Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
CA 02300369 2000-02-11
WO '99/07883 PCT/CA98/00768
METHOD AND KIT FOR HLA CLASS I TYPING DNA
1. INTRODUCTION
The present invention relates to methods and materials for determining
the HLA Class I type of a subject, wherein group-specific sequences are used
to
design primer molecules which may be used in amplification protocols which
accurately identify the HLA groups) and/or alleles) carried by the subject.
2. BACKGROUND OF THE INVENTION
The Histocompatibility Locus Antigen ("HLA") Class I genes
comprise three classical genes encoding the major transplantation antigens HLA-
A,
HLA-B, and HLA-C and seven other Class I genes of which HLA-E, HLA-F and
HLA-G are probably functional genes and HLA-H. HLA-I, HLA-K and HLA-L are
pseudogenes. The class I genes share a similar structure, which includes,
inter alia, 5'
-> 3', a 5' untranslated flanking region; a first exon ("exon 1 ") having a
length of
approximately 73 base pairs ("bp"); a first intron ("intron 1 ") having a
length of
approximately 130 bp; a second exon ("exon 2"), having a length of
approximately
250 bp; a second intron ("intron 2"), having a length of approximately 272 bp;
a third
exon ("exon 3"), having a length of approximately 276 bp; a third intron
("intron 3"),
having a length of approximately 588 bp; and a fourth exon ("exon 4").
The HLA Class I genes are highly polymorphic among individuals. As
of 1996, at least 73 alleles of HLA-A, 126 alleles of HLA-B and 35 alleles of
HLA-C
have been identified. This variability is of particular relevance when tissue
transplantation between a donor and a host is contemplated. The
histocompatibility
antigens of donor and host should be as similar as possible to avoid both
immune
rejection of the transplanted tissue as well as graft-versus-host disease. It
is therefore
important to accurately identify the HLA types of donor and host. In view of
the
exigencies implicit in tissue transplantation, it is desirable that the typing
be
accomplished as efficiently as possible.
Methods for determining alleles of HLA-A, HLA-Band HLA-C in a
patient sample have been heavily investigated because of the functional
importance of
these genes in transplant tissue matching and autoimmune diseases. The first
tests
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
developed used immunological methods to identify epitopes expressed by various
HLA loci. These tests (e.g., the complement-dependent cytotoxicity assay
described
in Terasaki and McClelland, Nature, 204:998, (1964)) identified broad
serological
specificities but were not capable of distinguishing between allelic members
of a
group, and sometimes mis-identified groups altogether. Unfortunately, even the
most
accurate of such low resolution assays cannot detect and distinguish all
functionally
significant transplant antigens (Anasetti et al. Hum. Immunol., 29:70 (1990)).
High resolution tests performed at the nucleic acid level which
distinguish among alleles of each group have become the focus of recent
research.
Current methods of high resolution typing include the following.
The Sequence Specific Oligonucleotide Probes ("SSOP") technique, as
described in United States Patent No. 5,451,512 assigned to Hoffman-La Roche,
Inc.,
uses a reverse dot blot format, wherein HLA-A probes are immobilized on a
membrane, and the labelled target (patient sample) DNA is hybridized to the
membrane-bound probe (as described in Saiki et al., 1989, Proc. Natl. Acad.
Sci.
86:6230-6234). The pattern of hybridization to the probes on the dot-blot
gives
information regarding the HLA type of the individual. However, because
hybridization is inherently not sufficiently specific to rule out minor
differences in
sequence between probe and patient sample, there is a possibility that the
patient
sample may contain an allelic variant which is not accounted for.
Another nucleic acid-based test is the Amplif cation Refractory
Mutation System (ARMS) as described in the "HLA Class I SSP ARMS-PCR Typing
Kit" Reference Manual, June 1995 edition, published by the Imperial Cancer
Research Fund. This assay is based on the need for complementarity (matching)
between the 3' end of an amplification primer and a target DNA sequence.
Absent
such matching, the primer will not function properly and no fragment will be
amplified. Sequence information is deduced by determining, for various pairs
of
primers acting on target DNA from a patient sample, whether or not a fragment
is
successfully amplified. The accuracy of the technique is limited by the number
of
primer pairs tested and by the possibility that allelic variations exist in
regions of
DNA which lie between the primers.
2
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
In order to overcome the foregoing shortcomings, it has been proposed
that typing be accomplished by direct DNA sequencing (Santamaria et al., "HLA
Class I Sequence-Based Typing" Hum. Immunol. 37, 39-50 (1993); WO 9219771;
US Pat. 5,424,184). However, while direct sequencing of a patient's Class I
HLA
locus may conceptually be the most accurate, such sequencing may require a
time-
frame unsuitable for clinical practice. The success of direct sequencing
methods may
be expected to rely upon the design of efficient protocols and relevant primer
sequences.
Prior to the present invention, direct sequencing protocols have
exhibited a number of disadvantages. For example, the method of Santamaria et
al.,
supra, fails to provide sufficient information because it focuses on cDNA
(exon)
sequences which, in view of exon sequence diversity, offer a very limited
selection of
conserved primer hybridization sites. In addition, because the Santamaria
sequencing
primers hybridize within an exon, they do not provide information for DNA
sequence
upstream of the primer which is potentially decisive for distinguishing among
alleles.
Further, the sites disclosed were determined before the recent discovery of
dozens of
more alleles that now need to be considered in identifying HLA type.
Intron sequences could provide the preferred hybridization sites for
amplification and sequencing primers for the HLA-A, HLA-B and HLA-C genes
because they may provide the DNA sequence of the full exon. Intron sequences
for
an HLA Class I gene were disclosed at least as early as 1985 {Weiss et al
Immunobiol
170:367-380, (1985)). Due to their substantial diversity, and the difficulties
in
sequencing, few intron sequences have been published subsequently.
A number of researchers have made limited use of intron based
oligonucleotides for limited aspects of HLA Class I typing.
Blasczyk et al. (Tissue Antigens 1996: 47: 102-110) used exon based
amplification primers to determine group specificity. After amplification,
universal
sequencing primers located in intron 2 were used to sequence the amplified
fragment.
The paper does not disclose any intron sequence motifs from intron 1 or 3 or
the 5'
untranslated region.
Cereb et al. (Tissue Antigens 1995: 45:1-11), undertook the
3
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
identification of intron sequences useful for locus-specific amplification
primer sets
for all Class I genes. These primer sets were designed to amplify all alleles
of the
same locus. No group specific amplification primers were sought or reported.
Further, amplified fragments were characterized by SSOP and not by direct
sequencing.
Johnston-Dow et al (Poster Presentation: 1995 ASHI Meeting, Dallas,
TX) presented a system for direct sequence determination of HLA-A wherein
degenerate exon based primers were used to amplify exons 1 to 5 of the genomic
HLA-A DNA sequence. As in Cereb et al., supra, the degenerate primer pool was
designed to amplify all alleles of the HLA-A locus. Group specificity was not
sought
or reported. Further, sequencing of the amplified fragment was obtained using
a
degenerate primer mix wherein primers hybridize to intron regions flanking
exons 2
and 3.
A rational approach to typing of classical HLA Class I loci would
provide a simplified series of steps for high resolution typing of each allele
of each
loci in a patient sample using intron based oligonucleotides. Further, this
method
would be able to identify new alleles without ambiguities.
An alternative method of intron based HLA Class I typing is the
subject of previously filed US Patent Application Serial No. 08/pending (Atty
Docket
No. VGEN.P-037-US), assigned to an assignee of the present invention.
3. SUMMARY OF THE INVENTION
The present invention relates to materials and methods for high-
resolution, nucleic acid-based typing of the three classical HLA Class I genes
(comprising the loci HLA-A, HLA-B and HLA-C) in a patient sample. It is based,
in
part, on the discovery of group-specific sequence motifs, derived from the
analysis of
numerous patient samples, which include sequences of the 5' flanking region,
intron l,
intron 2, and intron 3. Such sequence motifs may be used to design
amplification
primers which may be used to identify the HLA group or type of a subject. The
invention is also based, in part, on the determination of numerous allele-
specific
sequences which may be used to confirm the precise allelic type of a subject.
4
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
The present invention provides for substantially purified nucleic acids
which are capable of selectively hybridizing with group specific sequence
motifs in
untranslated regions of the HLA-A, HLA-B or HLA-C gene loci. Such nucleic
acids,
which may be comprised in a kit, may be used, alone or in conjunction with
exon-
based primers, to determine the group specificity of HLA-A, HLA-B, or HLA-C
alleles contained in a patient sample and to identify the specific alleles
present.
In particular embodiments, the present invention provides for methods
of ascertaining the HLA Class I type of a subject which comprise performing a
first
amplification reaction which identifies the group type of the subject, and a
second
amplification reaction which produces allele-specific nucleic acids for
sequencing.
3.I. DEFINITIONS
"Allele" means one of the alternative forms of the gene in question;
"Amplification" means the process of increasing the relative
abundance of one or more specific genes or gene fragments in a reaction
mixture with
respect to the other genes. A method of amplification which is well known by
those
skilled in the art is the polymerase chain reaction (PCR) as described in
United States
Patents Nos. 4,683,194, 4,683,195 and 4,683,202, which are incorporated herein
by
reference. The PCR process involves the use of pairs of primers, one for each
complementary strand of the duplex DNA (wherein the coding strand is referred
to as
the "sense strand" and its complementary strand is referred to as the
"antisense
strand"), that will hybridize at a site located near a region of interest in a
gene. Chain
extension polymerization (without a chain terminating nucleotide) is then
carned out
in repetitive cycles to increase the number of copies of the region of
interest many
times. The amplified oligonucleotides are then separated from the reaction
mixture
and used as the starting sample for the sequencing reaction. Gelfand et al.
have
described a thermostable enzyme, "Taq polymerase," derived from the organism
Thermus aquaticus, which is useful in this amplification process (see United
States
Patent Nos. 5,352,600 and 5,079,352 which are incorporated herein by
reference);
"Group" as used herein, refers to a subset of alleles of one. loci, all of
which share sequence features which distinguish them from other groups. For
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
example, serological group reactivity (in a lymphocytotoxicity assay) is the
conventional basis for nomenclature of HLA alleles. The first two digits of an
allele
refer to the serological group; for example, the designation A*0201, A*0202,
A*0217
all are members of the A2 group. Further, typically the nomenclature refers to
the
serological split group (e.g., A23 and A24 are serological splits of A9;
"Group-specific sequence motif' means a generally short, 1-25
nucleotide ("nt") sequence of nucleic acid which is found only in one or a few
groups.
Where a motif is shared by several groups in one region of the HLA locus,
group-
specific sequence motifs in other regions of the locus may serve as group-
distinguishing features. The motif may share one or more nucleotides with the
consensus sequence for the region;
"Haplotype" means the allele present on one chromosome;
"Heterozygote" means the presence of at least two different alleles of a
gene;
"Homozygote" means the presence of a single species of allele of a
gene;
"Locus" means a gene, such as HLA-A, HLA-B or HLA-C;
"Locus specific" means an event or thing associated with only one locus;
"Patient sample" means a sample collected from a patient in need of
HLA typing which contains a sufficient amount and quality of nucleic acid
(preferably DNA) for the performance of an amplification reaction. A
nonlimiting
example of a suitable source is peripheral blood lymphocytes, tissue
(including cell
cultures derived therefrom, mucosal scrapes, spleen and bone marrow;
"Primer" means a polynucleotide generally of 5-50 nucleotides length
which can serve to initiate a chain extension reaction;
"Sequencing" or "DNA sequencing" means the determination of the
order of nucleotides in at least a part of a gene. A well known method of
sequencing
is the "chain termination" method first described by Sanger et al., Proc.
Nat'1 Acad.
Sci. (USA) 74(12): 5463-5467 (1977) (recently elaborated in EP-B1- 655506, and
Sequenase 2.0 product literature (Amersham Life Sciences, Cleveland)
incorporated
herein by reference). Basically, in this process, DNA to be sequenced is
isolated,
6
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
rendered single stranded, and placed into four vessels. In each vessel are the
necessary components to replicate the DNA strand, which include a template-
dependant DNA polymerase, a short primer molecule complementary to a known
region of the DNA to be sequenced, and individual nucleotide triphosphates in
a
buffer conducive to hybridization between the primer and the DNA to be
sequenced
and chain extension of the hybridized primer. In addition, each vessel
contains a
small quantity of one type of optionally detectably labeled dideoxynucleotide
triphosphate, e.g., dideoxyadenosine triphosphate ("ddA"), dideoxyguanosine
triphosphate ("ddG"), dideoxycytosine triphosphate ("ddC"), or
dideoxythymidine
triphosphate ("ddT"). In each vessel, each piece of the isolated DNA is
hybridized
with a primer. The primers are then extended, one base at a time to form a new
nucleic acid polymer complementary to the isolated pieces of DNA. When a
dideoxynucleotide is incorporated into the extending polymer, this terminates
the
polymer strand and prevents it from being further extended. Accordingly, in
each
vessel, a set of extended polymers of specific lengths are formed which are
indicative
of the positions of the nucleotide corresponding to the dideoxynucleic acid in
that
vessel. These sets of polymers are then evaluated using gel electrophoresis to
determine the sequence.
"Specific hybridization" means hybridization of one strand of a nucleic
acid to its complement.
"Target sequence" means the preferred site for specific hybridization of
a primer; and
"Untransiated region" refers to a portion of an HLA locus which is not
transcribed into RNA and eventually translated into protein. Examples of
untranslated
regions are the 5' and 3' flanking regions and intron sequences. For example,
the 5'
flanking region is neither transcribed nor translated, and intron sequences
are
transcribed but not translated.
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
4. DESCRIPTION OF THE FIGLTRF~
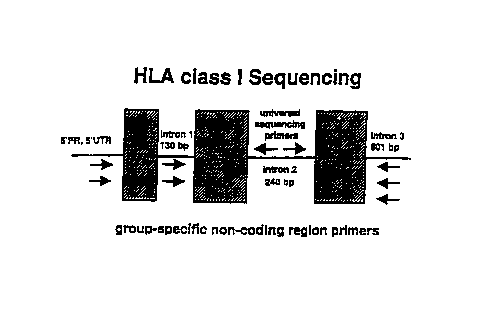
FIGURE 1 is an illustration of the principle for an HLA class I
sequencing strategy. Group-specific primers are used for PCR amplification,
and
universal primers located in the 2nd intron are used for sequencing,
regardless of the
amplified group. 5'FR= 5' flanking region; 5' UTR= 5' untranslated region (-1
to -23
from the ATG start codon in exon 1 ).
FIGURE 2A and 2B depict, in schematic form, a method of the
invention in which a cocktail of HLA-A group specific primers is used to
amplify
target DNA contained in a patient sample. The products of amplification are
then
separated electrophoretically in an agarose gel, allowing the identification,
by
fragment mobility, of fragments corresponding to groups A2 and A3. Primers
specific
for groups A2 and A3 are then used to amplify duplicate samples of target DNA
in
separate reactions, to produce A2 and A3 fragments which may then be sequenced
using universal sequencing primers. FIGURE 2C and 2D depict a strategy wherein
group type specificity is determined by reaction of aliquots of genomic DNA in
separate reactions with a panel of primer pairs.
FIGURE 3 depicts the nucleic acid sequences of the HLA-A 5'
flanking region in various alleles, including a consensus sequence (SEQ ID
NO:1) as
well as the sequences for the following alleles: A*O1 O1 (SEQ ID N0:2); A*0301
(SEQ ID N0:3); A* 1101 (SEQ ID N0:4); A* 1102 (SEQ ID NO:S); A*3001 (SEQ ID
N0:6); A*3002 (SEQ ID N0:7); A*3004 (SEQ ID N0:8); A*0201-11 (SEQ ID
N0:9); A*0215 (SEQ ID NO:10); A*0217 (SEQ ID NO:11 ); A*6801 (SEQ ID
N0:12); A*6802 (SEQ ID N0:13); A*6901 (SEQ ID N0:14); A*2301 (SEQ ID
NO:15); A*2402 (SEQ ID N0:16); A*2403 (SEQ ID N0:17); A*2404 (SEQ ID
N0:18); A*2405 (SEQ ID N0:19); A*2407 (SEQ ID N0:20); A*2501 (SEQ ID
N0:21); A*2601 (SEQ ID N0:22); A*3402 (SEQ ID N0:23); A*4301 (SEQ ID
N0:24); A*6601 (SEQ ID N0:25); A*6602 (SEQ ID N0:26); A*6603 (SEQ ID
N0:27); A*2901 (SEQ ID N0:28); A*2902 (SEQ ID N0:29); A*31012 (SEQ ID
N0:30); A*3201 (SEQ ID N0:31); A*3301 (SEQ ID N0:32); A*3303 (SEQ ID
N0:33}; A*7401 (SEQ ID N0:34); A*7402 (SEQ ID N0:36); A*7403 (SEQ ID
N0:37}; and A*8001 (SEQ ID N0:38).
8
CA 02300369 2000-02-11
WO 99!07883 PCT/CA98/00768
FIGURE 4 depicts the nucleic acid sequences of HLA-A intron 1 in
various alleles,
including a
consensus sequence
(SEQ ID N0:39)
as well as
the
sequences for
the following
alleles: A*0101
(SEQ ID N0:40);
A*0301 (SEQ
ID
N0:41 ); A* ID N0:42); A* 1102 (SEQ ID N0:43); A*3001
1101 (SEQ (SEQ ID
N0:44); A*3002 ID N0:45); A*3004 (SEQ ID N0:46); A*0201
(SEQ (SEQ ID
N0:47); A*0202 ID N0:44); A*0203 (SEQ ID N0:49); A*0204
(SEQ (SEQ ID
NO:50); a*0205
(SEQ ID NO:51);
A*0206 (SEQ
ID N0:52);
A*0207 (SEQ
ID
N0:53); A*0207 ID N0:54); A*0208 (SEQ ID NO:55); A*0209
(SEQ (SEQ ID
N0:56); A*0210 ID N0:57); A*0211 (SEQ ID N0:58); A*0215
(SEQ (SEQ ID
N0:59); A*0217 ID N0:60}; A*6801 (SEQ ID N0:61); A*6802
(SEQ (SEQ ID
N0:62); A*6901 ID N0:63); A*2301 (SEQ ID N0:64); A*2402
(SEQ (SEQ 1D
N0:65); A*2403 ID N0:66); A*2404 (SEQ ID N0:67); A*2405
(SEQ (SEQ ID
N0:68); a*2407
(SEQ ID N0:69);
A*2501 (SEQ
ID N0:70);
A*2601 (SEQ
ID
N0:71); A*3402 ID N0:72); A*6601 (SEQ ID N0:73}; A*6602
(SEQ (SEQ ID
N0:74) A*6603
(SEQ ID N0:75};
A*4301 (SEQ
ID N0:76);
A*2901 (SEQ
ID
N0:77); A*2902 ID N0:78); A*3101 (SEQ ID N0:79); A*3201
(SEQ (SEQ ID
N0:80); A*3301 ID N0:81); A*3303 (SEQ ID N0:82); A*7401
(SEQ (SEQ ID
N0:83); A*7402 ID N0:84); A*7403 (SEQ ID N0:85); and
(SEQ A*8001 (SEQ ID
N0:86).
FIGURE 5 depicts the nucleic acid sequences of HLA-A intron 2 in
various alleles, including a consensus sequence (SEQ ID N0:87) as well as
sequences
for the following alleles: A*OI01 (SEQ ID N0:88); A*0201 (SEQ ID N0:89);
A*0202 (SEQ ID N0:90); A*0203 (SEQ ID N0:91); A*0204 (SEQ ID N0:92);
A*0205 (SEQ ID N0:93); A*0206 (SEQ ID N0:94}; A*0207 (SEQ ID N0:95);
A*0208 (SEQ ID N0:96); A*0209 (SEQ ID N0:97); A*0210 (SEQ ID N0:98);
A*0211 (SEQ ID N0:99); A*0215 (SEQ ID NO:100); A*0217 (SEQ ID NO:101);
A*6801 (SEQ ID N0:102); A*6802 (SEQ ID N0:103); A*6901 (SEQ ID N0:104);
A*2501 (SEQ ID NO:105); A*2601 (SEQ ID N0:106); A*4301 (SEQ ID N0:107);
A*6601 (SEQ ID N0:108); A*6602 (SEQ ID N0:109); A*6603 (SEQ ID NO:110);
A*3402 (SEQ ID NO:111); A*2901 (SEQ ID N0:112}; A*2902 (SEQ ID N0:113);
A*3101 (SEQ ID N0:114); A*3201 (SEQ ID NO:115); A*3301 (SEQ ID N0:116);
9
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
A*3303 (SEQ ID N0:117); A*7401 (SEQ ID N0:118); A*7402 (SEQ ID N0:119);
A*7403 (SEQ ID N0:120); A*230I (SEQ ID N0:121); A*2402 (SEQ ID N0:122);
A*2403 (SEQ ID N0:123); A*2404 (SEQ ID N0:124); A*2405 (SEQ ID N0:125);
A*2407 (SEQ ID N0:126); A*0301 (SEQ ID N0:127); A*1101 (SEQ ID N0:128);
A*1102 (SEQ ID N0:129); A*3001 (SEQ ID N0:130); A*3002 (SEQ ID N0:131);
A*3004 (SEQ ID N0:132); and A*8001 (SEQ ID N0:133).
FIGURE 6 depicts the nucleic acid sequences of HLA-A mtron 3 in
various alleles, including a consensus sequence (SEQ ID N0:134) as well as
sequences
for the
following
alleles:
A*0101 (SEQ
ID N0:135);
A*0301 (SEQ
ID
N0:136); (SEQID N0:137); (SEQ ID N0:138); A*3001
A* 1101 A* 1102 (SEQ ID
N0:139); (SEQID N0:140); (SEQ ID N0:141); A*0201
A*3002 A*3004 (SEQ ID
N0:142); (SEQID N0:143); (SEQ ID N0:144); A*0204
A*0202 A*0203 (SEQ ID
N0:145); (SEQID N0:146); (SEQ ID N0:147); A*0207
A*0205 A*0206 (SEQ ID
N0:148); (SEQID N0:149); (SEQ ID NO:l SO); A*0210
A*0208 A*0209 (SEQ ID
NO:151 ); (SEQID N0:152); (SEQ ID N0:153); A*0217
A*0211 A*0215 (SEQ ID
N0:154); (SEQID NO:155); (SEQ ID N0:156); A*6901
A*6801 A*6802 (SEQ ID
N0:157); (SEQID N0:158); (SEQ ID N0:159); A*2403
A*2301 A*2402 (SEQ ID
N0:160); (SEQID N0:161 ); (SEQ ID N0:162); A*2407
A*2404 A*2405 (SEQ ID
N0:163); (SEQID N0:164); (SEQ ID N0:165); A*3402
A*2501 A*2601 (SEQ ID
N0:166); (SEQID N0:167); (SEQ ID N0:168); A*6602
A*4301 A*6601 (SEQ ID
N0:169); (SEQID N0:170); (SEQ ID NO:I71); A*2902
A*6603 A*2901 (SEQ ID
N0:172); (SEQID N0:173); (SEQ ID N0:174); A*3301
A*3101 A*3201 (SEQ ID
N0:175); (SEQID N0:176); (SEQ ID N0:177); A*7402
A*3303 A*7401 (SEQ ID
N0:178); (SEQID N0:179);
A*7403 and A*8001
(SEQ ID N0:180).
