Note : Les revendications sont présentées dans la langue officielle dans laquelle elles ont été soumises.
Claims:
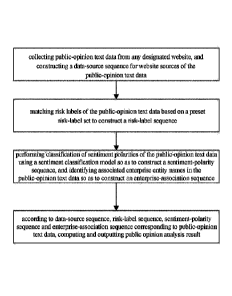
1. A method comprising:
collecting public-opinion text data from any designated website;
constructing a data-source sequence for website sources of the public-opinion
text data,
wherein a credit weight is assigned for each designated website;
matching risk labels of the public-opinion text data based on a preset risk-
label set to
construct a risk-label sequence, wherein the preset risk-label set includes
risk keywords
configured in a risk-label class wherein in each risk-label class has a risk
weight;
performing classification of sentiment polarities of the public-opinion text
data using a
sentiment classification model to construct a sentiment-polarity sequence;
identifying associated enterprise entity names in the public-opinion text data
to construct
an enterprise-association sequence; and
computing and outputting a public opinion analysis result according to the
data-source
sequence, the risk-label sequence, the sentiment-polarity sequence and the
enterprise-
association sequence corresponding to the public-opinion text data.
2. The method of claim 1, wherein constructing the data-source sequence for
the website
sources of the public-opinion text data comprises:
summing up a total number of the designated websites;
configuring the credit weight for each designated website, to construct a data-
source
sequence set dimensionally consistent with the total number;
identifying a location of the source website in the data-source sequence set;
constructing the corresponding data-source sequence; and
matching a corresponding credit weight.
22
3. The method of claim 1, further comprises:
constructing the risk-label set in advance, wherein the risk-label set
includes plural risk-
label classes, and each risk-label class corresponds to at least one risk
keyword; and
configuring the risk weight for each risk-label class in the risk-label set.
4. The method of claim 3, wherein matching risk labels of the public-opinion
text data based on
the preset risk-label set to construct the risk-label sequence comprises:
matching the risk keywords to the public-opinion text data by means of text
keyword
matching;
searching for corresponding risk-label class according to matching results;
and
based on locations of the risk-label classes in the risk-label set,
constructing the risk-label
sequence.
5. The method of claim 1, wherein training of the sentiment classification
model comprises:
extracting public opinion corpora of various sentiment polarities respectively
from
acquired public opinion corpora, to construct a tag-corpus set;
training the sentiment classification model based on the tag-corpus set using
a Long
short-term memory (LSTM) or convolutional neural network for text (TextCNN)
model
structure; and
wherein classifications of the sentiment polarities include one or more of
positive
sentiment, neutral sentiment, and negative sentiment, and the sentiment-
polarity sequence
is a sequence representation of one of the three sentiment polarities.
6. The method of claim 5, further comprises configuring a corresponding
polarity weight for
every kind of sentiment polarity.
7. The method of claim 1, wherein identifying the associated enterprise entity
names in the
public-opinion text data to construct the enterprise-association sequence
comprises:
23
constructing a monitored-enterprise list consisting of plural enterprise
entities in advance;
identifying the enterprise entity name associated with the public-opinion text
data by
means of keyword matching with a Chinese word segmentation tool and a named-
entity recognition (NER) naming entity identifying tool; and
based on a location of the enterprise entity name in the monitored-enterprise
list,
constructing the enterprise-association sequence.
8. The method of claim 1, further comprises:
presetting plural kinds of risk-early-warning levels; and
defining boundary intervals of each kind of risk-early-warning levels.
