Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
INTELLIGENT CODE DIFFERENCING USING CODE CLONE
DETECTION
TECHNICAL FIELD
[0001] The subject disclosure generally relates to code differencing, or
"diffing," systems that intelligently generate and output semantic
information.
BACKGROUND
[0002] A common task of code review is to be able to ascertain and
appreciate the
changes between a previous version of source code and a current version of
source code.
Conventional code differencing, or doffing, systems merely identify changes in
source
code or between versions of source code. These systems typically provide basic
information, such as where there are added and/or deleted lines in one source
file. A
code reviewer reviewing the results of a conventional diffing system is
therefore without
intuitive or other descriptive information upon which to focus on the nature
of the
changes to the files, e.g., whether semantic or lexical changes have occurred.
[0003] Software development typically employs multiple software
developers
concurrently and collaboratively developing or modifying source code. To
facilitate
such development, the same source code, or source code base, e.g., a group of
files
containing source code, is often modified by different developers.
Additionally, in some
cases, one developer may fix bugs in the source code while another developer
may
concurrently modify the same source code by moving lines of source code within
or
across different files. Moreover, different versions of the same source code
may be
generated because of concurrent processing in two or more different branches
by
different developers. The foregoing approaches each generate different
versions of the
same code. The versions of code may thus be quite similar and, as such, the
task of
understanding the changes between versions of source code can be difficult.
[0004] While the above-described diffing systems provide a limited amount
of
support to developers, as mentioned, they are not particularly informative.
The above-
described deficiencies of today's code diffing systems are merely intended to
provide an
overview of some of the problems of conventional systems, and are not intended
to be
exhaustive. Other problems with conventional systems and corresponding
benefits of the
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
various non-limiting embodiments described herein may become further apparent
upon
review of the following description.
SUMMARY
[0005] A simplified summary is provided herein to help enable a basic or
general understanding of various aspects of exemplary, non-limiting
embodiments
that follow in the more detailed description and the accompanying drawings.
This
summary is not intended, however, as an extensive or exhaustive overview.
Instead,
the sole purpose of this summary is to present some concepts related to some
exemplary non-limiting embodiments in a simplified form as a prelude to the
more
detailed description of the various embodiments that follow.
[0006] Various embodiments as provided herein are targeted for
integrated
development environments (IDEs) wherein code clone detection technology can be
employed. Various embodiments are also targeted for systems and techniques
employing code clone detection methods. The code clone detection technology
can
be employed as a preliminary step in generating semantic information that is
output to
a code reviewer. Other environments and contexts that can benefit from the
differencing techniques described herein are contemplated too.
[0007] Various embodiments employ code clone detection technology to
generate semantic information about changes between versions of code. The
semantic
information can be a characterization of the change between the versions. The
characterization can be output to the code reviewer and thereby aids software
development generally, and code review processes, in particular. In some
embodiments, information can be output to the developer to review changes made
by
the developer him/herself and therefore embodiments described herein can aid
in self-
review of changes previously-entered by the developer and/or review of changes
entered by third-parties and merely reviewed by the developer.
[0008] In some embodiments, visualization information can be generated
such
as architectural diagram or color coded information to display information
about the
changes between versions. The visualization information is output to a code
reviewer
for visually aiding the understanding of the changes.
[0009] Still further, other systems and methods described herein include
a
clone detection core and an importance engine in some embodiments. The clone
detection component, or core, is configured to generate information indicative
of a
2
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
determination of a type of content change between at least two versions of
source
code. The importance engine is configured to determine a level of importance
associated with the type of the content change, and output information
indicative of
the level of importance. The level of importance is related to the
characterization of
the change in some embodiments. In other embodiments, the level of importance
is
related to the type of change, e.g., whether a format, lexical or logical
change. The
level of importance can be expressed as a value, e.g., integer, fraction,
percentage, etc.,
or as a visualization, e.g., color coding.
[0010] These and other embodiments are described in more detail below.
BRIEF DESCRIPTION OF THE DRAWINGS
[0011] Various non-limiting embodiments are further described with
reference
to the accompanying drawings in which:
[0012] Figure 1 is a block diagram showing an exemplary non-limiting
implementation of an intelligent code diffing system in accordance with one or
more
embodiments;
[0013] Figure 2 is another block diagram showing an exemplary non-
limiting
implementation of an intelligent code diffing system in accordance with one or
more
embodiments;
[0014] Figure 3 is another block diagram showing an exemplary non-
limiting
implementation of an intelligent code diffing system in accordance with one or
more
embodiments;
[0015] Figure 4 is a flow diagram illustrating an exemplary non-limiting
process for intelligent code diffing using code clone detection technology;
[0016] Figure 5 is another flow diagram illustrating an exemplary non-
limiting process for intelligent code diffing using code clone detection
technology;
[0017] Figure 6 is another flow diagram illustrating an exemplary non-
limiting process for intelligent code diffing using code clone detection
technology;
[0018] Figure 7 is another flow diagram illustrating an exemplary non-
limiting process for intelligent code diffing using code clone detection
technology;
[0019] Figure 8 is a block diagram illustrating an exemplary non-
limiting
screenshot for intelligent code diffing using code clone detection technology;
[0020] Figure 9 is another block diagram illustrating an exemplary non-
limiting screenshot for intelligent code diffing using code clone detection
technology;
3
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
[0021] Figure 10 is another block diagram illustrating an exemplary non-
limiting screenshot for intelligent code diffing using code clone detection
technology;
[0022] Figure 11 is another block diagram illustrating an exemplary non-
limiting screenshot for intelligent code diffing using code clone detection
technology;
[0023] Figure 12 is another block diagram illustrating an exemplary non-
limiting screenshot for intelligent code diffing using code clone detection
technology;
[0024] Figure 13 is a block diagram showing an exemplary non-limiting
implementation of a system architecture for implementing intelligent code
diffing
using code clone detection technology;
[0025] Figure 14 is a block diagram representing exemplary non-limiting
networked environments in which various embodiments described herein can be
implemented; and
[0026] Figure 15 is a block diagram representing an exemplary non-
limiting
computing system or operating environment in which one or more aspects of
various
embodiments described herein can be implemented.
