Note: Descriptions are shown in the official language in which they were submitted.
PATENT
Attorney Docket No.: 09275.0348-00304
ARTIFICIAL INTELLIGENCE ASSISTED REVIEWER RECOMMENDER AND
ORIGINALITY EVALUATOR
Cross-Reference to Related Applications
[0001] This application claims priority to provisional patent applications
Nos.
63/181,539, and 63/181,560, filed April 29, 2021.
BACKGROUND
Field
[0002] Embodiments of the present disclosure relate to Artificial Intelligence
Tools for identifying reviewers and locating similar papers. In particular,
some
embodiments disclose a system and a method for identifying relent reviewers
for submissions, while some embodiments disclose a system for identifying
similar documents to a given submission.
Description of Related Art
[0003] Before the advent of modern machine learning, the peer review process
could be assisted only minimally by computers. Editors and managers of
scientific or academic journals or publishers rely on external reviewers in
the
field of a particular paper or submission to ensure the submission complies
with best practices and methodologies of the relevant scientific or academic
field.
[0004] However, one risk of identifying reviewers personally known to editors
and managers is reviewer fatigue - editors and managers who return to
known reliable reviewers time and again may exhaust the willingness of that
reviewers to contribute, or overburden the reviewer accidentally. Similarly,
1
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
without a pipeline from which to draw new reviewers outside of personal
connections, identifying new reviewers is a time-consuming and unreliable
process.
[0005] A similar problem exists for evaluating the originality of a
submission.
Conventional search techniques or reliance on the personal knowledge of
editors are limited by the ability of the editor in question to generate
search
terms or properly identify similar documents. Existing tools cannot accurately
perform this analysis.
[0006] Therefore, there is a need for improved methods for leveraging machine
learning to identify and recommend reviewers for scientific or academic
journal submissions, as well as to evaluate the originality of each
submission.
SUMMARY
[0007] One aspect of the present disclosure is directed to a method for
identifying similar structured text documents to a new structured text
document. The method comprises, for example, converting each structured
text document stored in a database into one or more vectors, each structured
text document in the database having a title, an abstract, and author. The
method further comprises, for example, building a search index using the one
or more vectors of the structured text documents stored in the database. The
method further comprises, for example, receiving a new structured text
document, the structured text document having a title, an abstract, and
2
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
author. The method further comprises, for example, converting the structured
text document into one or more vectors. The method further comprises, for
example, searching the search index using the one or more vectors of the
new structured text document; Finally, the method further comprises, for
example, generating a list of N structured text document from the database
similar to the new structured text document based on said search
[0008] Yet another aspect of the present disclosure is directed to suggesting
reviewers for a new structured text document. The method comprises, for
example, converting each structured text document stored in a database into
one or more vectors, each structured text document in the database
associated with a title, an abstract, an author, and a reviewer. The method
further comprises, for example, building a search index using the vectors of
the structured text documents stored in the database. The method further
comprises, for example, receiving a new structured text document, the
structured text document associated with a title, an abstract, and an author.
The method further comprises, for example, converting the new structured
text document into a one or more vectors. The method further comprises, for
example, searching the search index using the one or more vectors of the
new structured text document. The method further comprises, for example,
generating a list of N structured text document from the database similar to
the new structured text document based on said search. Finally, the method
further comprises, for example, compiling the authors and reviewers of the N
most similar structured text document from the database.
3
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
[0009] Yet another aspect of the present disclosure is directed to a system
for
identifying similar structured text documents to a new structured text
document. The system comprises, for example, at least one processor, and at
least one non-transitory computer readable media storing instructions
configured to cause the processor, to for example, convert each structured
text document stored in a database into one or more vectors, each structured
text document in the database having a title, an abstract, and an author. The
processor may also, for example, build a search index using the vectors of
the structured text documents stored in the database. The processor may
also, for example, receive a new structured text document, the structured text
document having a title, an abstract, and an author. The processor may also,
for example, convert the structured text document into one or more vectors.
The processor may also, for example, search the search index using the
vector of the new structured text document. Finally, the processor may also,
for example, and generate a list of N structured text document from the
database similar to the new structured text document based on said search.
[0010] Yet another aspect of the present disclosure is directed to a system
for
identifying similar structured text documents to a new structured text
document. The system comprises, for example, at least one processor, and at
least one non-transitory computer readable media storing instructions
configured to cause the processor, to for example, convert each structured
text document stored in a database into one or more vectors, each structured
text document in the database having a title, an abstract, and an author. The
4
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
processor may also, for example, build a search index using the vectors of
the structured text documents stored in the database. The processor may
also, for example, receive a new structured text document, the structured text
document having a title, an abstract, and an author. The processor may also,
for example convert the structured text document into a one or more vectors.