FIGURE 7 depicts a phylogenetic tree of the S' flanking and 5'
untranslated regions of HLA-A.
FIGURE 8 depicts a phylogenetic tree of introns 1-3 of the HLA-A
gene.
FIGURE 9 depicts a phylogenetic tree of introns I-3 of the HLA-B
gene.
FIGURE 10 depicts the results of amplification using group-specific
*rB
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
exon region primers to determine HLA-A group type, wherein the group
specificity is
determined to be 6601 and 3201 (see Table 7).
FIGURE 11 depicts the results of amplification using group-specific
exon region primers to determine HLA-A group type, wherein the group
specificity is
determined to be 020x and 680x (see Table 8).
FIGURE 12 depicts the nucleic acid sequences of the first intron of
HLA-B, inlcuding
a consensus sequence
(SEQ ID N0:246)
as well as the
sequences
for the following
alleles: B*0702
(SEQ ID N0:247),
B*0801 (SEQ ID
N0:248),
B* I302 (SEQ ID B* (SEQ ID N0:250),B* 1402 (SEQ ID N0:251),
N0:249), 1401
B*1501 (SEQ ID B*1502(SEQ ID N0:253),B*1505 (SEQ ID N0:254},
N0:252),
B*1508 (SEQ ID B*1510(SEQ ID N0:256),B*1512 (SEQ ID N0:251),
N0:255),
B*1513 (SEQ ID B*1517(SEQ ID N0:259),B*1525 (SEQ ID N0:260),
N0:258),
B*1532 (SEQ ID B*1801(SEQ ID N0:262),B*I805 (SEQ ID N0:263),
N0:261),
B*27052 (SEQ ID
N0:264), B*27053
(SEQ ID N0:265},
B*2707 (SEQ ID
N0:266),
B*3501 (SEQ ID B*3502(SEQ ID N0:268),B*3503 (SEQ ID N0:269),
N0:267),
B*3701 (SEQ ID B*3801(SEQ ID N0:271),B*3901 (SEQ ID N0:272),
N0:270),
B*3903 (SEQ ID B*3906(SEQ ID N0:274),B*4001 (SEQ ID N0:275),
N0:273),
B*4002 (SEQ ID B*4101(SEQ ID N0:277),B*4102 (SEQ ID N0:278),
N0:276),
B*4201 (SEQ ID B*4402(SEQ ID N0:280),B*4403 (SEQ ID N0:281),
N0:279),
B*4501 (SEQ ID B*4601(SEQ ID N0:283),B*4701 (SEQ ID N0:284),
N0:282),
B*4801 (SEQ ID B*4901(SEQ ID N0:286),B*5001 (SEQ ID N0:287),
N0:285),
B*5101 (SEQ ID B*5108(SEQ ID N0:289),B*5201 (SEQ ID N0:290),
N0:288),
B*5301 (SEQ ID B*5401(SEQ ID N0:292),B*5501 (SEQ ID N0:293),
N0:291),
B*5601 (SEQ ID B*5701(SEQ ID NO:295),B*5801 (SEQ ID
N0:294),
N0:296),B*5901 , B*6701
(SEQ ID N0:297) (SEQ ID
N0:298),
B*7301 (SEQ
ID
N0:299).
FIGURE 13A-B. depicts the nucleic acid sequences of the second
intron of HLA-B, including a consensus sequence (SEQ ID N0:300) as well as the
following alleles: B*0702 (SEQ ID N0:301), B*0801 (SEQ ID N0:302), B*1302
(SEQ ID N0:303), B* 1401 (SEQ ID N0:304), B* 1402 (SEQ ID N0:305),
B*1501(62) (SEQ ID N0:306), B*1505(62) (SEQ ID N0:307), B*1508(62) (SEQ ID
11
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
N0:308),B*1510(71)
(SEQ
ID
N0:309),
B*1513(77)
(SEQ
ID
N0:310),
B*1517(63) ID N0:311), *I532(62)
(SEQ B*1525(62) (SEQ ID
(SEQ ID
N0:312),
B
N0:313),B* (SEQ ID N0:314},B*2702 (SEQ ID B*2704 {SEQ
1801 N0:315), ID
N0:316),B*27052
(SEQ
ID
N0:317),
B*27053
(SEQ
ID
N0:318),
B*2707
(SEQ
ID
N0:319),B*3501(SEQ ID N0:320),B*3502 (SEQ ID B*3503 (SEQ
N0:321), ID
N0:322),B*3507(SEQ ID N0:323),B*3508 (SEQ ID B*3701 (SEQ
N0:324), ID
N0:325),B*3801(SEQ ID N0:326),B*3901 (SEQ ID B*3903 (SEQ
N0:327), ID
N0:328),B*3906(SEQ ID N0:329),B*4001 (SEQ ID B*4002 (SEQ
N0:330), ID
N0:331),B*4101(SEQ ID N0:332),B*4102 (SEQ ID B*4201 (SEQ
N0:333), ID
N0:334),B*4402(SEQ ID N0:335),B*4403 (SEQ ID B*4501 (SEQ
N0:337), ID
N0:338),B*4601{SEQ ID N0:339),B*4?O1 (SEQ ID B*4801 (SEQ
N0:340), ID
N0:341),B*4901(SEQ ID N0:342),B*5001 (SEQ ID B*5101 (SEQ
N0:343), ID
N0:344),B*5108(SEQ ID N0:345),B*5201 (SEQ ID B*5301 (SEQ
N0:346), ID
N0:347),B*5401(SEQ ID N0:348),B*SSO1 (SEQ ID B*5601 (SEQ
N0:350), ID
N0:351),B*5701(SEQ ID N0:352),B*5801 (SEQ ID B*5901 (SEQ
N0:353), ID
N0:354),B*6701(SEQ ID N0:355),B*7301 (SEQ ID
N0:356).
FIGURE 14A-E. depicts the nucleic acid sequences of the third intron
of HLA-B, including a consensus sequence (SEQ ID NO: 357) as well as the
following alleles: B*0702 (SEQ ID N0:358),B*0801 (SEQ ID N0:359), B*1302
(SEQ ID N0:360), B* 1401 (SEQ ID N0:361 ), B* 1402 (SEQ ID N0:362), B* 1 S01
(SEQ ID NO:363), B* 1502 (SEQ ID N0:364), B* 1510 (SEQ ID N0:365), B* 1513
(SEQ ID N0:366), B* 1517 (SEQ ID N0:367), B* 1525 (SEQ ID N0:368), B* 1801
(SEQ ID N0:369), B*27052 (SEQ ID N0:370), B*27053 (SEQ ID NO: 371 ),
B*3501 (SEQ ID N0:372), B*3502 (SEQ ID N0:373), B*3503 (SEQ ID N0:374),
B*3701 (SEQ ID N0:375), B*3801 (SEQ ID N0:376), B*3903 (SEQ ID N0:377),
B*3906 (SEQ ID N0:378), B*4001 (SEQ ID N0:379), B*4002 (SEQ ID N0:380),
B*4101 (SEQ ID N0:381), B*4102 (SEQ ID N0:382), B*4201 (SEQ ID N0:383),
B*4402 (SEQ ID N0:384), B*4403 (SEQ ID N0:385), B*4501 (SEQ ID N0:386},
B*4601 (SEQ ID N0:387), B*4701 (SEQ ID N0:388), B*4901 (SEQ ID N0:389),
B*5001 (SEQ ID N0:390), B*5101 (SEQ ID N0:391), B*5108 (SEQ ID N0:392),
B*5201 (SEQ ID N0:393), B*5301 (SEQ ID N0:394), B*5401 (SEQ ID N0:39S),
12
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
B*5501 (SEQ ID N0:396), B*5601 (SEQ ID N0:397).
5. DETAILED DESCRT_PTION OF THE INVENTION
The present invention relates to compositions and methods which may
be used to efficiently and accurately determine the HLA Class I type of a
patient
sample.
The present invention is based, in part, on the determination of group-
specific sequence motifs in regions of HLA Class I loci. These motifs may be
used to
design oligonucleotides which may be used as group-specific primers in nucleic
acid
amplification reactions. The present invention is also based, in part, on the
determination of the sequences of regions of a wide variety of alleles of HLA
Class I
loci; such sequences may be used to distinguish one allele from another.
Sequences of
regions including the 5' flanking region of HLA-A and introns 1, 2 and 3 of
HLA-A
are provided herein, and are set forth in Figures 3-6.
In general, the methods of the invention may be described as follows.
Comparison of nucleotide sequences of an HLA locus among members of an HLA
Class I group, which lie in either untranslated or exon regions, may be used
to identify
group-specific motif sequences. Identification of groups may be by
establishing
serological relationships or using phylogenetic information, as set forth in
Figures 7-
9. Based on the group-specific motif sequences, oligonucleotide primers may be
designed, synthesized, and used to amplify a portion of the HLA locus.
Oligonucleotides used in this manner are referred to herein as "group-specific
primers" and, in particular, as "group-specific untranslated region primers"
or "group-
specific exon region primers", as the case may be.
In preferred nonlimiting embodiments of the invention, the primers
correspond to untranslated regions of the HLA Class I locus ("group-specific
untranslated region primers"). Such primers may be used in pairs, wherein each
member of the pair hybridizes to an untranslated region lying on either side
of at least
one exon. For example, but not by way of limitation, primer pairs may be
oligonucleotide pairs which hybridize to group-specific motifs in the 5'
untranslated
region and the first, second, or third intron; the first intron and the second
or third
13
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
intron; or the second and third intron.
The group-specific primers may be used in several different methods
according to the invention. In a first series of nonlimiting embodiments, the
group-
specific primers may be used in a diagnostic manner to identify which allelic
groups
are present in a patient sample. In a second series of nonlimiting
embodiments, the
group-specific primers may be used to amplify sufficient amounts of a
particular
allelic fragment which is then subjected to direct nucleotide sequencing using
universal sequencing primers.
According to the first series of embodiments, the present invention
provides for a method of determining the HLA Class I group type of a subject
comprising (i) combining a group-specific primer pair with a target DNA sample
from
the subject under conditions such that primer-based amplification of the
target DNA
may occur; and (ii) determining whether a nucleic acid product is produced by
the
amplification; wherein the ability of a primer pair to produce a nucleic acid
product is
associated with a particular HLA group type. The group-specific primers may be
group-specific exon region primers or group-specific untranslated region
primers. In
related embodiments the present invention provides for a method of determining
the
HLA Class I group type of a subject comprising (i) combining a plurality of
group-
specific exon region primer pairs with a target DNA sample from the subject
under
conditions such that primer-based amplification of the target DNA may occur;
(ii)
determining the size of the nucleic acid products of the amplification; and
(iii)
correlating the size of the product with the predicted size of a fragment
associated
with a particular HLA group type. The plurality of primers is referred to as
an HLA
"cocktail" (see Figures 1 and 2). These first methods may be used to provide
useful
diagnostic information. For example, group type determination may serve as a
first
level of comparison for a histocompatibility analysis, even without
identification of
the specific alleles) involved. For example, if a potential donor and host are
being
evaluated for tissue transplantation, if it is found that their group types do
not match,
no further comparison may be necessary. If, alternatively, their types do
match, filr-
ther analysis, for example by direct sequencing, may be desirable.
According to the second series of embodiments, the present invention
14
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
provides for a method of determining the HLA Class I allelic type of a subject
comprising (i) combining a group-specific oligonucleotide primer pair with a
target
DNA sample from the subject under conditions such that primer-based
amplification
of the target DNA may occur; (ii) collecting the nucleic acid product of the
amplification; and (iii) determining the nucleic acid sequence of the product.
The
group-specific primer pair used may be determined based on the group type of
the
subject, as determined using the first method, described above. In preferred
embodiments of the invention, group-specific untranslated region primers which
span
a region of the HLA locus containing allele-specific sequence may be utilized.
If a
subject is heterozygous, separate amplification reactions are performed for
each group
identified (e.g., separate reactions to amplify fragment for group A2 and
group A3;
see Figure 2). Sequencing may be performed using universal sequencing primers
which will operate irrespective of HLA group or allelic type.
A more detailed description of the invention follows. Most alleles of
the classical HLA Class I gene loci (consisting of HLA-A, HLA-B and HLA-C) can
be distinguished on the basis of exon 2 and 3 alone. In one non-limiting
embodi-
ments, a method of the invention takes advantage of this fact, and employs the
strategy generally described in Figure 2, using the example of HLA-A. A
genomic
DNA sample is prepared from a patient sample according to well known
techniques.
Aliquots of the genomic DNA may then separately be reacted with a panel of
group-
specific exon region primer pairs (Figure 2C), wherein the successful
amplification of
a DNA fragment is associated with a particular group type. Alteratively, as
depicted
in Figure 2A), part of the sample may be treated with a cocktail of group-
specific
exon region primer pairs. Each primer pair in the cocktail will amplify only
selected
allelic groups because they specifically hybridize to group specific intron
sequence
motifs. Between them, under suitable polymerase chain reaction (PCR)
conditions,
the cocktail may amplify all known HLA-A groups, with each group specific
amplification product having a different length. When reaction products are
separated
on an agarose gel the groups) present in the patient sample may be identified
by
length.
Optionally, once the group specificity is determined, the direct
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
sequence of alleles may be determined for precise allelic identification. As
illustrated
in Figure 2 B), a further part of the patient sample DNA may be treated under
PCR
conditions with a pair of primers that are specific for the previously
determined group;
preferably such primers are group-specific untranslated region primers, which
span
greater distances of the locus. If two groups were detected, then two separate
reactions are performed. At completion of the second amplification, the
reaction
products are sequenced using an intron based "universal primer" which
hybridizes to
an intron sequence which is conserved among all alleles of the locus. Though
it is
theoretically possible to use a sequencing primer which is specific for the
amplified
group only, it is found that using a universal primer simplif es the method
and the
preparation of a kit. Various universal sequencing primers are specifically
provided
herein (see infra) which hybridize, respectively, to intron sequences flanking
the S'
end of exon 2, the 3' end of exon 2, the 5' end of exon 3 and the 3' end of
exon 3.
The substantial advantage of the method of the invention is that the
initial group specific amplification allows a PCR based separation of
haplotypes in
95% of patient samples. The separation of the haplotypes is a major
achievement of
this protocol since it permits the resolution of cis/trans linkages of
heterozygote
sequencing results which cannot be achieved with other protocols. With the
instant
invention, a separation of the haplotypes may be achieved in serological
heterozygous
samples with the sequencing primer mixes ("PMs") described in Table 2 (infra)
using
group-specific amplification corresponding to the serological families. The
selection
of the PMs used for sequencing depends on the amplification patterns of the
preceding
PCR-SSP low-resolution typing. The primers are designed to work with a in a
single
cycle protocol including, but not limited to, a PCR protocol on a Perkin Elmer
System
9600, maintaining typing capacities of the laboratory. All PCR products carry
sufficient sequence information for a complete subtyping. This approach is
superior to
a typing system using a single pair of generic primers followed by direct
sequencing
or SSO hybridization, even if the amplification strategy is locus-specific.
The
substantial advantage of Sequence Based Typing (SBT) is the def nition of the
cis/trans linkage of sequence motifs. SBT after generic PCR amplification
cannot
define the cis/trans linkage of sequence motifs and therefore mimics
oligotyping. The
16
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
rapidly growing number of newly identified alleles confirms that new alleles
have
arisen mainly from gene conversion events which have usually taken place
between
different alleles of the same locus. Newly identified alleles are not
characterized by
new sequence motifs, but by a new combination of already existing sequence
motifs.
From this observation it may be concluded that the amount of alleles at each
locus
may theoretically represent all possible combinations of known sequence
motifs. Of
course, some of them will fall victim to negative selection. Nevertheless, it
can be
expected that still an enormous amount of alleles are yet unidentified. PCR-
SSP
subtyping strategies using a restricted number of oligonucleotides which do
not cover
all possible sequence motifs suffer from this limitation. If the cis/trans
linkage of the
analyzed polymorphic regions is not defined some new alleles may be mistyped
as a
heterozygous combination of known alleles. This has consequences with respect
to
SBT strategies. An unambiguous typing result of SBT after generic PCR
amplification is only unambiguous with regard to the presently known HLA
sequence
databank. However,. with the detection of new alleles this result can become
ambiguous over the course of time. This observation has already been made in
PCR
based DRBl typing during the last five years and will probably also occur in
PCR
based class I typing. Considering the above points, the idea of the instant
SBT
approach is not only to identify the HLA-A, HLA-B and HLA-C subtypes, but to
cover as many of the polymorphic sites as possible and to define the cis/trans
linkage
of the polymorphic sequence motifs. Typing results obtained with this method
will
remain unambiguous independently of the growing HLA sequence databank.
In general, group-specific primers are desirably designed to facilitate
hybridization to their intended targets. It should be taken into account that
homology
between different groups, and indeed between group-specific motifs, may exist.
Accordingly, in preferred embodiments of the invention, a primer may be
designed
such that it hybridizes to its group target under relatively stringent
conditions. For
example, one or more mismatched residues may be engineered into the 3' domain
of
the molecule. Further, the primer may be designed such that it differs from
any
naturally occurnng or consensus sequence, but rather has mismatches inserted
which
serve to further reduce hybridization of the primer to target DNA of a group
other
17
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
than the intended target group. Under certain circumstances, one or more
mismatches
may be introduced into the 5' end to destabilize internal hairpin loops; such
changes
are not generally expected to enhance the efficiency of the primer.
The following nucleic acid sequences may be comprised in group-
specific untranslated region primers for HLA-A which are specific for the
groups as
indicated in Table 1. The sequences in Table 1 have the following sequence
identifiers: II-210 is SEQ ID N0:35, and the remaining sequences Il-230m
through
I3-282 have SEQ ID NOS 5:181-202, respectively.
Table 1.
DesignationSequence N Tm SpecificityPosition
I1-210m 5' ACC Cgg ggA gCC 18 64C A10 et 73-92
S ggg CCT 3' al.
II-230m 5' ggC Agg TCT CAg 18 60C A*O1, 03, 102-
S CgA CTg 3' 11, 119
30
II-226 5' CTC TgT ggg gAg 19 60C A802 29-47
S AAg CAA C 3'
I1-221m11 5' ggg AgC ggC gCC 17 64C A*0301 77-93
S ggg AC 3'
II-209 5' gAA gCA Agg ggC 18 64C A10 et 41-58
S CCg CCC 3' al.
I1-214m 5' CgC CTg gCg ggg 18 66C A*2301,24 54-71
S gGg CAA 3'
II-223d 5' gTg AgT gCg ggg 18 62C A19 1-19
S TCg Tgg 3'
I1-225m 5' gCC ggg Agg Agg 18 64C A*30 85-103
S gAC ggT 3'
II-237m14 5' ggC gCg CCC ggC 17 65C A*29 49-65
S ggg gA 3'
I1-240 5' ggA ggA ggg TCg 18 64C A*31,33 90-107
S ggC ggA 3'
5'FL-243 5' AgT gTC TTC gCg 19 62C A*I1 53-71
S gTC gCT C 3'
5'FR-257 5' CTC AgA TTC TCC 19 60C A all except6-24
S CCA gAC g 3' A* 11
5'FR-273 5' CATgCC gAg ggT TTC 20 64C A*28, 360-
S TCC CA 3' 6602,6603 380
BP202 S 5'CTg gCC CTg ACC CAg 19 64C A*7401,7403Exon
ACC A 3' 1,
49-68
BP203 S 5' GCT gAC CCA gAC 19 64C A*8001 Exon
CTg ggC A 3' 1,
55-73
18
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
BP142 AS 5' CAGGTAT CTG CGGAGC 19 64C A*0101/*24227-
CCG 3'
245
I3-236 5'gTC TgT CAg gAA gAgTCAgAA21 62C A*non02.28584..+2
AS 3'
I3-239 5'gTggAAAATTCTAgTCCCTgA22 62C A*multi, 415-
AS A3' not
A1,3,11,30,9436
I3-246 5' AgATCT ACA ggC gAT 20 60C A*30 24-43
AS CAg gA 3'
I3-247m6 5' gCC AgC CCg ggA 19 62C A*01,11 38-54
gTT CTA T 3'
AS
I3-249 5' CAg AgT CACTCTCTggTACAg21 62C All A, 148-
AS 3' weak
59,70,92,J,E,G168
,F
I3-280m18 5' gCg ATC gTC TTC 19 62C A*01,03,11,30221-
CCg TCA C 3'
AS 239
I3-282 5' AgAgTCACTCTC Tgg 21 62C A*8001 148-
AS TACAgA 3'
168
The present invention provides for nucleic acid molecules comprising
regions having the foregoing sequences or their functional equivalents.
"Functional equivalents" of a nucleotide sequence, as defined herein,
refers to nucleotide sequences which, when contained in a nucleic acid
molecule,
retain the specificity of the disclosed sequence and/or hybridize to the
complement of
the disclosed sequence under stringent hybridization conditions (e.g., .1 x
SSC at
65 °C).
In specific nonlimiting examples, oligonucleotides comprising the
above sequences, or functional equivalents thereof which retain specificity,
may be
used in a PCR amplification reaction in the following pairwise combinations to
generate group specific fragments of the lengths as indicated in Table 2.
19
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
Table 2.
Primer Mix Sense PrimerAntisense Size HLA-A specificity
No. Name Primer of
Product
1 1.1 I1-230m BP142 785 A*OI
by
2 1.2 S'FR-257 I3-247m6 1068 A*O1
by
3 1.3 I1-230m I3-247m6 870 A*01,11
by
4 2 I1-226 I3-249 1056 A*02
by
3 I1-221m11 I3-280m18 1078 A*03
by
6 11 S'FL-243 I3-249 1229 A* 11
by
7 9 I1-214m I3-249 1033 A*23,24
by
8 10.1 I1-210m I3-236 l4SObpA*10
9 10.2 I1-210m I3-249 1014 A*10,68,69
by
28 S'FR-273 I3-249 t 537 A*68,69,6602,6603
by
11 19.1 I1-223d I3-239 or 1084 A*29,31,32,33,74
I3-249 by
12 19.2 I1-240 I3-249 996 A*31,33
by
13 29 I1-237m14 I3-249 1037 A*29
by
14 30 I1-225m I3-249 1000 A*30
by
1S 74 BP202 (Exon I3-249 1109 A*7401,7403
1) by
16 80 BP203 I3-282 1103 A*8001 (untested)
by
The following nucleic acid sequences may be comprised in group-
specific exon region primers for HLA-A which are specific for the groups as
indicated
in Table 3 (sense primers) and Table 4 (antisense primers). The sequences in
Table 3,
primer numbers 85, 118, 120, 123, 127, 129, 134, 137, 140, 160, 167, 175, 193
and
202, have SEQ ID NOS:203-216, respectively. The sequences in Table 4, primer
numbers 98, 115, 116, 117, 126, 133, 135, 136, 138, 142, 144, 145, 152, 153,
154,
155, 161, 165, 168, and 180, have SEQ ID NOS:217-236, respectively, and primer
number 119 has SEQ ID N0:245. The present invention provides for nucleic acid
molecules comprising regions having the foregoing sequences or their
functional
equivalents. They may, in specific nonlimiting examples, be used in pairs as
set forth
in Table 5.