DETAILED DESCRIPTION
OVERVIEW
[0027] By way of introduction, for efficiency in programming, software
developers often duplicate sections of source code in numerous locations
within
programming projects. Reusing a portion of source code with or without some
degree
of modifications or adaptations is called "code cloning" and the resulting
portions of
code that match, or correspond, to one another with varying degrees of
exactness, are
called "code clones" or more simply, "clones." Additionally, in some
embodiments, a
group of one or more files of source code used to build a particular
functionality,
component or application is reused with or without some degree of modification
within or between the files. The group of one or more files is called a "code
base."
While the term "code" is used herein for consistency, it should be understood
that the
term can apply to a "code base" where applicable.
[0028] Code clone detection technology addresses the problem of
identifying
and analyzing code clones in source code, or across files of source code.
Typical code
clone detection systems receive source code, pre-process the text of the
source code to
break lines into tokens and remove non-essential differences, and analyze the
remaining code for similarities.
4
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
[0029] Code diffing systems typically generate information about
differences
between two source code files. For example, differences between two source
code
files can be output. However, these systems typically output only basic
information
such as information describing lines that have been added or deleted.
[0030] Various embodiments as provided herein are targeted for
integrated
development environments (IDEs) wherein code clone detection technology can be
employed. Various embodiments are also targeted for systems and techniques
employing code clone detection methods. The code clone detection technology
can
be employed as a preliminary step in generating semantic information that is
output to
a code reviewer.
[0031] In one embodiment, a method of performing intelligent source code
processing employing code clone detection technology comprises receiving at
least
two versions of source code; and processing the versions of the source code
using
code clone detection technology. Based on the code clone detection technology,
a
determination can be made as to different portions of the versions that
correspond to
one another.
[0032] Systems and methods described herein employ code clone detection
technology to generate semantic information about changes between versions of
code.
The semantic information is a characterization of the change between the
versions.
The characterization is output to the code reviewer and thereby significantly
aids
software development generally, and the code review process, in particular.
[0033] In one embodiment, a method of performing intelligent source code
processing employing code clone detection technology comprises receiving
information indicative of a correspondence between at least two versions of
source
code. A characterization of the correspondence between the versions is
determined.
The characterization is indicative of a semantic difference between the
versions, and
is based on the correspondence. The information indicative of the
characterization is
output. In some embodiments, the information is output to a software
development
station that may be accessed by a code reviewer.
[0034] In some embodiments, the systems and methods also generate
visualization information such as architectural diagram or color coded
information to
display information about the changes between versions. The visualization
information is output to a code reviewer for visually aiding the understanding
of the
changes.
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
[0035] Still further, other systems and methods described herein
generate
information indicative of a level of importance to one or more changes between
versions of the code. The level of importance is related to the
characterization of the
change in some embodiments. In other embodiments, the level of importance is
related to the type of change (e.g., whether a format, lexical or logical
change, for
example). The level of importance can be expressed as a value (e.g., integer,
fraction,
percentage) or as a visualization (e.g., color coding).
[0036] In one embodiment, a method of performing intelligent source code
processing employing code clone detection technology comprises generating
information indicative of a determination of a type of content change between
at least
two versions of source code. A level of importance associated with the type of
the
content change is determined. Information indicative of the level of
importance is
output. In some embodiments, a visualization of the level of importance of the
change is output. The output can be provided to a software development station
accessible by a code reviewer.
[0037] Herein, an overview of some of the embodiments for achieving
intelligent code diffing has been presented above. As a roadmap for what
follows next,
various exemplary, non-limiting embodiments and features for intelligent code
diffing
are described in more detail. Then, some non-limiting implementations and
examples
are given for additional illustration, followed by representative network and
computing environments in which such embodiments and/or features can be
implemented.
INTELLIGENT CODE DIFFING USING CODE CLONE DETECTION
[0038] It can be appreciated, however, that the embodiments provided
herein
are not intended to be limited to any specific database or system
implementation.
Further, unless stated otherwise, the various embodiments are not intended to
be
limited to any specific code diffing or code cloning implementation(s).
[0039] By way of further description with respect to one or more non-
limiting
aspects of an intelligent code diffing design that can be employed to generate
semantic information about changes between different versions of source code,
various non-limiting characteristics associated with exemplary schemes that
can be
implemented are now described. For example, Fig. 1 is a block diagram showing
an
exemplary non-limiting implementation of an intelligent code differencing
system
6
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
102. As shown in Fig. 1, code differencing system 102 is associated with one
or more
code base storage repositories 104, 106. In an embodiment, code base storage
repositories 104, 106 store one or more code bases.
[0040] In one embodiment, code base storage repository 104 stores a
first
version of source code while code base storage repository 106 stores a second
version
of source code. As such, a first version of source code 110 and a second
version of
source code 120 can be received by the code differencing system 102 from code
base
storage repositories 104, 106. However, the code bases need not be so stored
and, for
example, both versions of code bases can be stored in and received from the
same
code base storage repository 104 or 106.
[0041] Additionally, while the number of versions of source code is
indicated
as two in some embodiments, different numbers of versions of source code can
be
processed simultaneously or concurrently in some non-limiting embodiments. For
example, three or more versions of source code can be processed concurrently
or
sequentially using the systems and methods described herein.
[0042] Further, versions of source code can be generated as a result of
different types of processes. For example, the two versions of source code can
be the
same source code that has been processed in two different branches by
different
developers. As another example, in another embodiment, the two versions of
source
code can be a first version of source code created at time, t, and a second
version of
source code created by modifying the first version of source code at a time,
t+x. For
example, a first version of source code could be created and a second version
of
source code could be later created based on modifying the first version to
address
bugs in source code or to provide other enhancements.
