Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
1
Procédé d'analyse sémantique d'un texte
DOMAINE TECHNIQUE GENERAL
La présente invention concerne le domaine de la compréhension
sémantique par ordinateur.
Plus précisément elle concerne un procédé d'analyse sémantique
d'un texte en langage naturel par des moyens de traitement de données, en
vue de sa classification.
ETAT DE L'ART
L'analyse sémantique d'un texte en langage naturel vise à en établir
la signification en utilisant le sens des mots qui le constituent, suite à une
analyse lexicale qui permet de décomposer ce texte à l'aide d'un lexique ou
d'une grammaire. L'humain le réalise inconsciemment pour comprendre les
textes qu'il lit, et des développements récents visent à conférer des
capacités semblables aux machines.
On connait pour le moment des algorithmes d'analyse sémantique
automatisée conçus pour qu'un ordinateur puisse classer un texte dans
plusieurs catégories prédéterminées, par exemple des thèmes généraux
tels que nature , économie , littérature , etc.
Toutefois, cette classification s'avère très limitée et peu évolutive.
Dans la mesure où le choix des diverses catégories possible est souvent
arbitraire, des textes situés à la frontière de deux catégories peuvent poser
problème aux algorithmes. De plus, classifier plus finement dégrade
fortement les performances des algorithmes et entraîne des erreurs
d'appréciation, causées notamment par les ambiguïtés dues à certains
homonymes et certaines tournures (par exemple une double négation).
De façon générale, donner par un traitement informatique un sens
absolu à un texte est une opération très complexe et souvent
contestable. Par exemple, déterminer si un texte prend position pour
CA 02937930 2016-07-25
WO 2015/114014 PCT/EP2015/051722
2
ou contre une opinion est aujourd'hui hors de portée de l'analyse
sémantique informatisée.
Il serait souhaitable de disposer d'un procédé amélioré d'analyse
sémantique d'un texte par un ordinateur en vue de sa classification qui soit
significativement plus performant et plus fiable que tout ce qui fait
actuellement, et qui ne soit pas limité par des modèles sémantiques
préétablis.
PRESENTATION DE L'INVENTION
La présente invention propose un procédé d'analyse sémantique d'un texte
en langage naturel reçu par un équipement depuis des moyens de saisie, le
procédé étant caractérisé en ce qu'il comprend la mise en oeuvre par des
moyens de traitement de données de l'équipement d'étapes de :
(a) Découpage syntaxique d'au moins une partie du texte en une
pluralité de mots ;
(b) Filtrage des mots de ladite partie de texte par rapport à une pluralité
de liste de mots de référence stockées sur des moyens de stockage
de données de l'équipement chacune étant associée à une
thématique, de sorte à identifier :
= L'ensemble des mots de ladite partie du texte associés à au
moins une thématique,
= L'ensemble des thématiques de ladite partie du texte ;
(c) Construction d'une pluralité de sous-ensembles de l'ensemble des
mots de ladite partie du texte associés à au moins une thématique ;
(d) Pour chacun desdits sous-ensembles et pour chaque thématique
identifiée, calcul :
= d'un coefficient de couverture de la thématique et/ou d'un
coefficient de pertinence de la thématique en fonction
d'occurrences dans ladite partie du texte de mots de
référence associés à la thématique ;
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
3
= d'au moins un coefficient d'orientation de la thématique à
partir des mots de ladite partie du texte ne faisant pas partie
du sous-ensemble ;
(e) Pour chacun desdits sous-ensembles et pour chaque thématique
identifiée, calcul d'un coefficient sémantique représentatif d'un degré
de sens porté par le sous-groupe en fonction desdits coefficients de
couverture, pertinence et/ou orientation de la thématique.
(f) Sélection en fonction des coefficients sémantiques d'au moins un
couple sous-ensemble/thématique.
(g) Classification du texte en fonction dudit au moins un couple sous-
ensemble/thématique sélectionné.
