Note: Descriptions are shown in the official language in which they were submitted.
PUBLIC-OPINION ANALYSIS METHOD AND SYSTEM FOR PROVIDING EARLY
WARNING OF ENTERPRISE RISKS
BACKGROUND OF THE INVENTION
Technical Field
[0001] The present invention relates to the technical field of the Internet,
and more particularly
to a public-opinion analyzing method and a system thereof for providing early
warning
of enterprise risks.
Description of Related Art
[0002] Currently, practices of enterprise risk early warning increasingly
depend on and benefit
from applications of technologies like artificial intelligence and natural
language
processing. With the emergence of a great deal of net-based public opinions,
negative
public opinions to or risk events of enterprises have become critical to
identification and
early warning of enterprise risks.
[0003] For users having to pay special attention to enterprise risks, such as
loan approval
managers or risk control managers, it is a significant task to pay close
attention to risk
events of enterprises, thereby acquiring sufficient information about these
risk events and
in turn knowing the risk status of these enterprises. However, this task is
quite labor-
consuming and thus costly. When the number of monitored enterprises is large,
it is
difficult to collect comprehensive information through manual works.
Particularly, when
used to process the massive public-opinion information about enterprises of
interest
circulating over the Internet, manual read can take too much time to give risk
early
warning to relevant enterprises accurately.
SUMMARY OF THE INVENTION
[0004] One objective of the present invention is to provide a method of public-
opinion analysis
for providing early warning of enterprise risks, which can provide a relevant
enterprise
Date Regue/Date Received 2023-01-30
with public-opinion analysis service and early warning service accurately and
efficiently
with reduced human workloads.
[0005] To achieve the foregoing objective, the present invention in a first
aspect provides a
method of public-opinion analysis for providing early warning of enterprise
risks. The
method comprises:
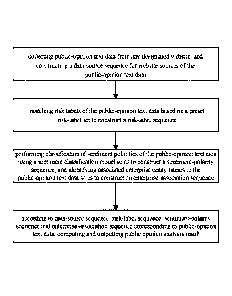
[0006] collecting public-opinion text data from any designated website, and
constructing a data-
source sequence for website sources of the public-opinion text data;
[0007] matching risk labels of the public-opinion text data based on a preset
risk-label set to
construct a risk-label sequence;
[0008] performing classification of sentiment polarities of the public-opinion
text data using a
sentiment classification model so as to construct a sentiment-polarity
sequence, and
identifying associated enterprise entity names in the public-opinion text data
so as to
construct an enterprise-association sequence; and
[0009] according to the data-source sequence, the risk-label sequence, the
sentiment-polarity
sequence and the enterprise-association sequence corresponding to the public-
opinion
text data, computing and outputting a public opinion analysis result.
[0010] Preferably, the step of constructing a data-source sequence for website
sources of the
public-opinion text data comprises:
[0011] summing up a total number of the designated websites and configuring a
credit weight
for each said designated website, so as to construct a data-source sequence
set
dimensionally consistent with the total number; and
[0012] identifying a location of the source website in the data-source
sequence set, constructing
the corresponding data-source sequence, and matching a corresponding said
credit weight
at the same time.
[0013] Preferably, before the step of matching risk labels of the public-
opinion text data with a
preset risk-label set, the method further comprises:
2
Date Recue/Date Received 2022-01-12
[0014] constructing the risk-label set in advance, wherein the risk-label set
includes plural risk-
label classes, and each said risk-label class corresponds to at least one risk
keyword; and
[0015] configuring a risk weight for each said risk-label class in the risk-
label set.
[0016] More preferably, the step of matching risk labels of the public-opinion
text data based on
a preset risk-label set to construct a risk-label sequence comprises:
[0017] performing matching of the risk keywords to the public-opinion text
data by means of
text keyword matching, and searching for corresponding said risk-label class
according
to matching results; and
[0018] based on locations of the risk-label classes in the risk-label set,
constructing the risk-label
sequence.
[0019] Preferably, training of the sentiment classification model comprises:
[0020] extracting public opinion corpora of various sentiment polarities
respectively from
acquired public opinion corpora, so as to construct a tag-corpus set; and
[0021] training the sentiment classification model based on the tag-corpus set
using an LSTM or
TextCNN model structure;
[0022] classifications of the sentiment polarities include positive sentiment,
neutral sentiment,
and negative sentiment, and the sentiment-polarity sequence is a sequence
representation
of one of the three sentiment polarities.
