Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
CA 02253744 1998-11-10
r
INDEXING DATABASES FOR EFFICIENT RELATIONAL QUERYING
FIELD OF THE INVENTION
The present invention is directed to an improvement in relational database
systems
and in particular to the indexing of relational databases to permit efficient
relational
queries on databases.
BACKGROUND OF THE INVENTION
In relational database systems, it is important to create indexes on columns
of the
tables in the database. It is well-known that the efficiency of relational
operations
such as the JOIN operation or the evaluation of query constraints (SELECTION)
is
improved if the relevant columns of the table across which the operation take
place
are indexed.
There have been many approaches to the problem of efficiently creating indexes
for
relational database tables that support fast access, and that use limited
amounts of
storage. The B-tree and variations are well-known data structures used for
indexing
relational databases.
From the point of view of speeding query processing, it is desirable to have
available
indexes for all columns (and combinations) of all tables in a relational
database.
However, it is often not advantageous (or even feasible) to do so, since the
time
required to individually create the indexes, and the storage used by all the
indexes
after creation, is prohibitive.
It is therefore desirable to simultaneously create a large number of indices
on all the
tables of a database in an space and time efficient manner.
-1-
CA 02253744 1998-11-10
SUMMARY OF THE INVENTION
According to one aspect of the present invention, there is provided an
improved index
for relational databases.
According to a further aspect of the present invention, there is provided an
indexing
system for structured or semi-structured source data comprising a tokenizer
for
accepting source data and generating tokens representing the source data, the
tokens
from the tokenization representing the source data in a relational view, where
for
tokens representing a subset of the source data, the system generates tokens
identifying the table and column of the subset of the data in the relational
view of the
source data, and an index builder for building index structures based on the
tokens
generated by the tokenizer, the index builder creating indexes which comprise
a set of
positional indexes for indicating the position of token data in the source
data, a set of
lexicographical indexes for indicating the lexicographical ordering of all
tokens, the
set of lexicographical indexes comprising a sort vector index and a join bit
index,
associated with the sort vector index, a set of data structures mapping
between the
lexicographical indexes and the positional indexes, comprising a lexicographic
permutation data structure, the index builder creating a temporary sort vector
data
structure for generating the lexicographic permutation data structure and the
sort
vector index.
According to a further aspect of the present invention, there is provided a
method for
accessing the indexing system to carry out relational queries involving
comparisons of
data in the source data, the method comprising the steps of accessing the sort
vector
index for tokens corresponding to source data to be compared, determining, by
following the associated join bit index, whether the source data to be
compared, as
indexed in the sort vector index, matches, signalling whether the source data
matches
or does not match. According to a further aspect of the present invention, the
method
comprises the further step of utilizing the positional indexes to return
source data for
where a match is signalled.
-2-
CA 02253744 1998-11-10
According to a further aspect of the present invention, there is provided a
method for
indexing structured or semi-structured source data comprising the steps of
accepting
source data and generating tokens representing the source data, the tokens
from the
tokenization representing the source data in a relational view, where for
tokens
representing a subset of the source data, the system generates tokens
identifying the
table and column of the subset of the data in the relational view of the
source data, and
building index structures based on the tokens generated by the tokenizer, the
step of
building index structures further comprising the steps of building a set of
positional
indexes for indicating the position of token data in the source data, building
a set of
lexicographical indexes for indicating the lexicographical ordering of all
tokens, the
set of lexicographical indexes comprising a sort vector index and a join bit
index, and
building a set of data structures mapping between the lexicographical indexes
and the
positional indexes, comprising a lexicographic permutation data structure, the
sort
vector index and the lexicographic permutation data structure being built from
a
temporary sort vector data structure.
Advantages of the present invention include the provision of indexes for
columns of
tables in relational databases which require relatively small amounts of
storage, and
which are capable of being accessed efficiently. A further advantage relates
to
minimizing disk access to help process queries much faster than traditional
SQL
products.
