Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
CA 02886466 2015-03-26
1
Système multicoeur de traitement de données à dispositifs
d'entrée/sortie locaux et globaux et interface graphique
comportant un tel système de traitement de données
La présente invention concerne les systèmes de traitement de
données multicoeurs. Dans une application non limitative, la présente
invention concerne en particulier les systèmes multicoeurs pour
interface graphique fondés sur l'utilisation d'un processeur de calcul
graphique (GPU, pour Graphic Processing Unit ) pouvant coopérer
avec une unité centrale de traitement (CPU, pour Central Processing
Unit ).
Elle se rapporte également à une interface homme/machine
utilisant un tel système de traitement.
Une application particulièrement intéressante de l'invention
concerne les systèmes de traitement de données pour interfaces
homme/machine embarquées à bord d'aéronefs.
Il existe en effet un besoin pour disposer d'interfaces
homme/machine tactiles à bord d'aéronefs.
Dans le domaine des interfaces graphiques, les systèmes de
traitement de données sont classiquement utilisés pour exécuter des
calculs graphiques et créer des contenus graphiques destinés à être
affichés sur un écran de l'interface. Il peut en particulier s'agir de
créer des contenus graphiques comportant des zones tactiles
manipulables manuellement, en l'espèce par un pilote, pour
l'exécution de fonctions prédé finies.
Dans l'état de la technique, de manière générale, les
architectures de traitement de données peuvent être réalisées sous la
forme de CPU simples coeurs, de d'unités centrales de traitement
multiples (multi-CPU) ou CPU multicoeurs. Pour la réalisation de
calculs graphiques, on utilise des architectures massivement
multicoeurs et l'on utilise en particulier des processeurs de calcul
CA 02886466 2015-03-26
2
graphique coopérant avec une unité centrale de traitement pour
augmenter la puissance de calcul.
En ce qui concerne les CPU simples c urs, le composant de
base d'une telle architecture est le processeur, qui est un composant
permettant l'interprétation d'instructions machine définissant des
programmes informatiques.
Comme on le sait, pour qu'un système intégrant un processeur
puisse fonctionner, il est couplé à une mémoire permanente, qui
permet le stockage du programme à exécuter, à une mémoire rapide
pour la lecture et l'écriture des variables utilisées lors de l'exécution
des programmes, et de périphériques, de type entrée/sortie, bus de
communication, contrôleur mémoire, ..., assurant l'échange de données
avec l'extérieur du système.
Les processeurs modernes intégrés sur puce intègrent
également un bus de communication et de la mémoire cache, très
rapide, pour le stockage, au plus près de la zone d'exécution du
programme, des variables utilisées par le programme, seules les
variables de taille relativement importante ou moins utilisées étant
envoyées vers la mémoire rapide.
Les SoC (pour System on Chip ) intègrent, en plus du
processeur, un certain nombre de périphériques.
Enfin, les microcontrôleurs sont des puces qui intègrent
l'ensemble des éléments nécessaires au fonctionnement du processeur,
à savoir mémoire et périphérique.
En ce qui concerne les CPU simples coeurs, les besoins
croissants de puissance pour les processeurs tendent à augmenter
progressivement la fréquence de fonctionnement, rendue possible par
la finesse de gravure du silicium toujours plus importante. Mais
l'augmentation de la fréquence provoque également une augmentation
très importante de la consommation, de sorte que le gain en puissance
devient marginal devant l'augmentation de la consommation. Il a donc
été proposé de répliquer les coeurs de calcul afin de paralléliser
l'exécution d'un programme sans pour autant augmenter la fréquence
de fonctionnement.
CA 02886466 2015-03-26
3
Dans une architecture CPU multicoeurs classique, chaque coeur
possède un premier niveau de mémoire cache dite mémoire cache de
premier niveau. Les différents coeurs peuvent partager ensuite une
autre mémoire cache dite de second niveau. Un troisième niveau de
mémoire cache peut être prévu lorsque l'on souhaite regrouper certains
coeurs.
La parallélisation des tâches et l'attribution à l'un ou l'autre
des coeurs des instructions à effectuer se fait via le jeu d'instructions
interprété par le processeur et par le système d'exploitation (OS)
implémenté qui peuvent attribuer telle ou telle tâche en fonction des
différents coeurs. On parle alors de processeur multicoeur. Une telle
stratégie d'implémentation peut également être applicable aux SoC
multicoeurs.