Selon d'autres caractéristiques avantageuses et non limitatives de
l'invention :
= un coefficient de couverture d'une thématique est calculé à l'étape (d)
comme le nombre N de mots de référence associés à la thématique
compris dans ledit sous-ensemble ;
= un coefficient de pertinence d'une thématique est calculé à l'étape (d)
par la formule N * (1+ ln(R)), où N est le nombre de mots de référence
associés à la thématique compris dans le sous-ensemble et R le nombre
total d'occurrences dans ladite partie du texte de mots de référence
associés à la thématique ;
= deux coefficients d'orientation de la thématique sont calculés à l'étape
(c), dont un coefficient de certitude de la thématique et un coefficient de
nuance de la thématique ;
= un coefficient de certitude d'une thématique est calculé à l'étape (d)
comme valant :
- 1 si les mots ne faisant pas partie du sous-ensemble sont
représentatifs d'une proximité affirmative avec la thématique ;
- -1 si les mots ne faisant pas partie du sous-ensemble sont
représentatifs d'une proximité négative avec la thématique ;
CA 02937930 2016-07-25
WO 2015/114014 PCT/EP2015/051722
4
- 0 si les mots ne faisant pas partie du sous-ensemble sont
représentatifs d'une proximité incertaine avec la thématique ;
= un coefficient de nuance d'une thématique est un scalaire positif
supérieur à 1 lorsque les mots ne faisant pas partie du sous-ensemble sont
représentatifs d'une amplification de la thématique, et un scalaire positif
inférieur à 1 lorsque les mots ne faisant pas partie du sous-ensemble sont
représentatifs d'une atténuation de la thématique ;
= le procédé comprend une étape (a0) préalable de découpage du texte
en une pluralité de proposition, chacune étant une partie du texte pour
laquelle les étapes (a) à (d) du procédé selon répétées de sorte à obtenir
pour chaque proposition un ensemble de coefficients de couverture, de
pertinence, et/ou d'orientation associés à la proposition, le procédé
comprenant préalablement à l'étape (e) une étape (e0) de calcul pour
chacun desdits sous-ensemble et pour chaque thématique identifiée pour
au moins une proposition du texte d'un coefficient global de couverture de la
thématique et/ou d'un coefficient global de pertinence de la thématique, et
d'au moins un coefficient global d'orientation de la thématique en fonction
de l'ensemble desdits coefficients associés une proposition ;
= un coefficient global de couverture d'une thématique est calculé à
l'étape (e0) comme la somme des coefficients de couverture de la
thématique associée à une proposition moins le nombre de mots de
référence de la thématique présents dans au moins deux propositions ;
= un coefficient global de pertinence d'une thématique est calculé à
l'étape (e0) comme la somme des coefficients de pertinence de la
thématique associée à une proposition ;
= un coefficient global d'orientation d'une thématique est calculé à
l'étape
(e0) comme la moyenne des coefficients d'orientation de la thématique
associés à une proposition pondérés par les coefficients de couverture de la
thématique associés ;
= l'étape (e0) comprend pour chacun desdits sous-ensembles et pour
chaque thématique le calcul d'un coefficient global de divergence de la
thématique correspondant à l'écart-type de la distribution des produits des
CA 02937930 2016-07-25
WO 2015/114014 PCT/EP2015/051722
coefficients d'orientation par les coefficients de couverture associés à
chaque proposition ;
= un coefficient sémantique d'un sous-ensemble A pour une thématique T
est calculé à l'étape (e) par la formule M(A,T) = coefficient de
5 pertinence(A,T) * coefficient d'orientation(A,T) * -\/- [1 + coefficient de
d ivergence(A,T)2] ;
= les couples sous-ensemble/thématique sélectionnés à l'étape (f) sont
ceux tels que pour toute partition du sous-ensemble en une pluralité de
parties dudit sous-ensemble, le coefficient sémantique du sous-ensemble
pour la thématique est supérieur à la somme des coefficients sémantiques
des sous-parties du sous-ensemble pour la thématique ;
= des groupes de couples sous-ensemble/thématique de référence sont
stockés sur les moyens de stockage de données, l'étape (g) comprenant la
détermination du ou des groupes comprenant au moins un couple sous-
ensemble/thématique sélectionné à l'étape (f) ;
= l'étape (g) comprend la création d'un nouveau groupe si aucun groupe
de couples sous-ensemble/thématique de référence ne contient au moins
un couple sous-ensemble/thématique sélectionné pour le texte ;
= chaque couple sous-ensemble/thématique de référence est associé à
un score stocké sur les moyens de stockage de données, le score d'un
couple sous-ensemble/thématique de référence diminuant avec le temps
mais augmentant à chaque fois que ce couple sous-ensemble/thématique
est sélectionné pour un texte ;
= le procédé comprend une étape (h) de suppression d'un couple sous-
ensemble/thématique de référence d'un groupe si le score dudit couple
passe en dessous d'un premier seuil, ou de modification sur les moyens de
stockage de données (12) de ladite pluralité de listes associées aux
thématiques si le score dudit couple passe au-dessus d'un deuxième seuil ;
= l'étape (g) comprend pour chaque groupe de couples sous-
ensemble/thématique de référence le calcul d'un coefficient de dilution
représentant le nombre d'occurrences dans ladite partie du texte de mots
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
6
de référence associés à des thématiques des couples sous-
ensemble/thématique de référence présents dans le texte rapporté au
nombre total de mots de référence associés auxdites thématiques ;
= tous les sous-ensembles de l'ensemble des mots de ladite partie du
texte associés à au moins une thématique sont construits à l'étape (c).
Selon un deuxième aspect, l'invention concerne un équipement
comprenant des moyens de traitement de données configurées pour mettre
en oeuvre suite à la réception d'un texte en langage naturel un procédé
selon le premier aspect de l'invention d'analyse sémantique du texte.
BREVE DESCRIPTION DES FIGURES
D'autres caractéristiques et avantages de la présente invention
apparaîtront à la lecture de la description qui va suivre d'un mode de
réalisation préférentiel. Cette description sera donnée en référence aux
dessins annexés dans lesquels :
- la figure 1 est un schéma d'une architecture réseau dans laquelle
s'inscrit l'invention ;
- la figure 2 est un diagramme représentant schématiquement les
étapes du procédé d'analyse sémantique selon l'invention.
