Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
FLINK STREAMING PROCESSING ENGINE METHOD AND DEVICE FOR REAL-
TIME RECOMMENDATION AND COMPUTER EQUIPMENT
BACKGROUND OF THE INVENTION
Technical Field
[0001] The present application relates to the field of big data recommendation
technology, and
more particularly to a Flink stream processing engine method for real-time
recommendation, and corresponding device and computer equipment.
Description of Related Art
[0002] With the upgrading of user experiences, higher and higher demand is
correspondingly put
on the real timeliness requirement of recommendation. The traditional double-
layered
recommendation framework (application layer, offline layer) engenders the
occurrence
of such phenomena as complicated function of the application layer, response
timeout
and data inconsistency. In addition, although realization of recommendation at
the offline
layer is quick, time precision of recommendation reaches only to the magnitude
of days;
however, since user interests generally diminish rapidly with the attenuation
of time, if
items of interest to users cannot be pushed to the users at the first time,
the conversion
rate would be reduced and even user loss ensues. This makes extremely valuable
the
creation of a set of real-time recommending system capable of analyzing users'
behaviors
in real time and so performing prediction that the system can respond timely.
[0003] Real-time recommendation means the capabilities to perceive changes in
users' behaviors
and to push precise contents to users according to users' behaviors generated
by the users
in real time. At present, the typical recommending system is a triple-layered
framework,
namely online, near-line and offline. By means of offline or near-line model
training,
near-line real-time feature engineering and callback and sorting, and finally
through
1
Date Recue/Date Received 2022-03-22
forced interference and bottom coverage of the business performed at the
online layer,
the value of the system is fully reflected in terms of highly speedy response
to scenarios
with massive data volumes.
[0004] The recommendation algorithm engine that is based on stream processing
is at the kernel
position of the near-line portion, whereas the traditional scheme that employs
STORM or
SPARKSTREAMING, for example, for realization is problematic in the following
aspects:
[0005] 1) There lacks utilization of the latest users' behavior data, and the
user feature model
cannot be updated, so it is impossible to perceive in real time the real-time
changes in
users' interests.
[0006] 2) It is impossible to give considerations to reliability, disaster
recovery, performance and
generality at the same time, thereby making it difficult to deploy the
algorithm model and
to complete real-time response.
[0007] 3) There are too many technical details by the use of JAVA or PYTHON
language for
development, whereby development is slow, and it is difficult to timely
respond to
business requirements.
SUMMARY OF THE INVENTION
[0008] In order to overcome at least one problem mentioned in the above
Description of Related
Art, the present application provides a Flink stream processing engine method
for real-
time recommendation, and corresponding device and computer equipment, with
technical
solutions being specified as follows.
[0009] According to the first aspect, there is provided a Flink stream
processing engine method
for real-time recommendation, which method comprises:
[0010] performing short-term feature calculation on a log in a message queue
according to a
calculation model file, and storing short-term features obtained by the
calculation in a
2
Date Recue/Date Received 2022-03-22
distributed storage layer, wherein the distributed storage layer stores
therein long-term
features obtained in advance;
[0011] reading a long-term feature and a short-term feature of a to-be-
recommended user from
the distributed storage layer, when an event is received from the message
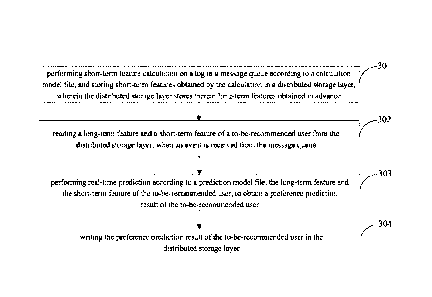
queue;
[0012] performing real-time prediction according to a prediction model file,
the long-term
feature and the short-term feature of the to-be-recommended user, to obtain a
preference
prediction result of the to-be-recommended user; and
[0013] writing the preference prediction result of the to-be-recommended user
in the distributed
storage layer.
[0014] Further, prior to the step of performing short-term feature calculation
on a log in a
message queue according to a calculation model file, the method further
comprises:
[0015] obtaining a configuration file that contains a configuration parameter;
and
[0016] loading from a model repository a model file well trained in advance to
which the
configuration parameter corresponds, and sending the model file to various
distributed
nodes of the Flink stream processing engine, wherein the model file includes
the
calculation model file and the prediction model file.
[0017] Further, the step of obtaining a configuration file includes:
[0018] synchronizing at least one configuration file from a distributed
configuration cluster, and
loading the at least one configuration file into a memory.
[0019] Further, the step of loading from a model repository a model file to
which the
configuration parameter corresponds includes:
[0020] reading a preconfigured model identification parameter from the
configuration parameter,
wherein the model identification parameter includes a namespace, a model name
and a
model version; and
[0021] loading from the model repository a model file to which the model
identification
parameter corresponds.
3
Date Recue/Date Received 2022-03-22
[0022] Further, the step of performing short-term feature calculation on a log
in a message queue
according to a calculation model file includes:
[0023] performing short-term feature calculation on the log according to the
calculation model
file through the various distributed nodes;
[0024] the step of performing real-time prediction according to a prediction
model file, the long-
term feature and the short-term feature of the to-be-recommended user, to
obtain a
preference prediction result of the to-be-recommended user includes:
[0025] generating a prediction model according to the prediction model file
through the various
distributed nodes; and
[0026] inputting the long-term feature and the short-term feature of the to-be-
recommended user
to the prediction model for real-time prediction, to obtain the preference
prediction result
of the to-be-recommended user.
