en cours de processus,
l'utilisateur commande la création d'un modèle exploitant
l'ensemble des données historiques (54, 55) et des données
enrichies (59, 60).
Le traitement de ces données étant très lourd, ce
traitement n'est pas réalisé sur le serveur d'administration
(100) ni sur l'équipement connecté (1 à 3) mais sur un serveur
dédié (200) comportant au moins une carte graphique.
CA 03071892 2020-02-03
WO 2019/025744 - 13 -
PCT/FR2018/052014
Ce serveur (200) est mutualisé pour l'ensemble des
utilisateurs.
Le traitement est basé sur des solutions
d'apprentissage profond avec un réseau de neurone à deux niveaux
LSTM (long/short term memory) ou de réseaux de neurones
récurrents. Il s'agit de systèmes dynamiques constitués d'unités
(neurones) interconnectés interagissant non-linéairement, et où
il existe au moins un cycle dans la structure. Les unités sont
reliées par des arcs (synapses) qui possèdent un poids. La sortie
d'un neurone est une combinaison non linéaire de ses entrées. On
peut étudier leurs comportements avec la théorie des
bifurcations, mais la complexité de cette étude augmente très
rapidement avec le nombre de neurones.
Le traitement est réparti en deux étapes :
- calcul du modèle prédictif
- exploitation du modèle prédictif.
Structure des réseaux de neurones
La figure 4 représente une vue schématique d'un
premier exemple de réseau de neurones pour l'apprentissage.
Dans l'exemple décrit, l'apprentissage met en uvre
quatre réseaux de neurones distincts de type LSTM (long/short
term memory), en fonction de la nature des données à traiter.
Le premier réseau est constitué par deux couches et
s'applique plus particulièrement aux situations où les données
d'entrée ne comportent qu'une seule information temporelle
correspondant au début de chaque évènement et si la quantité de
données additionnelles est limitée.
La première couche d'entrée (400) de 100 neurones
est commune aux deux réseaux (410, 420) de la couche suivante ;
elle réalise un apprentissage des données pour fournir des
données pondérées à la deuxième couche qui est constituée de
deux ensembles (410, 420) de 100 neurones chacun.
CA 03071892 2020-02-133
WO 2019/025744 - 14 -
PCT/FR2018/052014
Le premier ensemble (410) est spécialisé pour la
prédiction des évènements suivants. Il fournit un indicateur de
qualité correspondant à la probabilité de l'événement prédit.
Le deuxième ensemble (420) est spécialisé pour la
prédiction du début de l'évènement suivant.
La figure 5 représente une vue schématique d'un
deuxième exemple de réseau de neurones pour l'apprentissage.
Le deuxième réseau est constitué par deux couches de
type LSTM (long/short term memory), et s'applique plus
particulièrement aux situations où les données d'entrée
comportent deux informations temporelles correspondant
respectivement au début et à la fin de chaque événement et la
quantité de données additionnelles est importante.
La première couche d'entrée (500) de 100 neurones
est commune aux quatre réseaux (510, 520, 530, 540) de la couche
suivante ; elle réalise un apprentissage des données pour
fournir des données pondérées à la deuxième couche qui est
constituée de quatre ensembles (510, 520, 530, 540) de 100
neurones chacun.
Le premier ensemble (510) est spécialisé pour la
prédiction des évènements suivants. Il fournit un indicateur de
qualité correspondant à la probabilité de l'événement prédit.
Le deuxième ensemble (520) est spécialisé pour la
prédiction de la fin de l'évènement en cours.
Le troisième ensemble (530) est spécialisé pour la
prédiction du début de l'évènement suivant.
Le quatrième ensemble (540) est spécialisé pour la
prédiction de la fin de l'évènement suivant.
Calcul du modèle prédictif
Le modèle prédictif est calculé à l'aide de la
librairie KERAS (nom commercial) destinée à réaliser une
interface vers la librairie TENSORFLOW (nom commercial) écrit en
langage Python (nom commercial), permettant d'utiliser des
cartes graphiques pour la réalisation des calculs.