[0043] Code differencing system 102 includes a pre-processor 130
configured
to pre-process the first and second versions of the source code 110, 120 to
prepare the
source code for code clone detection. For example, the first and second
versions of
source code 110, 120 can be received by the code differencing system 102 and
the
pre-processor 130 can break lines into tokens and remove non-essential
differences
between the versions of source code 110, 120.
[0044] Code differencing system 102 includes a code clone detection core
140.
The code clone detection core 140 can perform the functions of code clone
detection
and processing.
7
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
[0045] In one non-limiting embodiment, the code clone detection that is
performed is as described in U.S. patent application number 12/752,942, filed
April 1,
2010, and entitled "CODE-CLONE DETECTION AND ANALYSIS," which is herein
incorporated by reference in its entirety, though for the avoidance of doubt,
the
various embodiments described herein are not limited to any particular code
clone
detection technology. The only requirement to a particular code clone
detection
technology is being able to detect both exact code clones and near-miss code
clones.
Near-miss code clones are those wherein further modifications such as add,
delete
and/or edit are performed on the source code after duplication.
[0046] In another embodiment, code clone detection includes identifying
one
or more portions within the two versions of source code that are similar to
one another.
As such, the code clone detection can detect portions that are not the same as
one
another and that are merely similar to one another. By way of further
clarification,
the code clone detection core 140 is configured to identify code that has
varying
degrees of similarity. As such, the code clone detection core 140 is able to
detect
portions, e.g., snippets, of code within the versions of code that are
different but
similar.
[0047] In some embodiments, for example, portions that are similar to
one
another are portions that are modified relative to one another with a deleted
code
snippet or function, a new code snippet or function, a duplicated code snippet
or
function, a moved function, a renamed function, a combination of moved and
renamed function, a modified function or the like.
[0048] In one embodiment, identifying the similar pieces of code
includes
outputting two code snippets, one code snippet from each of the versions of
code.
However, the embodiments herein are not so limited and identifying the similar
pieces
of code can include outputting information indicative of a location or
description of
the two code snippets within the two pieces of code. As shown in Fig. 1,
similar
pieces of code (or location or other information identifying the similar
pieces of code)
are output from the code differencing system 102. In one embodiment, the
similar
pieces of code or location or other information identifying the similar pieces
of code
is output to a software development station 150.
[0049] In one embodiment, the software development station 150 is
located
proximate to the code differencing system 102. In other embodiments, the
software
development station 150 is located remote from the code differencing system
102.
8
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
For example, in some cases, the code differencing system 102 is associated
with a
server and the software development station 150 is associated with a client
machine
that accesses the code differencing system 102 over a network.
[0050] The detected code snippets can be analyzed by a code reviewer
accessing the software development station 150 to enable the code reviewer to
focus
on the portions of the versions of code that has been changed. In large code
bases or
large files of code, the ability to focus on a selected portion can
significantly reduce
the outlay of time and resources.
[0051] In some embodiments, the code clone detection core 140 is also
configured, to generate a value corresponding to the degree of similarity
between the
two versions of source code 110, 120. The value may be an integer, fraction or
percentage value.
[0052] Fig. 2 is another block diagram showing an exemplary non-limiting
implementation of an intelligent code differencing system 202. As described
with
reference to Fig. 1, code differencing system 202 includes a pre-processor 130
and
code clone detection core 140. The code differencing system 202 receives first
and
second versions of source code 110, 120. In one non-limiting embodiment, as
shown
in Fig. 2, the first and second versions of source code 110, 120 are received
from the
code base storage repositories 104, 106.
[0053] As shown in Fig. 2, the code differencing system 202 also
includes a
characterization engine 210 determine a correspondence between the two
versions of
source code 110, 120. The correspondence is indicative of the change between
the
two versions of source code 110, 120, and is associated with a
characterization. The
characterization includes semantic information about the changes between the
two
versions of source code 110, 120.
[0054] As such, the code clone detection core 140 identifies similar
portions
of the source code and output such information to the characterization engine
210.
The characterization engine 210 abstracts that information to extract semantic
meaning describing the change between the two codes. The semantic meaning is
described by the characterization, which is output from the characterization
engine
210.
[0055] There are a number of different types of characterizations
possible in
various embodiments. For example, in one case, there are approximately six
different
characterizations of changes between the first and second versions of source
code 110,
9
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
120. In one embodiment, the different characterizations are new code snippets
or
functions (e.g., a new code snippet or function is added in one version of
code relative
to the other version of code is the change); duplicated code snippet or
function (e.g., a
new code snippet or function is duplicated by copy-and-paste); a deleted code
snippet
or function (e.g., a function is deleted in one version of code relative to
the other
version of code); a moved function (e.g., a function is moved from the source
file for
one version of code to the source file for the other version of code); a
renamed
function (e.g., a signature is changed in the code but the content has not
changed); or
a modified function (e.g., a signature is the same but the content has changed
in the
code). In various embodiments, a characterization can also be indicative of a
code
snippet or function having moved and renamed code snippets or functions
combined.
As used herein, the term "code snippet" means a segment of consecutive
statements in
a function.
[0056] The above six characterizations are output from the code
differencing
system 202 to the software development station 150. The characterization
engine 210
can therefore provide semantic information to the software development station
150
(and code reviewer accessing such software development station 150) about what
type
of change occurred between the first and second versions of source code 110,
120 as
opposed to merely providing the code reviewer with the changes and requiring
the
code reviewer to assess the type of changes that occurred. The code review
experience is therefore improved and made more efficient.
[0057] In one embodiment, as shown in Fig. 2, the code differencing
system
202 also includes a visualization engine 220. The visualization engine 220
generates
a visualization of the characterization. The visualization is a file
describing the
characterization, an architectural diagram graphically displaying the changes
between
the versions of source code 110, 120 or the characterization, and/or a color-
coded
listing of functions associated with the changes between the first and second
versions
of source code 110, 120 identified by the code clone detection core 140.
[0058] Information indicative of the characterization and/or the
visualization
of the characterization is output to the software development station 150 from
the
characterization engine 210 and/or the visualization engine 220, respectively.
