Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
SMART ETHERNET EDGE NETWORKING SYSTEM
FIELD OF THE INVENTION
The present invention generally relates to Ethernet access and, in particular,
to
bandwidth efficient Ethernet grid networking systems and bandwidth-efficient
Ethernet
LAN with Service Level Agreements.
BACKGROUND OF THE INVENTION
Ethernet is rapidly becoming the protocol of choice for consumer, enterprise
and
carrier networks. It is expected that most networks will evolve such that
Ethernet will be
the technology used to transport all the multimedia applications including,
for example,
triple-play, fixed-mobile-convergence (FMC), and IP multimedia sub-systems
(IMS).
Existing network elements which offer network access using Ethernet technology
are not
designed to make maximum use of the legacy network links existing at the edge
of the
carrier networks. The edge of the network is quickly becoming a bottleneck as
the new
applications are becoming more and more demanding for bandwidth.
Telecommunications carriers are constantly looking for new revenue sources.
They need to be able to deploy rapidly a wide ranging variety of services and
applications without the need to constantly modify the network infrastructure.
Ethernet
is a promising technology that is able to support a variety of application
requiring
different quality of service (QoS) from the network. The technology is now
being
standardized to offer different types of services which have different
combinations of
quality objectives, such as loss, delay and bandwidth. Bandwidth objectives
are defined
in terms of committed information rate (CIR) or excess information rate (EIR).
The CIR
guarantees bandwidth to a connection, while the EIR allows operation at higher
bandwidth when available.
RF SWITCH
In order to increase their revenue potential, the carriers need a cost
effective way
to reach new customers which cannot currently serviced because there is no
practical
way of providing them with a broadband physical connection. New high bandwidth
wireless technology, such as WiMAX or high speed RF technology allows the
carrier to
reach a new customer or a customer that is not currently serviced with high
bandwidth
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
2
without the high cost of deploying new fiber routes. The following description
uses
Wimax as an example, but any point-to-point RF technology could be used. By
deploying WiMAX at the access of the network, the carriers can rapidly open up
new
markets. However, currently the Ethernet access solutions using WiMAX
technology
are costly, from both operating cost (OPEX) and capital cost (CAPEX)
standpoints, as
each access point requires a combination of a WiMAX base-station 10 with a
router 11
(FIG. 1). Although WiMAX operates at higher speed, it is still important to
maximize
the use of its bandwidth since spectrum is a limited resource. But because the
(WiMAX
radio 105 and the router 102) are separate, the router has no knowledge of the
radio
status, it is difficult to make maximum use of the wireless bandwidth. WiMAX
currently
allows for multiple users to share a base station. If a subscriber does not
reach the base
station directly, it can tunnel through another subscriber which has
connectivity. This
architecture allows multiple subscribers to reach a base station which is
connected to the
wired network. One major issue with this architecture is that the bandwidth
consumed
1s by the tunneled subscriber is not managed and can affect the bandwidth and
QoS of the
service of the subscriber which is sharing the connectivity to the base
station. Such
architecture, which limits the subscribers to being not farther than two hops
from the
base station, is targeted for residential customers with less stringent QoS
requirements.
It is not well suited for designing enterprise networks or carrier
infrastructure.
ANTICIPATING RADIO LINK PERFORMANCE CHANGES
Compared to optical transmission, wireless links are regularly subjected to
iinpairments due to weather or other interferences. These impairments
temporarily affect
the bandwidth transmitted on the link. Since the base station 105 (FIG. 1) is
temporarily
decoupled from the switching network, there is no mechanism for the network
elements
to take into account link degradation and to manage the flow of data on the
network.
This will typically result in a large amount of packets being dropped at the
WiMAX
radio 105 as the Switch/Router 102 only knows if the Ethernet connector 103 is
up or
down and will send more packets than the radio can handle.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
3
PATH SELECTION
In existing IP/MPLS networks, each switching element or node needs to be
involved in determining the MPLS path, which requires a lot of processing
power and
software complexity and is operationally complex.
Most modern connection-oriented systems for packet networks use MPLS over
IP networks, and connections are setup by signaling protocols such as RSVP-TE.
These
protocols use shortest-path algorithms combined with non-real-time information
on
available QoS and bandwidth resources. Each node needs to maintain forwarding
tables
based on control traffic sent in the network. The paths available can be
constrained by
pruning links not meeting the bandwidth requirements. Bandwidth is wasted
because of
control messaging to establish and update forwarding tables. Protocols such as
OSPF,
LDP and RSVP are required to set up such paths, and these control protocols
consume
overhead bandwidth proportional to the size of the network and the number of
connections.
is Pure Ethernet networks require spanning tree and broadcast messages to
select a
"path". Packets are broadcast over the tree while reverse learning new MAC
addresses.
In heavily loaded networks this function uses a lot of bandwidth to find the
correct paths.
To properly engineer for QoS, this type of network requires ensuring the links
not in the
spanning tree are assumed to be fully utilized, thus wasting additional
resources.
The complexity of both Ethernet and MPLS/IP networks also affects the ability
to
perform network troubleshooting which increases significantly the operational
costs.
Routing consists of two basic tasks:
= Collect/maintain state information of the network.
= Search this information for a feasible, possibly optimal path.
Each link in the network is associated with multiple constraint parameters
which
can be classified into:
= Additive: the total value of an additive constraint for an end-to-end path
is
given by the sum of the individual link constraint values along the path
(e.g.: delay, jitter,
cost).
= Non-additive: the total value of a non-additive constraint for an end-to-end
path is determined by the value of that constraint at the bottleneck link
(e.g.: bandwidth).
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
4
Non-additive constraints can be easily dealt with using a preprocessing step
by
pruning all links that do not satisfy these constraints. Multiple simultaneous
additive
constraints are more challenging.
QoS or constraint-based routing consists of identifying a feasible route that
satisfies multiple constraints (e.g.: bandwidth, delay, jitter) while
simultaneously
achieving efficient utilization of network resources.
Multi-constrained path selection, with or without optimization, is an NP-
complete
problem (e.g., cannot be exactly solved in polynomial time) and therefore
computationally complex and expensive. Heuristics and approximation algorithms
with
polynomial-time complexities are necessary to solve the problem.
Most commonly used are shortest-path algorithms which take into account a
single constraint for path computation, such as hop-count or delay. Those
routing
algorithms are inadequate for multimedia applications (e.g., video or voice)
which
require multiple constraints to guarantee QoS, such as delay, jitter and loss.
Path computation algorithms for single-metric are well known; for example,
Dijkstra's algorithm is efficient in finding the optimal path that maximizes
or minimizes
one single metric or constraint.
However, using a single primitive parameter such as delay is not sufficient to
support the different types of services offered in the network.
Sometimes a single metric is derived from multiple constraints by combining
them in a formula, such as:
CC=BW/(D*J)
where CC = composite constraint, BW = bandwidth, D = delay, and J = jitter.
The single metric, a composite constraint, is a combination of various single
constraints.
In this case, a high value of the composite constraint is achieved if there is
high available
bandwidth, low delay and low jitter. The selected path based on the single
composite
constraint most likely does not simultaneously optimize all three individual
constraints
(maximum bandwidth, minimal delay and loss probability), and thus QoS may not
be
guaranteed. Any of the constraints by itself may not even satisfy the original
path
requirement.
To support QoS requirements, a more complex model of the network is required
that takes into account all constraints such as bandwidth, delay, delay
jitter, availability
and loss probability. Multiple routing metrics greatly increase the complexity
of path
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
computation. New algorithms have to be found that can compute paths that
satisfy
inultiple constraints in practical elapsed time.
Algorithms such as spanning trees are used to prevent loops in the data path
in
Ethernet networks because of their connectionless nature and the absence of a
Time-To-
5 Live (TTL) attribute, which can create infinite paths Such algorithms
proactively
remove links from being considered in a path in order to prevent loops. This
artifact of
the connectionless routing scheme is costly as it prevents the use of
expensive links,
which remain underutilized.
On top of the above issues, business policies, such as overbooking per QoS,
are
ignored by the algorithms establishing the paths. These business policies are
important
to controlling the cost of network operations. Because of these complexity
issues, it is
difficult for a carrier to deploy cost-efficiently QoS-based services in the
metropolitan
and access networks where bandwidth resources are restricted. In the core
networks,
where more bandwidth is available, the bandwidth is over-engineered to ensure
that all
the QoS objectives can be met.
With an offline traffic engineering system, the state of all existing
connection
requests and the utilization of all network links are known before the new
requested
paths are computed. Using topology information, such as link capacities and a
traffic
demand matrix, a centralized server performs global optimization algorithms to
determine the path for each connection request. Once a path design is
completed, the
connections are generally set up by a network management system. It is well
known that
an offline system with global optimization can achieve considerable
improvement in
resource utilization over an online system, if the traffic matrix accurately
reflects the
current load the network is carrying.
Existing traffic engineering systems do not keep in sync with the actual
network
or maintain real-time information on the bandwidth consumed while the network
changes due to link failures, variations in the traffic generated by the
applications, and
unplanned link changes. The existing traffic engineering systems also do not
take into
account business policies such as limiting how much high priority traffic is
going on a
link.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
6
PATH ASSOCIATION
Using MPLS, bi-directional connections are set up using two uni-directional
tunnels. A concept of pseudo-wire has been standardized to pair the two
tunnels at both
end-points of the tunnels (see FIG. 12). However intermediate nodes are not
aware of
the pairing and treat the two tunnels independently. Furthermore, the routing
mechanism
does not attempt to route both connections through the same path. It is
therefore
impossible for a carrier to use operation administration and maintenance (OAM)
packets,
in order to create loopbacks within the connection path to troubleshoot a
connection
without setting up out-of-service explicit paths. There is therefore a need
for a
mechanism to make a unidirectional path look like a bi-directional path.
This capability existed in ATM and frame relay technologies because they were
inherently connection-oriented and both paths of a connection (forward and
backward)
always went through the same route.
Carriers need the ability to set up flexible Ethernet OAM path in-service and
out-
of-service anywhere in the network in order to efficiently perform
troubleshooting.
E-LINE PROTECTION
In order to provide reliable carrier-grade Ethernet services, the Ethernet
technology has to be able to support stringent protection mechanisms for each
Ethernet
point-to-point (E-LINE) link.
There are two main types of protection required by a carrier, link protection
and
path protection. There are a number of standard link protection techniques in
the
marketplace, such as ring protection and bypass links which protect against a
node going
down. Generally connection oriented protocols such as MPLS use path protection
techniques. Most path protection techniques assume a routed network where the
routes
are dynamically configured and protected based on the resource requirements.
One issue with all these existing protection protocols is that they do not
take into
account business policies, such as desired level of protection, for
determining the
protected path.
Another issue with the current way protection paths are set up is that they
only
trigger when intermediate nodes or links encounter failure. If the end-point
outside of
the tunnel, receiving the traffic fails, the source continues to send the
traffic unaware of
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
7
the failure, until application-level reaction is triggered, thus wasting
precious bandwidth.
Such reaction can take up to several minutes.
ZERO-LOSS PROTECTION SWITCHING
Some communication applications, such as medical and security applications,
require a very reliable service. In these cases, a 50-ms switch over time may
be
inadequate due to the critical data lost during this time period. For example,
a 50-ms
switch over in a security monitoring application could be misconstrued as a
"man-in-the-
middle" attack, causing resources to be wasted resolving the cause of the
"glitch."
FLOW CONTROL
To address access challenges, telecommunications carriers have selected
Ethernet. They need to be able to deploy rapidly a wide ranging variety of
services and
applications without the need to constantly modify the network infrastructure.
1s Enterprises have long used Ethernet as the technology to support a variety
of applications
requiring different qualities of service (QoS) from the network. Carriers are
leveraging
this flexibility and are standardizing on this technology to offer data access
services.
Using this service definition, existing network elements which offer network
access using Ethernet technology are not designed to make maximum use of the
legacy
network links existing at the edge of the carrier networks. Many access
technologies
such as DSL or WiMAX are prone to errors which affect the link speed. The
network
devices are unable to react to these errors to ensure that the service level
agreements are
met. The following inventions are focused on addressing these challenges.
When a telecommunications provider offers an Ethernet transport service, a
service level agreement is entered with the customer which defines the
parameters of the
network connection. As part of this agreement, bandwidth objectives are
defined in
terms of Committed Information Rate (CIR) and Excess Information Rate (EIR).
The
CIR guarantees bandwidth to a connection while the EIR allows the connection
to send
at higher bandwidth when available. ,
The telecommunications provider verifies the traffic from each connection for
conformance at the access by using a traffic admission mechanism such as
policing or
traffic shaping. The policing function can take action on the non-conforming
packets
such as lowering the priority or discarding the packets. Policing is necessary
because the
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
8
service provider can not rely on an end-point not under the control of the
network
provider to behave according to the traffic descriptor. In case of mis-
behavior, the
performance of the whole network can be affected. Policing does not take into
account
the reality of the application traffic flow and the dynamic modification
encountered by a
traffic flow when it is moving through the network. As packets get multiplexed
and
demultiplexed to and from network links, their traffic characterization is
greatly
modified. Another issue with policing and static characterization is that it
is extremely
difficult to set these traffic descriptors (i.e., CIR, EIR and burst
tolerance) to match a
given application requirement. The needs of the application change with time
in a very
dynamic and unpredictable way. Traffic shaping, in turn, buffers the incoming
traffic
and transmits it into the network according to the contracted rate.