CA 03071892 2020-02-03
WO 2019/025744 - 15 -
PCT/FR2018/052014
Exploitation du modèle prédictif
Pour l'exploitation des modèles, l'utilisateur
commande une requête comportant des paramètres déterminant un
point de départ existant ou virtuel dans un processus. Le point
de départ est représenté par un parcours partiel, par exemple le
parcours en cours d'un individu ou un parcours partiel typique
ou d'un intérêt particulier.
Pour les deux types de réseaux de neurones susvisés,
le traitement est itéré de manière récursive, pour obtenir le
parcours complet et le cas échéant la durée totale et le moment
de chacun nouvel événement.
Afin d'optimiser le temps de calcul de la prédiction,
et limiter les échanges entre l'équipement connecté (1 à 3) et
le serveur de calcul (200), on exécute les traitements sur un
calculateur (200) comportant des cartes graphiques.
Ces solutions permettent de réaliser des simulations
concernant des parcours en cours, ou de cas virtuels nouveaux,
ou encore de gérer automatiquement des alertes.
L'exploitation des résultats du serveur de
prédiction installé sur le serveur de calcul (200) par
l'utilisateur est réalisé par l'intermédiaire d'un serveur Flask
(nom commercial) écrit en langage Python (nom commercial)
constituant l'interface de communication avec l'équipement
connecté (1 à 3).
Cette communication est réalisée selon un protocole
de type API REST (nom commercial).
Architecture matériel du serveur de calcul
La figure 6 représente une vue schématique d'un
serveur de calcul.
Le serveur de calcul (200) présente une architecture
matérielle comprenant une pluralité d'unités de traitement ou
c urs de traitement, ou multi-c urs (appelées architectures
CA 03071892 2020-02-133
WO 2019/025744 - 16 -
PCT/FR2018/052014
multi-cores en terminologie anglo-saxonne), et/ou multi-n uds.
Les unités centrales Central Processing Unit (CPU) multi-c urs
ou les cartes graphiques Graphics Processing Unit (GPU) sont des
exemples de telles architectures matérielles.
Une carte graphique GPU comprend un grand nombre de
processeurs de calcul, typiquement des centaines, le terme
d'architecture many-cores ou architecture massivement
parallèle est alors employé. Initialement dédiées aux calculs
relatifs au traitement de données graphiques, stockées sous
forme de tableaux de pixels à deux ou trois dimensions, les
cartes graphiques GPU sont actuellement utilisées de manière
plus générale pour tout type de calcul scientifique nécessitant
une grande puissance de calcul et un traitement parallèle des
données.
Classiquement, la mise en uvre d'un traitement de
données parallèle sur une architecture parallèle se fait par la
conception d'une application de programmation utilisant un
langage approprié permettant d'effectuer à la fois du
parallélisme de tâches et du parallélisme de données. Les
langages OpenMP (Open Multi-Processing, nom commercial), OpenCL
(Open Computing Language, nom commercial) ou CUDA (Compute
Unified Device Architecture, nom commercial) sont des exemples
de langages adaptés à ce type d'application.
Le serveur (200) comprend une machine serveur (201)
et un ensemble de quatre dispositifs de calcul (202 à 205).
La machine serveur (201) est adaptée à recevoir les
instructions d'exécution et à distribuer l'exécution sur
l'ensemble de dispositifs de calcul (202 à 205).
Les dispositifs de calcul (202 à 205) des cartes
graphiques GPU, par exemple des cartes NVIDIA Geforce GTX 1070
(nom commercial).
Les dispositifs de calcul (202 à 205) sont soit
physiquement à l'intérieur de la machine serveur (201), soit à
l'intérieur d'autres machines, ou n uds de calcul, accessibles
soit directement, soit via un réseau de communications.
CA 03071892 2020-02-03
WO 2019/025744 - 17 -
PCT/FR2018/052014
Les dispositifs de calcul (202 à 205) sont adaptés
à mettre en uvre des tâches exécutables transmises par la
machine serveur (201). Chaque dispositif de calcul (202 à 205)
comporte une ou plusieurs unités de calcul (206 à 208). Chaque
unité de calcul (206 à 208) comprend une pluralité d'unités de
traitement (209 à 210), ou c urs de traitement, dans une
architecture multi-c urs typiquement 1920 c urs. La machine
serveur (201) comprend au moins un processeur et une mémoire
apte à stocker des données et des instructions.
