Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
WO 9511-t27-i PCTlUS9-1113338
1 ~2152fifi8
pescription
MEMORY MANAGEMENT OF COMPRESSED MEMORY PAGES
Technical Field
The present invention relates to data compression, and more
particularly. to compression of memory pages in a limited memory computer
system.
Back, ound of the Invention
The history of the modern computer has been marked by the persistent
demands of users for ever increasing computer power and storage capacity in an
ever
decreasing amount of space. Early efforts at satisfying the users' demands
focused on
hardware improvements. that is, building memory devices that store the
greatest
amount of information in the smallest amount of space. While hardware
1~ improvements to date have been tremendous, they have always laQVed behind
the
desires of many computer users.
In recent years as the hardware improvements have approached the
boundaries of physical possibility, efforts have shifted away somewhat from
further
hardware improvements. Instead efforts have focused increasingly on software
data
compression--storing more data in existing memory devices. Data compression
technology ranges from simple techniques such as run length encoding to more
complex techniques such as HufJulan coding, arithmetic coding. and Lempel-Ziv
encodine.
Many present computer systems, such as common desktop computer
systems can store hundreds of millions of bytes of data. These systems
typically
employ several different types of memory devices of varying speeds. sizes and
costs.
For example, a common desktop computer system typically has read-only memory
(ROM), random-access memory (RAM), a hard drive, and at least one floppy disk
drive. Although RA11~I is much faster than a hard drive, it is also much more
expensive and requires more space, so the great majority of the data stored in
the
computer is stored on the hard drive and brought into RANI only as necessary
for
processing. l~lany commercial products currently exist to compress the data
stored
on the computer's secondary memory devices. i.e., the hard drive or floppy
disks
used in floppy drives. Most notably. Microsoft Corporation has incorporated
compression technology into its MS-DOS 6.0 operating system. The MS-DOS 6.0
operating system compresses the data on a hard drive or floppy disk and
decampresses the data and loads it into the R.AM for processing the data.
::~.
b
WO 95114274 PCT/US94113338
2
Recently, several hand-held computers have been developed that are
small enough to fit in the palm of the user's hand. These computers have only
ROM
and RAM memory devices, as they are too small for existing hard drives and
floppy
disk drives. Given that these computers have no secondary memory device,
existing
S compression products including the MS-DOS 6.0 operating system cannot be
used.
As a result existing hand-held computers can only store data in uncompressed
form in
an amount that is limited by the amount of random access memory that fits
within the
computer.
Summary of the Invention
A preferred embodiment of the present invention is directed to a
method of implementing data compression in a working memory of a computer, the
working memory being implemented using random access memory (RAM). The
compression method operates by dividing the working memory into a plurality of
memory blocks that includes an uncompressed memory block and a compressed
memory block. The compression method stores uncompressed data, including
instruction code, in the uncompressed memory block during processing of the
uncompressed data. Data that is not currently being processed is stored in
compressed form in the compressed memory block. When a portion of data, such
as
a 4 kilobyte data page, is desired for processing, the compression method
first
determines whether the page is located in the uncompressed or the compressed
memory block. If the data page is located in the compressed memory block, then
the
compression method creates space for the data page in the uncompressed memory
block by compressing one of the pages in the uncompressed memory block and
storing it in the compressed memory block. The requested compressed page is
then
transferred to the uncompressed memory block and is decompressed. Processing
continues with the decompressed page without the user or application knowing
that
the page was previously in compressed form.
Brief Description of the Drawines
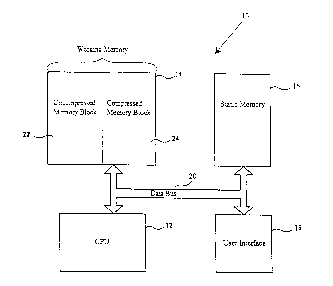
Figure 1 is a computer system employing the data compression
method of the present invention.
Figure 2 is a flow diagram of a data compression method used in
conjunction with the system shown in Figure 1.
Figure 3 is an address translation system used in accordance with the
system shown in Figure 1.
WO 95114274 ~ PGTIUS94l13338
3
Figure 4 is a block diagram illustrating a sample compression search
. data structure used in the system shown in Figure 1.