BRIEF DESCRIPTION OF THE DRAWINGS
The preferred embodiment of the invention is shown in the drawings,
wherein:
Figure 1 is a block diagram illustrating the structure of the index generator
of the
preferred embodiment of the invention;
Figure 2 is a block diagram illustrating the structure of the query processor
of the
preferred embodiment of the invention;
-3-
CA 02253744 1998-11-10
Figure 3 is a schematic representation of the data structures for position-
ordering of
the data in the preferred embodiment; and
Figure 4 is a schematic representation of the data structures for
lexicographic-ordering
of the data in the preferred embodiment.
In the drawings, the preferred embodiment of the invention is illustrated by
way of
example. It is to be expressly understood that the description and drawings
are only
for the purpose of illustration and as an aid to understanding, and are not
intended as a
definition of the limits of the invention.
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENT
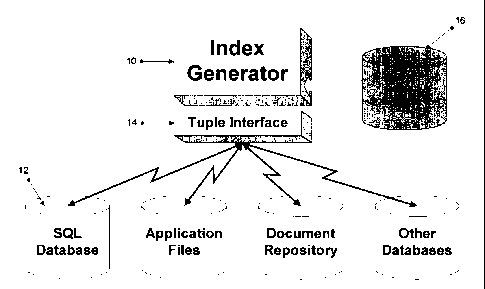
Figure 1 is a block diagram representing the architecture of the index
generator 10 of
the preferred embodiment of the invention. Figure 1 includes data sources 12,
which
are shown in the preferred embodiment as data sources accessed through a tuple
interface 14, an interface layer capable of providing tuples from relational
tables (such
as ODBC, JDBC, OLE-DB, etc.). The index generator of the invention is capable
of
handling any data presented through the tuple interface, and produces an index
16 (a
set of data structures described later) that is relatively small in size and
is capable of
being accessed to perform SQL operations. Both structured data sources (e.g.,
SQL
relational databases or other databases) and semi-structured data sources
(e.g., data
from application files such as word processing documents or spreadsheets, or
document repositories containing e-mail files, or SGML, HTML, XML tagged
files)
are supported. The index generator knows of the presence of one relational key
for
each table in each data sources that can be used to efficiently request
individual tuples
from the data sources.
The structure of the query processor 20 which makes use of the index 16, is
shown in
Figure 2. This figure shows query front-end 22 (an application program issuing
SQL
queries) that passes SQL queries to a SQL interface layer 24 (ODBC in the
preferred
embodiment) which sends the query to the query processor 20. The query
processor
-4-
CA 02253744 1998-11-10
20 uses the information in the index 16 to fully resolve the query by
obtaining the
keys of all the tuples that are part of the answer, using these keys to
request, through
the tuple interface 14, all the relevant tuples from the data sources 12. The
query
processor 20 assembles the data coming from the relevant tuples from the data
sources
into the answer table, which is then sent through the SQL interface 24 back to
the
requesting query front-end 22.
Where a query contains no conditions or joins, the query processor can pass
the query
directly to the data sources 12. Where a query requires no data from columns
of the
tuples in the data sources, such as a COUNT query, the query processor returns
the
answer to the query front-end without contacting the data sources.
Since the index generator 10 of Figure 1 and the query processor 20 of figure
2 both
rely on the standard API of the tuple interface 14, the actual layer of code
implementing the tuple interface can be changed from index generation to query
processing. Similarly, since the data sources 12 are accessed through the
tuple
interface layer, the actual data sources can be changed from index generation
to query
processing. If the data sources are changed, suitable copies of tuples from
the tables
that were indexed should be present in the changed data sources when they are
requested by the query processor.
The index generator system of the preferred embodiment converts a table from a
relational database into a token stream by requesting all the tuples of the
tables in the
data sources. An example table (Table R) is set out below in Example 1.
A B
Joe Smith abc cde
Sara Smith abc xyz
EXAMPLE 1
-5-
CA 02253744 1998-11-10
In creating the token stream, each value in the table is prefixed by a special
attribute
token identifying the table (in the example, table R) and column (either A or
B) that
the value comes from. The system maintains information about which tables
belong to
which data sources, along with further relevant information about the indexed
data
source schema in a relational catalog.