To implement the Ethernet transport service in a provider's network,
sufficient
bandwidth is allocated assuming the connections fully use the committed
bandwidth,
even though that is not always the case, leading to inefficiencies. In case of
excess low
1s priority traffic, the network generally over-provisions the network in
order to ensure that
sufficient traffic gets through such that the application performance does not
deteriorate.
Another inefficiency currently encountered in Ethernet networks is that
traffic
that has traveled through many nodes and has almost reached destination is
treated the
same as traffic just entering the network which has not consumed any
resources. Current
Ethernet network implementations handle congestion locally where it occurs, by
discarding overflow packets. This wastes bandwidth in the network in two ways:
1. bandwidth capacity is wasted as a result of retransmission of packets by
higher layer protocols (e.g., TCP)
2. Packets are lost throughout the network, wasting precious upstream
bandwidth which could be used by other connections generating more revenues
for the
carriers.
The Ethernet protocol includes a flow control mechanism referred to as
Ethernet
Pause. The problem with Ethernet Pause flow control is it totally shuts off
the
transmission of the port rather than shaping and backing off traffic that it
could handle.
It is currently acceptable to do this at the edge of the network, but for a
network link it
would cause too much transmission loss, and overall throughput would suffer
more than
causing a retransmission due to dropping packets.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
9
There is a need to define a flow control mechanism for Ethernet that
alleviates the
need for local handling of congestion and allows intelligent optimized
throttling of
source traffic. Instead of requiring that applications comply with static
traffic
descriptors, it would be desirable to use real time feedback such that the
applications can
adapt their packet transmission to match the network state, allowing for a
minimum
throughput to guarantee the minimum requirement for the application. Some
applications implicitly derive network status using jitter buffers, for
example, but all
other applications have to conform to a static set of traffic descriptors
which do not meet
their dynamic requirements.
FLEXIBLE SHAPER TO REDUCE DELAY OR LOSS
A traffic admission mechanism can be implemented using a policing function or
a traffic shaper. Traffic shaping has a number of benefits from both the
application and
the network point of view. However, the shaper can delay the transmission of a
packet
into the network if the traffic sent by the application is very different from
the configured
traffic descriptors. It would be useful to make the shaper flexible to take
into account the
delays that a packet encounters so that different actions, such as lowering
the priority or
discarding, can be applied.
NETWORK MIGRATION
The key to the success of any new networking technology is to ensure seamless
and cost-effective migration from existing legacy networks. Carriers cannot
justify
replacing complete networks to deploy new services, and thus the network
overhaul has
to be done gradually, ideally on a pay-as-you-grow basis.
AUTOMATIC BANDWIDTH RENEGOTIATION
Once a customer has entered a service level agreement ("SLA") with a carrier,
this is fixed and can not easily be changed. To engineer the SLA, each
customer
application is required to characterize its traffic in terms of static traffic
descriptors.
However it is very difficult to make such characterizations without over-
allocating
bandwidth. For example, traffic patterns for videoconferencing, peer-to-peer
communication, video streaming and multimedia sessions are very unpredictable
and
bursty in nature. These applications can be confined to a set of bandwidth
parameters,
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
but usually that is to the detriment of the application's performance or else
it would
trigger underutilization of the network. To add to this challenge, a
customer's
connections can carry traffic from multiple applications, and the aggregate
behavior is
impossible to predict. Also, the demand is dynamic since the number of new
5 applications is growing rapidly, and their behavior is very difficult to
characterize.
The demand for network resources also varies greatly depending on the time of
day and the type of applications. There is a need for mechanisms to allow the
applications to optimize their performance while maximizing the network usage.
10 SUB-CLASSES FOR ETHERNET QoS
Carriers market only a limited set of Ethernet classes of service, generally
three
or four services covering the need for low latency/low jitter, low loss with
guaranteed
throughput and best effort for bursting. Given the number and varying types of
applications and customers that a carrier handles, there is a need for further
differentiation within a class of service to allow a carrier more flexibility
in its tariff
strategies.
SLA-based ELAN
When a telecommunications provider offers an Ethernet LAN (E-LAN), a service
level agreement (SLA) is entered with the customer, defining the parameters of
the
network comiections. As part of this agreement, a bandwidth profile is defined
in terms
of Committed Information Rate (CIR), Committed Burst Size (CBS), Excess
Information
Rate (EIR) and Excess Burst Size (EBS). The CIR guarantees a minimum bandwidth
to
a connection while the EIR allows the connection to send at higher bandwidth
when
available.
Current Ethernet network implementations handle congestion locally where it
occurs, by discarding overflow packets. Also, E-LAN requires duplication to
support
unicast miss, multicast and broadcast. This wastes bandwidth in the network in
two
ways:
3. bandwidth capacity is wasted as a result of retransmission of packets by
higher layer protocols (e.g., TCP), and
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
11
4. packets are lost throughout the network, wasting precious upstream
bandwidth which could be used by other connections generating more revenues
for the
carriers.
In order to meet the QoS, the Service Provider (SP) allocates an amount of
bandwidth, referred to herein as the Allocated Bandwidth (ABW), which is a
function of
the CIR, CBS, EIR, EBS and the user line rate. Unless CBS is extremely small,
the
ABW is greater than the CIR in order to guarantee the QoS even when
connections are
bursting within the CBS.
To implement the Ethernet service in a provider's network, sufficient
bandwidth
needs to be allocated to each connection to meet the QoS, even though not
always used,
leading to inefficiencies. The service provider generally over-provisions the
network in
order to ensure that sufficient traffic gets through such that the application
performance
does not deteriorate.
When a customer subscribes to an E-LAN to receive connectivity between
multiple sites, the SP needs to allocate an amount of bandwidth at least equal
to ABW
for each possible path in the E-LAN in order to mesh all the sites, making the
service
unscalable and non-profitable. E-LAN can also provide different bandwidth
profiles to
different sites where a site needs to send more or less information. One site
can talk at
any time to another site (point-to-point or "pt-pt" - by using unicast address
of the
destination), or one site can talk at any time to many other sites (point-to-
multipoint or
"pt-mpt" - by using Ethernet multicast address). Also one site can send to all
other sites
(broadcast - by using Ethernet broadcast address).
In FIG. 35, an E-LAN is provisioned among five customer sites 6101 (sites 1,
2,
3, 4 and 5) in a network consisting of five nodes 6102 (nodes A, B, C, D, E
and F)
connected to each other using physical links 6103. The E-LAN can be
implemented
using VPLS technology (pseudowires with MPLS or L2TP) or traditional
crossconnects
with WAN links using PPP over DSC. The E-LAN can also be implemented using
GRE,
PPP or L2TP tunnels.
For this example, the physical links are 100Mbps. The customer subscribes to
an
E-LAN to mesh its sites with a CIR of 20Mbps and an EIR of 50Mbps. In order to
guarantee that each site can transmit the committed 20Mbps and the burst, the
SP needs
to allocate a corresponding ABW of 30Mbps between each possible pair of sites
104
such that if site 1 sends a burst to site 5 while site 4 sends a burst to site
5, they each
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
12
receive the QoS for the 20Mbps of traffic. Since any site can talk to any
other site, there
needs to be sufficient bandwidth allocated to account for all combinations.
Therefore, in
this example, (n-1)xABW needs to be allocated on the links 6104 between B and
C,
where n is the number of sites in the E-LAN. This situation is clearly un-
scalable, as
shown in FIG. 35 where the 100Mbps physical links can only support a single E-
LAN.
SUMMARY OF THE INVENTION
One embodiment of this invention provides a system for making connections in a
telecommunications system that includes a network for transporting
communications
between selected subscriber connections, and a wireless network for coupling
connections to the network. The network and wireless network are interfaced
with a
traffic management element and at least one radio controller shared by
connections, with
the traffic management element and the radio controller forming a single
integrated
network element. Connections are routed from the wireless network to the
network via
the single integrated network element.
In another embodiment of the present invention, a system is provided for
selecting connection paths in a telecommunications network having a
multiplicity of
nodes interconnected by a multiplicity of links. The system identifies
multiple
constraints for connection paths through the network between source and
destination
nodes, and identifies paths that satisfy all of the constraints for a
connection path
between a selected source node and a selected destination node. One particular
implementation selects a node adjacent to the selected source node; determines
whether
the inclusion of a link from the source node to the adjacent node, in a
potential path from
the source node to the destination node, violates any of the constraints; adds
to the
potential path the link from the source node to the adjacent node, if all of
the constraints
are satisfied with that link added to the potential path; and iterates the
selecting,
determining and adding steps for a node adjacent to the downstream node of
each
successive added link, until a link to the destination node has been added.
In another embodiment of the invention, a system is provided for optimizing
utilization of the resources of a telecommunications network having a
multiplicity of
nodes interconnected by a multiplicity of links. The system identifies
multiple
constraints for connection paths through the network, between source and
destination
nodes; establishes connection paths through the network between selected
source and
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
13
destination nodes, the established connection paths satisfying the
constraints; for each
established connection path, determines whether other connection paths exist
between
the selected source and destination nodes, and that satisfy the constraints;
and if at least
one such other connection path exists, determines whether any such other
connection
path is more efficient than the established connection path and, if the answer
is
affirmative, switches the connection from the established connection path to
the most
efficient other connection path.
Another embodiment provides a telecommunications system comprising a
network for transporting packets on a path between selected subscriber end
points. The
network has multiple nodes connected by links, with each node (a) pairing the
forward
and backward paths of a connection and (b) allowing for the injection of
messages in the
backward direction of a connection from any node in the path without needing
to consult
a higher OSI layer. In one implementation, each node switches to a backup path
when
one of the paired paths fails, and a new backup path is created after a path
has switched
to a backup path for a prescribed length of time.
In another embodiment, a system is provided for protecting connection paths
for
transporting data packets through an Ethernet telecommunications network
having a
multiplicity of nodes interconnected by a multiplicity of links. Primary and
backup paths
are provided through the network for each of multiple connections, with each
path
including multiple links. Data packets arriving at a first node common to the
primary
and backup paths are duplicated, and one of the duplicate packets is
transported over the
primary path, the other duplicate packet is transported over the backup path,
and the
duplicate packets are recombined at a second node common to the primary and
backup
paths.
Another embodiment of the present invention provides a method of controlling
the flow of data-packet traffic through an Ethernet telecommunications network
having a
multiplicity of nodes interconnected by multiple network links. Incoming data-
packet
traffic from multiple customer connections are received at a first node for
entry into the
network via the first node. Flow control messages are generated to represent
the states of
the first node and, optionally, one or more network nodes upstream from the
first node,
and these states are used as factors in controlling the rate at which the
incoming packets
are admitted to the network. Alternatively, the flow control messages may be
used to
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
14
control the rate at which packets generated by a client application are
transmitted to the
first node.
In one implementation, transit traffic is also received at the first node,
from one
or more other nodes of the network, and the flow control messages are used to
control
the rate at which the transit traffic is transmitted to the first node. The
transit traffic may
be assigned a higher transmission priority than the incoming traffic to be
admitted to the
network at the first node.
Another embodiment provides a method of controlling the entry of data-packet
traffic presented by a client application to the Ethernet telecommunications
network.
The rate at which the incoming packets from the client application are
admitted to the
network is controlled with a traffic shaper that buffers incoming packets and
controllably
delays admission of the buffered packets into the network. The delays may be
controlled
at least in part by multiple thresholds representing contracted rates of
transmission and
delays that can be tolerated by the client application. The delays may also be
controlled
in part by the congestion state of the network and/or by prescribed limits on
the
percentage of certain types of traffic allowed in the overall traffic admitted
to the
network.
A further embodiment provides a method of controlling the flow of data-packet
traffic in an Ethernet telecommunications network having a flow control
mechanism and
nodes that include legacy nodes. Loopback control messages are inserted into
network
paths that include the legacy nodes. Then the congestion level of the paths is
determined
from the control messages, and the flow control mechanism is triggered when
the
congestion level reaches a predetermined threshold. The control messages may
be
inserted only for each priority of traffic on the paths that include the
legacy nodes. In
one implementation, the delay in a path is determined by monitoring incoming
traffic
and estimating the actual link occupancy from the actual traffic flow on a
link. If nodes
transmitting and receiving the control messages have clocks that are not
synchronized,
the congestion level may be estimated by the delay in the path traversed by a
control
message, determined as the relative delay using the clocks of the nodes
transmitting and
receiving the control messages.
Another embodiment provides a method of automatically renegotiating the
contracted bandwidth of a client application presenting a flow of data-packet
traffic to an
Ethernet telecommunications network. The actual bandwidth requirement of the
client
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
application is assessed on the basis of the actual flow of data-packet traffic
to the
network from the client application. Then the actual bandwidth requirement is
compared
with the contracted bandwidth for the client application, and the customer is
informed of
an actual bandwidth requirement that exceeds the contracted bandwidth for the
client
5 application, to determine whether the customer wishes to increase the
contracted
bandwidth. If the customer's answer is affirmative, the contracted bandwidth
is
increased. In one implementation, the contracted bandwidth corresponds to a
prescribed
quality of service, and the contracted bandwidth is increased or decreased by
changing
the contracted quality of service.
