Note: Descriptions are shown in the official language in which they were submitted.
WO 2021/138216
PCT/US2020/066991
SYSTEMS AND METHODS FOR BUSINESS ANALYTICS MODEL SCORING AND
SELECTION
BACKGROUND
[0001] The present invention relates to systems and methods
for the objective
modeling and ultimate qualitative selection of business analytics models.
Business analytics
allows for improved insight into the current and future state of industries.
These models are
very useful to business decision makers, investors and operations experts.
[0002] Many factors influence the success or failure of a
business or other
organization. Many of these factors include controllable variables, such as
product
development, talent acquisition and retention, and securing business deals.
However, a
significant amount of the variables influencing a business' success are
external to the
organization. These external factors that influence an organization are
typically entirely out
of control of the organization, and are often poorly understood or accounted
for during
business planning. Generally, one of the most difficult variables for a
business to account for
is the general health of a given business sector.
[0003] While these external factors are not necessarily able
to be altered, being able
to incorporate them into business planning allows a business to better
understand the impact
on the business, and make strategic decisions that take into account these
external factors.
This may result in improved business performance, investing decisions, and
operational
efficiency. However, it has traditionally been very difficult to properly
account for, or model,
these external factors; let alone generate meaningful forecasts using many
different factors in
a statistically meaningful and user friendly way.
[0004] For example, many industry outlooks that current exist
are merely opinions of
so-called "experts" that may identify one or two factors that impact the
industry. While these
expert forecasts of industry health have value, they provide a very limited,
and often
inaccurate, perspective into the industry. Further these forecasts are
generally provided in a
qualitative format, rather than as a quantitative measure. For example, the
housing industry
may be considered "healthy" if the prior year demand was strong and the number
of housing
starts is up. However, the degree of 'health' in the market versus a prior
period is not
necessarily available or well defined.
- -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
[0005] As a result, current analytical methods are incomplete,
not quantitative, time
consuming and labor intensive processes that are inadequate for the today's
competitive,
complex and constantly evolving business landscape. A number of models for
predicting
business conditions exist, but there is often little guarantee as to the
accuracy or consistency
of these models. Currently, laborious manual review of the models is
undertaken to
determine if a model is "good" by various business experts. Not only is such
an endeavor
costly (both in time and resources), ultimately the result is the opinion of
one or more
individuals as to the health of the model. This also leads to considerable
inconsistency
between what is considered a "good- model based upon the subjective opinions
of the various
reviewers.
[0006] It is therefore apparent that an urgent need exists for
a robust automated
system for scoring and selection of business analytics models. These systems
and methods
for scoring and selecting models enables better organizational and investment
functioning.
SUMMARY
[0007] To achieve the foregoing and in accordance with the
present invention,
systems and methods for the scoring and selection of business analytics models
are provided.
Such systems and methods enable business persons, investors, and industry
strategists to
better understand the present state of their industries, and more importantly,
to have foresight
into the future state of their industry.
[0008] In some embodiments, six or more metrics that are
relevant to the model are
initially selected, and weights are assigned to each metric. A first subset of
the metrics are
selected, including metrics for model fit and model error. A primary
regression is performed
on this first subset of metrics, and the results are multiplied by the
corresponding weights. A
second subset of metrics including at least two penalty functions are then
selected. These
metrics are quantified by the percentage of incidence, and the results are
multiplied by the
corresponding penalty weights. The scores from the primary regression and
penalty
calculations are aggregated into a final score.
[0009] In some embodiments, a holdout sample regression is
also performed. These
holdout regressions are likewise weighted and aggregated into the score to
prevent over fit.
Additionally, simulation and consistency regressions can be performed,
including
multiplication by corresponding weights, and integration into the aggregate
score.
- 2 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
[0010] Generally the weights for the first subset of metrics
are a value between 0.01
and 0.3. The weights corresponding to the penalty metrics are generally values
between -0.5
and -4. The model fit metric is a predictive R-squared calculation, and the
model error metric
is a mean absolute percentage error (MAPE) calculation.
[0011] The penalty metrics may include at least a percentage
of variables in the
model with an incorrect sign and a percentage of variables in the model with a
p-value above
a threshold and a percentage of variables with a Variance Inflation Factor
(VIF) above a
threshold. In some instances, penalty metrics are not based upon this binary
measure of a
threshold, but may rather vary according to the p-value score and VIF levels.
These
modulated penalty metrics are linearly correlated to the p-values and VIF
measures.
[0012] In some alternate embodiments, the systems and methods
may be utilized to
select a "best" model. In this process the initial set of models are received
and are
represented as a binary string. The models are each scored in the manner
discussed above.
The models are then ranked by their scores, and a subset of the initial set of
models with a
ranking below a threshold are removed to yield a remaining set of models.
Randomly
selected variables from these remaining models are then exchanged to "breed"
new models to
make up for the removed models. These new models are then also scored, and the
full set of
models are re-ranked. This process may be iterated until a set of acceptable
models are
arrived at. This may include when all models have scores above a threshold, or
once the
newly scored models scores do not change much from one iteration to the next.
From this
"acceptable- set of models the model with the highest score is selected.
[0013] A random variable can randomly be selected for removal
or alteration when
the models are being "bred" in order to introduce additional variability. The
models removed
may be a set number of models (for example, half the models with the lowest
scores), or any
models below a set score threshold. The scoring of each model is stored in a
shared database
such that each model is only scored once.
[0014] Note that the various features of the present invention
described above may be
practiced alone or in combination. These and other features of the present
invention will be
described in more detail below in the detailed description of the invention
and in conjunction
with the following figures.
- 3 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
BRIEF DESCRIPTION OF THE DRAWINGS
[0015] In order that the present invention may be more clearly
ascertained, some
embodiments will now be described, by way of example, with reference to the
accompanying
drawings, in which:
[0016] Figure 1A is an example logical diagram of a data
management system for
business analytics management and modeling, in accordance with some
embodiments;
[0017] Figure 1B is a second example logical diagram of a data
management system
for business analytics management and modeling, in accordance with some
embodiments;
[0018] Figure 2A is an example logical diagram of an
application server, in
accordance with some embodiments;
[0019] Figure 2B is an example logical diagram of a runtime
server, in accordance
with some embodiments;
[0020] Figure 2C is an example logical diagram of a model
quality assessment and
selection server, in accordance with some embodiments;
[0021] Figure 3 is an example logical diagram of an automated
modeler, in
accordance with some embodiments;
[0022] Figure 4 is a flow chart diagram of an example high
level process for business
analytics management, in accordance with some embodiments;
[0023] Figure 5 is a flow chart diagram of manual data
management, in accordance
with some embodiments;
[0024] Figure 6 is a flow chart diagram of automated model
management, in
accordance with some embodiments;
[0025] Figure 7 is a flow chart diagram of automated data
ranking, in accordance with
some embodiments;
[0026] Figure 8 is a flow chart diagram of model scoring, in
accordance with some
embodiments;
[0027] Figure 9 is a flow chart diagram of model selection via
genetic algorithm, in
accordance with some embodiments;
- 4 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
[0028] Figure 10 is a flow chart diagram of user directed
model editing, in accordance
with some embodiments;
[0029] Figure 11 is a flow chart diagram of report generation,
in accordance with
some embodiments;
[0030] Figure 12 is an example illustration of a Durbin-Watson
Model Score Impact
Chart, in accordance with some embodiments;
[0031] Figures 13-15 are example illustrations of a model
selection matrix used in the
genetic algorithm, in accordance with some embodiments;
[0032] Figure 16 is an example chart of MAPE vs model scores,
in accordance with
some embodiments;
[0033] Figure 17 is an example chart of Model Overfit vs model
scores, in accordance
with some embodiments;
[0034] Figure 18 is an example chart of model coefficient
standard error vs model
scores, in accordance with some embodiments;
[0035] Figure 19 is an example illustration of the model
scoring function, in
accordance with some embodiments; and
[0036] Figures 20A and 20B illustrate exemplary computer
systems capable of
implementing embodiments of the data management and forecasting system.
