Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
1 337708
- 1 -
AN ADAPTIVE MULTIVARIATE ESTIMATING APPARATUS
Technical Field
This invention relates to classifying samples representing a real time
process into groups with each group coll~spollding to a state of the real time
process. In particular, the classifying is done in real time as each sample is
5 generated using statistical techniques.
Background and Problem
In many real time processes, a problem exists in alle~ing to
estimate the present state of the process in a ch~nging envilunlllent from present
and past samples of the process. One example of such a process is the ge~ alion
10 of speech by the human vocal tract. The sound produced by the vocal tract canhave a filnd~mçntal frequency - voiced state or no funcl~m~nt~l frequency -
unvoiced state. Further, a third state may exist if no sound is being produced -silence state. The problem of d~le~".;n;l-g these three states is referred to as the
voicing/silence decision. In low bit rate voice coders, degradation of voice quality
15 is often due to inaccurate voicing decisions. The difficulty in correctly making
these voicing decisions lies in the fact that no single speech pa~ el or classifier
can reliably distinguish voiced speech from unvoiced speech. In order to make
the voicing decision, it is known in the art to combine multiple speech cl~csifi~rc
in the form of a weighted sum. Such a method is illustrated in D. P. Prezas, et
20 al., "Fast and Accurate Pitch Detection Using Pattern Recognition and Adaptive
Time-Domain Analysis," Proc. IEEE Int. Conf. Acoust., Speech and Signal Proc.,
Vol. 1, pp. 109-112, April 1986. As described in that article, a frame of speechis declared voiced if a weighted sum of speech cl~csifiçrs is greater than a
specified threshold; and unvoiced otherwise. l~them~tic~lly, this relationship
25 may be expressed as a'x + b > 0 where "a'' is a vector comprising the weights,
"x" is a vector compricing the cl~csifi~rs, and "b" is a scalar represçnfing thethreshold value. The weights are chosen to m~ximi7Ç pelrG~ ce on a training
set of speech where the voicing of each frame is known. These weights form a
decision rule which provides cignifi~nt speech quality improvements in speech
30 coders colllp~ed to those using a single pala-llet~
A problem associated with the fixed weighted sum method is that it
does not pclrol,ll well when the speech enviro~ lent changes. Such changes in
the speech environment may be a result of a telephone conversation being carried
- 2- 1 ~3377t~8
on in a car via a mobile telephone or maybe due to different telephone
tr~n~",i~l~,.s. The reason that the fixed weighted sum methods do not perform well
in changing envilo~ tc is that many speech classifiers are influenced by
background noise, non-linear distortion, and filtçrin~ If voicing is to be
5 determined for speech with characteristics dirr~lel~ from that of the training set,
the weights, in general, will not yield s~ticf~ctory results.
One method for adapting the fixed weighted sum method to changing
speech env lvnl,~nt is disclosed in the paper of J. P. Campbell, et al.,
"Voiced/Unvoiced Classification of Speech with Application to the U.S.
10 Gove ll,l,ellt LPC-lOE Algorithm," EEE Tntern~tional Conference on Acoustics,Speech and Signal Processing, 1986, Tokyo, Vol. 9.11.4, pp. 473-476. This paper
discloses the utilization of different sets of weights and threshold values each of
which has been predete. ,.,ined from the same set of training data with different
levels of white noise being added to the training data for each set of weights and
15 threshold value. For each frame, the speech samples are processed by a set ofweights and a threshold value after the results of one of these sets is chosen on
the basis of the value of a signal-to-noise-ratio, SNR. The range of possible
values that the SNR can have is subdivided into subranges with each subrange
being assigned to one of the sets. For each frame, the SNR is calculated; the
20 subrange is detçrmined; and then, the detector associated with this subrange is
used to detçrmine whether the frame is unvoiced/voiced. The problem with this
method is that it is only valid for the training data plus white noise and cannot
adapt to a wide range of speech envi,~,n.,~llt~ and speakers. Therefore, there
exists a need for a voiced ~etector that can reliably determine whether speech is
25 unvoiced or voiced for a varying envi,vnlllellt and dirr.,lellt speakers.