A preferred embodiment of the present invention is directed to a
method of implementing data compression in a working memory of a computer, the
working memory preferably being implemented using random access memory
(RAM). As is well known, working memory is memory that stores data during
processing of the data by the computer. The compression method operates by
dividing the working memory into a plurality of memory blocks that includes an
uncompressed memory block and a compressed memory block. The compression
method stores uncompressed data, including instruction code, in the
uncompressed
memory block during processing of the uncompressed data. Data that is not
currently
being processed is stored in compressed form in the compressed memory block.
When a portion of data, such as a 4 kilobyte data page, is desired for
processing, the
compression method first determines whether the page is located in the
uncompressed or the compressed memory block. If the data page is located in
the
compressed memory block, then the compression method creates space for the
data
page in the uncompressed memory block by compressing one of the pages in the
uncompressed memory block and storing it in the compressed memory block. The
requested compressed page is then transferred to the uncompressed memory block
and is decompressed. Processing continues with the decompressed page without
the
user or application knowing that the page was previously in compressed form.
The data compression method operates in conjunction with a computer
system 10 shown in Figure 1. The computer system 10 includes a central
processing
unit (CPU) 12, a working memory 14, a static memory 16, and a user interface
18
connected to each other by a data bus 20. The user interface 18 can be any
conventional user interface that allows a user to input information into the
computer
system and allows the computer system to output information to the user.
Preferably,
the user interface 18 includes a display device, such as an LCD screen, and an
input
device such as a keyboard, a pen with a digitizing tablet, or a microphone
with a
voice recognition engine. The static memory 16 is non-volatile memory such as
read-only memory (ROM) or erasable, programmable read-only memory (EPROM).
In a preferred embodiment the static memory is Flash EPROM recently developed
by
INTEL Corp. in which the data is erasable and re programmable by voltage
pulses
without having to remove the Flash EPROM from the computer system.
WO 95114274 PCT/US94I13338
21~2sss
4
The working memory 14 is random access memory (RAM) that is
divided into an uncompressed memory block 22 and a compressed memory block 24.
In a preferred embodiment the working memory is 4 megabytes in size and is
divided
to produce a 1 megabyte uncompressed memory block and a 3 megabyte compressed
memory block. It will be appreciated that the division of the working memory
is
accomplished with software and is not an actual physical division; ~ Since the
data in
the 3 megabyte compressed memory block is compressed the actual memory
capacity
of the working memory is approximately 5 to 7 megabytes, depending upon the
compression ratio obtained.
As is conventional, the computer system 10 includes an operating
system that provides an interface between application programs and the
hardware of
the computer system, including the CPU 12. In the present invention, the
operating
system remains stored in the uncompressed memory block 22 and is never
compressed. In addition, the software code used to compress other data is
stored in
the uncompressed memory block 22 and is never compressed.
In a preferred embodiment of the present invention, the working
memory 14 is managed using 3 layers of memory addressing. The first layer,
known
as the logical or segmented address layer, is the layer at which an
application
program address the memory. The memory space at the logical layer is divided
into
units of memory called segments. Each segment is an independent, protected
address
space of varying size. Access to segments is controlled by data which
describe,
among other things, the size of the segment and whether the segment is present
in the
working memory.
The second address layer is known as the linear address layer and
provides an unsegmented mapping of all of the memory available to the
application
programs. Preferably, the data compression method allows approximately 6
megabytes of virtual memory to be addressed by the linear address layer even
though
the working memory actually stores only 4 megabytes of data. The linear
address
space is divided into numerous units known as pages. Each segment typically is
made of a plurality of pages although a single page could also include a
plurality of
segments.
The third address layer is the physical address layer. It refers to the
actual physical mapping of the 4 megabytes working memory 14. The present
invention employs a mechanism known as paging to translate the 6 megabytes of
linear addresses to the 4 megabytes of physical addresses. The paging
mechanism
keeps track of where each page of the 6 megabytes of linear addresses is
stored in the
4 megabytes of physical addresses. Such a three-layer addressing scheme is
~~5~sss
WO 95114274 PCTIUS94113338
supported by Intel's 80 x 86 family of microprocessors although the invention
is not
. limited to Intel processors.