DETAILED DESCRIPTION
[0037] The present invention will now be described in detail
with reference to several
embodiments thereof as illustrated in the accompanying drawings. In the
following
description, numerous specific details are set forth in order to provide a
thorough
understanding of embodiments of the present invention. It will be apparent,
however, to one
skilled in the art, that embodiments may be practiced without some or all of
these specific
details. In other instances, well known process steps and/or structures have
not been
described in detail in order to not unnecessarily obscure the present
invention. The features
and advantages of embodiments may be better understood with reference to the
drawings and
discussions that follow.
[0038] Aspects, features and advantages of exemplary
embodiments of the present
invention will become better understood with regard to the following
description in
- -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
connection with the accompanying drawing(s). It should be apparent to those
skilled in the
art that the described embodiments of the present invention provided herein
are illustrative
only and not limiting, having been presented by way of example only. All
features disclosed
in this description may be replaced by alternative features serving the same
or similar
purpose, unless expressly stated otherwise. Therefore, numerous other
embodiments of the
modifications thereof are contemplated as falling within the scope of the
present invention as
defined herein and equivalents thereto. Hence, use of absolute and/or
sequential terms, such
as, for example, -will," -will not," -shall," -shall not," -must," -must not,"
-only," -first,"
"initially,- "next,- "subsequently,- "before,- "after,- "lastly,- and
"finally,- are not meant to
limit the scope of the present invention as the embodiments disclosed herein
are merely
exemplary.
[0039] Note that significant portions of this disclosure will
focus on the management
and modeling of data for businesses. While this is intended as a common use
case, it should
be understood that the presently disclosed systems and methods are useful for
the modeling
and management of data based upon any time series data sets, for consumption
by any kind
of user. For example, the presently disclosed systems and methods could be
relied upon by a
researcher to predict trends as easily as it is used by a business to forecast
sales trends. As
such, any time the term 'business' is used in the context of this disclosure
it should be
understood that this may extend to any organization type: individual, investor
group, business
entity, governmental group, non-profit, religious affiliation, research
institution, and the like.
Further, references to business analytics, or business models should be
understood to not be
limited to commerce, but rather to any situation where such analysis may be
needed or
desired.
[0040] Lastly, note that the following description will be
provided in a series of
subsections for clarification purposes. These following subsections are not
intended to
artificially limit the scope of the disclosure, and as such any portion of one
section should be
understood to apply, if desired, to another section.
I. DATA MANAGEMENT SYSTEMS FOR MODELING BUSINESS
ANALYTICS
[0041] The present invention relates to systems and methods
for using available data
and metrics to generate an entirely new data set through transformations to
yield models.
Particularly, this disclosure shall focus on the scoring and ultimate
selection of models for
usage in business analytics forecasting. While various indices are already
known, the
- 6 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
presently disclosed systems and methods provide the ability to generate score
and select a
highly accurate model that is forward looking rather than providing merely a
snapshot of the
current situation. Such systems and methods allow for superior insight into
current and near
future health and activity of a given industry sector, product, company or
other dimension of
interest. This enables for better business planning, preparation, investment,
and generally
may assist in influencing behaviors in more profitable ways.
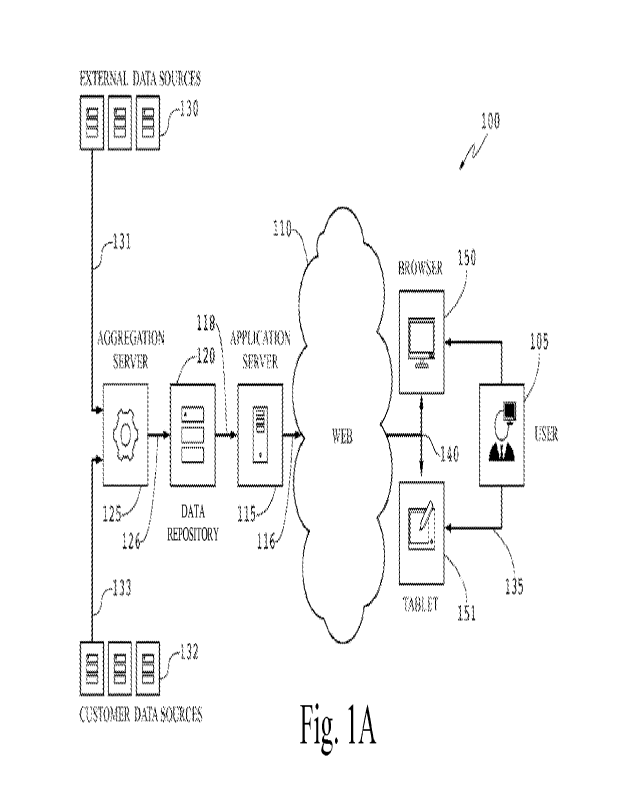
[0042] To facilitate discussion, Figure 1A is an example
logical diagram of a data
management system for business analytics modeling 100. The data analysis
system 100
connects a given analyst user 105 through a network 110 to the system
application server
115. A database/data repository 120 (or other suitable dataset based upon
forecast sought) is
linked to the system application server via connection 118 and the database
120 thus provides
access to the data necessary for utilization by the application server115.
[0043] The database 120 is populated with data delivered by
and through the data
aggregation server 125 via connection 126. Data aggregation server 125 is
configured to have
access to a number of data sources, for instance external data sources 130
through connection
131. The data aggregation server can also be configured to have access to
proprietary or
internal data sources, e.g. customer data sources, 132, through connection
133. The
aggregated data may be stored in a relational database (RDBM) or in big data-
related storage
facilities (e.g., Hadoop, NoSQL), with its formatting pre-processed to some
degree (if
desired) to conform to the data format requirement of the analysis component.
[0044] Network 110 provides access to the user or data analyst
(the user analyst).
User analyst 105 will typically access the system through an internet browser,
such as
Chrome or Mozilla Firefox, or a standalone application, such as an app on
tablet 151. As such
the user analyst (as shown by arrow 135) may use an internet connected device
such as
browser terminal 150, whether a personal computer, mainframe computer, or
VT100
emulating terminal. Alternatively, mobile devices such as a tablet computer
151, smart
telephone, or wirelessly connected laptop, whether operated over the internet
or other digital
telecommunications networks, such as a 4G network. In any implementation, a
data
connection 140 is established between the terminal (e.g. 150 or 151) through
network 110 to
the application server 115 through connection 116.
[0045] Network 110 is depicted as a network cloud and as such
is representative of a
wide variety of telecommunications networks, for instance the world wide web,
the internet,
- 7 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
secure data networks, such as those provided by financial institutions or
government entities
such as the Department of Treasury or Department of Commerce, internal
networks such as
local Ethernet networks or intranets, direct connections by fiber optic
networks, analog
telephone networks, through satellite transmission, or through any combination
thereof
[0046] The database 120 serves as an online available database
repository for
collected data including such data as internal metrics. Internal metrics can
be comprised of,
for instance, company financial data of a company or other entity, or data
derived from
proprietary subscription sources. Economic, demographic, and statistical data
that are
collected from various sources and stored in a relational database, hosted and
maintained by a
data analytics provider and made accessible via the internet. The data
analytics provider may
also arrange for a mirror of the datasets to be available at the company's
local IT
infrastructure or within a company intranet, which is periodically updated as
required.