[0027] Further, the distributed storage layer includes a cache component and a
persistence
component, and the step of reading a long-term feature and a short-term
feature of a to-
be-recommended user from the distributed storage layer, when an event is
received from
the message queue includes:
[0028] reading a long-term feature and a short-term feature of the to-be-
recommended user from
a local cache through the various distributed nodes;
[0029] reading a long-term feature and a short-term feature of the to-be-
recommended user from
the cache component, if reading from the local cache failed; and
[0030] reading a long-term feature and a short-term feature of the to-be-
recommended user from
the persistence component, if reading from the cache component failed, and
asynchronously writing the read features in the cache component.
[0031] Further, the calculation model file is an SQL model file, and the
prediction model file is
a PMML model file.
4
Date Recue/Date Received 2022-03-22
[0032] According to the second aspect, there is provided a Flink stream
processing engine device
for real-time recommendation, which device comprises:
[0033] an algorithm calculating module, for performing short-term feature
calculation on a log
in a message queue according to a calculation model file;
[0034] a data pushing module, for storing short-term features obtained by the
calculation in a
distributed storage layer, wherein the distributed storage layer stores
therein long-term
features obtained in advance; and
[0035] a feature enquiring module, for reading a long-term feature and a short-
term feature of a
to-be-recommended user from the distributed storage layer, when an event is
received
from the message queue;
[0036] the algorithm calculating module is further employed for performing
real-time prediction
according to a prediction model file, the long-term feature and the short-term
feature of
the to-be-recommended user, to obtain a preference prediction result of the to-
be-
recommended user; and
[0037] the data pushing module is further employed for writing the preference
prediction result
of the to-be-recommended user in the distributed storage layer.
[0038] Further, the device further comprises:
[0039] a configuration synchronizing module, for obtaining a configuration
file that contains a
configuration parameter; and
[0040] a model loading module, for loading from a model repository a model
file well trained in
advance to which the configuration parameter corresponds, and sending the
model file to
various distributed nodes of the Flink stream processing engine, wherein the
model file
includes the calculation model file and the prediction model file.
[0041] Further, the configuration synchronizing module is specifically
employed for:
[0042] synchronizing at least one configuration file from a distributed
configuration cluster, and
loading the at least one configuration file into a memory.
Date Recue/Date Received 2022-03-22
[0043] Further, the model loading module is specifically employed for:
[0044] reading a preconfigured model identification parameter from the
configuration parameter,
wherein the model identification parameter includes a namespace, a model name
and a
model version; and
[0045] loading from the model repository a model file to which the model
identification
parameter corresponds.
[0046] Further, the algorithm calculating module is specifically employed for:
[0047] performing short-term feature calculation on the log according to the
calculation model
file through the various distributed nodes;
[0048] the algorithm calculating module is specifically further employed for:
[0049] generating a prediction model according to the prediction model file
through the various
distributed nodes; and
[0050] inputting the long-term feature and the short-term feature of the to-be-
recommended user
to the prediction model for real-time prediction, to obtain the preference
prediction result
of the to-be-recommended user.
[0051] Further, the distributed storage layer includes a cache component and a
persistence
component, and the feature enquiring module is specifically employed for:
[0052] reading a long-term feature and a short-term feature of the to-be-
recommended user from
a local cache through the various distributed nodes;
[0053] reading a long-term feature and a short-term feature of the to-be-
recommended user from
the cache component, if reading from the local cache failed; and
[0054] reading a long-term feature and a short-term feature of the to-be-
recommended user from
the persistence component, if reading from the cache component failed, and
asynchronously writing the read features in the cache component.
[0055] Further, the calculation model file is an SQL model file, and the
prediction model file is
a PMML model file.
6
Date Recue/Date Received 2022-03-22
[0056] According to the third aspect, there is provided a computer equipment
that comprises a
memory, a processor and a computer program stored on the memory and operable
on the
processor, and the following operating steps are realized when the processor
executes the
computer program:
[0057] performing short-term feature calculation on a log in a message queue
according to a
calculation model file, and storing short-term features obtained by the
calculation in a
distributed storage layer, wherein the distributed storage layer stores
therein long-term
features obtained in advance;
[0058] reading a long-term feature and a short-term feature of a to-be-
recommended user from
the distributed storage layer, when an event is received from the message
queue;
[0059] performing real-time prediction according to a prediction model file,
the long-term
feature and the short-term feature of the to-be-recommended user, to obtain a
preference
prediction result of the to-be-recommended user; and
[0060] writing the preference prediction result of the to-be-recommended user
in the distributed
storage layer.
[0061] According to the fourth aspect, there is provided a computer-readable
storage medium
storing a computer program thereon, and the following operating steps are
realized when
the computer program is executed by a processor:
[0062] performing short-term feature calculation on a log in a message queue
according to a
calculation model file, and storing short-term features obtained by the
calculation in a
distributed storage layer, wherein the distributed storage layer stores
therein long-term
features obtained in advance;
[0063] reading a long-term feature and a short-term feature of a to-be-
recommended user from
the distributed storage layer, when an event is received from the message
queue;
[0064] performing real-time prediction according to a prediction model file,
the long-term
feature and the short-term feature of the to-be-recommended user, to obtain a
preference
prediction result of the to-be-recommended user; and
7
Date Recue/Date Received 2022-03-22
[0065] writing the preference prediction result of the to-be-recommended user
in the distributed
storage layer.