A preferred embodiment of a data compression method according to
the present invention is shown in Figure 2. The data compression method begins
by
5 receiving a request for access to a particular item of data, such as the
first line of a
subroutine from an application program in step 26. The application program
addresses the data unit with a logical address that includes a segment address
and an
offset address into the segment. A segmentation translation mechanism in the
CPU
translates the logical address into a linear address that includes a page
directory
address, a page address, and a page offset address. The page directory address
and
the page address together index a requested page that includes the requested
data
item.
In step 28 the compression method determines whether the requested
page is located in the compressed memory block 24. A complete discussion of
the
1 S step used to determine whether the requested page is located in the
compressed
memory block will be discussed in detail below in connection with Figure 3. If
the
requested page is in the compressed memory block, then the method must make
room
in the uncompressed memory block 22 to receive the requested page from the
compressed memory block. Although any page could be transferred from the
uncompressed memory block to the compressed memory block, the compression
method preferably locates a least recently used (LRU) page for transferal in
step 30.
In a preferred embodiment, the LRU page is determined by
monitoring the pages being accessed. Each page is associated with a page table
entry
that includes a bit known as the Accessed bit. Whenever a page is accessed for
reading or writing, the CPU 12 sets the Accessed bit. The operating system is
programmed to periodically clear and test the Accessed bit for each page. If
the
Accessed bit for a page has not been reset between periodic clearings by the
CPU,
then the operating system knows that the page has not been used. By keeping
track
of the number of times a page has been reset, the operating system knows which
page
has been least recently used.
In step 32 the method compresses the uncompressed LRU page
according to a predetermined compression scheme that will be discussed in more
detail in connection with Figure 4. The compressed page is then stored in an
' available location in the compressed memory block in step 34. The paging
mechanism stores the address of the compressed page in a table entry
associated with
the page as discussed below with respect to Figure 3. After the compressed
page is
WO 95114274 PCTIUS94113338
6
transferred to the compressed memory block 24, the uncompressed memory block
22
has sufficient space for receiving the requested page.
In step 36 the requested page is accessed according to the physical
address corresponding to the logical address used by the application program.
In step
38 the requested page is moved to the uncompressed memory, block into the
memory
locations that previously contained the LRU page that was just compressed. In
step
40 the requested page is then decompressed as describ~\d below in connection
with
Figure 4. After being decompressed the requested''page is then accessed by the
application program in step 42. The user and the application program have no
knowledge of whether the requested page was already located in the
uncompressed
memory block or whether it was transferred to the uncompressed memory block as
described above.
Shown in Figure 3 is a block diagram of the mechanisms for
translating a logical address to a physical address. As discussed above when
an
application program desires a data item, it gives the CPU 12 a logical address
of the
data item. The logical address includes a segment selector field 44 and a
segment
offset field 46. The segment selector field indexes a segment descriptor 48 in
a
descriptor table 50. The segment descriptor specifies information regarding
the
segment selected including the linear address of the first byte of the
segment. The
linear address of the first byte of the segment is added to the value of the
segment
offset field 46 specified in the logical address to obtain the linear address
of the
requested data item.
The linear address for the requested code item includes a page
directory field 52, a page table field 54, and a page offset field 56. The
page
directory field indexes a directory entry 58 in a page directory 60. The page
directory
field actually specifies an offset value that is added to the address of the
first line of
the page directory 60 which is specified by a page directory base register 62.
The
directory entry 58 indexes the beginning of a page table 64. The page table
field 54
of the linear address specifies an offset value from the beginning of the page
table 64
and indexes a page table entry 66. The page table entry 66 indexes the
beginning of
the requested page 68. The page offset field 56 of the linear address
specifies an
offset value from the beginning of the page to index the requested data item
70.
In addition to specifying the address of the beginning of the requested
page 68, the page table entry includes the accessed bit discussed above and a
Present
bit. The Present bit is set whenever the requested page associated with the
page table
entry is transferred to the uncompressed memory block 22. When the page is
compressed and returned to the compressed memory block 24, the CPU 12 clears
the
WO 95J1.127-i PCTlUS9-1113338
7
Present bit. As a result whenever a page is requested. the CPU checks the
Present bit
associated with the pale and issues a page fault if the Present bit is clear.
