Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
'~ -
TEXT SEARCHING AND INDEXING SYSTEM
Backqround of the Invention
The invention relates generally to text management
systems.
Each year organizations spend countless hours
searching through documents and images, organizing filing
systems and databases. Even with large information retrieval
systems, considerable resources are needed to index documents,
guess which key words will locate needed information, search
through pages one query at a time, and sort through all the
irrelevant data that the search actually yields.
A number of studies evaluating large information
retrieval systems show that these systems are retrieving less
than 20 percent of the documents relevant to a particular
search, and at that the same time only 30 percent of the
retrieved information is actually relevant to the intended
meaning of the search request. One of the key reasons for
poor retrieval results is that the people who perform
retrieval only know the general topics of their interest and
do not know the exact words used in the texts or in the
keyword descriptors used to index the documents.
Another study analyzed how long it would take to
index 5000 reports. It was assumed that each user was allowed
10 minutes to review each report, make indexing decisions by
selecting the keywords, and record the information. At this
rate, it would take 833 hours or 21 weeks for one full-time
person (at 40 hours per week) to process the documents. The
users would also need extra time to verify and correct the
70840-200
A
~ ~ Q ~
' . ",
data. Under such an approach, the user must index incoming
documents on a daily basis to keep the system from falling
hopelessly behind. In addition, since the user chooses the
relevant search terms, all unspecified terms are eliminated
for search purposes. This creates a significant risk that
documents containing pertinent information may not show up
during a search because of the user's subjective judgments in
selecting keywords.
- la -
70840-200
,. ~
CA 021009~6 1998-09-21
Many text retrleval systems utlllze lndex files whlch
contaln words ln the documents with the locatlon withln the
documents for each word. The lndexes provlde slgnlficant
advantages ln the speed of retrieval. One ma~or dlsadvantage of
this approach ls that for most of the systems the overhead of the
lndex ls 50 to 100 percent of the document database. Thls means
that a 100 Mbyte document database wlll requlre an index ranglng
from 50 to 100 Mbytes. Thls adds mass storage costs and overhead
to the system.
Automated lndexlng processes have been proposed. For
example, ln the book, INTRODUCTION TO MODERN INFORMATION
RETRIEVAL, by Salton and McGlll (McGraw Hlll, 1983) a process for
automatlcally lndexlng a document ls presented. Flrst, all the
words of the document are compared to a stop 11st. Any words
whlch are ln the stop 11st are automatlcally not lncluded ln the
lndex. Then, the stems of the remalnlng words are generated by
removlng sufflxes and preflxes. The generated stems are then
processed to determlne whlch wlll be most useful ln the search
process. The lnverse document frequency functlon ls an example
of such a process. The resultlng lndex of thls document, and
other documents, may then be searched for artlcles relevant to
the user.
The technlque of truncatlng words by deletlng preflxes
and sufflxes has also been applled to reduce storage requlrements
and accesslng tlmes ln a text processlng machlne for automatlc
70840-200
CA 021009~6 1998-09-21
spelllng verlflcation and hyphenation functions. U.S. Patent
4,342,085, lssued July 27, 1982 to Gllckman et al. descrlbes a
method for storlng a word 11st flle and accesslng the word list
flle such that legal preflxes and sufflxes are truncated and only
the unlque root element, or stem", of a word is stored. A set
of unlque rules ls provlded for preflx~sufflx removal durlng
compllatlon of the word 11st flle and subsequent accesslng of the
word 11st flle. Spelllng verlflcatlon ls accompllshed by
applylng the rules to the words whose spelling is to be verified
and appllcatlon of the sald rules provldes, under most
clrcumstances, a natural hyphenatlon break polnt at the prefix-
stem and stem-sufflx ~unctlons.
Summary of the Inventlon
In general, ln one aspect, the lnventlon ls an
apparatus for searchlng a collectlon of words based upon an lnput
word. The apparatus lncludes means for generatlng a first set of
words contalnlng members that are lexically related to the lnput
word, the flrst set of words lncludlng words that are other than
regular lnflectlonal nouns; and a search englne for searchlng the
collectlon of words to detect the occurrence of any of the words
from a group of search words, the group of search words
comprlslng the lnput word and the first set of words.
Preferred embodlments lnclude the followlng features.
The generatlng means ls a morphological analyzer. The collection
of words ls an lndex or text. The generating means generates
70840-200
CA 021009~6 1998-09-21
2b
certaln members of the flrst set of words by strlpplng from the
lnput word only sufflxes selected from a flrst group of sufflxes.
The flrst group lncludes only those sufflxes whlch do not
substantlally change the meanlng of words when strlpped
therefrom. In partlcular, the flrst group of sufflxes lncludes
members selected from a flrst subset contalnlng all lnflectlonal
sufflxes, #ful, #lsh, +ous, +lc, +al, #ar, #er, #or, +lve, +ory,
#able, +able, +lble, #ment, #ness, +lty, +ety, +ty, #ly, #ize,
+lfy, +fy, and #y. The morphologlcal analyzer includes a
recognition engine for recognizlng the input word and returnlng
derlvational informatlon about the recognized lnput word. The
recognition engine operates by parsing the input word to identify
70840-200
WO 92/14214 210 ~ 3 ~ B PCT/US91/00739
_ 3
any stems within the input word and, for each identified stem, to
identify suffixes which are added to produce the input word. The
recognition engine returns a derivational history including
information about any parses that were successfully performed by
the recognition engine on the input word. The derivational
history contains, for each successful parse of the input word,
the part of speech of the input word for that particular parse.