10 Yet another embodiment provides different sub-classes of service within a
prescribed class of service in an Ethernet telecommunications network by
setting
different levels of loss or delay for different customer connections having a
common
contracted class of service, receiving incoming data-packet traffic from
multiple
customer connections and transmitting the traffic through the network to
designated
15 destinations, generating flow control messages representing the states of
network nodes
through which the traffic flows for each connection, and using the flow
control messages
to control the data-packet flow in different connections at different rates
corresponding to
the different levels of loss or delay set for the different connections. In
specific
implementations, the different rates vary with prescribed traffic descriptors
(such as
contracted CIR and EIR) and/or with preset parameters. The connections in
which the
flow rates are controlled may be selected randomly, preferably with a weight
that is
preset or proportional to a contracted rate.
In another embodiment, a method of controlling the flow of data packet traffic
from a first point to at least two second point in an Ethernet
telecommunications network
having a multiplicity of nodes interconnected by multiple network links,
comprises
monitoring the level of utilization of a link between the first and second
points,
generating flow control messages representing the level of utilization and
transmitting
the control messages to the first point, and using the states represented in
the flow
control messages as factors in controlling the rate at which the packets are
transmitted
from the first point to the second point.
In another embodiment, a method of controlling the flow of data packet traffic
through an Ethernet telecommunications network having a multiplicity of nodes
interconnected by multiple network links, comprises receiving incoming data
packet
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
16
traffic from multiple customer connections at a first node for entry into the
network via
the first node, the first node having an ingress trunk, and limiting the rate
at which the
incoming data packets are admitted to the network via the ingress trunk.
BRIEF DESCRIPTION OF THE DRAWINGS
The invention will be better understood from the following description of
preferred embodiments together with reference to the accompanying drawings, in
which:
FIG. 1 is a diagram illustrating existing network architecture with separate
WiMAX base station and routers.
FIG. 2 illustrates an integrated network element containing a WiMAX base
station with an Ethernet switch networked and managed with a VMS
FIG. 3 illustrates one implementation for performing the switching in the
WiMAX switch in the integrated network element of FIG. 2.
FIG. 4 illustrates a logical view of the traffic management bloc.
FIG. 5 illustrates a radio impairment detection mechanism.
FIG. 6 illustrates one implementation of an algorithm that detects radio
impairments.
FIG. 7 illustrates one implementation of the path selection algorithm
FIG. 8 illustrates one implementation of the network pruning algorithm
FIG. 9 illustrates one implementation of the patll searching based on multiple
constraints.
FIG. 10 illustrates one implementation of the path searching based on multiple
constraints using heuristics.
FIG. 11 illustrates one implementation of a network resource optimization
algorithm.
FIG. 12 illustrates a prior art network where both directions of the
connections
use different paths.
FIG. 13 illustrates an example where both directions of the connection use the
same path.
FIG. 14 illustrates the pairing of the connection at each node and the use of
hairpins for continuity checking.
FIG. 15 illustrates the use of hairpins for creating path snakes.
FIG. 15a illustrates the management of rules
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
17
FIG. 16 Illustrates the use of control messages to trigger protection
switching
FIG. 17 illustrates the ability to duplicate packets to ensure zero-loss for a
path.
FIG. 18 illustrates one example of an implementation of a packet duplication
algorithm.
FIG. 19 illustrates one example of a packet recombination algorithm.
FIG. 20 is a diagram of an Ethernet transport service connection.
FIG. 21 is a diagram of an Ethernet transport service switch.
FIG. 22 is a diagram of an logical view of the traffic management bloc.
FIG. 23 is a diagram of an example of a threshold-based flow control
mechanism.
FIG. 24 is a diagram of an example of flow control elements
FIG. 25 is a diagram of an example of flow control handling at interim nodes
FIG. 26 is a diagram of one implementation of a flexible shaper mechanism.
FIG. 27 is a diagram of the use of control messages to estimate the behavior
of
non-participating elements.
FIG. 28 is a diagram of a typical delay curve as a function of utilization.
FIG. 29 is a diagram of the elements that can be involved in a bandwidth
renegotiation process.
FIG. 30 is a diagram of one implementation of a bandwidth renegotiation
mechanism.
FIG. 31 is a diagram of one implementation of a bandwidth renegotiation
mechanism.
FIG. 32 is a diagram of one implementation of a bandwidth renegotiation
mechanism.
FIG. 33 is a diagram of one implementation of a bandwidth renegotiation with a
logical network.
FIG. 34 is a diagram of one implementation of a bandwidth renegotiation with
real-time handling of client requests.
FIG. 35 is a diagram of an example network with existing E-LAN offering.
FIG. 36 is a diagram of an example network using network level flow control.
FIG. 37 is a diagram representing the terminology used in the description.
NOTE: In all figures depicting flow charts a loop control circle is used to
represent iterating at a high level. For example in FIG. 7, the circle 3106
"For each
constraint" is used to indicate that all constraints are traversed or iterated
over. The lines
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
18
connected to/from the loop control circle surround the set of blocks
representing
operations that are repeated in each iteration, which are blocks 3107 and 3108
in the
case of circle 3106.
DETAILED DESCRIPTION
Although the invention will be described in connection with certain preferred
embodiments, it will be understood that the invention is not limited to those
particular
embodiments. On the contrary, the invention is intended to cover all
alternatives,
modifications, and equivalent arrangements as may be included within the
spirit and
scope of the invention as defined by the appended claims.
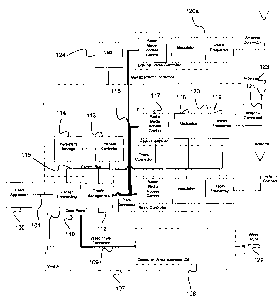
RF SWITCH
Existing Ethernet over WiMAX solutions as illustrated in FIG. 1 require a
separate packet switch 10 such as an Ethernet switch, MPLS switch or router to
switch
traffic between WiMAX radios 105 and client interfaces 100. The WiMAX (or
other
point-to-point RF) radio 105 connects Ethernet from the Ethernet switch or IP
router 102
and converts it into the WiMAX standard, then transmitted over a antenna
connector
106, then to the antenna 123, and then over the airways to the receiving
antenna.
Integrating the switching and WiMAX radio functions reduces operational costs
and
improves monitoring and control of WiMAX radios.
Integration of the switching of service traffic among WiMAX radio links and
access interfaces into a single network element, which is referred to as a
WiMAX switch
107, is depicted in FIG. 2. The switching can be accomplished by using
Ethernet
switching, MPLS label switching or routing technology. One embodiment
integrates
only the control 107c of the radio with an external radio controller with the
switching
function to prevent loosing packets between the switch and the radio
controller when the
radio bandwidth degrades. In this model, the external radio controller
provides periodical
information about the status of the wireless link and thus acts as an
integrated radio
controller. The client application 100, connects to the switch 107 based on
the service
interface type 101 and is switched to the appropriate antenna connector 121
then to the
antenna 123. The configuration of the switch is done by a management device
called the
VMS 124.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
19
FIG. 3 provides an example of an implementation for the switching. The network
element 107 includes one or more radio controllers 120 or external radio
controllers 120a
fully within the control of the network element and it can add/drop traffic
to/from
different types of interfaces 101 including but not limited to any number of
Ethernet,
ATM or T1/E1 interfaces. Different types of network trunks can also be added
using
optical links or other types of high speed links 122. The packet forwarding is
connection-oriented and can be done using simple labels such as multi-protocol
label
switching (MPLS) labels, Ethernet VLAN-ID or 802.16 connection ID (CID)
labels.
Connections are established by a traffic engineering element referred to as
the value
management system (VMS) 124, which is a network management system. The VMS
manages all the connections such that the QoS and path protection requirements
are met.
The WiMAX switch includes amongst other components, a data plane 110, which
includes packet forwarding 111 and traffic management 112. The packet
forwarding,
111 receives packets and performs classification to select which interface
101, trunk
connector 116 or wired trunk connector, 109 to queue the packet. The traffic
management 112 manages all the queues and the scheduling. It can also
implement
traffic shaping and flow control. The network and link configurations are sent
to the
Process controller 113 and stored in persistent storage 114. The Process
controller
configures the Packet Forwarding 111, the Traffic Management 112 and the Radio
Controller 120 using the Control Bus 115. One logical implementation is shown
in
FIG. 4. There is one traffic shaper 130 per connection. The traffic shaper can
be
optionally set up to react to flow control information from the network. The
scheduler
132 is responsible for selecting which packet to transmit next from any of the
connections that are ready to send on the outgoing connector (NNI, UNI or
Trunk).
Intermediate queues 131 can be optionally used to store shaped packets that
are awaiting
transmission on the link. These queues can be subject to congestion and can
implement
flow control notification.
The radio controller is monitored via the process controller to be immediately
notified of its state and operating speed.
Using a WiMAX switch, a grid network topology can be implemented which
permits the optimized use of the bandwidth as each subscriber's traffic is
controlled from
end-to-end. This topology alleviates the need for subscribers to tunnel
through another
subscriber and therefore removes the one-hop limitation.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
ANTICIPATING RADIO LINK PERFORMANCE CHANGES
In one embodiment, the radio is integrated with the switching layer (FIG. 3).
Since the two elements are integrated within the same system, the radio status
5 information is conveyed on a regular basis to the process controller 113
which can
evaluate impending degradation of the link and take proactive actions, such as
priority
discards, flow control, protection switching etc. The objective is to avoid
loss between
the traffic management 112 and the radio controller 120 when the link speed is
reduced
due to performance degradations..
10 The sceduler 132 as seen in FIG. 4 matches any change in throughput as a
result
of expected changing transmission speeds (e.g. drop from QAM 64 to QAM 16).
One
algorithm that estimates the link performance is as follows :
1. If the link performance is impaired, the scheduler 132 limits the rate
of traffic forwarded to the radio controller 120 and buffers this traffic
15 as necessary in queues 131 or 130 (FIG. 4).
2. If the link performance is improved, the scheduler 132 increases the
rate of traffic forwarded to the radio controller 120 and draining the
traffic buffered in queues 131 or 130 (FIG. 4).
The radio controller 120 is responsible to commute traffic between the trunk
20 connector 116 and the antenna comiector 121. The process includes 3
functions:
1. A radio media access controller 117 which controls how packets are
transmitted over the radio. It performs access control and negotiation
for transmission of packets.
2. A modulator 118 which prepares packets for transmission over the
air. It converts packets into a set of symbols to be transmitted over
the air. It also mitigates the "over-the-air" impairments.
3. A RF amplifier which takes the modulated symbols and passes these
to the antenna 123 over the antenna connector 121.
An example algorithm to anticipate radio link performance is shown in FIG. 5.
In this
example, the process controller 113 is responsible for handling the detection
of radio
performance 140. It starts by retrieving 141 performance statistics from
elements in the
radio controller 120. The process controller 113 needs to look at data from
the media
access controller 117 which includes radio grant times, retransmissions,
packet drops,
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
21
etc. From the modulator 118, the process controller retrieves the overall
performance of
the transmission of symbols across the air interface. The process controller
113 also
looks at the RF layer 119 to look at the current signal to noise ratio and
other radio
parameters. Changes in these levels can indicate changes in modulation are
required.
Once the process controller 113 has the current performance data, it is
processed
to produce the current trend data 142. Examples of these trends can be:
1. average rate of retransmission. When the measure reaches a particular
threshold for a period of time, it can indicate drop in the RF modem
rate is required to increase reliability.
2. RF noise floor level has raised itself for a period of time.
Once the trends have been calculated 143, the process controller 113 stores
this in
persistent storage 114. The process controller then retrieves the historical
data 144 and
compares the current trends to the historical trends 145.
Based upon this comparison, the process controller 113 decides whether the
is current trends will result in a change in radio performance 146. If the
radio will be
impaired, the process controller 113 adjusts the scheduler 132 in traffic
Management 112
to reduce/increase the amount of traffic 150 supplied to radio controller 120.
If the current trends have not resulted in a change radio performance, the
service
provider still may want to change the amount of traffic traversing the link.
To
implement this, the process controller 113 retrieves the radio impairment
policy 147
from persistent Storage 114. The Process Controller compares the current
trends against
the policy 148. If this is not considered a change radio performance 149, the
process
ends 151. If this is considered a change radio performance 149, the process
controller
113 adjusts the scheduler 132 in Traffic management 112 to reduce/increase 150
the
amount of traffic supplied to radio controller 120.
The effect of a reduction in the scheduler transmission may cause the queues
130
or 131 to grow. This can result in the execution of different local mechanisms
such as
priority discards, random early discards. It can also tie to end-to-end
mechanisms such as
flow control to reduce the rate of transmission at the source of the traffic.
The
degradation can also reach a level where process controller 113 triggers a
protection
switching on some of the traffic going on the degraded link.
The effect of an increase in the scheduler transmission may cause the queues
130
or 131 to empty thus underutilizing the link. This phenomenon can tie to an
end-to-end
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
22
mechanisms such as flow control to increase the rate of transmission at the
source of the
traffic.
Those skilled in the art will recognize that various modifications and changes
could be made to the invention without departing from the spirit and scope
thereof. It
should therefore be understood that the claims are not to be considered as
being limited
to the precise embodiments set forth above, in the absence of specific
limitations directed
to each embodiment.