[0059] Fig. 3 is another block diagram showing exemplary non-limiting
implementation of an intelligent code differencing system 302. As described
with
reference to Fig. 1, code differencing system 302 includes a pre-processor 130
and
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
code clone detection core 140. The code differencing system 302 receives first
and
second versions of source code 110, 120. In one non-limiting embodiment, as
shown
in Fig. 3, the first and second versions of source code 110, 120 are received
from the
code base storage repositories 104, 106.
[0060] As shown in Fig. 2, code differencing system 302 includes a
characterization engine 210 and, in some embodiments, a visualization engine
220.
As shown in Fig. 3, code differencing system 302 also includes an importance
engine
310 configured to associate a level of importance with the type of content
change
between the two versions of source code 110, 120 and/or based on a
characterization
generated by the characterization engine 210.
[0061] In some non-limiting embodiments wherein the type of content
change
is a characterization of the change, the level of importance is mapped from
the
associated characterization. For example, a moved function can be a
characterization
that is then mapped to a trivial level of importance change, thereby being
assigned the
lowest level of importance. As another example, a renamed function can be
mapped
to a minor change, thereby being assigned a moderate level of importance. As
another example, the modified function can be mapped to a major change,
thereby
being assigned the greatest level of importance. Referring to the previously-
described
characterizations, level of importance information can be provided for
duplicated
code snippet or function, moved function, renamed function or modified
function
characterizations.
[0062] In some embodiments, in lieu of, or in addition to, generating
level of
information based on the characterization, the level of importance can be
generated
based on the type of content change from the first to the second versions of
the source
code 110, 120.
[0063] For example, in one embodiment, the type of content change is a
format change or a comment change. Format and comment changes can be
associated
with a trivial level of change and therefore assigned the lowest level of
importance.
[0064] In another embodiment, the type of content change is a lexical
change
(e.g., variable re-naming). Lexical changes can be associated with a moderate
level of
change and therefore assigned a moderate level of importance.
[0065] In another embodiment, the type of content change is a logical
change.
A logical change can be associated with a major level of change, and therefore
assigned a highest level of importance.
11
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
[0066] In some non-limiting embodiments, the level of importance is
determined based on assigning a numeric (e.g., percentage or otherwise) value
to the
type of the content change and categorizing the level of importance according
to the
numeric value. For example, a value of a 5% change would represent a trivial
change,
which would be assigned the lowest level of importance, while a value of a 50%
(or
more) change would be a major change, which would be assigned the greatest
level of
importance. Additionally, in various embodiments, the value (e.g., the 5%
value
above) is utilized in conjunction with other code metrics to further enhance
to ability
to communicate the importance of a change. In one non-limiting embodiment, for
example, if 5% of code has changed semantically but the portion that has
changed is
the critical path of the application (based on test results), the relative
importance of
the actual portion of the code that has changed can be communicated by placing
a
value on a code metric associated with the portion of the code and/or by
selecting a
particular metric, value of a metric, importance level of a metric, etc. to
communicate
the importance of the portion of the code that has changed.
[0067] The level of importance is output from the importance engine 310
to
the software development station 150. In one embodiment, although not shown in
Fig.
3, the visualization engine 220 receives information about the level of
importance
generated by the importance engine 310, and generates and outputs the level of
importance as a visual representation.
[0068] Fig. 4 is a flow diagram illustrating an exemplary non-limiting
process
for performing intelligent code diffing using code clone detection technology.
At 400,
at least two versions of source code are received at the intelligent code
diffing system.
At 410, the two versions of source code are processed using code clone
detection
technology, and similar pieces of source code are identified. By way of
further
clarification, the code clone detection technology is configured to identify
source code
that has varying degrees of similarity. As such, the code clone detection
technology is
able to detect snippets of source code that are different but that are
similar.
[0069] In one embodiment, identifying the similar pieces of source code
includes outputting two source code snippets, one source code snippet from
each of
the versions of source code. However, the embodiments herein are not so
limited and
identifying the similar pieces of source code can include outputting
information
indicative of a location or description of the two source code snippets within
the two
pieces of source code.
12
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
[0070] At 420, the source code snippets (or information indicative of
the
location or description of the source code snippets) are processed by the code
diffing
system. Semantic analysis on the similar pieces of source code is performed to
determine a characterization of the differences between the two pieces of
source code.
[0071] Step 420 is described in greater detail in one non-limiting
embodiment
as follows. In one implementation, the code clone detection tool outputs a
clone pair
set {Pi},i =1, 2, ..., N, where Pi= [SAi, SBi], SA i is one code snippet (or
function)
from one version of source files, and SBi is one code snippet (or function) of
another
version of source files. At 420, then, each clone pair Pi is further analyzed.
[0072] Specifically, in one case, if SA i and SBi are exactly same and
with the
same location context (e.g., in the same source file and having the same
neighboring
functions), then this pair is ignored.
[0073] In another case, if SA i and SBi are exactly the same functions
but
having different location context (e.g., in different source files or having
different
neighboring functions), then SA i and SBi are characterized as moved
functions.
[0074] In another case, if SA i and SBi are near-miss cloned functions,
they
will be further categorized as follows: if their signatures are different and
have the
same body content, then they are characterized as renamed functions. If their
body
content are different, but have the same signature, then they are
characterized as
modified functions. Further, if they have different location context, then
they are
characterized as moved functions. If they have further different body content,
they are
characterized as moved and modified functions.
[0075] In addition, also at 420, code snippets and functions that are
not in the
list of set {Pi} are further analyzed to get deleted and/or added code
snippets or
functions. The deleted and/or added code snippets or functions are further
searched
against 13213 (e.g., with an index of a local code base) or 1334 (e.g., with
an index of
a set of code bases in the server side) to determine if they are duplicated
from other
places in the current code base or even from other code bases.
[0076] Turning back to FIG. 4, as described above, the characterization
is
based on the level and/or type of complexity of the changes between the two
versions
of source code in some embodiments.