DESCRIPTION DETAILLEE D'UN MODE DE REALISATION PREFERE
Architecture
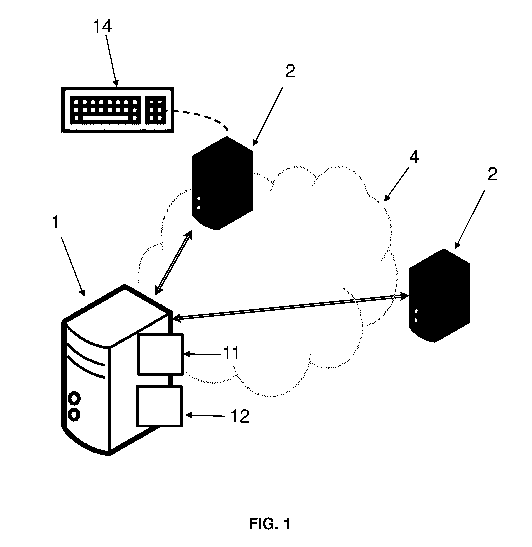
En référence à la figure 1, le présent procédé est mis en oeuvre par
des moyens de traitement de données 11 (qui consistent typiquement en un
ou plusieurs processeurs) d'un équipement 1. Ce dernier peut être par
exemple un ou plusieurs serveurs connectés à un réseau 4, typiquement
internet, via lequel il est relié à des clients 2 (par exemple des PC
personnels).
CA 02937930 2016-07-25
WO 2015/114014 PCT/EP2015/051722
7
L'équipement 1 comprend en outre des moyens de stockage de
données 12 (typiquement un ou plusieurs disques durs).
La notion de texte
Un texte est ici n'importe quel message en langage naturel et porteur
de sens. Le texte est reçu sous forme électronique, c'est-à-dire en un
format directement traitable par les moyens de traitement 11, par exemple
XML (eXtensible Markup Language). On comprendra que par reçu depuis
des moyens de saisie 14 , on entend une grande variété d'origines. De
façon générale, le terme moyens de saisie désigne tout moyens, hardware
et/ou software, permettant de récupérer le texte et de l'envoyer aux moyens
de traitement de données 11 sous un format lisible. Le texte peut être
directement tapé par un utilisateur, et les moyens de saisie 14 désignent
par exemple un clavier et un logiciel de traitement de texte. Alternativement,
le texte peut être un texte papier scanné et reconnu par OCR
(reconnaissance optique de caractères), et les moyens de saisie 14
désignent alors un scanner et un logiciel de traitement des données
numérisées, ou encore le texte peut être dicté et les moyens de saisie 14
désignent alors un microphone et un logiciel de reconnaissance vocale.
Enfin, le texte peut être reçu par exemple depuis un serveur du réseau
internet, éventuellement directement sous un format lisible. Le présent
procédé n'est limité à aucun type de texte. Dans une structure connectée du
type de la figure 1, les moyens de saisie sont typiquement ceux d'un client 2
ou un autre serveur 1.
Le texte est structuré en sections. Les sections peuvent être
séparées par des paragraphes ou êtres simplement enchainées. Les
sections se distinguent les unes des autres par le fait que les concepts
exposés sont sensiblement différents. La détection des sections non
marquées par l'auteur est une opération complexe.
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
8
Une section est composée de phrases séparées par une ponctuation
(deux points, point, point d'exclamation, point d'interrogation, tiret
d'alinea,
points de suspension, etc.).
Une phrase est composée de propositions séparées par une
ponctuation (virgule, point-virgule).
Une proposition est une suite de mots séparés par des espaces.
Un mot est un ensemble ordonné de lettres et de signes particuliers
(accents, tirets, etc.).
Dans certains textes, les ponctuations peuvent ne pas être
respectées. Certains textes peuvent contenir des mots abrégés ou des mots
éludés.
Dans une première étape (a), dite de parsing , au moins une
partie du texte est découpée syntaxiquement en une pluralité de mots.
Avantageusement, cette partie de phrase est une proposition, et le texte est
d'abord découpé proposition par proposition dans une étape (a0) avant que
chaque proposition soit tour à tour découpée en mots. On connait des
algorithmes capables, notamment grâce à des règles de grammaire,
d'identifier les propositions. Le découpage par propositions peut se faire
suite à un découpage par phrases, lui-même après un découpage par
sections. L'identification des mots se fait grâce aux espaces.
Typiquement, un parseur (le moteur mettant en oeuvre le parsing)
utilisant la ponctuation et la mise en forme comme délimiteur des
propositions peut suffire si les ponctuations sont respectées.
Au sein d'une proposition, l'homme du métier utilisera par exemple
un parseur mettant en oeuvre les règles suivantes :
- remplacement de chaque verbe par ce verbe à l'infinitif et association
à ce dernier de trois indices (le mode, le temps, la personne) ;
- remplacement de chaque nom par ce nom au singulier et association
à ce dernier de deux indices (le genre, le nombre) ;
- remplacement de chaque adjectif par cet adjectif au masculin
singulier et association à ce dernier de deux indices (le genre, le
nombre) ;
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
9
- conservation des adverbes ;
- suppressions des mots enjoliveurs de la langue (à l'aide d'une
liste) ;
- déclaration comme nom propre de tout autre terme ;
- inscription de chaque mot, son type et ses indices dans une liste
associée à la proposition.
Les présentes règles peuvent être modifiées ou supprimées, d'autres
règles peuvent enrichir le parseur.
La notion de catégories et thématiques
Un texte se classe dans une ou plusieurs catégories en fonction
du sens qu'il porte. Les catégories sont ici des ensembles mouvants.
Comme l'on verra plus loin, les catégories sont définies comme des
groupes d'anneaux et peuvent être induites par l'apparition d'un texte
relevant d'un sens nouveau.
Lorsqu'une catégorie devient trop peuplée il est souhaitable de la
segmenter en réduisant le spectre des sens admissibles dans chaque
groupe de textes formés par la scission de la catégorie initiale. Chaque
groupe de texte devient alors une catégorie. Une catégorie se représente
par une liste de thématiques.