PATH SELECTION
In the following embodiments, the establishment of the paths for the Ethernet
connections is executed using an offline provisioning system (referred to
herein as a
Value Management System or VMS). The system can set up paths using any
networking
technology, such as MPLS, GRE, L2TP or pseudowires. The VMS provides all the
benefits of an offline provisioning system, but it also understands business
rules and it is
kept constantly in synch with the network. The VMS is optimized to be used
with
connection oriented switching devices, such as the WiMAX switch described
above,
which implements simple low-cost switching without requiring complex dynamic
routing and signaling protocols.
FIG. 7 depicts one implementation of a path selection algorithm. The goal is
to
set up a main and optional backup paths 3100. At step 3101, a main path and an
optional
backup path are requested for a designated pair of end points (the source and
the
destination). These paths must satisfy designated customer requirements or
SLA,
including: a selected Class of Service (CoS), Bandwidth Profile (CIR, CBS,
EIR, EBS),
and QoS parameters (e.g., Delay, Delay Jitter, Loss Ratio, Availability). The
objective is
to find a path that meets the subscriber's requirements and optimizes the
provider's
concerns.
In other words, the goal of the algorithm is to find a path that allows the
provider
to satisfy the subscriber's requirements in the most efficient way. The most
efficient
path (from the provider's point of view) is the one that optimizes a
combination of
selected provider criteria such as cost, resource utilization or load
balancing.
The operator typically selects from various templates for CoS, QoS and
Bandwidth Profile. If required, some values may be modified from the default
values in
the templates to account for specific subscriber requirements.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
23
Step 3102 retrieves site-wide policies that capture non-path specific rules
that the
provider specifies for the entire network. These policies reflect the
provider's concerns
or priorities, such as:
= The relative priority of optimizing criteria such as load balancing,
resource
utilization, cost minimization
= Strict requirements such as Rules for including/excluding nodes/links based
on requested CoS, node/link attributes and utilization.
= Maximum cost per CoS (e.g.: Number of RF hops)
Step 3103 retrieves path-specific policies which can override site-wide
policies
io for the particular path being requested. For example:
= Change relative priority of optimizing criteria such as load balancing,
resource utilization, cost minimization
= Change strict requirements such as rules for including/excluding
nodes/links based on requested CoS, node/link attributes and utilization
= Minimum/maximum packet size per link
= Maximum cost per CoS (e.g.: Number of RF hops)
= Explicit node/link inclusion/exclusion lists
Step 3104 retrieves network state and utilization parameters maintained by the
VMS over time. The VMS discovers nodes and queries their resources, keeps
track of
reserved resources as it sets up paths through the network (utilization), and
keeps in sync
with the network by processing updates from nodes. The available information
that can
be considered when searching for paths includes:
= Node discovery
- List of available resources
- Links to neighbouring nodes
= Node updates
- Links down
- RF links status and performance (actual capacity, loss ratio)
- Down or shrunk links can be (operator's choice)
= ignored for path computation (with optional warnings)
= avoided
= Utilization
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
24
- VMS keeps track of resource allocation (and availability)per node,
per link, per CoS
Step 3105 prunes from the network invalid links and nodesusing a pruning sub-
routine, such as one illustrated in FIG. 8 described below.
s To ensure that there are at least some paths available in the network that
satisfy
each single constraint separately, step 3107 takes each additive constraint
(delay, jitter,
loss, availability) separately and finds the path with the optimal value for
that constraint
using, for example, Dijsktra's algorithm. For example, if the smallest path
delay is
higher than the requested delay, step 3108 determines that no path will be
found to
satisfy all constraints and sets a "Path setup failed" flag at step 3109.
= If one or more paths found optimizing one single constraint at a time
satisfy all constraints, we know there are feasible paths -> SUCCESS.
= If no path found satisfies all constraints -> UNKNOWN, so use gathered
data for heuristic functions in full multi-constraint algorithm.
The algorithm finds paths that optimize one constraint at a time. For each
constraint, the steps within a control loop 3106 are executed. This step is a
"sanity
check", because it will fail immediately if no paths are found that satisfy
any constraint
3108, avoiding the expensive multiple-constraint search which is bound to
fail. If the
answer is negative, the algorithm is terininated immediately. If the answer is
positive,
the loop is completed for that particular constraint. As indicated by the
control loop
3106, the steps 3107-3108 are repeated for each existing constraint.
The results of the single-constraint optimal paths can be saved for later use.
The
algorithm can also gather information about nodes and links by performing a
linear
traversal of nodes/links to compute for example minimum, maximum and average
values
for each constraint.
The previously collected information (best single-constraint paths and
node/link
information) can be used during the full multiple-constraint search to improve
and speed
up decisions if there is not enough time to perform an exhaustive search
(e.g.: when to
stop exploring a branch and move on to a different one). See SCALABLE PATH
SEARCH ALGORITHM below.
Once it is determined that there are possible optimal paths that could satisfy
all
constraints, the multi-constraint search algorithm FIG. 9 is performed 3110,
as described
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
below. If no path is found that satisfies all subscriber's requirements, the
path setup
failed 3112.
If at least one candidate path has been found, a main path is selected 3113
from
the list of candidate paths. Any provider-specific policies such as cost, load-
balancing,
5 resource utilization can be taken into account to select the most efficient
path from the
list.
If a backup path is required 3114, it is selected from the list pf candidate
paths.
When selecting the backup path 3115, the system will select the path that is
most distinct
from the main path and that also optimizes the carrier-specific policies.
10 Once both the main and backup paths have been selected they can be
provisioned
3116 (they are set up in the nodes), and the path setup is completed 3117.
FIG. 8 illustrates one implementation of the function used to prune the links
and
nodes from the network prior to search for the paths 3200. The algorithm
starts with the
entire network topology 3201, excludes node/links based on explicit exclusion
lists, or
ts exclusion rules.
For each node in the network the steps within a control loop 3202 are
executed.
The node exclusion list 3203 and the node exclusion policies 3204 are
consulted. If the
node is to be excluded 3205, it is removed 3206 from the set of nodes to be
considered
during the path search. As indicated by the control loop 3202, the steps 3203-
3206 are
20 repeated for each node in the network.
For each link in the network the steps within a control loop 3207 are
executed.
The link exclusion list and exclusion policies 3208 are consulted. If the link
is to be
excluded 3209, or violates non-additive or additive constraints 3210, it is
removed 3211
from the set of links to be considered during the path search. An example of a
link
25 violating a non-additive constraint is when its bandwidth is smaller than
the requested
path bandwidth. An example of a link violating an additive constraint is when
its delay
is longer than the total delay requested for the entire path. As indicated by
the control
loop 3207, the steps 3208-3211 are repeated for each link in the network
The links are pruned recursively and then nodes with no incoming or outgoing
links are pruned. For each node still remaining the steps within a control
loop 3212 are
executed. If there are no linlcs 3213 reaching the node, it is removed 3214.
As indicated
by the control loop 3212, the steps 3213-3214 are repeated for each node in
the network.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
26
Then for each link still remaining the steps within a control loop 3215 are
executed. If it does not reach any node 3216, it is removed 3217. As indicated
by the
control loop 3215, the steps 3216-3217 are repeated for each link in the
network.
The steps 3212-3217 are repeated while at least a node or link has been
removed
3218.
The pruning takes into account that the paths are bi-directional and they need
to
go through the same links in both directions. Once complete 3219, the
remaining set of
nodes and links is a subset of the entire network that is used as input into
the path search
algorithm.
FIG. 9 illustrates one example of a search algorithm that finds all paths
satisfying
a set of constraints 3300. The algorithm sees the network as a graph of nodes
(vertices)
connected by links (edges). A possible path is a sequence of links from the
source node
to the destination node such that all specified constraints are met. For each
path selected,
additive constraints are added 3307 to ensure they do not exceed the
requirements.
When setting up bi-directional paths, the algorithm checks both directions of
the path to
ensure that the constraints are met in both directions.
The algorithm starts by initializing the list of all candidate paths 3301, and
the
first path to explore starting at the source node 3302. The algorithm
traverses the
network graph depth first 33041ooking at each potential end-to-end path from
source to
destination considering all constraints simultaneously in both directions.
Other graph
traversing techniques, such as breadth first, could also be used. The steps
within the
depth first search control loop 3304 are executed. One of the adjacent nodes
is selected
3303 to explore a possible path to the destination. If the node is not yet in
the path 3305,
for each additive constraint the steps within a control loop 3306 are
executed. The path
total for that constraint is updated 3307 by adding the value of that
constraint for the link
to the node being considered. If any of the constraints for the entire path is
violated
3308, the node being considered is not added to the path. As indicated by the
control
loop 3306, the steps 3307-3308 are repeated for each additive constraint. If
all
constraints for the path are satisfied the node is added to the path 3309 and
one of its
adjacent nodes will be considered next 3304 & 3305. If the node just added
happens to
be the destination node 3310, the path is a candidate, so it is added to the
list of all
candidate paths 3311. As indicated by the control loop 3304, the steps 3305-
3311 are
repeated all nodes are traversed depth first.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
27
Every time a successful path to destination is found, or a branch is discarded
because a constraint is violated or because the destination node cannot be
reached, the
algorithm backtracks to the last node with adjacent nodes not yet explored
3304, thus
following a depth first traversal order. Once the whole graph representing the
relevant
subset of the network has been explored, the set of all candidate paths is
returned 3312.
SCALABLE PATH SEARCH ALGORITHM
As the size of the network increases, the time required to explore all
possible
paths grows exponentially, so finding all candidate paths and then picking the
best
according to some criteria becomes impractical.
If a maximum time is allocated to the path search, some heuristics are needed
to
pick which links to explore first. This may improve the chances of having a
good
selection of candidate paths to select from when the search time is up.
The standard depth first graph traversal goes through links in a fixed
arbitrary
order. A "sort function" can be plugged into the depth first search graph to
decide which
link from the current node to explore next (FIG. 10). The algorithm shown in
FIG. 10 is
based on the algorithm shown in FIG. 9 described above, with only two
differences to
highlight:
A new check is added to ensure the algorithm does not go over a specified time
limit 3400.
A sort function 3401 is used to choose in which order adjacent nodes are
explored 3401. The sort function 3401 can range from simple random order,
which
might improve load balancing over time, all the way to a complex composite of
multiple
heuristic functions with processing order and relative weight dynamically
adjusted based
on past use and success rate.
A heuristic function could for example look at the geographical location of
nodes
in order to explore first links that point in the direction of the
destination. Also heuristic
functions can make use of the information gathered while running single-
constraint
searches using Dijkstra's algorithm, or by traversing the nodes and links and
computing
minimum, maximum and average values for various parameters. Another heuristic
function could take into account performance stats collected over time to
improve the
chances of selecting a more reliable path. There are infinite heuristic
functions that can
be used, and the network wide view is available to the VMS to improve the
chances of
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
28
making better decisions along the path search. A practical limitation is that
the sorting
time should be much shorter than the path exploration time. To that effect
some data
may be consolidated over time by the VMS so it is pre-computed and efficient
to look up
and use.
This mechanism allows the use of any combination of heuristics making use of
collected and consolidated information and policies in order to handle network
scalability.
Two passes of the multiple-constraint path search may be needed when looking
for main and backup paths in a very large network. Even if the provider's
criteria to
io optimize both main and backup paths are identical, there is one crucial
difference: to
achieve effective protection, the backup path must be as distinct from the
main path as
possible, overriding all other concerns. Since not all paths can be examined
(time limit),
choosing which ones to explore first is important. When looking for candidates
for
backup path the main path must already be known, so being distinct from it can
be used
as a selection criterion. This means that the first pass results in a list of
candidates from
which the main path is selected, and the second pass results in a list of
candidate paths
from which the backup path is selected, as distinct as possible from the main
path.
When a new service (end-to-end connection) is requested, the VMS runs through
its path search algorithm to find candidate paths that satisfy the
subscriber's
requirements. Then it selects from those candidate paths the main and backup
paths that
optimize the provider's goals such as cost and load balancing. This selection
makes use
of business policies and data available at the time a new service is
requested, as reflected
by the constraints used in the algorithms described above in connection with
the flow
charts in FIGs.7-9. Those constraints are modified from time to time as the
provider's
policies change. Over time, more paths are requested, some paths are torn
down, the
network evolves (nodes and links may be added or removed), and the provider's
concerns
may change. The paths that remain active still satisfy the original
subscriber's
requirements, but the network resources may be not optimally utilized in the
new
context, i.e., new paths may exist that are more efficient under the current
constraints
established to reflect the provider's policies.
To optimize utilization of the network resources at any point in time, the VMS
runs the same path search algorithm to find the optimal paths that would be
allocated at
the present time to satisfy existing services (end-to-end connections). Using
the same
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
29
sorting mechanisms that drive the selection of the optimal paths from the
candidate list,
the VMS compares the currently provisioned paths with the new ones found. If
the new
paths are substantially better, the VMS suggests that those services be re-
implemented
with the new paths. The provider can then select which services to re-
implement.
One example of an algorithm for optimizing utilization of the network
resources
is illustrated by the flow chart in FIG. 11. The algorithm starts at step 3501
with an
empty list of services to optimize. For each existing service, the steps
within a control
loop 3502 are executed. First, a new set of main and backup paths is found at
step 3503,
using the same path search algorithm described above in connection with FIG.
9.