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98100768
Table 3.
Primer Localization Sequence
Number
85 Exon -14 - 5' CTC CTC gTC CCC Agg
2 5 CTC T 3'
118 Exon 6 - 19 5' TCC ATg Agg TAT TTC
2 TAC ACC 3'
120 Exon -6 - 5' ggC CAg gTT CTC AgA
3 12 CCA 3'
123 Exon 36 - 5' CCC ggC CCg gCA gTg
2 53 gA 3'
127 Exon 1- 20 5' gTT CTC ACA CCA TCC
3 AgA Tg 3'
129 Exon 4 - 25 5' TCA CAC CCT CCA gAT
3 gAT gTT 3'
134 Exon 63 - 5' ggg TAC CAg CAg gAC
3 80 gCT 3'
137 Exon 9 - 29 5' TCC ATg Agg TAT TTC
2 ACC ACA 3'
140 Exon -1 - 5' ggT TCT CAC ACC ATC
3 20 CAg ATA 3'
160 Exon 1 - 20 5' gTT CTC ACA CCA TCC
3 AgA gg
167 Exon 54 - 5' gAg CCC CgC TTC AAC
2 71 gCC 3'
175 Exon 63 - 5' CTT CCT CCg Cgg gTA
3 71 TgA A 3'
193 Exon 167 - 5' gCC ggA gTA TTg ggA
2 184 CCg 3'
202 Exon 49 - 5' CTg gCC CTg ACC CTg
1 67 ACC A 3'
Table 4. Antisense Primers
Primer Localization Sequence
Number
98 Exon 2 226 - 5' gCA ggg TCC CCA ggT
243 CCA 3'
115 Exon 3 195 - 5' CCT CCA ggT Agg CTC
213 TCA A 3'
116 Exon 3 195 - 5' CCT CCA ggT Agg CTC
213 TCC A 3'
117 Exon 3 195 - 5' CCT CCA ggT Agg CTC
213 TCT g 3'
119 Exon 2 184 - 5' CTT CAC ATT CCg TgT
203 CTC CT 3'
126 Exon 3 212 - 5' CCA CTC CAC gCA CgT
230 gCC A 3'
133 Exon 2 229 - 5' ggA gCg CgA TCC gcA
246 ggC 3'
135 Exon 3 2I6 - 5' ggA gCC ACT CCA Cgg
234 ACC g 3'
136 Exon 3 216 - 5' gAg CCA CTC CAC gCA
233 CTC 3'
138 Exon 2 186 - 5' ggC CTT CAC ATT CCg
206 TgT gTT 3'
142 Exon 3 228 - 5' CAg gTA TCT gCg gAg
246 CCC g 3'
144 Exon 2 165 - 5' Tgg TCC CAA TAC TCA
184 ggC CT 3'
145 Exon 2 226 - 5' gCA ggg TCC CCA ggT
243 TCg 3'
21
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
152 Exon 3 163 - 5' ggg CCg CCT CCC AgT
179 TgT 3'
153 Exon 2 179 - 5' TCT gTg AgT ggg CCT
197 aCA CA 3'
154 Exon 2 184 - 5' CCT TCA CAT TCC gTg
204 TCT gCA 3'
155 Exon 3 216 - 5' gAg CCA CTC CAC gCA
233 CgT 3'
161 Exon 2 209 - 5' CCA CTC ggT CAg TCT
228 CTg AC 3'
165 Exon 3 105 - 5' gAg CgCA ggT CCT CgT
124 TCA A 3'
168 Exon 2 198 - 5' gTC TgT gAg Tgg gCC
217 aTC AT 3'
180 Exon 2 12 - 31 5' CAg CCA TAC ATC CTC
Agg AC 3'
Table 5.
Group-specific exon pairs
Primer SenseAntisenseSize HLA-A specificity
mix PrimerPrimer of
No. Name Product
1 1 140 142 247 A*0101,0102,8001
by
2 2 85 98 256 A*0201-0220
by
3 3 140 126 230 A*0301,0302,0303
by
4 36 167 168 164 A*0101,3601
by
11 118 119 195 A*1101-1103
by
6 23 129 115 209 A*2301
by
7 24 129 116 209 A*2402-2411
+ I by
17
8 10.1 160 135 233 A*2501,2601-2603,2605,4301,6601
by
9 25 118 233 238 A*2501,2502
by
26 118 145 235 A* 2601,2602, 2604,4301
by
11 34 134 155 171 A*3401,3402
by
12 6602 134 136 240 A*6602,6603
by
13 10.2 118 161 222bp A*11,34,6601,6602,68011,6802,6901
14 43 118 154 196 A*4301
by
I5 68 120 152 185 A*68011,68012,6802,6803
by
16 69 193 180 375 A*6901
by
17 19 127 165 124 A*2901,2902,31012,3201,3301-3303
by A*7401-7403
18 29 137 145 236 A*2901-2902
by
22
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
19 30 175 115 162 A*3001-3004
+ 116 by
20 31 167 144 176 A*31012
by
21 32 167 133 159 A*3201,3202,2501,2502
by
22 33 137 138 198 A*3301-3303
by
23 74 202 153 370 A*7401,7403
by
24 80 140 136 234 A*8001
by
In general, the foregoing group-specific primers may be modified by
addition, deletion, or substitution of bases, to produce functionally
equivalent primers
with the substantially the same specificity, that is to say, such that the
group specific
polymorphism(s) are not removed. Such modifications may be constrained by
several
parameters. First, exact matching at the 3' end is particularly important for
primer
extension. Preferably, at least 5 nt are complementary to target DNA. When the
exactly conserved region is short, for example, less than 10 nt, it is not
advisable to
change the primer sequences. The primer is preferably less than 50% G or C.
Also,
the primers should be designed to avoid specific hybridization with
pseudogenes or
non-classical HLA Class I loci. In the examples which follow, the meiting
temperature of all primers used was about 62C to ensure uniform amplification
conditions.
For sequencing purposes, the following nucleic acid sequences are
sequences which hybridize to all alleles of the indicated loci, in the
locations indicated
(and hence are referred to as universal sequencing primers). The primers in
Table 6
are assigned consecutively SEQ ID NOS:237-244.
23
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
Table 6.
DesignationSequence LocationMelting
Temp.
5'-Ex2(Aw3)5' GCG CCG GGA GGA GGG TC Int-1 58-62C
3'
3'-Ex2 5' ATC TCG GAC CCG GAG ACT Int-2 58C
3'
5'-Ex3 5' GTT TCA TTT TCA GTT TAG Int-2 60C
GCC A 3'
3'-Ex3(Aw6}5' CGG GAG ATC TAC AGG CGA Int-3 58-62C
TCA GG 3'
5'-Ex2(Aw3)5'GCG CCG GGA GGA GGG TC Int-1 58-62C
3'
3'-Ex2 5'GTC GTG ACC TGC GCC CC Int-2 58-62C
3'
5'Ex3 5'GGG CGG GGC GGG GCT CGG Int-2 58-62C
G 3'
3'Ex3(Aw6) 5'CGG GAG ATC TAC AGG CGA Int-3 58-62C
TCA GG 3'
S'-Ex2 (Aw3)5' GCG CCG GGA GGA GGG TC Int-1 58-62C
3'
3'-Ex2(ABCwI)5' GGT CGT GAC CT(T/C)CGC Int-2 58-62C
CCC 3'
5'-Ex3(ABCw2)5' CCC GGT TTC ATT TTC 3' Int-2 58-62C
3'-Ex2(Aw6)5'CGG GAG ATC TAC AGG CGA Int-3 58-62C
TCA GG 3'
The foregoing three groups of primers include 5' and 3' primers for
sequencing across exons 2 and 3, respectively.
The selection of suitable universal sequencing primers is constrained
by a variety of rules including the following. Sequencing primer hybridization
sites
must lie within the fragment amplified by the group specific amplification
primers.
All primers are desirably selected to provide informative sequence and not
start too
far downstream of useful sequence. Preferred primers hybridize to conserved
sites
near the exon/intron boundaries.
Direct sequencing of the 2nd and 3rd exon may be performed from
either the 5' or 3' end using the primers of Table 6 supra which are located
in
conserved regions of the 1st, 2nd and 3rd intron as indicated. These conserved
regions
were found to be identical in all samples investigated, regardless of the
amplified
group.
An important issue of direct sequencing for HLA class I genes is the
generation of a specific PCR product, which is rather complicated due to the
24
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
extensive sequence homologies between the different HLA class I loci including
several pseudogenes. If an adequate PCR product has been generated, any
sequencing
chemistry should be applicable.
In the normal case, since group specific amplifications take place
before sequencing, only one allele at a time is sequenced, resulting in
unambiguous
homozygous sequencing results. In these cases alleles are relatively easy to
identify,
even without software.
However, in about 5% of cases, both alleles come from the same
group, but the sequence results show heterozygosity. In practice, when viewed
by a
fluorescence-detecting system, the sample appears as a normal sequence of
bases
with, sporadically, two bases at one site, each with half the peak height.
This result
flows from the high degree of similarity shared among all alleles of each HLA
gene;
sequence heterozygosity flows from base substitutions. The laborious task of
determining which alleles are present in the test sequence may be simplified
using
computer analysis. A software program called GeneLibrarian developed by
Visible
Genetics, the assignee of the present application, rapidly compares the test
sequence
to a database which includes all possible homozygote and heterozygote
combinations
of the alleles. The program identifies those stored sequences that are closest
matched
to the test sequence. The operator can then determine which allelic pair is in
the test
sample. If no allelic pair shows an exact match, the software allows the
operator to
review the test sequence to determine if errors in base-calling or other
artifacts are
interfering with the analysis.
The order of sequencing reactions may be selected by the operator.
Each exon of each locus may be sequenced on the sense strand or anti-sense
strand. A
preferred method is to obtain sequence from one strand from each exon. If the
results
contain ambiguities, then the amplicon is re-sequenced using the other primer
for the
same exon. The availability of both sequencing primers provides redundancy to
ensure robust results.
In some cases, it may be advantageous to employ an equimolar mixture
of 2 or more oligonucleotide species. Mixtures of oligonucleotides may be
selected
such that between them they will effectively prime the sequencing reactions
for all
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
alleles of the locus at the same site.
In an alternative technique, instead of using dye terminators, a dye-
labelled primer may be employed. In this case, the selected sequencing primers
is
labelled on the S' end with a detectable label, using phosphoramidite or
NHS/dye ester
techniques well known in the art. The label selected depends on the detection
instrument employed. The label for use with an OpenGene System (Visible
Genetics
Inc., Toronto, ON) is the fluorophore Cy5.5 (Amersham Life Sciences, Cleveland
OH). Fluorescein-isothio-cyanate may be used for detection with the ALF
Automated
Sequencer (Pharmacia, Piscataway NJ). In this method, which is well known to
one
skilled in the art, the sequencing reaction mixture is changed slightly to
include only
one ddNTP per reaction mixture. For detection of reaction products, the sample
may
be mixed with an equal volume of loading buffer (5% ficoll plus a coloured
dye). 1.5
ul of these samples may be loaded per lane of a MicroCel electrophoresis
cassette
loaded in a MicroGene Blaster automated DNA sequencer (Visible Genetics Inc.,
Toronto). The sample may be electrophoresed and read.
Results may be displayed and analyzed with GeneObjects software.
The sequence of bases may be determined, and the HLA allele to which the
sequence
corresponds may then be identified. This process may be performed for each
locus
(HLA-A, HLA-B, HLA-C) and the results may then be reported to the patient
file.
It is well known in the art that different variations of sequencing
chemistry may be employed with different automated DNA sequencing instruments.
Single dye instruments, such as the OpenGene System (Visible Genetics Inc.,
Toronto), the ALF Express (Pharmacia, Uppsala, Sweden) or the Li-Cor 4000L
(Lincoln City, Nebraska) generally use dye-labeled primers. In these systems a
single
chain termination sequencing reaction mixture is run per Lane.
Mufti-dye sequencers, such as the Prism 377 (applied Biosystems, Inc.,
Foster City, California) detect multiple dyes in a single lane. This
technology
conveniently employs dye-terminator chemistry, where the chain-terminating
nucleotides are themselves labeled with fluorophores (see United States Patent
No.
5,332,666, to Dupont de Nemours and Co.). In this case, the reaction products
carrying four different labels may be run in a single lane.
26
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
Either single dye or mufti-dye chemistry may be employed according
to the present invention, along with other sequencing chemistries. Additional
methods
for reducing the numbers of reactions required to obtain detailed sequence
information from the classical HLA Class I loci are disclosed in commonly
owned
United States Patent Applications USSN 08/577,858 (for single-track
sequencing) and
USSN 08/640,672 and 08/684,498 (for single-tube sequencing).
Directly analogous methods may be used to determine the HLA-B type
of an individual. As with the HLA-A gene, the second and third exon of the HLA-
B
gene are polymorphic, and therefore provide for sequencing based typing
strategies.
A list of primers, together with their sequence, length, and localization, is
provided in
Table 7 below. The primers in Table 7 are assigned consecutively SEQ ID
NOS:398-
435.
27
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
TABLE
7
HLA-B
PCR-SBT
primer
sequences
A. Amplification
primers
Primer OrientSequence ~ N Tm Localization
~ ~
EI-B121m17S 5' CCA CCT gCT gCT 9 64 Exon 1,
CTC ggg A 3' 1 27..45
E1-B129 S 5' CCT CCT gCT gCT 1862 Exon 1,
CTC ggC 3' 27..44
E1-B130 S 5' CTg CTg CTC Tgg 1862 Exon 1,
ggg gCA 3' 31..48
EI-B136 S 5' gAg ATg Cgg gTC 1860 Exon 1,
ACg gCA 3' -3..15
E1-B182 S 5' CTg ACC gAg ACC 1860 Exon 1,
Tgg gCT 3' 55..72
I1-B145 S 5' Agg Agg gTC ggg 1862 Intron 1,
Cgg gTT 3' 90..108
I1-B154mS 5' ggg TCT CAg CCC I 60 Intron 1,
CAC CTT 3' 8 114..121
I1-B167 S 5' gAg ggA AAT ggC 19G2 Intron 1,
CTC TgC C 3' 17..35
II-B168 S 5' Cgg ggg CgC Agg 1864 Intron 1,
ACC TgA 3' 59..76
II-B169 S 5' gCg CCg ggA ggA 1864 lntron 1,
ggg TCT 3' 83..100
I1-B170 S 5' gCC TCT gTg ggg 1860 Intron 1,
Agg AgA 3' 27..44
I1-B171 S 5' gCC TCT gTA ggg 1962 Intron 1,
Agg AgC A 3' 27..45
I1-B172 S S' gTC ggg Cgg gTC 1862 Intron 1,
TCA gCT 3' 97..114
I1-B173 S 5' Cgg ggg ACC gCg 1764 Intron 1,
CCg gT 3' 73..90
I1-B174 S 5' ggT CTC AgC CCC 1860 Intron 1,
TCC TCA 3' 105..122
I1-B175 S 5' gTg gAg TgC ggg 1860 Intron I,
gTC ggC 3' -5..12
I1-B326 S 5' gTg AgT gCg ggg 1760 Intton 1,
TCg gC 3' 1..17
II-B331 S 5' gAC CgC Agg Cgg 1762 Intron 1,
ggg CT 3' 50..66
II-B346 S 5' TCT CAg CCC CTC 1860 Intron 1,
CTC gCT 3' 107..124
I3-B126 AS 5' gCC ATC CCC ggC 1964 Intron 3,
gAC CTA T 3' 36..54
I3-B147 AS 5' ggg ACC CCT gAT 1960 Intron 3,
CAC TAT C 3' 220..238
I3-B AS 5' ggC CCT CAg Agg 1962 Intron 3,
164 AAA CTC g 3' 134..152
I3-B165 AS 5' Agg CCT gAg Agg 2162 Intron 3,
AAA AgT CAT 272..292
3'
I3-B166 AS S' Agg CgC TTT gCA 2162 Intron 3,
TCT CTC ATA 535..555
3'
I3-B187 AS 5' gAT CAg TAT TCT 2160 Intron 3,
Agg gAC TgA 209..229
3'
I3-B212 AS 5' gAA Tgg ACA ggA 2062 Intron 3,
CAC CTg gT 3' 481..500
28
CA 02300369 2000-02-11
WO 99/07883 PCTlCA98/00768
TABLE
7
HLA-B
PCR-SBT
primer
sequences
A. Amplification
primers
Primer OrientSequence NaTm Localization
I3-B305 AS 5' TCA TgC CAT TCT 2160 Intron 3,
CCA TTC AAC 106..126
3'
I3-B319 AS 5' CTA ggg ACT gTC 2062 Intron 3,
TTC CCC TA 3' 200..219
I3-B320 AS 5' CgC TgA TCC CAT 2060 Intron 3,
TTT CCT CT 3' 69..88
I3-B321 AS 5' CAg AgA ACA Agg 2060 Intron 3,
CCT gAg AA 3' 282..301
I3-B323 AS 5' AAC CCA gAC ACC 1960 Intron 3,
AgC ggA T 3' 443..463
I3-B332 AS S' ggA CTT CTg CTC 2060 Intron 3,
CTg ATC TA 3' 363..382
I3-B335 AS 5' gAg gCC ATC CCg 1862 Intron 3,
ggC gAT 3' 40-57
I3-B337 AS 5' ggA AAg TTC gAg 2162 Intron 3,
TCT CTg AgT 3' 392..412
I3-B342 AS 5' CTC ATg CCA TTC 2060 Intron 3,
TCC ATT CC 3' 108..127
I3-B347 AS 5' TgA CCA gCC TgA 1960 Intron 3,
gAA Tgg g 3' 494..512
I3-B348 AS 5' AAC Agg gAC TTC i960 Intron 3,
TgC TCC C 3' 369..387
I3-B349 AS 5' C CT A A A AAA TC 2062 Intron 3,
AC 3' 272..291
Suitable primer mixes for HLA-B typing are set forth
in Table 8 below.
TABLE
8
HLA-B
PCR-SBT
primer
mixes
PrimerMix Sense AntisenseSize of HLA-B specificity
o. primer primer product
ame
1 7 I1-B174 I3-B305 943bp 0702-0708,4801-4803,8101
2 8 I1-B167 I3-B323 1368bp 0801-0804,4201
3 13 I1-B175 I3-B319 1145bp 1301-1304
4 14 I1-B145 I3-B321 1132bp 1401,1402
S 15 E1-B121m17I3-B147 1204bp 1501-1537,4601
6 18 II-B154m I3-B164 960bp 1801-1805
7 27 E1-B182 I3-B349 1231bp 2701-2711,4002-4006,4008,
4009, 4701
29
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
TABLE
8
HLA-B
PCR-SBT
primer
mixes
timer MixSense AntisenseSize of HLA-B specificity
o_ primer primer product
fame
8 35 II-B168 3-B212 363bp 501-3521,5101-5109,5201,
I 1 3 301, 5302,5801,5802,7801,
5 802
7
9 37 I1-B326 3-B165 1213bp 801-1805,3701,3702
I 1
16 I1-B167 I3-B320 993bp 3801,3802,3901-3912,
6701,
1401, 1402
11 60 I1-B172 I3-B342 952bp 4001,4007,4010
12 41 I1-B172 I3-B323 1288bp 4101,4102
13 42 I1-B174 13-B323 1280bp 4201,4202
14 44 I 1-B 170 I3-B 126 1323bp 4402,4410
45 I1-B326 I3-B348 1307bp 4501
16 47 I1-B33 I3-B332 1254bp 4701,4702
t
17 48 I1-B174 I3-B332 1199bp 4801-4803
31 49 I1-B326 I3-B337 1332bp 4901
18 50 I1-B326 I3-B187 1155bp 5001,5002
~19 22 I1-B169 I3-B166 1394bp 5401,5501-5505,5601-5603,
5901
57 I1-B171 I3-B347 1407bp 5701-5704
21 73 I1-B173 I3-B335 909bp 7301
22 78 II-B168 I3-B212 1363bp 7801,7802
X23 82 I1-B346 I3-B126 868bp 8201
24 MultiI1-B326 I3-B126 975bp most 15,1801-1805,2701-2711
I1 4001-4010,4101,
4102,4501,4601,
4901,5001,5002,5701-5704
Multi I1-B167 I3-B126 959bp 0702-0708,0801-
I2 0804,1401,1402,
3801,
3802,3901-3912,4201,4202,
4801-4803,6701,7801,8101
.~ ~ __r _____~_ _ _ ...~..
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
TABLE
8
HLA-B
PCR-SBT
primer
mixes
PrimerMix Sense AntisenseSize of HLA-B specificity
o, primer primer product
ame
26 MultiI1-B168 I3-B126 917bp 0702-0708,0801-
I3 0804,1401,1402,
3501-
3521,3801,3802,3901-3912,
4201,4202,4801-4803,5101-
5109,
5201,5301,5302,5801,5802,
6701, 8101
27 MultiE1-B129 I3-B126 1022bp 0702-0708,0801-
E 0804,1401,1402,
1
3801,3802,3901-
3912,4001,4007,
4010,4101,4102,4201,4202,45
O1, 4801-
4803,4901,5001,5002,6701
28 MultiE1-B130 I3-B126 1018bp 1301-1304,1801-1805,2701-
E2 2711, 3501-
3521,3701,3702,4002-4006,
4008,4009,4402-4410,5101-
5109, 5201,5301,5302,5701-
5704,5801,
5802,7801,7802,8101
29 Multi E1B-182 I3-B126 994bp 1801-1805,2701-
E3 2711,3701,3702,
4002-
4006,4008,4009,4701
30 Multi E1B-136 I3-B126 1051bp 4001,4007,4010,4101,4102,45
E4 O1,
4901,5001,5002,5401,5501-
5505,5601-5603,5701-
5704,5901
Sequencing primers suitable for HLA-B typing are set forth in Table 9,
31
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
below.