Le thème est le sens est attaché à un ensemble de mots (dits mots
de référence) entrant dans la composition d'une proposition, présents dans
une liste appelée thématique. La thématique est attachée à une ou
plusieurs catégories.
Pour chaque thématique, la liste des mots de référence associée est
stockée sur les moyens de stockage 12 de l'équipement 1.
Par exemple, une thématique motorisation peut comprendre des
mots de référence {moteur, piston, cylindre, vilebrequin, arbre, bielle,
pédale, puissance, etc.}, et une thématique géométrie peut comprendre
les mots de référence {droite, angle, degré, étoile, rectangle, sphère,
cylindre, pyramide, etc.}. On voit notamment que le mot cylindre
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
présente plusieurs sens et est ainsi lié aux deux thématiques bien qu'elles
soient éloignées.
Dans la suite de la présente description, on prendra l'exemple d'une
proposition formulée comme suit : le moteur comprend trois pistons reliés
5 à un
vilebrequin par des bielles en étoile formant un angle de 1200 deux à
deux qui réagit à la moindre pression sur la pédale d'accélération , ou de
légères variation de cette proposition.
Dans l'étape (b), au moins une thématique est identifiée parmi la
pluralité de thématiques chacune associées à une liste de mots de
10 référence de la thématique stockée.
En particulier, il suffit qu'un mot de référence associé à la thématique
soit présent pour que la thématique soit associée. Alternativement, au
moins deux (voire plus) mots sont requis.
Dans notre exemple :
- le groupe de mots {moteur, piston, vilebrequin, bielle, pédale}
permet de détecter une thématique motorisation
- le groupe de mots {angle, 120 , étoile} permet de détecter une
thématique géométrie .
L'ensemble des mots de la partie du texte analysée associés à au
moins une thématique est également identifié. Il s'agit ici de {moteur,
piston,
vilebrequin, bielle, pédale, angle, 120 , étoile}
Anneaux sémantiques
Soit V un vocabulaire de Nv mots (en particulier l'ensemble des mots
de référence d'au moins une thématique).
Soit T un sous ensemble de V de Nt mots (en particulier l'ensemble
des mots de référence présents dans au moins une thématique), Nt Nv.
Soit P une proposition de Np mots, telle que Np Nv.
Soit Q le groupe de Nq mots communs à P et à T (il s'agit des mots
de la proposition appartenant à au moins une thématique), Nq Np.
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
11
Soit P(P) l'ensemble des parties de P et P(Q) l'ensemble des parties
de Q.
Par construction, P(P) et P(Q) sont des anneaux commutatifs
unitaires munis de deux opérateurs :
- un opérateur de différence symétrique noté A (relativement à
deux ensembles A et B, la différence symétrique de A et B est
l'ensemble contenant les éléments contenus dans A mais pas
dans B, et les éléments contenus dans B et pas dans A) ; et
- un opérateur d'intersection noté &.
P(P) est isomorphe à Z/NpZ et P(Q) est isomorphe à Z/NqZ
V A e P(P), P(A) est inclus dans P(P) et A est aussi un anneau
commutatif unitaire. A contient toutes les combinaisons complètes ou
partielles d'un groupe de mots. On appelle A un anneau sémantique . A
partir de l'ensemble des mots d'une proposition appartenant à une
thématique, un anneau sémantique est défini par un sous-ensemble de cet
ensemble.
Par exemple, si ce véhicule est grand et bleu est une proposition,
les anneaux sémantiques de cette proposition sont notés {}, {véhicule},
{grand}, {bleu}, {véhicule, grand}, {véhicule, bleu}, {véhicule, grand, bleu}.
Il
est important de comprendre que chaque anneau n'est pas la simple liste
des mots qui le compose, mais bien l'ensemble des ensembles comprenant
i E [[0,1(]] de ces mots (qui sont d'autres anneaux sémantiques). Par
exemple, l'anneau défini par véhicule et grand correspond en réalité à
l'ensemble { {} ; {véhicule} ; {grand} ; {véhicule, grand} 1.
Un anneau est dit centré s'il n'existe pas deux mots qu'il contienne
appartenant à deux thématiques différentes (mais il peut contenir des mots
n'appartenant à aucun thématique).
Un anneau est dit régulier s'il appartient aussi à P(Q), c'est-à-dire
que tous les mots qu'il contient appartiennent à l'une des thématiques.
Dans une étape (c), le procédé comprend la construction d'une
pluralité de sous-ensembles de l'ensemble des mots de ladite partie du
texte associés à au moins une thématique, en d'autres termes les anneaux
CA 02937930 2016-07-25
WO 2015/114014 PCT/EP2015/051722
12
sémantiques réguliers, et avantageusement le procédé comprend la
construction de la totalité de ces anneaux.
Si l'ensemble des mots associés à au moins une thématique
comprend K éléments, alors il y a 2K anneaux construits.
Matrices sémantiques
Dans l'étape (d), une représentation du sens des anneaux
sémantique d'une partie du texte (qui comme expliqué est typiquement une
proposition) est déterminée par les moyens de traitement de données 11 de
l'équipement 1. Cette représentation prend la forme d'une matrice formée
de vecteurs attachés aux thématiques et comprenant plusieurs dimensions
et stockée dans les moyens de stockage de données 12 de l'équipement.
Cette matrice est appelée matrice sémantique (ou matrice de sens).