Solution
The above described problem is solved and a technical advance is
achieved by an a~a~dlus that is responsive to real time samples from a physical
process to det~rmine st~tictic~l distributions for plurality of process states and
30 from the those distributions to est~blich decision regions. The latter regions are
used to determine the present process state as each process sample is ge.le~dted.
For use in making a voicing decision, the appaldtus adapts to a changing speech
envhonlnent by utilizing the statistics of classifiers of the speech. Statistics are
based on the cl~csifiers and are used to modify the decision regions used in the35 voicing decision. Advantageously, the apparatus estim~tes st~tictic~l distributions
1 337708
- 3 -
for both voiced and unvoiced frames and uses those st~ti~tic~l distributions fordeterrnining decision regions. The latter regions are then used to deterrnine
whether a present speech frame is voiced or unvoiced.
Advantageously, a voiced ~lçtector calculates the probability that the
5 present speech frarne is unvoiced, the probability that the present speech frarne is
voiced, and an overall probability that any frame will be unvoiced. Using these
three probabilities, the d~ector then calculates the probability distribution ofunvoiced frames and the probability distribudon of voiced frames. In addition, the
calculation for detellllinillg the probability that the present speech frame is voiced
10 or unvoiced is p~lrolllled by doing a n~i.. ,.. likelihood stadstical operation.
Also, the m~imulll likelihood st~ti~ti~l operation is responsive to a weight vector
and a threshold value in addition to the probabilities. In another embodiment, the
weight vector and threshold value are adaptively calculated for each frame. Thisadaptive calculation of the weight vector and the threshold value allows the
15 detector to rapidly adapt to ch~nging speech envin)~l-enLs.
Advantageously, an apparalus for de~ ing the presence of the
fim~l~m~nt~l frequency in frames of speech has a circuit ~ po~ e to a set of
cl~sifiers represçnting the speech attributes of a speech frame for calculating a set
of st~ti~tic~l parameters. A second circuit is responsive to the c~lcul~te~l set of
20 parameters defining the statistical distributions to calculate a set of weights each
associated with one of the cl~sifiçrs. Finally, a third circuit in response to the
calculated set of weights and classifiers and the set of pdl~el~s d~;le ...;ne~ the
presence of the fund~ment~l frequency in the speech frame or as it is collllllollly
e~ ,sed makes the unvoicedfvoiced decision.
Advantageously, the second circuit also c~lr~ trs a threshold value
and a new weight vector and co.-~.. ,lirates these values to the _rst circuit that is
responsive to these values and a new set of cl~sifiers for dele,...;.-ing another set
of st~ti~tir~l p;il~ S. This other set of st~ti~tic~l pdl~eL~.s is then used to
detçrmine the pl~sence of the filnrl~m~ntal frequency for the next frame of speech.
Advantageously, the first circuit is responsive to the next set of
cl~sifiers and the new weight vector and threshold value to calculate the
probability that the next frame is unvoiced, the probability that the next frame is
voiced, and the overall probabilit,v that any frame will be unvoiced. These
probabilities are then utilized with a set of values giving the average of classifiers
35 for past and present frames to detçrmine the other set of st~ti~tis~l p~lete.s.
1 337708
- 4 -
The method for detennining a voicing decision is pelrollllcd by the
following steps: estimating st~ti~ti~l distributions for voiced and unvoiced
frames, detçrrnining decision regions representing voiced and unvoiced speech inresponse to the st~tictic~l distributions, and making the voicing decision in
5 response to the decision regions and a present speech frame. In addition, the
statistical distributions are calculated from the probability that the present speech
frame is unvoiced, the probability that the present speech frame is voiced, and the
overall probability that any frame will be unvoiced. These three probabilities are
calculated as three sub-steps of the step of deterrnining the statistical distributions.