[0077] As such, the process of Fig. 4, provides information about what
type of
change occurred as opposed to merely providing the code reviewer with the
change
13
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
and requiring the code reviewer to assess the type of change that occurred.
The code
review experience is therefore improved.
[0078] While not shown in Fig. 4, in some embodiments, the
characterization
is output as a file that describes the differences between the versions of
source code.
However, a file is one non-limiting example.
[0079] In other non-limiting embodiments, for example, the
characterization
(or the change that the characterization indicates) is output visually. For
example, the
visualization can be that of an architectural diagram that graphically depicts
the
operations on the two versions of source code that result in the
characterization. For
example, a move operation could be depicted visually by indicating the
function of
interest and illustrating an arrow from the function in the first version of
source code
to the function in the second version of source code. As another example, the
visualization can be a color-coded diagram that illustrates different color-
coded code
snippets or functions or pieces of source code from the two versions of source
code.
The colors associated with the code snippets or functions or pieces of source
code are
assigned to different characterizations (e.g., red can represent a moved
function, while
yellow represents a duplicated code snippet or function, for example). The
code
reviewer can visually identify the type of changes between the two versions of
source
code.
[0080] While six different characterizations are described, these
characterizations are non-limiting and merely exemplary. Other
characterizations are
possible and, in some cases, a smaller number (or greater number) of
characterizations
is possible as determined by the system designer and the needs of the code
reviewer,
which may change from time to time.
[0081] The process of Fig. 4 can be separated into different processes,
each of
which having novelty and distinctive advantages over the conventional
approaches
and uses of code clone detection technology in general, and code diffing, in
particular.
[0082] For example, Fig. 5 is a flow diagram illustrating an exemplary
non-
limiting process for facilitating intelligent code diffing. At 500, two
versions of
source code are received. At 510, the two versions of source code are
processing
using code clone detection technology. At 520, using the code clone detection
technology, different portions of the source code that correspond to one
another are
determined. In non-limiting embodiments, the pieces of source code that
correspond
to one another are either the same pieces of source code or similar pieces of
source
14
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
code. As such, the process of Fig. 5 utilizes code clone detection technology
to detect
near matches of source code (and not merely exact matches of source code).
[0083] The detected source code can be output from an intelligent code
diffing
system and accessed by a code reviewer.
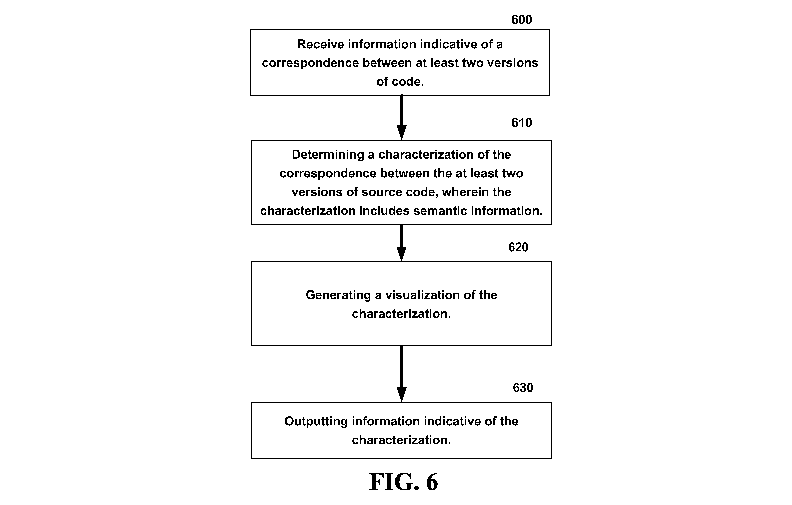
[0084] As another example, Fig. 6 is a flow diagram illustrating an
exemplary
non-limiting process for facilitating intelligent code diffing. At 600,
information
indicative of a correspondence between two versions of source code is
received. At
610, a characterization of the correspondence is determined. In one non-
limiting
embodiment, the correspondence is information indicative of the actual
differences
between the two versions of source code that is abstracted to determine
characterizations. For example, in one non-limiting embodiment, the
correspondence
is information indicative of a code snippet or function being deleted from a
first
version and a code snippet or function being added in the second version. By
contrast,
the characterization is the abstraction to the semantic meaning underlying the
added
and deleted code snippet or function. For example, if the added and deleted
code
snippet or function are the same code snippet or function, the semantic
meaning of the
deletion and addition is determined to be a move from one version to another
version
and the characterization is then determined to be a move described above with
reference to Fig. 4 (as opposed to merely outputting that a deletion of a
first file and
an addition of a second file occurred across the two versions with no addition
information as to whether the added and deleted content was the same or any
other
semantic information associated therewith).
[0085] At 620, a visualization of the characterization is generated. As
described previously, the visualization is a file describing the
characterization of the
changes between versions, an architectural diagram graphically displaying the
change
between the version and/or a color-coded listing of code snippet or functions
that
represent a change in one version of source code relative to the other version
of
source code.
[0086] At 630, the characterization is output. In some embodiments, the
changes that drive the identification of the characterization are also output.
[0087] As another example, Fig. 7 is a flow diagram illustrating an
exemplary
non-limiting process for facilitating intelligent code diffing. At 700,
information
indicative of a type of content change between versions of source code is
generated.
The type of content change can be a format change or comment change; a lexical
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
change (e.g., variable re-naming) or a logical change in different non-
limiting
embodiments. Further, in some non-limiting embodiments, the type of content
change is the characterization of the differences between the versions of
source code.
As such, the type of content change is a moved function, deleted code snippet
or
function or any number of the other types of code snippet and/or functions
described
above with reference to Figs. 4-6, for example.
[0088] At 710, a level of importance associated with the type of the
content
change is determined. In some non-limiting embodiments wherein the type of
content
change is a characterization of the change, the level of importance is mapped
from the
associated characterization. For example, a moved function can be a
characterization
mapped to a trivial change, thereby being assigned the lowest level of
importance. As
another example, a renamed function can be mapped to a minor change, thereby
being
assigned a moderate level of importance. As another example, the modified
function
can be mapped to a major change, thereby being assigned the greatest level of
importance. Referring to the previously-described characterizations, level of
importance information can be provided for duplicated code snippet or
function,
moved function, renamed function or modified function characterizations.