[0023] More preferably, after the step of performing classification of
sentiment polarities of the
public-opinion text data using a sentiment classification model so as to
construct a
sentiment-polarity sequence, the method further comprises:
[0024] configuring a corresponding polarity weight for every said kind of
sentiment polarity.
[0025] Preferably, the step of identifying associated enterprise entity names
in the public-opinion
text data so as to construct an enterprise-association sequence comprises:
[0026] constructing a monitored-enterprise list consisting of plural
enterprise entities in advance;
3
Date Recue/Date Received 2022-01-12
[0027] identifying the enterprise entity name associated with the public-
opinion text data by
means of keyword matching with a Chinese word segmentation tool and/or a NER
naming entity identifying tool; and
[0028] based on a location of the enterprise entity name in the monitored-
enterprise list,
constructing the enterprise-association sequence.
[0029] Preferably, before the step of according to the data-source sequence,
the risk-label
sequence, the sentiment-polarity sequence and the enterprise-association
sequence
corresponding to the public-opinion text data, computing and outputting a
public opinion
analysis result, the method further comprises:
[0030] presetting plural kinds of risk-early-warning levels, and defining
boundary intervals of
each kind of individual risk-early-warning levels.
[0031] More preferably, the step of according to the data-source sequence, the
risk-label
sequence, the sentiment-polarity sequence and the enterprise-association
sequence
corresponding to the public-opinion text data, computing and outputting a
public opinion
analysis result comprises:
[0032] using a public-opinion-risk-early-warning equation z
=riz_oRiLi+V_OWiSi+
Z1:_oQiTi to compute a risk value of the public-opinion text data; and
[0033] computing an early-warning value corresponding to the public-opinion
text data in view
of the enterprise-association sequence, and outputting the risk-early-warning
level based
on the boundary interval to which the early-warning value belongs;
[0034] wherein Ri denotes the risk weight of the corresponding risk-label
class, Li denotes the
risk-label sequence, n denotes a total number of the risk-label classes in the
risk-label
set, Wi denotes the credit weight of the designated website, Si denotes the
data-source
sequence, k denotes the total number of the designated websites, Qi denotes
the polarity
weight, Ti denotes sentiment-polarity sequence, and p denotes a total number
of the
sentiment polarities.
4
Date Recue/Date Received 2022-01-12
[0035] As compared to the prior art, the method of public-opinion analysis for
providing early
warning of enterprise risks provided by the present invention has the
following beneficial
effects:
[0036] in the method of public-opinion analysis for providing early warning of
enterprise risks
of the present invention, public-opinion text data are collected from any
designated
website, and are processed to construct website sources. The risk labels for
the public-
opinion text data are matched based on a preset risk-label set for
constructing a risk-label
sequence. Sentiment polarities of the public-opinion text data are classified
using a
sentiment classification model so as to construct a sentiment-polarity
sequence. The
entity names of enterprises associated with the public-opinion text data are
identified and
used to construct an enterprise-association sequence. At last, a public
opinion analysis
result is computed according to the data-source sequence, the risk-label
sequence, the
sentiment-polarity sequence and the enterprise-association sequence
corresponding to the
public-opinion text data, and then outputted.
[0037] It is thus clear that the present invention deeply digs potential risk
information of
enterprise through multi-dimensional data processing, so as to form a public-
opinion
analyzing process, thereby realizing smart early warning of potential risks
for enterprises
and helping risk business personnel to conduct enterprise risk control and
assessment
more efficiently.
[0038] In a second aspect, the present invention provides a system of public-
opinion analysis for
providing early warning of enterprise risks, which is applied to the method of
public-
opinion analysis for providing early warning of enterprise risks as described
in the
foregoing technical scheme. The system comprises:
[0039] a public-opinion-collecting module, for collecting public-opinion text
data from any
designated website, and constructing a data-source sequence for website
sources of the
public-opinion text data;
[0040] a risk label module, for matching risk labels of the public-opinion
text data based on a
Date Recue/Date Received 2022-01-12
preset risk-label set to construct a risk-label sequence;
[0041] a sentiment-polarity and entity-name identifying module, for performing
classification of
sentiment polarities of the public-opinion text data using a sentiment
classification model
so as to construct a sentiment-polarity sequence, and identifying associated
enterprise
entity names in the public-opinion text data so as to construct an enterprise-
association
sequence; and
[0042] an early warning outputting module, for according to the data-source
sequence, the risk-
label sequence, the sentiment-polarity sequence and the enterprise-association
sequence
corresponding to the public-opinion text data, computing and outputting a
public opinion
analysis result.