The processor may also, for example, search the search index using the one
or more vectors of the new structured text document. The processor may
also, for example, generate a list of N structured text document from the
database similar to the new structured text document based on said search.
Finally, the processor may also, for example, compile the authors and
reviewers of the N most similar structured text document from the database.
[0011] One aspect of the present disclosure is directed at a method for
identifying similar structured text documents to other structured text
documents. The method comprises, for example, converting each structured
text document stored in a database into one or more vectors, each structured
text document in the database having a title, an abstract, an author, a full
text,
and metadata. The method further comprises, for example using the vectors
of the structured text documents stored in a database to create a similarity
search index. The method further comprises, for example, for each structured
text document from the database, searching the search index using the one
or more vectors of the structured text document. The method further
comprises, for example, for each structured text document from the database,
generating a list of N other structured text document from the database
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
similar to the structured text document based on said search. Finally, the
method further comprises, for example storing each list of N other structured
text document from the database similar to the structured text document in a
table.
[0012] Yet another aspect of the present disclosure is directed at a system
for
identifying similar structured text documents to other structured text
documents, comprising at least one processor, and at least one non-transitory
computer readable media storing instructions configured to cause the
processor to, for example, convert each structured text document stored in a
database into one or more vectors, each structured text document in the
database having a title, an abstract, and an author. The processor may
further be configured to use the vectors of the structured text documents
stored in a database to create a similarity search index. The processor may
further be configured to, for each structured text document from the database,
search the search index using the one or more vectors of the structured text
document. The processor may further be configured to, for each structured
text document from the database, generate a list of N other structured text
document from the database similar to the structured text document based on
said search. Finally, the processor may further be configured to store each
list
of N other structured text document from the database similar to the
structured text document in a table.
6
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
BRIEF DESCRIPTION OF DRAWING(S)
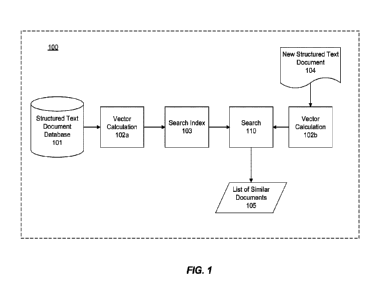
[0013] FIG. 1 depicts a system for performing a method of finding similar
structured text documents stored in a database to a new structured text
document.
[0014] FIG. 2 depicts further embodiments of the system from FIG. 1, where the
method is used to generate a list of recommended reviewers for the new
structured text document.
[0015] FIG. 3 depicts further embodiments of the system from FIG 2.
[0016] FIG. 4 depicts a system for performing a method of generating a table
of
similar structured text documents.
DETAILED DESCRIPTION
[0017] It is an object of embodiments of the present disclosure to improve the
workflow for editors and managers of scientific or academic publishing
houses. Scientific articles and other similar types of academic works,
submitted as structured text documents, require peer-review before
publication in order to ensure the structured text document comports with best
practices and methodologies of the relevant scientific or academic field. It
would also be useful to evaluate these structured text document for
originality
by comparing pre-publication works to published works. Methods are
provided for identifying reviewers and similar articles to structured text
documents.
7
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
[0018] It should be understood that the disclosed embodiments are intended to
be performed by a system or similar electronic device capable of
manipulating, storing, and transmitting information or data represented as
electronic signals as needed to perform the disclosed methods. The system
may be a single computer, or several computers connected via the internet or
other telecommunications means.
[0019] A method involves the comparison of structured text documents, the
structured text documents having a title, an abstract, and an author. A
structured text document may be a draft, a manuscript, a book, an article, a
thesis, a dissertation, a monograph, a report, a proceeding, a standard, a
patent, a preprint, a grant, or other working text. An abstract may be a
summary, synopsis, digest, precis, or other abridgment of the structured text
document. An author may be any number of individuals or organizations. A
structured text document may also have a full text, body, or other content. A
structured text document may also have metadata, such as citations. A
person of ordinary skill in the art would understand that a structured text
document could take many forms, such as a Word file, PDF, LaTeX, or even
raw text.
[0020] A method may involve the system receiving a new structured text
document. The new structured text document may be received by various
means, including electronic submission portal, email, a fax or scan of a
physical copy converted into a structured text document through a process
8
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
such as optical character recognition or similar means, or other means for
digital transmission.
[0021] The system may convert the new structured text document into a vector
or vectors using a natural language processing algorithm with a vector output.
