Note : Les descriptions sont présentées dans la langue officielle dans laquelle elles ont été soumises.
CA 03176450 2022-09-22
METHOD AND APPARATUS FOR IMPLEMENTING INCREMENTAL DATA
CONSISTENCY
BACKGROUND OF THE INVENTION
Technical Field
[0001] The present invention relates to the technical field of data
warehouses, and more
particularly to a method and an apparatus for implementing incremental data
consistency.
Description of Related Art
[0002] For constructing an operational data store (ODS) responsibility
relationship data table, a
big-data warehouse has to construct a consistent incremental data table, so as
to ensure
consistency of incremental data from different data tables that have
association
therebetween. Taking retail orders for example, a consistent incremental data
table
between the order header table and the sub-table for each order helps ensure
that a
changed order number exists in every order's incremental data table. This
prevents the
awkward situation that one changed order number is present in some tables but
absent
from others, which breaks association between incremental table data.
[0003] In the prior art, consistency of incremental data is typically realized
using solutions
described below.
[0004] The first method is about incrementally acquiring and feeding the data
in order header
table and sub-tables from the business system to the incremental data table of
the big-data
platform, then using hive/spark to generate the corresponding full data table,
generating
full changed order numbers according to incremental data table to brute-force
each table,
and finally generating a consistent incremental data table of the tables.
[0005] An alternative approach is implemented by incrementally acquiring the
order number
data from the order header table and sub-tables of the business system and
feeding them
1
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
to an order number change staging table of the business system, then, from the
business
system, acquiring business data of the order number corresponding to the
header table
and each sub-table according to order numbers in the order number change
staging table
using database indexes, and put the acquired business data to a consistent
incremental
data table of a data warehouse.
[0006] While the foregoing two solutions are easy to implement, they have some
defects and
shortcomings.
[0007] As to the former prior-art solution, it requires full reading of the
full order data to generate
a full data table in a Hive system. Assuming that there are originally 10
billion orders,
and the number of orders increases 2 million every day, for each time of
updating the data
of 2 million orders, reading and writing of the data of the 10 billion orders
have to be
done, and for generation of the consistent incremental data table, full
reading of the full
data table has to be done again. The process as a whole requires two time of
full reading
and one time of full writing to the full data table, leading to huge
consumption of the big
data platform resources and inefficiency.
[0008] Regarding the latter known solution, it requires the business system to
create and access
with writing permission on an order number change staging table. The business
system
has to read the business system table data twice, and the use relies on
business system
data table indexes. The entire process is highly dependent on the business
system, and
extraction can cause the database locked. Particularly, during large-scale
promotional
events, the system can be degraded. This will directly prevent data extraction
and in turn
suspend big data computing, making the system unable to generate analysis data
as
scheduled.
[0009] In addition, a Hive-based data warehouse does not support enquiry for
order number
indexes and is not suitable for tracing back of orders. For business analysis
scenarios like
after-sales service, it is necessary to associate the order data corresponding
to business,
and the time span for such order data is changeable, from one month to more
than one
year. Since a Hive table is basically incapable of indexing, such business
analysis is
relatively difficult to implement on basis of a Hive table.
2
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
SUMMARY OF THE INVENTION
[0010] For addressing the issues of the prior art, embodiments of the present
invention provide
a method and an apparatus for implementing incremental data consistency.
[0011] The present invention adopts the following technical schemes.
[0012] In one aspect, the present invention provides a method for implementing
incremental data
consistency, comprising:
[0013] initializing all data of data tables having an association relationship
in a business system,
and loading the data to a first database so as to generate plural full data
tables;
[0014] based on database logs of the business system, synchronizing real-time
data of each said
data table to the plural full data tables and to incremental data tables of a
second database;
[0015] extracting all business unique identities in the plural incremental
data table and merging
them in the second database to generate an incremental identity merged table;
and
[0016] according to the incremental identity merged table, making a query to
find out business
data associated with the incremental identity merged table from the plural
full data tables,
and correspondingly writing the business data into the consistent incremental
data table
of the second database.
[0017] In a preferred implementation, the step of based on database logs of
the business system,
synchronizing real-time data of each said data table to the plural full data
tables and to
incremental data tables of a second database comprises:
[0018] analyzing the database logs of the business system to get the real-time
data of each said
data table, and synchronizing the real-time data to a real-time data stream;
[0019] landing the data in the real-time data stream onto the plural full data
tables; and
[0020] writing the data in the real-time data stream into the plural
incremental data tables.