Une autre stratégie consiste à prévoir une architecture similaire
à l'architecture classique mais, au lieu de paralléliser le
fonctionnement, les différents coeurs sont utilisés pour fiabiliser le
traitement. Les coeurs exécutent les mêmes instructions au coup
d'horloge près, et les traitements sont ensuite comparés afin d'obtenir
un fonctionnement fiable dans des conditions critiques. Cette stratégie
est connue sous le terme de Lockstep .
Une autre stratégie consiste à répliquer un système plutôt qu'un
c ur. On parle alors de multiprocesseur. Chaque processeur est
indépendant et ne partage pas de mémoire cache avec les autres. Ce
type d'architecture est généralement implanté en externe pour réaliser
des supercalculateurs ou des groupes de serveurs reliés en réseau pour
réaliser des calculs relativement lourds nécessitant des ressources de
calcul importantes.
En ce qui concerne les architectures GPU, les unités de
traitement graphique sont, comme les CPU, des architectures de calcul
exécutant un jeu d'instructions. Un GPU est toutefois un processeur
optimisé pour les calculs graphiques tels que, accélération matérielle,
calculs tridimensionnels, décodage vidéo, ...
Depuis longtemps, les GPU sont composés de multiples c urs
de calcul qui se répartissent les tâches graphiques. Il s'agit
CA 02886466 2015-03-26
4
d'architectures de traitement parallèles. Comme
indiqué
précédemment, les GPU sont massivement multicoeurs et peuvent
comporter plus de 1000 coeurs, pour les plus performants. Les
différents coeurs se voient attribuer un certain nombre de calculs à
effectuer par un contrôleur.
En ce qui concerne les systèmes de traitement de données
destinés à être embarqués à bord d'aéronefs, comme on le conçoit, ce
type de système électronique est soumis à des contraintes sévères de
maîtrise du matériel employé et de déterminisme, qui impose de
déterminer de manière certaine le fonctionnement du système, par
exemple en ce qui concerne la durée de transfert de données. Ils
nécessitent une validation et une certification par les autorités
compétentes. Les systèmes de traitement de données pour les
interfaces homme-machine embarquées pour avions commerciaux
doivent ainsi satisfaire un certain nombre de règles et de
recommandations de développement.
Dans l'état de la technique, les systèmes de calcul embarqués
sont généralement réalisés à partir de composants pris sur étagère ou
COTS (pour Commercial Off The Shelf ), c'est-à-dire de
composants fabriqués en grande série pour réduire les coûts de
fabrication et de maintenance. Toutefois, l'utilisation de composants
COTS conventionnels pose en premier lieu des problèmes
d'obsolescence, imposant de provisionner un grand nombre de
composants et de les stocker afin de garantir la maintenabilité du
produit. Compte tenu du temps de développement et de la durée de vie
d'un produit pour l'aéronautique, qui peuvent atteindre plusieurs
dizaines d'années, il est courant que les composants utilisés lors de la
conception d'un système électronique soient en fait obsolètes même
avant la fin du processus de conception, obligeant à réaliser des phases
de modification et de recertification périodiques.
En second lieu, les composants électroniques COTS sont
généralement dérivés de marchés grands publics ou du secteur des
télécommunications et sont dès lors optimisés pour des applications
non aéronautiques. Leur utilisation dans le domaine aéronautique
5
implique la désactivation des applications d'origine, leur modification
pour les rendre compatibles avec le domaine aéronautique puis une
certification, engendrant des coûts supplémentaires.
Par ailleurs, les systèmes multicoeurs de traitement usuels
comportent uniquement des mémoires et des systèmes périphériques
partagés entre les différents c urs de calcul. Les coeurs communiquent
avec des interfaces d'entrée et de sortie de données via un bus
d'interface commun pour accéder à des ressources partagées entre les
c urs. Il en résulte un besoin d'arbitrage dans les accès potentiellement
concurrents auxdits systèmes périphériques. La gestion de ces accès
concurrents dans un système classique COTS est faite par un système de
cohérence non maitrisé. L'utilisation de composants de type COTS dans
un système aéronautique impose donc la mise en place d'un grand
nombre de verrous logiciels et matériels permettant de garantir le
fonctionnement du composant dans le respect des recommandations des
autorités de certification. L'ajout de ces verrous implique une
dégradation forte des performances des unités centrales de traitement de
données
Au vu de ce qui précède, l'invention se propose de pallier les
problèmes de déterminisme dans les accès concurrents rencontrés dans
les systèmes multifonctions de traitement de données en limitant les
arbitrages mis en uvre lors de l'accès à des ressources partagées.