En outre, la machine serveur (201) est adaptée à
exécuter un programme d'ordinateur comportant des instructions
de code mettant en uvre un procédé d'optimisation de traitement
parallèle de données proposé.
Par exemple, un programme mettant en uvre le procédé
d'optimisation de traitement parallèle de données proposé est
codé en un langage de programmation logiciel connu comme le
langage Python (nom commercial). Un langage de programmation
particulièrement adapté est la librairie TENSORFLOW (nom
commercial) interfaçable avec le langage CUDA (nom commercial)
et la bibliothèque cuDNN (nom commercial).
Architecture matérielle du système
La figure 7 représente une vue schématique détaillée
de l'architecture matérielle du système selon l'invention.
Le système comprend plusieurs serveurs qui sont
communs à tous les utilisateurs, à savoir un serveur
d'administration (100), un serveur de calcul à cartes graphiques
(200) et éventuellement un serveur d'acquisition de données
(300).
Comme indiqué précédemment, chaque utilisateur
accède au système par un équipement connecté (1 à 3) communiquant
avec les serveurs (100, 200, 300) susvisés.
Le serveur d'administration (100) gère les comptes
et les espaces de stockage de chacun des utilisateurs, ainsi que
l'application d'envoi d'alerte.
CA 03071892 2020-02-03
WO 2019/025744 - 18 -
PCT/FR2018/052014
Chacun des utilisateurs dispose d'un espace de
stockage dédié pour l'enregistrement :
- des données de configuration générales (50)
- des données de configuration pour chacun des parcours
(51)
- des données des historiques (55)
- des données additionnelles (60)
- du graphe numérique (71) pour chacun des parcours et des
indicateurs de qualité dudit graphe
- le modèle numérique (73) prédictif pour chacun des
parcours après son calcul sur le serveur de calcul (200).
Le serveur d'administration (100) comporte également
une mémoire pour l'enregistrement du code informatique de
l'application commandant l'exécution soit sur le calculateur
local, soit sur une machine virtuelle distante, de la génération
du graphe numérique.
Le serveur d'administration (100) comporte des
moyens pour l'établissement d'un tunnel sécurisé avec le serveur
de calcul (200) pour l'échange des données nécessaire au calcul
d'un graphe numérique ou d'un modèle prédictif et plus
généralement les échanges de données avec les différentes
ressources informatiques.
Les équipements connectés (1 à 3) exécutent une
application (600) directement ou via un navigateur. Cette
application (600) ne réalise aucun stockage sur l'équipement
connecté (1 à 3), toutes les données étant enregistrées sur le
serveur d'administration (200). Cela permet un accès par
l'utilisateur via un équipement connecté (1 à 3) quelconque, et
à sécuriser les données sensibles en évitant un enregistrement
permanent sur un équipement connecté (1 à 3) non sécurisé.
Cette application (600) communique avec le serveur
d'administration (100) pour :
- optionnellement, créer un compte, lors de la première
utilisation
CA 03071892 2020-02-133
WO 2019/025744 - 19 -
PCT/FR2018/052014
- télécharger sur l'équipement connecté (1 à 3), des
données de configuration (50) depuis l'espace de
stockage dédié à l'utilisateur sur le serveur
d'administration (100) et enregistrer en mémoire vive
ces données sans enregistrement dans une mémoire locale
permanente
- télécharger sur l'équipement connecté (1 à 3), des
données de parcours (55, 60), depuis l'espace de
stockage dédié à l'utilisateur sur le serveur
d'administration (100) ou depuis la ressource externe
pour les données de parcours (54, 59) et enregistrer
lesdites données en mémoire vive, sans enregistrement
dans une mémoire locale permanente, ou un sous-ensemble
de ces données (54, 55 ; 59, 60) correspondant par
exemple à une plage temporelle limitée ou une série
d'identifiants donnée
- en phase de configuration, transmettre depuis
l'équipement connecté (1 à 3),
o les données d'entrée hébergées localement (55)
o ou le lien vers les données d'entrées (54) hébergées
sur une ressource externe
- récupérer depuis le serveur d'administration (100) le
graphe numérique (71).
