Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
~ 2015S-424
METHOD USING A PROGRAMMED DIGITAL COMP~TER SYSI'EM FOR
. _ _ _ . . . _ .
TRA~SLATION BETWEEN NATURAL LANGUAGES
. ~
CROSS KEFERENCE TO MICROFIC~I~ APPENDIX
A microfiche appendix contains 21 microfiche with 1235
frames of listing, and with a total of 1276 frames of printed
text. The microfiche appendix is retained in the file and is not
printed, under the provisions of 37 C.F.R. 1.96.(b).
BACKGROUND OF THE INVENTION
_
This invention rela-tes to a method utilizing a digital
computer for translating between natural languages.
At-tempts have been made to utilize digi~al computers for
transla-ting from one language to another, i.e., from a source
language to a target language. The translation systems involve a
programmable digital computer system along with a program for
efEecting the translation. The approaches used were theoretical.
The theoretical language approach for syntaetieal analysis has not
been aeceptable because it starts out from linguistic assumptions
instead of considering -the capabilities of the program digital
eomputer and approaching the translation from the eomputer's point
of view.
One reason for the failures in the past was -that lingui-
sties and eomputer programmers worked in separate groups. The
inEormation exchanges be-tween these groups was negligible. Either
linguistic approaches were forced into the eomputer, in which ease
the eomputer was not used eorrectly, or they were modified to sueh
an extent that they eould not earry out the tasks.
s
L L~Z 9
- 2 - 20155-~2~
The idea of machlne translation was conceived in 1946 by
Warren Weaver and A.D. Booth. Many a-ttempts to achieve a machine
translation system and put it into opera-tion have been made inside
and outside the United States since tha-t -time. Due in par-t to
inadequacy of hardware, the projects outside of the United States
did not make significant progress. The projects in the United
States were directed toward developing linguistic theories
encompassing the whole natural language and then going to the
computer. This approach inevitably failed because the human mind
cannot encompass the totality of the language. The approaches
were also unsuccessful because the work was restricted to
experimental work on certain aspects of the problem.
The following is a brief resume in the approaches and
the theory behind them:
The General Analysis Technique (GAT) developed at
Georgetown University from 19S8 to 1963 used a linguistics
oriented computer coding scheme. Ad hoc solutions were introduced
and the whole system was confined within a hollow restricted
so-called Simulated Linguistic Computer ~SLC) system written in
octal language and not open for any further improvements.
The Fulcrum theory approach developed from 1959 to 1967
by the Bunker-Ramo Corporation, was directed toward solving, with
a relatively small dictionary, the problems occurring in a limited
Russian text. ~o attempt was made to introduce resolution of
multiple meanings; instead, several meanings were prin-ted in the
output, separated by sLashes.
An approach taken by International Business Machines in
2~
- 3 - 20l55-424
1957 to 1968, initiated by International Telemeter Corporation
was hardware oriented. ~n attempt was made to insert all the
words, and every compound in declinable form, in a photo disk for
a large scale dictionary lookup. Syntactic consideration were
very limited. Both the approach and hardware -failed because
compounds cannot be just translated as they occur, but have to
undergo a syntactic analysis. In addition, tiny unavoidable
accumulations of dirt or dust on the disk caused serious problems
resulting in unusable translations.
A predictive syntax system was developed by the ~ational
Bureau of Standards and Massachuse-tts Institute of Technology in
1960 to 1964. This approach failed because it considered only one
limited path to the sen-tence. This system was never implemented
on a larger scale, but was used just within a limited experimental
environment.
Transformational grammar was another approach. However,
this approach turned out to be absolutely incompatible with
computer translation re~uirements. Only small experimen-tal
systems have been developed on the basis of this theory, and they
had to be discontinued before any significant translation was
produced.
SUMMARY OF THE INVENTION
The appearance of fourth generation computers made it
possible to introduce approaches which would be capable of pro-
ducing acceptable machine translations. The best utilization of
the logical structures of -these computers, and maximal coordina-
tion of rapid transfer of data between auxiliary and high speed
,, `,
L~ 9
- 4 - ~ 20155-42~
storages, plus the development of a complete system, made it
possible to realize the goal of an automatic means to overcome the
communication problem between natural languayes.
The present invention, hereinafter called SYSTRAN, was
possible because of the combination o~ experiences as systems
analyst, linguist and computer programmer. The experience in the
three areas enabled the inventor to develop the approaches which
resulted in the invention. The unique solution which is elabora-
ted upon herein can be summarized as follows: computerized
syntax, a dictionary lookup which is based on the most efficient
exploitation of main and auxiliary storages and which uses four
different types of dictionaries, the combination of fixed and
variable length areas for full utilization of the computer, the
introduction of remembering switches, new ways of handling
multiple meaning problems, and system translation (SYSTRAN),
universality which makes it possible to change only tables and
parameters in most instances when source and/ or target languages
are changed.
The invention described here proceeded from its very
inception toward the goal of set-ting up a "universal" translation
system, defined as one in which most of the programs could be
universally applied to different source or target languages.
SYST~AN realizes thiæ goal - the only changes for different
languages are those necessitated by the inherent structures of the
languages. Dictionary arrangement, the lookup concept, the utili-
zation of memory switches durirlg syntactic analysis and -the reso-
lution of multiple meaning problems use the same basic approaches
L4~
- 5 - 20155-~24
regardless oE source or target languages.
SYSTRAN takes full advantage of coordinated usage of the
various auxiliary devices, which allows easy access to the various
dictionaries.
The computer is still handicapped in comparison to the
human mind, due first of all to -the size oE the computer's limited
high speed, rapid access, core memory. The SYSTRAN system over-
comes such a handicap to a considerable degree by setting up a
coordinated system of dictionaries. The dictionaries are updated
on magnetic tapes, for actual usage they are available on rapid
access disks and in the high speed core memory.
In addition, with SYSTR~N an en-tirely new approach to
syntactic analysis has been introduced. This approach involves
automatic parsing. None of the machine translation systems
developed prior to SYSTRAN achieved the ef-Eectiveness of this
automatic syntactic analysis technique. The computer is instruct-
ed in every instance what to remember, either by codes attached to
the words -from the source sentence, or by a temporary plug-in of a
sequence of these memory switches during particular passes.
During this analysis, the computer simulates the human translation
process in that it sets "remembering" switches as it passes
through the sentence. On the basis of which switches are set, the
decision to start a new routine is made when a new part of speech
is encountered.
Program sections, called routines, can call upon indivi-
dual subroutines to carry out those tasks w~ich must be carried
out repeatedly. A subroutine may use nested subroutines to check
......
- 6 -~ 20155-424
for certain parameters be~ore making a decision.
The System uses many unique approaches and methods at
every level in carrying out translation automatically from a
source language into a target language.
A program for translating between source and target
natural languages in accordance wi-th the present invention
involves a system wherein all the logical capabilities of the
digital computer are first considered and a programming system is
organized in a form which can be processed by the computer. To
this end, new features were introduced in the language theory. A
new part oE speech concept breaks with the traditional parts of
speech and organizes the functional classes in the language
according to their most suitable form for processing by the
computer. Codes are assigned to language units, to words, to
expressions, and even to complete phrases in order to enable a
program to correctly recognize the function of the words within
the sentence. This is in sharp contrast to previous systems where
codes were only assigned to individual words. The method involves
a complete system which starts with the reading in of source
language text, breaks the text down into individual words and
looks up these words in various dictionaries. Codes are attached
to the words which are indispensable for further processing and
computer understanding of the source text. With the help of codes
attached to individual words or expressions, -the computer carries
out a hierarchical analysis during which more and more codes are
attached to each word. These codes express for the computer the
syntax of the individual sentences and enable subsequent program
4'j~3
- 7 - 20155-42~
to find the meaning in the sentence as well as all those factors
which influence the meaning within or without the particular
sentence under analysis. On the basis of this procedure, an
unambiguous translation is carried out.
The program in accordance with the present invention is
capable of utilizing an unlimited number oE routines attached to
each source word. The routines are attached irrelevan-t of the
source and target languages under consideration. These routines
take into consideration the computer established syntactic inter-
connections of the words, phrases, etc. and using semantic cate-
gories, find the meaning influencing words for every individual
word with multiple meaning in the sentence. Unique to an embodi-
men-t o the present invention, a program is capable of attaching
to the individual source language entries a virtually unlimited
number of target language meanings and of organizing them accord-
ing to subject fields. During the translation, the Eirst selected
meaning reflects the subject field in which the translation -takes
place cutting down considerably on the multiple meaning problems.
To the general types of words which occur in every subject field,
routines are attached to solve their meaning within every possible
environment. Word groups are translated as a unit, either as
idiom or so-called limited semantic compound expressions (L.S.
expression). The advantage of the L.S. compound is that whenever
the source language is inflected, one such entry can translate
correctly the compound irrespective of which case or conjunctional
form it occurred in the text.
4;~3
- 8 - ~ 20155-~24
Another ~eature of the embodiment of the present inven-
tion is its open-endedness. In other words, the system is quite
modular and this is fe]t to be a primary feature of an embodiment
of the present invention. One feature of the modularity is that
there is no limit in adding compounds to the system. The number
of idiomatic expressions is limited only by the high speed core
memory used.
Also unique to one embodiment of the presen-t invention,
is that although an idiom i9 translated as a unit, the participa-
ting words may be undergoing a complete syntactic analysis. As aresult, the automa~ic translation does not suffer by the fact that
an idiom has been translated.
Another feature of an embodiment of the present inven-
tion is that limited semantic compounds are stored on disks and
are rapidly accessed in a way that the most ~requent ones are
available during the dictionary lookup procedure, and less fre-
quent ones are made available during the actual translation
process.
According to a preferred embodiment of the invention a
special up-date system is provided with independent rou~ines that
carry out changes within the various dictionaries, including the
general dictionaries, high frequency dictionaries, idiom dictiona-
ries and limited semantics (L.S.) compound dictionaries. The
update system has built in features for automatic controls so that
possible errors due to erroneous coding are automatically elimina-
ted. Whenever an entry is rejected as unacceptable, a message
indicates the type of error committed so that the dictionary
,8~4~
- 9 ~ 20155-~24
coder can easily find the problem. The computer is used to full
advantage by the use of a higher language which is adapted to the
special requiremen-ts of machine translation. Each instruction of
the higher language stands for a large number of machine language
sta-tements and facilitates the programming without undue core
storage requirements. This computer language is known as the
systran macro language for language translation and itself is felt
to be a unique feature of one embodiment of -the present inven-
tion.
~ccording to a preferred embodiment of the invention,
repeated scans are carried ou-t through the sentence for certain
grammar codes whih help the computer first to eliminate basic
ambiguities and establish through codes attached to the words,
basic interconnections between the words. More detailed semantic
tests are made in subsequent passes and phrases and clauses are
gradually delimited and higher sentence markers such as subjects
and/or predicates in the target language are established.
The last of the scans determines the function of every
word and resolves indeterminate or ambiguous syntactic relation-
ships between words in a sentence. These passes set up asyntactical profile o the sentence expressed by coded information
in a way which a computer can utilize. Resultant source sentences
with the generated codes are inserted into a predetermined cleaned
up location in the memory reserved for this purpose and codes are
generated after each word. Codes reflect all of the existing
interconnections between the words of the source sentence.
Although only one sentence is generally analyzed at a time, the
4~3
- 10 -~ 20155-424
system has provisions to store information in order to remember
from previous sentences information which should be taken into
consideration in resolving certain ambiguities in following
sentences. This is completely unique to the preferred embodiment
o-f the present invention. The connections between words are
expressed in codes which uniquely define the syntactic and seman-
tic connections in each sentence and between sentences.
According to a preferred embodiment of the present
invention, the program has the ability to resolve multiple mean-
ings. In order to accomplish such resolution, there is provided a
subject field glossary or topical glossary. For the first time in
machine translation, the ability is provided to attach to source
language entries in the dictionary target meanings which meanings
are located in the topical glossaries. Each time a text is trans-
lated an indication can be given to the computer which of the
topical glossaries should be consulted. If no indication is
available during translation as to which topical glossary or topi-
cal glossary sequences are to be used, a general meaning is selec-
ted from the main dictionary for every word to be translated.
According to a preferred embodiment of the present
invention, idiomatic expressions or idioms contain two or more
words in the source language which in a definite sequence repre-
sent a unique meaning unit and should be translated as such. An
algorithm determines during the translation phase the ~unction of
the idiom and accordingly selects the correct idiom, meaning, from
among a number of possible meanings. The meanings are in the
target language. The idiom meaning or meanings are attached to
~ 20155-~2~
the first source text word of an idiom. The rest of the words in
the idiom, i.e. the second and subsequent words, receive a tag
which marks them as being translated.
All of the words in an idiomatic expxession also undergo
a dictionary lookup procedure whereby they receive grammar and
meaning codes from -the main dictionary and are subjected to the
syntactical analysis discussed hereinabove. Thus, the idiom words
may become one or more syntactic units independent of the fact
that they together form an idiomatic semantic unit.
According to a preferred embodiment of the invention,
limited semantic compounds are used for resolving multiple mean-
ings and eliminating semantic problems. According to this proce-
dure, thousands of words with which a particular word may be com-
bined to form a limited semantic compound are stored in the stor-
age facilities of the computer and are selected for further use in
accordance with the particular results of the snytactic analysis.
The programming system has a unique capability to incorporate such
limited semantic compounds according to the various subject fields
and during translation, if a compound expression has more than one
meaning, it retrieves only that meaning which corresponds to the
subject field under translation. The compounds carry syntactic
and semantic codes which are used during the determination of
their function and their correct translation. Limited semantic
expressions usually contain a principal word which can undergo
declension or conjugation. Codes for such declension or conjuga-
tion in the target language are attached to -the compound in
question. The principal words in essence, which determines the
- 12 20155-424
meaning of a particular compound, carries, in a highly condensed
form, lnformation concerning the possible other words with which
the word may form a unique compound expression. The information
is coded as a sequence of numbers. This procedure for generating
the L.S. compound numbers assigns to every word in the source
language dictionary a unique L.S. number. ~ot only are indivi-
dually all the L.S. numbers of the participating word attached to
the principal word but there is also an indication of which posi-
tion in each compound the principal word occupies in relation to
its participating words, i.e. is the principal word the first
word, the second word, the third word, etc. in the compound. An
L.S. dictionary is provided and whenever a principal word is
encountered during dictionary lookup, 300 bytes (2400 bits) of
information of participating word numbers are attached immediately
to the principal word. If the L.S. information (in the form of a
sequence of numbers) for one principal word exceeds 2400 bits, the
information is not attached during dictionary lookup to the word,
but is left in the particular storage area from where it is
retrieved during translation procedure. The storage area is on a
disk. There is virtually no limit in the number of compounds
which can be attached to a principal word. Presently the longest
information attached in sequences of numbers to principal words
exceeds 14000 bytes (14000X8 bits).
Also in accordance with the preferred embodiment of the
present invention, the following step in the solution of the
multiple meaning problem are the lexical subroutines. The names
2~3
- 13 ~ 20155-424
of the subrout:ines are arranged in a binary table and whenever a
word occurs which carries a bit indicating that -the lexical rou-
tine should be called, the particular routine is identified and a
binary search is carried out in the list to call in the particular
routine. The frequently used routines are kept in the high speed
core memory whereas others are available for easy access on
auxiliary storage devices such as disks. These routines can be
called in a parallel operation to the translation process prevent-
ing waste of time. Although -the routines are prepared primarily
to handle multiple meanings, i.e. semantic problems, several of
them resolve syntactic ambiguities. Whenever a le~ical routine
determines the correct meaning, it attaches the meaning to a word
with proper synthesis codes. During translation, this newly
attached meaning is considered. Due to the new meaning, some of
the words in the sentence lose their previous meanings. As the
words are translated, they are marked with a tag as having been
translated.
According to a further preferred embodiment of the
invention, a subsequent step in the translation process involves
resolution of the generalized multiple meaning problem. According
to the unique concepts of a preferred embodiment of the invention,
a generalized approach has been implemented to solve the multiple
meaning ambiguities. The words in the source language rec~eive
semantic categorization codes. Each word may belong to a series
of seman-tic categories. These categories are arranged in groups
and attached in condensed bit format to the words in the diction-
ary. Each bit represents a category. If a particular bit is on,
~8~9
~ 20l55-424
the word belongs to such a category. If the bit is not on, t'ne
category is not applicable to the particular word.
Rules are e~pressed in decimal numbers which tell the
program which routine mus-t be called in order to resolve the ambi-
gulty of a particular word, and the rules are considered in se-
quence. Routines are carried out in exactly the same sequence as
the rules. The number of the rule indicates for the routine the
type of syntactic connection within which search should be carried
out the availability of semantic categories i.e., words which have
certain semantic category codes. Each time when within a defined
syntactic relationship a word with a certain seman-tic category bi-t
is encountered, a meaning will be selected which is indicated by
the respective meaning number in the rule. The rule may specify
that in order to select a particular meaning, more than one cate-
gory must be available and indicates what type of relationship the
word with its particular semantic categories mus-t be in relation
to an ambiguous word. Rules are of variable length -that are
attached to each word in the dictionary. These rules are intro
duced during dictionary lookup in a fashion resembling the intro-
duction of grammar codes and are used in the generalized semanticprogram to resolve the ambiguity of the particular word.