[0047] The application server 115 provides access to a system
that provides a set of
calculations based on system formula used to calculate the leading, lagging,
coincident,
procyclic, acyclic, and counter-cyclic nature of economic, demographic, or
statistical data
compared to internal metrics, e.g., company financial results, or other
external metrics. The
system also provides for formula that may be used to calculate a plurality of
models based on
projected or actual economic, demographic, and statistical data and company
financial or sold
volume or quantity data. Details of the formulas and processes utilized for
the calculation of
these models shall be provided in further detail below. These calculations can
be displayed
by the system in chart or other graphical format.
[0048] In some embodiments, changes observed in a metric may
also be classified
according to its direction of change relative to the indicator that it is
being measured against.
When the metric changes in the same direction as the indicator, the
relationship is said to be
`procyclic'. When the change is in the opposite direction as the indicator,
the relationship is
said to be -countercyclic'. Because it is rare that any two metrics will be
fully procyclic or
countercyclic, it is also possible that a metric and an indicator can be
acyclic¨e.g., the metric
exhibits both procyclic and countercyclic movement with respect to the
indicator.
[0049] The application residing on server 115 is provided
access to interact with the
customer datasource(s) 132 through the database 120 to perform automatic
calculations
which identify leading, lagging, and coincident indicators as well as the
procyclic, acyclic,
and counter-cyclic relationships between customer data and the available
economic,
- 8 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
demographic, and statistical data. Additionally, the models may be
automatically populated
on a periodic schedule, e.g. every month. Users 105 of the software
applications that can be
made available on the application server 115 are able to select and view
charts or monitor
dashboard modules displaying the results of the calculations performed by the
system. In
some embodiments, user 105 can select data in the customer repository for use
in the
calculations that may allow the user to forecast future performance, or tune
the business
analytics models. The types of indicators and internal data are discussed in
more detail in
connection with the discourse accompanying the following figures.
Alternatively, users can
view external economic, demographic, and statistical data only and do not have
to interface
with internal results, at the option of the user. In yet other embodiments,
all internal and
external data may be shielded from the user, and only the models and analytics
are provided
to the user for ease of use.
[0050_1 Data is collected for external indicators and internal
metrics of a company
through the data aggregation server 125. The formulas built into the
application identify
relationships between the data. Users 105 can then use the charting components
to view the
results of the calculations and models. In some embodiments, the data can be
entered into the
database 120 manually, as opposed to utilizing the data aggregation server 125
and interface
for calculation and forecasting. In some embodiments, the users 105 can enter
and view any
type of data and use the applications to view charts and graphs of the data.
[0051] Alternatively, in some system users may have sensitive
data that requires it to
be maintained within the corporate environment. Figure 1B depicts components
of the system
in an exemplary configuration to achieve enhanced data security and internal
accessibility
while maintaining the usefulness of the system and methods disclosed herein.
For example,
the data management system 101 may be configured in such a manner so that the
application
and aggregation server functions described in connection with Figure lA are
provided by one
or more internal application/aggregation servers 160. The internal server 160
access external
data sources 180 through metrics database 190, which may have its own
aggregation
implementation as well. The internal server accesses the metrics database 190
through the
web or other such network 110 via connections 162 and 192. The metrics
database 190
acquires the appropriate data sets from one or more external sources, as at
180, through
connection 182
[0052_1 The one or more customer data sources 170 may be
continue to be housed
internally and securely within the internal network. The internal server 160
access the various
- 9 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
internal sources 170 via connection 172, and implements the same type of
aggregation
techniques described above. The user 105 of the system then accesses the
application server
160 with a tablet 151 or other browser software 150 via connections 135 and
140, as in
Figure 1A. External data sources 130 and 180 may be commercial data
subscriptions, public
data sources, or data entered into an accessible form manually.
[0053] Figure 2A is an example logical diagram of an
application server 160 (or 115)
that includes various subcomponents that act in concert to enable a number of
functions,
including the generation of project dashboards and the generation, scoring and
selection of
business analytics models. Generally the data being leveraged for the
generation of models
includes economic, demographic, geopolitical, public record and statistical
data. In some
embodiments, the system utilizes any time series dataset. This time series
data stored in the
metrics database 120, is available to all subsystems of the application server
160 for
manipulation, transformation, aggregation, and analysis.
[0054] The application server 160 includes two main
components, a runtime server
201 responsible for model generation and deployment for the generation of
business analytics
dashboards, and a model quality assessment and selection server 203, which is
a specialized
system designed to consume historical data 120 and the generated models from
the runtime
server 201 to select models that have consistent and accurate performance.
[0055] The subcomponents of the runtime server 201 are
illustrated in Figure 2B as
unique modules within the server coupled by a common bus. While this
embodiment is
useful for clarification purposes, it should be understood that the presently
discussed runtime
server may consist of logical subcomponents operating within a single or
distributed
computing architecture, may include individual and dedicated hardware for each
of the
enumerated subcomponents, may include hard coded firmware devices within a
server
architecture, or any permutation of the embodiments described above. Further,
it should be
understood that the listed subcomponents are not an exhaustive listing of the
functionality of
the runtime server 201, and as such more or fewer than the listed
subcomponents could exist
in any given embodiment of the application server when deployed.
[0056] The runtime server 201 includes a correlation engine
210 which generates
initial information regarding the metrics that are utilized for the generation
of models. For
example, the degree of procyclic or counter-cyclic relationship that the
indicator expresses
may be determined by the correlation engine 210. Additionally, the correlation
engine 210
- itit -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
may determine factors such as the number of major and minor outliers for the
given index,
seasonality level of the indicator, degree of data overlap between the
indicator and other
indicators, difference of an indicator in terms of number of periods in the
last update, the
number of models already leveraging the indicator and frequency of the
indicator, for
example.
[0057] The runtime server 201 also includes a modeler 220. The
modeler's 220
functionality shall be discussed in considerable detail below; however, at its
root it allows for
the advanced compilation of many indicators (including other published
composite metrics
and forecasts) and enables unique manipulation of these datasets in order to
generate models
from any time series datasets. The modeler 220 may operate in close
conjunction with the
model quality assessment and selection server 203 for the final selection and
assessment of
the various models that are generated.
[0058] Some of the manipulations enabled by the modeler 220
are the ability to
visualize, on the fly, the R2, procyclic and countercyclic values for each
indicator compared
to the model, and may also allow for the locking of any indicators time
domain, and to shift
other indicators and automatically update statistical measures. Additionally,
the modeler 220
may provide the user suggestions of suitable indicators, and manipulations to
indicators to
ensure a 'best' fit between prior actuals and the forecast over the same time
period. The
'best' fit may include a localized maxima optimization of weighted statistical
measures. For
example, the R2, procyclic and countercyclic values could each be assigned a
multiplier and
the time domain offset used for any given indicator could be optimized for
accordingly. The
multipliers/weights could, in some embodiments, be user defined.
[0059] Figure 3 provides a greater detailed illustration of
the modeler 220. Critical to
the modeling is the determination of which indicators are to be utilized in a
given model. A
'strength score' may be calculated for each indicator to assist in this
determination. The
strength score generator and data ranker 310 consumes the indicator data,
along with metrics
compiled by the correlation engine 210, to generate the strength score for a
given indicator.
Note, that the model quality assessment and selection server 203 generates a
score for a given
model. These model scores, as will be discussed in considerable detail below,
are distinct
from the indicator strength scores discussed here. The indicators are then
ranked by their
strength indicators.