10 Brief Desc~ ion of the Drawin~
The invention may be better understood from the following ~let~
description which when read with the lcr~lel ce to the drawing in which:
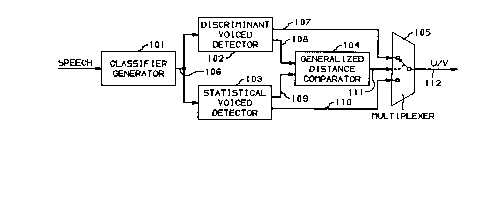
FIG. 1 is a block diagram of an apparatus using the present invention;
FIG. 2 illustrates, in block diagram form, the present invention;
FIGS. 3 and 4 illustrate, in greater detail, the functions pclrulllled by
statistical voiced detector 103 of FIG. 2; and
FIG. S illu~llales, in greater detail, functions pelrulllled by block 340
of FIG. 4.
Detailed Description
FIG. 1 illustrates an app~alus for pclrolllling the unvoiced/voiced
decision operation using as one of the voiced detectors a statistical voiced detector
which is the subject of this invention. The apparatus of FIG. 1 utilizes two types
of detectors: di~crimin~nt and statistical voiced detectors. St~tiCtir~l voiced
detector 103 is an adaptive detector that detects changes in the voice environment
25 and mo lifies the weights used to process classifiers coming from classifier
gen~la~or 101 so as to more accurately make the unvoiced/voiced decision.
Di~imin~nt voice detectQr 102 is utilized during initial start up or rapidly
ch~nging voice en~ nlll~,nt conditions when st~tistic~l voice detector 103 has not
yet fully adapted to the initial or new voice envilvr~e.l~.
Consider now the overall operation of the appala~us illustrated in
FIG. 1. C~ ifier generator 101 is responsive to each frame of speech to generateclassifiers which advantageously may be the log of the speech energy, the log ofthe LPC gain, the log area ratio of the first reflection coefficient, and the squared
correlation coefficient of two speech segments one frame long which are offset by
35 one pitch period. The calculation of these classifiers involves digitally sampling
l 3 3 7 7 0 8
analog speech, forming frames of the digital samples, and processing those frames
and is well known in the art. Generator 101 transmits the classifiers to
detectors 102 and 103 via path 106.
Deteclvl~ 102 and 103 are responsive to the classifiers received via
5 path 106 to make unvoiced/voiced decisions and transmit these decisions via
paths 107 and 110, respectively, to multiplexer 105. In addition, the detectors
det--rmine a flist~n~e measure between voiced and unvoiced frames and transmit
these distances via paths 108 and 109 to co~ tor 104. Advantageously, these
distances may be Mahalanobis distances or other generalized distances.
10 Colllp~ator 104 is responsive to the distances received via paths 108 and 109 to
control multiplexer 105 so that the latter multiplexer selects the output of thedetector that is generating the largest ~lict~nce~
FIG. 2 illustrates, in greater detail, st~tictir~l voiced detector 103. For
each frame of speech, a set of cl~csifiers also referred to as a vector of cl~csifiers
15 is received via path 106 from cl~ccifier geneldlo~ 101. Silence detector 201 is
~onsi~e to these cl~ssifiers to deterrnine whether or not speech is present in the
present frame. If speech is present, detector 201 transmits a signal via path 210.
If no speech (silence) is present in the frame, then only subtractor 207 and U/V~etermin~tor 205 are operational for that particular frame. Whether speech is
20 present or not, the unvoiced/voiced decision is made for every frame by
dele~...in~ol 205.