[0043] As compared to the prior art, the disclosed public-opinion analyzing
apparatus for
providing early warning of enterprise risks provides beneficial effects that
are similar to
those provided by the method of public-opinion analysis for providing early
warning of
enterprise risks as enumerated above, and thus no repetitions are made herein.
[0044] The present invention in a third aspect provides a computer readable
storage medium,
storing thereon a computer program. When the computer program is executed by a
processor, it implements the steps of the method of public-opinion analysis
for providing
early warning of enterprise risks as described previously.
[0045] As compared to the prior art, the disclosed computer-readable storage
medium provides
beneficial effects that are similar to those provided by the method of public-
opinion
analysis for providing early warning of enterprise risks as enumerated above,
and thus no
repetitions are made herein.
BRIEF DESCRIPTION OF THE DRAWINGS
[0046] The accompanying drawings are provided herein for better understanding
of the present
invention and foun a part of this disclosure. The illustrative embodiments and
their
6
Date Recue/Date Received 2022-01-12
descriptions are for explaining the present invention and by no means form any
improper
limitation to the present invention, wherein:
[0047] FIG. 1 is a schematic flowchart of a method of public-opinion analysis
for providing early
warning of enterprise risks according to one embodiment of the present
invention; and
[0048] FIG. 2 is another schematic flowchart of a method of public-opinion
analysis for
providing early warning of enterprise risks according to one embodiment of the
present
invention.
DETAILED DESCRIPTION OF THE INVENTION
[0049] To make the foregoing objectives, features, and advantages of the
present invention
clearer and more understandable, the following description will be directed to
some
embodiments as depicted in the accompanying drawings to detail the technical
schemes
disclosed in these embodiments. It is, however, to be understood that the
embodiments
referred herein are only a part of all possible embodiments and thus not
exhaustive. Based
on the embodiments of the present invention, all the other embodiments can be
conceived
without creative labor by people of ordinary skill in the art, and all these
and other
embodiments shall be embraced in the scope of the present invention.
[0050] Embodiment 1
[0051] Referring to FIG. 1 and FIG. 2, the present embodiment provides a
method of public-
opinion analysis for providing early warning of enterprise risks, comprises:
[0052] collecting public-opinion text data from any designated website, and
constructing a data-
source sequence for website sources of the public-opinion text data; matching
risk labels
of the public-opinion text data based on a preset risk-label set to construct
a risk-label
sequence; performing classification of sentiment polarities of the public-
opinion text data
using a sentiment classification model so as to construct a sentiment-polarity
sequence,
and identifying associated enterprise entity names in the public-opinion text
data so as to
construct an enterprise-association sequence; according to the data-source
sequence, the
risk-label sequence, the sentiment-polarity sequence and the enterprise-
association
7
Date Recue/Date Received 2022-01-12
sequence corresponding to the public-opinion text data, computing and
outputting a
public opinion analysis result.
[0053] In the method of public-opinion analysis for providing early warning of
enterprise risks
of the present invention, public-opinion text data are collected from any
designated
website, and are processed to construct website sources. The risk labels for
the public-
opinion text data are matched with a preset risk-label set for constructing a
risk-label
sequence. Sentiment polarities of the public-opinion text data are classified
using a
sentiment classification model so as to construct a sentiment-polarity
sequence. The
entity names of enterprises associated with the public-opinion text data are
identified and
used to construct an enterprise-association sequence. At last, a public
opinion analysis
result is computed according to the data-source sequence, the risk-label
sequence, the
sentiment-polarity sequence and the enterprise-association sequence
corresponding to the
public-opinion text data, and then outputted.
[0054] It is thus clear that the present invention deeply digs potential risk
information of
enterprise through multi-dimensional data processing, so as to form a public-
opinion
analyzing process, thereby realizing smart early warning of potential risks
for enterprises
and helping risk business personnel to conduct enterprise risk control and
assessment
more efficiently.
[0055] In the embodiment described above, the step of constructing a data-
source sequence
according to website sources of the public-opinion text data comprises:
[0056] summing up a total number of the designated website and configuring a
credit weight for
each said designated website, so as to construct a data-source sequence set
dimensionally
consistent with the total number; and identifying a location of the source
website in the
data-source sequence set, constructing the corresponding data-source sequence,
and
matching a corresponding said credit weight.