In broad terms, suitable algorithms accept text as input and render a
numerical representation of the input text, known as a vector, as output.
Suitable natural language processing algorithms include examples such as
Doc2Vec, GloVe/PCA projection, BERT, SciBERT, or SPECTER, or
Universal Sentence Encoder, though a person of ordinary skill in the art may
recognize other possible natural language processing algorithms. A vector, in
some embodiments, can be a mathematical concept with magnitude and
direction. In other embodiments, a vector can be a collection of values
representing a word's meaning in relation to other words. In yet other
embodiments, a vector can be a collection of values representing a text's
value in relation to other texts.
[0022] Two embodiments of a vector can be vector 1 with the values (A, B) and
vector 2 with the values (C, D) where A, B, C, and D are variables
representing any number. One possible measure of distance, the Euclidean
distance, between vector 1 and vector 2 is equal to ,AC
___________________________ - A)2 + (D - B)2. Of
course, one skilled in the art can recognize that vectors can have any number
of values. One skilled in the art would also recognize measures of distance
between vectors beyond the Euclidean distance.
9
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
[0023] In some embodiments, different components of a structured text
document may be converted into separate vectors. In other embodiments, not
all components of a structured text document are converted into a vector. For
example, if a structured text document has a title, abstract, author,
metadata,
and full text, the title and abstract may be converted into one vector, the
full
text into another, citation into another, the metadata into one or more
vectors,
and the author is not converted into a vector.
[0024] In some embodiments, the structured text document database may be
implemented as a collection of training data, such as MSPUBS database or
the Microsoft Academic Graph, or may be implemented using any desired
collection of structured text documents such as a journal's archive or
catalog.
The database may be implemented through any suitable database
management system such as Oracle, SQL Server, MySQL, PostgreSQL,
Microsoft Access, Amazon RDS, HBase, Cassandra, MongoDB, Neo4J,
Redis, Elasticsearch, Snowflake, BigQuery, or the like.
[0025] In some embodiments, the system may convert each structured text
document stored in a database into a vector or vectors using the same
algorithms as described for the new structured text document. The structured
text documents stored in the database may also have a reviewer, editor, or
other non-authorial contributor.
[0026] In some embodiments, the system may build a search index using the
vectors of the structured text documents stored in the database. The search
index may be of any suitable type, such as a flat index, a locality sensitive
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
hash(LSH), an inverted file index (IVF), or a Hierarchical Navigable Small
World (HNSW) graph. In embodiments where structured text documents are
converted into multiple vectors, the multiple vectors of a structured text
document can be concatenated into a single vector before the search index is
built. In other embodiments where structured text documents are converted
into multiple vectors, each type of vector is used to build a search index for
that type of vector.
[0027] In some embodiments, the system uses the vector or vectors of the new
structured text document to search the search index. The search may be
performed using any suitable algorithm, such as K-nearest neighbors or K-
means clustering. In embodiments using multiple vectors for structured text
documents, where the vectors are concatenated into one vector before the
search index is built, the multiple vectors of the new structured text
document
are likewise concatenated before searching the search index. In other
embodiments where structured text documents are converted into multiple
vectors, and where different search indexes are built for different types of
vectors, each vector of the additional structured text document are searched
separately, and the results ensembled together. Ensembling the results may
be as simple as averaging the results, though more complex methods of
ensembling are possible. Based on the search results, the system identifies
the N most similar structured text documents from the database to the new
structured text documents are. N may be any desired number, such as 10, or
100, based on the needs of the implementers. For example, after
11
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
experimentation, the inventors determined that looking at the top 100 most
similar structured text documents and compiling their authors and reviewers
led to a higher chance of overlap. The inventors found that 100 structured
text
documents strike a good balance between good results and manageable data
size and computation cost.
[0028] In some embodiments, once the system identifies the N most similar
structured text documents from the database, the system compiles the
reviewers and authors associated with the N most similar structured text
documents from the database. In one embodiment, the structured text
document database is queried to provide the information on authors and
reviewers for each of the N most similar structured text documents from the
database. In some embodiments, compilation may consist of listing all
authors and reviewers of each structured text document on the list of similar
documents. In some embodiments, compilation can consist of weighing
authors and reviewers, by, for example, listing authors and reviewers who
authored or reviewed more than one document from the list of similar
documents as the first recommended reviewers. In another embodiment,
compilation can consist of listing the authors and reviewers of the most
similar
structured text document to the new structured text document first on the list
of recommended reviewers.
