Note: Descriptions are shown in the official language in which they were submitted.
ADDRESS INFORMATION PARSING METHOD AND APPARATUS, SYSTEM AND
DATA ACQUISITION METHOD
Technical Field
[0001] The present invention relates to the field of address parsing, in
particular to a method, a device, and
a system for address information parsing, and a data acquisition method.
Background
[0002] The modern retailing companies generate a massive amount of sale data,
and the retailing
companies arc parsing the sale data to assist company decision making. In
particular, the address data in
the sale data is the basis for intelligent retailing analysis and decision
making. For example, the decisions
for small store locations, logistic resource allocations, and geological sale
data analysis are relying on
parsing the address data in the sale data. Therefore, the efficiency and
accuracy of address data parsing is
very significant.
[0003] The current methods to parse massive address data into gcocoding adopt
conditional data cleaning
techniques. In other words, a tric is constructed with all standard
administrative geological data and
conditions, and the geological data is extracted by means of regular
expression, to match the extracted
geological data with the trie for generating standard geological data.
Finally, the geological data is locally
converted into geocoding, to be applied for high-level retailing decisions.
[0004] However, in the aforementioned method, all standard administrative
geological data are gathered
to construct a tric with conditions, requiring a large volume of hard drive
resources. In the meanwhile, with
a large volume of sale data, the parsing process takes a long time.
[0005] Besides, the address information in the sale data is generally filled
by non-standard handwriting,
wherein a portion of data is not able to be converted into gcocoding,
consequently yielding low accurate
results.
[0006] The aforementioned problems are also emerging in address data parsing
process in the other service
fields.
Summary
[0007] An address information parsing method, device, and system, and a data
acquisition method are
provided in the present invention, to solve the problems of largely occupied
resources and long processing
time in the current technologies.
1
CA 03145918 2022-1-26
[0008] The technical proposal provided in the present invention includes:
[0009] acquiring parsing-pending address information from original data;
[0010] extracting features of the described parsing-pending address
information by a natural language
proccssing technology, selecting extracted features to be vectorized as an
identifying-pending feature vector;
[0011] inputting the identifying-pending feature vector into a pre-sct model
to obtain an initial array
comprising geographic entities and administrative division levels
corresponding to the geographic entities;
[0012] sorting and dcduplicating the geographic entities in the initial array
according to the administrative
division levels to obtain a standard array; and
[0013] encoding the standard array to obtain a geocoding result.
[0014] Preferably, bcforc cxtracting features of the described parsing-pending
address information by a
natural language processing technology, the described method further includes:
[0015] determining that if the described parsing-pending address information
has been parsed based on
pre-stored history address information parsing recorders, wherein the
described history address information
parsing recorders includes history address information and the corresponding
history geocoding data;
[0016] where if the described parsing-pending address information has been
parsed, acquiring the
associated history geocoding data as the geocoding result; and
[0017] the described extraction of described parsing-pending address
information features by a natural
language processing technology, comprising:
[0018] where if the described parsing-pending address information has not been
parsed, extracting
features of the dcscribcd parsing-pending address information by a natural
language processing
technology.
[0019] Preferably, bcforc encoding the standard array to obtain a geocoding
result, the described
method further includes:
[0020] matching the described standard array with the pre-stored geological
location tric tree, to determine
that if the described standard array has deficiency, wherein the described
geological location tric tree is
constructed according to administrative division levels;
[0021] where if the described standard array has deficiency, filling the
described standard array according
to thc described geological location tric tree; and
[0022] the described process of encoding the standard array to obtain a
geocoding result including
encoding the filled standard array to obtain a geocoding result.
[0023] Preferably, the described process of encoding the standard array to
obtain a geocoding result
consists of:
[0024] calling coding ports of an external server to encode the standard array
for obtaining a geocoding
result.
2
CA 03145918 2022-1-26
[0025] Preferably, the described method further includes the procedures of
constructing the described pre-
set model, including:
[0026] performing corpus annotation for the address data in a sample set to
obtain sample array annotated
with geographic entities and administrative division levels corresponding to
the geographic entities;
[0027] extracting elementary features of the address information in the
described sample set by a natural
language processing technology, selecting the elementary features satisfying
certain conditions as target
features, and vcctorizing the described target feature to obtain the sample
feature vectors; and
[0028] assigning the described sample feature vectors as inputs and the
corresponding sample array as
outputs, and training with the neural network and the conditional random field
algorithm to obtain the
described pre-set model.
[0029] Preferably, the described process of extracting elementary features of
the address information in
the described sample set by a natural language processing technology,
selecting the elementary features
satisfying certain conditions as target features, and vectorizing the
described target feature to obtain the
sample feature vectors consists of:
[0030] calculating the frequency of appearance of each elementary feature in
the address texts;
[0031] based on the described frequency, calculating the correlation between
each elementary feature and
each administrative division level as individual feature weights;
[0032] selecting the elementary features with the correlation and/or frequency
satisfying pre-set conditions
as the described target features;
[0033] calculating the correlation between each selected target feature and
each administrative division
level, and defining the averaged correlation of each target feature as the
weight of each target feature, to
construct a weighted matrix according to the described weights; and
[0034] vcctorizing the described target feature based on the described
weighted matrix to obtain the sample
feature vectors.