The
operating system receives the page fault. thereby determining that the
requested page
is located in the compressed memory block 24, as specified in step 28 of
Figure 2.
As discussed above, when a requested page is determined to be
located in the compressed memory block 24, an LRU page from the uncompressed
memory block 22 is compressed and transferred to the compressed memory block
to
make room for the requested page in the uncompressed memory block. While many
known compression methods could be used, the preferred embodiment of the
invention employs a form of Lempel-Ziv compression. While the discussion below
describes an exemplary form of Lempel-Ziv compression, additional discussion
may
be found in U.S. Patent No. 5,455,577 entitled "Method and System for Data
Compression" .
Lempel-Ziv compression replaces a current sequence of data bytes
with a pointer to a previous sequence of data bytes that match the current
sequence.
A pointer is represented by an indication of the position of the matching
sequence
(typically an offset from the start of the current sequence) and the number of
characters that match (the length). The pointers are typically represented as
<offset,
length> pairs. For example, the following string
"abcdabcdacdacdacdaeaaaaaa"
may be represented in compressed form by the following
"abcd<4,5>c,9>ea<1,5>"
Since the characters "abcd" do not match any previous character, they are
encoded as
a raw encoding. The pair <4,5> indicates that the string starting at an offset
of 4 and
extending for 5 characters is repeated "abcda". The pair <3,9> indicates that
the
sequence starting at an offset of 3 and extending for 9 characters is
repeated.
Compression is achieved by representing the repeated sequences as a
pointer with fewer bits than it would take to repeat the string. Preferably, a
single
byte is not represented as a pointer. Rather, single bytes are output with a
tag bit
indicating single byte encoding followed by the byte. The pointers are
differentiated
from a single byte encoding by different tag bit value followed by the offset
and
length. The offset and length can be encoded in a variety of ways known in the
art.
Variations of the basic Lempel-Ziv compression scheme can be
distinguished by the search data structures used to find matching data
strings. Figure
4 is a biock diagram illustrating a sample search data structure 71 in
conjunction with
a history buffer 72 in a preferred embodiment. The history buffer 72 contains
one or
more packets of an input stream of data bytes. which in the example are
represented
WO 95114274 PCTIUS94113338
215~~~8
8
by letters. The number above each letter in the history buffer indicates the
position
of the letter within the history buffer. For example, the letter "f' is at the
tenth
position within the history buffer.
The search data structure 71 is a multi-dimensional direct address
table that contains an entry for each possible byte-value. Thus, when a byte
contains
8 bits, the table contains 256 entries. For example, the byte-value for an
ASCII "a" is
61h. The entry indexed by 61h contains search information relating to byte
sequences that begin with an ASCII "a" or byte-value 61h. Each entry contains
a
number of slots. A slot contains information that identifies a previous
occurrence of
a byte sequence in the history buffer. In the example of Figure 4, each entry
contains
four slots. In a preferred embodiment, each entry contains eight slots. In an
alternate
embodiment, each entry has a variable number of slots based on the expected
frequency of the byte-value in an input stream. One skilled in the art would
appreciate that by using more slots, a greater amount of compression can be
achieved, but generally at the expense of a greater time of compression. When
an
entry contains four slots, the search data structure can contain information
for four
byte sequences that begin with the indexed byte-value. Each slot contains a
next byte
field 70B and a position field 71B. The next byte field contains the byte-
value of the
next byte after the indexing byte. The position field contains the position of
the next
byte in the history buffer. One skilled in the art would appreciate that a
next byte
field is included to speed searching. The byte-value of the next byte could be
obtained by using the position field as an index into the history buffer.
As shown in Figure 4, the search data structure 71 contains
information on the previous byte sequences when the current byte sequence
starts at
the ninth position in the history buffer as indicated by the arrow. The first
eight bytes
of the history buffer contain no matching byte sequences. The search data
structure
entry for "a" contains a slot that identifies each of the four previous byte
sequences
that begin with an "a", that is, "ad", "ac", "ab", and "ae." When the current
byte
sequence, "af' at positions 9 and 10, is processed, the search data structure
71 is
searched to determine whether an "af' is identified as a previous byte
sequence. In
this example, no slot for the entry indexed by "a" contains an "f' as the next
byte-
value. Consequently, the compression system overwrites the slot for the letter
"a"
that has been least recently updated. In this case, the slot identifying the
byte
sequence "ad" is replaced with information to identify the current byte
sequence "af'.