Although the subscriber's requirements have not changed, the paths found this
time may
be different from the paths found when the service was originally requested,
because
network utilization and the provider's concerns may be different. Step 3504
then
determines whether the new paths are more efficient than the ones currently
provisioned
3504. If the answer is affirmative, the service is added to the list of
services worth
optimizing at step 3505. If the answer is negative, the loop is completed for
that
particular service. As indicated by the control loop 3502, the steps 3503-3506
are
repeated for each existing service.
Once the list of services to optimize is completed, a report is presented to
the
provider that summarizes the benefits to be gained by rerouting those
services. For each
service proposed to be optimized 3506, the steps within a control loop 3506
are
executed. Step 3507 determines wllether the provider wants the service to be
re-
implemented by the new found paths. If the answer is affirmative, the service
is re-
routed at step 3508. If the answer is negative, the loop is completed for that
particular
service. As indicated by the control loop 3506, the steps 3507 and 3508 are
repeated for
each of the services on the list generated at step 3505, and then the
algorithm is
completed at step 3509.
For example: Consider the best effort, least paying activated services. There
may
be a currently existing path now that satisfies the service more efficiently
than the
currently provisioned path, from the point of view of the provider's current
policies such
as cost or load balancing. Thus, running the path search algorithm with the
same service
specification may result in a more efficient way of providing that service. A
switchover
can then be scheduled to minimize service interruption, if necessary.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
PATH ASSOCIATION
Given the ability of the VMS to ensure that each direction of the connection
uses
the same path (as per FIG. 13), each network element (e.g. WiMAX switch) is
able to (1)
pair each forward 4202 and backward 4203 path of a connection at each node in
the path
5 of a connection and (2) allow for injection of messages in the backward
direction of a
connection from any node in the path. This capability, depicted in FIG. 14, is
referred to
herein as creating a "hairpin" 4303. The knowledge of the pairs at each node
4201
allows creating loopbacks, and then using control packets at any point in a
connection in
order to perform troubleshooting. Loopbacks can also be created by the VMS or
10 manually generated. The pairing is possible in this case because the VMS
ensures that
both paths of the connections (forward and backward) take the same route which
is not
currently the case for Ethernet
Other examples of uses for this path association could be where two uni-
directional paths with different characteristics are paired (such as different
labels and
1s traffic engineering information in the case of MPLS), or where a single
path is the
hairpin connection for multiple unidirectional paths
The hairpin allows nodes in the network to send messages (such as port-state)
back to their ingress point by sending packets back along the hairpin path
without the
need to hold additional information about the entire path without the need to
consult
20 higher level functions outside of the datapath, or to involve the transit
end of the path. If
the path is already bi-directional, no hairpin is required for pairing.
Using the hairpin to its full potential requires the use of a new subsystem
referred
to herein as a "packet treatment rule" or "rules" for short. These rules are
assigned to an
ingress interface and consist of two parts (FIG. 15a):
25 (1) ingress matching criteria 4407: this is a check to see if the packet in
question is to be acted upon or to simply pass though the rule subsystem with
no action.
(2) an action mechanism 4408 that is called if a packet does meet the criteria
of a packet to be acted upon. An example of an action mechanism is where a
rule was
placed on an ingress interface looking for a prescribed bit-pattern within the
packet.
30 When the system receives a packet that matches the prescribed bit-pattern,
the action
mechanism is run. This action mechanism may be one that directs the system to
send
this packet back out the interface at which it was received after altering it
in some way.
All other packets pass through the system unaffected.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
31
Rules can be placed at each node along a path to use the hairpin to loop-back
one
or more types of packet, or all packets crossing a port. Rules can also be
activated by
types of packets or other rules, allowing complicated rules that activate
other rules upon
receiving an activation packet or and deactivate rules on receiving a
deactivation packet.
As exemplified in FIG. 14, the pairing 4302 allows the system to create
flexible
in-service or out-of-service continuity checking at any node 4201 in the path.
Rule
checking points can be set along a path from ingress to egress to allow
continuity checks
4304 at each hop along a path. Each rule can consist of looking for a
different pattern in
a packet, and only hairpin traffic matching that bit pattern, as defined in
the ingress
matching criteria 407 of each individual rule. The pattern or ingress matching
criteria
can consist of a special pattern in the header or the body of a packet, or any
way to
classify the packet against a policy to identify it should be turned around on
the hairpin.
This allows a network operator to check each hop while live traffic runs on
the path and
is unaffected (in-service loopback) or to provide an out-of-service loopback
that sends all
traffic back on the hairpin interfaces.
The creation of path snakes is also easily implementable using hairpins (see
FIG.
15). A snake of a path 4401 can be created using a number of rules, e.g., one
rule
causing a specific type of packet to be put on a path that exists on the node,
and then
other rules directing that packet to other paths or hairpins on the node to
allow a network
operator to "snake" packets across a number of paths to test connectivity of
the network.
This also allows a test port with a diagnostic device 4402 to be inserted into
a node to
source (inject) and receive traffic that does not require insertion on the
ingress or egress
of a path.
In the case of FIG. 15: a rule 4405 is placed on the ingress port for a path
4401
that sends all traffic, regardless of bit pattern, out a specific egress port
4404 towards a
downstream node 4201b. An additional rule 4403 placed on node 4201 ingress
port
sends all traffic with a unique (but configurable) bit-pattern out the
interface's hairpin
back towards node 4201. A final rule 4406 sends all traffic matching the
aforementioned
unique bit pattern out the interface connected to the test device 4407.
The hairpin is always available at each node for each connection. Rules can be
enabled (and later disabled) to look for specific types of control messages
(e.g., loop-
back) and act on them.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
32
Hairpins can also used for other mechanisms described below such as protection
switching, network migration and flow control.
E-LINE PROTECTION CONFIGURATION AND OPERATION
One embodiment provides sub-50msec path protection switching for Ethernet
point-to-point path failures in order to meet the reliability requirements of
the carriers
without using a large amount of control messages. Furthermore, the back-up
path is
established and triggered based not only on available resources but also on
business
policies as described above.
The back-up path is calculated using the VMS, and not via typical signaling
mechanisms, which configures the switches' 4201 control plane with the
protected path.
The back-up path is set up by the VMS and does not require use of routing
protocols
such as OSPF. Once the back-up path is set up, the VMS is not involved in the
protection
switching. The process is illustrated in FIG. 16. When a node 4201 detects a
link failure
1s 501 (via any well-known method, such as loss of signal), it creates a
control message
4504 and sends the message back along the system using the hairpin 4303 (as
described
above) to indicate to the source endpoint of each connection using the failed
link that
they need to switch to the back-up path. The switching is then done
instantaneously to
the back-up path 4505. If the uni-directional paths are MPLS-Label switched
paths, the
hairpin allows the system to send the message back to the path's origination
point
without the need to consult a higher-level protocol.
The node can use the same mechanisms to notify the sources that the primary
path failure has been restored. Depending on the business policies set up by
the carrier,
the connection can revert to the primary path.
After a connection has been switched to a back-up path, the VMS is notified
via
messaging that the failure has occurred. The VMS can be configured to make the
current
path the primary path and to recalculate a new back-up path for the connection
after
some predetermined amount of time has elapsed and the primary path was not
restored
(e.g., after 1 minute). The information about the new back-up path is then
sent down to
the nodes witliout impact to the current data flow, and the old configuration
(failed path)
is removed from the configuration. Alternatively, the VMS can also be
configured to
find a new primary path and send a notification for switch over. The backup
protection
path remains as configured previously.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
33
If the a User-Network-Interface (UNI) or Network-Network-Interface (NNI) at an
end-point of a path fails, the endpoint can also use hairpins to send a
control message to
the traffic source to stop the traffic flow until the failure is restored or a
new path to the
destination can be created by the VMS, which is notified of the failure via
messaging.
ZERO-LOSS PROTECTION SWITCHING
Leveraging the E-line protection scheme, the Switch 4201 can create duplicate
packet streams using the active and the backup paths. Sequence numbers are
used to re-
combine the traffic streams and provide a single copy to the server
application. If the
io application does not provide native sequence nunibers, they are added by
the system.
One implementation of this behavior is shown in FIG. 17. In this figure, a
client
application 4600 has a stream of packets destined for a server application
4601. A
packet duplication routine 4610 creates two copies of the packets sourced by
the client
application 4600. A sequence number is added to these duplicate packets, and
one copy
is sent out on an active link 4620 and another is sent out on a backup link
4621.
One example of a packet duplication routine is depicted in FIG. 18. A packet
is
received at the packet duplication system 4701 from a Client Application 4600.
The
packet is examined by the system 4702, which determines whether an appropriate
sequence number is already contained in the packet (this is possible if the
packet type is
known to contain sequence numbers, such as TCP). If no well-known sequence
number
is contained in the packet, a sequence number is added by the packet
duplication system
4703. The packet is then duplicated 4704 by being sent out both links, 4620
and 4621,
first on the active link 4704 and then on the back-up link 4705. If there is
no need to
add a sequence number 4702, because the packet already contains such a number,
the
routine proceeds to duplicate the packet 4704.
A packet recombination routine 4611 listens for the sequenced packets and
provides a single copy to the server application 4601. It removes the sequence
numbers
if these are not natively provided by the client application 4600 data.
One example of a packet recombination routine is shown in FIG. 19. In this
case
a packet is received 4801 by the packet recombination system 4611 from the
packet
duplication system 4610. The system exainines the sequence number and
determines if
it has received a packet with the same sequence number before 4802. If it has
not
received a packet with this sequence number before, the fact that is has now
received a
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
34
packet with this sequence number is recorded. If the sequence number was added
by the
packet duplication system 4803 then this sequence number is now removed from
the
packet and the packet system sends the packet to the Server Application 4804.
If the
sequence number was not added by the packet duplication system 4600, then the
packet
is sent to the Server Application 4601 unchanged 4805. If a new packet is
received by
the packet recombination system 4802 with a sequence number that was recorded
previously, then the packet is immediately discarded as it is known to be a
duplicate
4806.
This system does the duplication at the more relevant packet level as opposed
to
the bit level of other previous implementations (as data systems transport
packets not
raw bit-streams) and that both streams are received and examined, with a
decision to
actively discard the duplicate packet after it has been received at the far
end. Thus, a
switch or link failure does not result in corrupted packets while the system
switches to
the other stream, because the system simply stops receiving duplicated
packets.
FLOW CONTROL
As was previously discussed, Ethernet transport services provide point-to-
point connections. The attributes of this service are defined using a SLA
which may
define delay, jitter and loss objectives along with a bandwidth commitment
which must
be achieved by the telecommunication provider's network.
One option to iinplement this service is to leverage a connection-oriented
protocol across the access network. Several standard options can be used to
implement
this connection:
- MPLS
- PWE over MPLS
- 802.1a1i Provider Bridge Transport
- L2TP
- PWE over L2TP
- VPLS
All these technologies offer transparent transport over an access or core
network.
FIG. 20 illustrates the key attributes of an Ethernet transport service. The
telecommunications provider establishes a path between a client application
5100 and a
server 5101. The upstream path 5160 carries packets from the client
application 5100 to
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
the server application 5101 via switch 5120, switch 5140, sub-network 5150 and
switch
5130. Switch 5120 is the edge switch for the client application 5100. It is
the entry
point to the network. Switch 5140 is a transit switch for the client
application 5100. The
downstream path 5161 carries packets from the server 5101 to the client 5100
via the
5 switch 5130, sub-network 5150, switch 5140 and switch 5120. By definition,
these
paths take the same route in the upstream and downstream directions. As well,
the
switches 5120 and 5130 create an association between the upstream and
downstream
paths called hairpin connections 5129 and 5130 or "hairpins." These hairpins
are used
for control messaging.
10 FIG. 21 illustrates the elements required in the switch 5120 to provide
ethernet
transport services. The switch 5120 contains a process controller 5121 which
controls
the behavior of the switch. All the static behavior (e.g., connection
classification data
and VLAN provisioning) is stored in a persistent storage 5122 to ensure that
the switch
5120 can restore its behavior after a catastrophic failure. The switch 5120
connects the
15 client application 5100 to a sub-network 5150 via data plane 5124. Client
packets are
received on a client link 5140 and passed to a packet forwarding engine 5125.
Based
upon the forwarding policy (e.g., VLAN 5 onport 3 is forwarded on MPLS
interface 5
using label 60) downloaded from the process controller 5121 from the
persistent storage
5122 via control bus 5123, the client application 5100 data is forwarded to
the network
20 link 5141. The rate at which the client application data is passed to the
sub-network
5150 is controlled by a traffic management block 5126. The behavior of the
switch 5120
can be changed over time by a management application 5110 over a management
interface 5124 to add, modify or delete Ethernet transport services or to
change policies.
These changes are stored in the persistent storage 5122 and downloaded to the
data plane
25 5124.
FLOW CONTROL
To enforce the SLA between the customer and the telecommunications provider,
a traffic admission mechanism 5401 (see FIG. 20) is required. Referring to
FIG. 21, the
30 traffic admission mechanism monitors the traffic on the client link 5140.
To perform this
function, the switch 5120 classifies all the traffic in its packet forwarding
engine 5125
and passes this to the traffic management block 5126. The traffic management
block
5126 manages all the queues and the scheduling for the network link 5141.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
36
One implementation is shown in FIG. 22. Once a customer's traffic is
classified,
it is monitored using either a classic policing function or a traffic shaper
in the traffic
admission mechanism 5401 (FIG. 20). The advantage of using a traffic shaper at
the
edge instead of a policing function is that it smoothes the traffic sent by
the client
application to make it conforming to the specified traffic descriptors, making
the system
more adaptive to the application need. The traffic shaper is included in the
nodes, and is
therefore within the control of the network provider which can rely on its
behavior. In
case of a traffic shaper used for traffic admission, per-customer queues 5405
are
provided and are located where the traffic for a connection is admitted to the
network.