[0021] In a preferred implementation, the first database is a KY database, the
second database is
a Hive database.
[0022] In a preferred implementation, the step of according to the incremental
identity merged
table, making a query to find out business data associated with the
incremental identity
3
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
merged table from the plural full data tables comprises:
[0023] for every order number in the incremental identity merged table,
enquiring for the
business data matching the order number from the plural full data tables,
respectively,
through an SQL enquiry interface, so as to obtain the enquiry result.
[0024] In a preferred implementation, the method further comprises:
[0025] receiving a data backward enquiry instruction, enquiring the business
data associated with
the data backward enquiry instruction from the first database through the SQL
enquiry
interface, and returning data backward enquiry results.
[0026] In another aspect, the present invention provides an apparatus for
implementing
incremental data consistency, comprising:
[0027] an initializing module, for initializing all data of data tables having
an association
relationship in a business system, and loading the data to a first database so
as to generate
plural full data tables;
[0028] a real-time synchronizing module, for based on database logs of the
business system,
synchronizing real-time data of each said data table to the plural full data
tables and to
incremental data tables of a second database;
[0029] an identity merging module, for extracting all business unique
identities in the plural
incremental data table and merging them in the second database to generate an
incremental identity merged table;
[0030] an enquiring module, for according to the incremental identity merged
table, enquiring to
find out the business data associated with the incremental identity merged
table from the
plural full data tables; and
[0031] a writing module, for correspondingly writing the business data
associated with the
incremental identity merged table into the consistent incremental data table
of the second
database.
[0032] In a preferred implementation, the real-time synchronizing module is
specifically for:
[0033] analyzing the database logs of the business system to get the real-time
data of each said
data table, and synchronizing the real-time data to a real-time data stream;
[0034] landing the data in the real-time data stream onto the plural full data
tables; and
4
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
[0035] writing the data in the real-time data stream into the plural
incremental data tables.
[0036] In a preferred implementation, the first database is a KY database, the
second database is
a Hive database.
[0037] In a preferred implementation, the enquiring module is specifically
for:
[0038] as to every order number in the incremental identity merged table,
enquiring for the
business data matching the order number from the plural full data tables,
respectively,
through an SQL enquiry interface.
[0039] In a preferred implementation, the enquiring module is further for:
[0040] receiving a data backward enquiry instruction, enquiring the business
data associated with
the data backward enquiry instruction from the first database through the SQL
enquiry
interface, and returning data backward enquiry results.
[0041] The present invention provides a method and an apparatus for
implementing incremental
data consistency, which uses the database log to synchronize the real-time
data of each
data table in the business database to the data warehouse. Different from the
known
solution that uses a created order number change staging table to read the
table data of
the business system and thus is highly dependent on the use of data table
indexes of the
business system, the present invention basically has no interference with the
normal
operation of the business database when collecting data from the business
database, and
only require a single time of full reading for enquiring the business data
related to
incremental identity merged table from plural incremental data tables, thus
consuming
less database resources. Besides, the consistent incremental data table
obtained by writing
the enquiry results can ensure consistent incremental data across data tables.
In addition,
since data analysis of the consistent incremental data table supports analysis
based on
incremental data, all order-related analyses for data on the current day can
be easily
accomplished by retrieving the data of the current day in each table, without
the need of
retrieving data in the history zone, so the consumption to database resources
is smaller.
BRIEF DESCRIPTION OF THE DRAWINGS
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
[0042] To better illustrate the technical schemes as disclosed in the
embodiments of the present
invention, accompanying drawings referred in the description of the
embodiments below
are introduced briefly. It is apparent that the accompanying drawings as
recited in the
following description merely provide a part of possible embodiments of the
present
invention, and people of ordinary skill in the art would be able to obtain
more drawings
according to those provided herein without paying creative efforts, wherein:
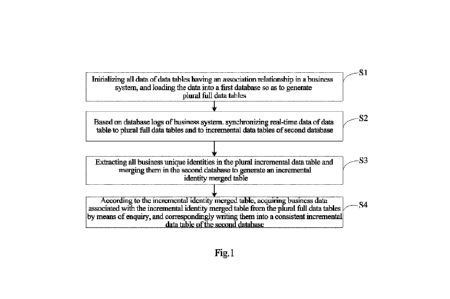
[0043] FIG. 1 shows a flowchart of a method for implementing incremental data
consistency of
the present invention;
[0044] FIG. 2 shows an implementation flowchart of an incremental order data
consistency in
an operational data store ODS according to the present invention; and
[0045] FIG. 3 shows a block diagram of an apparatus for implementing
incremental data
consistency of the present invention.