8
Date Recue/Date Received 2022-01-12
[0057] In particular implementations, the public-opinion-collecting module
serves to collect
public-opinion text data of enterprises and perfonn structurized data
extraction. The first
thing to do is to set and configure public-opinion data source. Sources of
public opinions
about enterprises primarily include news websites, government websites,
forums,
WEIBO, and websites receiving complaints. The source sequence is S = {S1, S2,
,SO.
According to the sources of public opinions, different credit weights Wi are
assigned.
The credit weights may alternatively be configured by users. The step further
includes
setting addresses, site sections, data-collecting frequencies, keywords of the
public-
opinion data sources. Then an Internet-based data collecting tool is used to
acquire public-
opinion text data. Afterward, a Python-based or Java-based html processing
tool is used
to denoise the webpages, clean data, and extract fields, so that data of
public-opinion
webpage data can be extracted in a structurized manner by fields like titles,
sources, links,
releasing date, text, summaries, and authors.
[0058] Exemplarily, collecting the public-opinion text data is realized
through the following
steps:
[0059] Step 1: using the Python-based or Java-based html processing tool to
denoise the
webpages, clean data, and extract fields, so that data of public-opinion
webpage data can
be extracted in a structurized manner by fields like titles, sources, links,
releasing date,
text, summaries, and authors. In an example, the set list of designated
websites is
['website 1", "website 2", "website 3", "website 4", "website 5, "website 6",
"website 7",
"website 8", "website 9"], and the credit weights assigned to the designated
websites are
(ranging from 1 to 5): [5, 5, 3, 5, 3, 3, 5, 5, 4].
[0060] Step 2: the extracted structurized text data are stored in the form of:
"title": "Fake products doing great harm, how to rule special formula milk
powder
products in a targeted way";
"content": "The powdered protein beverage event in XXXX is about falsely
claiming that
9
Date Recue/Date Received 2022-01-12
powdered protein beverage is a kind of special formula milk powder, and led to
severe
dysplasia among infants and babies. In this event, a series of violating
operations
including illegal propaganda, sales malpractice, and consumer fraud caused
health
damage to infants and babies .... ,>.
[0061] "datetime": "2020-06-08 09:40:31";
"source": "certain social media platform";
"ur1": http://food.china.com.cn/2020-06/08/content76137776.htm;
"author": "Wang XX",
"summary": ""
1.
[0062] In the embodiment described above, before the step of matching risk
labels of the public-
opinion text data based on a preset risk-label set, the method further
comprises:
[0063] constructing the risk-label set in advance, wherein the risk-label set
includes plural risk-
label classes, and each said risk-label class corresponds to at least one risk
keyword; and
configuring a risk weight for each said risk-label class in the risk-label
set.
[0064] The step of matching risk labels of the public-opinion text data based
on a preset risk-
label set to construct a risk-label sequence comprises:
[0065] performing matching of the risk keywords to the public-opinion text
data by means of
text keyword matching, and searching for corresponding said risk-label class
according
to matching results; and based on locations of the risk-label classes in the
risk-label set,
constructing the risk-label sequence.
[0066] The risk label module mainly serves to extract risk labels in public
opinions by means of
matching risk keywords according to a risk-label set created in advance.
First, a risk-label
set is constructed for classes of risk events that are commonly seen in public
opinions
about enterprises and classes of risk events the users care. Every risk label
is assigned
with a corresponding risk weight R. The risk weight may alternatively be
configured by
the users. A keyword set is developed for each of the risk labels, so as to
form a "label -
Date Recue/Date Received 2022-01-12
keyword dictionary". Then the public opinion text is matched with the risk
keywords by
means text keyword matching, and tagging is made according to the matching
results, so
as to generate a risk-label sequence L = {L1, L2, ,L) of the public opinions,
where n
is the total number of the risk labels, Li corresponds to the 0/1
identification
corresponding to the risk label, 1 denotes that there is the ith label in the
public opinions,
and 0 denotes that there is not the ith label in the public opinions.
[0067] Exemplarily, the risk label matching process performed on the public-
opinion text data is
achieved through the following steps:
[0068] Step 1, a risk-label set is created by performing label definition
wrangling on public
opinion risk class while concerning business requirements from the risk
management
field, e.g.:
[0069] [`bankruptcy and insolvency", "mortgage and pledge", "loss", "equity
change", "default
and thunder", "Illegal fundraising", "infringement and plagiarism", "contract
dispute",
"violation of regulations or laws", "falsity and fraud", "tax evasion",
"security events"];
wherein the risk weights (ranging from 1 to 10) corresponding to the risk-
label classes
are set as: [10, 5, 7, 10, 4, 3, 2, 2, 5, 3, 3].