The values from the table are also broken up into tokens, usually on spaces
between
words. The table in Example I is represented by the relational token string of
Example 2 below, where each individual token appears underlined:
R.A Joe Smith R.B abc cde R.A Sara Smith R.B abc xyz
EXAMPLE 2
In the token string of Example 2, all values from the table are prefixed by a
special
attribute token that starts with the character "@" and identifies the table
("R") and the
column for the value that follows ("A" or "B").
The tokenization process of the index generator of the preferred embodiment is
based
on textual tokens. While tokens are directly generated when the values in the
relational table are text values, the tokenizer must translate numerical
values into a
representation that will maintain a correct numerical ordering of the
represented
numeric data when applying a textual ordering of the representation. The
method for
generating the numerical-data representations for the indexed data is not set
out here
but is known to those skilled in the art.
As is apparent from the above description, all columns of all tables in the
data sources
are tokenized in the preferred embodiment. The tokenization process can be
made
more efficient by processing several token streams in parallel. It is possible
to create
token streams which relates to only certain specified columns of certain
tables. Those
-6-
CA 02253744 1998-11-10
columns that are not indexed in accordance with the preferred embodiment will
not be
available to the query processor.
Index 16 in Figures 1 and 2 does contain a number of different data structures
which
collectively make up the final index represented in those figures. The
description
below centres on the functions carried out by the index generator 10, and in
particular
on the data structures which are created by the index generator 10.
The index of the preferred embodiment has several data structures that are
created by
the index generator. The data constructs of the preferred embodiment may be
loosely
grouped in two. First, those data structures which relate to the position of
the token
data (which provide information about where in the data source tuples are
found), and
second those data structures which are based on a lexicographic ordering of
the tokens
(which provide information to resolve comparisons of the source data).
Included in
the data structures provided are those that themselves carry out a mapping
between
position related data structures and the data structures that relate to
lexicographically
sorted tokens. This permits the index to locate tuples in the source data that
the index
identifies as matching a query constraint or subject to a join operation.
The data structures which relate to the position of the data are described
with
reference to Figure 3, in which file 30 represents the token stream (TS).
Those skilled
in the art will appreciate that the description of the data structures will be
applicable
for the entire token stream, or for a subset.
Figure 3 also includes file 32 representing the Word List Strings file (WLS).
File 34
represents the Word List file (WL), and file 36 the Inverted file (IVF).
Figure 3 also
includes a depiction of file 38 the Keys file (KS). Although Figure 3 shows
files, it
will be apparent to those skilled in the art that any appropriate data
structure may be
used to represent the data.
The WLS file 32 is a sorted list of all unique tokens in the token stream. The
WLS
structure is used most often in conjunction with the WL file 34 to point to
the runs
within other structures that contain information for the corresponding token.
CA 02253744 1998-11-10
The IVF file 36 maps the position of unique tokens into their original data
source. IVF
file 36 contains as many entries as the total number of tokens in the input
stream.
Each entry contains a link to a tuple within the data source. The information
that is
stored includes the tuple id 31, and the offset of the token within the tuple
33. The
tuple id points to the value of the keys that can be found in the KS file 38
(and hence
the keys values can be used to request the tuple form the data source). In the
example
in the figure it is assumed that column B is a suitable key for relation R.
The runs
corresponding to each token in the IVF file 36 are sorted alphabetically in
the token
stream, and within each run the entries are sorted in position order.
WL file 34 is used to map a token from WLS file 32 into IVF file 36. WL file
34
contains one entry for each unique token in the stream (same number of entries
as
WLS file 32). Each entry contains an offset into IVF file 36 and a run length.
The
offset indicates where the token run starts in IVF file 36, and the length
represents the
number of entries in IVF file 36 for that token.
The process of constructing the WL, WLS, IVF and KS files, that is carried out
by the
index generator of the preferred embodiment is known to those skilled in the
art.
Note that the WL also maps into the SV structure (described below), since IVF
file 36
and the SV have the same number of runs corresponding to the same unique
tokens.