[0089] In some non-limiting embodiments, the level of importance can be
determined based on assigning a numeric (e.g., percentage or otherwise) value
to the
type of the content change and categorizing the level of importance according
to the
numeric value. For example, a value of a 5% change would represent a trivial
change,
which would be assigned the lowest level of importance while a value of a 50%
(or
more) change would represent a major change, which would be assigned the
greatest
level of importance.
[0090] At 720, information indicative of the level of importance is
output. As
described with regard to Figs. 4 and 6, the level of importance can be
depicted
visually.
[0091] Turning to Figs. 8-12, block diagrams illustrating exemplary
screenshot for intelligent code diffing are shown. Fig. 8 is a block diagram
illustrating an exemplary non-limiting screenshot for intelligent code diffing
using
code clone detection technology. As shown in Fig. 8, a developer made changes
to
multiple files of source code. The files are compared to previous versions and
information indicative of the change is indicated in the screenshot for each
edited file.
16
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
Additionally, new files that are added relative to previous versions are
indicated as
added.
[0092] Fig. 9 is another block diagram illustrating an exemplary non-
limiting
screenshot for intelligent code diffing using code clone detection technology.
The
code diffing system having embodiments described herein outputs information
indicative of function-level, intuitive changes to the versions of the source
code, as
shown in Fig. 9. The changes are labeled as one of the six characterizations
previously-described herein. As described herein, in various embodiments, the
amount of change can also be indicated by the code diffing system. By way of
example, the percentage of change between the versions (or the percentage of
similarity between the versions) is indicated along with the characterization
in some
embodiments.
[0093] Fig. 10 is another block diagram illustrating an exemplary non-
limiting
screenshot for intelligent code diffing using code clone detection technology.
The
code diffing system can receive inputs selecting a file such as the selection
of
NewFile.cs as shown in Fig. 10. The detailed changes between the versions is
described at a function, intuitive level. For example, for a duplicated code
snippet or
function, such as function NewFile::CopiedMethodl in file newFile.cs, the code
diffing system shows the detailed changes after duplication, including
signature (e.g.,
function definition) change and content (e.g., body) change (91% similarity).
[0094] By clicking an icon (or the file of interest) the detailed
changes can
also be output in an intuitive, semantic manner, as shown in Fig. 11. In this
embodiment, the change is a bug fix.
[0095] Fig. 12 is another block diagram illustrating an exemplary non-
limiting
screenshot for intelligent code diffing using code clone detection technology.
Fig. 12
shows the detailed changes between a function (NewFile::CopiedMethodl in file
newFile.cs shown in Fig. 10) and its duplicated version.
[0096] Fig. 13 is a block diagram showing an exemplary non-limiting
implementation of a system architecture for implementing intelligent code
diffing
using code clone detection technology. As shown in Fig. 13, the system
includes a
code clone analysis core 1310, an integrated development environment (IDE)
1320
and an application server 1350.
[0097] The code clone analysis core 1310 includes an indexer 1312 and
parser
1314 to respectively perform indexing and parsing associated with the code
received
17
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
by the code clone analysis core 1310. A parser interface 1315 is provided. The
code
clone analysis core 1310 includes a code clone detector 1316 configured to
detect
similar pieces of code. In one non-limiting embodiment, as mentioned, the code
clone
detector 1316 is configured to code clone detection and processing described
with
reference to U.S. patent application number 12/752,942, filed April 1, 2010,
titled
"CODE-CLONE DETECTION AND ANALYSIS." In addition to the code clone detection
capabilities, the code clone detector 1316 can be configured to characterize
the
changes between different versions of code at a semantic level and/or
generally
perform any of the functions described herein with reference to the
characterization
engine 210 of Fig. 2 and/or the importance engine 310 of Fig. 3.
[0098] The code clone analysis core 1310 also includes a difference
visualizer
1318 configured to generate information for visualization of a
characterization and/or
level of importance as previously-described with reference to the
visualization engine
220 of Fig. 2.
[0099] The IDE 1320 includes an augmented code review user interface
(UI)
1322, a code clone provider 1324 that includes an analysis driver 1326 and a
code
clone analysis core 1328. A language services component 1340 and
functionalities
for receiving information from other data providers are also provided at 1342.
[00100] Turning now to the application server 1350, as noted above, in
some
embodiments, the system also includes a code clone analysis service 1330 as
part of
the application server 1350. The code clone analysis service 1330 includes a
code
clone analysis core 1332 at a server for providing intelligent code diffing, a
code
clone search engine 1334 and a code clone detection engine 1336. The
application
server 1350 can also include existing services 1352 and a task manager 1354.
[00101] When the application server 1350 includes the code clone analysis
service 1330, indexing of large scale code bases (e.g., tens to hundreds of
millions of
lines of code from multiple code bases) can be processed and users can search
code
clones in larger scope. This enables the possibility of determining a code
snippet or
function that is a duplication of the source code in other solutions, although
it could
be new in the current solution. This further facilitates the developers/code
reviewers'
ability to understand the context of the code changes better. Without the code
clone
analysis service 1330, the intelligent code diffing is performed at the client
utilizing
the code clone analysis core 1310 and the IDE 1320 and relatively small code
bases
18
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
can be processed, however, such solutions are particularly light weight and
convenient.
EXEMPLARY NETWORKED AND DISTRIBUTED ENVIRONMENTS
[00102] One of ordinary skill in the art can appreciate that the various
embodiments of the intelligent code diffing systems and methods described
herein can
be implemented in connection with any computer or other client or server
device,
which can be deployed as part of a computer network or in a distributed
computing
environment, and can be connected to any kind of data store. In this regard,
the
various embodiments described herein can be implemented in any computer system
or
environment having any number of memory or storage units, and any number of
applications and processes occurring across any number of storage units. This
includes, but is not limited to, an environment with server computers and
client
computers deployed in a network environment or a distributed computing
environment, having remote or local storage.