[0066] The technical solutions provided by the present application at least
achieve the following
advantageous effects:
[0067] 1. Message reliability guarantee and capacity expansion and extraction:
the distributed
stream engine Flink itself brings about precise message reliability and
flexible capacities
to expand and extract, and makes it possible to reduce resource consumption in
normal
times but to increase resources in large-scale promotional activities to
respond to peak
flow.
[0068] 2. Reduction in algorithm development difficulty: the algorithm
personnel more often
employ such language systems as SQL, Python, and machine learning, rather than
the
JAVA language system, whereas the present application makes use of the SQL and
P]\4IML
general language standards, whereby development difficulty and time
consumption of the
algorithm are both reduced, and most technical problems are solved.
[0069] 3. Reduction in response duration: the response duration by the use of
an offline algorithm
is usually of the hourly magnitude, and the operation time usually cannot be
guaranteed,
whereas the response time based on the use of the current engine is of the
millisecond
magnitude, whereby real-time recommendation and feature engineering are made
possible.
[0070] 4. One-stop model deployment: models obtained by offline training can
be stored in a
general model repository, the current engine is subsequently specified to read
the model
of given coordinates before the engine automatically starts deployment,
whereby massive
deployment operations are dispensed with, and error and time cost are reduced.
BRIEF DESCRIPTION OF THE DRAWINGS
[0071] To more clearly describe the technical solutions in the embodiments of
the present
application, drawings required to be used in the description of the
embodiments will be
8
Date Recue/Date Received 2022-03-22
briefly introduced below. Apparently, the drawings introduced below are merely
directed
to some embodiments of the present application, while it is possible for
persons ordinarily
skilled in the art to acquire other drawings based on these drawings without
spending
creative effort in the process.
[0072] Fig. 1 is a view schematically illustrating data interaction between
the stream processing
engine and relevant components provided by the present application;
[0073] Fig. 2 is a view schematically illustrating the structure of the Flink
stream processing
engine provided by the present application;
[0074] Fig. 3 is a flowchart illustrating the Flink stream processing engine
method for real-time
recommendation provided by the present application;
[0075] Fig. 4 is a flowchart illustrating loading of the model file provided
by the present
application;
[0076] Fig. 5 is a flowchart illustrating reading of three-level cache
features provided by the
present application;
[0077] Fig. 6 is a view illustrating a cluster deployment framework provided
by the present
application; and
[0078] Fig. 7 is a view illustrating the internal structure of a computer
equipment provided by an
embodiment of the present application.
DETAILED DESCRIPTION OF THE INVENTION
[0079] To make more lucid and clear the objectives, technical solutions and
advantages of the
9
Date Recue/Date Received 2022-03-22
present application, the technical solutions in the embodiments of the present
application
will be more clearly and comprehensively described below with reference to the
accompanying drawings in the embodiments of the present application.
Apparently, the
embodiments as described are merely partial, rather than the entire,
embodiments of the
present application. All other embodiments obtainable by persons ordinarily
skilled in the
art on the basis of the embodiments in the present application without
spending creative
effort shall all fall within the protection scope of the present application.
[0080] As should be noted, unless explicitly demanded otherwise in the
context, such wordings
as "comprising", "including" and "containing" as well as their various
grammatical forms
as used throughout the Description and the Claims shall be understood to
indicate the
meaning of inclusion rather than the meaning of exclusion or exhaustion, in
other words,
they collectively mean "including, but not limited to...". In addition, unless
noted
otherwise, the wordings of "more" and "plural" indicate the meaning of "two or
more" in
the description of the present application.
[0081] Fig. 1 is a view schematically illustrating data interaction between
the stream processing
engine and relevant components provided by the present application. As shown
in Fig. 1,
black line arrows indicate data flows, grey line arrows indicate file flows,
and long-term
features are pushed by offline data synchronizer (Long Term Feature
Synchronizer) 101
to NOSQL storage layer 102 that at least contains a persistence component
(Persistence)
and a cache component (Cache). Stream processing engine (Stream Engine) 103
reads a
configuration file from distributed configuration cluster (Configuration
Zookeeper) 104,
and loads from model repository (Model Repository) 105 a model file (for
instance, SQL
model file and PMML model file) well trained in advance. Stream engine 103
uses a log
in message queue (MQ Kafka) 106 to perform short-term feature engineering,
calculates
and thereafter stores data in the persistence component and the cache
component in
NOSQL storage layer 102 before writes back an event to message queue 106.
Thereafter,
triggered by this event, predicting stream engine 103 obtains long-term
features and short-
Date Recue/Date Received 2022-03-22
term features from NOSQL storage layer 102, uses already loaded model text and
script
to perform real-time prediction, and finally writes the result in the
persistence component
and the cache component of NOSQL storage layer 102. A stream structure with
separated
reading and writing is thus formed. In actual application, with the use of the
Flink
component, the above stream processing is superior than Storm in terms of
message
supportability, volume of development, and throughput. The distributed
configuration
cluster is embodied as Zookeeper that can be combined with a Hadoop cluster.
The
message queue is embodied as Kafica that is characteristic of high throughput
and low
time delay, and conforms to log-type, message-triggering scenarios. The
persistence
storage component is embodied as HBase that possesses distributed, high-
writing and
low-reading, large storage capacity, and column-extensible characteristics.