DETAILED DESCRIPTION OF THE INVENTION
[0046] To make the foregoing objectives, features, and advantages of the
present invention
clearer and more understandable, the following description will be directed to
some
embodiments as depicted in the accompanying drawings to detail the technical
schemes
disclosed in these embodiments. It is, however, to be understood that the
embodiments
referred herein are only a part of all possible embodiments and thus not
exhaustive. Based
on the embodiments of the present invention, all the other embodiments can be
conceived
without creative labor by people of ordinary skill in the art, and all these
and other
embodiments shall be encompassed in the scope of the present invention.
[0047] Unless specified otherwise in the context, the terms "comprising",
"including", and the
like as used throughout the disclosure and the appended claims should be
construed with
inclusive meaning but not exclusive or exhaustive meaning. In other words,
these terms
are intended to mean "including but not limited to".
[0048] It is to be understood that, in the description of the present
invention, the terms "first",
"second", and so on are merely descriptive and shall not be understood as
indicating or
6
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
implying relative importance. Additionally, unless otherwise stated, in the
description of
the present invention, the term "plural" means two or more than two.
[0049] Embodiment 1
[0050] The embodiment of the present invention provides a method for
implementing
incremental data consistency, which is applicable to data warehouses (e.g., an
operational
data store, ODS), as shown in FIG. 1. The method comprises the following
steps.
[0051] Si: initializing all data of data tables having an association
relationship in a business
system, and loading the data to a first database so as to generate plural full
data tables.
[0052] In the present embodiment, data tables having association relationship
may have one-to-
one or one-to-multiple relationship. Among the data tables having one-to-
multiple
relationship, one data table may be the parent table, while the others are
each a child table.
For example, in a scenario involving retail transaction orders, the order
header table is
the parent table, and the order product table, the order payment table, and
the order
expansion table are all child tables.
[0053] Specifically, based on an ETL tool, all data of the data tables are
extracted from the
business database corresponding to the business system. The data are then
cleaned and
converted before being loaded into a first database to form plural full data
tables
corresponding to respective data tables.
[0054] For example, all the data of each of the order header table, the order
product table, the
order payment table, and the order expansion table in the business database
are loaded
into the first database to generate full data tables corresponding to the
order header table,
the order product table, the order payment table, and the order expansion
table,
respectively.
[0055] Therein, first database may be a KY (Key-Value) database. A key-value
database is a
database stores data by key-value pairs, and storage of and access to its data
are both
conducted using key-value pairs as marks, so that values can be found rapidly
using the
corresponding keys, and allows nice reading and writing operations from the
exterior. A
representative Key-value database may be redis.
[0056] S2 involves, based on the database log of the business system,
synchronizing real-time
7
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
data of each said data table to plural full data tables and to plural
incremental data tables
of a second database.
[0057] Therein, the real-time data are data newly added or changed with
respect to each data
table.
[0058] Therein, the second database is a Hive database. A Hive database is a
data warehouse tool
based on Hadoop, and can map structuralized data files into a database table
while
providing simple SQL enquiry functions. It can convert a SQL sentence into a
MapReduce task to be executed. It is advantageous because the learning cost is
low, and
fast and simple MapReduce statistics can be accomplished through SQL-like
sentences,
without the need of developing a dedicated MapReduce application, making it
very
suitable for statistical analyses of data warehouses.
[0059] Specifically, this involves analyzing the real-time data of each data
table from the
database log of the business system, and synchronizing the real-time data to a
real-time
data stream;
[0060] landing the data in the real-time data stream into the plural full data
table; and
[0061] writing data in the real-time stream into plural incremental data
tables of the second
database.
[0062] Therein, the database log records information of operations made to the
business database.
The database log may specifically be a Binlog, which can be analyzed regularly
using a
Binlog analyzer.
[0063] In the present embodiment, the database log may be acquired when the
database log has
been updated. Therein, the update includes addition, deletion, or modification
made to
any field in the data tables of the business database.
[0064] It is to be noted that, the step of landing the data of the real-time
data stream into the
plural full data tables and the step of writing the data of the real-time data
stream into the
plural incremental data tables may be conducted in any sequence, without
limitation. In
the present embodiment of the present invention, the two steps are preferably
conducted
at the same time.
[0065] S3: extracting all business unique identities in the plural incremental
data tables, and
8
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
merging them in the second database to generate an incremental identity merged
table.
[0066] Therein, the business unique identity may exclusively mark one business
record in the
database table. In an order-related scenario, the business unique identity is
the order
number.