In response to the signal from detector 201, cl~csifi~r averager 202
m~int~ins an average of the individual cl~ccifiers received via path 106 by
averaging in the cl~csiri~.~ for the present frame with the classifiers for previous
25 frames. If speech (non-silence) is present in the frame, silence detector 201signals st~ticti~?l c~ tor 203, g~,ne.~lor 206, and averager 202 via path 210.St~hstic~l calculator 203 calculates st~tictic~l distributions for voiced
and unvoiced frames. In particular, c~lcl~l~tor 203 is responsive to the signal
received via path 210 to calculate the overall probability that any frame is
30 unvoiced and the probability that any frame is voiced. In ad~lition, st~tictic~l
c~lc.ll~tor 203 c~lcul~tes the st~tictic~l value that each c!~ccifier would have if the
frame was unvoiced and the st~hch~l value that each cl~csifier would have if theframe was voiced. Further, calculator 203 calculates the covariance matrix of the
cl~ccifiers. Advantageously, that statistical value may be the mean. The
35 calculations p~rolmed by calculator 203 are not only based on the present frame
1 337708
- 6 -
but on previous frames as well. St~tiSt~ calculator 203 p~,lrOlll,s these
calculations not only on the basis of the classifiers received for the present frame
via path 106 and the average of the classifiers received path 211 but also on the
basis of the weight for each classifiers and a threshold value defining whether a
5 frame is unvoiced or voiced received via path 213 from weights calculator 204.Weights calculator 204 is responsive to the probabilities, covariance
matrix, and st~ti~tie~l values of the classifiers for the present frame as generated
by calculator 203 and received via path 212 to recalculate the values used as
weight vector a, for each of the cl~ssifiçrs and the threshold value b, for the
10 present frame. Then, these new values of a and b are tr~nsmitted back to
st~ti~ti-~l calculator 203 via path 213.
Also, weights calculator 204 transmits the weights and the st~tistic~l
values for the classifiers in both the unvoiced and voiced regions via path 214,dete~ ;tl~tnr 205, and path 208 to genelato~ 206. The latter genclalor is
15 responsive to this info....~tion to calculate the ~ t~n~e measure which is
subsequently tr~n~mitte~l via path 109 to CGI~atOl 104 as illu~llated in FIG. 1.U/V detefmin~tQr 205 is responsive to the inf .. ~I;on tr~n~mitted via
paths 214 and 215 to determine whether or not the frame is unvoiced or voiced
and to transmit this decision via path 110 to multiplexer 105 of FIG. 1.
Consider now in greater detail the operation of each block illustrated
in FIG. 2 which is now given in terms of vector and matrix mathematics.
Averager 202, st~ticti~l calculator 203, and weights calculator 204 implement animproved EM algolill~ similar to that suggested in the article by N. E. Day
entitled "F.~ t;,.g the Colll~onenls of a Mixture of Normal Distributions",
Biometrik~ Vol. 56, no. 3, pp. 463-474, 1969. Utilizing the concept of a
decaying average, cl~sifier averager 202 calculates the average for the cl~sifiers
for the present and previous frames by calculating following equations 1, 2, and 3:
n=n+l if n<2000 (1)
z = l/n (2)
-
7 l 3 3 7 7 0 8
Xn = ( 1--Z) Xn-l + ZXn
xn is a vector representing the cl~ ifier~ for the present frarne, and n is the
number of frames that have been processed up to 2000. z represents the decaying
average coefficient, and Xn represents the average of the classifiers over the
5 present and past frames. Statistical calculator 203 is responsive to receipt of the
z~ xn and Xn information to calculate the covariance matrix, T, by first calculating
the matrix of sums of squares and products, Qn, as follows:
Qn = (1--Z) Qn-l + Z Xn x n (4)
After Qn has been calculated, T is c~ ted as follows:
T = Qn -- Xn X n (S)
The means are subtracted from the c~ ifiers as follows:
xn = xn -- Xn (6)