The generation of the sort vector data structure is accomplished as described
below.
As will be apparent, the sort vector is created by first building a temporary
sort vector
data structure (.tsv file). This data structure is similar to the sort vector,
but the entries
are not sorted lexicographically. In other words, the temporary sort vector
contains
data which will permit the source data to be rebuilt, by following the self
referential
links in the temporary sort vector. The temporary sort vector does not,
however,
contain information which shows the relative lexicographical values of the
tokens in
the sort vector.
To generate the sort vector from the temporary sort vector, a lexicographical
sort is
performed on the entries in the temporary sort vector, and during the sort
process, a
permutation is created (this reflects the mapping of the entries in the
temporary sort
_g_
CA 02253744 1998-11-10
vector into the entries in the sort vector). The permutation data is stored in
a file
referred to as the lexicographic permutation file (.lp file).
The sort vector itself does not contain information about where in the source
data the
tokens in the sort vector are located. It is the .ivf file which maintains
this
information. However, the temporary sort file maps to the .ivf file and
therefore
maintaining the .lp file permits a token in the sort vector file to be found
in the source
data, by following the .lp link to the .ivf file. The location in the source
data is
directly read from the .ivf file.
It is combination of the sort vector, the . permutation file and the inverted
file which
permit data in the sort vector to be mapped to the source file.
Figure 4 represents the data structures which relate to the lexicographic sort
of the
token. Sort Vector (SV) file 50, Join Bit (JB) file 52, and Lexicographic
Permutation
(LP) file 54 are shown in Figure 4. The SV structure is used to reconstruct
the
ordering of the token stream. SV file 50 contains one entry for each token
(same
number of entries as IVF file 36). It is sorted lexicographically, which is a
different
ordering than IVF file 36 (although for the example in the figure the
orderings
coincide)
A lexicographic sort may be thought of as an alphanumeric sort of tokens where
tokens of identical value are arranged by considering the tokens which follow
the
identical value tokens in the token stream. The token stream of Example 3
(each
token consists of three characters) can be used to illustrate a lexicographic
sort:
Stream: abc xyz abc efg
Token #: 1 2 3 4
EXAMPLE 3
The lexicographical sorting by token number is: 3, l, 4, 2. Token 3 is first
since
when the token 'abc' is considered with the token stream which follows it
('efg'), the
-9-
CA 02253744 1998-11-10
token sorts before 'abc' when considered with its following token stream
('xyzabcefg'). In other words, 'abcefg' sorts before 'abcxyzabcefg'
Each entry in the SV file 50 (represented by the right column in SV file 50
shown in
Figure 4) is an index into SV file 50, itself. The entry in SV file 50 points
to the token
that follows that word. Each attribute chain of tokens is ended by an index to
the zero
entry, which is reserved for this purpose. By following the chain of entries
in SV file
50, each attribute value can be reconstructed by using the SV structure.
Example 4 shows the SV structure for a simple stream of single character
tokens.
Each SV entry is an index to the token following that word in the token
stream. For
example, the entry for the token 'd' is 1, meaning that the word in position 1
('a')
follows the 'd' in the token stream. Notice that the third entry is for the
last token 'b',
and its value is 0 indicating that 'b' ends the token stream.
-10-
CA 02253744 1998-11-10
Token Stream: a f b d a f b
Lexicographical order: 2 7 4 5 1 6 3
Token I Following tokens I SV structure
a fb 6
a fbdafb 7
b 0
b dafb 5
d afb 1
f b 3
f bdafb 4
Example 4
Figure 4 also shows JB table 52 which is related to the SV file 50 and may be
used to
perform SQL table joins. JB table 52 contains the same number of entries as SV
file
50. Each entry (the left column in JB table 52) is a pointer to the next
entry, or a null
pointer. This can be implemented simply by a single bit (0 or 1). Two adjacent
entries
in JB table 52 are the same value (i.e. either both 0 or both 1 ) if and only
if the token
that the two entries respectively correspond to have identical following
tokens in the
token strings representing the attributes in which the tokens are found. In
other
words, the lexicographic values of the two tokens (relative to their
respective
attributes) is identical. Recall that the SV chaining is stopped at the end of
each
-11-
CA 02253744 1998-11-10
attribute, so the comparison for setting the JB bits checks the attribute
values only.