9. The method of claim 8, wherein according to the data-source sequence, the
risk-label
sequence, the sentiment-polarity sequence and the enterprise-association
sequence
corresponding to the public-opinion text data, computing and outputting a
public opinion
analysis result comprises:
using a public-opinion-risk-early-warning equation z = ElLo RiLi +Elc-oWiSt +
Ef_oQiTi to compute a risk value of the public-opinion text data;
computing an early-warning value corresponding to the public-opinion text data
in view
of the enterprise-association sequence;
outputting the risk-early-warning level based on the boundary interval to
which the early-
warning value belongs;
wherein Ri denotes a risk weight of a corresponding risk-label class, Li
denotes the risk-
label sequence, n denotes a total number of the risk-label classes in the risk-
label set, Wi
denotes a credit weight of the designated website, Si denotes the data-source
sequence, k
denotes the total number of the designated websites, Qi denotes a polarity
weight, Ti
denotes the sentiment-polarity sequence, andp denotes a total number of the
sentiment
polarities.
24
10. The method of any one of claims 1 to 9, wherein the public-opinion text
data are collected
from any designated website, and are processed to construct the website
sources, wherein the
sources of public opinions about enterprises include one or more of news
websites,
government websites, forums, micro blogging, and websites receiving
complaints, the source
sequence is S = {S1, S2, ..., Sk}., wherein the sources of public opinions,
different credit
weights Wi are assigned, wherein the credit weights are configured by users,
wherein setting
addresses, site sections, data-collecting frequencies, keywords of the public-
opinion data
sources are performed, wherein an Internet-based data collecting tool is used
to acquire the
public-opinion text data.
11. The method of any one of claims 1 to 10, wherein collecting the public-
opinion text data
comprises:
using a Python-based or Java-based html processing tool to denoise webpages,
clean data,
and extract fields, so that data of public-opinion webpage data is extracted
in a structured
manner by fields including titles, sources, links, releasing date, text,
summaries, and
authors;
storing the extracted structured text data.
12. The method of any one of claims 1 to 10, wherein the risk-label set is
constructed for classes
of risk events that are commonly seen in public opinions about enterprises and
classes of risk
events the users care about, wherein every risk label is assigned with a
corresponding risk
weight Rj, wherein the risk weight may alternatively be configured by the
users, wherein a
keyword set is developed for each of the risk labels, to form a "label -
keyword dictionary",
wherein the risk-label sequence is L = {L1, L2, ..., Ln} of the public
opinions, wherein n is the
total number of the risk labels, Li corresponds to the 0/1 identification
corresponding to the
risk label, wherein 1 denotes that there is the ith label in the public
opinions, and 0 denotes
that there is not the ith label in the public opinions.
13. The method of any one of claims 1 to 12, wherein the sentiment-polarity
and entity-name
identifying module extract public-opinion data sets of three polarities,
including positive,
neutral, and negative sentiment from the acquired public opinion corpora
according to pre-
defined positive and negative sentiment dictionary for a certain enterprise to
form the tag-
corpus set.
14. The method of any one of claims 1 to 13, wherein for every sentiment
polarity, a
corresponding polarity weight Qi is set, wherein Qi = {Q1, Q2, Q3}, wherein
the sentiment-
polarity sequence Ti = {T1, T2,T3}, T1 denotes positive sentiment, T2 denotes
neutral
sentiment, and T3 denotes negative sentiment, wherein Q1 denotes the polarity
weight
corresponding to the positive sentiment, Q2 denotes the polarity weight
corresponding to the
neutral sentiment, and Q3 denotes the polarity weight corresponding to the
negative
sentiment.
15. The method of any one of claims 1 to 14, wherein a public-opinion
processing platform is
used to identify enterprise entities from the collected public-opinion text
data, to extract the
risk labels from the data and to analyze the sentiment polarities of the data,
wherein a
personalized configuring service provides standardized application
configuration interface.
16. The method of any one of claims 1 to 15, wherein the enterprise entities
associated with the
public-opinion text data are identified based on a dictionary of full names,
short names, and
aliases of monitored enterprises through a list of enterprises monitored,
wherein the public-
opinion text data are associated with the enterprise entities to form an
enterprise-association
sequence is E = E2,
Em}, where m is the number of all the monitored enterprises, Ei
is the 0/1 label, wherein 1 denotes the public opinion is associated with the
ith enterprise, and
0 denotes not associated, wherein synchronization of the monitored-enterprise
list, updating
of a sentiment polarity dictionary, and setting of the public opinion sources
and risk label
weights is supported.