-11 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
[0060] As noted, an R-squared value for each indicator can be
calculated. R-squared
calculation is known, and involves the degree of variance in the dependent
variable (the
modeled variable) that is predicted from the independent variable (here the
indicator). For
example, the R-squared value may be calculated by first computing the mean of
observable
data (y):
Y
[0061] The total sum of squares is calculated:
SStot = Y)2
[0062] The regression sum of squares is next computed using
predicted values (f):
SSõfl ¨ (ft ¨ y
[0063] The sum of the squares of the residuals is then
calculated:
SSrõ = fi)2 = e i2
[0064] Lastly the coefficient of determination (R-squared) is
calculated:
R2 = 1 ¨
ootot
[0065] The R-squares value for any given indicator will vary
based upon the variable
it is being used to model. In addition to the R-squared value, the degree of
procyclic
relationship between the indicator and the model is received from the
correlation engine 210.
Also, as noted, the number of minor and major outliers for the indicator are
computed.
Additionally, the correlation engine will note if an indicator exhibits
seasonality. If it does,
then that indicator receives a value of 0.95, whereas a non-seasonal indicator
is assigned a
value of 1.05. Data overlap between the primary indicator (aka dependent
variable) and each
of the (explanatory) indicators is provided. The overlap is the number of data
points that is
shared between the two.
[0066] The difference in the last updated date, as a number of
periods, the number of
models the indicator is used in, the total number of models, and the frequency
of the indicator
- 12 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
is also received. In some embodiments, the frequency is one of monthly,
quarterly,
semiannual, or annual. These frequencies are assigned values of 54, 18, 9 or
5, respectively.
[0067] In some embodiments, the strength score is determined
by first adding
together the R-squared and procyclic values. A frequency of use factor is
calculated as the
number of models the indicator is used in divided by the total number of
models, and the
result added to one. A last update factor is calculated as the last updated
date minus two the
result divided by twenty, and the result then subtracted from one. An outlier
factor is
computed as one minus the number of minor outliers divided by one hundred, the
result then
minus the number of major outliers divided by twenty. A minimum length factor
is lastly
calculated as the data overlap divided by the frequency value.
[0068] The summed R-squared and procyclic value is multiplied
the seasonality
factor, the frequency of use factor, the last update factor, the outlier
factor, the minimum
length factor and one hundred to generate the strength score. For example,
assume an
indicator has the following values:
R-squared 0.5593
Procyclic 0.6032
Minor Outlier count 3
Major Outlier count 1
Seasonality No (1.05)
Difference in last updated date 2
Number of models using the index 50
Total number of models 500
Frequency Monthly (54)
[0069] This example indicator's strength score would then be
calculated as the
following:
- 13 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
R-Squared + Procyclic 0.5593+0.6032 0.34
Seasonality Factor 1.05 1.05
Frequency of use factor 1+(50/500) 1.1
Last updated Factor 1 ¨ (2 ¨ 2) 1
Outliers Factor 1 3 1 0.92
¨ ¨ ¨ ¨
100 20
Minimum Length Factor 64 1.19
54
Strength Score 0.34 x 1.5 x 1.1 x 1 x 0.92 x 1.19 x 100
61
[0070] The indicators are ranked in order from the highest
strength score to the lowest
strength score. They are then assigned to one of four 'buckets' to be utilized
in model
generation by a data bucketizer 320. These buckets include macroeconomic
datasets, datasets
applicable to the specific industry. datasets applicable to the demand
industry, and
miscellaneous datasets. Besides the macroeconomic bucket, the datasets in each
bucket
ideally have local (state level) data as well as country level datasets. When
local data is
unavailable, country level data may be substituted for. The datasets
populating each of the
buckets may be selected based upon their strength scores and their applicable
tags. For
example, if the demand industry bucket is for steel, only datasets tagged for
steel would be
used to populate the bucket.
[0071] Returning to Figure 2B, the runtime server 201 also
includes a workbench
manager 230 for the consolidated display of projects, data related to the
projects and
associated models. The workbench manager 230 keeps track of user access
controls, recent
activity and data updates. This information may be compiled and displayed to
the user in an
easily understood interface.
[0072] The application server 160 also includes an access
controller (not illustrated)
to protect various data from improper access. Even within an organization, it
may be
desirable for various employees or agents to have split access to various
sensitive data
sources, forecasts or models. Further, within a service or consulting
organization, it is very
important to separate various clients' data, and role access control enables
this data from
- 14 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
being improperly comingled. A projects organization engine 240 may include the
access
controller, or work in concert with it, in order to provide a consolidated
interface where the
projects associated with the user are displayed.
[0073] An analytics engine 250 may take the output from the
modeler 220, and any
additional data, and provide analytical analysis of the results. For example,
models may be
backtested, where the as-of dates may be altered and the resulting forecast is
compared
against actuals. Contribution information, accuracy measures, and definitions
are all
provided by the analytics engine 250. This component also allows the users to
interact with
and edit any model they have access to, and add annotations to the model
results. All this
information may be compiled in a configurable manner into one or more reports.
[0074] Lastly, a publisher 260 allows for the reports
generated by the analytics engine
250, and/or specific models generated via the modeler 220 to be published,
with appropriate
access controls, for visualization and manipulation by the users or other
intended audiences.
[0075] Turning to Figure 2C, the model quality assessment and
selection server 203 is
provided in greater detail. As noted previously, model data 235 from the
modeler 220 is
consumed by the model quality assessment and selection server 203, along with
historical
data 120 in the scoring and selection of the models. A model quantifier 205
consumes the
various generated models and analyzes the various model metrics for each
regression run and
potentially applies penalty scores to various indicators. These indicators are
likewise
weighted, and a final aggregate score for the model is generated. The specific
process for the
model scoring will be discussed in considerable detail below. The model scores
have utility
in themselves, but may also be leveraged by the genetic algorithm model
selector to undergo
an iterative process whereby known models are scored, parsed through, expanded
and
rescored until a list of high scoring models is identified. At this stage, the
"best" model based
upon the score is selected for usage.
[0076] The model selection not only identifies a best model,
but also determines
variables that are correlated with a high scoring model. These variables may
optionally be
fed back to the modeler 220 via the Al model building feedback system 225 for
improved
future model generation. In alternate embodiments, only the model score, and
the underlying
variables that are used to generate the score are provided back in the
feedback loop. The
modeler may then utilize these scores and variables to select for improved
future models.
- 15 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
[0077] By automating an otherwise time-consuming and labor-
intensive process, the
above-described model generation, scoring and selection system offers many
advantages,
including the generation of highly relevant and accurate models that are
forward looking, and
the ability to directly compare the models to historical actual data. Further,
through the usage
of regression models, specific forecast model metrics can be consumed by the
regression
model to predict model accuracy. As such, the application server no longer
requires
significant user expertise. The result is substantially reduced user effort
needed for the
generation of timely and accurate business analytics reports.
[0078] Now that the systems for data management for
generating, scoring and
selecting models have been described in considerable detail, attention will be
turned towards
methods of operation in the following subsection.
DATA MANAGEMENT AND MODELING SCORING AND SELECTION METHODS
[0079] To facilitate the discussion, a series of flowcharts
are provided. Figure 4 is a
flow chart diagram of an example high level process 400 for data management
and business
analytics reporting. In this example process, the user of the system initially
logs in (at 410)
using a user name and password combination, biometric identifier, physical or
software key,
or other suitable method for accessing the system with a defined user account.
The user
account enables proper access control to datasets to ensure that data is
protected within an
organization and between organizations.