BRIEF DESCRIPTION OF THE DRAWINGS
FIG. 1 is a generalized flow diagram illustrating the
SYSTR~N translation system embodying the present invention;
FIG. lA is a more detailed flow diagram o-f the SYSTR~
IBM 360/65 operation embodying the present invention;
L4~
- 15 - 20155-424
FIG. 2 is a generalized sketch illus-trating the high
frequercy/idiom lookup operation of FIG. lA;
F'IG. 3 is a generalized Elow diagram illustrating the
main dictionary lookup operation of FIG. lA;
FIG. 4 is a more detailed Elow diagram illustrating the
high frequency/idiom lookup for a specific Russian sentence;
FIG. 5 is a flow diagram illustrating the sequence of
operation during stem lookup operation for the Russian sentence
shown in FIG. 4;
FIG. 6 is a more detailed flow diagram illustrating an
example of limited semantics lookup operation for the Russian
sentence shown in FIG. 4;
FIG. 7 is a detailed flow diagram illustrating the
sequence of operation o-E the LOADTXT program;
FIG. ~ is a detailed flow diagram illustrating the
sequence of operation for the MDL program;
FIG. 9 is a flow diagram illustrating the sequence of
operation during the INITCALL program;
FIG. 10 is a detailed flow diayram illustrating the
sequence for the GETSENTN program;
FIG. 11 is a detailed flow diagram illustrating the
sequence of operation for the ST~PASS0 program;
FIG. 12 is a detailed flow diagram illustrating the
sequence of operation for the STRPASSl program;
FIG. 13 is a detailed flow diagram illustrating -the
sequence of operation during the STRPASSl program for a noun-10
part of speech;
33L L~'2 9
- 16 -~ 20155-424
FIG. 14 is a detailed flow diagram illus-trating the
sequence of operation during the STRPASS l program for a verb-04
part of speech;
FIG. 15 is a flow diagram illustrating the sequence of
operation during the STRPASS l program for an adjective parti-
clpl.e-20 and 80 part of speech;
FIG. l~ is a detailed flow diagram illustrating the
sequence of operation for the STRPASS 2 program;
FIG. 17 is a flow diagram illustrating the sequence of
operation for a STRPASS 3 program;
FIG. 18 is a detailed flow diagram illustrating the
sequence of operation for the STRPASS 4 program,
FIG. 19 is a detailed flow diagram illustrating the
sequence of operation for the PREPTR program;
FIG. 20 is a detailed flow diagram illustrating the
sequence of operation for the LEXICAL program;
FIG. 21 is a de-tailed flow diagram illustrating the
sequence of operation for the SEMANTIC program;
FIG. 22 is a detailed flow diagram illustrating the
sequence of operation for the REARR program;
FIG. 23 is a detailed flow diagram illustrating the
sequence of operation for the PRI~T program;
FIG. 24 through 33 are detailed flow diagrams illustra-
ting the sequence of operation for the TLSY~ (ESY~) program;
FIG. 34 is a detailed flow diagram illustrating the
sequence of operation for the program RUM0;
~ ~3~14'~3
- 17 20155-42~
FIG. 35 is a detailed flow diagram illustrating the
sequence of operation for the SYSNOUN program; and
FIG. 36 is a detailed Elow diagram illustrating the
sequence of operation for the SYSVERB program;
DESCRIPTION OF THE PREFE~RED EMBODIMENT
1. General Descrlption of Systran Translation System
The appendices hereto yive a symbolic listing of the
SYSTRAN programs. The meaning of the symbolic language is ex-
plained in the book *IBM System/360 Operating System Assembler
Language, File Number S360-21, Form Number C28-6514-4, published
by IBM. The symbolic listing is converted to actual machine code
for the IBM 360/65 through the assembler program which is a normal
part of every IBM 360/65 computer.
FIG. 1 is a flow diagram which illustrates an overall
programming system used on programmable digital data processing
systems Eor translation from one natural language to another. The
specific programming system disclosed herein by way of example is
for translation from Russian to English and is known as the
"Systran System". However, the inventive concepts are applicable
to translation between any two natural languages such as English
and Chinese, Spanish, etc.
Referring to FIG. 1, the first step consists of the
preparation of -the Russian text for computer translation. This is
accomplished by having the text typed on a magnetic tape Selectric
typewriter (MTST) made by the International Business Machines
Corporation (IBM). The typewriter is used to replace each
*Trade-mark
Z~3
- 18 - 20155-424
Cyrillic letter in the Russian text with a I,atin let-ter or combi-
nation of letters. The MTST codes the Latin characters and
records the coded characters on magnetic tapes in cartridges. To
provide print format control of the English translation, special
coded control characters are typed interspersed with the text.
The text on the MTST tape cartridge is converted to characters
suitable for processing by the IBM 360/65 digital computer~ The
conversion is made to IBM 360/65 characters and recorded on mag-
netic tape utilizing the Data Corporation MTST converter or the
Litton Systems, Inc. converter, Mode] 9209.
Having passed through this preparatory stage, the
Russian text is next translated by processing on the IBM 360/65
digital computer. The present minimum requirements of SYSTR~N on
the IBM 360/65 are 512 bytes of core memory, one input and one
output tape and four disk storage drives for dictionary program,
and data manipulation usage. The disk storage drives are sold by
IBM under the number 2314. The steps of processing are described
in subsequent paragraphs.
The output from the IBM 360/65 system is a magnetic tape
with the English translation. This tape is processed on a digital
computer sold by IBM known as the IBM 1401 computer for the pur-
pose o~ preparing the English translation listing. The actual
listing is on a printer attached to the IBM 1401 computer system.
The IBM 1401 computer has a special upper and lower case print
chain for capitalization indication, as well as additional special
characters to compose a 120 character print chain.
- 19 ~ 20155-4~
A set of tables is located at the end of the specifica-
tion and is referred to hereinafter. Table I gives a list of the
computer programs used in the SYSTRAN SYSTEM together with a brief
description of the meaning of each program.
The translation process on the IBM 360/65 system com-
prises the following 12 programs listed in Table 1 STRPASS0;
STRPASSl; STRPASS2; STRPASS3; STRPASS4; LSLOOKUP; LEXICAL;
SEMANTIC; PREPTR; REARR; TI.SYN(ESYN) and TRPRINT. The program
MT/ST edits and converts the MT/ST text. The programs LOADTXT
through SYSVERB perform dictionary look-up functions, gather
information and attached the information to the source text words.
The programs STRPASS-0 through STRPASS 4 prepare the input text
together with information from certain translation dictionaries
(which will be described in detail) for the programs LEXICAL
through TLSYN(ESYN) which performs the actual translation. The
functions of the individual programs are presented below.
The rest of the general description is directed to the
operations of the SYSTRA~ SYSTE~ using the IBM 360/65 and the IBM
1401.
There are inherent difficulties associated with substi-
tuting a computer for a human translator to perform language
translation. The human mind has the capability of "understanding"
the text by making almost simultaneous, structural inter-
connections between words. The computer's limitations in this
area are overcome by utili~ing its great speed, storage of unlimi-
ted source material, and ability to perform repetitious and
tedious tasks wi-thout succumbing to error. The system presented
429
- 20 ~0155-42~
herein has minimized the machine limitations, while capitalizing
on the computer's capabilities.
The logic employed in the translation process can be
divided into three primary phases. The first is DICTIONARY LOOKUP
in which the computer storage is drawn upon to symbolically
classify the source words. The second phase is the SY~TACTICAL
analysis of the text, e.g., the establishment of interrelation-
ships between words within a sentence. The third phase is the
actual SYNT~ESIS into the target language or languages. Each of
these steps will be dealt with independently, both in terms of the
computer system design and the translation scheme.
A DICTIONARY LOOKUP
This phase of the translation process involves programs
LOADTXT and MDL and is distinguished by the implementation of
various computer tables that carry information necessary for the
accurate translation of the source text. Many of these tables are
penetrated through the use of address linkages which point to or
locate the expanded information on disk. Codes and addresses are
affixed to the source text during this phase and are carried from
this phase into SY~TACTICAL A~ALYSIS and SY~T~IESIS.
FIGS. 2 and 3 illustrate the dictionaries used during
DICTIO~ARY LOOKUP and the way in which they are interconnected by
address linkages or oEfset addresses. LOADTXT ~TABLE 1) is the
program which executes the instructions for input and work during
this phase and separates the words into individual records.
4'~9
- 21 ~ 20155-~24
The pro~rams for the ac-tual dictionary lookup are high
frequency and idiom lookup and main dictionary lookup. These
processes are brieEly described below.
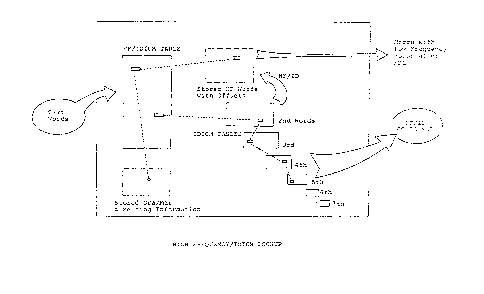
(1) High Frequency and Idiom Lookup
FIG. 2 is a generalized sketch illustrating the sequence
of operations during High Frequency and Idiom Lookup.
FIG. 7 shows a flow diagram of the LOADTXT program. The
source text words are read in and stored in main core memory by
the LOADTXT program. As each individual word enters the core
memory, the program matches the word against a dictionary of high
frequency words which also contain the fixst words of all idioms.
This dictionary is called the FlF/IDIOM DICTIONARY. The high fre-
quency words are a relatively small number of frequently en-
countered words in the source language, such as conjunctions,
prepositions, and punctuation marks. Looking these up separately
from low frequency words saves considerable search time, since the
EF/IDIOM DICTIONARY is kept in core memory and does no-t have to be
brought in from auxiliary disk s-torage. The important advantage
of separating the high frequency words is that the high frequency
words do not carry the string of grammar and meaning information
on disk that the low frequency words carry. Rather, the high
frequency words have their grammar and meaning information separa-
tely stored in a dictionary which is later referenced by offset or
address linkages. The offset or address linkages indica-te the
location of the corresponding grammar and meaning information in
the core memory. These address linkages are stored with each word
in the HF/IDIOM DICTIO~ARY.
~Z8~4'~9
- 22 - 20155-424
A word that is a high frequency word is detected by a
match with a word in the HF/IDIOM DICTIONAR~. Then the appropri
ate address linkages from the dictionary are attached to the
source word and are held in a working file known as the HIGH
FREQUE~CY FILE to be later merged with low frequency source text
words. If a word, (irrelevant whether it is part of an idiom or
not), is not a high frequency word, it is sent directly to a LOW
FREQUENCY FILE from which a Dictionary Lookup (MDL) operation is
performed.
If a word is the first word of an idiom, it is indicated
by a field associated with the word in the HF/IDIOM DICTIONARY.
Upon countering, it must be determined whether any of the words
following such first word of an idiom could participate in an
idiomatic expression. Each idiomatic phrase may have one through
seven words to handle the 2nd through 7th possible idiom words. A
se-t of 2nd word -throuyh 7th word IDIOM TABLES are provided. The
first word idiom words in the ~IF/IDIOM TABLE have an offset to a
word in the 2nd word IDIOM TABLE which has an offset to a word in
the 3rd word IDIO~ table, etc. Thus, once a first word of an
idiom is found, the 2nd word IDIOM TABLE is searched which con-
tains all possible second words that could follow that particular
first word in an idiom. The search continues for third, fourth,
to a maximum of seven words, until a match is found for a complete
idiom phrase. The last idiom word has associated therewith an
offset address linkage to a meaning for the particular idiom, The
meaning of the entire idiom is then obtained and attached -to the
first word of the idiom and all words in the idiom are marked as
29
- 23 -~ 20155-42~
already translated. If the Eirst word is a high fre~uency word,
as well as being the first word of an idiom, it is written in the
high frequency file and it receives the same types of codes as the
other high frequency words. If the first word of an idiom is a
low frequency word, it is written into the HIGH FREQUENCY FILE for
the unique purpose of carrying -the meaning, otherwise it goes to a
low frequency (LF) file for processing by MDJ.
The words in the LF FILE are then sorted in ascending
alphabetical sequence for lookup in the MASTER STEM DICTIONARY ~Y
A ~TANDARD SORT PROGRAM, (not disclosed herein).
(2) Main Dictionary Lookup
FIG. 3 is a generalized sketch illustrating the sequence
of operation during execution of the program main dictionary look-
up (MDL). FIG. 8 is a flow diagram illustrating the sequence of
operation by the program MDLo Main dictionary lookup is handled
by the MDL program. The stem words for the source language are
kept on disk and are called or brought into core memory by the
INITCALL PROGRAM as they are needed. Although not essential to
the broader concepts of the invention, a preferred embodiment of
the invention has the stems stored on three different disks A, B
and C, according to Iength (1-3 characters, 4-7 characters, 8-24
characters), however, this may be modified to a single disk stor-
age. Each entry contains a source language stem word and attached
to each stem in this dictionary are paradigmatic set codes (PST)
which signify the endings permitted for that stem. Also, there is
an address at the stem in the dictionary which points to a disk
location carrying additional grammar and meaning information and
3.X8~
- 24 - 2015S-424
to LS information. Information in the dictionary also indicates
if each word may function as a principal or supplementary word in
an LS expression. Full form entries which need no ste~ ending
comparison for match are also kept in the stem dictionary.
The program main dictionary lookup (MDL) obtains or
calls in the words from the LOW FREQUENCY FILE and accumulates
them on disk. Then a portion of the text words, along with por-
tions of each of the STEM DICTIONARIES on disks are read into core
memory. The stem dictionaries also contain full forms. They are
in alphabetic sequence as are the source text words. For each
disk of STEM DICTIONARIES, there are two areas in the core. The
first area (Al, ~l~ Cl, Xl) is filled with a portion of text words
and STEM DICTIONARIES for the disks. When -this is filled, work
begins on it by the IB~ 360/65 computer and the second area (A2,
B2, C2, X2) is filled with more words or stems. The second area
acts as a buffer so that actual work by the computer need not stop
to read in more data. Simultaneous work and read-in is accom-
plished. The words in the LOW FREQUENCY FILE are compared one by
one with -the stem words in the STEM DICTIONARIES obtaining gramma-
tical and meaning information from the dictionary for each wordfor which an equality is detected and attaching such grammatical
and meaning information with the source word. The above described
procedure continues until all low frequency words have been match-
ed in the dictionary.
During the dictionary look-up whenever only a portion of
the source word matches with the stem, the ending is analy~ed to
determine whether it is an allowable ending and if so, what
L4h,!~
-- 25 -~ 20155~42~
additional qrammatical information can be derived from the parti-
cular stem and ending combination. Each stem belongs to a defined
declensional or conjugational pattern. Such patterns are express-
ed by PST codes. In addi-tion, every word has a code which indica-
tes whether particular declensional or conjugational patterns
should be taken into consideration. On -the basis of these codes,
one of the following three programs may be activated by MDL:
RUMO, SYSNOUN or SYSVERB (FIGS. 34, 35 and 36). These programs
contain VALID ENDINGS TABLES for every declensional or conjuga-
tional pattern of the source language and attach on -the basis of
such tables grammatical information to the words.
If a word is not in the STEM DICTIONARIES, it is analyz-
ed for its component letters, numbers, and/or endings to establish
its possible function and subsequently stored until a sufficient
number have been accumulated and printed out in an error list.
After all the low frequency words of a text have been looked up,
they are sor-ted back into their original text, and are merged with
the HIGH FREQUENCY FILE words which are kept in their original
source text sequence, and put into a file known as MERGED FILE.
The original sequence of the source text is determined ~rom serial
numbers attached to each source word before dic-tionary lookup
commencedO
B. Syntactical Analysis
The programs GETSENTN through PRINT are initiated and
sequentially ordered by the program called INITCALL as generally
depicted in FIG. 9.
4 ~9
- 26 ~ 20155~424
The program GE~'SENTN, called by INITCALL, initiates the
analysis of the words as they Eunction in the sentence. FIG. 10
is a flow diagram illustrating the sequence of operation of
GETSE~TN. At this time, each separate sentence is handled as the
basic unit for structural and syntactical analysis. It is this
phase of translation which a-ttempts to compensate for -the com-
puter's lack of understanding of the words it reads. GETSENTN
first clears the analysis area in the core memory. The sentences
are then individually called from the MERGED FILE into the
analysis area in the core memory. FIG. 10 is a flow diagram
illustrating the sequence of operation by the program GETSE~T~. A
typical example of a listing or print out of one sentence in the
source text and associated information is contained in Table 24.
(1) Lo~kup of Limited Semantic Expressions (LSLOOKUP)
Lookup of limited semantic expressions is done by the
program LSLOOKUP. Before the consideration of words or word
groups as entities determined by relative position, a match is
done to see if they participate in a limited semantic expression
(i.e. multiple meaning is resolved within limited environment). A
sketch generally illustrating the sequence of operation during
LSLOOKUP is shown in FIG. 6. The lookup is done by scanning the
sentence looking for attachad tags indicating the word is a
possible principal word (this information is attached during
DICTIO~ARY LOOKUP). If a principal word is encountered, then
words on both sides of it are examined for tags indicating supple-
mentary words. Such an arrangement is based on the fact that
every word in the dictionary carries a unique L.S. number which
8~L4~9
- 27 -~ 20155-~24
identifies the word or the purpose of limited seman-tics. The
principal word carries the L.S. numbers of all supplementary words
with which they may function in a compound. If a principal word
has adjacent supplementary words, then a small work area is built
in core memory at -these words and a LS COMPOUND DICTIO~ARY is
searched for all compound e~pressions having that principal word
occupying that particular position. A match is then done with the
supplementary words. If the words are determined to be partici-
pants in a limited semantic expression, the information for the
expression is a-ttached to the principal word.
(2) Structural Passes
The structural pass programs are known as STRPASS and
operate on each sentence in an area of memory which has been
cleaned for this analysis. There are five passes known as
ST~PASS-O through STRPASS-4 and each pass elucidates in some way
on the previous one. The information gained during a pass is not
static and may be elaborated upon as new information is gained.