Example 5 shows an example of a join bit table, shown as an additional column
added
to an SV file.
S V I Token I JB
bit
abc 1 this token resolves to 'abc cde'
6 abc 1 this token also resolves to 'abc
cde'
7 abc 0 this token resolves to 'abc xyz',
so the bit is
flipped
3 bj 1 single token chain, different:
bit is flipped
4 cde 0 this token resolves to 'cde',
from above
0 cde 0 this token also resolves to 'cde',
from above
2 xyz 1 token change: bit is flipped
5
EXAMPLE 5
There are two other data structures which are found in the preferred
embodiment and
which map between the SV file and the IVF file. The LP file 54 maps SV file 50
into
IVF file 36. The LP contains the same number of entries as IVF file 36 and SV
file 50.
Given an entry in SV file 50, the LP maps the token into IVF file 36, which
then
indicates the exact position of the word in the data source.
-12-
CA 02253744 1998-11-10
The second of these data structures is the Inverse Lexicographic Permutation
(LP 1 ),
not shown in the figure since in this particular example it coincides with the
LP. The
LP1 structure maps an IVF index into a SV entry (the inverse of the LP). The
LPl
contains the same number of entries as IVF file 36 and SV file 50. Given an
entry in
IVF file 36, the LP1 maps the token which that index represents into SV file
50.
The process of constructing the LP1, LP, SV and JB files, that is carried out
by the
index generator of the preferred embodiment is as follows. A pass is made over
the
token stream TS to produce a file, called the TSV, that like the SV file
points to the
next token in the sequence within the TSV structure itself, but that has
entries within
each run in position order (the same order as the IVF). In the example
presented in
Figures 3 and 4 the TSV coincides with the SV, so it is not shown in the
figures. Once
the TSV is produced, it is sorted run by run (following the chain of pointers
within the
TSV to resolve the lexicographic ordering) to produce the LP1 (the inverse of
which
is the LP). With the permutation LP1 as input it is possible to make a pass
over the
TSV and generate the SV on a run by run basis (by rearranging the entries
within each
run according to the permutation). Finally, the JB can be generated by taking
the SV
as input an following the chain of pointers within the SV to resolve equality
of
attribute entries.
The data structures described above, when utilized to generate an index for a
relational database, permit the data to be indexed in a memory-efficient
manner and
permit relational algebra, and in particular JOINs and constrained queries, to
be
carried out at high speed. The lexicographic sorting of the token streams for
attributes
and the use of the join bit indicator permits efficient attribute matching.
The
alphanumeric sorting of the token streams permits the efficient location of
tuples in
the data source which relate to attributes located in the lexicographically
sorted data.
More detailed descriptions of how constrained queries and JOINs may be
implemented on the data structures of the preferred embodiment are set out
below.
A method for performing a constant column comparison involves a query
constraint
of the form "where A.b = tl t2 ... tn". This represents a constant column
comparison
on column b of table A, where the value is equal to tl t2 ... tn. The sequence
of words
-13-
CA 02253744 1998-11-10
tl ... tn represents the tokenized value to compare against. An example
constant
column comparison is "select A.b from A where A.b = 'abc efg"'. The algorithm
for
processing queries of this form is as follows:
adjust the token stream to be "@A.b tl t2 ... tn"
set last range = (0,0)
fori=nto 1
find range = range of ti in SV
{computed from the WL structure}
reduce range to the set of indices which point into last range
[This step is done by two binary searches at the ends of range. A binary
search
works since the tokens are sorted lexicographically.]
if range is empty, then there are no matching rows
set last range = range
last range is the set of '@A.b' SV entries whose corresponding value is 'tl t2
... tn'.