L'application (600) communique avec le serveur de
calcul (200) pour récupérer à la volée sur l'équipement connecté
(1 à 3) le résultat du calcul de prédiction (prochain événement,
temps de parcours, etc.) et transmettre les instructions de
pilotage du calcul du modèle de prédiction.
Applications particulières
Les données d'entrées peuvent être constituées par
les données provenant d'objets connectés, par exemple les
téléphones cellulaires de passants dans un espace public, par
exemple un hall d'aéroport ou de gare, un pôle commercial, un
CA 03071892 2020-02-133
WO 2019/025744 - 20 -
PCT/FR2018/052014
site urbain, ou un supermarché ou un hôpital. Les données sont
captées par des balises recevant les signaux de service, par
extraction des données techniques transportées par le protocole
de communication, par exemple l'identifiant IMSI, l'horodatage
et la puissance du signal.
Le système selon l'invention permet d'automatiser
l'analyse des déplacements et de réaliser des prédictions de
flux de déplacement.
Pour des objets connectés, l'identifiant analysé est
par exemple l'adresse Mac, pour des communications de type WIFI
ou LoraWan.
Détermination d'un modèle numérique prédictif de l'évolution
d'un processus de préparation de commandes
La description qui suit concerne une variante
particulière, mettant en uvre un modèle prédictif qui,
contrairement à certains modèles prédictifs connus, n'est pas
limité à des situations où les étapes intermédiaires sont
constantes, avec des lois d'évolution linéaires, ce qui ne
correspond pas à la réalité, mais est adapté à un système de
préparation de commande comportant une pluralité de postes
intermédiaires, avec des cheminements parfois complexes des
articles entre le stock et le poste d'expédition des commandes
Présentation schématique d'un entrepôt de préparation
La figure 8 représente un exemple d'organisation
d'un entrepôt pour la préparation de commandes d'articles, à
partir d'un nombre limité de références (quelques dizaines à
quelques centaines, pour un nombre élevé de commandes (quelques
dizaines de milliers), chaque commande regroupant quelques
articles ou quelques dizaines d'articles, correspondant à
quelques références, et à quelques articles par références. Les
ordres de commandes ( pursue order en anglais) arrivent au
CA 03071892 2020-02-03
WO 2019/025744 - 21 -
PCT/FR2018/052014
fil de l'eau avec une distribution présentant un ou plusieurs
maximum et une variabilité importante.
L'expédition des commandes préparées est réalisée
par lots, par exemple pour permettre le regroupement de commandes
en fonction du volume utile du transporteur. Ces regroupements
sont organisés en parallèle, par exemple pour le chargement de
plusieurs zones ou dizaines de zones, correspondant chacune à un
secteur de livraison.
Le problème général est l'optimisation de
l'organisation de l'entrepôt et des ressources affectées pour
réduire le délai entre l'arrivée des ordres de commandes et le
chargement pour l'expédition des commandes préparées et
regroupées, et réduire les points d'accumulation, alors même que
les données prévisionnelles sont imparfaites.
A titre d'exemple, la figure 8 présente une zone de
traitement des ordres de commandes et de préparation des
commandes.
Cette zone comprend un local technique (101)
constituant un poste de commande avec un opérateur et un
ordinateur (102) connecté au système d'information du
fournisseur des articles.
Les ordres de commandes sont reçus sur l'ordinateur
(102) relié à une imprimante (103) pour l'impression, à la
réception de chaque ordre de commande, d'une fiche comprenant :
= Le type d'article et le nombre
= Le destinataire et l'adresse d'expédition de
la commande.
Ces fiches (14) sont déposées dans une bannette par
séries de X, par exemple par séries de 100 fiches.
L'installation comporte par ailleurs une pluralité
de postes de préparation (106 à 108).
Chaque poste de préparation (106 à 108) comporte N
armoires (61 à 62 ; 71 à 73 ; 81 à 82) chargée avec un stock
d'une partie des références disponibles. Ainsi, la totalité des
références est répartie sur les N postes de préparation, sous
CA 03071892 2020-02-03
WO 2019/025744 - 22 -
PCT/FR2018/052014
forme de sous-ensembles de références, chaque poste de
préparation (106 à 108) comportant Lp armoires de stockage
intermédiaire d'une référence donnée d'article.