The cache
component is embodied as Redis that possesses distributed, high-reading and
high-
writing, small storage capacity characteristics, and conforms to application
scenarios.
[0082] Fig. 2 is a view schematically illustrating the structure of the Flink
stream processing
engine provided by the present application. As shown in Fig. 2, the Flink
stream
processing engine (Stream Engine) comprises the following modules: a
configuration
synchronizing module (Configuration Synchronizer), a model loading module
(Model
Loader), an MQ connecting module (MQ connector), a feature enquiring module
(Query er), an algorithm calculating module (Algorithm Calculation), and a
data pushing
module (Data Pusher). Of these, the configuration synchronizing module, the
model
loading module and the MQ connecting module can be disposed on the same
scheduler,
and the feature enquiring module and the algorithm calculating module can be
disposed
on various distributed nodes in the distributed cluster, while the scheduler
can perform
information interaction with the various distributed nodes.
[0083] The configuration synchronizing module is employed for synchronizing
various
differently typed configuration files from the distributed configuration
cluster, loading
the same in the memory, and providing necessary parameter configurations for
the
11
Date Recue/Date Received 2022-03-22
recommending system, including, but not limited to, model hyperparameters,
feature
weights, and number restriction of recommendation results, etc., for example,
selecting a
corresponding recommendation algorithm for prediction from the model
repository
according to user configuration parameters, while it is further possible for
the business
personnel to interfere configurable recommendation results through the system
configuration page to certain extent.
[0084] The model loading module is employed for loading SQL model files or
PMML model
files from the model repository, and sending the files to the various
distributed nodes by
means of the distributed file caching principle for standby use by distributed
tasks.
[0085] The MQ connecting module is employed for obtaining log data from the
message queue
MQ so as to perform short-telin feature calculation through the algorithm
calculating
module, for obtaining an event from the message queue so as to facilitate the
algorithm
calculating module to base on the event to obtain long-term features and short-
term
features from the NOSQL storage layer, and additionally for writing the
response event
returned by the algorithm calculating module in the message queue MQ for use
by
downstream systems.
[0086] The feature enquiring module is employed for enquiring feature data
from the NOSQL
cluster per piece or in batches. Due to the big data scenario, the requirement
for reading
feature data is short while reading in great batches and persistent. To meet
such
performance requirement, it is possible to employ the mode of a triple-layered
cache plus
a separated reading and writing mechanism.
[0087] The algorithm calculating module is located on the various distributed
nodes, and uses
the model file loaded in advance by the model loading module, after having
received an
event from the message queue, it uses the native stream SQL calculating
function to
calculate features or uses the PMML predicting function to predict results.
12
Date Recue/Date Received 2022-03-22
[0088] The data pushing module writes the resultant data in the persistence
component and the
cache component simultaneously, and writes the triggered event after obtaining
response
from the persistence component and the cache component in the message queue
for
downstream use.
[0089] In order to realize functional requirements of near-line streaming
recommendation in a
recommending system, and to give considerations at the same time to such
problems as
concerning message reliability, disaster recovery, performance, and
transaction that
possibly occur during the operating process of the recommending system, the
present
application ensures storage administration of global and local statuses and
precise
reliability guarantee through the distributed stream calculation framework
Flink,
performs prediction calculation by means of a general model repository client
end and
model files that conform to the SQL and PMML standards, realizes automatic
model
loading, and solves the problem in which it is difficult to deploy the
algorithm model and
it is difficult to respond in real time; quick reading and reliability of
massive data are
guaranteed through reading and writing separation and triple-layered caching
mechanism
of the feature data repository.
[0090] The technical solutions of the present application are further
described below through a
plurality of embodiments.
[0091] In one embodiment, there is provided a Flink stream processing engine
method for real-
time recommendation, with reference to Fig. 3, the method can comprise the
following
steps.
[0092] 301 ¨ performing short-term feature calculation on a log in a message
queue according
to a calculation model file, and storing short-term features obtained by the
calculation in
a distributed storage layer, wherein the distributed storage layer stores
therein long-term
13
Date Recue/Date Received 2022-03-22
features obtained in advance.
[0093] The message queue is a mode of implementation of a message middleware,
such as a
kafca message queue, the message queue stores therein log data, the log data
can include
behavior data generated by user behavior operations within a preset time
period, and the
behavior operations are for instance browsing, clicking, listing as favorite,
and sharing of
a certain commodity object operated by a user on a certain APP page. The
preset time
period can be set according to practical requirements, for instance,1 day, 3
days or 7 days,
etc., in addition, the present application makes no restriction to the source
of the log data,
and the log data can for example come from an application APP.
[0094] The distributed storage layer can be embodied as an NOSQL storage layer
(a non-
relational database) that includes a cache component and a persistence
component, of
which the cache component can be embodied as cache component Redis that
possesses
distributed, high-reading and high-writing, small storage capacity
characteristics, and can
store data within a period of time (such as within 1 year); the persistence
storage
component can be embodied as persistence storage component HBase that
possesses
distributed, high-writing and low-reading, large storage capacity, and column-
extensible
characteristics, and can store data that has been overdue longer (such as
exceeding 1 year).
Both the cache component and the persistence component can be used to store
long-term
features and short-term features related to user operational behaviors.