[0070] Step 2, the risk-label classes corresponding to risk keyword set are
wrangled to form a
"label -keyword dictionary"; for example:
[0071] {
[0072] bankruptcy and insolvency: bankruptcy and insolvency, bankruptcy,
frozen, business
closed, business suspend, suspend business for rectification, seized, revoked,
detained,
non-standard opinion;
[0073] mortgage and pledge: debt collateralizing, collateralizing debt, asset
value less than
issued debt, asset mortgage, security for loan, pledge of equity;
[0074] loss: loss, aggravation, arrears, perfoimance increase, sales decrease;
[0075] equity change: equity change, pledge of equity, changes in equity,
increase holdings,
11
Date Recue/Date Received 2022-01-12
decrease holdings, capital reduction, split-up, merged;
[0076] default and thunder: debt default, thunder, runaway, overdue, dishonest
person,
uncertainty of cashing, arrears in contribution, P2P, blacklist, executed,
risk;
[0077] contract dispute: contract dispute, contract cancellation, labor
dispute, labor lawsuit;
[0078] falsity and fraud: financial fraud, suspected fraud, financial scandal,
fraud;
[0079] Illegal fundraising: Illegal fundraising, fundraising fraud;
[0080] tax evasion: tax dodging, tax fraud, tax avoiding;
[0081] infringement and plagiarism: infringement, plagiarism;
[0082] security events: incident, information leakage, private data, data
leakage, production
incident;
[0083] violation of regulations or laws: violation of law, violation of
regulation, complaint, right
protection, MLM, economic investigation intervention, arbitration, commission,
loan
shark, criminal case, prosecuted, involved in gangs or vices, official
investigation;
[0084] 1.
[0085] Step 3, through keyword matching, the public opinion text is matched
with the risk
keywords, and according to the matching results, tagging is made with the
labels, so as
to obtain a risk-label sequence.
[0086] Assuming that one collected entry of public-opinion text data is "A
series of incidents
happened in constructions undertaken by )00CX and the company is now forbidden
from
managing new projects by the Housing and Construction Office due to violation
",
and the word "violation" in the public-opinion text data matches a risk
keyword in the
risk label of "violation of regulations or laws", the risk label matching the
public-
opinion text data is "violation of regulations or laws". Because the other
risk labels are
all unmatched, "1"is only used to mark the risk-label sequence at the location
of the
element corresponding to "violation of regulations or laws", and the locations
of the other
elements in the risk-label sequence are marked with "0". As a result, the risk-
label
sequence corresponding to the foregoing public-opinion text data is [0, 0, 0,
0, 0, 0, 0, 0,
12
Date Recue/Date Received 2022-01-12
0, 0, 1].
[0087] In the embodiment described above, training of the sentiment
classification model
comprises:
[0088] extracting public opinion corpora of various sentiment polarities from
acquired public
opinion corpora, so as to construct a tag-corpus set; and training the
sentiment
classification model based on the tag-corpus set using an LSTM or TextCNN
model
structure; in which the sentiment polarities include positive sentiment,
neutral sentiment,
and negative sentiment, and the sentiment-polarity sequence is a sequence
representation
of one of the three sentiment polarities.
[0089] In particular implementations, the sentiment-polarity and entity-name
identifying module
extract public-opinion data sets of three polarities, including positive,
neutral, and
negative sentiment kinds (i.e., positive sentiment, neutral sentiment, and
negative
sentiment) from acquired public opinion corpora according to pre-defined
positive and
negative sentiment dictionary for a certain enterprise to form a tag-corpus
set. For
example:
[0090] [
[0091] The public opinion corpora of "negative sentiment":
[0092] A loss as high as 1.7 billion CNY, with power stations devalued; Is the
case of X tech-
company a common suffering of the industry;
[0093] New movies scheduled for February are halted again, 90% film and
television stocks hit
the limit down and cinema stocks enter the "Glacier Era";
[0094] Takkyubin accused: a network technology company presumed to increase
pricing and
graft price differences;
[0095] A courier company in Shanghai is so inefficient that couriers quit for
other careers;
[0096] ....
[0097] The public opinion corpora of "public opinion corpora":
[0098] Challenging "vaccine leader" XXXX! First domestic vaccines launched;
13
Date Recue/Date Received 2022-01-12
[0099] With a burst of bullish news in the tera-scale plate blasted another
harden of hundred-
billion leading stocks;
[0100] Bullish news continuously come in the hydrogen energy industry and two
sectors are
expecting long-temi growth;
[0101] certain video platform is still "solid";
[0102] ....