TABLE 9
B.B. Seauencing primers
Bseq2 AS 5' ggA TCT Cgg ACC Cgg AgA CTC g 3' 22 74°C Intron 2,
70..91
Mismatch for B*7301 at Pos. 9 and 10
from 3' end For Sequencing of HLA-B
exon 2
Bseq3 S 5' ACC Cgg TTT CAT TTT CAg TTG 3' 21 60°C Intron
2,153..173
For Sequencing of HLA-B exon 3
Bseq3AB S 5' TTT ACC Cgg TTT CAT TTT CAg TT 3'23 62°C Intron
2,150..172
For Sequencing of HLA-A and B exon
3
Mismatch for B*7301 at Pos. 8 and 9
from 3' end
Mismatch for A*8001 at Pos. 19 from
3' end
HLAB3X3.SEQ 5'TCC CCA CTG CCC CTG GTA 18 55°C Intron 3, 2-19
(also BC33, 3IN3BC02)
No requirement for DEAZA
HLAB5X3.SEQ 5'GGK CCA GGG TCT CAC A 16 55-C Intron 2, 258-
(also BC5X3INEX) Exon 3, 9
Requirement for DEAZA
HLAB3X2.SEQ 5'ATC TCG GAC CCG GAG ACT 18 60°C Intron 2, 78-98
(also A seq3)
Requirement for DEAZA
HLABSX2.SEQ 5'TCC CAC TCC ATG AGG TAT TTC 21 55°C Exon 2, 3-23
(also ABC25, SPE2, 5PE2)
No requirement for DEAZA
The primers in Table 9 are assigned consecutively SEQ ID NOS:436-
442.
The protocol described in working example 8, infra, may be used to
accomplish HLA-B typing using the foregoing materials.
The nucleic acids described above may be comprised in a kit for use in
practicing the methods of the invention. In addition to the group-specific
primers and
primer pairs disclosed, such kits may further comprise buffers, reagents, and
enzymes
such as, amplification enzymes including but not limited to, Taq polymerase.
In
32
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
specific, non-limiting embodiments, the kit may comprise group-specific exon
region
primers (for example, as a "cocktail" comprising a plurality of primers) as
well as
group-specific untranslated region primers; such primers may be contained in
individual tubes.
In a specific, nonlimiting embodiment of the invention, the following
method may be used to perform allele typing, here exemplified for HLA-B but,
depending on the choice of primers, applicable to HLA-A as well. The following
reagents may be used: 2.5 mM deaza dNTP Mix (2.5 mM dATP, 2.5 mM dCTP, 2.5
mM dTTP, 1.25 mM dGTP, 1.25 mM 7-DEAZA dGTP); 166 mM ammonium
sulphate (Sigma BioSciences); 100% DMSO; PCR primers (e.g., pairs selected
from
Table 8); genomic DNA control (60 ng/pl); Sequencing Buffer (260 mM Tris-HCI,
pH 8.3, 39 mM MgCIZ); 300:1 deaza terminators, including deaza A terminator
(750
pM dATP, 750 pM dCTP, 560 pM dGTP, 750 ~M dTTP, 190 pM 7-deaza dGTP, 2.5
~M ddATP), deaza C terminator (750 uM dATP, 750 ~M dCTP, 560 pM dGTP, 750
1rM dTTP, 190 uM 7-deaza dGTP, 2.5 pM ddCTP), deaza G terminator (750 ~M
dATP, 750 pM dCTP, 560 ~.M dGTP, 750 pM dTTP, 190 pM 7-deaza dGTP, 2.5 p.M
ddGTP) and deaza T terminator (750 pM dATP, 750 pM dCTP, 560 pM dGTP, 750
pM dTTP, 190 pM 7-deaza dGTP, 2.5 ~M ddTTP); Sequencing Primers Sx2.seq,
3x2.seq,5x3.seq, 3x3.seq (see, e.g., Table 9); Thermosequencase 32 U ~l (e.g.,
Thermosequenase cycle sequencing core kit, Amersham LifeScience, Product No.
US
79610); Enzyme Dilution Buffer ( 10 mM Tris-HCI, pH 8, I mM 2-ME, 0.5% (v/v)
Tween-20, 0.5% (v/v) NP-40 ; e.g., from Amersham LifeScience); Pink Loading
Dye
(Amersham); lOX PCR Buffer II (10 mM Tris-HCI, pH 8.3; S00 mM KCl); Taq DNA
polymerase (e.g., Perkin Elmer or Roche); 25 mM MgClz; molecular grade water,
and
mineral oil (to prevent evaporation if a thermocycler without a heated lid is
used).
Apparatus used in the method may include a thermocycler (e.g., PE 9600 or MJ
PTC)
wherein the ramping time is adjusted to 1°C/sec, and tubes and trays
supplied by the
manufacturer of the thermocycler, wherein the use of trays and tubes
fabricated from
polypropylene rather than polystyrene is preferred.
First, according to the specific embodiment referred to in the preceding
paragraph, the following HLA Locus Amplification Protocol may be used.
Reagents
33
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
(except enzyme) may be thawed at room temperature, vortexed, and microfuged
briefly, and placed on ice prior to use. Enzyme may be removed from the
freezer
when needed. On ice, the following master mix may then be prepared by
combining,
in the following order, (quantities provide for one 25 pl reaction): molecular
grade
water 7.75 pl; l OX PCR Buffer II (without MgCl2) 2.5 ~1; 2.5 mM deaza dNTP
Mix
2.0 pl; 25 mM MgCh 1.5 pl; 100% DMSO 2.5 pl; 166 mM Ammonium Sulphate 2.5
pl; PCR primers 1.0 pl; and SU/~l Tag polymerase 0.25 (pipet gently up and
down to
mix). The master mix (which has a volume of 201} may then be introduced into a
labelled 0.2 ml thin-walled amplification tube, and 5 ~l of 60 ng/pl genomic
DNA
may be added to produce a final concentration of 300 ng of DNA per reaction.
The
resulting reaction mixture may then be subjected to the following cycles in a
thermocycler to result in amplification:
( 1 ) denaturation at 94°C for 5 minutes, cycle 1 X with
(2) denaturation at 94°C for 30 seconds;
(3) annealing at 63°C for 30 seconds, cycle 35X with
(4) extension at 72°C for 60 seconds;
(5) extension at 72°C for 5 minutes, cycle 1X; and
(6) soak at 4°C, cycle 1 X.
To analyze the resulting amplification product, a 1% agarose gel
containing ethidium bromide may be prepared, and 4 pl of the PCR product may
be
loaded on the gel. Samples may then be run into the gel electrophoretically,
along
with size markers, and the size of the fragment may be compared with the size
of the
expected product (see, for example, Table 8).
The resulting amplification product may then be sequenced as follows.
Four .2 ml thin-walled tubes may be placed on ice and labelled A, C, G and T,
respectively. Three microliters each of deaza A, C, G and T terminators may be
introduced into the appropriately labeled tube. Thermosequenase enzyme may
then be
diluted 1/10 in a separate tube by combining 1 pl of thermosequenase with 9 pl
of
enzyme dilution buffer, on ice. In a separate .5 ml tube, on ice, the
following may be
combined to form a master sequencing mix: Sequencing Buffer 2.5 p.l;
Sequencing
34
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
Primer 2.5 pl; 100% DMSO 3.5 wl; amplification product 4.5 pl; molecular grade
water 6.0 pl; 1/10 diluted Thermosequenase 3.0 ~1 (TOTAL VOLUME 22 pl). Five
microliters of the foregoing master sequencing mix may then be added to each
of the
four tubes containing the deaza terminators. If necessary, the reaction
mixtures may
be covered with 8 ~.l of mineral oil and subjected to the following cycle
sequence:
( 1 ) denaturation at 94°C for 2 minutes, cycle 1 X with
(2) denaturation at 94°C for 30 seconds;
(3) annealing at 55°C for 30 seconds, cycle 35X with
' (4) extension at 70°C for 60 seconds;
(5) extension at 70°C for 2 minutes, cycle 1X; and
(6) soak at 4°C.
The reaction products may then be run on a sequencing gel to ascertain
the sequence of the amplification product, using standard techniques.
Methods of high resolution typing are detailed in the examples below,
which examples are set out to exemplify the method of the invention and not to
limit
the scope of it in any way.
6.EXAMPLE: DETERMINATION OF HLA-A GRO TYPE
Genomic DNA was prepared from patient samples according to
standard methods, such as a standard salting-out procedure (as provided by the
Puregene DNA Isolation Kit, Gentra Systems, Inc., Minneapolis) or by detergent
and
proteinase K treatment (Current Protocols in Molecular Biology, Eds. Ausubel,
F.M.
et al, (John Wiley & Sons; 1995)).
All primers were synthesized on a Gene Assembler plus (Pharmacia,
Uppsala, Sweden), and purified by fast protein liquid chromatography. The
sequence,
length, melting temperature (Tm), group specificity localization of the
primers are
given in Tables 3 (sense primers), 4 (antisense primers) and S (primer pairs).
Internal
positive control primers were: 5' primer hGHI 5'GCC TTC CCA ACC ATT CCC
TTA 3', (SEQ ID N0:336) 2lmer, Tm=64°C, nucleotide position 5560-
5580; 3'
primer hGHI 5' TCC ATG TCC TTC CTG AAG CA 3', (SEQ ID N0:349) 20mer,
Tm=60°C, nucleotide position 6614-6633. These control primers amplify a
1074 by
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
fragment of the human growth hormone gene.
Group-specific identification was performed as follows. Aliquots of
genomic DNA were separately reacted with a panel of 24 group-specific exon
region
primer pairs set forth in Table S, supra (see Blasczyk et al., 1995, Tissue
Ant. 46:86-
9S). An amplification cocktail for pairs of primers was prepared in 10 pl
volume
using standard lOx Perkin-Ehner buffer (lx buffer: SO mM KCI; 1.5 mM MgClz; 10
mM Tris-Hcl, pH 8.3; 0.001% (w/v) gelatin) supplemented with S% glycerol and
0.1
pl Cresol-red, sodium salt (Cresol-red stock solution:l0 mg/ml). The use of
glycerol
and cresol red avoids the necessity of using an agarose gel loading buffer.
Additionally, glycerol increases the PCR yield.
The PCR mix for a single SSP tube was as follows:
Genomic DNA 100 ng - 1.00 pl
Taq polymerase, 0.4 U - 0.08 ~ 1
dNTPs, 10 mM - 0.80 ~1
Buffer, lOx - 1.00 pl
Glycerol - 0.50 pl
Cresol red lOmg/ml - 0.10 pl
dHzO - 1.52 pl
Primer Pair + Control
Primer Pair - 5.00 ul
Total 10.00 pl
The PCR solution was prepared in volumes that would accommodate
30 reactions. The amount of primers used in each 10 pl PCR volume was 3 pmol
of
each HLA-A primer and 0.8 pmol of each internal control primer.
The reaction mixture was mixed well, then heated in a Thermo-Cycler
9600 (Perkin-Elmer, Inc) and subjected to the following protocol. After an
initial
denaturation, a first round with 10 two-temperature cycles was followed by 20
three-
temperature cycles.
1 ) Initial denaturation at 9S°C for S min.
2) First 10 cycles
i) Denaturation at 95°C for 30 sec.
ii) Annealing and extension at 6S°C for SO sec.
3) Last 20 cycles
i) Denaturation at 9S°C for 30 sec.
36
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
ii) Annealing at 62°C for 50 sec.
iii) Extension at 72°C for 30 sec.
The reaction tube was then cooled on ice. For visualization, 8 ul of the
amplification product were run on a 2 % agarose gel prestained with ethidium
bromide (0.2 ug/ml). The results were compared to a control lane with known
size
markers. The reaction products were visualized either as two bands (alleles
from
different groups) or a single band (alleles from same group). The size of the
bands)
were determined and group specificity was assigned according to the length
assignments in Table 5.
Figures 10 and 1 I show typical gel results, which, as shown in Tables
7 and 8, were interpreted to determine what group specificities were present
in
genomic DNA samples tested. In Tables 10 and I 1, the column titled "Position"
refers
to the primer mix no. of Table 5.
Table 10.
PositionHj,~S_necificitv Kontr. Species ampl. PM
1 A*0101,0102,8001 1
2 A*0201-0217 2
3 A*0301,0302 3
4 A*0101,3601 36
S A*1101,1102 11
6 A*2301 23
7 A*2402-2407 24
8 A*2603,2605,6601 X I0.1
9 A*2501 25
A*2601,2602,2604,4301 26
11 A*3401,3402 34
12 A*6602 6602
13 A*1I01,1I02,3401,3402, X 10.2
6601,6602,
A*68011,6802,6901
14 A*4301 43
1 S A*68012,6802,6803 68
16 A*6901 69
17 A*2901,2902,3101,3201 X 19
3301-3303, A*7401
18 A*2901,2902 29
19 A*3001-3004 30
A*3101 31
21 A*3201,250I X 32
37
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
Table 11.
PositionHLA Specificity Kontr. ies Amy PM
Spec
1 A*0101,0102,8001 1
2 A*0201-0217 X 2
3 A*0301,0302 3
4 A*0101,3601 36
A* 1 I 01,1102 11
6 A*2301 23
7 A* 2402-2407 24
8 A*2501,2601-2603, 10.1
2605,6601
9 A*2501 25
A*2601,2602,2604,4301 26
11 A*3401,3402 34
12 A*6602 6602
13 A* 11 Ol ,1102,3401,3402 X 10.2
6601,6602, A*68011,6802,
6901
14 A*4301 43
I S A*6801,6802 X 68
16 A*6901 69
I 7 A*2901-2902,3101,3201, 19
3301-3303, A*7401
18 A*2901,2902 29
19 A*3001-3004 30
7. EXAMPLE: DETERMINATION OF GROUP SPECIFICITY USING
A PRIMER COCKTAIL
Group specific low-resolution typing of the patient sample may be
performed as follows. First, a stock PCR amplification reaction mixture may be
prepared for 30 reactions:
dNTPs IOmM 24
Glycerol 100% 1 S
lOx PCR Buffer* 30
Cresol-red ( l Omg/ml)3.0
H20 45
final 117
38
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
* 1 X PCR Buffer comprises 10 MM Tris-HCl pH 8.3, SO mM KCL, 1.5 mM MgCl2
and 0.001 % (w/v) gelatin.
The stock mixture may be prepared in a large volume and be stored for
at least one month at 4°C or be aliquoted (1 I7.0 ~.1) and stored at -
30°C for at least
six months. Repeated thawing and freezing should be avoided.
A mixture containing all the HLA-A group specific amplification
primers listed in Table 5 may be prepared separately (the "Cocktail"). One
member of
each primer pair is Labelled on the S' end with a fluorescent Label. Final
Cocktail
concentrations may be designed to provide 3 pmol of each HLA-A primer per S
~.1.
Optionally, an internal control primer may be added (to determine among other
things, the success of amplification) in the amount of 0.8 pmol per 5 u1.
Suitable
internal control primers amplify a 1074 by fragment of the human growth
hormone
gene (see supra).
To perform the low resolution amplification reaction, the reaction
mixture may be prepared as follows:
Volume
Stock Mixture 5 ~1
Cocktail 5 ~l
Patient sample DNA 100-250 ng 1 ~l
Taq Polymerase Enzyme 0.4 U 0.08 ~l
PCR cycle parameters may be adjusted for a Perkin-Elmer System
9600 thermal cycler. After an initial denaturation, a first round with 10 two-
temperature cycles may be followed by 20 three-temperature cycles: I ) Initial
Denaturation at 95°C for 5 min; 2) First 10 cycles i) Denaturation at
95°C far 30
seconds and ii} Annealing and extension at 65°C for 50 seconds; 3) Last
20 cycles i)
Denaturation at 95°C for 30 seconds, ii) Annealing at 62°C for
SO seconds and iii)
Extension at 72°C for 30 seconds.
The reaction tube may then be cooled on ice. For visualization, 2u1 of
the amplification product may be run on a polyacrylamide gel giving single
nucleotide
length resolution such as in a MicroGene Blaster. The results were compared to
a
control lane with known size markers. The reaction products may be visualized
either
39
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
as two bands (alleles from different groups) or a single band (alleles from
same
group). The size of the bands) may be determined and group specificity may be
assigned according to the length assignments in Table 5.
8. EXAMPLE: DETER_M_INATION OF ALLELIC TYPE BY SE~L1-ENCING
After determining group type specificity, group specific amplification
of a fresh portion of the patient sample may be performed using a single pair
of
primers specific for the group in question to generate sequencing template. In
a pre-
ferred, nonlimiting embodiment, amplification primers may be selected from
Table 2,
supra, which lists group-specific untranslated region primers. This second
amplification serves two purposes. First, it confirms, by successful
amplification, the
group determination of the low resolution test. Second, it generates sequence
information which may be used for accurate allele identification. If two
groups are
identified, two separate reactions may be performed each using a different
primer pair.
8.1. PCR PROTOCOL
The same PCR protocol may be used for all primer mixes used for
template generation. The PCR amplification may be set up in a total volume of
50u1
in order to produce enough PCR product for more than 10 sequencing reactions.
This
ensures that, if anything fails during the sequencing process, sequencing can
be
repeated without generation of a new template. The high stringency of the PCR
primers and protocol detailed below makes the use of a "hot start approach"
unnecessary. The following PCR reaction mix may be used:
volu~e_ per reaction
5X PCR buffer* 10.01
DMSO 1.O~cl
2.SmM each dNTP S.O,u1
ddH20 27i8u1
Total 43.8,u1
Sense primer** (lOpmol/~1) 1.0/cl
Antisense primer**(l0pmol/ul) l.Oul
Taq Polymerase (SU/~l) 0.2~c1
Genomic DNA (100ng/~cl) 4.Oul
Final Total 50.O~c1
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
*Composition of SX PCR buffer:75mM (NH4)2S04; l7.SmM MgClz; and
300mM Tris-HCL, pH 9.0
**The pair of group specific amplification primers may be selected from
those disclosed in Table 2, supra.
PCR cycle parameters may be adjusted for a Perkin-Elmer System
9600 thermal cycler. After an initial denaturation, a first round with 10 two-
temperature cycles may be followed by 20 three-temperature cycles.
1.) Initial Denaturation at 95 C for 5 min
2.) First 10 cycles
i) Denaturation at 95 C for 30 seconds
ii) Annealing and extension at 65 C for 50 seconds
3.) Last 20 cycles
i) Denaturation at 95 C for 30 seconds
ii) Annealing at 62 C for SO seconds
iii) Extension at 72 C for 30 seconds
l0~cl of the PCR product may then be run on a 2 % agarose gel
prestained with ethidium bromide (0,2 ~g/ml). A distinct band of the expected
size
should be seen.
8.2. SEQUENCING REACTION PROTOCOL
The sequencing reactions may be carried out with AmpliTaqTM DNA
Polymerase FS dye terminator cycle sequencing chemistry using the Ready
Reaction
DyeDeoxy Terminator Cycle Sequencing Kit FS (Perkin Ehner Applied Biosystems
Division, Foster City, CA) according to the manufacturer's protocol. This Kit
contains
the four ddNTPs with different fluorescence labels (=Dye Terminators). The PCR
fragments may be used directly for sequencing without any prior purification
step.
To simplify the pipetting steps, a master mix may be prepared
consisting of the 5'Biotin labeled sequencing primer, ddH20 and the Kit
reagents.
This master mix should be prepared immediately prior to use and can be kept at
room
temperature until use. The sequencing master mix for one reaction may comprise
3.0
~1 of a lpmol/~1 solution of sequencing primer; 6.0 ~1 ddH20, and 8.0 ul of
premixed
sequencing reagents; for 36 + 1 reactions, these amounts are increased,
respectively,
41
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
to 111.0 p.l; 222.0 ~1; and 296.0 pl, respectively. The sequencing primer may
be
selected from the sequencing primers for HLA-A set forth in Table 6, supra.:
The master mix may be aliquoted in a volume of 17,u1 for each
sequencing reaction in a 200,u1 PCR tube and 3/cl of the unpurified PCR
product are
added. The reaction mixes may then be subjected to 25 cycles in a Perkin Elmer
thermal cycler 9600. Each cycle consists of 10 sec 95 C, 5 sec 50 C and 4 min
60 C.
8.3. PURIFICATION OF EXTENSIO~PR_ODUCTS
After the sequencing reaction the extension products are desirably
separated fi-om the unincorporated Dye Terminators which would otherwise
interfere
with the fluorescence-based detection process of the electrophoretically
separated
sequencing fragments.
For each sequencing reaction, 50 pg (5 p.l) Streptavidin-coated
Dynabeads M-280 (Dynal Inc., Oslo, Norway) may be washed in 5 pl of 2x Binding
and Washing buffer ("B&W"; 2X B&W buffer: 2M NaCI, lOmM Tris-HCl pH 7.5,
1mM EDTA). The beads may then be resuspended in 20 ~1 of 2x B&W.
To each 201 sequencing reaction, 20~c1 of resuspended beads may be
added, and the mixture may be incubated at room temperature (20-25 C) for 15
minutes. The beads may then be immobilized, the supernatant may be removed,
and
then the beads may be washed once in 70% ethanol by pipetting up and down five
times. Then, as much as possible of the ethanol may desirably be removed,
because
residual ethanol may interfere with electrophoretic gel mobility.
For each sequencing reaction, 4ul of loading buffer (S:1 Formamide-
25mM EDTA pH 8.0, SOmg/ml Dextran Blue) may be added.
8.4. ELECTROPHORESIS AND DATA~OLLECTION
Samples prepared by the foregoing methods may be used immediately
or be stored at 4 C at least for 24 hours before starting the electrophoretic
separation.
Prior to the electrophoretic separation, each reaction may be incubated at 90
C for 2
minutes. 3u1 of each sample may be loaded on a prerun sequencing gel. For an
automated ABI 377 sequencer (Applied Biosystems, Foster City, CA) a 0,2mm
thick
5% polyacrylamide (acrylamide:bisacrylamide = 29:1) - 7 M urea gel may be used
42
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
[gel composition: 21.0 g urea, 8.4 ml 30% acrylamide (stock solution: 58g
acryl-
amide, 2g bisacrylamide in bidistilled water), 6.0 ml TBE buffer (lOx TBE-
buffer:
108.0 g tris base, 55.0 g boric acid, 7.4 g Na2EDTA), 15 ul TEMED, 350 ~cl 10%
Ammoniumpersulfate ( 1.0 g Ammoniumpersulfate in 10 ml ddHzO), 20.0 ml
ddH2oJ. Electrophoresis may be run at constant 48 watt for 8h. Data collection
may be
initiated immediately after starting the electrophoresis on the ABI377. Data
analyses
may be performed thereafter using the ABI analysis software (version 2.1.1).
8.5. DATA INTERPRETATION AND HLA TYPING
After data collection, the chromatograms may be printed and
sequences may be compared manually to existing HLA data in the EMBL databank
and the sequences compiled by Arnett and Parham. Due to the group-specific
amplification and the lack of heterozygous positions, manual analysis is
typically very
fast. Alternatively, sequences may be checked with the data analysis editor
(Sequence
NavigatorTM, Applied Biosystems) and aligned with any sequence alignment
program.
Various publications are cited herein, the contents of which are hereby
incorporated by reference in their entireties.