[00103] Distributed computing provides sharing of computer resources and
services by communicative exchange among computing devices and systems. These
resources and services include the exchange of information, cache storage and
disk
storage for objects, such as files. These resources and services also include
the sharing
of processing power across multiple processing units for load balancing,
expansion of
resources, specialization of processing, and the like. Distributed computing
takes
advantage of network connectivity, allowing clients to leverage their
collective power
to benefit the entire enterprise. In this regard, a variety of devices may
have
applications, objects or resources that may participate in the mechanisms as
described
for various embodiments of the subject disclosure.
[00104] Fig. 14 provides a schematic diagram of an exemplary networked or
distributed computing environment. The distributed computing environment
comprises computing objects 1410, 1412, etc. and computing objects or devices
1420,
1422, 1424, 1426, 1428, etc., which may include programs, methods, data
stores,
programmable logic, etc., as represented by applications 1430, 1432, 1434,
1436,
1438. It can be appreciated that computing objects 1410, 1412, etc. and
computing
objects or devices 1420, 1422, 1424, 1426, 1428, etc. may comprise different
devices,
such as personal digital assistants (PDAs), audio/video devices, mobile
phones, lVfP 3
players, personal computers, laptops, etc.
19
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
[00105] Each computing object 1410, 1412, etc. and computing objects or
devices 1420, 1422, 1424, 1426, 1428, etc. can communicate with one or more
other
computing objects 1410, 1412, etc. and computing objects or devices 1420,
1422,
1424, 1426, 1428, etc. by way of the communications network 1440, either
directly or
indirectly. Even though illustrated as a single element in Fig. 14,
communications
network 1440 may comprise other computing objects and computing devices that
provide services to the system of Fig. 14, and/or may represent multiple
interconnected networks, which are not shown. Each computing object 1410,
1412,
etc. or computing object or device 1420, 1422, 1424, 1426, 1428, etc. can also
contain
an application, such as applications 1430, 1432, 1434, 1436, 1438, that might
make
use of an API, or other object, software, firmware and/or hardware, suitable
for
communication with or implementation of the various embodiments of the subject
disclosure.
[00106] There are a variety of systems, components, and network
configurations that support distributed computing environments. For example,
computing systems can be connected together by wired or wireless systems, by
local
networks or widely distributed networks. Currently, many networks are coupled
to the
Internet, which provides an infrastructure for widely distributed computing
and
encompasses many different networks, though any network infrastructure can be
used
for exemplary communications made incident to the code differencing systems as
described in various embodiments.
[00107] Thus, a host of network topologies and network infrastructures,
such as
client/server, peer-to-peer, or hybrid architectures, can be utilized. The
"client" is a
member of a class or group that uses the services of another class or group to
which it
is not related. A client can be a process, i.e., roughly a set of instructions
or tasks, that
requests a service provided by another program or process. The client process
utilizes
the requested service without having to "know" any working details about the
other
program or the service itself
[00108] In a client/server architecture, particularly a networked system,
a client
is usually a computer that accesses shared network resources provided by
another
computer, e.g., a server. In the illustration of Fig. 14, as a non-limiting
example,
computing objects or devices 1420, 1422, 1424, 1426, 1428, etc. can be thought
of as
clients and computing objects 1410, 1412, etc. can be thought of as servers
where
computing objects 1410, 1412, etc., acting as servers provide data services,
such as
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
receiving data from client computing objects or devices 1420, 1422, 1424,
1426, 1428,
etc., storing of data, processing of data, transmitting data to client
computing objects
or devices 1420, 1422, 1424, 1426, 1428, etc., although any computer can be
considered a client, a server, or both, depending on the circumstances. Any of
these
computing devices may be processing data, or requesting transaction services
or tasks
that may implicate the differencing techniques as described herein for one or
more
embodiments.
[00109] A server is typically a remote computer system accessible over a
remote or local network, such as the Internet or wireless network
infrastructures. The
client process may be active in a first computer system, and the server
process may be
active in a second computer system, communicating with one another over a
communications medium, thus providing distributed functionality and allowing
multiple clients to take advantage of the information-gathering capabilities
of the
server. Any software objects utilized pursuant to the techniques described
herein can
be provided standalone, or distributed across multiple computing devices or
objects.
[00110] In a network environment in which the communications network 1440
or bus is the Internet, for example, the computing objects 1410, 1412, etc.
can be Web
servers with which other computing objects or devices 1420, 1422, 1424, 1426,
1428,
etc. communicate via any of a number of known protocols, such as the hypertext
transfer protocol (HTTP). Computing objects 1410, 1412, etc. acting as servers
may
also serve as clients, e.g., computing objects or devices 1420, 1422, 1424,
1426, 1428,
etc., as may be characteristic of a distributed computing environment.
EXEMPLARY COMPUTING DEVICE
[00111] As mentioned, advantageously, the techniques described herein can
be
applied to any device where it is desirable to perform code differencing. It
can be
understood, therefore, that handheld, portable and other computing devices and
computing objects of all kinds are contemplated for use in connection with the
various
embodiments. Accordingly, the below general purpose remote computer described
below in Fig. 15 is but one example of a computing device.
[00112] Although not required, embodiments can partly be implemented via
an
operating system, for use by a developer of services for a device or object,
and/or
included within application software that operates to perform one or more
functional
aspects of the various embodiments described herein. Software may be described
in
21
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
the general context of computer-executable instructions, such as program
modules,
being executed by one or more computers, such as client workstations, servers
or
other devices. Those skilled in the art will appreciate that computer systems
have a
variety of configurations and protocols that can be used to communicate data,
and
thus, no particular configuration or protocol should be considered limiting.
[00113] Fig. 15 thus illustrates an example of a suitable computing
system
environment 1500 in which one or aspects of the embodiments described herein
can
be implemented, although as made clear above, the computing system environment
1500 is only one example of a suitable computing environment and is not
intended to
suggest any limitation as to scope of use or functionality. Neither should the
computing system environment 1500 be interpreted as having any dependency or
requirement relating to any one or combination of components illustrated in
the
exemplary computing system environment 1500.