[0067] Specifically, this is about extracting all the business unique
identities from the plural
incremental data tables, and merging and de-duplicating the business unique
identities,
so as to generate the incremental identity merged table.
[0068] In the present embodiment, all the business unique identities may be
merged into a set,
with the repeated business unique identities removed. The business unique
identities after
de-duplication form the incremental identity merged table, which is stored in
the Hive
database.
[0069] S4: according to the incremental identity merged table, acquiring
business data associated
with the incremental identity merged table from the plural full data tables by
means of
enquiry, and correspondingly writing them into a consistent incremental data
table of the
second database.
[0070] Specifically, the process may comprise:
[0071] for every order number in the incremental identity merged table,
through the SQL enquiry
interface, enquiring for business data matching the order number from plural
full data
tables.
[0072] In a practical implementing process, a SQL enquiry interface may be
developed to
integrate KY database enquiries to the SQL, so as to make development easier,
thereby
achieving real-time association between the Hive database and the KY database
by means
of SQL.
[0073] Since the Hive database and the KY database can be associated through
SQL, the full
data table in the KY database can support fast retrieval based on the order
numbers,
thereby providing the function of data index retrieval, without increasing
burden on the
Hadoop platform or the business system.
[0074] Further, in addition to the foregoing steps, the method disclosed in
the embodiment of the
present invention may further comprise:
9
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
[0075] based on the consistent incremental data table in the second database,
performing
analyses of indicators, dimensions, and attributes related to the business
subject, wherein
the business subject may be ordering, payment or product return/exchange.
[0076] Since data analysis of the consistent incremental data table supports
analysis based on
incremental data, all order-related analyses for data on the current day can
be easily
accomplished by retrieving the data of the current day in each table, such as
wide tables
with respect to ordering, payment, or product return/exchange, without the
need of
retrieving data in the history zone, so the consumption to database resources
is smaller.
[0077] Further, in addition to the foregoing steps, the method disclosed in
the embodiment of the
present invention may further comprise:
[0078] receiving a data backward enquiry instruction, enquiring the business
data associated with
the data backward enquiry instruction from the first database through the SQL
enquiry
interface, and returning data backward enquiry results.
[0079] Exemplarily, dealing with a customer complaint is now described as an
example. If the
customer complaint is with respect to an order made long time ago, retrieval
in a Hive
table for a long time span can be inefficient. Instead, a backward enquiry
made to a KY
database through a SQL enquiry interface can efficiently lead to search for
customer order
information throughout full data table, thereby effectively dealing with
business scenarios
for after-sales services where retrieval of the past order data and
acquisition of associated
orders for dimensional analyses are required, with improved performance of
retrieval and
reduced consumption of the database resources.
[0080] The following description is directed to an order scenario for further
explaining the
method for implementing incremental data consistency of the Embodiment 1 of
the
present invention. FIG. 2 shows a process for implementing incremental order
data
consistency for an operational data store ODS. The process comprising:
[0081] Step 1: initializing all data in the parent table and its child tables
of the business system,
and loading the data into a KY database to form plural full data tables;
[0082] Step 2: synchronizing the data from the business system to a data
stream through a
database log in a real-time manner;
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
[0083] Step 3: landing the data in the real-time data stream into the
incremental data table of the
Hive database;
[0084] Step 4: writing data of the real-time data stream into the full data
table of the KY database
correspondingly;
[0085] Step 5: merging and de-duplicating all the order numbers extracted from
the incremental
data tables and writing them into the incremental order number merged table of
the Hive
database; and
[0086] Step 6: enquiring and calling the data of each full data table
according to the incremental
order number merged table through the SQL enquiry interface, and writing the
enquiry
results into the consistent incremental data table of the Hive database.
[0087] With the foregoing steps, the consistent incremental data table of the
Hive database of the
operational data warehouse ODS and the full data table of the KY database can
be
eventually generated.
[0088] The method for implementing incremental data consistency disclosed in
the present
invention uses the database log to synchronize the real-time data of each data
table in the
business database to the data warehouse. Different from the known solution
that uses a
created order number change staging table to read the table data of the
business system
and thus is highly dependent on the use of data table indexes of the business
system, the
present invention basically has no interference with the normal operation of
the business
database when collecting data from the business database, and only require a
single time
of full reading for enquiring the business data related to incremental
identity merged table
from plural incremental data tables, thus consuming less database resources.