Dans l'hypothèse d'un traitement proposition par proposition, une suite de
matrices sémantiques est déterminée, et dans une étape (e0) une matrice
sémantique globale du texte est déterminée en fonction des matrices
sémantiques des anneaux des propositions.
Une matrice sémantique comprend au moins deux dimensions,
avantageusement trois, voire quatre : la couverture, la pertinence (au moins
une parmi ces deux est requise), la certitude, la nuance (les deux dernières
peuvent être regroupées en une seule dimension, l'orientation). La matrice
globale d'un texte peut comprendre une cinquième dimension (la
divergence).
Coefficient de couverture d'une thématique
Le procédé comprend pour chaque sous-groupe (i.e. anneau
sémantique) et chaque thématique identifiée, le calcul dans d'un coefficient
de couverture de la thématique et/ou d'un coefficient de pertinence de la
thématique (avantageusement les deux), en fonction d'occurrences dans
l'anneau de mots de référence associés à la thématique.
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
13
Le coefficient de couverture d'une thématique matérialise la proximité
entre l'anneau et la thématique, et se représente par un nombre entier,
typiquement le nombre N de mots de la thématique compris dans l'anneau.
Il est possible d'adjoindre des pondérations (par exemple à certains mots
essentiels de la thématique).
Dans l'exemple précédent, la proximité entre la proposition et la
thématique motorisation est plus forte que celle avec la thématique
géométrie (coefficient de cinq contre trois).
Coefficient de pertinence d'une thématique
Le coefficient de pertinence est calculé par les moyens de traitement
de données 11 comme le coefficient de couverture mais en prenant en
compte le nombre total d'occurrence des mots du thème.
En particulier, si N est le nombre de mots de la thématique contenus
dans l'anneau, ou chaque mot ne compte qu'une fois (en d'autres termes le
coefficient de couverture de la thématique) et R est le nombre de mots de la
thématique contenus dans l'anneau, ou chaque mot compte autant de fois
qu'il apparait dans la proposition (nombre d'occurrence total, qui croit avec
la longueur de la proposition), le coefficient de pertinence est par exemple
donné par la formule N * (1 + ln(R)), avec In le logarithme népérien.
Le calcul d'un coefficient de pertinence n'est pas limité à cette
formule, et l'homme du métier pourra par exemple utiliser les formules ch()
avec ch le cosinus hyperbolique, ou encore 1* atan() avec atan l'arc
tangente, selon le nombre et la taille des thématiques existantes. Chacune
de ces formules peut être normalisée.
L'utilisation de l'arc tangente amortit l'effet des grandes valeurs de R,
alors qu'on contraire le cosinus hyperbolique accentue l'effet des grandes
valeurs de R.
Coefficient de certitude d'une thématique
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
14
Le procédé comprend également le calcul, toujours pour chaque
sous-groupe (i.e. anneau sémantique) et chaque thématique identifiée, d'au
moins un coefficient d'orientation de la thématique à partir des mots de
ladite partie du texte ne faisant pas partie de l'anneau (en particulier ceux
n'appartenant à aucun anneau).
En particulier, deux coefficients d'orientation de la thématique sont
calculés à l'étape (d), dont un coefficient de certitude de la thématique et
un
coefficient de nuance de la thématique.
La certitude est véhiculée par un ensemble de mots dont l'ordre et la
nature peut changer radicalement le sens porté par la proposition. Il s'agit
typiquement des mots tels que des négations, de la ponctuation, des mots
interrogatifs/négatifs, dont une liste peut être stockée sur les moyens de
stockage de données 12. La position de ces mots les uns par rapport aux
autres (typique de certaines tournures) donne par ailleurs des indices sur la
certitude.
Selon ces mots, la proximité peut être affirmative, négative ou
incertaine. Dans l'exemple précédent, la proximité est affirmative (faute de
mots modifiant la certitude).
Par comparaison, dans une proposition qui serait formulée aucun
moteur ne comprenant aucune bielle ni aucun piston n'équipe ce véhicule à
pédale , la motorisation est une anti-thématique, révélée par les mots
répétés aucun(e) , ni et n' .
La proximité entre ce texte et la thématique motorisation est
négative.
Par comparaison encore, dans l'exemple : ce véhicule serait-il
équipé d'un moteur à piston et d'un vilebrequin à bielles ? , la proximité
entre le texte et la catégorie motorisation est interrogative du fait de
la
tournure interrogative et la présence du point d'interrogation.
La certitude peut ainsi se représenter par trois valeurs :
- 1 pour l'affirmative
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
- -1 pour la négative
- 0 pour l'incertitude (interrogatif, interronégatif, affirmatif et
négatif entremêlés, etc.)
5 Coefficient de nuance d'une thématique
La nuance est véhiculée par un ensemble de mots dont l'ordre et la
nature peut altérer le sens porté par la proposition. Cette altération peut
être
un renforcement ou un affaiblissement de la proximité avec la thématique,
10 par
exemple grâce à des adverbes tels que certainement ,
assurément , probablement , éventuellement . Comme pour la
nuance, il est possible de stocker sur les moyens de stockage 12 une liste
des mots caractéristiques d'un renforcement ou d'un affaiblissement de la
proximité avec une thématique. Les moyens de traitement de données 11
15 comparent
les mots non associés avec la thématique avec cette liste et en
déduisent la valeur du coefficient de nuance, qui est en particulier un
scalaire positif (supérieur à 1 pour un renforcement et inférieur à 1 pour un
affaiblissement)
Dans l'exemple : Assurément ce moteur comprend bien un
vilebrequin et des bielles, la nuance est un renforcement de la thématique
(grâce à assurément ), et le coefficient est par exemple 1.5.