26
17. The method of any one of claims 1 to 16, wherein a risk early warning
score is computed
according to early warning labels and list of enterprises monitored is J =
U1,12,
=== 'La
wherein Ji is a 0/1 label, subscribed by the user and according to data-source
sequences,
credit weights, risk-label sequences, risk weights, sentiment-polarity
sequences, polarity
weights, and the enterprise-association sequence of public-opinion text data,
early warning
level is determined according to a risk threshold value, wherein enterprise
public opinion
information that satisfies requirements is pushed to the user as early
warning.
18. The method of any one of claims 1 to 17, wherein the risk-early-warning
level A= {no early
warning, normal, important, serious}, boundary intervals corresponding to
every risk-early-
warning level is: H = {H1, H2, H3}, wherein score is smaller than Hi, the
corresponding risk-
early-warning level is not to give early warning, wherein the score is greater
than H1 and
smaller than H2, the corresponding risk-early-warning level is normal, wherein
the score is
greater than H2 and smaller than H3, the corresponding risk-early-warning
level is important,
wherein the score is greater than H3, the corresponding risk-early-warning
level is serious,
wherein the score corresponding to sentiment polarity is Q = {Q1, Q2, Q3}, and
the sentiment-
polarity sequence corresponding to the public-opinion text data is T = {T1,
T2, T3}.
19. The method of any one of claims 1 to 18, wherein risk early warning score
of entry of public-
opinion text data is computed by:
Image
wherein a vector inner product represented by (x, y), the equation is:
z = (R,L) + (W,S)+ (Q,T);
wherein the sequence information of the associated enterprise combined is:
z' = z = E((E,J));
wherein E(x) is a unit step function is:
Image
27
wherein the enterprise entity name shown in this entry of public-opinion text
data exists
in monitored-enterprise list, the value of E(x) is 1, wherein the risk early
warning score is
computed, wherein the enterprise entity name mentioned in the entry of public-
opinion
text data does not exist in the list of enterprises monitored, the value of
E(x) is 0, wherein
no more computation for the risk early warning score is conducted.
20. The method of any one of claims 1 to 19, wherein early warning mark is:
Output (z') =
(Y (z' ), 11), wherein Y(x) = {y1(x), y2(x), y3(x), y4 (x)}, and the values of
the two-value
function (x), y2 (x), y3 (x), y4(x) is True or False, 1 or 0, wherein:
y1(x) = 0 x < H1;
y2(x) = x < H2 ;
y3 (X) = H2 X < H3 ;
y4(x) = x H3 ; and
wherein Output (z') is output as the early warning mark: no early warning,
normal,
important, or serious.
21. A system comprising:
a public-opinion-collecting module, configured to:
collect public-opinion text data from any designated website;
construct a data-source sequence for website sources of the public-opinion
text
data, wherein a credit weight is assigned for each designated website;
a risk label module, for matching risk labels of the public-opinion text data
based on a
preset risk-label set to construct a risk-label sequence, wherein the preset
risk-label set
includes risk keywords configured in a risk-label class wherein in each risk-
label class
has a risk weight;
28
a sentiment-polarity and entity-name identifying module, configured to:
perform classification of sentiment polarities of the public-opinion text data
using a sentiment classification model to construct a sentiment-polarity
sequence;
identify associated enterprise entity names in the public-opinion text data to
construct an enterprise-association sequence; and
an early warning outputting module, for computing and outputting a public
opinion
analysis result according to the data-source sequence, the risk-label
sequence, the
sentiment-polarity sequence and the enterprise-association sequence
corresponding to the
public-opinion text data.