L'invention a donc pour objet, selon un premier aspect, un
système multicoeur de traitement de données, comprenant un ensemble
de coeurs de traitement de données et dans lequel une partie au moins de
chaque coeur de traitement de données comporte un ensemble
d'interfaces locales d'entrée et de sortie de données pour l'accès à des
dispositifs périphériques dédiés auxdits coeurs.
Le système multicceur comporte en outre un ensemble
d'interfaces globales d'entrée et de sortie de données pour l'accès à des
dispositifs périphériques partagés entre lesdits c urs, comprenant un
ensemble d'au moins un processeur de calcul graphique (GPU)
Date Reçue/Date Received 2021-08-30
5a
comprenant des coeurs de traitement de données comprenant lesdites
interfaces locales et lesdites interfaces globales, et en ce qu'il comprend
au moins une unité centrale de traitement (CPU) et au moins un
processeur de calcul graphique (GPU) qui communique avec l'unité
centrale de traitement, les c urs de traitement de l'unité centrale de
traitement étant chacun reliés à un coeur de traitement du processeur de
calcul graphique par un unique moyen de transfert de données de
manière à réaliser un transfert de données en parallèle entre ledit
processeur de calcul graphique et ladite unité centrale de traitement.
Ainsi, en prévoyant des interfaces locales d'entrée et de sortie,
chacun des coeurs de calcul a accès à ses propres mémoires et/ou
s stèmes eéri ehérieues locaux de sorte eue chaeue coeur de calcul est
Date Reçue/Date Received 2021-08-30
CA 02886466 2015-03-26
6
totalement indépendant et autonome vis-à-vis des autres. Chacun des
coeurs de calcul est donc capable de fonctionner sans interaction avec
les autres coeurs.
Selon une autre caractéristique de l'invention, le système
comprend un ensemble d'au moins une unité centrale de traitement
comprenant des coeurs de traitement de données comprenant lesdites
interfaces locales et lesdites interfaces globales.
En d'autres termes, les coeurs de traitement constituent une
unité centrale CPU.
Selon encore une autre caractéristique de l'invention, le
système multicoeur comprend un ensemble d'au moins un processeur
de calcul graphique comprenant des coeurs de traitement de données
comprenant lesdites interfaces locales et lesdites interfaces globales.
Les coeurs de traitement de données constituent ainsi des
processeurs de calcul graphique.
Dans un mode de réalisation, le système comprend au moins
une unité centrale de traitement et au moins un processeur de calcul
graphique qui communique avec l'unité centrale de traitement, les
c urs de traitement de l'unité centrale de traitement étant chacun
reliés à un c ur de traitement du processeur de calcul graphique par
un unique moyen de transfert de données de manière à réaliser un
transfert de données en parallèle entre ledit processeur de calcul
graphique et ladite unité centrale de traitement.
On obtient ainsi une augmentation de la puissance de calcul
tout en répondant au problème de certification aéronautique en
multipliant les coeurs de traitement CPU/GPU pour obtenir une
architecture clonée ayant les mêmes avantages de parallélisation des
tâches qu'une architecture multicoeur, en limitant les inconvénients de
complexité et éventuellement de ressources partagées non contrôlées
qui ne sont pas envisageables pour des raisons de sécurité et de
criticité aéronautique.
Avantageusement, les c urs de traitement de données sont
reliés à un moyen de transfert de données local interne relié auxdites
interfaces.
CA 02886466 2015-03-26
Le moyen de transfert de données local interne peut être relié à
des dispositifs périphériques dédiés chacun à un coeur de traitement.
Par ailleurs, les coeurs de traitement de données sont
avantageusement reliés à un moyen de transfert de données global
interne audit processeur de calcul graphique ou à ladite unité centrale
de traitement et relié à des dispositifs périphériques partagés entre les
coeurs de traitement.
De préférence, une partie au moins de chaque coeur de
traitement comporte un système d'exploitation dédié.
L'invention a encore pour objet une interface graphique pour
cockpit d'aéronef comprenant un système multicoeur de traitement de
données tel que défini ci-dessus.