[0035] Preferably, the describe method further includes saving the described
gcocoding and the described
original data jointly.
[0036] Preferably, the described prediction model is assigned in the spark
computation engine, and the
described gcocoding result and the original data are jointly stored into the
clasticsearch searching engine.
[0037] From an other perspective, a data acquisition method is provided in the
present invention,
comprising:
[0038] receiving candidate address information;
[0039] parsing the described candidate address information according to the
method in the claim 7 to
obtain the parsed candidate geocoding data; and
3
CA 03145918 2022-1-26
[0040] calculating in a correlation table of the prc-stored geocoding results
and the original data based on
the described candidate geocoding data and a pre-set geological range, to
obtain the stored geocoding results
and the original data within the prc-set geological range.
[0041] From an othcr perspective, an address information parsing device is
provided in the present
invention, comprising:
[0042] a parsing-pending address information acquisition unit, configured to
acquire parsing-pending
addrcss information from original data;
[0043] a feature extraction unit, configured to extract features of the
described parsing-pending address
information by a natural language processing technology, sclect extracted
features to bc vectorized as an
idcntifying-p ending fcaturc vector;
[0044] a model prediction unit, configured to input the identifying-pending
fcaturc vector into a prc-set
model for obtaining an initial array comprising geographic entities and
administrative division levels
corresponding to the geographic entities, wherein the described pre-set model
is constructed by training in
combination of the neural network and the conditional random field algorithm;
[0045] a sorting unit, configured to sort and dcduplicate the geographic
entities in the initial array
according to the administrative division levcls to obtain a standard array;
and
[0046] a geocoding unit, configured to encode the standard array to obtain a
geocoding result.
[0047] From an other perspective, a computer system is further provided in the
present invention,
comprising:
[0048] one or more proccssors; and
[0049] a storagc medium related to the described one or mom processors,
configured for storing the
program commands, wherein the described program commands arc executed by the
described one or more
processors for performing the following procedures:
[0050] acquiring parsing-pending address information from original data;
[0051] extracting features of the described parsing-pending address
information by a natural language
proccssing technology, selecting extracted features to be vectorized as an
identifying-pending fcaturc vector;
[0052] inputting the identifying-pending feature vector into a pre-sct model
to obtain an initial array
comprising geographic entities and administrative division levcls
corresponding to the geographic entities;
[0053] sorting and dcduplicating the geographic entities in the initial array
according to the administrative
division levels to obtain a standard array; and
[0054] encoding the standard array to obtain a geocoding result.
[0055] In accordance with the embodiments in the present invention, the
following technical bcncfits are
provided by the prcscnt invcntion that,
4
CA 03145918 2022-1-26
[0056] the technical proposal in the present invention extracts address
information features to be vectorized
as identifying-pending feature vectors by a natural language processing
technology; takes the identifying-
pending feature vectors as model inputs to predict and obtain an original
array containing geographic
entities and associated administrative division levels; then sorts and
dcduplicates the gcocoding to yield
parsing results. The process does not require a full volume trie with
conditions, to reduce the occupancy on
hard drive resources under lower execution environment. With the model
prediction, the standard
geological data extraction is performed for a massive amount of address
information without considering
input format, wherein varying data changes are adapted, and no manual
maintenance is required for
improving extraction efficiency of standard geological data. Furthermore, the
optimized prediction model
by the feature selection algorithm in the present invention discards various
features with low correlation to
the administrative division levels, achieving better accuracy of geological
data extraction than the
traditional conditional matching, wherein model calculation speed is improved
with more accurate extracted
geological data.
[0057] Moreover, the address information coding functions can be packed as
batch parsing ports in an
external independent server, wherein geological data analysis extraction
computation resources are not
further occupied to improve coding efficiency for more real-time data
processing. Besides, the described
method can fill address information missing administrative division levels,
yielding more accurate parsing
results.
[0058] Obviously, any application or product implementing the present
invention is not necessary to
include all aforementioned benefits.
Brief descriptions of the drawings
[0059] For better explanation of the technical proposal of embodiments in the
present invention, the
accompanying drawings are briefly introduced in the following. Obviously, the
following drawings
represent only a portion of embodiments of the present invention. Those
skilled in the art are able to create
other drawings according to the accompanying drawings without making creative
efforts.
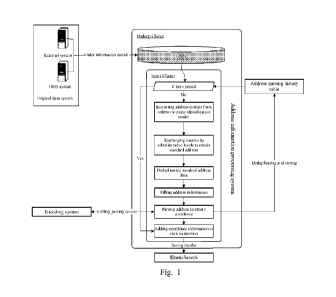
[0060] Fig. 1 is a system structure diagram provided in embodiments of the
present invention.
[0061] Fig. 2 is a flow diagram of the detailed address information parsing
process provided in
embodiments of the present invention.
[0062] Fig. 3 is a flow diagram of the address information parsing method
provided in embodiments of
the present invention.
[0063] Fig. 4 is a device structure diagram provided in embodiments of the
present invention.
[0064] Fig. 5 is a computer system structure diagram provided in embodiments
of the present invention.