According to the type of sentence under analysis, certain blanks
in the analysis area are gradually filled with information by the
five passes. The following gives a description of each:
(a) STRP~SS-0
FIG. ll is a flow diagram illustrating the sequence of
operation during the ST~PASS-0 program. STRPASS-0 is a program
which, before the actual structural passes are performed, resolves
parts of speech ambiguities when they occur. Homograph ambigui-
ties are indicated by the same numeral codes in each language.
Special subroutines are accessed through these codes which analyze
!~ ~
4~9
- 28 ~ 20155-424
the relationship of the ambiguous word to other words in the
sentence (i.e. their part of speech, POS, and other codes), and
determine its part of speech on this basis. The subroutines are
adjusted according to the particular source language being used.
Words that are definite objects are recognized and
appropriate bits or tags are set on in association with each
source word in the analysis area.
(b) STRPASS 1
FIG. 12 is a flow diagram illustrating the sequence of
operation during execution of the STRPASS 1 program. STRPASS 1 is
a program which moves from the end of the sentence to the beginn-
ing as more relationships are established in this manner. Each
part of speech code encountered initiates a routine that sets
switches or tags associated with each word which indicates its
position and possible function. This is made possible by having a
dictionary system in which the part of speech (POS) indication is
used to initiate selected routines. FIGS. 13, 14 and 15 are flow
diagrams illlustrating the sequence of operation for the POS noun,
POS verb and POS adjective/participle respectively. Although the
routines vary according to the source language, the software
support for all natural languages is the same. The switches
"remember" previously encountered situations and ~eneralized sub-
routines are called which make decisions on the basis of these
switches. For instance, the determination of the definite object
of a verbal form is identical for English, Russian, German,
French, etc. The consideration of transitivity or case
requirement in some languages is an e~ample of the reason for
4~9
- 29 20155-424
minor variances in subroutines.
(c) STRPASS 2
FIG. 16 is a flow diagram illustrating the sequence of
operation during execution of the program STRPASS-2. STRPASS-2 is
a program which determines the extent to which commas and conjunc-
tions serve as separators between multiple objects, phrases and
clauses. It also carries out specialized routines at quotation
marks, dashes, and other punctuation marks that have a function in
the language of interest. Each punctuation mark has a POS code by
which it is recogniæed. The POS was previously attached during
dictionary lookup. Parentheses are classified according to the
type of construction they enclose. Also in this pass, the addi-
tional information gained from the recogni-tion of punctuation
marks is used to mark structures that were not discovered in
STRPASS l.
(d) STRPASS 3
FIG. 17 is a flow diagram illustrating the sequence of
operation during execution of STRPASS-3. STRPASS-3 is a program
which locates subject(s) and predicate(s). First a search is
carried out for primary predicates based on assigned POS tags
attached to the source words. If none of these are available in
the sentence, other words which may function as predicates are
searched for with the priorities for search being based on the
probability of certain parts of speech becoming predicates before
others. A-fter the predicate is determined, the subject is search-
ed ~or. This also proceeds on the basis of probabilities. For
example, in the case of Russian and German, nominative nouns are
~s~ t3
- 30 - 201~5-424
searched for first as they are the primary candidates for sub-
jects. The subjects and predicates must agree in number and
gender (if applicable).
Any commas with indeterminate function are analyzed in
this pass to see if they serve as subsentence unit separators.
The location of the subject and predicate enable the discernmen-t
of embedded clauses, and multiple predicates and subjects are
recognized and noted by assigning codes.
The discovery of a subject by this pass may modify
information previously inserted in the analysis area relative to
function that word. For example, if a noun is called an object in
STRPASS 1 and STRPASS 3 does not locate a subject and the predi-
cate is a personal verb, the object must become the subject. In
this way the input of new information caused a reevaluation of the
sentence structure.
(e3 STRPASS 4
FIG. 1~ is a flow diagram illus-trating the sequence of
operation during execution of the program STRPASS 4. STRPASS 4 is
a program which looks over the entire sentence for words which
have not been previously recognizedO For instance, if a word has
attached tags indicating it requires an ob~ect, and no object was
found in previous passes, -then its object is discovered at this
time. Also, a specific feature of this pass is to check whether
each word has either a governing or subordinate function. Some
words will, of course, be marked twice as being both governors and
subordinates. STRPASS 4 continues until all the words of the
sentence have been marked with the appropriate codes.
8~ 3
- 31 20155-424
After the structural passes, a number of programs may be
used to perform a variety of functions, depending on the target
language. For instance, the text sentence may be scanned for
article insertion or for the insertion of proper prepositions.
Numbers may be assigned to the source language words which may be
used in rearranging the target synthesis to correspond to common
usage. Special rules may be called to reso]ve multiple meaning
problems. These aspects must be specifically oriented to parti-
cular languages and will not be discussed here in depth. These
passes are handled by the programs LEXICAL, SEMANTICS, and PREPTR
preposition translation) flow diagrams of which are shown in FIGS.
20, 21 and 19 respectively.
Both the LE~ICAL and SEMANTIC programs have their own
supervisory programs which decide at which words is the text these
programs should go into effect. The LEXICAL program is composed
of many individual subroutines. One of these routines will be
activated on the basis of the encountered word during transla-
tion.
SEMANTIC is a generalized program which is activated
each time a multiple meaning word is encountered which has been
supplied with parameters for this program. According to the para-
meters~ the program analy7es in a hierarchical sequence the seman-
tic categories of certain words in the sentence with which the
multiple meaning word is in defined syntactic relationship. The
semantic categories reflect the semantic properties of the words.
Each source language word may belong to one or more semantic
categories.
~83~'3
- 32 - 20L55-424
The lexica:L routines illustrated by E'IG. 20 are indivi-
dual subroutines. Each routine consists o-f sequences of machine
steps which are called into action at the occurrence of specific
words in the text to he translated. FIG. 21 illustrates -the
semantic program which consists of many program units each con-
sisting of sequences of machine steps. The whole program is
called each time a word is encountered for which the semantic
program is updated with parameters. On the basis of such para-
meters, certain machine steps of the different program units are
carried out.
The lexical routines represent individual approaches to
meaning problems within which syntactic transformations are some-
times carried out (i.e., an ohject of a proposition is made to
become a subject). The semantic program is a generalized large
program. Sections of this program are activated by parameters
expressed in the ~orm of rules and attached to the individual
words which may be translated with different meanings.
The lexical routines carry out their task on the basis
of checking the environment of the word for which they are called
upon. The semantic program analyzes the semantic categories of
those words which are in defined syntactic relationships with the
word with a meaning ambiguity. The analysis takes place on a
hierarchical order indicated by the parameters and rules attached
to words with multiple meanings. The types of categories as well
as the syntactic connections within which these categories are
looked for by the program are also expressed in the form of
categories at the individual words which participate in the
~V~ 3
- 33 - 20155-424
generalized program.
There is no direct connection be-tween LEXICAL and
SEM~NTIC. Both are independent program units within the transla-
tion system. Both have their own supervisory programs Eor con-
trolling their operation.
The supervisory program for SEMANTIC is in the Appendix
program listing under "Project 3". In the program listings, the
label is PROJ3AC and the card number of the instruction B870. If
this instruction finds that the word participates in the semantic
program, the following instruction loads the address of the
Semantic Word Table (SEMWDTBL) to find out for which word the
parameters should be used in the generalized program to resolve
the multiple meaning of the word.
The supervisory program for the LEXICAL program is at
level LEX01, card A680 and it continues at labels ACTION (A800)
and ACTIONA (A930), where a branch is carried out to search in the
LEXTBL (Lexical Table) for the routine which should be activated
according to the source word.
C Synthesis into Target Language
The synthesis phase of the translation process is car-
ried out by the programs REARR, TLSYN (ESYN) (Target language
synthesis) and PRINT, flow diagrams of which are shown in FIGS. 22
and 24 through 33, respectively. These programs vary somewhat
when changing languages depending on the inherent characteristics
of the source and target languages. Basically, the synthesis is
done by branching on each part of speech. In the case of some
parts of speech, tables are interrogated to discover the proper
,~ ,
- 3~ -~ 20155-~24
translation. For instance, the verb rou-tines which translate into
English, use tables in the computer memory. The tables are
selected depending on whether a verb is active, reElexive, or
whether the auxiliary 'be' is conjugated. Tables Eor the transla-
tion of the reflexive verbs are further subdivided depending on
-the types of codes verb reflexive codes (IVB) w~ich exist for the
translation of the reflexivity. Each table checks for tense,
aspect, person, number, condition, question and negation, and
decides accordingly which auxiliary or pronoun should be inserted
and what verbal form to be used. TABLES 2-A, 2-B, 2-~ and 2-D
show a chart of typical verb tables used during synthesis. This
approach to synthesizing the target language is completely unique
to this system.
During the coding of the source language into the
tables, codes are given to the translation which ensure the proper
translation. Among these are Topical Glossary Codes (TG) which
diferentiate be-tween meanings on the basis of the scientific area
of interest. In other words, the translation of t'ne word HEAD may
be different in the target language, depending upon whether -the
text being translated is in the area of biology or mechanical
engineering.
Since prepositions play a primary role in most
languages, a special program handles their translation. This
program is known as PREPTR (FIG. 19). This program considers the
codes which are available at words which govern the preposition or
at the objects which are governed by the preposition. In
addition, if necessary, a more extended environment analysis also
takes place.
- 35 -~ 20155-~24
Each language has a unique word order that must be
considered when going from one language to another. The program
called REARR (FIG. 22) deals with this aspect and con-tains the
rules governing -the word order in the target language. These
rules, together with the grammatical codes produced, attached to
each word o-f the source language by the System, enable the program
to first establish the correct sequence of words symbolically and
later to print all the words according to this established
sequence.
An article routine known as ARTICLE may be called on if
necessary. Such a routine considers the parameters of the source
and target languages, to decide where an article should be insert-
ed, if at all, and what kind. The routine functions within the
target language synthesis program (TLSYN).
2. Detailed Description of Components of SYSTRAN Trans-
lation System
A. ~ICTIO~ARIES
(l) General
Dictionaries are prepared in two ormats: (1) for main-
tenance processing, and (2) for translation processing. Eachformat is designed with respect to its own operational tasks to
provide ease and eficiency during computer processing. All
operations involving the dictionaries have been established to
operate in a production environment, i.e., large volumes of addi-
tions and modifications may be rapidly coded and processed in one
con-tinuous computer updating run. This is one of the important
features o an embodiment of the present invention.
J,,L9/1 ~9
~ 36 - 20155 424
The master or base dictionaries are those used in main-
tenance pxocessing and are maintained on magnetic tape. Standard
data processing practices are followed in retaining backup cycles
of both the master dictionary and updating chanye transactions to
enable recovery from accidental dictionary destruction or updating
processing errors. From these dictionaries are created the com-
pact indexed disk dictionaries for fast random access during
translation processing.
Table 3 gives a list of the dictionaries of interest.
The master dictionaries consist of two lexical data
files. One is the SI'EM DICTIONARY and the other is an IDIOM/LS
EXP~ESSION DICTIONARY composed of idioms and Limited Semantics
expressions. The translation dictionaries created from these
files are STEM LOOKUP AND GRAMMAR DICTIONARY, HIGH FREQUENCY WORD
AND GRAMMAR DICTIONARY, IDIOM CORRESPONDENCE DICTIONARY and
LIMITED SEMANTICS COMPOUNDS DICTIONARY.
(2) MASTER STEM DICTIONARY
The MASTER STEM DICTIONARY is maintained on magnetic
tape in a compound variable length record format. Table 4 illus-
trates the word format for each entry in the STEM DICTIONARY. Thecontrol portion of each entry has a Eixed format with record sub-
part offset pointers (record oEfset) to variable grammar sections
of the record. The grammar sections will be discussed herein-
after. Updating control is on the stem (STEM) and stem number
(SN) fields which make up a unique identity o~ the dictionary
record. The stem number (~N) identifies the entry as a stem of a
word characterized by inflections which as a set belong to a
:, .. .
3~ 63
37 - 20155-42~
specific part of speech which i9 either a noun, an adjective or a
verb. Entries that cannot be inElected (preposi-tions, abbrevia-
tions, acronyms, adverbs, etc.), are treated as full foras and are
so here recognized. Other pertinent information contained in the
field indicates whether the stem can function as a principal
and/or supplementary word in a Limited Semantics expression.
The first grammar subpart oE the MASTER STEM DICTIONARY
entries contains information identified as PART-OF-SPEECH CODES.
Here is contained the DPQ and flag byte, the PART-OF-SPEECH CODE,
a more detailed PART-OF-SPEECH CODE, and codes specifying the
appropriate gender, number, case, person, tense and the paradigms
of nouns and adjectives. This subpart is shown in more detail in
table 5 and will be described below.
(a) DPQ and flag byte identify whether
(1) the stem is a noun, adjective, verb/participle or
full form;
(2) High frequency word;
(3) Reflexive full-form usage,
(4) Full-form adjective usage;
(5) Homograph functional capability;
(b) PART-OF-SPEECH CODE (POS). This is the general
PART-OF-SPEECH CODE identifying computer routines to be executed
during translation processing.
(c) Basic PART-OF-SPEECH CODE (BPQ). This is a more
definitive code to qualify PART-OF-SPEECH functions.
(d) Gender
(1) Masculine
-.,
~.28~
- 38 - 20155-424
(2) Feminine
(3) Neuter
(e) Number
(l) Plural
(2) 5ingular
(f) Cases for full-form noun, adjective or participle stems
(l) Nominative
(2) Genitive
(3) Dative
(4) Accusative
(5) Instrumental
(6) Locative
(g) Person for full-form verb stems
(1) First person singular
(2) Second person singular
(3) Third person singular
(4) First person plural
(5) Second person plural
(6) Third person plural
(h) Tense for full-form finite verb stems, mood
(l) Present
(2) Past
(3) Future
(4) Imperative
(i) PST (paradigmatic set codes) for other than full-form
stem entries. These are codes used by morphological analysis
programs executed during dictionary lookup to determine the the
validity of the text word endings with a particular stem.
'3
- 39 -~ 20155--424
The second grammar subpart, of the MASTER STE~
DICTIONARY entries is identified as SYNTA~ CODES, is illustrated
in more detail in Table 6 and contains information of case
requirements, prepositional requirements and syntactic function
codes. The con-tents are:
(a) Case determiners
(1) Genitive
(2) Dative
(3) Accusative
(4) Instrumental
(5) Locative
(b) Prepositional requirements for the Russian words CEREZ,
DL4, DO, IZ, IZO, K, KO, NA, OT, PO, POD, PRI, PROTIV, S, U, V,
ZA, or any combination thereof.
(c) Miscellaneous requirements including the following
Syntactic function codes
(l) Satisfiable independently by infinitive
~2) Satisfiable by direct object
(3) Satisfiable by adverbial form
(4) Personal/impersonal
(5) Participle, never adverb
(6) Noun-adjective
(7) Relative adjective
(8) ~oun defining adjective
- (9) Never an adverb, only predicate-adjective
shortform-neuter-singular
(10) Verbal aspect
- 40 - 20155-424
(11) Satisfiable by prepositional phrase
(12) Predicate (short forms or adverbs)
(13) Never predicate
(14) Animateness
(15) Subordinate clause opener
The third portion of the grammar part in each MASTER
STEM DICTIONARY entry contains case/prepositional translation
codes (CASE/PREP CODES) which relate to a table of English
prepositions to be used in the translation. The word format is
shown in more deta;l in Table 7. Specifically one embodiment of
this inven-tion was the following in the Case/Prepositional Trans-
lation Codes:
(a) Translation of the instrumental if the governing word is
in the active voice or if there is no governor.
(b) Translation of the instrumental if the governing word is
in the reflexive form (passive voice).
(c) Translation of the dative if the governing word is in
the active voice.
(d) Translation of -the dative if the governing word is in
the reflexive form (passive voice).
(e) Prepositional translation control bytes for ZA, V, VO,
S, SO, RADI, PROTIV, PRI, PO, CEREZ, PERED, OT, OKOLO, O, OB, POD,
NAD, NA, K, KO, IZ-ZAI IZ, IZO, DO, U.
The fourth and largest subpart of each MASTER STEM
DICTIONARY entry con-tains the target language information such as
the Topical Glossary codes, English synthesis codes and the
English meaning. Table 8 shows the word format in more detail and
indicates:
~ I'
29
- ~1 20155-424
(a) TG (Topical Glossary code). This code identifies which
group of the English meanings is to be used for the technological
discipline being translated as the meaning can be considerably
different for various types of technical texts. During the trans-
]ation, multiple Topical Glossary codes may be specified with a
preference order for their use and this specification may vary at
any point or points in the text.
(b) Target synthesis codes are Yariable depending on the
words involved. By way of example these codes may include:
(1) Identity of the use of the meaning as a verb, noun
adjective or other
(2) Article usage code
(3) Synthesis code for various forms of the verbs and
adjectives and for pluralizing the noun
(4) Specification as to which word in an e~pression is
to be synthesized.
The last part of the grammar portion of each MASTER STEM
DICTIO~ARY entry is called ~DDITIO~AL VERB ST~MS and is present
for each verb infinitive and contains a table of all additional
~0 forms derived from this infinitive so that these additional stem
records may be updated automatically whenever the infinitive is
updated. In this manner, it can be assured that all forms of the
verb will have the same grammar codes as the infinitive. The
format of the ADDITIONAL VERB STEM is shown in more detail in
Table 9.
(3) STEM DICTIO~ARY UPDATING
A Stem Dictionary Coding Sheet has been designed to make
2~3
- ~2 - 20155-424
possible that any subpart of the grammar sec-tion of the dictionary
record maybe completely revised or to permit that merely an
individual bit of information be changed. This is carried out by
Transac-tion Codes specifying the normal data processing updating
functions of "add", "delete", "modify" and "replace".