[0080] The user role access is confirmed (at 420) and the user
is able to search and
manipulate appropriate datasets. This allows the user to access project
dashboards (at 430)
for enhanced analysis of a given project. An example of a project splashpage
900 is provided
in relation to Figure 9, which a user may be routed to after login. In this
splashpage the user
is identified/greeted. Only projects the user is authorized to access are
provided on the left
hand side of this example splashpage. Permissions for sharing projects is also
enabled from
this screen, as well as the creation or deletion of projects. For the purposes
of this discussion
a -project" requires permissions to access either view only or editing
permission). Data and
reports are project agnostic, and therefore may be accessed without attendant
permissions.
[0081] After the projects dashboards have been accessed the
user may decide to
manage the data manually or via automated indicator scoring (at 440). Figure 5
provides a
flow diagram of manual data management/selection process 450 in greater
detail. Data is
added as a primary indicator to a given workbench (at 510), and may
additionally be added as
- 16 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
a primary indicator to a given model (at 520). Data is determined to be a
primary indicator
by user. Selection of the primary indicator may employ the user searching for
a specific
dataset using a keyword search and/or using predefined metadata tags. The
matching datasets
are presented to the user for selection. The search results are ordered by
best match to the
keyword and/or tags as well as by alternate metrics, such as popularity of a
given indicator
(used in many other forecast models), quality of indicator data, or frequency
of indicator data
being updated. Search results may further be sorted and filtered by certain
characteristics of
the data series, for instance, by region, industry, category, attribute, or
the like. In some
cases, search display may depend upon a weighted algorithm of any combination
of the
above factors. In addition to utilizing all or some of the above factors for
displaying search
results, some embodiments of the method may generate suggestions for
indicators to the user
independent of the search feature. Likewise, when a user selects an indicator,
the system may
be able to provide alternate recommendations of 'better' indicators based on
any of the above
factors.
[0082] After data has been manually managed (or if only
automatic management is
desired) the models may be managed (at 460) using the data that has been
identified and
organized. Figure 6 provides greater detail into this model management
process. Initially,
data is received for the model (at 605). The model target horizon (length of
model), demand
industry, target industry and locale are all received (at 610), which
correspond to the
bucketized datasets already identified. The output format requirements are
also received (at
620). The datasets from the applicable buckets (already identified in the
prior process) are
selected (at 630), and the data may be automatically ranked (at 635). Figure 7
provides
greater detail of this automated process for ranking indicators for automated
selection. In this
process, the datasets are normalized (at 705). This may include transforming
all the datasets
into a percent change over a given time period, an absolute dollar amount over
a defined time
period, or the like. Likewise, periods of time may also be normalized, such
that the analysis
window for all factors is equal.
[0083] The next step for the automated score generation is the
computation of a
strength score (at 715) as discussed previously in considerable detail. As
noted before,
strength scores are dependent upon R-squared, procyclic calculation and a
number of
additional factors such as numbers of outliers, numbers of models, frequency
of updates, etc.
These factors are used to calculate metrics (e.g., seasonality factor,
frequency of use factor,
etc.) which are then multiplied together to generate a final score.
- 17 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
[0084] The various indicators are then presented to the user
for selection (at 725).
Generally this results in between 20-40 indicators being selected by the user
which are
believed to be -good" candidates for the final model. The user also selects a
target horizon
for the indicators, and determines the classification for each indicator (at
735). The process
helps to ensure that the model has an appropriate number of indicators and an
even mix of
statistically significant economic, industry-specific and geography-specific
indicators.
[0085] Returning to Figure 6, the indicators selected and
characterized in step 635
become the input to the parallel modeling (at 640). At this point in the
process, the initial
indicators that are used come up with an initial population of models to be
scored (at 650).
Model scoring is described in greater detail in relation to Figure 8.
Initially the model
metrics are selected (at 810), and weights are applied to the various selected
metrics (at 820).
In some embodiments, between 8 and 14 metrics may be selected for model
scoring. In some
specific embodiment, between 10 and 12 metrics are utilized. In some
embodiments, these
metrics may include measurements for model fit, model error, variable
diversity, overfit
prevention, various performance expectations, auto-correlations, residual
trends, a series of
penalty functions, and target horizon penalties. In some particular
embodiments, for
example, model fit may be measured as a predictive R2, and model error may be
calculated as
a MAPE (Mean Absolute Percentage Error) value. In alternate embodiments, model
fit is
calculated as a combination of predictive R-squared and model trend. Penalty
functions may
include percentage values that are the wrong sign or have p-values above a
threshold. In
some embodiments, penalty values may vary based upon p-values and VIF metrics,
and are
not reliant upon a threshold (no longer considered -binary" in nature). Auto
correlation may
be calculated by a Durbin Watson test. Additional metrics may be derived from
any
combination of the above model metrics, or other model metrics not listed.
[0086] The weights applied to the metrics generally vary by
metric type. For
example, for most recursion metrics the weights may be set to a value between
0.01 and 0.3.
For example, model fit measures may be assigned a weight set between 0.15 and
0.25, while
Auto-correlation metrics may be assigned a value between 0.05 and 0.15.
Penalty metrics
may be provided a negative weight. For example, generally these metrics are
assigned a
weight of -0.5 to -4. In some embodiments, a wrong sign metric, for example
may be
assigned a weight set between -2.5 to -3.5. Of course, p-value and VIF may be
more
nuanced, and may receive a penalty that is linearly correlated to the p-value
or V1F.
- 18 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
[0087] After weights have been assigned, the various selected
metrics are mapped to
model attributes which are being measured. These model attributes may include
categories
such as forecasting ability, accuracy of the insight, client requirements,
model overfit
protection, model longevity and model stability, for example. In some
embodiments, the
weights applied to the individual metrics may be applied to the model
attribute(s) which the
metric is mapped to, and then summed for all metrics that apply to the
attribute. For
example, model fit may apply to forecast ability, and model longevity (in
addition to other
attributes). Model error, in contrast, may map only to forecast ability.
Assume for a moment
that only these two indicators are used in calculating the score. If model fit
were assigned a
weight of 0.3 and model error were assigned a weight of 0.15 (for example),
then the total
weight of forecasting ability would be 0.45, while the total weight of model
longevity would
only be 0.3, in this particular example.
[0088] In some embodiments, it may be desired to have the
forecasting ability weight
sum be set between 0.5 and 0.75. Likewise, the client requirements attribute
may be set
between 0.05 and 0.25, the model overfit prevention may be set between 0.25
and 0.5, and
the model longevity and model stability weight sums may be set between 0.35
and 0.70. In
some embodiments, based upon metric mapping the weights of the various metrics
may be
optimized to ensure the total weight sums of the model attributes are within
the required
ranges.
[0089] After mapping, and metric weight determination, the
initial regression
(primary regression) may be applied to a first set of the metrics (at 840).
These may include
a single regression model created with the full input dataset using all of the
variables in the
model. For example, the model fit, as determined as a predictive R-square
indicates how well
a regression model predicts responses for new observations. 'The predictive R2
is calculated
by systematically removing each observation from the data set, estimating the
regression
equation, and determining how well the model predicts the removed observation.
This may
be calculated by the following, for example:
predictive R-squared = [1 - (PRESS / sums of squares total)] * 100
;where PRESS- Predicted Residuals Error Sum of Squares
- 19 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
[0090] Like adjusted R-squared, predicted R-squared can be
negative and it is lower
than R-squared. Because it is impossible to predict random noise, the
predicted R-squared
will drop for an overfit model. Thus, if a predicted R-squared is much lower
than the regular
R-squared, the model likely has too many terms. This predicted R-squared is
then multiplied
by its respective weight to yield the component associated with model fit
metric.
[0091] Similarly, the M.APE is calculated for the model as a
measure of prediction
accuracy of a forecasting method in statistics. Its accuracy is expressed as a
percentage, and
is defined by the formula:
(1 \ 'Actual ¨ Forecast)
*10 0
lActuall
[0092] Unlike the model fit component, the MAPE calculation is
a percentage, and
this is divided by 100. The result is subtracted from 1, and this is then
multiplied by the
model accuracy weight.