D'autres buts, caractéristiques et avantages de l'invention
apparaîtront à la lecture de la description suivante, donnée uniquement
à titre d'exemple non limitatif, et faite en référence aux dessins
annexés sur lesquels :
- la figure 1 illustre l'architecture générale d'un système de
traitement de données conventionnel réalisé à partir de composants
COTS ;
- la figure 2 est un schéma synoptique d'une partie d'un
système multicoeurs de traitement de données conventionnel, montrant
le partage de périphériques ;
- la figure 3 illustre l'architecture générale d'un système de
traitement de données conforme à l'invention ;
- la figure 4 montre une partie d'un système de traitement de
données conforme à l'invention montrant l'utilisation de périphériques
dédiés à chaque coeur de traitement et de dispositifs périphériques
partagés ; et
- les figures 5a et 5b sont des vues montrant le couplage entre
un CPU et un GPU, selon l'état de la technique et selon l'invention,
respectivement.
On se référera tout d'abord à la figure 1, qui illustre
l'architecture d'un système de traitement de données multicoeur selon
l'état de la technique, utilisant des composants sur étagère COTS.
CA 02886466 2015-03-26
8
Comme on le voit sur cette figure, ce système de traitement de
données est articulé autour d'un processeur double coeur P associé à
des mémoires cache locales 1 et 2, dédiées respectivement au stockage
de données et au stockage d'instructions, et à une mémoire cache
partagée 3 de niveau supérieur utilisée lorsque les mémoires cache
locales 1 et 2 sont pleines et associée à un contrôleur de mémoire 4
partagé permettant l'accès à des mémoires externes, par exemple de
type DDR (pour Double Data Rate ).
Un bus commun 5 intégrant un protocole de cohérence de cache
associé à des premiers dispositifs périphériques 6 de contrôle de
communication et des deuxièmes dispositifs périphériques 7 d'entrée
et sortie assure l'échange des données avec le processeur P.
Comme indiqué précédemment, ce type d'architecture présente
un certain nombre d'inconvénients portant sur le partage de la
mémoire cache 3, du contrôleur de mémoire 4 et du bus commun 5
L'emploi de moyens partagés nécessite en effet de prévoir un
arbitrage poussé pour autoriser l'accès au processeur. En outre, le
temps de transfert de données sur le bus n'est pas garanti. En
particulier, lorsque le nombre de coeurs augmente, la gestion des
priorités et le calcul des temps d'accès s'avèrent plus complexes à
mettre en oeuvre. En outre, le nombre d'entrées et sorties est limité.
Ainsi, le fonctionnement déterministe de ce type de
composants, notamment en ce qui concerne la durée de transfert de
données qui ne peut être déterminée de manière certaine sans mettre en
oeuvre des moyens rédhibitoires, n'est-pas garanti.
En se référant maintenant à la figure 2, sur laquelle on a
schématiquement représenté plusieurs coeurs de traitement de données
core#1 , core#2 , core#3 associés chacun à une mémoire
cache Li et à une mémoire cache L2 de niveau supérieure qui
communiquent via bus local B, on voit que selon une architecture
conventionnelle, des interfaces d'Entrée/Sortie (1/0) telles que 101 et
102 assurant la communication avec des dispositifs externes
traditionnellement partagées de sorte que l'accès à ces interfaces
CA 02886466 2015-03-26
9
d'Entrée/Sortie qui s'effectue via un bus d'interface B' implique un
arbitrage des accès.
Comme indiqué précédemment, les architectures multicceurs
traditionnelles, destinées à être embarquées à bord d'aéronefs, doivent
être soumises à des règles et des recommandations de développement
éditées par les autorités de certifications. Ces règles pénalisent
économiquement et techniquement le développement d'une
architecture à base de composants COTS.
On a représenté sur la figure 3 l'architecture générale d'un
système multicoeur de traitement de données selon l'invention, pour
interface graphique.
Pour répondre aux règles et recommandations éditées par les
autorités de certification, toutes les mémoires (Flash, RAM, Cache)
sont ici séparées entre les coeurs pour ainsi limiter l'utilisation de
ressources partagées. Pour garantir un accès déterministe à toutes les
autres ressources partagées, un élément de communication partitionné
est utilisé pour réaliser la communication des différents coeurs CPU.
Cet élément peut, par exemple, être un bus ou un réseau sur puce NoC
(pour Network On chip ).
La même stratégie est utilisée au niveau des coeurs GPU. Ceux-
ci sont indépendants et reliés à un unique c ur CPU via un bus dédié.