Besides, the
consistent incremental data table obtained by writing the enquiry results can
ensure
consistent incremental data across data tables. In addition, since data
analysis of the
consistent incremental data table supports analysis based on incremental data,
all order-
related analyses for data on the current day can be easily accomplished by
retrieving the
data of the current day in each table, without the need of retrieving data in
the history
zone, so the consumption to database resources is smaller.
11
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
[0089] Embodiment 2
[0090] The embodiment of the present invention provides an apparatus for
implementing
incremental data consistency. As shown in FIG. 3, the apparatus comprises the
components detailed below.
[0091] An initializing module 31 is for initializing all data of data tables
having an association
relationship in a business system, and loading the data to a first database so
as to generate
plural full data tables.
[0092] A real-time synchronizing module 32 is for, based on logs of business
databases,
synchronizing real-time data of each said data table to plural full data
tables and to plural
incremental data tables of a second database.
[0093] A identity merging module 33 is for extracting all business unique
identities in the plural
incremental data tables, and merging them in the second database to generate
an
incremental identity merged table.
[0094] An enquiring module 34 is for, according to the incremental identity
merged table,
enquiring to find out the business data associated with the incremental
identity merged
table from the plural full data tables.
[0095] A writing module 35 is for correspondingly writing the business data
associated with the
incremental identity merged table into the consistent incremental data table
of the second
database.
[0096] Further, the real-time synchronizing module 32 is specifically for:
[0097] analyzing the database logs of the business system to get the real-time
data of each said
data table, and synchronizing the real-time data to a real-time data stream;
[0098] landing the data in the real-time data stream onto the plural full data
tables; and
[0099] writing the data in the real-time data stream into the plural
incremental data tables.
[0100] Further, the first database is a KY database, and the second database
is a Hive database.
[0101] Further, the enquiring module 34 is specifically for:
[0102] as to every order number in the incremental identity merged table,
enquiring for the
business data matching the order number from the plural full data tables,
respectively,
through an SQL enquiry interface.
12
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
[0103] Further, the enquiring module 34 is further for:
[0104] receiving a data backward enquiry instruction, enquiring the business
data associated with
the data backward enquiry instruction from the first database through the SQL
enquiry
interface, and returning data backward enquiry results.
[0105] The apparatus for implementing incremental data consistency of the
present invention
uses the database log to synchronize the real-time data of each data table in
the business
database to the data warehouse. Different from the known solution that uses a
created
order number change staging table to read the table data of the business
system and thus
is highly dependent on the use of data table indexes of the business system,
the present
invention basically has no interference with the normal operation of the
business database
when collecting data from the business database, and only require a single
time of full
reading for enquiring the business data related to incremental identity merged
table from
plural incremental data tables, thus consuming less database resources.
Besides, the
consistent incremental data table obtained by writing the enquiry results can
ensure
consistent incremental data across data tables. In addition, since data
analysis of the
consistent incremental data table supports analysis based on incremental data,
all order-
related analyses for data on the current day can be easily accomplished by
retrieving the
data of the current day in each table, without the need of retrieving data in
the history
zone, so the consumption to database resources is smaller.
[0106] All the alternative technical schemes described above may be combined
in any manner
to form more alternative embodiments of the present invention and no
enumeration is
made herein.
[0107] It is to be noted that work division among the foregoing functional
modules of the
apparatus for implementing incremental data consistency of the present
embodiment to
implement the method for implementing incremental data consistency are merely
exemplary. In practical implementations, the work division may be made
differently
among functional modules. In other words, the internal architecture of the
apparatus for
implementing incremental data consistency may be reconfigured with different
functional
modules to perform all or a part of the functions as described previously. In
addition,
13
Date Regue/Date Received 2022-09-22
CA 03176450 2022-09-22
since the apparatus for implementing incremental data consistency of the
present
embodiment and the disclosed method for implementing incremental data
consistency in
the previous embodiment stem from the same conception, the details of its
implementation can be learned from the description made to the method of the
previous
embodiment, and no repetition is made herein.
[0108] As will be appreciated by people of ordinary skill in the art,
implementation of all or a
part of the steps of the method of the present invention as described
previously may be
realized by hardware components, or by having a program instruct related
hardware
components. The program may be stored in a computer-readable storage medium,
wherein the abovementioned storage medium may be a ROM, a magnetic disk, an
optical
disk or the like.
[0109] The preferred embodiments of the present invention described previously
are not intended
to limit the present invention. Any modification, equivalent replacement, and
improvement made under the spirit and principle of the present invention shall
be
included in the scope of the present invention.
14
Date Regue/Date Received 2022-09-22