The dictionary coding sheet entries are keypunched and
then processed by the computer programs known as DEDIT and DUPDT
(see Table l) in the updating series which performs editing and
formating functions. Since the coding sheet is a general form
used for updating all types of dictionary stems, each entry is
audited for content and permissible usage with the particular stem
being updated. An error list i9 printed of each deviation and the
transaction record is rejected from further processing. Valid
transactions are then formated for updating the Master
Dictionary.
The valid transactions from the edit program are sorted
to a Master Dictionary control sequence (stem and stem number) and
matched against the Master File. Upon a match, the Master
Dictionary record is disassembled into table area with fixed base
locations within the memory of the computer. The Transaction Code
of the change entry is examined and the corresponding portion of
the dictionary entry is updated. Prior to actual modification of
the master record, updating codes, in addition to the transaction
code, are examined to insure the validity and accuracy in up-
dating. Any transactions which would result in updating errors
are rejected and an Error Listing is prepared.
Since linguistic codes can be developed faster than the
~'~814~
- ~3 -~ 20155-424
Master File format and the programs utilizing the file can be
modified, these codes are entered on the General Coding Sheet, but
are listed on Future Code Lists. These lists are saved and when
the computer system has been modified, the future code lists are
reintroduced into the updating process.
Upon completion of updating a master record, it is con-
densed back into a compact compound variable length record and
written out to a new master file. At this time, if the master is
a verb infinitive, an updating transaction record is prepared for
updating all the additional stem forms of the infinitive. These
transactions are sorted to dictionary control sequence and the
intermediate new master is read and the updating process is
repeated for the additional verb stem modifications. This run
produces the final ~EW MASTER STEM DICTIONARY.
During the updating run, a printout is provided in which
all change transactions are listed by rejection errors, duplicate
transactions, and future codes. The MASTER STEM DICTIO~ARY
changes are listed by updated records and deleted records. In
addition, a statistical report is prepared giving the counts o~
updating action, the counts of the different types of stems (full
forms, nouns, adjectives, and verbs), and an indication of the
length of the longest MASTER STEM DICTIONARY record.
In addition to the listing of dictionary records during
the updating process, a separate program is available for listing
the entire MASTER STEM DXCTIONARY, or selected portions thereof,
or particular stem records having certain characteristics. In the
latter case, specialized routines with selection criteria can be
~3~ 9
- ~4 ~ 20155 424
individually assembled and called by a master dictionary print
program throuyh use oE processing control cards. The dictionary
is printed in character where words are present and in hexadecimal
where bit codes are present.
(4) MASTER IDIOM/I..S. EXPRESSIO~ DICTIONARY
The Master Idiom/L.S. Expression Dictionary is also
maintained on magnetic tape in a compound variable length record
format. An example of the format of each entry is shown in Table
10. In one embodiment of the invention, there are 3,279 idioms
and 156,134 L.S. expressions in the dictionary. The control
portion of the record has a fixed format containing the Russian
expression and source language codes. This part is followed by a
variable length target language section. Included here are the
Topical Glossary Code (TG), English synthesis codes (SY~. CODES)
and the TARGET MEA~I~G (or English meaning). Multiple Topical
Glossary (TG) entries may be present and each may have multiple
English meanings attached.
(a) Russian level source codes include~
~1) Prepositional object
(2) ~umber object
(3) Prepositional object definite article
(4) Verbal type compound
(5) Direct object
(~) Eliminate preposition
(7) Pronoun
(8) Object case
~3~429
- ~5 -~ 20155-424
(b) The TG code and SYN codes are the same as the entries in
the MASTER STEM DICTIONARY.
(5) MASTER IDIOM/L.S. DICTIO~ARY UPDATING
A separate coding sheet from the stem dictionary coding
sheet is utilized to update the Idiom/L.S. Dictionary. Each
Topical Glossary target transla-tion record may be updated inde-
pendently from each other. These coding sheet entries are key-
punched and introduced into the updating process beginning with an
Editing and Formating Program. Each coding sheet entry is examin-
ed -for validity of content and the transaction record is rejected
if any invalid codes are present with a listing prepared thereof.
The valid coding sheet transactions are formated into a
variable length updating record and written to a separate file.
This file is sorted to Master Idiom/L.S. Dictionary sequence and
then matched on the Russian expression against the dictionary.
Matching entries result in either a deletion or replacement.
Unmatching entries result in an addition or error of unmatching
deletion. During the updating run, a listing is prepared of all
transaction activity by addition, replacement and deletion.
A separate program is also available for printing the
entire dictionary, portions thereof and records based on a selec-
tion criteria. The latter is effected in the same manner as with
the stem dictionary print program.
(6) TRANSLATION DICTIONARIES
The dictionaries actually used during SYNTACTICAL
ANALYSIS AND SYNTHESIS are created from the tape MASTER STEM
'3
- ~6 ~ 20~55-~24
DICTIONARY and MASTER IDIOM/L.S. DICTIONARY and are located on
disks in various forms of lookup dictionaries. All o~ the
dictionaries are interrelated by disk address pointers and memory
offset pointers. Three Operating System Programs available from
IBM, known as QSAM, BSAM and BDAM, are utilized to access the
various dictionaries. The various dictionaries and -the table
illustrating the word format of each entry in each dictionary are
as follows:
(a) STEM LOOKUP A~D GRAMMAR TRANSL~TION DICTIONARIES
(Table 11)
(b) ~IGH FREQUENCY WORD AND GRAMMAR DICTIONARIES (Table 12)
(c) IDIOM CORRESPONDENCE DICTIONARY (Table 13)
(d) L.S. COMPOUND MASTER DICTIONARY (Table 14)
The STEM LOOKUP AND GRAMMAR TRANSLATIO~ DICT'~ONARIES
(Table ll) are created in two disk files by the DICTLOAD program.
Referring to Table ll, the STEM LOOKUP DICTIOMARY is composed of
the stem part o~ the Master Stem Dictionary less the stem number
(SN) bu-t including the PST (paradigmatic set) codes. Each stem
entry also includes the disk address of the grammar part of the
dictionary record (GRAM DISK ADDRESS) and the disk address of the
L.S. Compound Dictionary record (LS DISK ADDRESS) if this stem can
participate as a principal word in an L.S. expression. The
entries in the STEM LOOKUP DICTIONARY are arranged alphabetically
and into groups by those stems that begin with the same charac-
ters. The first stem determines the first unique beginning
characters and a new group is started when a shorter stem is
encountered or is not equal on the same beginning characters.
~8~ 9
- ~7 -~ 2015~-~2~
Access to the STEM LOOKUP DICTIONARY is accomplished with the
program called BSAM to efficiently control access to two of three
buffer loads simultaneously. The linkage to the GRAMMAR
DICTIONARY and L.S. COMPOUND DICTIONARY is reali~ed by relative
track address and byte offse-t utilizing the program called BDAM,
thus enabling all grammar and L.S. information to be randomly
accessed. Entries in the STEM LOOKUP AND GRAM~R DICTIONARIES
include all MASTER STEM DICTIONARY records excep-t high frequency
words. Thus, words forming part of an idiom are included.
The HIGH FREQUENCY WORD AND GRAMMAR DICTIONARIES are
created in two disk files by the program HFC (H.F. creation). The
high frequency words are selected from the MASTER STEM DICTIONARY
and built into sequent~al fixed length records containing the high
frequency source word and a memory o-Efset (GRAM OFFSET) to the
corresponding gralnmar information which is built into variable
length records. The entries are arranged alphabetically by high
frequency source word. These dic-tionaries are later accessed
sequentially utilizing the program known as QSAM and loaded in
their entirety into core memory during the translation run. The
GRAMMAR DICTIONARY is a variable length table with the GRAMMAR
OFFSET key located with each high frequency word item. The HIGH
E'REQ~ENCY WORD DICTIONAR~ is a fixed length table which is scanned
in a binary search method during translation processing.
The IDIOM CORRESPO~DENCE DICTIONARY is separated in two
disk dictionaries composed of the source or Russian idiom
expression and the corresponding target or English meaning. The
target meaning dictionary includes the field: ENG. OFFSET shown
- 48 -~ 20155-4~4
in Table 13. The field ENG. OFFSET i5 an address offset linkage
which links the source dictionary par-t to the target meaning
dictionary part. These dictionaries are built in the same compu-
ter run that builds -the HIGH FREQUENCY WORD DICTIONARY by merging
the MASTER STEM and MASTER IDIOM/LS DICTIONARIES selecting high
frequency words from the MASTER STEM DICTIONARY and Russian idioms
from the MASTER IDIOM/L.S. DICTIONARY. Both files are built as
variable length records using the program QSAM and are loaded
fully in memory during the translation run. The Russian ex-
pressions are located randomly during the translation phase byutilizing binary and sequential searches. The first word of the
Russian idiom is located in the HIGH FREQUENCY WORD DICTIONARY.
Separate tables for 2nd through 7th possible words in the same
idiom are provided. The HIGH FREQUENCY WORD DICTIONARY for the
1st word idiom has a memory offset address ~IDIOM OFFSET, table
12) to the second idiom word in the second IDIOM DICTIONARY and
the second word has a memory offset address to the third idiom
word in the third IDIOM DICTIONARY. Each idiom word in an IDIOM
WORD DICTIONARY has a memory offset address to the next idiom
word. The words are arranged in -the order whereby the longest
expression appears first. The corresponding English meaning is
located directly with a table byte offset address associated with
each Russian idiom.
The L.S. COMPOUND DICTIONARY is created as a randomly
accessed file utilizing the program BDAM with a relative track
address and byte offset. Six programs are executed to create this
dictionary and update the MASTER STEM DICTIONARY with this
~L~8~4~29
- 49 -~ 20L55-424
lnEormation. The first four steps (L.S. expression selection and
high frequency word lookup, sort, main dictionary lookup and
sort), are executed similarly to an actual translation run wit'n
the purpose of gathering all L.S. control numbers and grammar
information together for each L.S. expression. The following step
builds a single L.S. compound record Eor the principal word of the
expression. The principal word is determined by examining the
part of speech for each word in the Russian expression. The order
for selection is:
(a) Finite verb
(b) Finite auxiliary
(c) Pure noun
(d) Proper noun
(e) Profession or title
(f) Abbreviation
(g) ~ound/adjective
(h) Pronoun adjective
(i) Pure adjective
(j) Adverb
High frequency words are eliminated from selection as
the principal woxd. If no principal word is determined by the
program, the expression is printed for analysis. These records
are then sorted by principal word and a Master Dictionary is
created. Each L.S. COMPOUND DICTIO~ARY record is accessed
randomly during translation by relative track address and byte
offset information associated with each principal word of the
Russian expression. The English meaning of each expression
L~
- 50 -~ 20155-~24
compound is located by a byte displacement address to a table of
English meanings included in the variable ]ength compound record.
Supplementary and principal word indication records are built and
information from them is updated in the MASTER STEM DICTIONARY.
Additional forms of the verb are updated in a second pass to
produce the final updated version of the MASTER STEM DICTIONARY.
The HIGH FREQUENCY and STEM DICTIO~ARIES are now recreated,
re-flecting the updated L.S. information and are now ready for
translation processing.
B Hexadecimal Printout Format
During translation, as the computer analyzes each
sentence, it attaches codes to the words to express their inter-
relationship. On an IBM 360/65 computer system, these codes are
expressed using the hexadecimal system. Whenever required, the
computer prepared analysis can be printed and a hexadecimal print-
out is obtained. Table 24 illustrates such a printout. To give a
general insight into the content of such a printout, some informa-
tion is given in the Eollowing:
1. The subject of the sentence (iOe., its sen-tence sequence
number) is listed at the beginning of each subsentence unit (SSU).
2. The sentence sequence number of the predicate is indica-
ted at the beginning of each subsentence unit (PRED).
3. Each word of the source language is numbered along the
left side of Table 24 in the sequence it appears in the sentence.
4. The two pairs of numbers immediately to the right of the
sentence sequence number refer to the part of speech (POS) and
basic part of speech (BPQ) of the word. 10/10 means that the word
4Z~3
- 51 -~ 20155-42~
is a pure noun; 20/20 is a pure adjective; 40/45 is a finite
auxiliary. The assigned part of speech codes are suitable for
machine translation purposes and have no necessary correlation to
usual grammarsO
5. The next word to the right is the word in the source
language (i.e. OBYCNYl). In the example given, the word is
Russian but transliterated from Cyrillic into the Latin alphabet.
6. Toward the middle of each entry is the translation of
the source language word in the target language (i.e. MN-CAN)~
Articles, prepositions, and auxiliaries are inserted, if necess-
ary, before these words depending on the internal analysis.
The 160 bytes of information after each word are ex-
pressed in hexadecimal. Each two digits represent a full byte of
information, while one of the pair represents half a byte of
information. In order to aid in the location of a particular
byte, there are numbers placed among the bytes to act as reference
points. These are three digit numbers followed by a dash. In the
example, 008- locates byte 8 for the word OBYCNYl, which means
that the next pair of digits, i.e. 20, are byte 8. So if, for
instance, one were searching for byte 59 for the word OBYC~Yl in
the example, one would scan the hexadecimal printout for a number
close to 59, in this case 056-, and count over to the third pair
of digits, i.e. to digits 01.
In some bytes, the number may be symbolic of a certain
condition, for instance, an 08 in byte 50 means that the word must
be the object of a preposition. The numbers are written in
hexadecimal, that is, an alphanumeric system with a base of 1~.
I
429
- 52 -~ 20155-424
The maximum amount that can be written into one byte is E'E' hexa-
decimal, i.e. 255 decimal.
7. Byte 008 is a reEerence number which aids in the quick
location of bytes.
8. TG-0 is the Topical Glossary subject field of the trans-
lated word.
9. The eight digit (four bytes) following TG- (i.e.
92000104 for OBYCNYl) contain inEormation about the syn-thesis of
the target word (e.g. articles to be inserted, plurali~ation,
etc.).
10. The end oE the line following TG- (i.e. ORDINARY for
OB~CNYl) is the word or words in the target language from which
the translation is obtained. An adjustment is made in the actual
translation for tense, etc., and, if the word is a verbal form,
the reflexive translation may also be listed here.
C. Example of Operation of S~STRA~ While Translating Between
Russian Source and English Target Languages
SYSTRAN translation capabilities can be demonstra-ted
through the use of different pairs of languages. The following
illustration uses Russian as the source language and English as
the target languageO A description is given of how the original
Russian text is received, how it is read in the compu-ter, and the
operations necessary to achieve the final translation.
The selection of the computer Eor machine translation
system is hased on its universality. Due to hardware limitations,
any large-scale translation sys-tem must be writ-ten in a language
closes-t to that of the computer. The Russian tex-t to be
L~ 3
- 53 -~ 20155-~24
translated is first typewritten on the IBM magnetic tape Selectric
typewriter and recorded in the MTST code on rnagnetic tape. The
information from the MTST tapes is converted and placed onto mag-
netic tapes which can be read directly by an IBM 360/65 (see FIG.
1). The principles of the applied logic within the translation
system could be put into operation on any 3rd generation computer,
but it should be reprogrammed in the closest computer language for
the particular hardware utilized.
The Russian text recorded in MTST code on tape is trans-
lated to IBM 360/65 coded format and recorded on magnetic -tape by
the Model 9209 converter, manufactured and sold by Litton Systems,
Inc. The converter is described in Technical Bulletin TB(S)
69/0001/OOC dated Jan. 30, 1970.
The Russian text to be used as an example is taken from
a Russian text appearing in Cyrillic characters in the journal
NAUCNOTEXNICRSKAIA INE`ORMATSIIA (Nov. 6, 1970) entitled "The
Evaluation of the Quality of Automatic Translation". By way of
example, the steps of translation are given for the fifth sentence
of the last paragraph on page 32 of the text.
FIG. 4 illustrates schematically what takes place in the
high speed core of -the computer at the time the fifth sentence is
being read in. For purposes of explanation, the Russian text in
MTST coded characters are schematically illustrated in the upper
left hand corner of FIG. 1 on magnetic tape 10a. The complete
Russian text is actually magnetically recorded on magnetic tape
10a and a conventional magnetic tape transport 10 used in the IBM
- 54 -~ 20155-~2~
360/65 computer system serially reads the text presenting the text
for storage in a core memory 12 which also forms a part of the IBM
360/65 computer system. The MTST program accomplishes this opera-
tion. The words of the sentence in core memory 12 are illustrated
schematically to the left one by one. A contimlation is expressed
by three dots and the period is the last word. At that time, the
core memory already contains three dictionaries read beforehand by
the LOADTXT program from disk file 14. The three dictionaries are
the HIGH FREQUENCY WORD DICTIONARY, the RUSSIAN IDIOM CORRESPOND-
ENCE DICTIONARY and the ENGLISH MEANI~G DICTIONARY. The E~GLISH
MEANING DICTIONARY contains the English language equivalent(s) for-the Russian idioms. All three dictionaries change if the source
and target languages change, but the same program, namely,
LOADTXT, reads them in and arranges them for the purposes of text
processing at the beginning of the translation. Usually during
translation, a whole text is read into the computer in one pass.
A single sentence was used for illustrative purposes only.
The HIGH FREQUENCY WORD DICTIONARY contains high fre-
quency words as well as first words of idioms. These words are
arranged in alphabetic sequence to make core binary search
possible.
The Russian IDIOM CORRESPONDENCE DICTIONARY contains
idiom tables arranged according to the second and following words
of an idiom. Each time a match has been achieved with a word
which may function as the first word of an idiom, possible second
words to that idiom are matched with following text words.