22. The system of claim 21, wherein constructing the data-source sequence for
the website
sources of the public-opinion text data comprises:
summing up a total number of the designated websites;
conftguring the credit weight for each designated website, to construct a data-
source
sequence set dimensionally consistent with the total number;
identifying a location of the source website in the data-source sequence set;
constructing the corresponding data-source sequence; and
matching a corresponding credit weight.
23. The system of claim 21, further comprises:
constructing the risk-label set in advance, wherein the risk-label set
includes plural risk-
label classes, and each risk-label class corresponds to at least one risk
keyword; and
configuring the risk weight for each risk-label class in the risk-label set.
24. The system of claim 23, wherein matching risk labels of the public-opinion
text data based
on the preset risk-label set to constuct the risk-label sequence comprises:
29
matching the risk keywords to the public-opinion text data by means of text
keyword
matching;
searching for corresponding risk-label class according to matching results;
and
based on locations of the risk-label classes in the risk-label set,
constructing the risk-label
sequence.
25. The system of claim 21, wherein training of the sentiment classification
model comprises:
extracting public opinion corpora of various sentiment polarities respectively
from
acquired public opinion corpora, to construct a tag-corpus set;
training the sentiment classification model based on the tag-corpus set using
a Long
short-term memory (LSTM) or convolutional neural network for text (TextCNN)
model
structure; and
wherein classifications of the sentiment polarities include one or more of
positive
sentiment, neutral sentiment, and negative sentiment, and the sentiment-
polarity sequence
is a sequence representation of one of the three sentiment polarities.
26. The system of claim 25, further comprises configuring a corresponding
polarity weight for
every kind of sentiment polarity.
27. The system of claim 21, wherein identifying the associated enterprise
entity names in the
public-opinion text data to construct the enterprise-association sequence
comprises:
constructing a monitored-enterprise list consisting of plural enterprise
entities in advance;
identifying the enterprise entity name associated with the public-opinion text
data by
means of keyword matching with a Chinese word segmentation tool and a named-
entity recognition (NER) naming entity identifying tool; and
based on a location of the enterprise entity name in the monitored-enterprise
list,
constructing the enterprise-association sequence.
28. The system of claim 21, further comprises:
presetting plural kinds of risk-early-warning levels; and
defining boundary intervals of each kind of risk-early-warning levels.
29. The system of claim 28, wherein according to the data-source sequence, the
risk-label
sequence, the sentiment-polarity sequence and the enterprise-association
sequence
corresponding to the public-opinion text data, computing and outputting a
public opinion
analysis result comprises:
Image
using a public-opinion-risk-early-warning equation
Image to compute a risk value of the public-opinion text data;
computing an early-warning value corresponding to the public-opinion text data
in view
of the enterprise-association sequence;
outputting the risk-early-warning level based on the boundary interval to
which the early-
warning value belongs;
wherein Ri denotes a risk weight of a corresponding risk-label class, Li
denotes the risk-
label sequence, n denotes a total number of the risk-label classes in the risk-
label set, Wi
denotes a credit weight of the designated website, Si denotes the data-source
sequence, k
denotes the total number of the designated websites, Qi denotes a polarity
weight, Ti
denotes the sentiment-polarity sequence, andp denotes a total number of the
sentiment
polarities.
31
30. The system of any one of claims 21 to 29, wherein the public-opinion text
data are collected
from any designated website, and are processed to construct the website
sources, wherein the
sources of public opinions about enterprises include one or more of news
websites,
government websites, forums, micro blogging, and websites receiving
complaints, the source
sequence is S = {S1, S2, ..., Sk}., wherein the sources of public opinions,
different credit
weights Wi are assigned, wherein the credit weights are configured by users,
wherein setting
addresses, site sections, data-collecting frequencies, keywords of the public-
opinion data
sources are performed, wherein an Internet-based data collecting tool is used
to acquire the
public-opinion text data.
31. The system of any one of claims 21 to 30, wherein collecting the public-
opinion text data
comprises:
using a Python-based or Java-based html processing tool to denoise webpages,
clean data,
and extract fields, so that data of public-opinion webpage data is extracted
in a structured
manner by fields including titles, sources, links, releasing date, text,
summaries, and
authors;
storing the extracted structured text data.