Also in preferred embodiments, the apparatus includes a
thesaurus database and the generating means uses that thesaurus
database to generate a group of synonyms, the members of which
are synonyms of certain members of the first set of lexically
related words. The group of search words further includes the
group of synonyms. The generating means generates a second group
of words from selected - hers of the group of synonyms by adding
only those suffixes to selected members of said group of synonyms
which are selected from a second group of suffixes. The group of
search words further includes the second group of words. The
members of the second group of suffixes includes only those
suffixes which do not substantially change the meaning of words
when added thereto. In particular, the second group of suffixes
includes members selected from a second subset containing all
inflectional suffixes, #ful, tish, +ous, +ic, +al, #ar, #er, #or,
+ive, +ory, #able, +able, +ible, #ment, tness, +ity, +ety, +ty,
#ly, and #y.
In addition, the morphological analyzer further includes a
generation engine for generating a second set of words that are
lexically related to selected members of the group of synonyms.
The generation engine generates the second set of words based
upon information supplied by the recognition engine for the input
word. The group of search words also includes the second set of
words. The apparatus further includes a selection means for
selecting members of the group of synonyms to iden~ify the
selected members.
In general, in another aspect, the invention is a subject
expansion system for expanding an input word into a plurality of
WO 92/14214 2 1 ~ ;~ 9 ~ 6 PCT/US91/00739
ated words. The system includes means for receiving the input
word; and means for generating a first group of words from the
input word, wherein the generating means generates at least some
of the first group of words by subtracting only suffixes selected
from a first group of suffixes, the - hers of the first group of
suffixes including only those suffixes which do not substantially
change the meaning of words when stripped therefrom.
Preferred embodiments have the following features. The
generating means also generates at least some of the first group
of words by adding to words derived from the input word only
those suffixes which are selected from a ~ecQnA group of
suffixes, the members of the secnn~ group of suffixes including
only those suffixes which do not substantially change the meaning
of words when added thereto. The subject eYrAncion system also
includes a thesaurus database, which the generating means uses to
generate a group of synonyms, wherein the - h~rs of the group of
synonyms are synonyms of certain members of the first group of
words. The generating means expands the group of synonyms into a
larger group of words by Ad~ ing to selected members of the group
of synonyms only those suffixes which are selected from the
second group of suffixes. The generating means includes a
morphological analyzer, which, in turn, includes a recognition
engine for generating a base history for the input word. The
base history identifies one or more base words for the input
word, each of the base words representing the input word with one
or more suffixes l _ved.
In general, in yet another aspect, the invention is a
subject eYrAncion system for gene~ing a group of words from an
input word. The system includes means for removing suffixes from
the input word to generate one or more base words; and a
thesaurus means adapted to receive one or more of the base words
and generate a group of synonyms for certain of them. The
generating means includes a recognition engine for generating a
base history for the input word, the base history identifying the
one or more base words. The generating means further includes a
WO92/14214 210 ~ ~ 5 ~ PCT/US91/00739
-
generation engine for generating a second set of words containing
~ hFrs that are lexically related to selected - h~rs of the
group of synonyms. The system also includes a selection means
for select~ng members of the group of synonyms to identify the
selected members.
In general, in still another aspect, the invention is an
apparatus for generating an index for a collection of words. The
apparatus includes means for selecting an input word from the
collection of words; means for generating words that are
lexically related to the input word, wherein the input word and
the lexically related words form a group of words; and an
in~ying engine for representing the oc~urLence in the collection
of words of any of the members of the group by a single member of
the group.
In general, in another aspect, the invention is an apparatus
for generating a plurality of topic words from a collection~of
words having certain informational content. The invention
includes means for selecting a subset of words from the
collection of words; a morphological analyzer for generating
morphological information about each of the words in the subset
of words; means for evaluating whether a given word of the subset
of words cG.-~eys information about the content of the collection
of words, the evaluation means basing its determination upon the
morphological information generated by the morphological
analyzer; and means for generating a topic word cG~-F-~on~ing to
the given word, if the evaluation means determines that the given
word conveys information about the content of the collection of
words.
Preferred embodiments include the following features. The
collection of words is text. The means for selecting includes a
stop list containing words which do not qualify as topic words,
and the means for selecting excludes from the subset of words
those words from the collection of words that fall within the
stop list. The means for selecting also includes a keep list
containing words which automatically qualify as topic words, and
..
WO 92/l42l4 2 1 0 0 3 5 ~ Pcr/usgl/00739
the means for selecting includes in the subset of words those
from the collection of words that fall within the keep list. The
apparatus further includes an in~rying engine, wherein the
indexing engine uses the topic word generated for the given word
to create an index for the collection of words.
Also in preferred embodiments, the morphological analyzer
includes a recognition engine for recognizing one or more
successful parses of the given word, wherein a successful parse
exists when the recognition engine is able to dec_ ose the given
word into an underlying stem and a sequence of one or more
suffixes which when added to the underlying stem form the given
word. The recognition engine generates a morphological history
for each successful parse of the given word. The morphological
history for a c~cessful parse identifies a part of speerh for
the given word, one or more base words associated within the
given word and a part of speerh for each of the base words. The
evaluating means evaluates whether the given word conveys
information about the content of the collection of words based
- upon the number of surcessful parses of the given word, and based
upon the one or more parts of s~eech identified for the given
word. The topic word generating means selects as the topic word
either the given word or one of the base words identified within
a morphological history associated with a successful parse of the
given word.