L4~
- 55 - 20155-424
The ENGLISH MEANING DICTIONARY contains the English
equivalents to the idioma-tic expressions. The program LOADTXT
scans the Russian source tex-t comparing each word for equality
with the HF WORD entries in the HIGH FREQUENCY WORD DICTIONARY
(see Table 12). When the first word of an idiom is found, the
second and subsequent words o-f idiomatic phrases in the second and
subsequent IDIOM DICTIONARIES are compared with subsequent words
in the Russian source text. Whenever a complete match has been
achieved between sequences of Russian source words and all words
for one complete idiomatic phrase in IDIOM DICTIONARIES of the
IDIOM CORRESPONDENCE DICTIONARY, the address offset with the last
word of the idiom is used to obtain the English equivalent of the
idiom is taken from the ENGLISH MEANING DICTIONARY and is attached
to the first word of the idiom. A typical selection of the HIGH
FREQUENCY WORD DICTIONARY is shown in Table 16. From the selected
sentence, the Russian word KOTORYE appears in the H.F. table. As
can be seen, most of the forms which can be derived from the
Russian stem KOTOR appear as high frequency words. This is due to
the fact that these words occur quite fxequently in Russian texts
introducing qualifying subordinate clauses. All of the words of a
text, in this case, of khe selected sentence, which were found in
the HIGH FREQUENCY WORD DICTIONARY are supplied with a so-called
"grammar offset 38".
During the translation phase/ the GRAMMAR DICTIONARY
(see FIG. 4) is kept in the high speed core memory 12 and contains
total grammar and target meaning inEormation for the high
L~~ 9
- 56 - ~0155-424
frequency wordsO The grammar offset determines how far such gram-
matical and target meaning ineormation is from a common reference
point (i.e. fro~ the beginning of the table) and in this sense can
be referred to as an address linkage.
First words of idioms are indicated in the HIGH FRE-
QUENCY WORD DICTIONARY by special codes in the field named IDIOM
OFFSET which is monitored by the LOADTXT program. Whenever the
LOADTXT program detects an idiom, the meaning of the idiom is
located and is attached to the first word. The LOADTXT program
puts text words for whic'n a match has been achieved ei-ther as an
idiom or as a high frequency word~ in a high frequency file on a
magnetic tape. All the words for which no match has been achiev-
ed are put in a low frequency file.
An idiom in the SYSTRAN System can serve syntactic pur-
poses. The two words "NAPRIMER", (NAPRIMER and the following
comma) have been entered as an idiom with the purpose to eliminate
the comma from considera-tions during the syntactic analysis phase,
thus assuring the correct location of subject and predicate. It
should be noted here that in spite of the fact that a word parti-
cipates in an idiom, if it is not a member of a high frequencyword table, it still undergoes a regular dictionary lookup. As a
result, it is written into the so-called "low frequency" file.
Although T. and P. together with the conjunction "I" form an
idiom, they still undergo their individual dictionary lookup
later, due to the fact that they are not members of the high fre-
quency table.
A typical page of the IDIOM CORRESPONDENCE DICTIONARY is
~14-~
~ 57 -~ 20155-42~
ilLustrated in Table ]7. The idiom I.T.P. occurs as the ninth
idiom. The listing of this page illustrates how the idioms are
being kept for reference and update purposes. At the beginning of
each translation, a program places the words of all idioms into
tables. The first word of every idiom is merged with the HIGH
FREQUENCY WORD DICTIONARY, consecutive words are arranged in sepa-
rate tables (i.e. 2nd, 3rd...7th IDIOM CORRESPONDENCE DICTIONA-
RIES) and the meanings are placed in-to the MEANING FILE.
FIG. 5 graphically illustrates the sequence of operation
involved in the main dictionary lookup and the type of procedures
that take place in the high speed core memory at that time. As
mentioned before, all the words which are not found in the HIG~
FREQUENCY WORD DICTIONARY are put into a so-called "low frequency"
file which was recorded on magnetic tapes. Subsequently, these
words are alphabetically sorted and attached with a serial number
code identi-fying their order in the original Russian source text.
The words are brought in now in alphabetic sequence into the high
speed core memory 12 to undergo the main dictionary lookup.
During main dictionary lookup, the STEM LOOKUP DICTIO~A-
RY is used. The dictionary is in the same alphabetic sequencethat the text words in -the LOW FREQUENCY FILE were sorted into.
The dictionary encompasses all the words in the source language
and associated with each word grammar codes and meanings in sever-
al subject fields are attached. In the case of those languages
which are highly in1ected, like Russian, the dictionary contains
mostly s-tems and hence the name STEM LOOKUP DICTIONARY.
During the dictionary lookup, a stem and ending analysis
- 58 ~ 20155~2~
takes place and on -the basis of such an analysls, additional gram-
ma-tical information is obtained. Referring to FIG. 5, the first
word of the sentence being used as the illustration appears in
alphabetic sequence is OBYCNYl.
The illustration shows how -this word is matched with the
dictionary entry. A portion of the dictionary is presented with
the dictionary codes presently available. The dictionary con-tains
OBYCN indicating that this is an adjective and has declensional
pattern 197, and also the code "PS" in field L.S. shown in Table 4
indicates that it can be a principal word and a supplementary word
of a compound. The word in question has a general meaning
"usual". General meaning is given by the fact that after PS there
is a zero (O) which means "general glossary"~ A one (l) means
"physics glossary", and a three (3) means "computer glossary".
The meanings are "usual", "usual" and ordinary". Also illustrated
here is another entry from the dictionary which, immediately
following the word OBCYN0, is in the adverbial form with the
meaning "usually".
During dictionary lookupl the program MDL first attempts
to match the full word with a dictionary entry. If unsuccessful,
then one letter is dropped and comparison is reattempted. If
unsuccessful, then a second letter is dropped, and at that point,
a match is obtained with OBYCN.
At this juncture, on -the basis of the morphological code
197, the routine SYSNOUN within MDL compares the chopped off end-
ings with all allowable endings which may follow this stem to
decide a certain ~orm. In this case, the ending is Yl, which
~L~a ~ ~9
- 59 -~ 20155-424
means that the stem form f~mctions here as nominative singular
masculine. The ending A4 would have been nominative singular
feminine. OE would have been nominative neuter singular. OGO
would have been genitive masculine or neuter singular, and also
accusative if it refers to an animate being, etc. In addition to
obtaining the grammatical codes -from the dictionary during
dictionary lookup, the operaation at-taches all other codes from
the dictionary (Preposition, Case, Translation, etc~) as well as
meanings with synthesis code to the word.
The next text word would be PEREVOD. The illustration
presents all the codes and meanings that are attached to PEREVOD
in the dictionary and also signifies that PEREVOD has been entered
with paradigmatic set number 044. This number indicates that the
possible endings that can be attached to this word are A, U, OM,
and E in singular, and Y, OV, AM, Y, AMI and AX in plural. After
the paradigma-tic code number 044, a Russian word appears which
indicates an example of the type of declension that may take place
with 04~.
Note that NOV (appearing at mid-page) carries code
number 197, the same code number which is attached to OBYCN. This
identical numbering means that both words have the same declension
pattern. Such a coding system facilitates the work of the native
Russians who are continually adding new words -to the low frequency
dictionary.
During MAIN DICTIONARY LOOKUP, all the words receive
grammatical and target meaning informa-tion (with synthesis codes)
Eor all those subject fields in which the words may function with
~ ,od ~ 4~9
- 60 ~- 20155-~24
different meanings.
~ fter such a lookup, a sort program sorts the words
again into original text sequence using the attached serial number
and stores them on tape or disk in a sorted low frequency file.
The sorted words are then brought back into the core memory 12 in
two files. One is the HIGH FREQUENCY FILE and the other is the
RESOXTED LOW FREQUENCY FILE.
The computer program GETSE~TN now merges the words from
the two files and for each sentence in the computer memory a so-
called analysis area is set up where the sentence can be syntac-
tically anal~zed resulting in a computer intermediate language
which expresses structure and semantic functions o-E all the words
in the sentence and their syntactic interconnections.
FIG. 6 illustrates schematically that the program
LSLOOKUP (LSLU) determines the first two words of the sentence to
be a Limited Semantic (L.S.) compound, and the meaning "human
translation" was attached instead of "usual" or "ordinary transla-
tion".
On the top of the Eigure, the first three words of the
sentence appear. At this time, the program LSLU reads into the
core memory 12 from disk 14 the portions of the I.IMITED SEMANTICS
DICTIONARY which are relevant to the principal word of this
compound, which is PEREVOD. Every expression for which the word
PEREVOD (translation "transEer") functions as a principal word i8
being read into -the high speed core memory. A list of entries
appears on the bottom left and right sides of the page. The leEt
group contains those LIMITED SEMANTICS DICTIONARY entries
':
4~9
- 61 - 20L5~-~24
where the word PEREVOD appears a-t the beginniny, and the right
side contains a few entries where the word PEREVOD appears as a
second word preceded by an adjective. The particular matching
compound is encircled. The word OBYCN carries an indication (L.S.
II) that it may participate in a LI~ITED SEMANTICS compound. The
LIMITED SEMANTICS record of the word PEREVOD is arranged in a way
that first all the compounds are listed where this principal word
is the first word then all those where it is -the second, third,
Eourth, and so on. The compound shown here has been located among
those expressions where the word PEREVOD functions as the second
word of a compound and there is no third member. The reflexive
indicator in the second line applies in only those instances when
the principal word is a verb, so it can be disregarded in this
case. In the comparison area in the high speed core memory
(shown) the compounds were looked up belonging to PEREVOD where
PEREVOD is the second word of a compound. The LIMITED SEMA~TICS
numbers L.S. ~A23 and L.S. #B39 are attached to the words OBYCN
and PEREVOD by the programs CLSl, CLS2 AND CLS3 during the crea
tion of the L.S. DICTIONARY FILE. The program LSLU detects the
LIMITED SEMANTICS words and compares the L.S. numbers against the
LIMITED SEMANTICS entries for PEREVOD. Finding a ma-tch between
the numbers A23 and B39 attached to PEREVOD and between these same
numbers as they occur after dictionary lookup attached ~o the
words in the sentence, this compound is transla-ted by LSLU as
"human translation".
The actual L.S. numbers are sequentially assigned each
time a new L.S. compound dictionar~ is generated. They are unique
~8~9
- 62 - 20155-424
numbers and each word can have only one such number. The numbers
are arranged in exactly the same sequence as -the words appear in
the compounds. A program organiæes different groups according to
the position of the principal word. Such oryanization is taken
into account during the L.S. lookup. As far as this sentence is
concerned, only the first two words have been located as an L.S.
compound, and in the hexadecimal printout which illustrates the
generated computer intermediate language there is a corresponding
mark indicating that these words form a compound.
Table 18 illustrates a typical page from the listings of
LIMITED SEMA~TICS compounds. The listings correspond to the
arrangement where these compounds are kept on magnetic tapes for
update purposes. In order to use the listings during translation,
a special program arranges them on disks, assigns each participat-
ing word an ~.S. number, locates the principal word and sets up an
actual direct sub-system of compounds in the source language which
is used by the translation systemO
Table 24 is a reproduction of a computer printout which
illustrates the analysis area in the computer core memory at the
time the sentence is analyzed. On the top of the page, the param-
eter information appears as an exact duplication of the instruc-
tions that the system received before being called upon to carry
out the translation. It contains those parameters under which the
translation should be carried out. Its appearance is only for
reference so that when desired, the analyst should be able to
locate the conditions under which the System carried out the
g
- 63 20155-42~
translation and instructions the System used to carry out the
translation. The parameter information is explained later.
The STRPASS proyrams generate syntactic codes to express
the interconnections between words in a sentence. The following
describes the most important of the codes generated by STRPASSES
for the first eight words of the example Russian sen-tence shown in
FIG. 4.
Byte 111 of the first word contains the sequence number
i.e. 02 of the subject of the first sentence unit and byte 108
contains similar information i.e. 03 of the predicate for the
first sentence unit ~main clause). These two informations also
appear printed separately on the top left side of the Table 24.
Byte 16 of the first word contains the sentence sequence
number of the second word (02). This information in this byte ex-
presses the fact that the first word belongs to the second word in
an agreement relationship, and the second word is the principal
word of the syntactic unit. It can also be said that the first
word "points" or is linked to the second word in byte 16.
Byte 26 of the second word points to the first word of
the source te~t indicating that the first word of this agreement
relationship is the first word of the sentence.
Byte 21 of third word, MOJET, points to word 04. The
21-31 relationship expresses an infinitive government structure,
i.e., the word which governs the infinitive contains the sentence
sequence number of the infinitive (03) in byte 21, while the
infinite contains the sentence sequence number of its governor in
byte 31.
~3~ 9
- 64 -~ 20155-~24
Byte 18 of word 04, OBLADAT6, points to the word 05,
MASSOl, expressing that the latter is the direct object of
OBLADAT6. Byte 28 of MASSOl points back to word 04, OBLADAT6, ex-
pressing the direct object dependency relationship.
Byte 20 of MASSOl points to word 06, ~EDOSTATKOV, and
byte 30 of NEDOSTATKOV points back to word 05, MASSO1. These
codes express adnominal genitive relationship.
The comma, word 07, has 'FF' in b~te 51, expressing that
it is making a sentence cut.
The first seven words in the sentence contain 'Fl' in
byte 140. This 'El' means that they belong to a main clause.
Starting with word 08, the Fl changes to 01, a signalling that a
qualifying clause begins.
The qualifying clause initiator KOTORYE contains 06 in
byte 52, which means that it refers to the sixth word in the sen-
tence, i.e, to the word ~EDOSTATKOV~ ~EDOSTATKOV contains 08 in
byte 52, pointing to KOTORYE.
Word OF is an opening parenthesis ~part of speech DO).
All the words which belong to the sentence unit sur-
rounded by parentheses are marked with '50' in byte 148.
The SYS~'RA~ Dictionaries contain both slashed and single
meanings. Sometimes the person who reads the translation prefers
two meanings separated by slashes, in the case of multiple mean-
ings. Others prefer the closest possible meaning. The parameter
slash indicates to the System that slashed entries should be
printed. In the absence of this parameter, each time a slashed
~'L4Z9
- 65 -~ 20155-~2~
entry occurs in the target language, the meaning which most close-
ly re1ects the real meaning oE the source language is printed.
The parameter entry W indicates that during the transla-
tion process, the console typewriter should indicate each time 50
sentences have been translated.
The asterisks indicate the facility to insert additional
programs for special printouts, diagnostics, etc. G stands for
GETSENTN (get sentence). The syntactic passes 0-4 are denoted by
their respective numbers 0, 1, 2, 3, 4. L is the L.S. program. X
means Lexical Routines. P represents prepositions, ~-rearrange-
ment, E English synthesis, or the synthesis into whatever target
language it takes place, D-diagnostics, P-print, and L-Syntactic
level program which is only at the end because it was added at a
later stage to the system.
Next to the parameter information is the date, when the
translation was carried out followed by an indication as to which
-topical glossary had preference during translation. Should no
meaning be available in the indicated glossaries, general meanings
are used. The sentence sequence number in -the translation is next
followed by the page number indexing each particular sentence. On
the following line, SSU means the subsentence unit. The sub-
sentence units are established during various levels in the analy-
sis phase. Each subsentence unit should have a predicate and a
subject if the predicate is not impersonal. The sentence sequence
number of the subject and predicate is printed next to the SSU
indication. Each time a new subsentence unit begins, there is
2~
- 66 -- 20]55-~24
a new SSU print.
Preceding each source language word is a sentence se-
quence number. On this same line appear the primary and secondary
parts of speed followed by the source language word as it appeared
in the input.
Primary parts of speech (POS) broadly reflect the parts
of speech function of the word while the secondary POS further
specifies such function. Primary POS's have been selected to en-
able automatic branching and consequently immediate entering of
the routines controlled by the parts of speech.
Next is a target language meaning and an indication
whether the particular word under consideration functioned as a
member of a compound or a member of an idiom. Also between the
source language print and the meaning, cer-tain symbolic letters
may appear indicating the lexical subroutine which was called upon
during the translation of this word. Such lexical routines are
arranged on the basis of their symbolic notation in a binary table
and each time a particular word occurs which carries an indication
that its translation may require a lexical routine a binary search
is carried out among the lexical routines to establish which
routine should go into effect.
The 160 bytes appearing after each word which is analyz-
ed for translation purposes is a unique SYSTRAN feature. These
bytes contain compressed dictionary information, addresses to
additional information, and, as a result of the analysis, coded
information which reflects the syntactic and semantic interconnec-
tions of all words in the sentence. The information placed in
4~
- 67 -~ 20L55~24
these bytes by sequences of programs can also be regarded as a
computer intermediate language which analyzed the sentence to such
degree that automatic translation of the sentence can be carried
out.
The condensed dictionary information, as well as the
variable length in~ormation which is cross-referenced from the
bytes area, is attached to the individual words either as a result
of the dictionary looXup or, if the entry was a hlgh frequency
word, the displacement was used to retrieve and attach the in-
formation from the high frequency grammar and meaning table at thetime when the analysis area was set up for the particular
sentence.
Table l9 gives a resume of all the in~ormation possible
in the 160 bytes of the analysis area shown in Appendix A. Tables
20 and 21 show the codes for the primary and secondary parts of
speech.
It should be noted here that some modifications take
place whenever the part of speech approach is applied to other
source languages, although the basic semantic characteristics of
the speech structure is used consistently. For example, the
Russian qualifying clause initiator KOTORYE carries a particular
part of speech code-7C. The same 7C is being applied in every
source language which has a corresponding clause initiator. The
same approach is used for other clause initiators, for certain
types of adverbs, etc.
The contents of the 160 bytes is exhaustive. Additional
information, available on the basis of various addresses in the
byte fields, is printed after the 160th byte. Such information
IL4~9
68 -~ 20l55-424
is for example, the C/P (case preposition) information which is
case translation applicable in the case of those languages which
are highly inflected and the words function in different cases.