[0095] The aforementioned long-term features are used to reflect long-term
preference of a user
with respect to a designated commodity, including user basic feature, user
long-term
behavior feature and other features, of which the user basic feature includes,
for instance,
age, gender, profession, place of residence and preference of the user; the
user behavior
feature means shopping behavior statistic values at an e-commerce platform
within a
period of time, such as the statistic feature of operational behaviors of the
user under a
certain commodity category within 30 days, 90 days, 180 days. Long-term
features can
14
Date Recue/Date Received 2022-03-22
be extracted out of user data, for example, a long-term model well trained
through offline
data is used to extract long-teini features of the user from user data, to
which no specific
restriction is made in the embodiments of the present application.
[0096] The aforementioned short-term features are used to reflect short-term
preference of a user
with respect to a designated commodity, and can be extracted and obtained from
behavior
operation data generated by the user within a preset time period, such as the
behavior
operation data generated within 7 days.
[0097] Specifically, the Flink stream processing engine can obtain log data
from the message
queue according to a preset time interval, employ a preset calculation model
file to
perform short-term feature calculation on the user behavior data in the log
data, and store
short-term features obtained by such calculation respectively in the cache
component and
the persistence component of the distributed storage layer. The preset time
interval can
be set according to practical requirements, such as 10 seconds. A machine
learning
algorithm can be employed to train primary data of a sample user to generate a
short-term
model, and to obtain a calculation model file of the short-term model. The
machine
learning algorithm can be embodied as an iterative decision tree, logic
regression or a
support vector machine, to which no restriction is made in the embodiments of
the present
application.
[0098] 302 ¨ reading a long-term feature and a short-term feature of a to-be-
recommended user
from the distributed storage layer, when an event is received from the message
queue.
[0099] After the Flink stream processing engine has stored the short-term
features of the user in
the persistence component and the cache component in the distributed storage
layer, an
event will be written back to the message queue.
[0100] Specifically, having determined that the message queue has successfully
received the
Date Recue/Date Received 2022-03-22
event, triggered by this event, the Flink stream processing engine can obtain
a long-term
feature and a short-term feature of a to-be-recommended user from the cache
component
and the persistence component in the distributed storage layer. There may be
one or more
to-be-recommended user(s), to which no restriction is made in the embodiments
of the
present application.
[0101] The to-be-recommended user can be a user requiring to be recommended
with interesting
contents, the contents here can be commodity information, and the to-be-
recommended
user can be determined based on a preset user identification.
[0102] 303 ¨ performing real-time prediction according to a prediction model
file, the long-term
feature and the short-term feature of the to-be-recommended user, to obtain a
preference
prediction result of the to-be-recommended user.
[0103] The preference prediction result of the to-be-recommended user can
include commodity
objects to be recommended.
[0104] Specifically, the Flink stream processing engine can generate a
prediction model
according to a prediction model file obtained in advance, and perform real-
time prediction
on the long-term feature and the short-term feature of the to-be-recommended
user
according to the prediction model to obtain the preference prediction result
of the to-be-
recommended user.
[0105] A machine learning algorithm can be employed to train to generate a
prediction model
and to obtain a prediction model file of the prediction model on the basis of
the long-term
feature and the short-term feature of a sample user and preference commodity
objects of
the sample user as training samples. The machine learning algorithm can be
embodied as
an iterative decision tree, logic regression or a support vector machine, to
which no
restriction is made in the embodiments of the present application.
16
Date Recue/Date Received 2022-03-22
[0106] In this embodiment, since the prediction model file is obtained by
training and learning
of the long-term feature and short-term feature of the user, long-term feature
data of the
user is not only used, but short-term (latest) feature data of the user is
also given
consideration, whereby it is made possible to more precisely predict
preference
commodity objects of the to-be-recommended user, and to effectively enhance
precision
and reliability of contents recommended to the user.
[0107] 304 ¨ writing the preference prediction result of the to-be-recommended
user in the
distributed storage layer.
[0108] Specifically, the Flink stream processing engine can write the
preference prediction result
of the to-be-recommended user simultaneously in the cache component and the
persistence component in the distributed storage layer, and write the
triggered event in
the message queue after obtaining response result returned from the cache
component
and the persistence component, so as to dispose the preference prediction
result of the to-
be-recommended user for use by downstream systems.
[0109] This embodiment of the present application provides a Flink stream
processing engine
method for real-time recommendation, the distributed stream engine Flink
itself brings
about precise message reliability and flexible capacities to expand and
extract, thus makes
it possible to guarantee message reliability and capacities to expand and
extract of the
system, and makes it possible to reduce resource consumption in normal times
but to
increase resources in large-scale promotional activities to respond to peak
flow; the
response duration by the use of an offline algorithm is usually of the hourly
magnitude,
and the operation time usually cannot be guaranteed, whereas the response time
based on
the use of the current engine is of the millisecond magnitude, whereby real-
time
recommendation and feature engineering are made possible, and response
duration is
thereby effectively reduced.
17
Date Recue/Date Received 2022-03-22
[0110] In one embodiment, prior to the aforementioned step 301 of performing
short-term feature
calculation on a log in a message queue according to a calculation model file,
the method
can further comprise:
[0111] obtaining a configuration file that contains a configuration parameter;
and
[0112] loading from a model repository a model file well trained in advance to
which the
configuration parameter corresponds, and sending the model file to various
distributed
nodes of the Flink stream processing engine, wherein the model file includes
the
calculation model file and the prediction model file.
[0113] The step of obtaining the configuration file can include:
[0114] synchronizing at least one configuration file from a distributed
configuration cluster, and
loading the at least one configuration file into a memory.