A scheduler 5402 (FIG. 22) is responsible for selecting which packet to
transmit
next from any of the connections that are ready to send on the outgoing link
5403 (NNI,
UNI or Trunk). Each outgoing link 5403 requires a scheduler 5402 that is
designed to
prioritize traffic. The prioritization takes into account the different CoS
and QoS
supported such that delay and jitter requirements are met. Furthermore, the
scheduler
5402 treats traffic that is entering the network at that node with lower
priority than transit
traffic 5406 that has already gone over a link, since the transit traffic has
already
consumed network resources, while still ensuring fairness at the network
level. There
exist several different types of schedulers capable of prioritizing traffic.
However, the
additional ability to know which traffic is entering the network at a given
node is
particularly useful, given the connection-oriented centrally managed view of
the system.
The scheduler 5402 can queue the traffic from each connection separately or
combine
traffic of multiple connections within a single intermediate queue 5404.
Multiple intermediate queues 5404 can be used to store packets that are
awaiting
transmission on the link. At this point in switch 5120, traffic is aggregated,
and the rate
at which traffic arrives at the queuing point may exceed the rate at which it
can leave the
queuing point. When this occurs, the intermediate queues 5404 can monitor
their states
and provide feedback to the traffic admission mechanism 5401.
FIG. 23 shows an example of how the queue state is monitored. For each queue,
multiple sets of ON/OFF thresholds are configured. When the queue size reaches
the
ON1 threshold, a flow control message indicating that this level has been
reached is sent
to the traffic admission function for this connection. The state is stored for
this
connection to avoid continuous flow of control messages to this connection.
For each
subsequent packet passed to this queue, if the queue state of the connection
does not
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
37
match the local queue state, a flow control message is transmitted back to its
traffic
admission function, and its local queue state is updated.
Flow control messages are very small and are sent at the highest priority on
the
hairpin of the connection. The probability of losing a backward flow control
message
s while the forward path is active is very low. Flow control messages are only
sent to
indicate different levels of congestion, providing information about the state
of a given
queuing point.
When a message is received by the traffic admission mechanism 5401, it reduces
the rate at which the customer's traffic is admitted to the network. In
general, this is
io accomplished by reducing the rate of EIR traffic admitted. For a policing
function, more
traffic is discarded at the ingress client link 5140 (FIG. 21). For a traffic
shaper, packets
are transmitted to the network at a reduced rate.
If an intermediate queue 5404 continues to grow beyond the ON2 threshold,
another message is sent, and the traffic admission mechanism further reduces
the
15 customers EIR. When the queue size is reduced to below the OFF21eve1, a
control
message is sent to indicate that this level is cleared, and the traffic
admission mechanism
starts to slowly ramp up. More thresholds allow for a more granular control of
the traffic
shapers, but can lead to more control traffic on the network. Different
threshold
combinations can be used for different types of traffic (non-real-time vs.
real-time). One
20 simplistic implementation of this technique is to generate control messages
when packets
are being discarded for a given connection, because the queue overflowed or
some
congestion control mechanism has triggered it.
The response of the traffic admission mechanism to a flow control message is
engineered based on the technique used to generate the message. In the case
where
25 queue size threshold crossing is used, as described above, the traffic
admission
mechanism steps down the transmission rate each time an ON message is
received, and
steps up the transmission rate each time an OFF message is received. The size
of the
steps can be engineered. For example, the step down can be exponential while
the step
up is linear. The step can also be proportional to the traffic descriptors to
ensure
30 fairness. The system slowly oscillates between the increase and decrease of
the rates
until some applications need less bandwidth. If the number of connections
using the
flow controlled queue is available to each traffic admission mechanism, the
steps can be
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
38
modified accordingly. With a larger number of connections, a smaller step is
required
since more connections are responsive to the flow control.
In order for the flow control mechanism to work end-to-end, it may be applied
to
all queuing points existing in the path. That is, the flow control mechanism
is applied to
all points where packets are queued and congestion is possible, unless non-
participating
nodes are handled using the network migration technique described below.
FIG. 24 illustrates the flow control mechanism described above. Flow control
messages 5171 from a queuing point 5404 in a switch 5130 in the path of a
connection
are created when different congestion levels are reached and relieved. The
flow control
message 5171 is conveyed to the connection's traffic admission mechanism 5401
which
is located where the connection's traffic enters the network. The control
messages 5171
can be sent directly in the backward path of the connection using a hairpin
5139 (as
described above). This method minimizes the delay before the flow control
information
reaches the traffic admission mechanism 5401. The quicker the flow control
information
reaches the traffic admission mechanism 5401, the more efficient is the
control loop.
If multiple queues in the path are sending flow control messages, the traffic
admission mechanism 5401 keeps all the information, but responds to the most
congested state. For example, when one node notifies an OFF2 level, and
another node
is at OFF3, the traffic admission mechanism adjusts to the OFF3 level until an
ON3 is
received. If an ON1 is received for that node before the other node which was
at OFF2
level has sent an ON2, then the traffic shaper remains at OFF2.
Alternatively, each interim node can aggregate the state of its upstream queue
states and announce the aggregate state queue downstream. FIG. 25 depicts an
example
of this implementation. Each connection using an intermediate queue 5154 or
5404
maintains a local queue state and a remote queue state. If a queue 5404
reaches the ON 1
threshold, a flow control message is generated and sent downstream to the
traffic
admission mechanism 5401. When a switch 5151 receives the flow control
message, it
updates the remote congestion state for the customer connection. If the local
state of the
connection is less than the remote connection state, the flow control message
is
forwarded to the traffic admission mechanism 5401. Subsequently, if the
intermediate
queue 5154 should enter the ON2 state, the local connection state is higher
than the
remote connection state. As a result, an additional flow control message is
communicated downstream.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
39
To clear the reported thresholds, both queues need to clear their congestion
state.
In the example using FIG. 25, if an intermediate queue 5404 reaches OFF1, a
flow
control message is generated to indicate the new queue state. The switch 5150
receives
the flow control message and clears the remote queue state for the customer
connection.
However, a flow control message is not generated upstream since the local
queue state is
in the ON2 state. When the local queue state changes, such as reaching OFF2, a
flow
control message is generated and sent to the traffic admission mechanism 5401
which
affects the shaping rate.
Other methods can be used to generate the flow control. For example, instead
of
actual queue sizes, the rate at which the queue grows can be used to evaluate
the need for
flow control. If the growth rate is beyond a predetermined rate, then a flow
control
message indicatixig the growth rate is sent to the traffic admission mechanism
5401.
When the growth rate is reduced below another predetermined rate, then another
message indicating a reduction in the rate is sent to the traffic admission
mechanism
1s 5401. Again, multiple thresholds can be configured to create a more
granular control
loop. But the number of thresholds is directly proportional to the amount of
traffic
consumed by the control loop.
Another technique consists of having each queuing point calculate how much
traffic each comiection should be sending and periodically send control
messages to the
traffic shapers to adjust to the required amount. This technique is more
precise and
allows better network utilization, but it requires per-connection information
at each
queuing point, which can be expensive or difficult to scale.
When a new connection is established, there are different ways it can join the
flow control. One approach is to have the traffic admission mechanism start at
its
minimum rate (CIR) and slowly attempt to increase the transmission rate until
it reaches
the EIR or until it receives a flow control message, at which point it
continues to operate
according to the flow control protocol. Another more aggressive approach is to
start the
rate at the EIR and wait until a congestion control message is received to
reduce the rate
to the required by the flow control protocol level. A third approach consists
of starting to
send at the CIR and have the nodes programmed to send the actual link state
when it first
detects that a connection is transmitting data. Each approach generates
different
behavior in terms of speed of convergence to the fair share of the available
bandwidth.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
Optionally, the queuing point can include the number of connections sharing
this
queue when the flow control is triggered, which can help the traffic shaper
establish a
more optimal shaping rate.
Optionally, the traffic admission mechanism can extend the flow control loop
in
5 FIG. 25 by conveying the status, e.g., using an API, of the shaper to the
upper-layer
application either in real-time or periodically such that an application can
be design to
optimized its flow based on the network status. Even if the reaction of the
application
cannot be trusted by the network, the information can be used to avoid loss at
the traffic
shaper, preventing the resending of packets and therefore optimizing the
network end-to-
1o end.
The robust flow control mechanism meets several objectives, including:
- Minimize packet loss in the network during congestion, thus not wasting
network
resources, i.e., once a packet enters the network, it should reach the
destination.
- Minimize the amount of control messages used and how much bandwidth they
15 use. When there is no congestion, no control messages should be required.
- Minimize the delay for the control messages to reach the traffic shaper.
- Ensure that there is no interference between the flow control information
sent by
different nodes.
- Maximize utilization of bandwidth, i.e., ensure that the traffic shaper can
increase
20 the rates as soon as congestion is alleviated.
- Resilience to the loss of control messages.
- Isolation of connections in case of mis-behavior (failure of shaper).
- Fairness among all connections, where fairness definition can be implemented
in
a variety of modes.
25 - Keep the per-connection intelligence and the complexity at the edge and
minimize the per-connection information required at each queuing point.
FLEXIBLE SHAPER TO REDUCE DELAY OR LOSS
When a traffic shaper is used as the traffic admission mechanism, delay can be
30 added to packets at the network edge. A flexible traffic shaping algorithm
can take delay
into account when transmitting the packets into the network to ensure that SLA
delay
budgets are not violated.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
41
An example of such a flexible traffic shaper algorithm is shown in FIG. 26. In
this example, the function is triggered when each packet reaches the front of
a shaper
queue 5101. At this point the time to wait before that packet would conform to
CIR and
EIR is calculated at 5102, in variables C and E, respectively. There are
several known
methods to perform these calculations. If there is time to wait until the
packet conforms
to CIR but the packet has already been queued for longer than a predetermined
WaitThreshold, determined at 5103, then the packet is discarded at 5110 as it
is deemed
no longer useful for the client application. If C is lower than a
predetermined threshold
WaitForCIR, determined at 5104, then the shaper waits and sends the packet
unmarked
at 5109. Otherwise, if E is greater than another predetermined threshold
WaitForEIR,
determined at 5105, then the packet is discarded at 5110. If the difference in
wait time
between compliance to CIR and EIR is less than another predetermined threshold
DIFF,
determined at 5106, then the packet is sent as CIR after a delay of C at 5109.
Otherwise
the packet is sent, marked low priority, after a delay of EIR at 5107. In
either case, once
the packet is transmitted, the shaper timers are updated at 5108.
The settings of these thresholds can enable or disable the different behaviors
of
the algorithm. Also, the setting of the threshold impacts the average delay
for the
packets to get through the shapers and the amount of marked packets sent into
the
network.
The shaper can respond to flow control messages as described above (FIG. 24),
but the algorithm shown still applies except that the actual sending of the
message might
be delayed further depending on the rate at which the shaper is allowed to
send by the
network.
Furthermore, the traffic shaper can perform different congestion control
actions
depending upon the type of traffic that it is serving. For example, a deep
packet
inspection device could be placed upstream from the traffic shaper and use
different
traffic shapers for different types of traffic sent on a connection. For
TCP/IP type traffic,
the traffic shaper could perform head-of-the-line drop to more quickly notify
the
application that there is congestion in the network. Other types of congestion
controls
such as Random Early Discard could be applied for other types of traffic as
configured
by the operator. Another configuration could limit the overall amount of
Ethernet
multicast/broadcast traffic admitted by the traffic shaper. For example, the
shaper could
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
42
only allow 10% broadcast and 30% multicast traffic on a particular customer's
connection over a pre-defined period.
NETWORK MIGRATION
Network migration is a critical consideration when using systems that include
an
end-to-end flow control protocol into an existing network. The flow control
protocol
must operate, even sub-optimally, if legacy (or non-participating) nodes in
the sub-
network 5150 are included in the path (see FIG. 27).
The path across the sub-network 5150 can be established in a number of ways
io depending on the technology deployed. The path can be established
statically using a
VLAN, an MPLS LSP or a GRE tunnel via a network management element. The path
can also be established dynamically using RSVP-TE or LDP protocol in an MPLS
network, SIP protocol in an IP network or PPPoE protocol in an Ethernet
Network.
Another approach is to multiplex paths into a tunnel which reserves an
aggregate
bandwidth across a sub-network 5150. For example, if the network is MPLS, a
MPLS-
TE tunnel can be established using RSVP-TE. If the network is IP, a L2TP
connection
can be created between the switches 5120 and 5130. The paths are mapped into
L2TP
sessions. If the network is Ethernet, a VLAN can be reserved to connect
traffic between
switches 5120 and 5130. Then paths can use Q-in-Q tagging over this VLAN to
transport traffic through the sub-network 5150.
Once switches 5120 and 5130 have established a path upstream (5160) and
downstream (5161), switch 5130 uses its hairpin 5139 to determine the behavior
of that
path and estimate the congestion level and failures. To estimate the behavior
of the
upstream path 5160, switch 5120 inserts a periodic timestamped control message
5170 in
the path being characterized. The control message is set at the saine priority
as the
traffic. The switch 5120 does not need to insert control messages for each
connection
going from the downstream to the upstream node, only one for each priority of
traffic.