43
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
SEQUENCE LISTING
<110> BLASCZYK, RAWER
LEUSHNER, JAMES
< 120> METHOD AND KIT FOR CLAS S I HLA TYPING
<130> 30861A
<140> 08/909,290
<141> 1997-08-11
<150> 08/766,189
<151> 1996-12-12
< 160> 442
<170> FastSEQ for Windows Version 3.0
<210> 1
<211 > 450
<212> DNA
<213> homo Sapiens
<400> 1
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctcttttg ggagccgtac ccggggcagg gagaggaaag tgaaaagtag ggcattagag 420
acagggactt gacctgaggg actgagggtg 450
<210> 2
<211 > 449
<212> DNA
<213> homo Sapiens
<400> 2
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct acttcctggg atgcatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
44
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cgcttcgcga gacagagtta cagagggact cagaaccggg tcctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gtaatagaga~ 420
cagggacttg acctgaggga ctgagggtg 449
<210> 3
<211> 449
<212> DNA
<213> homo Sapiens
<400> 3
gagccgcaga cccctcttag actcagggcc acccacgcac gcccgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct acttcctggg atgcatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgagac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cgcttcgcga gacagagtta cagagggact cagaaccggg tcctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gtaatagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 4
<211 > 449
<212> DNA
<213> homo sapiens
<400> 4
gagccccaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttctcgctgg 60
cgcttctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct acttcctggg atgcatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgagaaca 300
cgcttcgcga gacagagtta cagagggact cagaaccggg tcctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gtaatagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 5
<211> 449
<212> DNA
<213> homo sapiens
<400> 5
gagccccaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttctcgctgg 60
cgettctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct acttcctggg atgcatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgagaaca 300
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
cgcttcgcga gacagagtta cagagggact cagaaccggg tcctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gtaatagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 6
<211 > 449
<212> DNA
<213> homo sapiens
<400> 6
gagccgcaga cccctcttag actcagggcc acccacgcac gcccgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct acttcctggg atgcatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgacact gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cgcttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gtaatagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 7
<211> 449
<212> DNA
<213> homo sapiens
<400> 7
gagccgcaga cccctcttag actcagggcc acccacgcac gcccgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct acttcctggg atgcatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgacact gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cgcttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gtaatagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 8
<211 > 449
<212> DNA
<213> homo sapiens
<400> 8
gagccgcaga cccctcttag actcagggcc acccacgcac gcccgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct acttcctggg atgcatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgacact gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cgcttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
46
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gtaatagaga 420
cagggacttg acctgaggga ctgagggtg ~ 449
<210> 9
<211> 448
<212> DNA
<213> homo Sapiens
<400> 9
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gggggttagg tatgtggcgg aagccccgga 240
ctctgggact ctcggtgcgg accccgggac cctgaagcgg gactggggag acgaagacac 300
ggttcgcgag acagagttac agagggactc agaaccgggt tctcgacaga ctctttgttc 360
cctctttggg agccgtaccc ggggcaggga gaggaaagtg aaaaataggg cattagagac 420
agggacttga cctgagggac tgagggtg 448
<210> 10
<211 > 449
<212> DNA
<213> homo sapiens
<400> 10
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaagaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 11
<211> 449
<212> DNA
<213> homo Sapiens
<400> 11
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaagaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
47
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
cagggacttg acctgaggga ctgagggtg 449
<210> 12
<211> 449
<212> DNA
<213> homo sapiens
<400> 12
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgta 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 13
<211 > 449
<212> DNA
<213> homo sapiens
<400> 13
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgta 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 14
<2I 1> 449
<212> DNA
<213> homo sapiens
<400> 14
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgta 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
48
CA 02300369 2000-02-11
WO 99/07883 PCT1CA98/00768
<210> 15
<211> 449
<212> DNA
<213> homo Sapiens
<400> 15
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaagaca 300
cggttcgcga gacagagtta cagagggact tagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 16
<211> 449
<212> DNA
<213> homo sapiens
<400> 16
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaagaca 300
cggttcgcga gacagagtta cagagggact tagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 17
<211 > 449
<212> DNA
<213> homo Sapiens
<400> 17
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaagaca 300
cggttcgcga gacagagtta cagagggact tagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 18
49
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<211 > 449
<212> DNA
<213> homo sapiens
<400> 18
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaagaca 300
cggttcgcga gacagagtta cagagggact tagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 19
<211> 449
<212> DNA
<213> homo sapiens
<400> 19
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaagaca 300
cggttcgcga gacagagtta cagagggact tagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 20
<2 I 1 > 449
<212> DNA
<213> homo sapiens
<400> 20
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttgtcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaagaca 300
cggttcgcga gacagagtta cagagggact tagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 2l
<211> 449
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<212> DNA
<213> homo sapiens
<400> 21
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg GO
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccgtctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgaga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 22
<211 > 449
<212> DNA
<213> homo sapiens
<400> 22
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatatggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 3G0
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 23
<211> 449
<212> DNA
<213> homo sapiens
<400> 23
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 24
<211> 449
<212> DNA
51
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo sapiens
<400> 24
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatatggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 25
<211> 449
<212> DNA
<213> homo sapiens
<400> 25
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 26
<211> 449
<212> DNA
<213> homo sapiens
<400> 2G
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgta 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 27
<211> 449
<212> DNA
<213> homo sapiens
52
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 27
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgta 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaaatagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 28
<211 > 449
<212> DNA
<213> homo sapiens
<400> 28
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccgtctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgaga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 29
<211 > 449
<212> DNA
<213> homo sapiens
<400> 29
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccgtctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgaga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 30
<211 > 449
<2I2> DNA
<2I3> homo sapiens
<400> 30
53
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180.
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccatgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gacccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 31
<211> 449
<212> DNA
<213> homo Sapiens
<400> 31
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccgtctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 32
<211> 449
<212> DNA
<213> homo Sapiens
<400> 32
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag I 20
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg I 80
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccatgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gacccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 33
<211> 449
<212> DNA
<213> homo sapiens
<400> 33
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
54
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg - 240
actctgggac tctcggtgcg gaccccggga ccatgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gacccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 34
<211 > 449
<212> DNA
<213> homo sapiens
<400> 34
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccgtctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 35
<211> 18
<212> DNA
<213> homo Sapiens
<400> 3 5
acccgggaag ccgggcct 1 g
<210> 36
<211> 449
<212> DNA
<213> homo sapiens
<400> 36
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccgtctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 37
<211 > 449
<212> DNA
<213> homo Sapiens
<400> 37
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt taccctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccgtctccct cttttctttg 180
acgcctcaac cccttagggg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cggttcgcga gacagagtta cagagggact cagaaccggg ttctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 38
<211 > 449
<212> DNA
<213> homo Sapiens
<400> 38
gagccgcaga cccctcttag actcagggcc acccacgcac gcctgaaatc ttggcgctgg 60
cgctgctgtg actaaccgaa gagacctttg ggctgtgggt tatcctcact cttgacccag 120
gcgcagcact cataggtcct tcttcctggg atgtatccaa ccctctccct cttttctttg 180
acgcctcaac cccttagagg ttccgaccct gaggggttag gtatgtggcg gaagccccgg 240
actctgggac tctcggtgcg gaccccggga ccctgaagcg ggactgggga gacgaggaca 300
cgcttcgcga gacagagtta cagagggact cagaaccggg tcctcgacag actctttgtt 360
ccctctttgg gagccgtacc cggggcaggg agaggaaagt gaaaagtagg gcattagaga 420
cagggacttg acctgaggga ctgagggtg 449
<210> 39
<211> 130
<212> DNA
<213> homo sapiens
<400> 39
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaagggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgcccccag 130
<210> 40
<211> 130
<2I2> DNA
<213> homo sapiens
<400> 40
56
*rB
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gtgagtgcgg ggtcgggagg gaaaccgcct ctgcggggag aagcaagggg ccctcctggc 60
gggggcgcag gaccggggga gccgcgccgg gaggagggtc gggcaggtct cagccactgc 120
tcgcccccag 130
<210> 41
<211> 130
<212> DNA
<213> homo Sapiens
<400> 41
gtgagtgcgg ggtcgggagg gaaaccgcct ctgcggggag aagcaagggg ccctcctggc 60
gggggcgcag gaccggggga gccgcgccgg gacgagggtc gggcaggtct cagccactgc 120
tcgcccccag 130
<210> 42
<211> 130
<212> DNA
<213> homo Sapiens
<400> 42
gtgagtgcgg ggtcgggagg gaaaccgcct ctgcggggag aagcaagggg ccctcctggc 60
gggggcgcag gaccggggga gccgcgccgg gaggagggtc gggcaggtct cagccactgc 120
tcgcccccag 130
<210> 43
<211> 130
<212> DNA
<213> homo sapiens
<400> 43
gtgagtgcgg ggtcgggagg gaaaccgcct ctgcggggag aagcaagggg ccctcctggc 60
gggggcgcag gaccggggga gccgcgccgg gaggagggtc gggcaggtct cagccactgc I20
tcgcccccag 130
<210> 44
<211> 130
<212> DNA
<213> homo Sapiens
<400> 44
gtgagtgcgg ggtcgggagg gaaaccgcct ctgcggggag aagcaagggg ccctcctggc 60
gggggcgcag gaccggggga gccgcgccgg gaggagggtc ggtcaggtct cagccactgc 120
tcgcccccag 130
<210> 45
<211> 130
57
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<212> DNA
<213> homo sapiens
<400> 45
gtgagtgcgg ggtcgggagg gaaaccgcct ctgcggggag aagcaagggg ccctcctggc 60
gggggcgcag gaccggggga gccgcgccgg gaggagggtc ggtcaggtct cagccactgc 120
tcgcccccag 130
<210> 46
<211> 130
<212> DNA
<213> homo Sapiens
<400> 46
gtgagtgcgg ggtcgggagg gaaaccgcct ctgcggggag aagcaagggg ccctcctggc 60
gggggcgcag gaccggggga gccgcgccgg gaggagggtc ggtcaggtct cagccactgc 120
tcgcccccag 130
<210> 47
<211> 130
<212> DNA
<213> homo sapiens
<400> 47
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 48
<211> 130
<212> DNA
<213> homo sapiens
<400> 48
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 49
<211> 130
<212> DNA
<213> homo Sapiens
<400> 49
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
58
CA 02300369 2000-02-11
W 0-99/07883 PCT/CA98/00768
<210> 50
<211> 130
<212> DNA
<213> homo Sapiens
<400> 50
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 51
<211> 130
<212> DNA
<213> homo sapiens
<400> 51
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
aQggacQcaa aacccgQ~aa accgcgccgg Qaoaagggtc gggcgggtct cagccactcc 120
oa a o a o as a a as
tcgtccccag 130
<210> 52
<211> 130
<212> DNA
<213> homo Sapiens
<400> 52
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 13 0
<210> 53 _
<211> 130
<212> DNA
<213> homo Sapiens
<400> 53
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 54
<211> 130
<212> DNA
<213> homo Sapiens
59
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> S4
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> SS
<211> I30
<212> DNA
<213> homo sapiens
<400> SS
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> S6
<211> 130
<212> DNA
<2I3> homo Sapiens
<400> 56
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> S7
<211> 130
<212> DNA
<213> homo sapiens
<400> S 7
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> S8
<211> 130
<212> DNA
<213> homo Sapiens
<400> S 8
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> S9
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<211> 130
<212> DNA
<213> homo Sapiens
<400> 59
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 60
<211> 130
<212> DNA
<213> homo sapiens
<400> 60
gtgagtgcgg ggtcgggagg gaaacggcctctgtggggag aagcaacggg cccgcctggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 61
<211> 130
<212> DNA
<213> homo Sapiens
<400> 61
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaagggg cccgcccggc 60
gggggcgcag gacccgggaa gccgcgcctg gaggagggtc gggcgggtct cagccactcc 120
tcgcccccag 130
<210> 62
<211> 130
<212> DNA
<213> homo sapiens
<400> 62
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaagggg cccgcccggc 60
gggggcgcag gacccgggaa gccgcgcctg gaggagggtc gggcgggtct cagccactcc 120
tcgcccccag 130
<210> 63
<211> 130
<212> DNA
<213> homo Sapiens
<400> 63
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaagggg cccgcccggc 60
61
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gggggcgcag gacccgggaa gccgcgcctg gaggagggtc gggcgggtct cagccactcc 120
tcgcccccag ~ 130
<210> 64
<211> 130
<212> DNA
<213> homo Sapiens
<400> 64
gtgagtgcgg ggtcgggagg gaaacggcct ctgcggggag aagcaagggg cccgcctggc 60
gggggcgcaa gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 65
<211> 130
<212> DNA
<213> homo sapiens
<400> 65
gtgagtgcgg ggtcgggagg gaaacggcct ctgcggggag aagcaagggg cccgcctggc 60
gggggcgcaa gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 66
<211> 130
<212> DNA
<213> homo Sapiens
<400> 66
gtgagtgcgg ggtcgggagg gaaacggcct ctgcggggag aagcaagggg cccgcctggc 60
gggggcgcaa gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 67
<211> 130
<212> DNA
<213> homo Sapiens
<400> 67
gtgagtgcgg ggtcgggagg gaaacggcct ctgcggggag aagcaagggg cccgcctggc 60
gggggcgcaa gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 68
<211> 130
<212> DNA
62
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo Sapiens
<400> 68
gtgagtgcgg ggtcgggagg gaaacggcct ctgcggggag aagcaagggg cccgcctggc 60
gggggcgcaa gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 69
<211> 130
<212> DNA
<213> homo Sapiens
<400> 69
gtgagtgcgg ggtcgggagg gaaacggcct ctgcggggag aagcaagggg cccgcctggc 60
gggggcgcaa gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
tcgtccccag 130
<210> 70
<211> 129
<212> DNA
<213> homo Sapiens
<400> 70
gtgagtgcgg ggtcgtgggg aaaccgcctc tgcggggaga agcaaggggc ccgcccggcg 60
gggacgcagg acccgggtag ccgcgccggg aggagggtcg ggtgggtctc agccactcct 120
cgcccccag 129
<210> 71
<211> 130
<212> DNA
<213> homo sapiens
<400> 71
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaagggg cccgcccggc 60
gggggcgcag gacccgggaa gccgcgcctg gaggagggtc gggcgggtct cagccactcc 120
tcgcccccag 130
<210> 72
<211> 130
<212> DNA
<213> homo sapiens
<400> 72
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaagggg cccgcccggc 60
gggggcgcag gacccgggaa gccgcgcctg gaggagggtc gggcgggtct cagccactcc 120
tcgcccccag 130
63
CA 02300369 2000-02-11
WO 99/07883
PCT/CA98/Ob768
<210> 73
<211> 130
<212> DNA
<213> homo sapiens
<400> 73
gtgagtgcgg ggtcgggagg gaaacggcctctgtggggag aagcaagggg cccgcccggc 60
gggggcgcag gacccgggaa gccgcgcctg gaggagggtc gggcgggtct cagccactcc 120
tcgcccccag 130
<210> 74
<211> 130
<212> DNA
<213> homo sapiens
<400> 74
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaagggg cccgcccggc 60
gggggcgcag gacccgggaa gccgcgcctg gaggagggtc gggcgggtct cagccactcc 120
tcgcccccag 130
<210> 75
<211> 130
<212> DNA
<213> homo sapiens
<400> 75
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaagggg cccgcccggc 60
gggggcgcag gacccgggaa gccgcgcctg gaggagggtc gggcgggtct cagccactcc 120
tcgcccccag 130
<210> 76
<211> 130
<212> DNA
<213> homo sapiens
<400> 76
gtgagtgcgg ggtcgggagg gaaacggcct ctgtggggag aagcaagggg cccgcccggc 60
gggggcgcag gacccgggaa gccgcgcctg gaggagggtc gggcgggtct cagccactcc 120
tcgcccccag 130
<210> 77
<211> 129
<212> DNA
<213> homo sapiens
<400> 77
64
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gtgagtgcgg ggtcgtgggg aaaccgcctc tgcggggaga agcaaggggc ccgcccggcg 60
gggacgcagg acccgggtag ccgcgccggg aggagggtcg ggtgggtctc agccactcct 120
cgcccccag I29
<210> 78
<211> 129
<212> DNA
<213> homo Sapiens
<400> 78
gtgagtgcgg ggtcgtgggg aaaccgcctc tgcggggaga agcaaggggc ccgcccggcg 60
gggacgcagg acccgggtag ccgcgccggg aggagggtcg ggtgggtctc agccactcct 120
cgcccccag 129
<210> 79
<211> 129
<212> DNA
<213> homo sapiens
<400> 79
gtgagtgcgg ggtcgtgggg aaaccgcctc tgcggggaga agcaaggggc ccgcccggcg 60
ggggcgcagg acccgggtag ccgcgccggg aggagggtcg ggcggatctc agccactcct 120
cgcccccag 129
<210> 80
<211> 129
<212> DNA
<213> homo sapiens
<400> 80
gtgagtgcgg ggtcgtgggg aaaccgcctctgcggggaga agcaaggggc ccgcccggcg 60
ggggcgcagg acccgggtag ccgcgccggg aggagggtcg ggcgggtctc agccactcct 120
cgcccccag 129
<210> 81
<211> 129
<212> DNA
<213> homo Sapiens
<400> 81
gtgagtgcgg ggtcgtgggg aaaccgcctc tgcggggaga agcaaggggc ccgcccggcg 60
ggggcgcagg acccgggtag ccgcgccggg aggagggtcg ggcggatctc agccactcct 120
cgcccccag 129
<210> 82
<211> 129
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<212> DNA
<213> homo Sapiens
<400> 82
gtgagtgcgg ggtcgtgggg aaaccgcctc tgcggggaga agcaaggggc ccgcccggcg 60
ggggcgcagg acccgggtag ccgcgccggg aggagggtcg ggcggatctc agccactcct 120
cgcccccag 129
<210> 83
<211> 129
<2I2> DNA
<213> homo sapiens
<400> 83
gtgagtgcgg ggtcgtgggg aaaccgcctc tgcggggaga agcaaggggc ccgcccggcg 60
ggggcgcagg acccgggtag ccgcgccggg aggagggtcg ggcgggtctc agccactcct 120
cgcccccag 129
<210> 84
<211> 129
<212> DNA
<213> homo Sapiens
<400> 84
gtgagtgcgg ggtcgtgggg aaaccgcctctgcggggaga agcaaggggc ccgcccggcg 60
ggggcgcagg acccgggtag ccgcgccggg aggagggtcg ggcgggtctc agccactcct 120
cgcccccag 129
<210> 85
<211> 129
<212> DNA
<213> homo Sapiens
<400> 85
gtgagtgcgg ggtcgtgggg aaaccgcctc tgcggggaga agcaaggggc tcgcccggcg 60
ggggcgcagg acccgggtag ccgcgccggg aggagggtcg ggcgggtctc agccactcct 120
cgcccccag 129
<210> 86
<211> 130
<212> DNA
<213> homo sapiens
<400> 86
gtgagtgcgg ggtcgggagg gaaacggcct ctgcggggag aagcaagggg cccgcccggc 60
gggggcgcag gacccgggaa gccgcgccgg gaggagggtc gggcgggtct cagccactcc 120
66
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
tcgcccccag 130
<210> 87
<211> 241
<212> DNA
<213> homo Sapiens
<400> 87
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 88
<211> 241
<212> DNA
<213> homo sapiens
<400> 88
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggactccg agacccttgt 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggcgggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 89
<211> 241
<212> DNA
<213> homo sapiens
<400> 89
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg GO
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 90
<211> 241
<212> DNA
<213> homo Sapiens
<400> 90
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
67
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 91
<211> 241
<212> DNA
<213> homo sapiens
<400> 91
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 92
<211> 241
<212> DNA
<213> homo sapiens
<400> 92
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 93
<211 > 241
<212> DNA
<213> homo Sapiens
<400> 93
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 94
<211> 241
<212> DNA
<213> homo Sapiens
<400> 94
68
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 95
<211> 241
<212> DNA
<213> homo Sapiens
<400> 95
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
8 241
<210> 96
<211> 241
<212> DNA
<213> homo Sapiens
<400> 96
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 97
<211> 241
<212> DNA
<213> homo Sapiens
<400> 97
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 98
<211> 241
<212> DNA
<213> homo Sapiens
69
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 98
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 99
<211> 241
<212> DNA
<213> homo sapiens
<400> 99
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 100
<211> 241
<212> DNA
<213> homo sapiens
<400> 100
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 101
<211> 241
<212> DNA
<213> homo sapiens
<400> 101
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 102
<211> 241
<212> DNA
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo Sapiens
<400> 102
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggcgggg cggggctcgg gggaccgggc tgacctcggg gtccgggcca 240
g 241
<210> 103
<211> 241
<212> DNA
<213> homo Sapiens
<400> 103
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggcgggg cggggctcgg gggaccgggc tgacctcggg gtccgggcca 240
g 241
<210> 104
<211> 241
<212> DNA
<213> homo sapiens
<400> 104
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccaggttggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtccgggcca 240
g 241
<210> 105
<211> 241
<212> DNA
<213> homo sapiens
<400> 105
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggcgggg cggggctcgg gggaccgggc tgacctcggg gtccgggcca 240
g 241
<210> 106
71
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<211> 241
<212> DNA
<213> homo Sapiens
<400> 106
gtgagtgacc ccggcccggg gcgcaggtca cgacccctcatcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggcgggg cggggctcgg gggaccgggc tgacctcggg gtccgggcca 240
g 241
<210> 107
<211 > 241
<212> DNA
<213> homo Sapiens
<400> 107
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggcgggg cggggctcgg gggaccgggc tgacctcggg gtccgggcca 240
g 241
<210> 108
<211> 241
<212> DNA
<213> homo sapiens
<400> 108
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggcgggg cggggctcgg gggaccgggc tgacctcggg gtccgggcca 240
241
<210> 109
<211> 241
<212> DNA
<213> homo Sapiens
<400> 109
gtgagtgacc ccggcccggg gcgcaggtca cgacccctcatcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggcgggg cggggctcgg gggaccgggc tgacctcggg gtccgggcca 240
g 241
72
*rB
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 110