CA 03145918 2022-1-26
Detailed descriptions
[0065] The technical proposals in embodiments of the present invention will be
explained further in detail
precisely below with references to the accompanying drawings. Obviously, the
embodiments described
below are only a portion of embodiments of the present invention and cannot
represent all possible
embodiments. Based on the embodiments in the present invention, the other
applications by those skilled
in the art without any creative works arc falling within the scope of the
present invention.
[0066] The present invention aims at providing an address information parsing
method, to extract address
information features and select features with high correlations to be
vectorized as feature vectors by a
natural language processing technology; predict geographic entities and
associated administrative division
levels based on a pre-constructed model and the feature vectors; then sort and
&duplicate for standard
format geological data, and further perform geocoding to get location
coordinates to complete the address
information parsing. The feature extraction and vectorization of the address
information allows to extract
features with high correlation to the administrative division levels, speeding
up following model prediction
with improved prediction accuracy. In the meanwhile, the process does not
require a full volume tric with
conditions, to reduce the occupancy on hard drive resources under lower
execution environment.
Embodiment 1
[0067] The system structure diagram is shown in Fig. 1, comprising an original
data system, an address
information processing system and a coding system with independent hardware
configurations. The original
data system is an original data system configured to provide the original
data, such as an external system
or OMS (order management system). The address information processing system
acquires original data
from the original data system, such as order information, then processes the
address information of the
original data to obtain the standard geological data. The coding system is
used to code the described
standard geological data to obtain geocoding results (generally as
coordinates). In particular, the coding
system packs with batch parsing ports, wherein the address information
processing system can perform
coding of the standard geological data by calling the batch parsing ports of
the coding system.
[0068] In particular, the system information processing system can jointly
store the geocoding obtained
from the coding system with the corresponding original data in clasticscarch
searching engine, so as for the
following query of associated data.
[0069] As shown in Fig. 1, the address information processing system can
further store the joined parsed
address information and corresponding geocoding results as history parsing
records in address parsing
history tables. When the address information processing system receives
address information, the address
information is firstly matched in the address parsing history table. Where if
the same address information
is matched, the corresponding geocoding result can be directly acquired and
the following processes are
6
CA 03145918 2022-1-26
not required, wherein the present parsing result is not needed to be stored
into the address parsing history
table. Where if no same address information is matched, the address
information is identified as first being
parsed, and the addrcss information processing system follows the proccssing
procedures with the coding
systcm to complete parsing and coding of the present address information,
wherein the present geocoding
result is stored in the address parsing history table.
[0070] In thc systcm structurc from an other embodiment, the original data
systcm and the address
information proccssing system can sharc thc same scrvcr, as well as the coding
systcm and thc address
information processing systcm can share the same server. In comparison, an
independent server of the
coding systcm with packed batch parsing ports to complete coding tasks does
not occupy computation
resources of address information analysis and extraction by address
information system, improving coding
efficiency and achieving more real-time data processing.
[0071] The following cmbodiments of the prcscnt invention allocate thc coding
system and thc address
information processing systcm into different servers, and arc explained with
examples of order data as the
original data.
[0072] In the order data, different ficlds are used to represent diffcrcnt
information properties, such as a
single person, price, addrcss, etc. The address information can be quickly
identified based on these fields.
Due to majorly handwritten address information in thc original data, with
various mistakcs and lack of
standardization, the address information processing systcm first convcrts the
address information into
standard geological data. For example, the address information is "Mr. Li, 18
Xingangcrhao St., Binhai
new district, Tianjin", with non-geological information. The converted
standard gcological data is "Tianjin
Binhai ncw district l TangGu neighborhood 18 Xingangcrhao St.".
[0073] In order to convert non-proccssed address information into standard
geological data, in the present
invcntio, the geological cntitics and associatcd administrative district
lcvels arc extracted. Thc geological
cntitics are Tianjin, Binhai, Tanggu, etc., and the associated administrative
district levels arc country,
province, city, county, etc. As discussed in the current technologies, thc
gcological cntitics and associatcd
administrative district levels are extracted from character strings satisfying
certain conditions by regular
cxprcssion, wherein the condition base construction is required, and the
character strings for addresses
should follow certain rules. The character strings not satisfying the
conditions are not able to be extracted.
Aiming at the problcm, thc prescnt invention provides a political and
gcological cntity rclation idcntification
model optimized based on the feature selection algorithm. The natural language
proccssing technology is
used for selecting address information features, and computing to obtain
feature vectors. The feature vectors
are used as input, and the prcdiction results are obtained by a well-trained
political geological entity relation
identification modcl. In other words, the prediction result is a binary
geological entity relationship array,
7
CA 03145918 2022-1-26
political rclation, formcd by gcological cntitics and associated
administrative district 10\7-cis, in thc following
equation:
[0074] political relation = [(el, 0), (c2, t2), ..., (en, tn)]
[0075] wherein el.. .en rcpresent identified gcological entities, ti ...tn
represent administrativc levels, and
the lcvel classifications are referred to Table 1. The administrative levels
in binary arrays can bc replaced
by symbol words in Tablc 1. For example, a city can be rcpresented by Cl. The
non-geological and non-
administrativc lova information arc identified as rcdundant information. In
addition, repeatcd geological
information is also idcntificd as rcdundant information.