Chaque coeur GPU produit une image graphique liée à l'application
qu'il gère. Les différentes images produites sont ensuite assemblées
par un mixeur pour produire, en définitive, une image d'écran qui est
destinée à être affichée sur l'écran d'une interface homme-machine.
Ainsi, chaque couple CPU/GPU héberge une application
graphique distincte et indépendante des autres. Cette architecture
permet donc le développement parallèle et par plusieurs fournisseurs
d'applications d'interfaces homme-machine pour différents systèmes
avioniques commerciaux. Cette architecture entièrement partitionnée
permet de réaliser une certification incrémentale. En d'autres termes,
il est possible de mettre à jour un coeur sans impact sur les autres.
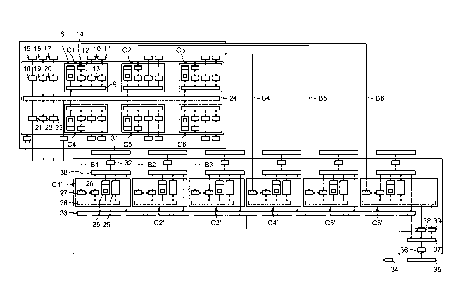
On voit sur la figure 3 que l'unité centrale de traitement CPU
et le processeur de calcul graphique GPU comportent chacun un
CA 02886466 2015-03-26
ensemble de coeurs de traitement de données CI-C6 et C' 1-C'6,
respectivement, ici au nombre de six, reliés entre eux par des bus Bi-
B6 dédiés ou, de manière générale, par un moyen de transfert de
données dédié,
5 Ainsi, les
problèmes d'arbitrage et de temps de transfert non
garanti ne se posent plus dans cette architecture, les données étant
véhiculées entre les coeurs de traitement sur des bus non partagés.
Comme on le voit, les coeurs de traitement de données de
l'unité centrale de traitement sont organisés sur le même modèle et
10 sont fondés sur
l'utilisation d'un coeur de calcul, tel que 8. Chaque
coeur de traitement comporte un bus de communication interne 9 ou, de
manière générale, un moyen de transfert de données, qui assure la
communication au sein du coeur entre les divers composants qui le
composent et avec des dispositifs périphériques locaux.
Chaque coeur de traitement comporte en effet différents types
de mémoires, avec entre autre, une mémoire permanente 10, par
exemple de type Flash ainsi qu'une mémoire vive 11, par exemple de
type DDR, associées respectivement à un contrôleur de mémoire
permanente 12 et à un contrôleur de mémoire vive 13. Bien entendu,
on ne sort pas du cadre de l'invention lorsque les coeurs de calculs sont
dotés d'autres types de dispositifs périphériques locaux, notamment
d'autres types de mémoire. Comme cela sera précisé en référence à la
figure 4, chaque coeur de traitement comporte également un certain
nombre de périphériques locaux d'entrée et de sortie de données qui
peuvent être différents d'un coeur à l'autre. Des périphériques de
communication 14 assurent la communication entre les bus dédiés Bi-
B6 et le bus de communication interne 9 associé.
A côté des périphériques locaux et mémoires 10 et 11 dédiées à
chaque coeur de traitement, l'unité centrale de traitement CPU
comporte en outre des mémoires et périphériques globaux, partagés
entre les coeurs. Il s'agit en particulier des mémoires 15, 16 et 17
associées à leurs contrôleurs de mémoire respectifs 18, 19 et 20. Il
s'agit à titre illustratif, mais de façon nullement limitative, de
mémoires de type Flash, DDR ou de périphériques globaux partagés
CA 02886466 2015-03-26
11
21, 22 et 23, par exemple de types ARINC 429 ou ARINC 825. Dans
l'application envisagée, qui concerne les interfaces graphiques pour
équipement de cockpit pour aéronef, de telles mémoires peuvent, par
exemple, être utilisées pour l'enregistrement d'informations
concernant un vol.
Un bus global interne 24 ou, de manière générale, un élément
de transfert de données, assure l'échange de données entre les coeurs
de traitement de données CI-C6, avec les mémoires 15, 16 et 17 et
avec les dispositifs périphériques globaux 21, 22 et 23.