[0115] Specifically, the configuration synchronizing module in the Flink
stream processing
engine can synchronize differently typed configuration files from the
distributed
configuration cluster, and send the configuration file to the algorithm
calculating module
located at the various distributed nodes, so that the algorithm calculating
module loads
the configuration file to the memories of the distributed nodes.
[0116] The step of loading from a model repository a model file to which the
configuration
parameter corresponds can include:
[0117] reading a preconfigured model identification parameter from the
configuration parameter,
and loading from the model repository a model file to which the model
identification
parameter corresponds, wherein the model identification parameter includes a
namespace,
a model name and a model version.
[0118] In a concrete example as shown in Fig. 4, the aforementioned process of
loading the
model file can include the following steps:
18
Date Recue/Date Received 2022-03-22
[0119] a) initializing the model repository client end at the application
submission phase of the
Flink stream processing engine;
[0120] b) loading the model file and the relevant script configuration file to
the equipment in
which the Flink stream processing engine resides;
[0121] c) employing distributed file cache by the equipment to submit the
model and the relevant
file to the various distributed nodes;
[0122] d) loading the model repository client end during task loading at the
various nodes,
obtaining the model required to be used according to the configuration and
loading the
model to the memory, and generating corresponding UDF; and
[0123] e) employing the model file in the memory during prediction to perform
prediction.
[0124] In this embodiment, after the model file trained offline has been
submitted to the model
repository, it suffices to automatically load the model to the stream
processing engine and
operate the model through the model identification parameter of the model file
required
to be used in the configuration parameter, so that the difficulty in deploying
the algorithm
model and the difficulty in completing real-time response are avoided, one-
stop automatic
start and deployment of the model is realized, massive deployment operations
are
dispensed with, and error and time cost are reduced.
[0125] In one embodiment, the aforementioned step 301 of performing short-term
feature
calculation on a log in a message queue according to a calculation model file
can include:
[0126] performing short-term feature calculation on the log according to the
calculation model
file through the various distributed nodes.
[0127] The aforementioned step 303 of performing real-time prediction
according to a prediction
model file, the long-term feature and the short-term feature of the to-be-
recommended
user, to obtain a preference prediction result of the to-be-recommended user
can include:
[0128] generating a prediction model according to the prediction model file
through the various
distributed nodes; and
19
Date Recue/Date Received 2022-03-22
[0129] inputting the long-term feature and the short-term feature of the to-be-
recommended user
to the prediction model for real-time prediction, to obtain the preference
prediction result
of the to-be-recommended user.
[0130] In the present application, the characteristic of distributed message
response of Flink itself
is utilized, whereby its parallel capability is maximally utilized to enhance
the computing
capability and to shorten prediction time at the same time.
[0131] In one embodiment, the distributed storage layer includes a cache
component and a
persistence component, and the aforementioned step 302 of reading a long-term
feature
and a short-term feature of a to-be-recommended user from the distributed
storage layer,
when an event is received from the message queue can include:
[0132] reading a long-term feature and a short-term feature of the to-be-
recommended user from
a local cache through the various distributed nodes; reading a long-telln
feature and a
short-term feature of the to-be-recommended user from the cache component, if
reading
from the local cache failed; and reading a long-term feature and a short-term
feature of
the to-be-recommended user from the persistence component, if reading from the
cache
component failed, and asynchronously writing the read features in the cache
component.
[0133] Specifically, different features in the NOSQL storage layer are read by
each distributed
node through the feature enquiring module (Query er) and based on the
configuration
parameter obtained in advance.
[0134] More specifically, with reference to the flowchart illustrating reading
of three-level cache
features in Fig. 5, the feature enquiring module firstly reads from a local
primary cache,
return directly ensues if hit, reads from a distributed secondary cache if not
hit, return
ensues from the secondary cache if hit, reads from a persistence layer if not
hit, and
employs a data synchronizer to asynchronously write back the result to the
secondary
cache for standby use next time.
Date Recue/Date Received 2022-03-22
[0135] The primary cache is the host memory that only retains related data, is
relatively small in
capacity, the expiration time thereof is relatively short (the expiration time
should be
configured according to the business), and utilizes the LRU policy. The
secondary cache
is a distributed cache that stores partial data, is relatively large in
capacity, the expiration
time thereof is relatively long (the expiration time should be configured
according to the
business), likewise utilizes the LRU policy, and random increase and decrease
of the
expiration time are performed within a certain range in order to avoid the
avalanche effect.
The tertiary is persistence, retains total data, can be set to expire as one
year or longer,
and can be exchanged to an offline data warehouse if it should be retained for
more longer
time. The data synchronizer possesses a queue, and invoking of the cache
method merely
effects simple disposal in the queue; a thread can be separately initiated,
and data in the
queue is then consumed by the thread to enter distributed cache.
[0136] In this embodiment, through the guarantee by the three-level caching
mechanism, loss of
feature data can be greatly reduced, or the possibility of erring in the
recommendation
result caused by error in the process of loading the feature data can be
reduced, so that
the reading performance and reliability of the feature data can be ensured at
the same
time, whereby robustness of the entire system is enhanced.
[0137] In one embodiment, the calculation model file is an SQL model file, and
the prediction
model file is a PMML model file.