Dans l'exemple : Matthieu croit savoir que le moteur contient un
vilebrequin et des bielles, la nuance est un affaiblissement de la
thématique (grâce à croire ), et le coefficient est par exemple 0.75.
Il est à noter que chaque mot représentatif d'une nuance peut être
stocké associé à un coefficient, le coefficient de nuance pour la proposition
étant par exemple le produit des coefficients des mots trouvés dans la
proposition. Alternativement, le coefficient de nuance pour la proposition
peut être la somme des coefficients des mots trouvés dans la proposition.
Le tableau ci-dessous donne deux exemples d'ensembles de
coefficients de quelques mots porteurs de nuances, aussi bien dans une
composition par produit (colonne de gauche) que par somme (colonne de
CA 02937930 2016-07-25
WO 2015/114014 PCT/EP2015/051722
16
droite). On comprendra que l'invention n'est limitée à aucun mode de calcul
du coefficient de nuance.
TERME NUANCE
Exemple 1 Exemple 2
Bien plus, beaucoup, énormément 2 +20%
Plus, un peu plus, deux fois plus 1,25 +10%
Peu, moins, un peu moins 0,8 -10%
Très peu, pratiquement pas 0,5 -20%
Coefficient d'orientation d'une thématique
Les coefficients de nuance et de certitude peuvent constituer deux
dimensions distinctes de la matrice sémantique, ou être traitées ensemble
comme un coefficient d'orientation ( l'orienteur ).
Il est peut être calculé comme le produit des coefficients de certitude
et de nuance. En effet, ces deux concepts sont indépendants. La proximité
à une thématique peut par exemple être renforcée dans le négatif par une
formulation telle que le véhicule ne comprend certainement pas de
moteur , qui correspondra par exemple a un coefficient de -1.75
Le coefficient d'orientation est ainsi typiquement un nombre réel :
<O pour la certitude négative
> 0 pour la certitude affirmative
0 pour l'incertitude
Et dont la valeur absolue est
> 1 pour un renforcement
< 1 pour une relativisation
=1 pour une orientation neutre
A l'issue de l'étape (d), la matrice sémantique obtenue a
préférentiellement une structure du type
Thème 1 Thème 2 Thème 3 Thème i
Couverture 1 Couverture 2 Couverture 3 Couverture i
Pertinence 1 Pertinence 2 Pertinence 3 Pertinence i
Orienteur 1 Orienteur 2 Orienteur 3 Orienteur
i
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
17
Composition de matrices sémantiques
Comme expliqué plus haut, un texte est formé de plusieurs phrases
formées elles-mêmes de plusieurs propositions. Une matrice sémantique
est avantageusement générée pour un anneau pour chaque proposition.
Dans une étape (e0), les matrices sémantiques d'un anneau sont
combinées en une matrice globale : est calculé par les moyens de
traitement de données 11 pour chaque anneau et chaque thématique
identifiée pour au moins une proposition du texte un coefficient global de
couverture de la thématique et/ou d'un coefficient global de pertinence de la
thématique, et d'au moins un coefficient global d'orientation de la
thématique en fonction de l'ensemble desdits coefficients associés une
proposition.
Les matrices de deux propositions sont complémentaires si elles
portent sur des thèmes différents. La matrice de sens de l'ensemble des
deux propositions est constituée de la juxtaposition des deux matrices
(puisqu'aucune thématique n'est commune).
Les matrices de deux propositions sont cohérentes si elles portent
sur des thèmes communs avec des orienteurs similaires.
Les matrices de deux propositions sont opposées si elles portent sur
des thèmes communs avec des orienteurs opposés (de signes différents,
i.e. la différence porte sur le coefficient de certitude de la thématique).
Dans le cas général deux matrices A et B portent sur certains thèmes
communs et sur d'autres différents. La matrice résultante S est alors
composée d'une colonne par thème appartenant à l'une ou l'autre
proposition.
Par exemple les règles suivantes peuvent s'appliquer à la
composition de deux colonnes pour un même thème :
- un coefficient global de couverture d'une thématique est calculé
comme la somme des coefficients de couverture de la thématique
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
18
associée à une proposition moins le nombre de mots de référence
de la thématique présents dans au moins deux propositions (en
d'autres termes il ne faut compter qu'une fois chaque mot. La
couverture de la somme est ainsi comprise entre la plus grande
des couvertures (cas ou tous les mots de référence de la
thématique trouvés dans une proposition sont également dans
l'autre), et la somme (cas ou aucun mot de référence n'est
commun aux deux couvertures thématiques). Il est à noter que le
coefficient global de couverture peut être facilement recalculé
comme le nombre Nmax de mots de la thématique contenus dans
l'ensemble des propositions) ;
- un coefficient global de pertinence d'une thématique est calculé
comme la somme des coefficients de pertinence de la thématique
associée à une proposition (puisque les occurrences multiples
sont prises en compte) ;
- un coefficient global d'orientation d'une thématique est calculé
comme la moyenne des coefficients d'orientation de la thématique
associés à une proposition pondérés par les coefficients de
couverture de la thématique associés. Par exemple, le coefficient
global d'orientation du texte S formé des propositions A et B est
donné par la formule OS = (0A*CA + OB*CB) / OS
Par ailleurs, on définit la divergence thématique comme
représentant les variations de sens pour une thématique dans un texte.