[0093] Similar calculations are made for variable diversity,
The purpose of the
Diversity of Variables metric is to show preference for models that include a
broader range of
variable classifications. A model that has a wider variety of predictor types
provides model
stability in the event one of the relationships with a predictor breaks down.
Diversity of
variables is calculated by counting the number of unique classifications
represented by the
model variables and dividing it by the total number of unique classifications
available.
Diversity of variables is a percentage-based number that is multiplied by the
weight to
generate the model score component.
[0094] Auto correlation is calculated using a Durbin Watson
statistic, which is used to
detect the presence of autocorrelation in the residuals (prediction errors)
from a regression
analysis. Autocorrelation is the similarity of a time series over successive
time intervals. It
can lead to underestimates of the standard error and can cause you to think
predictors are
significant when they are not. Figure 12 provides an example illustration of a
Durbin Watson
chart, at 1200. Generally Durbin Watson values between 1.5 and 2.5 can be
considered
relatively normal. As such, to calculate the model score component for auto-
correlation, the
Durbin Watson value has 2 subtracted from it, and the absolute vale is taken
of the result.
This is then subtracted from 2, the result divided by 2, and multiplied by the
weight. Similar
metrics may be measured for residual trends, which are likewise multiplied by
the weight to
generate a model score component.
- 20 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
[0095] After the primary regressions have been calculated for
the first metrics to
generate a first set of model score components, the penalty metrics may be
calculated and
applied (at 850). In some cases, penalties are viewed as "binary" metrics that
may disqualify
a given model from having a high score. These tend to include factors such as
a high p-value
(above a threshold), or a correlation with a wrong sign. The percentage of the
variables that
fall into these "unacceptable" categories is then subtracted by I, and
multiplied by the penalty
weight. As these weights tend to be relatively large, the presence of these
penalties may
significantly impact the overall model score. In other embodiments however, p-
values and
VIF metrics are more accurately refined, and are not 'binary' in nature. In
these cases, the
penalty value may correlate, in a linear fashion, with the p-values and VIF
metrics.
[0096] After penalties are calculated, the method applies a
secondary holdout sample
regression (at 860) to add to the component score. This is a loop of multiple
regression
models created with sample of the full input dataset using all of the
variables in the model.
Over-fitting a model is traditionally defined as building a model that
memorizes the data but
fails to predict well in the future. With the huge number of indicators
available for use in
models, these exists a high risk of over-fitting a model as it is possible to
find all kinds of
correlations that are ultimately meaningless. With a large set of explanatory
variables, that
actually have no relation to the dependent variable being predicted, some
variables will in
general be spuriously found to be statistically significant and the model
builder may retain
them in the model, thereby overfitting the model. The essence of overfilling
is to have
unknowingly extracted some of the residual variation (e.g., the noise) as if
that variation
represented underlying model structure. Cross-validation (holdout samples) are
one of the
ways to deal with this.
[0097] The holdout loop is a series of iterations that
continues until a stable average
holdout MAPE value is measured (above a minimum iteration threshold). These
iterations
include pulling a random sample from the model dataset, generating a
regression model for
the sample, predicting the holdout sample values using the model, calculating
the MAPE, and
averaging the MAPE values across alliterations. When the incident MAPE value
is
comparable to the average, then the MAPE is considered stable and the
iterations may be
discontinued. This final average MAPE value is defined as a holdout MAPE
value, and may
be multiplied by the holdout MARE weight.
1100981 Finally, the consistency regression may be applied (at
870). This is a loop of
regression models created with a sample of the full input dataset using all of
the variables in
- 21 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
the model. It differs from the holdout loop in that its goal is to simulate
going back in time,
building a model, scoring it, and then moving forward in time and repeating
the process.
This may be performed with the oldest two years of data available, and can be
used to build a
model to a target horizon. The model predictions are then compared against
historical actual
data. This process may be repeated for other periods of historical data, and
once all data has
been processed in this manner the average single period error and average
aggregate error can
be calculated.
[0099] In addition to using historical error information
(backwards looking accuracy
measure) the system may employ regression models that consume forecast model
metrics in
order to predict the forecast model error (forwards looking accuracy measure).
This
regression model has consumed over sixteen million simulations in order to
quantify the
impact metrics such as coefficient p-values and variance inflation factors
(VIF) have on
model performance.
[00100] The error for a single period shows how consistently
accurate the model is for
the given period (again by comparing the model predictions versus the actual
historical data).
Average aggregate error is the accuracy over a cumulative period, then
averaged over the
entire regression period. Each of these metrics are multiplied by their
respective weights in
determining consistency of the model.
[00101] Once all model score components are thus calculated,
they may be aggregated
together into a final model score (at 880). This is done through a simple
summation of the
individual component calculations, or may include an average of the component
calculations.
Often the model score is normalized to zero to one signal. The distributions
within the score
are "stretched" between this normalized range in order to leverage the full
'signal'
bandwidth. In some embodiments, normalization trims predictive R-square to 0.2
(thereby
removing very badly scored models from consideration) and stretch the
remaining
distribution to better separate the model scores.
[00102] Returning now to Figure 6, model scoring may be
employed by the system to
select a -best" model (at 660) using what is referred to as a 'genetic
algorithm'. Figure 9
provides a more detailed view of the process employed for the model selection.
An initial
population of "individuals" are first generated. An individual is defined as a
group of
variables that are used as predictors of a model, represented by a binary
string. For example,
if there are 10 candidate predictors Xl, X2, ... X10, then individual {Xl, X2,
X3} is
- 22 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
represented by 1110000000; and individual {X8, X9, X10} will be represented by
0000000111. A "population" is then the total listing of individuals in a given
iteration of the
process. After this initial population has been generated, the individuals are
each scored (at
920) in the manner described previously. This results in a set of individuals
that may be
ranked (at 930) by their scores. Unless the population is considered a "strong-
set of
individuals (at 940), the process iterates by eliminating some portion of the
lowest ranked
individuals in the population (at 950). This may include eliminating a set
number of
individuals (e.g., the lowest half of the population), or individuals with
scores below a
required threshold.
[00103] This process may be illustrated as a matrix for
clarity. Figure 13, for example,
illustrates a set of eight individuals with 12 variables in a matrix (at
1300). These individuals
have been scored and ranked. Here the bottom half of the individuals are
selected for
elimination.
[00104] Returning to Figure 9, a set of variables are randomly
selected for the
remaining population (at 960). These variables are then swapped from the other
remaining
models in order to "breed" additional individuals (at 970). Additionally,
randomized
variables may be altered as "mutations- to the set of individuals. This may
result in
replacement of all the individuals that were eliminated in step 950. The
process may then be
repeated with the new population being scored.
[00105] Figure 14 illustrates this randomized variable
selection, at 1400. Here
variables 4-6 are selected for swapping between the individuals 1 and 2 in
order to generate
two new individuals. Additionally, variable 12 of individual 1 is selected for
"mutation".
Figure 15 illustrates these newly generated individuals, at 1500.
[00106] Returning to Figure 9, as noted, the process of
eliminating and 'breeding' new
individuals repeats over multiple iterations until a "strong" set of
individuals is identified (at
940). This may be determined once the variation between all model/individual
scores in the
population are within a set percentage of one another, or within a threshold
level of one
another. Alternatively, the -strong" set of individuals may be determined when
from one
iteration to the next, the scores of the population do not vary more than a
set threshold.