When the upstream node receives the message, an analysis function 5138
calculates different metrics based on the timestamp. The analysis function can
calculate
various metrics and combine them to estimate the level of congestion,
including, for
example:
- Delay in the path for control message i, i.e., D; =(Current time; -
timestamp;)
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
43
- Rolling average delay using different averaging periods (hours, days,
months) to
smooth out the jitter in the statistics.
- Minimum and maximum values obtained in a given time period.
- Jitter in the delay (by calculating the variance of the delay measurements).
- The actual traffic flow on the link to estimate the actual link occupancy.
The analysis function can also estimate the average growth in the delay to
estimate the growth of the delay curve, such as:
AD; = D;-Di_1
which provides an estimate as to when the non-participating elements are
reaching the
knee of the curve (FIG. 28).
The analysis function can also keep a history of delay and loss measurements
based on different time of day periods. For example during work day time, the
network
may be generally more loaded but congestion would occur more slowly, and in
the
evening the load on the network is lighter, but congestion (e.g., due to
simultaneous
downloads) will be immediate and more severe.
Based on these metrics, the analysis function 5138 estimates congestion on the
sub-network 5150 assuming that the packet delay follows the usual trend as a
function of
network utilization, as shown in FIG. 28. Using this assumption, delays
through a
network which exceeds approximately 60-70% utilization rise sharply. The
analysis
function can estimate when the sub-network 5150 reaches different levels of
utilization.
If the analysis function 5138 determines that the upstream path is becoming
congested, the switch 5130 generates an indication to switch 5120, using a
protocol
consistent with the flow control implemented in the participating node. It can
then
trigger flow control notifications to the source end-point by sending a high
priority flow
control message 5171 in the downstream path 5161, as per the flow control
description
above.
Ideally, to calculate accurate delay measurements, both nodes 5120 and 5130
need to have synchronized clocks, such that the timestamp provided by the
upstream
node 5120 can be compared to the clock of the downstream node 5130. If this
capability
is not available, the clocks from the upstream and downstream nodes can be
used and
only a relative delay value is measured. That is sufficient to estimate
possible congestion
or delay growth in the non-participating element. Another technique is for the
downstream node to look at the time it is expecting messages (e.g., if they
are sent every
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
44
100 msec.) and compare that to the time it is actually receiving the messages.
That also
provides estimates on the delay, jitter and delay growth through the non-
participating
element. The drift in clocks from both nodes is insignificant compared to the
delay
growth encountered in congestion.
This information can be used even for:
- non-delay-sensitive connections as it allows estimating the congestion in
the non-
participating elements.
- for delay-sensitive connections, the information can be used to trigger a
reroute to
a backup path when the QoS is violated.
The analysis function is set up when the path is created. If the path is
statically
provisioned, this policy is provided to the switch 5130 using the management
interface.
If the path is dynamically established, this policy may be signaled in-band
with the path-
establishment messages.
If the analysis function detects that periodic control messages are no longer
1s received, it can indicate to the source via control messages that the path
in the non-
participating element has failed. This mechanism is particularly useful when
the path
across subnetwork 5150 is statically provisioned.
Sequence numbers can be added to the control message 5170 so that the analysis
function can detect that some of the control messages are lost. The analysis
function can
then also estimate the loss probability on the path and take more aggressive
flow control
or protection switching actions in order to alleviate/minimize the loss.
Using such techniques, flow-controlled network elements can be deployed on a
pay-as-you-grow basis around existing network nodes.
AUTOMATIC BANDWIDTH RENEGOTIATION
Once a network has migrated to provide end-to-end flow control, the network
provides the ability to assess an application's bandwidth requirement
dynamically.
Depending on the types of customers, service providers can leverage data
available from
the traffic shapers to enable new revenue streams.
A system which leverages the end-to-end flow control elements is shown in FIG.
29. This figure contains the elements required to establish a service between
a client
application 5100 and a server application 5101. Examples of these applications
are:
1. A VoIP phone connecting to a registrar or proxy server via SIP.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
2. A video set top box registering with a video middleware server via HTTP.
3. A PC connecting to the Internet via PPPoE or DHCP.
The client application 5100 connects to an access network 5150 through a
switch
5120, which operates as described above. A network management element 5110
oversees
5 all the switches in the sub-network 5150. It provides an abstraction layer
for higher-level
management elements to simplify the provisioning and maintenance of services
implemented in the access network.
Access to the server application 5101 is controlled by a service signaling
element
5130 and a client management system 5112. The service signaling element 5130
10 processes requests from the client application 5100. It confers with the
client
management system 5112 to ensure that the client application 5100 can access
the server
application 5101. The client management system 5112 can also initiate a
billing record
(i.e., a CDR) as these events occur.
The service management system 5111 oversees network and customer
is management systems 5110 and 5112 to provision and maintain new services.
Both need
to be updated to allow a new client to access the server application 5101.
One method to leverage flow control is for the service management system 5111
to be notified when a particular client's service demands continually exceed
or underrun
the service level agreement between the client and the service provider. One
possible
20 method to implement this is depicted in FIG. 30, which leverages the
network definitions
of FIG. 29.
In this case, a process controller 5121 polls the data plane 5124 for client
application 5100 statistics at 5200. These statistics are stored for future
reference at
5201 and passed to the network management system 5110 at 5202. If the
customer's
25 demand exceeds the current service level agreement 5203, the network
management
system 5110 informs the service management system 5111 5204. The service
management system 5111 contacts the client management system 5112 5205. If
customer management decides to contact the client application 5100 5206, the
service
management element 51,11 contacts the customer at 5207. If the customer
decides to
30 change the service level agreement at 5208, the service management element
5111
contacts the network management system 5110 to increase the bandwidth at 5209.
The
network management system 5110 changes the bandwidth profile for the customer
and
informs the process controller 5121 in the switch 5120 at 5210. The process
controller
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
46
5121 changes the provisioning of the customer in the traffic management
element 5126
at 5211.
Information provided by the traffic shaper 5126 (or 5401 in FIG. 24) can
include,
for example:
- Average delay for packets in the traffic shaper queue.
- Average delay for each packet when reaching the front of the shaper queue
(to
indicate how far off the application's traffic pattern in from the traffic
descriptors)
- % of time packets are dropped at the tail of the traffic shaper, queue.
- % of time packets are marked by the traffic shaper, if applicable.
- % of time packets are dropped at the head of the traffic shaper, if
applicable.
- Average number of packets waiting for transmission in the traffic shaper.
The above information can be manipulated in different types of averaging
periods
and is sufficient to evaluate whether a connection's traffic descriptors match
the
applications' requirements for a given time period. The information can also
be used to
figure out time-of-day and time-of-year usage patterns to optimize the network
utilization.
The per-client statistics and the server application usage statistics can be
aggregated to provide usage patterns by the service management system to
create "Time-
of-Day" and "Time-of-the-Year" patterns. These patterns can be used to "re-
engineer" a
network on demand to better handle the ongoing service demand patterns. One
possible
method to implement this is depicted in FIG. 31.
In this case, the service management system 5111 decides to change the level
of
service for a set of customers at 5200 and 5201. For each customer in the
list, the service
management system 5111 contacts the client management system 5112 to retrieve
the
customer profile at 5203. The service management system 5111 programs the
changes
into network management at 5204 which is passed to the process controller 5121
at 5205.
The process controller 5121 changes the provisioning of the customer in
traffic
management 5126 at 5206. This process is repeated at 5207 and 5208 until all
customers
have been updated.
For some applications, it is desirable to perform these changes in real-time
and
allow the changes to persist for a limited period of time. An example of an
application
of this nature is "on-line" gaming. The client requires a low bandwidth with
low delay
connection-type to the server application. When the client logs into the
server, the
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
47
service signaling engine can tweak the access network to classify and provide
the correct
QoS treatment for this gaming traffic. One method to implement this is
depicted in FIG.
32.
The client application 5100 initiates a service to the service application
5101 at
5200. The switch 5120 passes this request through the packet network 5150 to
the
signaling server 5130 at 5201 and 5202. To validate the client's permissions,
the service
signaling element 5130 validates the request using the client management
system 5112 at
5203 5204. Assuming the request is valid, the service request is passed to the
server
application 5101 at 5205. Based upon the service, the server application 5101
decides to
tweak the customers profile and contacts the service management system 5111 to
modify
the client access link 5140 at 5206. The service management system 5111
contacts the
client management system 5112 to retrieve the customer profile at 5207 and
programs
the changes into the network management at 5208. The change is passed to the
process
controller 5121 at 5209, which changes the provisioning of the customer in
traffic
1s management 5126 at 5210, and the classification of the customer's traffic
in the packet
forwarding block at 5211. Network management also adjusts all other switches
in the
packet access network 5150 to ensure smooth service at 5212.
An alternative to handling these QoS changes in real-time is to allow the
process
controller 5121 to participate in the service signaling path between the
client application
5100 and the server application 5101. The service provider could create a
logical
network (i.e., a VLAN) to handle a particular application. Examples for these
on-
demand applications are:
1. VoIP signaled using SIP. The service provider can map this to a high
priority/low latency path.
2. Peer-to-Peer protocols using the bit torrent protocol. The service provider
can map this to a best-effort service.
Based upon this traffic classification, the service management system 5111 can
provision
this logical network in the access network 5150. One possible method to
implement this
is depicted in FIG. 33.
In this case, the service management system 5111 decides to create, and
instructs
the network management system 5110 to implement, a new virtual LAN at 5200.
The
network management system determines which customers are affected, and the
switches
require the new virtual LAN at 5201. Since the client application 5100 is
affected, the
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
48
switch 5120 is modified to apply the new LAN at 5202. The change is passed to
the
process controller 5121 at 5203 and stored in persistent storage to ensure the
behavior
can be restored across reboots at 5204. Then the changes are provisioned in
traffic
management 5126 at 5206, and the packet forwarding block at 5205 and 5206. To
completely enable the service, the process controller changes the
classification of the
customer's traffic in the packet forwarding block at 5211 to add the new
virtual LAN.
Now that the LAN is enabled, the real-time handling of the client application
request is effected as depicted in FIG. 34. This process affects the behavior
of the switch
5120 based upon service signaling. The client application signals the server
application
5101 to start a new session at 5200. This packet arrives in the switch 5120
via the client
link 5140 and is processed by the dataplane. The packet forwarding bloc
classifies the
packet and sees that the packet matches the virtual LAN at 5201 and 5202. The
request
is forwarded to the process controller which identifies the packet as a
request for the new
virtual LAN at 5203, 5204 and 5205. This request is forwarded to server
application
5101 via the access network 5150 at 5206. The request is accepted and the
response is
forwarded back to the client application 5100 via the access network 5150 at
5207.
When the response arrives back at the switch 5120, the packet forwarding block
identifies the packet and forwards to the process controller 5121 at 5209 and
5210. The
process controller 5121 notices that the client applications request has been
accepted by
the server application 5101, and changes are provisioned in traffic management
5126 at
5206 and the packet forwarding block at 5211 and 5212. Then the response is
forwarded
to the client application 5100 at 5213.
SUB-CLASSES FOR ETHERNET QoS
Once end-to-end flow control has been enabled and a traffic admission
mechanism is implemented to provide per customer SLA handling, the system
provides
for differentiation within a class of service (CoS). Differentiation can be
applied by
providing different levels of loss or delay to different connections.
One method to differentiate SLAs with a particular class of service is to
provision
a flow control handling policy. This policy can be unique for every path
providing
different handling at each level of congestion of flow control. The
flexibility makes
traffic engineering more difficult. To address this, the policies can be
defined as
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
49
templates to reduce the complexity and limit the amount of system resources
needed to
store and implement these policies.
Alternatively, different levels of service within a service class can be
implemented by triggering the flow control to connections proportional to a
service
weight. Therefore, upon flow control notification from the network, a
connection with a
larger weight reduces its transmission rate faster than a connection with a
lower weight.
When the flow control allows the connection to increase the weights, the
connection with
the larger weight increases its transmission rate more slowly than the one
with the
smaller weight Alternatively, it can be implemented such that a connection
with a
smaller weight reduces its transmission rate faster than a connection with a
higher
weight. The use of a weight allows differentiating connections with the same
traffic
descriptors.
Another implementation, which does not require the use of an additional weight
parameter, decreases and increases the transmission rate in proportion to the
existing
traffic descriptors, i.e., the weight is calculated as a function of CIR and
EIR. For
example, a weight for connection i could be calculated as follows:
Wi = (EIRi-CIRi)/AccesslinkRate;
Using such weight calculation, the connections that have the lower CIR have a
lower service weights and therefore trigger the flow control more
aggressively. It is
assumed in this example that such connections pay a lower fee for their
service.
Instead of using weights to define how flow control messages are handled, the
nodes could randomly choose which connections to send flow control information
to (to
increase or decrease the rate) and use the service weights to increase or
decrease the
probability that a given type of connection receives a flow control message.
This
characterization can be implemented in several ways, such as, for example,
having the
nodes agnostic to the sub-class differentiation and triggering backoff
messages to all the
connections, but the connections would react according to their sub-class's
policy.