32. The system of any one of claims 21 to 31, wherein the risk-label set is
constructed for classes
of risk events that are commonly seen in public opinions about enterprises and
classes of risk
events the users care about, wherein every risk label is assigned with a
corresponding risk
weight Rj, wherein the risk weight may alternatively be configured by the
users, wherein a
keyword set is developed for each of the risk labels, to form a "label -
keyword dictionary",
wherein the risk-label sequence is L = {L1, L2, ..., Ln} of the public
opinions, wherein n is the
total number of the risk labels, Li corresponds to the 0/1 identification
corresponding to the
risk label, wherein 1 denotes that there is the ith label in the public
opinions, and 0 denotes
that there is not the ith label in the public opinions.
32
33. The system of any one of claims 21 to 32, wherein the sentiment-polarity
and entity-name
identifying module extract public-opinion data sets of three polarities,
including positive,
neutral, and negative sentiment from the acquired public opinion corpora
according to pre-
defined positive and negative sentiment dictionary for a certain enterprise to
form the tag-
corpus set.
34. The system of any one of claims 21 to 33, wherein for every sentiment
polarity, a
corresponding polarity weight Qi is set, wherein Qi = {(21, Q2, Q3}, wherein
the sentiment-
polarity sequence Ti = {T1, T2,T3}, T1 denotes positive sentiment, T2 denotes
neutral
sentiment, and T3 denotes negative sentiment, wherein Q1 denotes the polarity
weight
corresponding to the positive sentiment, Q2 denotes the polarity weight
corresponding to the
neutral sentiment, and Q3 denotes the polarity weight corresponding to the
negative
sentiment.
35. The system of any one of claims 21 to 34, wherein a public-opinion
processing platform is
used to identify enterprise entities from the collected public-opinion text
data, to extract the
risk labels from the data and to analyze the sentiment polarities of the data,
wherein a
personalized configuring service provides standardized application
configuration interface.
36. The system of any one of claims 21 to 35, wherein the enterprise entities
associated with the
public-opinion text data are identified based on a dictionary of full names,
short names, and
aliases of monitored enterprises through a list of enterprises monitored,
wherein the public-
opinion text data are associated with the enterprise entities to form an
enterprise-association
sequence is E = {E1,E2,
where m is the number of all the monitored enterprises, Ei
is the 0/1 label, wherein 1 denotes the public opinion is associated with the
ith enterprise, and
0 denotes not associated, wherein synchronization of the monitored-enterprise
list, updating
of a sentiment polarity dictionary, and setting of the public opinion sources
and risk label
weights is supported.
33
37. The system of any one of claims 21 to 36, wherein a risk early warning
score is computed
according to early warning labels and list of enterprises monitored is J =1,,
I
2, = = = 'La
wherein Ji is a 0/1 label, subscribed by the user and according to data-source
sequences,
credit weights, risk-label sequences, risk weights, sentiment-polarity
sequences, polarity
weights, and the enterprise-association sequence of public-opinion text data,
early warning
level is determined according to a risk threshold value, wherein enterprise
public opinion
information that satisfies requirements is pushed to the user as early
warning.
38. The system of any one of claims 21 to 37, wherein the risk-early-warning
level A= {no early
warning, normal, important, serious}, boundary intervals corresponding to
every risk-early-
warning level is: H = {H1, H2, H3}, wherein score is smaller than Hi, the
corresponding risk-
early-warning level is not to give early warning, wherein the score is greater
than H1 and
smaller than H2, the corresponding risk-early-warning level is normal, wherein
the score is
greater than H2 and smaller than H3, the corresponding risk-early-warning
level is important,
wherein the score is greater than H3, the corresponding risk-early-waming
level is serious,
wherein the score corresponding to sentiment polarity is Q = {Q1, Q2, Q3}, and
the sentiment-
polarity sequence corresponding to the public-opinion text data is T = {T1,
T2, T3).