Specifically, the next byte field is overwritten with an "f' and the position
field is
overwritten with a 10. When the next byte sequence beginning with an "a" is
encountered, "ae" at position 11, the compression system searches for a slot
in the
WO 95114274 c~ ~ PCT/US94113338
9
entry indexed by "a" identifying a matching sequence, that is, a previous byte
sequence "ae". Since the fourth slot contains an "e", a matching sequence is
found.
The fourth slot points to position 8 as the location of the last byte of the
matching
sequence ("e"). The compression system attempts to extend the matching
sequence
by comparing the byte at position 12 with the byte at position 9 and finds the
matching sequence "aea". The compression system compares the byte at position
13
with the byte at position 10, but is unable to extend the matching sequence.
The
compression system encodes the current byte sequence "aea" as a match code
including a pointer to the matching sequence "aea" beginning at position 7 and
a
count value of the length of the matching sequence for a match code
representing (7,
3). The compression method appends the match code and a match flag to an
encoded
page and updates the search structure 70 by replacing the position in the
fourth slot
with position 12 to identify the current byte sequence.
An LRU (least-recently updated) data structure 74 contains an entry
for each byte-value and is indexed by the byte-value. The entries identify the
least
recently updated slot for the corresponding entry in the search data
structure. The
LRU structure (as shown) actually contains the slot number (0...3) of the most
recently updated slot. The least recently updated slot is obtained by adding 1
to the
value in the LRU entry. For example, the least recently updated slot for "a"
is slot 0;
so the LRU data structure contains a 3 (3 + 1 mod 4 = 0). When the current
byte
sequence does not match any byte sequence in the search data structure, the
LRU is
updated to point to the next slot (in a circular fashion) and the next slot is
overwritten
with the first byte and position of the current byte sequence. One skilled in
the art
would appreciate that an estimate of a least recently updated slot can be made
by
selecting the slot with the smallest position value and thus making the LRU
data
structure unnecessary.
In alternate embodiments, the matching byte sequence can be any
number of bytes. The search data structure could be implemented as a direct
access
table indexed by two bytes and thus having 216 entries. Alternatively, the
search
data structure could be implemented as a hash table. When a hash table is
used, byte
sequences with different first bytes could hash to the same entry causing a
collision.
When a collision occurs, the first byte of each byte sequence identified by a
slot
would need to be checked to determine a match. In another embodiment, the
slots for
each entry could be maintained as a linked list. The linked list could be
implemented
as an array parallel to the input stream with a slot for each byte in the
input stream.
Each entry in the search data structure would point to a linked list of slots
identifying
next byte values. The slots in the linked list would link together next byte
values for
WO 95114274 PCT/US94113338
2~.5~668
- 10
the same first byte. When searching the linked list, only a certain number of
slots are
checked for a match. When no match is found, a new slot is added to the
beginning
of the linked list to identify the current byte sequence. When a matching slot
is
found, it is preferably removed from the linked list and a new slot added to
the
beginning of the linked list to identify the current byte sequence.
As will be appreciated from the foregoing discussion, the present
invention provides a data compression method for use in computer systems
having no
secondary memory devices. By dividing the working memory into compressed and
uncompressed memory blocks, the present invention simulates the compression
schemes, such as MS DOS 6.0 operating system, that are used in computer
systems
having secondary memory devices such as hard drives. The compression method
provides a virtual memory system that appears to have a much greater memory
capacity than is actually physically present in the working memory of the
computer
system. Pages of data are stored in compressed form in the compressed memory
block when not in use. When one of the compressed pages is desired, the
compressed page is transferred to the uncompressed memory block and is
decompressed for processing by the computer's CPU. By transferring data pages
to
the uncompressed memory block on an "as needed" basis, the present invention
greatly increases the memory capacity of the working memory and results in a
more
powerful computer system.
From the foregoing it will be appreciated that, although specific
embodiments of the invention have been described herein for purposes of
illustration,
various modifications may be made without deviating from the spirit and scope
of the
invention. Accordingly, the invention is not limited except as by the appended
claims.