Table 1
Symbol word Original word
Administrative district
level meaning
CO country
Country
PR province
Provincc
CI city City
AR area Area
ST street
Neighborhood
RO road Road
or strcct
BU building
Building
OT other
othcr
[0076] As shown in Fig. 2, taking thc address information of "Mr. Li, 18
XingangerhaoR St., Binhai new
district, Tianjin, thanks for corporation" as an example, the prediction
process with the model will yield:
[`Tianjin', 'Cl'), (18 Xingangcrhao St.', `R0'), (`Binhai ncw district',
'AR'), (`Mr. Li', 'OT'),
('thanks for', 'OT'), ('corporation', 'OT')]
[0077] Obviously, the aforementioned binary array has some drawbacks of
[0001] lack of some gcological entities. For example, ncighborhood information
is missed in between the
Binhai new district and Xingangcrhao St.
2. existing of some rcdundant information. To clarify, where if the same
gcological information
appcars multiple times in thc aforcmcntioncd address, only onc will rcmain
while the rcst of the rcpcatcd
information is classified as rcdundant information.
[0078] In ordcr to solve the aforementioned two problems, based on the order
of administrative district
lcvels, each administrativc district lcycl and thc gcological cntity
associated with thc administrative district
lcvel are identified as a nodc, to construct a tier tree of thc country's
administrative gcological information.
8
CA 03145918 2022-1-26
[0079] By sorting and dcduplicating the aforementioned binary array predicted
by the model, the
redundant information is removed, and the array is sorted according to the
order of administrative district
levels. The resultant binary array is a standard address. In particular,
according to the administrative
standard CO>PR>C1>AR>ST>R0>BU, the classification coding is performed, and the
array is sortcd
asccndingly based on the coding, while the information without any
administrative district level information
and repeated information are removed. After the aforementioned sorting and
dcduplicating process as
shown in Fig. 2, the following array is obtained:
[('Tianjin', 'Cr), (`Binhai new district', 'AR'), ('18 Xingangcrhao St.',
`R0')]
[0080] Then, the sorted and dcduplicatcd binary array is matched with the tric
tree to determine that if any
geological information is missed. In detail, the recursive method can be used
to fill and complete. For
example, the geological information of Tanggu neighborhood is missed in
between the Binhai new district
and Xingangcrhao St in the aforementioned binary array.
[0081] Where if some geological information is missed, the binary array is
filled and completed according
to the tric trcc to obtain standard geological data, as shown in Fig. 2:
'Tianjin', 'Cl'), (`Binhai new district', 'AR'), (`Tanggu neighborhood',
`ST'), ( '18 Xingangcrhao
St.', `R0')]
[0082] After acquiring the standard geological data, the aforementioned coding
technology can be used
for coding the geological data, to obtain the gcocoding result.
[0083] The aforementioned political and geological entity relation
identification model optimized based
on the feature selection algorithm provided in the present invention is
described in the following in terms
of the construction and training process.
[0084] First, based on the natural language processing technology, features of
sample address information
are extracted and selected, to calculate for sample feature vectors. The
detailed procedures include:
[0001] constructing sample sets of address information corpus, wherein the
address information corpus
can be obtained from the original data system in Fig. 1. To further improve
the accuracy, the present
invention permits the classification of the original address information
corpus obtained from the original
data system into data with no location coordinate, data to acquire incorrect
location coordinate, and data
to acquire correct location coordinate. Individual classes are evenly filtered
from the original address
information corpus as the basic corpus. The selected corpus is segmented and
annotated with sample
geological entities and associated administrative district levels
(administrative-geological identification)
for each segment. A certain percentage of the annotated data are selected
randomly for model training,
while a certain percentage of annotated data are reserved for model
verifications.
[0002] Feature extraction and selection:
9
CA 03145918 2022-1-26
2.1. extracting features of the annotated address data used for model
training, then calculating
repeating frequency of the extracted features for each geological
administrative level, FC. NIk
represcnts the occurrence time of a feature in the address information text,
as shown in Eqn (1),
and N1 is the overall occurrence of features in the address information text.
FCik = Nik
¨ (1)
Ni
2.2. Calculating the correlation between each feature, pw, and each
administrative district level,
t, to obtain feature weight, W, as shown in Eqn (2):
Cik
Nik* S * F
¨ FCik)
W(pw, t) lg __________________________________________________ (2)
k=Nik + UNik)(Nik + EXik)
wherein, Ek is the number of occurrences of a feature, pw, in administrative
district levels
other than the level t; UN* is the number strings without feature pw existing
in the
administrative district level t; and S is the total number of geological
entities in all
administrative entity classes.
2.3. Calculating the averagc weight, Wayg, and the mcan feature frequency FCõ-
g, wherein
FN in Eqn (3) and (4) is the total feature type number. When a feature weight
satisfies W>
Wawg or (W < Wõ-g and FC > FCõ,-g), the described feature is a selected target
feature.