[0029] For an illustrative example of compiling the reviewers and authors,
consider a system configured to identify the two most similar (N = 2)
structured text documents. The system identifies Text 1, and Text 2. Text 1
12
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
has a similarity score of 0.5 and the authors author 1, author 2, and author 3
and the reviewers reviewer 1, reviewer 2, and reviewer 3. The system also
identifies Text 2 with similarity score 0.4, authors author 1, author 4, and
author 5, and reviewers reviewer 4, reviewer 2, and reviewer 3. In some
embodiments, the similarity score of a structured text document is 1 minus
the distance between the vector of the additional structured text document
and the structured text document, though other methods of calculating
similarity score are possible. The compilation of authors would result in the
follows ranking:
= Author 1 = 0.5 + 0.4 = 0.9
= Author 2 = 0.5
= Author 3 = 0.5
= Author 4 = 0.4
= Author 5 = 0.4
The compilation of reviewers would result in the follows ranking:
= Reviewer 2 = 0.5 + 0 . 4 = 0.9
= Reviewer 3 = 0.5 + 0.4 = 0.9
= Reviewer 1 = 0.5
= Reviewer 4 = 0.4
[0030] A further method may involve the system converting each structured text
document stored in a database into a vector, each structured text document
in the database having a title, an abstract, and an author. A structured text
document may be a draft, a manuscript, a book, an article, a thesis, a
13
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
dissertation, a monograph, a report, a proceeding, a standard, a patent, a
preprint, a grant, or other working text. An abstract may be a summary,
synopsis, digest, precis, or other abridgment of the structured text document.
An author may be any number of individuals or organizations. A structured
text documents may also have a full text, body, or other content. A structured
text document may also have metadata, such as citations. The structured text
documents stored in the database may also have a reviewer, editor, or other
non-authorial contributor. A person of ordinary skill in the art would
understand that a structured text document could take many forms, such as a
Word file, PDF, LaTeX, or even raw text.
[0031] In some embodiments, the structured text document database may be
implemented as a collection of training data, such as Microsoft Academic
Graph, or may be implemented using any desired collection of structured text
documents such as a journal's archive or catalog. The database may be
implemented through any suitable database management system such as
Oracle, SQL Server, MySQL, PostgreSQL, Microsoft Access, Amazon RDS,
HBase, Cassandra, MongoDB, Neo4J, Redis, Elasticsearch, Snowflake,
BigQuery, or the like.
[0032] The system's conversion of each structured text document into a vector
or vectors may be accomplished by a natural language processing algorithm
with a vector output. In broad terms, suitable algorithms accept text as input
and render a numerical representation of the input text, known as a vector, as
output. Suitable natural language processing algorithms include examples
14
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
such as Doc2Vec, GloVe/PCA projection, BERT, SciBERT, SPECTER, or
Universal Sentence Encoder, though a person of ordinary skill in the art may
recognize other possible natural language processing algorithms. A vector, in
some embodiments, can be a mathematical concept with magnitude and
direction. In other embodiments, a vector can be a collection of values
representing a word's meaning in relation to other words. In yet other
embodiments, a vector can be a collection of values representing a texts
value in relation to other texts.
[0033] In some embodiments, different components of a structured text
document may be converted into separate vectors by the system. In other
embodiments, not all components of a structured text document are
converted into a vector. For example, if a structured text document in the
structured text document database has a title, abstract, author, full text,
and
metadata, the title and abstract may be converted into one vector, the full
text
into another, metadata into one or more vectors, and the author is not
converted into a vector.
[0034] In some embodiments, the system may build a search index using the
vectors of the structured text documents stored in the database. The search
index may be of any suitable type, such as a flat index, a locality sensitive
hash(LSH), an inverted file index (IVF), or a Hierarchical Navigable Small
World (HNSW) graph. In embodiments where structured text documents are
converted into multiple vectors, the multiple vectors of a structured text
document can be concatenated into a single vector before the search index is
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
built. In other embodiments where structured text documents are converted
into multiple vectors, each type of vector is used to build a search index for
that type of vector. In embodiments where structured text documents are
converted into multiple vectors, the multiple vectors of a structured text
document can be concatenated into a single vector before the search index
is built. In other embodiments where structured text documents are converted
into multiple vectors, each type of vector is used to build a search index for
that type of vector.