[00107] From this strong model set/population, the highest
scoring model is then
selected (at 980). It should be noted that while a model may show up several
times
throughout the process (and as the process converges, there will be many
duplicates) each
- 23 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
unique model is only scored once. This is accomplished through a shared
database of model
scores that is added to with every generation. Without this feature, every
model would be
rescored, and the process cycle time would extend to an unacceptable level.
Additionally,
variables with very high p-values may be removed from consideration early in
the process to
speed up convergence.
[00108] Returning now to Figure 6, once the model has been thus
selected it may be
used for viewing (670) and additional analytics such as backtesting (at 680)
and editing (at
690). Editing, as seen in greater detail in relation to Figure 10, may include
editing pre-
adjustment factors (at 1010), post adjustment factors (at 1020) indicator
weights (at 1030)
and/or indicator time offsets (at 1040). Pre-adjustment factors and post-
adjustment factors are
multipliers to the forecast and/or indicators that account for some anomaly in
the data. For
example, a major snowstorm impacting the eastern seaboard may have an
exaggerated impact
upon heating costs in the region. If the forecast is for global demand for
heating oil, this
unusual event may skew the final forecast. An adjustment factor may be
leveraged in order
to correct for such events. The weight may be any positive or negative number,
and is a
multiplier against the indicator to vary the influence of the indicator in the
final model. A
negative weight will reverse procyclic and countercyclic indicators.
Determining whether an
indicator relationship exists between two data series, as well as the nature
and characteristics
of such a relationship, if found, can be a very valuable tool. Armed with the
knowledge, for
example, that certain macroeconomic metrics are predictors of future internal
metrics,
business leaders can adjust internal processes and goals to increase
productivity, profitability,
and predictability. The time offset allows the user to move the time domain of
any indicator
relevant to the forecast. For example, in the above example of global heating
oil, the global
temperature may have a thirty day lag in reflecting in heating oil prices. In
contrast, refining
capacity versus crude supply may be a leading indicator of the heating oil
prices. These two
example indicators would be given different time offsets in order to refine
the forecast.
[00109] For any forecast indicator, an R2 value, procyclic
value and countercyclic
value is generated in real time for any given weight and time offset. These
statistical
measures enable the user to tailor their model according to their concerns. In
some
embodiments the weights and offsets for the indicators may be auto-populated
by the method
with suggested values
[00110] Modeling formulas may be configured using machine
learning, or expert
input. These models may be leveraged by a typical user without any additional
interaction.
- 24 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
However for a more advanced user, it may be desirable to allow editing of
model formulas.
In some embodiments, the formula is freeform, allowing the user to tailor the
formula
however desired. In alternate embodiments, the formula configuration includes
a set of
discrete transformations, including providing each indicator with a weight,
and allowing the
indicators to be added/subtracted and/or multiplied or divided against any
other single or
group of indicators.
[00111] Returning to Figure 4, after model management, reports
may be generated (at
470) using the selected model and the model may be published (at 480). Report
generation
includes compiling desired model metrics together. Report generation may
additionally
include analysis of the model. For example, Figure 11 provides a more detailed
flowchart for
the process of analyzing a model forecast. Initially the primary indicator is
charted overlying
each explanatory indicator (at 1110). This charting allows a user to rapidly
ascertain, using
visual cues, the relationship between the primary indicator and each given
metric. Humans
are very visual, and being able to graphically identify trends is often much
easier than using
numerical data sets. In addition to the graphs, the R2, procyclic values, and
countercyclic
values may be presented (at 1120) alongside the charted indicators.
[00112] Where the current method is particularly potent is its
ability to rapidly shift the
time domains, on the fly, of any of the indicators to determine the impact
this has on the
forecast. In some embodiments, one or more time domain adjusters may be
utilized to alter
the time domain of indicators, and alter and redefine the time domain in which
the selected
metrics for a report are displayed. Additionally, the time domain of any given
indicator may
be locked (at 1130) such that if an indicator is locked (at 1140) any changes
to the time
domain will only shift for non-locked indicators. Upon a shift in the time
domain, the charts
that are locked are kept static (at 1150) as the other graphs are updated.
[00113] In addition to presenting the graphs comparing
indicators to the forecast, in
some embodiments, the forecast may be displayed versus actual values (for the
past time
period), trends for the forecast are likewise displayed, as well as the future
forecast values (at
1160). Forecast horizon, mean absolute percent error, and additional
statistical accuracy
measures for the forecast may also be provided (at 1170). Lastly, the eventual
purpose of the
generation of the forecast is to modify user or organization behaviors (at
1180).
[00114] In some embodiments, modifying behaviors may be
dependent upon the user
to formulate and implement. In advanced embodiments, suggested behaviors based
upon the
- 25 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
outlook scores (such as commodity hedging, investment trends, or securing
longer or shorter
term contracts) may be automatically suggested to the user for implementation.
In these
embodiments, the system utilizes rules regarding the user, or organization,
related to
objectives or business goals. These rules/objectives are cross referenced
against the outlook
scores, and advanced machine learning algorithms may be employed in order to
generate the
resulting behavior modification suggestions. In some other embodiments, the
user may
configure state machines in order to leverage outlook scores to generate these
behavior
modification suggestions. Lastly, in even further advanced embodiments, in
addition to the
generation of these suggestions, the system may be further capable of acting
upon the
suggestions autonomously. In some of these embodiments, the user may configure
a set of
rules under which the system is capable of autonomous activity. For example,
the outlook
score may be required to have above a specific accuracy threshold, and the
action may be
limited to a specific dollar amount for example.
[00115] Ultimately, the result of the above disclosed process
is the generation and
selection of reliably accurate models. An example of this, using real world
data, is provided
in the following Figures 16-18. For example, Figure 16 illustrates a chart
between model
scores and MAPE values (including predicted MAPE), shown generally at 1600. As
can be
seen, there is a strong relationship where as the model score increases, the
MAPE values
decrease. This means that, empirically, models with larger scores have lower
error levels.
[00116] Likewise, Figure 17 provides a measure of model overfit
against model score,
at 1700. As model scores increase, empirically, model overfit (as measured by
the R-square
minus the Predicted R-square, as discussed before) decreases.
[00117] Finally, turning to Figure 18, the standard error of
coefficients are shown as
compared to the model score, at 1800. Again, empirically these is a strong
correlation
between model score increase and a decrease of the standard error of model
coefficients.
[00118] Each of these empirical charts prove that the scoring
of models, as disclosed
herein, is an accurate, automated, and repeatable method of determining which
models are
better performing in the moment, and over time.
[00119] Lastly, turning to Figure 19, an overview of the model
scoring is provided in
an illustrative format 1900. The model quality scoring function is comprised
of two main
attributes that together account for model accuracy, stability and forecasting
accuracy. Each
attribute ties to a model outcome and is modeled separately. In addition, each
attribute has a
- 26 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
measured and predicted component, as discussed above. The measured component
is derived
by backwards looking at model performance versus historical error data. The
forward
looking predictive component leverages a regression model that consumes the
metrics of the
forecast model to predict its accuracy. Residual trends, MAPE, and predictive
R-squared
were found to be especially critical, and are retained from the previous model
score in their
previous form. Together these three metrics represent a separate attribute
that is called the
'model fit-.
[00120] Model accuracy and prediction of insights is a
collation of predicted bias and
predicted efficiency. This is combined with the predicted forecast accuracy,
the model fit,
and measured model metrics to arrive at the final model score.