1
Wavg = ¨FN + W2 + = + Wn)
(3)
1
FCava = ¨ (FC1 + FC2 + = = = + FCn)
(4)
FN
3. Calculating sample feature vectors for target features
3.1. With number of X of administrative district levels, number of X of
correlations are
obtained for each selected target feature, wherein the mean value of the X
correlations is
assigned as the wcight of cach word. The wcightcd matrix Arc is obtained
according to the
feature weights:
Arc ¨ (Wij ai)ngc
(5)
3.2. calculating feature vectors. Setting Y E rn) with n non-related feature
vectors,
when the major feature value ml satisfies
Im21 = I, for any administrative
geological entities, the feature vcctor v = co. Vector serics,{ck} and IVO are
constructed with
the following method:
CA 03145918 2022-1-26
Ck = Ac(k1)1
, k = 1,2, ...,
(6)
1.1 = maxvk,
II =
consequently,
lim(k)Rk = m1
(7)
lim(k)Ck = __________________________________________ (8)
maxfxi)
Based on equations (2), (5), (6), (7), and (8), a weighted normalized sample
feature vector
is constructed as shown in Eqn (9):
Ave
= AC0 = AVo =
maxvi maxAvo
A2Vo V2 A2 Vo
V = V2 = A2ci ¨ __________ , c2
(9)
maxAvo maxv2 maxA2 vo
Avo Akvo
µ, Vk = ____________
maxA0(-1)vo, Ck
maxAkvo
[0085] The resulted sample feature vectors V are inputted as the model
training vectors, wherein the
vectorized training corpus are trained with the neural network and the
conditional random field algorithm,
such as RNN loop neural network and CRF conditional random field algorithm, to
obtain the political
geological entity relation identification model. The final output by the model
is a binary geological entity
relationship set as shown below:
political relation = [(el, t1), (c2, t2),
(en, tn)]
[0086] In the described model construction, the selected target features are
highly correlated with
administrative district levels, wherein some random features with low
correlation with administrative
district levels are discarded, to reduce negative effects by these random
features and reduce model input
volume. Algorithm optimization is achieved with the aforementioned features
selections, wherein the model
input parameters are not non-standard address information and the optimized
feature vectors are inputted.
Therefore, the correlation between input parameters and associated
administrative districts are improved,
to speed up model prediction with improved prediction accuracy.
[0087] Based on formal conditional address data parsing, the tric tree
construction with full-volume
standard geological information and the address rules requires 4GB memory on a
server. With the technical
proposal in the present invention, the political geological entity
identification model can replace the full-
volume geological information trie tree, taking 200MB memory only. Compared
with the current
technologies, the present invention requires only 4.88% memory, reducing
operational costs.
[0088] Besides, the present method solves the problem of low geological data
quality in the current
technologies, to improve effective address information parsing volume and
provide more accurate data for
the basis of high-level decision making.
11
CA 03145918 2022- 1-26
[0089] The address parsing technology combining standard geological trio
construction and regular
extraction sometimes reflects many limitations. The dirty data of the address
information due to human
factors are not able to provide correct geological data by processing via
conventional technologies. Herein,
for the address parsing, the evaluation metrics are identified as accuracy,
parsing rate, and effective parsing
rate.
[0090] As the following, R represents a record set of correct coordinates
obtained by address parsing;
G(wr)] represents a type of wrong result set i, wherein the major false type
is deviations of the coordinate;
T is the total number of addresses to be parsed; S is a record set with
coordinate obtained via success address
parsing; and E represents a failure record set with no coordinate obtained
after the address parsing. The
final accuracy of the address parsing is shown in Eqn (10), the parsing rate
is calculated by Eqn (11), and
the effective parsing rate is calculated by Eqn (12).
Parsing correct result set: R.
(Parsing wrong result set: W = G wr)]
Total sample number: T Parsing success result
set: S = T ¨ E Parsing failure result set:
E
=
_______________________________________________________________________________
_____________________________________________ (10)
R + W
P2 -
_______________________________________________________________________________
__________________________________________ (1 1 )
S E
P3 -
_______________________________________________________________________________
__________________________________________ (12)
S + E
[0091] The testing result of 10000 pieces of address information are compared
and evaluated. The
correction rate by tric and regular matching technology is 86.41%, wherein
13.59% wrong parsing results
arc due to redundant information, disordered strings, and other data quality
issues. In the meanwhile, the
data quality issues further lead to a portion of data parsing failure without
coordinate acquired. The parsing
rate with the described technology is only 81%. Under the same samples, the
method of present invention
achieves parsing rate of 98%, improving 17% compared with the current
technologies. The effective parsing
rate is improved from 70% to 93%, as shown in Table 2.
Old technology New
technology Evaluation metrics
Traditional data clean Data
clean based on improvement
geological entity selection
Correction rate P1 86.41% 94.89%
8.48%
Parsing ratc P2 81% 98%
17%
Effective parsing rate 70% 93%
23%
P3
12
CA 03145918 2022- 1-26
[0092] Based on the feature selection algorithm, the political geological
entity rclation idcntification model
is optimized, with a higher correction rate than traditional conditional
matching. The extracted geological
data are more accurate.
[0093] The following is an application of the embodiment 1 in the present
invention:
[0094] Basis data synchronization tasks are gcncratcd, to store the raw
recorded address information from
thc original data system in to the HDFS of a parsing task cluster. The parsing
task cluster is based on spark
tcchniquc and dcvelops data proccssing tasks via Java, to allocatc and
schedule tasks.