Such cases are translated into the target language by different
prepositions which are indicated in the C/P field. In addition,
particular source language prepositions must be translated in
different ways depending upon what types of codes are attached to
the individual words for the translation of prepositions. Word 02
PEREVOD carries the preposition code 14 (in the English
Preposition Table, Table 15) for the Russian preposition PRI,
meaning that should this word be governed by the Russian preposi-
tion PRI, then the translation should be DURI~G. The same Russian
word may also strongly govern the Russian preposition NA (22 on
the English Preposition Table) indicating that if PEREVOD governs
N~ and NA governs in accusative, the translation should be INTO.
The last line contains target meaning information and
synthesis codes.
The first word in the sentence, the adjective OBYCNYl,
for example, has 90 in the first byte. This indication is made up
of the target language part of speech indication (DPQ), which is
80 for adjectives. Added to this is 10, which indicates that AN
is used to modify this adjective, since it begins with a vowel.
Byte 2 is not for adjectives at the present time. Byte 3 indi-
cates which word is to be synthesized. In this case, since there
is only one word in the English meaning, the number 1 has been
placed there. Byte 4 contains the comparative and superlative
l42~3
- 69 - 20155-~24
codes for the adjective. In this case, one can say "more
ordinary" or "most ordinary" rather than adding the endinys "er"
and "est" as, for instance, one would for "black".
The noun PEREVOD, the second word in Byte 1, has ~0
indicating the DPQ for nouns. 10 was not added here since the
noun does not begin with a vowel. IE it had begun with a vowel, a
50 would have been idicated. Byte 2 holds the code for articles.
Byte 3 contains the sequence number of the word to be synthesized.
In this case, the second word changes. The 0~ in Byte 4 indicates
that the plural of the noun is made by adding "s".
The verb OBLADAT6 (fourth word3 has CO in Byte 1, which,
again is the DPQ oE the word. 10 also would have been added if
the verb in the English has a vowel beginning. This is used for
the participles which are generated from the verb and which may
require articles. Also indicated in this byte is the sequence
number of the word to be synthesized. It may be left out, as
here, if only one word appears in the English meaning. Byte 2 has
a code if there is a different meaning in the English for the
reflexive form of the verb. Byte 3 contains the code reflecting
the choice of translation in English for the verb if it appears in
the reflexive in Russian. Byte ~ indicates the conjugation
pattern of the verb.
The computer prepared intermediate language, expressed
symbolically in the bytes area, makes it possible for a synthesis
program to carry out the actual translation. All the computer
generated codes as well as targe-t language requirements are taken
into consideration during the final translation process. Words
_ 70 -~ 20155--4~4
are placed into the required form, phasss are built up, and the
word order is determined based on the requirements of the target
language. If the target language has articles (i.e English) defi-
nite and inde-finite articles are placed before noun phrases when-
ever required. The multiple meaning problems are handled on four
levels: idioms, L.S. compounds, lexical routines, and generalized
routines to resolve semantic problems. These routines consider
the influence of semantic categories within defined syntactic
relationships. To words with multiple meanings, generalized
routines are attached. They should be interrogated in a sequence
as they follow each other.
MEMORY SWITCHES
STRPASS 1 is the most important syntactic pass through
the sentence. The program carries out its operation right to left
and "remembers" the various conditions with the help of so-called
memory switches. These switches are set to remember the types of
words that have been encountered previously, and to indicate to
the program the type of decision to be made at individual words.
Routines are initiated by the parts of speech. The remembering is
carried out on the basis of the types of words encountered.
Certain words "clear" all these switches, i.e., they signify
certain breaks in the sentence in regard to syntactic interconnec-
tions.
Table 25 illustrates the sequence with which the
switches are set for this analysis field illustrated in Table 24
for the example Russian sentence. Each word in the example is
indicated by its sentence sequence number shown to the left in
Table 24. After the sentence sequence number all those switches
4~3
- 71 ~ 20155-~24
which were "on" at the time the word was analyzed by the program
of pass 1, are printed with their symbolic names.
At the time words lD and lC are encountered, switches
are not yet set.
When lB is analyzed, the NSW (noun switch) is set by lC.
~his is how "P" is remembered.
At word lA, the reserve noun switch (R~S) is set with
word lC.
At word 19, only the ILI switch is se-t. This switch was
set by the Russian conjunction I at the same time the reserve noun
switch was cleared.
At word 18, it can be seen that the noun switch was set
with word 19, and that the ILI switch is still on.
At the time word 17 is reached, the noun switch (~SW)
and the left agreement unloading switch (LAG) are set, indicating
that an agreement relationship started, i.e., word 18 modifies
word 19. (After it is established that the preposition (word 17)
governs the noun (word 19), both ~SW and LAG are cleared). Word
16 sets the ~SW.
The next noun, word 15, causes the noun switch set by
word 16, to become a reserve noun switch, while the noun switch is
then set by word 15.
Word 14 will be recognized as modifying word 15, and
conse~uently the LAG switch will be set.
When a new noun (word 13) is encountered, the previous
noun switch will become a reserve noun switch, and the le~t agree-
ment unloading switch (LAG) will become a reserve left agreement
~LX~3~
72 -~ 20~55-424
unloading swi-tch (RLA).
At word 11, the RNS will be set by word 13 since a new
noun (word ]2~ has been encountered. This noun will not set a new
switch since i-t is preceded by a comma, which prevents immediate
syntactic relationships to the left. The comma has cleared the
reserve noun and reserve left agreement unloading switches, and
set the comma switch (COM).
The beginning parenthesis, word OF, part of speech DO
clears all the switches.
New switches are set with words OE and OD. (~SW, LAG).
After finding that word OC governs OE, and that word OD is in
agreement with OE, these switches are cleared.
Word OB, being an infinitive, sets the infinitive (INF0
and verb form (VER) switches. After it is established that OA
governs the infinitive, only the verb form switch remains.
Due to its particular function, the word KOTORYE sets
the NSW. The comma befvre KOTORYE clears all the switches, and
when the word NEDOSTATKOV (06) is encountered, only the comma
switch is set. Word 06 sets the noun switch. This switch was
changed to the reserve noun switch when word 05 MASSOl, was
encountered.
After it is established that word 04 governs the noun
switch, such switch is cleared. Word 04 sets the INF switch,
which is in turn cleared after it has been established that word
03 governs 04. At that point, only the verb switch and comma
switch are set.
L4~
~ 73 -~ 20155-424
Word 02 sets the noun switch, and word 01 the LAG
switch. These switches are still on when the beginning of the
sentence, i.e., a first zero word (dummy word) is encountered. It
should be noted that only by having a word area (160 bytes) clear-
ed and considered before every sentence can it be assured that
indications about the status of the first word can be given, and
that looping operations can begin with the first word.
The final English target language translation of the
Russian source language text shown in FIG. 4 is shown in Table
23.
In addition to the uniqueness of the translation ap-
proach, special MACR0 instructions were developed to facilitate a
more direct communication with the computer. The advantage of
these special instructions, expressly developed for machine trans-
lation purposes over other computer languages is, that they
consider the direct requirements of natural language translation.
The MACRO instructions are converted using a special ~ACRO assem-
bly and this assembly at the same time eliminates most of the
coding errors. In the following, the MACRO instructions inherent
to the SYSTRAN System are listed with a brief description of their
function.
CMPWC-Compare beginning characters of the source language and
branch under certain conditions.
CMPWD-Compare source word and branch if certain conditions
are met~
CMP~E-Compare the end characters of the source language and
branch under certain conditions.
2~
- 74 -~ 20155-~2~
CMPWP-Compare a word pointer (address indication) with
another pointer in the sentence.
DICTM-Put in a special meaning or any word overruling any
other dictionary meaning.
GOTO- Branch to another location.
IFOFF-Test a switch and branch if off.
IFON- Test a switch and branch if on.
MVEHM-Move the analysis area of a h omograph word to replace
the analysis area of a word in the original sentence
sequence.
SCANL/SCANR-Scan left or right in the sentence, within
sentence or subsentence boundaries looking for certain
yrammar codes, words or any other information pertinent
to the translation program. The scan also allows the
jumping of words, phrases or clauses.
SETB~-Set a bit on (Indicate certain information in the most
economic way).
SETBE'-Turn off the information set on.
SETBM-Merge the information in 16 bits (2 bytes).
SETCH-Set a character equal to the value of another
character.
SETMA-Set a meaning to appear after the main meaning of a
word.
SETMB-Set a meaning to appear before the main meaning of a
word.
SETM~-Set the main meaning of a word and mark it translated.
SETMT-Make the source word equal to the target meaning.
4~
- 75 - 20155-~2
SETTR-Mark a word translated.
SETWI-Set indicator equal to sentence sequence number of a
word poin-ted to by a word pointer.
SETWP-Set a word pointer to a specified word or dictionary
meaning entry.
SMSG- Provide a snap dump of the analysis area preceded by an
identifying message.
SWOFF-Set a memory switch off.
SWO~- Set a memory switch on.
TESTB-Test a set of bits relative to another set of bits and
branch if the condition is satisfied.
TESTX-Test contents of a series of bits or test character
relative to another test character.
The modularity of the translation system enables the
inclusion of more MACRO instructions as the necessity during the
processing of natural languages arises.
- - 76 - ~0.~55-~2
TABLlE 1
LlSr OF COM~UTER PJ~ M5 USED 1~ SYSrR~tl
DESCR.lP~lON
_~NSI_A~lO~J PRO~I~MS
~o~ S~
~IDL M~ ~ loo~ bw 61 H
~1
P.U~gO ~MO w~ 8 ~)r~ P~ ~4
SYSNOU? SYS~ ~e w~d e:~B 33
SYSVE~ SY~ ~ ~ ~ ~ 36
INITC~LL ~ æ9~ ~ ~
~ 10 M
ST~P~SSO Stn~wd ~y~ p~ O I I
SrRPA~;SI Str~ ~y~ p~4 1 12-1~ 0
S~P~S~;2 S9S~ ~J~ f~f~ 2 ~6 P
STR~ASS3 Sw~ aæ~ p~ 3 1~ Q
LSLOO~ LS. w Dpo~d u~J~s# S
I,E~CICAL Mlul~ ~8 s~ ~a ~ 2~ T
b~ of ~1
SEM~N~C Ga~81i~ ID~8ip2e ~ 21
P2E~ 9 u
~UU ~ W
TLSY~d Tu~ y~ 2~ 33 X
PP~I~ Di~o~p~pn~o 23 `~
DEDI~ h )J
DU~DT S~a die~ up~tfe A
.~VS~
HFC Hi~ ~ua2q~ ~ c~ 11
DI~AD M~i~ dis~ b~d KIC
(DISI~LO~)~
IEDr~ ry ~h
IUPDT IdiD~JI~ pd~ D
CLSI L.S. p~ ~ fo~ hi~ 'roq~cy
WOf~
CLS2 LS. ~3 <~Qa~ l~kup ~OF bw
;C154 L.S. di~iol9a~ ~u~a EE
r~UPDl-LS UpJ~le LS. i~lfon~io l i~ ~e~ FF:
d~
~3~Z~
- 77 20155-42
TABLE l~ondnuod
DIESC~II~lON
TIR.~NSLATION Pl-OOR~MS
~ 3. No. A~p~du
DPIU?~ P~l ~ d~
~P~T P~ ~ ~ ~ M~
Dt5PL~Y AA
l~aCAL CC
IlOUTtN~
TAE~LE 2-A
A~~ Al~L ~L V~
~
2 P~ I ~ I N Y T 7 Y
3 IPI~ ~ ~ I Y 7 1' 1`
Pi~ I N N 1~ 1
li tll I Y 16 T T
7 1~ 1~ Nl T 10 T
~ ~ ~ Y 10 ~ ~ I
9 PA N N N N T
I l I'A N Y N 11 T T
12 'tA Y N 1
7 Y
1~ ~A N N ~ Y T 3 4
'~1 F' N Y Y ~ 'r 1' 1
U ~
TA~ÇlLE~ 2-B
~0. ~ ~ILL Ao~ V~W l~
1;11. I N Y T 1~ Y I Y
6 PR 1~ lo T ~ y
~ p~, r N 2~ T ~ Y
12 A ~ Y N r 11 T I Y
~ ~ r~ N
Nue
U ~
z9
~ 78`- 20155-424
u w~ . ~A
~ ;~
PR ¦ I I Y 12 T T
L~ 2~ondnuod
A~ ~L A-~L J~I~L Verbd
~C~C==~
Iql I Y 13 T T
7 ~IIL 11' N 'r 19 T 1
PR P Y 10 T T13 . d
5'~ 2 1 ~ T 1~ T
PA 2 I Y 1- T T
Il p~ N N r ~ T 4
la PA N Y 5. T T
11 P.~ Y N r It T1~ 1
16 I'A Y Y 31 T T13
1~ N 13 4
7 Y1~ 6
r~
U
T~LE W~
~=~
/~L~. A~ A~ILV8bEI
~ I I t N T la T ~
2 ~ 8 I t Y 1~ T T 6
4 Pl~ I 2 I Y 1~ T T
Pll I N T ~ T
7 PIL P - Nl N 11'tO T 13
3 I'll 2' Y N10 S T 1 4
~4 p,~ ~ y 11 ~r ~ 15 6
I~ ~ IJ
16 ~ 7'J 1~ 6
~ .
0~ J
g
-79, 20155-424
HIGH FREQUENCY WORO AND GR~M~
TAEILE 3 IDIOM COI~RESPO~DENOE
MASTER DlCllONA~ES LIMm~ S~CS
HIGH[ I~QUENCY WORD ~ND ~;RAM~
MASIl~ I~DIOM/LS EXP~ION IDIOM CORRESPONDENOE
TR~NSL.AT~ON DI~IONAIUE~;
S~EM LOOICUP AND G~M1
TJUaLE!
_..
~\ ~
ST~
~Lo~ ~S~d~ ~
`` ~2~3~4zg
- 80 ~ 20155-a~2'1
TABLE 5
~ARl- OF SPEE~ C.ODES
50U~CE-
~ENDER A?~D NU
~--
--PAI~T-O~
--D~2 AN~ b~ ODES
0~_ ~_
tMD S~VE~ s (IF SOURCE~-RMD)¦
m I~A3~DIO~A SFI' CODIE
SAi~E ~S FULL FOR~ STEMS
.
~Trrr~
! J ~ ~ I' ~
R~ PR~P.
~n~
D1~5V.MIN~
INmA~O~ ~UI~
~nplW~ ~QV~E~rr3
--M~SI: I~E?n-S
--C~SE DE~SI~EA3
~I?.~ECnV it~ll~AnON AV,~ I E
~ I
VAaL~ GTH ll~NS. Cl~DES
V~ L ~n~s
_
- ~X~142g
~ 81` ~ 20155-~2a~
T~!3LE 8
TAII~GET I~NaUAOe
~IES
/ ~ ~ ~ ~ J ~ ~ ~ ~ ~ ~ ~ ~
--TAROEI' ~EAN~Na ~JO~
--l`~CIE~ ~ffleSlS CODES
-AD~L SU~.
--M~a D~ NUP S~EI~
N~L ~ULS. ~S
PlC.~a ~L06SAIIY ~De
_ ~ _
T~BL3E 9
rr~ ` ~
DDlL ~NT~
-VERII SrEI~I
~ o~ o~ v~ m~
--NUM. OF VEJU ST~ E~U~S
~AlaLE 10
~ \
\
\
~,~
I.E~Ol' l OF T~G~'T
MI~NI~G
29
82~- 20155-a~24
TABLE ll
.T I AD~ CODE rDlS~
TAEILE 12 ~ TAEILE 12~D~inued
_~ ___ ~ _I _~V ~UDUI. GRAbl~
WORf~ Of~ O~SET J~ iVOiUD~ e ~ ~ _EN'T'~U~S, I
IDI~I ~N~Dæ~ DlC~ti~_
- - - - ~ - - - - - - ~
O~Eg ~ S~N ~e5 L _ ~ ~. ENm
~,V~14~ '
- g3 - 20155-424
TA13LE 14__
~r~
. ~ ~ ~i ~ ~ ~ ~'
I A~ ?~. ~ \
I ~u ~ \
L~T~O~
L~A~o
u~
;'~ 0~ \ \
L ~
~ , \
-~a. ~UL'r. ~ ,~ \
~C ~L OL~ARlr ~W
111~8 O~F~Fr TO T~aO~!T ~N~O ,~
~ ~ ~ ~' ~
I
-~~rffO
O~T
,,_~ e ~ts
--P.E.~ ~.
~os~ P L., ~D~t~
--~IOE* S)~ OROU~ E~S
4~9
- ~4 ` 20155-D~2a~
L~g o~ ~h P~t~t
~9 No ;1~1hb ~doa 4~ DOWN
lo te b~od ~-ah~ ~7 PlEXr TO
01 A130UI U OPPOSrrE
02 ACCOitDlNO TO ~ ~ESIDE
09 AF~ ~ E31DE5
0~ .~OAINSl' ~1 ~IROUGH
0~ ALONC~ 12 PE.II
06 AS S3 AP.OUND
aJ A1' 5~11 AWAY FP.OM
03 A~l'THE PS)I~ CP ~5 NEJ~R
0~ a~:AUSE OF ~ DUe TO
1~ 9~E ~'7 01~ Ul~
~a ~ usl~
13 I~Y 60 ON ~IE IIAS15 OF
l ON~
1~ 5 2C*I~ ~ IN ~9S Ols
111 F~O~ ~E~IIND U AS A I~ESULT 012
19 IN ~S ~E Ol~
20 IP FltO~T OF ~7 i~RlORTO
al IPan~ EO~ ~ ~v~n RE~CHEI~
2~ 0
2~
2~ ON
n o~
30 TOWA~D
31 UN~ER
32 1~11.