[0035] In some embodiments, the system uses the vector or vectors of the new
structured text document to search the search index. The search may be
performed using any suitable algorithm, such as K-nearest neighbors or K-
means clustering. In embodiments using multiple vectors for structured text
documents, where the vectors are concatenated into one vector before the
search index is built, the multiple vectors of the new structured text
document
are likewise concatenated before searching the search index. In other
embodiments where structured text documents are converted into multiple
vectors, and where different search indexes are built for different types of
vectors, each vector of the additional structured text document are searched
separately, and the results ensembled together. Ensembling the results may
be as simple as averaging the results, though more complex methods of
ensembling are possible. Based on the search results, the system identifies
the N most similar structured text documents from the database to the new
structured text documents. N may be any desired number, such as 50, based
16
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
on the needs of the implementers. For example, after experimentation, the
inventors determined that looking at the top 50 most similar structured text
documents led to higher quality lists of similar structured text documents.
The
inventors found that 50 structured text documents strike a good balance
between good results and manageable data size and computation cost.
[0036] In some embodiments, the system may select the list of similar
documents based on the search of the similarity search index for most similar
vectors to the vector of the new structured text document. The list of similar
documents may be the N-nearest structured text documents to each
structured text document, or it may be all structured text documents within a
certain distance D of each structured new structured text document.
[0037] In some embodiments, the system stores each list of similar documents
in a table constructed by aggregating each list of similar documents for each
document in the structured text document database. In some embodiments,
the table may be implemented as a simple array of arrays or list of lists. In
other embodiments, the table may be a more sophisticated data structure,
such as an Oracle, SQL Server, MySQL, PostgreSQL, Microsoft Access,
Amazon RDS, HBase, Cassandra, MongoDB, Neo4J, Redis, Elasticsearch,
Snowflake, or BigQuery database or data structure store.
[0038] New structured text documents may be searched against the database
of structured text documents. The new structured text document may be
received by various means, including electronic submission portal, email, a
fax or scan of a physical copy converted into a structured text document
17
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
through a process such as optical character recognition or similar means, or
other means for digital transmission.
[0039] Once received by the system performing a disclosed embodiment, the
new structured text document may be converted into a vector. Conversion of
the new structured text document into a vector may be accomplished as
previously described. Then, the vector of the new structured text document is
searched against the vectors of each structured text document in the
database, which are stored in the similarity search index. Based on that
comparison a list of similar documents is generated, consistent with the
preceding description generating a list of similar documents. The list of
similar
documents for the new structured text document is added to the results table.
[0040] FIG 1 shows a schematic block diagram 100 of a system for performing
the disclosed exemplary embodiment of a method including computerized
systems for identifying similar structured text documents. In some
embodiments, system 100 involves structured text document database 101,
vector calculations 102a and 102b, search index 103, search 110, new
structured text document 104, and a list of similar documents 105.
[0041] In some embodiments, system 100 should be understood as a computer
system or similar electronic device capable of manipulating, storing, and
transmitting information or data represented as electronic signals as needed
to perform the disclosed methods. System 100 may be a single computer, or
several computers connected via the internet or other telecommunications
means.
18
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
[0042] In some embodiments, the structured text document database 101 may
be implemented as a collection of training data, such as the Microsoft
Academic Graph, or may be implemented using any desired collection of
structured text documents such as a journal's archive. The database may be
implemented through any suitable database management system such as
Oracle, SQL Server, MySQL, PostgreSQL, Microsoft Access, Amazon RDS,
HBase, Cassandra, MongoDB, Neo4J, Redis, Elasticsearch, Snowflake,
BigQuery, or the like.
[0043] In some embodiments, vector calculation 102a and 102b may be
implemented by system 100 using a natural language processing algorithm
with a vector output. In broad terms, suitable algorithms accept text as input
and render a numerical representation of the input text, known as a vector, as
output. Suitable natural language processing algorithms include examples
such as Doc2Vec, GloVe/PCA projection, BERT, SciBERT, or SPECTER, or
Universal Sentence Encoder, though a person of ordinary skill in the art may
recognize other possible natural language processing algorithms. A vector, in
some embodiments, can be a mathematical concept with magnitude and
direction. In other embodiments, a vector can be a collection of values
representing a word's meaning in relation to other words. In yet other
embodiments, a vector can be a collection of values representing a texts
value in relation to other texts.
[0044] In some embodiments, different components of a structured text
document may be converted into separate vectors. In other embodiments, not
19
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
all components of a structured text document are converted into a vector. For
example, if a structured text document has a title, abstract, author, full
text
and metadata, the title and abstract may be converted into one vector, the
full
text into another, the metadata into one or more vectors, and the author is
not
converted into a vector. In other embodiments, different components of a
structured text documents may be combined and converted into a single
vector or may be converted into respective vectors.