Les coeurs de traitement de données C'I-C'6 du processeur de
calcul graphique ont une structure similaire et sont fondés sur
l'utilisation d'un coeur de calcul tel que 25. Ce c ur de calcul 25
communique avec un bus de communication interne 26 ou de manière
générale avec un moyen de transfert de données, lequel est relié via
des liens de communication 27 et 28 avec les bus dédiés B I-B6.
A côté du coeur de calcul 25, chaque coeur de traitement de
données C' I-C'6 incorpore en outre un c ur GPLT de calcul graphique
29 relié au bus interne 26. Enfin, un bus local 30 ou un moyen de
transfert de données, qui communique avec les liens de communication
27 et 28, avec le coeur de calcul 25 et avec le coeur de calcul GPU 29
est relié à une mémoire locale 31 externe associée à un contrôleur
correspondant 32.
Par ailleurs, l'unité de traitement graphique GPU comporte un
mixeur 33 relié au bus local 30 de chaque unité de traitement de
données C'1-C'6.
En effet, chaque couple CPU/CiPU assure l'exécution d'une
tâche qui lui est affectée et génère une portion de l'image finale. Le
mixeur 33 procède à la combinaison de ces diverses images pour
l'élaboration de l'écran final affiché sur l'interface homme-machine.
De manière optionnelle, le système de traitement qui vient d'être
décrit peut être doté d'une entrée vidéo 34, d'une mémoire externe 35
associée à un contrôleur 36 correspondant et à un système d'arbitrage
37 pour l'accès à des données externes partagées. Un dispositif 38 de
récupération d'images associé à un gestionnaire de flux 39 permet de
CA 02886466 2015-03-26
12
combiner des vidéos ou images récupérées de l'entrée 34 ou de la
mémoire 35 pour générer l'image finale.
Comme on le conçoit, l'architecture qui vient d'être décrite
s'apparente à une architecture multiprocesseur intégrée à une seule et
même puce. En effet, chaque coeur étant indépendant et possédant ses
propres contrôleurs mémoire et périphériques dédiés, l'architecture
selon l'invention est analogue à une architecture multi-SoC.
En se référant à la figure 4, sur laquelle on a représenté une
stratégie d'implantation de système d'exploitation dans un système de
traitement de données conforme à l'invention, on voit que chaque coeur
de traitement, noté C"2 ou C"3 incorpore un certain nombre
d'interfaces d'Entrée/Sortie 42, 43, 44 qui communiquent avec un
c ur core#1 , core#2 ou core143 via un bus local B, tandis
que d'autres interfaces d'Entrées/Sorties 45 sont partagés entre les
coeurs de traitement avec lesquels elles communiquent via un bus
d'interface B'. Cette stratégie peut aussi bien s'appliquer à l'unité
centrale de traitement qu'au processeur de calcul graphique. En
d'autres termes, selon l'invention, on dispose de deux niveaux de
d'interfaces d'Entrée/Sortie, l'architecture intégrant à la fois des
interfaces d'Entrée/Sortie locales dédiées à un coeur et des interfaces
d'Entrée/Sortie globales qui sont partagées entre les c urs.
On conçoit que les interfaces I/O locales, d'accès direct, sans
partage et sans arbitrage permettant un accès plus rapide à des
périphériques locaux dédiés à un coeur, tandis que les interfaces I/O
globales permettent un accès à des dispositifs périphériques partagés.
On notera par ailleurs que, dans un mode de mise en oeuvre, les
coeurs de traitement du GPU et du CPU peuvent intégrer un système
d'exploitation dédié.
L'accès déterministe aux ressources partagées rend souhaitable
l'utilisation d'un bus d'accès partagé 24 (figure 3) maîtrisée.
Ainsi, le bus 24 est associé à des moyens d'arbitrage servant à
arbitrer les échanges de données avec les dispositifs partagés ou, en
d'autres termes, à arbitrer l'accès des c urs aux ressources partagées.
A titre d'exemple, ces arbitrages peuvent prendre la forme d'un
CA 02886466 2015-03-26
13
ordonnanceur, par exemple intégré au bus, attribuant de manière
périodique des temps de communication pour chaque coeur et ce, les
uns après les autres.
Enfin, en se référant aux figures 5a et 5b, on conçoit que
contrairement aux architectures CPU/GPU classiques qui utilisent un
seul bus de communication partagé 46, le système de traitement de
données selon l'invention s'appuie sur un bus dédié 47 indépendant
entre chaque coeur CPU et son coeur GPU associé. Ces bus séparés
permettent ainsi des transferts de données parallèles et performants.