III. SYSTEM EMBODIMENTS
[00121] Now that the systems and methods for the generation,
scoring and selection of
models and management of these models and data have been described, attention
shall now
be focused upon systems capable of executing the above functions. To
facilitate this
discussion, Figures 20A and 20B illustrate a Computer System 2000, which is
suitable for
implementing embodiments of the present invention. Figure 20A shows one
possible
physical form of the Computer System 2000. Of course, the Computer System 2000
may
have many physical forms ranging from a printed circuit board, an integrated
circuit, and a
small handheld device up to a huge super computer. Computer system 2000 may
include a
Monitor/terminal 2002, a Display 2004, a Housing 2006, one or more storage
devices and
server blades 2008, a Keyboard 2010, and a Mouse 2012. Disk 2014 is a computer-
readable
medium used to transfer data to and from Computer System 2000.
[00122] Figure 20B is an example of a block diagram for
Computer System 2000.
Attached to System Bus 2020 are a wide variety of subsystems. Processor(s)
2022 (also
referred to as central processing units, or CPUs) are coupled to storage
devices, including
Memory 2024. Memory 2024 includes random access memory (RAM) and read-only
memory (ROM). As is well known in the art, ROM acts to transfer data and
instructions uni-
directionally to the CPU and RAM is used typically to transfer data and
instructions in a bi-
directional manner. Both of these types of memories may include any suitable
of the
computer-readable media described below. A Fixed medium 2026 may also be
coupled bi-
directionally to the Processor 2022; it provides additional data storage
capacity and may also
include any of the computer-readable media described below. Fixed medium 2026
may be
used to store programs, data, and the like and is typically a secondary
storage medium (such
- 27 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
as a hard disk) that is slower than primary storage. It will be appreciated
that the information
retained within Fixed medium 2026 may, in appropriate cases, be incorporated
in standard
fashion as virtual memory in Memory 2024. Removable Disk 2014 may take the
form of any
of the computer-readable media described below.
[00123] Processor 2022 is also coupled to a variety of
input/output devices, such as
Display 2004, Keyboard 2010, Mouse 2012 and Speakers 2030. In general, an
input/output
device may be any of: video displays, track balls, mice, keyboards,
microphones, touch-
sensitive displays, transducer card readers, magnetic or paper tape readers,
tablets, styluses,
voice or handwriting recognizers, biometrics readers, motion sensors, brain
wave readers, or
other computers. Processor 2022 optionally may be coupled to another computer
or
telecommunications network using Network Interface 2040. With such a Network
Interface
2040, it is contemplated that the Processor 2022 might receive information
from the network,
or might output information to the network in the course of performing the
above-described
generation, scoring and selection of models. Furthermore, method embodiments
of the
present invention may execute solely upon Processor 2022 or may execute over a
network
such as the Internet in conjunction with a remote CPU that shares a portion of
the processing.
[00124] Software is typically stored in the non-volatile memory
and/or the drive unit.
Indeed, for large programs, it may not even be possible to store the entire
program in the
memory. Nevertheless, it should be understood that for software to run, if
necessary, it is
moved to a computer readable location appropriate for processing, and for
illustrative
purposes, that location is referred to as the memory in this disclosure. Even
when software is
moved to the memory for execution, the processor will typically make use of
hardware
registers to store values associated with the software, and local cache that,
ideally, serves to
speed up execution. As used herein, a software program is assumed to be stored
at any
known or convenient location (from non-volatile storage to hardware registers)
when the
software program is referred to as "implemented in a computer-readable
medium." A
processor is considered to be "configured to execute a program" when at least
one value
associated with the program is stored in a register readable by the processor.
[001251 In operation, the computer system 2000 can be
controlled by operating system
software that includes a file management system, such as a disk operating
system. One
example of operating system software with associated file management system
software is
the family of operating systems known as Windows from Microsoft Corporation
of
Redmond, Washington, and their associated file management systems. Another
example of
- 28 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
operating system software with its associated file management system software
is the Linux
operating system and its associated file management system. The file
management system is
typically stored in the non-volatile memory and/or drive unit and causes the
processor to
execute the various acts required by the operating system to input and output
data and to store
data in the memory, including storing files on the non-volatile memory and/or
drive unit.
[00126] Some portions of the detailed description may be
presented in terms of
algorithms and symbolic representations of operations on data bits within a
computer
memory. These algorithmic descriptions and representations are the means used
by those
skilled in the data processing arts to most effectively convey the substance
of their work to
others skilled in the art. An algorithm is, here and generally, conceived to
be a self-consistent
sequence of operations leading to a desired result. The operations are those
requiring
physical manipulations of physical quantities. Usually, though not
necessarily, these
quantities take the form of electrical or magnetic signals capable of being
stored, transferred,
combined, compared, and otherwise manipulated. It has proven convenient at
times,
principally for reasons of common usage, to refer to these signals as bits,
values, elements,
symbols, characters, terms, numbers, or the like.
[00127] The algorithms and displays presented herein are not
inherently related to any
particular computer or other apparatus. Various general purpose systems may be
used with
programs in accordance with the teachings herein, or it may prove convenient
to construct
more specialized apparatus to perform the methods of some embodiments. The
required
structure for a variety of these systems will appear from the description
below. In addition,
the techniques are not described with reference to any particular programming
language, and
various embodiments may, thus, be implemented using a variety of programming
languages.
[00128] In alternative embodiments, the machine operates as a
standalone device or
may be connected (e.g., networked) to other machines. In a networked
deployment, the
machine may operate in the capacity of a server or a client machine in a
client-server network
environment or as a peer machine in a peer-to-peer (or distributed) network
environment.
[00129] The machine may be a server computer, a client
computer, a personal
computer (PC), a tablet PC, a laptop computer, a set-top box (STB), a personal
digital
assistant (PDA), a cellular telephone, an iPhone, a Blackberry, a processor, a
telephone, a
web appliance, a network router, switch or bridge, or any machine capable of
executing a set
of instructions (sequential or otherwise) that specify actions to be taken by
that machine.
- 29 -
CA 03160715 2022- 6-3
WO 2021/138216
PCT/US2020/066991
[00130] While the machine-readable medium or machine-readable
storage medium is
shown in an exemplary embodiment to be a single medium, the term "machine-
readable
medium" and -machine-readable storage medium" should be taken to include a
single
medium or multiple media (e.g., a centralized or distributed database, and/or
associated
caches and servers) that store the one or more sets of instructions. The term
"machine-
readable medium" and "machine-readable storage medium" shall also be taken to
include any
medium that is capable of storing, encoding or carrying a set of instructions
for execution by
the machine and that cause the machine to perform any one or more of the
methodologies of
the presently disclosed technique and innovation.
[00131] In general, the routines executed to implement the
embodiments of the
disclosure may be implemented as part of an operating system or a specific
application,
component, program, object, module or sequence of instructions referred to as
"computer
programs." The computer programs typically comprise one or more instructions
set at
various times in various memory and storage devices in a computer, and when
read and
executed by one or more processing units or processors in a computer, cause
the computer to
perform operations to execute elements involving the various aspects of the
disclosure.
[00132] Moreover, while embodiments have been described in the
context of fully
functioning computers and computer systems, those skilled in the art will
appreciate that the
various embodiments are capable of being distributed as a program product in a
variety of
forms, and that the disclosure applies equally regardless of the particular
type of machine or
computer-readable media used to actually effect the distribution
[00133] While this invention has been described in terms of
several embodiments,
there are alterations, modifications, permutations, and substitute
equivalents, which fall
within the scope of this invention. Although sub-section titles have been
provided to aid in
the description of the invention, these titles are merely illustrative and are
not intended to
limit the scope of the present invention. It should also be noted that there
are many
alternative ways of implementing the methods and apparatuses of the present
invention. It is
therefore intended that the following appended claims be interpreted as
including all such
alterations, modifications, permutations, and substitute equivalents as fall
within the true
spirit and scope of the present invention.
- 30 -
CA 03160715 2022- 6-3