In the parsing task cluster, the pre-trained political geological entity
relation identification model is
allocated, to recognize the administrativc district levcis and geological
entity relationships from low-
quality address information and extract effective information. In particular,
the corc political gcological
entity relation identification model is devcloped with python, and trained
bascd on RNN recurrent neural
network and CRF conditional random field field algorithm. With embeddcd
geological entity feature
optimization algorithm, the human-based interference information is filtered.
Then, with the administrative
sorting algorithm, the geological entities are sorted so as for filling data
with the aforementioned tric tree
to obtain standard geological data. Therefore, high-quality address
information is provided for the
following coding process.
[0095] The gcocoding function can be developed and scheduled via spark task
cluster. With RESTful style
http parsing batch address parsing ports devcloped with Java, thc model
extracted and filled address
information arc encoded to obtain standard gcocoding information. To improve
parsing efficiency, the
tasks can be schcdulcd parallclly, and in the meanwhile, single-time batch
submission is adopted for batch
data parsing and encoding, to improvc parsing and cncoding handling capacity
without prcssurizing
clusters.
[0096] Bccausc of indcpcndent batch encoding parsing service, the calculation
resources arc not occupied
while parsing time is significantly rcduccd. With the political geological
entity relation identification
model embedded into the spark computation engine, 100 million pieces of data,
wherein 15 days were
expected for completing parsing, only requires 10 hours with adopting the
method in the present invention,
as 36 times faster.
Embodiment 2
[0097] According to the formcntioncd descriptions, the embodiment 2 in the
present invention provides a
address information parsing method, as shown in Fig. 3, comprising:
[0098] S31, acquiring parsing-pending address information from original data;
13
CA 03145918 2022-1-26
[0099] S32, extracting features of thc described parsing-pending address
information by a natural language
processing technology, selecting extracted features to be vectorized as an
identifying-pending feature
vector;
[0100] S33, inputting the identifying-pending feature vector into a pre-set
model to obtain an initial array
comprising geographic entities and administrative division levels
corresponding to the geographic entities;
[0101] S34, sorting and dcduplicating the geographic entities in the initial
array according to the
administrative division levels to obtain a standard array; and
[0102] S35, encoding the standard array to obtain a geocoding result.
[0103] Preferably, before extracting features of the described parsing-pending
address information by a
natural language processing technology, the described method further includes:
[0104] determining that if the described parsing-pending address information
has been parsed based on
pre-stored history address information parsing recorders, wherein the
described history address
information parsing recorders includes history address information and the
corresponding history
gcocoding data;
[0105] where if the described parsing-pending address information has been
parsed, acquiring the
associated history gcocoding data as the gcocoding result; and
[0106] where if the described parsing-pending address information has not
beenparsed, extracting features
of the described parsing-pending address information by a natural language
processing technology.
[0107] To prevent incomplete information in data arrays, before encoding the
standard array to
obtain a gcocoding result, the described method further includes:
[0108] matching the described standard array with the pre-stored geological
location tric tree, to determine
that if the described standard array has deficiency, wherein the described
geological location tric tree is
constructed according to administrative division levels;
[0109] where if the described standard array has deficiency, filling the
described standard array according
to the described geological location tric tree; and
[0110] the described process of encoding the standard array to obtain a
gcocoding result including
encoding the filled standard array to obtain a gcocoding result.
[0111] The method in the present invention application further includes
procedures for constructing the
described pre-set model, including:
[0112] performing corpus annotation for the address data in a sample set to
obtain sample array annotated
with geographic entities and administrative division levels corresponding to
the geographic entities;
[0113] extracting elementary features of the address information in the
described sample set by a natural
language processing technology, selecting the elementary features satisfying
certain conditions as target
features, and vcctorizing the described target feature to obtain the sample
feature vectors; and
14
CA 03145918 2022-1-26
[0114] assigning the described sample feature vectors as inputs and the
corresponding sample array as
outputs, and training with the neural network and the conditional random field
algorithm to obtain the
described pre-set model.
[0115] Preferably, the described process of extracting elementary features of
the address information in
the described sample set by a natural language processing technology,
selecting the elementary features
satisfying certain conditions as target features, and vcctorizing the
described target feature to obtain the
sample feature vectors consists of:
[0116] calculating the frequency of appearance of each elementary feature in
the address texts;
[0117] based on the described frequency, calculating the correlation between
each elementary feature and
each administrative division level as individual feature weights;
[0118] selecting the elementary features with the correlation and/or frequency
satisfying pre-set conditions
as the described target features;
[0119] calculating the correlation between each selected target feature and
each administrative division
level, and defining the averaged correlation of each target feature as the
weight of each target feature, to
construct a weighted matrix according to the described weights; and
[0120] vcctorizing the described target feature based on the described
weighted matrix to obtain the sample
feature vectors.
[0121] The aforementioned pre-construction of the described pre-set model can
be further referred to the
aforementioned model training process for more details.
[0122] The aforementioned gcocoding results can be combined with other data as
a data basis for following
decision making. Therefore, in the present invention, thc aforementioned
gcocoding results and the
associated original data can be stored jointly.