One advantage of the invention is that it substantially
improves the completeness of results in document and/or text
searches. Furthermore, the invention automatically PYpAn~C
keywords in a search to include lexically related words, synonyms
of certain of said lexically related words, and words that are
lexically related to the synonyms. In addition, the invention
gives a user the ability to search text and other documents for
concepts without knowing the exact form in which the concepts are
discussed. Furthermore, the invention is capable of analyzing
and expanding a keyword to include synonyms even when the keyword
is not in a thesaurus.
WO 92/14214 2 1 ~ ~ ~ S ~ PCT/USgl/00739
Another advantage of the invention is that it can be used to
substantially reduce this overhead in document indexing by
identifying the words that are important to the content of the
document and generating an index containing this subset of words.
This not only saves disk space but also processing time, since
the search operations can be performed on a much smaller index.
The invention generates a list of topic words from text, each of
which is informative about the content of the text, and it
excludes words from text that do not convey much information.
Using linguistic information to perform this task provides
several principled ways of distingl~iRhing words with high
information content from words with low information content.
Another advantage is that the invention helps eliminate
additional Le~ ncy in an index of cc.,oel~ts found within text
by identifying words that are related by inflection or derivation
(e.g., "category" and "categories, n "subject," "subjects," and
"subjectness"). Instead of ~e~L ~.nting each instance of a word
that differs slightly from previous instAnces, a base of the word
is stored and used to represent all forms that can be derived
from it. Thus, for example, "category" may be stored once in the
list and it can represent "category," "categories," and even
"categorical." This greatly re~l~Ges the storage required for
indexes to text.
The filtering procedures described in this application were
applied to a number of text samples for evaluation, inc}uding a
153-word paragraph from a linguistics article, a 447-word
financial memo, and a page from a functional specification
containing 550 words. The resulting lists for these three
contained 23%, 25%, and 17% of the words in the original text,
respectively. The results obtained by testing other text samples
were consistent with these numbers. The filtering mech~nisms of
the invention can identify 75% to 80% of the text as irrelevant
to the topic of the text.
.
WO 92/142l4 210 0 ~ ~ G PCT/US91/00739
- 8
Other advantages and features will become apparent from the
following description of the preferred ~ ho~ jment and from the
claims.
Description of the Preferred Embodiment
Fig. 1 is a block diagram showing a morphological analyzer
and a lexicon.
Fig. 2 is a base history for 'fish';
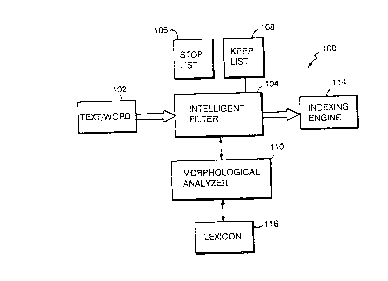
Fig. 3 is a block diagram of an indexing system which
includes an intelligent filter;
Figs. 4a-d present a pseudo-code description of the
operation of the intelligent filter;
Fig. 5 is a topic data structure used by the intelligent
filter to pass topic information back to the application;
Fig. 6 illustrates the use of the intelligent filter to
analyze text, one block at a time;
Fig. 7 is a block diagram of a text searching system
including a subject ~YpAncion module;
Fig. 8 is à block diagram of the subject e~an~ion module
shown in Fig. 7;
Figs. 9a-b present a pseudo-code description of the
operation of SESrecword;
Fig. 10 is an information object which is a - her of the
information list data structure created by SESrecword;
Fig. ll is a list of suffixes which can be added to a word
and a list of suffixes which can be stripped from a word without
significantly changing the -~ning of the word;
Fig. 12 is a block diagram of another embodiment of the
subject eY~n~ion module shown in Fig. 7;
Fig. 13 is a pseudo-code description of the operation of
SESexplist; and
Fig. 14 is a pseudo-code description of the operation of
SESqen.
WO g2/14214 21 0 D ~ PCT/US91/00739
Structure and ODeration
Referring to Fig. 1, two principal components of the
embodiments described herein are a morphological analyzer 10 and
a lexicon 12.
The Lexicon
Lexicon 12, contains information about the underlying
(lexical) forms of all the words that can be generated or
recognized (in their surface form) by morphological analyzer 10.
lo Lexicon 12 is not simply a listing of all these words in their
underlying form, but instead contains morphological items,
referred to as morphr -s, that are combined to build the lexical
forms of words. For example, the morphemes 's~ccecs' + 'ful' +
'ly' form the word 's~cc~Rcfully'. Associated with each morpheme
is information that can include the part of speech the morpheme
forms, related forms, and a list of what kinds of morphemes can
follow the current one.
~he MorDholoaical Analyzer
The main functions of morphological analyzer 10 are
recognition and generation. An internal function, referred to as
WFSrecoqnize, implements the ~ec~-J..ition capabilities of
morphological analyzer 10. Another internal function, referred
to as WFSgenerate, implements the generation capabilities of
morphological analyzer 10. h~SLe~Gy~,ize analyzes a word to
determine its morpholoqical structure, and WFSgenerate generates
the co~re~L spelling of a word given its underlying morphological
structure.
When performing recognition, morphological analyzer 10
analyzes an input string, identifying its root (or roots), any
intervening words in its derivational history, any suffixes it
may contain, and the lexical categories of all words in the
derivational history. If the input string is 5llrcescfully parsed
(i.e., if a stem and the associated suffixes required to form the
input word are found), morphological analyzer 10 returns a base
2100~6
WO 92/14214 PCT/US91/00739
, ' 10
history. If the input word has more than one parse, a base
history for each is returned, each history (or path) presenting a
listing of each form of the input word as each successive suffix
is stripped. Thus, for example, in the case of 'fishes', two
histories, shown in Fig. 2, are returned.