Next, calculator 203 ~et~.rrnines the probability that the frame represented by the
present vector xn is unvoiced by solving equation 7 shown below where,
15 advantageously, the components of vector a are initi~li7.Yl as follows: com~,ollent
corresponding to log of the speech energy equals 0.3918606, con~ollent
corresponding to log of the LPC gain equals -0.0520902, col~ollent
corresponding to log area ratio of the first reflection coefficient equals 0.5637082,
and component cc.ll~sponding to squared correlation coefficient equals 1.361249;20 and b initially equals -8.36454:
1 337708
- 8 -
P( I ) 1 (7)
After solving equation 7, c~lsul~tor 203 determines the probability that the
cl~ifi~rs represent a voiced frame by solving the following:
P(v I xn) = 1--P(u Ixn) (8)
S Next, cals~ tor 203 determines the overall probability that any frame will be
unvoiced by solving equation 9 for Pn:
Pn = (1--Z) Pn-l + z P(u I xn) (9)
After lele. "~ g the probability that a frame will be unvoiced,
c~lc~ tor 203 then determines two vectors, u and v, which give the mean values
10 of each cl~sifier for both unvoiced and voiced type frames. Vectors u and v are
the st~h~h~ ~1 averages for unvoiced and voiced frames, respectively. Vector u,
statistical average unvoiced vector, contains the mean values of each cl~sifier if a
frame is unvoiced; and vector v, st~h~hc~l average voiced vector, gives the meanvalue for each cl~c~ifi.o,r if a frame is voiced. Vector u for the present frarne is
lS solved by calculating equation 10, and vector v is determined for the present frame by c~lc~ ting equation 11 as follows:
Un = (1--z) Un_l + Z Xn P(u I Xn)/Pn--ZXn (10)
Vn = (1--z) vn-l + z Xn P(vlxn)l(l--Pn)--zxn (11)
Calculator 203 now con-.. -i~ates the u and v vectors, T matrix, and probability p
20 to weights calculator 204 via path 212.
9 1 3 3 7 7 0 8
Weights calculator 204 is responsive tO this information to calculate
new values for vector a and scalar b. These new values are then tr~n~mittecl back
to statistical calculator 203 via path 213. This allows detector 103 to adapt
rapidly to ch~nging environm~nt~. Advantageously, if the new values for vector a5 and scalar b are not tr~n~mitted back to st~ti~tis~l calculator 203, detector 103 will
continue to adapt to changing env--ol-l"ents since vectors u and v are being
p~te~ As will be seen, det~rmin~tQr 205 uses vectors u and v as well as vector
a and scalar b to make the voicing decision. If n is greater than
advantageously 99, vector a and scalar b are calculated as follows. Vector a is
10 de~e.ll~ined by solving the following equation:
a = T (Vn~Un) (12)
l--pn(l--pn) (un--vn) T l(un--vn)
Scalar b is determined by solving the following equation:
b = 2 a'(un+vn) + log[(l-pn)lpn ] (13)
After calculating equations 12 and 13, weights c~lc~ tor 204 trans_its vectors a,
15 u, and v to block 205 via path 214. If the frame contained silence only equation 6
is c~ ated
D~t~....;nAtor 205 is responsive to this tr~nc~ ed infoll~ation to
decide wL~,Illcr the present frame is voiced or unvoiced. If the ~olem~nt of vector
(vn - un) coll~ onding to power is positive, then, a frame is declared voiced if20 the following equation is true:
a Xn ~ a (un+vn)/2 > 0; (14)
or if the elçm~nt of vector (vn - un) corresponding to power is negative, then, a
lo - 1 3 3 7 7 0 8
frame is declared voiced if the following equation is true:
a xn--a (un+vn)/2 < 0 . (15)
Equation 14 can also be rewritten as:
a'xn + b--log[(l-pn)/pn] ~ 0 -
S Equation 15 can also be It~liu~n as:
a'xn + b - log[(l-pn)/pn] ~ 0 -
If the previous conditions are not meet, determin~tor 205 declares the frame
unvoiced. Equations 14 and 15 fe~l~;sent decision regions for making the voicingdecision. The log term of the ~ il~n forms of equations 14 and 15 can be
10 elimin~ted with some change of ~ ro~ nce Advantageously, in the present
example, the e~ nt co.l~j~ollding to power is the log of the speech energy.