~9 W~l~
wm~rr
3~ A¢:11106S
3~ ~E~W
8EI~EE~
41 ~MO~3
Sl~
U~O~
AS FAIII AS
- 85 ~ 20155-a~24
O~o~ ~ 0~
,,, g., ~,~ f Sj~ J~ ~i 3 X :- ~
3 o~c~oo o o oc~ oo~
o~ oo o o o~ ooo
~ o o g o o o o o o o ~ g
P ooooo o o oo o~o
u o o $ o o o o c~ o o o
o o o o o C~ o o o o
~ o ~ o ,, ~ o
u~ I,o Ifl
.
.
o o o o ~ o o
oc- oc~ oo oo C-O
o o o o C~ o o ~ o o
U o C>OOOOOC~ C700 g
o oOcD~000C~ 0 00
o ~ 06~0~0~0000 oo
oooc~oooo~o oo
O ' OS~O~OG~OOOOO oe
~ ~ g C~ o g o o
Z ~ o oo~ooooc~c~o oo
c~ o ~ ~` ~ ~~ $ ~ ~
P ~ c ~coa_oooo oo
2~ .
P
~2
b~ ~3 ~
.,
., ~ ~ o
Q. ~ Z 2 ~: æ
3~ I ~
x~ ~ o o ~ o
_ fq o oa c 3~ o o c~ ~ o
o o ~ ~ ~ g ~ ~ . o
~J O O ~ O ~ ~ b~
O
u, a~ 2 Z Z ~
~3 o o ~
~ C~ o ~ o ~ i~ I o ~ ~ I
O C~ ~ ~ ~ ~ ~ ~ b~ O
~ ~ o~l o~ OU o
o o C~ V o o
> o C~ o o o
~ ..
O ~ O
;~ W o o o
4'~9
- 86' - 20155-~24
~ -~ S ~ ~ ~ S ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
ooooo oo oo o oo oo ~o
o o o o o o o o o o o o Z ~ e
cq ~ ~ ~0 U~ y 5;~ 20
1~ ~ S O ¢ O O S
o o o o o o o ~a ~ a V c~ ~
OO OO O~ OO OO oOO 00 0o O~ ~
I o ~ O o O O O O O O o o O ~ O O O o o o ~,~ O O O O O O
O I C ~ ~ , O ~ ~ 0 0 o~ O ~, 0,, 0 _~ 0_, o o o
a o _~ _ _ _~ _ O O O _
A~ O O O O O O O O O O
o z ¢ 8o o o o o o o o o o
_ O I~ U1~ L1.3 l-l U ~ U DJ U
. w ¦~ oo o o o ~ o i~
2 ~ I ~ ` o ~ ~ " z ~ z æ
t:~ ~ Id1~ ~1 2 111 ~ b~ d 2
O Z OZ 0 C~ ~ ~ 0 0 5~ O ~ OZ O
UO ~ ~ oj~ C, o O O
O b~o ~ r W ~ ~ ~ r u~
o ~ o ~ o ~ o ~ ~~ o o3 o ~/ o ~J o ~ o ~ o ~ o
O O O O o o o o o o o x
~ ~ O
W t3 S ~ ~ 2 W r :~: x _ ~ ~ ~ o o ~ a ~
& ~ ¢O/1O 0 ~ ~ O ~O ~ O Y
X ~ X ~ X X ~ ~c~c X Y ~ ~ ~----~ ~ >~--~--
4~1
- 87~ ~ 20155-42
ZU ~ ~
111 ~ b
P ~ ~ 200~ P ~ 0 0
s = s ~ O ~ 8 ~ n y ~ ~ ~ ~ ~ s ~
z ~c z ~ o z ~ æ j~ ~ ~; o ~ $ ~ O
OooooOOooooooOOO ooooooo
_ I P ooooooC~ooooo~ooo~oooa~ooo~ooooc~oooooo~ooooo
--¦ 8 3 G ~ ~ C _ -- ~ c 5 a o ~
--C~VC~OOOOOOOOOOOOOOOOOOClOO OOS3
U A Z g~ ~
~o 3 YoG~ t~ s~3 Y~ ~
" ~L2~3~L42~3
- 8~ - 20155-424
TA~LE 17
EXAMrLF, OF CCI~T OF lI tlO!~I
_ CCtl~llESPONctE~lCE DICIIO~ARY
Ru~ Id~o-o
A Code~ TO E Cod~ ~ 0cu~g
L SLEDOYATEL6?~0 ~ O ax~X) 0d ~
I aEz TOGO Pl OXOItml001 0 ~0 it Jt ~d ~th
~tba
I C)ELO S KONQCtl~~401 0 am~o ~ ~hst c~ ts d~ed
I It,ON~;ty V VO~t~t ll~mO01 D 03XlG000 Lssl QC ~e wiil l~e
I N~_tl~O9.ar ImD~tl ~0
I SLOVObl I DELCt~l ~lX10051 O Ci~ ~ wcx~J tllld ~bd
I SOTl~.UCtNlKA~I11~00 0 OWOOalD ~ ~t
I T D ~ao~ O axla~D 6~
I T ~ COOO O x~xmo u~ c~t ~t
I TAlt ~OOUOI ~ ~lo ~d th~u
I ~DA ~CI;ImDI O ~1001
PaEV~ DUX ~QIm0 O ~ml4327 TA~ ~
~AW~OI ~CO O m0a0100 ~CHlNle ~S'AllE
~EVESrl V ~DOE SoS~4~1E 0~!40 0 01~1DJ:~9 90LI~
~E~ VWUD ~ 0 aW3DII S~ T O~
PE~V~I DVWATEIA a#WOI~ 7 ~P Fl.E~ ENOIN~
PE!IIEVOD aSI~ ~ II O amlg~ ~SLA~lON OF ~M9il~EltS
~aEVOD DNLYOV V ~T1~7' IXI~IOOISO I ~ ~H OENrlld~ElI ~t)MV2ASlOM
.I~OD EDI~Q hUt~ IIQY ~05 SOI~DOO I ~001alO~I CONVe~SiON or ~S TO cos UNnS
I'E~VOD IZ ODNDt I~lNlQ bll~ Y DalX31E ~ItiO 7 ~104 RCAL~TID~
M1~7 lI'aOl~U~CClJ
P81U~OD ~ILD~ NA Pal~O~ ~ 7 ~ OOWV~UJ~
~OIZVODSI~O
~VaD ~ NA ~ ~OOI~D 7 IX~ 0NV~}AI~
P~!OIZVOD~VO
L4~g
- 88a - 20155-424
OZ
~o2 ~vc,
CYC~ , ~
L I z ~0 Z 2
L ~ ~ Z Z
CC~: ~ h~ L Z ~ O ~ ~
~ ~, ~ . ~ 3 e c o z ~, z 2 0 2 Z ~
_ 2 g CY ~ ~ C~ O ~
C~lOOO_gOOOOOgOOOOO
O O O O O O O O O O O O O O O O O
C ~ o o ~o o o o o o o o o o o o o o
o o r_ o o c~ 1~ o ~ O r~ O
OOOOooO
c~ ~oo~ oo~ ~oo~ ~oooo
es
~o
ocv~
, ~S- ~ o,,
c~ o
LLI ~ C~ 0 2 ~
- O CY ~ ~o
s ,9 2 ~ e~' 2 2 C )
. ~ ~Y ~ O ~D e -- ~ 2 "~ ' el ~
IeS , ~ 1-- ~ ~ O 2 L l 9 c. cY 2
2 ~ M O L S C~ o o y E~3 X
cC O ~ L~ l ~ C~ 1:~ Q_ ~ O CY
h~ Zoooooooooo
CY C~ ~ CY CY CY ~ CY CY CY ~ CY Y ~ CY CY CY
C~ ~ CL C~ C~ C~A C~ C~ C~
- 89 -~ 14~9 20155-~24
TABLE l9
I~FORMATIO~ CO~TAINED IN EACH BYTE
OF INFORMATIO~ I~ AMALYSIS AREA
BYTE 0: Word sequence-number in the source language sentence.
BYTE l: Primary parts of speech indication in the source
language.
BYTE 2: Singular cases for nouns, adjectives, participles.
Person and number indication for verbs. Individual bit
indication for pronouns.
0 BYTE 3: Plural cases for nouns and adjectives. Tense and mood
for verbs.
BYTE 4: Gender and number in-formation for nouns, adjectives,
participles, verbs. Additional information for verbs.
BYTE 5: Indication of direct object requirement.
BYTE 6: Various dictionary codes (condensed).
BYTE 7. Various dictionary codes (condensed).
BYTE 8: Secondary parts of speech.
BYTE 9: Codes indicating, with bits, the strong prepositional
requirements.
0 BYTE 10: Codes indicating, with bits, the strong prepositional
requirements.
BYTE ll: Some semantic codes, like Human and Inanimate, Codes
expressing clause initiators which this word may govern.
BYTE 12: Condensed parts of speech information.
BYTES 13-15: Address in the core storage indicating additional
grammatical and meaning information.
. . ~
~V~t~4~9
- 90 -~ 20155-4~
BYTE 16: Agreement in-formation. Words that participate in agree-
ment points to the central word of the agreemen-t.
BYTE 17: Agreement relationship where the agreeing word is to the
right of the central word. The word points to the
central word.
BYTE 18: Government indication. A pointer to the governed word.
In the case of multiple government, the pointer in this
location points to the last object.
BYTE 19: The same as BYTE 18, in the case that one word has two
direct objects. The pointer to the second direct object
is indicated.
BYTE 20: Pointer to the adnominal genitive of this word.
BYTE 21: Pointer to the infinitive governed by this word.
BYTE 22: Pointer to a clause initiator governed by the word.
BYTE 23: Pointer to a second clause initiator governed by the
word.
BYTE 24: Pointer to a strongly governed preposition. In the case
oE multiple prepositions, the pointer points to the last
preposition.
0 BYTE 25: The same as BYTE 24 in the case that the particular word
governs more than one different preposition.
BYTE 26: A central word of an agreement points to the first word
of the agreement.
BYTE 27: A central word of an agreement points to the last word of
the agreement which is to the right of -this word.
BYTE 28: An object points back to its governor.
:, . ' "'`'
~Z1~4'~9
- 9~ -~ 20]55-424
BYTE 29: An object points back to its governor, in the case that
the same governor has more than one object.
BYTE 30: An adnominal genitive points back to i-ts governor.
BYTE 31: An infinitive points to its governor.
BYTE 32: A subordina-te clause initiator points back to its
governor.
BYTE 33: A subordinate clause initiator points back to its
governor.
BYTE 34: Indications for rearrangement purposes.
BYTE 35: A strongly governed preposition points back to its
governor.
BYTE 36: Various types of information relating to subject or non-
subject functions, like definite subject, multiple
subject, apposition, etc.
BYTE 37: Predicate information. The fact that the word is a
predicate or can become a predicate.
BYTE 38: Condensed information. The word is governed by another
word.
BYTE 39: Condensed information. The word has a governing function
in the sentence.
BYTE 40: Enumeration codes.
BYTE 41: Ambiguity codes on the basis of which they can be
resolved.
BYTE 42: Merged case information.
BYTE 43: Cases in which the word finally functions in the
sentence.
~ 3lfl~9
- 92 20155-42~
BYTE ~4: Gender and number in which the word has been established
to function in the sentence.
BYTE 45: Eliminated government codes. Government codes which are
still there after syntactic analysis.
BYTE 46: Eliminated secondary government codes.
BYTE 47: Enumeration pointer.
BYTE 48: Enumeration pointer to a word which is in the same form.
BYTE 49: Polnter to a word which is not in the same form.
BYTE 50: Additional types of information, like types of phrases.
BYTE 51: Indication of subsentence boundaries.
BYTE 52: A relative pronoun has a pointer pointing to -the word in
the previous subsentence unit which it replaces.
BYT~ 53: Miscellaneous da-ta, like the word already translated.
For example, some routines translate the word and it
should be avoided that the synthesis routine translates
it again. Also, indications such as certain words have
been rearranged and r,lust be translated differently, or
abbreviation indication words canno-t have genitive
attributes, etc.
BYTE 54: Commands to -the target language synthesis program.
BYTE 55: Sequenca number of a word if it is a homograph.
BYTE 56: Lexical routine indication.
BYTE 57: Used in the rearrangement program.
BYTE 58: Original dictionary gender number information.
BYTE 59: Sequence with which the word functions in the target
language.
- ~3 - 20155--424
BYI'E 60: Length of the mean;ng in ~he target language to be
printed.
BYTES ~1-63: Address of the meaning to be printed in the target
language.
BYTE 64: Length of the word in the source language.
BYTES 65-~4: Contains the word in -the source language. The hexa-
decimal indlcation of this word appears on -the right side
above the byte indication and the interpretation of this
hexadecimal information appears immediately after the
parts of speech.
BYTES 85-87: Address for the information, where data is available,
concerning the translation of cases (wherever applicable)
and the prepositions.
BYTES 88-90: Limited Semantics number of the particular word.
This is a unique number assigned to each word during L.S.
update.
BYTE 91: Source language information concerning the origin of the
ending. Regular high frequency dictionaryl for instance,
whether it is a homograph, etc.
0 BYTE 92: Indication that the word functions in an idiom or L.S.
compound and what position the word takes in such an
expression.
BYTES 93-95: Address pointing to the possible meanings of an L.S.
compound principal word.
BYTES 96: Information concerning dashes, short form adjectives and
participles. A lexical rou-tine places a code into this
byte to indicate whether adverbial endings should or
should not be used.
4~9
- 94 ~ 20155 ~24
BYTE 97: Pass zero (0) p]aces code into this byte assuring
priorities in assigning functions for a participle.
BYTE 98: Type of pronoun, if any, that should be inserted in the
target language work synthesis when translating the
verbal form.
BYTE 99: Phrase pointer, a comma, which begins a phrase points to
a comma which ends the phrase.
BYTE 100: A comma which ends a phrase points to a comma which
begins the phrase.
O BYTE lOl: Indication of the topical glossary from which the target
meaning has been taken.
BYTE 102: Temporarily empty.
BYTE 103: Data concerning auxiliaries to be used when translating
participles.
BYI'E 104: Indication of which preposition should be translated by
special subroutine.
BYTE 105: Indication for capitalization.
BYTE 106: Data for saxonic genitives, whenever applicable.
BYTE 107: Data concerning synthesis in the target language.
0 BYTE 108: The first word of a sentence or sentence unit contains
the sentence serial number of the word which functions
as predicate. In addition, this information is placed
on the top left side of the printout.
BYTE 109: One predicate poin-ts to the next predicate within the
same sentence unit.
BYTE 110: The first predicate points to the last predicate.
- 95 -~ 20155-424
BYTE 111: The first word of a sentence or sentence unit points to
the first subject in the unit.
BYTE 112: The Eirst subject in the sentence unit points to the
next subject.
BYTE 113: The first subject points to the last subject.
BYTES 114~115: Pointers used to express apposi-tion relationship of
the dash.
BYTE 116: Miscellaneous information.
BYTES 117-159: Condensed semantic codes used in generali~ed pro-
lQ grams to translate words with multiple meanings. The
bits, in these bytes, express individual semantic cate-
gories and, on the basis of syntactic relationships and
semankic categories, the correct meanings can be select-
ed during translation.
- 96 - 20155-424
TAE~LE ~O __ l A~LE 20~ondnued
TAIDLE OF CODES FO~
TAt~LE OF OOD&; ~OR PRIMA5~Y PARTS OF SPE~
Pul ~ ~
Spch Me ninll Specch _ Sp~:b M~nin~_ __ Sp~ch
E~ D~ AdVerb con~ur~io~ ~0
~2, ~;9 ~IA,;a. E~ PREJDE Ad~0 p~bios~ ~
011 59~ ; e W 2~1, 2C. ~ 2 IO EC MA~tjC~ ~ 0C
10 P~ nou~ 10 ch~ <, >. -
F2
IC Ab~ 12 15 FC Camlu wb,llin id.;o~ _
2~ N~l~d~CajVe ~bl~iq~ as TA~LE 2~
2~ P~ 22 -- TAIILE OF CODES FOA
1C Or~ P SECO~DARY PAR1rS OF SPECH
ICO, E~e p~ d
rc~ Deu~ 5~S~ . 2D, 51 sj~b Meui~ _ S~c.b
3C .]E 01 q~ell ~C~I D0
40 F81~ 3~;11U~ 45 25 C!2 Cb~
43, 44 04 Dou
4C GUAd ~ ~ ~ 05 P~oa CC
SO P~epcd*l- 51,12, 53, AO I~F S6 ~cd~ OC
17 Colo~
51 ESt'6 ~7
SC ~, NO, XOT4, NA~IME~ Z~T~, 6~ , ~ 09 C~ ~0
ITAX.4 ~OMU, ODN~XO, Q,~ * ~C
PCCEM4 0111 H~ F0
60 C001~YI 09 0C M-(l~l r~PI~:OO EC
U I ~ eh~m <, >, -.