Each base history includes one or more records showing the
bases that result from successively stripping off suffixes. Note
that the word left after a suffix has been .. .ved is called the
base of the word with the suffix added. If no more suffixes can
be stripped off a word, the word is the root of the other words.
Each record contains the word from which a suffix is stripped,
the part of speech of that word, an index referring to the record
in the history that contains the base that is formed after the
suffix is stripped, the suffix which is added to the base to make
the word and the rating of the suffix which was added. The
suffix rating is a number that is used to classify a suffix and
the word it forms. Suffixes are grouped according to the
closeness in meaning before and after the suffix is added. For
example, inflectional ~n~ings, which simply change grammatical
features of the original word, have a rating of l. Derivational
endings, which usually change the part of speech of the original
word and generate a word more distant in meAni~g~ have a rating
of 2.
When performing generation, morphological analyzer lO
synthesizes words that are lexically related to a given word,
adding suffixes, if~appropriate, using any restrictions specified
with the input regarding suffixes or lexical category to control
the size and content of the set of words reLu~..ed. Generation
involves the following sub-tasks. Morphological analyzer lO
first does recognition on the input string to find out: how many
parses the input string has; its stem or stems; and if it already
contains suffixes. Morphological analyzer lO then identifies the
stem which is to be used for synthesis. Next, morphological
analyzer lO determines what suffixes can be added to it and
WO 92/14214 2 i Q O ~ ~ ~ PCT/US9l/00739
11
returns all surface strings that can be synthesized from the
lexical input word.
Text Management Functions
In accordance with one aspect of the invention, the
morphological analyzer is used to aid text management functions,
such as indexing and searching. Embodiments for carrying out
this tex~ management function will now be described.
Referring to Fig. 3, in an in~pying system 100, input words
102 from a block of text are p~sed to an intelligent filter 104
that automatically identifies which of the input words are topic
or concept words, i.e., words which describe the meAning of the
text in which the words appear. Intelligent filter 104 uses
several me~h~nisms to identify the topic words, including a stop
list 106, which lists words that are automatically rejected as
topic words, a keep list 108, which lists words that are
automatically accepted as topic words, and a morphological
analyzer 110, which analyzes the input word to identify its
morphological structure. Morphological analyzer 110 makes use of
a lexicon 116 to perform the morphological analysis of the input
words that are p~sse~ to it. Intelligent filter 104 uses the
morphological information derived for the input words that are
sent to morphological analyzer 110 to determine which of the
input words are most likely to be topic words. The list of topic
words generated by intelligent filter 104 then p~ses to a
conventional in~Ying engine 114, which uses th~ topic words to
generate an index for the text from which the input words were
extracted . Tndeyi ng engine 11~ may use any one of a number of
known in~PYing technjgues to either produce index cards for the
text being indexed or to generate an index identifying the
location of the topic words within the body of thé text.
Stop list 106 contains a list of words that typically do not
convey topic information, such as articles, prepositions,
' conjunctions, and other function words. A substantial number of
the words in this list can be identified from a dictionary on the
WO 92/14214 2 1 0 0 9 ~ ~ PCT/US91/00739
basis of their part of speech. The value of adding all of such
words to a stop list is that intelligent filter 104 need not
waste time and computational resources of morphological analyzer
110 to analyze those words. Stop list 106 also includes words
that were identified by running samples of text throuqh
intelligent filter 104 and then analyzing the results to identify
words that appear at the output but clearly do not convey topic
information. Thus, another value of stop list 106 is that it
serves to catch those few words that are not caught by the
analytic component of the intelligent filter 104.
Keep list 108 serves the opposite function to that of stop
list 106. It specifies words that the analytic 5C': ~ Dnent of
intelligent filter 104 might tend to reject even though they
convey topic information. Keep list 108 may be empirically
generated by running several sample do -nts through intelligent
filter 104 and then identifying those words which were rejected
but which the user feels should be included among a list of topic
words. In this way, keep list 108 provides a -C~nism for fine
tuning the system and for customizing the system to the
particular needs and the unique vocAhul~ry of particular users.
The operation of intelligent filter 104 will now be
described with the aid of the flow diagram presented in Figs. 4a-
d. When a text indexing application ~G~r am needs to index a
block of text, it first calls an initialization function to open
up the functions and lexicons (i.e., the reference works) that
will be used by intelligent filter 104 to analyze the words
passed to it. The application which calls intelligent filter 104
also allocates space for a topic st~ucture 124 (see Fig. 5),
which is used by intelligent filter 104 to pass topic information
back to the application. Topic structure 124 includes a field
115 for the input word which was analyzed, a field 119 for an
array of pointers to the bases that were found in the input word,
and a field 117 for the number of bases within the array.
In its call to intelligent filter 104, the application
passes an input word 102, i.e., the current word. Referring to
WO 92/14214 21 0 0 ~ ~ 6 PCI/US91/00739
~."~..~
13
Figs. 4a-d, intelligent filter 104 first determines whether the
current word qualifies for morphological analysis by ch~t king
whether it contains alphabetic characters (step 130). If it does
not have alphabetic characters, filter 104 rejects the current
5 word as a topic word and requests the next word from the
application program (step 132). If the current word does have
alphabetic characters, filter 104 ~-h~ckc whether there are
quotation marks around it (step 134). If the current word is a
quoted string, filter 104 identifies it as a topic word and
10 passes this information to in~eYing engine 114 using topic data
structure 124 so that in~PYing engine 114 can index the current
word (step 136). Then filter 104 requests another word. On the
other hand, if the current word is not a guoted string, filter
104 looks up the word in keep list 108 (step 138).