Genc.~tor 206is~ onsi~e to the mrolLlalion received via path 214
from c~ tor 204 to c~lc~ te the (li5t~nce measure, A, as follows. First, the
;n~nt variable, d, is calculated by equation 16 as follows:
d = a'xn + b--lOg[(l~pn)/pn] (16)
Advantageously, it would be obvious to one skilled in the art to use diLrelcnt
types of voicing de~ to gcllcl~te a value similar to d for use in the following
equations. One such detector would be an auto-correlation detector. If the frameis voiced, the equations 17 through 20 are solved as follows:
- 11- 1 337708
m~ z) ml + zd, (17)
sl = (l-z) sl + zd2, and (18)
kl=sl-m2l (19)
where ml is the mean for voiced frames and kl is the variance for voiced frames.The probability, Pd, that deterrnin~tQr 205 will declare a frame
unvoiced is calculated by the following equation:
Pd = (1--z) Pd (20)
Advantageously, Pd is initially set to .5.
If the frame is unvoiced, equations 21 through 24 are solved as
10 follows:
mO = (1-z) mO + zd, (21)
sO=(l-z)sO+zd2,and (22)
- 12 - l 3377 08
ko = so - mO (23)
The probability, Pd, that determinator 205 will declare a frame
unvoiced is calculated by the following equation:
Pd = (1--z) Pd + z (24)
5 After calculating equation 16 through 22 the distance measure or merit value is
calculated as follows:
A2 Pd (1 --Pd) (ml mO) (25)
(1--Pd)kl + Pdko
Equation 25 uses Hotelling's two-sample T2 statistic to c~ te the distance
measure. For equation 25, the larger the merit value the greater the separation.10 However, other merit values exist where the smaller the merit value the greater
the separation. Advantageously, the distance measure can also be the Mahalanobisdistance which is given in the following equation:
(1-Pd)k1 +Pdko (26)
Advantageously, a third technique is given in the following equation:
1 337708
- 13 -
(kl + ko) (27)
Advantageously, a fourth technique for calculating the distance
measure is illustrated in the following equation:
A2 = a'(vn--un) (28)
Discrimin~nt detector 102 makes the unvoiced/voiced decision by
ll,.n~ g info...~;on to multiplexer 105 via path 107 in(lic~ting a voiced frame
if a'x + b > 0. If this con(lifion is not true, then detector 102 inclicates an
unvoiced frame. The values for vector a and scalar b used by detector 102 are
advantageously iclenti( ~l to the initial values of a and b for statistical voiced
10 detector 103.
Detector 102 determines the distance measure in a manner similar to
ge.~elat~r 206 by p~,.rulm-ng calc~ tiQns similar to those given in equations 16through 28.
In flow chart form, FIGS. 3 and 4 illustrate, in greater detail, the
15 operations pclrolll.ed by statistical voiced detector 103 of FIG.2. Blocks 302
and 300 implement blocks 202 and 201 of FIG. 2, respectively. Blocks 304
through 318 implem~nt st~tieti~l calculator 203. Blocks 320 and 322 implement
weights calc~ tor 204, and blocks 326 through 338 implement block 205 of
FIG.2. Cel e.alor 206 of FIG. 2 is implemented by block 340. Subtractor 207 is
20 impl~ nled by block 308 or block 324.