[0103] The public opinion corpora of "neutral sentiment":
[0104] What exactly the "long-termism" advocated by A, B, and C is;
[0105] An image to the quotations in 2020;
[0106] Say goodbye to the getting-ready 2019 and enter the deep transformation
in 2020;
[0107] Why Central Bank of certain country decided to cut the requirement
reserve ratio in early
January? For providing the market with liquidity;
[0108] ....
[0109]
[0110] After text pre-processing is performed on the public opinion corpora, a
word embedding
model that has been trained with a large quantity of public opinion text about
enterprises
of interest is used as a text vector representative for model training.
Afterward, the
sentiment classification model was trained based on LSTM/TextCNN. As training
sentiment classification models is known in the art, no detailed description
is given and
discussion herein is merely made to the results. As demonstrated by the
statistics, the
sentiment classification model according to the present embodiment when based
on 100
thousand entries of data provided an accuracy rate of 87%, satisfying
expectation.
[0111] In the embodiment described above, after the step of classifying
sentiment polarities of
the public-opinion text data using a sentiment classification model so as to
construct a
sentiment-polarity sequence, the method further comprises:
[0112] For every sentiment polarity, a corresponding polarity weight Qt is
set, wherein Qi=
(Qi,Q2P Q3). In the sentiment-polarity sequence Ti = fT1, T2, T3), T1 denotes
positive
14
Date Recue/Date Received 2022-01-12
sentiment, T2 denotes neutral sentiment, and T3 denotes negative sentiment. Q1
denotes the polarity weight corresponding to the positive sentiment, Q2
denotes the
polarity weight corresponding to the neutral sentiment, and Q3 denotes the
polarity
weight corresponding to the polarity weight.
[0113] In the embodiment described above, the step of identifying associated
enterprise entity
names in the public-opinion text data so as to construct an enterprise-
association sequence
comprises:
[0114] constructing a monitored-enterprise list consisting of plural
enterprise entities in advance;
using a Chinese word segmentation tool and/or a NER naming entity identifying
tool to
identify the enterprise entity name associated with the public-opinion text
data by means
of keyword matching; and based on a location of the enterprise entity name in
the
monitored-enterprise list, constructing the enterprise-association sequence.
[0115] In particular implementations, a public-opinion processing platform is
used to identify
enterprise entities from the collected public-opinion text data, to extract
risk labels from
the data and to analyze sentiment polarities of the data. Meantime, a
personalized
configuring service provides standardized application configuration interface.
[0116] First, the public-opinion input module performs text pre-processing on
titles, content text,
and summary text of public-opinion text data collected in a real-time manner
from public-
opinion data sources according to subscription, so as to remove undesired stop
words and
conduct Chinese word segmentation. The second step is to process public-
opinion labels
and classify sentiment polarities. The pre-processed public-opinion text data
are entered
into a risk label module to generate risk-label sequences and are entered into
the sentiment
polarity analyzing module to generate sentiment polarity labels, such as
positive
sentiment, neutral sentiment or negative sentiment. At the third step, the
enterprise
entities associated with the public-opinion text data are identified using the
combination
Date Recue/Date Received 2022-01-12
of the Chinese word segmentation tool and the NER naming entity identifying
tool as
well as keyword matching, based on the dictionary of full names, short names,
and aliases
of monitored enterprises through the list of enterprises monitored. The public-
opinion
text data are associated with the enterprise entities to form an enterprise-
association
sequence E = 1,E1, E2, , Ern), where m is the number of all the monitored
enterprises,
Ei is the 0/1 label, in which 1 denotes the public opinion is associated with
the ith
enterprise, and 0 denotes not associated. The personalized configuring module
of the
platform supports synchronization of the monitored-enterprise list, updating
of the
sentiment polarity dictionary, and setting of the public opinion sources and
the risk label
weights.
[0117] Exemplarily, for public-opinion text data saying "A series of incidents
happened in
constructions undertaken by XXXX and the company is now forbidden from
managing
new projects by the Housing and Construction Office due to violation ..... ",
this entry of
data is classified by its sentiment polarity to confirm that the public
opinion sentiment
label is negative sentiment. Through extraction of the associated enterprise
entities, the
monitored enterprise list sequence corresponding to the public opinion
association
enterprises is generated as
[0118] [ ... , 0, 1,0, ..