If the current word Arpe~rs in keep list 108, filter 1û4
indexes the word and moves on to the next word (step 140). If
the current word does not ~ppe~r in keep list 108, filter 104
compares it against stop list 106 (step 142). If the current
word appears in stop list 106, filter 104 rejects the word and
20 requests the next word (step 144). If the current word does not
appear in stop list 106, filter 104 calls upon the ~eoG~J~.ition
capability of morphological analyzer 110, namely, w~S~- Gy..ize,
to obtain a morphological analysis of it (step 146).
WFSreco~nize identifies the stems within the current word
25 and determines which suffixes have been added to those stems to
create the current word. The analysis begins with the first
character in the current word and E~6c ~e~l-c one character at a
time until each stem and any suffixes which have been attached to
that stem are found. That is, w~S.ecG-J.,ize parses the input
30 word. When the analysis is complete, WFSrecognize ~e~u~ns a base
history for the current word. The base history consists of a
list of history arrays, each of which contains the records of a
corresponding one of the successful parses which were found.
It is possible that WFSrecognize will not find the current
35 word or any base words for the current word within lexicon 116.
WO 92/14214 210 ~ 3 ~ 6 PCT/US9l/00739
1~
In that case, WFSrecognize indicates that the word was not
recognized. This occurs for words such as some proper names
(e.g., Nixon). When WFSrecognize reports tha. the current word
was not recognized, filter 10A treats the current word as a topic
word, indexes it and then requests the next word (step 148).
It is also possible that the current word contains a
character that cannot be processe~ by WFSrecognize. In such
cases, filter 104 indexes the word and then moves onto the next
word (step 150).
If WFSrecognize succ~e~g in parsing the current word,
intelligent filter 104 uses the returned base history information
to evaluate whether the current word is a topic word. First,
filter 104 checkc whether the current word has only one part of
speech associated with it (i.e., was there only one s~cce~sful
parse of the word?) (step 152). If only one part of speech was
returned, filter 104 checks what the part of speech is. If the
part of speech is a noun, filter 104 indexes the ~u~-en~ word and
moves on to the next word (step 154). For example, the current
word might be 'history' or 'science', both of which are nouns, in
which case, filter 104 indexes the word.
on the other hand, if the part of ~ee~h is an adjective,
such as 'historic' or 'scientific', filter 104 obtains the base
of the current word and chec~c its part of speech (step 156).
(Recall that the base is identified in the base field of the
history record for the current word.) If the part of speech of
the base of the current word is a noun, filter 104 in~Y~s the
base and then moves onto the next word (steps 158-160). If the
part of speech of the base is an adjective, filter 104 obtains
the base of the base and checks its part of speech (steps 162-
164). For adjective bases, filter 104 indexes the base only if
the base of the base is a noun (step 168). Otherwise, it rejects
the word and moves on to the next word (step 170). For example,
if the current word is 'historical', i.e., an adjective having a
noun base of 'history', filter 104 indexes 'history'. If the
WO 92/14214 210 0 ~ S ~ PCT/US91/00739
base is neither a noun nor an adjective, filter 104 also rejects
the current word and moves on to the next word.
If the current word is an adverb, filter 104 performa a
simil~r ~nalysis to that wh~ch it performed for an ad~ectlve
(steps 174-202). ~hat is, filter 104 gets the base of the
current word and checks its part of speech. If the base is a
noun, filter indexes the base and moves on to the next word.
However, if the base is an adjective, filter 114 looks at the
next level, i.e., the base of the base. ~f the base of the base
lo is a noun, as in the case of 'scientifically', filter 104 indexes
the base of the base (i.e., 'science') and moves on. If the base
of the base is an adjective, however, filter moves to the next
level of the history for the ~u--el,~ word and looks at the base
of the base of the base, if one exists. If the ba~e of the base
of the base is a noun, filter 104 in~yes that base, otherwise,
it rejects the word and moves on.
If the current word has only one part of .~ch and if it is
not a noun, an adjective or an a-lv~b, filter 104 rejects it.
Similarly, if the current word is an adverb but its base is
neither a noun nor an adjective, filter 104 rejects it.
For the cases in which the current word has two (and only
two) parts of s~eecl, (i.e., it is ambiguous), filter 104 indexes
the word only if one part of ~peech is a noun and the other part
of speech is not an adverb (steps 206-212).
For the cases in which the current word has three parts of
speech (and only three), filter 104 indexes the word only if one
of its parts of speech is a noun (steps 214-220).
Finally, for those cases in which the current word has more
than three parts of ~,ee~h, filter does not index the word (steps
222-224).
In the above description, it should be noted that if the
current word is ambiguous (e.g., 'leaves' may be the plural of
'leaf' or the third person singular of the verb 'le~ve'), filter
104 will output more than one base for the word.
WO 92t14214 2 1 o o ~ 5 6 PCr/USgl/00739
16
After filter 104 has processed all of the words in the text,
the application frees up any allocated tables that were used and
it closes the reference work.
After the application has used the information in the topic
structure that was passed to the application, the application
also frees the memory allocated for it.
In the above-described emho~ t, text is procecse~ one
word at a time. That is, the application program pacc~ each
word to intelligent filter 104, one word at a time, and generates
an index using whatever is returned. It is also possible for the
application to pass a block of text to intelligent filter 104, in
which case filter 104 generates an array of topic structures, one
structure for each topic word identified in the block of text.
In that case, the application ~Gy~am calls a~text analysis~
program which operates as shown in the flow diagram of Fig. 6.