Block 302 c~lcul~t~s the vector which l~stnls the average of the
cl~esifiçrs for the present frame and all previous frames. Block 300 clçte ..~ es
whether speech or silence is present in the present frame; and if silence is present
in the present frame, the mean for each cl~sifier is subtracted from each classifier
25 by block 324 before control is transferred to decision block 326. However, ifspeech is present in the present frame, then the st~fistic~l and weights calculations
are p~ro~mcd by blocks 304 through 322. First, the average vector is found in
block 302. Second, the sums of the squares and products matrLx is calculated in
- 14- l 337708
block 304. The latter matrix along with the vector X representing the mean of the
classifiers for the present and past frames is then utilized to calculate the
covariance matrix, T, in block 306. The mean X is then subtracted from the
cl~ccifier vector xn in block 308.
S Block 310 then c~ tes the probability that the present frame is
unvoiced by utili7ing the present weight vector a, the present threshold value b,
and the cl~csifier vector for the present frame, xn. After calculating the
probability that the present frame is unvoiced, the probability that the presentframe is voiced is calculated by block 312. Then, the overall probability, Pn. that
10 any frame will be unvoiced is calculated by block 314.
Blocks 316 and 318 calculate two vectors: u and v. The values
contained in vector u represent the st~tisti-~l average values that each classifier
would have if the frame were unvoiced. Whereas, vector v contains values
representing the st~tictic~l average values that each cl~csifier would have if the
15 frame were voiced. The actual vectors of classifiers for the present and previous
frames are clustered around either vector u or vector v. The vectors represçnting
the cl~sifiçrs for the previous and present frames are clustered around vector u if
these frames are found to be unvoiced; otherwise, the previous classifier vectors
are clustered around vector v.
After execution of blocks 316 and 318, control is transferred to
decision block 320. If N is greater than 99, control is transferred to block 322;
otherwise, control is transferred to block 326. Upon receiving control, block 322
then calculates a new weight vector a and a new threshold value b. The vector a
and value b are used in the next sequential frame by the preceding blocks in
25 FIG. 3. Advantageously, if N is required to be greater than in_nity, vector a and
scalar b will never be changed, and detector 103 will adapt solely in response to
vectors v and u as illustrated in blocks 326 through 338.
Blocks 326 through 338 implement u/v dGt~ ;n~t~r 205 of FIG. 2.
Block 326 determines wh~ el the power term of vector v of the present frame is
30 greater than or equal to the power term of vector u. If this condition is true, then
decision block 328 is executed. The latter decision block dele~ es whether the
test for voiced or unvoiced is met. If the frame is found to be voiced in decision
block 328, then the frame is so marked as voiced by block 330 otherwise the
frame is m~rked as unvoiced by block 332. If the power term of vector v is less
35 than the power term of vector u for the present frame, blocks 334 through 338
- 15- l 337708
function are executed and function in a similar manner. Finally, block 340
calculates the distance measure.
In flow chart form, FIG. S illu~ es, in greater detail the operations
p~rc,ll~ed by block 340 of FIG. 4. Decision block S01 dct~ es whether the
5 frame has been in~ic~ted as unvoiced or voiced by e~mining the calculations
330, 332, 336, or 338. If the frame has been ~esign~ted as voiced, path 507 is
selected. Block S10 c~lr~ tes probability Pd, and block 502 recalculates the
mean, ml, for the voiced frames and block 503 recalculates the variance, kl, forvoiced frames. If the frame was dete~nined to be unvoiced, decision block S01
10 selects path 508. Block 509 recalculates probability Pd, and block 504
rec~lcul~tes mean, mO, for unvoiced frarnes, and block SOS recalculates the
variance ko for unvoiced frames. Finally, block 506 c~lclll~tes the distance
measure by p~lrO~ g the c~lcul~tions in~lic~te~
It is to be understood that the afore-described embodirnent is merely
15 illustrative of the principles of the invention and that other arrangcll.cals may be
devised by those skilled in the art without departing from the spirit and the scope
of the invention. In particular, the calc~ tion~ pc.Çu.lllcd per frame or set could
be pclro~ ed for a group of frames or sets.