Avantageusement, l'étape (e0) comprend ainsi pour chaque
thématique le calcul d'un coefficient global de divergence de la thématique.
Il se calcule par exemple comme étant l'écart type de la distribution des
produits des orienteurs par les couvertures des propositions concernées
ramenée au produit holiste de l'orienteur par la couverture du texte global.
Un texte à forte divergence est un texte dans lequel le sujet porté par
la thématique est abordé avec des interrogations, des comparaisons, des
CA 02937930 2016-07-25
WO 2015/114014 PCT/EP2015/051722
19
confrontations. Un texte à faible divergence est un texte présentant
constamment le même angle de vue.
Anneaux sémantiques croissants et décroissants
La notion d'anneau sémantique croissant ou décroissant est relative
à un morphisme, permettant de calculer un coefficient sémantique ,
représentatif d'un degré de sens porté par le sous-groupe en fonction
desdits coefficients de couverture, pertinence et/ou orientation de la
thématique, en particulier les coefficients globaux.
Ce coefficient est calculé par les moyens de traitement de données à
l'étape (e) du procédé.
Par exemple, soit M le morphisme de P(P) ¨> R tel que
V A E P(P), avec T E P(V), M(A,T) = pertinence(A,T) * orienteur(A,T)
* -\/- [1 + divergence(A,T)2]
M(A,T) est le coefficient sémantique de l'anneau A de la proposition
P par rapport à la thématique T selon le vocabulaire V.
M(A) est le coefficient sémantique de l'anneau A de la proposition P
par rapport à toutes les thématiques selon le vocabulaire V.
Alternativement, sont possibles (en particulier dans un mode de
réalisation ne comprenant pas le calcul d'un coefficient de divergence) des
morphismes M tels que
V A E P(P), avec T E
P(V), M(A,T) = [pertinence(A,T)]2 *
orienteur(A,T), ou encore
V A E P(P), avec T E P(V), M(A,T) =
pertinence(A,T) *
couverture(A,T)
Toutes ces formules peuvent également être normalisées.
Quelque soit le morphisme choisi, le coefficient sémantique permet
de sélectionner des couples anneaux/thématique les plus porteurs de sens
dans une étape (f). En particulier, ce peut être ceux pour lesquels le
coefficient est le plus élevé, mais alternativement on peut utiliser le
critère
de croissance des anneaux sémantiques.
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
On appelle anneau sémantique croissant selon M, tout élément A de
P(Q) pour lequel :
- v A' E P(A),
- 3 T, M(A,T) > M(A',T) + M(A'AA,T)
5 - Avec cardinalité(A) > 1
En d'autres termes, un anneau sémantique croissant est un anneau
porteur d'un sens plus grand que la somme des sens de ses parties. Pour
reformuler encore, il existe une thématique telle que pour toute partition de
l'anneau, la somme des coefficients sémantiques des parties de la partition
10 de l'anneau par rapport à cette thématique est inférieure au coefficient
sémantique de l'anneau entier par rapport à cette thématique.
Par opposition, les autres anneaux sémantiques sont dit
décroissants.
Avantageusement, les couples sous-ensemble/thématique
15 sélectionnés à l'étape (f) sont ceux pour lesquels l'anneau est croissant
pour cette thématique.
Le choix du morphisme est déterminant pour sélectionner les
anneaux sémantiques. Un morphisme trop lâche conduira à ce que tous les
anneaux soit des anneaux sémantiques croissants. Un morphisme trop
20 strict conduira à l'absence d'anneaux sémantiques croissants.
Pour illustrer cette notion d'anneaux croissants/décroissants, dans la
proposition ce véhicule est grand dedans et petit dehors , les anneaux
{véhicule, grand} et {véhicule, petit} portent plus de sens que l'anneau
global {véhicule, grand, petit}, puisque la présence simultanée des termes
grand et petit fait baisser l'orienteur. L'anneau {véhicule, grand, petit} est
donc décroissant.
Dans la proposition : ce véhicule est grand et bleu , les anneaux
{véhicule, grand} et {véhicule, bleu} portent moins de sens que l'anneau
global {véhicule, grand, bleu}. Ce dernier est croissant.
L'union de deux anneaux sémantiques décroissants est un anneau
sémantique décroissant. L'union d'un anneau sémantique décroissant et
d'un anneau sémantique croissant est un anneau sémantique décroissant.
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
21
L'union de deux anneaux sémantiques croissants est un anneau
sémantique soit croissant, soit décroissant. Le caractère croissant est
récessif vis-à-vis de l'union.
Un anneau sémantique expressif est un ensemble de mots porteur
d'un sens culturel supérieur à celui de l'union de ses parties.
Par exemple dans l'expression : ce véhicule est une vraie bombe ,
l'anneau expressif {véhicule, bombe} associée à une nuance de
renforcement ( vraie ) porte un sens expressif non présent dans les
anneaux singletons {véhicule} et {bombe} et non présent dans l'anneau
décroissant {véhicule, bombe}.
Un anneau expressif A est un anneau décroissant devenu croissant
par un renforcement de nuance (i.e. grâce à un coefficient de nuance élevé
dû à la présence de vraie entrainant un orienteur élevé). Le morphisme
M présente alors une discontinuité au voisinage de A.