The application program first initializes the text analysis
program, and the appropriate data stru~LuLes and it opens the
reference work containing the text that is to be in~ye~ (step
225). Then, the application ~ G~Lam fills a buffer with a first
block of text to be analyzed and pAs6es this to the text analysis
program which, in turn, tokenizes the text to identify the
individual words within it (steps 229 and 231). Known techniques
may be used to tokenize the text, using, for example, spaces
and/or quotation marks as indicators of word boundaries. The
text analysis program calls intelligent filter 104 for each word
found within the block of text (step 233). Intelligent filter
104 processes the words pA~se~ to it and builds a topic structure
array including the individual topic structures produced for each
of the topic words found among the words from the block of text.
After the topic structure array for the entire block of text is
complete, the application ~rO~ am retrieves the individual topic
structures within the array and checks each topic word to see if
it has already been identified for the text. If it has not, the
topic word is added to a list of concepts associated with the
text ~steps 235-237).
WO 92/14214 2 l 0 n ~ 5 5 ~ PcT/US9l/oo739
17
The application ~lo~,am continues in this fashion through
the text, one block at a time until the entire text has been
indexed (step 239). After processing all of the text, the
application program frees up the memory which was used during the
text analysis operation and closes all relevant files.
Note that intelligent filter 104 tends to compress the size
of the index required for any given text for at least two
reasons. First, it identifies words that qualify as topic words
and rejetcs other words which do not relate to content of the
text. In addition, for many text words it supplies a word that
is lexically related to the text word and the ind~yjng engine
indexes the lexically related word. As a consequence, a group of
lexically related words within the text tends to be represented
by a single word selected from the group of lexically related
words.
The approach of using a single word to represent a group of
lexically related words in a text index may be employed by
itself. In that case, the user might manually select a word from
text which is to be ~e~Lesented in the index and then use the
recognition capabilities of the morphological analyzer to produce
a group of words that are lexically related to the selected word.
As the i~~Ye~ word, the indexing engine would then use a word
selected from the set of words formed by the original word and
its lexically related words. In other words, each word in the
resulting index Le~ esents a set of lexically related words
within the text. In that case, each of the lexically related
words in the text does not ~ppeAr as a separ_te word in the
index.
Fig. 7 illustrates a system lO in which morphological
analyzer llO assists in searching text. In text search system
201, an input word 203, which is part of a search request
generated by a user, is passed to a Subjéct Expansion Module (SES
module) 205 where it is expanded into a list of related subjects.
A search engine 213 uses the expanded list generated from the
input word to search text stored in a memory 207 and to return as
WO 92/14214 210 0 ~ ~ 6 PCT/US91/00739
18
output the identity of those documents which refer to any of the
items appearing on the expanded list. To perform its subject
expansion functions, SES module utilizes morphological analyzer
110 to generate a list of words lexically related to the input
word. Morphological analyzer 110 relies upon the information
stored in a lexicon 110 to perform a morphological analysis of
the input word and generate a corresponding base history. The
history contains the different bases found within the input word
and the suffixes that are attached to those bases to generate the
input word. Using the information developed by morphological
analyzer 110, SES module 205 uses a thesaurus lexicon 211 to
expand certain of the lexically related words into a list of
synonyms for those words. In general, the eYrAncion is done for
each of the definitions that are found for the input word, i.e.,
for each part of speech. However, since synonyms are not
available for all words, in the cases when synonyms are not found
for the input word, SES module 205 uses lexically related words
that are found within the base history generated for the input
word.
The operation of SES module 205 is generally illustrated by
the block diagram shown in Fig. 8. When an input word is pAcse~
to SES module 205, it calls an SESinit function 215 to initialize
the data structures, functions and lexicons which will be used
during its operation. After initialization, a SESrecword
function 217 uses morphological analyzer 110 to construct a base
history for the input word and, using the information available
in the base history, generates a list of synonyms from thesaurus
lexicon 211. For each of the words and the synonyms generated by
SESrecword, a secon~ function SESexplist 219, takes the words and
synonyms generated by SESrecword 217 and generates a set of
lexically related words and synonyms and lexically related
synonyms, which it passes along with the input word and its
lexically related words to search engine 213 as an expanded list
to be used for searching. After the exrAncion task is completed,
a SESfini function 221 frees up the memory that was initialized
WO 92/14214 2 1 0 ~ ~ S 6 PCT/US91/00739
19
,,~
for this operation and closes the lexicons. SESrecword 217 and
SESexplist 219 will now be described in greater detail.
SESrecword 217 operates as shown in Figs. 9a-b. When the
rullctlon is first called, it uses WFSrecognize to analyze the
inPut word that is passed as part of the function call (step
230). For each successful parse of the input word WFSrecognize
returns a history. Each history contains, among other things,
the stem, the suffixes which are attached to the stem to form the
input word and the part of ~eech of the input word. Since it is
possible that more than one definition of the word exists,
WFSrecognize may find more than one successful parse.
After WFsreco~llize completes its recognition function and
returns the information, ~S~e~ d 217 loops through each
definition (i.e., path in the history) that is L~u~.lel (step
232) and for each path, it performs the following operations.
First, it r~ whether the ~ e.,L path has the same part of
speech as any other path which it has proces~ed thus far (step
254). If the ~L.en~ path has the same part of speech as a
previously y~ocesse~ path, S~S~e~.d 217 skips the current path
and moves on to the next one (step 236). Note that the ~Yr~ncion
of a path that yields the same part of ~eerh as a previously
eYrAn~ed path will also yield the same ~r~nsion.