[0045] In some embodiments, the system may build a search index 103 using
the vectors of the structured text documents stored in the database. The
search index may be of any suitable type, such as a flat index, a locality
sensitive hash (LSH), an inverted file index (IVF), or a Hierarchical
Navigable
Small World (HNSW) graph.
[0046] In some embodiments, the system uses the vector or vectors of the new
structured text document to search 110 the search index 103. The search
may be performed using any suitable algorithm, such as K-nearest neighbors
or K-means clustering. In embodiments using multiple vectors for structured
text documents, where the vectors are concatenated into one vector before
the search index is built, the multiple vectors of the new structured text
document are likewise concatenated before searching the search index. In
other embodiments where structured text documents are converted into
multiple vectors, and where different search indexes are built for different
types of vectors, each vector of the additional structured text document are
searched separately, and the results ensembled together. Ensembling the
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
results may be as simple as averaging the results, though more complex
methods of ensembling are possible. Based on the search results, the system
identifies the N most similar structured text documents from the database to
the new structured text documents are. N may be any desired number, such
as 10, or 100, based on the needs of the implementers. For example, after
experimentation, the inventors determined that looking at the top 100 most
similar structured text documents and compiling their authors and reviewers
led to a higher chance of overlap. The inventors found that 100 structured
text
documents strike a good balance between good results and manageable data
size and computation cost.
[0047] In some embodiments, the new structured text document 104 may be a
draft, manuscript, a book, an article, a thesis, a dissertation, a monograph,
a
report, a proceeding, a standard, a patent, a preprint, a grant, or other
working text. An abstract may be a summary, synopsis, digest, precis, or
other abridgment of the structured text document. An author may be any
number of individuals or organizations. The new structured text documents
may also have a full text, body, or other content. The new structured text
document may also have metadata, such as citations.
[0048] In some embodiments, the system may select the list of similar
documents 105 based on the search 110 of the search index 103 using the
vector of the new structured text document 104. The list of similar documents
105 may be the N-nearest structured text documents to the new structured
21
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
text document, or it may be all structured text documents within a certain
distance D of the new structured text document.
[0049] Referring now to FIG. 2, further embodiments of the disclosed system
100 are shown for performing the disclosed methods of providing a list of
recommended reviewers for a new structured text document. In one
embodiment, the structured text document database 101 includes information
on the authors and reviewers of the structured text documents it contains.
[0050] The vector calculation 102a and 102b, search index 103, search 110
new structured text document 104, and list of similar documents 105 should
be understood to have the same scope and functionality as disclosed in FIG.
1.
[0051] In some embodiments, the system performs compilation 201 after the list
of similar documents, 105, is generated. For each structured text document
on the list of similar documents 105, the structured text document database is
queried to provide the information on authors and reviewers for each
document. This information is compiled to provide a list of recommended
reviewers for the new structured text document, 202.
[0052] In some embodiments, the system performs compilation 201 by
generating a list, stored as an index or other data structure, consist of all
authors and reviewers of each structured text document on the list of similar
documents. In some embodiments, the list generated as a result of
compilation 201 can consist of a ranked list where authors and reviewers are
listed in order of, for example, the number of times their name appears as an
22
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
authors or reviewers of a document on the list of similar documents 105. In
another embodiment, the list generated by compilation 201 can consist of a
listing of the authors and reviewers in order of how similar the structured
text
document they are associated with is to the new structured text document.
[0053] Referring now to FIG. 3, further embodiments of the disclosed system
100 for performing the disclosed methods are shown. The vector calculation
102, new structured text document 104, and list of similar documents 105
should be understood to have the same scope and functionality as disclosed
in FIG. 1. The compilation 201 and list of recommended reviewers, 202
should be understood to have the same scope and functionality as disclosed
in FIG. 2.
[0054] In the disclosed embodiments consistent with FIG. 3, the search 310
should be understood as being performed using the KNN algorithm for
calculating the N-nearest structured text document vectors to the new
structured text document vector. Distance between vectors can be calculated
using any measure of similarity for comparing vectors, such as the Euclidian
distance, Gaussian distance, or cosine similarity.