[00114] With reference to Fig. 15, an exemplary remote device for
implementing one or more embodiments includes a general purpose computing
device
in the form of a computer 1510. Components of computer 1510 may include, but
are
not limited to, a processing unit 1520, a system memory 1530, and a system bus
1522
that couples various system components including the system memory to the
processing unit 1520.
[00115] Computer 1510 typically includes a variety of computer readable
media and can be any available media that can be accessed by computer 1510.
The
system memory 1530 may include computer storage media in the form of volatile
and/or nonvolatile memory such as read only memory (ROM) and/or random access
memory (RAM). Computer readable media can also include, but is not limited to,
magnetic storage devices (e.g., hard disk, floppy disk, magnetic strip),
optical disks
(e.g., compact disk (CD), digital versatile disk (DVD)), smart cards, and/or
flash
memory devices (e.g., card, stick, key drive). By way of example, and not
limitation,
system memory 1530 may also include an operating system, application programs,
other program modules, and program data.
[00116] A user can enter commands and information into the computer 1510
through input devices 1540. A monitor or other type of display device is also
connected to the system bus 1522 via an interface, such as output interface
1550. In
addition to a monitor, computers can also include other peripheral output
devices such
as speakers and a printer, which may be connected through output interface
1550.
22
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
[00117] The computer 1510 may operate in a networked or distributed
environment using logical connections to one or more other remote computers,
such
as remote computer 1570. The remote computer 1570 may be a personal computer,
a
server, a router, a network PC, a peer device or other common network node, or
any
other remote media consumption or transmission device, and may include any or
all
of the elements described above relative to the computer 1510. The logical
connections depicted in Fig. 15 include a network 1572, such local area
network
(LAN) or a wide area network (WAN), but may also include other networks/buses.
Such networking environments are commonplace in homes, offices, enterprise-
wide
computer networks, intranets and the Internet.
[00118] As mentioned above, while exemplary embodiments have been
described in connection with various computing devices and network
architectures,
the underlying concepts may be applied to any network system and any computing
device or system.
[00119] Also, there are multiple ways to implement the same or similar
functionality, e.g., an appropriate application programming interface (API),
tool kit,
driver source code, operating system, control, standalone or downloadable
software
object, etc. which enables applications and services to take advantage of
techniques
provided herein. Thus, embodiments herein are contemplated from the standpoint
of
an API (or other software object), as well as from a software or hardware
object that
implements one or more aspects of the diffing techniques described herein.
Thus,
various embodiments described herein can have aspects that are wholly in
hardware,
partly in hardware and partly in software, as well as in software.
[00120] The word "exemplary" is used herein to mean serving as an
example,
instance, or illustration. For the avoidance of doubt, the subject matter
disclosed
herein is not limited by such examples. In addition, any aspect or design
described
herein as "exemplary" is not necessarily to be construed as preferred or
advantageous
over other aspects or designs, nor is it meant to preclude equivalent
exemplary
structures and techniques known to those of ordinary skill in the art.
Furthermore, to
the extent that the terms "includes," "has," "contains," and other similar
words are
used, for the avoidance of doubt, such terms are intended to be inclusive in a
manner
similar to the term "comprising" as an open transition word without precluding
any
additional or other elements.
23
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
[00121] As mentioned, the various techniques described herein may be
implemented in connection with hardware or software or, where appropriate,
with a
combination of both. As used herein, the terms "component," "system" and the
like
are likewise intended to refer to a computer-related entity, either hardware,
a
combination of hardware and software, software, or software in execution. For
example, a component may be, but is not limited to being, a process running on
a
processor, a processor, an object, an executable, a thread of execution, a
program,
and/or a computer. By way of illustration, both an application running on
computer
and the computer can be a component. One or more components may reside within
a
process and/or thread of execution and a component may be localized on one
computer and/or distributed between two or more computers.
[00122] The aforementioned systems have been described with respect to
interaction between several components. It can be appreciated that such
systems and
components can include those components or specified sub-components, some of
the
specified components or sub-components, and/or additional components, and
according to various permutations and combinations of the foregoing. Sub-
components can also be implemented as components communicatively coupled to
other components rather than included within parent components (hierarchical).
Additionally, it is noted that one or more components may be combined into a
single
component providing aggregate functionality or divided into several separate
sub-
components, and that any one or more middle layers, such as a management
layer,
may be provided to communicatively couple to such sub-components in order to
provide integrated functionality. Any components described herein may also
interact
with one or more other components not specifically described herein but
generally
known by those of skill in the art.
[00123] In view of the exemplary systems described supra, methodologies
that
may be implemented in accordance with the described subject matter can also be
appreciated with reference to the flowcharts of the various figures. While for
purposes
of simplicity of explanation, the methodologies are shown and described as a
series of
blocks, it is to be understood and appreciated that the various embodiments
are not
limited by the order of the blocks, as some blocks may occur in different
orders and/or
concurrently with other blocks from what is depicted and described herein.
Where
non-sequential, or branched, flow is illustrated via flowchart, it can be
appreciated
that various other branches, flow paths, and orders of the blocks, may be
implemented
24
CA 02820758 2013-06-07
WO 2012/079230
PCT/CN2010/079801
which achieve the same or a similar result. Moreover, not all illustrated
blocks may be
required to implement the methodologies described hereinafter.
[00124] In addition to the various embodiments described herein, it is to
be
understood that other similar embodiments can be used or modifications and
additions
can be made to the described embodiment(s) for performing the same or
equivalent
function of the corresponding embodiment(s) without deviating therefrom. Still
further, multiple processing chips or multiple devices can share the
performance of
one or more functions described herein, and similarly, storage can be effected
across a
plurality of devices. Accordingly, the invention should not be limited to any
single
embodiment, but rather should be construed in breadth, spirit and scope in
accordance
with the appended claims.