[0138] In this embodiment, the stream processing engine is realized on the
basis of the FLINK
and PMML technologies, which enable the algorithm personnel without Java
language
capability to process features in real time and to perform model prediction in
real time
merely by using streaming SQL and PMML model files in a general model
repository, so
as to solve the problems in which there are too many technical details by the
use of JAVA
or PYTHON language for development, whereby development is slow, and it is
difficult
21
Date Recue/Date Received 2022-03-22
to timely respond to business requirements.
[0139] Fig. 6 is a view illustrating a cluster deployment framework provided
by the present
application, the cluster deployment framework is employed to realize the Flink
stream
processing engine method for real-time recommendation in the aforementioned
embodiments, specifically, the cluster deployment framework can be deployed by
the
mode described below:
[0140] 1. preparation of a Zookeeper cluster: the specific Zookeeper cluster
deployment mode
has already been mature, and can be deployed or self-tuned according to the
mode
recommended in Fig 6. However, as should be noted, one set can be used for
Zookeeper
relevant to Hadoop, while another set should be used for Kafka.
[0141] 2. preparation of a Hadoop cluster: the specific Hadoop cluster
deployment mode has
already been mature, to which no repetition is redundantly made in this
context, and it is
suggested that a physical machine rather than a virtual machine be used, and
it is also
required to install HBase and Flink components on the cluster.
[0142] 3. preparation of a Redis cluster: the suggested deployment mode is
three sentinels plus
N*2 sets of servers, where N is the number of master nodes, the specific N
should be
determined according to business scale, it is N*2 because one master is
equipped with a
one standby. The specific Redis cluster deployment method has already been
mature, to
which no repetition is redundantly made in this context, but it is suggested
that it be
deployed close to the calculation node, best within the single route to ensure
lower
network time delay.
[0143] 4. preparation of a Kafka cluster: the specific Kafka cluster
deployment mode has already
been mature, to which no repetition is redundantly made in this context, and
reference
can be made to the official website.
[0144] 5. preparation of a scheduler: Hadoop and Flink components are
installed for submission
of engine application.
[0145] 6. The Zookeeper, HDFS, YARN, Kafka and Redis clusters are started.
[0146] 7. A model repository is newly created on HDFS, and well trained models
are released in
22
Date Recue/Date Received 2022-03-22
the repository.
[0147] 8. Flink submission script is used and command line parameters are
designated on the
scheduler, wherein coordinates of the models are indispensable parameters,
while the
remaining is optional.
[0148] In one embodiment, there is provided a Flink stream processing engine
device for real-
time recommendation, which device can comprise:
[0149] an algorithm calculating module, for performing short-term feature
calculation on a log
in a message queue according to a calculation model file;
[0150] a data pushing module, for storing short-term features obtained by the
calculation in a
distributed storage layer, wherein the distributed storage layer stores
therein long-term
features obtained in advance; and
[0151] a feature enquiring module, for reading a long-term feature and a short-
term feature of a
to-be-recommended user from the distributed storage layer, when an event is
received
from the message queue;
[0152] the algorithm calculating module is further employed for performing
real-time prediction
according to a prediction model file, the long-term feature and the short-term
feature of
the to-be-recommended user, to obtain a preference prediction result of the to-
be-
recommended user; and
[0153] the data pushing module is further employed for writing the preference
prediction result
of the to-be-recommended user in the distributed storage layer.
[0154] In one embodiment, the device further comprises:
[0155] a configuration synchronizing module, for obtaining a configuration
file that contains a
configuration parameter; and
[0156] a model loading module, for loading from a model repository a model
file well trained in
advance to which the configuration parameter corresponds, and sending the
model file to
various distributed nodes of the Flink stream processing engine, wherein the
model file
includes the calculation model file and the prediction model file.
23
Date Recue/Date Received 2022-03-22
[0157] In one embodiment, the configuration synchronizing module is
specifically employed for:
[0158] synchronizing at least one configuration file from a distributed
configuration cluster, and
loading the at least one configuration file into a memory.
[0159] In one embodiment, the model loading module is specifically employed
for:
[0160] reading a preconfigured model identification parameter from the
configuration parameter,
wherein the model identification parameter includes a namespace, a model name
and a
model version; and
[0161] loading from the model repository a model file to which the model
identification
parameter corresponds.
[0162] In one embodiment, the algorithm calculating module is specifically
employed for:
[0163] performing short-term feature calculation on the log according to the
calculation model
file through the various distributed nodes;
[0164] the algorithm calculating module is specifically further employed for:
[0165] generating a prediction model according to the prediction model file
through the various
distributed nodes; and
[0166] inputting the long-term feature and the short-term feature of the to-be-
recommended user
to the prediction model for real-time prediction, to obtain the preference
prediction result
of the to-be-recommended user.
[0167] In one embodiment, the distributed storage layer includes a cache
component and a
persistence component, and the feature enquiring module is specifically
employed for:
[0168] reading a long-term feature and a short-term feature of the to-be-
recommended user from
a local cache through the various distributed nodes;
[0169] reading a long-term feature and a short-term feature of the to-be-
recommended user from
the cache component, if reading from the local cache failed; and
[0170] reading a long-term feature and a short-term feature of the to-be-
recommended user from
24
Date Recue/Date Received 2022-03-22
the persistence component, if reading from the cache component failed, and
asynchronously writing the read features in the cache component.
[0171] In one embodiment, the calculation model file is an SQL model file, and
the prediction
model file is a PMML model file.