39. The system of any one of claims 21 to 38, wherein risk early warning score
of entry of
public-opinion text data is computed by:
Image
wherein a vector inner product represented by (x, y), the equation is:
z = (R, L) + (W , S) + (Q , T);
wherein the sequence information of the associated enterprise combined is:
Image
wherein E(x) is a unit step function is:
Image
34
wherein the enterprise entity name shown in this entry of public-opinion text
data exists
in monitored-enterprise list, the value of E(x) is 1, wherein the risk early
warning score is
computed, wherein the enterprise entity name mentioned in the entry of public-
opinion
text data does not exist in the list of enterprises monitored, the value of
E(x) is 0, wherein
no more computation for the risk early warning score is conducted.
40. The system of any one of claims 21 to 39, wherein early warning mark is:
Output (z =
(Y (z' ), 11), wherein Y(x) = {y1(x), y2(x), y3(x), y4 (x)}, and the values of
the two-value
function (x), y2 (x), y3 (x), y4(x) is True or False, 1 or 0, wherein:
y1(x) = 0 x < H1;
y2(x) = x < H2 ;
y3 (X) = H2 X < H3 ;
y4(x) = x H3 ; and
wherein Output (z') is output as the early warning mark: no early warning,
nonnal,
important, or serious.
41. A computer readable storage medium, storing thereon a computer program is
executed by a
processor configured to:
collect public-opinion text data from any designated website;
construct a data-source sequence for website sources of the public-opinion
text data,
wherein a credit weight is assigned for each designated website;
match risk labels of the public-opinion text data based on a preset risk-label
set to
construct a risk-label sequence, wherein the preset risk-label set includes
risk keywords
configured in a risk-label class wherein in each risk-label class has a risk
weight;
perform classification of sentiment polarities of the public-opinion text data
using a
sentiment classification model to construct a sentiment-polarity sequence;
identify associated enterprise entity names in the public-opinion text data to
construct an
enterprise-association sequence; and
compute and output a public opinion analysis result according to the data-
source
sequence, the risk-label sequence, the sentiment-polarity sequence and the
enterprise-
association sequence corresponding to the public-opinion text data.
42. The storage medium of claim 41, wherein constructing the data-source
sequence for the
website sources of the public-opinion text data comprises:
summing up a total number of the designated websites;
conftguring the credit weight for each designated website, to construct a data-
source
sequence set dimensionally consistent with the total number;
identifying a location of the source website in the data-source sequence set;
constructing the corresponding data-source sequence; and
matching a corresponding credit weight.
43. The storage medium of claim 41, further comprises:
constructing the risk-label set in advance, wherein the risk-label set
includes plural risk-
label classes, and each risk-label class corresponds to at least one risk
keyword; and
configuring the risk weight for each risk-label class in the risk-label set.
44. The storage medium of claim 43, wherein matching risk labels of the public-
opinion text data
based on the preset risk-label set to construct the risk-label sequence
comprises:
36
matching the risk keywords to the public-opinion text data by means of text
keyword
matching;
searching for corresponding risk-label class according to matching results;
and
based on locations of the risk-label classes in the risk-label set,
constructing the risk-label
sequence.
45. The storage medium of claim 41, wherein training of the sentiment
classification model
comprises:
extracting public opinion corpora of various sentiment polarities respectively
from
acquired public opinion corpora, to construct a tag-corpus set;
training the sentiment classification model based on the tag-corpus set using
a Long
short-term memory (LSTM) or convolutional neural network for text (TextCNN)
model
structure; and
wherein classifications of the sentiment polarities include one or more of
positive
sentiment, neutral sentiment, and negative sentiment, and the sentiment-
polarity sequence
is a sequence representation of one of the three sentiment polarities.
46. The storage medium of claim 45, further comprises configuring a
corresponding polarity
weight for every kind of sentiment polarity.