A chaque poste de préparation de préparation (106 à
108) est associé un ou plusieurs postes de rechargement (106 à
108) des armoires. Optionnellement, un poste de rechargement
(116 à 118) peut être associé à plusieurs postes de préparation.
L'opérateur du poste de préparation (106 à 108) prend
une fiche, identifie les articles le concernant, et extrait des
armoires correspondants les articles visés, pour les quantités
mentionnées sur la fiche et les déposent dans un carton (120)
associé à une fiche donnée. Ce carton (20) est ensuite déplacé
sur tapis convoyeur (21) jusqu'au poste de préparation suivant,
puis envoyé vers un ou plusieurs postes de palettisation (130)
où sont regroupées plusieurs cartons destinées à la même zone de
livraison et au même transporteur.
Alternativement, chacun des cartons reçoit les
références d'un seul poste de préparation (106 à 108).
Les palettes sont ensuite transportées par des
chariots mobiles (31, 32) jusqu'à la zone de chargement dans des
camions (33).
Modélisation numérique de l'organisation de l'entrepôt
et du flux de commande.
Le cheminement des commandes, depuis l'ordre de
commande jusqu'à la zone de chargement, est modélisé sous forme
d'un graphe.
Ce graphe se traduit par :
- des sommets correspondants aux étapes de
traitement, correspondant dans l'exemple au traitement :
- de réception au niveau du local technique
constituant un poste de commande (101)
- de préparation de commande sur les postes de
préparation (106 à 108)
CA 03071892 2020-02-03
WO 2019/025744 - 23 -
PCT/FR2018/052014
- de rechargement des postes de préparation (106 à
108)
- de l'étape de palettisation (30)
- de chargement des camions (33) à l'aide de chariots
(31, 32).
Les arcs reliant deux sommets correspondent aux
transitions réelles entre deux sommets, conformément au
formalisme usuel des réseaux de Petri stochastiques généralisés.
Ces arcs sont équipés de lois de probabilités
permettant de modéliser les lois de transition.
Ces lois de probabilités peuvent être déterminées
soit à partir des données historiques, soit fixées par un
opérateur, en fonction de données d'expert ou d'hypothèses de
simulation.
Par ailleurs, la modélisation comprend une
estimation de la répartition (40) des ordres de commandes au
cours de la journée, en fonction des données historiques ou en
fonction de données d'expert ou d'hypothèses de simulation.
Traitement selon l'invention
On procède ensuite à une simulation par un calcul
probabiliste de la propagation des ordres de commandes arrivant
au fil de l'eau au poste de commande (101), pour représenter
l'évolution des différents n uds au cours de la journée, le taux
d'occupation de chacun des n uds et la durée de parcours de
chacun des ordres de commande.
Cette simulation peut être réalisée par un outil tel
que le logiciel Cosmos
(nom commercial) qui est un model
checker statistique édité par l'Ecole Normale supérieure de
Cachan. Il a pour formalisme d'entrée les réseaux de Petri
stochastiques et évalue des formules de la logique quantitative
HASL. Cette logique, basée sur les automates hybrides linéaires,
permet de décrire des indices de performance complexes relatifs
aux chemins d'exécution acceptés par l'automate. Cet outil
CA 03071892 2020-02-03
WO 2019/025744 - 24 -
PCT/FR2018/052014
fournit ainsi un moyen d'unifier l'évaluation de performance et
la vérification dans un cadre très général.
On procède ensuite à des itérations de cette
simulation plusieurs dizaines de milliers de fois pour obtenir
une convergence de l'estimation de chacun de ces résultats, et
en particulier :
- le nombre moyen d'ordres de commande dans la file
d'attente locale de chacun des postes de traitement, et de son
évolution dans le temps
- le temps cumulé de traitement de la totalité des
ordres de commandes.
Ce temps cumulé est calculé en utilisant la logique
stochastique à automate hybride (HASL) appliquée au système de
modélisation précité.