[0172] Specific definitions relevant to the user recommending device based on
stream processing
may be inferred from the aforementioned definitions to the Flink stream
processing
engine method for real-time recommendation, while no repetition is made in
this context.
The various modules in the aforementioned the user recommending device based
on
stream processing can be wholly or partly realized via software, hardware, and
a
combination of software with hardware. The various modules can be embedded in
the
form of hardware in a processor in a computer equipment or independent of any
computer
equipment, and can also be stored in the form of software in a memory in a
computer
equipment, so as to facilitate the processor to invoke and perform operations
corresponding to the aforementioned various modules.
[0173] In one embodiment, a computer equipment is provided, the computer
equipment can be
a server, and its internal structure can be as shown in Fig. 7. The computer
equipment
comprises a processor, a memory, and a network interface connected to each
other via a
system bus. The processor of the computer equipment is employed to provide
computing
and controlling capabilities. The memory of the computer equipment includes a
nonvolatile storage medium, and an internal memory. The nonvolatile storage
medium
stores therein an operating system, and a computer program. The internal
memory
provides environment for the running of the operating system and the computer
program
in the nonvolatile storage medium. The network interface of the computer
equipment is
employed to connect to other equipment via network for communication. The
computer
program realizes a Flink stream processing engine method for real-time
recommendation
when it is executed by a processor.
Date Recue/Date Received 2022-03-22
[0174] As understandable to persons skilled in the art, the structure
illustrated in Fig. 7 is merely
a block diagram of partial structure relevant to the solution of the present
application, and
does not constitute any restriction to the computer equipment on which the
solution of
the present application is applied, as the specific computer equipment may
comprise
component parts that are more than or less than those illustrated in Fig. 7,
or may combine
certain component parts, or may have different layout of component parts.
[0175] In one embodiment, there is provided a computer equipment that
comprises a memory, a
processor and a computer program stored on the memory and operable on the
processor,
and the following steps are realized when the processor executes the computer
program:
[0176] performing short-term feature calculation on a log in a message queue
according to a
calculation model file, and storing short-term features obtained by the
calculation in a
distributed storage layer, wherein the distributed storage layer stores
therein long-term
features obtained in advance;
[0177] reading a long-term feature and a short-term feature of a to-be-
recommended user from
the distributed storage layer, when an event is received from the message
queue;
[0178] performing real-time prediction according to a prediction model file,
the long-term
feature and the short-term feature of the to-be-recommended user, to obtain a
preference
prediction result of the to-be-recommended user; and
[0179] writing the preference prediction result of the to-be-recommended user
in the distributed
storage layer.
[0180] In one embodiment, there is provided a computer-readable storage medium
storing
thereon a computer program, and the following steps are realized when the
computer
program is executed by a processor:
[0181] performing short-term feature calculation on a log in a message queue
according to a
calculation model file, and storing short-term features obtained by the
calculation in a
distributed storage layer, wherein the distributed storage layer stores
therein long-term
26
Date Recue/Date Received 2022-03-22
features obtained in advance;
[0182] reading a long-term feature and a short-term feature of a to-be-
recommended user from
the distributed storage layer, when an event is received from the message
queue;
[0183] performing real-time prediction according to a prediction model file,
the long-term
feature and the short-term feature of the to-be-recommended user, to obtain a
preference
prediction result of the to-be-recommended user; and
[0184] writing the preference prediction result of the to-be-recommended user
in the distributed
storage layer.
[0185] As comprehensible to persons ordinarily skilled in the art, the entire
or partial flows in
the methods according to the aforementioned embodiments can be completed via a
computer program instructing relevant hardware, the computer program can be
stored in
a nonvolatile computer-readable storage medium, and the computer program can
include
the flows as embodied in the aforementioned various methods when executed. Any
reference to the memory, storage, database or other media used in the various
embodiments provided by the present application can all include nonvolatile
and/or
volatile memory/memories. The nonvolatile memory can include a read-only
memory
(ROM), a programmable ROM (PROM), an electrically programmable ROM (EPROM),
an electrically erasable and programmable ROM (EEPROM) or a flash memory. The
volatile memory can include a random access memory (RAM) or an external cache
memory. To serve as explanation rather than restriction, the RAM is obtainable
in many
forms, such as static RAM (SRAM), dynamic RAM (DRAM), synchronous DRAM
(SDRAM), dual data rate SDRAM (DDRSDRAM), enhanced SDRAM (ESDRAM),
synchronous link (Synchlink) DRAM (SLDRAM), memory bus (Rambus) direct RAM
(RDRAM), direct Rambus dynamic RAM (DRDRAM), and Rambus dynamic RAM
(RDRAM), etc.
[0186] Technical features of the aforementioned embodiments are randomly
combinable, while
all possible combinations of the technical features in the aforementioned
embodiments
27
Date Recue/Date Received 2022-03-22
are not exhausted for the sake of brevity, but all these should be considered
to fall within
the scope recorded in the Description as long as such combinations of the
technical
features are not mutually contradictory.
[0187] The foregoing embodiments are merely directed to several modes of
execution of the
present application, and their descriptions are relatively specific and
detailed, but they
should not be hence misunderstood as restrictions to the inventive patent
scope. As should
be pointed out, persons with ordinary skill in the art may further make
various
modifications and improvements without departing from the conception of the
present
application, and all these should pertain to the protection scope of the
present application.
Accordingly, the patent protection scope of the present application shall be
based on the
attached Claims.
28
Date Recue/Date Received 2022-03-22