Another way is to have the nodes knowledgeable of the subclass differentiation
and
trigger the flow control based on each connection's policies. That
implementation
requires more information on a per connection basis at the node, along with
multiple
flow control triggers, but the nodal behavior is more predictable.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
These mechanisms allow a carrier to deploy many different types of sub-classes
within one service type and charge different customers based on the
preferential
treatment their connections are receiving.
5 EFFICIENT SLA-based ELAN
As was previously discussed, Ethernet services provide point-to-multipoint
connections referred to as E-LAN or V-LAN. With an E-LAN, any site can talk to
any
one or more sites at a given time. The attributes of this service are defined
using an SLA
which defines a bandwidth profile and may include quality of service (QoS)
objectives
io such as delay, jitter and loss which must be achieved by the service
provider.
In the embodiment depicted in FIG. 36, an E-LAN that includes multiple
customer sites 101 a, 101 b, 101 c, 101 d and 101 e is created using an
Ethernet network
having a number of Ethernet switching elements 6201 a, 6201 b, 6201 c, 6201 d
and 6201 e.
The Ethernet switching elements, performing Media Access Control (MAC)
switching,
15 can be implemented using native Ethernet or VPLS (layer 2 VPN or MPLS using
pseudowires). Transit nodes such as the node 6202, performing physical
encapsulation
switching (e.g., label switching), are used to carry the trunks 6203a, 6203b,
6203c and
6203d to establish the E-LAN connectivity. Trunks can be established using
pseudowires (MPLS/L2TP), GRE (Generic Routing Encapsulation) or native
Ethernet.
20 Each of the Ethernet switching elements 6201 a- 6201 e has one or more
subscriber interfaces, such as interfaces 6210a, 6210b, 6210c, 6210d and
6210e, and one
or more trunk interfaces, such as interfaces 6212a, 6212b, 6212c, 6212d,
6214a, 6214b,
6214c and 6214d. The transit nodes do not have trunks or subscriber ports;
they provide
physical connectivity between a subscriber and an Ethernet switch or between
Ethernet
25 switches.
For the purpose of this description, from a given point in the network the
term
"upstream" refers to the direction going back to the source of the traffic,
while the term
"downstream" refers to the direction going to the destination of the traffic,
as depicted in
FIG. 37.
30 The Ethernet switches 6201 a- 6201 e and the transit node 6202 in the
network
perform flow control, at the subscriber and trunk levels, respectively, to
adapt the
transmission rates of the subscribers to the bandwidth available. One way to
evaluate the
bandwidth available is for each node to monitor the queues sizes at the egress
ports or
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
51
analyze changes in the size of the queue and/or change in delay (e.g., at the
queue 6204)
and buffer traffic outgoing on a link.
There are two levels of notification, the MAC-level status control message
(MCM) and the trunk-level status control messages (TCM) that are controlling
the
s subscriber and trunk shapers, respectively. Status control messages can
include a status
level for a link ranging from 0 to n (n 1) depending on the size of the queue,
where level
0 indicates that there is no or little contention for the link and n means the
queue is
nearly full.
For each site in the E-LAN, there is a subscriber shaper 6206a, 6206b, 6206c,
6206d or 6206e that is responsible for keeping track of the status of the MCM
and
adapting the traffic rate accordingly. At each trunk interface 6212a, 6212b,
6212c and
6212d there is a pair of trunk shapers 6207a, 6207b, 6207c, 6207d, 6208a,
6208b, 6208c
and 6208d, which dynamically shape the traffic according to the TCM. The trunk
shapers modify the transmission rate between maximum and minimum trunk rates
1s depending on the status control message. The modification can be done in
multiple
programmable steps using multiple status levels. The maximum can correspond to
the
physical line rate, or the configured LAN (CIR+EIR). The minimum trunk rate
can
correspond to CIR. The shaper is a rate-limiting function that can be
implemented using
traffic shaping functions or policing functions.
At least one subscriber shaper, such as shapers 6206a, 6206b, 6206c, 6206d and
6206e, is located at each subscriber interface 6210a, 6210b, 6210c, 6210d and
6210e to
shape the traffic between maximum and minimum subscriber rates depending on
the
status level indicated in the MCM. The maximum and minimum subscriber rates
can
correspond to the (CIR+EIR) and CIR, respectively. The subscriber shaper can
also be
located on the customer side of the UNI. The MCM information can also be
carried over
the UNI to the application to extend the control loop.
Each transit node tracks the status of its queues and/or buffers and, if
necessary, it
sends the TCM according to the level of congestion and current state to the
upstream
nodes such that the corresponding shapers adapt to the status of the transit
node. Each
Ethernet switch tracks the status of its queues and creates MCM notifications
when
necessary, and also tracks downstream MCM status for each destination MAC
address.
It also takes into account the TCM provided by the transit nodes.
The network can include one or more E-LANs with the same characteristics.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
52
Point-to-Point transmission
Based on the network described above (FIG. 36), an example of a flow-
controlled
pt-pt transmission is provided. Assume site 5 sends traffic to site 4, but
there is
contention on the link 103 at node F 6202 because of other traffic (not shown)
sharing
the same link 103.
The queue in node F 6204 grows, and a TCM is sent to node E 6201 e which
maintains the status infonnation and controls the trunk shaper 6207c. The
trunk shaper
adapts the rate according to the TCM. As the trunk shaper slows its rate, the
trunlc
shaper queue grows, and the node E enters the flow control mode at the MAC
level and
io starts generating MCM upstream. Another embodiment sends the MCM upstream
immediately upon receipt. Since traffic is originating from site 5 101 e, node
E sends the
MCM notification to node C 6201c through interface El 6214a. Node E keeps
track of
the trunk status through the trunk shaper queue status and also keeps track of
the MCM.
Each Ethernet switch maintains a table of the status of its links.
is An example of the table for node E, based on the above scenario, is as
follows:
Node E status table
Destination MAC address Local status Downstream Interfaces Notified
Site 4 Level 3 Level 3 El
Node E notifies node C of the contention through MCM. The subscriber shaper
6206d controlling the site 5 to site 4 transmissions is modified according to
the MCM.
Node C updates its MAC status table to reflect the status of the path to site
4. It also
20 includes information to indicate that the user-network interface (UNI)
6210d to site 5 has
been notified.
An example of the table is as follows:
Node C status table
Destination MAC address Local status Downstream Interfaces Notified
Site 4 Level 0 Level 3 C1
Each node can optionally keep track of congestion downstream, and only convey
25 worst-case congestion upstream to the source in order to reduce overhead.
The node uses the table to set the shapers of any subscribers trying to
transmit to
any destination.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
53
Now, if site 2 6201 a starts to send traffic to site 4, node E 6201 e receives
the
traffic on interface E3 6214c. Since interface E3 is not in the list of
interfaces notified in
its status table, node E sends a MCM to node C with the current level as it
starts to
receive traffic. Node C 6201c updates its status table accordingly and
modifies the
shaper controlling the traffic of site 2 6206b. Node E updates its table
accordingly:
Node E status table
Destination MAC address Local status Downstream Interfaces Notified
Site 4 Level 3 Level 3 E1, E3
The node A 6201 a status table includes the following information:
Node A status table
Destination MAC address Local status Downstream Interiaces Notified
Site 4 Level 0 Level 3 A2
If site 1 subsequently sends to site 4, then node 1 already knows the status
of the
path and sets the shaper of site 1 accordingly while updating the table as
follows :
Node A status table
Destination MAC address Local status Downstream Interfaces Notified
Site 4 LevelO Level 3 A2, A1
Congestion can happen not only on a transit node but at any egress link,
including
egress to a subscriber LTNI and, depending on the node architecture, at
intermediate
points in the nodes.
When the congestion level at the queue 6204 reduces, the transit node 6202
indicates to node E 6201 e via a TCM lower level of congestion. Node E updates
the
corresponding entry in the status table, updates its trunk shaper and sends
status control
is message with a lower level to all interfaces that had been notified of the
status (in this
case El and E3) such that node A and node C can also update their entries and
control
their shapers. The entries in the tables are updated as follows :
Node E status table
Destination MAC address Local status Downstream Interfaces Notified
Site 4 Level 1 Level 1 E1, E3
Node C status table
Destination MAC address Local status Downstream Interfaces Notified
Site 4 Level 0 Level 1 C1
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
54
Node A status table
Destination MAC address Local status Downstream Interfaces Notified
Site 4 Level 0 Level 1 A2, Al
When a MCM at level 0 is received by node C, it clears the corresponding entry
in the status table and sends a status control message with the level 0 to all
interfaces that
had been notified of the status.
If a node ages a MAC address because it has not been used by any of its
interfaces for a predetermined amount of time, it clears the corresponding
entry in the
status table and sends a MCM to all the interfaces that had been using the
address. The
node also indicates to the downstream node that it has aged the MAC address so
that the
downstream node can remove it from its list of notified interfaces.
For example, if node E 6201 e determines that site 5 101 e has not sent
traffic for a
predetermined amount of time, node E ages the MAC address of site 5 and sends
the
notification to interface C 1 clearing the status. The node E status table
becomes
Node E status table
Destination MAC address Local status Downstream Interfaces Notified
Site 4 Level 1 Level 1 E3
There can be a single subscriber shaper per UNI or multiple, e.g., one for
each
possible path on the E-LAN. Another possibility is to have a shaper per
congestion
level. At any given time, a subscriber port can have stations speaking to many
other
stations in the LAN. While these conversations proceed, each of these stations
can be
experiencing different levels of congestion across the LAN. As such, the
subscriber
traffic is metered at different rates based upon the destination addresses.
These rates
change over time based upon the MCM messages received from downstream nodes.
As
one embodiment of this subscriber dynamic shaper, there could be three rates
used:
1. unicast traffic,
2. multicast traffic, and
3. broadcast and unicast miss.
The contrains the amount of broadcast traffic on the LAN and ensures unicast
traffic
flow.
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
Point-to-Multipoint transmission
The same mechanism can also be applied to point-to-multipoint transmission.
The Ethernet switches maintain a table of which of its interfaces is used to
reach a given
MAC address. In the case of pt-to-mpt, the node maintains a table for each
group
5 address of any of its interfaces that are used to reach all the
destinations.
Using the same network shown in FIG. 36 as an example, if site 1 lOla
initiates a
pt-mpt transmission to Group 1 and eventually site 3 101 c and site 4 10 1 d
request to join
Group 1, node E maintains the following table and notifies the source (site 1)
of the
worst case congestion of all sites - in this case level 3 10
Node E status table
Destination address Interfaces Local status Downstream Interfaces Notified
used
Site 1, Group 1 E4 Level 0 Level 0 E3
Site 1, Group 1 E2 Leve1 3 Level 0 E3
If another subscriber located on node D were to request to join Group 1, no
change to the
table would be necessary as interface E4 is already notified of the congestion
level.
In node A,
Node A status table
Destination address Interfaces Local status Downstream Interfaces Notified
used
Group I A3 Level 0 Level 3 Al
is This scheme applies to multicast, anycast and broadcast. Any type of
multicast
addressing can be used for these tables, including PIM, IGMPv2, IGMPv3 and
MLD.
Node A uses the table to set the dynamic shaper to the rate corresponding to
the
worst case status of the group addresses, in this case site 4, and therefore
slows down
transmission to all destinations to account for the slowest leaf.
20 A similar approach can be used for broadcast and anonymous multicast.
Using this type of flow control on an E-LAN allows minimizing the amount of
bandwidth allocated for each path while still meeting the QoS objectives. In
the above
CA 02648197 2008-09-30
WO 2007/113645 PCT/IB2007/000855
56
example, only the CIR needs to be allocated once for each path in the network,
as
opposed to allocating the ABW for each combination of possible paths.
EFFICIENT SLA-based RATE-LIMITED E-LAN
The entire E-LAN bandwidth may be limited by rate limiting the E-LAN to an E-
LAN-specific bandwidth profile that is independent of the customer bandwidth
profile.
The bandwidth profile defines the maximum rate that the trunk shapers 6208a,
6208b,
6208c and 6208d can achieve at the ingress to the E-LAN. All the sites that
are
transmitting through the E-LAN are rate-limited by the trunk bandwidth such
that the
total E-LAN bandwidth consumed is controlled with limited or no packet loss in
the E-
LAN, allowing for deterministic engineering and reduced packet loss. Using a
rate-
limited E-LAN allows significant reduction of the bandwidth allocated to a
single E-
LAN while maintaining the SLA.
For example, the E-LAN is configured such that each ingress trunk 6208a
6208b, 6208c and 6208d is rate-limited to 10Mbps over a link speed of 100Mbps.
Each
site transmitting on the ingress trunk sends within its bandwidth profile
using the
subscriber shaper, but it is further confined within the rate limited by the
trunk, so the
total traffic transmitted by all the sites on one node does not exceed the
10Mbps. By rate
limiting at the ingress trunk shaper, MCM flow control can be triggered when
multiple
subscribers are sending simultaneously. In another embodiment, the trunks
internal
to the E-LAN 6207a, 6207b, 6207c and 6207d are also rate-limited to further
control the
amount of bandwidth that is consumed by the E-LAN within the network. These
trunks
trigger flow control when multiple traffic flows overlap simultaneously,
causing queue
levels to grow.
Those skilled in the art will recognize that various modifications and changes
could be made to the invention without departing from the spirit and scope
thereof. It
should therefore be understood that the claims are not to be considered as
being limited
to the precise embodiments set forth above, in the absence of specific
limitations directed
to each embodiment.