<211> 241
<212> DNA
<213> homo sapiens
<400> 110
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccgc cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggcgggg cggggctcgg gggaccgggc tgacctcggg gtccgggcca 240
g 241
<210> 111
<211> 241
<212> DNA
<213> homo Sapiens
<400> 111
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccggg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggcgggg cggggctcgg gggaccgggc tgacctcggg gtccgggcca 240
g 241
<210> 112
<211> 241
<212> DNA
<213> homo Sapiens
<400> 112
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccggg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccgga cggggctcgg gggactgggc tgaccgtggg gtcggggcca 240
g 241
<210> 113
<211> 241
<212> DNA
<213> homo sapiens
<400> 113
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccggg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccgga cggggctcgg gggactgggc tgaccgtggg gtcggggcca 240
73
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
g 241
<210> 114
<211> 241
<212> DNA
<213> homo Sapiens
<400> 114
gtgagtgacc ccagcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcacccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccgga cggggctcgg gggactgggc tgaccgtggg gtcggggcca 240
g 241
<210> 115
<211> 241
<212> DNA
<213> homo sapiens
<400> 115
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccgga cggggctcgg gggactgggc tgaccgtggg gtcggggcca 240
g 241
<210> 116
<211> 241
<212> DNA
<213> homo Sapiens
<400> 116
gtgagtgacc ccagcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcacccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccgga cggggctcgg gggactgggc tgaccgtggg gtcggggcca 240
g 241
<210> 117
<211> 241
<212> DNA
<213> homo sapiens
<400> 117
gtgagtgacc ccagcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcacccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
74
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccgga cggggctcgg gggactgggc tgaccgtggg gtcggggcca 240
g 241
<210> 118
<211> 241
<212> DNA
<213> homo sapiens
<400> 118
gtgagtgacc ccggccgggg gcgcaggtca ggacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccgga cggggctcgg gggactgggc tgaccgtggg gtcggggcca 240
g 241
<210> I 19
<211> 241
<212> DNA
<213> homo sapiens
<400> 119
gtgagtgacc ccggcccggg gcgcaggtca cgacctctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccgga cggggctcgg gggactgggc tgaccgtggg gtcggggcca 240
g 241
<210> 120
<211> 241
<212> DNA
<213> homo Sapiens
<400> 120
gtgagtgacc ccggccgggg gcgcaggtca ggacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccgga cggggctcgg gggactgggc tgaccgtggg gtcggggcca 240
g 241
<210> 121
<211> 241
<2 i 2> DNA
<213> homo sapiens
<400> 121
CA 02300369 2000-02-11
WO 99107883 PCT/CA98/00768
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccggg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc cttaacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 122
<211> 241
<212> DNA
<213> homo sapiens
<400> 122
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccggg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc cttaacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 123
<211> 241
<212> DNA
<213> homo sapiens
<400> 123
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccggg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc cttaacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 124
<211> 241
<212> DNA
<213> homo Sapiens
<400> 124
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccggg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc cttaacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 125
<211> 241
<212> DNA
<213> homo sapiens
76
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 125
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccggg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc- 120
cccgggagag gcccaggcgc cttaacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 126
<211> 241
<212> DNA
<213> homo sapiens
<400> 126
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccggg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc cttaacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 127
<211> 241
<212> DNA
<2I3> homo Sapiens
<400> 127
gtgagtgacc ccggccgggg gcgcaggtca ggacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc l 80
ccgggttggt cggggctggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 128
<211> 241
<212> DNA
<213> homo sapiens
<400> 128
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tggcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccggg cagggcttgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 129
<211> 241
<212> DNA
77
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo sapiens
<400> 129
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tggcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggttggt cggggccggg cagggcttgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 130
<211> 241
<212> DNA
<213> homo Sapiens
<400> 130
gtgagtgacc ccggccgggg gcgcaggtca cgacccctcatcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttga 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaattccc 180
ccgggttggt cggggctggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 131
<211> 241
<212> DNA
<213> homo Sapiens
<400> 131
gtgagtgacc ccgcccgggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttga 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaattccc 180
ccgggttggt cggggctggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 132
<211> 241
<212> DNA
<213> homo Sapiens
<400> 132
gtgagtgacc ccggccgggg gcgcaggtca cgacccctca tcccccacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttga 120
cccgggagag gcccaggcgc ctttacccgg tttcattttc agtttaggcc aaaaattccc 180
ccgggttggt cggggctggg cggggctcgg gggactgggc tgaccgcggg gtcggggcca 240
g 241
<210> 133
78
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<211> 241
<212> DNA
<213> homo sapiens
<400> 133
gtgagtgacc ccggcccggg gcgcaggtca cgacccctca tcccctacgg acgggccagg 60
tcgcccacag tctccgggtc cgagatccac cccgaagccg cgggaccccg agacccttgc 120
cccgggagag gcccaggcgc ctttagccgg tttcattttc agtttaggcc aaaaatcccc 180
ccgggtgggt cggggcgggg cggggctcgg gggaccgggc tgaccgcggg gtcggggcca 240
g 241
<210> 134
<211 > 602
<212> DNA
<2I3> homo sapiens
<400> 134
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgag cacaattaag ggataaaaat ctctgaagga atgacgggaa gacgatccct 240
cgaatactga tgagtggttc cctttgacac acaccggcag cagccttggg cccgtgactt 300
ttcctctcag gccttgttct ctgcttcaca ctcaatgtgt gtgggggtct gagtccagca 360
cttctgagtc cctcagcctc cactcaggtc aggaccagaa gtcgctgttc cctcttcagg 420
gactagaatt ttccacggaa taggagatta tcccaggtgc ctgtgtccag gctggtgtct 480
gggttctgtg ctcccttccc catcccaggt gtcctgtcca ttctcaagat agccacatgt 540
gtgctggagg agtgtcccat gacagatgca aaatgcctga atgttctgac tcttcctgac 600
ag 602
<210> 135
<211> 579
<212> DNA
<213> homo sapiens
<400> 13 5
gtaccagggg ccacggggcg cctccctgat cgcctataga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcac cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggagt gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacaccg gcagcagcct tgggcccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
agtctctcag cctccactca ggtcaggacc agaagtcgct gttcccttct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcgtg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 579
79
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 136
<211> 578
<212> DNA
<213> homo Sapiens
<400> 136
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcac cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttc cagatcctgt accagagagt gactctgagg ttccgccctg 180
ctctctgaca caattaaggg ataaaatctc tgaaggagtg acgggaagac gatccctcga 240
atactgatga gtggttccct ttgacaccgg cagcagcctt gggcccgtga cttttcctct 300
caggccttgt tctctgcttc acactcaatg tgtgtggggg tctgagtcca gcacttctga 360
gtccctcagc ctccactcag gtcaggacca gaagtcgctg ttcccttctc agggaataga 420
agattatccc aggtgcctgt gtccaggctg gtgtctgggt tctgtgctct cttccccatc 480
ccgggtgtcc tgtccattct caagatggcc acatgcgtgc tggtggagtg tcccatgaca 540
gatgcaaaat gcctgaattt tctgactctt cccgtcag $7g
<210> 137
<211> 579
<212> DNA
<213> homo Sapiens
<400> 137
gtaccagggg ccacggggcg cctccctgat cgcctataga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcac cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggagt gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacaccg gcagcagcct tgggcccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
agtctctcag cctccactca ggtcaggacc agaagtcgct gttcccttct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcgtg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 579
<210> 138
<211> 579
<212> DNA
<213> homo Sapiens
<400> 138
gtaccagggg ccacggggcg cctccctgat cgcctataga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcac cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggagt gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacaccg gcagcagcct tgggcccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
agtctctcag cctccactca ggtcaggacc agaagtcgct gttcccttct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ~ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcgtg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 579
<210> 139
<211> 579
<212> DNA
<213> homo sapiens
<400> 139
gtaccagggg ccacggggcg ccttcctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcac cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggagt gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacaccg gcagcagcct tgggcccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
agtccctcag cctccactca ggtcaggacc agaagtcgct gttcccttct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcgtg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 579
<210> 140
<211> 579
<212> DNA
<213> homo sapiens
<400> 140
gtaccagggg ccacggggcg ccttcctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcac cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac tcaattaagg gataaaatct ctgaaggagt gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacaccg gcagcagcct tgggcccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
agtccctcag cctccactca ggtcaggacc agaagtcgct gttcccttct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcgtg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 579
<210> 141
<211> 579
<212> DNA
<213> homo sapiens
<400> 141
gtaccagggg ccacggggcg ccttcctgat cgcctgtaga tctcccgggc tggcctccca 60
81
*rB
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
caaggagggg agacaattgg gaccaacact agaatatcac cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg faccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggagt gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacaccg gcagcagcct tgggcccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
agtccctcag cctccactca ggtcaggacc agaagtcgct gttcccttct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcgtg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 579
<210> 142
<211 > 600
<212> DNA
<213> homo Sapiens
<400> 142
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 143
<211 > 600
<212> DNA
<2I3> homo Sapiens
<400> 143
gtaccagggg ccacggggcg cctccctgat cgcctgtaga 60
tctcccgggc tggcctccca
caaggagggg agacaattgg gaccaacact agaatatcgc 120
cctccctctg gtcctgaggg
agaggaatcc tcctgggttt ccagatcctg taccagagag 180
tgactctgag gttccgccct
gctctctgac acaattaagg gataaaatct ctgaaggaat 240
gacgggaaga cgatccctcg
aatactgatg agtggttccc tttgacacac acaggcagca 300
gccttgggcc cgtgactttt
cctctcaggc cttgttctct gcttcacact caatgtgtgt 60
gggggtctga gtccagcact 3
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt 420
cgctgttccc tcttcaggga
ctagaatttt ccacggaata ggagattatc ccaggtgcct 480
gtgtccaggc tggtgtctgg
gttctgtgct cccttcccca tcccaggtgt cctgtccatt
ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat 600
gatctgactc ttcctgacag
<210> 144
<211 > 600
82
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<212> DNA
<213> homo Sapiens
<400> 144
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 145
<2I I > 600
<212> DNA
<213> homo Sapiens
<400> 145
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 146
<211 > 600
<212> DNA
<213> homo Sapiens
<400> 146
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
83
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 147
<211> 600
<212> DNA
<213> homo Sapiens
<400> 147
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 148
<211 > 600
<212> DNA
<213> homo Sapiens
<400> 148
gtaccagggg ccacggggcg cctccctgat cgcctgtaga60
tctcccgggc tggcctccca
caaggagggg agacaattgg gaccaacact agaatatcgc120
cctccctctg gtcctgaggg
agaggaatcc tcctgggttt ccagatcctg taccagagag180
tgactctgag gttccgccct
gctctctgac acaattaagg gataaaatct ctgaaggaat240
gacgggaaga cgatccctcg
aatactgatg agtggttccc tttgacacac acaggcagca300
gccttgggcc cgtgactttt
cctctcaggc cttgttctct gcttcacact caatgtgtgt60
gggggtctga gtccagcact 3
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt420
cgctgttccc tcttcaggga
ctagaatttt ccacggaata ggagattatc ccaggtgcct480
gtgtccaggc tggtgtctgg
gttctgtgct cccttcccca tcccaggtgt cctgtccatt
ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat600
gatctgactc ttcctgacag
<210> 149
<211 > 600
<212> DNA
<213> homo sapiens
<400> 149
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
84
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gctctctgac acaattaagg gataaaatct ctgaaggaat240
gacgggaaga cgatccctcg
aatactgatg agtggttccc tttgacacac acaggcagca300
gccttgggcc cgtgactttt
cctctcaggc cttgttctct gcttcacact caatgtgtgt360
gggggtctga gtccagcact
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt420
cgctgttccc tcttcaggga
ctagaatttt ccacggaata ggagattatc ccaggtgcct480
gtgtccaggc tggtgtctgg
gttctgtgct cccttcccca tcccaggtgt cctgtccatt
ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat600
gatctgactc ttcctgacag
<210> 150
<211 > 600
<212> DNA
<213> homo sapiens
<400> 150
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 151
<211 > 600
<212> DNA
<213> homo sapiens
<400> 151
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 152
<211 > 600
<2I2> DNA
<213> homo sapiens
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 152
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg - 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 153
<211 > 600
<212> DNA
<213> homo sapiens
<400> 153
gtaccagggg ccacggggcg cctccctgat cgcctgtaga60
tctcccgggc tggcctccca
caaggagggg agacaattgg gaccaacact agaatatcgc120
cctccctctg gtcctgaggg
agaggaatcc tcctgggttt ccagatcctg taccagagag180
tgactctgag gttccgccct
gctctctgac acaattaagg gataaaatct ctgaaggaat240
gacgggaaga cgatccctcg
aatactgatg agtggttccc tttgacacac acaggcagca300
gccttgggcc cgtgactttt
cctctcaggc cttgttctct gcttcacact caatgtgtgt60
gggggtctga gtccagcact 3
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt420
cgctgttccc tcttcaggga
ctagaatttt ccacggaata ggagattatc ccaggtgcct480
gtgtccaggc tggtgtctgg
gttctgtgct cccttcccca tcccaggtgt cctgtccatt
ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat600
gatctgactc ttcctgacag
<210> 154
<211 > 600
<212> DNA
<213> homo sapiens
<400> 154
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
86
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 155
<211 > 600
<212> DNA
<213> homo sapiens
<400> 155
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 156
<211> 600
<212> DNA
<213> homo sapiens
<400> 1 S 6
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 157
<211> 600
<212> DNA
<213> homo sapiens
<400> 157
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg I20
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac acaggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
87
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
tctgagtcct tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gatctgactc ttcctgacag 600
<210> 158
<211> 579
<212> DNA
<213> homo Sapiens
<400> 158
gtaccagggg ccacggggcg cctacctgat cgcctgtagg tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgacggaat gacggaaaga cgatccctcg 240
aatactgatg actggttccc tttgacaccg gcagcagcct tgggaccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
agtccctcag cctccactca ggtcaggacc agaagtcgct gttccctcct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcatg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 579
<210> 159
<211> 579
<212> DNA
<213> homo sapiens
<400> 159
gtaccagggg ccacggggcg cctacctgat cgcctgtagg tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgacggaat gacggaaaga cgatccctcg 240
aatactgatg actggttccc tttgacaccg gcagcagcct tgggaccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
agtccctcag cctccactca ggtcaggacc agaagtcgct gttccctcct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcatg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 579
<210> 160
<211> 579
<212> DNA
<213> homo Sapiens
<400> 160
gtaccagggg ccacggggcg cctacctgat cgcctgtagg tctcccgggc tggcctccca 60
88
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
caaggagggg agacaattgg gaccaacact agaatatcgc
cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag180
tgactctgag gttccgccct
gctctctgac acaattaagg gataaaatct ctgacggaat240
gacggaaaga cgatccctcg
aatactgatg actggttccc tttgacaccg gcagcagcct300
tgggaccgtg acttttcctc
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg360
gtctgagtcc agcacttctg
agtccctcag cctccactca ggtcaggacc agaagtcgct420
gttccctcct cagggaatag
aagattatcc caggtgcctg tgtccaggct ggtgtctggg480
ttctgtgctc tcttccccat
cccgggtgtc ctgtccattc tcaagatggc cacatgcatg540
ctggtggagt gtcccatgac
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag
579
<210> 161
<211> 579
<212> DNA
<213> homo sapiens
<400> 161
gtaccagggg ccacggggcg cctacctgat cgcctgtagg tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgacggaat gacggaaaga cgatccctcg 240
aatactgatg actggttccc tttgacaccg gcagcagcct tgggaccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
agtccctcag cctccactca ggtcaggacc agaagtcgct gttccctcct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcatg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 579
<210> 162
<211> 579
<212> DNA
<213> homo sapiens
<400> 162
gtaccagggg ccacggggcg cctacctgat cgcctgtagg tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgacggaat gacggaaaga cgatccctcg 240
aatactgatg actggttccc tttgacaccg gcagcagcct tgggaccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
agtccctcag cctccactca ggtcaggacc agaagtcgct gttccctcct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcatg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 579
<210> 163
<211> 579
89
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<212> DNA
<213> homo Sapiens
<400> 163
gtaccagggg ccacggggcg cctacctgat cgcctgtagg tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgacggaat gacggaaaga cgatccctcg 240
aatactgatg actggttccc tttgacaccg gcagcagcct tgggaccgtg acttttcctc 300
tcaggccttg ttctctgctt cacactcaat gtgtgtgggg gtctgagtcc agcacttctg 360
agtccctcag cctccactca ggtcaggacc agaagtcgct gttccctcct cagggaatag 420
aagattatcc caggtgcctg tgtccaggct ggtgtctggg ttctgtgctc tcttccccat 480
cccgggtgtc ctgtccattc tcaagatggc cacatgcatg ctggtggagt gtcccatgac 540
agatgcaaaa tgcctgaatt ttctgactct tcccgtcag 5'79
<210> 164
<211 > 600
<212> DNA
<213> homo sapiens
<400> 164
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 165
<211> 600
<212> DNA
<213> homo sapiens
<400> 165
gtaccagggg ccacggggcg cctccctgat cgcctgtaga60
tctcccgggc tggcctccca
caaggagggg agacaattgg gaccaacact agaatatcgc120
cctccctctg gtcctgaggg
agaggaatcc tcctgggttt ccagatcctg taccagagag180
tgactctgag gttccgccct
gctctctgac acaattaagg gataaaatct ctgaaggaat240
gacgggaaga cgatccctcg
aatactgatg agtggttccc tttgacacac accggcagca300
gccttgggcc cgtgactttt
cctctcaggc cttgttctct gcttcacact caatgtgtgt60
gggggtctga gtccagcact 3
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt420
cgctgttccc tcttcaggga
ctagaatttt ccacggaata ggagattatc ccaggtgcct480
gtgtccaggc tggtgtctgg
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 166
<211 > 600
<212> DNA
<213> homo Sapiens
<400> 166
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 167
<211 > 600
<212> DNA
<213> homo sapiens
<400> 167
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 168
<211 > 600
<212> DNA
<213> homo Sapiens
<400> 168
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
91
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gctctctgac acaattaagg gataaaatct ctgaaggaat
gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca300
gccttgggcc cgtgactttt
cctctcaggc cttgttctct gcttcacact caatgtgtgt360
gggggtctga gtccagcact
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt420
cgctgttccc tcttcaggga
ctagaatttt ccacggaata ggagattatc ccaggtgcct480
gtgtccaggc tggtgtctgg
gttctgtgct cccttcccca tcccaggtgt cctgtccatt540
ctcaagatag ccacatgtgt
gctggaggag tgtcccatga cagatgcaaa atgcctgaat600
gttctgactc ttcctgacag
<210> 169
<211 > 600
<212> DNA
<213> homo sapiens
<400> 169
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 170
<211 > 600
<212> DNA
<213> homo Sapiens
<400> 170
gtaccagggg ccacggggcg cctccctgat cgcctgtaga60
tctcccgggc tggcctccca
caaggagggg agacaattgg gaccaacact agaatatcgc120
cctccctctg gtcctgaggg
agaggaatcc tcctgggttt ccagatcctg taccagagag180
tgactctgag gttccgccct
gctctctgac acaattaagg gataaaatct ctgaaggaat240
gacgggaaga cgatccctcg
aatactgatg agtggttccc tttgacacac accggcagca300
gccttgggcc cgtgactttt
cctctcaggc cttgttctct gcttcacact caatgtgtgt60
gggggtctga gtccagcact 3
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt420
cgctgttccc tcttcaggga
ctagaatttt ccacggaata ggagattatc ccaggtgcct480
gtgtccaggc tggtgtctgg
gttctgtgct cccttcccca tcccaggtgt cctgtccatt
ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat600
gttctgactc ttcctgacag
<210> 171
<211> 600
<212> DNA
<213> homo Sapiens
92
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 171
gtaccggggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 172
<211 > 600
<212> DNA
<213> homo Sapiens
<400> 172
gtaccggggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 173
<211 > 600
<212> DNA
<213> homo sapiens
<400> 173
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcac cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctgtgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatta cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
93
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 174
<211> 600
<212> DNA
<213> homo sapiens
<400> 174
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 175
<211 > 600
<212> DNA
<213> homo sapiens
<400> 175
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcac cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctgtgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatta cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 176
<211 > 600
<212> DNA
<213> homo sapiens
<400> 176
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcac cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctgtgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
94
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatta cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<2I0> 177
<211 > 600
<212> DNA
<213> homo Sapiens
<400> 177
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgcct gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 178
<211> 600
<212> DNA
<213> homo Sapiens
<400> 178
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
caaggagggg agacaattgg gaccaacact agaatatcgc cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg taccagagag tgactctgag gttccgccct 180
gctctctgac acaattaagg gataaaatct ctgaaggaat gacgggaaga cgatccctcg 240
aatactgatg agtggttccc tttgacacac accggcagca gccttgggcc cgtgactttt 300
cctctcaggc cttgttctct gcttcacact caatgtgtgt gggggtctga gtccagcact 360
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt cgctgttccc tcttcaggga 420
ctagaatttt ccacggaata ggagattatc ccaggtgctt gtgtccaggc tggtgtctgg 480