~2 oD
6C CC~I~ POK~æST ~ 3~ 0E~
~ n 0~
w~Jei 10 1~ ~ 10
~b~ 12 Pn~cf bl~ It
78 EE, EnO, IX 7~, 711, 7C:, 7D A~o~ IC
7C ~OTORYI 7~ ~UI 14 I~:d eo~l ~ bs 1 A0
30 P~ p~e l~dpk 93 15 Wrin~ c~l ~ A0
~ p~V~: pulidpb 3~ 16 Ihellll C~ Rl~ba~ A0
tC P~cnl ~ve ~ddpb ~7, ~ 2C Sb2~1 k~l ~ ~ 011
90 SEM 74 ~D Shon hn~ 3J
9~ Comp~uve, ~3LEa ~ EE 27. 29, 2~ 2a ~5
2E ~sr~: rcnu~e
9S ~Y
9C U 67 2F 10
~0 ~rdi~l ~IDDbm 14, ~3, 16, 37. 1~
1~, IA 31 M~OGO. ~LO, T~e ~a~ 34
A4 li~l c~ ~b~ 1 5a 13 ~1/; 30
A- D~ p~b, ~A 6D, 67, 6A 14 Ma1NO 30
AC ~jecdo~ l'OL6XD
ubj~l or ~o~ - 71 36 PIIEJDE 09
7 ~ki~ nae~
C .`OEIY, 1CO<)DA 59 ~ la ~ 94
ac l`USr4 SXOL6KO, POSXOL6XU, U~, S~ ~C 99. 39
CTO, CIDI~ IICUI~A. OTKUDA, 4~ 92, 9E ~ llE ~ ~n plw~l
IC~lt. TOL6KO, 130 W6
C4 Coba 07 60 3C NULL ~b~ y o~
CC PcrblL ~ elel-~ 05, 0~ oa. 92 3D ~ic3te ~
01, 90 3E r~dic~ ly ~0
W Opee bnc~ 3F qliout ~ KV
p~th~
P~ 01 2 ReSb~ l~he
D~ 3 Wo~l~lkYiv~ ihhl~hiV'~
DC D~e~udod wonb ~ Re~ivt i~rmid~ ~
E0 Word~ fou~ S Fuu~t ~ ry ~
~ic~ary
~ 97 20155~424
TABLE 21-conlin~ TAaLE 21-corlt3nued
T~PL OF CODES FOQ -e TAIILE OF CODES FOR
SECONDARY P~rS OF SPEECII SECOt.'DARY P~QTS OF SPEECI~
P~ Pli~ l~n ~ PuU Prinwy P-n
Sp~cch Mc-nin~ Sp~ ' Sp~ch Me~nin~ _ 5p~ech
Infi~ ~ili~ M ~5 tl~ivo p U ~ivc U
4~ ~sr~ ~9 P~
U Imp~dv~ Dl S6 Ik~v~ 3C~S U
.~9 ~10 ~
4A Co ~7 ~ p~em ~iv~ac
4<: U ~dbd~ p~eKnt ai~ ~C
4D p~h
4E $9 R~ve ~erund~C
4F S~ C. 4C
SKOL61CO EC
~l O)d p~liC~ de 50 ac POSKOL61CU ~C
O P~ y ~0 tE~
9F
Opco preDLh~ DO
93 Quoudo~ a
S9 CIOIIY, ICOODA, E5LI B~l ~
5A 9-
SD ~11 rnb ~ rx
~E 99 ClO X
51' 9~ 13DE OC
~0 DAJE ~11, sa XUD~, OrKUDA, OTCEOO ac
E4. 9~ 91
61 ~ 30 9D
62 Cu~:d~ec~ 64, 9E! liC
L ILI U, 9p
Co~J~io~ . ~OI~MEST, SC, AO DO 50
VYUDU 6C Al IZ. IZO ~O
TOODA, TAY T -P_ T.X.. 1-~, 35 A~ yt, 1~3 ~0
TD_ V~TO, IT~ Xa:'A, A~ NA 50
N~PIU~E~ l~ESr6, ~OtTOMU, A~
6S ODN~)tO, NESMal~ ~7 n. oa ~o
66 NT 0~ OICOLO
67 Putick At, 3C, S~ 9 OT IO
U l~ AC A~ l'e11ED 5~
~9 A13 CD~EZ 50
6A DA A3 AC PO 50
6B E~E 3il ~D PIU JO
LIW4 CU~ EDV~ ZJaLI liO S, SO IO
6D VOT DC 1~1 11 80
112 V, VO 50
6~ 7
8.~ ~06LE 50
71 ~aua . ~ubject o~ no3 E10 50 5 DU SO
n P~ r~ o~Y 70 ~7 8LAOODAIU 50
A ~ ItROME ~O
3~1~ vSLE~s,'rVlE ~
7~ OE~ 3 S~EDLS~6 IO
7~ ~E, WO, IX 7855 ItC ~SIIIOTIR~
76 KO~RYI 7C ~D ML~10 ~
77 I~E VNVllU S7
79 CS~ TOt 2~
7A Cl TOMU 22
1a EE 7S~0 C2 TE ll
7C eGO 71 CS TAlt.OI 2J
7D IX 7a C4 ~OM 21
7~ C5 'ro 2~
7F C~ TOCiO 2S
DO No~iv~ ~d C C7 lEX 21
s~n rO~ ~ ~r ~ 6~ 228
prdcipk C9 TA
12 Shon ~orm pu~pk Od CA TC31 21
U r~ po~ivtpni~le tO C~l llJ 233
U P~ p2 ticigle 3~ C~: lEMI
Z~
- 98 - 20155-424
TAIILE 2l~con~lnu
TADLI~ Oil CODES FOI~
SECOr~l)APr ~,~ TS 01: SP~ECH_
59~h
CD
0
D0
Dl
Dl 21
1~ liur~l o~relir~l nun-bm A0.
1- AD.~holhn~lauelW A0
1~ L~ A0
IA Ut~l eonll~ ub~m A0
~d~ 1~ ~S 'tt_ 'C
lC
IQ
20 PDn I~lJ:~iv 20
2~ ~ ~ 2~
2~ ~ ~ Kl~ 04
2~ l~slor~bul c~ 2~`
27
~w o~pr~ 94
OLEE~ ~e~ 4
DA
Dl~
DD
l:lE
Dl'
E2
E~
E7
E~
ec
EP~
SYSllU~?~ TR~NSLAr~ON OP RIJSSIAN
SE~ENCI~ SIIOWN IN. FlC3. 4
H~lm~ t~ t;~n c~ po~e:~ n ~9~ of dctick
w~icb c~n in pri~cip,e be ~nt ~rom zo~CluDe trul~b~
tio~2 (for i~nr~e, tbe h~ophy of ~e tc~lurcs of the
ir~di~idu l ~tyle ~Jf 1I bw~ tJ~I~ or in ~be truul-t~Y2
Icllt uld ~ on).
~ i
- 99~- 20155-424
Oo oa oo Q
o ~ c) o o O
o O c~ o o
COI OO g O O O O
2 Dcl ~ CO~ O
g ~, o o ~ 2 0
~ o o o ~ o ~
o~ ol o 7 o~, o o o o o ~
o o ` :~ o ~ o ~ ~ el o ~-
o-- ,4 Q ~ _ o---- o ~ _~
o o o ~ oo _00 ~000
o o o o O ~ o O ~ 4~ o cl
e" o o o~ ._ o g o o o ~ g
O ~S O~ O O V r~ o D O u o o o
o o ~) o~ ~ o e~ ~ o o o ~ o ~ o
U~9~0 ~D~10 1~000 ~ono
O O o C~ o C U n o Q Q o o
~o o o C~ " n ~o~oO ~ uoO~ ~
<~t~ v g c~ oO ~ o o s~ o o
n ~ n rl dl~ ~ ~ ~ n
s~o~< oo~ oo - ~ oo~
0 0 0 0 0 6~ ~ V
D ~ 8 o u g ~ o o o g
o o o ~ o 0 " o o o
g D O O ~ ~ g Cl `5~ Cl O o
00~ 00 ~O-> 0~0
7 0 0 O ~ O ~
$ ~ o 8 v c ~
o 8 o n O g ~ o o o
C~ o O aO~ ~ ~ o a o
o ~ o ~ o o ~ ~ v o
_ ~ o
o o ~~Q 113 r'i O O ~ O C~ ~i
O O O g ~ ~~ o d O
g O O O S~ O g ~ ,,j g o y ~
oO o ~~ ~ ~j O o o O ~ o o~ o
00~~C~C~O 000 00~0
O o g'3 ~ g ~j y o o o o
O ~ O~ 1~ ~ ~ O ~ o O V S-
r~ O 00 ; o o al ~ S o Uj 01 ~
_ .n r~ r~ n ~ ~ ri 2
o ~ -soo~O oo-- oo~
~, o o,~ v e, o~ o o ~ o o
VOo800~t oog o22
~0~DOO~ '~00 _~00
oo~oos~o. ~-oo ~ooo
o ~ oo o ~ ~ o 8 i
O ~ OC~ 1~ o ~q o o v o o ~
~ " T ~ ~ ~ " '` " ''
o ~ o ~t ~ ~ o ~ ~ o ~
o 0 s~ 0 0 ^~ O O - U O O - U 0j
~ g~ o~ ci.~c,O~i~O~ ooæ
~ o g o o o ~, o g ~,--o o ~ o g ~. .. o o o ~i
_~n Ooo~-CIoooe~ ooooo~ooooo
.-1 .'1 0 1:1 0 ~--I ~ O ;l ~ d O o O ~ O O O o g
uOOOg~OO0éi~owiooo ~ooooo
a o _~ o o ~ ~ o o o ~ o o o cj g oO O o
;;~ ~ ~ ~. .~ ~ e ~ ~ ~ o o g ~ ~ ~ ~ ~ ` ~
v~ ,~ ~ .r
v~
4~9
- 100 - 20155-424
o oo o o oo o o o ~ ~ = o o
o oo o o ooo o o o o o o o o o
~ g o o oa o o o o o o ~ o o o o o o o o o
o ~ o o ~. o ~ `o~ ~ o t,. o ~ Q
O o o o o O ,0 O~ O~ O~ O O ~ 0~ . --U
o o ~ o o ~- o O ~O o o ~DQ 0 ~ , o ." ~ .~ o ` '' ~ '' '
0_~t~Orl_~ 0_~ ~V~ ~~~ DO--~ '~--~ ----
ooo~100O C~O 0~000 ~oo ~nooo r~oo ooo
O O O ~ O O O O O O OSl~ O O O O 0 1'1 0 0 0 0 0 0 ~O O O
~ bl O ~ o 3~ O o O ~ O O ~ O O O O O O D O O O
,, o o o o o og 5 C~ ~ ' h 0 ~O 1~ O O ~
~O;~0 0 . 000~000 C~ooO l~OC~O 1~1000 000 Vooo
O ~ ~ U g Y ~ O O _~ bo O O ~ e.~ o ~ U o o ~ - ~ ~
_ O ~ ~ 'n 2 '' ~ ~ ~ ~ ~ ~ o o o o v o o o
a o ~ oO ~ o ~~ O ~ ~ $ ~ o ~o n 0 ~ ' o ... o o o
00~OC~r~00~O~r~ oe>r1 oo~ oo--- oO~ oo---
oooouooooooa~ oooooo c~ooooo ooo
o a ~ A C~O ~ O O ~ r~ o C~ oo ", Oo o U Oo o ~. oO oO ~ oO
o al oO a ~O O O O ~ o oO U 00 o g 00 U O o ~n o~00000000 00~ 000C~OO ooo ~ o ooo
oaoo.O oo joO jyo
r~O~ O O~ 20~ ~ O O~ Oo, o ov~ , o O
OUOOUooUo OUO OU O-o OUOO O-
O ~ O~ O ~ Oo r oO ~ o Y ~
o o o O ~ O O O o ~ ~ o O ~ ~ O
o o ù ~ o o ~ u o o ~ ~ ~ S
oooo~o oo2 o oo~
S ~ ~ o o o ~ ~
O O o ~ o o o o o
- lO~ - 20155-424
oo oo oo oo oo oo oo oo .. oo
og oo o g gO00 O 0 00 O'.7 ~ O O
o O O O 0O 0OO 00 oo a O O
o o o o o o 0 0 0 0 g O O O o O . O O
oO oO O~ oooo oo oo oo U o.o
oO 0~ 00 oOoo oo a oo oo ~ 00
O 0 O O O O U o o ~ o
O O o g o O o O O Oa o ~ o og o U o 0 o
O ~ OO o ~O b. O o o o o o oo ~o oa '' o o O O O a O O O
oOO ooO oOO C~o~o,o,o,o,oo~o, ~ U
O ~i~O O ~oo o ~0 o o ~ o o Wo O ~ 0 0 ~ o ~ a o ~
~_~_ 0_ _ 0~ o~tJO_r4 0~_~ o~ 0__~ oo~
U o o oc> on O O O o o oa 0 o 0 0 ~ ' ~
~"oo ooo uooo aog ~ 3 ' "' a
~ ~ ooo ~ooo C OO UoOO ooo VooO
~ooooooo.ooc- oooo,, oooc,o~ooo ~ooo ~oOO
~1000000UOOO 00~ ooo r~~JQ ~ ~1000
uoaovooaO_~o n~ouoonblOoc~uooo oooo ~0OO
80~ oooaOoO oo~aOOoaOoo ug '`
~ oo ou o o o o o OU O c ou o ~ o a o O n ~ o o o ~,~ 0 '^
c~ o o oo o oa o o O~ o o~ c- o o ~ O 0 O Z4 0 O O u o o o
o o ~qo o ~1 o o ~ o ~ ~o o ,4 o o .- O O--~ O -I o o--t
o~ooc~oooo c~o~ooo oooooo ooo ooo
g .vg ~ oo o ~ ao ~ c~o ,~ O Oo ~ O ~ O O ,,j O
oXo c-ooo~o o~o o~o~4~C30~0 ' ~0 _.. Co
o ~ o ~ O o o O O - O O Da O O u- o o Cl~ O a o
e~ o ~o o o~ o o o 2 go o e~ 0 g g o o ~ o o o
ooo ooo ~oo oooooooc~c~ooo o~o oo~
,~ 2 o o " o og c~ ov o o . c~ g o o o
,o ~ oo o oo o o o o~o o o o g o o o o .. o o o o
o o o oo2 ooo co oog ooo
'~ S 9 ~ l ~ ~ O ~ t~O ~r Oj " lo l S ol l S
V~O ~'P.~O ~0 ~ 0~F~O ~0 ~r~o ~-0
~, O O ~ ~ O O _O O ~ O O _ ~ O O O .- O O-- O e- '1 0 0
t;OQ o o o C ~-oo ~oOOo~,, Gol o ~ o o~o
~12 ~r o o ~o ~ o o ~ o o o c~o o o o ~ Oo o o o u o ~ o u o
~oooo oos~ ooo ~,oooc,o ooo ~ooo 000 ~000
¢o o 2 0 " o o o oo o o o o gI r~ ~ o~æ ~i o ~ ~~ `' ~ ~ "
o ~ o ~ o s~ o o ~ g _ O O ~ ~ 0 ~'j g~ O ~ 0 ~ o ~ o o ~ o ~ O ~, O
i~ooo I o oo~ ~e~ 0OOO S~o ;~oO Zg ~ ~'-
o c~ o o o o~" o o o o g ~O~~ g O O~ C7 oO Or- O o ~ o o o ~ O - O
~ ~' S ~ ~ -i O O~ e- Io g~ ~ ~o o~ o~
1~ 0 0--~ O O ~~ O O ~i ~~ O O rl O~ o o rlO~ 0 0 r~ , O
O O ~ O O" ~r o o r9 O~ O 0 3~ a O ~E 2 0 0æ ~ O oO S ~ ~0
O O Oj~ O Cl OO C-- ~ O r~ e~ 0 o 0 `O O O O O 0 00 0 0 ~ O O O
'llI~OO j~O ,00~ 000 000ql~OO r~ o ~OC~ ~00 ~00
~ ~ o o o o o o o o o o ~ o o o ~ o e~ ~ o o o o o o o $ o ~ ~ o o
~ o 8~ 0 0 ~0 0 0 , 0 0,
00,"0"0" ~oog2 oooo vooooox ~0000~00 ~ ~~
,~oooo_ 00000~300000 ooc,o ~ooooo o~oo~3~o~oo ooooo~oooor~
o o _ _ O O o O O O O _ O O O O O O O O ~ _ _ ~
U o ~ ~
4~9
- 102 - 20155~424
o o o o o o o o o o o o o o o o
o j o n ~ o o o o o O o o o o i o ~
~ o ~O Q o o ~o O O ~ O ~9 ~ ~ '~ ~ O d '-~ ~
O O ~ o O O _ o o O o O O ~ o O O
w~io = o ~o~ ~ ~-- 8 aj Q
O O ~ O G ~1 0 0 .~ O o 3 o o 3 o o 3 o o ~ o o ~
o o o o .... ... ., . --~ . o . ~ . o
., ., ., ., ., ., .,, ., ., .,, ., '.. ..
o~ .,j ... o~ ... o~
~1: d ~ n ~ w
~ ù ~ ~ ~ u ~ o ~ ~ ~ ~ ~
c ~ ff ~ o ~ O ~ d O O O o O O O o o
~ _ _ O ~ ~ _ _ O O ' . O ~ ,,, O O O .. .....
4~9
- 103`- 20155-424
WD-ID
C
WD.II~ NS~IC
WD.IA Yl.NS~IC
WD.19 IU~IA
Wl~10 NS~V~19 ILI-IA
7 11S~V~19 L~O~lt
~ .16 SLI~I~
WD.19 NS~
~IS NSW l~ ; LAai~ IU-I/~
W~12 N5~13 ~IS~ IS ILI~iA
W~ll a.N . 13 IU~ IW~IA
~13 lLI-lA COM~I I
WD~
W~4 ,
WD.OD NSW 0
WWC NSW~Ce L'-O~
WD-aA ~4}1 VE~08
WD~ ~lel~4A
WW~
WD47 Ng~V~4a ~1
00~-07
? 5~46 COPq~7
WW3 1#1~4~ RNSOS V~44 COM~7
DU~r
~Drr c
11~ D
L0~17~ ~I
~DL H
RU~IO
S~N J
s~rsveR~ 1
WTCALL L
CE~N N
s~u~so o
SlU~ASSI
S;~U?AS~ Q
SS~
SllU~iS4
~;i~ S
~C~L U
~r
ES nd y
PPR~
~Nr
WSPL~Y ~
DD
CIS3 ~E
C~SO ,
DU~r~d 00
SEM~r~ n
NFC
DISIUOAD ~
s~plU?~ M
~OI~T
~'~