If the part of ~e~ch for the ~u~.erl~ path is new,
SESrecword 217 checks whether the current part of ~eech is
inflected (step 236). If it is inflected, there is the
possibility that the base for the current path has already been
found for a previous path. For example, the past tense and the
past participle of a verb have the same base and, therefore,
yield the same eYr~ncion. To avoid duplicating previous work and
in the case of inflected words, SESrecword 217 checks the base of
the current path against other bases that have been found for
other paths (step 240). Information about the other paths is
stored in an information list that SESrecword 217 is building
during this process to return its results to the application
program. The information list, which is a collection of
WO 92/14214 PCT/US91/00739
~10~95G ~o
different forms that are recognized for the input word, is a
linked list of information objects 223, as illustrated in Fig.
10. If the base is found within the information list, SESrecword
217 skips the current path. Otherwise, it checks whether the
base form is in thesaurus lexicon 211. If the base form is in
the thesaurus lexicon, SESrecword 217 builds a new information
object 223 for the base and adds the new object to the
information list. The new object contains all of the synonyms
that were found in the thesaurus lexicon associated with that
base.
Referring back to Fig. 10, each object 223 includes a field
223(a) containing the word for which synonyms were found, a
pos list 223(b) identifying the parts of speech associated with
the word, a thesaurus buffer (TH buffer) 223(c) which contains
all of the synonyms for the word, and a pointer 223(i) to the
next object in the list. Each information object also includes a
num words field 223(d) for specifying the number of synonyms in
TH buffer 223(c), a num meanings field 223(c) for the number of
different -Anings or connotations that were listed for the word,
and a pos sum field 223(f) for predetermined statistics about the
average number of generated forms that will typically result from
~YpAn~ing the word as a function of its part of speech. In other
words, pos sum provides a basis for estimating how many words an
expansion of the list of words in TH buffer 223(c) will produce.
Experience indicates that the number of words that an eYpansion
will produce dep~c on the part of speech of the word. For
example, a noun typically results in three words when eYpAn~ed, a
verb results in seven words and an adjective results in four
words. This information is used later by the eYpansion function
to determine how many words of the TH buffer to eYp~n~.
Each information object 223 also includes a sample
information (sample info) field 223(q) containing an array of
pointers to each of the possible samples within TH buffer 223(c)
and a selection info field 223(b). A sample is defined as a
possible meaning or connotation of the word. In the case of the
WO 92/14214 21 ~ O ~ 5 ~ PCT/US91/00739
~1
College Thesaurus, synonyms are organized into different meaning
categories. The pointers in sample info field 223(q) identify
the beginning of each of the categories within TH buffer 223(c).
As will be explained in greater detail shortly, in some
embodiments, the user is offered the option of selecting which
samples to include within the eyp~ncion performed by SESexplist
219. The user's indications are recorded in selection info field
223(k) for later use.
Referring again to steps 238-248 in Fig. sa, after
constructing the information object for the base or after
determining that the base form is not found in the thesaurus
lexicon, SESrecword 217 also cherks whether the input word is in
the thesaurus as an inflection (step 246). If it is, SESrecword
builds another information object for the input word (step 248).
For the cases in which the part of D~e~cl- for the current
path is not inflected, S~S~e~_~Ld 217 rhec~c if the word is in
the thesaurus lexicon (step 252). If the word is in the
thesaurus lexicon, an information object is built for the word
and added to the information list (step 256). On the other hand,
if the word is not in the thesaurus, ~S.~ 217 examines its
history to determine whether a suffix can be stripped from the
word to form a base having substantially the same meaning (steps
258-260). The words have substantially the same ~ning means,
for example, if the function of the words created by stripping
2S the suffix is semantically the same as the function of the word
from which the suffix i5 stripped. Only certain suffixes can be
stripped without significantly changing the meaning of the word.
A list of those suffixes appe~rs in Fig. 11. (Note that '+' and
'~' are ho~ ry characters or markers following Aronoff, Mark
(1976) Word Formation in Generative Grammar, Linguistic Inquiry
Monograph 1, MIT Press, Cambridge, Massachusetts.) Such a list
is stored in a table which SESrecword access~s to determine
whether it is permissible to strip the current suffix so as to
create a word from which synonyms may be generated. If the
suffix can be stripped, SESrecword 217 tries to find the
WO 92/14214 2 1 0 0 ~ ~ 6 PCT/US91/00739
",,
resulting base in the thesaurus lexicon. If the base is found,
the function builds a word information object for the base. If
it cannot be found, however, the function builds a word
information object for the input word without any thesaurus data.
After SESrecword has looped through each path and performed
the operations described above, it returns the completed list of
information objects to the application program.
As shown in Fig. 12, in another embodiment, SES module 205
is modified to permit the user to skip over information objects
for exr~ncion or to select the synonyms within an information
object for which eYrAncion will be performed (an operation
referred to generally as sampling). In the modified version of
SES module 205, the application pAsses the ou~L of SESrecword
217 to a SESsample function 223 which selects a subset of words
from each category (i.e., from each meaning) and the application
displays these subsets of words to the user. In the present
~ ho~i ent (i.e., with the College Thesaurus), SESsample 223
selects the first two words in each category for display. The
user then selects which information objects are to be ~ippe~ and
the categories within information objects for which ~Yr~nsion is
desired. Another function, namely, SF-SA~d sel 227, stores the
user's selections in selection info field 223(b) of the
appropriate information object 223 (see Fig. 10).
In both embodiments described above, the actual ~p~ncion of
the words returned by SESrecword 217 is performed by two other
functions, namely, SESexplist 219 and SESgen 221 and illustrated
in the flow diagrams of Figs. 13 and 14, respectively. Each of
those functions will now be described.