gttctgtgct cccttcccca tcccaggtgt cctgtccatt ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat gttctgactc ttcctgacag 600
<210> 179
<211 > 600
<212> DNA
<213> homo Sapiens
<400> 179
gtaccagggg ccacggggcg cctccctgat cgcctgtaga tctcccgggc tggcctccca 60
*rB
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
caaggagggg agacaattgg gaccaacact agaatatcgc
cctccctctg gtcctgaggg 120
agaggaatcc tcctgggttt ccagatcctg faccagagag180
tgactctgag gttccgccct
gctctctgac acaattaagg gataaaatct ctgaaggaat240
gacgggaaga cgatccctcg
aatactgatg agtggttccc tttgacacac accggcagca300
gccttgggcc cgtgactttt
cctctcaggc cttgttctct gcttcacact caatgtgtgt360
gggggtctga gtccagcact
tctgagtccc tcagcctcca ctcaggtcag gaccagaagt420
cgctgttccc tcttcaggga
ctagaatttt ccacggaata ggagattatc ccaggtgcct480
gtgtccaggc tggtgtctgg
gttctgtgct cccttcccca tcccaggtgt cctgtccatt
ctcaagatag ccacatgtgt 540
gctggaggag tgtcccatga cagatgcaaa atgcctgaat600
gttctgactc ttcctgacag
<210> 180
<211> 583
<212> DNA
<213> homo sapiens
<400> 180
gtaccagggg ccacggggcg ccttcctgat cgcctgtaga60
tctcccgggc tggcctccca
caaggagggg agacaattgg gaccaacact agatatcacc120
ctccctctgc tcctgaggga
gaggaatcct cctgggtttc cagattctgt accagagagt180
gactctgagg ttccgccctg
ctctctgaca caattaaggg ataaaaatct ctgaaggaat240
gacgggaaga cgatccctcg
aatactgatg agtggttccc tttgacacac accggcggca300
gccttgggcc cgtgactttt
cctctcaggc cctgttctct gcttcacact caatatgtgt
gggggtctga gtccagcact 360
tctgagtctc tcagcctcca ctcaggtcag gaccagaagt420
cgctgttccc tcgtcaggga
atagaagatt atcccaggtg cctgtgtcca ggctggtgtc
tgggttctgt gctctcttcc 480
ccatcccagg tgtcctgtcc atcctcaaaa tggccacatg540
cgtgctggtg gagtgtccca
tgacagatgc aaaatggctg aattttctga ctcttcccgt
cag 583
<210> 181
<211> 18
<212> DNA
<213> homo sapiens
<400> 181
ggcaggtctc agcgactg 1 g
<210> 182
<211> 19
<212> DNA
<213> homo sapiens
<400> 182
ctctgtgggg agaagcaac 19
<210> 183
<211> 17
<212> DNA
96
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo sapiens
<400> 183
gggagcggcg ccgggac 17
' <210> 184
<211> 18
<212> DNA
<213> homo Sapiens
<400> 184
gaagcaaggg gcccgccc lg
<210> 185
<211> 18
<212> DNA
<213> homo sapiens
<400> 185
cgcctggcgg gggggcaa 1 g
<210> 186
<211> 18
<212> DNA
<213> homo sapiens
<400> 186
gtgagtgcgg ggtcgtgg 1 g
<210> 187
<211> 18
<212> DNA
<213> homo Sapiens
<400> 187
gccgggagga gggacggt lg
<210> 188
<211> 17
<212> DNA
<213> homo Sapiens
<400> 188
ggcgcgcccg gcgggga 17
<210> 189
97
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<211> 18
<212> DNA
<213> homo Sapiens
<400> 189
ggaggagg~ cgggcgga 18
<210> 190
<211> 19
<212> DNA
<213> homo Sapiens
<400> 190
agtgtcttcg cggtcgctc 19
<210> 191
<211> 19
<212> DNA
<213> homo Sapiens
<400> 191
ctcagattct ccccagacg 19
<210> 192
<211> 20
<212> DNA
<213> homo Sapiens
<400> 192
catgccgagg gtttctccca 20
<210> 193
<211> 19
<212> DNA
<213> homo Sapiens
<400> 193
ctggccctga cccagacca 19
<210> 194
<211> 19
<212> DNA
<213> homo Sapiens
<400> 194
cctgacccag acctgggca 19
98
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 195
<211> 19
<212> DNA
<213> homo Sapiens
<400> 195
caggtatctg cggagcccg 19
<210> 196
<211> 21
<212> DNA
<2I3> homo Sapiens
<400> 196
gtctgtcagg aagagtcaga a 21
<210> 197
<21 I > 22
<212> DNA
<213> homo Sapiens
<400> 197
gtggaaaatt ctagtccctg as 22
<210> 198
<211> 20
<212> DNA
<213> homo Sapiens
<400> 198
agatctacag gcgatcagga 20
<210> 199
<2I I> 19
<2I2> DNA
<213> homo Sapiens
<400> 199
gccagcccgg gagttctat 19
<210> 200
<211> Z1
<212> DNA
<213> homo sapiens
<400> 200
99
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
cagagtcact ctctggtaca g 21
<210> 201
<211> 19
<212> DNA
<213> homo Sapiens
<400> 201
gcgatcgtct tcccgtcac 19
<210> 202
<211> 21
<212> DNA
<213> homo Sapiens
<400> 202
agagtcactc tctggtacag a 21
<210> 203
<211> 19
<212> DNA
<213> homo Sapiens
<400> 203
ctcctcgtcc ccaggctct 19
<210> 204
<211> 21
<212> DNA
<213> homo Sapiens
<400> 204
tccatgaggt atttctacac c 21
<210> 205
<211> 18
<212> DNA
<213> homo Sapiens
<400> 205
ggccaggttc tcagacca 1 g
<210> 206
<211> 17
<212> DNA
<213> homo sapiens
100
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 206
cccggcccgg cagtgga ~ 17
<210> 207
<211> 20
' <212> DNA
<213> homo Sapiens
<400> 207
gttctcacac catccagatg 20
<210> 208 '
<211> 21
<212> DNA
<213> homo Sapiens
<400> 208
tcacaccctc cagatgatgt t 21
<210> 209
<211> 18
<212> DNA
<213> homo sapiens
<400> 209
gggtaccagc aggacgct 1 g
<210> 210
<211> 21
<212> DNA
<213> homo Sapiens
<400> 210
tccatgaggt atttcaccac a 21
<210> 211
<211> 21
<212> DNA
<213> homo sapiens
<400> 211
ggttctcaca ccatccagat a 21
<210> 212
<211> 20
<212> DNA
101
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo sapiens
<400> 212
gttctcacac catccagagg 20
' <210> 213
<211> 18
<212> DNA
<213> homo sapiens
<400> 213
gagccccgct tcaacgcc 1 g
<210> 214
<211> 19
<212> DNA
<213> homo Sapiens
<400> 214
cttcctccgc gggtatgaa 19
<210> 215
<211> 18
<212> DNA
<213> homo sapiens
<400> 215
gccggagtat tgggaccg 1 g
<210> 216
<211> 19
<212> DNA
<213> homo sapiens
<400> 216
ctggccctga ccctgacca 19
<210> 217
<211> 18
<212> DNA
<213> homo sapiens
<400> 217
gcagggtccc caggtcca 1 g
<210> 218
102
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<21I> 19
<212> DNA
<213> horilo sapiens
<400> 2I8
' cctccaggta ggctctcaa 19
<210> 219
<211> 19
<212> DNA
<213> homo sapiens
<400> 219
cctccaggta ggctctcca 19
<210> 220
<211> 19
<2I2> DNA
<213> homo sapiens
<400> 220
cctccaggta ggctctctg 19
<210> 221
<211> 19
<212> DNA
<213> homo sapiens
<400> 221
ccactccacg cacgtgcca 19
<210> 222
<211> 18
<212> DNA
<213> homo sapiens
<400> 222
ggagcgcgat ccgcaggc 1 g
<210> 223
<211> 19
<212> DNA
<2I3> homo sapiens
<400> 223
ggagccactc cacggaccg 19
103
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 224
<211> 18
<212> DNA
<213> homo Sapiens
<400> 224
gagccactcc acgcactc 1 g
<210> 225
<211> 21
<212> DNA
<2I3> homo Sapiens
<400> 225
ggccttcaca ttccgtgtgt t 21
<210> 226
<211> 19
<212> DNA
<213> homo Sapiens
<400> 226
caggtatctg cggagcccg 19
<210> 227
<211> 20
<212> DNA
<213> homo Sapiens
<400> 227
tggtcccaat actcaggcct 20
<210> 228
<211> 18
<212> DNA
<213> homo Sapiens
<400> 228
gcagggtccc caggttcg 1 g
<210> 229
<211> 18
<212> DNA
<213> homo Sapiens
<400> 229
104
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gggccgcctc ccagttgt 1 g
<210> 230
<211> 20
<212> DNA
<213> homo Sapiens
<400> 230
tctgtgagtg ggcctacaca 20
<210> 231
<211> 21
<212> DNA
<213> homo Sapiens
<400> 231
ccttcacatt ccgtgtctgc a 21
<210> 232
<211> 18
<212> DNA
<213> homo Sapiens
<400> 232
gagccactcc acgcacgt 1 g
<210> 233
<211> 20
<212> DNA
<213> homo sapiens
<400> 233
ccactcggtc agtctctgac 20
<210> 234
<211> 20
<212> DNA
<213> homo Sapiens
<400> 234
gagcgcaggt cctcgttcaa 20
<2I0> 235
<211> 20
<212> DNA
<213> homo Sapiens
105
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 235
gtctgtgagt gggccatcat ~ 20
<210> 236
<211> 20
<212> DNA
<213> homo Sapiens
<400> 236
cagccataca tcctcaggac 20
<210> 237
<211> 17
<212> DNA
<213> homo Sapiens
<400> 237
gcgccgggag gagggtc 17
<210> 238
<211> 18
<212> DNA
<213> homo sapiens
<400> 238
atctcggacc cggagact 1 g
<210> 239
<211> 22
<212> DNA
<213> homo Sapiens
<400> 239
gtttcatttt cagtttaggc ca 22
<210> 240
<211> 23
<212> DNA
<213> homo Sapiens
<400> 240
cgggagatct acaggcgatc agg 23
<210> 241
<211> 17
<212> DNA
106
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo sapiens
<400> 241
gtcgtgacctgcgcccc 17
<210> 242
<211> 19
<212> DNA
<213> homo Sapiens
<400> 242
gggcggggcg gggctcggg 19
<210> 243
<211> 19
<212> DNA
<213> homo sapiens
<400> 243
ggtcgtgacc ttccgcccc 19
<210> 244
<211> 15
<212> DNA
<213> homo Sapiens
<400> 244
cccggtttca ttttc 1 S
<210> 245
<211> 20
<212> DNA
<213> homo sapiens
<400> 245
cttcacattc cgtgtctcct 20
<210> 246
<211> 129
<212> DNA
<213> homo Sapiens
<400> 246
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
107
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 247
<211> 128
<212> DNA
<213> homo Sapiens
<400> 247
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
acccccag 128
<210> 248
<211> 128
<212> DNA
<213> homo Sapiens
<400> 248
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 249
<211> 129
<212> DNA
<213> homo Sapiens
<400> 249
gtgagtgcgg gatcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtct ggcgggtctc agcccctcct 120
ggcccccag 129
<210> 250
<21I> 128
<212> DNA
<213> homo sapiens
<400> 250
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtttca gcccctcctc 120
gcccccag 128
<210> 251
<211> 128
<212> DNA
<213> homo Sapiens
<400> 251
108
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtttca gcccctcctc 120
gcccccag 128
<210> 252
<211> 129
<212> DNA
<213> homo sapiens
<400> 252
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 253
<211> 128
<212> DNA
<213> homo Sapiens
<400> 253
gtgagtgcgg gtcgggaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 254
<211> 129
<212> DNA
<213> homo Sapiens
<400> 254
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 255
<211> 129
<212> DNA
<213> homo sapiens
<400> 255
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 256
<211> 129
109
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<212> DNA
<213> homo Sapiens
<400> 256
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 257
<211> 129
<2I2> DNA
<213> homo Sapiens
<400> 257
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 258
<2I 1> 128
<212> DNA
<213> homo Sapiens
<400> 258
gtgagtgcgg gtcgggaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 259
<211> 128
<212> DNA
<213> homo sapiens
<400> 259
gtgagtgcgg gtcgggaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 260
<211> 128
<212> DNA
<213> homo Sapiens
<400> 260
gtgagtgcgg gtcgggaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
I10
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gcccccag 128
<210> 261
<211> 129
<212> DNA
<213> homo Sapiens
<400> 261
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 262
<211> 129
<212> DNA
<213> homo sapiens
<400> 262
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
tgcccccag 129
<210> 263
<211> 129
<212> DNA
<213> homo Sapiens
<400> 263
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
tgcccccag 129
<210> 264
<211> 129
<212> DNA
<213> homo sapiens
<400> 264
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 265
<211> 129
<212> DNA
<213> homo Sapiens
111
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 265
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 266
<211> 129
<212> DNA
<213> homo Sapiens
<400> 266
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 267
<2I1> 129
<212> DNA
<213> homo Sapiens
<400> 267
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acctgaggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 268
<211> 129
<212> DNA
<213> homo sapiens
<400> 268
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acctgaggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 269
<211> 129
<212> DNA
<213> homo Sapiens
<400> 269
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acctgaggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 270
112
*rB
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<211> 129
<212> DNA
<213> homo Sapiens
<400> 270
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 271
<211> 128
<212> DNA
<213> homo sapiens
<400> 271
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 272
<211> 128
<212> DNA
<213> homo Sapiens
<400> 272
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 273
<211> 128
<212> DNA
<213> homo sapiens
<400> 273
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 274
<211> 128
<212> DNA
<213> homo Sapiens
<400> 274
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
113
CA 02300369 2000-02-11
WO 99/0?883 PCT/CA98/00?68
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 275
<211> 128
<212> DNA
<213> homo sapiens
<400> 275
gtgagtgcgg gtcggcaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gctcctcctc 120
gcccccag 128
<210> 276
<211> 129
<212> DNA
<213> homo sapiens
<400> 276
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 277
<211> 128
<212> DNA
<213> homo sapiens
<400> 277
gtgagtgcgg gtcggcaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gctcctcctc I20
gcccccag 128
<210> 278
<211> I28
<212> DNA
<213> homo sapiens
<400> 278
gtgagtgcgg gtcggcaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gctcctcctc I20
gcccccag 128
<210> 279
<211> 128
<212> DNA
114
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo Sapiens
<400> 279
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc I20
acccccag 128
<210> 280
<211> I29
<212> DNA
<213> homo Sapiens
<400> 280
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagagagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct I20
cgcccccag 129
<210> 281
<211> 129
<212> DNA
<213> homo sapiens
<400> 281
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagagagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 282
<211> 128
<212> DNA
<213> homo Sapiens
<400> 282
gtgagtgcgg gtcggcaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 283
<211> 129
<212> DNA
<213> homo sapiens
<400> 283
gtgagtgcgg ggtcggcagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
115
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 284
<211> 129
<212> DNA
<213> homo sapiens
<400> 284
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggctcagg acccggggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 285
<211> 128
<212> DNA
<213> homo sapiens
<400> 285
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
acccccag 128
<210> 286
<211> 128
<212> DNA
<213> homo Sapiens
<400> 286
gtgagtgcgg gtcggcaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc I20
gcccccag 128
<210> 287
<211> 128
<212> DNA
<213> homo Sapiens
<400> 287
gtgagtgcgg gtcggcaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 288
<211> 129
<212> DNA
<213> homo sapiens
<400> 288
116
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acctgaggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 289
<211> 129
<212> DNA
<213> homo Sapiens
<400> 289
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acctgaggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 290
<211> 129
<212> DNA
<213> homo sapiens
<400> 290
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acctgaggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 291
<211> 129
<212> DNA
<213> homo sapiens
<400> 291
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acctgaggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 292
<211> 128
<212> DNA
<213> homo sapiens
<400> 292
gtgagtgcgg gtcgggaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtctg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 293
<211> 128
117
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<212> DNA
<213> homo sapiens
<400> 293
gtgagtgegg gtcgggaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtctg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 294
<2I 1> 128
<212> DNA
<213> homo sapiens
<400> 294
gtgagtgcgg gtcgggaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtctg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 295
<211> 128
<212> DNA
<213> homo Sapiens
<400> 295
gtgagtgcgg gtcggcaggg aaatggcctc tgtagggagg agcaagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 296
<211> 129
<212> DNA
<213> homo sapiens
<400> 296
gtgagtgcgg ggtcgggagg gaaatggcct ctgtggggag gagcgagggg accgcaggcg 60
ggggcgcagg acctgaggag ccgcgccggg aggagggtcg ggcgggtctc agcccctcct 120
cgcccccag 129
<210> 297
<211> 128
<212> DNA
<213> homo sapiens
<400> 297
gtgagtgcgg gtcgggaggg aaatggcctc tgtggggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggga ggagggtctg gcgggtctca gcccctcctc 120
118
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gcccccag 128
<210> 298
<211> 128
<212> DNA
<2I3> homo Sapiens
<400> 298
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cctgaggagc cgcgccggga ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 299
<211> 128
<212> DNA
<213> homo Sapiens
<400> 299
gtgagtgcgg gtcgggaggg aaatggcctc tgccgggagg agcgagggga ccgcaggcgg 60
gggcgcagga cccggggagc cgcgccggta ggagggtcgg gcgggtctca gcccctcctc 120
gcccccag 128
<210> 300
<211 > 245
<212> DNA
<213> homo Sapiens
<400> 300
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggtcggg 240
gccag 245
<210> 301
<211> 245
<212> DNA
<2I3> homo Sapiens
<400> 301
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccgga 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggact gggctgaccg cggggccggg 240
gccag 245
119
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/04768
<210> 302
<211> 246
<212> DNA
<213> homo Sapiens
<400> 302
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgg acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggttggtcggggc ggggcggggctcggggggac ggggctgacc gcggggccgg 240
ggccag 24G
<210> 303
<211> 245
<212> DNA
<213> homo Sapiens
<400> 303
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgg acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggttggtcggggc ggggcggggctcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 304
<211> 246
<212> DNA
<213> homo Sapiens
<400> 304
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgg acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac tgggctgacc gcgggggcgg 240
ggccag 246
<210> 305
<211> 246
<212> DNA
<213> homo Sapiens
<400> 305
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgg acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tgggcggggc ggggcggggc tcggggggac tgggctgacc gcgggggcgg 240
120
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
ggccag 246
<210> 306
<211 > 246
<212> DNA
<213> homo sapiens
<400> 306
gtgagtgacc ccggcctggg gcgcaggtca cgactccccatcccccacgtacggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccaaacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggcctg 240
ggccag 246
<210> 307
<211> 245
<212> DNA
<213> homo sapiens
<400> 307
gtgagtgacc ccggcctggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccaaacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggcctgg 240
gccag 245
<210> 308
<211> 245
<212> DNA
<213> homo sapiens
<400> 308
gtgagtgacc ccggcctggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccaaacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggcctgg 240
gccag 245
<210> 309
<211> 245
<212> DNA
<213> homo sapiens
<400> 309
gtgagtgacc ccggcctggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccaaacc 120
121
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggcctgg 240
gccag 245
<210> 310
<211> 245
<212> DNA
<213> homo sapiens
<400> 310
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggttggtcggggc ggggcggggctcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 311
<211> 245
<212> DNA
<213> homo Sapiens
<400> 311
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccaaacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggcctgg 240
gccag 245
<210> 312
<211 > 246
<212> DNA
<213> homo Sapiens
<400> 312
gtgagtgacc ccggcctggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccaaacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggcctg 240
ggccag 246
<210> 313
<211 > 246
<212> DNA
<213> homo Sapiens
<400> 313
122
<212> DNA
<213> homo Sapiens
<400> 303
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gtgagtgacc ccggcctggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccaaacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggcctg 240
ggccag 246
<210> 314
<211 > 246
<212> DNA
<213> homo Sapiens
<400> 314
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggccgg 240
ggccag 246
<210> 315
<211 > 243
<212> DNA
<213> homo Sapiens
<400> 315
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccgaggcc gcgggacccg cccagaccct 120
cgaccggcga gagcccaggc gcgtttaccc ggtttcattt tcagttgagg ccaaaatccc 180
cgcgggttgg tcggggcggg gcggggctcg gggggacggg gctgaccgcg ggggcggggc 240
cag 243
<210> 316
<211> 244
<212> DNA
<213> homo Sapiens
<400> 316
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccgaggcc gcgggacccg cccagaccct 120
cgaccggcga gagccccagg cgcgtttacc cggtttcatt ttcagttgag gccaaaatcc 180
ccgcgggttg gtcggggcgg ggcggggctc ggggggacgg ggctgaccgc gggggcgggg 240
ccag 244
<210> 317
<211> 244
<212> DNA
<213> homo Sapiens
123
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 317
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccgaggcc gcgggacccg cccagaccct 120
cgaccggcga gagccccagg cgcgtttacc cggtttcatt ttcagttgag gccaaaatcc 180
ccgcgggttg gtcggggcgg ggcggggctc ggggggacgg ggctgaccgc gggggcgggg 240
ccag 244
<210> 318
<211 > 244
<212> DNA
<213> homo sapiens
<400> 318
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccgaggcc gcgggacccg cccagaccct 120
cgaccggcga gagccccagg cgcgtttacc cggtttcatt ttcagttgag gccaaaatcc 180
ccgcgggttg gtcggggcgg ggcggggctc ggggggacgg ggctgaccgc gggggcgggg 240
ccag 244
<210> 319
<2 I 1 > 244
<212> DNA
<213> homo sapiens
<400> 319
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccgaggcc gcgggacccg cccagaccct 120
cgaccggcga gagccccagg cgcgtttacc cggtttcatt ttcagttgag gccaaaatcc 180
ccgcgggttg gtcggggcgg ggcggggctc ggggggacgg ggctgaccgc ggggccgggg 240
ccag 244
<210> 320
<211 > 245
<212> DNA
<213> homo sapiens
<400> 320
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggttggtcggggc ggggcggggctcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 321
<211> 245
<212> DNA
124
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo Sapiens
<400> 321
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 322
<2I 1 > 245
<212> DNA
<213> homo sapiens
<400> 322
gtgagtgacc ccggcccggg gcgcaggtca cgactccccatcccccacgtacggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 323
<211> 245
<212> DNA
<213> homo sapiens
<400> 323
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat I 80
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 324
<211> 245
<2I2> DNA
<213> homo Sapiens
<400> 324
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 325
125
CA 02300369 2000-02-11
WO 99/07883 PCTlCA98/00768
<211> 246
<212> DNA
<213> homo sapiens
<400> 325
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggccgg 240
ggccag 246
<210> 326
<211> 246
<212> DNA
<213> homo sapiens
<400> 326
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggccgg 240
ggccag 246
<210> 327
<211> 246
<212> DNA
<213> homo sapiens
<400> 327
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggccgg 240
ggccag 246
<210> 328
<211> 246
<212> DNA
<213> homo sapiens
<400> 328
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggttggtcggggc ggggcggggctcggggggac ggggctgacc gcggggccgg 240
ggccag 246
126
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 329
<211> 246
<212> DNA
<213> homo sapiens
<400> 329
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggccgg 240
ggccag 246
<210> 330
<211> 245
<212> DNA
<213> homo sapiens
<400> 330
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccaa ccccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggact gggctgaccg cggggccggg 240
gccag 245
<210> 331
<211> 244
<212> DNA
<213> homo Sapiens
<400> 331
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccgc ccccgaggcc gcgggacccg cccagaccct 120
cgaccggcga gagccccagg cgcgtttacc cggtttcatt ttcagttgag gccaaaatcc 180
ccgcgggttg gtcggggcgg ggcggggctc ggggggacgg ggctgaccgc ggggccgggg 240
ccag 244
<210> 332
<211 > 246
<212> DNA
<213> homo Sapiens
<400> 332
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgg acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggcctg 240
127
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
ggccag 246
<210> 333
<211> 246
<212> DNA
<213> homo Sapiens
<400> 333
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggccgg 240
ggccag 246
<210> 334
<211> 246
<212> DNA
<213> homo Sapiens
<400> 334