[0119] In the embodiment described above, before the step of according to the
data-source
sequence, the risk-label sequence, the sentiment-polarity sequence and the
enterprise-
association sequence corresponding to the public-opinion text data, computing
and
outputting a public opinion analysis result, the method further comprises:
[0120] presetting plural kinds of risk-early-warning levels, and defining
boundary intervals of
each kind of risk-early-warning level.
[0121] In particular implementations, a risk early warning score is computed
according to the
early warning labels and the list of enterprises monitored I = U1i2, ...,J,i)
(where Ji
16
Date Recue/Date Received 2022-01-12
is a 0/1 label) subscribed by the user and according to the data-source
sequences, credit
weights, risk-label sequences, risk weights, sentiment-polarity sequences,
polarity
weights, and enterprise-association sequence of public-opinion text data, the
early
warning level is determined according to a risk threshold value. Then
enterprise public
opinion information that satisfies the requirements is pushed to the user as
early warning.
[0122] Exemplarily, for the risk-early-warning level A= {no early warning,
normal, important,
serious), the boundary intervals corresponding to every risk-early-warning
level is: H =
tHi, H2, H3). In other words, when the score is smaller than Hi, the
corresponding risk-
early-warning level is not to give early warning. When the score is greater
than Hi and
smaller than H2, the corresponding risk-early-warning level is normal. When
the score
is greater than H2 and smaller than H3, the corresponding risk-early-warning
level is
important. When the score is greater than H3, the corresponding risk-early-
warning level
is serious. The score corresponding to the sentiment polarity is Q = (Q1, Q2,
Q3), and the
sentiment-polarity sequence corresponding to the public-opinion text data is T
=
(T1, T2, T3), where only Ti is 1, and the other two are 0.
[0123] The step of according to the data-source sequence, the risk-label
sequence, the sentiment-
polarity sequence and the enterprise-association sequence corresponding to the
public-
opinion text data, computing and outputting a public opinion analysis result
comprises:
[0124] using a public-opinion-risk-early-warning equation z = J
R1L -EV-007A +
El_oQiTi to compute a risk value of the public-opinion text data; and
computing an
early-warning value corresponding to the public-opinion text data in view of
the
enterprise-association sequence to, and outputting the risk-early-warning
level based on
the boundary interval to which the early-warning value belongs; the Ri denotes
the risk
weight of the corresponding risk-label class, Li denotes the risk-label
sequence, n
denotes a total number of the risk-label classes in the risk-label set, Wi
denotes the credit
weight of the designated website, Si denotes the data-source sequence, k
denotes the
total number of the designated websites, Qi denotes the polarity weight, Ti
denotes
17
Date Recue/Date Received 2022-01-12
sentiment-polarity sequence, and p denotes a total number of the sentiment
polarities.
[0125] In particular implementations, for some user, the risk early warning
score of some entry
of public-opinion text data can be computed using the equation below:
[0126] z = RiLi +ZI[_OWiSi
[0127] With the vector inner product represented by (x, y), the equation above
can be rewritten
as
[0128] z = (R , L) + (W , S) + (Q ,T)
[0129] With the sequence information of the associated enterprise combined, it
is obtained that
[0130] z' = z = e((E , J))
[0131] where E(x) is a unit step function,
[0132] E(x) = [ 0, 1, > 0
x < 0
[0133] It is understandable that when the enterprise entity name shown in this
entry of public-
opinion text data exists in the monitored-enterprise list, the value of E(x)
is 1. At this
time, a risk early warning score is computed. When the enterprise entity name
mentioned
in the entry of public-opinion text data does not exist in the list of
enterprises monitored,
the value of E(X) is 0. In this case, nor more computation for the risk early
warning score
is conducted thereto.
[0134] Further, the early warning mark is Output (z') = (Y (Z), A) , where
Y(x) =
fy, (x), y2 (x),y3(x),y4(x)} , and the values of the two-value function
yi(x), y2(x), y3(x), y4(x) is True or False (i.e., 1 or 0) :
[0135] y1(x) = 0 x <
[0136] y2 (x) = x <H2
[0137] y3(x) = H2 X < H3
[0138] y4(x) = x H3
[0139] Output(z') is output as the early warning mark: no early warning,
nomial, important,
or serious.
18
Date Recue/Date Received 2022-01-12
[0140] For example, risk-early-warning level A= {no early warning, normal,
important, serious),
corresponding threshold value: H = ( H1 = 5, H2 = 10, H3 = 30).