Le résultat fournit par l'outil Cosmos (nom
commercial) est un fichier de données décrivant l'évolution dans
le temps du graphe, et notamment l'évolution temporelle du nombre
d'ordres dans la file d'attente de chacun des postes. Ce calcul
peut être visualisé par une courbe représentée en figure 9.
En procédant à des itérations de ce traitement, on
obtient une information sur la distribution des paramètres du
réseau, et notamment du nombre d'ordre de commande en attente,
du temps de traitement cumulé de l'ensemble des ordres de
commandes et le temps de parcours de chaque ordre de commande.
La figure 10 représente un exemple de représentation
de la valeur moyenne du temps de traitement cumulé (courbe 50)
et intervalles de confiance à 99% (courbe 51, 52).
Exploitation de ces informations
Ces résultats permettent de déterminer d'éventuels
dépassements d'une valeur seuil de temps cumulé sur une période
prédéterminée (une journée par exemple ou tranche de N heures).
Dans le cas d'identification de risques de dépassement,
l'exploitant peut soit modifier ses contraintes et/ou engagement
vis-à-vis du donneur d'ordre, soit modifier les ressources
CA 03071892 2020-02-03
WO 2019/025744 - 25 -
PCT/FR2018/052014
allouées à un ou plusieurs postes, et procéder à une nouvelle
simulation pour vérifier si cette modification conduit à une
suppression du dépassement de la valeur seuil.
Ils permettent également de redéfinir l'organisation
et de procéder à une nouvelle simulation pour déterminer l'impact
sur des paramètres clés.
Ils permettent également d'organiser les
débordements sur une période temporelle suivante, par exemple
plus le traitement d'une partie des ordres de commande le
lendemain.
L'objectif global de l'invention est d'optimiser
l'organisation physique d'un entrepôt de traitement de commande
afin d'anticiper des situations empêchant le respect de
contraintes relatives au temps de traitement des ordres de
commande dont on ne connaît que de manière approximative le flux
futur et notamment de faire évoluer l'affectation des ressources
futures de manière optimale, en temps quasi-réel.
Les données historiques sont enregistrées sous forme
de fichiers de logs horodatés, à partir des données fournies par
chacun des postes de travail. Ces informations peuvent
optionnellement comprendre les identifiants des opérateurs afin
de permettre une amélioration de la pertinence des simulations
par la prise en compte des opérateurs présents sur chaque poste
de travail et optimiser la composition des équipes en fonction
des objectifs visés.
En particulier l'invention permet de réaliser des
traitements sans nécessiter de moyens de collecte de données sur
chacun des postes de travail. Ainsi, l'invention est applicable
sur des organisations basées sur des opérateurs manuels
utilisant des fiches papier, sur des postes dépourvus
d'équipements de saisies d'informations et/ou de traçabilité en
temps réel.
CA 03071892 2020-02-03
WO 2019/025744 - 26 -
PCT/FR2018/052014
Traitement des données manquantes
Lorsque les données sont incomplètes, l'invention
propose une solution consistant à créer un serveur d'imputation
à l'aide de techniques d'apprentissage profond, typiquement les
techniques d'auto-encodeurs connues sous la désignation de
variational auto-encoders . Un auto-encodeur, ou auto-
associateur est un réseau de neurones artificiels utilisé pour
l'apprentissage non supervisé de
caractéristiques
discriminantes. L'objectif d'un auto-encodeur est d'apprendre
une représentation (encodage) d'un ensemble de données,
généralement dans le but de réduire la dimension de cet ensemble.
Le concept d'auto-encodeur est utilisé pour l'apprentissage de
modèles génératifs Les avantages par rapport aux technique
usuellement utilisées comme MICE, multivariate imputation by
chained equations sont :
- Mise à jour continue et en temps du modèle
d'imputation avec l'arrivée de nouvelles données.
Il permet de réduire le temps d'imputation dès que le modèle est
ajusté et offre la possibilité de faire rapidement de
l'imputation multiple pour évaluer l'incertitude due à la
présence de valeur manquantes, permettant d'obtention d'un
indicateur de confiance pour les prédictions qui intègre la
présence des manquants.