[0055] In some embodiments, KNN, or K-nearest neighbor, can be implemented
using any measure of distance between vectors as previously described,
such as Euclidian or Cosine distance. The algorithm is performed by a system
such as system 100. Given a vector and a number of neighbors, K (hence the
name, K nearest neighbor), the algorithm could calculate the distance
between the vector and each vector in the search index. In practice, this is
not
23
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
done to improve search efficiency. Instead, the different types of search
index, such as inverted file index (IVF), or a Hierarchical Navigable Small
World (HNSW) graph break the search index into partitions of vectors, and
KNN operates to search some of those partitions to identify the K-nearest
vectors in the search index to the vector being using to search the search
index. For example, if the search index is an IVF, the partitions are
constructed as a Dirichlet tessellation. In a Dirichlet tessellation, the
partitions
start with centroids, which are fictional vectors placed into the search index
as
dividing points, but not associated with a structured text document. Each
centroid defines a partition consisting of all vectors closer to the centroid
than
any other centroid. Searching the IVF search index with a vector (the search,
or query vector) begins with identifying the centroid closed to the search
vector. Then, the KNN algorithm is used to compute the distances between
each vector in that centroid's partition, and the search vector. The K vectors
in the partition associated with the K smallest distances are reported by the
KNN algorithm as the K-nearest neighbors to the search vector. In some
embodiments, the KNN algorithm is used to compute the distances between
the search vector and the vectors associated with the centroids adjacent to
the centroid closest to the search vector, to avert omitting vectors that are
close to the search vector but in another partition.
[0056] FIG 4 shows a schematic block diagram 400 of a system for performing
the disclosed exemplary embodiment of another method including
computerized systems for identifying similar structured text documents. In
24
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
some embodiments, system 400 involves structured text document database
401, vector calculation 402a, and 402b, search 403, new structured text
document 404, a list of similar documents 405, results table 407 and
similarity
search index 406.
[0057] In some embodiments, system 400 should be understood as a computer
system or similar electronic device capable of manipulating, storing, and
transmitting information or data represented as electronic signals as needed
to perform the disclosed methods. System 400 may be a single computer, or
several computers connected via the internet or other telecommunications
means.
[0058] In some embodiments, the structured text document database 401 may
be implemented as a collection of training data, such as the Microsoft
Academic Graph, or may be implemented using any desired collection of
structured text documents such as a journal's archive. The database may be
implemented through any suitable database management system such as
Oracle, SQL Server, MySQL, PostgreSQL, Microsoft Access, Amazon RDS,
HBase, Cassandra, MongoDB, Neo4J, Redis, Elasticsearch, Snowflake,
BigQuery, or the like.
[0059] In some embodiments, vector calculation 402a and 402b may be
implemented using a natural language processing algorithm with a vector
output. In broad terms, suitable algorithms accept text as input and render a
numerical representation of the input text, known as a vector, as output.
Suitable natural language processing algorithms include examples such as
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
Doc2Vec, GloVe/PCA projection, BERT, SciBERT, SPECTER, or Universal
Sentence Encoder, though a person of ordinary skill in the art may recognize
other possible natural language processing algorithms. A vector, in some
embodiments, can be a mathematical concept with magnitude and direction.
In other embodiments, a vector can be a collection of values representing a
word's meaning in relation to other words. In yet other embodiments, a vector
can be a collection of values representing a text's value in relation to other
texts.
[0060] In some embodiments, different components of a structured text
document may be converted into separate vectors by vector calculations
402a, and 402b. In other embodiments, not all components of a structured
text document are converted into a vector by vector calculations 402a, and
402b. For example, if a structured text document in structured text document
database 401 has a title, abstract, author, full text, and metadata, the title
and
abstract may be converted into one vector, the full text into another,
metadata
into one or more vectors, and the author is not converted into a vector.
[0061] In some embodiments, the similarity search index 406 is constructed by
system 100, which converts each structured text document stored in the
structured text document database 401 into a vector through vector
calculation 402a. The vector for each structured text document is stored in
the
similarity search index. The search index may be of any suitable type, such
as a flat index, a locality sensitive hash (LSH), an inverted file index
(IVF), or
a Hierarchical Navigable Small World (HNSW) graph. In some embodiments,
26
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
the similarity search index 406 may be a implemented using specialized
vector search index tools such as FAISS (Facebook Al Similarity Search) or
Non-Metric Space Library (NMSLIB). In embodiments where structured text
documents are converted into multiple vectors, the multiple vectors of a
structured text document can be concatenated into a single vector before the
search index 406 is built. In other embodiments where structured text
documents are converted into multiple vectors, each type of vector is used to
build a search index 406 for that type of vector.
[0062] In some embodiments, the search 403 is a mathematical operation that
can be performed by system 100 using any measure of similarity for
comparing vectors, such as the Euclidian distance, Gaussian distance, or
cosine similarity.