47. The storage medium of claim 41, wherein identifying the associated
enterprise entity names
in the public-opinion text data to construct the enterprise-association
sequence comprises:
constructing a monitored-enterprise list consisting of plural enterprise
entities in advance;
identifying the enterprise entity name associated with the public-opinion text
data by
means of keyword matching with a Chinese word segmentation tool and a named-
entity recognition (NER) naming entity identifying tool; and
based on a location of the enterprise entity name in the monitored-enterprise
list,
constructing the enterprise-association sequence.
37
48. The storage medium of claim 41, further comprises:
presetting plural kinds of risk-early-warning levels; and
defining boundary intervals of each kind of risk-early-warning levels.
49. The storage medium of claim 48, wherein according to the data-source
sequence, the risk-
label sequence, the sentiment-polarity sequence and the enterprise-association
sequence
corresponding to the public-opinion text data, computing and outputting a
public opinion
analysis result comprises:
Image
using a public-opinion-risk-early-warning equation
Image tO compute a risk value of the public-opinion text data;
computing an early-warning value corresponding to the public-opinion text data
in view
of the enterprise-association sequence;
outputting the risk-early-warning level based on the boundary interval to
which the early-
warning value belongs;
wherein Ri denotes a risk weight of a corresponding risk-label class, Li
denotes the risk-
label sequence, n denotes a total number of the risk-label classes in the risk-
label set, Wi
denotes a credit weight of the designated website, Si denotes the data-source
sequence, k
denotes the total number of the designated websites, Qi denotes a polarity
weight, Ti
denotes the sentiment-polarity sequence, andp denotes a total number of the
sentiment
polarities.
38
50. The storage medium of any one of claims 41 to 49, wherein the public-
opinion text data are
collected from any designated website, and are processed to construct the
website sources,
wherein the sources of public opinions about enterprises include one or more
of news
websites, government websites, forums, micro blogging, and websites receiving
complaints,
the source sequence is S = S2, wherein the sources of public opinions,
different
credit weights Wi are assigned, wherein the credit weights are configured by
users, wherein
setting addresses, site sections, data-collecting frequencies, keywords of the
public-opinion
data sources are performed, wherein an Internet-based data collecting tool is
used to acquire
the public-opinion text data.
51. The storage medium of any one of claims 41 to 50, wherein collecting the
public-opinion text
data comprises:
using a Python-based or Java-based html processing tool to denoise webpages,
clean data,
and extract fields, so that data of public-opinion webpage data is extracted
in a structured
manner by fields including titles, sources, links, releasing date, text,
summaries, and
authors;
storing the extracted structured text data.
52. The storage medium of any one of claims 41 to 51, wherein the risk-label
set is constructed
for classes of risk events that are commonly seen in public opinions about
enterprises and
classes of risk events the users care about, wherein every risk label is
assigned with a
corresponding risk weight Rj, wherein the risk weight may alternatively be
configured by the
users, wherein a keyword set is developed for each of the risk labels, to form
a "label -
keyword dictionary", wherein the risk-label sequence is L = {L1, L2, ...,Ln}
of the public
opinions, wherein n is the total number of the risk labels, Li corresponds to
the 0/1
identification corresponding to the risk label, wherein 1 denotes that there
is the ith label in
the public opinions, and 0 denotes that there is not the ith label in the
public opinions.
39
53. The storage medium of any one of claims 41 to 52, wherein the sentiment-
polarity and entity-
name identifying module extract public-opinion data sets of three polarities,
including
positive, neutral, and negative sentiment from the acquired public opinion
corpora according
to pre-defined positive and negative sentiment dictionary for a certain
enterprise to form the
tag-corpus set.