[0123] For example, wherein the sale data is the original data, after parsing
the original data to obtain
accurate gcocoding results, the described gcocoding result and the original
data arc jointly stored, to obtain
product selling statistics at a certain geological location. For ease of
following query, the joint information
can be stored in the clasticsearch searching engine.
Embodiment 3
[0124] With the aforementioned joint storage as the basis, for example, some
data related to a geological
region is requested, and a data acquisition method is provided in the present
invention, including:
[0125] receiving candidate address information;
[0126] parsing the described candidate address information according to the
method in the claim 7 to
obtain the parsed candidate gcocoding data; and
CA 03145918 2022-1-26
[0127] calculating in a correlation table of the pre-stored geocoding results
and the original data based on
the described candidate geocoding data and a pre-set geological range, to
obtain the stored geocoding
results and the original data within the pre-set geological range.
[0128] Based on the aforementioned method, the gcocoding can be used to
acquire the original data within
a certain range ofgeological region, so as for providing data basis for
following sale, promotions, and other
decision making.
Embodiment 4
[0129] Corresponding to the method in the aforementioned embodiment 2, the
embodiment 4 in the present
invention provides an address information parsing device, as shown in Fig. 4,
comprising:
[0130] a parsing-pending address information acquisition unit 41, configured
to acquire parsing-pending
address information from original data;
[0131] a primary feature extraction unit 42, configured to extract features of
the described parsing-pending
address information by a natural language processing technology, select
extracted features to be vectorized
as an identifying-pending feature vector;
[0132] a model prediction unit 43, configured to input the identifying-pending
feature vector into a pre-set
model for obtaining an initial array comprising geographic entities and
administrative division levels
corresponding to the geographic entities, wherein the described pre-set model
is constructed by training in
combination of the neural network and the conditional random field algorithm;
[0133] a sorting unit 44, configured to sort and deduplicate the geographic
entities in the initial array
according to the administrative division levels to obtain a standard array;
and
[0134] a geocoding unit 45, configured to encode the standard array to obtain
a geocoding result.
[0135] Preferably, the described device further includes
[0136] a parsing record determination unit 46 connected with the parsing-
pending address information
acquisition unit 41, configured to determine that if the described parsing-
pending address information has
been parsed based on pre-stored history address information parsing recorders,
wherein the described
history address information parsing recorders includes history address
information and the corresponding
history geocoding data; and
[0137] a parsing record acquisition unit 47, connected with the parsing record
determination unit 46,
configured to acquire the associated history geocoding data as the geocoding
result where if the described
parsing-pending address information has been parsed.
[0138] The described primary feature vectorization unit 42 is particularly
configured to extract
features of the described parsing-pending address information by a natural
language processing
technology where if the described parsing-pending address information has not
been parsed.
16
CA 03145918 2022-1-26
[0139] To prevcnt potential deficicncy of the data array information, the
described device further
includes that
[0140] before encoding the standard array to obtain a geocoding result, the
described method further
includes:
[0141] a filling unit 48, configured to match the described standard array
sorted by the sorting unit 44 with
thc pre-stored geological location tric trcc, for determining that if the
described standard array has
deficiency, whcrcin the dcscribcd gcological location trie tree is constructed
according to administrative
division levc1s; and
[0142] the geocoding unit 45, configured to cncodc the filled standard array
to obtain a geocoding result.
[0143] The device in thc prcscnt invention further includes a unit for
constructing the dcscribcd pre-set
model, comprising:
[0144] a secondary fcaturc vcctorization unit, configured to extract features
of the describcd parsing-
pending address information by a natural language processing technology, and
select extracted features to
be vcctorizcd as an identifying-pending fcaturc vector. The detailed process
of the prcscnt step can refer
to descriptions in the embodiment 1. In particular, the secondary feature
vectorization unit and the primary
fcaturc vcctorization unit can be the samc or not thc same.
[0145] Samplc administrative entity rclationship unit, configurcd to perform
corpus annotation for the
address data in a sample sct, obtaining sample array annotated with geographic
cntitics and administrative
division levcls corresponding to thc geographic entities;
[0146] modcl training unit, configured to assign the described samplc fcaturc
vectors as inputs and the
corrcsponding sample array as outputs, and train with the RNN rccurrcnt ncural
nctwork and thc CRF
conditional random field algorithm to obtain the described pre-set model.
[0147] The aforementioned geocoding result can be combincd with othcr data so
as for providing data
basis for decision making. Therefore, the described device in the prcscnt
invention further includes a joint
storage unit, configured to jointly store the dcscribcd geocoding rcsult and
the original data.
[0148] For cxample, whercin thc sale data is the original data, after parsing
the original data to obtain
accurate geocoding results, the described geocoding result and the original
data arc jointly storcd, to obtain
product selling statistics at a ccrtain geological location. For easc of
following query, the joint information
can be stored in the clasticsearch scarching cnginc.