[0063] In some embodiments, the system uses the vector or vectors of each
structured text document to search the search index 406. The search 403
may be performed using any suitable algorithm, such as K-nearest neighbors
or K-means clustering. In embodiments using multiple vectors for structured
text documents, where the vectors are concatenated into one vector before
the search index is built, the multiple vectors of the structured text
document
are likewise concatenated before searching the search index. In other
embodiments where structured text documents are converted into multiple
vectors, and where different search indexes are built for different types of
vectors, each vector of each structured text document are searched
separately, and the results ensembled together. Ensembling the results may
27
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
be as simple as averaging the results, though more complex methods of
ensembling are possible. Based on the search results, the system identifies
the N most similar structured text documents from the database to each
structured text documents are. N may be any desired number, such as 50,
based on the needs of the implementers. For example, after experimentation,
the inventors determined that looking at the top 50 most similar structured
text
documents led to higher quality lists of similar structured text documents.
The
inventors found that 50 structured text documents strike a good balance
between good results and manageable data size and computation cost.
[0064] In some embodiments, the system may select the list of similar
documents 405 based on the search 403 of the similarity search index for
most similar vectors to the vector of the new structured text document 404.
The list of similar documents 405 may be the N-nearest structured text
documents to each structured text document, or it may be all structured text
documents within a certain distance D of each structured new structured text
document.
[0065] In some embodiments, the results table 407 is constructed by system
100 by aggregating each list of similar documents for each document in the
structured text document database 401. In some embodiments, the results
table 407 may be implemented as a simple array of arrays or list of lists. In
other embodiments, results table 407 may be a more sophisticated data
structure, such as an Oracle, SQL Server, MySQL, PostgreSQL, Microsoft
28
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
Access, Amazon RDS, HBase, Cassandra, MongoDB, Neo4J, Redis,
Elasticsearch, Snowflake, or BigQuery database or data structure store.
[0066] In some embodiments, the new structured text document 404 may be a
draft, manuscript, a book, an article, a thesis, a dissertation, a monograph,
a
report, a proceeding, a standard, a patent, a preprint, a grant, or other
working text. An abstract may be a summary, synopsis, digest, precis, or
other abridgment of the structured text document. An author may be any
number of individuals or organizations. The new structured text documents
may also have a full text, body, or other content. The new structured text
document may also have metadata, such as citations
[0067] In some embodiments, the new structured text document 404 is
converted into one or more vector using vector calculation 402b. Then, the
vector of the new structured text document is searched 403 against the
vectors of each structured text document in the database, which are stored in
the similarity search index 406. Based on that search 403 a list of similar
documents 405 is generated, consistent with the preceding description
generating a list of similar documents 405. The list of similar documents 405
for the new structured text document 404 is added to the results table 407.
[0068] While the present disclosure has been shown and described with
reference to particular embodiments thereof, it will be understood that the
present disclosure can be practiced, without modification, in other
environments. The foregoing description has been presented for purposes of
illustration. It is not exhaustive and is not limited to the precise forms or
29
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
embodiments disclosed. Modifications and adaptations will be apparent to
those skilled in the art from consideration of the specification and practice
of
the disclosed embodiments. Additionally, although aspects of the disclosed
embodiments are described as being stored in memory, one skilled in the art
will appreciate that these aspects can also be stored on other types of
computer readable media, such as secondary storage devices, for example,
hard disks or CD ROM, or other forms of RAM or ROM, USB media, DVD,
Blu-ray, or other optical drive media.
[0069] While illustrative embodiments have been described herein, the scope of
any and all embodiments having equivalent elements, modifications,
omissions, combinations (e.g., of aspects across various embodiments),
adaptations and/or alterations as would be appreciated by those skilled in the
art based on the present disclosure. The limitations in the claims are to be
interpreted broadly based on the language employed in the claims and not
limited to examples described in the present specification or during the
prosecution of the application. The examples are to be construed as non-
exclusive. Furthermore, the steps of the disclosed methods may be modified
in any manner, including by reordering steps and/or inserting or deleting
steps. It is intended, therefore, that the specification and examples be
considered as illustrative only, with a true scope and spirit being indicated
by
the following claims and their full scope of equivalents.
[0070] Computer programs based on the written description and disclosed
methods are within the skill of an experienced developer. Various programs
CA 03172963 2022- 9- 22
PATENT
Attorney Docket No.: 09275.0348-00304
or program modules can be created using any of the techniques known to
one skilled in the art or can be designed in connection with existing
software.
For example, program sections or program modules can be designed in or by
means of .Net Framework, .Net Compact Framework (and related languages,
such as Visual Basic, C, etc.), Python, Java, C/C++, Objective-C, Swift,
HTML, HTML/AJAX combinations, XML, or HTML with included Java applets.
31
CA 03172963 2022- 9- 22