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgg acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcggggccgg 240
ggccag 246
<210> 335
<211> 243
<212> DNA
<213> homo Sapiens
<400> 335
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccgaggcc gcgggacccg cccagaccct 120
cgaccggcga gagccccagg cgcgtttacc cggtttcatt ttcagttgag gccaaaatcc 180
ccgcgggttg gtcggggcgg ggcggggctc gggggacggg gctgaccgcg gggccggggc 240
cag 243
<210> 336
<211> 21
<212> DNA
<213> homo Sapiens
<400> 336
gccttcccaa ccattccctt a 21
128
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 337
<211 > 243
<212> DNA
<213> homo Sapiens
<400> 337
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccgaggcc gcgggacccg cccagaccct 120
cgaccggcga gagccccagg cgcgtttacc cggtttcatt ttcagttgag gccaaaatcc 180
ccgcgggttg gtcggggcgg ggcggggctc gggggacggg gctgaccgcg gggccggggc 240
cag 243
<210> 338
<211> 245
<212> DNA
<213> homo Sapiens
<400> 338
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggcctgg 240
gccag 245
<210> 339
<211 > 245
<212> DNA
<213> homo Sapiens
<400> 339
gtgagtgacc ccggcctggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccaaacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggcctgg 240
gccag 245
<210> 340
<211 > 243
<212> DNA
<213> homo sapiens
<400> 340
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccgaggcc gcgggacccg cccagaccct 120
cgaccggcga gagcccaggc gcgtttaccc ggtttcattt tcagttgagg ccaaaatccc 180
cgcgggttgg tcggggcggg gcggggctcg gggggacggg gctgaccgcg gggcctgggc 240
129
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
cag 243
<210> 341
<211> 245
<212> DNA
<213> homo sapiens
<400> 341
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggact gggctgaccg cggggccggg 240
gccag 245
<210> 342
<211> 244
<212> DNA
<213> homo Sapiens
<400> 342
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccag gcgcgtttac ccggtttcat tttcagttga ggccaaaatc 180
cccgcgggtt ggtcggggcg gggcggggct cgggggacgg ggctgaccgc ggggcctggg 240
ccag 244
<210> 343
<211 > 245
<212> DNA
<213> homo sapiens
<400> 343
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccgc ccccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggcctgg 240
gccag 245
<210> 344
<211> 246
<212> DNA
<213> homo Sapiens
<400> 344
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
130
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
ctcgaccggc gagaggcccc aggcgcgttt acccggtttc attttcagtt gaggccaaaa I80
tccccgcggg ttggtcgggg cggggcgggg ctcgggggac ggtgctgacc gcggggccgg 240
ggccag 246
<210> 345
<211> 245
<212> DNA
<213> homo Sapiens
<400> 345
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gtgctgaccg cggggccggg 240
gccag 245
<210> 346
<211 > 245
<212> DNA
<2I3> homo Sapiens
<400> 346
gtgagtgacc ccggcccggg gcgcaggtca cgactccccatcccccacgtacggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gtgctgaccg cggggccggg 240
gccag 245
<210> 347
<211> 245
<212> DNA
<213> homo sapiens
<400> 347
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 348
<211 > 244
<212> DNA
<213> homo Sapiens
<400> 348
I31
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagaccccag gcgcgtttac ccggtttcat tttcagttga ggccaaaatc 180
cccgcgggtt ggtcggggcg gggcggggct cgggggacgg ggctgaccgc ggggccgggg 240
ccag 244
<210> 349
<211> 20
<212> DNA
<213> homo sapiens
<400> 349
tccatgtccttcctgaagca 20
<210> 350
<211 > 245
<212> DNA
<213> homo sapiens
<400> 350
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggttggtcggggc ggggcggggctcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 351
<211> 245
<212> DNA
<213> homo sapiens
<400> 351
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggt tggtcggggc ggggcggggc tcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 352
<211> 246
<212> DNA
<213> homo sapiens
<400> 352
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ccccctgagg ccgcgggacc cgcccagacc 120
132
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggttggtcagggc ggggcggggctcggggggac ggggctgacc gcggggccgg 240
ggccag 246
<210> 353
<211> 245
<212> DNA
<213> homo Sapiens
<400> 353
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggttggtcggggc ggggcggggctcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 354
<211> 245
<212> DNA
<213> homo Sapiens
<400> 354
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggttggtcggggc ggggcggggctcgggggacg gggctgaccg cggggccggg 240
gccag 245
<210> 355
<211 > 246
<212> DNA
<213> homo sapiens
<400> 355
gtgagtgacc ccggcccggg gcgcaggtca cgactcccca tcccccacgt acggcccggg 60
tcgccccgag tctccgggtc cgagatccac ctccctgagg ccgcgggacc cgcccagacc 120
ctcgaccggc gagagcccca ggcgcgttta cccggtttca ttttcagttg aggccaaaat 180
ccccgcgggttggtcggggc ggggcggggctcggggggac ggggctgacc gcggggccgg 240
ggccag 246
<210> 356
<211 > 246
<212> DNA
<213> homo Sapiens
<400> 356
133
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gtgagtgacc ccggcctggg gcgcaggtca cgacccctcc ccaaccccga cgtacggccc 60
gggtctcctc gagtctctag gtccgagatc oaccccgagg ccgcgggacc cgcccagaac 120
ctcgaccgca gagagcccca ggcgacttta cccggtttca ttttcagttg aggtcaaaat i 80
ccccgcgggt tggtcggggc ggggcggggc tcggggggac ggggctgacc gcgaggcctg 240
ggccag 246
<210> 357
<2I1> 575
<212> DNA
<213> homo sapiens
<400> 357
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 358
<211> 574
<212> DNA
<213> homo sapiens
<400> 358
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctccgttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctagaca attaaggaat 180
gacgtctctg aggaaatgga ggggaagaca gtccctagaa tactgatcag gggtcccctt 240
tgacccctgc agcagccttg ggaaccgtga cttttcctct caggccttgt tctctgcctc 300
acactcagtg tgtttggggc tctgattcca gcacttctga gtcactttac ctccactcag 360
atcaggagca gaagtccctg ttccccgctc agagactcga actttccaat gaataggaga 420
ttatcccagg tgcctgcgtc caggctggtg tctgggttct gtgccccttc cccaccccag 480
gtgtcctgtc cattctcagg ctggtcacat gggtggtcct agggtgtccc atgaaagatg 540
caaagcgcct gaattttctg actcttccca tcag 574
<2I0> 359
<211> 572
<212> DNA
<213> homo Sapiens
<400> 359
134
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctagaca attaagggat 180
gacgtctctg aggaaatgga ggggaagaca gtccctagaa tactgatcag gggtcccctt 240
tgacccctgc agcagccttg ggaaccgtga cttttcctct caggccttgt tctctgcctc 300
acactcagtg tgtttggggc tctgattcca gcacttctga gtcactttac ctccactcag 360
atcaggagca gaagtccctg ttccccgctc agagactcga actttccaat gaataggaga 420
ttatcccagg tgcctgcatc cgctggtgtc tgggttctgt gccccttccc caccccaggt 480
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag ggcgtgccat gagagatgca 540
aagcgcctga attttctgac tcttcccatc ag 572
<210> 360
<211> 575
<212> DNA
<213> homo Sapiens
<400> 360
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgt aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 361
<211> 572
<212> DNA
<2I3> homo Sapiens
<400> 361
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagaag aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccatg acttttcttc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtctct gttccccgct cagagactcg aactttccaa tgaatagatt 420
atcccaggtg cctgcgtcca ggctggtgtc tgggttctgt gtcccttccc caccccaggt 480
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag ggtgtcccat gagagatgca 540
aagcgcctga attttctgac tcttcccatc ag 572
<210> 362
135
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<211> 572
<212> DNA
<213> homo Sapiens
<400> 362
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagaag aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccatg acttttcttc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtctct gttccccgct cagagactcg aactttccaa tgaatagatt 420
atcccaggtg cctgcgtcca ggctggtgtc tgggttctgt gtcccttccc caccccaggt 480
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag ggtgtcccat gagagatgca 540
aagcgcctga attttctgac tcttcccatc ag 572
<210> 363
<211> 575
<212> DNA
<213> horno Sapiens
<400> 363
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctagg atagtgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 364
<211> 575
<212> DNA
<213> homo sapiens
<400> 364
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctagg atagtgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
136
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat S40
gcaaagcgcc tgaattttct gactcttccc atcag S7S
<210> 36S
<211> S7S
<212> DNA
<213> homo sapiens
<400> 365
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctagg atagtgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat S40
gcaaagcgcc tgaattttct gactcttccc atcag S7S
<210> 366
<211> S7S
<212> DNA
<213> homo sapiens
<400> 366
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctagg atagtgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat S40
gcaaagcgcc tgaattttct gactcttccc atcag S7S
<210> 367
<211> S7S
<212> DNA
<213> homo sapiens
<400> 367
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
137
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagao agtccctagg atagtgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 368
<211> 575
<212> DNA
<213> homo Sapiens
<400> 368
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctagg atagtgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 369
<211> 572
<212> DNA
<2I3> homo Sapiens
<400> 369
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctagg atagtgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccatg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtctct gttccccgct cagagactcg aactttccaa tgaatagatt 420
atcccaggtg cctgcgtcca ggctggtgtc tgggttctgt gccccttccc caccccaggt 480
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag ggtgtcccat gagagatgca 540
aagcgcctga attttctgac tcttcccatc ag 572
<210> 370
<211> 575
<212> DNA
138
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo sapiens
<400> 370
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctagg atagtgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 371
<211> 575
<212> DNA
<213> homo sapiens
<400> 371
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcccgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 372
<211> 575
<212> DNA
<213> homo sapiens
<400> 372
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacacca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
139
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 373
<211> 575
<212> DNA
<213> homo sapiens
<400> 373
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca GO
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacacca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 374
<211> 575
<212> DNA
<213> homo Sapiens
<400> 374
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacacca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 375
<211> 572
<212> DNA
<213> homo sapiens
<400> 375
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
140
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
ttgacccctg cagcagcctt gggaaccatg acttttcctc300
tcaggccttg ttctctgcct
cacactcagt gtgtttgggg ctctgattcc agcacttctg360
agtcacttta cctccactca
gatcaggagc agaagtctct gttccccgct cagagactcg420
aactttccaa tgaatagatt
atcccaggtg cctgcgtcca ggctggtgtc tgggttctgt480
gccccttccc caccccaggt
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag540
ggtgtcccat gagagatgca
aagcgcctga attttctgac tcttcccatc ag 572
<210> 376
<211> 572
<212> DNA
<213> homo Sapiens
<400> 376
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccaa 60
cgagaagaag aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccatg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtctct gttccccgct cagagactcg aactttccaa tgaatagatt 420
atcccaggtg cctgcgtcca ggctggtgtc tgggttctgt gccccttccc caccccaggt 480
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag ggtgtcccat gagagatgca 540
aagcgcctga attttctgac tcttcccatc ag 572
<210> 377
<211> 572
<212> DNA
<213> homo Sapiens
<400> 377
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagaag aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccatg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtctct gttccccgct cagagactcg aactttccaa tgaatagatt 420
atcccaggtg cctgcgtcca ggctggtgtc tgggttctgt gccccttccc caccccaggt 480
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag ggtgtcccat gagagatgca 540
aagcgcctga attttctgac tcttcccatc ag 572
<210> 378
<211> 572
<212> DNA
<213> homo Sapiens
141
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 378
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccaa 60
cgagaagaag aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccatg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtctct gttccccgct cagagactcg aactttccaa tgaatagatt 420
atcccaggtg cctgcgtcca ggctggtgtc tgggttctgt gccccttccc caccccaggt 480
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag ggtgtcccat gagagatgca 540
aagcgcctga attttctgac tcttcccatc ag 572
<210> 379
<211> 574
<212> DNA
<213> homo sapiens
<400> 379
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctccgtgga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctagaca attaaggaat 180
gacgtctctg aggaaatgga ggggaagaca gtccctagaa tactgatcag gggtcccctt 240
tgacccctgc agcagccttg ggaaccgtga cttttcctct caggccttgt tctctgcctc 300
acactcagtg tgtttggggc tctgattcca gcacttctga gtcactttac ctccactcag 360
atcaggagca gaagtccctg ttccccgctc agagactcga actttccaat gaataggaga 420
ttatcccagg tgcctgcgtc caggctggtg tctgggttct gtgccccttc cccaccccag 480
gtgtcctgtc cattctcagg ctggtcacat gggtggtcct agggtgtccc atgaaagatg 540
caaagcgcct gaattttctg actcttccca tcag 574
<210> 380
<211> 575
<212> DNA
<213> homo sapiens
<400> 380
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
142
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 381
<211> 572
<212> DNA
<213> homo sapiens
<400> 381
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctagaca attaagggat 180
gacgtctctg aggaaatgga ggggaagaca gtccctagaa tactgatcag gggtcccctt 240
tgacccctgc agcagccttg ggaaccgtga cttttcctct caggccttgt tctctgcctc 300
acactcagtg tgtttggggc tctgattcca gcacttctga gtcactttac ctccactcag 360
atcaggagca gaagtccctg ttccccgctc agagactcga actttccaat gaataggaga 420
ttatcccagg tgcctgcatc cgctggtgtc tgggttctgt gccccttccc caccccaggt 480
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag ggtgtgccat gagagatgca 540
aagcgcctga attttctgac tcttcccatc ag 572
<210> 382
<211> 572
<212> DNA
<213> homo sapiens
<400> 382
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctagaca attaaggaat 180
gacgtctctg aggaaatgga ggggaagaca gtccctagaa tactgatcag gggtcccctt 240
tgacccctgc agcagccttg ggaaccgtga cttttcctct caggccttgt tctctgcctc 300
acactcagtg tgtttggggc tctgattcca gcacttctga gtcactttac ctccactcag 360
atcaggagca gaagtccctg ttccccgctc agagactcga actttccaat gaataggaga 420
ttatcccagg tgcctgcatc cgctggtgtc tgggttctgt gccccttccc caccccaggt 480
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag ggtgtgccat gagagatgca 540
aagcgcctga attttctgac tcttcccatc ag 572
<210> 383
<211> 572
<212> DNA
<213> homo Sapiens
<400> 383
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctagaca attaagggat 180
gacgtctctg aggaaatgga ggggaagaca gtccctagaa tactgatcag gggtcccctt 240
tgacccctgc agcagccttg ggaaccgtga cttttcctct caggccttgt tctctgcctc 300
acactcagtg tgtttggggc tctgattcca gcacttctga gtcactttac ctccactcag 360
143
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
atcaggagca gaagtccctg ttccccgctc agagactcga actttccaat gaataggaga 420
ttatcccagg tgcctgcatc cgctggtgtc tgggttctgt gccccttccc caccccaggt 480
gtcctgtcca ttctcaggct ggtcacatgg gtggtcctag ggtgtgccat gagagatgca 540
aagcgcctga attttctgac tcttcccatc ag 572
<210> 384
<211> 575
<212> DNA
<213> homo sapiens
<400> 384
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 385
<211> 575
<212> DNA
<213> homo Sapiens
<400> 385
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 386
<211> 573
<212> DNA
<213> homo sapiens
<400> 386
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
144
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctagaca attaagggat 180
gacgtctctg aggaaatgga ggggaagaca gtccctagaa tactgatcag gggtcccctt 240
tgacccctgc agcagccttg ggaaccgtga ctttcctctc aggccttgtt ctctgcctca 300
cactcagtgt gtttggggct ctgattccag cacttctgag tcactttacc tccactcaga 360
tcgggagcag aagtccctgt tccccgctca gagactcgaa ctttccaatg aataggagat 420
tatcccaggt gcctgcgtcc aggctggtgt ctgggttctg tgccccttcc ccaccccagg 480
tgtcctgtcc attctcaggc tggtcacatg ggtggtccta gggtgtccca tgagagatgc 540
aaagcgcctg aattttctga ctcttcccat cag 573
<210> 387
<211> 575
<212> DNA
<213> homo Sapiens
<400> 387
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctagg atagtgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 388
<211> 575
<212> DNA
<2I3> homo sapiens
<400> 388
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactta 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 389
<211> 575
145
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<212> DNA
<213> homo sapiens
<400> 389
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccact cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 390
<211> 576
<212> DNA
<213> homo Sapiens
<400> 390
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagtc agtccctagg aatagtgatc aggggtcccc 240
tttgacccct gcagcagcct tgggaaccgt gacttttcct ctcaggcctt gttctctgcc 300
tcacactcag tgtgtttggg gctctgattc cagcacttct gagtcacttt acctccactc 360
agatcaggag cagaagtccc tgttccccgc tcagagactc gaactttcca atgaatagga 420
gattatccca ggtgcctgcg tccaggctgg tgtctgggtt ctgtgcccct tccccacccc 480
aggtgtcctg tccattctca ggctggtcac atgggtggtc ctagggtgtc ccatgagaga 540
tgcaaagcgc ctgaattttc tgactcttcc catcag 576
<210> 391
<211> 575
<212> DNA
<213> homo sapiens
<400> 391
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacacca 480
146
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 392
<211> 575
<212> DNA
<213> homo sapiens
<400> 392
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacacca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 393
<211> 575
<212> DNA
<213> homo Sapiens
<400> 393
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagtc agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacacca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 394
<211> 575
<212> DNA
<213> homo sapiens
<400> 394
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
147
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacacca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc catgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 395
<211> 575
<212> DNA
<213> homo Sapiens
<400> 395
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcctct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc tatgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 396
<21I> 575
<212> DNA
<213> homo Sapiens
<400> 396
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcccct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc tatgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 397
<211> 575
<212> DNA
<213> homo sapiens
148
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 397
gtaccagggg cagtggggag ccttccccat ctcctatagg tcgccgggga tggcctccca 60
cgagaagagg aggaaaatgg gatcagcgct agaatgtcgc cctcccttga atggagaatg 120
gcatgagttt tcctgagttt cctctgaggg ccccctcttc tctctaggac aattaaggga 180
tgacgtctct gaggaaatgg aggggaagac agtccctaga atactgatca ggggtcctct 240
ttgacccctg cagcagcctt gggaaccgtg acttttcctc tcaggccttg ttctctgcct 300
cacactcagt gtgtttgggg ctctgattcc agcacttctg agtcacttta cctccactca 360
gatcaggagc agaagtccct gttccccgct cagagactcg aactttccaa tgaataggag 420
attatcccag gtgcctgcgt ccaggctggt gtctgggttc tgtgcccctt ccccacccca 480
ggtgtcctgt ccattctcag gctggtcaca tgggtggtcc tagggtgtcc tatgagagat 540
gcaaagcgcc tgaattttct gactcttccc atcag 575
<210> 398
<211> 19
<212> DNA
<213> homo Sapiens
<400> 398
ccacctgctg ctctcggga 19
<210> 399
<211> 17
<212> DNA
<213> homo sapiens
<400> 399
ctcctgctgc tctcggc 17
<210> 400
<211> 18
<212> DNA
<213> homo Sapiens
<400> 400
ctgctgctct ggggggca 1 g
<210> 401
<211> 18
<212> DNA
<213> homo Sapiens
<400> 401
gagatgcggg tcacggca 1 g
<210> 402
<211> 18
149
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<212> DNA
<213> homo sapiens
<400> 402
ctgaccgaga cctgggct 1 g
<210> 403
<211> 18
<212> DNA
<213> homo Sapiens
<400> 403
aggagggtcg ggcgggtt 1 g
<210> 404
<211> 18
<212> DNA
<213> homo Sapiens
<400> 404
gggtctcagc cccacctt 1 g
<210> 405
<211> 19
<212> DNA
<213> homo Sapiens
<400> 405
gagggaaatg gcctctgcc 1 ~
<210> 406
<211> 18
<2I2> DNA
<213> homo Sapiens
<400> 406
cgggggcgca ggacctga 1 g
<210> 407
<211> 18
<212> DNA
<213> homo Sapiens
<400> 407
gcgccgggag gagggtct 1 g
150
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 408
<211> 18
<212> DNA
<213> homo sapiens
<400> 408
gcctctgtgg ggaggaga 1 g
<210> 409
<211> 19
<212> DNA
<213> homo sapiens
<400> 409
gcctctgtag ggaggagca 19
<210> 410
<211> 18
<212> DNA
<213> homo Sapiens
<400> 410
gtcgggcggg tctcagct 1 g
<210> 411
<211> 17
<2I2> DNA
<213> homo sapiens
<400> 411
cgggggaccg cgccggt 17
<2I0> 412
<211> 18
<212> DNA
<213> homo sapiens
<400> 412
ggtctcagcc cctcctca 1 g
<210> 413
<211> 18
<212> DNA
<213> homo sapiens
<400> 413
151
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
gtggagtgcg gggtcggc 1 g
<210> 414
<211> 17
<212> DNA
' <213> homo sapiens
<400> 414
gtgagtgcgg ggtcggc 17
<210> 415
<211> 17
<212> DNA
<213> homo sapiens
<400> 415
gaccgcaggc gggggct 17
<210> 416
<211> 18
<212> DNA
<213> homo Sapiens
<400> 416
tctcagcccc tcctcgct 1 g
<210> 417
<211> 19
<212> DNA
<213> homo Sapiens
<400> 417
gccatccccg gcgacctat 19
<210> 418
<211> 19
<212> DNA
<213> homo sapiens
<400> 418
gggacccctg atcactatc 19
<210> 419
<211> 19
<212> DNA
<213> homo sapiens
152
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<400> 419
ggccctcaga ggaaactcg ~ 19
<210> 420
<211> 21
<212> DNA
<213> homo Sapiens
<400> 420
aggcctgaga ggaaaagtca t 21
<210> 421
<211> 21
<212> DNA
<213> homo Sapiens
<400> 421
aggcgctttg catctctcat a 21
<210> 422
<211> 21
<212> DNA
<213> homo Sapiens
<400> 422
gatcagtatt ctagggactg a 21
<210> 423
<2 I 1 > 20
<212> DNA
<213> homo sapiens
<400> 423
gaatggacag gacacctggt 20
<210> 424
<211> 21
<212> DNA
<213> homo Sapiens
<400> 424
tcatgccatt ctccattcaa c 21
<210> 425
<211> 20
<212> DNA
153
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<213> homo Sapiens
<400> 425
ctagggactg tcttccccta 20
' <210> 426
<211> 20
<212> DNA
<213> homo sapiens
<400> 42G
cgctgatccc attttcctct 20
<210> 427
<211> 20
<212> DNA
<213> homo sapiens
<400> 427
cagagaacaa ggcctgagaa 20
<210> 428
<211> 19
<212> DNA
<213> homo sapiens
<400> 428
aacccagaca ccagcggat 19
<210> 429
<211> 20
<212> DNA
<213> homo Sapiens
<400> 429
ggacttctgc tcctgatcta 20
<210> 430
<211> 18
<212> DNA
<213> homo Sapiens
<400> 430
gaggccatcc cgggcgat 1 g
<210> 431
154
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<211> 21
<212> DNA
<213> homo sapiens
<400> 431
' ggaaagttcg agtctctgag t 21
<210> 432
<211> 20
<212> DNA
<213> homo Sapiens
<400> 432
ctcatgccat tctccattcc 20
<210> 433
<211> 19
<212> DNA
<213> homo Sapiens
<400> 433
tgaccagcct gagaatggg 19
<210> 434
<211> 19
<212> DNA
<213> homo Sapiens
<400> 434
aacagggact tctgctccc 19
<210> 435
<211> 20
<212> DNA
<213> homo sapiens
<400> 435
ggcctgagag gaaaagtcac 20
<210> 436
<211> 21
<212> DNA
<213> homo Sapiens
<400> 436
ggatctcgga cccggagact c 21
155
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
<210> 437
<211> 21
<212> DNA
<213> homo sapiens
<400> 437
acccggtttc attttcagtt g 21
<210> 438
<211> 23
<212> DNA
<213> homo Sapiens
<400> 438
tttacccggt ttcattttca gtt 23
<210> 439
<211> 18
<212> DNA
<213> homo sapiens
<400> 439
tccccactgc ccctggta 1 g
<210> 440
<211> 15
<212> DNA
<213> homo Sapiens
<400> 440
ggccagggtc tcaca 15
<210> 441
<211> 18
<212> DNA
<213> homo sapiens
<400> 441
atctcggacc cggagact 1 g
<210> 442
<211> 21
<212> DNA
<213> homo Sapiens
<400> 442
156
CA 02300369 2000-02-11
WO 99/07883 PCT/CA98/00768
tcccactcca tgaggtattt c 21
157