Embodiment 5
[0149] Corresponding to the aforementioned method and dcvicc, a computer
system is provided in the
embodiment 5 in the present invention, including:
[0150] one or more processors; and
17
CA 03145918 2022-1-26
[0151] a storage medium related to the described one or more processors,
configured for storing the
program commands, wherein the described program commands are executed by the
described one or more
processors for performing the following procedures:
[0152] acquiring parsing-pending address information from original data;
[0153] extracting features of the described parsing-pending address
information by a natural language
processing technology, selecting extracted features to be vcctorizcd as an
identifying-pending feature
vector;
[0154] inputting the identifying-pending feature vector into a pre-set model
to obtain an initial array
comprising geographic entities and administrative division levels
corresponding to the geographic entities;
[0155] sorting and dcduplicating the geographic entities in the initial array
according to the administrative
division levels to obtain a standard array; and
[0156] encoding the standard array to obtain a geocoding result.
[0157] In particular, a schematic of the computer system structure, shown in
Fig. 5, comprises a processor
1510, a video display adapter 1511, a disk driver 1512, an input/output
connection port 1513, an interact
connection port 1514, and a memory 1520. The aforementioned processor 1510,
video display adapter
1511, disk driver 1512, input/output connection port 1513, and internet
connection port 1514 are connected
and communicated via the system bus control 1530.
[0158] In particular, the processor 1510 can adopt a universal CPU (central
processing unit), a
microprocessor, an ASIC (application specific integrated circuit) or the use
of one or more integrated
circuits. The processor is used for executing associated programmes to achieve
the technical strategies
provided in the present invention.
[0159] The memory 1520 can adopt a read-only memory (ROM), a random access
memory (RAM), a
static memory, a dynamic memory, etc. The memory 1520 is used to store the
operating system 1521 for
controlling the electronic apparatus 1500, and the basic input output system
(BIOS) 1522 for controlling
the low-level operations of the electronic apparatus 1500. In the meanwhile,
the memory can also store the
internct browser 1523, data storage management system 1524, the device label
information processing
system 1525, etc. The described device label information processing system
1525 can be a program to
achieve the aforementioned methods and procedures in the present invention. In
summary, when the
technical strategies are performed via software or hardware, the codes for
associated programs are stored
in the memory 1520, then called and executed by the processor 1510.
[0160] The input/output connection port 1513 is used to connect with the
input/output modules for
information input and output. The input/output modules can be used as
components that arc installed in the
devices (not included in the drawings), or can be externally connected to the
devices to provide the
described functionalitics. In particular, the input devices may include
keyboards, mouse, touch screens,
18
CA 03145918 2022-1-26
microphones, various types of sensors, etc. The output devices may include
monitors, speakers, vibrators,
signal lights, etc.
[0161] The intcrnct connection port 1514 is used to connect with a
communication module (not included
in the drawings), to achieve the communication and interaction between the
described device and other
equipment. In particular, the communication module may be connected by wire
connection (such as 11SB
cables or interact cables), or wireless connection (such as mobile data, W1FI,
Bluctooth, etc.)
[0162] The system bus control 1530 includes a path to transfer data across
each component of the device
(such as the processor 1510, the video display adapter 1511, the disk driver
1512, the input/output
connection port 1513, the intcrnct connection port 1514 and the memory 1520).
[0163] Besides, the described electronic device 1500 can access the collection
condition information from
the collection condition information database 441 via a virtual resource
object, so as for conditional
statements and other purposes.
[0164] To clarify, although the schematic of the aforementioned device only
includes the processor 1510,
the video display adapter 1511, the disk driver 1512, the input/output
connection port 1513, the interact
connection port 1514, the memory 1520 and the system bus control 1530, the
practical applications may
include the other necessary components to achieve successful operations. It is
comprehensible for those
skilled in the art that the structure of the device may comprise of less
components than that in the drawings,
to achieve successful operations.
[0165] By the aforementioned descriptions of the applications and embodiments,
those skilled in the art
can understand that the present invention can be achieved by combination of
software and necessary
hardware platforms. Based on this concept, the present invention is considered
as providing the technical
benefits in the means of software products. The mentioned computer software
products are stored in the
storage media such as ROM/RAM, magnetic disks, compact disks, etc. The
mentioned computer software
products also include using several commands to have a computer device (such
as a personal computer, a
server, or a network device) to perform portions of the methods described in
each or some of the
embodiments in the present invention.
[0166] The embodiments in the description of the present invention are
explained step-by-step. The similar
contents can be referred amongst the embodiments, while the differences
amongst the embodiments are
emphasized. In particular, the system and the corresponding embodiments have
similar contents to the
method embodiments. Hence, the system and the corresponding embodiments are
described concisely, and
the related contents can be referred to the method embodiments. The described
system and system
embodiments are for demonstration only, where the components that arc
described separately can be
physically separated or not. The components shown in individual units can be
physical units or not. In
other words, the mentioned components can be at a single location or
distributed onto multiple network
19
CA 03145918 2022-1-26
units. All or portions of the modules can be used to achieve the purposes of
embodiments of the present
invention based on the practical scenarios. Those skilled in the art can
understand and apply the associated
strategies without creative works.
[0167] The data processing method, device, and apparatus provided in the
present invention application
arc explained in detail. A portion of applications arc used to explain the
principles and implementation of
the present invention, wherein the aforementioned embodiment is used to
provide better understanding of
the method and core concept of the present invention. In the meanwhile, for
those skilled in the art,
modifications may be applied to practical applications according to the core
concepts of the present
invention. To summarize, the content of the descriptions shall not limit the
present invention.
CA 03145918 2022-1-26