SESexplist 219 takes the information list ~et~.,e~ by
SESrecword 217 and ~xr~nAs it to include lexically related words
generated from the recognized forms of the input word and the
synonyms found by SESrecword 217. Referring to Fig. 13, when
SESexplist 219 is first called, it loops through the list of
information objects (step 270) and computes the total number of
3~ words in the TH buffers from the numbers in num words fields
WO92/14214 2 1 0 ~ ~ 5 6 PCT/US91/00739
223(d) (see Fig. 10) (step 272). Then, using the information
stored in pos sum field 223(f), SESexplist 219 estimates the
total number of words likely to result from exp~n~ng all of the
sampled categories obtained through the thesaurus (step 274).
(If the sampling feature is not present, it is assumed that words
from all categories will be expanded.) ~he total number i~ then
scaled to reflect any limitations that might exist on available
memory. In a DOS environment, for example, the memory space
limitations can be quite severe; whereas, in other environments,
such as virtual memory systems, it may not be necessAry to limit
the number of words that are generated. Using the scaled number,
SESexplist 219 computes the number of words that can be safely
chosen from each sampled category for eYpAncion without eycee~ing
the available memory. The distribution of words rhosen from the
categories is performed so as to fairly L~lesent all of the
sample categories in the TH buffers 223(c). That is, some number
is chosen from all selected categories with the larger categories
receiving larger representation than the smaller categories.
After SESexplist 219 determines the number of words that can
20 - be exrAn~e~ from each category, it loops through the list of
information objects again to perform the actual eYr~ncion
operations (step 276). For the current information object,
SESexplist 219 first chec~c whether it was selected to be skipped
(step 278). If the current object is marked to be skipped,
SESexplist 219 moves on to the next information object. ~f the
current object is not selected to be skipped, SESexplist 219
checks whether it has been sampled by examining the contents of
its selection info field 223(h). If the object has been sampled
and selections were made, SESexplist calls SESgen 221 on those
selections. In this phase of operation, SESgen 221 ~yrAn~c the
permitted h~r of words within the sampled category based upon
the computations performed in steps 272 and 274, above.
If the object has neither been skipped nor sampled,
SESexplist 219 calls SESgen 221 on all of the data present in the
object (step 282). During this step, SESgen only expands the
9 5 G
WO 92/14214 PCT/US91/00739
24
number of words in each category that are permitted by the
limitations computed in steps 272 and 274, above.
When SESexplist 219 is done ~yp~n~jng the word in a given
information object, it frees up any space associated with that
object (step 284). After SESexplist has looped through all
information objects, it returns the results of the expansion to
search engine 213, which constructs a search based upon the
information in the ~YpAn~ed list. In other words, search engine
213 conducts its search using the input word, words that are
lexically related to the input word, synonyms of the input word
and of the words that are lexically related to the input word (if
any such synonyms exist), and words that are lexically related to
the synonyms. Search engine 213 uses any one of a number of
known te~hnigues to use the ~yrAnAed list to cG~ the search
for all ~9_ -nts or locations within do~. ~nts that refer to any
words on the exrAn~e~ list.
The repeated calls to SESgen 221 generate the result list
that is returned. As shown in Fig. 14, when SESgen is called, it
first identifies the input word and its part of speech from the
information found within the appropriate fields of the
information object (step 290). For the input word, SESgen calls
a generation function, ~ n~rate, which causes morphological
analyzer llO to produce all inflections and derivations that can
be generated from that word by the addition of one suffix. It
also pro~ces any inflections of the derivational forms.
WFSgenerate returns an ouL~t history data structure, which is an
array of histories for all of the expansions that were found.
The first record in each history contains the input word, and the
last record contains an inflected form, a derivational form, or
an inflection of a derivational form. In this last case, a
middle record will contain the derivational form, i.e., the input
word with one derivational suffix attached.
From among the histories that were produced, SESgen 221
selects all inflectional forms and adds those to a result list
3~ (step 294). If derivational forms are also included within the
WO 92/14214 2 10 0 9 S 6 PCT/US91/00739
. ,.
output history data structure, SESgen 221 selects only those
derivations that have a suffix which can be attached to the
current part of speech of the input word without significantly
changing the meaning of the word. Only certain derivational
suffixes may be attached to a base without significantly changing
its meaning. As in the case of stripping suffixes, words formed
by adding suffixes will have substantially the same meaning as
the base word, for example, if the function of the words created
by adding the suffix is semantically the same as the function of
the word to which the suffix is added. A list of those suffixes
appears under the appropriately labelled column in ~ig. 11. Such
a list of suffixes is stored in a table which SESgen accesses to
determine whether any derivations have a suffix that can be
attached to the ~L .el.~ part of 6peerh. It adds only those
entries to the result list.
After SESgen has procec~o~ the input word of the information
object, it loops through the synonyms found within the TH buffer
in the information object (step 296). For the current synonym,
SESgen 221 compares its part of ~ee~l~ with that of the input
word (step 298). If the parts of sp~ch are the same, SESgen 221
performs the same ~yr~ncion as was described above. That is, it
generates all inflections and derivations of the synonym which
have only one suffix added to the ~yl~ol~m and it adds the
inflections and only those derivations that have a suffix which
can be attached to the current part of speech of the synonym to
the result list for the information object (steps 300 and 302).
After SESgen 221 has looped through all of the synonyms for
which eYr~ncions are to be generated, it ,e-u.,.s the result list
to SESexplist 219 (step 300).
Note that a limited form of subject eyrancion can be
employed which does not use a thesaurus. In that case, the
search is conducted using the input word plus the group of
lexically related words that are generated by the morphological
analyzer.
Other embodiments are within the following claims.