For each SV entry in last range, it can be converted into an IVF index through
the LP
structure, which then yields the information to access the row from the data
source.
Turning now to a two-table join, a method is set out which accomplishes the
joining
of two tables A and B over columns x and y respectively. This represents the
selection of all row pairs from each table where the value in column in x is
the same
as column y. The table join to perform is of the form: where A.x = B.y
(columns x in
table A is the same value as column y in table B).
Due to the structure of the SV file data structure, the range of indices on
the SV file
corresponding to '@A.x' tokens will identify the values of the x column in
table A.
The SV file maintains a linked list of the tokens in each attribute. The
initial token
identifies the attribute ('@A.x'). The next token in the linked list of the SV
file will
be the first token in the attribute itself, and so forth until the 0 pointer
in the linked list
is reached (signifying the end of the tokens in that attribute). Because the
SV file
-14-
CA 02253744 1998-11-10
groups all identical tokens together, the @A.x tokens will all be located
contiguously.
Because the sort is lexicographical, the indices on the SV file (i.e. the
first pointers in
the linked list) will point to the first tokens in the @A.x column attributes,
and these
tokens will appear in order.
The range of indices in the SV corresponding to '@B.y' tokens will identify
the
values of the y column in table B.
Because the tokens corresponding to the '@A.x' and '@B.y' ranges are in sorted
order, since the SV structure is in lexicographical order, SV[Ai] < SV[Ai+1],
and
SV[Bi] < SV[Bi+1] for all i.
In the JB (join bit) structure, there is one bit (0 or 1) for each SV entry.
In addition,
JB [i] = JB [i + 1 ] if SV [i] and SV [i+1 ] correspond to the same token
chain for the
attribute (the SV entries stop at the end of each attribute). This means that
inspecting
the join bit for any first token of an attribute in the SV file will indicate
whether the
attribute as a whole is identical to the previous attribute. This is exactly
the
information which is important for the join operation. The identity of a first
attribute
to a second is therefore determined by locating the marker for the beginning
of the
attribute tokens in the SV file (for example '@A.x'), and following the linked
list of
the SV file to the value for the first token in a first attribute. The join
bit will then
indicate whether there are any other identical attributes in the database (if
the join bit
changes from the first token in the first attribute). If there are other
identical
attributes, they can be identified to see whether they are attributes which
are of
interest (for example, whether any @B.y tokens point to them, if attributes in
the B.y
column are being compared).
-15-
CA 02253744 1998-11-10
The general approach can be illustrated in Example 6, below:
Range of first
@A.x indices entries for A.x
A1, A2, ... An SV[A1]... SV[An]
1 1
sv ~ ~
T
@B.y indices Range of first
B1, B2, ... Bm entries for B.y
SV[B1]... SV[Bm]
EXAMPLE 6
A method to carry out the two table join on the databases of the preferred
embodiment
is set out below:
for i = 1 to n { A1, A2, ... An j
forj=ltom {B1,B2,...Bm}
jb_start = SV[i]
j bend = S V [j ]
exchange jb start and jb end if jb start > jb end
bit = JB[jb start]
join = TRUE
for k = jb start + 1 to jb end
if JB [k] ? bit
-16-
CA 02253744 1998-11-10
{ Ai and Bj do not join. Due to the lexicographical sorting, no other Bj can
join, so move to the next Ai }
join = FALSE
leave this for-loop
if join == FALSE
{ move to the next Ai }
leave this for-loop
else
{ SUCCESS! Ai and Bj do join. Mapping though the LP structure, it is
possible to convert SV[i] and SV[j] into tuple ids... record that SV[i] and
SV[j] join }
As can be seen from the method set out above, the use of the JB table permits
equality
of attribute values to be quickly determined. The structure of the SV file
permits
access to the appropriate JB table entries to be efficiently made. The result
is that the
JOIN operation can be carried out with little memory access and with great
speed.
Although a preferred embodiment of the present invention has been described
here in
detail, it will be appreciated by those skilled in the art, that variations
may be made
thereto, without departing from the spirit of the invention or the scope of
the appended
claims.
-17-