[0141] The score corresponding to the sentiment polarities (positive
sentiment, neutral sentiment,
and negative sentiment) is Q = (1,2,3) , and the sentiment-polarity sequence
corresponding to this entry of the public-opinion text data is T = (0,04
[0142] Taking inputting the public-opinion text data: "A series of incidents
happened in
constructions undertaken by XXXX and the company is now forbidden from
managing
new projects by the Housing and Construction Office due to violation .....
"for example,
the public-opinion text data came from NetEase, and the corresponding data-
source
sequence vector is [0, 0, 0, 1, 0, 0, 0, 0, 0]. The early warning label
subscribed by the user
is "security incident", and the list of monitored enterprises include XXXX.
[0143] According to the equation below, the risk early warning score is:
[0144] z = (R,L) + (W,S) + (Q, T) = 5 + 3 + 3 = 11
[0145] Since the public-opinion text data contains an associated enterprise
(XXXX) that is one of
the enterprises monitored by the user monitoring, (E ,J) > 0, so c((E ,J)) =
1, thereby
obtaining that z' = z = z((E ,J)) = z = 11.
[0146] Further, because H2 <z' <H3, H3 Y(z') = (0,0,1,0), and therefore the
resulting early
warning mark is Output (z') = (Y (Z), A)= "important". The early warning
outputting
module thus outputs the public opinion "A series of incidents happened in
constructions
undertaken by XXXX and the company is now forbidden from managing new projects
by the Housing and Construction Office due to violation .................. "
to the user as an
"important" early warning.
[0147] To sum up, the schemes of the present embodiment are intended to dig
potential risk
19
Date Recue/Date Received 2022-01-12
information about enterprises of interest, and provide automated and
personalized
configuration, so as to form a public-opinion analyzing process and give smart
early
warning of potential risks to relevant enterprises, thereby helping risk
business personnel
to conduct enterprise risk control and assessment more efficiently.
[0148] Embodiment 2
[0149] The present embodiment provides a system of public-opinion analysis for
providing early
warning of enterprise risks. The system comprises:
[0150] a public-opinion-collecting module, for collecting public-opinion text
data from any
designated website, and constructing a data-source sequence according to
website sources
of the public-opinion text data;
[0151] a risk label module, for matching risk labels of the public-opinion
text data based on a
preset risk-label set to construct a risk-label sequence;
[0152] a sentiment-polarity and entity-name identifying module, for performing
classification of
sentiment polarities of the public-opinion text data using a sentiment
classification model
so as to construct a sentiment-polarity sequence, and identifying associated
enterprise
entity names in the public-opinion text data so as to construct an enterprise-
association
sequence; and
[0153] an early warning outputting module, for according to the data-source
sequence, the risk-
label sequence, the sentiment-polarity sequence and the enterprise-association
sequence
corresponding to the public-opinion text data, computing and outputting a
public opinion
analysis result.
[0154] As compared to the prior art, the system of public-opinion analysis for
providing early
warning of enterprise risks of the present embodiment provides beneficial
effects that are
similar to those provided by the method of public-opinion analysis for
providing early
warning of enterprise risks as enumerated in the previous embodiment, and thus
no
repetitions are made herein.
Date Recue/Date Received 2022-01-12
[0155] Embodiment 3
[0156] The present embodiment provides a computer-readable storage medium,
storing thereon
a computer program. When the computer program is executed by a processor, it
implements the steps of the method of public-opinion analysis for providing
early
warning of enterprise risks as described previously.
[0157] As compared to the prior art, the computer-readable storage medium of
the present
embodiment provides beneficial effects that are similar to those provided by
the method
of public-opinion analysis for providing early warning of enterprise risks as
enumerated
in the previous embodiment, and thus no repetitions are made herein.
[0158] As will be appreciated by people of ordinary skill in the art,
implementation of all or a
part of the steps of the method of the present invention as described
previously may be
realized by having a program instruct related hardware components. The program
may
be stored in a computer-readable storage medium, and the program is about
performing
the individual steps of the methods described in the foregoing embodiments.
The storage
medium may be a ROM/RAM, a hard drive, an optical disk, a memory card or the
like.
[0159] The present invention has been described with reference to the
preferred embodiments
and it is understood that the embodiments are not intended to limit the scope
of the present
invention. Moreover, as the contents disclosed herein should be readily
understood and
can be implemented by a person skilled in the art, all equivalent changes or
modifications
which do not depart from the concept of the present invention should be
encompassed by
the appended claims. Hence, the scope of the present invention shall only be
defined by
the appended claims.
21
Date Recue/Date Received 2022-01-12