Il est à noter qu'avant même la mise en oeuvre de l'étape (f), certains
filtres peuvent éliminer certains anneaux selon un paramétrage du moteur.
Il est à noter qu'une notion de connexité entre anneaux et
thématiques peut être surveillée par les moyens de traitement de données
11. Un anneau fortement connexe à une thématique sera toujours
sélectionné en couple avec cette thématique et jamais une autre (voir plus
loin).
Classification du texte
Un schéma global du procédé d'analyse sémantique selon l'invention
est représenté par la figure 2.
La première partie, qui correspond aux étapes (a) à (f) déjà décrite,
est mise en oeuvre par un bloc appelé l'analyseur permettant de
sélectionner les couples anneaux/thématiques représentatifs du sens du
texte.
Dans une étape (g), un classificateur associe les catégories aux
textes à l'aide des anneaux sélectionnés. En particulier, les catégories
CA 02937930 2016-07-25
WO 2015/114014
PCT/EP2015/051722
22
correspondent à des groupes de couples sous-ensemble/thématique de
référence sont stockés sur les moyens de stockage de données 12, et les
catégories dans lesquelles le texte est classifié sont celles comprenant au
moins un couple sous-ensemble/thématique sélectionné à l'étape (f).
D'autres paramètres peuvent contribuer à la classification, telle que
la dilution . L'étape (g) peut ainsi comprendre le calcul d'un coefficient
dit
de dilution, qui représente le nombre d'occurrences de termes des
thématiques liées à la ou les catégories déterminées (en d'autres termes les
thématiques des couples des groupes associés aux catégories), présents
dans le texte rapporté au nombre total de termes desdites thématiques. On
dit alors que le texte est de catégorie X selon la dilution D.
Dans un souci d'optimisation, une estimation de ces paramètres et
notamment du coefficient de dilution peut être plus précoce dans le
procédé.
Apprentissage et enrichissement
Comme expliqué, les catégories ne sont pas figées et peuvent
évoluer. En particulier de nouvelles catégories peuvent être générées et
d'autres segmentées.
Si aucune catégorie n'est retenue, une nouvelle catégorie pourra être
générée portant un sens nouveau : un nouveau groupe est créé si aucun
groupe de couples sous-ensemble/thématique de référence ne contient au
moins un couple sous-ensemble/thématique sélectionné pour le texte. Les
couples sous-ensemble/thématique deviennent ceux de référence de ce
groupe.
Lorsqu'une catégorie devient trop peuplée, une segmentation
paramétrable la scinde en deux ou plusieurs catégories.
Par ailleurs, les anneaux de propositions non traités par la
classification et répondant à certains critères (de score) peuvent être placés
dans une pile d'attente.
CA 02937930 2016-07-25
WO 2015/114014 PCT/EP2015/051722
23
Ainsi, chaque couple sous-ensemble/thématique de référence peut
être associé à un score stocké sur les moyens de stockage de données 12,
le score d'un couple sous-ensemble/thématique de référence diminuant
avec le temps (par exemple suivant un amortissement hyperbolique) mais
augmentant à chaque fois que ce couple sous-ensemble/thématique est
sélectionné pour un texte.
En d'autres termes, l'enrichissement repose sur deux mécanismes
simultanés :
- Le score d'un couple anneau/thématique augmente à chaque
fois qu'un même anneau est issu de l'analyse
- Le score d'un couple anneau/thématique s'érode avec le temps
selon un amortissement hyperbolique.
Et le procédé peut alors comprendre une étape (h) de suppression
d'un couple sous-ensemble/thématique de référence d'un groupe si le score
dudit couple passe en dessous d'un premier seuil, ou de modification sur
les moyens de stockage de données 12 de ladite pluralité de listes
associées aux thématiques si le score dudit couple passe au-dessus d'un
deuxième seuil.
En particulier, si le score dépasse le deuxième seuil, plusieurs cas
peuvent se présenter selon la connexité entre l'anneau et la thématique,
comme évoqué précédemment.
La connexité entre un anneau et une thématique peut en effet être
représentée par un coefficient représentant pour chaque thématique la
fréquence d'apparition de cette thématique parmi les thématiques telles que
le couple anneau/thématique associé a déjà été sélectionné. En d'autres
termes la connexité entre un anneau et une thématique est par exemple
donnée comme le score de ce couple anneau/thématique sur la somme des
scores associés à des couples de cet anneau avec une thématique de
référence.
Les différents cas qui peuvent se présenter sont :
- les anneaux non connexes aux thématiques donnent naissance à
de nouvelles thématiques (création d'une nouvelle thématique
CA 02937930 2016-07-25
WO 2015/114014 PCT/EP2015/051722
24
pour laquelle la liste de mot associée est définie par l'anneau du
couple dont le score a dépassé le deuxième seuil) ;
- les anneaux
fortement connexes à une thématique (par exemple
connexité supérieure à 90%) sont fusionnés dans la thématique
connexe (par exemple, si un anneau est très proche d'une
thématique mais comprend un mot de plus, ce mot finit par être
ajouté à la liste de mots associée à la thématique).
A l'inverse, un anneau fortement érodé (score passant en-dessous
du premier seuil) disparait de la pile. Les deux seuils peuvent être définis
manuellement en fonction de la sensibilité , c'est-à-dire le niveau
souhaité d'évolutivité du système. Des seuils proches (premier seuil élevé
et/ou deuxième seuil bas) entrainent un fort renouvellement des
thématiques et catégories.