54. The storage medium of any one of claims 41 to 53, wherein for every
sentiment polarity, a
corresponding polarity weight Qi is set, wherein Qi = {Q1, Q2, Q3}, wherein
the sentiment-
polarity sequence Ti = {T1, T2, T3}, T1 denotes positive sentiment, T2 denotes
neutral
sentiment, and T3 denotes negative sentiment, wherein Q1 denotes the polarity
weight
corresponding to the positive sentiment, Q2 denotes the polarity weight
corresponding to the
neutral sentiment, and Q3 denotes the polarity weight corresponding to the
negative
sentiment.
55. The storage medium of any one of claims 41 to 54, wherein a public-opinion
processing
platform is used to identify enterprise entities from the collected public-
opinion text data, to
extract the risk labels from the data and to analyze the sentiment polarities
of the data,
wherein a personalized configuring service provides standardized application
configuration
interface.
56. The storage medium of any one of claims 41 to 55, wherein the enterprise
entities associated
with the public-opinion text data are identified based on a dictionary of full
names, short
names, and aliases of monitored enterprises through a list of enterprises
monitored, wherein
the public-opinion text data are associated with the enterprise entities to
form an enterprise-
association sequence is E = E2, Em}, where m is the number of all the
monitored
enterprises, Ei is the 0/1 label, wherein 1 denotes the public opinion is
associated with the
enterprise, and 0 denotes not associated, wherein synchronization of the
monitored-enterprise
list, updating of a sentiment polarity dictionary, and setting of the public
opinion sources and
risk label weights is supported.
57. The storage medium of any one of claims 41 to 56, wherein a risk early
warning score is
computed according to early warning labels and list of enterprises monitored
is]. =
=== 'La wherein Ji is a 0/1 label, subscribed by the user and according to
data-source
sequences, credit weights, risk-label sequences, risk weights, sentiment-
polarity sequences,
polarity weights, and the enterprise-association sequence of public-opinion
text data, early
warning level is determined according to a risk threshold value, wherein
enterprise public
opinion information that satisfies requirements is pushed to the user as early
warning.
58. The storage medium of any one of claims 41 to 57, wherein the risk-early-
warning level A=
{no early warning, normal, important, serious}, boundary intervals
corresponding to every
risk-early-warning level is: H = {H1, H2, H3), wherein score is smaller than
H1, the
corresponding risk-early-warning level is not to give early warning, wherein
the score is
greater than H1 and smaller than H2, the corresponding risk-early-warning
level is normal,
wherein the score is greater than H2 and smaller than H3, the corresponding
risk-early-
warning level is important, wherein the score is greater than H3, the
corresponding risk-early-
warning level is serious, wherein the score corresponding to sentiment
polarity is Q =
[Q1, Q2, Q3), and the sentiment-polarity sequence corresponding to the public-
opinion text
data is T = {T1, T2, T3).
59. The storage medium of any one of claims 41 to 58, wherein risk early
warning score of entry
of public-opinion text data is computed by:
Image
wherein a vector inner product represented by (x, y), the equation is:
z = (R,L) + (141,S) + (Q,T);
wherein the sequence information of the associated enterprise combined is:
z' = z = E((E,J));
wherein z(x) is a unit step function is:
41
Image
wherein the enterprise entity name shown in this entry of public-opinion text
data exists
in monitored-enterprise list, the value of E(x) is 1, wherein the risk early
warning score is
computed, wherein the enterprise entity name mentioned in the entry of public-
opinion
text data does not exist in the list of enterprises monitored, the value of
E(x) is 0, wherein
no more computation for the risk early warning score is conducted.
60. The storage medium of any one of claims 41 to 59, wherein early warning
mark is:
Output (z ') = (Y(z'), A), wherein Y(x) = { (x), y2 (x), y3(x), y4(x)}, and
the values of
the two-value function yi(x), y2(x), y3 (x), y4(x) is True or False, 1 or 0,
wherein:
y1(x) = 0 x < H1;
y2(x) = H1 5 x < H2 ;
y3 (X) = H2 5 x < H3 ;
y4(x) = x H3 ; and
wherein Output (z') is output as the early warning mark: no early warning,
normal,
important, or serious.
42